
Research on Automatic Question Answering of Generative Knowledge Graph Based on Pointer Network



Abstract
:1. Introduction
- BERT pre-trained language model is adopted to obtain the word vectors of the question sentence, combining the semantic features of the word frequency of the entity words in the question sentence, which are combined together as the input sequence.
- Knowledge graph combined with the source text information is used to construct a vocabulary as a pointer to generate a soft link of the network, and point to the corresponding entity for fusion to generate the corresponding answer.
2. Related Work
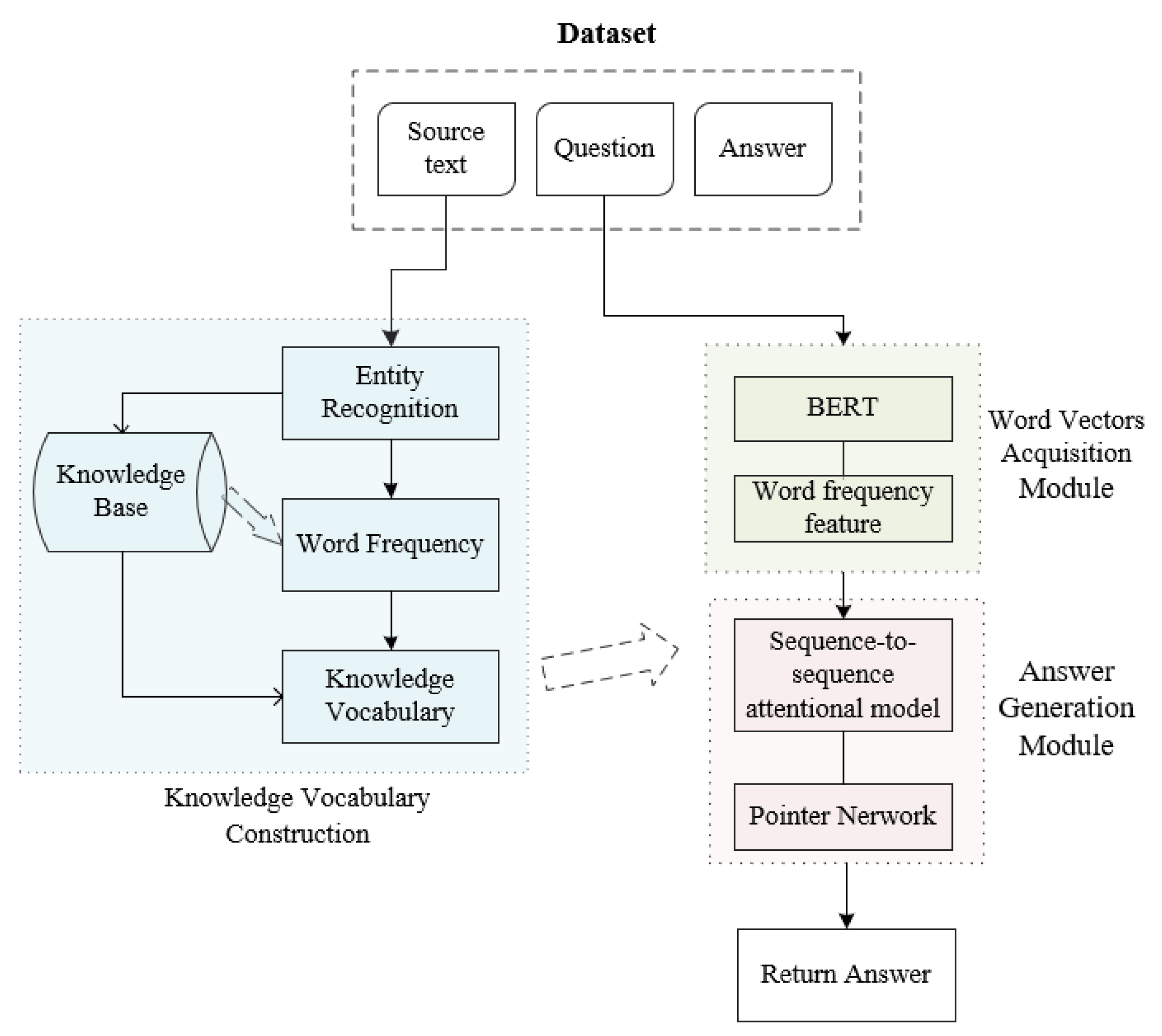
3. Construction of Generative QA System
3.1. Knowledge Vocabulary Construction
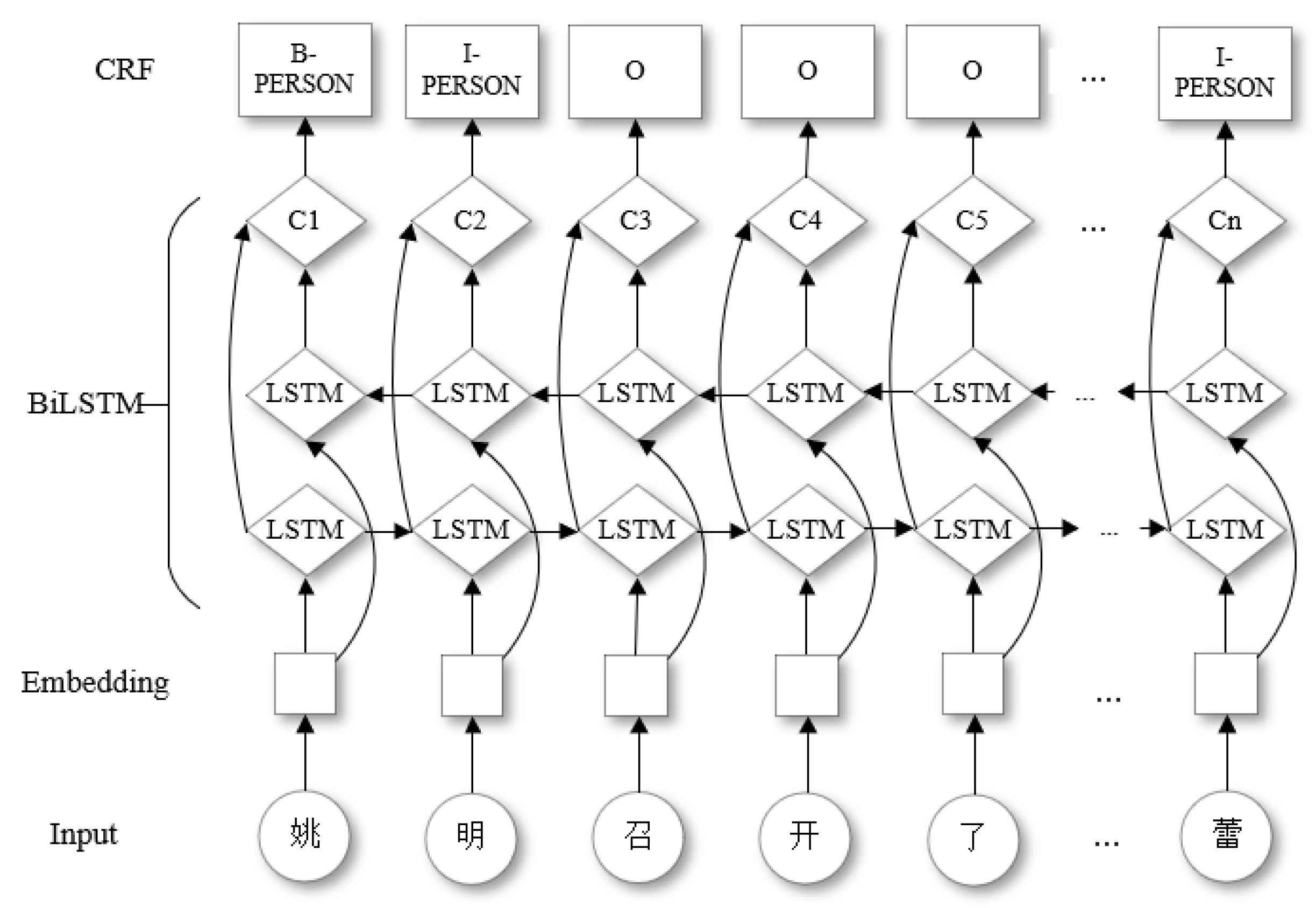
3.1.1. Entity Recognition
- BiLSTM Module
- 2.
- CRF Module
3.1.2. Vocabulary Construction
3.2. Answer Generation Model
3.2.1. Word Vectors Acquisition
- BERT Module
- 2.
- Frequency Feature
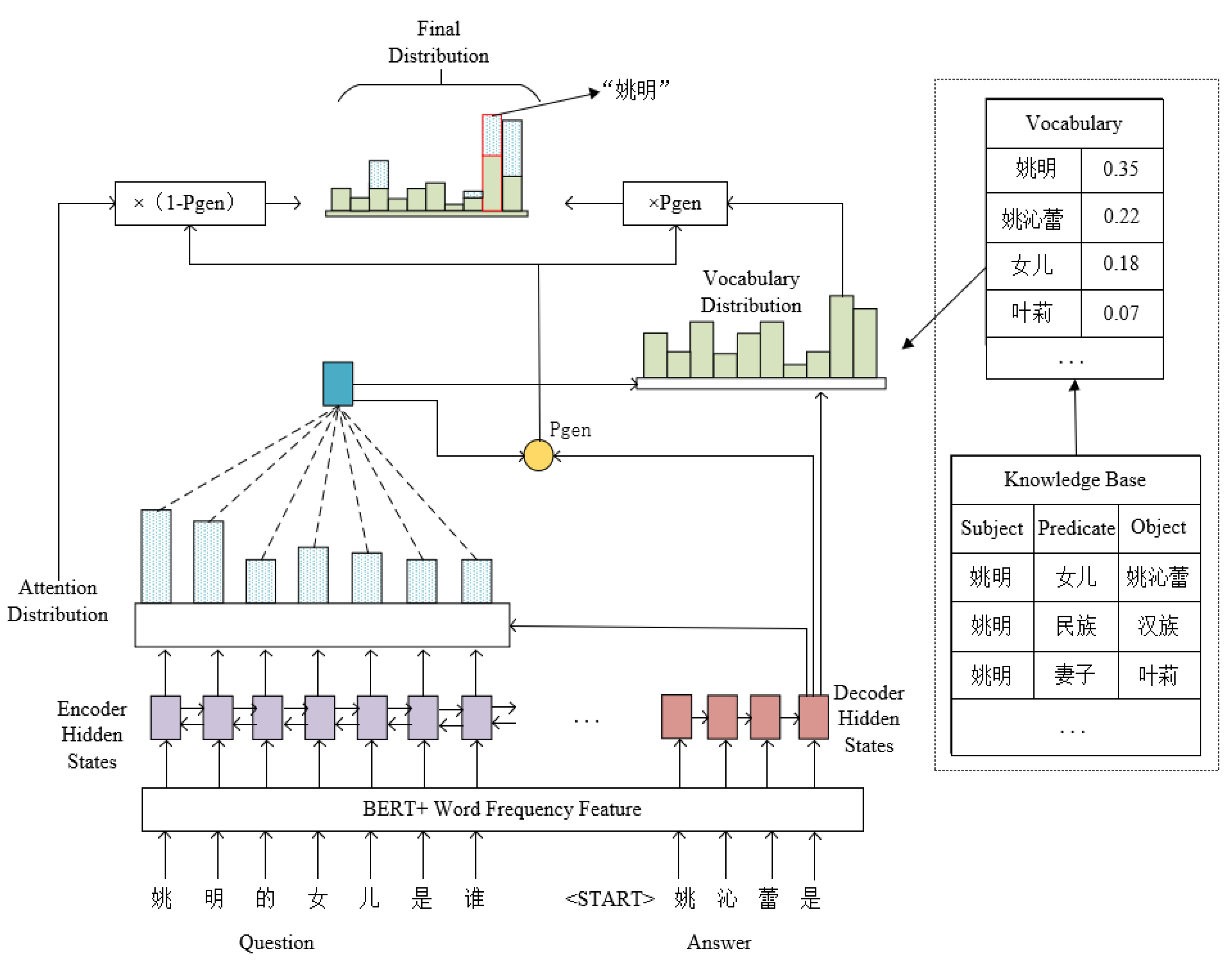
3.2.2. Pointer-Generator Network Model
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Experimental Environment
4.4. Parameter Setting
4.5. Experimental Results and Analysis
4.5.1. Entity Recognition Module
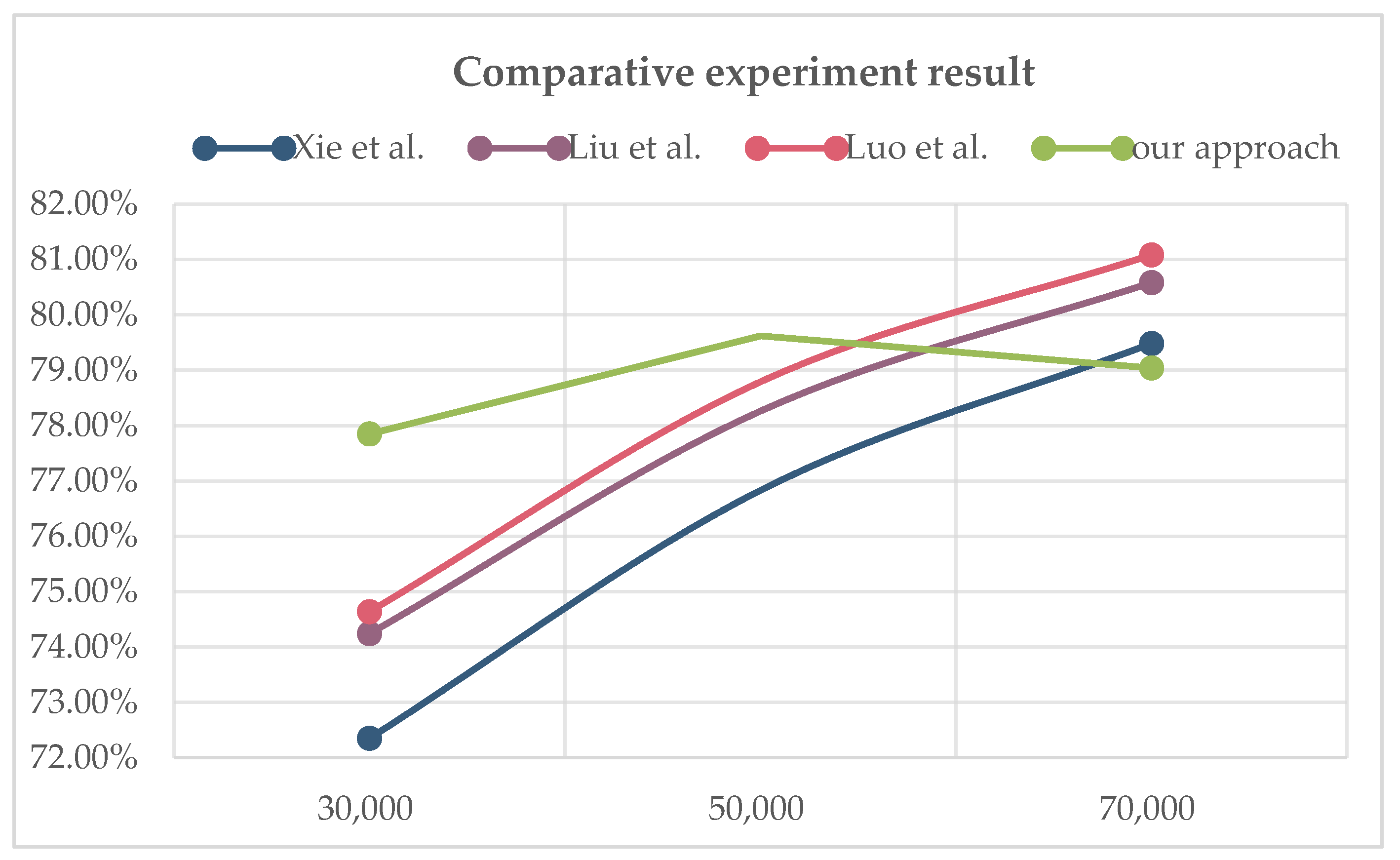
4.5.2. Answer Generation Module
- Xie et al. [45]: The model proposed by Xie et al. uses TEEM for entity recognition, and then applies a deep structured semantic model to calculate the semantic similarity of the question and predicate in the candidate knowledge triples.
- Liu et al. [46]: Liu et al. proposed a method based on entity sorting and joint fact selection. This method uses BiLSTM-CRF for pattern extraction, and then uses similarity matching to sort the candidate entities, and finally uses the joint fact selection model to enhance the selection of the correct entity relationship pair using multi-level coding.
- Luo et al. [47]: Luo et al. proposed a relationship detection model based on a multi-angle attention mechanism, which uses the attention mechanism to extract the correlation between question patterns and candidate relationships from word level and relationship level.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Turing, A.M. Computing Machinery and Intelligence. Mind 1950, 59, 433–460. [Google Scholar] [CrossRef]
- Abramson, D. Turing’s Responses to Two Objections. Minds Mach. 2008, 18, 147–167. [Google Scholar] [CrossRef]
- Fedushko, S.; Ustyianovych, T.; Gregus, M. Real-time high-load infrastructure transaction status output prediction using operational intelligence and big data technologies. Electronics 2020, 9, 668. [Google Scholar] [CrossRef] [Green Version]
- Amit, S. Introducing the Knowledge Graph: Things, Not Strings. Available online: https://blog.google/products/search/introducing-knowledge-graph-things-not/ (accessed on 19 March 2021).
- Biega, J.; Kuzey, E.; Suchanek, F.M. Inside YAGO2s: A transparent information extraction architecture. In Proceedings of the 22nd International Conference on World Wide Web Companion, Rio de Janeiro, Brazil, 13–17 May 2013; International World Wide Web Conferences Steering Committee: Rio de Janeiro, Brazil, 2013; pp. 325–328. [Google Scholar]
- Erxleben, F.; Günther, M.; Krötzsch, M.; Mendez, J.; Vrandečić, D. Introducing wikidata to the linked data web. In Proceedings of the 13th International Semantic Web Conference, Riva del Garda, Italy, 19–23 October 2014. [Google Scholar]
- Bizer, C.; Lehmann, J.; Kobilarov, G.; Auer, S.; Becker, C.; Cyganiak, R.; Hellmann, S. DBpedia-A crystallization point for the Web of data. J. Web Semant. 2009, 7, 154–165. [Google Scholar] [CrossRef]
- Wang, Z.; Li, J.; Wang, Z.; Li, S.; Li, M.; Zhang, D.; Shi, Y.; Liu, Y.; Zhang, P.; Tang, J. XLore: A Large-scale English-Chinese Bilingual Knowledge Graph. In Proceedings of the Meeting of the International Semantic Web Conference (Posters & Demos), Sydney, Australia, 21–25 October 2013. [Google Scholar]
- Niu, X.; Sun, X.; Wang, H.; Rong, S.; Qi, G.; Yu, Y. Zhishi me-weaving chinese linking open data. In Proceedings of the Semantic Web–ISWC 2011, Bonn, Germany, 23–27 October 2011; Springer: Berlin, Germany, 2011; pp. 205–220. [Google Scholar]
- MrYener. OwnThink Knowledge Graph. Available online: https://www.ownthink.com/ (accessed on 17 March 2021).
- Rajarshi, D.; Manzil, Z.; Siva, R.; Andrew, M. Question Answering on Knowledge Bases and Text using Universal Schema and Memory Networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 358–365. [Google Scholar]
- Sun, H.; Bhuwan, D.; Manzil, Z.; Kathryn, M.; Ruslan, S.; Cohen, W. Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 30 July–4 August 2018; pp. 4231–4242. [Google Scholar]
- Wang, J.; Liu, J.; Bi, W.; Liu, X. Improving Knowledge-aware Dialogue Generation via Knowledge Base Question Answering. arXiv 2019, arXiv:1912.07491. [Google Scholar] [CrossRef]
- Xiong, W.; Yu, M.; Chang, S.; Guo, X.; William, Y. Improving Question Answering over Incomplete KBs with Knowledge-Aware Reader. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4258–4264. [Google Scholar]
- Wei, M.; He, Y.; Zhang, Q.; Si, L. Multi-Instance Learning for End-to-End Knowledge Base Question Answering. arXiv 2019, arXiv:1903.02652. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get to the Point: Summarization with Pointer-Generator Networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1073–1083. [Google Scholar]
- Shen, Y.; He, X.; Gao, J.; Deng, L.; Grégoire, M. A latent semantic model with convolutional-pooling structure for information retrieval. In Proceedings of the ACM Conference on Information and Knowledge Management, Shanghai, China, 19–23 November 2011; pp. 101–110. [Google Scholar]
- Hu, S.; Zou, L.; Yu, J.; Wang, H.; Zhao, D. Answering natural language questions by subgraph matching over knowledge graphs. IEEE Trans. Knowl. Data Eng. 2017, 30, 824–837. [Google Scholar] [CrossRef]
- Xu, K.; Feng, Y.; Huang, S.; Zhao, D. Hybrid question answering over knowledge base and free text. In Proceedings of the 26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016; pp. 2397–2407. [Google Scholar]
- Bordes, A.; Chopra, S.; Jason, W. Question Answering with Subgraph Embeddings. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 615–620. [Google Scholar]
- Hao, Y.; Zhang, Y.; Liu, K.; He, S.; Wu, H.; Zhao, J. An end-to-end model for question answering over knowledge base with cross-attention combining global knowledge. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 221–231. [Google Scholar]
- Bordes, A.; Usunier, N.; Chopra, S.; Weston, J. Large-scale simple question answering with memory networks. arXiv 2015, arXiv:1506.02075. [Google Scholar]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 1247–1250. [Google Scholar]
- Sorokin, D.; Gurevych, I. Modeling Semantics with Gated Graph Neural Networks for Knowledge Base Question Answering. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 13–18 December 2018; pp. 3306–3317. [Google Scholar]
- Denis, L.; Asja, F.; Jens, L.; Sören, A. Neural Network-based Question Answering over Knowledge Graphs on Word and Character Level. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1211–1220. [Google Scholar]
- Wang, Y.; Zhang, R.; Xu, C.; Mao, Y. The APVA-TURBO Approach To Question Answering in Knowledge Base. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 13–18 December 2018; pp. 1998–2009. [Google Scholar]
- Ilya, S.; Oriol, V.; Quoc, V. Sequence to Sequence Learning with Neural Networks. arXiv 2017, arXiv:1409.3215v3. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Li, P.; Li, W.; He, Z.; Wang, X.; Cao, Y.; Zhou, J.; Xu, W. Dataset and Neural Recurrent Sequence Labeling Model for Open-Domain Factoid Question Answering. arXiv 2016, arXiv:1607.06275. [Google Scholar]
- Xu, B.; Xu, Y.; Liang, J.; Xie, C.; Liang, B.; Cui, W.; Xiao, Y. CN-DBpedia: A Never-Ending Chinese Knowledge Extraction System. In Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Arras, France, 27–30 June 2017; Springer: Cham, Switzerland, 2017; pp. 428–438. [Google Scholar]
- Khodra, M.L.; Wahyudi; Prihatmanto, A.S.; Machbub, C. Knowledge-Based Graph Compression Using Graph Property on Yago. In Proceedings of the 3rd International Conference on Science in Information Technology (ICSITech), Bandung, Indonesia, 25–26 October 2017; pp. 136–141. [Google Scholar]
- Sun, J. Jieba. Available online: https://github.com/fxsjy/jieba (accessed on 17 March 2021).
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics, San Diego, CA, USA, 2–7 June 2016; pp. 260–270. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F. Conditional Random Fields: Porbabilistic models for segmenting and labeling sequence data. In Proceedings of the Eighteenth International Conference on Machine Learning, San Francisco, CA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent Neural Network Regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Fu, Z.; Lam, W.; So, A.; Shi, B. A Theoretical Analysis of the Repetition Problem in Text Generation. arXiv 2020, arXiv:2012.14660. [Google Scholar]
- Sean, W.; Ilia, K.; Jaedeok, K.; Richard, Y.; Kyunghyun, C. Consistency of a Recurrent Language Model with Respect to Incomplete Decoding. arXiv 2020, arXiv:2002.02492. [Google Scholar]
- Rong, X. word2vec Parameter Learning Explained. arXiv 2014, arXiv:1411.2738. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. OpenAI, 2018. Available online: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf (accessed on 19 March 2021).
- Vinyals, Q.; Fortunato, M.; Jaitly, N. Pointer Networks. arXiv 2015, arXiv:1506.03134. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Xie, Z.; Zeng, Z.; Zhou, G.; He, T. Knowledge base question answering based on deep learning models. In Natural Language Understanding and Intelligent Applications; Springer: Cham, Switzerland, 2016; pp. 300–311. [Google Scholar]
- Liu, Y.; Zhang, L.; Yang, Y.; Zhang, G.; Zhang, C. Simple question answering with entity ranking and joint fact selection. Appl. Res. Comput. 2020, 37, 3321–3325. [Google Scholar]
- Luo, D.; Su, J.; Li, P. Multi-view Attentional Approach to Single-fact Knowledge-based Question Answering. Comput. Sci. 2019, 46, 215–221. [Google Scholar]
- Xu, T.; Wu, M. An Improved Naive Bayes Algorithm Based on TF-IDF. Comput. Technol. Dev. 2020, 30, 75–79. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Project | Environment |
|---|---|
| Operating system | Ubuntu16.04 |
| GPU | Geforce GTX 1660Ti |
| Hard disk | 200 G |
| Memory | 8 G |
| Parameter | Value |
|---|---|
| Epochs | 30 |
| Batch_size | 128 |
| dropout | 0.5 |
| Learning_rate | 0.001 |
| embed | 300 |
| hidden | 200 |
| Parameter | Value |
|---|---|
| BERT_batch_size | 16 |
| BERT_Learning_rate | 0.001 |
| BERT_dropout | 0.5 |
| PGN_batch_size | 16 |
| PGN_hidden | 256 |
| Optimistic algorithm | Adagrad |
| P% | R% | F1% |
|---|---|---|
| 89.91 | 87.85 | 88.87 |
| Method | F1% |
|---|---|
| CRF | 76.35 |
| CNN | 82.57 |
| BiLSTM | 79.46 |
| LSTM-CRF | 85.52 |
| Our approach | 88.87 |
| Method | Accuracy% |
|---|---|
| Xie et al. | 76.83 |
| Liu et al. | 78.26 |
| Luo et al. | 78.79 |
| Our approach | 79.62 |
| Question | Method | Answer |
|---|---|---|
| Chinese: 勇敢的心霍啸林的父亲是谁出演的? | Xie et al. | 杨志刚 (Yang Zhigang) |
| Liu et al. | 霍绍昌 (Huo Shaochang) | |
| English: Brave Heart Who starred in Huo Xiaolin’s father? | Luo et al. | 霍绍昌 (Huo Shaochang) |
| Our approach | 寇振海是霍啸林的父亲 (Kou Zhenhai is Huo Xiaolin’s father.) |
| Method | Accuracy% |
|---|---|
| PGN | 76.43 |
| BERT-PGN | 78.37 |
| Our approach | 79.62 |
| Our approach(use TF-IDF) | 79.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Tan, N.; Ge, Y.; Lukač, N. Research on Automatic Question Answering of Generative Knowledge Graph Based on Pointer Network. Information 2021, 12, 136. https://doi.org/10.3390/info12030136
Liu S, Tan N, Ge Y, Lukač N. Research on Automatic Question Answering of Generative Knowledge Graph Based on Pointer Network. Information. 2021; 12(3):136. https://doi.org/10.3390/info12030136
Chicago/Turabian StyleLiu, Shuang, Nannan Tan, Yaqian Ge, and Niko Lukač. 2021. "Research on Automatic Question Answering of Generative Knowledge Graph Based on Pointer Network" Information 12, no. 3: 136. https://doi.org/10.3390/info12030136
APA StyleLiu, S., Tan, N., Ge, Y., & Lukač, N. (2021). Research on Automatic Question Answering of Generative Knowledge Graph Based on Pointer Network. Information, 12(3), 136. https://doi.org/10.3390/info12030136