
Automatic Eligibility of Sellers in an Online Marketplace: A Case Study of Amazon Algorithm



Abstract
:1. Introduction
1.1. Literature Review
1.2. Related Work
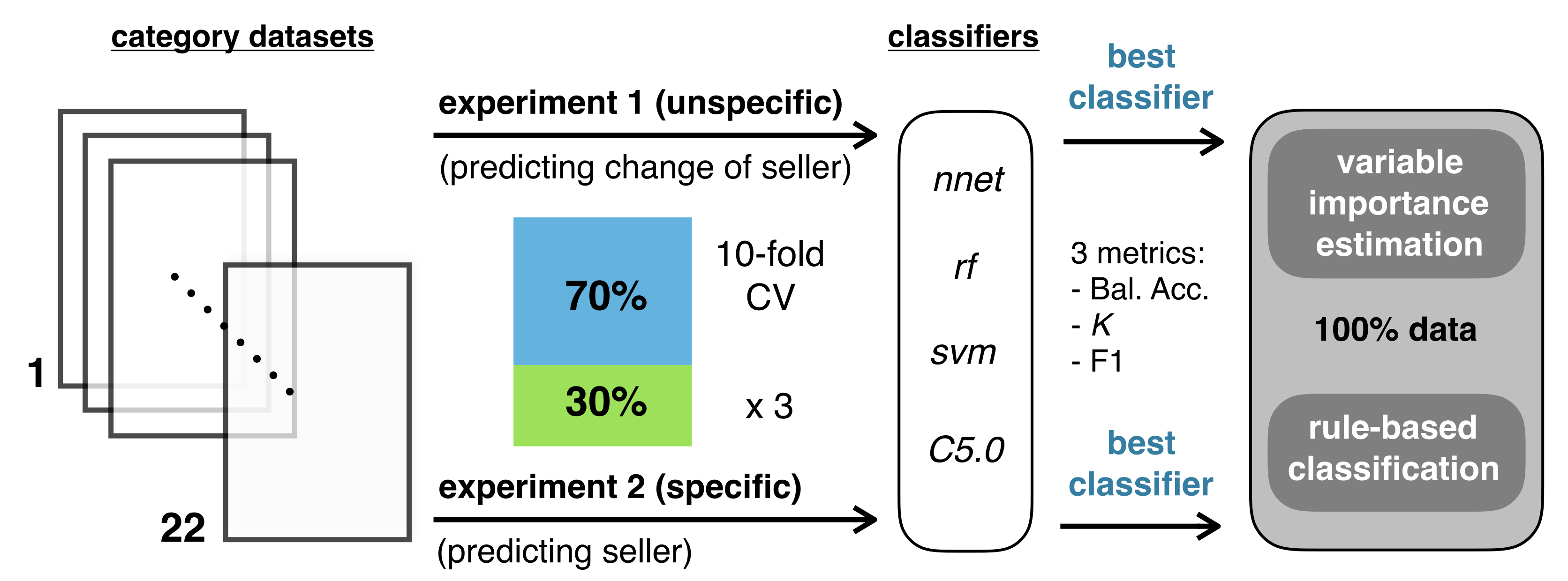
2. Materials and Methods
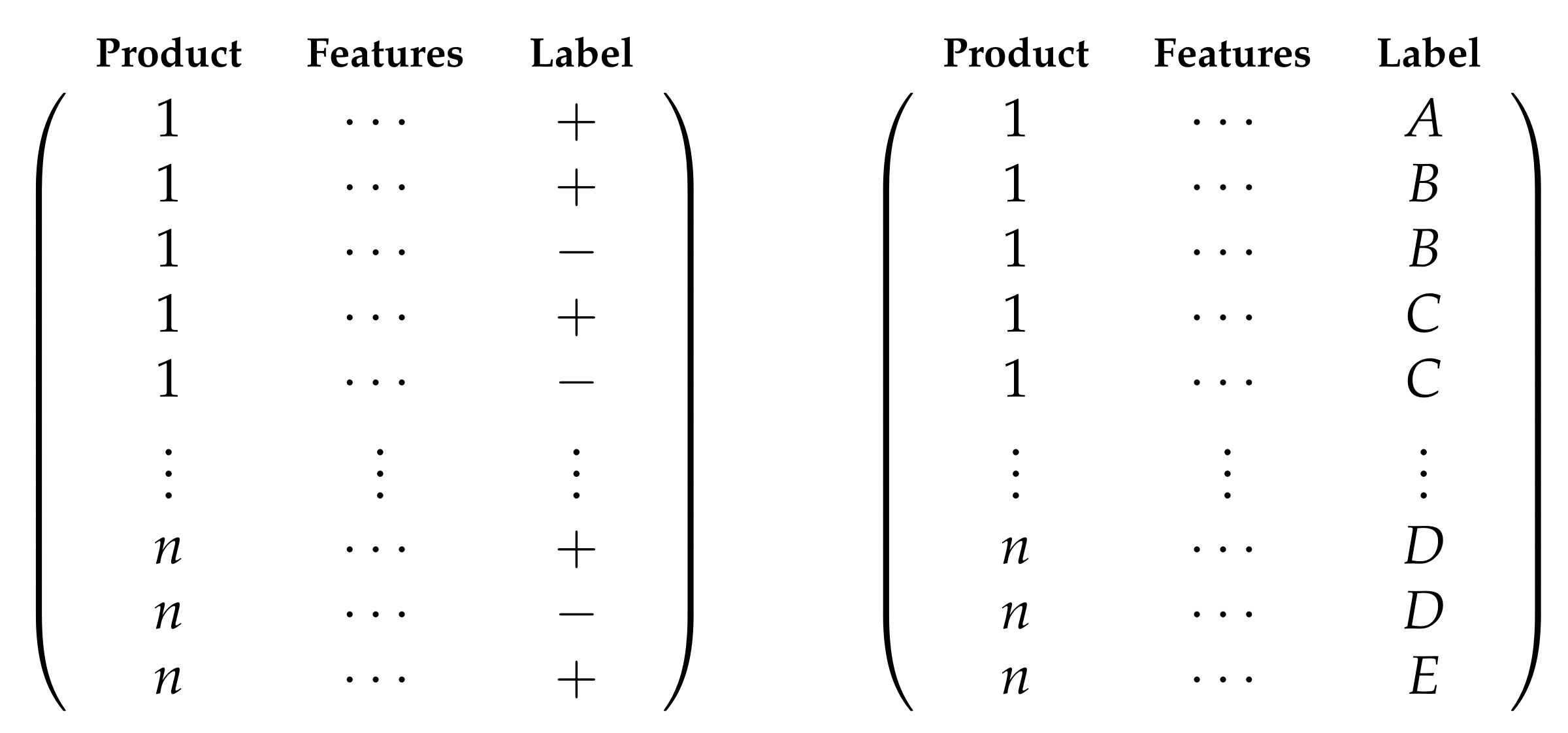
2.1. Datasets and Features
2.2. Proposed Classification Problems
2.2.1. Classification Algorithms
2.2.2. Performance Evaluation
- TP: which corresponds to the number of instances correctly classified as +/A.
- FN: which corresponds to the number of instances +/A misclassified as −/≠A.
- FP: which corresponds to the number of instances −/≠A misclassified as +/A.
- TN: which corresponds to the number of instances correctly classified as −/≠A.
- Recall = , the proportion of correctly classified +/A instances from the total number of actual +/A instances, aka Sensitivity.
- Precision = , relates to the ability of the classifiers to identify +/A instances.
- Specificity = , proportion of correctly classified −/≠A instances from the total number of actual −/≠A instances.
2.3. Predictor Importance and Rule-Based Classification
3. Results and Discussion
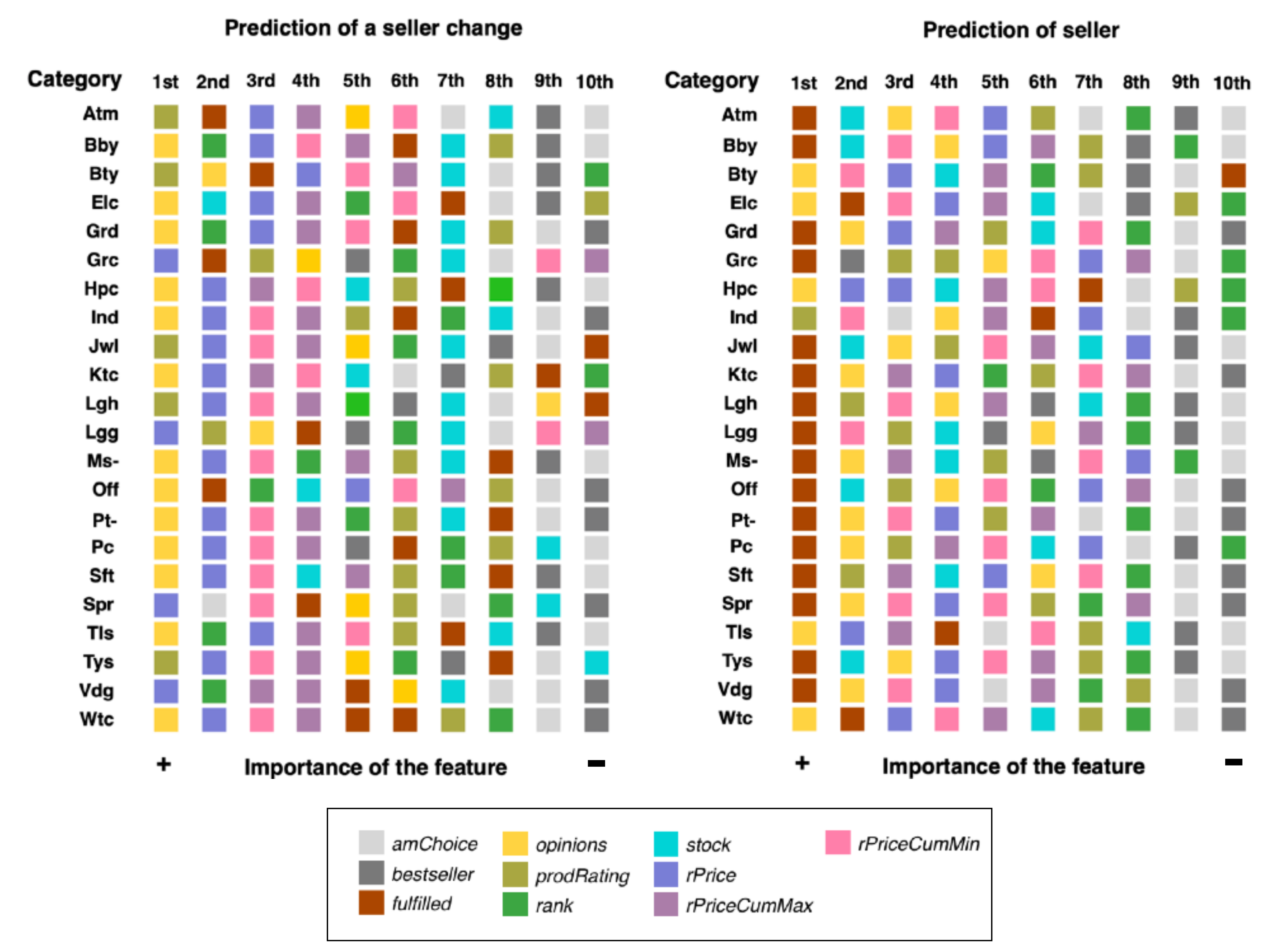
3.1. Predictor Importance
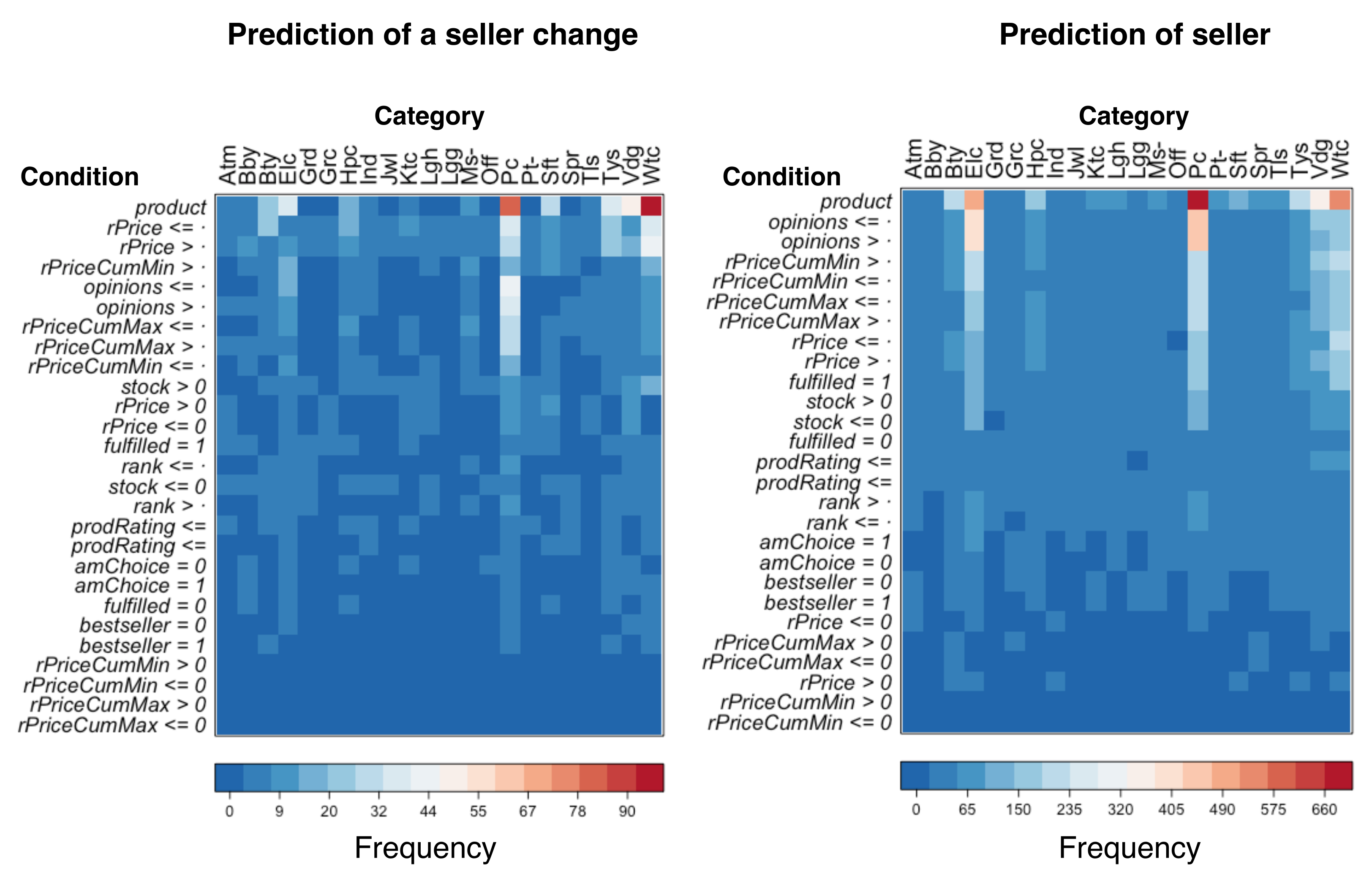
3.2. Rule-Based Classification
4. Conclusions
5. Disclaimer
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hannák, A.; Sapiezynski, P.; Molavi-Kakhki, A.; Krishnamurthy, B.; Lazer, D.; Mislove, A.; Wilson, C. Measuring personalization of web search. In Proceedings of the WWW ’13: 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 527–538. [Google Scholar]
- Hannák, A.; Wagner, C.; Garcia, D.; Mislove, A.; Strohmaier, M.; Wilson, C. Bias in online freelance marketplaces: Evidence from TaskRabbit and Fiverr. In Proceedings of the CSCW ’17: 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing, Portland, OR, USA, 25 February–1 March 2017; pp. 1914–1933. [Google Scholar]
- Chen, L.; Ma, R.; Hannák, A.; Wilson, C. Investigating the impact of gender on rank in resume search engines. In Proceedings of the CHI ’18: 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018. Paper No. 651. [Google Scholar]
- Duch-Brown, N. The Competitive Landscape of Online Platforms; JRC Digital Economy Working Paper 2017-04 (JRC106299); Publications Office of the European Union: Luxembourg, 2017. [Google Scholar]
- Inci, D. Competing with Amazon: How Amazon’s Top e-Commerce Competitors Survive and Thrive. Available online: https://www.bigcommerce.com/blog/Amazon-competitors/ (accessed on 4 December 2021).
- Statista. E-Commerce Market Share of Leading e-Retailers Worldwide in 2020, Based on GMV. Available online: https://www.statista.com/statistics/664814/global-e-commerce-market-share/ (accessed on 4 December 2021).
- Lin, Y.-C.; Das, P.; Trotman, A.; Kallumadi, S. A dataset and baselines for e-commerce product categorization. In Proceedings of the ICTIR’19: 2019 ACM SIGIR International Conference on the Theory of Information Retrieval, Santa Clara, CA, USA, 2–9 October 2019. [Google Scholar]
- Ding, Y.; Fensel, D.; Klein, M.; Omelayenko, B.; Schulten, E. The role of ontologies in e-commerce. Handbook on Ontologies. In International Handbooks on Information Systems; Springer: Berlin, Germany, 2004; pp. 593–615. [Google Scholar]
- Alaa, R.; Gawish, M.; Fernández-Veiga, M. Improving recommendations for online retail markets based on ontology evolution. Electronics 2021, 10, 1650. [Google Scholar] [CrossRef]
- Amazon Buy Box, Feedvisor. Available online: https://feedvisor.com/university/Amazon-buy-box (accessed on 4 December 2021).
- Adamopoulou, E.; Moussiades, L. Chatbots: History, technology, and applications. Mach. Learn. Appl. 2020, 2, 100006. [Google Scholar] [CrossRef]
- Ahmed, A.; Saleem, K.; Khalid, O.; Rashid, U. On deep neural network for trust aware cross domain recommendations in E-commerce. Expert Syst. Appl. 2021, 174, 114757. [Google Scholar] [CrossRef]
- Poirson, E.; Da Cunha, C. A recommender approach based on customer emotions. Expert Syst. Appl. 2019, 122, 281–288. [Google Scholar]
- Portugal, I.; Alencar, P.; Cowan, D. The use of machine learning algorithms in recommender systems: A systematic review. Expert Syst. Appl. 2018, 97, 205–227. [Google Scholar] [CrossRef] [Green Version]
- Boysen, N.; de Koster, R.; Weidinger, F. Warehousing in the e-commerce era: A survey. Eur. J. Oper. Res. 2019, 277, 396–411. [Google Scholar] [CrossRef]
- Zhang, D.; Pee, L.G.; Cui, L. Artificial intelligence in E-commerce fulfilment: A case study of resource orchestration at Alibaba’s Smart Warehouse. Int. J. Inf. Manag. 2021, 57, 102304. [Google Scholar] [CrossRef]
- Gupta, R.; Pathak, C. A Machine learning framework for predicting purchase by online customers based on dynamic pricing. Procedia Comput. Sci. 2014, 36, 599–605. [Google Scholar] [CrossRef] [Green Version]
- Bauer, J.; Jannach, D. Optimal pricing in e-commerce based on sparse and noisy data. Decis. Support Syst. 2018, 106, 53–63. [Google Scholar] [CrossRef]
- Gonçalves de Souza, E.A.; Nagano, M.S.; Alencar Rolim, G. Dynamic Programming algorithms and their applications in machine scheduling: A review. Expert Syst. Appl. 2022, 190, 116180. [Google Scholar] [CrossRef]
- Hannák, A.; Soeller, G.; Lazer, D.; Mislove, A.; Wilson, C. Measuring price discrimination and steering on e-commerce web sites. In Proceedings of the MC ’14: 2014 Conference on Internet Measurement Conference, Vancouver, BC, Canada, 5–7 November 2014; pp. 305–318. [Google Scholar]
- Chen, L.; Mislove, A.; Wilson, C. Peeking beneath the hood of Uber. In Proceedings of the IMC ’15: 2015 Internet Measurement, Tokyo, Japan, 28–30 October 2015; pp. 495–508. [Google Scholar]
- Kolotylo-Kulkarni, M.; Xia, W.; Dhillon, G. Information disclosure in e-commerce: A systematic review and agenda for future research. J. Bus. Res. 2021, 126, 221–238. [Google Scholar] [CrossRef]
- Abdallah, A.; Maarof, M.A.; Zainal, A. Fraud detection system: A survey. J. Netw. Comput. Appl. 2016, 68, 90–113. [Google Scholar] [CrossRef]
- Tax, N.; Jan de Vries, K.; de Jong, M.; Dosoula, N.; van den Akker, B.; Smith, J.; Thuong, O.; Bernardi, L. Machine learning for fraud detection in e-Commerce: A research agenda. In Deployable Machine Learning for Security Defense. MLHat 2021. Communications in Computer and Information Science; Wang, G., Ciptadi, A., Ahmadzadeh, A., Eds.; Springer: Cham, Switzerland, 2021; Volume 1482. [Google Scholar]
- Pallathadka, M.; Ramirez-Asis, E.-H.; Loli-Poma, T.-P.; Kaliyaperumal, K.; Magno Ventayen, R.J.; Naved, M. Applications of artificial intelligence in business management, e-commerce and finance. Mater. Today Proc. 2021, in press. [Google Scholar] [CrossRef]
- Liu, C.-J.; Huang, T.-S.; Ho, P.-T.; Huang, J.-C.; Hsieh, C.-T. Machine learning-based e-commerce platform repurchase customer prediction model. PLoS ONE 2020, 15, e0243105. [Google Scholar] [CrossRef]
- Wang, P.; Xu, Z. A novel consumer purchase behavior recognition method using ensemble learning algorithm. Math. Probl. Eng. 2020, 2020, 6673535. [Google Scholar] [CrossRef]
- Boute, R.N.; Gijsbrechts, J.; van Jaarsveld, W.; Vanvuchelen, N. Deep reinforcement learning for inventory control: A roadmap. Eur. J. Oper. Res. 2021, 298, 401–412. [Google Scholar] [CrossRef]
- Goltsos, T.E.; Syntetos, A.A.; Glock, C.H.; Ioannou, G. Inventory–forecasting: Mind the gap. Eur. J. Oper. Res. 2021, in press. [Google Scholar] [CrossRef]
- Shen, D.; Ruvini, J.D.; Mukherjee, R.; Sundaresan, N. A study of smoothing algorithms for item categorization on e-commerce sites. Neurocomputing 2012, 92, 54–60. [Google Scholar] [CrossRef]
- Liesiö, J.; Salo, A.; Keisler, J.M.; Morton, A. Portfolio decision analysis: Recent developments and future prospects. Eur. J. Oper. Res. 2021, 293, 811–825. [Google Scholar] [CrossRef]
- Policarpo, L.M.; da Silveira, D.E.; da Rosa Righi, R.; Antunes Stoffel, R.; André da Costa, C.; Victória Barbosa, J.L.; Scorsatto, R.; Arcot, T. Machine learning through the lens of e-commerce initiatives: An up-to-date systematic literature review. J. Comput. Sci. Rev. 2021, 41, 100414. [Google Scholar] [CrossRef]
- Song, X.; Yang, S.; Huang, Z.; Huang, T. The Application of artificial intelligence in electronic commerce. J. Phys. Conf. Ser. 2019, 1302, 032030. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine learning: Algorithms, real-world applications and research directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef] [PubMed]
- Mice, A.; Geru, M.; Capatina, A.; Avram, C.; Rusu, R.; Panait, A.A. Leveraging e-Commerce performance through machine learning algorithms. Ann. Dunarea Jos Univ. Galati 2019, 2, 162–171. [Google Scholar]
- Änäkkälä, T. Exploring Value in e-Commerce. Artificial Intelligence and Recommendation Systems; University of Jyväskylä: Jyväskylä, Finland, 2021. [Google Scholar]
- Bertolini, M.; Mezzogori, D.; Neroni, M.; Zammori, F. Machine Learning for industrial applications: A comprehensive literature review. Expert Syst. Appl. 2021, 175, 114820. [Google Scholar] [CrossRef]
- Moorthi, K.; Dhiman, G.; Arulprakash, P.; Suresh, C.; Srihari, K. A survey on impact of data analytics techniques in e-commerce. Mater. Today Proc. 2021, in press. [Google Scholar] [CrossRef]
- Chen, L.; Mislove, A.; Wilson, C. An empirical analysis of algorithmic pricing on Amazon Marketplace. In Proceedings of the WWW ’16: 25th International Conference on World Wide Web, Montréal, QC, Canada, 11–15 April 2016; pp. 1339–1349. [Google Scholar]
- Kunh, M.; Wing, J.; Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Cooper, T.; Mayer, Z.; Kenkel, B.; Benesty, M.; et al. Caret: Classification and Regression Training. R Package Version 6.0-84. 2019. Available online: https://CRAN.R-project.org/package=caret (accessed on 12 October 2021).
- Muhammad, A. Decision tree algorithms C4.5 and C5.0 in data mining: A review. Int. J. Database Theory Appl. 2018, 11, 1–8. [Google Scholar]
- Breiman, L. Random forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers: Burlington, VT, USA, 1993. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modelling; Springer: New York, NY, USA, 2013. [Google Scholar]
- Kim, K.-K.K.; Patrón, E.R.; Braatz, R.D. Standard representation and unified stability analysis for dynamic artificial neural network models. Neural Netw. 2018, 98, 251–262. [Google Scholar] [CrossRef] [PubMed]
- Li, F.F.; Karpathy, A.; Johnson, J. CS231n: Convolutional Neural Networks for Visual Recognition; Standford University: Standford, CA, USA, 2021. [Google Scholar]
- Gove, R.; Faytong, J. Machine learning and event-based software testing: Classifiers for identifying infeasible GUI event sequences. Adv. Comput. 2012, 86, 109–135. [Google Scholar]
- Nisbet, R.; Miner, G.; Yale, K. Chapter 8-Advanced algorithms for data mining. In Handbook of Statistical Analysis and Data Mining Applications; Nisbet, R., Elder, J., Miner, G., Eds.; Academic Press: Boston, MA, USA, 2009; pp. 151–172. [Google Scholar]
- Dietterich, T.G. Approximate statistical tests for comparing supervised classification learning algorithms. Neural Comput. 1998, 7, 1895–1923. [Google Scholar] [CrossRef] [Green Version]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Kuhn, M.; Weston, S.; Culp, M.; Coulter, N.; Quinlan, R. RuleQuest Research; C5.0 Decision Trees and Rule-Based Models. R Package Version 0.1.5; Rulequest Research Pty Ltd.: Sydney, Australia, 2019; Available online: https://topepo.github.io/C5.0/ (accessed on 4 October 2021).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Definition | Values (min, max) | Role |
|---|---|---|---|
| seller | Retailer featured in the Buy Box | Seller Id-Experiment 1 | Response |
| (0—no, 1—yes)-Experiment 2 | |||
| amChoice | Product featured by Amazon as recommendable | (0—no, 1—yes) | Predictor |
| best-seller | Product with highest position in sales | (0—no, 1—yes) | Predictor |
| fulfilled | Product is fulfilled by Amazon | (0—no, 1—yes) | Predictor |
| opinions | Number of opinions received from customers | (1, 7003) | Predictor |
| product | Product featured in the Buy Box | Product Id | Predictor |
| prodRating | Customer satisfaction after purchasing the product | (0, 5) | Predictor |
| rank | Position of the product in the best-seller page | (1, 100) | Predictor |
| stock | Availability of the product | (0—no, 1—yes) | Predictor |
| rPrice | Variation rate of the price at time t with respect to time t − 1 | (−95.9, 402) % | Predictor |
| rPriceCumMax | Variation rate of price at time t with respect to | (−96.8, 0) % | Predictor |
| the accumulated maximum price | |||
| rPriceCumMin | Variation rate of price at time t with respect to | (0, 3111.3) % | Predictor |
| the accumulated minimum price |
| Category | Abbr. | Instances | Sellers/Products |
|---|---|---|---|
| Automotive | Atm | 3245 | 32/14 |
| Baby | Bby | 1747 | 20/7 |
| Beauty | Bty | 5066 | 101/24 |
| Electronics | Elc | 14,060 | 179/33 |
| Garden | Grd | 1286 | 31/11 |
| Grocery | Grc | 1205 | 14/7 |
| Health & personal care | Hpc | 5229 | 69/20 |
| Industrial | Ind | 1526 | 25/8 |
| Jewellery | Jwl | 1933 | 33/15 |
| Kitchen | Ktc | 2646 | 51/15 |
| Lightning | Lgh | 2355 | 36/19 |
| Luggage | Lgg | 2082 | 42/21 |
| Musical instruments | Ms- | 2857 | 40/22 |
| Office | Off | 1708 | 17/6 |
| Pc | Pc | 22,149 | 153/38 |
| Pet-supplies | Pt- | 5334 | 59/24 |
| Software | Sft | 5548 | 61/41 |
| Sports | Spr | 1392 | 46/11 |
| Tools | Tls | 2461 | 66/17 |
| Toys | Tys | 6308 | 92/41 |
| Video games | Vdg | 11,697 | 93/58 |
| Watches | Wtc | 11,678 | 82/78 |
| Actual Class | Predicted Class | |
|---|---|---|
| + | − | |
| + | True Positive (TP) | False Negative (FN) |
| − | False Positive (FP) | True Negative (TN) |
| nnet | rf | svm | C5.0 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Category | Bal. Acc. | K | F1 | Bal. Acc. | K | F1 | Bal. Acc. | K | F1 | Bal. Acc. | K | F1 |
| Atm | 0.77 | 0.63 | 0.97 | 0.82 | 0.66 | 0.97 | 0.50 | 0.00 | 0.91 | 0.81 | 0.69 | 0.98 |
| Bby | 0.50 | 0.00 | 0.98 | 0.77 | 0.61 | 0.99 | 0.50 | 0.00 | 0.97 | 0.75 | 0.61 | 0.99 |
| Bty | 0.72 | 0.51 | 0.95 | 0.82 | 0.67 | 0.96 | 0.50 | 0.01 | 0.93 | 0.80 | 0.65 | 0.96 |
| Elc | 0.69 | 0.41 | 0.85 | 0.80 | 0.60 | 0.88 | 0.55 | 0.12 | 0.81 | 0.80 | 0.59 | 0.87 |
| Grd | 0.77 | 0.62 | 0.97 | 0.75 | 0.56 | 0.96 | 0.50 | 0.00 | 0.94 | 0.77 | 0.60 | 0.96 |
| Grc | 0.62 | 0.37 | 0.98 | 0.75 | 0.58 | 0.98 | 0.53 | 0.11 | 0.98 | 0.81 | 0.70 | 0.99 |
| Hpc | 0.84 | 0.69 | 0.94 | 0.87 | 0.71 | 0.95 | 0.51 | 0.04 | 0.90 | 0.88 | 0.73 | 0.95 |
| Ind | 0.77 | 0.58 | 0.93 | 0.75 | 0.56 | 0.93 | 0.52 | 0.05 | 0.90 | 0.71 | 0.48 | 0.92 |
| Jwl | 0.50 | 0.00 | 0.96 | 0.62 | 0.31 | 0.96 | 0.55 | 0.15 | 0.96 | 0.64 | 0.36 | 0.97 |
| Ktc | 0.76 | 0.62 | 0.97 | 0.84 | 0.70 | 0.97 | 0.50 | 0.00 | 0.95 | 0.83 | 0.68 | 0.97 |
| Lgh | 0.50 | 0.00 | 0.94 | 0.70 | 0.47 | 0.95 | 0.50 | 0.00 | 0.94 | 0.62 | 0.35 | 0.95 |
| Lgg | 0.72 | 0.55 | 0.97 | 0.72 | 0.56 | 0.98 | 0.50 | 0.00 | 0.96 | 0.71 | 0.55 | 0.98 |
| Ms- | 0.80 | 0.60 | 0.89 | 0.83 | 0.65 | 0.91 | 0.75 | 0.46 | 0.84 | 0.80 | 0.61 | 0.90 |
| Off | 0.62 | 0.34 | 0.98 | 0.79 | 0.72 | 0.99 | 0.50 | 0.46 | 0.84 | 0.76 | 0.68 | 0.99 |
| Pt- | 0.77 | 0.64 | 0.98 | 0.86 | 0.77 | 0.98 | 0.52 | 0.06 | 0.96 | 0.85 | 0.77 | 0.98 |
| Pc | 0.68 | 0.40 | 0.89 | 0.81 | 0.63 | 0.92 | 0.55 | 0.14 | 0.88 | 0.78 | 0.61 | 0.92 |
| Sft | 0.71 | 0.50 | 0.95 | 0.80 | 0.64 | 0.96 | 0.66 | 0.44 | 0.95 | 0.79 | 0.63 | 0.96 |
| Spr | 0.74 | 0.55 | 0.91 | 0.81 | 0.61 | 0.90 | 0.50 | 0.00 | 0.86 | 0.81 | 0.64 | 0.91 |
| Tls | 0.71 | 0.48 | 0.93 | 0.80 | 0.62 | 0.94 | 0.52 | 0.08 | 0.91 | 0.79 | 0.62 | 0.94 |
| Tys | 0.72 | 0.51 | 0.94 | 0.79 | 0.60 | 0.94 | 0.50 | 0.01 | 0.91 | 0.75 | 0.54 | 0.93 |
| Vdg | 0.77 | 0.61 | 0.96 | 0.85 | 0.71 | 0.96 | 0.50 | 0.00 | 0.93 | 0.70 | 0.64 | 0.96 |
| Wtc | 0.70 | 0.47 | 0.91 | 0.81 | 0.64 | 0.93 | 0.53 | 0.10 | 0.88 | 0.60 | 0.52 | 0.92 |
| Average | 0.70 | 0.46 | 0.94 | 0.78 | 0.62 | 0.95 | 0.53 | 0.08 | 0.92 | 0.79 | 0.62 | 0.95 |
| nnet | rf | svm | C5.0 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Category | Bal. Acc. | K | F1 | Bal. Acc. | K | F1 | Bal. Acc. | K | F1 | Bal. Acc. | K | F1 |
| Atm | 0.86 | 0.89 | 0.78 | 0.94 | 0.96 | 0.91 | 0.88 | 0.88 | 0.82 | 0.95 | 0.96 | 0.90 |
| Bby | 0.91 | 0.96 | 0.86 | 0.93 | 0.97 | 0.87 | 0.79 | 0.82 | 0.71 | 0.94 | 0.97 | 0.88 |
| Bty | 0.71 | 0.73 | 0.53 | 0.87 | 0.86 | 0.77 | 0.79 | 0.74 | 0.67 | 0.88 | 0.87 | 0.78 |
| Elc | 0.53 | 0.35 | 0.10 | 0.80 | 0.66 | 0.63 | 0.70 | 0.55 | 0.49 | 0.80 | 0.87 | 0.78 |
| Grd | 0.71 | 0.77 | 0.55 | 0.95 | 0.96 | 0.95 | 0.94 | 0.89 | 0.88 | 0.98 | 0.95 | 0.96 |
| Grc | 0.92 | 0.94 | 0.90 | 0.98 | 0.97 | 0.97 | 0.95 | 0.93 | 0.94 | 0.98 | 0.97 | 0.98 |
| Hpc | 0.66 | 0.69 | 0.40 | 0.87 | 0.83 | 0.78 | 0.79 | 0.71 | 0.66 | 0.86 | 0.84 | 0.76 |
| Ind | 0.81 | 0.75 | 0.68 | 0.87 | 0.77 | 0.78 | 0.87 | 0.78 | 0.79 | 0.87 | 0.78 | 0.78 |
| Jwl | 0.83 | 0.91 | 0.75 | 0.92 | 0.95 | 0.86 | 0.80 | 0.92 | 0.72 | 0.91 | 0.94 | 0.85 |
| Ktc | 0.74 | 0.87 | 0.61 | 0.93 | 0.95 | 0.89 | 0.90 | 0.91 | 0.86 | 0.90 | 0.94 | 0.84 |
| Lgh | 0.84 | 0.83 | 0.77 | 0.93 | 0.86 | 0.85 | 0.86 | 0.80 | 0.79 | 0.93 | 0.87 | 0.89 |
| Lgg | 0.88 | 0.96 | 0.85 | 0.96 | 0.98 | 0.94 | 0.95 | 0.98 | 0.93 | 0.95 | 0.98 | 0.92 |
| Ms- | 0.74 | 0.72 | 0.59 | 0.79 | 0.74 | 0.62 | 0.75 | 0.73 | 0.59 | 0.76 | 0.75 | 0.61 |
| Off | 0.73 | 0.50 | 0.60 | 0.89 | 0.74 | 0.84 | 0.79 | 0.49 | 0.72 | 0.87 | 0.82 | 0.83 |
| Pt- | 0.69 | 0.83 | 0.51 | 0.93 | 0.96 | 0.88 | 0.85 | 0.89 | 0.79 | 0.94 | 0.96 | 0.90 |
| Pc | 0.54 | 0.44 | 0.14 | 0.85 | 0.79 | 0.73 | 0.71 | 0.58 | 0.53 | 0.86 | 0.80 | 0.72 |
| Sft | 0.81 | 0.79 | 0.70 | 0.94 | 0.89 | 0.87 | 0.90 | 0.85 | 0.84 | 0.94 | 0.90 | 0.89 |
| Spr | 0.82 | 0.71 | 0.69 | 0.88 | 0.76 | 0.78 | 0.85 | 0.73 | 0.78 | 0.86 | 0.75 | 0.74 |
| Tls | 0.84 | 0.78 | 0.76 | 0.90 | 0.87 | 0.84 | 0.87 | 0.77 | 0.81 | 0.91 | 0.88 | 0.86 |
| Tys | 0.58 | 0.62 | 0.26 | 0.85 | 0.82 | 0.73 | 0.77 | 0.74 | 0.64 | 0.85 | 0.82 | 0.72 |
| Vdg | 0.57 | 0.56 | 0.22 | 0.89 | 0.86 | 0.81 | 0.79 | 0.68 | 0.65 | 0.90 | 0.86 | 0.80 |
| Wtc | 0.58 | 0.51 | 0.22 | 0.84 | 0.81 | 0.71 | 0.77 | 0.61 | 0.63 | 0.84 | 0.80 | 0.69 |
| Average | 0.74 | 0.73 | 0.57 | 0.90 | 0.86 | 0.82 | 0.83 | 0.77 | 0.74 | 0.90 | 0.87 | 0.82 |
| Importance | Order | Prediction of Seller Change | Prediction of Seller | |
|---|---|---|---|---|
| Most relevant features | 1st | 1 | opinions (13) | fulfilled (16) |
| 2 | prodRating (5) | opinions (5) | ||
| 3 | rPrice (4) | prodRating (1) | ||
| 2nd | 1 | rPrice (11) | opinions (7) | |
| 2 | rank (4) | stock (5) | ||
| 3 | fulfilled (3) | rPriceCumMin, fulfilled (3) | ||
| Least relevant features | 9th | 1 | amChoice (8) | amChoice (10) |
| 2 | best-seller (8) | best-seller (8) | ||
| 3 | stock (2) | prodRating, rank (2) | ||
| 10th | 1 | amChoice, best-seller (7) | amChoice, best-seller (8) | |
| 2 | fulfilled, rank, rPriceCumMax (2) | rank (5) | ||
| 3 | fulfilled, stock (1) | fulfilled (1) |
| Prediction of a Seller Change | Prediction of Seller | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Category | Rules | Conditions | Accuracy | Lift | Lift | Rules | Conditions | Accuracy | Lift | Lift | ||
| () | () | Ranking | () | () | Ranking | |||||||
| Atm | 9 | 18 | 2.0 | 0.86 | 7.4 | 6 | 52 | 162 | 3.1 | 0.86 | 163.6 | 10 |
| Bby | 12 | 29 | 2.4 | 0.89 | 14 | 1 | 26 | 83 | 3.2 | 0.84 | 130.9 | 17 |
| Bty | 28 | 75 | 2.7 | 0.85 | 4.2 | 13 | 214 | 846 | 4.0 | 0.79 | 244.2 | 5 |
| Elc | 39 | 155 | 4.0 | 0.80 | 2.4 | 21 | 717 | 3050 | 4.3 | 0.72 | 368.9 | 2 |
| Grd | 7 | 17 | 2.4 | 0.89 | 5.0 | 11 | 39 | 119 | 3.1 | 0.84 | 98.3 | 18 |
| Grc | 7 | 11 | 1.6 | 0.82 | 12.0 | 3 | 20 | 55 | 2.8 | 0.82 | 75.4 | 21 |
| Hpc | 19 | 74 | 3.9 | 0.89 | 2.7 | 19 | 178 | 735 | 4.1 | 0.80 | 196.9 | 7 |
| Ind | 8 | 21 | 2.6 | 0.85 | 2.7 | 20 | 42 | 152 | 3.6 | 0.82 | 94.8 | 19 |
| Jwl | 5 | 9 | 1.8 | 0.88 | 7.5 | 5 | 42 | 126 | 3.0 | 0.80 | 134.3 | 15 |
| Ktc | 14 | 37 | 2.6 | 0.85 | 7.3 | 7 | 78 | 267 | 3.4 | 0.83 | 190.5 | 8 |
| Lgh | 8 | 14 | 1.8 | 0.86 | 5.8 | 8 | 75 | 234 | 3.1 | 0.82 | 92.1 | 20 |
| Lgg | 3 | 4 | 1.3 | 0.86 | 7.9 | 4 | 39 | 94 | 2.4 | 0.85 | 153.1 | 11 |
| Ms- | 15 | 47 | 3.1 | 0.77 | 2.2 | 22 | 61 | 200 | 3.3 | 0.72 | 131.5 | 16 |
| Off | 6 | 11 | 1.8 | 0.83 | 12.4 | 2 | 22 | 73 | 3.3 | 0.81 | 136.5 | 4 |
| Pc | 100 | 398 | 4.0 | 0.84 | 3.2 | 16 | 781 | 3428 | 4.4 | 0.77 | 386.6 | 1 |
| Pt- | 6 | 13 | 2.2 | 0.87 | 5.5 | 9 | 93 | 361 | 3.9 | 0.87 | 216.7 | 6 |
| Sft | 32 | 99 | 3.1 | 0.87 | 5.1 | 10 | 131 | 443 | 3.4 | 0.84 | 185.5 | 9 |
| Spr | 8 | 16 | 2.0 | 0.86 | 2.9 | 18 | 90 | 326 | 3.6 | 0.76 | 68.9 | 22 |
| Tls | 6 | 17 | 2.8 | 0.79 | 3.2 | 17 | 99 | 320 | 3.2 | 0.82 | 138.4 | 13 |
| Tys | 40 | 125 | 3.1 | 0.83 | 4.7 | 12 | 228 | 966 | 4.2 | 0.81 | 309.1 | 4 |
| Vdg | 34 | 138 | 4.1 | 0.88 | 3.9 | 14 | 412 | 1813 | 4.4 | 0.82 | 312.0 | 3 |
| Wtc | 82 | 288 | 3.5 | 0.82 | 3.5 | 15 | 570 | 2515 | 4.4 | 0.79 | 148.7 | 12 |
| Feature | Prediction of a Seller Change | Prediction of Seller | ||
|---|---|---|---|---|
| Absolute Frequency | % | Absolute Frequency | % | |
| amChoice | 35 | 2.2 | 280 | 1.7 |
| best-seller | 15 | 0.9 | 136 | 0.8 |
| fulfilled | 48 | 3.0 | 1109 | 6.8 |
| opinions | 167 | 10.3 | 3094 | 18.9 |
| product | 398 | 24.6 | 3338 | 20.4 |
| prodRating | 45 | 2.8 | 622 | 3.8 |
| rank | 58 | 3.6 | 541 | 3.3 |
| stock | 86 | 5.3 | 1245 | 7.6 |
| rPrice | 461 | 28.5 | 1847 | 11.3 |
| rPriceCumMax | 147 | 9.1 | 1923 | 11.7 |
| rpriceCumMin | 156 | 9.7 | 2233 | 13.6 |
| Sum | 1616 | 100 | 16,368 | 100 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gómez-Losada, Á.; Asencio-Cortés, G.; Duch-Brown, N. Automatic Eligibility of Sellers in an Online Marketplace: A Case Study of Amazon Algorithm. Information 2022, 13, 44. https://doi.org/10.3390/info13020044
Gómez-Losada Á, Asencio-Cortés G, Duch-Brown N. Automatic Eligibility of Sellers in an Online Marketplace: A Case Study of Amazon Algorithm. Information. 2022; 13(2):44. https://doi.org/10.3390/info13020044
Chicago/Turabian StyleGómez-Losada, Álvaro, Gualberto Asencio-Cortés, and Néstor Duch-Brown. 2022. "Automatic Eligibility of Sellers in an Online Marketplace: A Case Study of Amazon Algorithm" Information 13, no. 2: 44. https://doi.org/10.3390/info13020044
APA StyleGómez-Losada, Á., Asencio-Cortés, G., & Duch-Brown, N. (2022). Automatic Eligibility of Sellers in an Online Marketplace: A Case Study of Amazon Algorithm. Information, 13(2), 44. https://doi.org/10.3390/info13020044