

Computing the Sound–Sense Harmony: A Case Study of William Shakespeare’s Sonnets and Francis Webb’s Most Popular Poems


Abstract
:1. Introduction
- Low and mid vowels evoke a sense of brightness, peace and serenity;
- High, front and back vowels evoke a sense of surprise, seriousness, rigor and gravity;
- Obstruent and unvoiced consonants evoke a sense of harshness and severity;
- Sonorant and continuant consonants evoke a sense of pleasure, softness and lightness.
- -
- Low, middle, high-front, high-back
- -
- Obstruents (plosives, affricates), continuants (fricatives), sonorants (liquids, vibrants, approximants)plus the distinction into
- -
- Voiced vs. unvoiced.
2. Materials and Methods
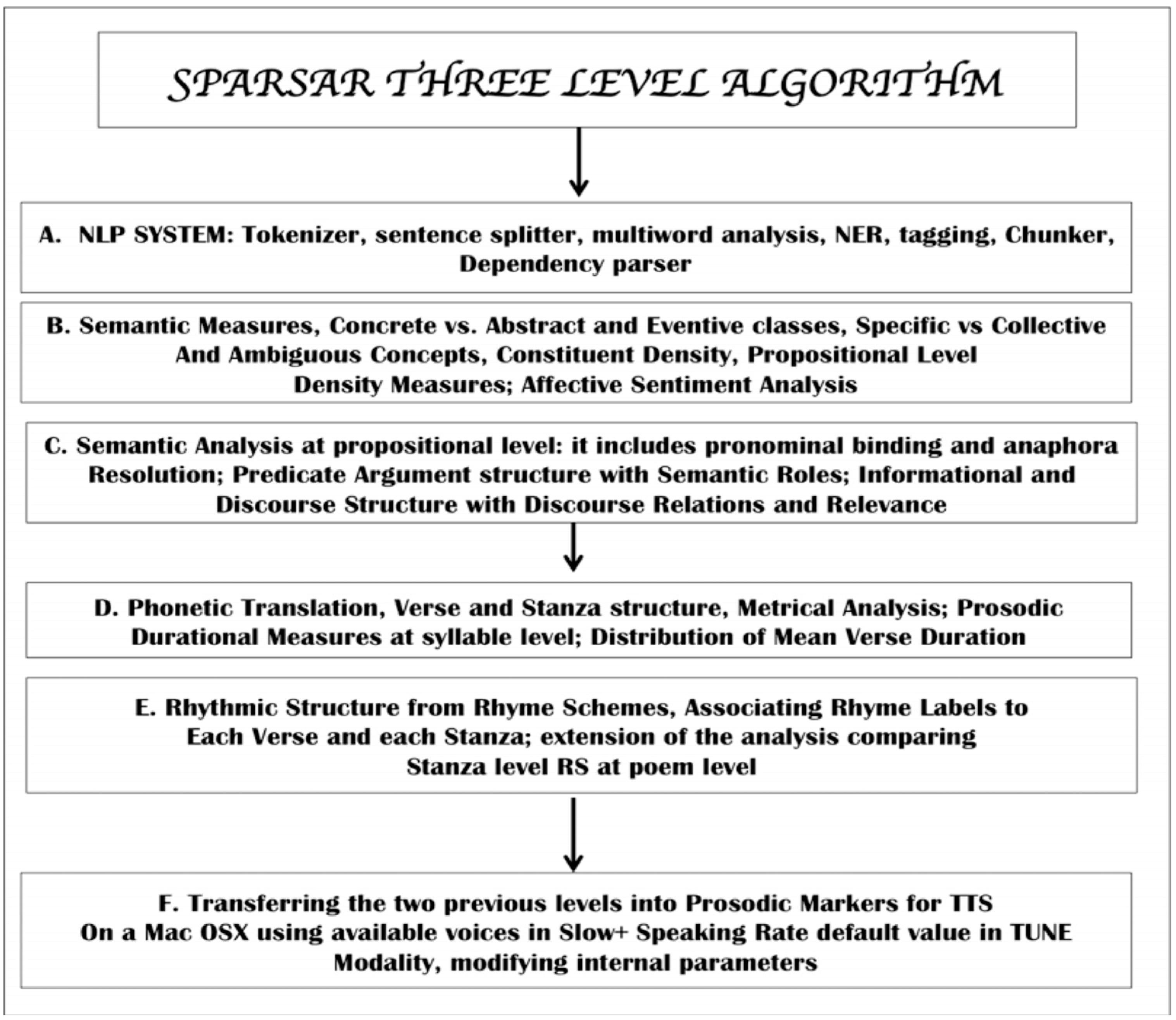
2.1. SPARSAR—A System for Poetry Analysis and Reading
- -
- Syntactic heads which are quantified expressions;
- -
- Syntactic heads which are preverbal subjects;
- -
- Syntactic constituents that starts and ends an interrogative or an exclamative sentence;
- -
- Distinguish realis from irrealis mood;
- -
- Distinguish deontic modality including imperative, hortative, optative, deliberative, jussive, precative, prohibitive, propositive, volitive, desiderative, imprecative, directive and necessitative, etc.;
- -
- Distinguish epistemic modality including assumptive, deductive, dubitative, alethic, inferential, speculative, etc.;
- -
- Any sentence or phrase which is recognized as a formulaic or frozen expression with specific pragmatic content;
- -
- Subordinate clauses with inverted linear order, distinguishing causal from hypotheticals and purpose complex sentences;
- -
- Distinguishing parentheticals from appositives and unrestricted relatives;
- -
- Discourse Structure to distinguish satellite and dependent clauses from the main clause;
- -
- Discourse structure to check for discourse moves—up, down and parallel;
- -
- Discourse relations to tell foreground relations from backgrounds;
- -
- Topic structure to tell the introduction of a new topic or simply a change at relational level.
2.2. The Modules for Syntax and Semantics
2.3. The Modules for Phonetic and Prosodic Analysis
2.4. Computing Metrical Structure and Rhyming Scheme
2.5. From Sentiment Analysis to the Deep Pragmatic Approach by ATF
3. Results
3.1. Sound Harmony in the Sonnets
3.1.1. Periods and Themes in the Sonnets
- A first period that goes from 1592 to 1597, where we have the majority of the cases of VS (214 over 421 total cases).
- A second period that goes from 1598 to 1603, where the number of cases is reduced by half, but the proportion remains the same (109 over 213 total cases). A third period that goes from 1604 to 1608, where the proportion of cases is reverted (95 over 317 total cases) and VS cases are the minority.
3.1.2. Measuring All Vowel Classes
- Sonnet 1: FRONT—increase, decease, spring, niggarding, be, thee;
- Sonnet 2: BACK—use, excuse, old, cold;
- Sonnet 3: HIGH—thee, see, husbandry, posterity, be, thee;
3.1.3. Distributing Vowel and Diphthong Classes into Thematic Periods
3.2. Rhyming and Rhythm: The Sonnets and Poetic Devices
3.2.1. Contractions vs. Rhyme Schemes
- -
- SUFFIXES attached at word end, for example (’s, ‘d, ’n, ‘st, ’t, (putt’st));
- -
- PREFIXES elided at word beginning, for example (‘fore, ‘gainst, ’tis, ‘twixt, ‘greeing);
- -
- INFIXES made by consonant elision inside the word (o’er, ne’er, bett’ring, whate’er, sland’ring, whoe’er, o’ercharg’d, ‘rous).
3.2.2. Rhythm and Rhyme Violations

Commenting on David Crystal’s Point of View
| anon/alone | 75 | -should be alone/anon (Vietor:70) both the order and the governor are wrong. It should be: pronounce ALONE as ANON with a short or long /o/ |
| are/care | 48 | -the order should be care/are, but then the mistake is ARE transcribed like CARE [kEUR :r] |
| are/care | 112, 147 | -the order is correct but the transcription is wrong as before |
| are/compare | 35 | -the order should be compare/are, transcription correct |
| are/prepare | 13 | -the order should be prepare/are, transcription wrong: ARE is pronounced like PREPARE [pEUR :r] |
| are/rare | 52 | -order correct and in transcription ARE is like RARE [rEUR :r]—but it should be the opposite. RARE should sound like ARE, rare/are even though the line with RARE comes first. |
| beloved/removed | 25 | -order correct, but the transcription is wrong: remove is transcribed with the vowel of beloved |
| brood/blood | 19 | the order should be blood/brood: the transcription is also wrong BROOD is transcribed like BLOOD. see Vietor:87, whilst [u] in blood, flood, good, wood s. seems to be the usual Elizabethan sound. |
| dear/there | 110 | correct order but the pronunciation of DEAR is transcribed wrongly as [di:r] while the one of THERE is [thEUR :re] |
| doom/come | 107,116,145 | correct order but the pronunciation should be governed by DOOM, a short or long [u](Vietor:86): transcription of DOOM is instead with the vowel of COME |
3.2.3. Rhyming Constraints and Rhyme Repetition Rate
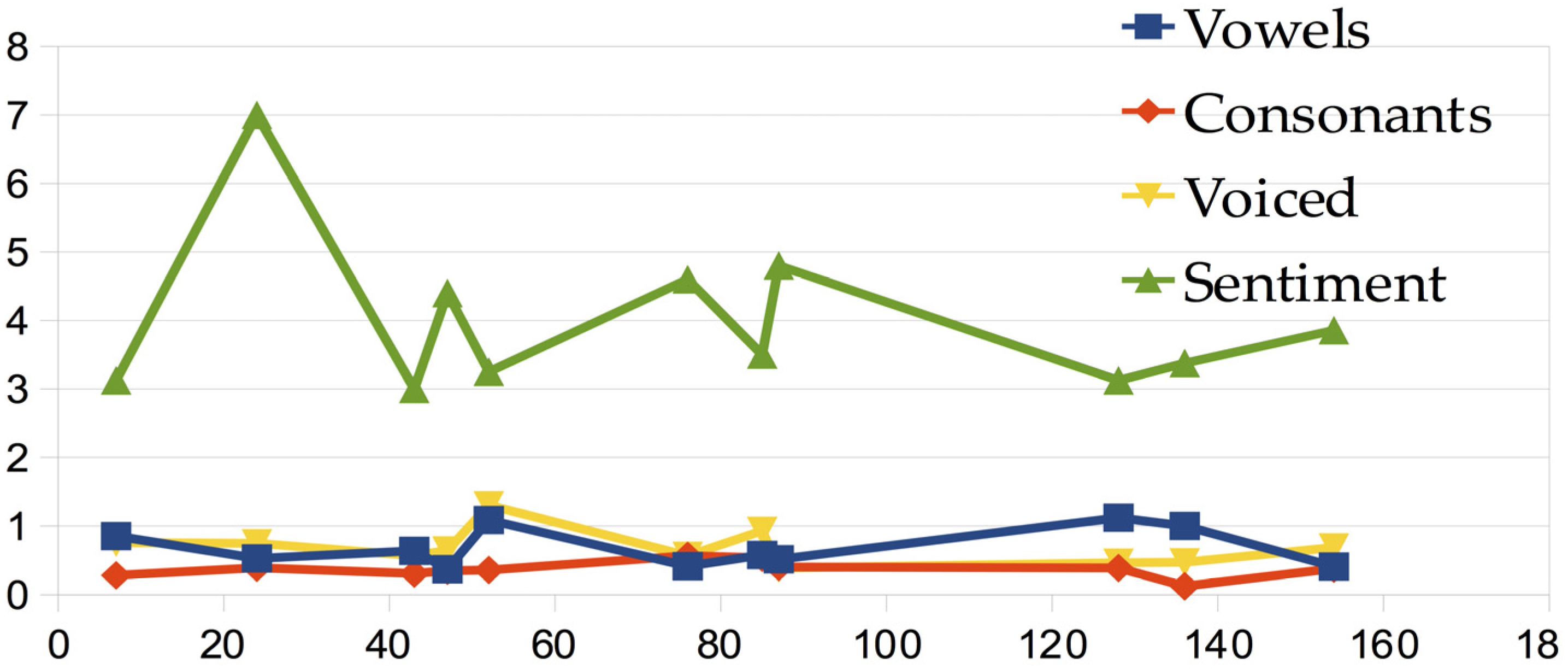
3.2.4. The Sound–Sense Harmony Visualized in Charts
3.2.5. From Sentiment to Deep Semantic and Pragmatic Analysis with ATF
- SONNET 8
- SONNET 21
- Affect is every emotional evaluation of things, processes or states of affairs, (e.g., like/dislike); it describes proper feelings and any emotional reaction within the text aimed towards human behaviour/process and phenomena.
- Judgement is any kind of ethical evaluation of human behaviour, (e.g., good/bad), and considers the ethical evaluation on people and their behaviours.
- Appreciation is every aesthetic or functional evaluation of things, processes and state of affairs (e.g., beautiful/ugly; useful/useless), and represent any aesthetic evaluation of things, both man-made and natural phenomena.

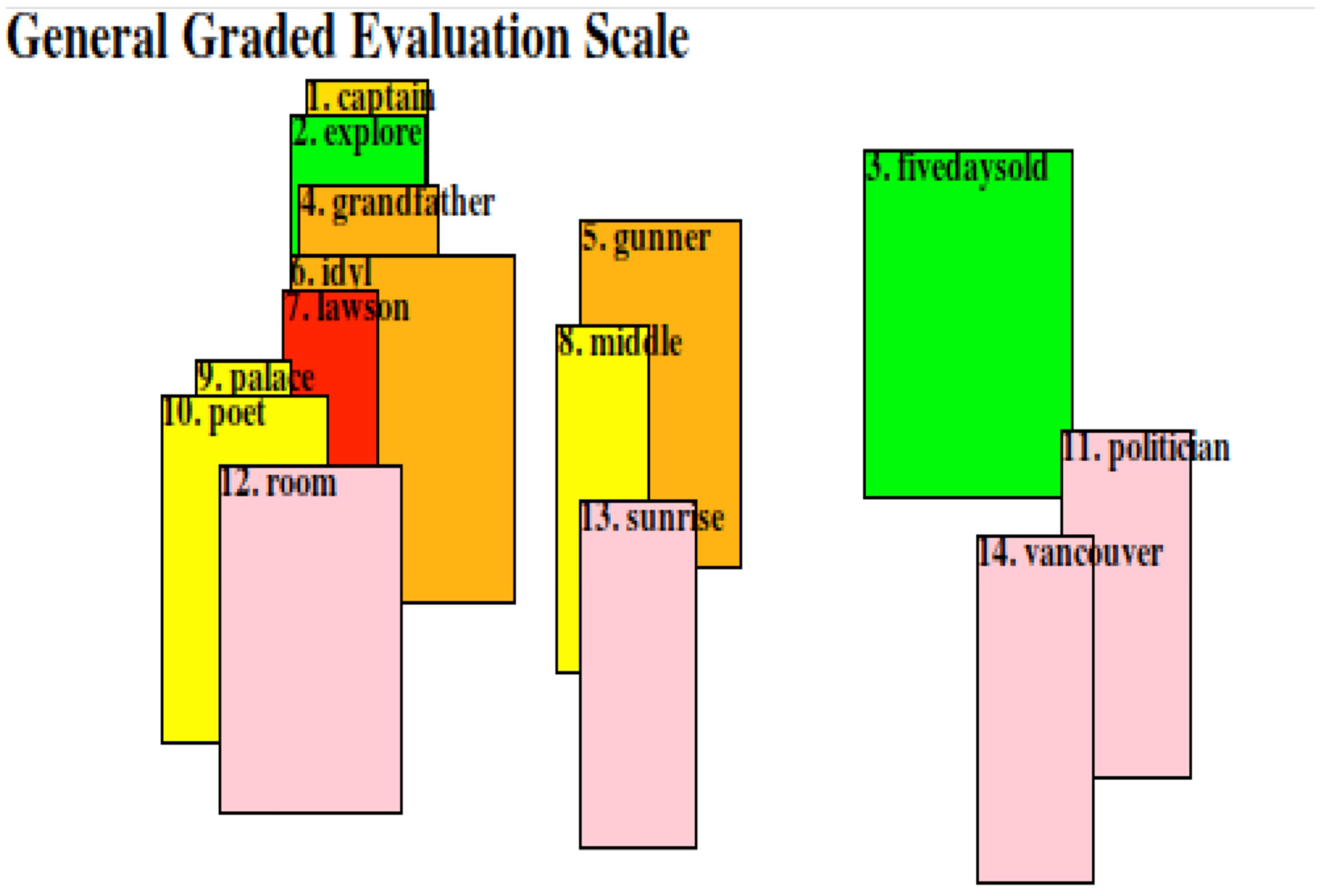
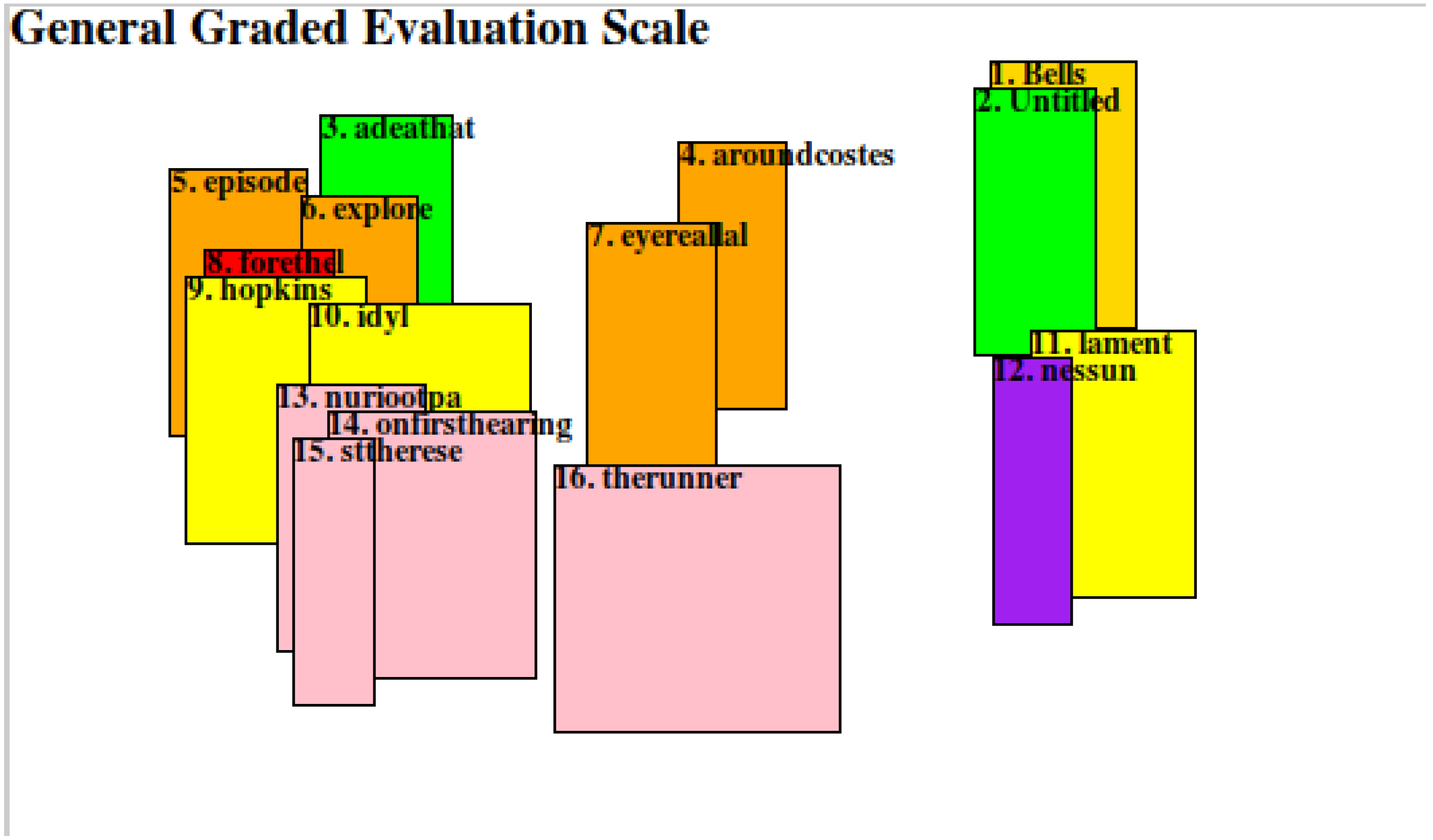
3.2.6. Matching ATF Classes with the Algorithm for Sound–Sense Harmony (ASSH)
- Correlation between Vowels and Judgement: −0.1254;
- Correlation between Voicing and Judgement: −0.1468;
- Correlation between Vowels and Affect: −0.08859;
- Correlation between Voicing and Affect: −0.01346;
- Correlation between Judgement and Affect: −0.1376;
- Correlation between Affect and Appraisal: −0.0351.
- Correlation between Vowels and Judgements: −0.0594;
- Correlation between Voicing and Judgements: −0.0677;
- Correlation between Judgement and Affect: −0.0439;
- Correlation between Judgement and Appraisal: −0.0522.
- Correlation data for Affect are only partly negative:
- Correlation between Vowels and Affect: 0.09;
- Correlation between Voicing and Affect: −0.1435;
- Correlation between Affect and Appraisal: 0.2594.
- Correlation between Vowels and Appraisal: −0.2068;
- Correlation between Voicing and Appraisal: −0.0103.


3.3. Sound and Harmony in the Poetry of Francis Webb
- -
- Class A:
- -
- Class C:
- -
- Class B:
4. Discussion
5. Conclusions
Supplementary Materials
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jakobson, R. Six Lectures on Sound and Meaning; MIT Press: Cambridge, MA, USA, 1978. [Google Scholar]
- Jakobson, R.; Waugh, L. The Sound Shape of Language; Indiana University Press: Bloomington, IN, USA, 1978. [Google Scholar]
- Mazzeo, M. Les voyelles Colorées: Saussure et la Synesthésie. Cah. Ferdinand Saussure 2004, 57, 129–143. [Google Scholar]
- Fónagy, I. The Functions of Vocal Style. In Literary Style: A Symposium; Chatman, S., Ed.; Oxford University Press: Oxford, UK, 1971; pp. 159–174. [Google Scholar]
- Macdermott, M.M. Vowel Sounds in Poetry: Their Music and Tone Colour, Psyche Monographs, No.13; Kegan Paul: London, UK, 1940. [Google Scholar]
- Tsur, R. What Makes Sound Patterns Expressive: The Poetic Mode of Speech-Perception; Duke University Press: Durham, NC, USA, 1992. [Google Scholar]
- Brysbaert, M.; Warriner, A.B.; Kuperman, V. Concreteness ratings for 40 thousand generally known English word lemmas. Behav. Res. Methods 2014, 46, 904–911. [Google Scholar] [CrossRef] [PubMed]
- Mohammad, S. Even the Abstract have Colour: Consensus in Word Colour Associations, 2011b. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011. [Google Scholar]
- Melchiori, G. Shakespeare’s Sonnets; Adriatica Editrice: Bari, Italy, 1971. [Google Scholar]
- Taboada, M.; Grieve, J. Analyzing appraisal automatically. In AAAI Spring Symposium on Exploring Attitude and Affect in Text: Theories and Applications; AAAI Press: Washington, DC, USA, 2004; pp. 158–161. [Google Scholar]
- Delmonte, R. Visualizing Poetry with SPARSAR—Poetic Maps from Poetic Content. In Proceedings of the NAACL-HLT Fourth Workshop on Computational Linguistics for Literature, Denver, CO, USA, 4 June 2015; pp. 68–78. [Google Scholar]
- Montaño, R.; Alías, F.; Ferrer, J. Prosodic analysis of storytelling discourse modes and narrative situations oriented to Text-to-Speech synthesis. In Proceedings of the 8th ISCA Speech Synthesis Workshop, Barcelona, Spain, 31 August–2 September 2013; pp. 171–176. [Google Scholar]
- Delmonte, R.; Tonelli, S.; Boniforti, M.A.P.; Bristot, A. VENSES—A Linguistically-Based System for Semantic Evaluation. In Machine Learning Challenges; Quiñonero-Candela, J., Dagan, I., Magnini, B., Florence , d’Alché-Buc, F., Eds.; Springer: Berlin, Germany, 2005; pp. 344–371. [Google Scholar]
- Bresnan, J. (Ed.) The Mental Representation of Grammatical Relations; The MIT Press: Cambridge, MA, USA, 1982. [Google Scholar]
- Bresnan, J. (Ed.) Lexical-Functional Syntax; Blackwell Publishing: Oxford, UK, 2001. [Google Scholar]
- Baayen, R.H.; Piepenbrock, R.; Gulikers, L. The CELEX Lexical Database (CD-ROM); CELEX2 LDC96L14. Web Download; Linguistic Data Consortium: Philadelphia, PA, USA, 1995. [Google Scholar]
- Bacalu, C.; Delmonte, R. Prosodic Modeling for Syllable Structures from the VESD—Venice English Syllable Database. In Atti 9 Convegno GFS-AIA; Sirea: Venice, Italy, 1999. [Google Scholar]
- Tsur, R. Poetic Rhythm: Structure and Performance: An Empirical Study in Cognitive Poetics; Sussex Academic Press: Eastbourne, UK, 2012; p. 472. [Google Scholar]
- Greene, E.; Bodrumlu, T.; Knight, K. Automatic Analysis of Rhythmic Poetry with Applications to Generation and Translation. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, Cambridge, MA, USA, 9–11 October 2011; pp. 524–533. [Google Scholar]
- Carvalho, P.; Sarmento, L.; Silva, M.; de Oliveira, E. Clues for detecting irony in user-generated contents: Oh...!! it’s so easy;-). In Proceedings of the 1st International CIKM Workshop on Topic-Sentiment Analysis for Mass Opinion, Hong Kong, 6 November 2009; ACM: New York, NY, USA, 2009; pp. 53–56. [Google Scholar]
- Kao, J.; Jurafsky, D. A Computational Analysis of Style, Affect, and Imagery in Contemporary Poetry. In Proceedings of the NAACL Workshop on Computational Linguistics for Literature, Montréal, ON, Cananda, 8 June 2012. [Google Scholar]
- Kim, S.-M.; Hovy, E. Determining the sentiment of opinions. In Proceedings of the 20th International Conference on Computational Linguistics—COLING, Stroudsburg, PA, USA, 23–27 August 2004; pp. 1367–1373. [Google Scholar]
- Reyes, A.; Rosso, P. Mining subjective knowledge from customer reviews: A specific case of irony detection. In Proceedings of the 2nd Workshop on Computational Approaches to Subjectivity and Sentiment Analysis WASSA ’11, Stroudsburg, PA, USA, 24 June 2011; pp. 118–124. [Google Scholar]
- Weiser, D.K. Shakespearean Irony: The ‘sonnets’. In Neuphilologische Mitteilungen; Modern Language Society: NY, USA, 1983; Volume 84, pp. 456–469. Available online: http://www.jstor.org/stable/43343552 (accessed on 6 July 2023).
- Weiser, D.K. Mind in Character—Shakespeare s Speaker in the Sonnets; The University of Missouri Press: Columbia, MI, USA, 1987. [Google Scholar]
- Attardo, S. Linguistic Theories of Humor; Mouton de Gruyter: Berlin, Germany; New York, NY, USA, 1994. [Google Scholar]
- Schoenfeldt, M. Cambridge Introduction to Shakespeare’s Poetry; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Ingham, R.; Ingham, M. Chapter 5: Subject-verb inversion and iambic rhythm in Shakespeare’s dramatic verse. In Stylistics and Shakespeare’s Language: Transdisciplinary Approaches; Ravassat, M., Culpeper, J., Eds.; Continuum: London, UK, 2011; pp. 98–118. [Google Scholar]
- Delmonte, R. Exploring Shakespeare’s Sonnets with SPARSAR. Linguist. Lit. Stud. 2016, 4, 61–95. Available online: https://www.hrpub.org/journals/jour_archive.php?id=93&iid=772 (accessed on 6 July 2023). [CrossRef]
- Delmonte, R. Poetry and Speech Synthesis, SPARSAR Recites. In Ricognizioni—Rivista di Lingue, Letterature e Culture Moderne; Università Di Torino: Torino, Italy, 2019; Volume 6, pp. 75–95. Available online: http://www.ojs.unito.it/index.php/ricognizioni/article/view/3302 (accessed on 6 July 2023).
- Crystal, D. Sounding out Shakespeare: Sonnet Rhymes in Original Pronunciation. 2011. Available online: https://www.davidcrystal.com/GBR/Books-and-Articles (accessed on 6 July 2023).
- Mazarin, A. The Developmental Progression of English Vowel Systems, 1500–1800: Evidence from Grammarians, in Ampersand. 2020. Available online: https://reader.elsevier.com/reader/sd/pii/S2215039020300011?token=BCB9A7B6C95F35D354C940E08CBA968ED124CF160B0AC3EF5FE9146C4B3885E825A878104ED06E127685F139918CCEB6 (accessed on 6 July 2023).
- Crystal, D. Think on My Words: Exploring Shakespeare’s Language; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- McGuire, P.C. Shakespeare’s non-shakespearean sonnets. Shakespear. Q. 1987, 38, 304–319. [Google Scholar] [CrossRef]
- Attardo, S. Irony as relevant inappropriateness. J. Pragmat. 2000, 32, 793–826. [Google Scholar] [CrossRef]
- Martin, J.; White, P.R. Language of Evaluation, Appraisal in English; Palgrave Macmillan: London, UK; New York, NY, USA, 2005. [Google Scholar]
- Read, J.; Carrol, J. Annotating expressions of appraisal in English. Lang. Resour. Eval. 2012, 46, 421–447. [Google Scholar] [CrossRef]
- Delmonte, R.; Busetto, N. Detecting irony in Shakespeare’s sonnets with SPARSAR. In Proceedings of the Sixth Italian Conference on Computational Linguistics, Bari, Italy, 13–15 November 2019; Available online: https://dblp.org/rec/bib/conf/clic-it/DelmonteB19 (accessed on 6 July 2023).
- Webb, F. Collected Poems; Davidson, T., Ed.; University of Western Australia Publishing: Crawley, Australia, 2011. [Google Scholar]
- Delmonte, R. What’s wrong with deep learning for meaning understanding. In Proceedings of the 2nd Italian Workshop on Explainable Artificial Intelligence (XAI.it 2021), Virtual, 1–3 December 2021. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Phon. Class | High-Front | Mid | Low | High-Back | Total |
|---|---|---|---|---|---|
| No. Class | 119 | 159 | 142 | 111 | 531 |
| StrVowDiph | 493 | 861 | 587 | 314 | 2155 |
| No. Classes | 4-Class | 3-Class | 2-Class | 1-Class | Total |
|---|---|---|---|---|---|
| No. Sonnets | 77 | 64 | 12 | 1 | 154 |
| N. | Un/StressVow/Con | Following Vowel/ Consonant | Freq Occ | High | Middle | Low | Consonant |
|---|---|---|---|---|---|---|---|
| 1 | ay | d, er, f, l, m, n, r, t, v, z | 109 | 109 | |||
| 2 | ey | d, jh, k, l, m, n, s, t, v, z | 81 | 81 | |||
| 3 | n_ | d, iy, jh, s, t, z | 80 | 80 | |||
| 4 | r_ | ay1, d, ey1, iy, iy1, k, n, ow, ow1, s, t, th, uw1, z | 68 | 68 | |||
| 5 | eh | d, jh, k, l, n, r, s, t, th | 68 | 68 | |||
| 6 | ih | d, l, m, n, ng, r, s, t, v | 51 | 51 | |||
| 7 | ao | d, l, n, ng, r, s, t, th, z | 40 | 40 | |||
| 8 | iy | d, f, ih, k, l, m, n, p, s, t, v, z | 45 | 45 | |||
| 9 | s | iy, st, t | 38 | 38 | |||
| 10 | uw | d, m, n, s, t, th, v, z | 47 | 47 | |||
| 11 | ah | d, l, n, s, t, z | 34 | 34 | |||
| 12 | ow | k, l, n, p, t, th, z | 21 | 25 | |||
| 13 | t | er, ey1, iy, s, st | 21 | 21 | |||
| 14 | ah | d, k, m, n, ng | 17 | 17 | |||
| 15 | aa | n, r, t | 16 | 16 | |||
| 16 | ae | ch, d, k, ng, s, v | 14 | 14 | |||
| 17 | d_z | 13 | 13 | ||||
| 18 | er | ay1, d, iy, z | 11 | 11 | |||
| Total final sounds | 778 | 168 | 200 | 190 | 220 |
| (a) | ||||
|---|---|---|---|---|
| Low | Middle | High | Total | |
| Period 1 | 40 | 42 | 57 | 139 |
| Period 2 | 105 | 68 | 102 | 275 |
| Period 3 | 111 | 105 | 136 | 352 |
| Period 4 | 59 | 79 | 122 | 260 |
| Period 5 | 66 | 60 | 99 | 225 |
| Totals | 381 | 354 | 516 | 1251 |
| (b) | ||||
| Low | Middle | High | Total | |
| Period 1 | 2.3529 | 2.4706 | 3.3529 | 8.1765 |
| Period 2 | 3.0882 | 2 | 3 | 8.0882 |
| Period 3 | 2.4667 | 2.3334 | 3.0223 | 7.8223 |
| Period 4 | 1.9667 | 2.6334 | 4.0667 | 8.6667 |
| Period 5 | 2.3571 | 2.1429 | 3.5357 | 8.0357 |
| Totals | 30.529% | 28.365% | 41.106% | 100% |
| (a) | |||
|---|---|---|---|
| Low | Middle | Total | |
| Phase 1 | 50 | 46 | 96 |
| Phase 2 | 78 | 103 | 181 |
| Phase 3 | 112 | 154 | 266 |
| Phase 4 | 81 | 72 | 153 |
| Phase 5 | 65 | 85 | 150 |
| Totals | 386 | 460 | 846 |
| (b) | |||
| Low | Middle | Total | |
| Phase 1 | 2.9412 | 2.7059 | 5.6471 |
| Phase 2 | 2.2941 | 3.0294 | 5.3235 |
| Phase 3 | 2.4889 | 3.4223 | 5.9112 |
| Phase 4 | 2.7 | 2.4 | 5.1 |
| Phase 5 | 2.3214 | 3.357 | 5.3571 |
| Totals | 45.626% | 54.373% | 100% |
| Low | Middle | High | Total | |
|---|---|---|---|---|
| Vowels | 381 | 354 | 567 | 1312 |
| Diphthongs | 386 | 460 | 854 | |
| Total | 767 | 814 | 567 | 2166 |
| Sonnets Interval | No. Rhyme Violations/ No. Sonnets | Ratio % | |
|---|---|---|---|
| Phase I | 1–17 | 22/17 | 1.2941 |
| Phase II | 18–51 | 40/34 | 1.1765 |
| Phase III | 52–96 | 34/45 | 0.7556 |
| Phase IV | 97–126 | 18/30 | 0.6 |
| Phase V | 127–154 | 23/28 | 0.8214 |
| Total | 137/154 | 0.8896 |
| Author/ Quanti- Ties | Rhyme- Pair Repeat Types | Rhyme- Pair Repeat Token | Hapax or Unique Rhyme- Pairs |
|---|---|---|---|
| Shakespeare | 18.02% | 65.21% | 34.79% |
| Spenser | 17.84% | 47.45% | 53.55% |
| Sydney | 22.37% | 72.08% | 27.02% |
| X Typ | FX Tok | Sum FX | Sum FX + X | % Sum FX + X |
|---|---|---|---|---|
| 28 | 1 | 28 | 28 | 2.72 |
| 17 | 1 | 17 | 45 | 4.37 |
| 14 | 2 | 28 | 73 | 7.09 |
| 12 | 2 | 24 | 97 | 9.43 |
| 10 | 1 | 10 | 107 | 10.4 |
| 9 | 5 | 45 | 152 | 14.77 |
| 8 | 3 | 24 | 176 | 17.1 |
| 7 | 1 | 7 | 183 | 17.78 |
| 6 | 6 | 36 | 219 | 21.28 |
| 5 | 10 | 50 | 269 | 26.14 |
| 4 | 29 | 116 | 385 | 37.41 |
| 3 | 37 | 111 | 496 | 48.2 |
| 2 | 87 | 174 | 670 | 65.11 |
| 1 | 359 | 359 | 1029 | 100.0 |
| Appr.Pos | Appr.Neg | Affct.Pos | Affct.Neg | Judgm.Pos | Judgm.Neg | |
|---|---|---|---|---|---|---|
| Sum | 56 | 25 | 53 | 77 | 32 | 122 |
| Mean | 2.533 | 1.133 | 2.4 | 3.466 | 1.444 | 5.466 |
| St.Dev. | 8.199 | 3.691 | 7.732 | 11.202 | 4.721 | 17.611 |
| Appr.Neg | Appr.Pos | Affct.Pos | Affct.Neg | Judgm.Pos | Judgm.Neg | |
|---|---|---|---|---|---|---|
| Sum | 139 | 65 | 64 | 81 | 59 | 37 |
| Mean | 5.346 | 2.5 | 2.461 | 3.115 | 2.269 | 1.423 |
| St.Dev. | 18.82 | 8.843 | 8.707 | 11.009 | 8.029 | 5.047 |
| Appr.Pos | Appr.Neg | Affct.Pos | Affct.Neg | Judgm.Pos | Judgm.Neg | |
|---|---|---|---|---|---|---|
| Sum | 88 | 59 | 89 | 109 | 49 | 8 |
| Mean | 3.034 | 2.034 | 3.068 | 3.758 | 1.689 | 0.275 |
| St.Dev. | 1.268 | 7.638 | 11.482 | 14.052 | 6.368 | 1.079 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Delmonte, R. Computing the Sound–Sense Harmony: A Case Study of William Shakespeare’s Sonnets and Francis Webb’s Most Popular Poems. Information 2023, 14, 576. https://doi.org/10.3390/info14100576
Delmonte R. Computing the Sound–Sense Harmony: A Case Study of William Shakespeare’s Sonnets and Francis Webb’s Most Popular Poems. Information. 2023; 14(10):576. https://doi.org/10.3390/info14100576
Chicago/Turabian StyleDelmonte, Rodolfo. 2023. "Computing the Sound–Sense Harmony: A Case Study of William Shakespeare’s Sonnets and Francis Webb’s Most Popular Poems" Information 14, no. 10: 576. https://doi.org/10.3390/info14100576
APA StyleDelmonte, R. (2023). Computing the Sound–Sense Harmony: A Case Study of William Shakespeare’s Sonnets and Francis Webb’s Most Popular Poems. Information, 14(10), 576. https://doi.org/10.3390/info14100576