
Multi-Task Learning for Sentiment Analysis with Hard-Sharing and Task Recognition Mechanisms



Abstract
:1. Introduction
- The proposed model addresses the issue of interference and generalization of the shared feature space during multi-task learning.
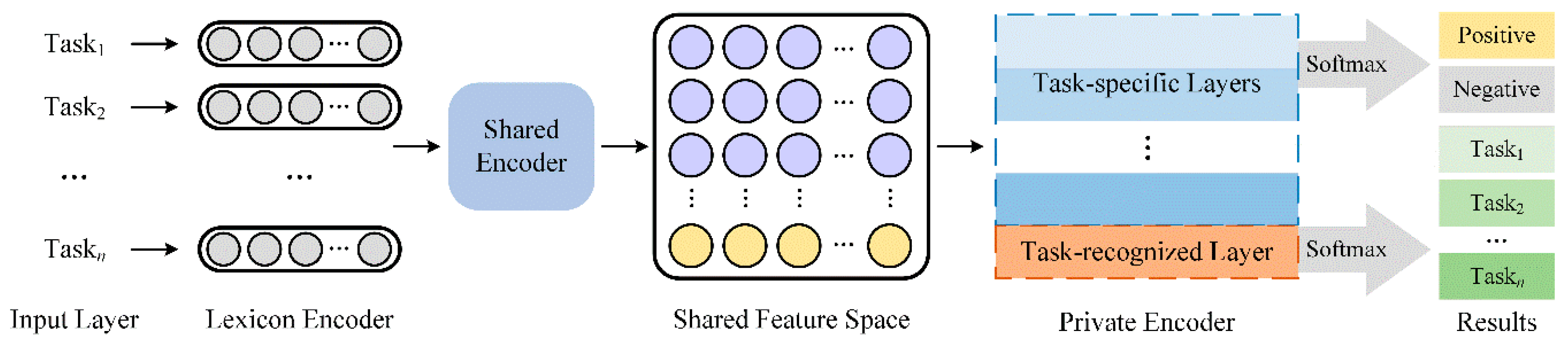
- The proposed model comprises three encoders, including a lexicon encoder, a shared encoder, and a private encoder, to improve the quality of extracted features.
- We propose a task recognition mechanism that makes the shared feature space have unique representation for different tasks.
2. Related Works
3. Methodology
3.1. The Lexicon Encoder
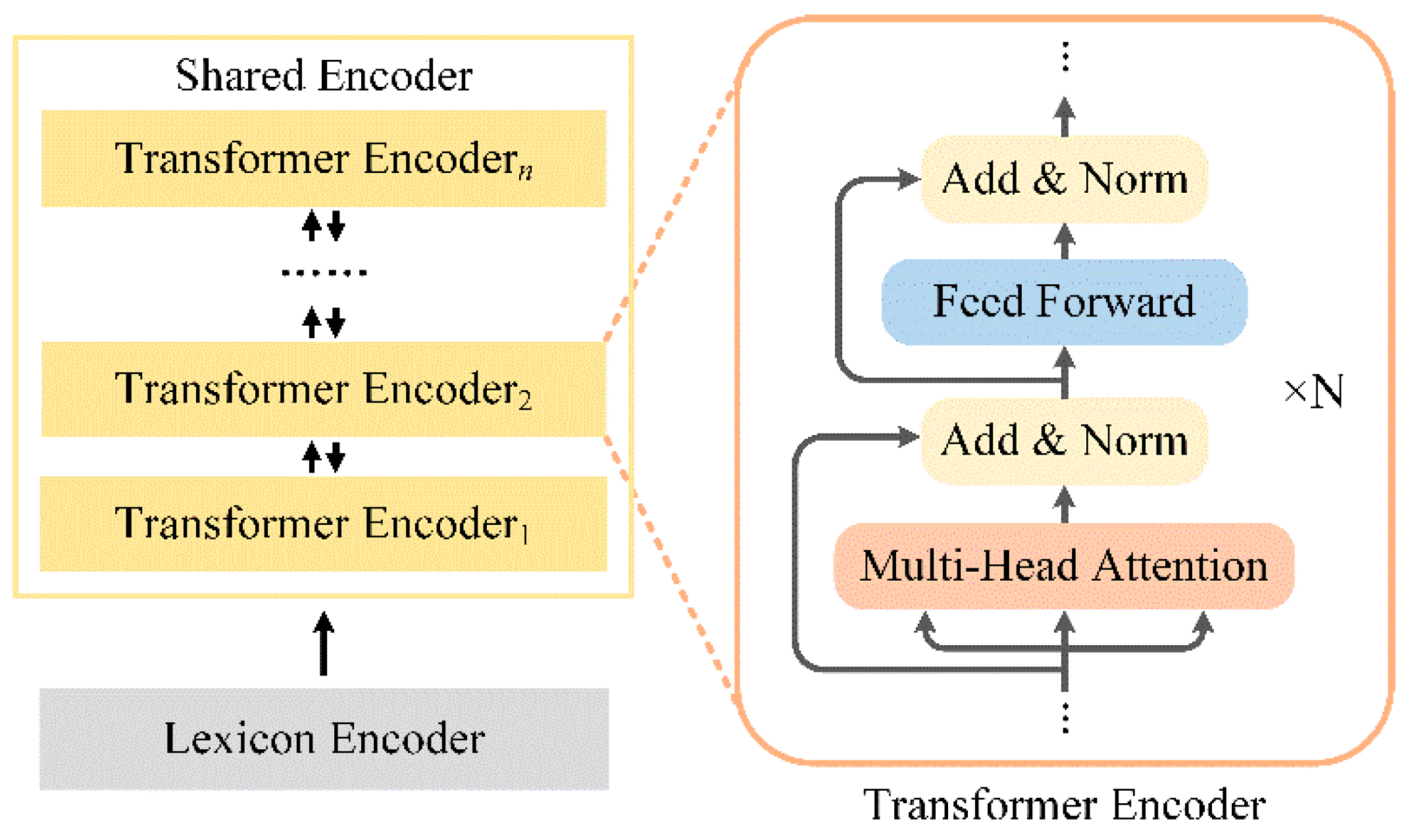
3.2. Shared Encoder
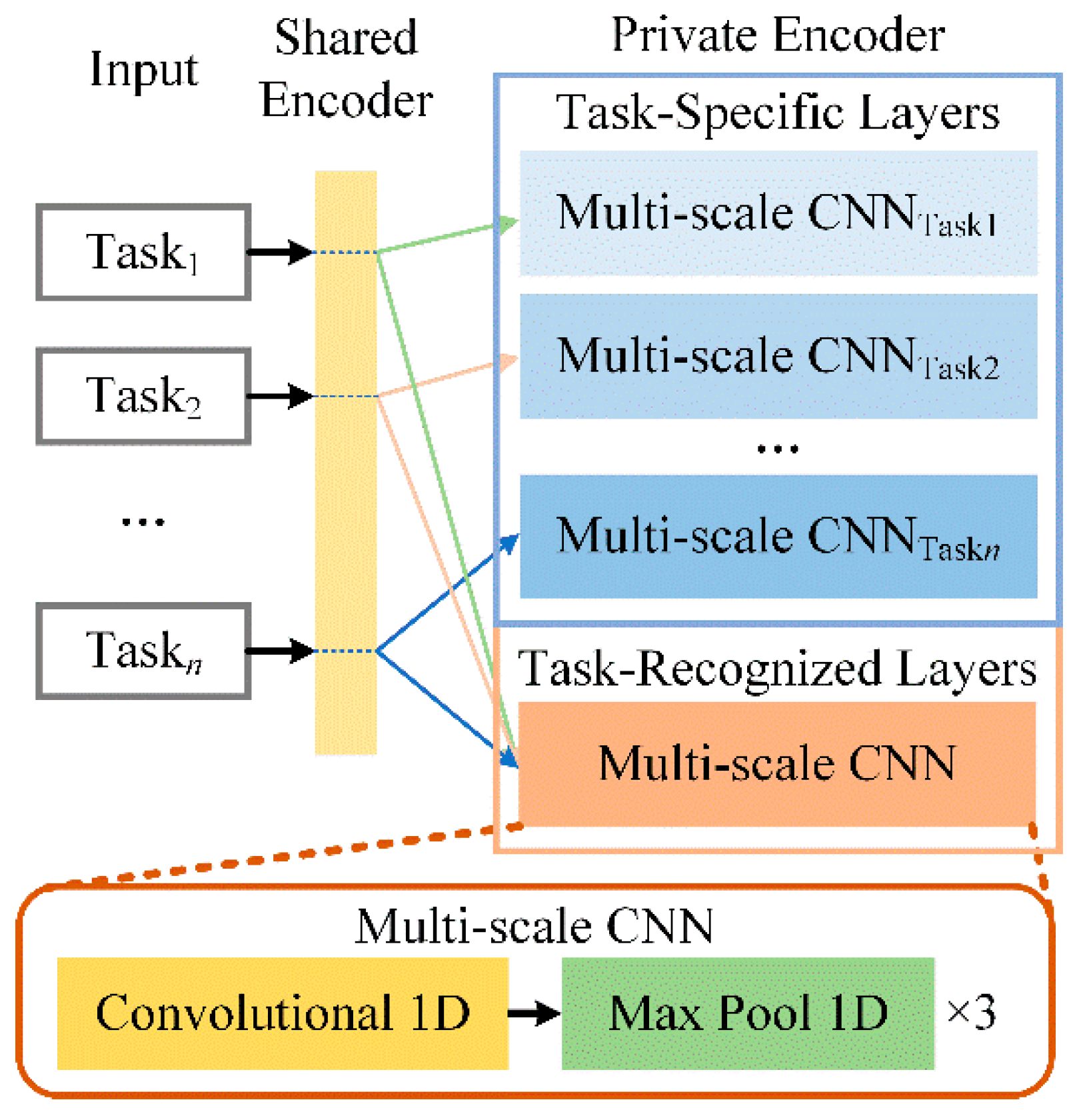
3.3. Private Encoder
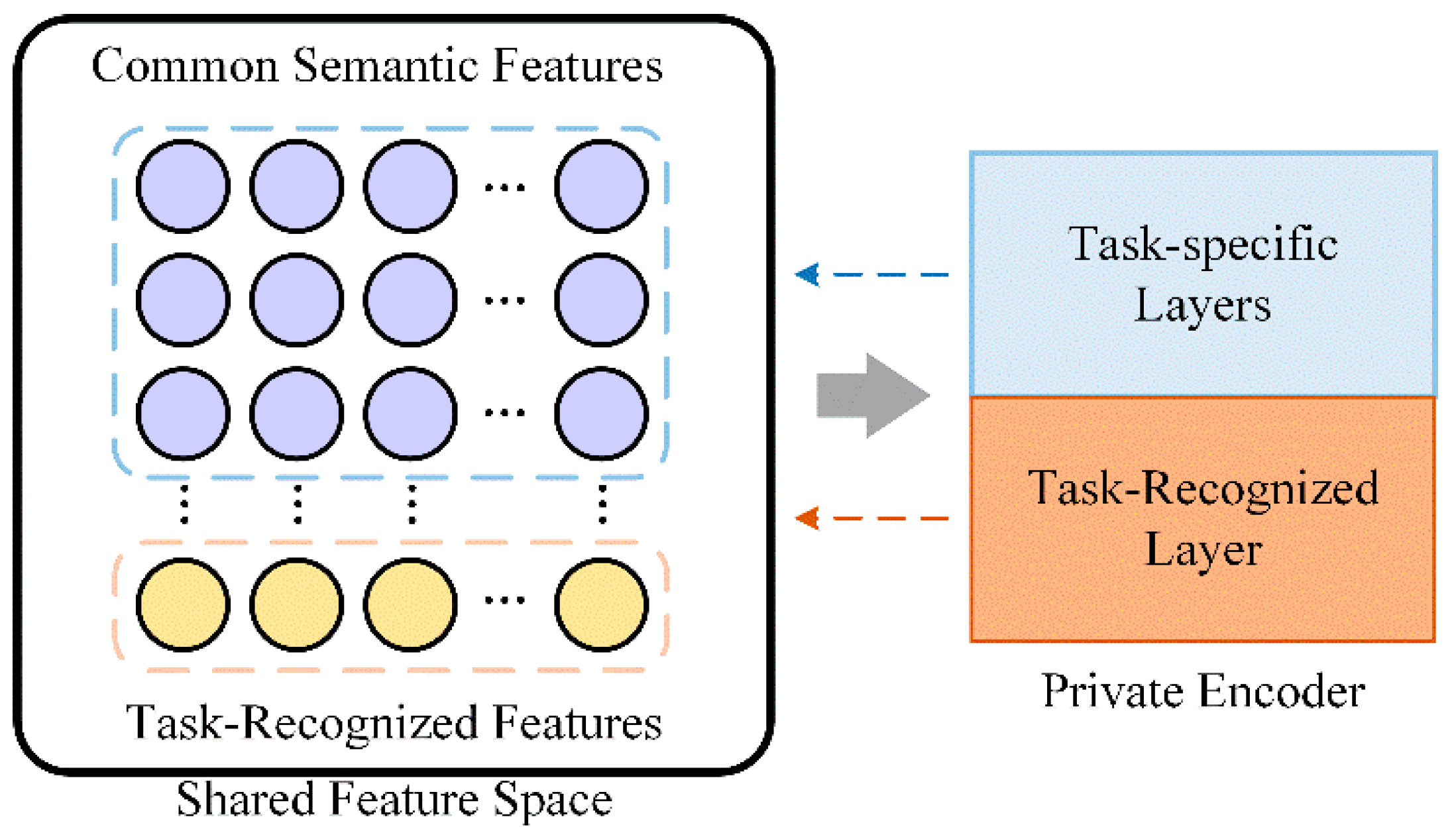
3.4. The Task Recognition Mechanism
4. Experimental Process and Results
4.1. Dataset and Metrics
4.2. Compared with Other Sentiment Classification Methods
4.3. Model Self-Comparision
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gómez-Adorno, H.; Fuentes-Alba, R.; Markov, I.; Sidorov, G.; Gelbukh, A. A convolutional neural network approach for gender and language variety identification. J. Intell. Fuzzy Syst. 2019, 36, 4845–4855. [Google Scholar] [CrossRef]
- Dejun, Z.; Mingbo, H.; Lu, Z.; Fei, H.; Fazhi, H.; Zhigang, T.; Yafeng, R. Attention Pooling-Based Bidirectional Gated Recurrent Units Model for Sentimental Classification. Int. J. Comput. Intell. Syst. 2019, 12, 723–732. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Misra, I.; Shrivastava, A.; Gupta, A.; Hebert, M. Cross-Stitch Networks for Multi-task Learning. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3994–4003. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Recurrent Neural Network for Text Classification with Multi-Task Learning. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; AAAI Press: Palo Alto, CA, USA; pp. 2873–2879. [Google Scholar]
- Ruder, S.; Bingel, J.; Augenstein, I.; Søgaard, A. Latent Multi-Task Architecture Learning. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4822–4829. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J. A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning. In Proceedings of the 25th international conference on Machine learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Subramanian, S.; Trischler, A.; Bengio, Y.; Pal, C.J. Learning General Purpose Distributed Sentence Representations via Large Scale Multi-Task Learning. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Liu, X.; He, P.; Chen, W.; Gao, J. Multi-Task Deep Neural Networks for Natural Language Understanding. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4487–4496. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Janvin, C. A Neural Probabilistic Language Model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Bing, L. Sentiment Analysis and Opinion Mining; Morgan & Claypool: San Rafael, CA, USA, 2012. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Adversarial Multi-task Learning for Text Classification. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2017; pp. 1–10. [Google Scholar]
- Sun, S.; Luo, C.; Chen, J. A review of natural language processing techniques for opinion mining systems. Inf. Fusion 2017, 36, 10–25. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, CA, USA, 5–10 December 2013; Curran Associates Inc.: Red Hook, NY, USA, 2013; Volume 2, pp. 3111–3119. [Google Scholar]
- Nyberg, K.; Raiko, T.; Tiinanen, T.; Hyvönen, E. Document Classification Utilising Ontologies and Relations between Doc-uments. In Proceedings of the Eighth Workshop on Mining and Learning with Graphs, Washington, DC, USA, 5 August 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 86–93. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2014; pp. 1746–1751. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Pang, B.; Lee, L. Seeing Stars: Exploiting Class Relationships for Sentiment Categorization with Respect to Rating Scales. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), Ann Arbor, MI, USA, 25–30 June 2005; Association for Computational Linguistics: Stroudsburg, PA, USA, 2005; pp. 115–124. [Google Scholar]
- Yanmei, L.; Yuda, C. Research on Chinese Micro-Blog Sentiment Analysis Based on Deep Learning. 2015 8th Int. Symp. Comput. Intell. Des. 2015, 1, 358–361. [Google Scholar] [CrossRef]
- Graves, A.; Jaitly, N.; Mohamed, A.-R. Hybrid speech recognition with Deep Bidirectional LSTM. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–13 December 2013; pp. 273–278. [Google Scholar]
- Wen, S.; Wei, H.; Yang, Y.; Guo, Z.; Zeng, Z.; Huang, T.; Chen, Y. Memristive LSTM Network for Sentiment Analysis. IEEE Trans. Syst. Man, Cybern. Syst. 2021, 51, 1794–1804. [Google Scholar] [CrossRef]
- Zhang, S.; Xu, X.; Pang, Y.; Han, J. Multi-layer Attention Based CNN for Target-Dependent Sentiment Classification. Neural Process. Lett. 2020, 51, 2089–2103. [Google Scholar] [CrossRef]
- Caruana, R. Multitask Learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Do-main-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. Facial Landmark Detection by Deep Multi-Task Learning. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 94–108. [Google Scholar]
- Daumé, H. Bayesian Multitask Learning with Latent Hierarchies. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, Canada, 18–21 June 2009; AUAI Press: Arlington, VA, USA, 2009; pp. 135–142. [Google Scholar]
- Sun, T.; Shao, Y.; Li, X.; Liu, P.; Yan, H.; Qiu, X.; Huang, X. Learning Sparse Sharing Architectures for Multiple Tasks. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Association for the Advancement of Artificial Intelligence (AAAI): Palo Alto, CA, USA, 2020; Volume 34, pp. 8936–8943. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Deep Multi-Task Learning with Shared Memory for Text Classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2016; pp. 118–127. [Google Scholar]
- Hessel, M.; Soyer, H.; Espeholt, L.; Czarnecki, W.; Schmitt, S.; Van Hasselt, H. Multi-Task Deep Reinforcement Learning with PopArt. In Proceedings of the 2019 AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Association for the Advancement of Artificial Intelligence (AAAI): Palo Alto, CA, USA, 2019; Volume 33, pp. 3796–3803. [Google Scholar]
- Liu, X.; Gao, J.; He, X.; Deng, L.; Duh, K.; Wang, Y.-Y. Representation Learning Using Multi-Task Deep Neural Networks for Semantic Classification and Information Retrieval. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2015; pp. 912–921. [Google Scholar]
- Li, J.; Monroe, W.; Shi, T.; Jean, S.; Ritter, A.; Jurafsky, D. Adversarial Learning for Neural Dialogue Generation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2017; pp. 2157–2169. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Ad-versarial Nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Bangkok, Thailand, 18–22 November 2020; MIT Press: Cambridge, MA, USA, 2014; Volume 2, pp. 2672–2680. [Google Scholar]
- Blitzer, J.; Dredze, M.; Pereira, F. Biographies, Bollywood, Boom-Boxes and Blenders: Domain Adaptation for Sentiment Classification. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, 25–27 June 2007; Association for Computational Linguistics: Stroudsburg, PA, USA, 2007; pp. 440–447. [Google Scholar]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning Word Vectors for Sentiment Analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24June 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 142–150. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Mohamed, A.-R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2013; pp. 6645–6649. [Google Scholar]
- Lu, G.; Gan, J.; Yin, J.; Luo, Z.; Li, B.; Zhao, X. Multi-task learning using a hybrid representation for text classification. Neural Comput. Appl. 2020, 32, 6467–6480. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Commodity Type | Example | Label |
|---|---|---|
| Books | this is a resource used by all nps i have talked to. great addition to your library. | 1 |
| it was a mistake to buy it. only few pages were interestin | 0 | |
| Electronics | great product but is only $ 30 at iriver.com’s stor | 1 |
| i dont like this mouse, i brought, and never work, its useles | 0 | |
| DVD | an awesome film with some suspense and raunchiness all rolled in to one | 1 |
| i love pablo’s act on comedy central. this one does n’t even touch it | 0 | |
| Kitchen | it is very light and worm. i love it. definitely worth the price! | 1 |
| for the price, you get what you pay for. they are not the best quality | 0 | |
| Apparel | recipient was very satisfied with this blanket as pb are his initials | 1 |
| a red star !?!? i bet this wo n’t sell well in eastern europe. | 0 | |
| Camera | everything was excellent. the digital camera, the delivery. thank you a lot !!!! | 1 |
| have had it for a few weeks and glad i brought it great procuc | 0 | |
| Health | great tasting bar. nice and soft make it easy to eat | 1 |
| it does n’t get hot enough, nor does it stay hot for more than 10 min | 0 | |
| Music | i just love lynch mixed with dooms production. it is what real is | 1 |
| this cd isnt real good if you like compilations than get the ruff ryders c | 0 | |
| Toys | these make meals a lot more fun for children... i know my son loves them | 1 |
| fisher price is selling the same item for only $ 33. $ 139.99 has to be a mistake | 0 | |
| Video | this is an excellent documentary of shangri-la and its elusive transcendental nature | 1 |
| i love norm macdonald and this is the dumbest movie of all tim | 0 | |
| Baby | great product—i heard from other mommies that this was the pump to get; i agree | 1 |
| rent a hospital grade medalia pump. you wont be sorr | 0 | |
| Magazines | the magazine was shipped in a timely manner, i would use this vendor again | 1 |
| i still have not received this magazine, what is taking so long !! | 0 | |
| Software | my husband is using the rosetta stone spanish program and loves it | 1 |
| the “bad serial number” routine as the first reviewer. | 0 | |
| Sports | excellent quality; much easier to put on than the cap i used before | 1 |
| this pillow is too small and it is not comfortable at all | 0 | |
| IMDB | this is a truly magnificent and heartwrenching film !!! | 1 |
| argh! this film hurts my head. and not in a good way. | 0 | |
| MR | it’s a feel-good movie about which you can actually feel good. | 1 |
| a decidedly mixed bag. | 0 |
| Commodity Type | Training Set | Validation Set | Test Set | Total | |||
|---|---|---|---|---|---|---|---|
| Positive | Negative | Positive | Negative | Positive | Negative | ||
| Books | 798 | 802 | 105 | 95 | 97 | 103 | 2000 |
| Electronics | 705 | 693 | 97 | 103 | 198 | 202 | 1998 |
| DVD | 802 | 798 | 95 | 105 | 102 | 98 | 2000 |
| Kitchen | 706 | 694 | 102 | 98 | 192 | 208 | 2000 |
| Apparel | 690 | 710 | 95 | 105 | 215 | 185 | 2000 |
| Camera | 706 | 692 | 99 | 100 | 194 | 206 | 1997 |
| Health | 812 | 788 | 98 | 102 | 90 | 110 | 2000 |
| Music | 698 | 702 | 103 | 97 | 199 | 201 | 2000 |
| Toys | 794 | 806 | 99 | 101 | 107 | 93 | 2000 |
| Video | 694 | 706 | 93 | 107 | 213 | 187 | 2000 |
| Baby | 800 | 700 | 103 | 97 | 97 | 103 | 1900 |
| Magazines | 682 | 688 | 101 | 99 | 217 | 183 | 1970 |
| Software | 788 | 727 | 102 | 98 | 110 | 90 | 1915 |
| Sports | 712 | 687 | 98 | 102 | 190 | 210 | 1999 |
| IMDB | 795 | 805 | 98 | 102 | 101 | 99 | 2000 |
| MR | 778 | 822 | 102 | 98 | 106 | 94 | 2000 |
| Total | 11,960 | 11,820 | 1590 | 1609 | 2428 | 2372 | 31,779 |
| Commodity Type | Example | Label |
|---|---|---|
| Daily Necessities | great product—i heard from other mommies that this was the pump to get; i agree | 1 |
| rent a hospital grade medalia pump. you wont be sorr | 0 | |
| Literature | an excellent book for anyone that barbecues | 1 |
| imposible to do so with no item received | 0 | |
| Entertainment | thank you, i like this program and it does what i need it to do | 1 |
| i would not buy it ! hard to use. my machine runs slower since the install. | 0 | |
| Media | i received “the piano” promptly, and in pristine, excellent condition. | 1 |
| if this is n’t worst dead album then in the dark is | 0 |
| Commodity Type | Training Set | Validation Set | Test Set | Total | |||
|---|---|---|---|---|---|---|---|
| Positive | Negative | Positive | Negative | Positive | Negative | ||
| Daily Necessities | 1609 | 1486 | 199 | 199 | 187 | 213 | 3893 |
| Literature | 2257 | 2305 | 308 | 292 | 420 | 380 | 5962 |
| Entertainment | 2285 | 2219 | 299 | 301 | 407 | 393 | 5904 |
| Media | 2978 | 3007 | 389 | 411 | 613 | 584 | 7982 |
| Total | 9129 | 9017 | 1195 | 1203 | 1627 | 1570 | 23,741 |
| Task | Single Task | Multiple Tasks | |||||||
|---|---|---|---|---|---|---|---|---|---|
| CNN | LSTM | Bi-LSTM | LSTM_Att | Avg. | MTL-CNN | MTL-GRU | MTL-ASP | Proposed | |
| Books | 0.87 | 0.865 | 0.9 | 0.9 | 0.884 | 0.89 | 0.88 | 0.84 | 0.915 |
| Electronics | 0.825 | 0.84 | 0.848 | 0.852 | 0.841 | 0.862 | 0.842 | 0.868 | 0.885 |
| DVD | 0.8 | 0.835 | 0.87 | 0.855 | 0.840 | 0.85 | 0.82 | 0.855 | 0.875 |
| Kitchen | 0.848 | 0.878 | 0.85 | 0.855 | 0.858 | 0.86 | 0.872 | 0.862 | 0.865 |
| Apparel | 0.875 | 0.865 | 0.872 | 0.86 | 0.868 | 0.855 | 0.872 | 0.87 | 0.895 |
| Camera | 0.855 | 0.878 | 0.865 | 0.85 | 0.862 | 0.88 | 0.892 | 0.892 | 0.888 |
| Health | 0.845 | 0.855 | 0.865 | 0.83 | 0.849 | 0.885 | 0.875 | 0.882 | 0.865 |
| Music | 0.825 | 0.838 | 0.825 | 0.812 | 0.825 | 0.842 | 0.83 | 0.825 | 0.845 |
| Toys | 0.845 | 0.875 | 0.89 | 0.88 | 0.873 | 0.855 | 0.865 | 0.88 | 0.875 |
| Video | 0.872 | 0.88 | 0.882 | 0.875 | 0.877 | 0.878 | 0.885 | 0.845 | 0.91 |
| Baby | 0.885 | 0.875 | 0.875 | 0.855 | 0.873 | 0.89 | 0.9 | 0.882 | 0.865 |
| Magazines | 0.852 | 0.85 | 0.865 | 0.855 | 0.856 | 0.882 | 0.9 | 0.922 | 0.9 |
| Software | 0.89 | 0.905 | 0.885 | 0.885 | 0.891 | 0.905 | 0.895 | 0.872 | 0.91 |
| Sports | 0.858 | 0.858 | 0.85 | 0.84 | 0.852 | 0.875 | 0.862 | 0.857 | 0.908 |
| IMDB | 0.84 | 0.86 | 0.89 | 0.875 | 0.866 | 0.865 | 0.855 | 0.855 | 0.925 |
| MR | 0.73 | 0.74 | 0.715 | 0.755 | 0.735 | 0.72 | 0.7 | 0.767 | 0.79 |
| AVG | 0.845 | 0.856 | 0.859 | 0.852 | 0.853 | 0.862 | 0.859 | 0.861 | 0.882 |
| STD | 0.0373 | 0.0348 | 0.0416 | 0.0326 | 0.0347 | 0.0402 | 0.0471 | 0.0327 | 0.0321 |
| Task | Single Task | Multiple Tasks | |||||||
|---|---|---|---|---|---|---|---|---|---|
| CNN | LSTM | Bi-LSTM | LSTM_Att | Avg. | MTL-CNN | MTL-GRU | MTL-ASP | Proposed | |
| Daily Necessities | 0.850 | 0.850 | 0.865 | 0.852 | 0.854 | 0.855 | 0.848 | 0.865 | 0.878 |
| Literature | 0.860 | 0.834 | 0.845 | 0.831 | 0.843 | 0.851 | 0.829 | 0.850 | 0.865 |
| Entertainment | 0.870 | 0.861 | 0.851 | 0.878 | 0.865 | 0.874 | 0.869 | 0.860 | 0.898 |
| Media | 0.845 | 0.854 | 0.865 | 0.863 | 0.857 | 0.845 | 0.866 | 0.858 | 0.880 |
| AVG | 0.856 | 0.850 | 0.857 | 0.856 | 0.855 | 0.856 | 0.853 | 0.858 | 0.880 |
| STD | 0.0108 | 0.00991 | 0.00876 | 0.0171 | 0.00805 | 0.0108 | 0.0160 | 0.00540 | 0.0118 |
| Statistical Methods | Levene’s Test | Wilcoxon Signed-Rank Test | ||
|---|---|---|---|---|
| p-Value | Evaluation | p-Value | Evaluation | |
| Proposed-CNN | 0.93 | homogeneity of variance | 1 | significant difference |
| Proposed-LSTM | 0.781 | homogeneity of variance | 0.998 | significant difference |
| Proposed-Bi-LSTM | 0.977 | homogeneity of variance | 0.999 | significant difference |
| Proposed-LSTM_Att | 0.717 | homogeneity of variance | 1 | significant difference |
| Proposed-MTL-CNN | 0.952 | homogeneity of variance | 0.997 | significant difference |
| Proposed-MTL-GRU | 0.723 | homogeneity of variance | 0.994 | significant difference |
| Proposed-MTL-ASP | 0.858 | homogeneity of variance | 0.991 | significant difference |
| Task | Single Task | Multiple Tasks | ||||||
|---|---|---|---|---|---|---|---|---|
| CNN | LSTM | Bi-LSTM | LSTM_Att | MTL-CNN | MTL-GRU | MTL-ASP | Proposed | |
| Time (s) | 30.93 | 34.32 | 57.29 | 58.83 | 30.80 | 58.75 | 188.28 | 3282 |
| Memory (MB) | 577 | 647 | 647 | 647 | 577 | 647 | 649 | 1145 |
| Task | Without BERT | Without Task Recognition Mechanism | With BERT | |||
|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | |
| Books | 0.915 | 0.915 | 0.91 | 0.91 | 0.915 | 0.912 |
| Electronics | 0.832 | 0.819 | 0.855 | 0.844 | 0.885 | 0.876 |
| DVD | 0.84 | 0.845 | 0.855 | 0.853 | 0.875 | 0.876 |
| Kitchen | 0.85 | 0.84 | 0.852 | 0.844 | 0.865 | 0.856 |
| Apparel | 0.865 | 0.87 | 0.892 | 0.9 | 0.895 | 0.902 |
| Camera | 0.878 | 0.873 | 0.88 | 0.881 | 0.888 | 0.888 |
| Health | 0.875 | 0.859 | 0.875 | 0.857 | 0.865 | 0.846 |
| Music | 0.832 | 0.835 | 0.862 | 0.859 | 0.845 | 0.845 |
| Toys | 0.875 | 0.886 | 0.87 | 0.883 | 0.875 | 0.886 |
| Video | 0.888 | 0.894 | 0.905 | 0.911 | 0.91 | 0.914 |
| Baby | 0.9 | 0.895 | 0.855 | 0.854 | 0.865 | 0.862 |
| Magazines | 0.878 | 0.881 | 0.878 | 0.887 | 0.9 | 0.91 |
| Software | 0.915 | 0.922 | 0.915 | 0.922 | 0.91 | 0.916 |
| Sports | 0.872 | 0.862 | 0.885 | 0.875 | 0.908 | 0.901 |
| IMDB | 0.91 | 0.91 | 0.91 | 0.913 | 0.925 | 0.925 |
| MR | 0.755 | 0.749 | 0.81 | 0.812 | 0.79 | 0.788 |
| AVG | 0.867 | 0.866 | 0.876 | 0.875 | 0.882 | 0.881 |
| STD | 0.0390 | 0.0417 | 0.0268 | 0.0300 | 0.0321 | 0.0346 |
| Task | Without BERT | Without Task Recognition Network | With BERT | |||
|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | |
| Daily Necessities | 0.85 | 0.84 | 0.852 | 0.841 | 0.878 | 0.869 |
| Literature | 0.864 | 0.867 | 0.869 | 0.875 | 0.865 | 0.871 |
| Entertainment | 0.854 | 0.854 | 0.884 | 0.884 | 0.898 | 0.899 |
| Media | 0.852 | 0.855 | 0.882 | 0.884 | 0.88 | 0.882 |
| AVG | 0.755 | 0.749 | 0.81 | 0.812 | 0.882 | 0.881 |
| STD | 0.00539 | 0.00957 | 0.0128 | 0.0177 | 0.0118 | 0.0119 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Yan, K.; Mo, Y. Multi-Task Learning for Sentiment Analysis with Hard-Sharing and Task Recognition Mechanisms. Information 2021, 12, 207. https://doi.org/10.3390/info12050207
Zhang J, Yan K, Mo Y. Multi-Task Learning for Sentiment Analysis with Hard-Sharing and Task Recognition Mechanisms. Information. 2021; 12(5):207. https://doi.org/10.3390/info12050207
Chicago/Turabian StyleZhang, Jian, Ke Yan, and Yuchang Mo. 2021. "Multi-Task Learning for Sentiment Analysis with Hard-Sharing and Task Recognition Mechanisms" Information 12, no. 5: 207. https://doi.org/10.3390/info12050207
APA StyleZhang, J., Yan, K., & Mo, Y. (2021). Multi-Task Learning for Sentiment Analysis with Hard-Sharing and Task Recognition Mechanisms. Information, 12(5), 207. https://doi.org/10.3390/info12050207