1. Introduction
Information science and information technology are closely connected to tourism. In 2014, Pedrana claimed that information technology had supported the tourism revolution by altering conventional tourism and product experiences, culminating in a virtual tourism model [
1]. The basic foundation for virtual tourism is the natural tourist landscape. By creating an online environment, people might be able to enjoy immersive travel while staying at home, and the Internet or virtual technology will surpass the appeal of physical discovery [
2,
3,
4,
5].
Even though the online travel industry has received much attention as a new kind of tourist industry, there are still some disagreements over people’s views and opinions of this model. According to Dale, 2016; Julia Lekgau, Harilal and Feni, 2021; Yang et al., 2022 [
6,
7,
8], virtual tourism has developed a new tourist model with several benefits, for example, recreating the initial chronological arrival of a destination and preserving intangible heritage. It may make tourism more accessible to travelers with physical disabilities, financial constraints, or limited time [
9,
10]. Opposers dispute the claim that visitors might not have an outstanding virtual adventure because all experiences must engage with the surrounding world to be entirely inspired [
5,
11]. Some heritage destination administrators are also afraid that the online adventures may jeopardize the factual validity of the place and will refuse to use them.
Even though the virtual travel industry has been available for more than a dozen years, most travellers are still unaware of it and have many comments; some might have positive comments, while others may have negative or neutral comments. In the prior literature, the authors [
12] observed that virtual travel problems were centred on non-crisis and ordinary scenarios and recommended investigations to inspect the prospects of virtual tourism during and after crisis settings. Kim et al. argue that virtual travel is a viable option when access to the actual world is restricted [
11]. What is the proper perception of viewers toward virtual travel in a crisis? It is still challenging to provide a definitive response. Importantly, elucidating the popular understanding of virtual travel will give additional perspectives and create possible recommendations for the long-term growth of virtual travel.
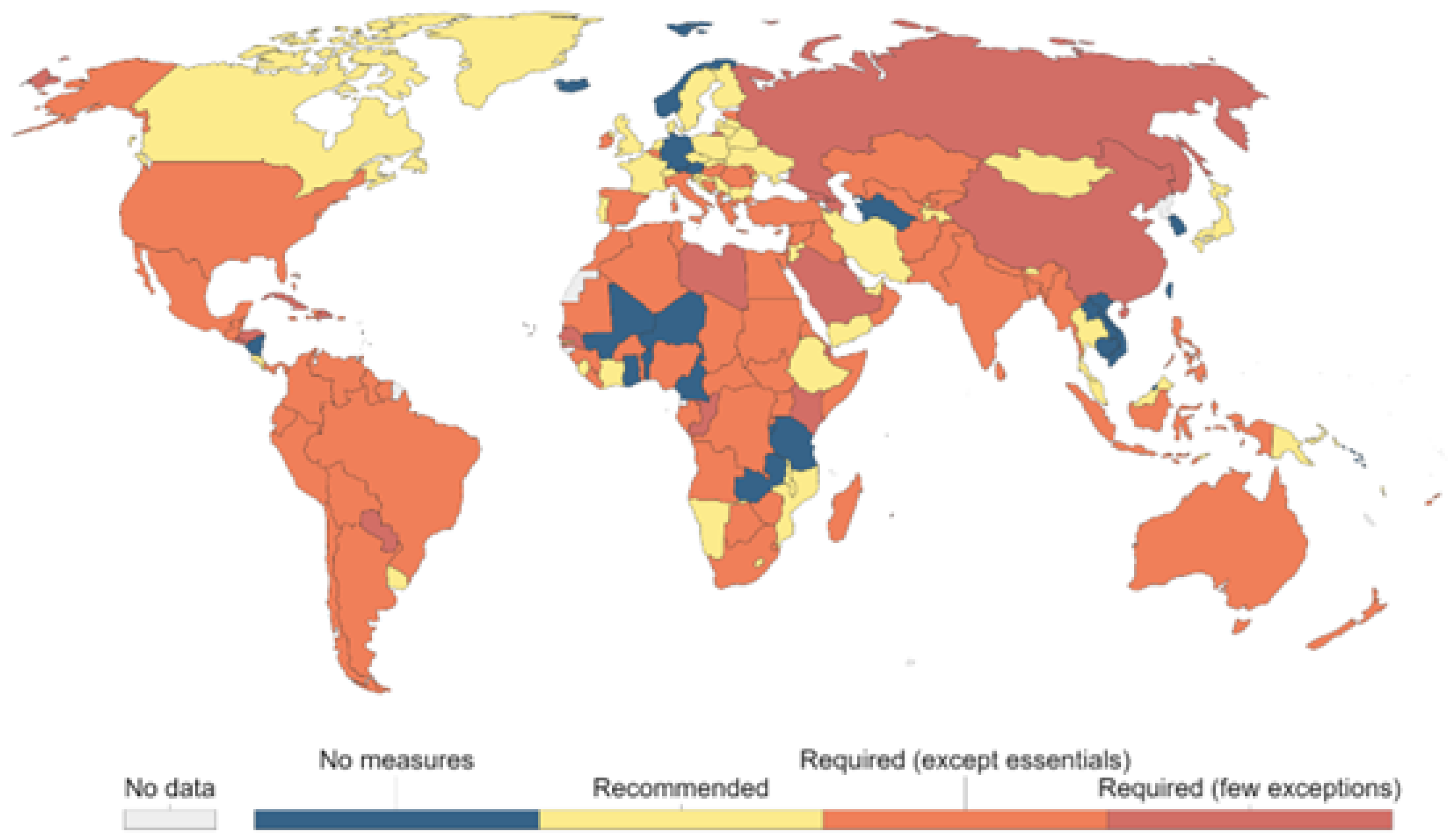
Since the beginning of COVID-19, worldwide financial and social growth has suffered significantly. COVID-19, in contrast to previous pandemics, has a more extended incubation duration and less frequent signs, and it disperses more rapidly and widely [
13]. Avoiding the public and movement is an effective strategy for minimizing transmission of the COVID-19 pandice. In just several months, the approach of the international tourist strategy transitioned from unrestricted travel to limited tourism [
14]. Most nations have implemented travel bans [
13]. According to OurWorld in Data [
15], the highest possible travel ban density might have been around May 2020, as shown in
Figure 1 and
Figure 2.
Youtube is the largest video platform in the world [
16]. It produces millions of metadata in audio–video content that enables researchers to operate NLP and investigate opinions and sentiments [
17]. The analysis of feedback in the form of comments left by viewers on Youtube channels is an essential source of unstructured data for further research [
18,
19]. Additionally, Youtube is a dedicated video-sharing platform that amasses a significant amount of data that can be channeled to study the sentiments of individuals (also known as opinion mining) towards a product or phenomenon [
20].
Comments from Youtube videos have been historically studied to mine individuals’ opinions regarding trending topics [
21]. Dubovi and Tabak (2020) in their study involving knowledge co-creation from Youtube videos revealed that “comments went beyond information sharing to argumentative negotiation, reaching a higher level of knowledge construction” [
22]. They have further added that Youtube comments provide an informal setting for science discussions. Yu, Wen, and Yang (2020) extracted comments from Youtube videos to explore the visitation intention of individuals wth respect to suicide tourism [
23]. Their study reveals that unobserved social proclivities can be revealed from mining Youtube video comments. Similarly, Raja Chakravarthi et al. (2021) examined Youtube comments to identify hate/violent speech against the lesbian, gay, bisexual, transgender, and queer community [
24]. Compared to content from other content sharing platforms such as Snapchat, Instagram, and Imgur, content from Youtube is more generationally diverse and far-reaching [
24]. Furthermore, comments from Youtube videos have been investigated to understand a plethora of sociocultural processes and societal norms such as cyberbullying of overweight people [
25], anti-NATO sentiment [
26], ethnic insults [
27], and misogyny [
28]. The antecedents presented herewith provide substantial empirical merit to the current study’s authors to adopt Youtube commentaries as their preferred medium of analysis.
This study investigates public opinions regarding virtual tourism in the context of COVID-19 via watching YouTube [
5]. The percentage of viewers who watch 360-degree videos vs. unidirectional movies was measured. We also summarized the frequency of watching videos during the peak of COVID-19 compared with other periods. Such problems have not yet been addressed and must thus be investigated further.
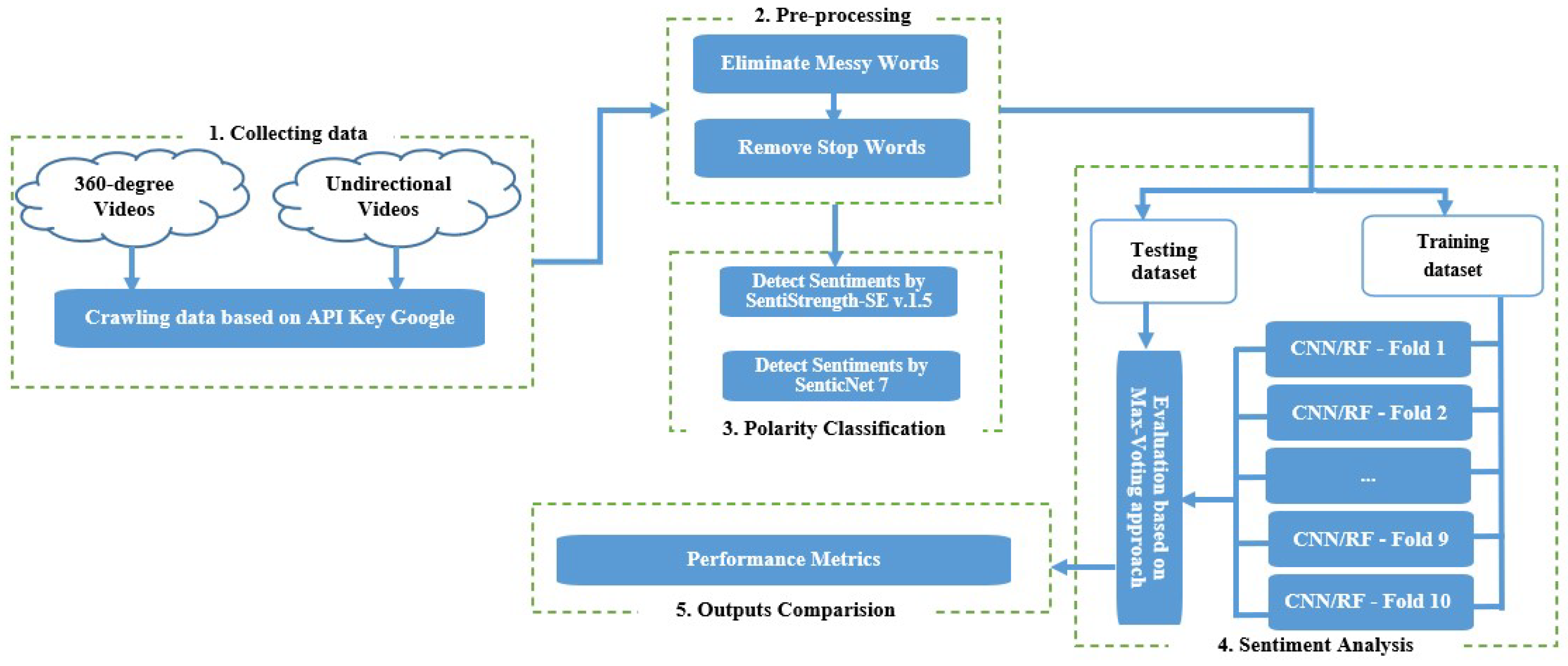
Regarding the relevant dataset for this research, online comments from YouTube were collected using Python. There are two kinds of videos that were collected, one is 360-degree [
29], and the other is unidirectional videos. Each video should have two more million views and more than one thousand comments. Furthermore, a five-level sentiment analysis technology [
5] to investigate the features and laws of public opinion toward online travel and the SentiStrength-SE [
30] tool was applied in this paper.
2. Related Works
Sentiment analysis (SA), often known as opinion mining, is a natural language approach for examining people’s feelings on a particular product or problem [
31]. SA is the automatic examination of an online document, such as a blog, remark, review, or comment, to decide if it is a solid positive, positive, negative, strong negative, or neutral (Pang & Lee, 2008). SA may be used to predict polarity results [
32], give product information to businesses and organizations, automate product descriptions or summaries in reviews, and even forecast the stock market on online shopping sites [
33].
In general, the categorization of emotions is crucial in contemporary SA research. This method assigns the opinion polarity of words and phrases that express sentiments to identify a document’s subjectivity/objectivity orientation, positive, negative, or neutral [
34]. Two types of sentiment classification strategies are reported in the literature, supervised and unsupervised SA [
33]. This type of classification is related to the method used by the computer to generate sentiment classifications. Machine learning techniques such as support vector machine (SVM), maximum entropy, k-nearest neighbour, Naïve Bayes, Decision Tree, and Artificial Neural Network are utilized [
20,
33,
35,
36]. The supervised learning approach makes use of labelled training data that have been annotated by hand, as well as testing data.
On the other hand, the unsupervised technique does not require labelled training data. The current paper’s primary methods are linguistics-based and lexicon-based [
37]. The lexicon-based approach entails statistically calculating feelings based on the text’s semantic orientation of words or phrases [
38]. The fundamental premise behind lexicon-based techniques is that the most critical indicators of emotion in the natural language literature are words that communicate opinions. A pre-compiled lexicon of positive and negative phrases is necessary for this strategy.
SentiWordNet [
39] is another well-known lexical resource intended exclusively for sentiment classification and analysis applications. Based on linguistics, the SA divides natural language information into more than individual constituent words and sentences. It also detects their syntactic structures to determine a syntactic part-of-speech category, such as an adjective or verb phrase, most likely to be mentioned in an opinion. Each word’s polarity score in the text is employed to categorize the emotion of the textual material. For example, if a phrase in the lexicon matches a positive emotion score, the material’s positive polarity score is increased. As a result, if the positive polarity score surpasses the negative polarity score, the substance is deemed positive; otherwise, it is termed negative. A substantial study has been conducted to locate frequently used words reflecting sentiment in an online review using a learning lexicon-based technique and natural language processing to reveal typical terms that indicate opinion mining [
34,
40].
Thet et al. [
30] suggested a linguistic approach for the SA of topic postings in discussion forums based on clause-level opinion analysis. SentiWordNet, a purpose-built domain lexicon (movie review domain), obtained the above word emotion ratings. The emotion score for each phrase was then calculated by analysing the natural language syntactic relationships of words, using syntactic dependency trees and taking pattern rule into account.
Thelwall et al. [
41] created the SentiStrength technique enhanced by machine learning to evaluate consumer behaviour and sentiment strength in textual data. Islam et al. utilized SentiStrength to create a database to classify specific content in the double polarity (positive or negative), and SentiStrength identified 298 positive and 465 negative phrases [
30]. In addition, Alrehaili et al. adopted SentiStrength to classify positive and negative sentiments based on the comments of YouTube videos for kids [
39]. However, SentiStrength-SE also includes domain-specific phrases in the software development area that do not contain any sentiments [
30]. According to [
42,
43], SentiStrength-SE is more efficient than the general-domain lexicon at detecting sentiment polarity in application circumstances. Based on the advantages of SentiStrength-SE, this article will use it to classify polarity sentiment.
Last but not the least, SenticNet7 was proposed by E Cambria et al. [
44]. It is a level of acquaintance used by the sentic computing structure for concept-level sentiment analysis [
45]. It involves polarity recognition and emotion identification by leveraging the denotative and connotative information in connection with phrases and multi-word expressions rather than depending exclusively on term co-occurrence frequency ranges. Furthermore, Sentic APIs (sentic.net/api) are a set of application programming interfaces built to handle numerous sentiment analysis activities in various languages. Because all APIs are built on the Sentic Computing Structure, they use a combination of SenticNet and deep learning.
On the other hand, various sentiment analysis techniques have been adopted, ranging from tree-based classifiers to neural network-based methods [
20,
36,
46]. They include Naïve Bayes, Decision Trees, Random Forest, Support Vector Machines, Gradient Boosting, Multiplayer Perceptron, and Convolutional Neural Networks.
Multi-layer Perceptron (MLP) is a feedforward network [
47,
48]. Its components have three layers: input, hidden, and output. It is wholly connected, with each node linked to every node in the before and the following layer. The input layer will receive a list of factors, for example, factor 1 to factor k, as a list dataset for training. MLP might be trained to learn new things. A set of the training dataset, consisting of a group of input and output vectors, is required for training. It is continually provided with training data while training, and the network’s weights are modified until the proper input–output mapping is achieved. Pattern categorization, recognition, prediction, and approximation are MLP’s most typical uses. In 2020, M. Almaghrabi et al. adopted this model to improve sentiment analysis in Arabic and English languages [
49]. Moreover, Xia et al. (2021) also used MLP in Tweet sentiment analysis of the 2020 United State Presidential Election [
50].
The Naïve Bayes Classifier is a technique based on Bayes Theorem [
35,
46]. The Naïve Bayes classifier works on the idea that the existence of one attribute in a class has nothing to do with the presentation of any other feature. For massive data sets, the Naïve Bayes model is beneficial. Naïve Bayes is renowned for outperforming even the most complex classification systems due to its simplicity. According to Kausar et al. [
46], Google currently uses it to determine whether or not an e-mail is spam.
Decision Trees are a classification method commonly utilized in the scientific world [
46]. Text is classified into sentiment polarity using the decision tree. It belongs to the category of machine learning. Several studies [
20,
33,
35,
36] use decision trees to sort positive, negative, and neutral comment categories.
Support Vector Machine (SVM) might be the most famous machine learning technique [
46]. Since the 1990s, it has been popular and is still the leading strategy for a high-performance algorithm. It is a discriminant classifier that builds an ideal hyperplane for new sample classification by using labelled training data. The SVM model can predict unknown input based on the training.
Random Forest (RF) is a branch of artificial intelligence that can be used for regression and classification [
46]. It also performs reasonably well in the contexts of dimensional-reduction approaches, incomplete data, outlier values, and other critical processes in data discovery. It is an ensemble classifier in which a group of poor models is combined to create a better model. Each tree assigns a categorization to a new object’s various attributes. The forest selects the categorization with the most votes and averages the outputs of the different trees. In 2019, Karthika et al. used RF to classify positive, neutral, and negative customer opinions [
51]. They also stated that RF outperformed SVM. Furthermore, Ravinder Ahuja et al. (2019) conducted an investigation that showed that RF might perform more accurately than DT, SVM, and Naïve Bayes [
52].
Moreover, deep learning-based approaches, particularly convolutional neural networks (CNNs), have demonstrated consistent performance across many applications in medical image processing and documenting classification problems in recent years. As mentioned by Rani et al. (2019), CNNs are four-layer feedforward neural networks [
53]. The first is the input layer, representing sentences
in size. The second layer is the convolutional layer, followed by the global max-pooling layer, and finally, the fully connected layer, which produces output results. The convolutional layer is CNN’s primary building block because it performs most computations. A feature extraction layer extracts local features using filters, then produces a feature map using the convolutional kernels function and sends it to the pooling layer. In 2022, Priyanka Malhotra et al. presented research in the area of medical image segmentation using CNN [
54]. They highlighted the benefits and drawbacks of the most widely used deep learning-based models used for the segmentation of medical lesions. Similar research was also studied by Sarvamangala et al. (2022), they stated that CNN is a common method for resolving medical image problems [
55]. In addition, Chetanpal Singh et al. proposed CNN approach for sentiment analysis of COVID-19 reviews on Twitter [
56]. The authors stated that their approach outperforms SVM and RF. Furthermore, Hoc et al. (2022) studied MLP, deep learning, and the multiple regression model in terms of software effort estimation; they showed that the deep learning approach leads to higher accuracy than the other [
57]. Based on this discussion, we use the CNN approach to build a classification model based on collected datasets. The performance of CNN approach also compared with RF model.
8. Results and Discussion
Table 3 and
Table 4 present the percentages of sentiment analysis for seven datasets, from dataset 1 to dataset 6, where dataset 7 contains six results. Sentiment analysis for those datasets is executed by using the SentiStrength-SE and SenticNet7 approaches. The results indicate that the sentiments between 360-degree and unidirectional videos range from strongly negative to strongly positive on the sensitivity scale in
Table 1. The sentiment analysis using those approaches shows a substantial difference between the viewer sentiments of a virtual-reality-enabled video and a unidirectional one. As can be seen, the percentage of positive comments obtained from dataset 1 is lower than that obtained from dataset 2 using both approaches. The analysis results on dataset 3 vs. 4 and dataset 5 vs. 6 also give similar outcomes. Furthermore, the proportion of viewers who have neutral opinions when watching 360 videos appears to be higher than that of unidirectional videos. This may be because 360-degree videos appear no more interesting than unidirectional videos on YouTube. From these findings, we can answer RQ1 by saying that the unidirectional video garnered more positive sentiments than the other.
To measure the level of agreement between SentiStrength-SE and SenticNet7 among seven given datasets based on the same categories, we employed the Matthews correlation coefficient (MMC). It was introduced by Brian W. Matthews (1975) [
68], and its score can reveal the agreement between two raters based on the same categories [
69].
Table 5 presents the scores of MMC between the two approaches. As can be seen in this table, their scores range from 0.37 to 0.518. These results might reveal that there is some agreement between the two approaches, the most moderate agreement comes from dataset 3, and the least agreement comes from dataset 4.
However, the ratios of neutral attitude obtained from SentiStrength-SE among the six videos ranged from 37.09% to 58.57%, whereas the corresponding ratios obtained from SenticNet7 were lower, ranging from 12.23% to 26.09% (see
Table 3 and
Table 4). By contrast, the ratios of positive and negative comments found by SenticNet7 might be higher than those from SentiStrength-SE. These findings can allow us to answer RQ2 by saying that SentiStrength-SE might be unable to identify the proper polarity of the comments compared with SenticNet7. This issue might come from limitationsof the dictionary used; the new dictionary SenticNet’s method might have significantly outperformed SentiStrength-SE. Based on these findings, we encourage researchers to consider modern techniques (such as SenticNet7) for sentiment analysis in the future.
On the other hand, the study has classified the sentiment analysis based on datasets obtained from SenticNet7 by deploying the CNN and RF models.
Table 6 and
Table 7 present the performance metrics of CNN-based and RF-based models based on 10 folds, and the 10-folds-based max-voting approach. As can be seen, the accuracy obtained from CNN and RF models based on dataset1 in 10 folds is in the range of 0.68–0.73 and 0.68–0.77, respectively, while when the max-voting approach is used, the accuracy increases to 0.73, and 0.78, respectively. Similarity, precision, recall, and F1-score achieved from dataset1 by employing this approach also outperform an individual fold. Significantly, the precision obtained from dataset5 in 10 folds is in the range of 0.52 to 0.65 for the CNN-based model and 0.52 to 0.65 for the RF-based model. However, when the max-voting method is used, the precision improves to 0.67 and 0.66 for CNN-based and RF-based models. These findings are similar to those for the rest of the datasets. We can answer RQ3 by saying that the majority voting approach provides the most robust parameters of model selection in terms of Accuracy, F1 Score, Recall, and Precision.
Furthermore, the accuracy obtained from the CNN model based on dataset 3 and dataset 5 is better than that obtained from the RF model. As can be shown in
Table 7 at the max-voting section, the accuracy of the CNN model for dataset3 is 85% and 67% for dataset5, compared with 75% and 66%, respectively, obtained from the RF model. In addition, the F1 score was obtained from those datasets given the similarity results. Although the Random Forest approach slightly outperformed the CNN-based model compared with other datasets, these differences are insignificant.
Last but not least, there are several researchers who have compared performance between RF and CNN approach in terms of sentiment analysis. According to Gordeev, D., the RF algorithm outperforms other machine learning classifiers in terms of consistency and robustness, but it performed poorly for the Russian language [
70]. He also stated that CNN classifiers (and deep learning in general) are viewed as more insightful and promising. Furthermore, Shaheen et al. studied machine learning methods such as RF, CNN, and Naïve Bayes in terms of sentiment analysis [
71]. They conducted that RF outperformed all other approaches. They discovered that RF outperformed all other methods. However, they also stated that CNN was discovered to be useful for a specific dataset.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}