
CFM-RFM: A Cascading Failure Model for Inter-Domain Routing Systems with the Recovery Feedback Mechanism


Abstract
:1. Introduction
2. Related Work
2.1. Optimal Valid Path Prediction Method for Inter-Domain Networks
2.2. Types of Attacks and Costs
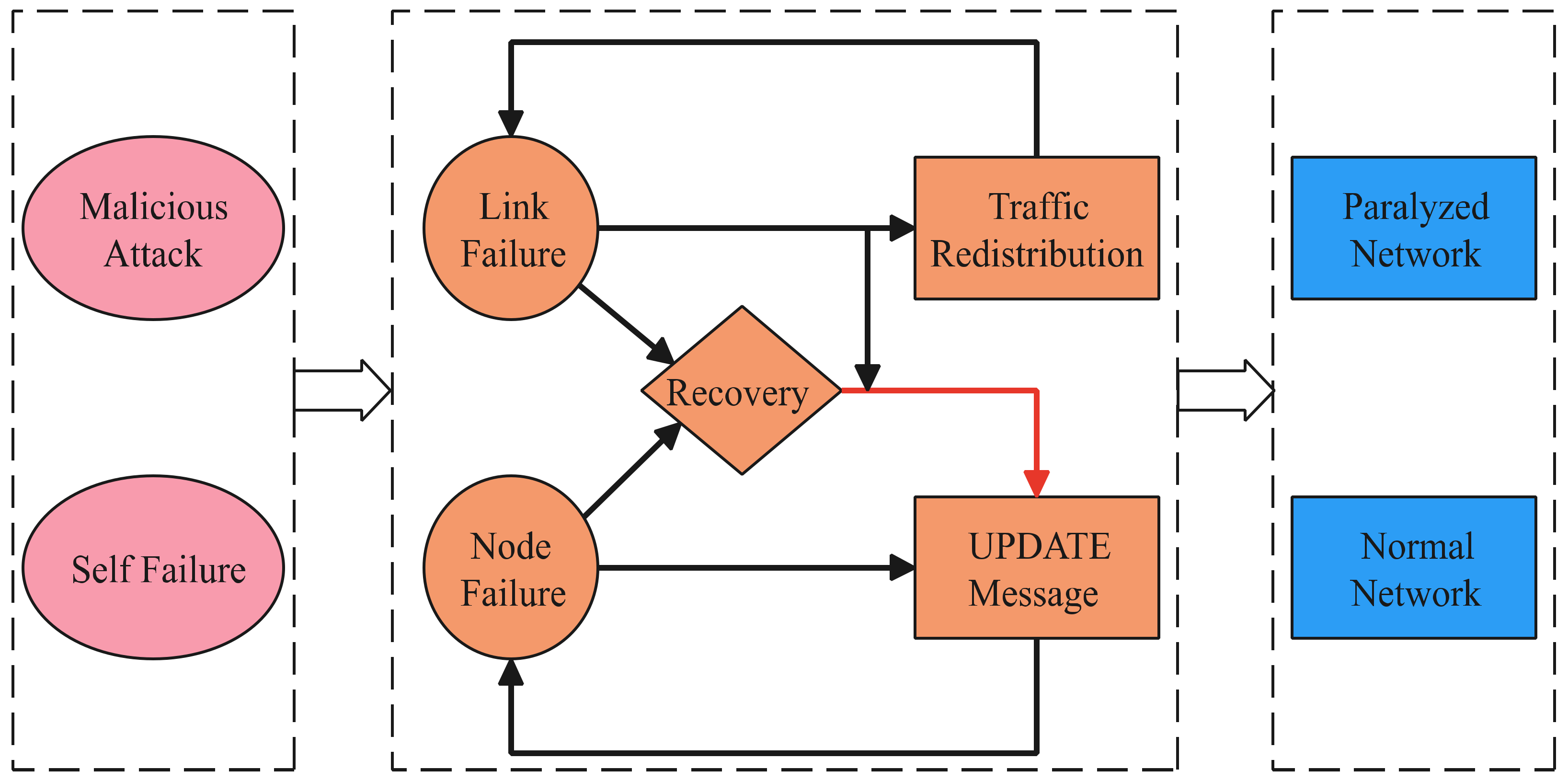
3. Analysis of the Cascading Failure Principle for the Inter-Domain Routing System
4. CFM-RFM
4.1. Notations
4.1.1. The Load and Capacity of Nodes
4.1.2. The Load and Capacity of Links
4.2. Propagation Mechanism of UPDATE Messages
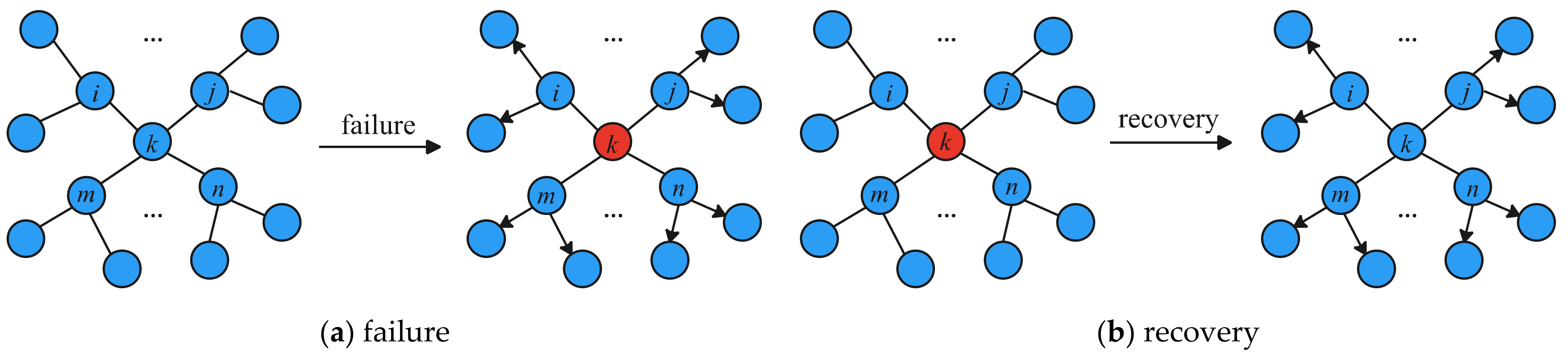
4.2.1. Failure of the Node Causes the Propagation Process of the UPDATE Message
4.2.2. Re-Triggered UPDATE Message Propagation
4.2.3. Pseudocode
| Algorithm 1. The propagation algorithm. |
| Input:G, LoadNode, InvalidNodeSet, RecoverNodeSet |
| Output: The updated state of the node |
| 1: While InvalidNodeSet do |
| 2: Find all the neighbors (NeighborSet) of the node in the InvalidNode; |
| 3: NeighborSet sends UPDATE messages to reachable ,; |
| 4: LoadNode [] ← LoadNode [] + 1; |
| 5: IF LoadNode [] > R, InvalidNodeSet.add (), RecoverNodeSet.add (); |
| 6: End while |
| 7: While RecoverNodeSet and do |
| 8: Find all the neighbors (NeighborSet) of the node in the RecoverNodeSet; |
| 9: NeighborSet sends UPDATE messages to reachable ,; |
| 10: LoadNode [] ← LoadNode [] + 1; |
| 11: IF LoadNode [] > R, InvalidNodeSet.add (), RecoverNodeSet.add (); |
| 12: End while |
4.3. Traffic Redistribution
| Algorithm 2. Traffic redistribution algorithm. |
| Input: G, LoadLink, InvalidLinkSet, OptimalValidPaths, |
| Output: The updated state of the link |
| 1: Check p in OptimalValidPaths; |
| 2: While do |
| 3: For do |
| 4: LoadLink [] ← LoadLink [] − ; |
| 5: End for |
| 6: OptimalValidPaths.delete (p); |
| 7: End while |
| 8: Find the new optimal valid path ; |
| 9: OptimalValidPaths.add (); |
| 10: For do |
| 11: LoadLink [] ← LoadLink [] + ; |
| 12: IF LoadLink [] > , InvalidLinkSet.add (); |
| 13: End for |
4.4. Modeling the Process of Cascading Failure
5. Experiments and Analysis
5.1. Data and Parameter Setup
5.2. Metric of Evaluation for Cascading Failure
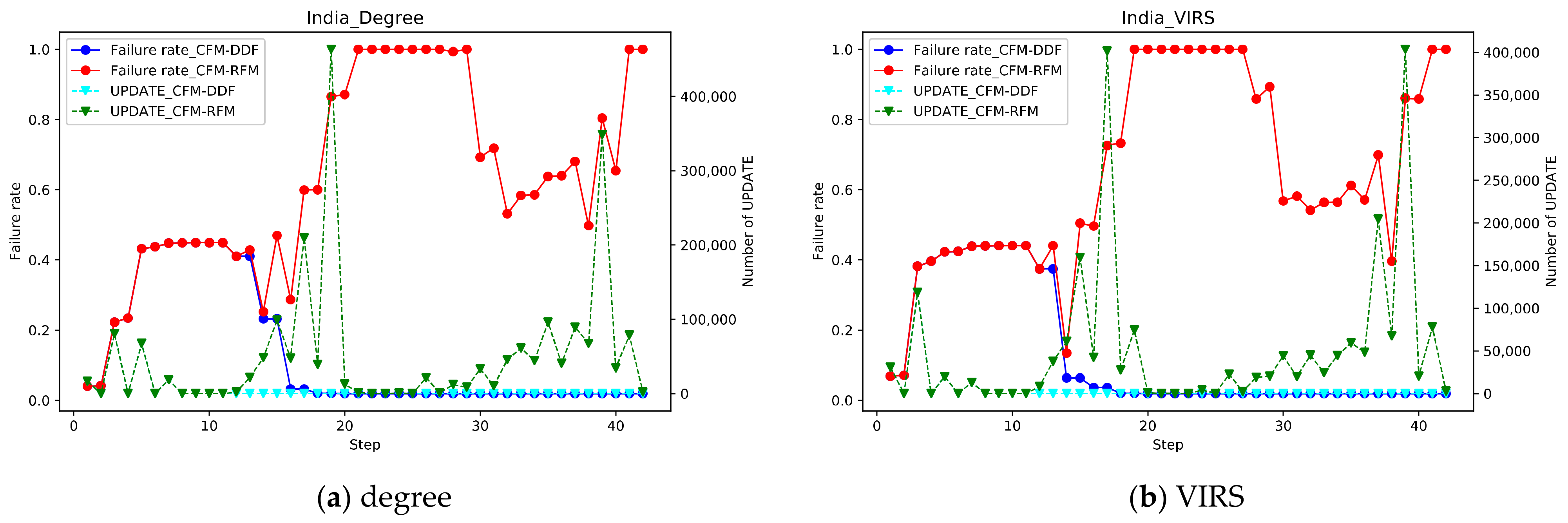
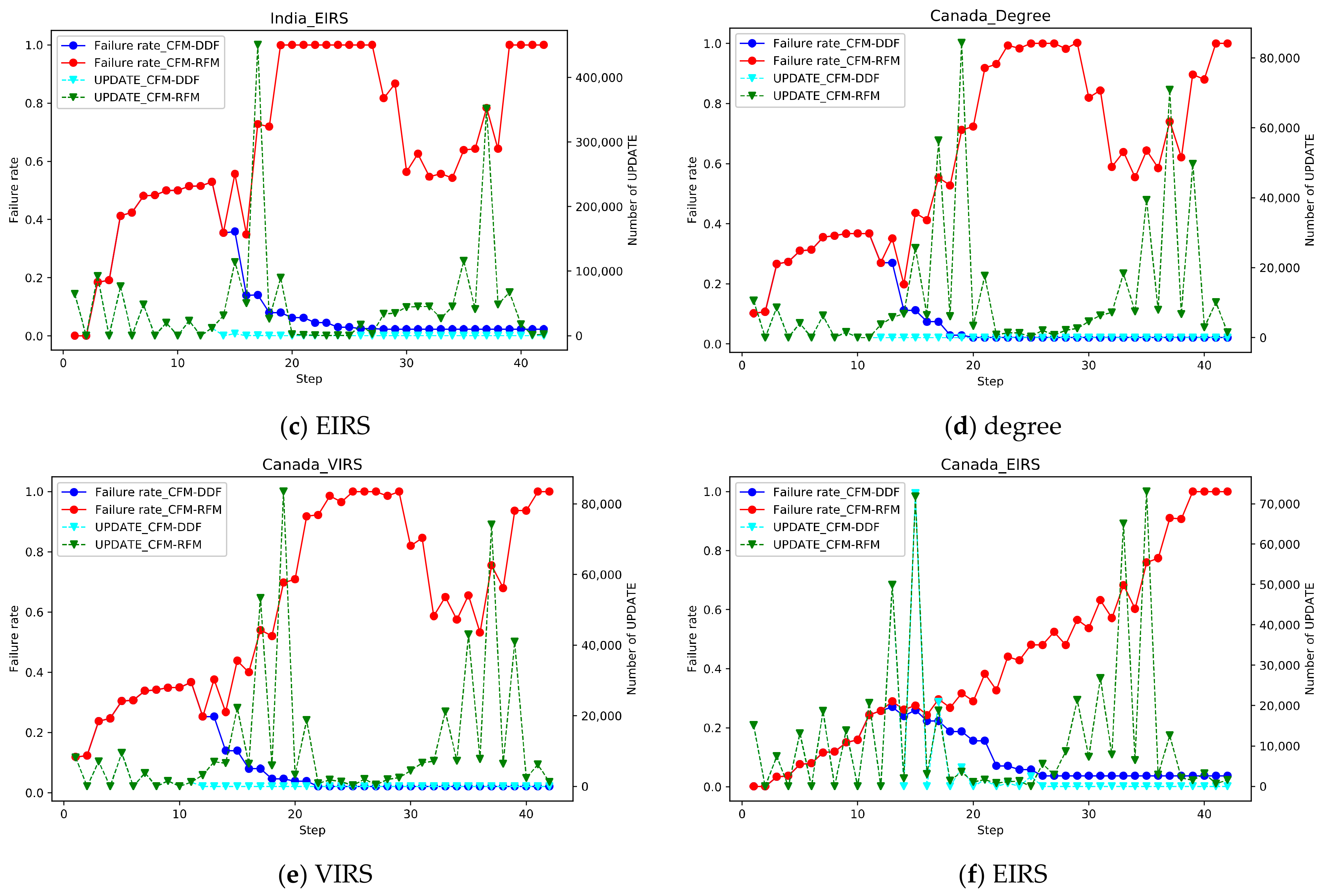
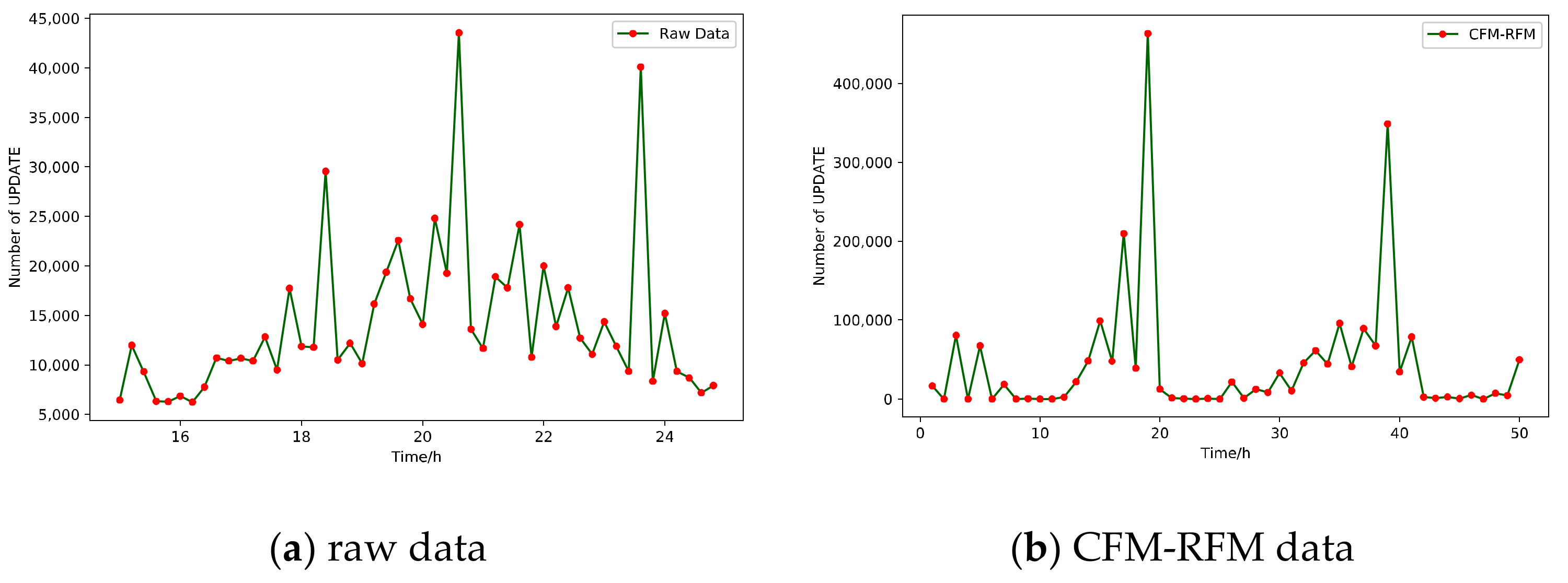
5.3. Impact of Recovery Feedback Mechanism
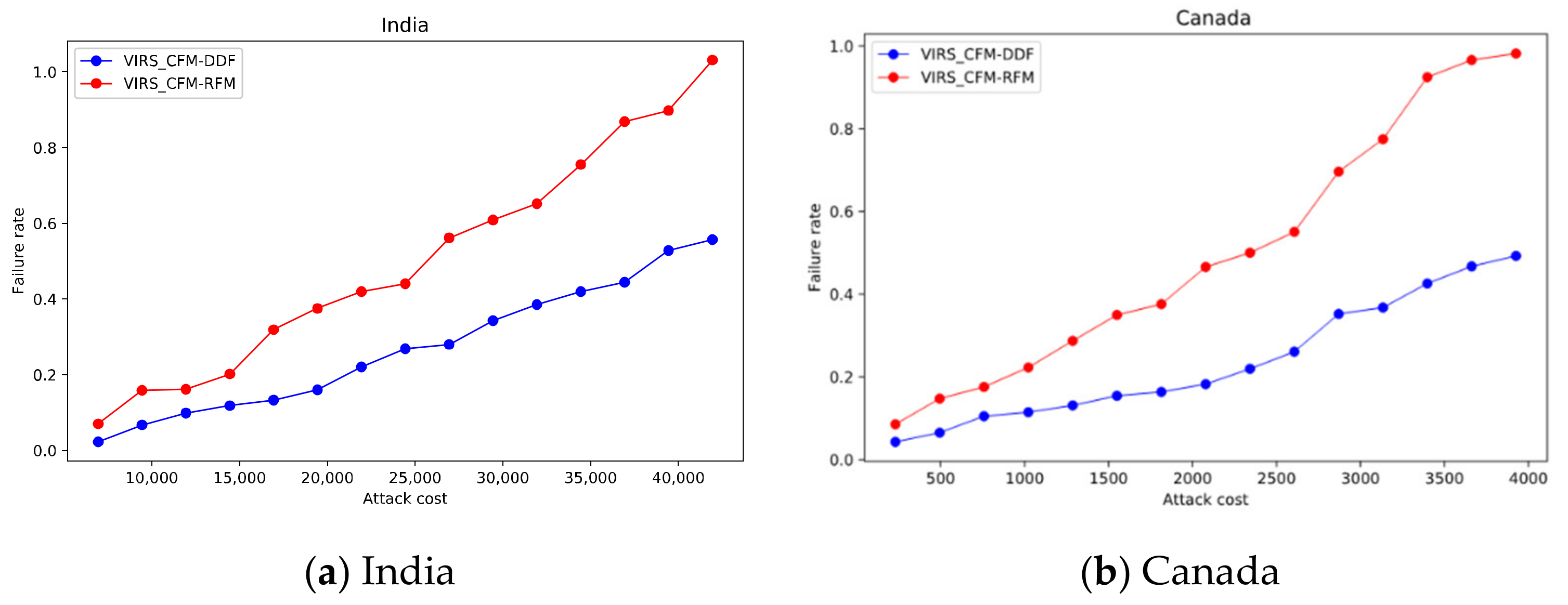
5.4. Analysis of Attack Costs
5.5. Validity of CFM-RFM
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Butler, K.; Farley, T.R.; Mcdaniel, P.; Rexford, J. A Survey of BGP Security Issues and Solutions. Proc. IEEE 2009, 98, 100–122. [Google Scholar] [CrossRef]
- Li, S.; Zhuge, J.W.; Li, X. Study on BGP Security. J. Softw. 2013, 24, 121–138. [Google Scholar] [CrossRef]
- Goldberg, S. Why is it taking so long to secure internet routing? Queue 2014, 12, 20–33. [Google Scholar] [CrossRef]
- Vervier, P.A.; Thonnard, O.; Dacier, M. Mind Your Blocks: On the Stealthiness of Malicious BGP Hijacks. In Proceedings of the Network & Distributed System Security Symposium, San Diego, CA, USA, 8–11 February 2015. [Google Scholar]
- Murphy, S. BGP Security Vulnerabilities Analysis. 2006. Available online: https://datatracker.ietf.org/doc/rfc4272 (accessed on 17 May 2021).
- Zou, C.; Gong, W.; Towsley, D. Code red worm propagation modeling and analysis. In Proceedings of the 9th ACM Conference on Computer and Communications Security, CCS 2002, Washington, DC, USA, 18–22 November 2002; pp. 138–147. [Google Scholar] [CrossRef] [Green Version]
- Hakimi, R.; Saputra, Y.M.; Nugraha, B. Case Studies Analysis on BGP: Prefix Hijacking and Transit AS. In Proceedings of the IEEE International Conference on Telecommunication Systems Services and Applications (TSSA’16), Denpasar, Indonesia, 6–7 October 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Schuchard, M.; Mohaisen, A.; Foo Kune, D.; Hopper, N.; Kim, Y.; Vasserman, E.Y. Losing control of the internet: Using the data plane to attack the control plane. In Proceedings of the 17th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 4–18 October 2010; pp. 726–728. [Google Scholar]
- Deng, W.; Zhu, P.; Lu, X.; Plattner, B. On Evaluating BGP Routing Stress Attack. J. Commun. 2010, 5, 13–22. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Zhu, J.; Qiu, H.; Wang, Q.; Zhou, T.; Li, H. The new threat to internet: DNP attack with the attacking flows strategizing technology. Int. J. Commun. Syst. 2015, 28, 1126–1139. [Google Scholar] [CrossRef]
- Motter, A.E.; Lai, Y.C. Cascade-based Attacks on Complex Networks. Phys. Rev. E 2003, 66, 065102. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Wang, Z.; Luo, S.; Wang, Y. A cascading failure model for interdomain routing system. Int. J. Commun. Syst. 2012, 25, 1068–1076. [Google Scholar] [CrossRef]
- Liu, Y.; Wei, P.; Su, J.; Wang, Z. Assessing the Impact of Cascading Failures on the Interdomain Routing System of the Internet. New Gener. Comput. 2014, 32, 237–255. [Google Scholar] [CrossRef]
- Gao, L. On inferring autonomous system relationships in the Internet. IEEE/ACM Trans. Netw. 2001, 9, 733–745. [Google Scholar] [CrossRef]
- Lu, Y.; Yang, B. Analyzing and modeling cascading failures for inter-domain routing system. J. Syst. Eng. Electron. 2016, 38, 172–178. [Google Scholar]
- Zhu, H.; Qiu, H.; Wang, Q. Double Damage Factor Based Inter-Domain Routing System Cascading Failure Model. Comput. Eng. Appl. 2019, 55, 92–99. [Google Scholar]
- Zhang, J.; Zhang, J.; Xiong, X.; Wang, Y. Optimal valid path prediction method for inter-domain networks considering commercial relationships. J. Phys. Conf. Ser. 2020, 1693, 012023. [Google Scholar] [CrossRef]
- Bonacich, P.F. Factoring and weighting approaches to status scores and clique identification. J. Math. Sociol. 1972, 2, 113–120. [Google Scholar] [CrossRef]
- Zhang, L.; Xia, J.; Cheng, F.; Qiu, J.; Zhang, X. Multi-Objective Optimization of Critical Node Detection Based on Cascade Model in Complex Networks. IEEE Trans. Netw. Sci. Eng. 2020, 7, 2052–2066. [Google Scholar] [CrossRef]
- Zhang, Y.; Mao, Z.M.; Wang, J. Low-Rate TCP-Targeted DoS Attack Disrupts Internet Routing. In Proceedings of the NDSS, San Diego, CA, USA, 28 February–2 March 2007. [Google Scholar] [CrossRef]
- Wang, L.; Zhao, X.; Pei, D.; Bush, R.; Massey, D.; Mankin, A.; Wu, S.F.; Zhang, L. Observation and analysis of BGP behavior under stress. In Proceedings of the 2nd ACM SIGCOMM Workshop on Internet Measurement, Marseille, France, 6–8 November 2002; pp. 183–195. [Google Scholar]
- Chang, D.F.; Govindan, R.; Heidemann, J. An empirical study of router response to large BGP routing table load. In Proceedings of the 2nd ACM SIGCOMM Workshop on Internet Measurement, Marseille, France, 6–8 November 2002; pp. 203–208. [Google Scholar] [CrossRef] [Green Version]
- CAIDA. Available online: https://www.caida.org (accessed on 17 May 2021).
- RIPE’s Routing Information Service. Available online: https://www.ripe.net (accessed on 17 May 2021).
- Coffman, E.G.; Ge, Z.; Misra, V.; Towsley, D. Network Resilience: Exploring Cascading Failures within BGP. In Proceedings of the 40th Annual Allerton Conference on Communications, Computing and Control, Allerton House, IL, USA, 27–29 September 2002. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Descriptions |
|---|---|
| Topology of inter-domain routing network. | |
| V | The set of nodes. |
| E | The set of links. |
| A node . | |
| A link . | |
| / | The load of or . |
| The capacity of . | |
| The capacity of . | |
| Tolerance parameter. | |
| Recovery delay of . | |
| Recovery delay of . | |
| Basic unit flow. | |
| VIRS | Betweenness. |
| EIRS | Betweenness of links. |
| The set of reachable nodes of . |
| Parameter | Value_India | Value_Canada |
|---|---|---|
| Num_V | 2406 | 1523 |
| Num_E | 4052 | 2508 |
| Step | 50 | 50 |
| 1 | 1 | |
| 0.3 | 0.3 | |
| 250 | 150 | |
| 5 | 5 | |
| 5 | 5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, W.; Wang, Y.; Xiong, X.; Li, Y. CFM-RFM: A Cascading Failure Model for Inter-Domain Routing Systems with the Recovery Feedback Mechanism. Information 2021, 12, 247. https://doi.org/10.3390/info12060247
Zhao W, Wang Y, Xiong X, Li Y. CFM-RFM: A Cascading Failure Model for Inter-Domain Routing Systems with the Recovery Feedback Mechanism. Information. 2021; 12(6):247. https://doi.org/10.3390/info12060247
Chicago/Turabian StyleZhao, Wendian, Yongjie Wang, Xinli Xiong, and Yang Li. 2021. "CFM-RFM: A Cascading Failure Model for Inter-Domain Routing Systems with the Recovery Feedback Mechanism" Information 12, no. 6: 247. https://doi.org/10.3390/info12060247
APA StyleZhao, W., Wang, Y., Xiong, X., & Li, Y. (2021). CFM-RFM: A Cascading Failure Model for Inter-Domain Routing Systems with the Recovery Feedback Mechanism. Information, 12(6), 247. https://doi.org/10.3390/info12060247