GOTRIPLE: A User-Centric Process to Develop a Discovery Platform

 ,
,  , ,
, ,
Abstract
:1. Introduction
2. Results
3. Methods
3.1. Methods for Result 1: Definition of the Main Features of the GOTRIPLE Platform
3.1.1. A User-Centric Approach
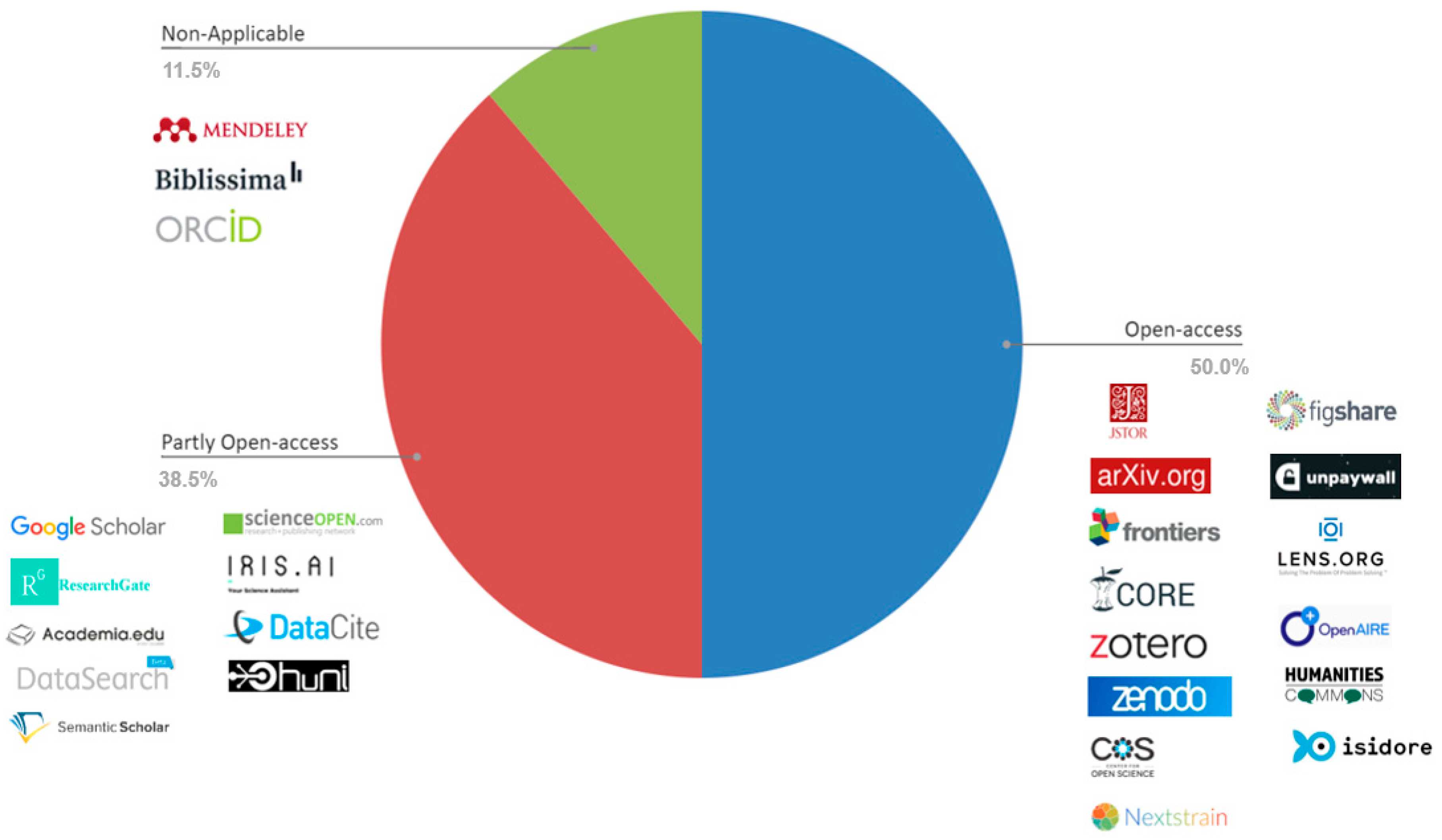
3.1.2. Market Analysis and Benchmark Activities
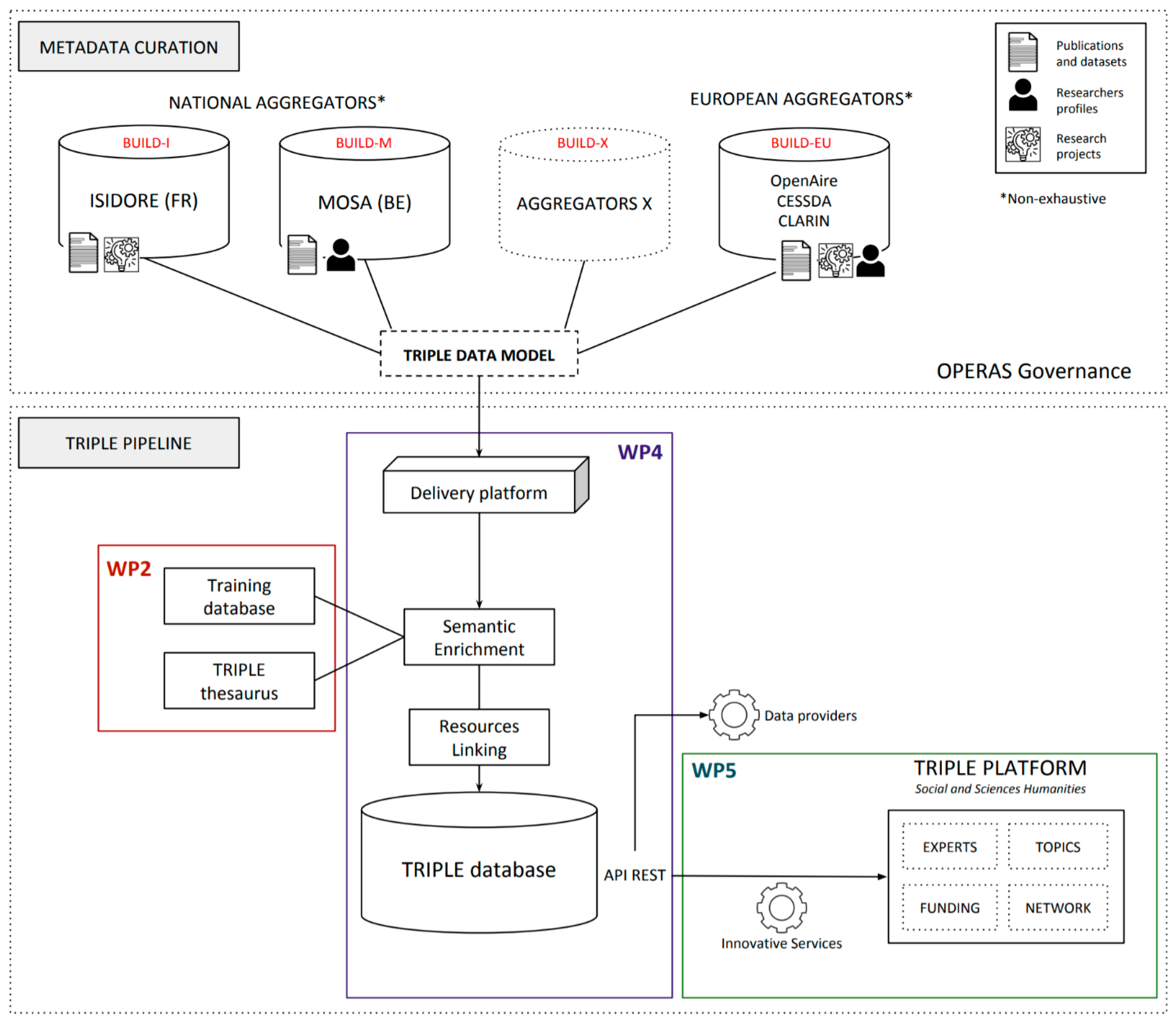
3.2. Method for Result 2: Interoperability of the GOTRIPLE Platform with the EOSC
3.3. Methods for Result 3: A Multilingual, Multidisciplinary and Multicultural Platform
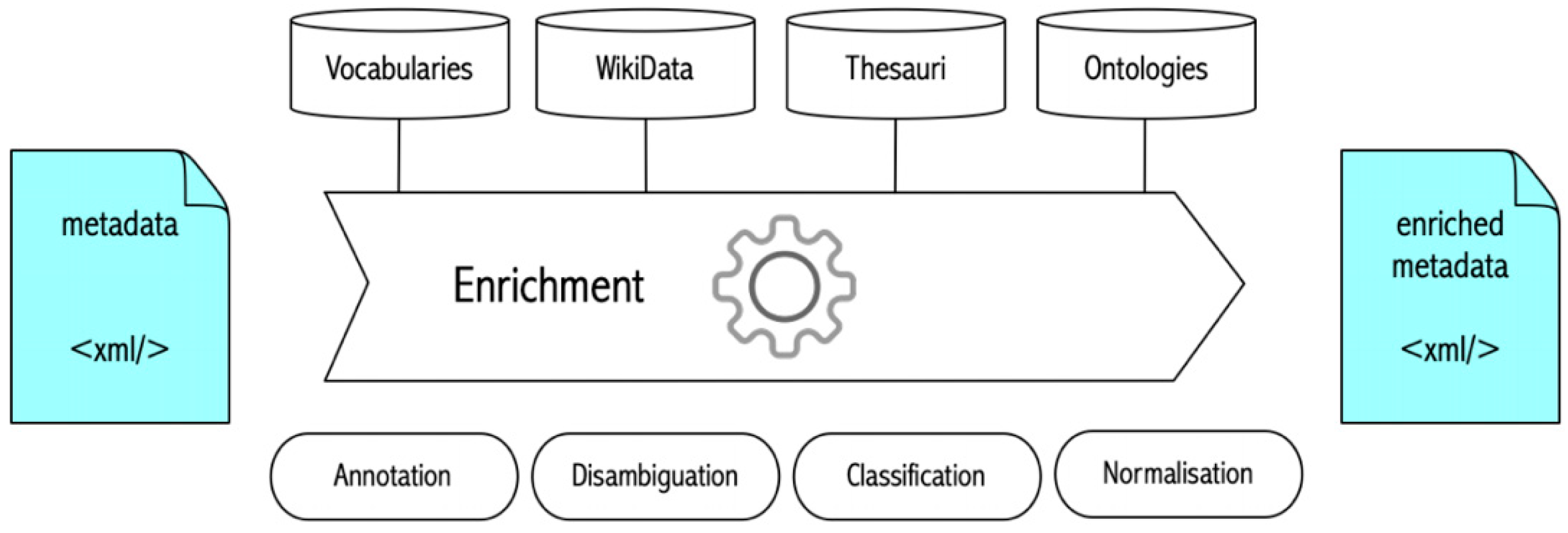
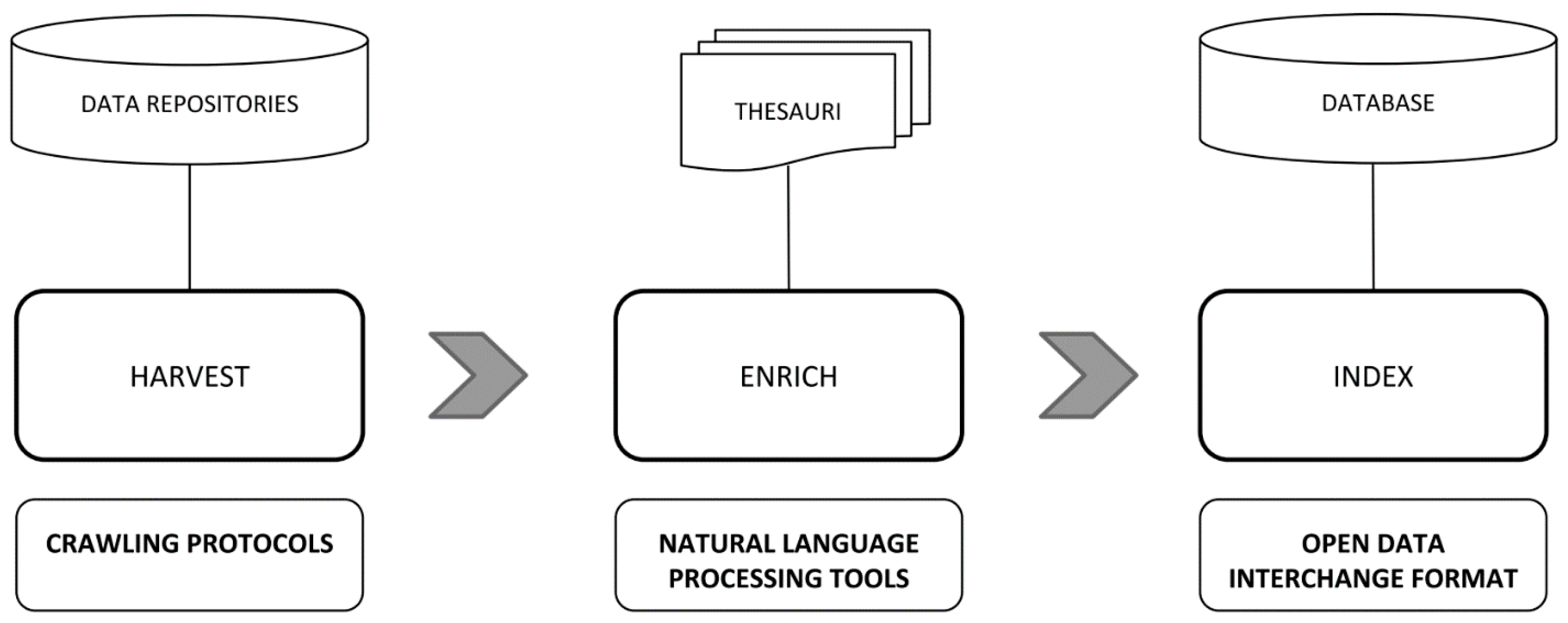
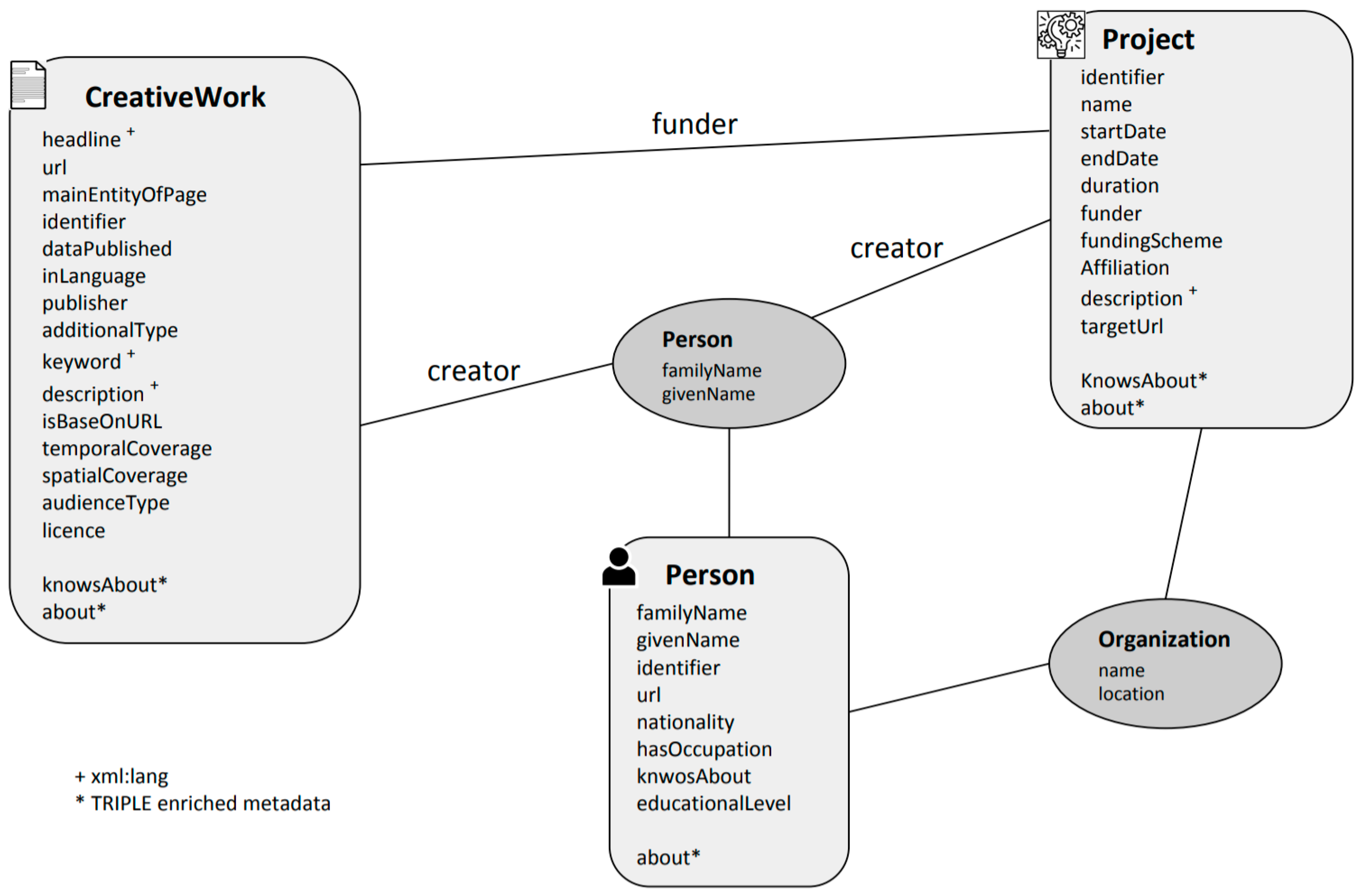
3.3.1. Advance Approach for Metadata Enrichment
- classification based on a training scholarly article database and using advanced methods based on statistics and language analysis;
- normalization using thesauri;
- semantic annotations with a disambiguation tool using thesauri and the Wikidata database.
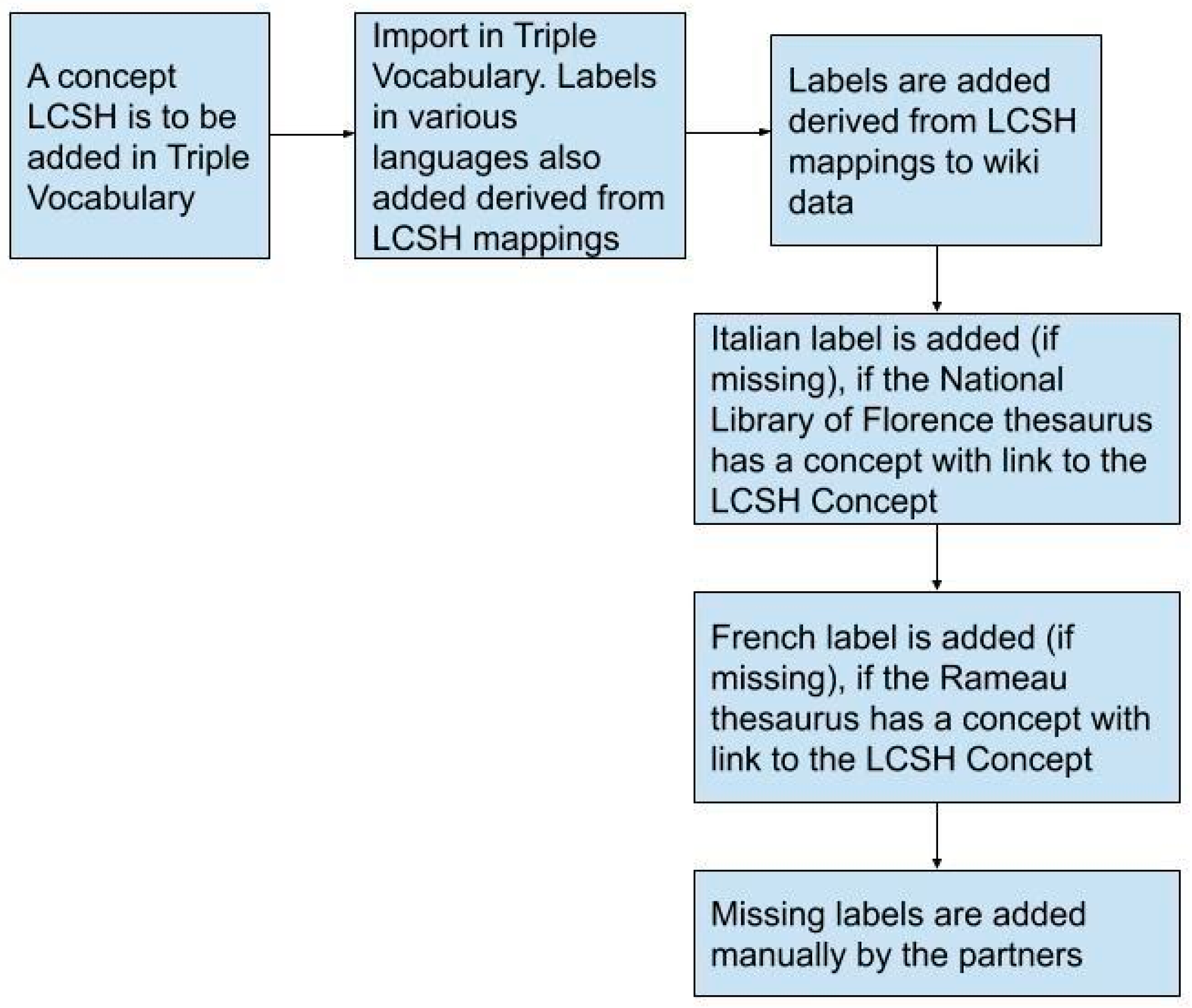
3.3.2. Vocabulary Alignment
3.3.3. Thesauri Alignment
4. Materials
4.1. Diversity of Materials for the Identification of GOTRIPLE Features
4.1.1. Personas and Scenarios
- 7.1 The user shall be able to Search ordering by ‘impact’
- 7.2 The user shall be able to Search by most recent publication
- 7.3 The user shall be able to Search for Projects
- 7.4 The user shall be able to Search for presentations (slides/video format)
- 7.5 The user shall be able to View academic profile
- 7.6 The user shall be able to see contact details of an academic
- 7.7 The user shall be able to View amount of funding crowd-funding calls obtained
- 5.1 The user shall be able to Obtain tailored search results
- 5.2 The user shall be able to View an ‘Article Overview’ for a publication
- 5.3 The user shall be able to Share an individual file
- 5.4 The user shall be able to Share a folder
- 5.5 The user shall be able to Tag a dataset
- 5.6 The user shall be able to Color-code a file/dataset
- 5.7 The user shall be able to Download a single publication
- 5.8 The user shall be able to get an overview of a research topic
- 5.9 The user shall be able to get a visual representation of research topics
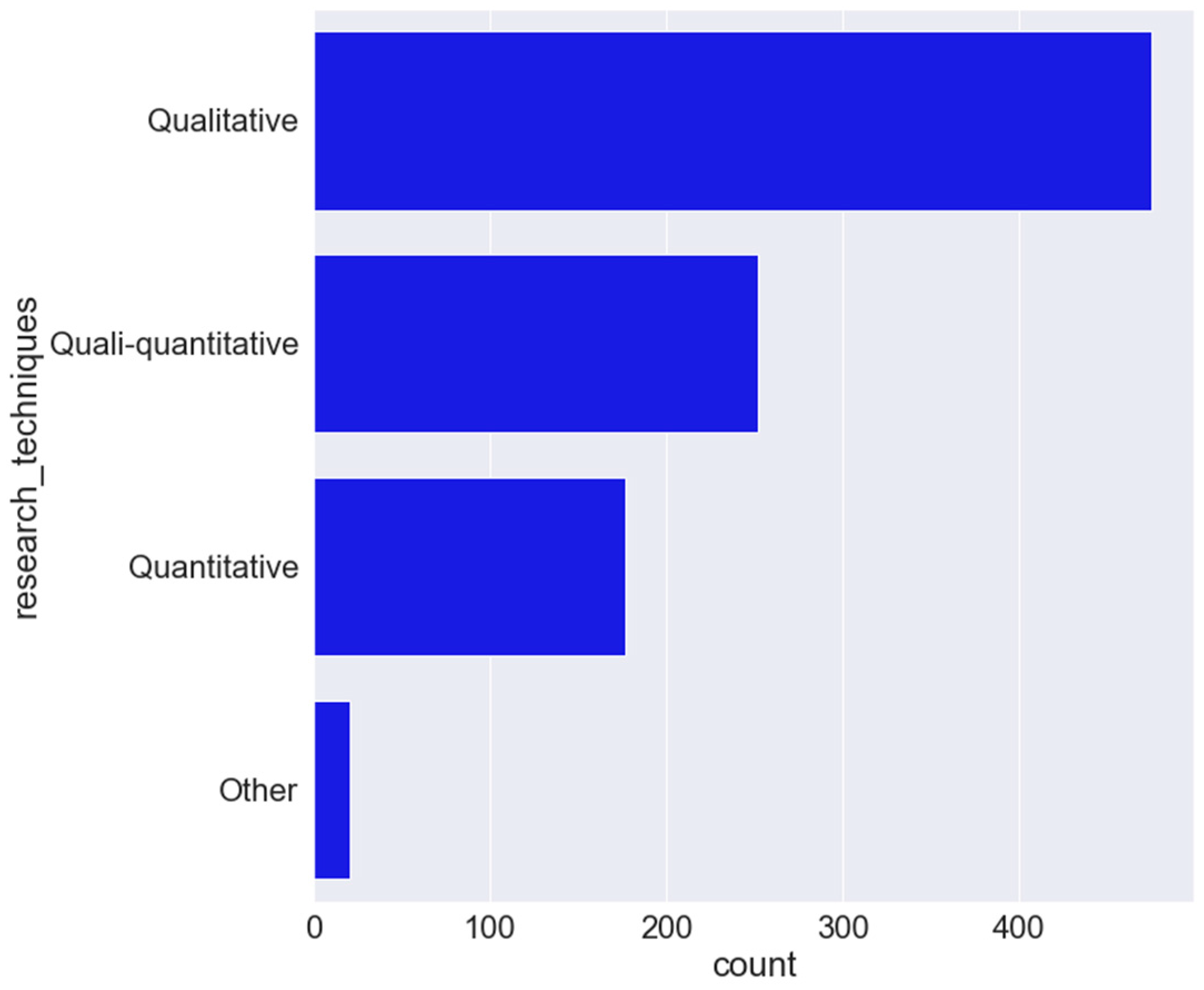
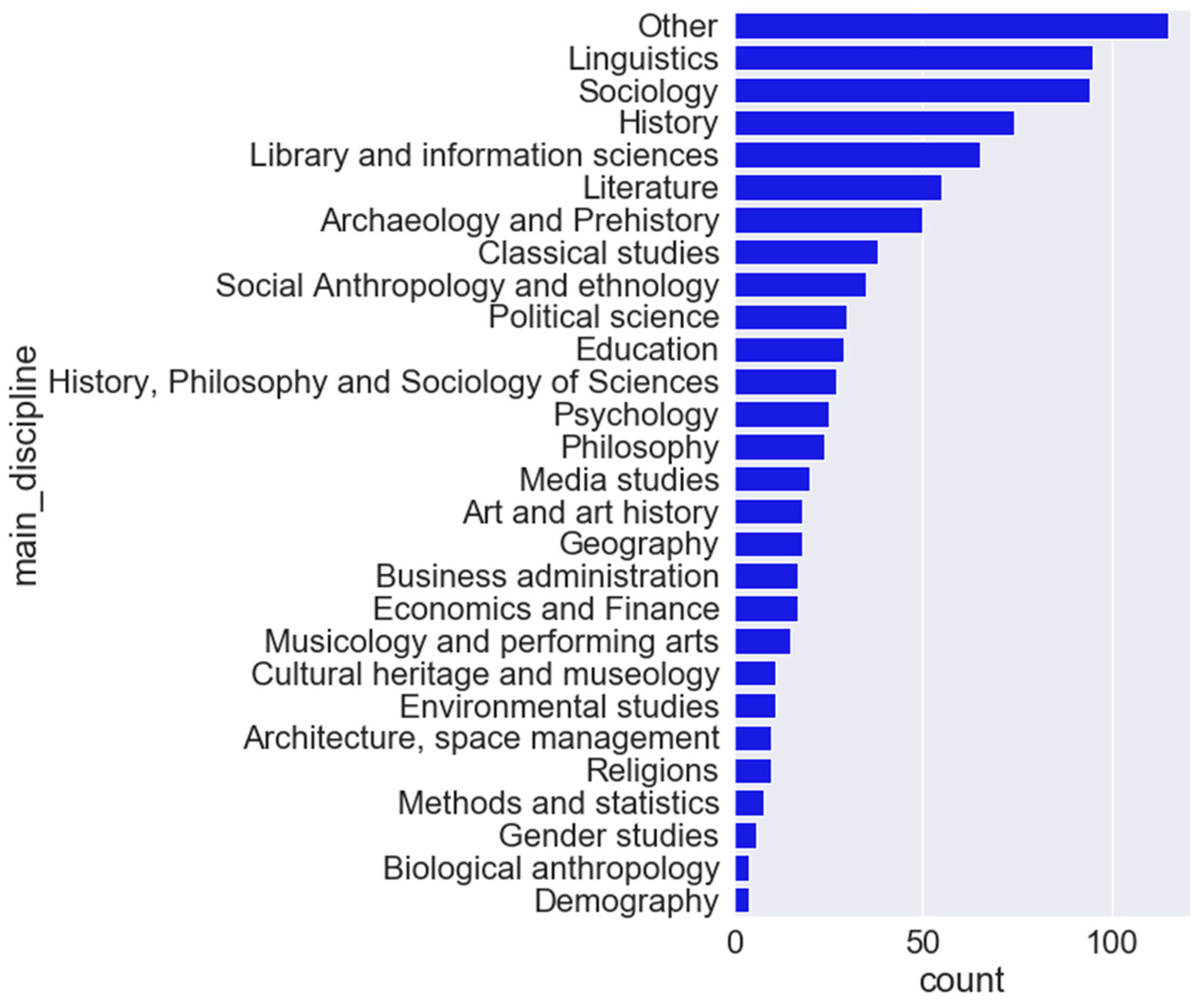
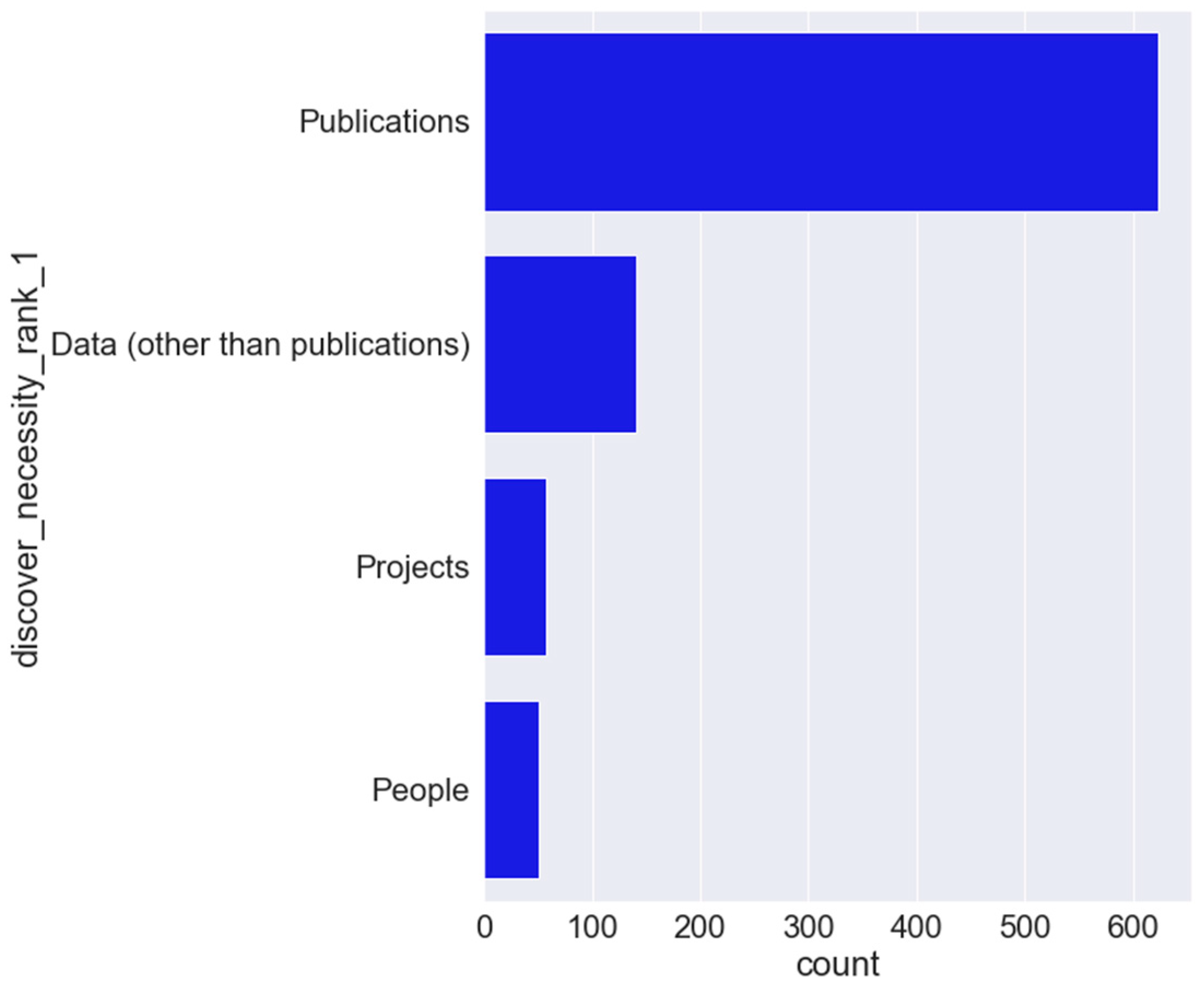
4.1.2. End-User Questionnaire
4.1.3. Market Analysis and Benchmark Activities
4.2. Materials for the Interoperability of the GOTRIPLE Platform with the EOSC
4.3. Materials for Having a Multilingual, Interdisciplinary and Multicultural Discovery Platform
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- European Commission. Open Innovation, Open Science, Open to the World: A Vision for Europe; Directorate-General for Research and Innovation, European Commission: Brussels, Belgium, 2016. [Google Scholar] [CrossRef]
- OECD. Making Open Science a Reality. In Science, Technology and Industry Policy Papers, 25; OECD Publishing: Paris, France, 2015. [Google Scholar]
- De la Fuente, G.B. What Is Open Science? Introduction. Available online: https://www.fosteropenscience.eu/content/what-open-science-introduction (accessed on 30 September 2020).
- Wenger, E. Communities of Practice: Learning, Meaning, and Identity; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar] [CrossRef]
- Norman, D.A. The psychology of everyday things. In Basic Books; American Psychological Association: Washington, DC, USA, 1988. [Google Scholar]
- Edwards, R.; Holland, J. What Is Qualitative Interviewing? A&C Black: London, UK, 2013. [Google Scholar]
- Marshall, B.; Cardon, P.; Poddar, A.; Fontenot, R. Does sample size matter in qualitative research? A review of qualitative interviews in IS research. J. Comput. Inf. Syst. 2013, 54, 11–22. [Google Scholar] [CrossRef]
- Braun, V.; Clarke, V. Using thematic analysis in psychology. Qual. Res. Psychol. 2006, 3, 77–101. [Google Scholar] [CrossRef] [Green Version]
- Forbes, P.; De Paoli, S.; Błaszczyńska, M.; Maryl, M. TRIPLE Deliverable: D3.1 Report on User Needs (Version Draft). Zenodo 2020. [Google Scholar] [CrossRef]
- Kensing, F.; Blomberg, J. Participatory design: Issues and concerns. Comput. Supported Coop. Work 1998, 7, 167–185. [Google Scholar] [CrossRef]
- Breitfuss, G.; Barreiros, C.; Dumouchel, S.; Blotière, E.; Bouillard, M.; Di Donato, F.; Forbes, P. TRIPLE Deliverable: D7.1 Report on Stakeholder and Opportunity Analysis (Version Draft). Zenodo 2020. [Google Scholar] [CrossRef]
- Cooper, A.; Reimann, R.; Cronin, D. About Face 3: The Essentials of Interaction Design; John Wiley and Sons: Hoboken, NJ, USA, 2007. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Competitor Platform | Type of Platform | Alexa Site Rank |
|---|---|---|
| Google Scholar | academic search engine | 1 |
| Researchgate | science-oriented social media | 165 |
| Academia.edu | science-oriented social media | 238 |
| Elsevier Data Search | academic search engines | 6292 |
| Semantic Scholar | academic search engines | 1124 |
| JSTOR | search engines and directories for OA (Open Access) resources | 1247 |
| arXiv.org | search engines and directories for OA resources | 2129 |
| Frontiers | academic search engines | 3641 |
| Mendeley | science-oriented social media | 4169 |
| ORCID | multidisciplinary academic databases | 5151 |
| CORE | search engines and directories for OA resources | 5660 |
| Zotero | science-oriented social media | 13,117 |
| zenodo | Repositories—institutional or subject | 50,563 |
| Center of Open Science | dissemination platform | 58,660 |
| Nextstrain | disciplinary academic database | 62,172 |
| figshare | repositories—institutional or subject | 71,192 |
| ScienceOpen | dissemination platform | 212,714 |
| unpaywall | search engines and directories for OA resources | 220,255 |
| Lens.org | academic search engines | 311,403 |
| OpenAIRE Explore | repositories—institutional or subject | 369,908 |
| Humanities commons | science-oriented social media | 383,307 |
| DataCite | multidisciplinary academic databases | 407,533 |
| Iris.ai | academic search engines | 619,629 |
| Isidore | academic search engines | 1,523,750 |
| Biblissima | shadow library | 4,535,602 |
| huni | library catalogues and discovery systems | n.a |
| BASIC DESCRIPTION |
| Platform Name: Site URL: Platform Logo: |
| Origin of platform provider/operator. |
| Short description of platform (Mission, Vision, etc.) |
| Overview on Offerings (Services, Products, Features, Functions) |
| Size of the platform (Number of users/documents etc.) |
| Focus (regional, geographic, specific research domains or target groups, language versions) |
| Organization Insights (board, team, legal form etc.) |
| Financing (type of revenue streams, budget figures, cost factors) |
| Marketing/Dissemination |
| Partners and Stakeholders |
| DETAILED CONTENT DESCRIPTION |
| Most relevant functions and features (Please indicate main functions and features and describe with screenshots and short explanations) |
| Value add of platform for stakeholders (What feature/function is unique/outstanding? What add on benefits does the platform offer? How would you describe the Unique Selling Proposition of the platform?) |
| USABILITY/UX |
| Clearly and understandable symbols and wording? |
| User Orientation—Can I navigate within the platform with relative ease? |
| Design of user interface—Clear arranged, not confusing. Is the interface well organized, logically laid out, ease to navigate—or is it the opposite (cluttered, illogical, complicated)? |
| User motivation—Are users motivated to use the platform more often, if yes, how? |
| Learnings concerning usability/UX for TRIPLE—What should we transfer to TRIPLE, what should we avoid? |
| SUMMARY and CONCLUSION |
| Strengths and Weaknesses |
| Personal rating (1 = very bad, 10 = best in class) |
| Relevance for consideration within TRIPLE—What can we learn or should take into consideration for TRIPLE Platform? |
| Type | Competitor Platform | Search and Filter | Recommendation | Social | Annotation Tools | Visual Discovery |
|---|---|---|---|---|---|---|
| Academic search engine | Google Scholar | Yes | Yes | Partly | ||
| Elsevier Data Search | Yes | |||||
| Semantic Scholar | Yes | Yes | ||||
| Frontiers | Yes | Yes | Partly | |||
| Lens.org | Yes | Yes | ||||
| Iris.ai | Yes | Yes | ||||
| Isidore | Yes | Yes | Partly | |||
| Search engines and directories for OA resources | JSTOR | Yes | Yes | |||
| arXiv.org | Yes | Yes | Partly | Partly | ||
| CORE | Yes | Yes | ||||
| unpaywall | Yes | Yes | ||||
| Science-oriented social media | Researchgate | Yes | Yes | Yes | ||
| Academia.edu | Yes | Yes | Yes | |||
| Mendeley | Yes | Yes | Yes | Yes | ||
| Zotero | Yes | Yes | Yes | |||
| Humanities commons | Yes | Yes | Yes | |||
| Dissemination platform | Center of Open Science | Yes | Yes | |||
| ScienceOpen | Yes | Yes | ||||
| Repositories - institutional or subject | zenodo | Yes | Yes | |||
| figshare | Yes | Partly | ||||
| OpenAIRE Explore | Yes | |||||
| Multidisciplinary academic databases | ORCID | Yes | ||||
| DataCite | Yes | Partly | ||||
| Nextstrain | Yes | Partly | ||||
| Library catalogues and discovery systems | huni | Yes | Partly | |||
| Shadow library | Biblissima | Yes | Yes |
| EOSC Working Group | Analysed Reports |
|---|---|
| FAIR | Turning FAIR into reality |
| The final report and action plan from the European Commission Expert Group on FAIR Data of 2018, setting up the conditions to data FAIRness. | |
| FAIR metrics for EOSC (Provisional) (February 2020) | |
| The document reports on the activities of the RDA (Research Data Alliance) WG (Working Group) on the FAIR data maturity model, the FAIRsFAIR project, and more focused works (e.g., FAIR software). The FAIR metrics and the FAIR assessment tools are intended to guide progression towards FAIRness—which partly contradicts the fact that the FAIR metrics will also be part of the FAIR certification: are the FAIR metrics an auto-assessment tool or a technical requirement to be part of the EOSC? The report contains a list of FAIR data indicators which will be detailed by the WG in a future work. | |
| EOSC service certification for FAIR outputs (Provisional) (February 2020) | |
| The draft report mainly suggests using the CoreTrustSeal certification for repositories as a tool to build a FAIR ecosystem. The certification could then be used to establish a «European Network of trustworthy repositories». It is planned to combine the certification with the FAIR metrics. The document contains reports on various workshops and surveys organized by the FAIR WG and the project FAIRsFAIR which all seem to have a very provisional nature. | |
| PID (Persistent Identifier) (policy for EOSC (Second version) (May 2020) | |
| The draft report (final version planned for October 2020) provides definitions and recommendations for a sustainable PID infrastructure. It contains details on technical requirements, distribution of roles, and governance. The link with FAIR principles, and more precisely FDOs (FAIR Digital Object), is explicit. Not very precise is the nature of the “PID infrastructure” itself, partly because the actual target audience of the policy is unclear, partly because the responsibility of EOSC as a legal entity in this context is mentioned but not defined. | |
| Recommendations for Services in a FAIR Data Ecosystem (August 2020) | |
| The document reports on workshops co-organized by FAIRsFAIR, RDA Europe, OpenAIRE (European Open Science Infrastructure, for open scholarly and scientific communication), EOSC-hub, and FREYA. The recommendations address the FAIR principles from an ecosystemic point of view, considering that there is a lot of activity around the concept of FAIR data “but it is much less clear what should be expected from a data service in the FAIR data ecosystem”. The report thus analyzes the gaps, both for each actor of the ecosystem and between each of them (researchers, data stewards, service providers, etc.). A first workshop was held for “service providers and research infrastructures”, a second one with “research support staff and researchers”, each group defining its own recommendations. A third workshop established a prioritization process of the recommendations. Interestingly, the report notes that different skills have to be combined to realize a FAIR ecosystem (technical/domain expertise), and that there are some discrepancies between the “Turning FAIR into reality” report and the communities priorities, thus suggesting that the official roadmap for FAIRification could be reshaped through their insights. | |
| EOSC AAI (Authentication and Authorization Infrastructure) First Principles (April 2020) | |
| This report identifies three principles for EOSC AAI: (1) User experience is the only touchstone; (2) All trust flows from communities; (3) There is no center in a distributed system. | |
| These principles clearly state that the design of the EOSC AAI will be user centered, and the implementation will be a distributed architecture. | |
| EOSC AAI Architecture 2019 (June 2020)—This is a draft report, currently shared internally among the Working Group Members. | |
| This report captures the current status of the EOSC AAI architecture discussions that are based on the AARC Blueprint Architecture 2019 (Authentication and Authorisation for Research and Collaborations). It also identifies the challenges and the areas that require further work. | |
| The potential benefits are: Being a GOTRIPLE user, s/he can also access EOSC services. On the other hand, EOSC SSH (Social Sciences and Humanities) researchers and other Science communities’ users by default become GOTRIPLE users and are able to use the GOTRIPLE platform—this will enlarge the TRIPLE user-base and make TRIPLE more visible to European science communities. | |
| PID Architecture (draft) (June 2020) - | |
| This is a draft report, currently shared internally among the Working Group Members. | |
| This report describes the main components of a global PIC architecture microcontrollers of memory organization (ram,rom,stack), and the PID registration and resolution framework. It discusses some existing technology for implementing such a PID framework, and examples of the PID services. | |
| In GOTRIPLE, ORCID identifier (Open Researcher and Contributor ID) is adopted for data registration and processing, which is interoperable with the proposed EOSC PID Architecture. TRIPLE also closely interacts with relevant EOSC projects such as FREYA, a 3-year project collaborating with OpenAIRE Advance and EOSC-hub and focusing on developing a PID infrastructure for EOSC. |
| Project | Analysed Deliverables |
|---|---|
| EOSC-hub brings together multiple service providers to create the Hub: a single contact point for European researchers and innovators to discover, access, use and reuse a broad spectrum of resources for advanced data-driven research. | Deliverables related to Architecture WG D4.2 Operational Infrastructure Roadmap—relevant as it describes the guidelines for the actions that are to be taken in order to ensure interoperability at the level of EOSC-hub service catalogue which can be taken as lessons learned for the work in TRIPLE D5.3 1st Report on maintenance and integration of federation and collaboration services D6.2 First report on the maintenance and integration of common services D7.2 First report on Thematic Service architecture and software integration D10.3 Technical Architecture and standards roadmap v1—relevant as it gives examples how Research Enabling services benefit from diverse features of Access Enabling services when being incorporated within a unified Hub. D10.4 EOSC Hub Technical Architecture and standards roadmap v2—relevant for the TRIPLE plans for managing researchers’ identity D10.5 Requirements and gap analysis report v1 |
| FREYA is a 3-year project funded by the European Commission under the Horizon 2020 program. The project aims to extend the infrastructure for persistent identifiers (PIDs) as a core component of open research, in the EU and globally. FREYA will improve discovery, navigation, retrieval, and access to research resources. | D2.1 PID Resolution Services Best Practices—relevant for WP2 (Work Package dedicated to data acquisition) and WP4 D3.1 Survey of Current PID Services Landscape—relevant for WP2, especially to discuss the needs of a TRIPLE ID D3.2 Requirements for Selected New PID Services—relevant for TRIPLE WP2 and WP5, especially for the links to innovative service |
| OpenAIRE-Advance continues the mission of OpenAIRE to support the Open Access/Open Data mandates in Europe. By sustaining the current successful infrastructure, comprising a human network and robust technical services, it consolidates its achievements while working to shift the momentum among its communities to Open Science, aiming to be a trusted e-Infrastructure within the realms of the European Open Science Cloud. | D 4.2—A multi-module Open science kit—relevant for Task 6.3 as a preliminary work on Open Science training D 7.3. Interoperability with Research Infrastructures—relevant as it highlights how the work that focuses on services built on the basis of Open Science publishing practices supports cross-community communication and collaboration. Moreover, this deliverable allows the drawing of a distinction between the OpenAIRE services and the implemented and envisaged ones of the TRIPLE project. |
| EOSC Enhance project is committed to improve the EOSC Portal by making it the added value one-stop shop/entry point for the EOSC users and stakeholders, by enabling easy access to EOSC resources such as services, data, scientific products and other resources to European scientists. | D 2.2 EOSC Processes Development and Consensus D 2.4: EOSC Service Catalogue Analysis—relevant for TRIPLE because it facilitates the discoverability of EOSC resources across disciplines D 3.1: EOSC Portal Functional and Non-Functional Specifications D 3.2: EOSC Portal Open APIs Specifications of Service and Resources Providers—relevant for TRIPLE as it shows the requirements needed to be integrated in the EOSC portal |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dumouchel, S.; Blotière, E.; Breitfuss, G.; Chen, Y.; Donato, F.D.; Eskevich, M.; Forbes, P.; Georgiadis, H.; Gingold, A.; Gorgaini, E.; et al. GOTRIPLE: A User-Centric Process to Develop a Discovery Platform. Information 2020, 11, 563. https://doi.org/10.3390/info11120563
Dumouchel S, Blotière E, Breitfuss G, Chen Y, Donato FD, Eskevich M, Forbes P, Georgiadis H, Gingold A, Gorgaini E, et al. GOTRIPLE: A User-Centric Process to Develop a Discovery Platform. Information. 2020; 11(12):563. https://doi.org/10.3390/info11120563
Chicago/Turabian StyleDumouchel, Suzanne, Emilie Blotière, Gert Breitfuss, Yin Chen, Francesca Di Donato, Maria Eskevich, Paula Forbes, Haris Georgiadis, Arnaud Gingold, Elisa Gorgaini, and et al. 2020. "GOTRIPLE: A User-Centric Process to Develop a Discovery Platform" Information 11, no. 12: 563. https://doi.org/10.3390/info11120563
APA StyleDumouchel, S., Blotière, E., Breitfuss, G., Chen, Y., Donato, F. D., Eskevich, M., Forbes, P., Georgiadis, H., Gingold, A., Gorgaini, E., Moranville, Y., Pohle, S., Paoli, S. d., Petitfils, C., & Toth-Czifra, E. (2020). GOTRIPLE: A User-Centric Process to Develop a Discovery Platform. Information, 11(12), 563. https://doi.org/10.3390/info11120563