
Multimodal Approaches for Indoor Localization for Ambient Assisted Living in Smart Homes


Abstract
:1. Introduction
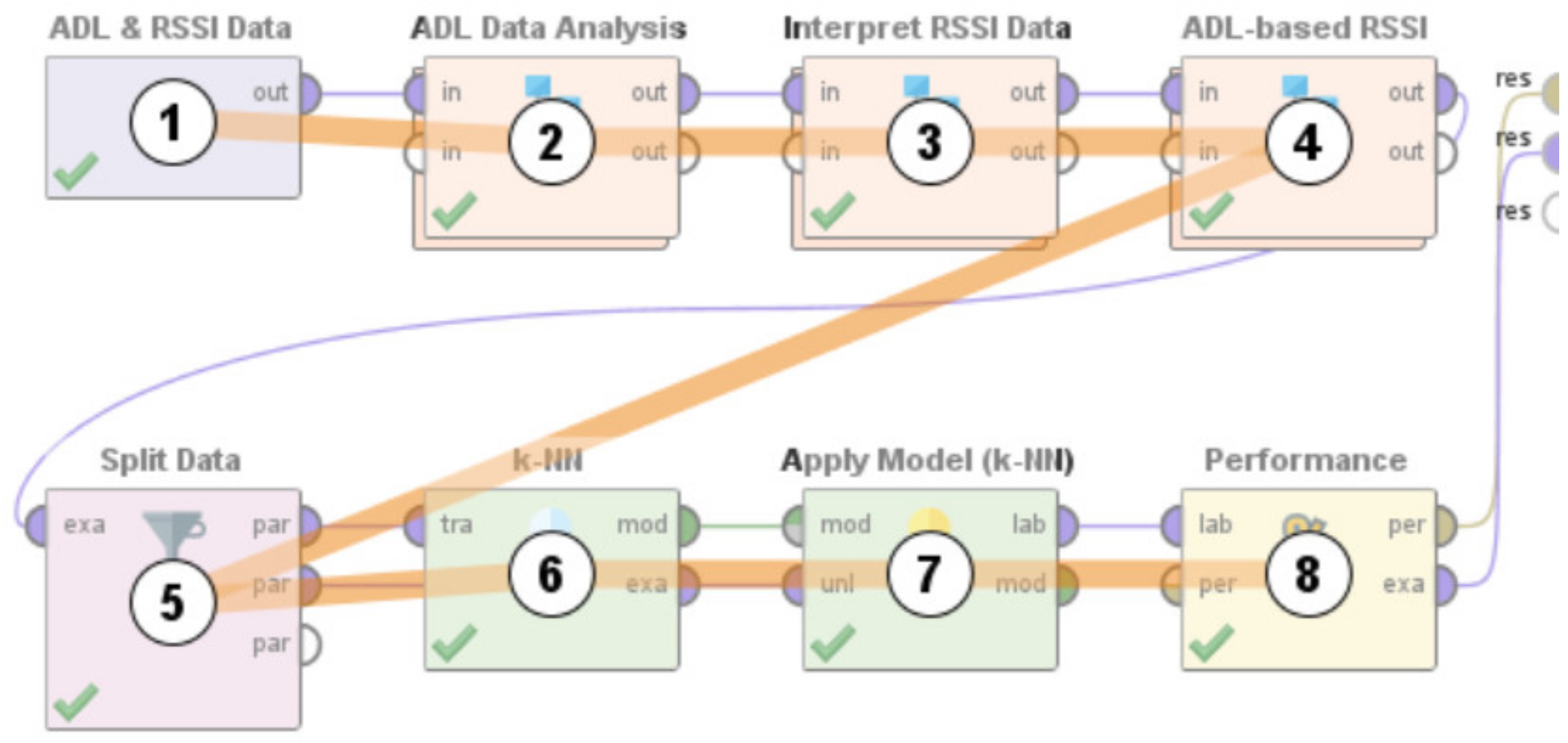
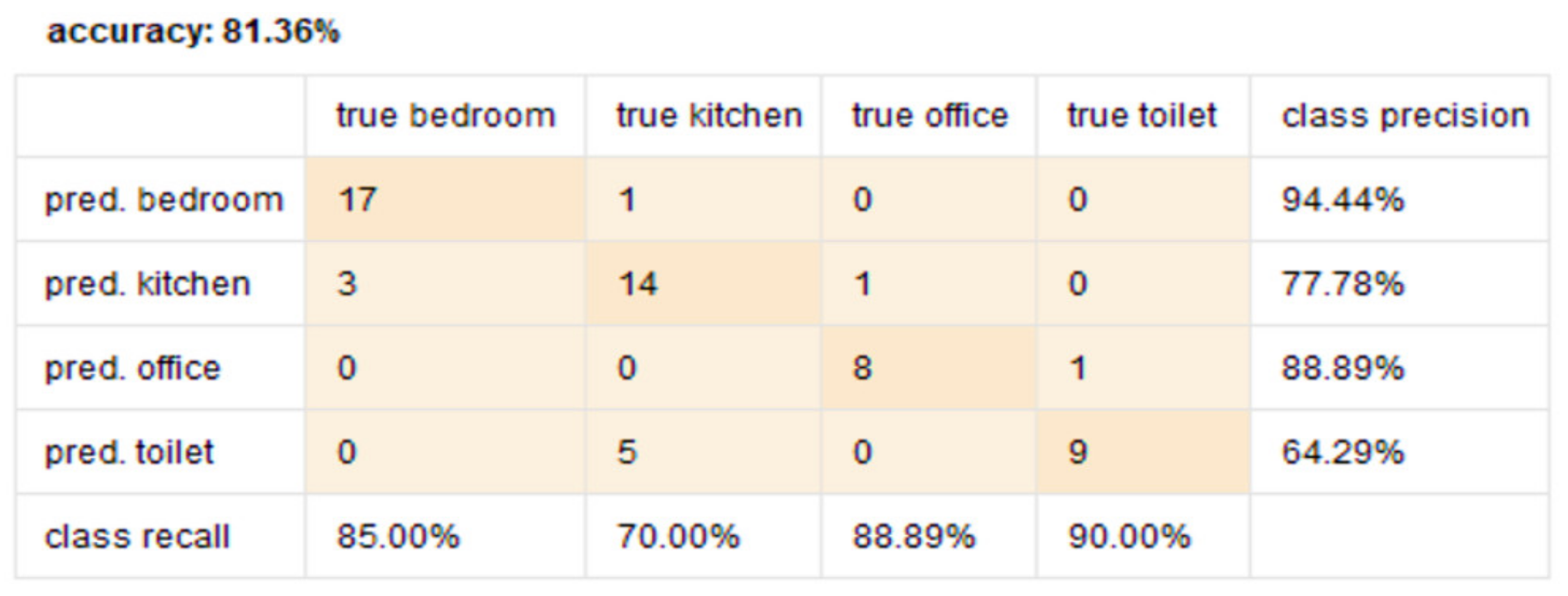
- Big-Data driven methodology that studies the multimodal components of user interactions and analyzes the data from BLE beacons and BLE scanners to track a user’s indoor location in a specific ‘activity-based zone’ during Activities of Daily Living. This approach was developed by using a k-nearest neighbor (k-NN)-based learning approach. When tested on a dataset it achieved a performance accuracy of 81.36%.
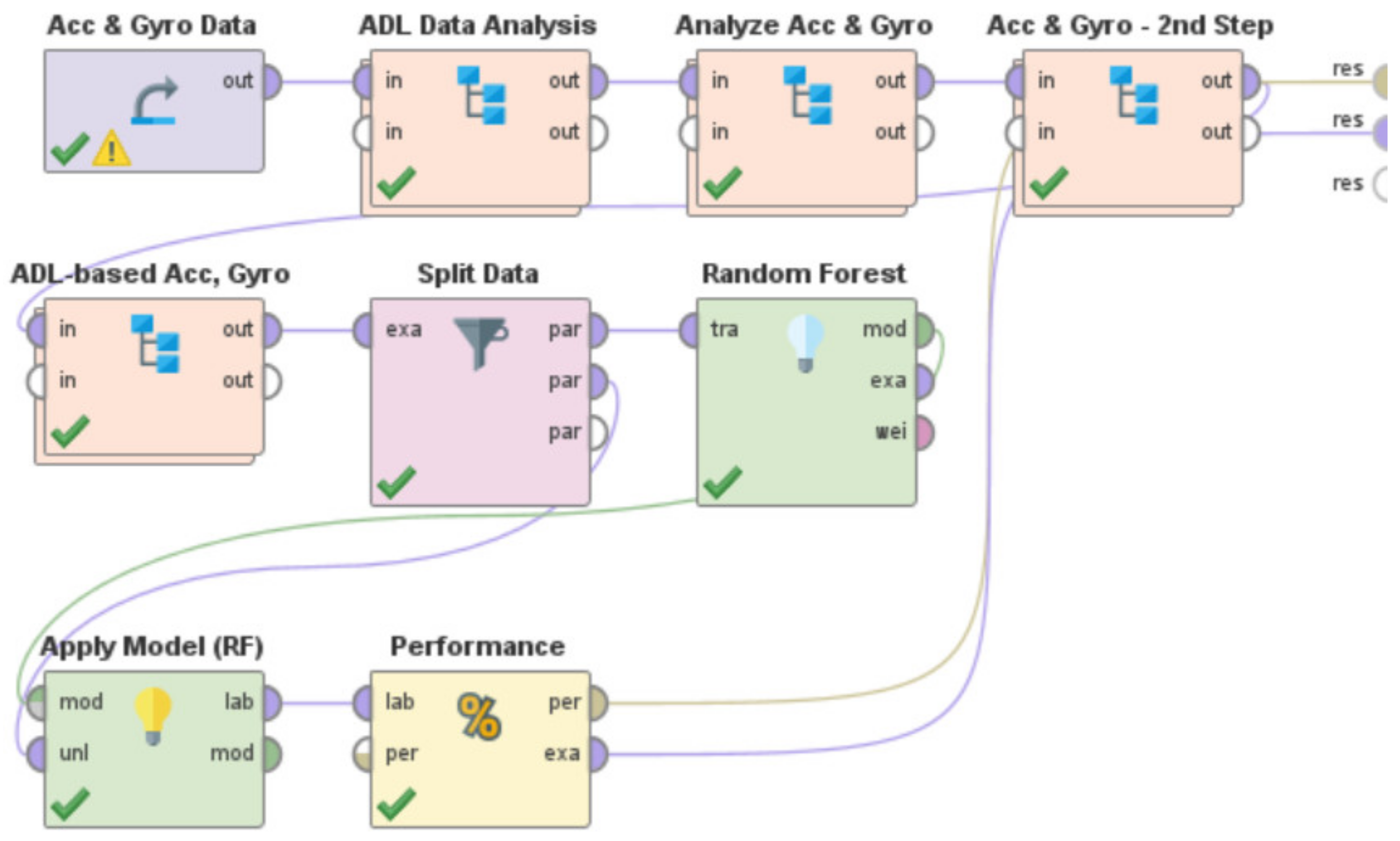
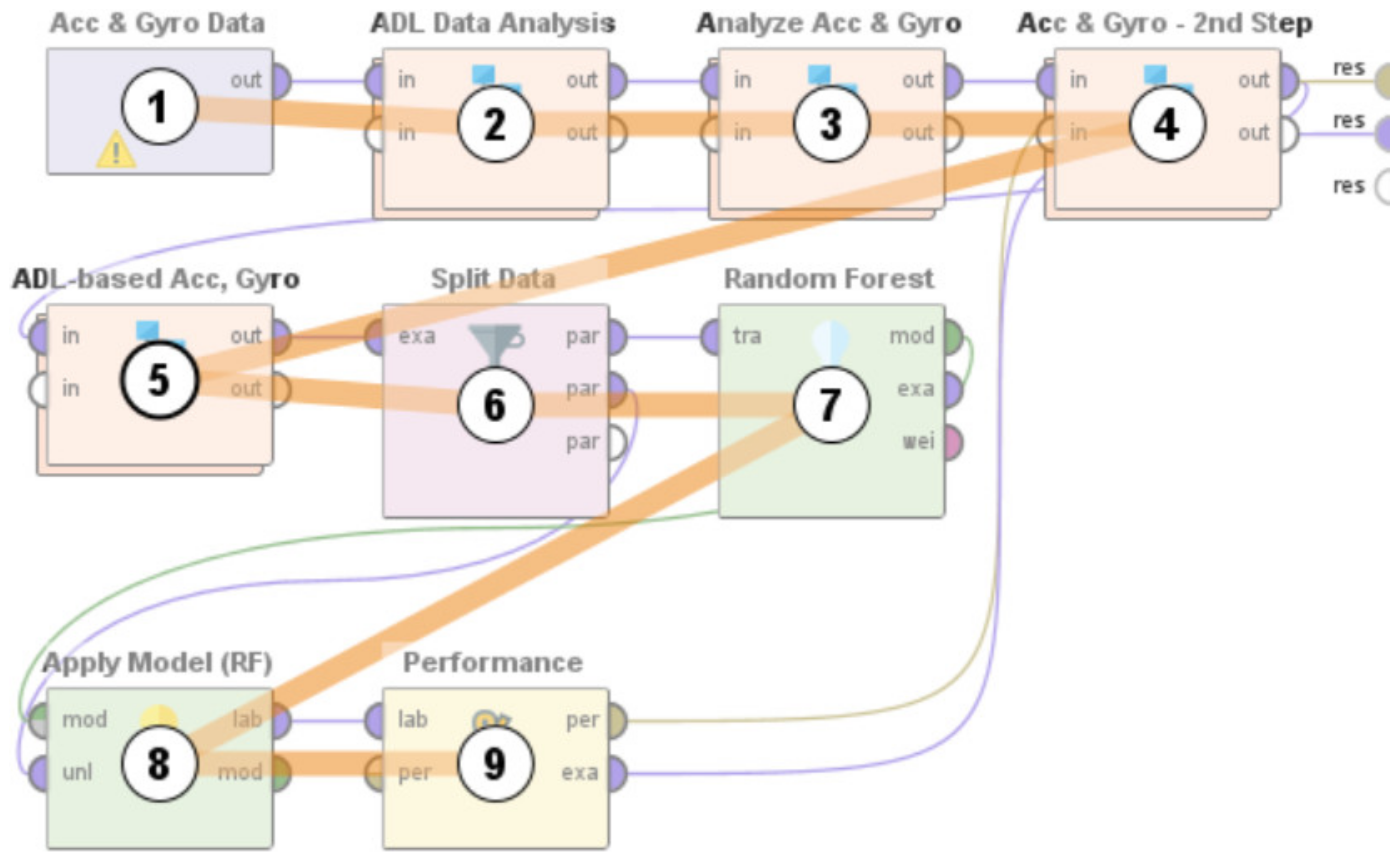
- A context independent approach that can interpret the accelerometer and gyroscope data from diverse behavioral patterns to detect the ‘zone-based’ indoor location of a user in any IoT-based environment. Here, the ‘zone-based’ mapping of a user’s location refers to mapping the user in one of the multiple ‘activity-based zones’ that any given IoT-based environment can be classified into based on the associated context attributes. This methodology was developed by using a Random Forest-based learning approach. When tested on a dataset it achieved a performance accuracy of 81.13%.
- A methodology to detect the spatial coordinates of a user’s indoor position based on the associated user interactions with the context parameters and the user-centered local spatial context, by using a reference system. The performance characteristics of this system were evaluated as per three metrics stated in ISO/IEC18305:2016 [31], which is an international standard for testing Localization and Tracking Systems. These metrics included root mean squared error (RMSE) in X-direction, RMSE in Y-direction, and the Horizontal Error, which were found to be 5.85 cm, 5.36 cm, and 7.93 cm, respectively. A comparison of the performance characteristics of this approach with similar works in this field that used the RMSE evaluation method showed that our system outperformed all recent works that had a similar approach.
- A comprehensive comparative study of different machine learning approaches that include—Random Forest, Artificial Neural Network, Decision Tree, Support Vector Machine, k-NN, Gradient Boosted Trees, Deep Learning, and Linear Regression, with an aim to address the research challenge of identifying the optimal machine learning-based approach for Indoor Localization. The performance characteristics of each of these learning methods were studied by evaluating the RMSE in X-direction, the RMSE in Y-direction, and the Horizontal Error as per ISO/IEC18305:2016 [31]. The results and findings of this study show that the Random Forest-based learning approach can be considered as the optimal learning method for development of Indoor Localization and tracking related technologies.
2. Literature Review
- The AAL-based activity recognition, activity analysis, and fall detection systems currently lack the ability to track the indoor location of the user. It is highly essential that in addition to being able to track, analyze, and interpret human behavior, such systems are also able to detect the associated indoor location information, so that the same can be communicated to caregivers or emergency responders, to facilitate a timely care in the event of a fall or any similar health related emergencies. Delay in care from a health-related emergency, such as a fall, can have both short-term and long-term health related impacts.
- Several Indoor Localization systems are context-based and are functional only in the specific environments in which they were developed. For instance, [26] was developed for factory environments, [27] was developed for indoor parking, [28] was developed for hospital settings, [29] was developed for tracking forklift trucks in industry-based settings, and [30] was developed for performing Indoor Localization in academic environments for taking attendance of students. The future of interconnected Smart Cities would consist of a host of indoor environments in the living and functional spaces of humans, which would be far more diverse, different, and complicated as compared to the environments described in [26,27,28,29,30]. The challenge is thus to develop a means for Indoor Localization that is not environment dependent and can be seamlessly deployed in any IoT-based setting irrespective of the associated context parameters and their attributes.
- In view of the average dimensions of the living spaces in Smart Homes, the RMSE of the existing Indoor Localization systems are still high and greater precision and accuracy for detection of indoor location in the need of the hour.
- A range of machine learning-based approaches—Random Forest, Artificial Neural Network, Decision Tree, Support Vector Machine, k-NN, Gradient Boosted Trees, Deep Learning, and Linear Regression, have been used by several researchers [9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25] for development of various types of Indoor Localization systems for IoT-based environments. Identification of the optimal machine learning model that can be used to develop the future of Indoor Localization systems, Indoor Positioning Systems, and Location-Based Services is highly necessary.
3. Technology Review
- It provides built-in “operators” with distinct functionalities that can be directly used or modified for development and implementation of Machine Learning, Data Science, Artificial Intelligence, and Big Data related algorithms and applications.
- RapidMiner is developed using Java. This makes RapidMiner “processes” platform independent and Write Once Run Anywhere (WORA), which is a characteristic feature of Java.
- The tool allows downloading multiple extensions for seamless communication and integration of RapidMiner “processes” with other software and hardware platforms.
- Scripts written in any programming language, such as Python and R can also be integrated in a RapidMiner “process” to add additional functionalities to the same.
- The tool allows development of new “operators” and seamless sharing of the same via the RapidMiner community.
- It also consists of “operators” that allow this software tool to connect with social media profiles of the user, such as Twitter and Facebook, to extract tweets, comments, posts, reactions, and related social media activity.
4. Development of the Proposed Methodologies for Indoor Localization
- (a)
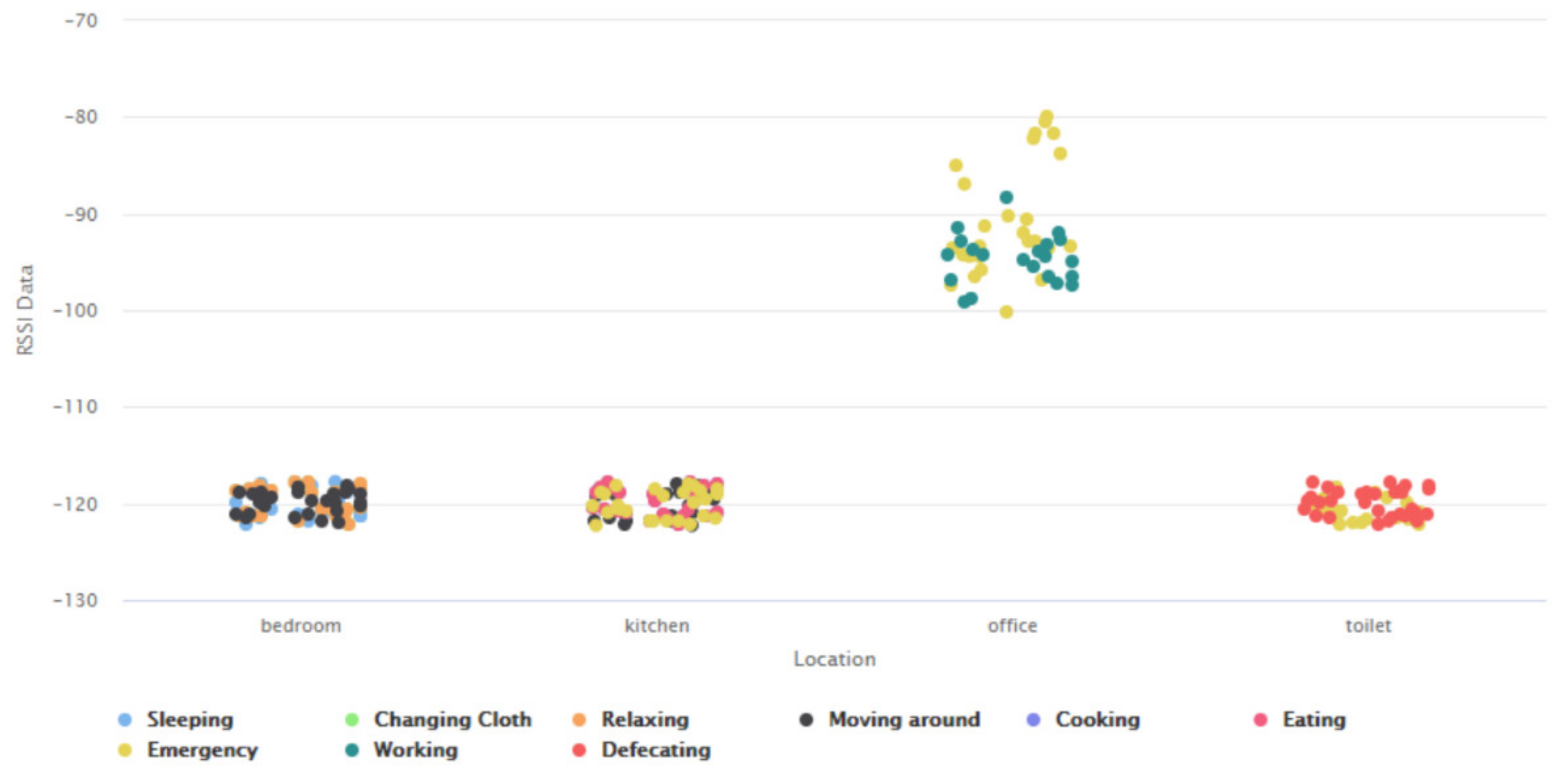
- The Received Signal Strength indicator (RSSI) data coming from BLE scanners and BLE beacons can be studied and analyzed to detect the changes in a user’s instantaneous location during different activities, which are a result of the varying user interactions with dynamic context parameters.
- (b)
- The dynamic changes in the spatial configurations of a user during different activities can be interpreted by the analysis of the behavioral patterns that are localized and distinct for different activities.
- (c)
- Tracking and analyzing the user interactions with the context parameters along with the associated spatial information, by using a reference system, helps to detect the dynamic spatial configurations of the user.
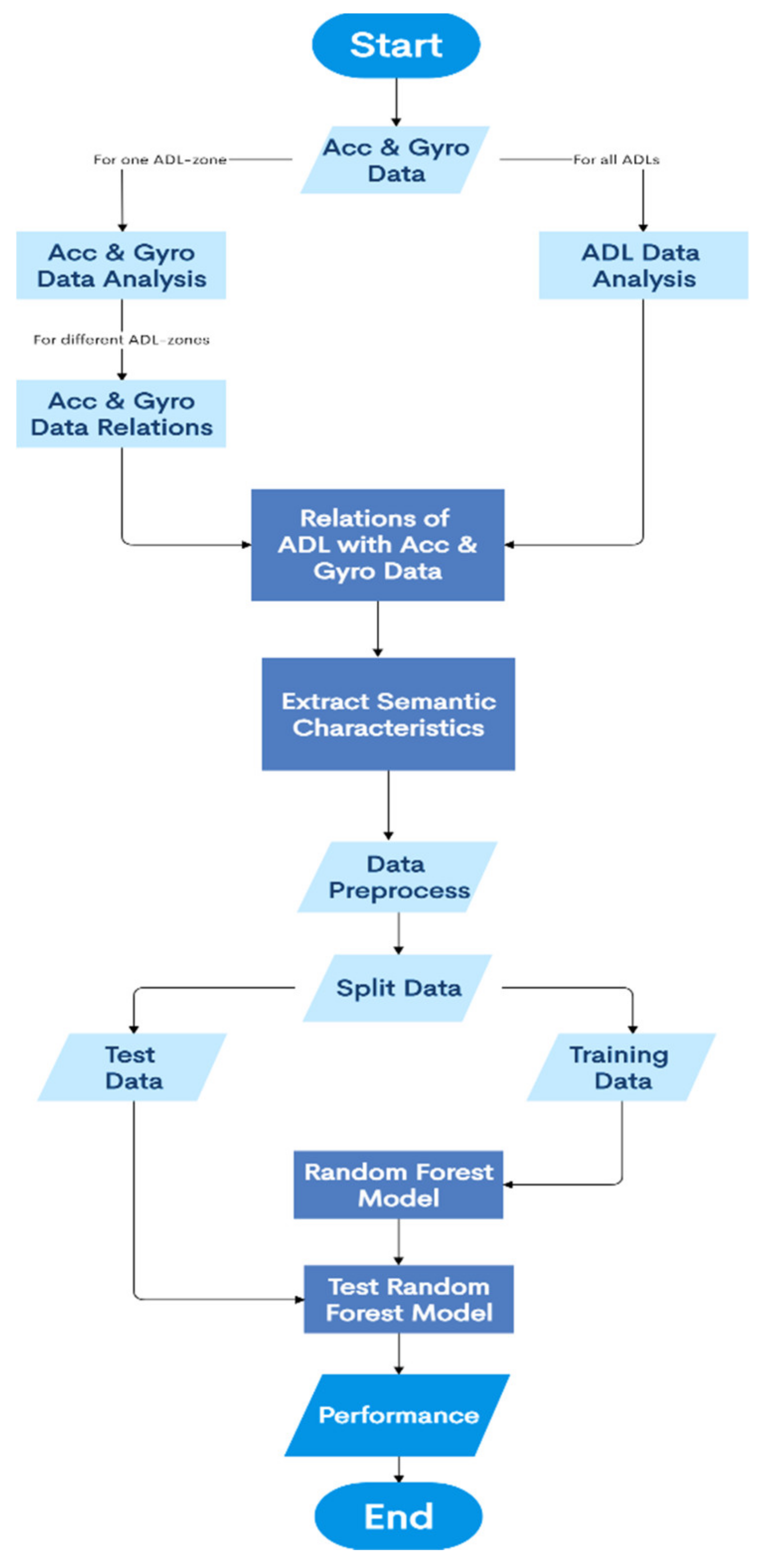
4.1. Indoor Localization from BLE Beacons and BLE Scanners Data during ADLs
- i.
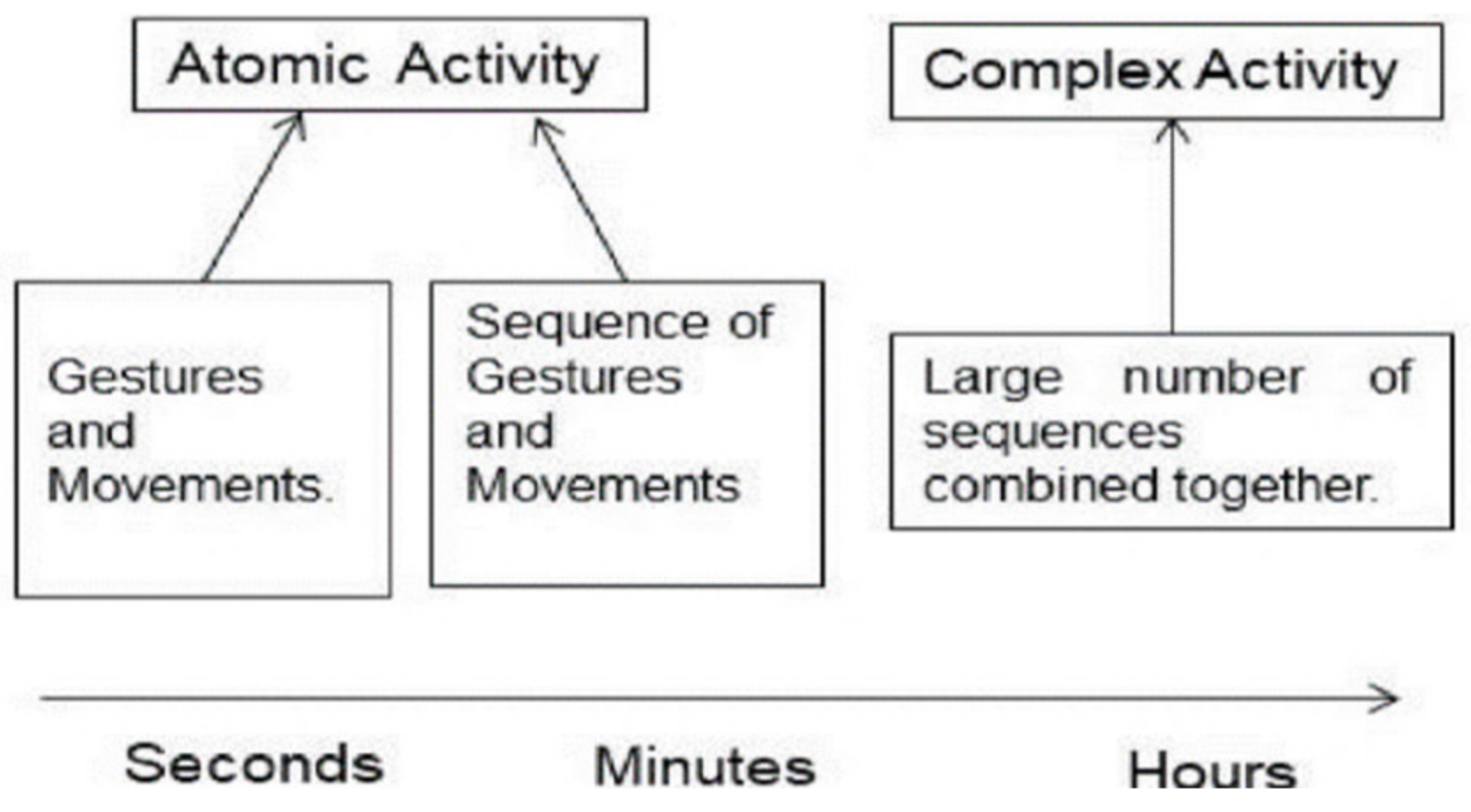
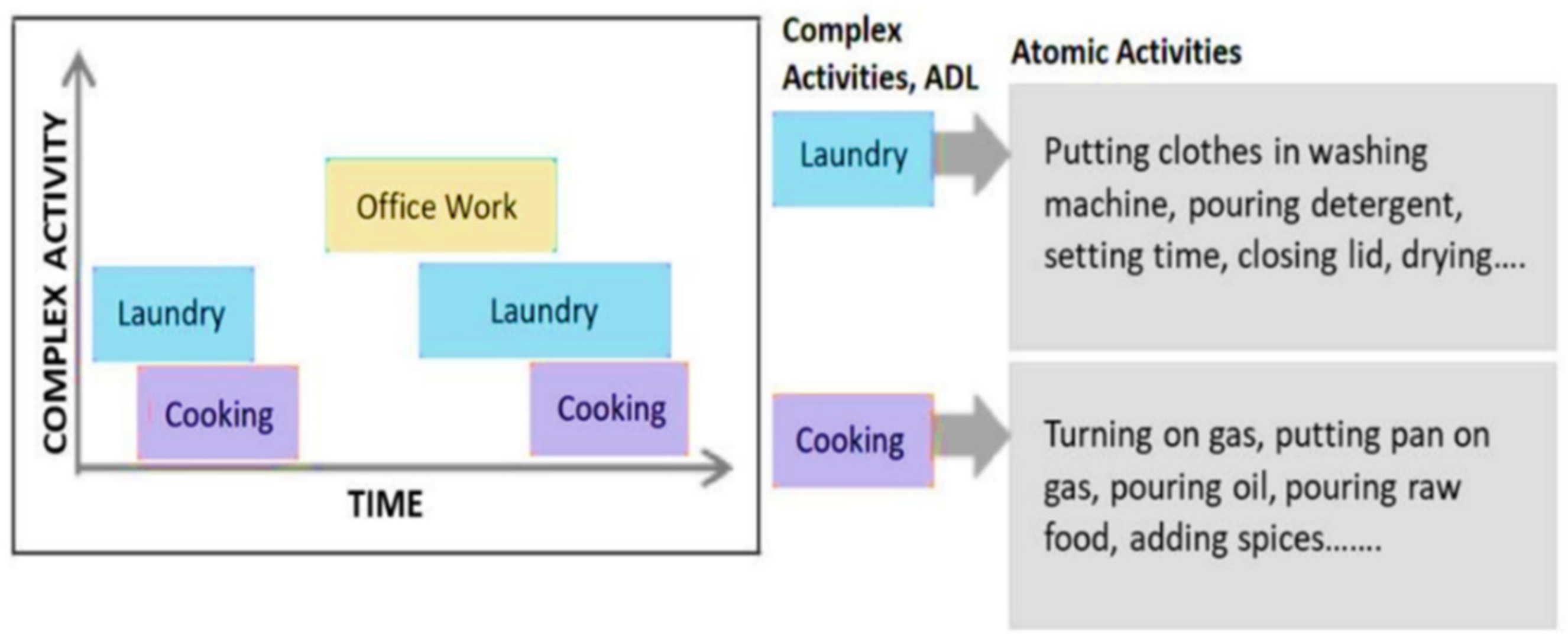
- Set up an IoT-based environment, within a spatial context such as indoor layout of rooms with furniture’s and appliances, using wearables and wireless sensors to collect the Big Data related to different ADLs. The associated representation scheme involves mapping the entire spatial location into non-overlapping ‘activity-based zones’, distinct to different complex activities, by performing complex activity analysis [63].
- ii.
- Analyze the ADLs in terms of the associated atomic activities, context attributes, core atomic activities, and core context attributes and their associated threshold values by probabilistic reasoning principles [63].
- iii.
- Infer the semantic relationships between the changing dynamics of atomic activities, context attributes, core atomic activities, and core context attributes associated to different ADLs to study and interpret the spatial and temporal features of these ADLs.
- iv.
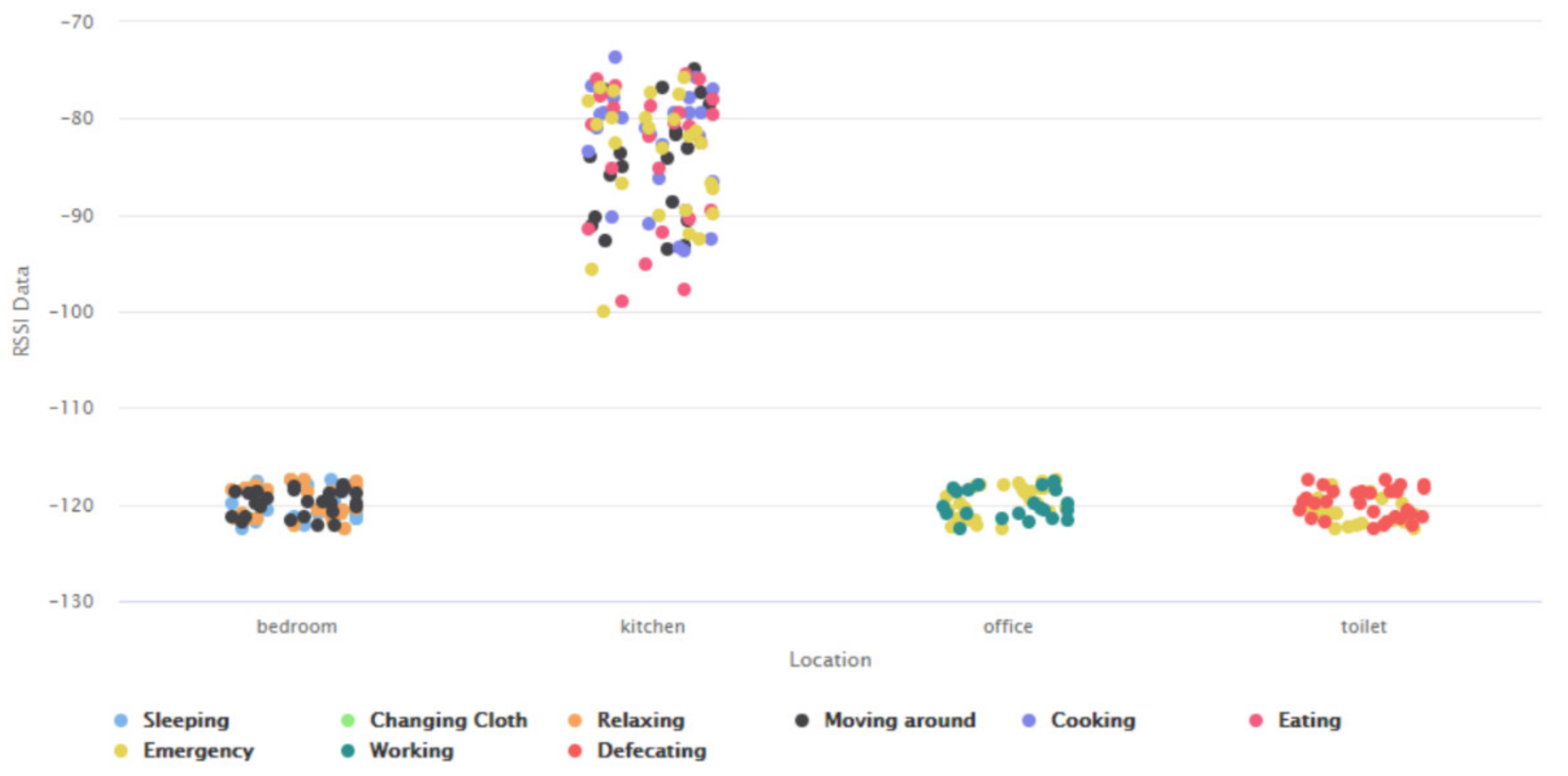
- Study the characteristics of the data coming from the wireless sensors to analyze the associated RSSI data from BLE beacons and BLE scanners, recorded during different ADLs, based on the user’s proximity to the context attributes in each ‘activity-based zone’. This information helps to infer the user’s presence or absence in each of these ‘activity-based zones’. For instance, when the user performs a typical complex activity—cooking using microwave, based on the user’s proximity to the microwave, the user’s presence can be deduced in a ‘zone’ where the microwave is present.
- v.
- Associate the relationships from (iii) with the characteristics of the RSSI data from BLE beacons and BLE scanners and map the entire IoT-based environment into non-overlapping ‘activity-based zones’, that are distinct to each ADL, by taking into consideration all possible complex activities that may be performed in the confines of the given IoT-based space. For instance, in a typical IoT-based environment [4], if the complex activities performed include—Watching TV, Using Laptop, Listening to Subwoofer, Using Washing Machine, Cooking Food, and Taking Shower; the associated ‘activity-based zones’ could be TV zone, Laptop zone, Subwoofer zone, Washing Machine zone, Cooking zone, and Bathroom zone. This inference of the respective ‘zones’ is based on the complex activity analysis [63] of all these activities as presented in [4].
- vi.
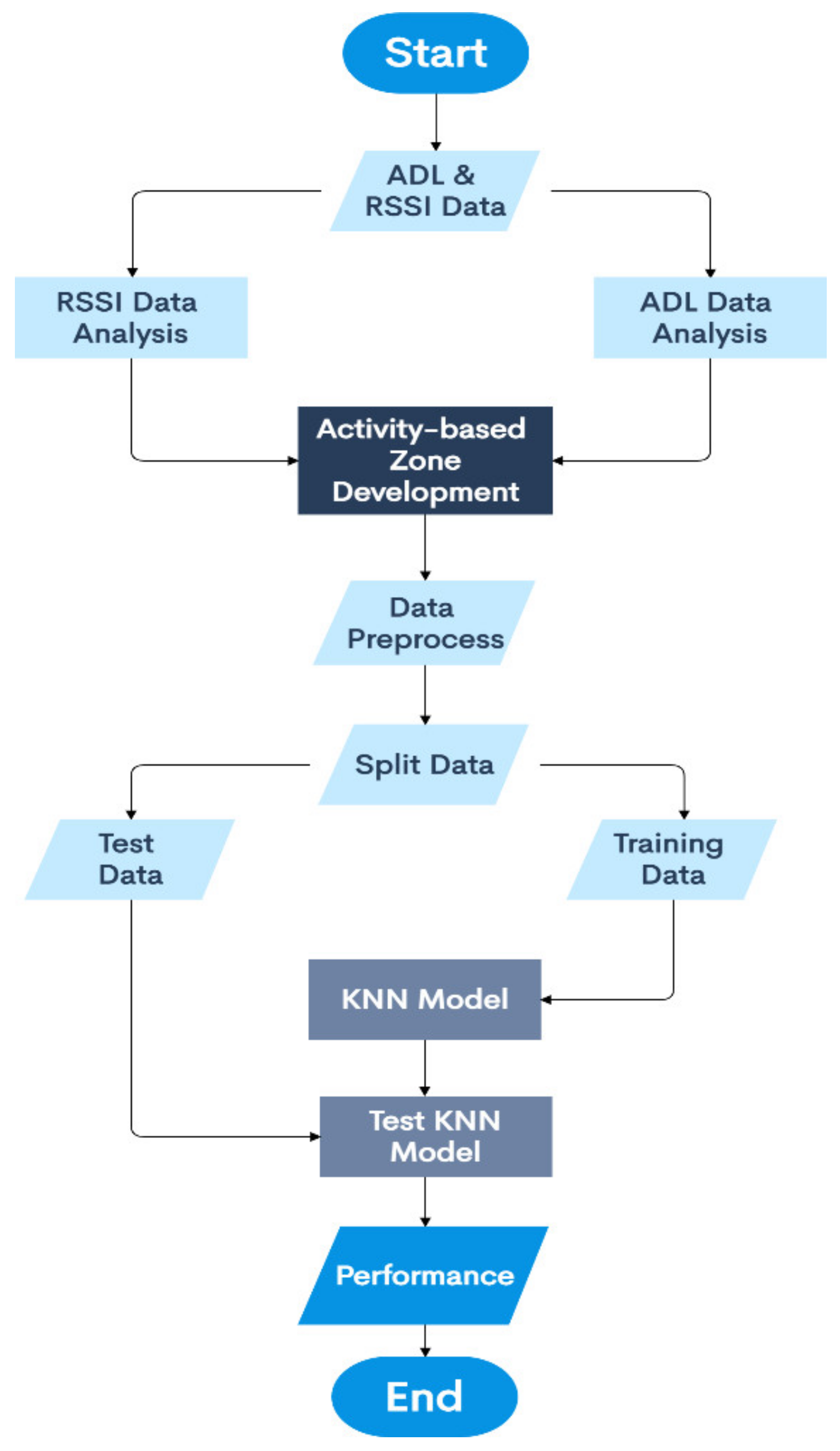
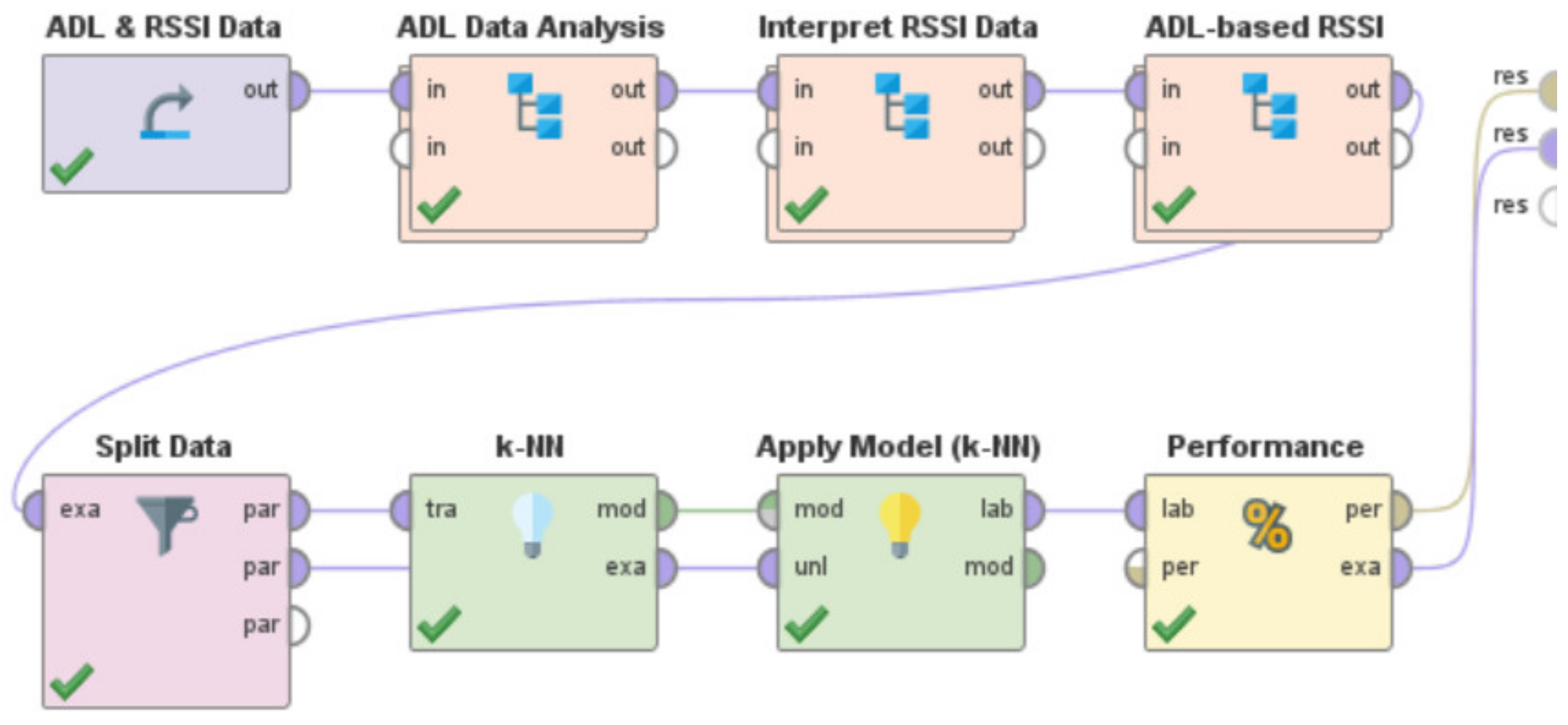
- Split the data into training set and test set and train a learning model to study these relationships and patterns in the data to detect the indoor location associated with the given ADL, based on detecting the user’s presence or absence in a specific ‘activity-based zone’ at a specific point of time.
- vii.
- Analyze the performance characteristics of the learning model by using a confusion matrix.
4.1.1. System Architecture of the Methodology for Indoor Localization from BLE Beacons and BLE Scanners Data during ADLs
4.2. Context Independent Indoor Localization from Accelerometer and Gyroscope Data
- i.
- Set up an IoT-based environment, within a spatial context such as indoor layout of rooms with furniture’s and appliances, using wearables and wireless sensors to collect the Big Data related to different ADLs. The associated representation scheme involves mapping the entire spatial location into non-overlapping ‘activity-based zones’, distinct to different complex activities, by performing complex activity analysis [63] as outlined in Section 4.1.
- ii.
- Analyze the ADLs in terms of the associated atomic activities, context attributes, core atomic activities, and core context attributes, and their associated threshold values based on probabilistic reasoning principles [63].
- iii.
- Infer the semantic relationships between the changing dynamics of atomic activities, context attributes, core atomic activities, and core context attributes along with the associated spatial and temporal information.
- iv.
- Study and analyze the semantic relationships between the accelerometer data (in X, Y, and Z directions), gyroscope data (in X, Y, and Z directions) and the associated atomic activities, context attributes, core atomic activities, and core context attributes within each ‘activity-based zone’.
- v.
- Study and analyze the semantic relationships between the accelerometer data (in X, Y, and Z directions), gyroscope data (in X, Y, and Z directions) and the associated atomic activities, context attributes, core atomic activities, and core context attributes across different ‘activity-based zones’ based on the sequence in which the different ADLs took place and the related temporal information.
- vi.
- Integrate the findings from (iv) and (v) to interpret the interrelated and semantic relationships between the accelerometer data and the gyroscope data with respect to different ADLs performed in all the ‘activity-based zones’ in the given IoT-based space.
- vii.
- Split the data into training set and test set and develop a machine learning-based model to detect the location of a user, in terms of these spatial ‘zones’ based on the associated accelerometer data (in X, Y, and Z directions) and gyroscope data (in X, Y, and Z directions).
- viii.
- Evaluate the performance characteristics of the model by using a confusion matrix.
4.2.1. System Architecture of the Methodology for Context Independent Indoor Localization from Accelerometer and Gyroscope Data
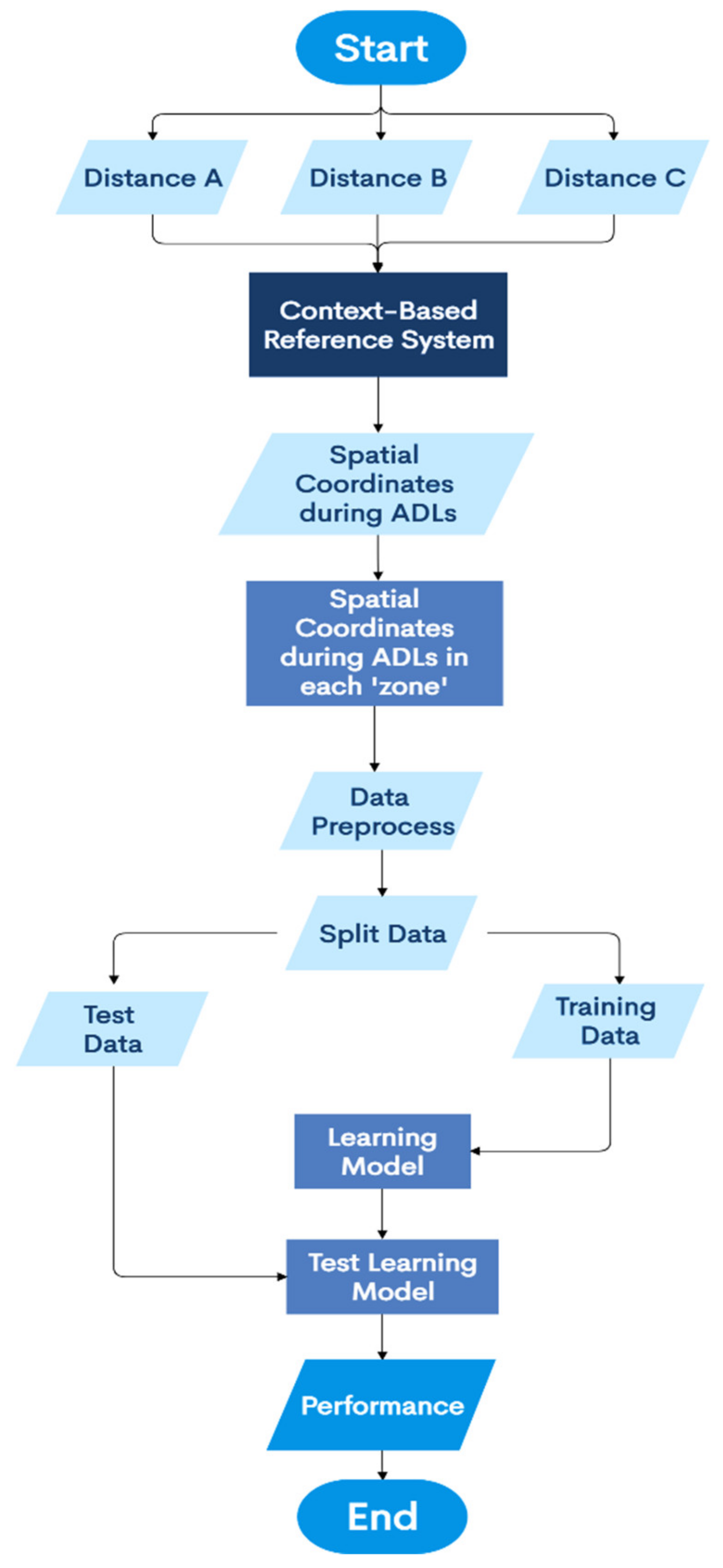
4.3. Detection of the Spatial Coordinates of the User in any ‘Activity-Based Zone’
- i.
- Set up an IoT-based environment, within a spatial context such as indoor layout of rooms with furniture’s and appliances, using wearables, and wireless sensors to collect the Big Data related to different ADLs.
- ii.
- The associated representation scheme involves setting up a context-based reference system in the given IoT-based environment. This system would track the instantaneous X and Y coordinates of the user’s position information with respect to the origin of this reference system.
- iii.
- Study each ADL performed in a specific ‘activity-based zone’ in terms of the multimodal user interactions performed on the context parameters local to that ‘zone’. This involves studying the atomic activities, context attributes, core atomic activities, core context attributes, start atomic activities, start context attributes, end atomic activities, and end context attributes.
- iv.
- For each of these user interactions with the context parameters, track the spatial configurations and changes in the user’s position information, by using this reference system.
- v.
- Study the changes in the instantaneous spatial configurations of the user as per this reference system with respect to the dynamic temporal information associated with each user interaction performed in the given ‘activity-based zone’.
- vi.
- Study and record all the user interactions as per (v), specific to the given ADL, in a given ‘activity-based zone’.
- vii.
- Split the data into training set and test set and use the training set to train a machine learning-based model for detection of the varying X and Y coordinates of the user’s position information in any ‘activity-based’ zone, as per the dynamic user interactions with context parameters.
- viii.
- Evaluate the performance characteristics of the model by using the root mean squared error method.
4.3.1. System Architecture of the Methodology for Detection of the Spatial Coordinates of the User in any ‘Activity-Based Zone’
5. Results and Findings
5.1. Indoor Localization from BLE Beacons and BLE Scanners Data during ADLs
5.2. Context Independent Indoor Localization from Accelerometer and Gyroscope Data
5.3. Detection of the Spatial Coordinates of the User in Any ‘Activity-Based Zone’
- stands for RMSE in the X-direction
- stands for RMSE in the Y-direction
- stands for Horizontal Error that considers RMSE in the X-direction and RMSE in the Y-direction
- stands for squared errors in the X-direction
- stands for squared errors in the Y-direction
- N stands for sample size

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description of Performance Characteristic | Value |
|---|---|
| Root Mean Squared Error for detection of X-coordinate | 5.85 cm |
| Root Mean Squared Error for detection of Y-coordinate | 5.36 cm |
| Horizontal Error | 7.93 cm |
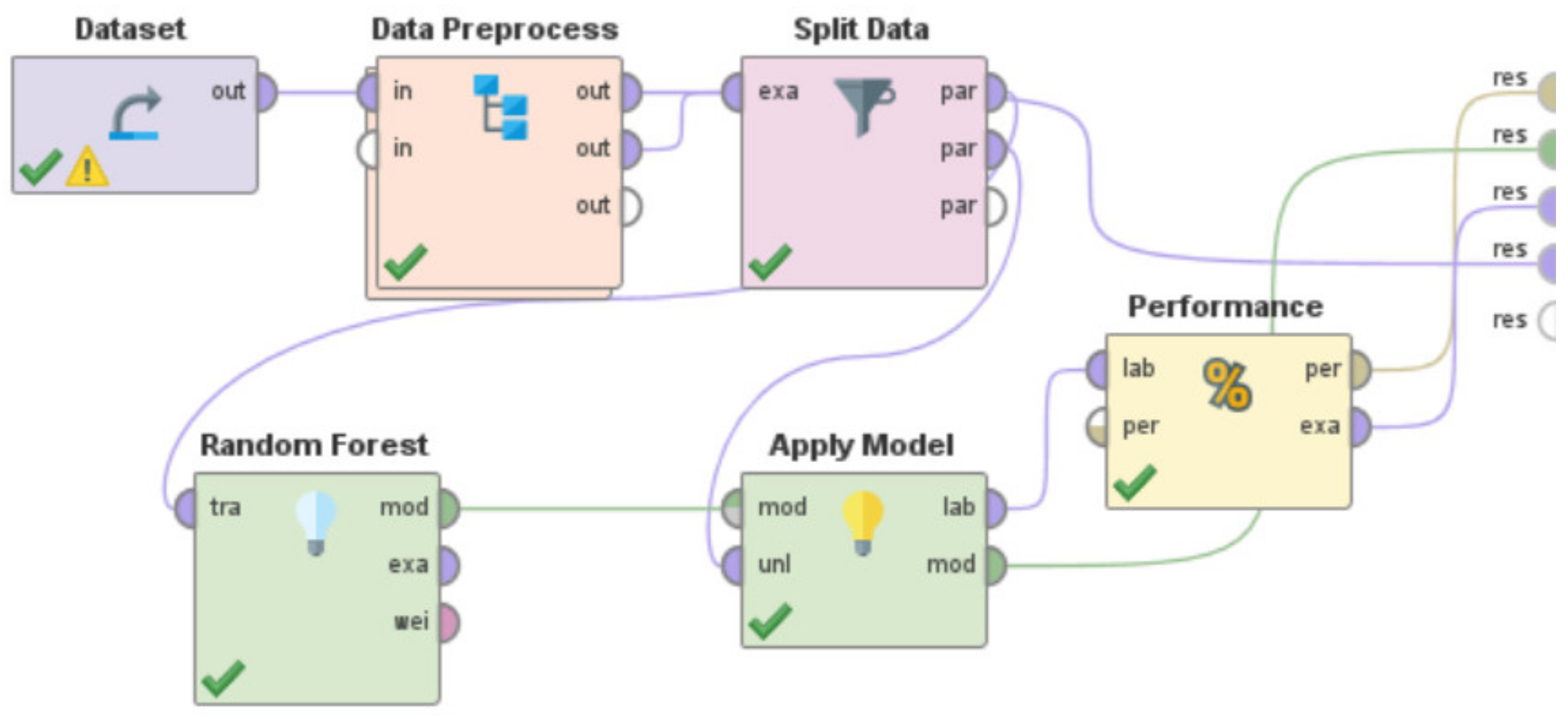
6. Deducing the Optimal Machine Learning Model for Indoor Localization
- i.
- Use the ‘Dataset’ “operator” to import the dataset [67] into the RapidMiner “process”.
- ii.
- Utilize the ‘Data-Preprocess’ “operator” to perform multiple preprocessing steps (Steps iii to vi in Section 4.3) prior to splitting the data for training and testing. We developed this ‘Data-Preprocess’ “operator”.
- iii.
- Use the built-in “operator” called ‘Split Data’ to divide the dataset into training set and test set. The dataset [67] consisted of 250 rows. We used 70% of the data for training and the remaining 30% for testing.
- iv.
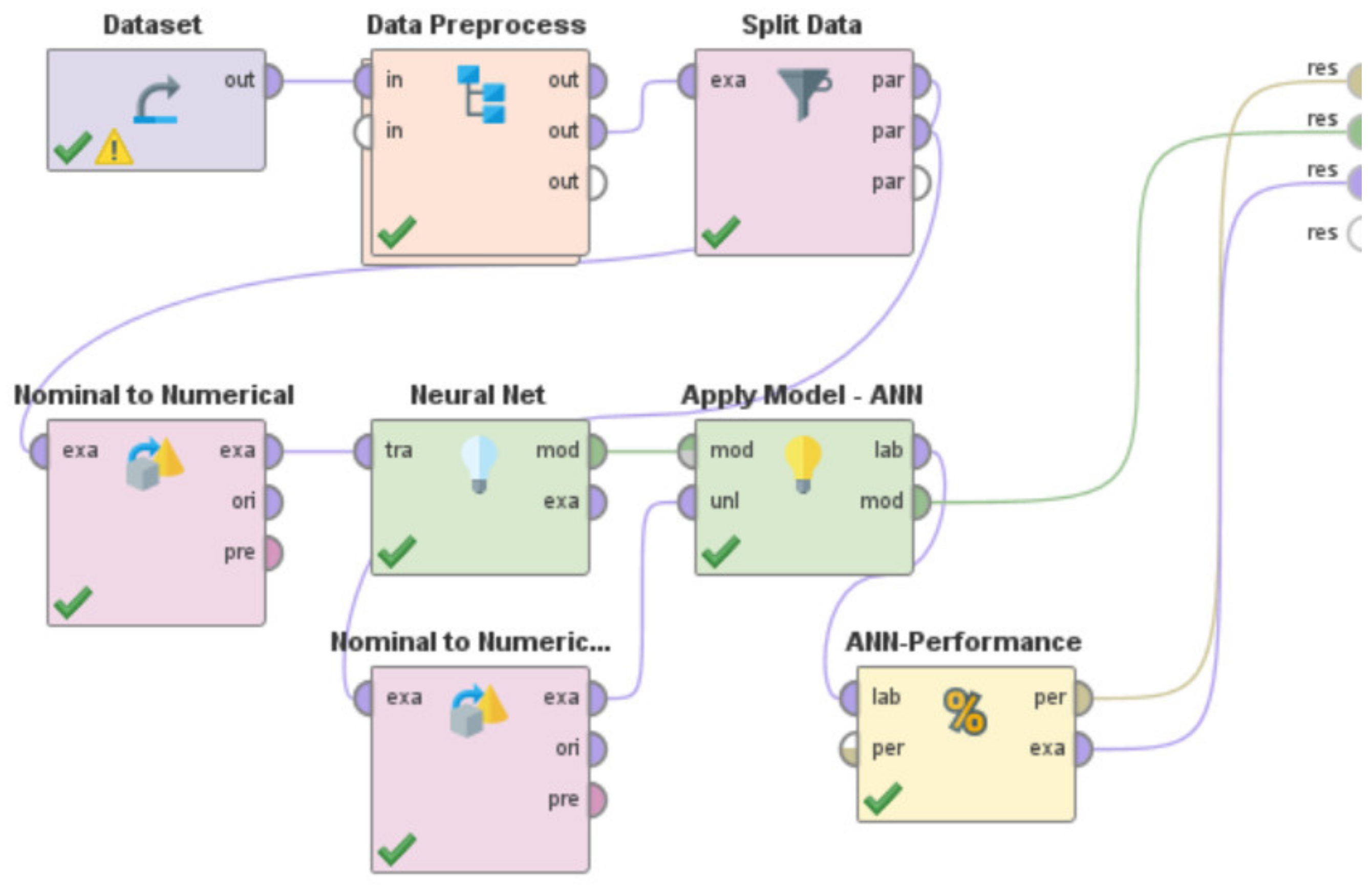
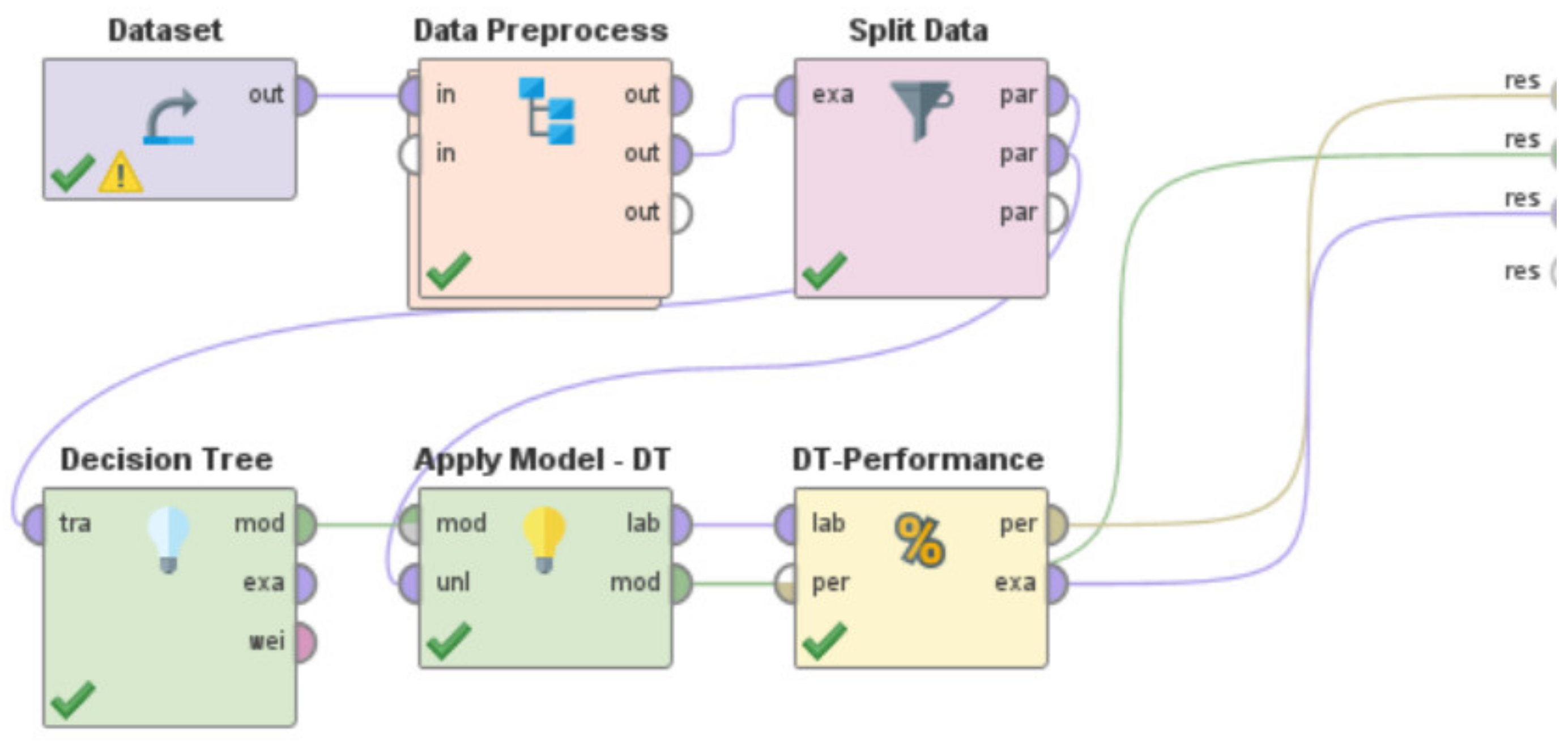
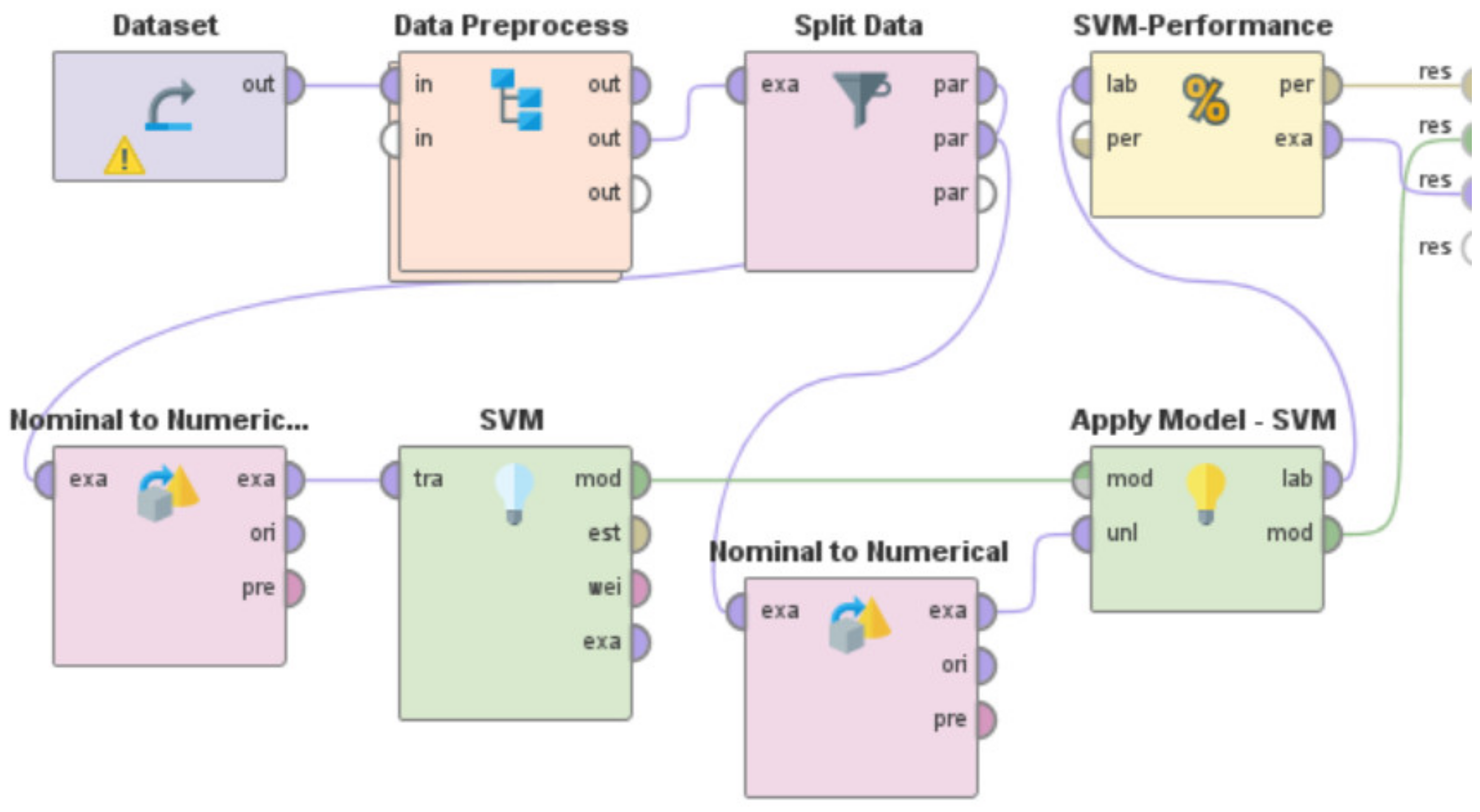
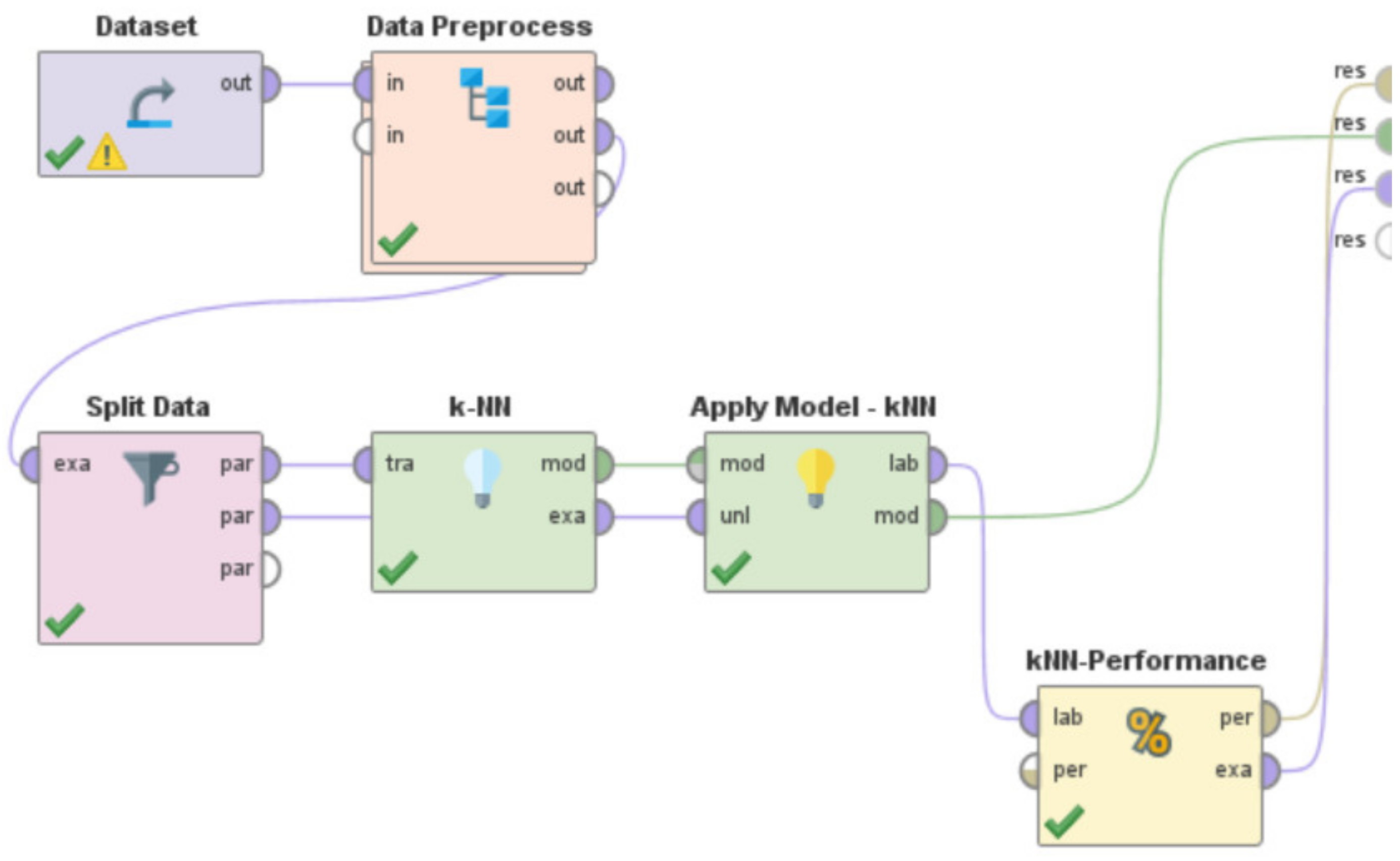
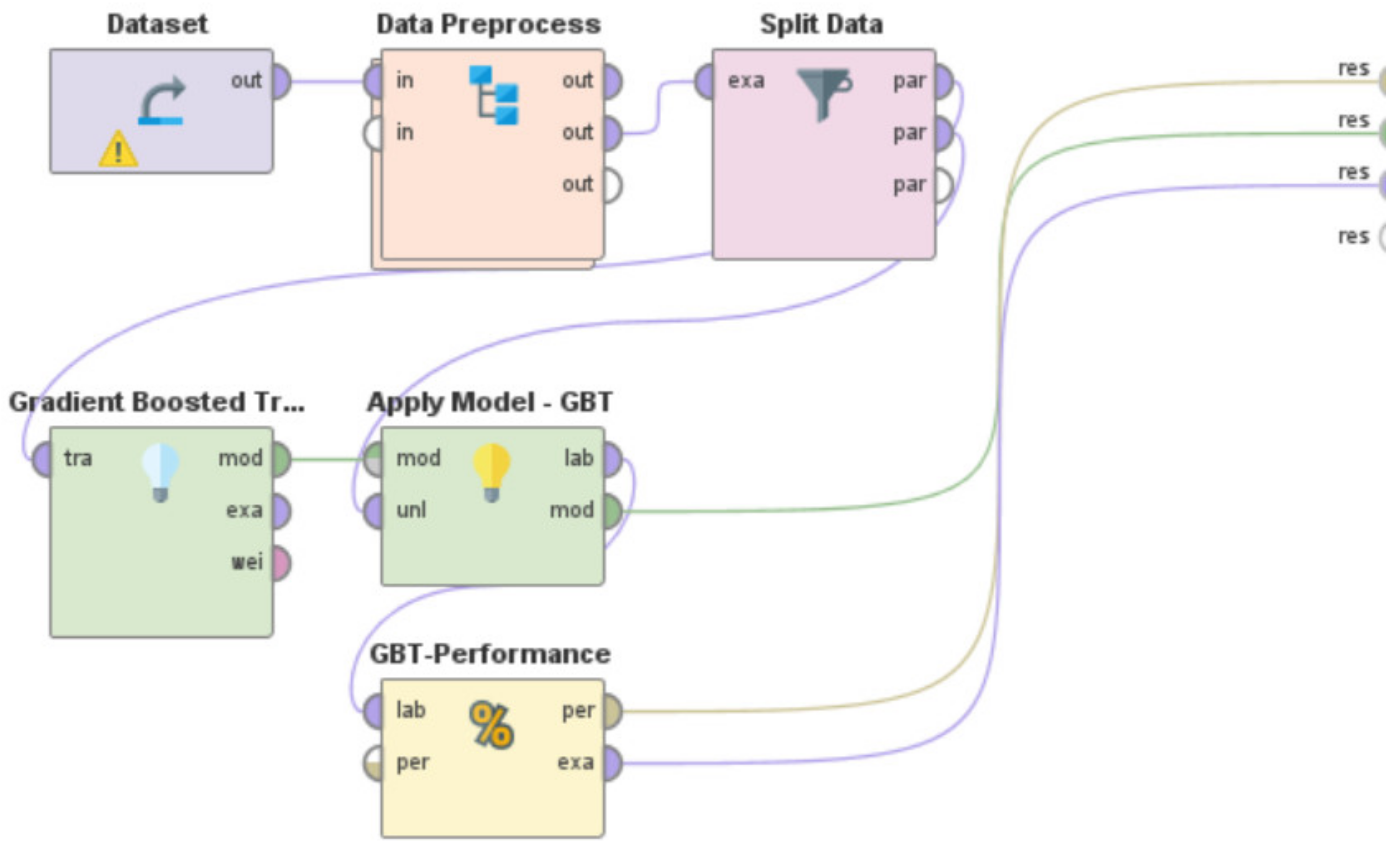
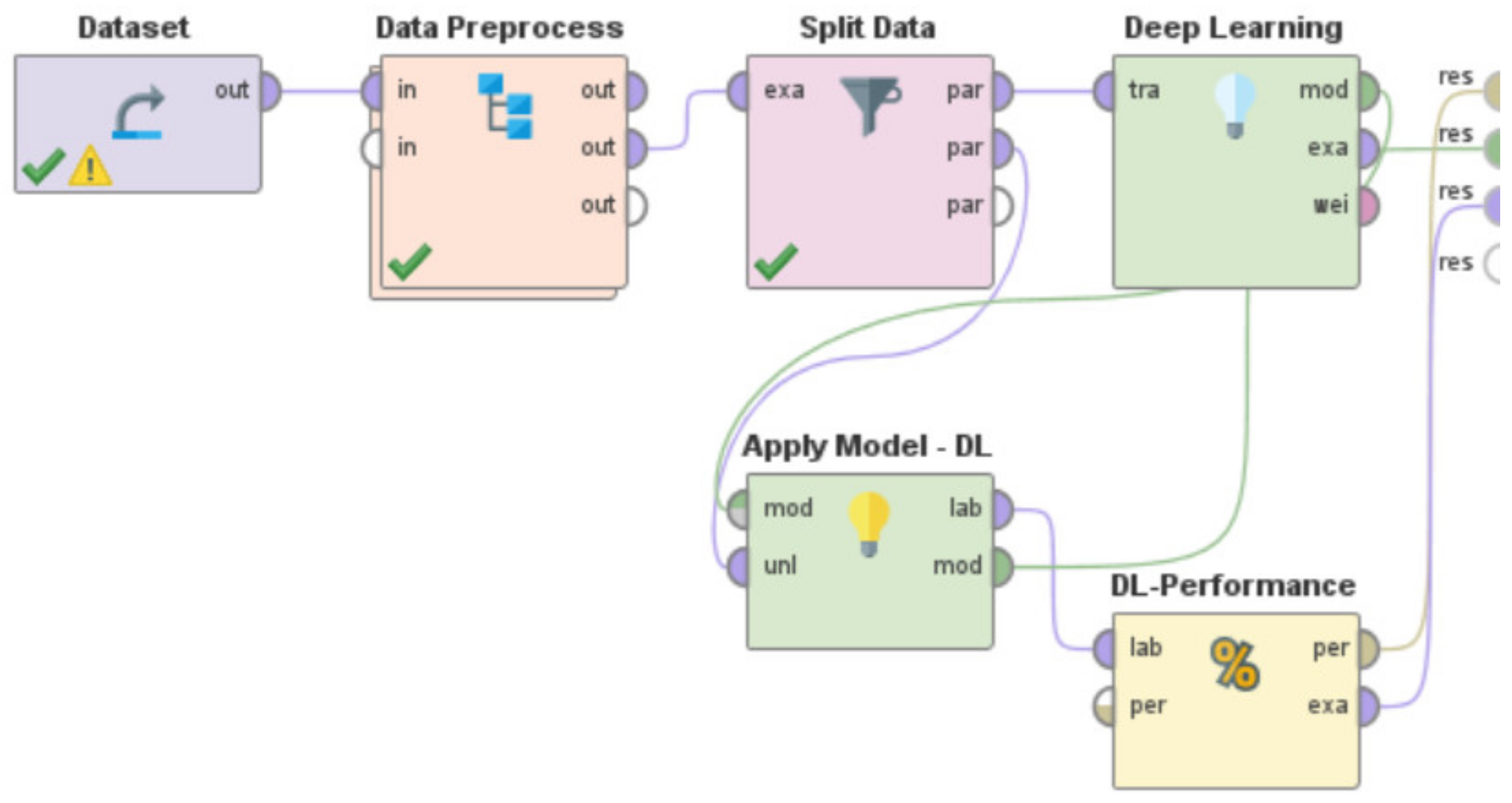
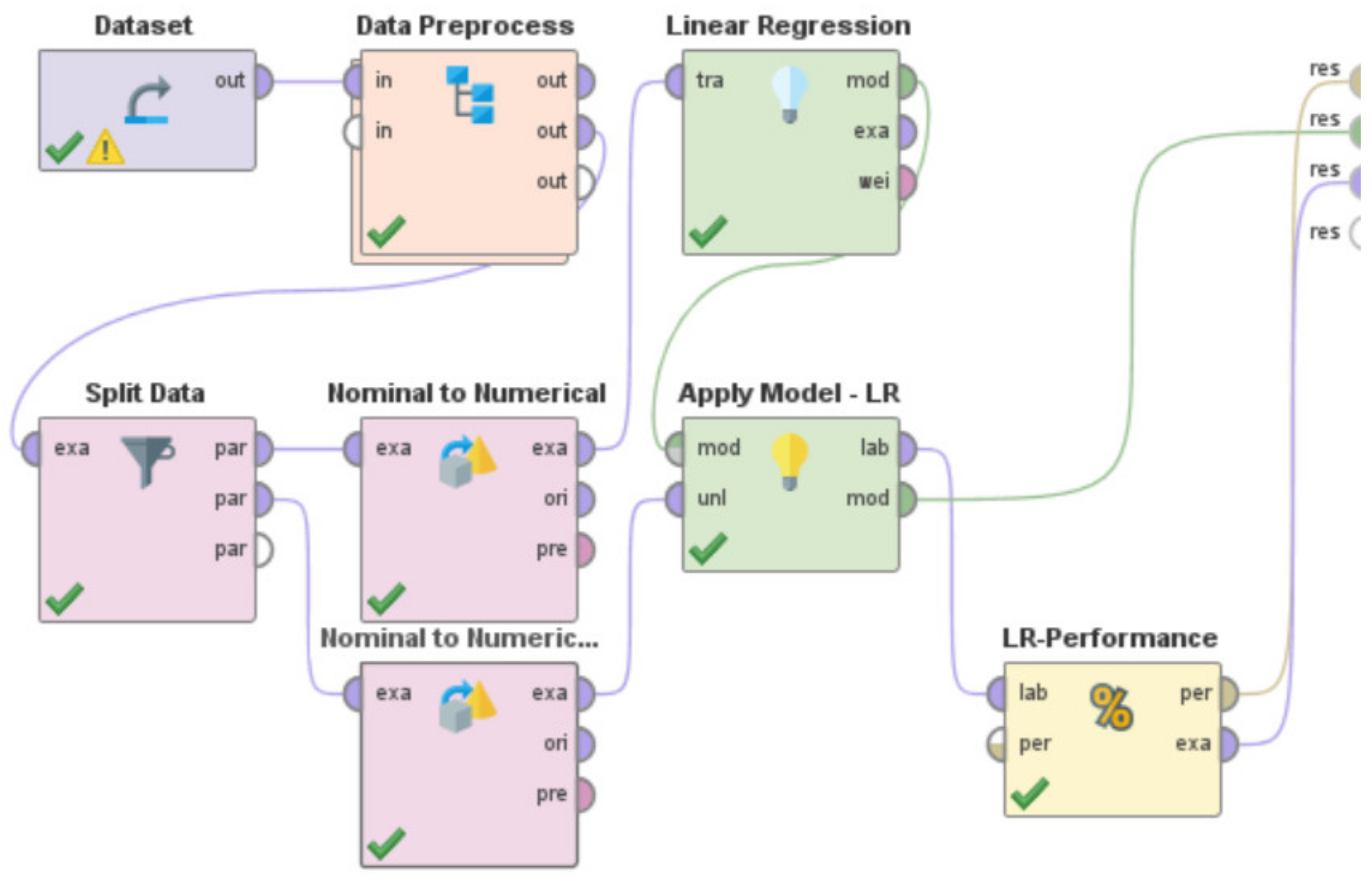
- Use the specific machine learning model to train the system. By specific machine learning model, we mean either the usage of the Artificial Neural Network or Decision Tree or Support Vector Machine or k-NN or Gradient Boosted Trees or Deep Learning or Linear Regression. These machine learning models are present in RapidMiner as built-in “operators” that can be directly used. However, a few of these learning models in RapidMiner such as Artificial Neural Network, Support Vector Machines, and Linear Regression sometimes need the ‘nominal to numerical’ “operator” for training and testing of the model, based on the characteristics and nature of the dataset being used.
- v.
- Utilize the built-in ‘Apply Model’ “operator” to apply the learning model on the test data. This “operator” was renamed in each of these “processes”, as per the specific learning model that was being developed and evaluated, to indicate the differences in the associated functionalities of this “operator” for each of these RapidMiner “processes”. For the RapidMiner “process” that used the Artificial Neural Network, the ‘Apply Model’ “operator” was renamed to ‘Apply Model—ANN’. Similarly, for the machine learning models—Decision Tree, Support Vector Machine, k-NN, Gradient Boosted Trees, Deep Learning, and Linear Regression, this “operator” was renamed to ‘Apply Model—DT’, ‘Apply Model—SVM’, ‘Apply Model—kNN’, ‘Apply Model—GBT’, ‘Apply Model—DL’, and ‘Apply Model—LR’, respectively.
- vi.
- Use the built-in ‘Performance’ “operator” to evaluate the performance characteristics of the “process” by calculating the RMSE in X-direction, the RMSE in Y-direction, and the Horizontal Error as per Equations (1)–(3), respectively. This “operator” was renamed in each of these “processes”, as per the specific learning model that was being developed and evaluated, to indicate the differences in the associated functionalities of this “operator” for each of these RapidMiner “processes”. For the RapidMiner “process” that used the Artificial Neural Network, the ‘Performance’ “operator” was renamed to ‘ANN-Performance’. Similarly, for the machine learning models—Decision Tree, Support Vector Machine, k-NN, Gradient Boosted Trees, Deep Learning, and Linear Regression, this “operator” was renamed to ‘DT-Performance’, ‘SVM-Performance’, ‘kNN-Performance’, ‘GBT-Performance’, ‘DL-Performance’, and ‘LR-Performance’, respectively.
- i.
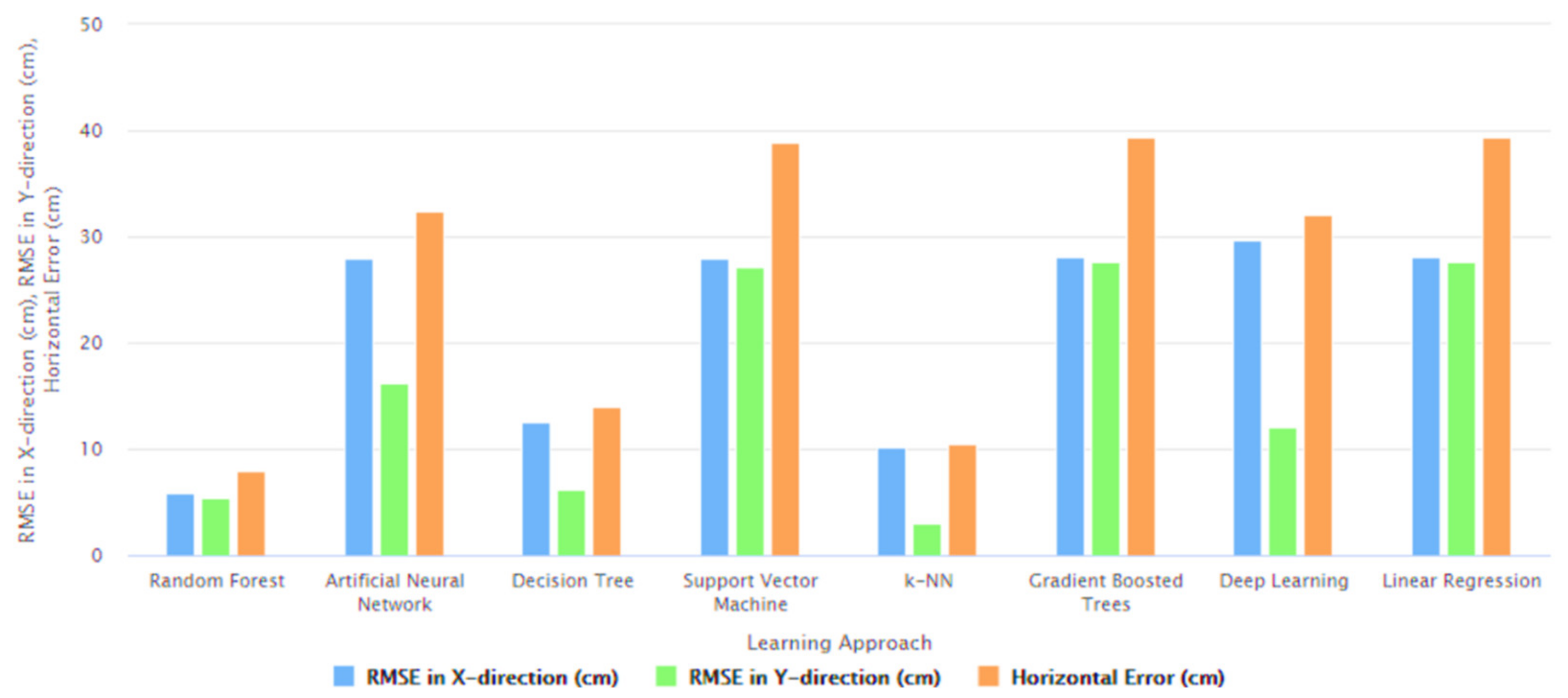
- The Random Forest-based learning approach has the least Horizontal Error of 7.93 cm and the Gradient Boosted Trees-based learning approach has the highest Horizontal Error of 39.44 cm. Considering Horizontal Error as a function, where Horizontal Error (x) gives the Horizontal Error of ‘x’, where ‘x’ is a machine learning model; the Horizontal Errors of these machine learning models can be arranged in an increasing to decreasing order as: Horizontal Error (Random Forest) < Horizontal Error (k-NN) < Horizontal Error (Decision Tree) < Horizontal Error (Deep Learning) < Horizontal Error (Artificial Neural Network) < Horizontal Error (Support Vector Machine) < Horizontal Error (Linear Regression) < Horizontal Error (Gradient Boosted Trees).
- ii.
- The RMSE in X-direction is least for the Random Forest-based learning approach and is highest for the Deep Learning-based learning approach with the respective values being 5.85 cm and 29.67 cm, respectively. Considering RMSE in X-direction as a function, where RMSE in X-direction (p) gives the RMSE in X-direction of ‘p’, where ‘p’ is a machine learning model; the RMSE in X-directions of these machine learning models can be arranged in an increasing to decreasing order as: RMSE in X-direction (Random Forest) < RMSE in X-direction (k-NN) < RMSE in X-direction (Decision Tree) < RMSE in X-direction (Support Vector Machine) < RMSE in X-direction (Artificial Neural Network) < RMSE in X-direction (Linear Regression) < RMSE in X-direction (Gradient Boosted Trees) < RMSE in X-direction (Deep Learning).
- iii.
- The RMSE in Y-direction is least for the k-NN-based learning approach with a value of 2.96 cm and this metric is highest for the Gradient Boosted Trees-based learning approach with a value of 27.65 cm. Considering RMSE in Y-direction as a function, where RMSE in Y-direction (q) gives the RMSE in Y-direction of ‘q’, where ‘q’ is a machine learning model; the RMSE in Y-directions of these machine learning models can be arranged in an increasing to decreasing order as: RMSE in Y-direction (k-NN) < RMSE in Y-direction (Random Forest) < RMSE in Y-direction (Decision Tree) < RMSE in Y-direction (Deep Learning) < RMSE in Y-direction (Artificial Neural Network) < RMSE in Y-direction (Support Vector Machine) < RMSE in Y-direction (Linear Regression) RMSE in Y-direction (Gradient Boosted Trees)
7. Comparative Discussion
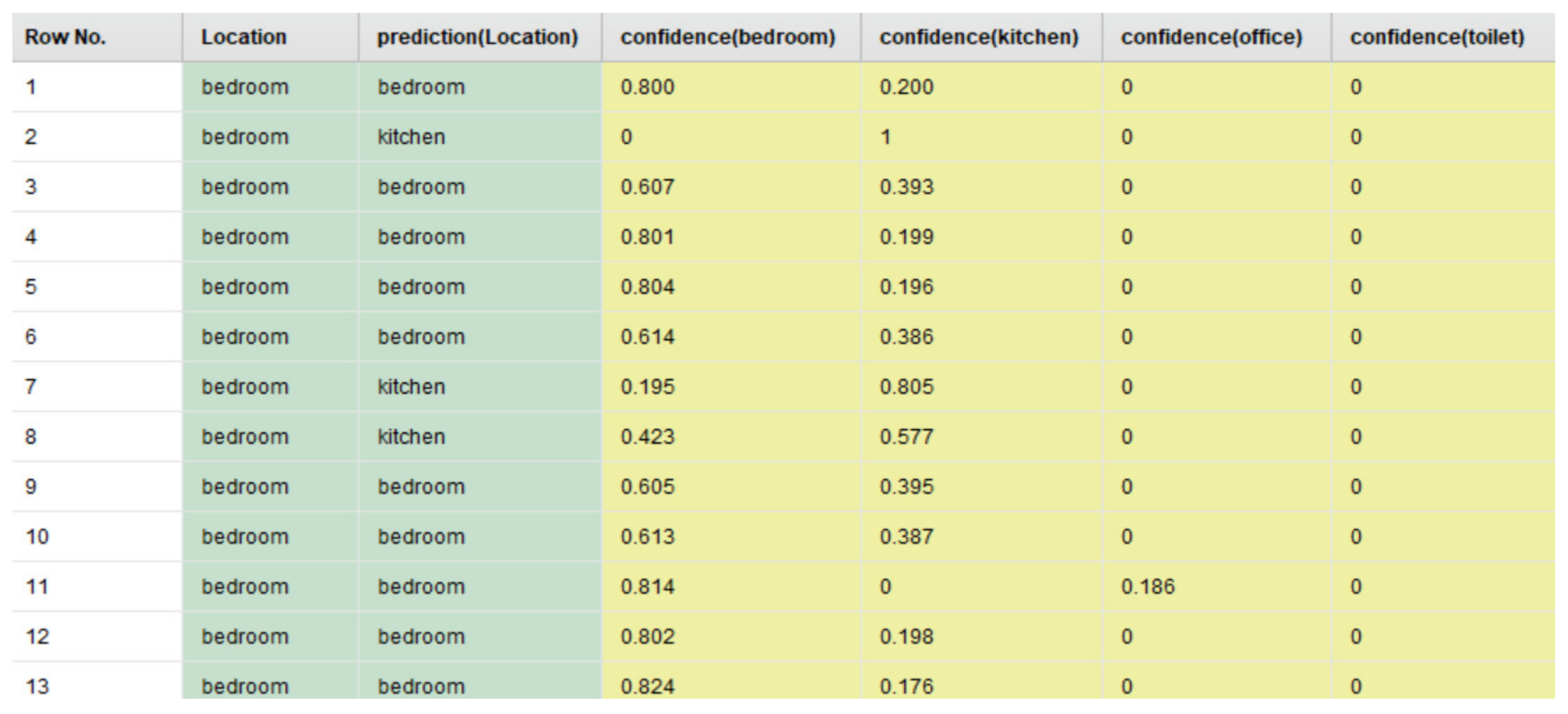
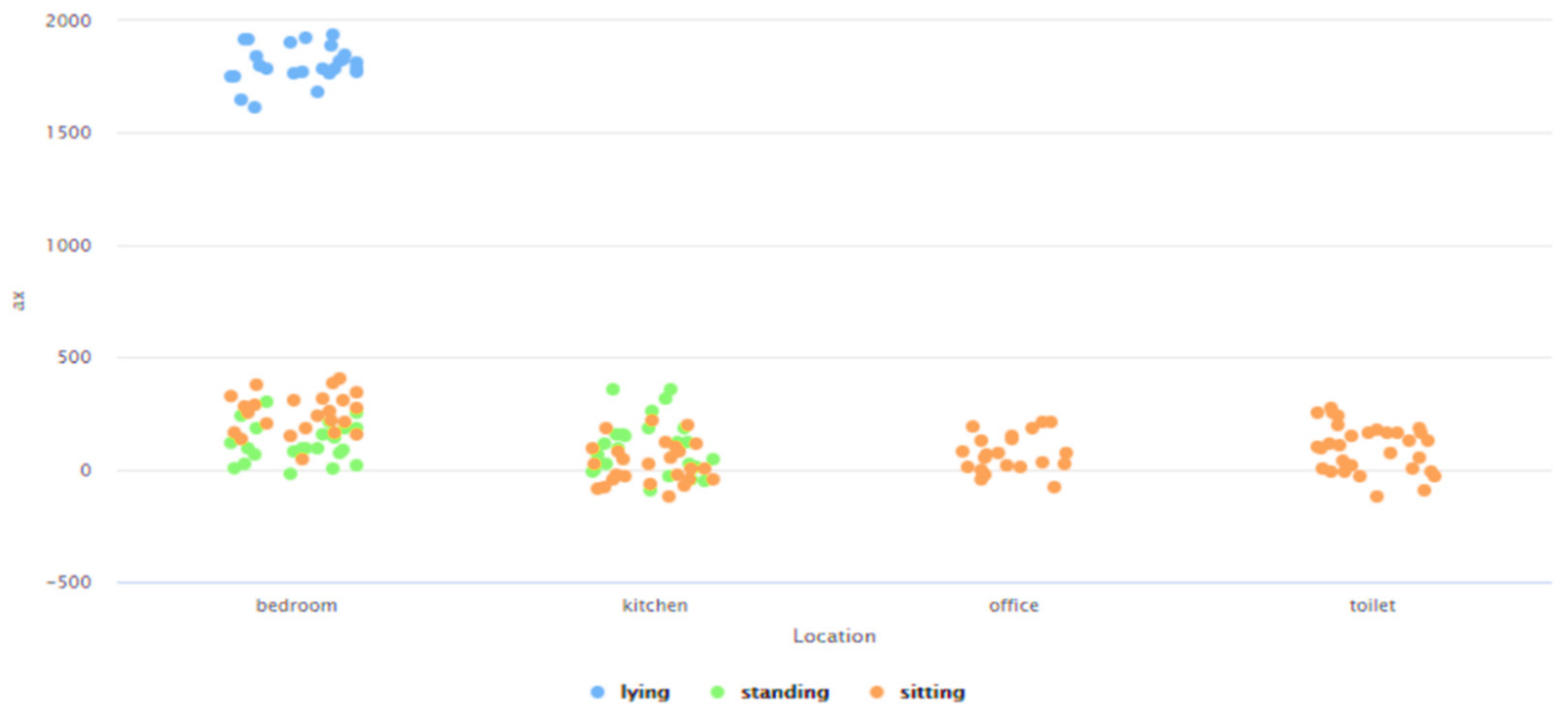
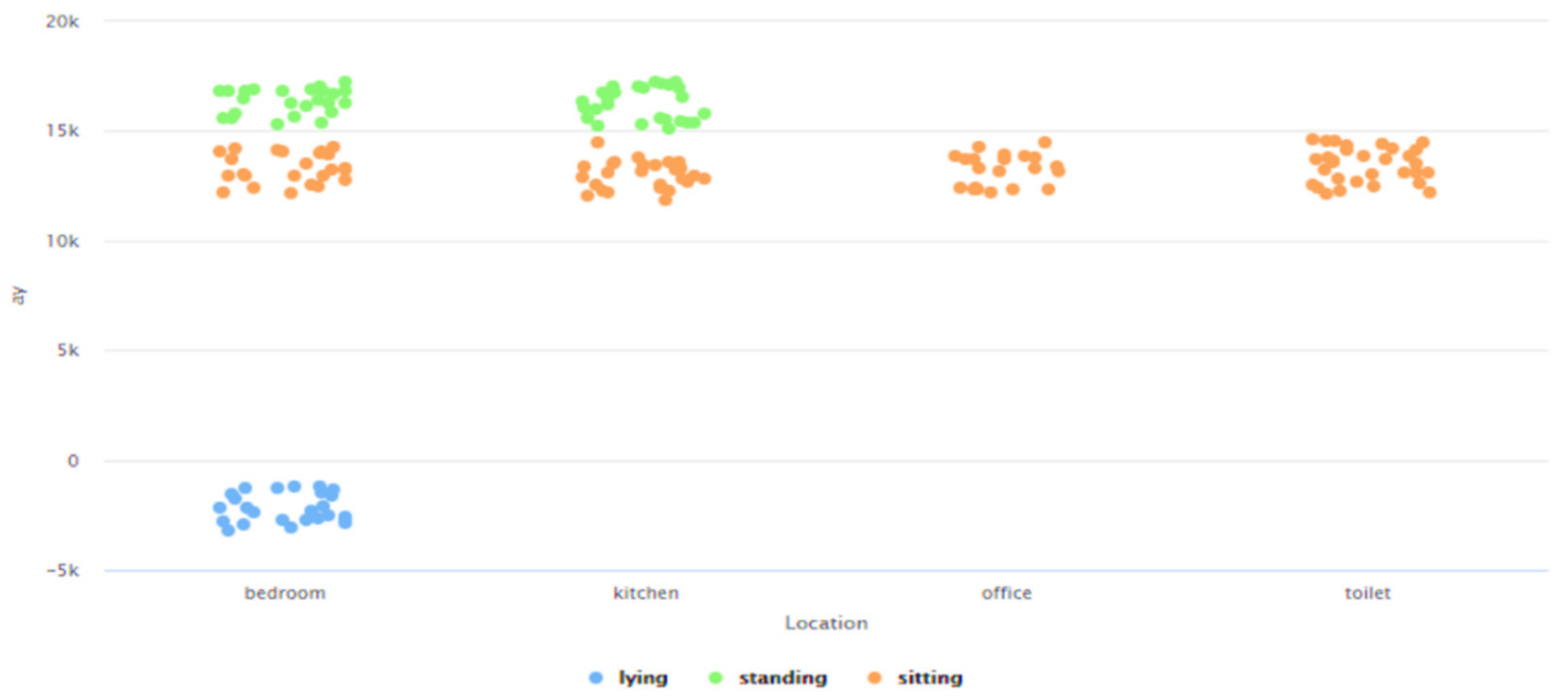
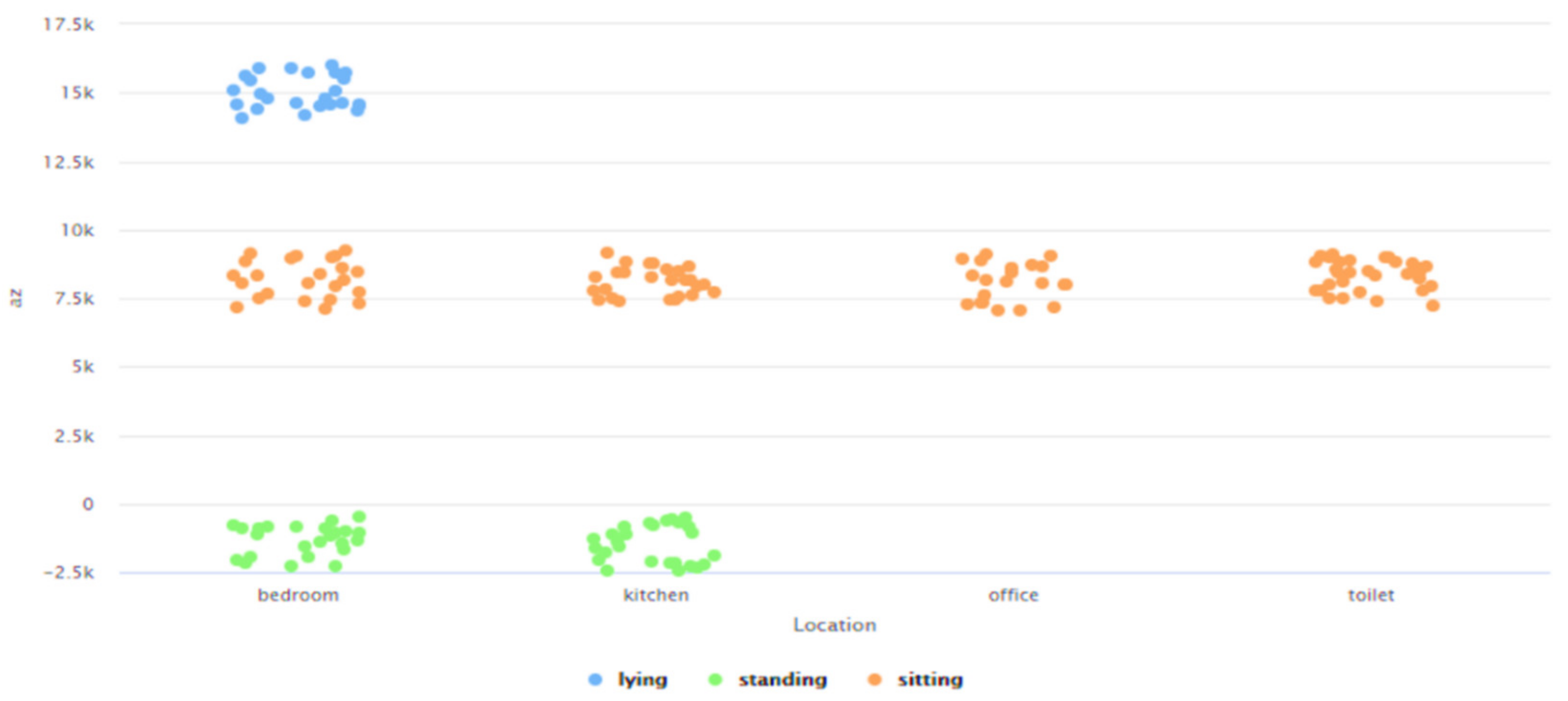
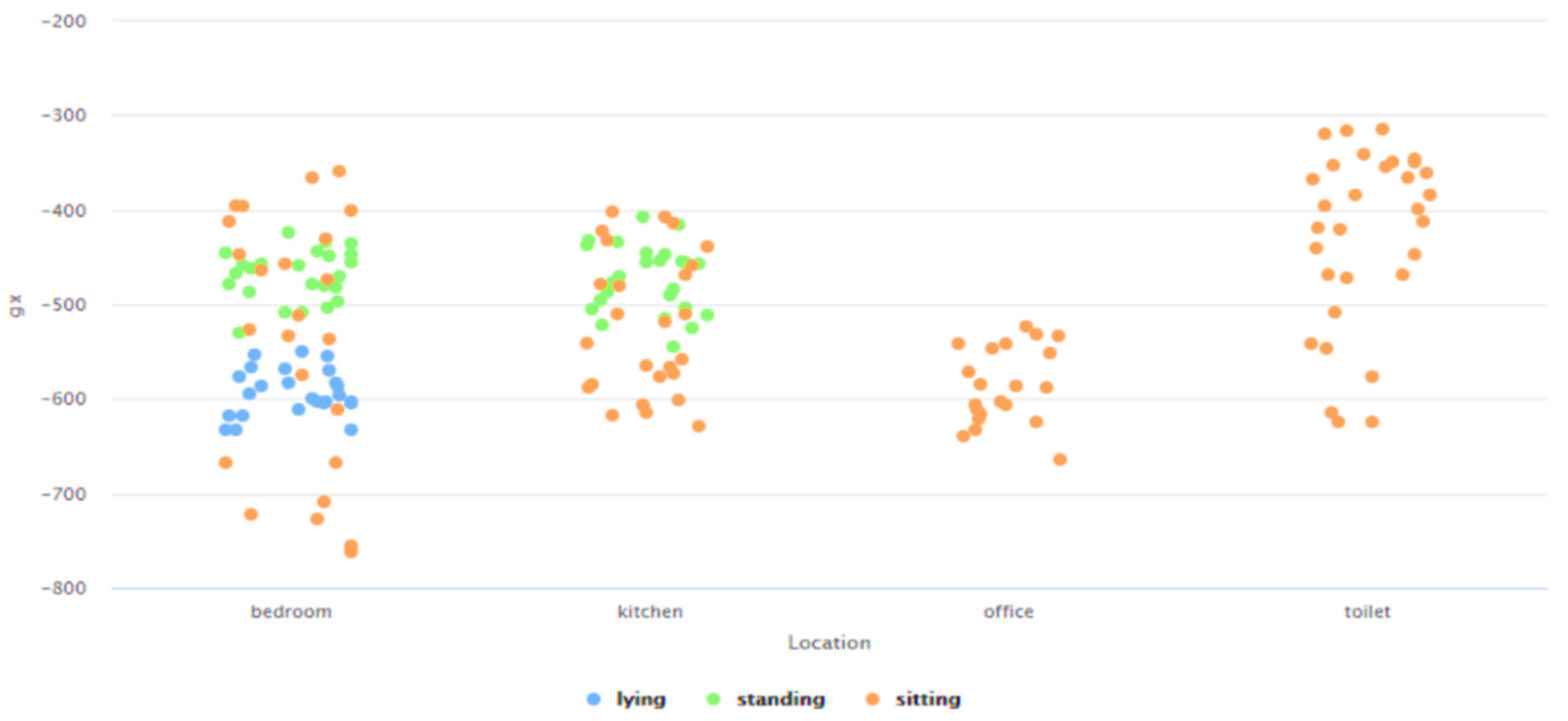
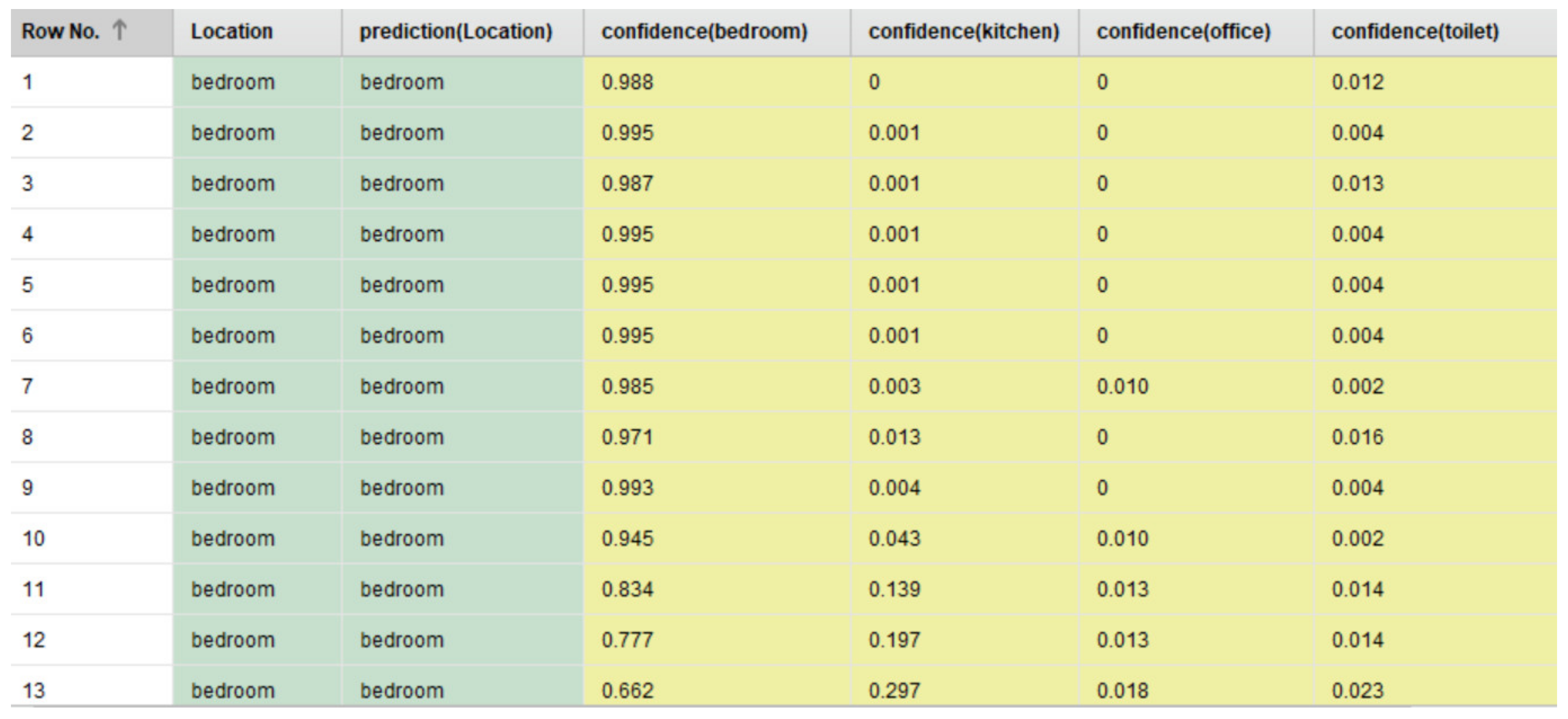
- Need for AAL-based activity recognition and activity analysis-based systems to be able to track the indoor location of the user: The AAL-based systems currently lack the ability to track the indoor location of the user. There have been several works done [46,47,48,49,50,51] in these interrelated fields of activity recognition, activity analysis, and fall detection, but none of these works have focused on Indoor Localization. Being able to track the indoor location of a user is of prime importance and of crucial need for AAL-based systems to be able to contribute towards improving the quality of life of individuals in the future of living environments, such as, Smart Homes. For instance, an elderly person could be staying in an apartment which is a part of a multistoried building such as Taipei 101 [70] or Burj Khalifa [71]—both of which are amongst the tallest buildings in the world. When this elderly person experiences a fall, a fall detection system such as [51], could detect a fall and alert caregivers but the current GPS-based technologies would only provide the building level information. The lack of the precise location information in terms of the specific floor, apartment, and room, could cause delay of medical attention or assistive care. Such delay of care can have both short-term and long-term health-related impacts to the elderly such as long lie [72], that can cause dehydration, rhabdomyolysis, pressure injuries, carpet burns, hypothermia, pneumonia, and fear of falling, which could lead to decreased independence and willingness in carrying out daily routine activities. Long lie can even lead to death in some cases. Thus, it is the need of the hour that AAL-based systems should not only be able to track, monitor, and analyze human behavior but they should also be equipped with the functionality to detect the indoor location of the users. The work presented in this paper addresses this challenge by proposing a novel Big-Data driven methodology that can study the multimodal components of user interactions during Activities of Daily Living (ADLs) (Table 1 and Table 2) and analyze the data from BLE beacons and BLE scanners to track a user’s indoor location in a specific ‘activity-based zone’ during different ADLs (Figure 6). This approach was developed by using a k-nearest neighbor (k-NN)-based learning approach (Section 4.1). When tested on a dataset (Figure 17, Table 3) it achieved a performance accuracy of 81.36% (Figure 18 and Figure 19).
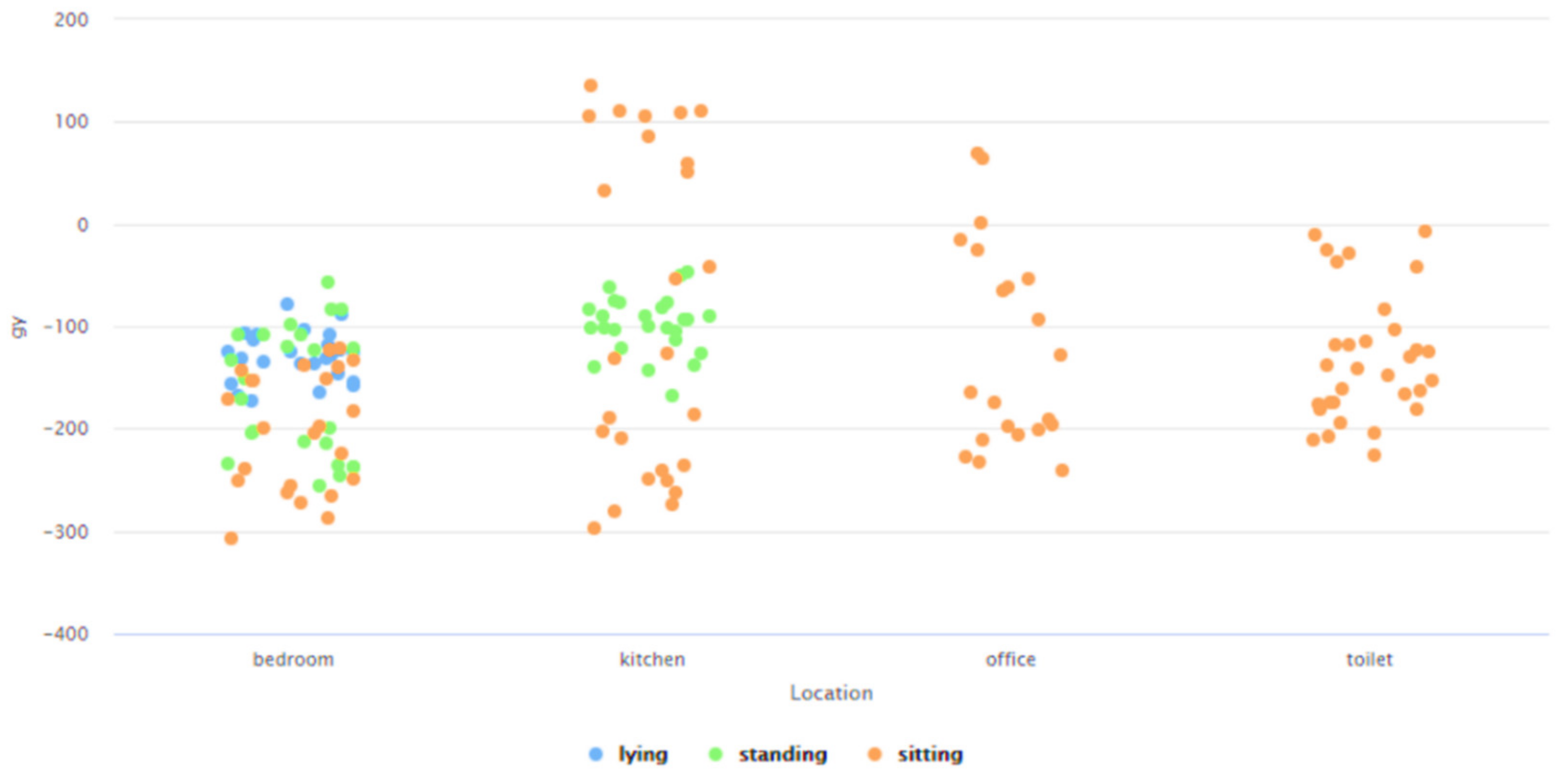
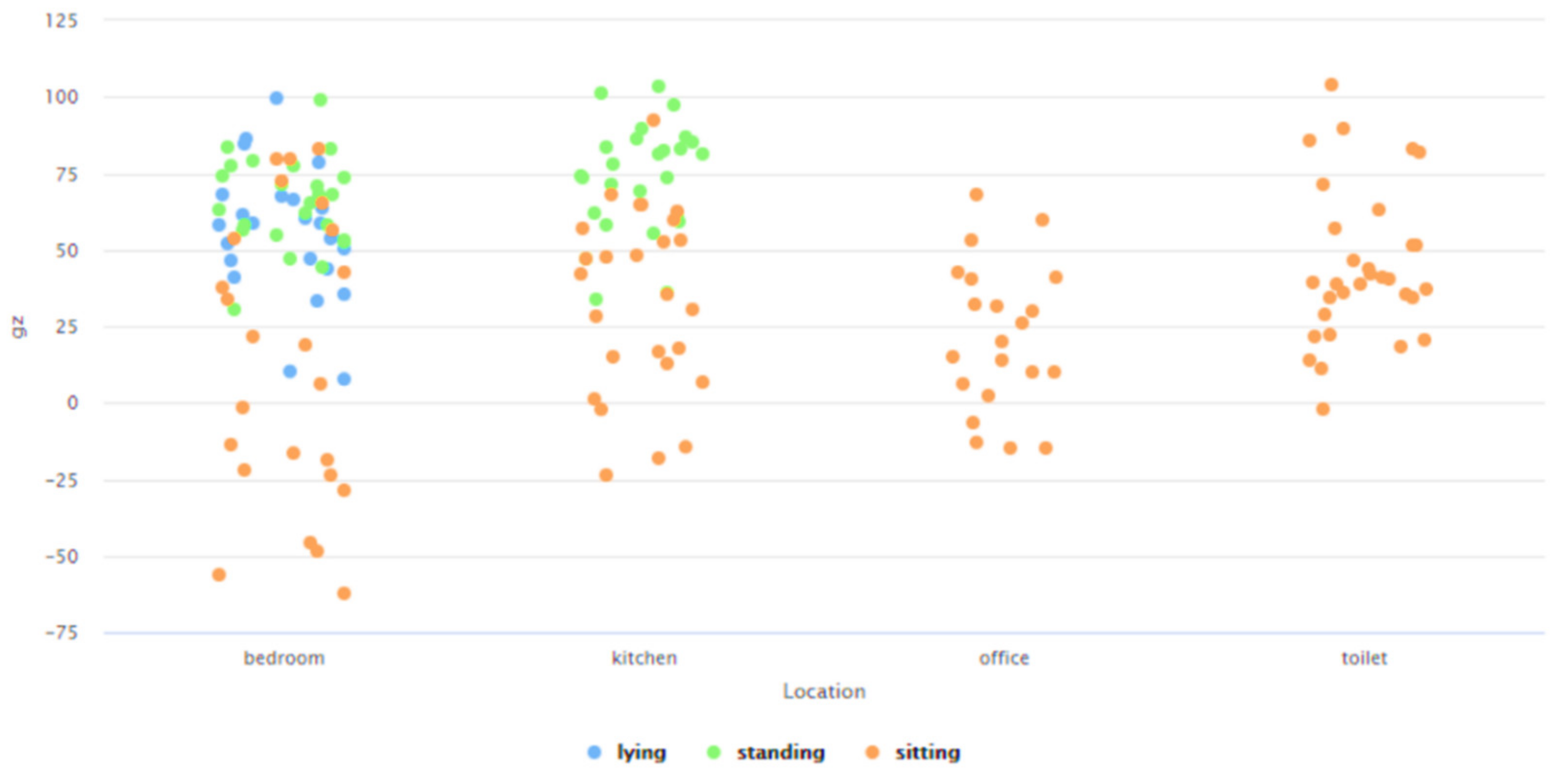
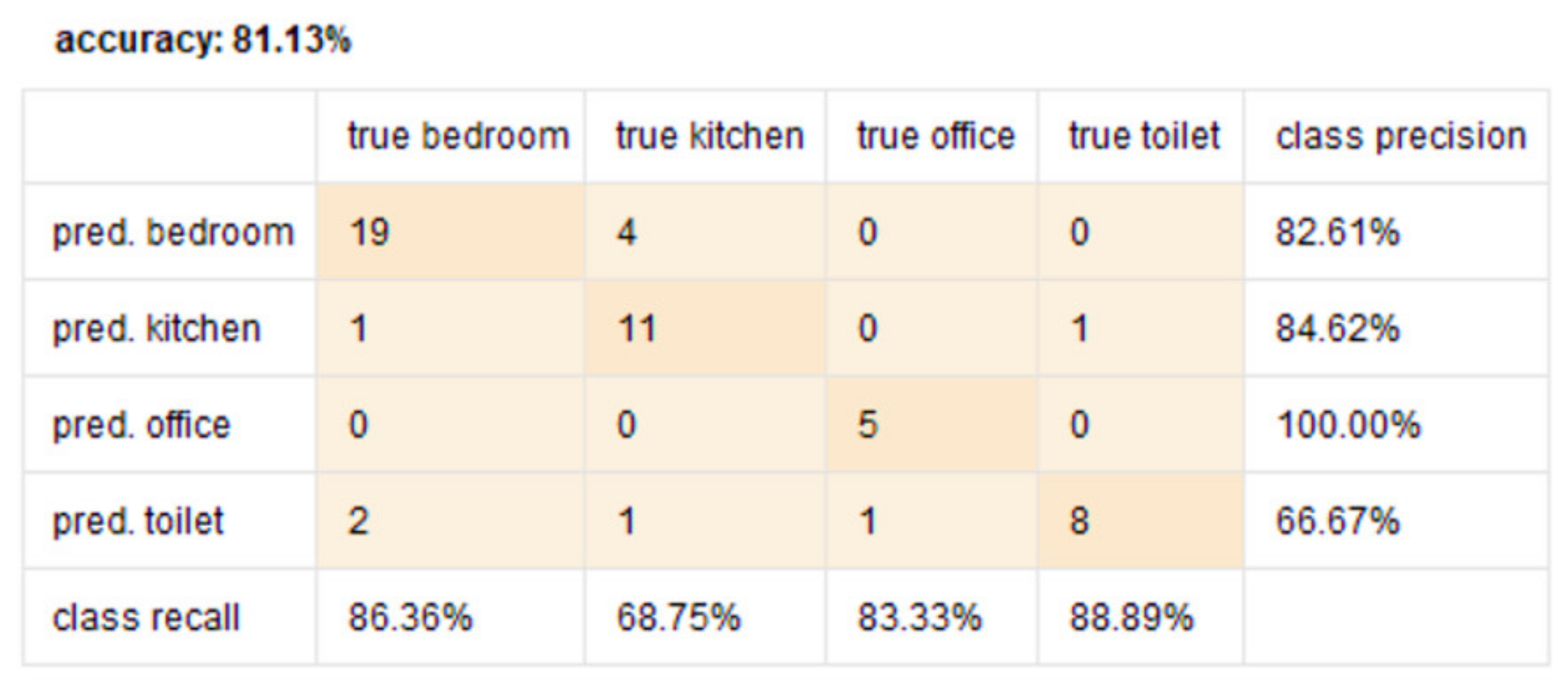
- Need for context-independent Indoor Localization systems: As outlined in Section 2, several recent works related to Indoor Localization systems are context-based and are only functional in the specific environments for which they were developed [26,27,28,29,30]. These specific environments include—factories [26], indoor parking [27], hospitals [28], industry-based settings [29], and academic environments [30]. For instance, the methodology proposed in [29] is not functional in any of the settings described in [26,27,28,30]. The future of interconnected Smart Cities would consist of a host of indoor environments in the living and functional spaces of humans, which would be far more diverse, different, and complicated as compared to the environments described in [26,27,28,29,30]. The challenge is thus to develop a means for Indoor Localization that is not environment dependent and can be seamlessly deployed in any IoT-based setting irrespective of the associated context parameters and their attributes. The work proposed in this paper addresses this challenge by proposing a novel context independent approach that can interpret the accelerometer and gyroscope data from diverse behavioral patterns to detect the ‘zone-based’ indoor location of a user in any IoT-based environment (Section 4.2). This proposed approach (Figure 9) can study, analyze, and interpret the distinct behavioral patterns, in terms of the associated accelerometer and gyroscope data, local to each such ‘zone’, in the confines of any given IoT-based space without being affected by the changes or variations in the context parameters or environment variables. It uses a Random Forest-based learning approach for the training and the same was evaluated on a dataset (Figure 26, Table 4). The performance accuracy of this method for detecting a user’s location in each of these ‘zones’, that were present in this dataset [66], was found to be 81.13% (Figure 27 and Figure 28). Here, the ‘zone-based’ mapping of a user’s location refers to mapping the user in one of the multiple ‘activity-based zones’ that any given IoT-based environment can be classified into based on the specific activity being performed by the user. The accelerometer and gyroscope data are user behavior dependent and not context parameter dependent and neither is this approach of spatially mapping a given IoT-based space into ‘activity-bases zones’ dependent on any specific set of context parameters, as explained in Section 4.2. This upholds the context independent nature of this methodology. In other words, this proposed methodology can be seamlessly applied to any IoT-based environment, including all the environments described in [26,27,28,29,30], as well as in any other IoT-based setting that involves different forms of user interactions on context parameters or environment variables, which can be characterized by the changes in the associated behavioral data.
- The RMSE of the existing Indoor Localization systems [33,34,35,36,37,38,39,40,41,42,43] are still high and greater precision and accuracy for detection of indoor location is the need of the hour. Several performance metrics have been used by researchers for studying the characteristics of Indoor Localization systems, Indoor Positioning Systems, and Location-Based Services. However, ISO/IEC18305:2016, an international standard for evaluating localization and tracking systems [31], which is one of the recent works in this field, lists several metrics and the associated formulae for evaluating the performance characteristics of such systems. These include the formulae for determination of the RMSE in the X-direction, Y-direction, and in the X-Y plane. When the RMSE is determined in the X-Y plane, it is referred to as Horizontal Error as per the definitions of the standard [31]. We have presented and discussed the associated formulae in Equations (1)–(3). Upon reviewing the recent works [33,34,35,36,37,38,39,40,41,42,43] related to this field, as presented in Section 2, it can be observed that the RMSE of the works are still significantly high in view of the average dimensions of an individual’s living space. As per [44,45], (1) the average dimensions of newly built one-bedroom apartments and two-bedroom apartments in United States in 2018 were 757 square feet (70.3276 square meters) and 1138 square feet (105.7236 square meters), respectively. In view of these dimensions of these apartments, it can be concluded that higher precision is needed for the future of Indoor Localization systems. Such systems should have much lower values of RMSE in X and Y directions as well as their overall Horizontal Error should be low. The work presented in this paper addresses this research challenge by proposing a methodology to detect the spatial coordinates of a user’s indoor position based on the associated user interactions with the context parameters and the user-centered local spatial context, by using a reference system. In Section 4.3 we have presented the steps for development of this approach for Indoor Localization and the results of the same are discussed in Section 5.3. While RMSE is sometimes calculated by using vector analysis where a single value of RMSE is calculated instead of RMSE along X and Y directions, but as ISO/IEC18305:2016 [31] presents two separate formulae (Equations (1) and (2)) for calculation of RMSE in X-direction and RMSE in Y-direction and a third formula (Equation (3)) for Horizontal Error calculation, so, we calculated RMSE in X and Y directions separately and then calculated the Horizontal Error as per Equations (1)–(3), respectively. As can be seen from the results (Table 7), the performance characteristics of our approach are—RMSE in X-direction: 5.85 cm, RMSE in Y-direction: 5.36 cm, and Horizontal Error: 7.93 cm. As can be seen from [33,34,35,36,37,38,39,40,41,42,43], RMSE is usually represented in meters, so upon converting these metrics from Table 7 to meters (correct to 2 decimal places) the corresponding values are: RMSE in X-direction: 0.06 m, RMSE in Y-direction: 0.05 m, and Horizontal Error: 0.08 m. The RMSE of these existing works [33,34,35,36,37,38,39,40,41,42,43], in increasing to decreasing order are shown in Table 16. From Table 16, it can be concluded that Bolic et al.’s work [34] has the best performance accuracy out of all the works reviewed in [33,34,35,36,37,38,39,40,41,42,43] with the RMSE being 0.32 m. Upon comparing the performance metrics of our approach (Table 7) with Bolic et al.’s work [34], it can be easily concluded that our work outperforms the same in terms of performance accuracy as the RMSE values (RMSE in X-direction: 0.06 m, RMSE in Y-direction: 0.05 m, and Horizontal Error: 0.08 m) of our methodology are significantly lower. As our work outperforms Bolic et al.’s work, which has the best accuracy out of all the works reviewed in [33,34,35,36,37,38,39,40,41,42,43], so, it can also be concluded that our work outperforms all the other works as well [33,35,36,37,38,39,40,41,42,43], in terms of the RMSE method of performance evaluation, as recommended by ISO/IEC18305:2016 [31].
- Need for an optimal machine learning-based approach for Indoor Localization: A range of machine learning approaches—Random Forest, Artificial Neural Network, Decision Tree, Support Vector Machine, k-NN, Gradient Boosted Trees, Deep Learning, and Linear Regression, have been used by several researchers [9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25] for development of various types of Indoor Localization systems for IoT-based environments. While each of these systems seem to perform reasonably well but none of these works attempted to develop an optimal machine learning model for Indoor Localization systems. Additionally, due to variations in the data source, differences in the types of data, varied methods of data collection, different training set to test set ratios, dissimilar data preprocessing steps, as well as because of differences in the simulated or real-world environments in which these respective systems were developed, implemented, and deployed, the performance metrics of these systems cannot be directly compared to deduce the optimal approach. These works [9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25] along with the machine learning approaches that were used in each are outlined in Table 17. There is a need to address this research challenge of identifying the optimal machine learning methodology for Indoor Localization. The work presented in this paper addresses this challenge. In Section 6—we developed, implemented, and tested the performance characteristics of different learning models to perform Indoor Localization by using the same dataset [67], the same data preprocessing steps, the same training and test ratios, and the same methodology, which we presented in Section 4.3. The learning models that we developed and studied included—Random Forest, Artificial Neural Network, Decision Tree, Support Vector Machine, k-NN, Gradient Boosted Trees, Deep Learning, and Linear Regression. These models were developed to detect the spatial coordinates of a user’s indoor location as per the methodology outlined in Section 4.3. RapidMiner was used to develop these machine learning models, and the corresponding RapidMiner “processes” are shown in Figure 12 and Figure 39, Figure 40, Figure 41, Figure 42, Figure 43, Figure 44 and Figure 45, respectively. We evaluated the performance characteristics of these models based on three performance metrics as outlined in ISO/IEC18305:2016—an international standard for evaluating localization and tracking systems [31]. These include—RMSE in X-direction, RMSE in Y-direction, and Horizontal Error (Equations (1)–(3)). The performance characteristics of these respective machine learning models are shown in Table 7, Table 8, Table 9, Table 10, Table 11, Table 12, Table 13 and Table 14. In Table 15 and Figure 46, we present the comparisons amongst these learning models to deduce the optimal machine learning approach for development of an Indoor Localization system. Based on the findings presented in Table 15 and Figure 46, the following can be observed:
- i.
- Out of all these learning approaches, the Random Forest-based learning approach has the least Horizontal Error of 7.93 cm. In an increasing to decreasing order, the Horizontal Errors of these machine learning models can be arranged as: Horizontal Error (Random Forest) < Horizontal Error (k-NN) < Horizontal Error (Decision Tree) < Horizontal Error (Deep Learning) < Horizontal Error (Artificial Neural Network) < Horizontal Error (Support Vector Machine) < Horizontal Error (Linear Regression) < Horizontal Error (Gradient Boosted Trees).
- ii.
- Out of all these learning approaches, the RMSE in X-direction is the least for the Random Forest-based learning approach, which is equal to 5.85 cm. In an increasing to decreasing order, the RMSE in X-direction of these machine learning models can be arranged as: RMSE in X-direction (Random Forest) < RMSE in X-direction (k-NN) < RMSE in X-direction (Decision Tree) < RMSE in X-direction (Support Vector Machine) < RMSE in X-direction (Artificial Neural Network) < RMSE in X-direction (Linear Regression) < RMSE in X-direction (Gradient Boosted Trees) < RMSE in X-direction (Deep Learning).
- iii.
- Out of all these learning models, the RMSE in Y-direction of the k-NN-based learning approach is the lowest and the RMSE in Y-direction of the Random Forest-based learning approach is the second lowest. Their respective values being 2.96 cm and 5.36 cm, respectively. In an increasing to decreasing order, the RMSE in Y-direction of these machine learning models can be arranged as: RMSE in Y-direction (k-NN) < RMSE in Y-direction (Random Forest) < RMSE in Y-direction (Decision Tree) < RMSE in Y-direction (Deep Learning) < RMSE in Y-direction (Artificial Neural Network) < RMSE in Y-direction (Support Vector Machine) < RMSE in Y-direction (Linear Regression) RMSE in Y-direction (Gradient Boosted Trees)
- iv.
- From (i) and (ii), it can be deduced that for the RMSE in X-direction and for the Horizontal Error (Equations (1) and (3)) methods of performance evaluation, the Random Forest-based learning approach outperforms all the other learning approaches—Artificial Neural Network, Decision Tree, Support Vector Machine, k-NN, Gradient Boosted Trees, Deep Learning, and Linear Regression. Even though the k-NN-based learning approach performs better than the Random Forest-based learning approach for determination of the RMSE in Y-direction, as can be seen from (iii), however, the difference between RMSE in Y-direction for the k-NN based learning approach and the RMSE in Y-direction for the Random Forest based learning approach is not high. To add, for the other two performance metrics—RMSE in X-direction and Horizontal Error, the k-NN based learning approach does not perform as good as the Random Forest-based learning approach and its error values are much higher. Thus, based on these findings and the discussions, which are presented in an elaborate manner in Section 6, it can be concluded that a Random Forest-based learning approach is the optimal machine learning model for development of Indoor Localization systems, Indoor Positioning Systems, and Location-Based Services.
8. Conclusions and Scope for Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Langlois, C.; Tiku, S.; Pasricha, S. Indoor Localization with Smartphones: Harnessing the Sensor Suite in Your Pocket. IEEE Consum. Electron. Mag. 2017, 6, 70–80. [Google Scholar] [CrossRef]
- Zafari, F.; Papapanagiotou, I.; Devetsikiotis, M.; Hacker, T.J. An iBeacon based proximity and indoor localization system. arXiv 2017, arXiv:1703.07876. [Google Scholar]
- Dardari, D.; Closas, P.; Djuric, P.M. Indoor Tracking: Theory, Methods, and Technologies. IEEE Trans. Veh. Technol. 2015, 64, 1263–1278. [Google Scholar] [CrossRef] [Green Version]
- Thakur, N. Framework for a Context Aware Adaptive Intelligent Assistant for Activities of Daily Living. Master’s Thesis, University of Cincinnati, Cincinnati, OH, USA, 2019. Available online: http://rave.ohiolink.edu/etdc/view?acc_num=ucin1553528536685873 (accessed on 10 December 2020).
- Thakur, N.; Han, C.Y. An Improved Approach for Complex Activity Recognition in Smart Homes. Available online: https://link.springer.com/chapter/10.1007/978-3-030-22888-0_15 (accessed on 3 March 2021).
- United Nations: 2020 Report on Ageing. Available online: http://www.un.org/en/sections/issuesdepth/ageing/ (accessed on 22 November 2020).
- United States Census Bureau Report: An Aging World: 2015. Available online: https://www.census.gov/library/publications/2016/demo/P95-16-1.html (accessed on 17 December 2020).
- Key Facts of Dementia. Available online: https://www.who.int/news-room/fact-sheets/detail/dementia (accessed on 24 November 2020).
- Musa, A.; Nugraha, G.D.; Han, H.; Choi, D.; Seo, S.; Kim, J. A decision tree-based NLOS detection method for the UWB indoor location tracking accuracy improvement. Int. J. Commun. Syst. 2019, 32, e3997. [Google Scholar] [CrossRef]
- Yim, J. Introducing a decision tree-based indoor positioning technique. Expert Syst. Appl. 2008, 34, 1296–1302. [Google Scholar] [CrossRef]
- Sjoberg, M.; Koskela, M.; Viitaniemi, V.; Laaksonen, J. Indoor location recognition using fusion of SVM-based visual classifiers. In Proceedings of the 2010 IEEE International Workshop on Machine Learning for Signal Processing, Kittila, Finland, 29 August–1 September 2010; pp. 343–348. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Guo, J.; Wang, W.; Hu, J. Indoor 2.5D Positioning of WiFi Based on SVM. In Proceedings of the 2018 Ubiquitous Positioning, Indoor Navigation and Location-Based Services (UPINLBS) Conference, Wuhan, China, 22–23 March 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Zhang, L.; Zhao, C.; Wang, Y.; Dai, L. Fingerprint-based Indoor Localization using Weighted K-Nearest Neighbor and Weighted Signal Intensity. In Proceedings of the 2nd International Conference on Artificial Intelligence and Advanced Manufacture, Association for Computing Machinery (ACM), Manchester, UK, 15–17 October 2020; pp. 185–191. [Google Scholar]
- Ge, X.; Qu, Z. Optimization WIFI indoor positioning KNN algorithm location-based fingerprint. In Proceedings of the 2016 7th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 26–28 August 2016; pp. 135–137. [Google Scholar]
- Hu, J.; Liu, D.; Yan, Z.; Liu, H. Experimental Analysis on Weight KK -Nearest Neighbor Indoor Fingerprint Positioning. IEEE Internet Things J. 2018, 6, 891–897. [Google Scholar] [CrossRef]
- Khan, I.U.; Ali, T.; Farid, Z.; Scavino, E.; Rahman, M.A.A.; Hamdi, M.; Qiao, G. An improved hybrid indoor positioning system based on surface tessellation artificial neural network. Meas. Control. 2020, 53, 1968–1977. [Google Scholar] [CrossRef]
- Labinghisa, B.A.; Lee, D.M. Neural network-based indoor localization system with enhanced virtual access points. J. Supercomput. 2021, 77, 638–651. [Google Scholar] [CrossRef]
- Qin, F.; Zuo, T.; Wang, X. CCpos: WiFi Fingerprint Indoor Positioning System Based on CDAE-CNN. Sensors 2021, 21, 1114. [Google Scholar] [CrossRef]
- Varma, P.S.; Anand, V. Random Forest Learning Based Indoor Localization as an IoT Service for Smart Buildings. Wirel. Pers. Commun. 2020, 1–19. [Google Scholar] [CrossRef]
- Gao, J.; Li, X.; Ding, Y.; Su, Q.; Liu, Z. WiFi-Based Indoor Positioning by Random Forest and Adjusted Cosine Similarity. In Proceedings of the 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 1426–1431. [Google Scholar]
- Ben Jamâa, M.; Koubâa, A.; Baccour, N.; Kayani, Y.; Al-Shalfan, K.; Jmaiel, M. EasyLoc: Plug-and-Play RSS-Based Localization in Wireless Sensor Networks. In Complex Networks & Their Applications IX; Springer: Berlin, Germany, 2013; Volume 507, pp. 77–98. [Google Scholar]
- Barsocchi, P.; Lenzi, S.; Chessa, S.; Furfari, F. Automatic virtual calibration of range-based indoor localization systems. Wirel. Commun. Mob. Comput. 2011, 12, 1546–1557. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Wang, Y. A 3D mobile positioning method based on deep learning for hospital applications. EURASIP J. Wirel. Commun. Netw. 2020, 2020, 1–15. [Google Scholar] [CrossRef]
- Poulose, A.; Han, D.S. Hybrid Deep Learning Model Based Indoor Positioning Using Wi-Fi RSSI Heat Maps for Autonomous Applications. Electronics 2020, 10, 2. [Google Scholar] [CrossRef]
- Wang, Y.; Lei, Y.; Zhang, Y.; Yao, L. A robust indoor localization method with calibration strategy based on joint distribution adaptation. Wirel. Netw. 2021, 1–15. [Google Scholar] [CrossRef]
- Lin, Y.-T.; Yang, Y.-H.; Fang, S.-H. A case study of indoor positioning in an unmodified factory environment. In Proceedings of the 2014 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Busan, Korea, 27–30 October 2014; pp. 721–722. [Google Scholar]
- Liu, J.; Chen, R.; Chen, Y.; Pei, L.; Chen, L. iParking: An Intelligent Indoor Location-Based Smartphone Parking Service. Sensors 2012, 12, 14612–14629. [Google Scholar] [CrossRef]
- Jiang, L.; Hoe, L.N.; Loon, L.L. Integrated UWB and GPS location sensing system in hospital environment. In Proceedings of the 2010 5th IEEE Conference on Industrial Electronics and Applications, Taichung, Taiwan, 15–17 June 2010; pp. 286–289. [Google Scholar]
- Barral, V.; Suárez-Casal, P.; Escudero, C.J.; García-Naya, J.A. Multi-Sensor Accurate Forklift Location and Tracking Simulation in Industrial Indoor Environments. Electronics 2019, 8, 1152. [Google Scholar] [CrossRef] [Green Version]
- Zadeh, A.M.H.; Koo, A.C.; Abadi, H.G.N. Design of Students’ Attendance system based on mobile indoor location. In Proceedings of the International Conference on Mobile Learning, Application & Services, Malacca, Malaysia, 18–20 September 2012; pp. 1–4. [Google Scholar]
- ISO/IEC 18305:2016 Information Technology—Real Time Locating Systems—Test and Evaluation of Localization and Tracking Systems. Available online: https://www.iso.org/standard/62090.html (accessed on 13 February 2021).
- EVARILOS—Evaluation of RF-based Indoor Localization Solutions for the Future Internet. Available online: https://www2.tkn.tu-berlin.de/tkn-projects/evarilos/index.php (accessed on 13 February 2021).
- Correa, A.; Llado, M.B.; Morell, A.; Vicario, J.L.; Barcelo, M. Indoor Pedestrian Tracking by On-Body Multiple Receivers. IEEE Sens. J. 2016, 16, 2545–2553. [Google Scholar] [CrossRef]
- Bolic, M.; Rostamian, M.; Djuric, P.M. Proximity Detection with RFID: A Step toward the Internet of Things. IEEE Pervasive Comput. 2015, 14, 70–76. [Google Scholar] [CrossRef]
- Angermann, M.; Robertson, P. FootSLAM: Pedestrian Simultaneous Localization and Mapping without Exteroceptive SensorsHitchhiking on Human Perception and Cognition. Proc. IEEE 2012, 100, 1840–1848. [Google Scholar] [CrossRef]
- Evennou, F.; Marx, F. Advanced Integration of WiFi and Inertial Navigation Systems for Indoor Mobile Positioning. EURASIP J. Adv. Signal Process. 2006, 2006, 86706. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Lenz, H.; Szabo, A.; Bamberger, J.; Hanebeck, U.D. WLAN-Based Pedestrian Tracking Using Particle Filters and Low-Cost MEMS Sensors. In Proceedings of the 2007 4th Workshop on Positioning, Navigation and Communication, Hannover, Germany, 22 March 2007; pp. 1–7. [Google Scholar]
- Klingbeil, L.; Wark, T. A Wireless Sensor Network for Real-Time Indoor Localisation and Motion Monitoring. In Proceedings of the 2008 International Conference on Information Processing in Sensor Networks (ipsn 2008), St. Louis, MO, USA, 22–24 April 2008; pp. 39–50. [Google Scholar]
- Pei, L.; Liu, J.; Guinness, R.; Chen, Y.; Kuusniemi, H.; Chen, R. Using LS-SVM Based Motion Recognition for Smartphone Indoor Wireless Positioning. Sensors 2012, 12, 6155–6175. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Chen, R.; Pei, L.; Guinness, R.; Kuusniemi, H. A Hybrid Smartphone Indoor Positioning Solution for Mobile LBS. Sensors 2012, 12, 17208–17233. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Zou, H.; Jiang, H.; Zhu, Q.; Soh, Y.C.; Xie, L. Fusion of WiFi, Smartphone Sensors and Landmarks Using the Kalman Filter for Indoor Localization. Sensors 2015, 15, 715–732. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zhang, P.; Lan, H.; Zhuang, Y.; Niu, X.; El-Sheimy, N. A modularized real-time indoor navigation algorithm on smartphones. In Proceedings of the 2015 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Banff, AB, Canada, 13–16 October 2015; pp. 1–7. [Google Scholar]
- Chen, Z.; Zhu, Q.; Soh, Y.C. Smartphone Inertial Sensor-Based Indoor Localization and Tracking With iBeacon Corrections. IEEE Trans. Ind. Inform. 2016, 12, 1540–1549. [Google Scholar] [CrossRef]
- Statistics: Average Size of Newly Built One-Bedroom Apartments in the United States from 2008 to 2018. Available online: https://www.statista.com/statistics/943956/size-newly-built-one-bed-apartments-usa/ (accessed on 7 February 2021).
- Statistics: Average Size of Newly Built Two-Bedroom Apartments in the United States from 2008 to 2018. Available online: https://www.statista.com/statistics/943958/size-newly-built-two-bed-apartments-usa/ (accessed on 7 February 2021).
- Ranieri, C.; MacLeod, S.; Dragone, M.; Vargas, P.; Romero, R.A. Activity Recognition for Ambient Assisted Living with Videos, Inertial Units and Ambient Sensors. Sensors 2021, 21, 768. [Google Scholar] [CrossRef] [PubMed]
- Fahada, L.G.; Tahir, S.F. Activity recognition and anomaly detection in smart homes. J. Neurocomput. 2021, 423, 362–372. [Google Scholar] [CrossRef]
- Suriani, N.S.; Rashid, F.A.N. Smartphone Sensor Accelerometer Data for Human Activity Recognition Using Spiking Neural Network. Int. J. Machine Learn. Comput. 2021, 11, 298–303. [Google Scholar]
- Mousavi, S.A.; Heidari, F.; Tahami, E.; Azarnoosh, M. Fall detection system via smart phone and send people location. In Proceedings of the 2020 28th European Signal Processing Conference (EUSIPCO), Amsterdam, The Netherlands, 18–22 January 2021; pp. 1605–1607. [Google Scholar]
- Alarifi, A.; Alwadain, A. Killer heuristic optimized convolution neural network-based fall detection with wearable IoT sensor devices. J. Meas. 2021, 167, 108258. [Google Scholar] [CrossRef]
- Al-Okby, M.F.R.; Al-Barrak, S.S. New Approach for Fall Detection System Using Embedded Technology. In Proceedings of the 24th IEEE International Conference on Intelligent Engineering Systems (INES), Reykjavík, Iceland, 8–10 July 2020; pp. 209–214. [Google Scholar]
- Nikoloudakis, Y.; Panagiotakis, S.; Markakis, E.; Pallis, E.; Mastorakis, G.; Mavromoustakis, C.X.; Dobre, C. A Fog-Based Emergency System for Smart Enhanced Living Environments. IEEE Cloud Comput. 2016, 3, 54–62. [Google Scholar] [CrossRef]
- Navarro, J.; Vidaña-Vila, E.; Alsina-Pagès, R.M.; Hervás, M. Real-Time Distributed Architecture for Remote Acoustic Elderly Monitoring in Residential-Scale Ambient Assisted Living Scenarios. Sensors 2018, 18, 2492. [Google Scholar] [CrossRef] [Green Version]
- Nikoloudakis, Y.; Markakis, E.; Mastorakis, G.; Pallis, E.; Skianis, C. An NF V-powered emergency system for smart enhanced living environments. In Proceedings of the 2017 IEEE Conference on Network Function Virtualization and Software Defined Networks (NFV-SDN), Berlin, Germany, 6–8 November 2017; pp. 258–263. [Google Scholar]
- Facchinetti, D.; Psaila, G.; Scandurra, P. Mobile cloud computing for indoor emergency response: The IPSOS assistant case study. J. Reliab. Intell. Environ. 2019, 5, 173–191. [Google Scholar] [CrossRef]
- Fundació Ave Maria, A Non-Profit Organization in Spain. Available online: https://www.avemariafundacio.org/ (accessed on 3 March 2021).
- Anderson, G.O. Technology Use and Attitude among Mid-Life and Older Americans. AARP Res. 2018, 1–29. [Google Scholar] [CrossRef]
- Vaportzis, E.; Clausen, M.G.; Gow, A.J. Older Adults Perceptions of Technology and Barriers to Interacting with Tablet Computers: A Focus Group Study. Front. Psychol. 2017, 8. [Google Scholar] [CrossRef] [Green Version]
- Elguera Paez, L.; Zapata Del Río, C. Elderly Users and Their Main Challenges Usability with Mobile Applications: A Systematic Review. In Design, User Experience, and Usability. Design Philosophy and Theory; HCII 2019, Lecture Notes in Computer Science; Marcus, A., Wang, W., Eds.; Springer: Berlin, Germany, 2019; Volume 11583, pp. 423–438. [Google Scholar]
- Mierswa, I.; Wurst, M.; Klinkenberg, R.; Scholz, M.; Euler, T. YALE: Rapid prototyping for complex data mining tasks. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’06), Philadelphia, PA, USA, 20–23 August 2006; pp. 935–940. [Google Scholar]
- Waikato Environment for Knowledge Analysis (WEKA). Available online: https://en.wikipedia.org/wiki/Weka_(machine_learning) (accessed on 16 February 2021).
- MLC++. Available online: http://robotics.stanford.edu/~ronnyk/mlc.html (accessed on 16 February 2021).
- Saguna, S.; Zaslavsky, A.; Chakraborty, D. Complex activity recognition using context-driven activity theory and activity signatures. ACM Trans. Comput. Interact. 2013, 20, 1–34. [Google Scholar] [CrossRef]
- Chakraborty, S.; Han, C.Y.; Zhou, X.; Wee, W.G. A Context Driven Human Activity Recognition Framework. In Proceedings of the 2016 International Conference on Health Informatics and Medical Systems, Monte Carlo Resort, Las Vegas, NV, USA, 25–28 July 2016; pp. 96–102. [Google Scholar]
- Tao, M. A Framework for Modeling and Capturing Social Interactions. Ph.D. Thesis, University of Cincinnati, Cincinnati, OH, USA, 2014. Available online: https://etd.ohiolink.edu/apexprod/rws_olink/r/1501/10?clear=10&p10_accession_num=ucin1423581254 (accessed on 12 February 2021).
- Tabbakha, N.E.; Ooi, C.P.; Tan, W.H. A Dataset for Elderly Action Recognition Using Indoor Location and Activity Tracking Data. Mendeley Data. 2020. [CrossRef]
- Indoor Positioning Dataset of Bluetooth Beacons Readings Indoor. Available online: https://www.kaggle.com/liwste/indoor-positioning (accessed on 29 December 2020).
- Root Mean Square. Available online: https://en.wikipedia.org/wiki/Root_mean_square (accessed on 13 February 2021).
- Confusion Matrix. Available online: https://en.wikipedia.org/wiki/Confusion_matrix (accessed on 13 February 2021).
- Taipei 101. Available online: https://en.wikipedia.org/wiki/Taipei_101 (accessed on 9 February 2021).
- Burj Khalifa. Available online: https://en.wikipedia.org/wiki/Burj_Khalifa (accessed on 9 February 2021).
- Masud, T.; Morris, R.O. Epidemiology of falls. Age Ageing 2001, 30, 3–7. [Google Scholar] [CrossRef]














































| Complex Activity WCAtk (PB Atk)—PB (0.73) | |
|---|---|
| Ati | At1: Standing (0.10) At2: Walking Towards Toaster (0.12) At3: Putting bread into Toaster (0.15) At4: Setting the Time (0.15) At5: Turning off toaster (0.25) At6: Taking out bread (0.18) At7: Sitting Back (0.05) |
| Cti | Ct1: Lights on (0.10) Ct2: Kitchen Area (0.12) Ct3: Bread Present (0.15) Ct4: Time settings working (0.15) Ct5: Toaster Present (0.25) Ct6: Bread cool (0.18) Ct7: Sitting Area (0.05) |
| AtS and CtS | At1, At2, and Ct1, Ct2 |
| AtE and CtE | At6, At7, and Ct6, Ct7 |
| γAt and ρCt | At3, At4, At5, At6 and Ct3, Ct4, Ct5, Ct6 |
| Complex Activity WCAtk (EL Atk)—EL (0.72) | |
|---|---|
| Ati | At1: Standing (0.08) At2: Walking Towards Dining Table (0.20) At3: Serving Food on a Plate (0.25) At4: Washing Hand/Using Hand Sanitizer (0.20) At5: Sitting Down (0.08) At6: Starting to Eat (0.19) |
| Cti | Ct1: Lights on (0.08) Ct2: Dining Area (0.20) Ct3: Food Present (0.25) Ct4: Plate Present (0.20) Ct5: Sitting Options Available (0.08) Ct6: Food Quality and Taste (0.19) |
| AtS and CtS | At1, At2, and Ct1, Ct2 |
| AtE and CtE | At5, At6, and Ct5, Ct6 |
| γAt and ρCt | At2, At3, At4 and Ct2, Ct3, Ct4 |
| Attribute Name | Description |
|---|---|
| Row No | The row number in the output table |
| Location | The actual instantaneous zone-based location of the user |
| Prediction (Location) | The predicted instantaneous zone-based location of the user |
| Confidence (bedroom) | The degree of certainty that the user was in the bedroom |
| Confidence (kitchen) | The degree of certainty that the user was in the kitchen |
| Confidence (office) | The degree of certainty that the user was in the office area |
| Confidence (toilet) | The degree of certainty that the user was in the toilet |
| Attribute Name | Description |
|---|---|
| Row No | The row number in the output table |
| Location | The actual instantaneous zone-based location of the user |
| Prediction (Location) | The predicted instantaneous zone-based location of the user |
| Confidence (bedroom) | The degree of certainty that the user was in the bedroom |
| Confidence (kitchen) | The degree of certainty that the user was in the kitchen |
| Confidence (office) | The degree of certainty that the user was in the office area |
| Confidence (toilet) | The degree of certainty that the user was in the toilet |
| Attribute Name | Description |
|---|---|
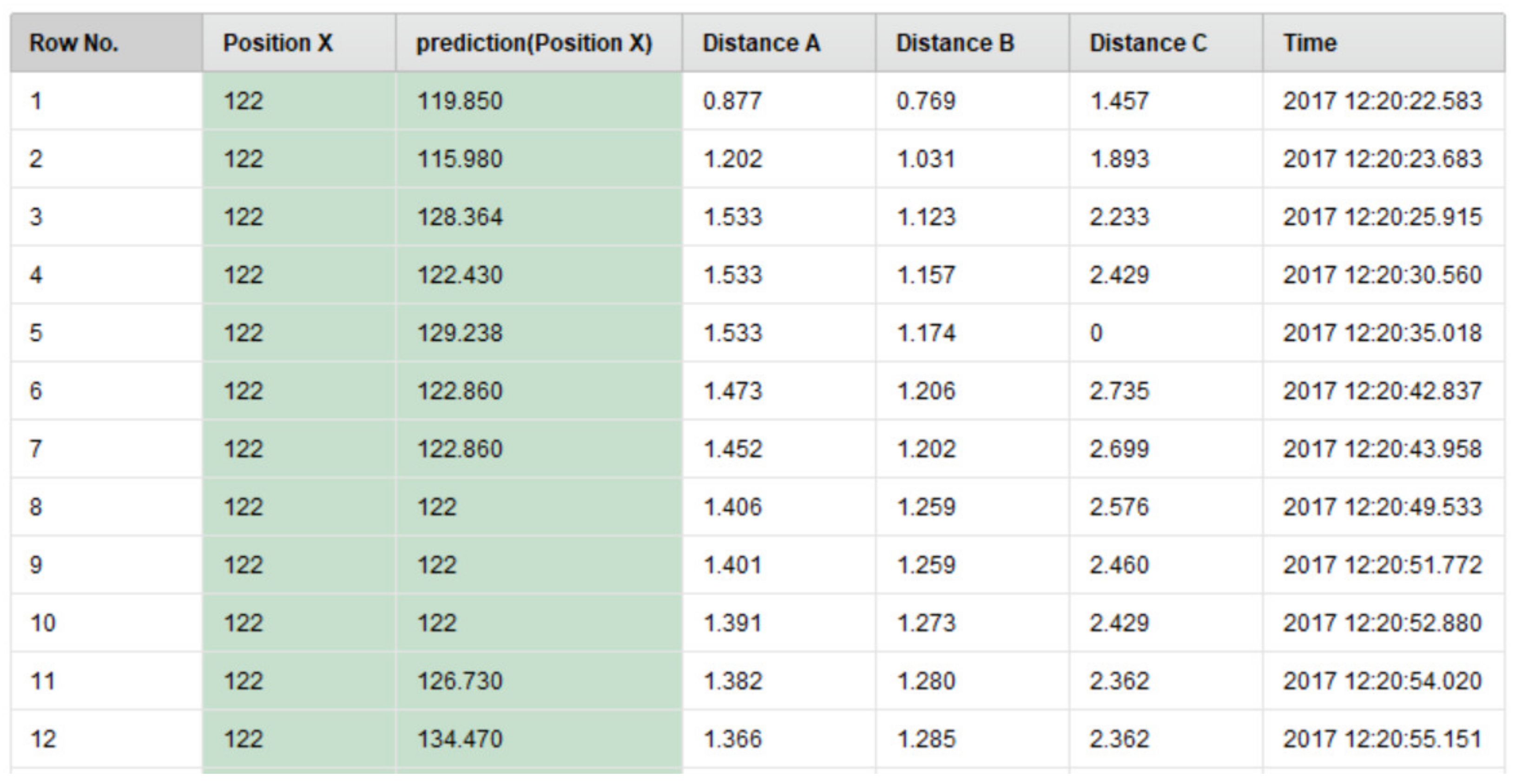
| Row No | The row number in the output table |
| Position X | The actual X coordinate of the user’s position |
| Prediction (Position X) | The predicted X coordinate of the user’s position |
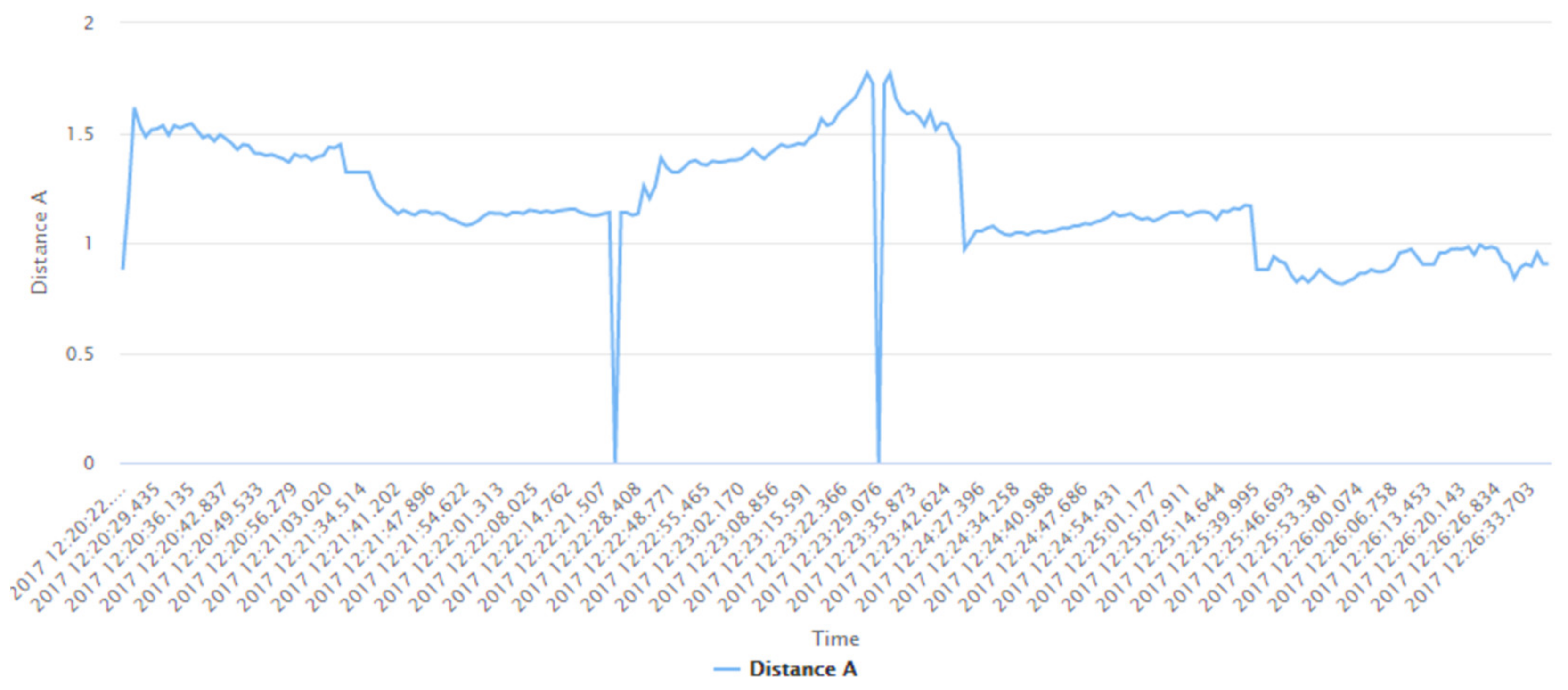
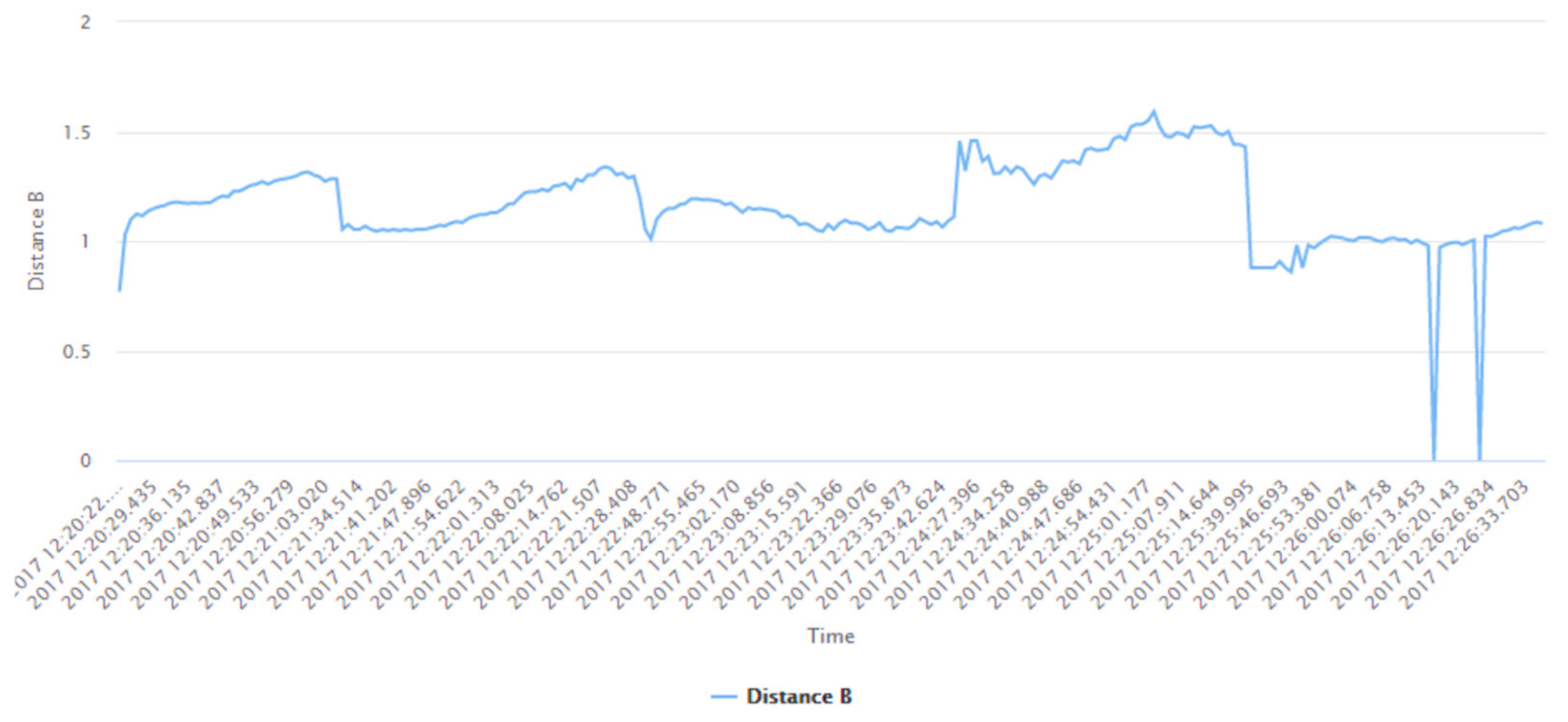
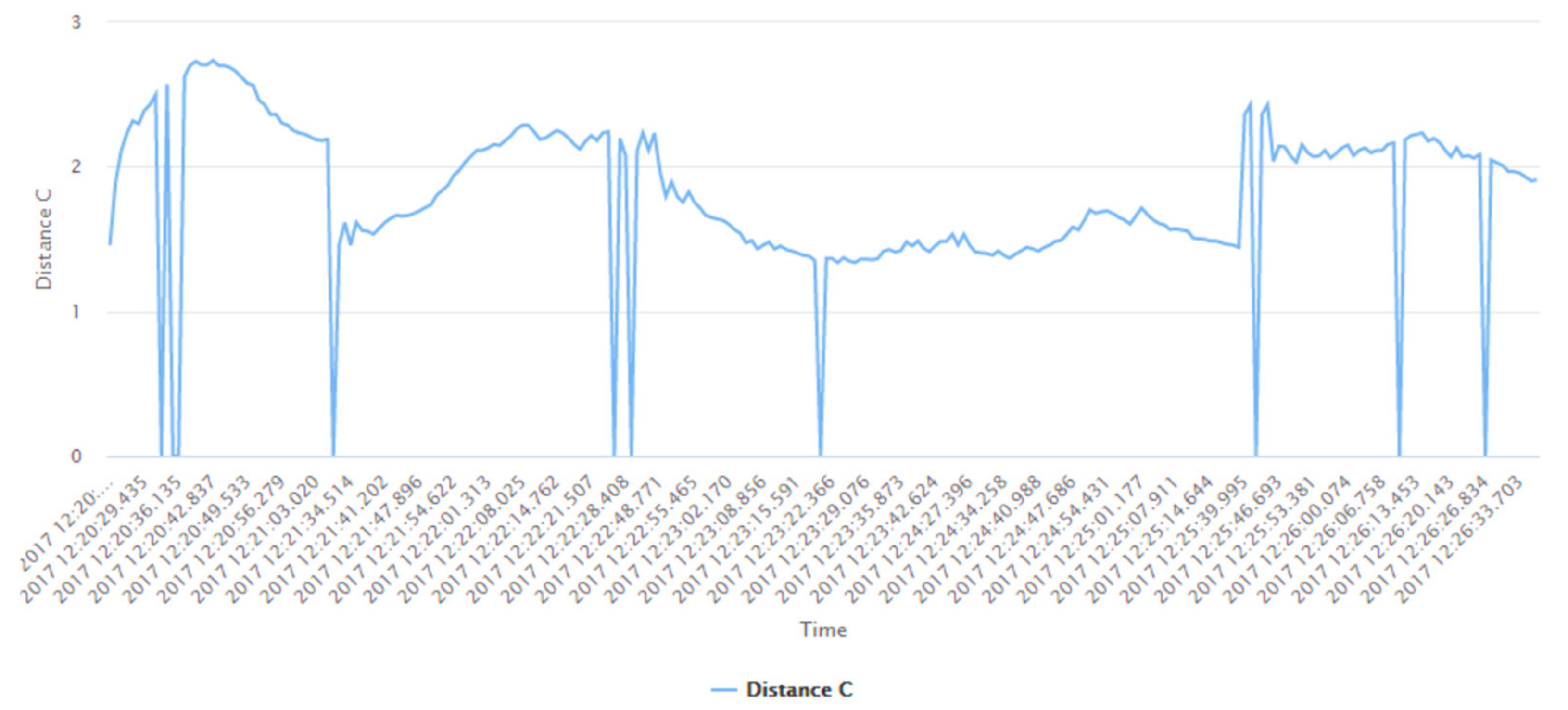
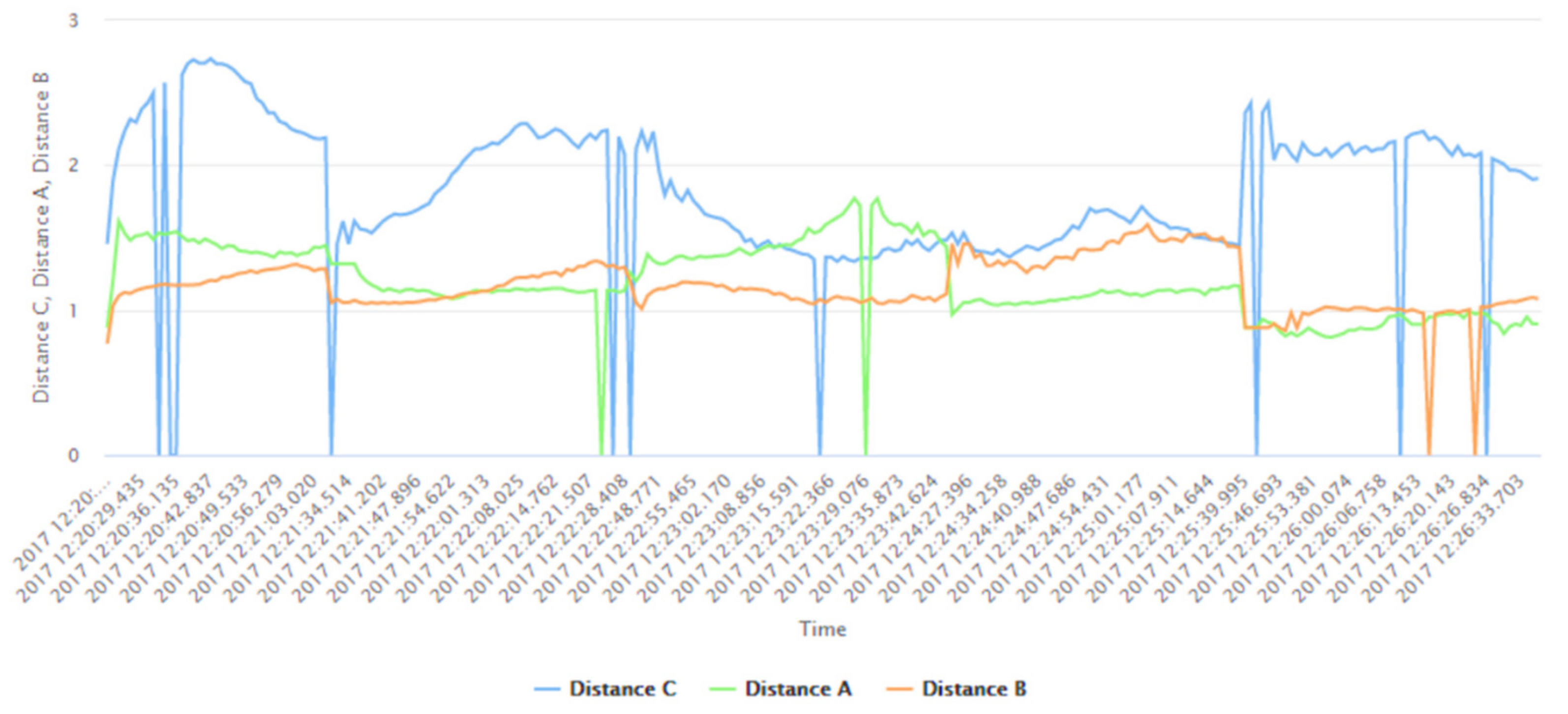
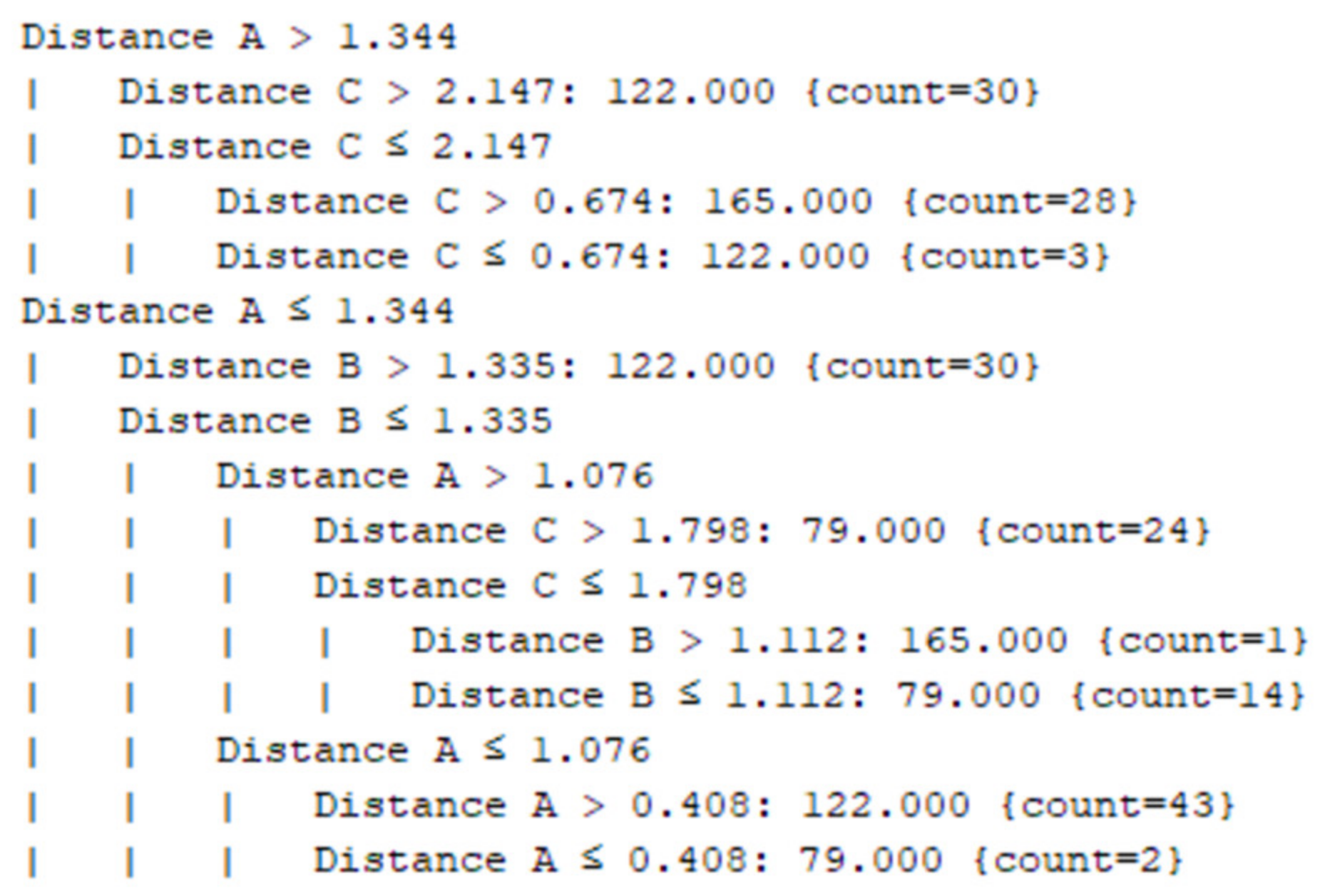
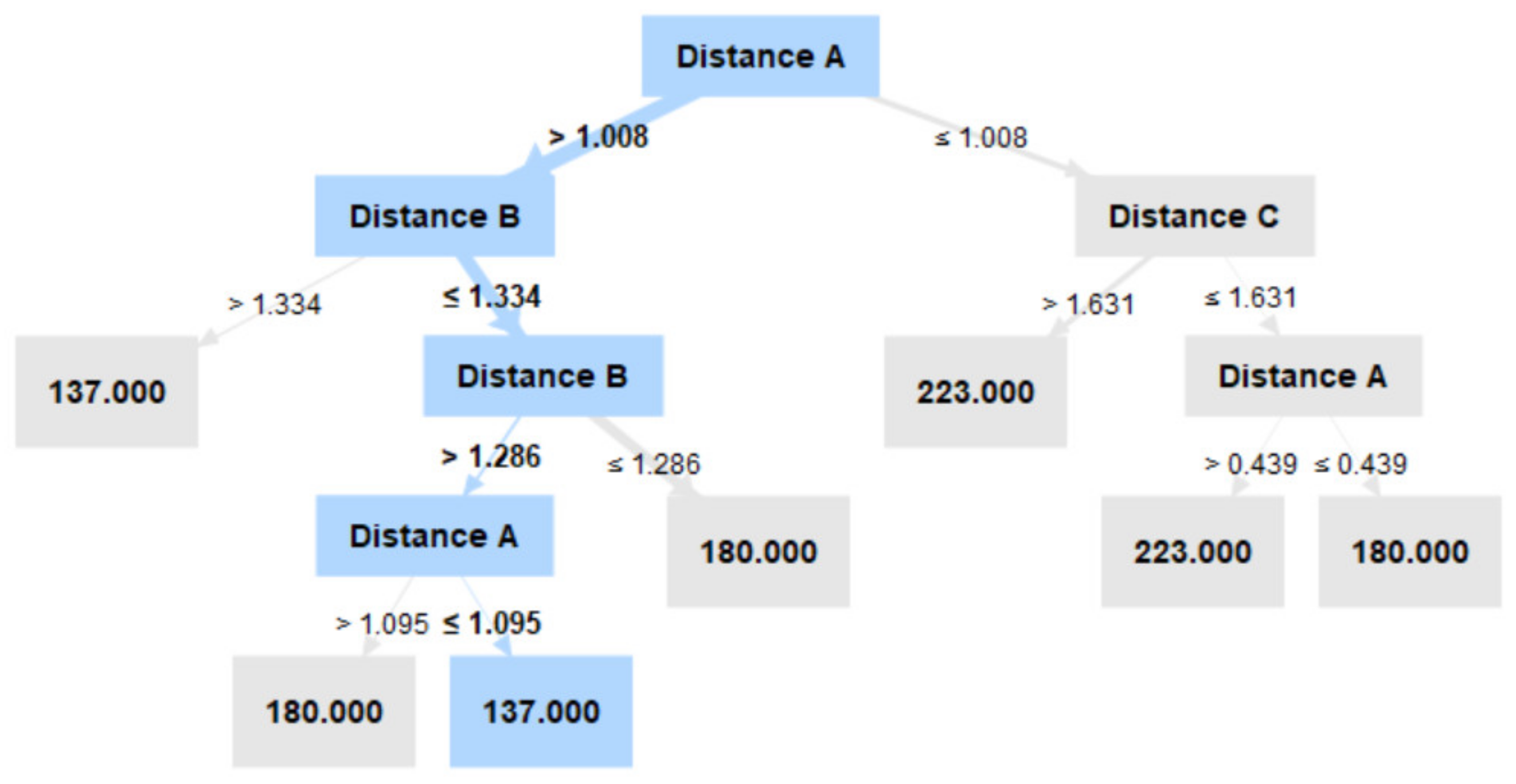
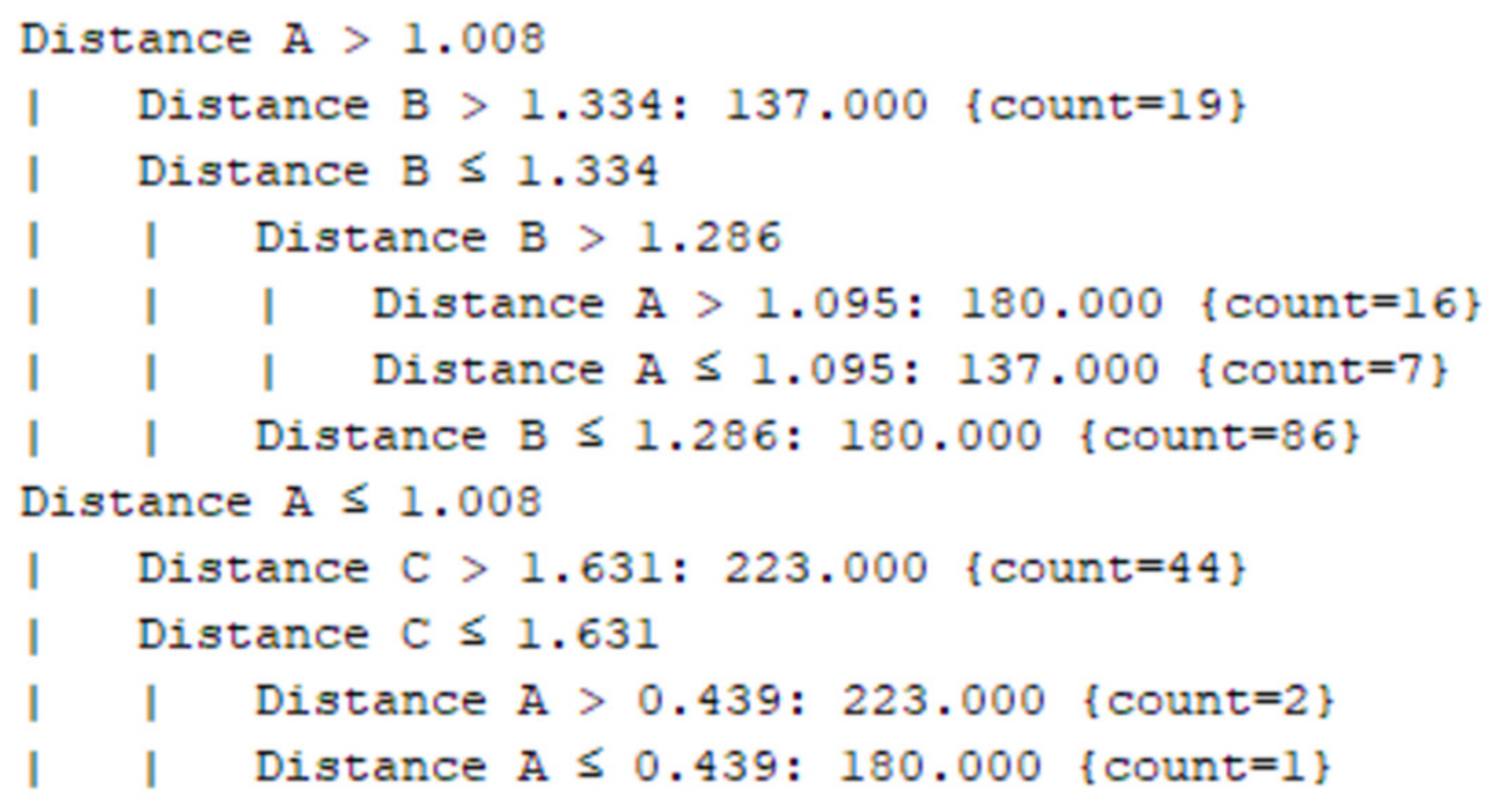
| Distance A | The actual distance of the user from the first Bluetooth beacon |
| Distance B | The actual distance of the user from the second Bluetooth beacon |
| Distance C | The actual distance of the user from the third Bluetooth beacon |
| Time | The associated timestamp information |
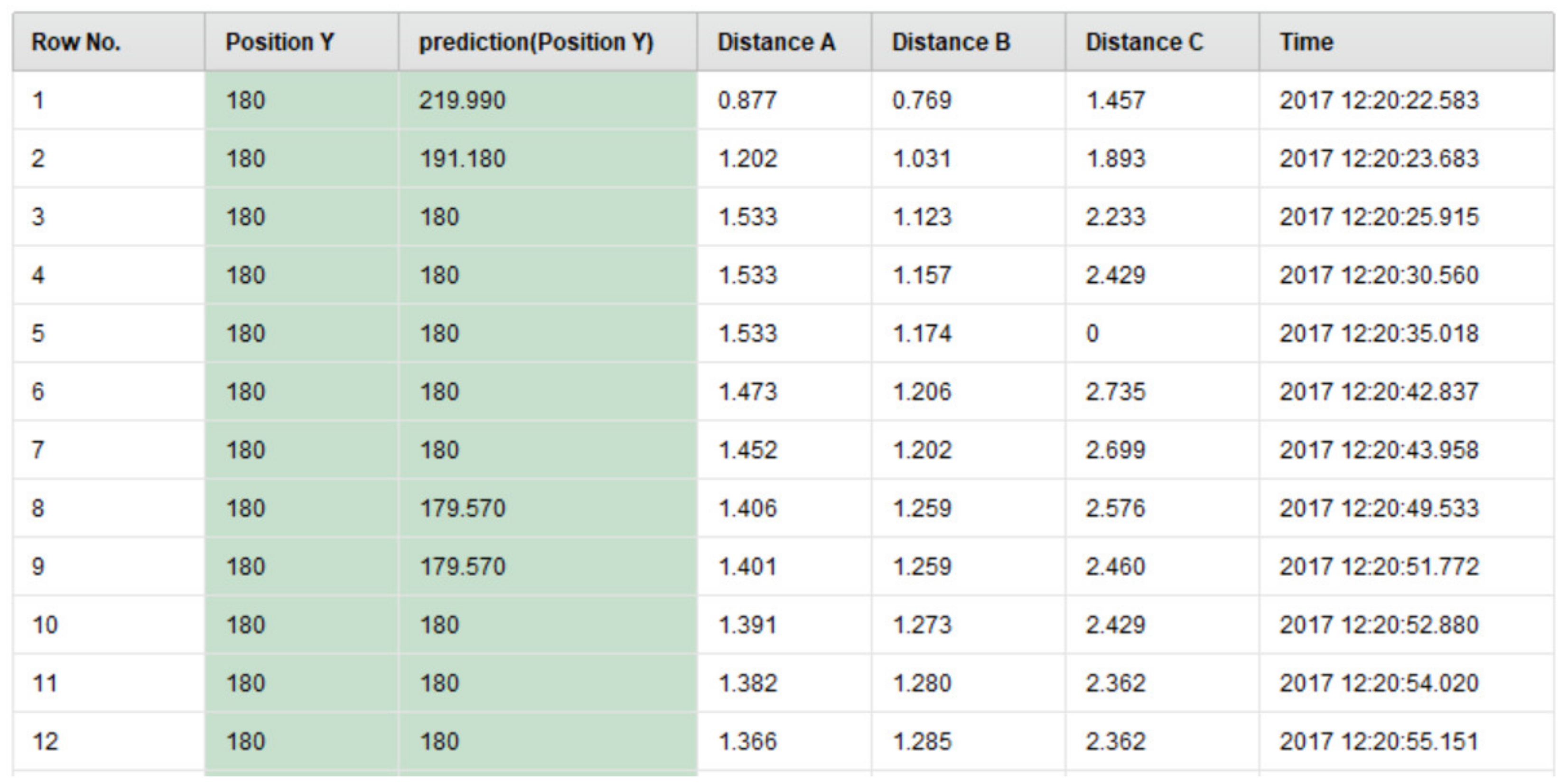
| Attribute Name | Description |
|---|---|
| Row No | The row number in the output table |
| Position Y | The actual Y coordinate of the user’s position |
| Prediction (Position Y) | The predicted Y coordinate of the user’s position |
| Distance A | The actual distance of the user from the first Bluetooth beacon |
| Distance B | The actual distance of the user from the second Bluetooth beacon |
| Distance C | The actual distance of the user from the third Bluetooth beacon |
| Time | The associated timestamp information |
| Description of Performance Characteristic | Value |
|---|---|
| Root Mean Squared Error for detection of X-coordinate | 28.00 cm |
| Root Mean Squared Error for detection of Y-coordinate | 16.16 cm |
| Horizontal Error | 32.33 cm |
| Description of Performance Characteristic | Value |
|---|---|
| Root Mean Squared Error for detection of X-coordinate | 12.52 cm |
| Root Mean Squared Error for detection of Y-coordinate | 6.19 cm |
| Horizontal Error | 13.97 cm |
| Description of Performance Characteristic | Value |
|---|---|
| Root Mean Squared Error for detection of X-coordinate | 27.92 cm |
| Root Mean Squared Error for detection of Y-coordinate | 27.17 cm |
| Horizontal Error | 38.96 cm |
| Description of Performance Characteristic | Value |
|---|---|
| Root Mean Squared Error for detection of X-coordinate | 10.11 cm |
| Root Mean Squared Error for detection of Y-coordinate | 2.96 cm |
| Horizontal Error | 10.54 cm |
| Description of Performance Characteristic | Value |
|---|---|
| Root Mean Squared Error for detection of X-coordinate | 28.12 cm |
| Root Mean Squared Error for detection of Y-coordinate | 27.65 cm |
| Horizontal Error | 39.44 cm |
| Description of Performance Characteristic | Value |
|---|---|
| Root Mean Squared Error for detection of X-coordinate | 29.67 cm |
| Root Mean Squared Error for detection of Y-coordinate | 12.04 cm |
| Horizontal Error | 32.02 cm |
| Description of Performance Characteristic | Value |
|---|---|
| Root Mean Squared Error for detection of X-coordinate | 28.064 cm |
| Root Mean Squared Error for detection of Y-coordinate | 27.630 cm |
| Horizontal Error | 39.382 cm |
| Learning Approach | Performance Metrics | ||
|---|---|---|---|
| RMSE in X-Direction | RMSE in Y-Direction | Horizontal Error | |
| Random Forest | 5.85 cm | 5.36 cm | 7.93 cm |
| Artificial Neural Network | 28.00 cm | 16.16 cm | 32.33 cm |
| Decision Tree | 12.52 cm | 6.19 cm | 13.97 cm |
| Support Vector Machine | 27.92 cm | 27.17 cm | 38.96 cm |
| k-NN | 10.11 cm | 2.96 cm | 10.54 cm |
| Gradient Boosted Trees | 28.12 cm | 27.65 cm | 39.44 cm |
| Deep Learning | 29.67 cm | 12.04 cm | 32.02 cm |
| Linear Regression | 28.06 cm | 27.63 cm | 39.38 cm |
| RMSE Value (in Meters) | Work(s) |
|---|---|
| 0.32 | Bolic et al. [34] |
| 1.00 | Chen et al. [41] |
| 1 to 2 | Angermann et al. [35] |
| 1.20 | Klingbeil et al. [38] |
| 1.28 | Chen at al. [43] |
| 1.40 | Correa et al. [33] |
| 1.53 | Evennou et al. [36] |
| 2.90 | Li et al. [42] |
| 3.10 | Liu et al. [40] |
| 4.30 | Wang et al. [37] |
| 4.55 | Pei et al. [39] |
| Learning Approach Used | Work(s) |
|---|---|
| Random Forest | Varma et al. [19], Gao et al. [20] |
| Artificial Neural Network | Khan et al. [16], Labinghisa et al. [17], Qin et al. [18] |
| Decision Tree | Musa et al. [9], Yim et al. [10] |
| Support Vector Machine | Sjoberg et al. [11], Zhang et al. [12] |
| k-NN | Zhang et al. [13], Ge et al. [14], Hu et al. [15] |
| Gradient Boosted Trees | Wang et al. [25] |
| Deep Learning | Zhang et al. [23], Poulose et al. [24] |
| Linear Regression | Jamâa et al. [21], Barsocchi et al. [22] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thakur, N.; Han, C.Y. Multimodal Approaches for Indoor Localization for Ambient Assisted Living in Smart Homes. Information 2021, 12, 114. https://doi.org/10.3390/info12030114
Thakur N, Han CY. Multimodal Approaches for Indoor Localization for Ambient Assisted Living in Smart Homes. Information. 2021; 12(3):114. https://doi.org/10.3390/info12030114
Chicago/Turabian StyleThakur, Nirmalya, and Chia Y. Han. 2021. "Multimodal Approaches for Indoor Localization for Ambient Assisted Living in Smart Homes" Information 12, no. 3: 114. https://doi.org/10.3390/info12030114
APA StyleThakur, N., & Han, C. Y. (2021). Multimodal Approaches for Indoor Localization for Ambient Assisted Living in Smart Homes. Information, 12(3), 114. https://doi.org/10.3390/info12030114