Asymmetric Residual Neural Network for Accurate Human Activity Recognition


Abstract
:1. Introduction
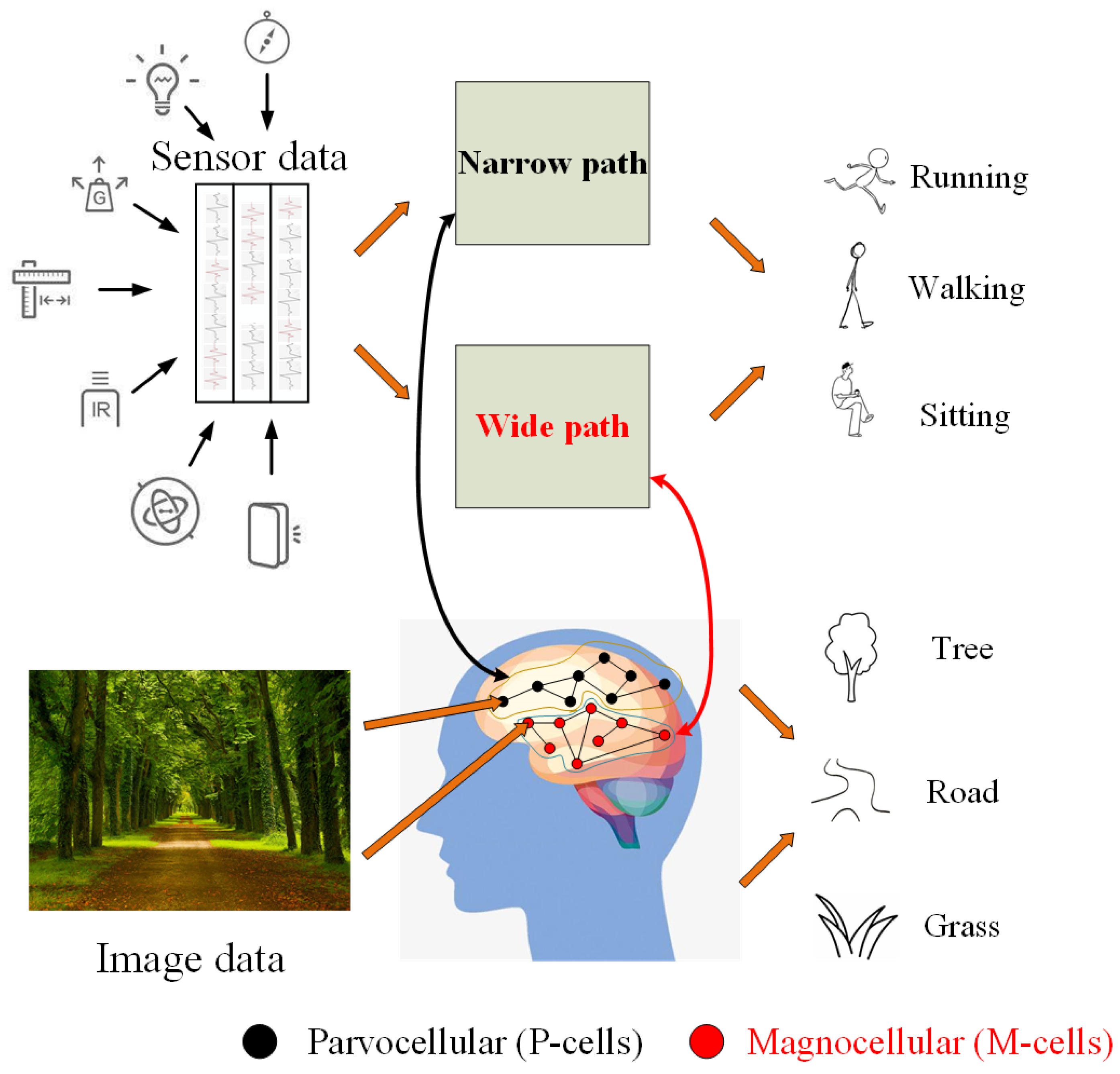
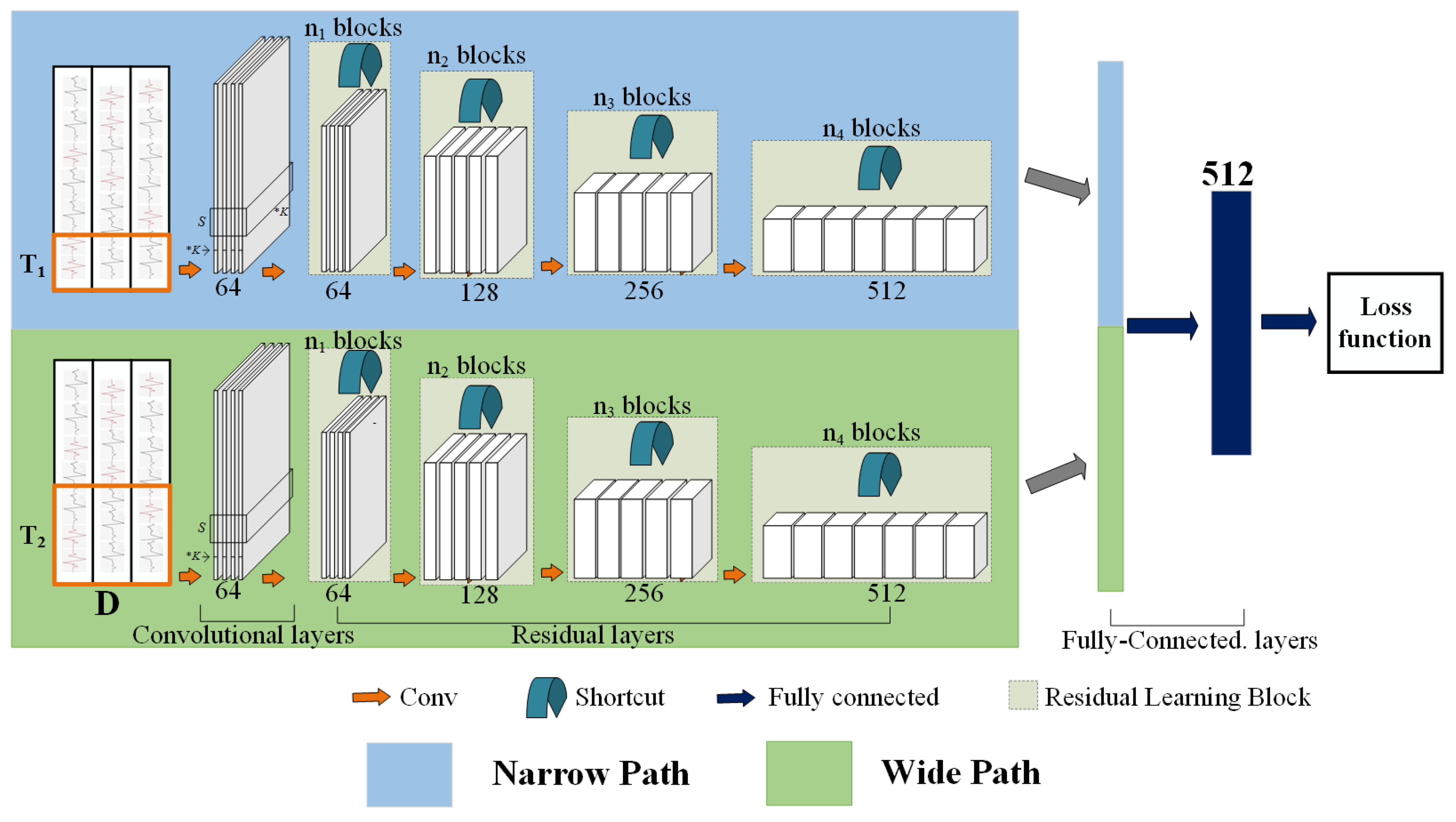
- We propose a novel symmetric neural network based on ResNet for HAR, termed ARN, which is an asymmetric network and has two paths separately working at short and long slide windows. Our wide path is designed to capture global features but few spatial details, analogous to M-cells, and our narrow path is lightweight, similar to the small receptive field of P-cells.
- We design a network that consists of an asymmetric residual net that not only can effectively manage information flow, but will also automatically learn effective activity feature representation, while capturing the fine feature distribution in different activities from wearable sensor data.
- We compare the performance of our method to other relevant methods by carrying out extensive experiments on benchmark datasets. The results show that our method outperforms other methods.
2. Related Work
2.1. Methods for Human Activity Recognition
2.1.1. Hand-Crafted Features
2.1.2. Codebook Approach
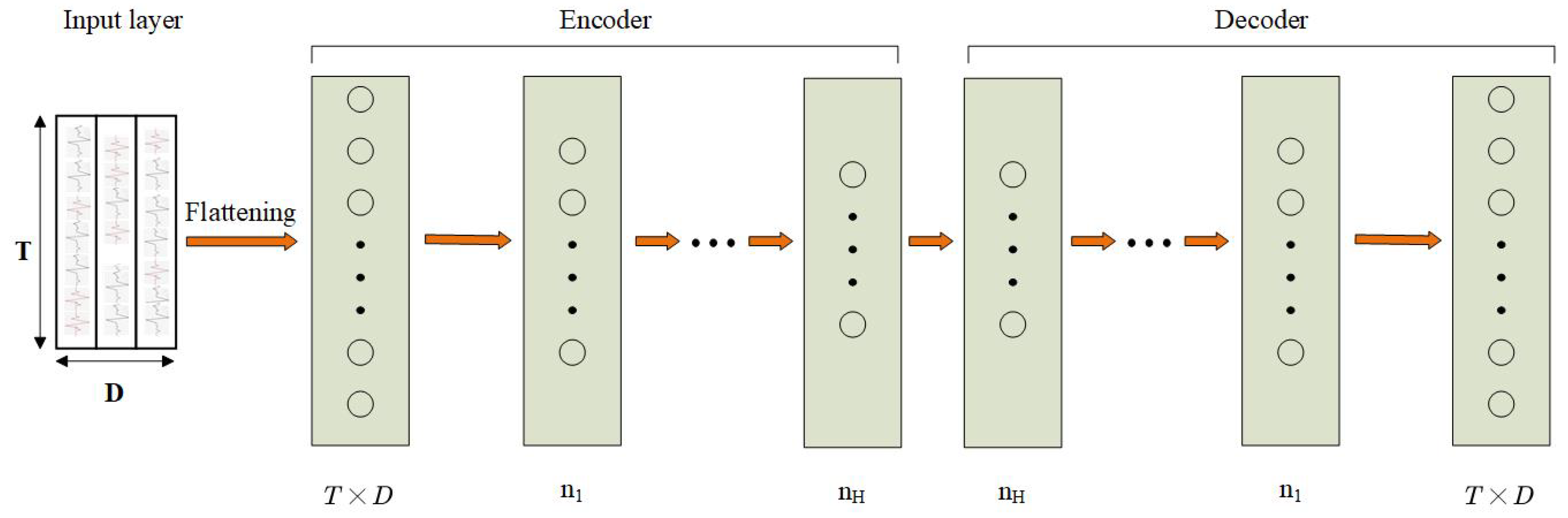
2.1.3. Autoencoders Approach
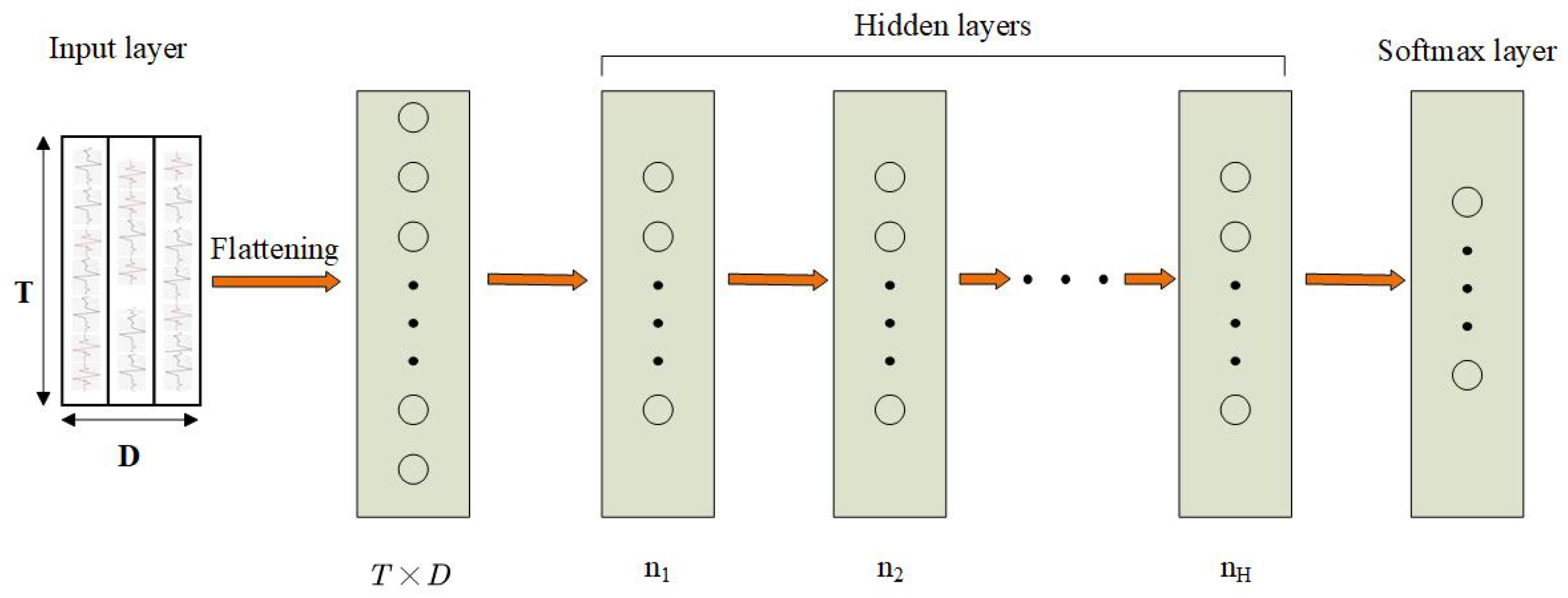
2.1.4. Multi-Layer Perceptron
2.1.5. Convolutional Neural Networks
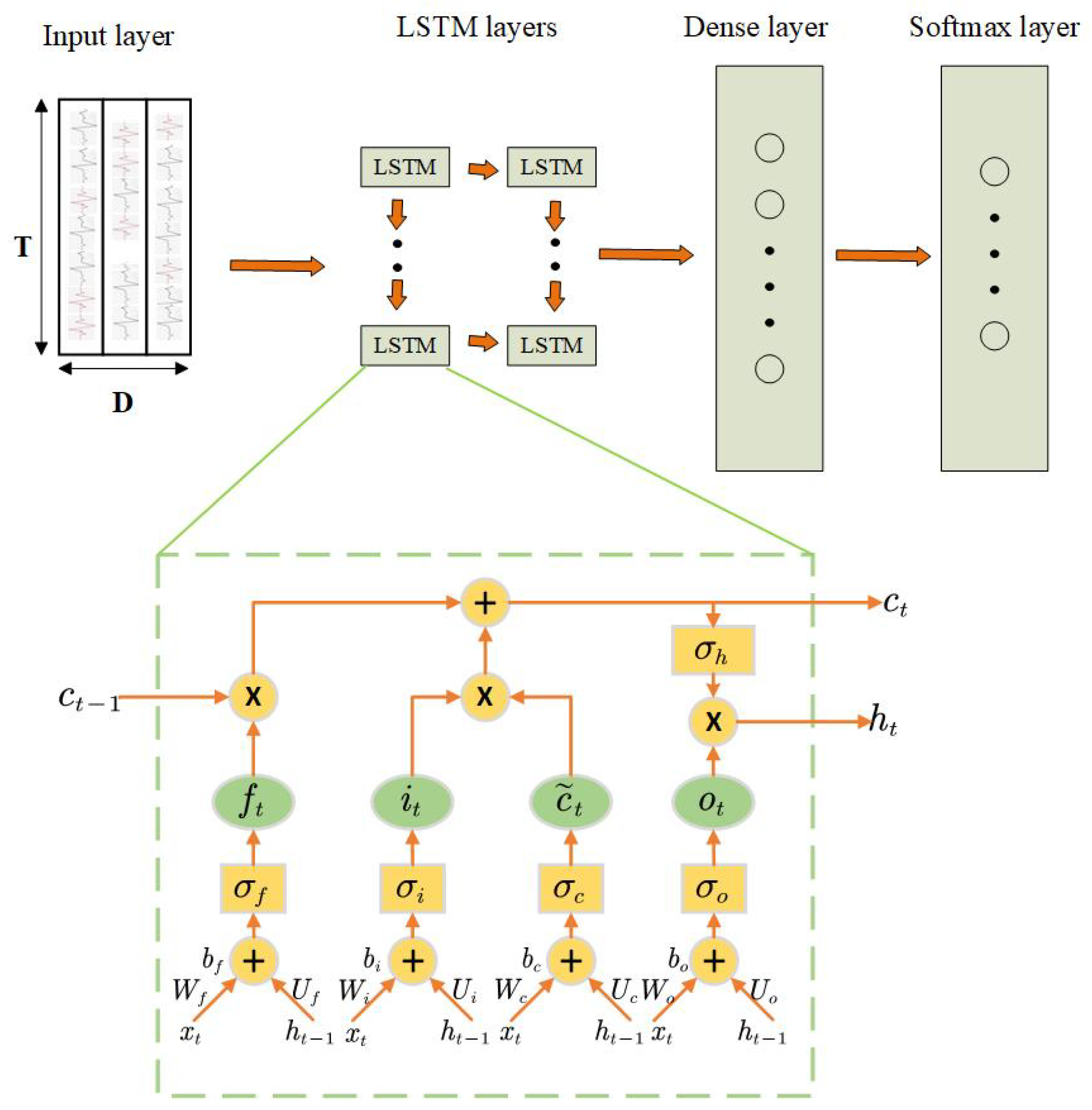
2.1.6. Recurrent Neural Networks and Long-Short Term Memory Networks
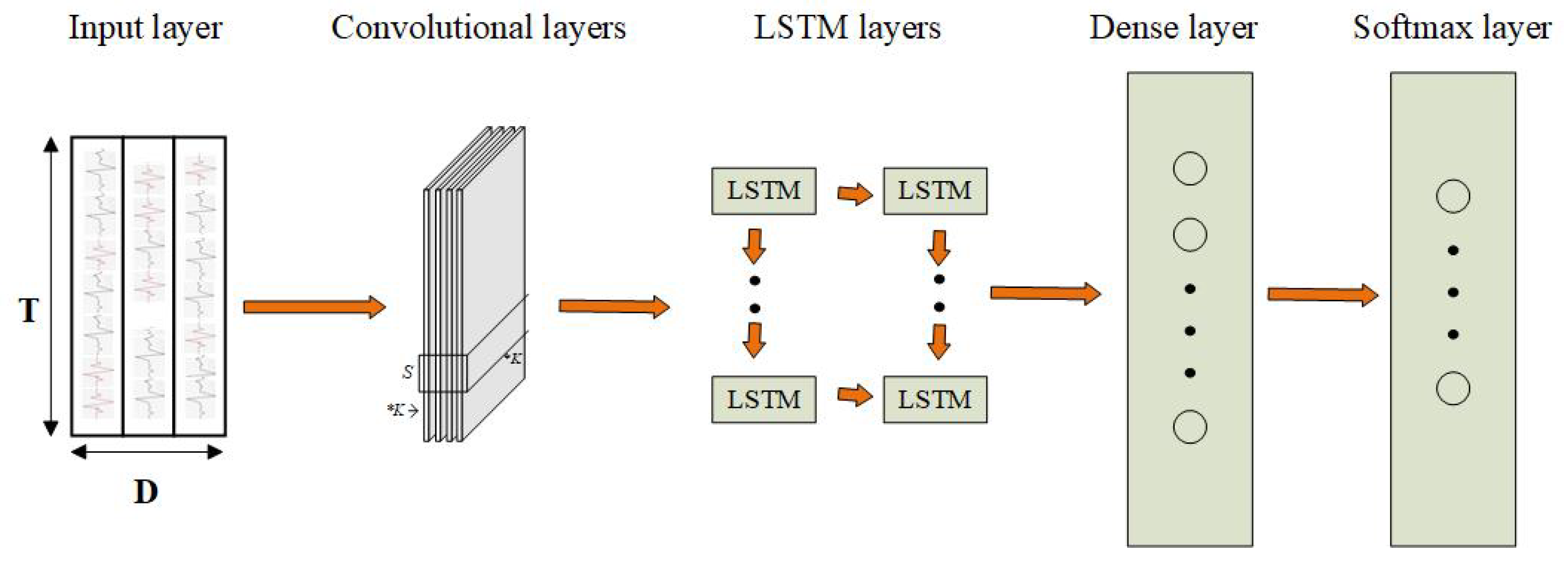
2.1.7. Hybrid Convolutional and Recurrent Networks
2.1.8. Deep Residual Learning
3. Asymmetric Residual Network
3.1. Network Architecture
3.2. Narrow Path
3.3. Wide Path
3.4. Lateral Concatenation
3.5. Loss Function
4. Experiments
4.1. Dataset
4.2. Baseline
4.3. Implementation and Setting
4.4. Performance Measure
4.5. Results and Discussion
4.6. Hyper-Parameter Evaluation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sukor, A.S.A.; Zakaria, A.; Rahim, N.A.; Kamarudin, L.M.; Setchi, R.; Nishizaki, H. A hybrid approach of knowledge-driven and data-driven reasoning for activity recognition in smart homes. J. Intell. Fuzzy Syst. 2019, 36, 4177–4188. [Google Scholar] [CrossRef]
- Xiao, Z.; Lim, H.B.; Ponnambalam, L. Participatory Sensing for Smart Cities: A Case Study on Transport Trip Quality Measurement. IEEE Trans. Ind. Inform. 2017, 13, 759–770. [Google Scholar] [CrossRef]
- Fortino, G.; Ghasemzadeh, H.; Gravina, R.; Liu, P.X.; Poon, C.C.Y.; Wang, Z. Advances in multi-sensor fusion for body sensor networks: Algorithms, architectures, and applications. Inf. Fusion 2019, 45, 150–152. [Google Scholar] [CrossRef]
- Qiu, J.X.; Yoon, H.; Fearn, P.A.; Tourassi, G.D. Deep Learning for Automated Extraction of Primary Sites From Cancer Pathology Reports. IEEE J. Biomed. Health Inform. 2018, 22, 244–251. [Google Scholar] [CrossRef] [PubMed]
- Oh, I.; Cho, H.; Kim, K. Playing real-time strategy games by imitating human players’ micromanagement skills based on spatial analysis. Expert Syst. Appl. 2017, 71, 192–205. [Google Scholar] [CrossRef]
- Lisowska, A.; O’Neil, A.; Poole, I. Cross-cohort Evaluation of Machine Learning Approaches to Fall Detection from Accelerometer Data. In Proceedings of the 11th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2018)—Volume 5: HEALTHINF, Funchal, Madeira, Portugal, 19–21 January 2018; pp. 77–82. [Google Scholar] [CrossRef]
- Attal, F.; Mohammed, S.; Dedabrishvili, M.; Chamroukhi, F.; Oukhellou, L.; Amirat, Y. Physical Human Activity Recognition Using Wearable Sensors. Sensors 2015, 15, 31314–31338. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S. Activity recognition using cell phone accelerometers. SIGKDD Explor. 2010, 12, 74–82. [Google Scholar] [CrossRef]
- Bao, L.; Intille, S.S. Activity Recognition from User-Annotated Acceleration Data. In Proceedings of the Pervasive Computing, Second International Conference—PERVASIVE 2004, Vienna, Austria, 21–23 April 2004; pp. 1–17. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Englebienne, G.; de Toledo, P.; van Kasteren, T.; Sanchis, A.; Kröse, B.J.A. In-Home Activity Recognition: Bayesian Inference for Hidden Markov Models. IEEE Pervasive Comput. 2014, 13, 67–75. [Google Scholar] [CrossRef]
- Ramamurthy, S.R.; Roy, N. Recent trends in machine learning for human activity recognition—A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8. [Google Scholar] [CrossRef]
- Gu, F.; Khoshelham, K.; Valaee, S.; Shang, J.; Zhang, R. Locomotion Activity Recognition Using Stacked Denoising Autoencoders. IEEE Internet Things J. 2018, 5, 2085–2093. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Shirahama, K.; Grzegorzek, M. On the Generality of Codebook Approach for Sensor-Based Human Activity Recognition. Electronics 2017, 6, 44. [Google Scholar] [CrossRef]
- Van Gemert, J.C.; Veenman, C.J.; Smeulders, A.W.M.; Geusebroek, J. Visual Word Ambiguity. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1271–1283. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Raymond, O.I.; Sun, W.; Long, J. Deep Attention-Guided Hashing. IEEE Access 2019, 7, 11209–11221. [Google Scholar] [CrossRef]
- Sarkar, A.; Dasgupta, S.; Naskar, S.K.; Bandyopadhyay, S. Says Who? Deep Learning Models for Joint Speech Recognition, Segmentation and Diarization. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing, Calgary, AB, Canada, 15–20 April 2018; pp. 5229–5233. [Google Scholar] [CrossRef]
- Kumar, A.; Irsoy, O.; Ondruska, P.; Iyyer, M.; Bradbury, J.; Gulrajani, I.; Zhong, V.; Paulus, R.; Socher, R. Ask Me Anything: Dynamic Memory Networks for Natural Language Processing. In Proceedings of the 33nd International Conference on Machine Learning, New York City, NY, USA, 19–24 June 2016; pp. 1378–1387. [Google Scholar]
- Shi, Z.; Zhang, J.A.; Xu, R.; Fang, G. Human Activity Recognition Using Deep Learning Networks with Enhanced Channel State Information. In Proceedings of the IEEE Global Communications Conference, Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Xu, W.; Pang, Y.; Yang, Y.; Liu, Y. Human Activity Recognition Based On Convolutional Neural Network. In Proceedings of the 24th International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; pp. 165–170. [Google Scholar] [CrossRef]
- Hammerla, N.Y.; Halloran, S.; Plötz, T. Deep, Convolutional, and Recurrent Models for Human Activity Recognition Using Wearables. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 1533–1540. [Google Scholar]
- Neverova, N.; Wolf, C.; Lacey, G.; Fridman, L.; Chandra, D.; Barbello, B.; Taylor, G.W. Learning Human Identity From Motion Patterns. IEEE Access 2016, 4, 1810–1820. [Google Scholar] [CrossRef]
- Yang, J.; Nguyen, M.N.; San, P.P.; Li, X.; Krishnaswamy, S. Deep Convolutional Neural Networks on Multichannel Time Series for Human Activity Recognition. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 3995–4001. [Google Scholar]
- Yang, Z.; Raymond, O.I.; Zhang, C.; Wan, Y.; Long, J. DFTerNet: Towards 2-bit Dynamic Fusion Networks for Accurate Human Activity Recognition. IEEE Access 2018, 6, 56750–56764. [Google Scholar] [CrossRef]
- Ronao, C.A.; Cho, S. Deep Convolutional Neural Networks for Human Activity Recognition with Smartphone Sensors. In Proceedings of the Neural Information Processing—22nd International Conference, Istanbul, Turkey, 9–12 November 2015; pp. 46–53. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Milenkoski, M.; Trivodaliev, K.; Kalajdziski, S.; Jovanov, M.; Stojkoska, B.R. Real time human activity recognition on smartphones using LSTM networks. In Proceedings of the 41st International Convention on Information and Communication Technology, Electronics and Microelectronics, Opatija, Croatia, 21–25 May 2018; pp. 1126–1131. [Google Scholar] [CrossRef]
- Meng, B.; Liu, X.; Wang, X. Human action recognition based on quaternion spatial-temporal convolutional neural network and LSTM in RGB videos. Multimed. Tools Appl. 2018, 77, 26901–26918. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques, 3rd ed.; Morgan Kaufmann: Burlington, MA, USA, 2011. [Google Scholar]
- Morales, F.J.O.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef]
- Baldi, P.; Sadowski, P.J. A theory of local learning, the learning channel, and the optimality of backpropagation. Neural Netw. 2016, 83, 51–74. [Google Scholar] [CrossRef] [Green Version]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1310–1318. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Pinz, A.; Wildes, R.P. Spatiotemporal Residual Networks for Video Action Recognition. In Proceedings of the Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; pp. 3468–3476. [Google Scholar]
- Wang, X.; Girshick, R.B.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar] [CrossRef]
- Li, F.; Shirahama, K.; Nisar, M.A.; Köping, L.; Grzegorzek, M. Comparison of Feature Learning Methods for Human Activity Recognition Using Wearable Sensors. Sensors 2018, 18, 679. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. arXiv 2018, arXiv:1812.03982. [Google Scholar]
- Roggen, D.; Calatroni, A.; Rossi, M.; Holleczek, T.; Förster, K.; Tröster, G.; Lukowicz, P.; Bannach, D.; Pirkl, G.; Ferscha, A.; et al. Collecting complex activity datasets in highly rich networked sensor environments. In Proceedings of the Seventh International Conference on Networked Sensing Systems, Kassel, Germany, 15–18 June 2010; pp. 233–240. [Google Scholar] [CrossRef]
- Micucci, D.; Mobilio, M.; Napoletano, P. UniMiB SHAR: A new dataset for human activity recognition using acceleration data from smartphones. arXiv 2016, arXiv:1611.07688. [Google Scholar]
- Baños, O.; García, R.; Terriza, J.A.H.; Damas, M.; Pomares, H.; Ruiz, I.R.; Saez, A.; Villalonga, C. mHealthDroid: A Novel Framework for Agile Development of Mobile Health Applications. In Proceedings of the Ambient Assisted Living and Daily Activities—6th International Work-Conference, Belfast, UK, 2–5 December 2014; pp. 91–98. [Google Scholar] [CrossRef]
- Reiss, A.; Stricker, D. Creating and benchmarking a new dataset for physical activity monitoring. In Proceedings of the 5th International Conference on PErvasive Technologies Related to Assistive Environments, Heraklion, Greece, 6–9 June 2012; p. 40. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Yang, Z.; He, X.; Gao, J.; Deng, L.; Smola, A.J. Stacked Attention Networks for Image Question Answering. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 21–29. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Manual f. | High-Level f. | Spatial f. | Temporal f. | Unsupervised | Supervised |
|---|---|---|---|---|---|---|
| HC [11] | ✓ | × | × | × | ✓ | × |
| CBH [14] | ✓ | × | × | × | ✓ | × |
| CBS [15] | ✓ | × | × | × | ✓ | × |
| AE [12] | ✓ | × | × | × | ✓ | × |
| MLP [13] | ✓ | × | × | × | ✓ | × |
| CNN [20] | × | ✓ | × | × | ✓ | ✓ |
| LSTM [27] | × | ✓ | × | × | × | ✓ |
| Hybrid [28] | ✓ | ✓ | × | × | × | ✓ |
| ResNet [26] | ✓ | ✓ | × | × | ✓ | ✓ |
| ARN (this work) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Stage | Narrow Path | Wide Path |
|---|---|---|
| Conv1 | ||
| Max-pooling | /2 | /2 |
| res1 | ||
| res2 | ||
| res3 | ||
| res4 | ||
| concate | global average pool | global average pool |
| fc. | 512 | 512 |
| Datasets | OPPORTUNITY | UniMiB-SHAR |
|---|---|---|
| Types of sensors | Custom bluetooth wireless accelerometers, gyroscopes, Sun SPOTs and InertiaCube3, Ubisense localization system, a custom-made magnetic field sensor | A Bosh BMA220 acceleration sensor |
| Number of sensors | 72 | 3 |
| Number of samples | 473 K | 11,771 |
| Acquisition periods | 10–20 (min) | 0.6 (min) |
| Class | Proportion | Class | Proportion |
|---|---|---|---|
| Open Door 1/2 | 1.87%/1.26% | Open Fridge | 1.60% |
| Close Door 1/2 | 6.15%/1.54% | Close Fridge | 0.79% |
| Open Dishwasher | 1.85% | Close Dishwasher | 1.32% |
| Open Drawer 1/2/3 | 1.09%/1.64%/0.94% | Clean Table | 1.23% |
| Close Drawer 1/2/3 | 0.87%1.69%/2.04% | Drink from Cup | 1.07% |
| Toggle Switch | 0.78% | NULL | 72.28% |
| Class | Proportion | Class | Proportion |
|---|---|---|---|
| StandingUpfromSitting | 1.30% | Walking | 14.77% |
| StandingUpfromLaying | 1.83% | Running | 16.86% |
| LyingDownfromStanding | 2.51% | Going Up | 7.82% |
| Jumping | 6.34% | Going Down | 11.25% |
| F(alling) Forward | 4.49% | F and Hitting Obstacle | 5.62% |
| F Backward | 4.47% | Syncope | 4.36% |
| F Right | 4.34% | F with ProStrategies | 4.11% |
| F Backward SittingChair | 3.69% | F Left | 4.54% |
| Sitting Down | 1.70% |
| Model | Parameters |
|---|---|
| AE | 5000 |
| 5000 | |
| MLP | 2000 |
| 2000 | |
| 2000 | |
| CNN | ((11,1),(1,1),50,(2,1)) |
| ((10,1),(1,1),40,(3,1)) | |
| ((6,1),(1,1),30,(1,1)) | |
| 1000 | |
| LSTM | (64,600) |
| (64,600) | |
| 512 | |
| Hybrid | ((11,1),(1,1),50,(2,1)) |
| (27,600) | |
| (27,600) | |
| 512 |
| Method | T (Time Window) | OPPORTUNITY | UniMiB-SHAR |
|---|---|---|---|
| HC [11] | 32 | 84.95 | 22.83 |
| 64 | 85.56 | 22.19 | |
| 96 | 85.69 | 21.96 | |
| CBH [14] | 32 | 84.37 | 64.51 |
| 64 | 85.21 | 65.03 | |
| 96 | 84.66 | 64.36 | |
| CBS [15] | 32 | 85.53 | 67.54 |
| 64 | 86.01 | 67.97 | |
| 96 | 85.39 | 67.36 | |
| AE [12] | 32 | 82.87 | 68.37 |
| 64 | 84.54 | 68.24 | |
| 96 | 83.39 | 68.39 | |
| MLP [13] | 32 | 87.32 | 73.33 |
| 64 | 87.34 | 75.36 | |
| 96 | 86.65 | 74.82 | |
| CNN [20] | 32 | 87.51 | 74.01 |
| 64 | 88.03 | 73.04 | |
| 96 | 87.62 | 73.36 | |
| LSTM [27] | 32 | 85.33 | 69.24 |
| 64 | 86.89 | 69.49 | |
| 96 | 86.21 | 68.81 | |
| Hybrid [28] | 32 | 87.91 | 73.19 |
| 64 | 88.17 | 73.22 | |
| 96 | 87.67 | 72.26 | |
| ResNet [26] | 32 | 88.91 | 76.19 |
| 64 | 89.17 | 76.22 | |
| 96 | 87.67 | 75.26 | |
| ARN | 32–96 (n)-(w) | 90.29 | 76.39 |
| Method | T (n)-(w) (Time Window) | OPPORTUNITY | UniMiB-SHAR |
|---|---|---|---|
| ARN_1 | 32–64 | 90.21 | 77.23 |
| ARN_2 | 32–96 | 90.29 | 76.39 |
| ARN_3 | 64–96 | 90.19 | 76.04 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Long, J.; Sun, W.; Yang, Z.; Raymond, O.I. Asymmetric Residual Neural Network for Accurate Human Activity Recognition. Information 2019, 10, 203. https://doi.org/10.3390/info10060203
Long J, Sun W, Yang Z, Raymond OI. Asymmetric Residual Neural Network for Accurate Human Activity Recognition. Information. 2019; 10(6):203. https://doi.org/10.3390/info10060203
Chicago/Turabian StyleLong, Jun, Wuqing Sun, Zhan Yang, and Osolo Ian Raymond. 2019. "Asymmetric Residual Neural Network for Accurate Human Activity Recognition" Information 10, no. 6: 203. https://doi.org/10.3390/info10060203
APA StyleLong, J., Sun, W., Yang, Z., & Raymond, O. I. (2019). Asymmetric Residual Neural Network for Accurate Human Activity Recognition. Information, 10(6), 203. https://doi.org/10.3390/info10060203