
Research on Generation Method of Grasp Strategy Based on DeepLab V3+ for Three-Finger Gripper



Abstract
:1. Introduction
- It proposes a grasp strategy generation neural network (grasp network with atrous convolution) based on the idea of semantic segmentation and, based on DeepLab V3+ with atrous spatial pyramid pooling (ASPP), it achieves a good grasp accuracy rate and outputted pixel-level results in the current research;
- It explores the effect of different rates of the atrous space convolution pooling pyramid on the recognition of the images in Cornell Grasp dataset, and analyzes the value of the rates of ASPP for different targets.
2. Materials and Methods
2.1. Theoretical Analysis
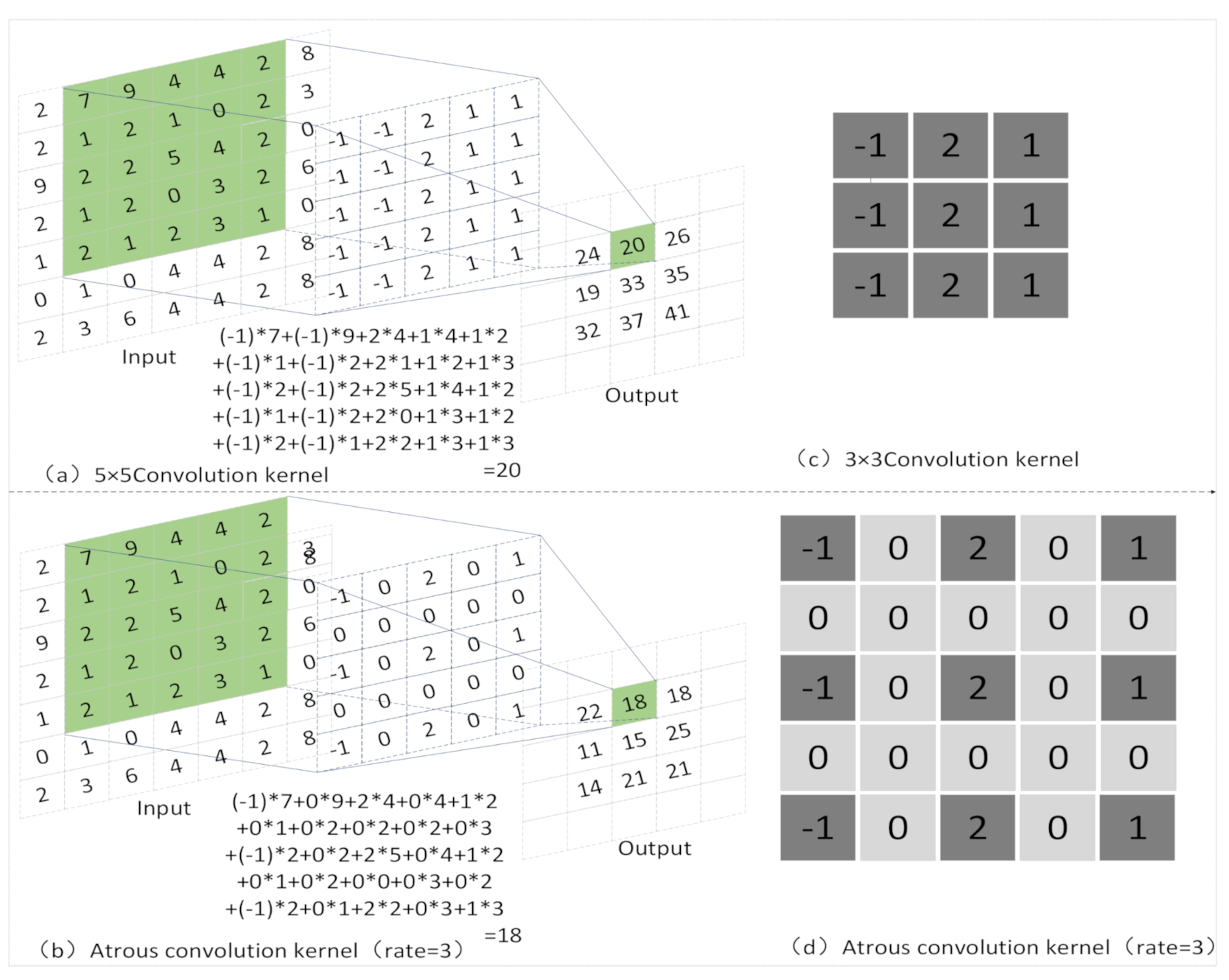
2.1.1. Convolution Kernel
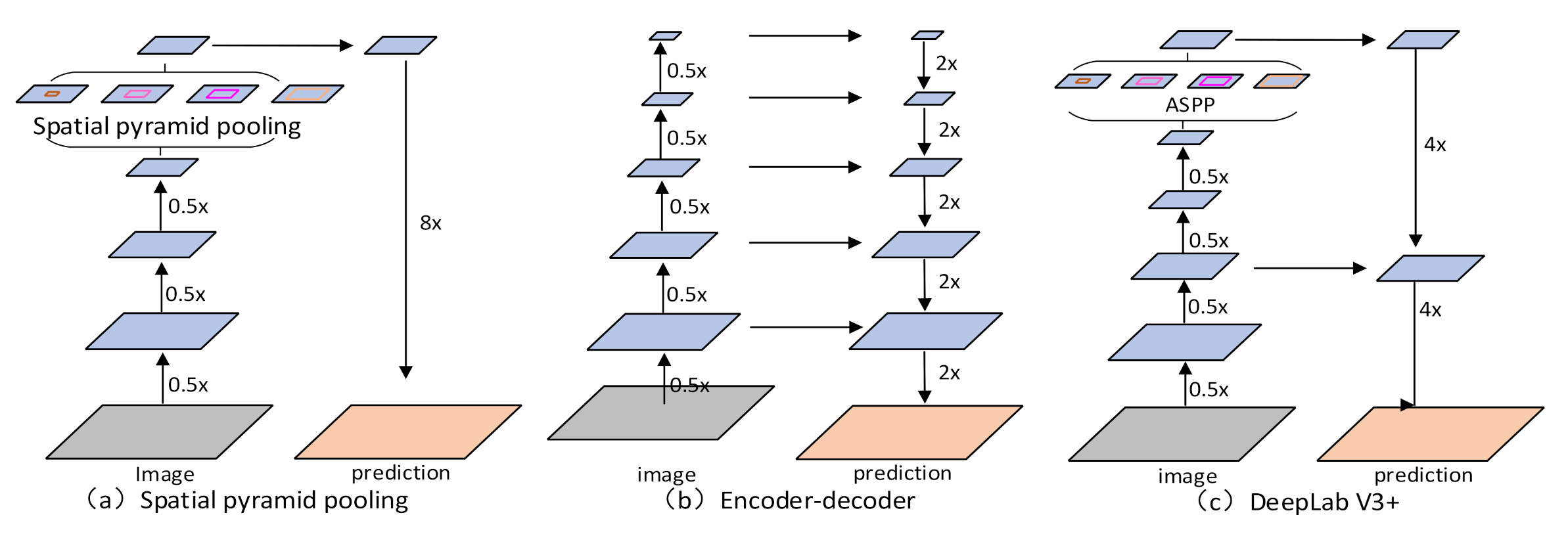
2.1.2. DeepLab V3+ NETWORK
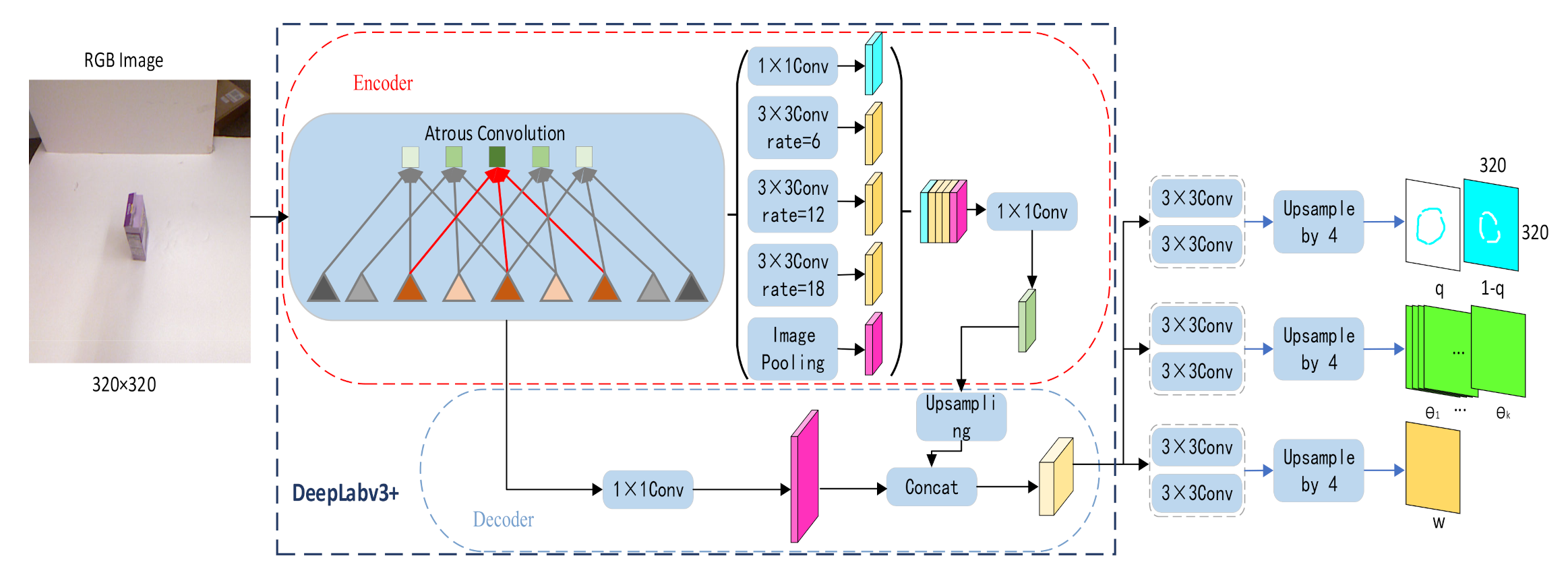
2.1.3. Network Architecture
2.2. Generating Grasp Strategy
2.3. Experiment Setup
2.3.1. Dataset
2.3.2. Implementation Details
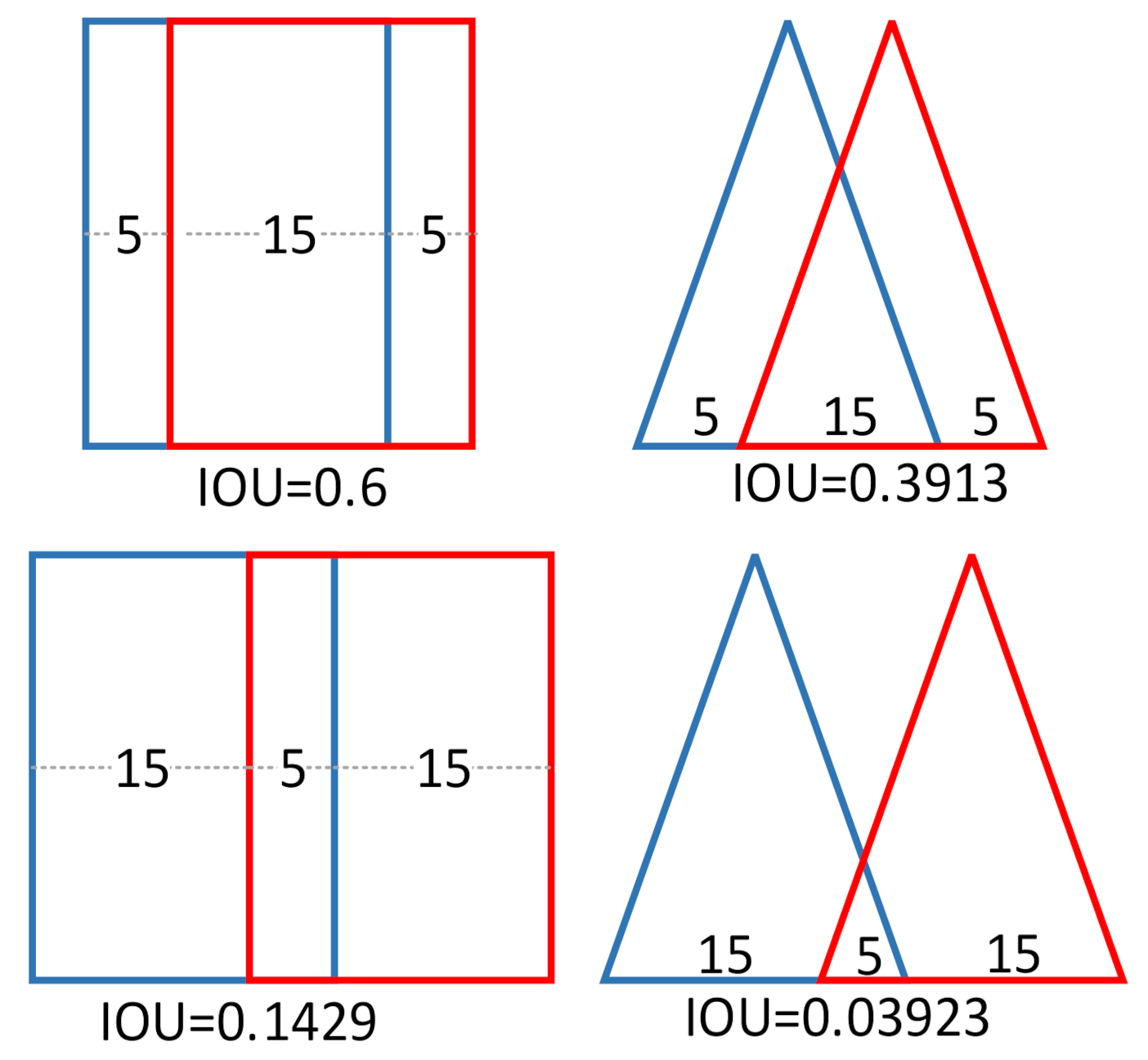
2.3.3. Test Methods Metric
- Image-wise split (IW): The image dataset was randomly divided into a test set and a training set. This method was mainly used to test the neural network’s ability to recognize previously seen targets in new positions and new directions;
- Object-wise split (OW): We divided the dataset at an object instance level. All the images of an instance were put into the same set. This method was mainly used to test the neural network’s ability to recognize new targets.
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, D. SGDN: Segmentation-Based Grasp Detection Network For Unsymmetrical Three-Finger Gripper. arXiv 2020, arXiv:2005.08222. [Google Scholar]
- Chan-Viquez, D.; Hasanbarani, F.; Zhang, L.; Anaby, D.; Turpin, N.A.; Lamontagne, A.; Feldman, A.G.; Levin, M.F. Development of vertical and forward jumping skills in typically developing children in the con-text of referent control of motor actions. Dev. Psychobiol. 2020, 62, 711–722. [Google Scholar] [CrossRef] [PubMed]
- Guo, D.; Sun, F.; Liu, H.; Kong, T.; Fang, B.; Xi, N. A hybrid deep architecture for robotic grasp detection. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1609–1614. [Google Scholar]
- Jiang, Y.; Moseson, S.; Saxena, A. Efficient Grasping from RGBD Images: Learning Using a New Rectangle Representation. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3304–3311. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Brachmann, E.; Krull, A.; Michel, F.; Gumhold, S.; Shotton, J.; Rother, C. Learning 6D Object Pose Estimation Using 3D Object Coordinates. Trans. Petri Nets Other Models Concurr. XV 2014, 2, 536–551. [Google Scholar] [CrossRef] [Green Version]
- Lenz, I.; Lee, H.; Saxena, A. Deep learning for detecting robotic grasps. Int. J. Robot. Res. 2015, 34, 705–724. [Google Scholar] [CrossRef] [Green Version]
- Kumra, S.; Kanan, C. Robotic grasp detection using deep convolutional neural networks. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 769–776. [Google Scholar]
- Bicchi, A.; Kumar, V. Robotic grasping and contact: A review. In Proceedings of the 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation. Symposia Proceedings (Cat. No.00CH37065), San Francisco, CA, USA, 24–28 April 2000; Volume 1, pp. 348–353. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Bai, Q.; Li, S.; Yang, J.; Song, Q.; Li, Z.; Zhang, X. Object Detection Recognition and Robot Grasping Based on Machine Learning: A Survey. IEEE Access 2020, 8, 181855–181879. [Google Scholar] [CrossRef]
- Chen, J.; Kira, Z.; Cho, Y.K. LRGNet: Learnable Region Growing for Class-Agnostic Point Cloud Segmentation. IEEE Robot. Autom. Lett. 2021, 6, 2799–2806. [Google Scholar] [CrossRef]
- Monica, R.; Aleotti, J. Point Cloud Projective Analysis for Part-Based Grasp Planning. IEEE Robot. Autom. Lett. 2020, 5, 4695–4702. [Google Scholar] [CrossRef]
- Zhuang, C.; Wang, Z.; Zhao, H.; Ding, H. Semantic part segmentation method based 3D object pose estimation with RGB-D images for bin-picking. Robot. Comput. Manuf. 2021, 68, 102086. [Google Scholar] [CrossRef]
- Song, Y.; Gao, L.; Li, X.; Shen, W. A novel robotic grasp detection method based on region proposal networks. Robot. Comput. Manuf. 2020, 65, 101963. [Google Scholar] [CrossRef]
- Kumra, S.; Joshi, S.; Sahin, F. Antipodal Robotic Grasping using Generative Residual Convolutional Neural Network. Comput. Sci. 2019, arXiv:1909.04810v4. [Google Scholar]
- Chu, F.-J.; Xu, R.; Vela, P.A. Real-World Multiobject, Multigrasp Detection. IEEE Robot. Autom. Lett. 2018, 3, 3355–3362. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Wang, L.; Yang, A.; Chen, L.; Ynag, A. GraspCNN: Real-Time Grasp Detection Using a New Oriented Diameter Circle Representation. IEEE Access 2019, 7, 159322–159331. [Google Scholar] [CrossRef]
- Zhang, H.; Lan, X.; Bai, S.; Zhou, X.; Tian, Z.; Zheng, N. ROI-based Robotic Grasp Detection for Object Overlapping Scenes. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4768–4775. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 6, 84–90. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. Comput. Sci. 2014, 4, 357–361. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Redmon, J.; Angelova, A. Real-time grasp detection using convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1316–1322. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Rates of ASPP | 500 Epochs | 1500 Epochs | ||
|---|---|---|---|---|
| IW (%) | OW (%) | IW (%) | OW (%) | |
| [NO_ASPP] | 92.27 | 94.06 | 95.45 | 94.97 |
| [1,2,4,6] | 91.74 | 89.54 | 97.71 | 96.82 |
| [1,3,6,9] | 91.32 | 90.00 | 96.35 | 96.82 |
| [1,6,12,18] | 90.41 | 90.00 | 95.43 | 95.00 |
| Approach | Year | Grasp Representation | Algorithm | Accuracy (%) | Speed (ms) | |
|---|---|---|---|---|---|---|
| IW | OW | |||||
| Jiang [4] | 2011 | Five-dimensional representation | Fast Search | 60.5 | 58.3 | 5000 |
| Lenz [7] | 2015 | SAE, struct.reg | 73.9 | 75.6 | 1350 | |
| Guo [3] | 2017 | ZF-net | 93.2 | 89.1 | - | |
| Zhang [19] | 2019 | ROI-GD, ResNet-101 | 93.6 | 93.5 | 39.75 | |
| Chu [17] | 2018 | ResNet-50, Deep Grasp | 96.5 | 96.1 | 20 | |
| Kumra [16] | 2020 | GR-ConvNet-RGB-D | 97.7 | 96.6 | 20 | |
| Yanan [15] | 2020 | ResNet-50(RGD) | 95.6 | 97.1 | - | |
| Wang [1] | 2020 | Oriented base-fixed triangle | SGDN | 96.8 | 92.27 | 19.4 |
| OURS | 2021 | GNAC | 97.71 | 96.82 | 19.1 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, S.; Li, S.; Bai, Q.; Yang, J.; Miao, Y.; Chen, L. Research on Generation Method of Grasp Strategy Based on DeepLab V3+ for Three-Finger Gripper. Information 2021, 12, 278. https://doi.org/10.3390/info12070278
Jiang S, Li S, Bai Q, Yang J, Miao Y, Chen L. Research on Generation Method of Grasp Strategy Based on DeepLab V3+ for Three-Finger Gripper. Information. 2021; 12(7):278. https://doi.org/10.3390/info12070278
Chicago/Turabian StyleJiang, Sanlong, Shaobo Li, Qiang Bai, Jing Yang, Yanming Miao, and Leiyu Chen. 2021. "Research on Generation Method of Grasp Strategy Based on DeepLab V3+ for Three-Finger Gripper" Information 12, no. 7: 278. https://doi.org/10.3390/info12070278
APA StyleJiang, S., Li, S., Bai, Q., Yang, J., Miao, Y., & Chen, L. (2021). Research on Generation Method of Grasp Strategy Based on DeepLab V3+ for Three-Finger Gripper. Information, 12(7), 278. https://doi.org/10.3390/info12070278