
Explainable Stacking-Based Model for Predicting Hospital Readmission for Diabetic Patients



Abstract
:1. Introduction
- The exploration of class imbalanced techniques and feature selection methods on the dataset with high-class imbalance problems. Measure the importance of the features to reduce the feature dimensions in machine learning models.
- We utilised a stacking-based model for predicting the readmission risk for diabetic patients and studied deeply into interpreting the readmission predictions using interpretable machine learning tools.
2. Materials and Methods
2.1. Data Collection
2.2. Data Preprocessing
2.2.1. Handing Missing Data and Outlier Detection
2.2.2. Feature Engineering
2.3. Handing Class Imbalance
2.4. Feature Selection
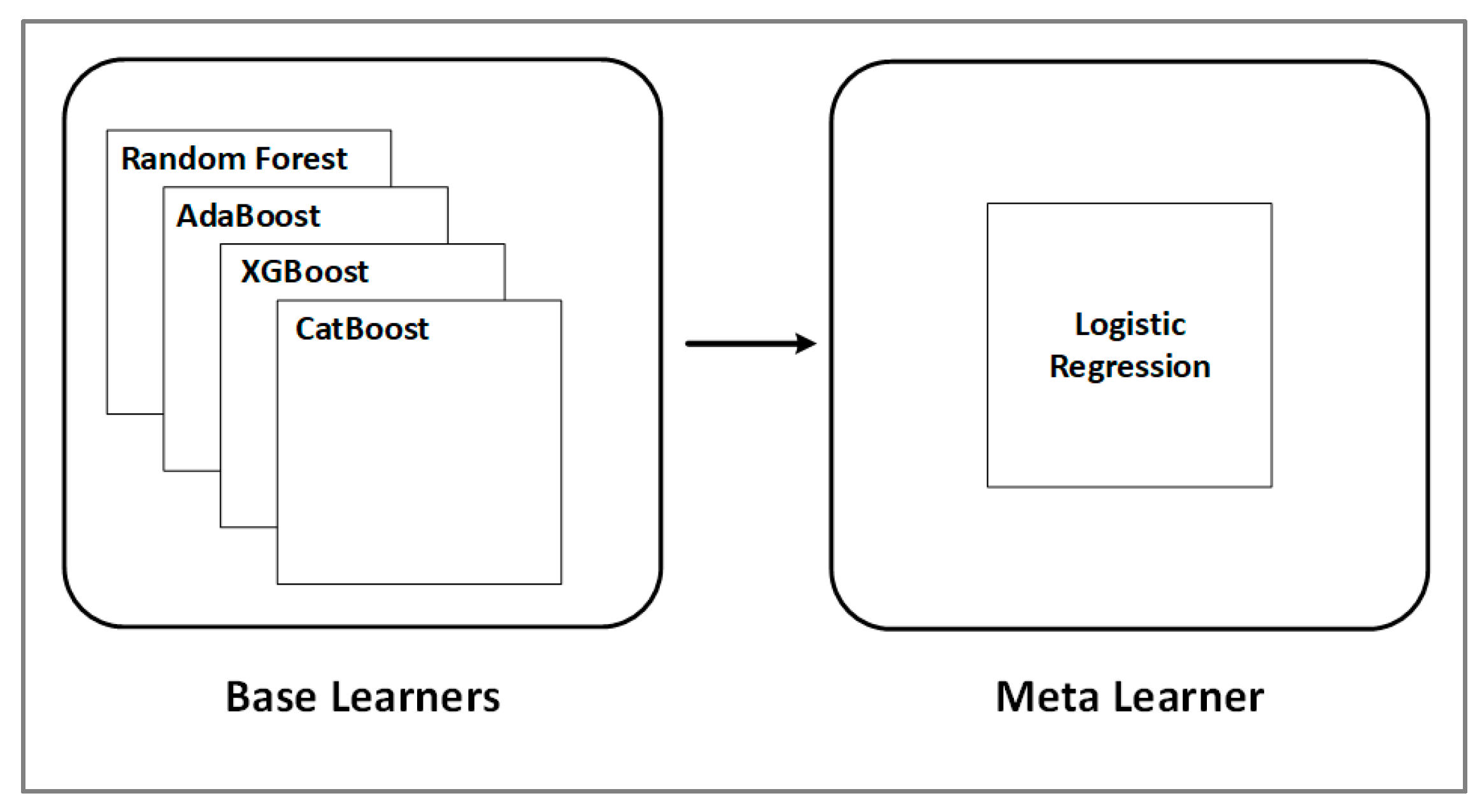
2.5. Stacking-Based Model
2.6. Interpretable Machine Learning Applications
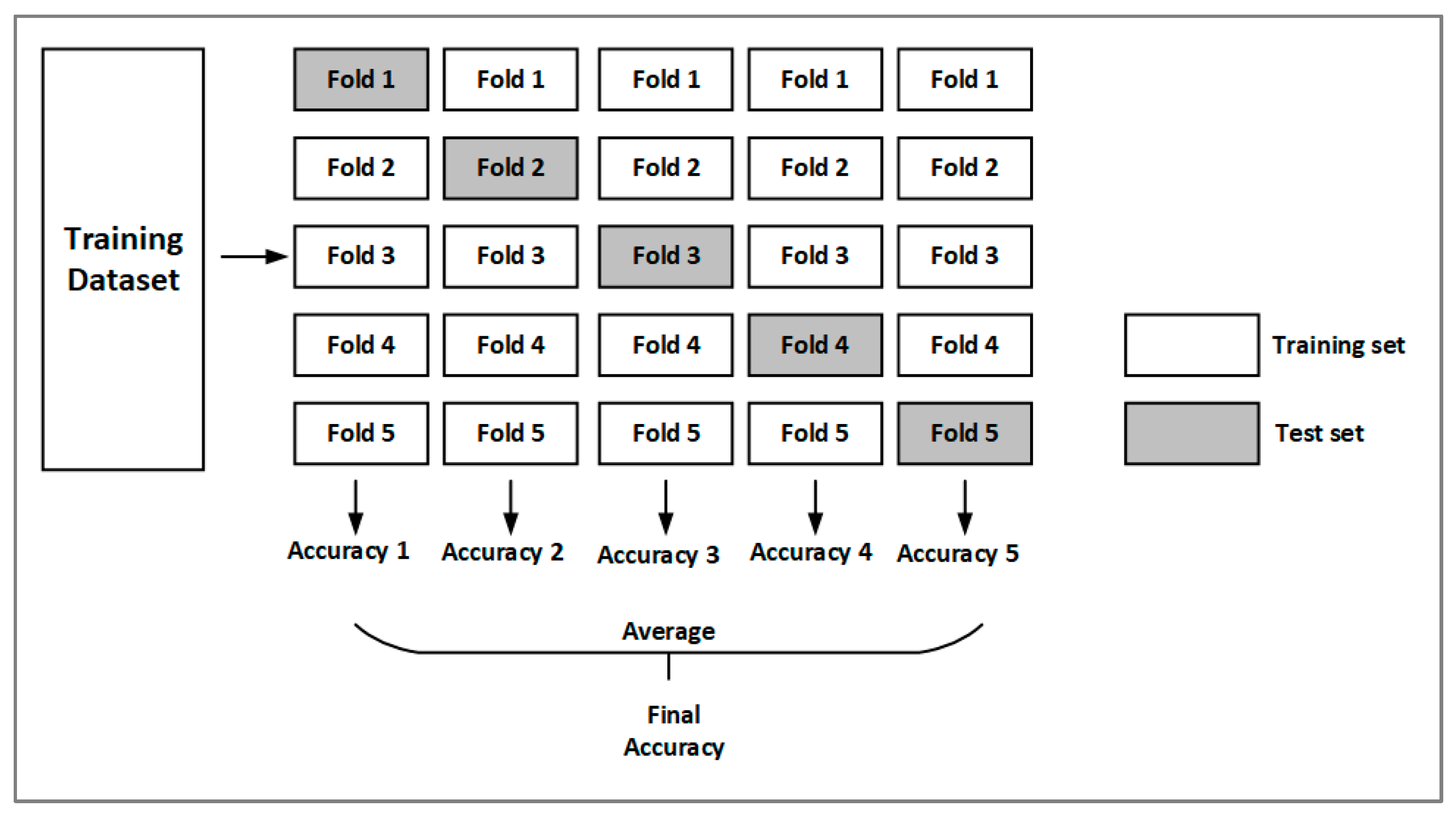
2.7. Validation and Evaluation
3. Results
3.1. Results of Models during the Training Phase
3.2. Results of Feature Selection and Stacking-Based Model
3.3. Comparison with the Other Studies of the Present Literature
3.4. Model Interpretability
3.4.1. Feature Importance
3.4.2. LIME
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef]
- Amann, J.; Blasimme, A.; Vayena, E.; Frey, D.; Madai, V.I. Explainability for artificial intelligence in healthcare: A multidisciplinary perspective. BMC Med. Inform. Decis. Mak. 2020, 20, 310. [Google Scholar] [CrossRef] [PubMed]
- Antoniadi, A.; Du, Y.; Guendouz, Y.; Wei, L.; Mazo, C.; Becker, B.; Mooney, C. Current Challenges and Future Opportunities for XAI in Machine Learning-Based Clinical Decision Support Systems: A Systematic Review. Appl. Sci. 2021, 11, 5088. [Google Scholar] [CrossRef]
- Nusinovici, S.; Tham, Y.C.; Yan, M.Y.C.; Ting, D.S.W.; Li, J.; Sabanayagam, C.; Wong, T.Y.; Cheng, C.-Y. Logistic regression was as good as machine learning for predicting major chronic diseases. J. Clin. Epidemiol. 2020, 122, 56–69. [Google Scholar] [CrossRef]
- Khan, A.; Uddin, S.; Srinivasan, U. Chronic disease prediction using administrative data and graph theory: The case of type 2 diabetes. Expert Syst. Appl. 2019, 136, 230–241. [Google Scholar] [CrossRef]
- Hossain, E.; Uddin, S.; Khan, A. Network analytics and machine learning for predictive risk modelling of cardiovascular disease in patients with type 2 diabetes. Expert Syst. Appl. 2020, 164, 113918. [Google Scholar] [CrossRef]
- Ramírez, J.C.; Herrera, D. Prediction of diabetic patient readmission using machine learning. In Proceedings of the IEEE Colombian Conference on Applications in Computational Intelligence, Barranquilla, Colombia, 5–7 June 2019; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Strack, B.; DeShazo, J.P.; Gennings, C.; Olmo, J.L.; Ventura, S.; Cios, K.J.; Clore, J.N. Impact of HbA1c Measurement on Hospital Readmission Rates: Analysis of 70,000 Clinical Database Patient Records. BioMed Res. Int. 2014, 2014, 781670. [Google Scholar] [CrossRef]
- Considine, J.; Fox, K.; Plunkett, D.; Mecner, M.; O’Reilly, M.; Darzins, P. Factors associated with unplanned readmissions in a major Australian health service. Aust. Health Rev. 2019, 43, 1–9. [Google Scholar] [CrossRef]
- Caughey, G.E.; Pratt, N.; Barratt, J.D.; Shakib, S.; Kemp-Casey, A.; Roughead, L. Understanding 30-day re-admission after hospitalisation of older patients for diabetes: Identifying those at greatest risk. Med. J. Aust. 2017, 206, 170–175. [Google Scholar] [CrossRef]
- Donzé, J.; Lipsitz, S.; Bates, D.W.; Schnipper, J.L. Causes and patterns of readmissions in patients with common comorbidities: Retrospective cohort study. BMJ 2013, 347, f7171. [Google Scholar] [CrossRef] [Green Version]
- Fonarow, G.C.; Konstam, M.A.; Yancy, C.W. The Hospital Readmission Reduction Program Is Associated with Fewer Readmissions, More Deaths: Time to Reconsider; American College of Cardiology Foundation: Washington, DC, USA, 2017. [Google Scholar]
- Ostling, S.; Wyckoff, J.; Ciarkowski, S.L.; Pai, C.-W.; Choe, H.M.; Bahl, V.; Gianchandani, R. The relationship between diabetes mellitus and 30-day readmission rates. Clin. Diabetes Endocrinol. 2017, 3, 3. [Google Scholar] [CrossRef] [PubMed]
- Bhuvan, M.S.; Kumar, A.; Zafar, A.; Kishore, V. Identifying diabetic patients with high risk of readmission. arXiv 2016, arXiv:1602.04257. [Google Scholar]
- Rubin, D.J. Hospital Readmission of Patients with Diabetes. Curr. Diabetes Rep. 2015, 15, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Cui, S.; Wang, D.; Wang, Y.; Yu, P.-W.; Jin, Y. An improved support vector machine-based diabetic readmission prediction. Comput. Methods Programs Biomed. 2018, 166, 123–135. [Google Scholar] [CrossRef]
- Hammoudeh, A.; Al-Naymat, G.; Ghannam, I.; Obied, N. Predicting Hospital Readmission among Diabetics using Deep Learning. Procedia Comput. Sci. 2018, 141, 484–489. [Google Scholar] [CrossRef]
- Hung, M.; Lauren, E.; Hon, E.; Xu, J.; Ruiz-Negrón, B.; Rosales, M.; Li, W.; Barton, T.; O’Brien, J.; Su, W. Using Machine Learning to Predict 30-Day Hospital Readmissions in Patients with Atrial Fibrillation Undergoing Catheter Ablation. J. Pers. Med. 2020, 10, 82. [Google Scholar] [CrossRef]
- Arnaud, E.; Elbattah, M.; Gignon, M.; Dequen, G. Deep Learning to Predict Hospitalization at Triage: Integration of Structured Data and Unstructured Text. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 4836–4841. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the ICML’96, Bari, Italy, 3–6 July 1996. [Google Scholar]
- Wolpert, D.H. Stacked generalisation. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Radovanović, S.; Delibašić, B.; Jovanović, M.; Vukićević, M.; Suknović, M. Framework for integration of domain knowledge into logistic regression. In Proceedings of the WIMS’18: 8th International Conference on Web Intelligence, Mining and Semantics, Novi Sad, Serbia, 25–27 June 2018; Volume 24. [Google Scholar] [CrossRef]
- Yu, K.; Xie, X. Predicting Hospital Readmission: A Joint Ensemble-Learning Model. IEEE J. Biomed. Health Inform. 2019, 24, 447–456. [Google Scholar] [CrossRef]
- Alahmar, A.; Mohammed, E.; Benlamri, R. Application of data mining techniques to predict the length of stay of hospitalised patients with diabetes. In Proceedings of the 2018 4th International Conference on Big Data Innovations and Applications (Innovate-Data), Barcelona, Spain, 6–8 August 2018. [Google Scholar]
- Breunig, M.M.; Kriegel, H.-P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000. [Google Scholar]
- Centers for Disease Control and Prevention. International Classification of Diseases, Ninth Revision, Clinical Modification (ICD-9-CM). 2015. Available online: https://www.cdc.gov/nchs/icd/icd9cm.htm (accessed on 19 September 2021).
- Khushi, M.; Shaukat, K.; Alam, T.M.; Hameed, I.A.; Uddin, S.; Luo, S.; Yang, X.; Reyes, M.C. A Comparative Performance Analysis of Data Resampling Methods on Imbalance Medical Data. IEEE Access 2021, 9, 109960–109975. [Google Scholar] [CrossRef]
- Artetxe, A.; Beristain, A.; Graña, M. Predictive models for hospital readmission risk: A systematic review of methods. Comput. Methods Programs Biomed. 2018, 164, 49–64. [Google Scholar] [CrossRef] [PubMed]
- Prusa, J.; Khoshgoftaar, T.M.; Dittman, D.J.; Napolitano, A. Using Random Undersampling to Alleviate Class Imbalance on Tweet Sentiment Data. In Proceedings of the 2015 IEEE International Conference on Information Reuse and Integration, San Francisco, CA, USA, 13–15 August 2015. [Google Scholar]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation importance: A corrected feature importance measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the IJCAI-95, Montreal, Canada, 20–25 August 1995. [Google Scholar]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef]
- Hempstalk, K.; Mordaunt, D. Improving 30-day readmission risk predictions using machine learning. In Proceedings of the Health Informatics New Zealand (HiNZ) Conference, Auckland, New Zealand, 31 October 2016. [Google Scholar]
- Alloghani, M.; Aljaaf, A.; Hussain, A.; Baker, T.; Mustafina, J.; Al-Jumeily, D.; Khalaf, M. Implementation of machine learning algorithms to create diabetic patient re-admission profiles. BMC Med. Inform. Decis. Mak. 2019, 19, 253. [Google Scholar] [CrossRef]
- Shang, Y.; Jiang, K.; Wang, L.; Zhang, Z.; Zhou, S.; Liu, Y.; Dong, J.; Wu, H. The 30-days hospital readmission risk in diabetic patients: Predictive modeling with machine learning classifiers. BMC Med. Inform. Decis. Mak. 2021, 21, 57. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Diagnosis Code | Diseases |
|---|---|
| [140, 240) | Neoplasms |
| 250.x | Diabetes |
| [390, 460) and 785 | Circulatory |
| [460, 520) and 786 | Respiratory |
| [520, 580) and 787 | Digestive |
| [800, 1000) | Injury |
| [700, 740) | Musculoskeletal |
| [500, 630) and 788 | Genitourinary |
| ‘V’, ‘E’ and others | Other diseases |
| Model | Accuracy (%) | Standard Deviation |
|---|---|---|
| KNN | 53.42 | 0.0114 |
| SVM | 57.61 | 0.0135 |
| DT | 54.17 | 0.0119 |
| RF | 60.35 | 0.0114 |
| AdaBoost | 61.18 | 0.0122 |
| XGBoost | 61.49 | 0.0116 |
| CatBoost | 61.53 | 0.0104 |
| Model | AUC | Precision | F1-Score | Accuracy (%) |
|---|---|---|---|---|
| KNN | 0.5584 | 0.8164 | 0.6658 | 59.00 |
| SVM | 0.6358 | 0.8321 | 0.7341 | 67.79 |
| DT | 0.6624 | 0.8423 | 0.7117 | 64.70 |
| RF | 0.6690 | 0.8448 | 0.6959 | 62.69 |
| AdaBoost | 0.6639 | 0.8410 | 0.7226 | 66.13 |
| XGBoost | 0.6542 | 0.8398 | 0.7196 | 65.75 |
| CatBoost | 0.6660 | 0.8425 | 0.6977 | 62.96 |
| Stacking | 0.6736 | 0.8542 | 0.7434 | 68.63 |
| Study | Best Performances | Comments |
|---|---|---|
| Hempstalk and Mordaunt [42] | Logistic Regression with AUC: 0.670 (10-fold training result) | This study developed classic machine learning models to improve 30-day readmission risk predictions with no explainability involved. In addition, they only provided training performance (i.e., no test AUC provided). |
| Alloghani et al. [43] | Naïve Bayes with AUC: 0.640 | This study focused on recognising patterns and combinations of risk factors. |
| Shang et al. [44] | Random Forest with AUC: 0.64 (over-sampling) and AUC: 0.661 (down-sampling) | It used different machine learning classifiers to predict the 30-day readmission, and the random forest model achieved the best performance. No further analysis for features importance etc. |
| Ramírez and Herrera [7] | Multilayer perceptron (MLP) with AUC 0.6548. | This study heavy relied on the data preprocessing methods. Such as the reduction of several variables’ domains. Overfitting might occur. We only consider the result from the second best-performed model, which is MLP. |
| This study | Stacking model with AUC: 0.6736 | This study can assess the risk of 30-day readmission of diabetic patients with explainable AI techniques. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, H.; Uddin, S. Explainable Stacking-Based Model for Predicting Hospital Readmission for Diabetic Patients. Information 2022, 13, 436. https://doi.org/10.3390/info13090436
Lu H, Uddin S. Explainable Stacking-Based Model for Predicting Hospital Readmission for Diabetic Patients. Information. 2022; 13(9):436. https://doi.org/10.3390/info13090436
Chicago/Turabian StyleLu, Haohui, and Shahadat Uddin. 2022. "Explainable Stacking-Based Model for Predicting Hospital Readmission for Diabetic Patients" Information 13, no. 9: 436. https://doi.org/10.3390/info13090436
APA StyleLu, H., & Uddin, S. (2022). Explainable Stacking-Based Model for Predicting Hospital Readmission for Diabetic Patients. Information, 13(9), 436. https://doi.org/10.3390/info13090436