1. Introduction
In today’s world, Internet of Things (IoT) devices have become increasingly pervasive, finding applications across various domains. These devices, equipped with sensors and communication tools, gather and transmit vast amounts of data from the physical environment to digital networks. Their uses span industrial automation, healthcare monitoring, smart home systems, and environmental sensing. However, managing and processing the immense data streams generated by IoT devices pose significant challenges. This is where the integration of cloud computing (CC) comes into play. CC offers a scalable and adaptable platform for handling and storing IoT data. By leveraging the capabilities of the cloud, organizations can analyze these data in real time, extract actionable insights, and make data-driven decisions. This symbiotic relationship between IoT devices and CC underscores the synergy between cutting-edge technologies, paving the way for a plethora of innovative solutions with substantial potential for research and development in security, communication, and AI.
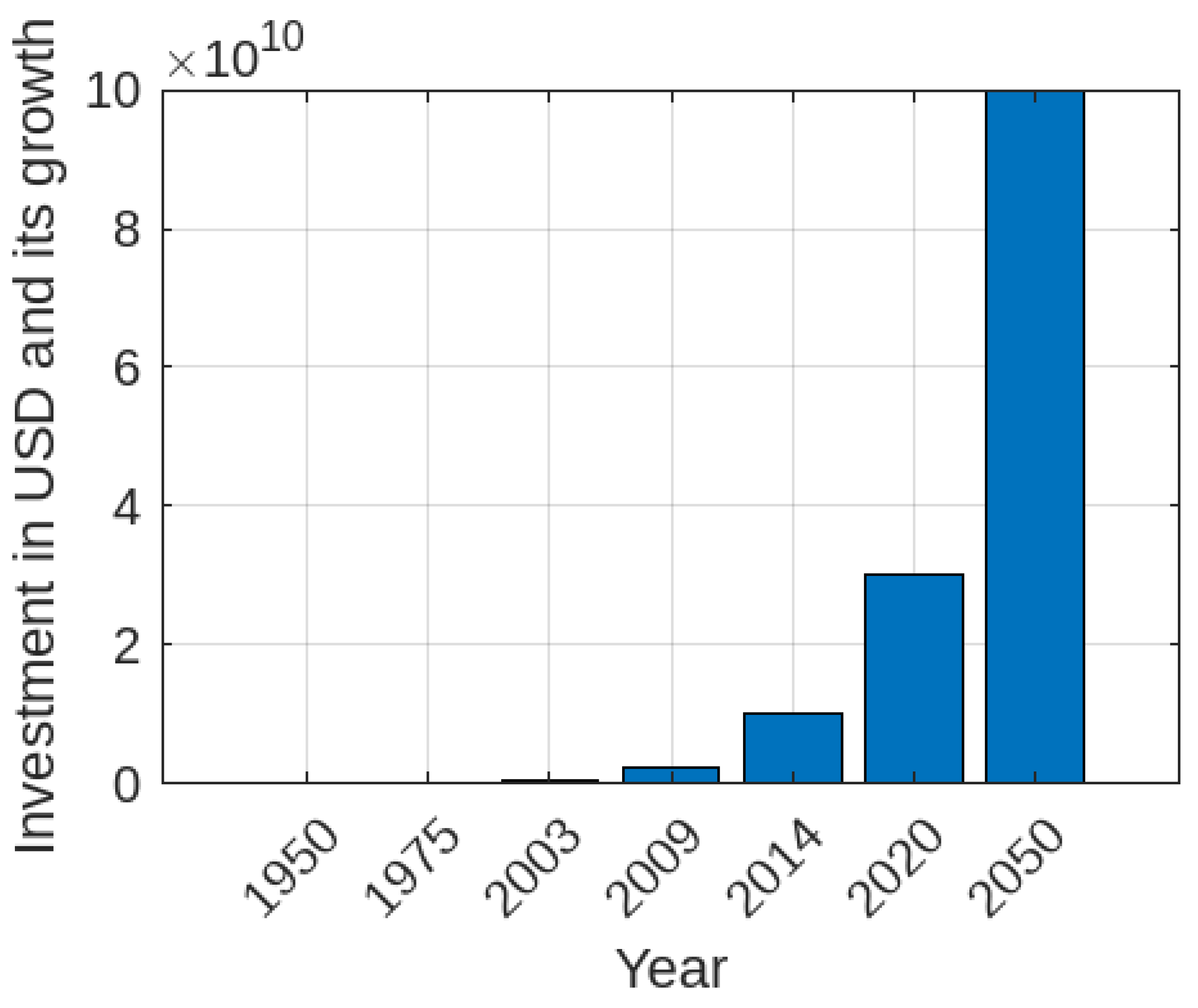
The transformative impact of Internet of Things (IoT) technologies on consumer behaviors and enterprise operational models is increasingly evident. This phenomenon is catalyzed by the reduction in device deployment costs and the surging consumer demand, as illustrated in
Figure 1. According to Gartner [
1], a renowned advisory and research entity, the number of connected device installations surged from 23.14 billion units in 2018 to a projected 30.73 billion units in 2020. Such exponential growth offers an opportune landscape for various stakeholders, including investors and corporations, to amass extensive data.
Financial projections indicate that businesses could invest nearly 5 trillion USD in expanding the IoT market and developing new applications by the end of 2021. Moreover, long-term investments in this sector are expected to surpass 100 billion USD by the mid-21st century. As the volume of devices and associated data continues to soar, the significance of sophisticated data management infrastructures, such as CC, becomes increasingly pivotal. The efficient orchestration of dynamic resource allocation within the domain of CC’s Infrastructure as a Service (IaaS) is crucial for ensuring the prudent utilization of computational assets. The continuous oversight of these assets and adherence to service-level agreements (SLAs), evaluated through a set of defined quality indicators, will be instrumental in realizing the potential of adaptive resource governance.
The convergence of the IoT and CC has revolutionized the accessibility and management of resources for end users, providing unprecedented convenience and flexibility [
2]. However, from the standpoint of cloud service providers (CSPs), meeting these demands necessitates robust resource management capabilities to accommodate dynamic workloads and evolving tasks. Consequently, contemporary CC systems must embody intelligence and resource abundance.
IoT devices and cloud systems play a pivotal role in managing peak workloads and facilitating the design and implementation of enterprise systems, empowering businesses to achieve their objectives. Cloud computing (CC), in particular, fosters the creation of an IT utilities marketplace commonly known as market-oriented cloud computing.
From an end user’s viewpoint, CC presents an illusion of infinite resource availability, while CSPs are tasked with efficiently managing these resources while optimizing energy consumption [
3]. Achieving this balance is challenging and requires the utilization of cloud monitoring and prediction techniques.
Cloud monitoring is critical to the reliability and performance of cloud-based infrastructures. It entails systematic data gathering, analysis, and visualization for the numerous elements of cloud services, such as resource use, network latency, and security events. From a third-party standpoint, cloud monitoring solutions are clearly vital for enterprises that rely on CC, as they provide critical insights into the health and effectiveness of their cloud-based applications and services. Businesses can use this technology to proactively identify and prevent problems, improve resource allocation, and maintain a high degree of service availability. Third-party observers identify cloud monitoring as an essential tool in guaranteeing the flawless functioning of cloud environments while improving the overall security and performance in an era where digital transformation is a primary goal. Public CC environments like Amazon Web Services (AWS) provide organizations with the resources to host critical services and applications [
4,
5]. The continuous monitoring of these cloud-hosted services is essential to ensure consistent performance throughout their operational lifespan [
6].
Cloud resource prediction is an important feature of CC, as it ensures the optimal allocation of compute, storage, and network resources inside cloud settings. Based on a third party, precise resource prediction enables cloud service providers and users to optimize their infrastructure, reduce costs, and improve cloud-based applications and services’ overall performance and dependability. Forecasting resource demand is an important aspect of cloud resource prediction. This includes forecasting the future resource requirements of cloud workloads based on user traffic patterns, data volumes, and application performance metrics. Advanced machine learning and data analysis techniques are frequently used to anticipate and predict these resource demands precisely. This proactive strategy enables cloud providers to dynamically assign resources, scaling up or down as needed, avoiding under- or over-provisioning, which can lead to inefficiencies and increased costs. Additionally, cloud resource prediction includes the prediction of potential resource deviations and failures. Deviations from expected resource use patterns can be recognized by continuously monitoring and evaluating system data. These variations may suggest potential breakdowns or bottlenecks in performance. Third-party observers understand the importance of these predictive skills in reducing service disruptions and assuring cloud service availability. In essence, cloud resource prediction is a critical component of intelligent cloud management, allowing both providers and customers to make informed decisions and optimize their cloud infrastructures for increased efficiency and reliability.
The forthcoming era of CC holds promise for the technology industry, as it paves the way for autonomous cloud infrastructure management, reducing the need for manual intervention [
7]. The properties associated with CC will accelerate future technologies, enabling faster operations than the immediate environment.
Dynamic allocation mechanisms, such as auto-scaling techniques widely adopted by AWS, allow resources to be provisioned and de-provisioned based on current and future resource demands [
8]. Quality of service (QoS) and service-level agreements (SLAs) vary for different cloud environments [
9]. The challenge lies in scaling resources for distributed computational workloads worldwide.
Resource provisioning can be categorized into predictive and reactive tactics [
10]. Reactive techniques respond to the system’s current state, considering VM utilization and client requests. Predictive approaches, on the other hand, forecast future resource requirements, leading to better resource utilization and accurate response time estimates.
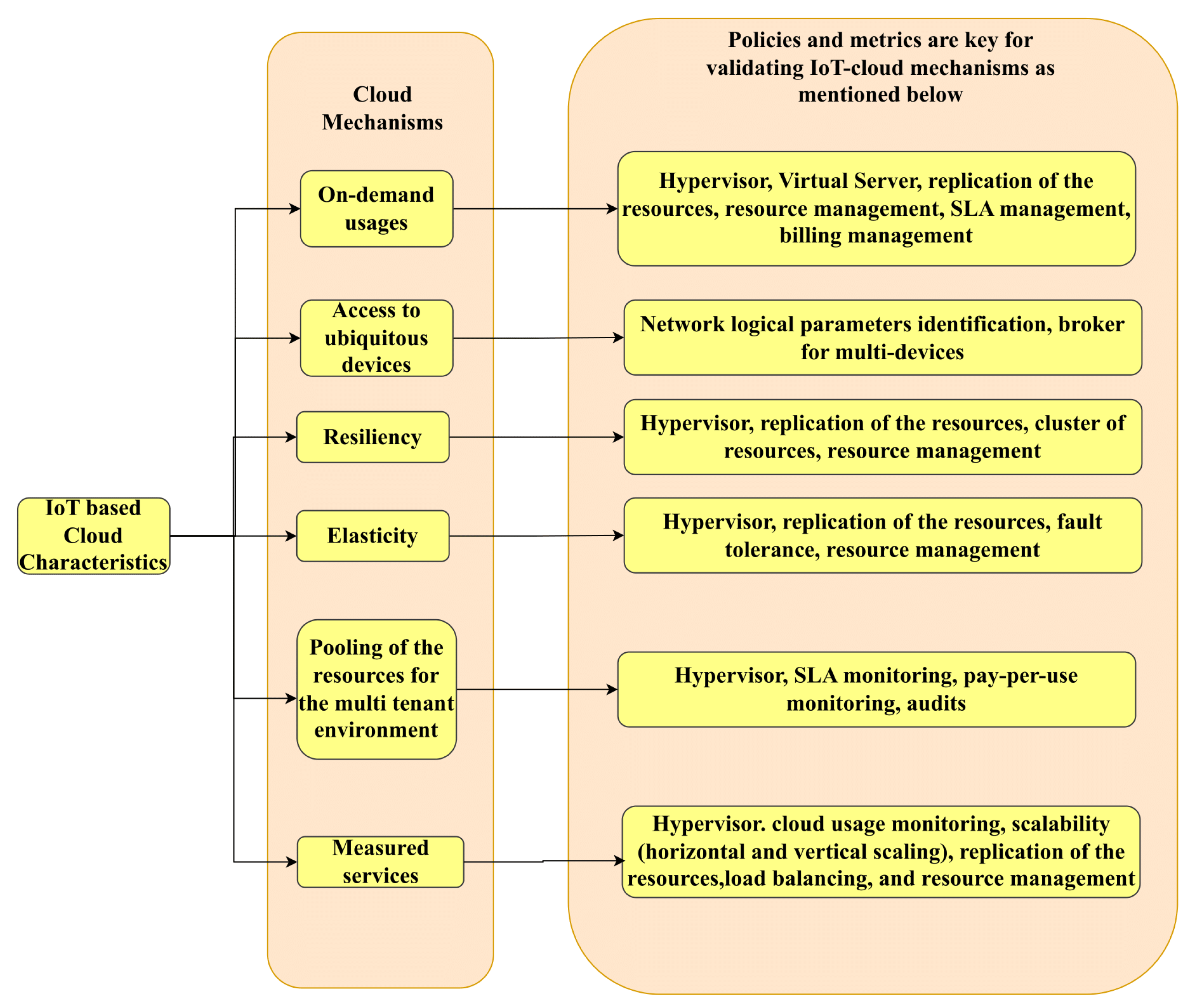
1.1. Metrics and Policies in CC
Metrics and policies in CC are critical components of effectively managing and administering cloud resources. These factors are crucial in ensuring the proper operation of cloud environments, allowing firms to align their cloud usage with business goals, security requirements, and cost efficiency.
Metrics are necessary for evaluating the performance of cloud resources. These metrics include a variety of factors, such as response times, throughput, latency, and availability. According to third-party observers, these indicators provide a comprehensive picture of how well cloud services meet their service-level agreements (SLAs). Organizations may detect bottlenecks, optimize resource allocation, and guarantee that cloud services offer the desired level of performance to fulfill business goals by regularly monitoring and evaluating key performance data.
Cost is an important factor in CC, and cost indicators are critical for keeping track of cloud spending. These metrics monitor resource utilization, pricing structures, and usage trends. According to third-party experts, cost optimization policies driven by these indicators enable firms to decrease wasteful spending by detecting idle resources, setting budget constraints, and choosing cost-effective cloud service models. Businesses may make educated decisions regarding resource provisioning and consumption by matching cost indicators with cloud regulations.
Cloud security is critical, and security metrics are used to assess the effectiveness of security measures. These metrics include intrusion detection, access controls, and vulnerability evaluations. According to third-party assessments, security policies specify the rules and processes for protecting data and applications in the cloud. Organizations can assure compliance with industry rules and best practices by aligning security metrics with security policies, reducing the risks associated with data breaches and cyber-attacks.
Scalability is a crucial feature of cloud computing, and resource scaling measures are critical for reacting to changing workloads. Resource utilization, auto-scaling triggers, and capacity planning are examples of these measures. According to third-party experts, scalability rules drive resource allocation decisions, dictating when and how resources can be scaled up or down to meet demand while controlling costs. Properly aligned policies ensure that cloud resources can handle fluctuating workloads efficiently and without service interruptions.
Monitoring and enforcing compliance with organizational policies, industry standards, and legal requirements is part of CC governance. Governance metrics evaluate adherence to these laws and regulations, ensuring accountability and openness. Third-party viewpoints emphasize the significance of governance policies, which offer guidelines for data access, data preservation, and auditing methods. Organizations may maintain control over their cloud resources, enforce compliance, and show stakeholders and regulators their commitment to responsible cloud usage by aligning governance metrics with governance principles.
Furthermore, measurements and policies in CC are inextricably linked components of good cloud administration. These components enable businesses to assess and manage cloud performance, costs, security, scalability, and governance. Businesses can employ cloud resources strategically by aligning these KPIs with well-defined rules, ensuring that cloud computing corresponds with their objectives, regulatory requirements, and best practices.
Implementing auto-scaling techniques in the cloud involves using various metrics alongside policies that align with QoS parameters and SLAs, including performance metrics and thresholds [
11]. Defining these parameters without human intervention presents challenges in comprehending their impact on cloud utility performance. Autonomic techniques, requiring minimal human intervention, are essential in such environments, enabling the system to make decisions based on specified metrics and policies.
The failure to define metrics can result in several issues, including the following:
An inability to measure client resource requirements [
12].
The over- or under-provisioning of resources [
13].
Ambiguity in describing delivered work [
14].
Tedious resource monitoring and management [
15].
An inability to impose penalties for non-compliance [
16].
1.3. Contribution
Service-level agreements (SLAs) play a pivotal role in cloud computing, shaping contract terms, negotiations, and performance metrics. This article makes several significant contributions:
Discussion of Various SLAs: We provide a comprehensive exploration of diverse service-level agreements (SLAs) and their associated parameters. These discussions shed light on the intricate aspects of SLAs and their integral role in cloud service contracts and negotiations.
Linking SLAs to Quality of Service (QoS): Recognizing the crucial relationship between SLAs and quality of service (QoS), we emphasize how SLAs directly impact the quality of the services provided. This linkage underscores the paramount importance of SLAs in delivering satisfactory user experiences.
Exploration of SLA Metrics: We conduct an in-depth examination of SLA metrics and their profound significance in the realm of IT resource management. These metrics serve as indispensable tools for assessing service quality, enabling providers and users to maintain agreed-upon service standards.
Utilization of Metrics for CC Monitoring and Management: We shed light on the practical applications of metrics in cloud computing (CC) monitoring and management techniques. These metrics play a pivotal role in ensuring the efficient utilization of resources and the fulfillment of SLAs.
Case Study on IoT-based Cloud Resource Utilization: This article culminates with a detailed case study showcasing the application of metrics to maintain CPU utilization in an Internet of Things (IoT)-based cloud environment. This real-world example highlights the practical relevance of the concepts discussed throughout this article.
Cloud monitoring and prediction are fundamental components of modern cloud computing (CC), providing crucial insights into the performance, availability, and resource utilization of cloud-based services and infrastructures. These practices are essential not only for optimizing cloud operations but also for improving security and ensuring cost efficiency.
Cloud monitoring involves the continuous collection and analysis of various data points within a cloud environment, including system performance metrics, application logs, network traffic, and security events. Real-time visibility into these aspects is vital for detecting abnormalities, identifying performance bottlenecks, and proactively addressing issues that may affect service quality and availability.
Predictive analytics in cloud monitoring goes beyond real-time insights, utilizing historical data and complex algorithms to estimate future patterns and potential issues. This predictive capability is critical in cloud management, enabling organizations to anticipate resource requirements, prepare for scalability, and minimize security threats before they manifest. Predictive analytics empowers cloud providers and consumers to optimize resource allocation and reduce the risk of service outages.
Cloud security monitoring is essential for detecting and preventing security risks and breaches. Security Information and Event Management (SIEM) solutions correlate security data across cloud services and applications. Predictive analytics can help identify suspicious trends and predict potential security attacks, allowing for timely actions and an overall improvement in cloud security posture.
Given the pay-as-you-go model of CC, effective cost control is crucial. Cloud cost monitoring and forecasting track resource usage and project future cost trends. Predictive insights enable organizations to make informed decisions about resource provisioning, scalability, and consumption, thereby reducing wasteful costs. These practices also assist in capacity planning, ensuring that cloud resources can meet rising demand by forecasting future resource requirements based on past consumption trends.
Cloud monitoring and prediction are invaluable tools for modern cloud management, offering real-time insights, enabling a proactive issue response, improving security, lowering costs, and facilitating effective capacity planning. Organizations can ensure the reliable and cost-effective delivery of cloud-based services by integrating monitoring and predictive analytics into cloud operations, aligning their cloud resources with business objectives and user expectations.
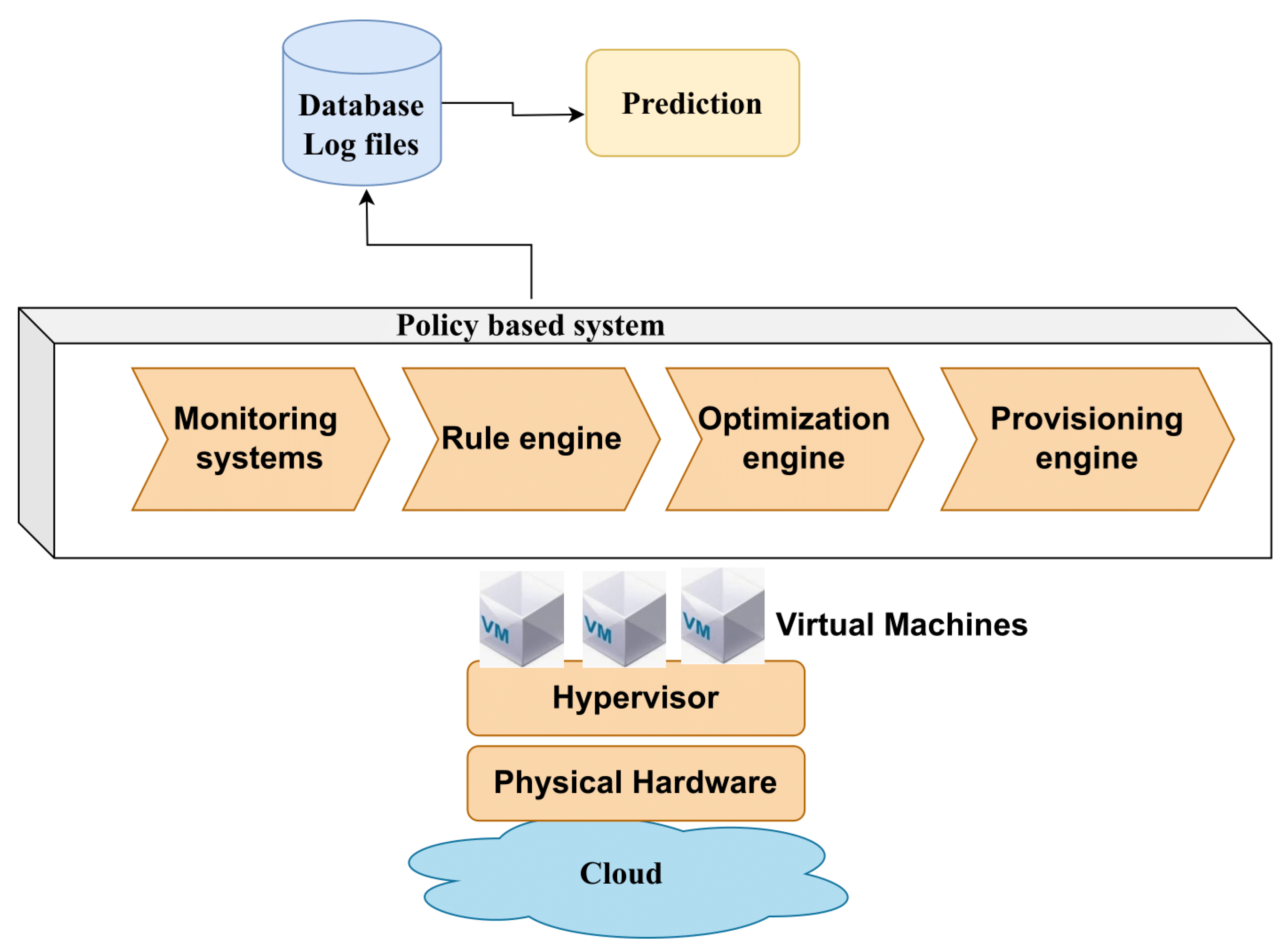
3. Policies and SLA Management
Let us delve into how policies play a pivotal role in SLA management.
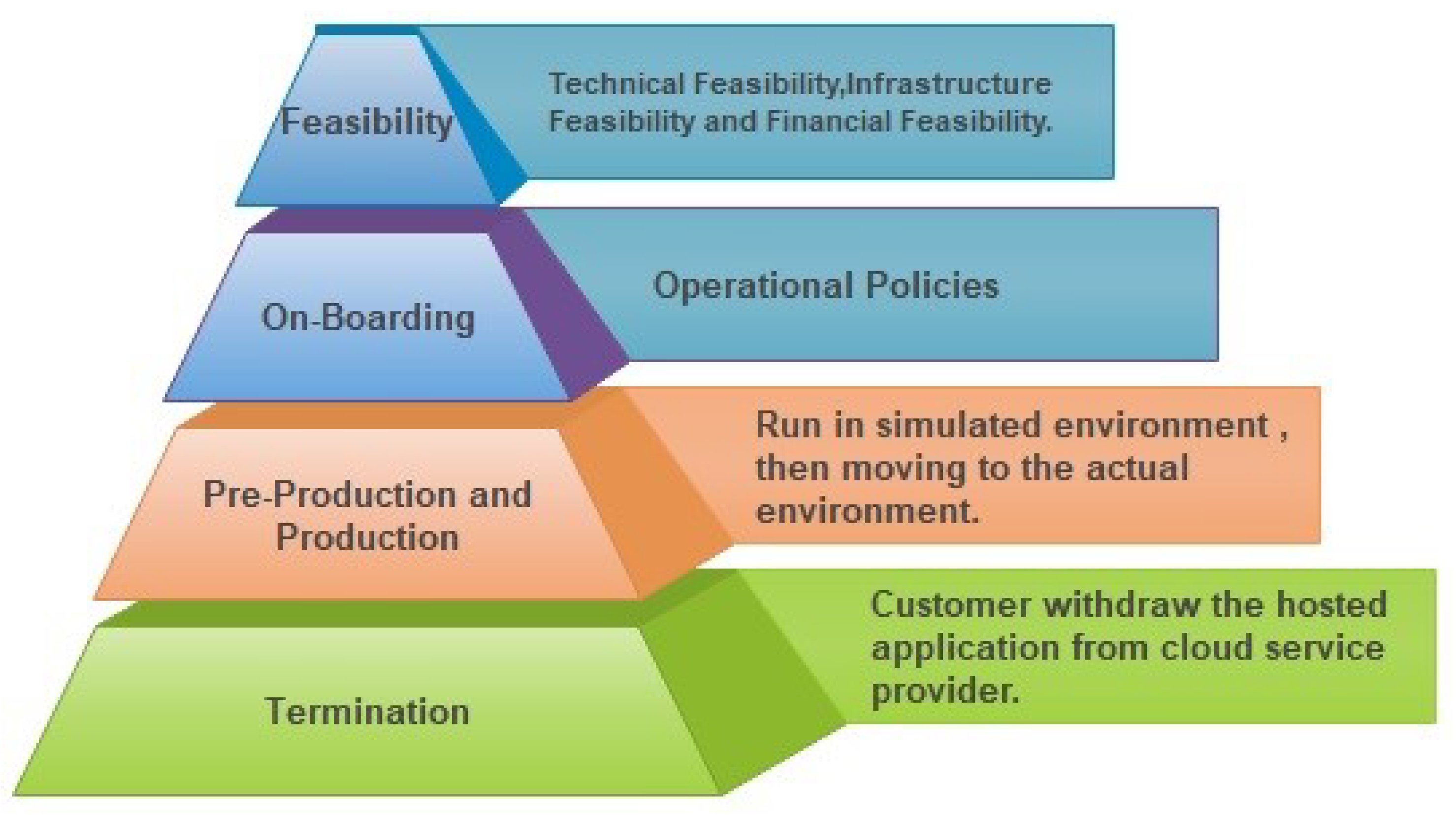
Figure 3 illustrates the four phases through which SLAs govern applications hosted in the cloud: feasibility, on-boarding, pre-production/production, and termination [
23].
As previously discussed, policies are instrumental in making auto-scaling decisions, and it becomes evident that efficient resource utilization hinges on the criteria set by policies [
24], which are chosen based on the metrics in use.
In the realm of cloud computing (CC), service-level agreements (SLAs) and policy management are closely related and play pivotal roles in ensuring the effective and reliable delivery of cloud services. Firstly, SLAs are the written contracts that specify the terms and conditions under which cloud services are provided. These agreements cover a wide range of topics, including data security, response times, performance, and availability. In contrast, policy management is responsible for establishing and upholding the guidelines that control how cloud resources are used. SLAs frequently include policies that specify how services should be provided, what resources can be assigned, and when specific actions should be taken in a CC environment. For instance, to ensure the service complies with the established performance standards, a cloud provider may set up a policy that directs resource allocation based on particular SLA parameters.
Second, to guarantee that cloud services comply with customer expectations and legal requirements, SLAs and policy management work closely together. SLAs establish performance standards, and policies direct cloud infrastructure behavior to achieve those standards. For example, a policy can specify that when the system performance drops below a certain SLA-specified level, more resources have to be allocated automatically. This proactive resource management, based on defined policies, ensures that the SLAs are satisfied when conditions change, like abrupt spikes in user demand.
Finally, due to the dynamic nature of CC, both SLAs and policies must be continuously monitored and adjusted. Policies must adapt to these changing requirements, and SLAs may change as a result of changing client needs. Together, the two offer the responsiveness and flexibility needed in a cloud setting. Effective policy management guarantees resource allocation in accordance with SLAs, and the feedback loop between SLAs and policies enables the continuous optimization of cloud services to meet changing demands while upholding compliance and service quality. As a result, in cloud computing, SLAs and policy management go hand in hand. SLAs establish performance standards, while policies direct resource allocation and service behavior to fulfill those standards. When combined, they empower cloud service providers to offer excellent, adaptable, and flexible services while maintaining compliance with industry norms and client demands.
In
Figure 4, we provide a detailed breakdown of the four phases of the SLA and policy management:
Feasibility Analysis: This phase involves three types of feasibility analysis: technical, infrastructure, and financial. It aims to determine the suitability of resources to ensure that the projected demands of the applications can be met.
On-boarding: On-boarding refers to the process of migrating an application to the cloud, accompanied by the use of corresponding SLAs. This phase also involves the creation of the policies (comprising various rules and operational policies) necessary to ensure the fulfillment of service-level objectives (SLOs) specified in the application’s SLAs.
Pre-Production and Production: In the pre-production phase, the application operates in a simulated environment to test its adherence to the specified SLAs. If this phase proceeds smoothly, the application moves on to the production phase, where it runs in the actual cloud environment.
Termination: When a customer decides to withdraw an application running in the cloud, the termination phase is initiated, leading to the cessation of the application.
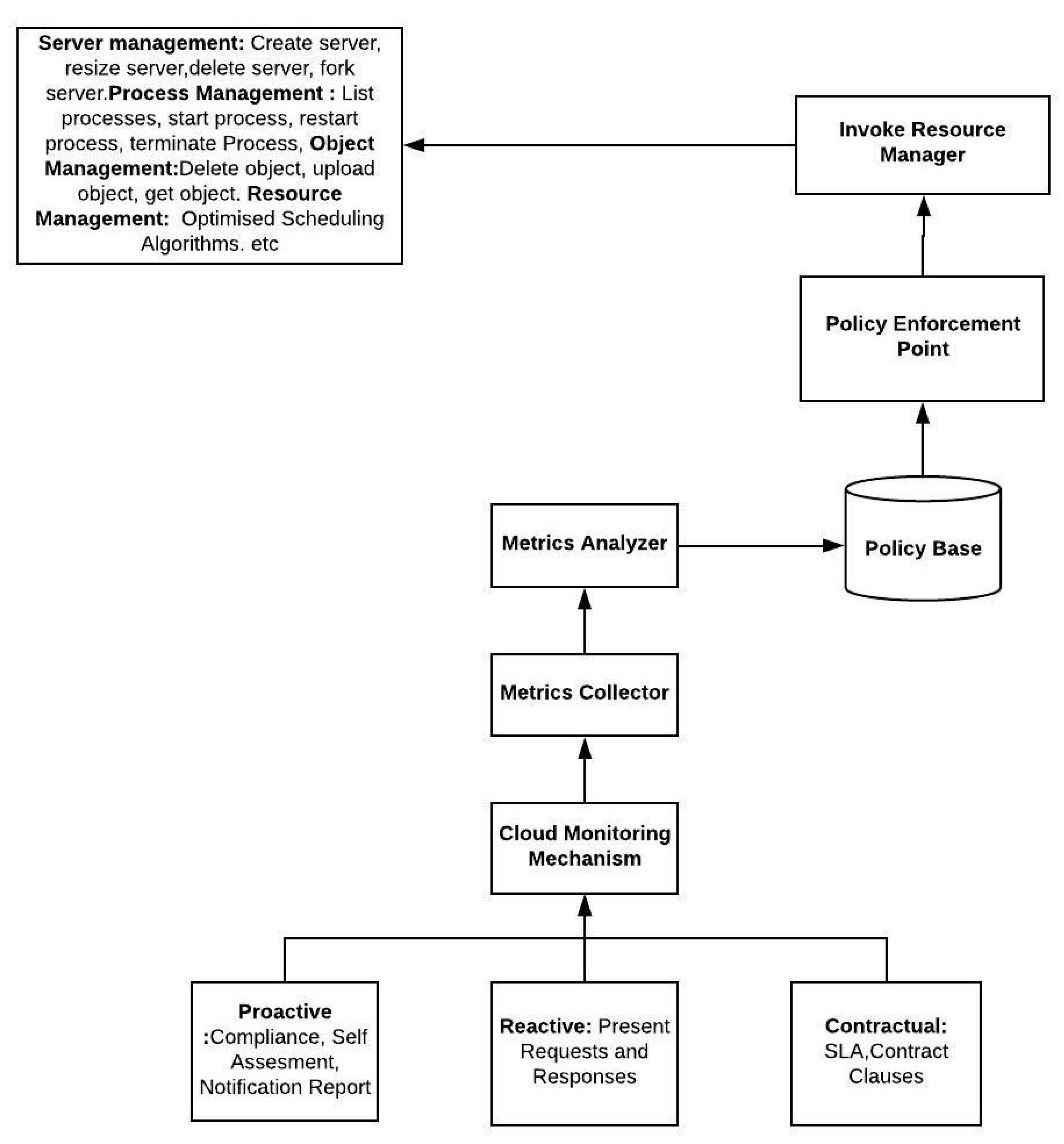
5. Relationship between the Metrics and Policies
The relationship between the metrics and policies in cloud computing (CC) is depicted in
Figure 5. This relationship is a critical aspect of the effective management and optimization of cloud resources [
132]. The monitoring mechanism in the cloud environment is classified into proactive, reactive, and contractual methods:
Proactive: Proactive monitoring involves making decisions based on predefined rules before tasks are allocated to the cloud environment.
Reactive: Reactive monitoring entails making decisions by observing the current requests and their response parameters.
Contractual: Contractual monitoring relies on decisions based on service-level agreements (SLAs).
In the monitoring process, the current state is observed, and subsequently, the metrics collector is triggered, which then activates the metrics analyzer. The metrics analyzer identifies the appropriate policies and parameters necessary to fulfill the requirements of the end users’ requests. Finally, the request is transmitted to the resource manager, as illustrated in
Figure 5.
Table 4,
Table 5 and
Table 6 present the various metrics [
133] used in CC environments, along with the associated policies and descriptions for each metric. The terminology for identifying threshold values and creating policies is crucial, and dynamic threshold mechanisms are utilized to adapt to varying workloads.
The formulation of these policies hinges upon the precise determination of threshold values. This determination process, involving conditions such as “X should be less than or equal to” or “greater than,” assumes a pivotal role in policy creation. The complexity of this task necessitates the use of dynamic threshold mechanisms.
Notably, cloud environments are dynamic and subject to evolving workloads. Consequently, the application of static thresholds, which remain constant over time, may prove to be inadequate in effectively managing the performance of cloud resources. To address this challenge, dynamic or adaptive thresholds are introduced. These adaptive thresholds are established based on the observed behavior of the cloud environment and the specific metrics under consideration. This dynamic approach ensures that performance policies remain relevant and responsive to the ever-changing demands and conditions within the cloud infrastructure.
Dynamic thresholds indeed play a crucial role in adjusting to the changing conditions and demands within a cloud environment. These thresholds are designed based on the statistical analyses of the goal line metrics, which are akin to the benchmarks established during the baseline period. The baseline period is determined under ideal environmental conditions and serves as the reference point for evaluating the system’s performance over a specific time frame. The concept of moving the window baseline phases involves assessing the performance based on the variance from a certain number of days preceding the present date. This approach enables a more responsive and adaptive mechanism for regulating the system’s performance in dynamic cloud environments.
Not all metrics within the context of cloud computing require the implementation of dynamic thresholds; rather, their necessity is contingent upon the specific criteria outlined in the research. These criteria include factors such as the magnitude of the load the system is handling, the specific types of load being processed, the overall utilization of system resources, and the responsiveness of the system, as indicated by its response time. These key considerations play a crucial role in determining whether a particular metric would benefit from the adoption of dynamic thresholds, thereby ensuring an adaptive and responsive approach to managing the performance of cloud resources. Such insights are discussed in detail in various research papers within the domain.
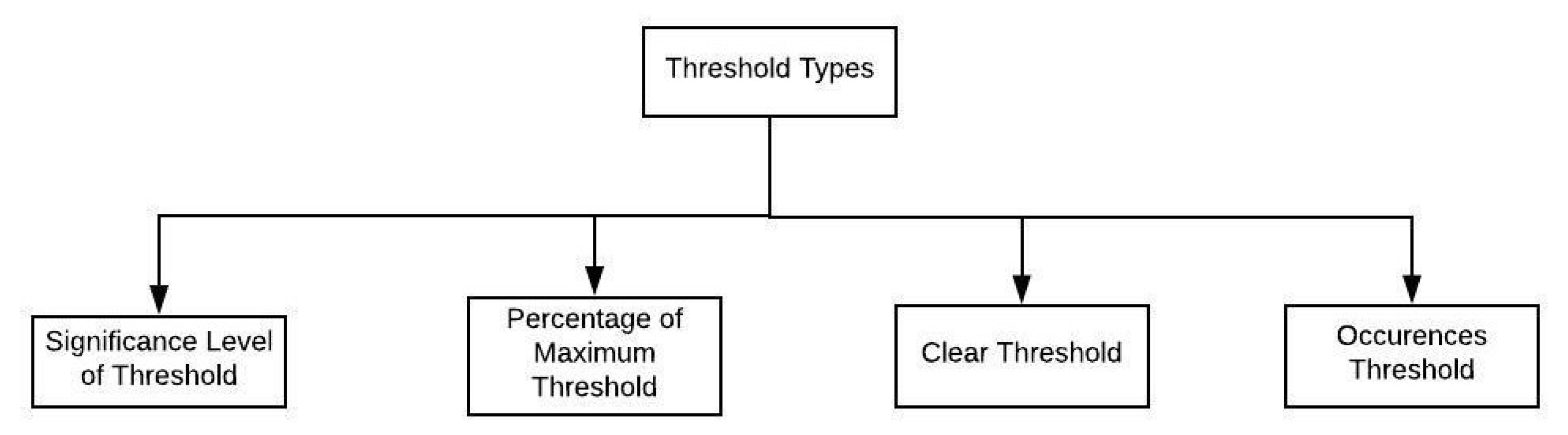
Figure 6 visually presents the diverse kinds of threshold values employed within a cloud environment. The significance level of these thresholds is crucial in determining the statistical implications, enabling the identification of present values that deviate significantly from the norm. Additionally, the percentage of the maximum threshold is utilized to gauge the proportion of the highest practical value attainable within a specified time frame, thereby aiding in the assessment of the performance bounds.
Clear thresholds indicate a state where no alert will be generated, and historical data are not removed. Occurrences thresholds check the successive quantity of occurrences before raising an alert. Based on the discussions above, threshold values can be generated and used for setting policies for the respective metrics. These metrics and policies can serve market-oriented cloud computing.
Table 4,
Table 5,
Table 6 and
Table 7 provide a comprehensive overview of the various metrics and policies, and their descriptions, encompassing a wide array of features and aspects in cloud computing environments.
6. Market-Oriented Architecture for the Data Centers
An application of SLA management and policies is the implementation of a market-oriented architecture (MOA). MOA is a pioneering approach to data center management that incorporates service-level agreements (SLAs) and operational standards. MOA emerges as a fundamental paradigm in the constantly evolving world of cloud computing (CC) and data center management, supporting the optimization of resource allocation, cost effectiveness, and customer satisfaction.
MOA makes use of a market-based system in which resources are treated as commodities, and allocation is governed by dynamic pricing models. By including SLAs in this architecture, data center operators may provide predictable performance assurances to clients, increasing trust and reliability. Operational policies are critical components of this architecture because they specify the rules that govern resource allocation, provisioning, and de-provisioning. These policies are crucial in balancing cost optimization and achieving SLAs, ensuring that the data center works in accordance with the business objectives.
MOA is further supported by significant data analytics and machine learning algorithms that examine historical data as well as real-time performance measurements. These analytics help not only estimate resource demands but also fine-tune pricing techniques to optimize resource utilization. MOA emerges as a powerful framework to address the complexities of modern data center management, contributing significantly to both cost efficiency and customer satisfaction, with its emphasis on market-driven resource allocation, SLA adherence, and data-driven decision making.
Data centers serve as the foundational infrastructure for cloud computing (CC) services. They are the backbone that supports the delivery of cloud services to users.
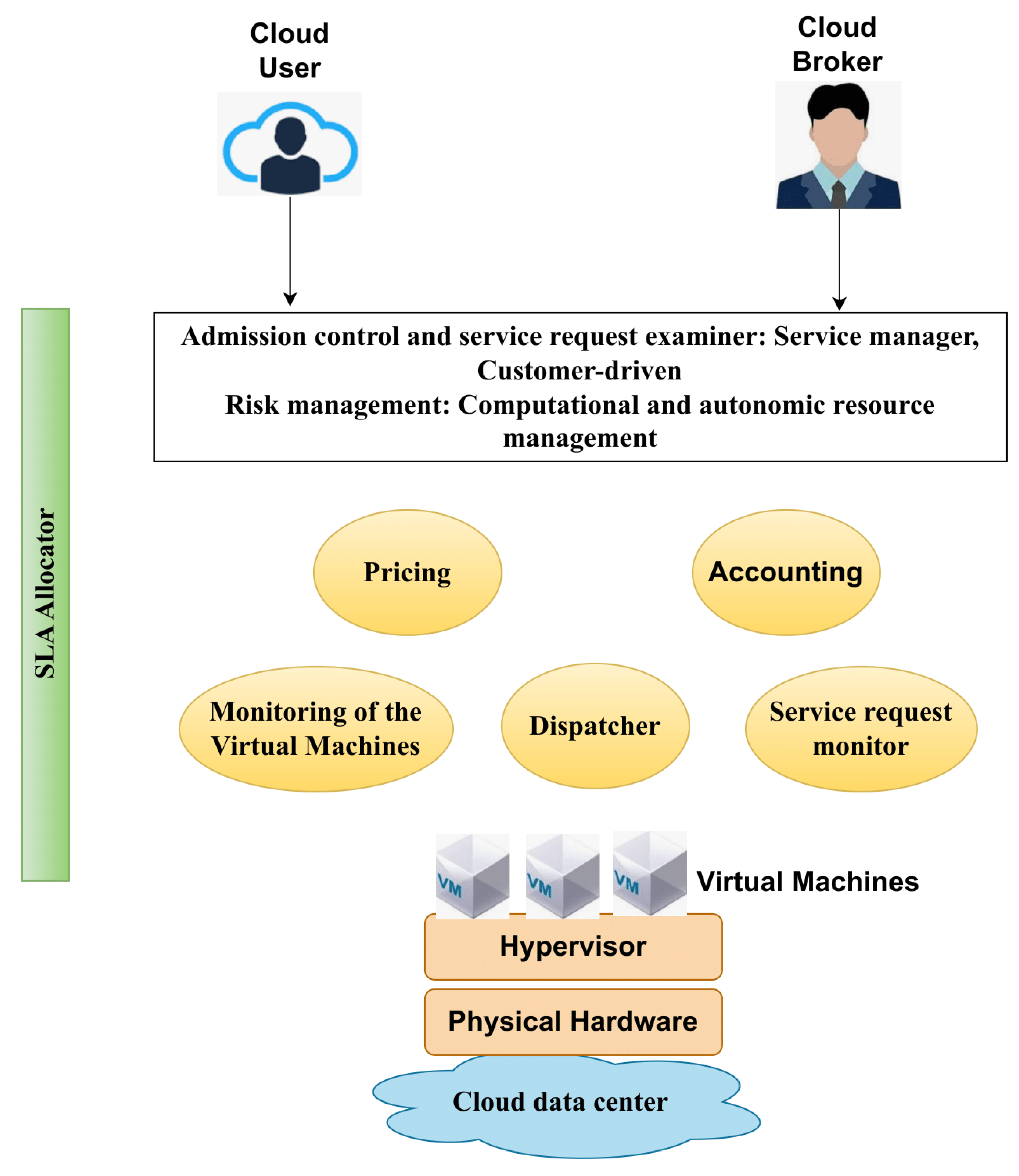
Figure 7 provides an overview of the key components supporting MOA (market-oriented architecture) in the context of CC data center management [
134]. These components work together to optimize resource allocation, ensure adherence to service-level agreements (SLAs), and enhance overall data center efficiency. This reference architecture illustrates how MOA integrates SLAs, operational policies, and dynamic resource allocation into the data center environment, contributing to the effective and market-driven management of cloud resources.
Here are the descriptions of the significant components within this architecture:
Users and Brokers: These entities play a crucial role in initiating workloads that the data center will manage. They are responsible for interacting with the data center and making requests for various cloud services.
SLA Resource Allocation Mechanism: This component serves as the vital interface between the cloud service provider and the data center [
135]. Its primary objective is to ensure that the services provided align with the service-level agreements (SLAs) agreed upon with the clients. It facilitates the allocation of resources in accordance with these SLAs.
Admission Control Module and Service Request Examiner: This module evaluates the current state of the data center, including the availability of resources. It is responsible for scheduling and allocating requests for execution based on the available resources and the defined SLAs.
Module for Pricing: This component is responsible for determining the charges for users based on the terms specified in their SLAs. It considers parameters, such as virtual machines, memory, computing capacity, disk size, and usage time.
Accounting Module: This module generates billing data based on the actual resource usage by the users. It plays a critical role in maintaining transparency and accuracy in billing processes.
Dispatcher: The dispatcher is responsible for instructing the infrastructure to deploy the necessary machines to fulfill user requests. It plays a significant role, particularly in the case of Infrastructure as a Service (IaaS), by managing the allocation of resources.
Resource Monitor: This component is continuously engaged in monitoring the status of computing resources, including both physical and virtual resources. It plays a critical role in ensuring the optimal utilization and performance of the available resources.
Services of Request Monitor: This component tracks the progress of service requests, providing valuable insights into the system’s performance and offering quality feedback on the provider’s capabilities. It helps in maintaining a high level of service quality and user satisfaction.
Virtual Machines (VMs): VMs are fundamental units within the cloud computing (CC) infrastructure. They serve as the building blocks for addressing various user requirements and enabling the provisioning of different cloud services.
Physical Machines: At the lowest level of the architecture, the physical machines constitute the core physical infrastructure, which can encompass one or more data centers. This layer provides the necessary physical resources required to meet the demands of the users and the services they request.
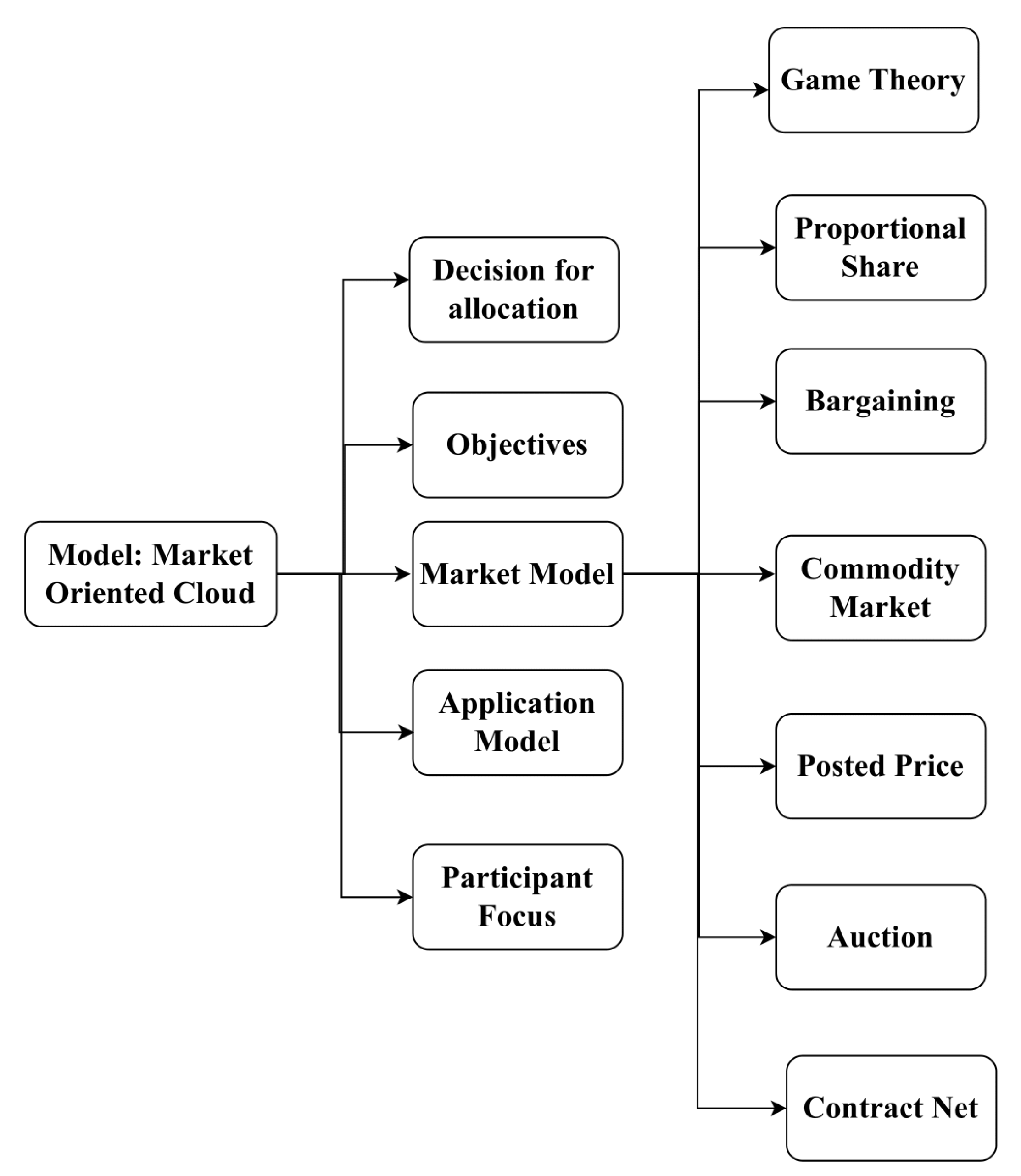
In [
23], an analysis and the taxonomy of the schedulers were presented, as depicted in
Figure 8. These schedulers were classified based on their allocation decisions, market models, objectives, participant focus, and application models. Notably, the market model plays a critical role in facilitating trade between providers and users within the cloud computing environment. The classification of market models was outlined as follows:
Game Theory: Users engage in a provision game with various payoffs based on specific actions and different strategies. Game theory provides a framework for understanding strategic interactions among rational decision-makers.
Proportional Share: This approach aims to allocate tasks fairly across a set of resources, with shares directly related to the user’s bid. It ensures proportional distribution based on user demands and resource availability.
Market Commodity: Cloud data center providers charge consumers based on their resource usage, and these charges may vary over time. This model allows for flexible pricing that can adapt to changes in demand and resource availability.
Posted Price: Similar to the market commodity model, the posted price approach may include special discounts and offers for specific users. It offers transparency in pricing and allows users to make informed decisions based on the available options.
Contract Net: End users advertise their requirements and invite resource owners to submit bids. Resource owners respond based on their resource availability and capabilities. The end user then consolidates the bids and selects the most favorable one, creating a contractual agreement.
Bargaining: Negotiations between providers and resource consumers determine the final resource price. This model allows for flexibility and mutual agreement between the parties involved, ensuring that both parties benefit from the transaction.
Auction: Initially, resource prices are unknown, and competitive bids, regulated by a third party (the auctioneer), determine the final price. Auctions provide a competitive environment where users can bid based on their willingness to pay, resulting in optimal resource allocation and fair pricing.
Service-level agreements (SLAs) are integral to the operation of e-commerce cloud-hosted applications and market-oriented cloud design architectures. These agreements, coupled with cloud metrics and policies, ensure that cloud services meet performance and reliability standards. Comprehensive details regarding SLAs, including specific metrics and economic considerations, are elaborated in
Table 3 and
Table 6. These tables provide a structured framework for understanding the relationships between SLAs, metrics, and policies within the context of cloud computing.
7. Case Study: Utilizing Metrics, Policies, and Machine Learning for IoT-Based Cloud Monitoring
This case study outlines the pivotal role of metrics, policies, and machine learning in the context of IoT-based cloud monitoring. The integration of these elements is vital for ensuring the seamless operation, performance optimization, and reliability of IoT applications within cloud computing ecosystems. By leveraging metrics and service-level agreement (SLA) management, organizations can achieve comprehensive monitoring capabilities, enabling the real-time analysis of IoT device and cloud service performance. This capability is crucial for timely issue detection and resolution, preventing disruptions that could impact the functionality of IoT applications.
Furthermore, the dynamic scaling of cloud resources, facilitated by these systems, allows for efficient resource allocation and optimization in response to fluctuating demands from IoT devices. This dynamic resource allocation not only enhances the overall system efficiency but also contributes to cost effectiveness, a critical aspect of resource management. Additionally, metrics and SLA management serve as guardians of the quality of service (QoS) standards, defining, monitoring, and ensuring compliance with stringent performance and reliability criteria that are essential for high-quality IoT applications.
In terms of security and privacy, these systems play a significant role by integrating security and privacy provisions into SLAs, safeguarding sensitive IoT data from unauthorized access or breaches. They also facilitate cost control by providing accurate usage statistics and cost metrics, allowing organizations to monitor and regulate cloud expenditure effectively. The architecture incorporates fault detection and recovery mechanisms, swiftly identifying performance deviations and implementing recovery protocols in the event of service outages, thereby minimizing downtime and interruptions.
Moreover, these systems facilitate continuous improvement by analyzing performance data, identifying areas of weakness, and enabling informed decisions and adjustments to enhance the scalability, reliability, and performance of IoT and cloud services over time. Lastly, metrics and SLA management support capacity planning by offering valuable insights into usage patterns and resource requirements, enabling organizations to ensure that their IoT applications and cloud services are equipped to handle future growth and evolving needs.
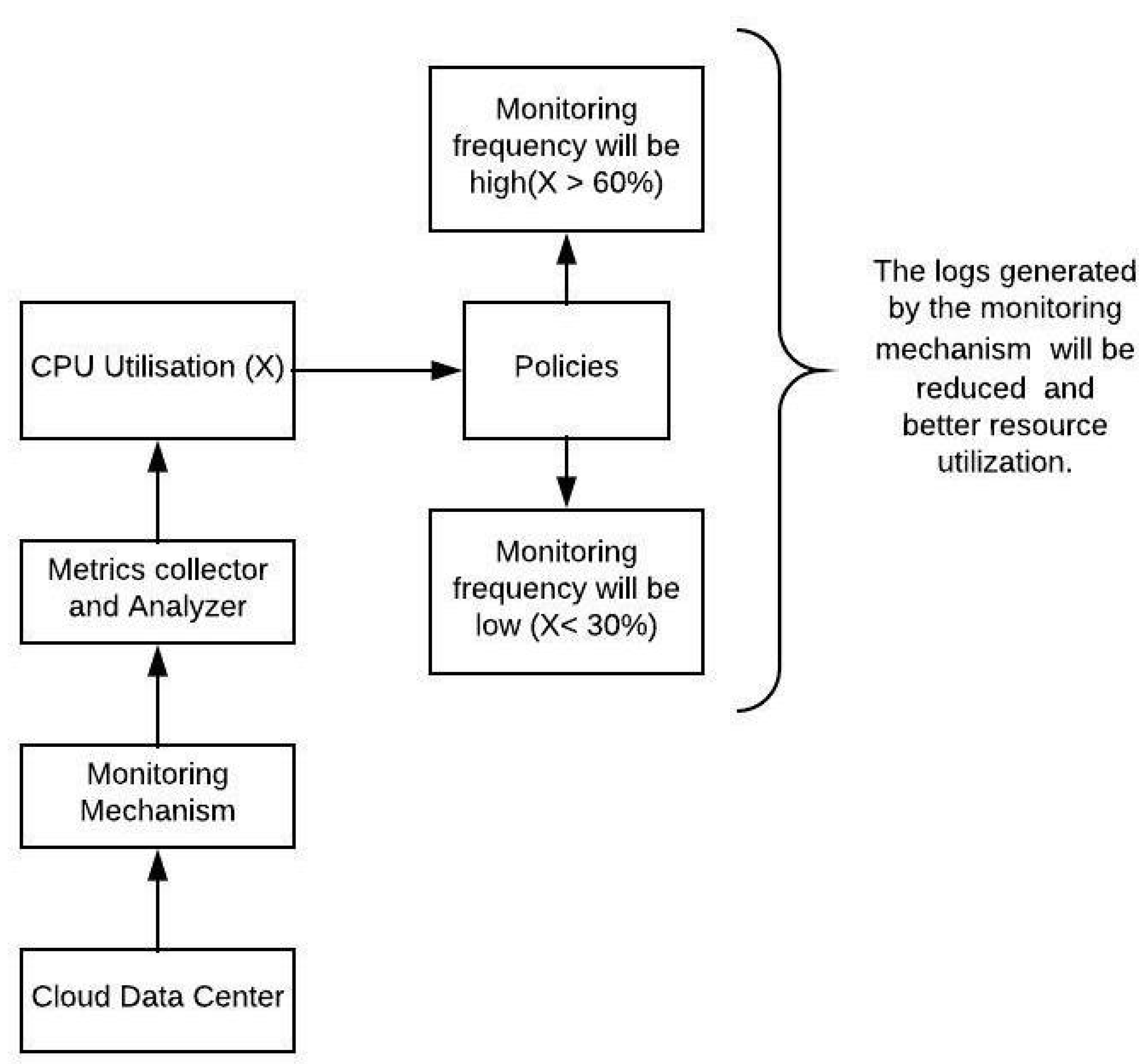
Cloud monitoring is a vital component in the effective management of cloud-based systems, enabling the efficient handling of dynamic scheduling, cross-layer monitoring, and the identification of diverse fault scenarios [
136]. The case study presented here highlights the significant role of metrics and policies within cloud computing, specifically focusing on their application in addressing the challenge of monitoring overhead. By leveraging these metrics and implementing effective policies, organizations can enhance their ability to ensure optimal performance, reliability, and security within their cloud environments.
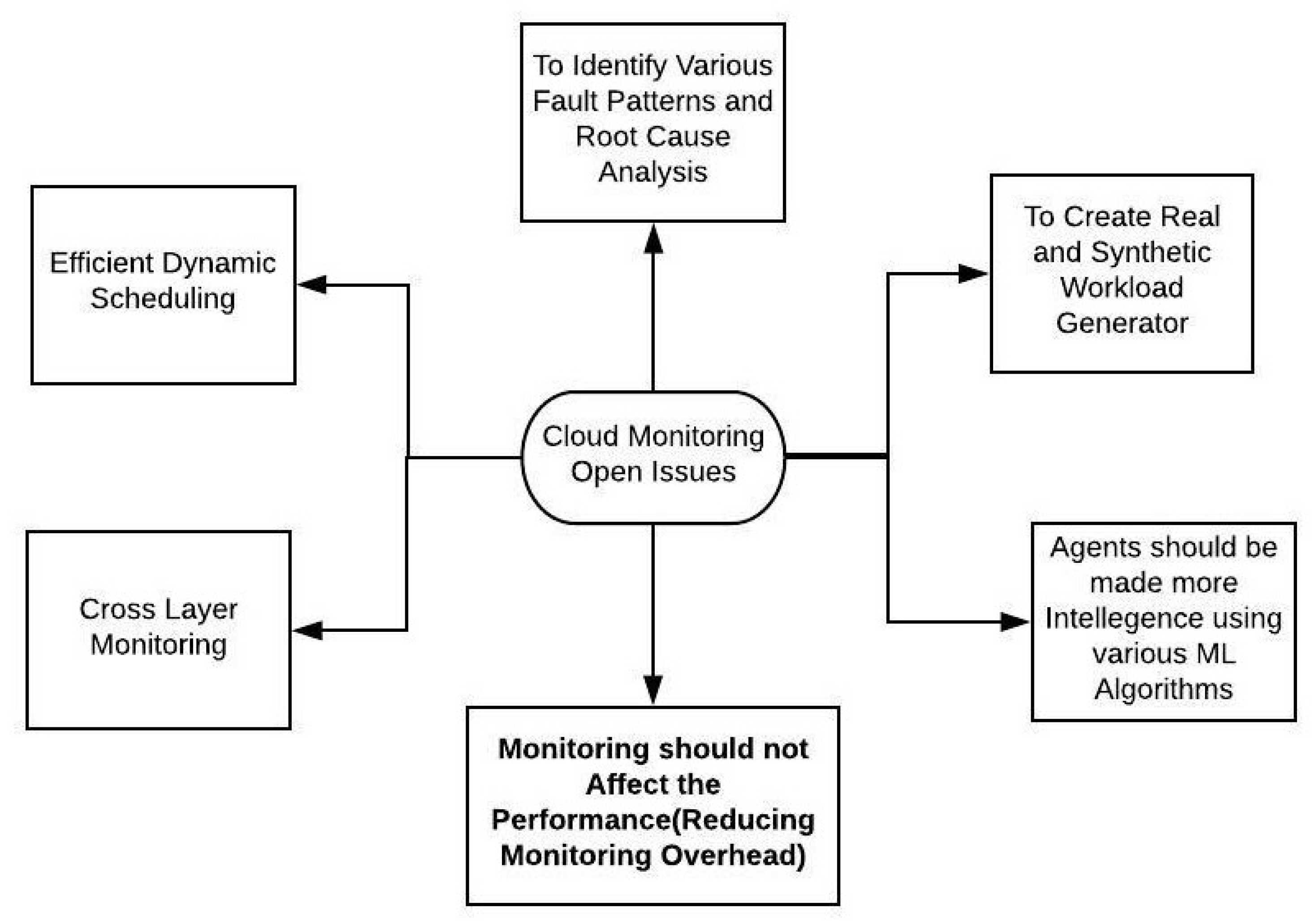
The visual depiction in
Figure 9 effectively highlights critical open issues in cloud monitoring, such as pattern and root cause analysis, workload generation, intelligent agents, and the reduction in monitoring overhead. These challenges underscore the importance of implementing efficient metrics and policies to effectively address these concerns and optimize the overall performance of cloud-based systems.
7.4. Solution Approach
The ubiquity of the Internet of Things (IoT) has revolutionized the way in which everyday activities are interconnected. IoT devices, equipped with sensors, software, and embedded electronics, seamlessly gather, transmit, and process large volumes of data, often referred to as “big data.” However, this data deluge presents a significant challenge for both internet infrastructure and cloud computing (CC) systems. To effectively manage this surge in data, CC systems must navigate the complexities of handling substantial network traffic while upholding stringent quality of service (QoS) standards. Consequently, the efficient management of resources becomes a critical priority. In this context, the various parameters of Infrastructure as a Service (IaaS) cloud systems have been meticulously considered to devise a comprehensive solution approach.
7.4.2. Machine Learning Predictions
Workload Utility Levels and Metrics: The identification of workload utility levels, including low utility, moderate utility, or high utility, in the context of CC, involves a complex process influenced by various metrics and policies. These components form the basis for cloud resource allocation and optimization strategies, taking into consideration resource utilization factors, such as CPU, network bandwidth, and other Infrastructure as a Service (IaaS) resources. Cloud providers rely on a wide range of resource utilization metrics to accurately classify workloads. CPU utilization serves as a critical metric in these measurements, delineating the differences between low-utility tasks with occasional, minor CPU demands and high-utility workloads that necessitate persistent and substantial CPU resources. Similarly, network bandwidth consumption is an essential indicator, with high-utility applications consistently requiring more network throughput than their low-utility counterparts.
Resource Allocation Policies: The thorough assessment of workload utility levels encompasses metrics for storage, memory, and I/O activities, providing a comprehensive understanding of resource requirements. Cloud resource allocation policies are meticulously designed to align with workload utility levels. Low-utility workloads often favor resource consolidation and cost reduction, promoting resource sharing and dynamic allocation. On the other hand, average-utility workloads are met with balanced resource allocations, ensuring optimal performance while optimizing costs. High-utility workloads, which demand continuous and high-performance delivery, typically receive dedicated and premium resource allocations.
Role of Machine Learning and Predictive Analytics: Machine learning and predictive analytics play a crucial role in forecasting workload utility levels with a degree of accuracy. By analyzing historical data, cloud providers can identify consumption trends, enabling automated resource allocation decisions. This data-driven approach ensures that the cloud ecosystem can swiftly respond to changes in workload utility levels. The inherent agility of the cloud allows for real-time adjustments in resource allocation, which is invaluable for adapting to fluctuations in workload utility levels.
Dynamic Resource Scaling: When workloads display indications of transitioning across utility categories, policies can be established to trigger resource scaling. For instance, if a typical utility application experiences sudden spikes in the CPU or network demand, automated scaling mechanisms are activated to ensure uninterrupted resource provision. These mechanisms guarantee that the application continues to receive the necessary resources without interruption, maintaining performance levels.
Customer-Centric Utility Levels: The classification of workload utility levels within a user-centric paradigm is closely linked to customer-defined service-level agreements (SLAs). Users define their desired utility levels based on resource performance and availability, directly influencing how the cloud manages workloads. This approach ensures that consumers receive the promised utility level, aligning with their operational requirements and resource investment preferences.
Optimizing Resource Allocation: To summarize, defining workload utility levels within the cloud ecosystem is a multifaceted process supported by measurements, policies, and advanced analytics. It represents an ongoing effort aimed at enhancing resource allocation while maintaining a balance between cost effectiveness and performance, all while remaining responsive to the evolving demands and expectations of cloud customers.
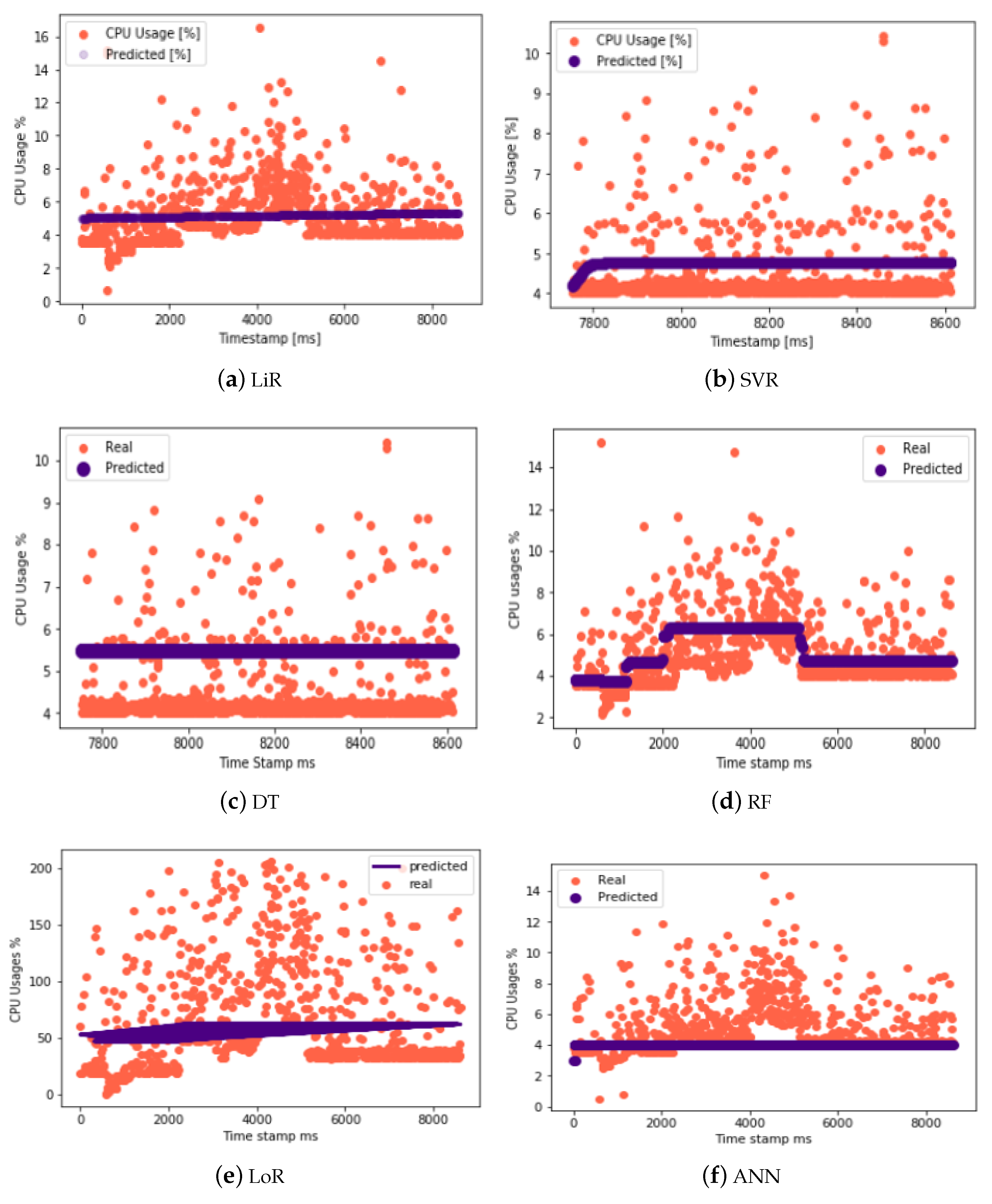
Incorporating a diverse range of machine learning (ML) algorithms is crucial for accurate workload prediction. The utilization of various algorithms such as Linear Regression (LiR), Support Vector Regression (SVR), Decision Tree (DT), Random Forest (RF), Logistic Regression (LoR), and Artificial Neural Network (ANN) enables the comprehensive analysis and forecasting of the workload. These algorithms, when applied to the dataset, facilitate precise and robust workload predictions, ensuring the effective management and allocation of resources within the cloud ecosystem.
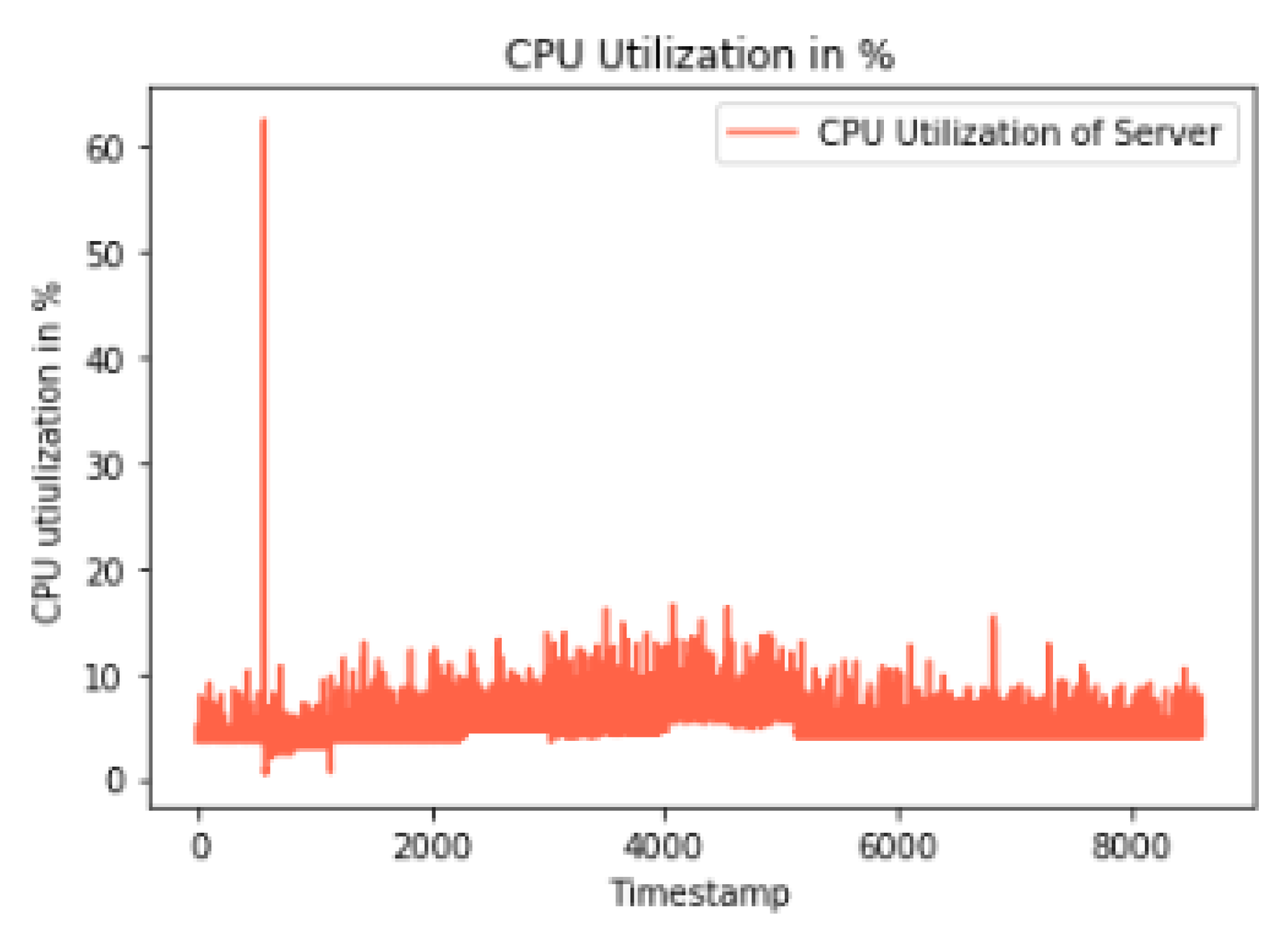
Figure 12 illustrates the predictions for CPU utilization using a range of machine learning techniques, including Linear Regression (LiR), Support Vector Regression (SVR), Decision Tree (DT), Random Forest (RF), Logistic Regression (LoR), and Artificial Neural Network (ANN). These predictive models enable accurate forecasting of the CPU utilization, providing valuable insights into the resource demands and usage patterns within the cloud environment.
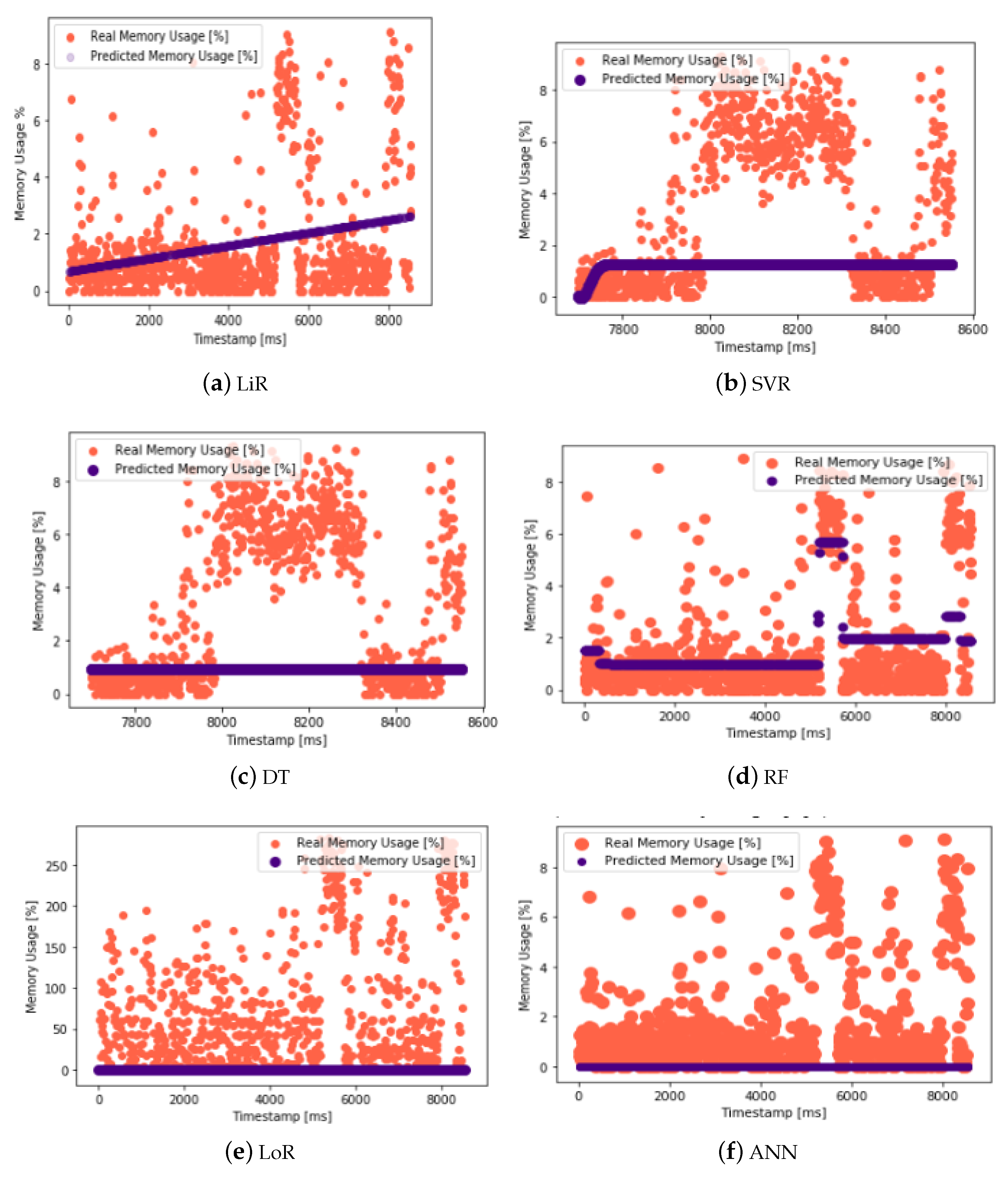
Figure 13 demonstrates the predictions for memory usage using various machine learning techniques, including Linear Regression (LiR), Support Vector Regression (SVR), Decision Tree (DT), Random Forest (RF), Logistic Regression (LoR), and Artificial Neural Network (ANN). These predictive models enable the accurate forecasting of memory utilization, providing insights into the memory usage trends and patterns within the cloud infrastructure.
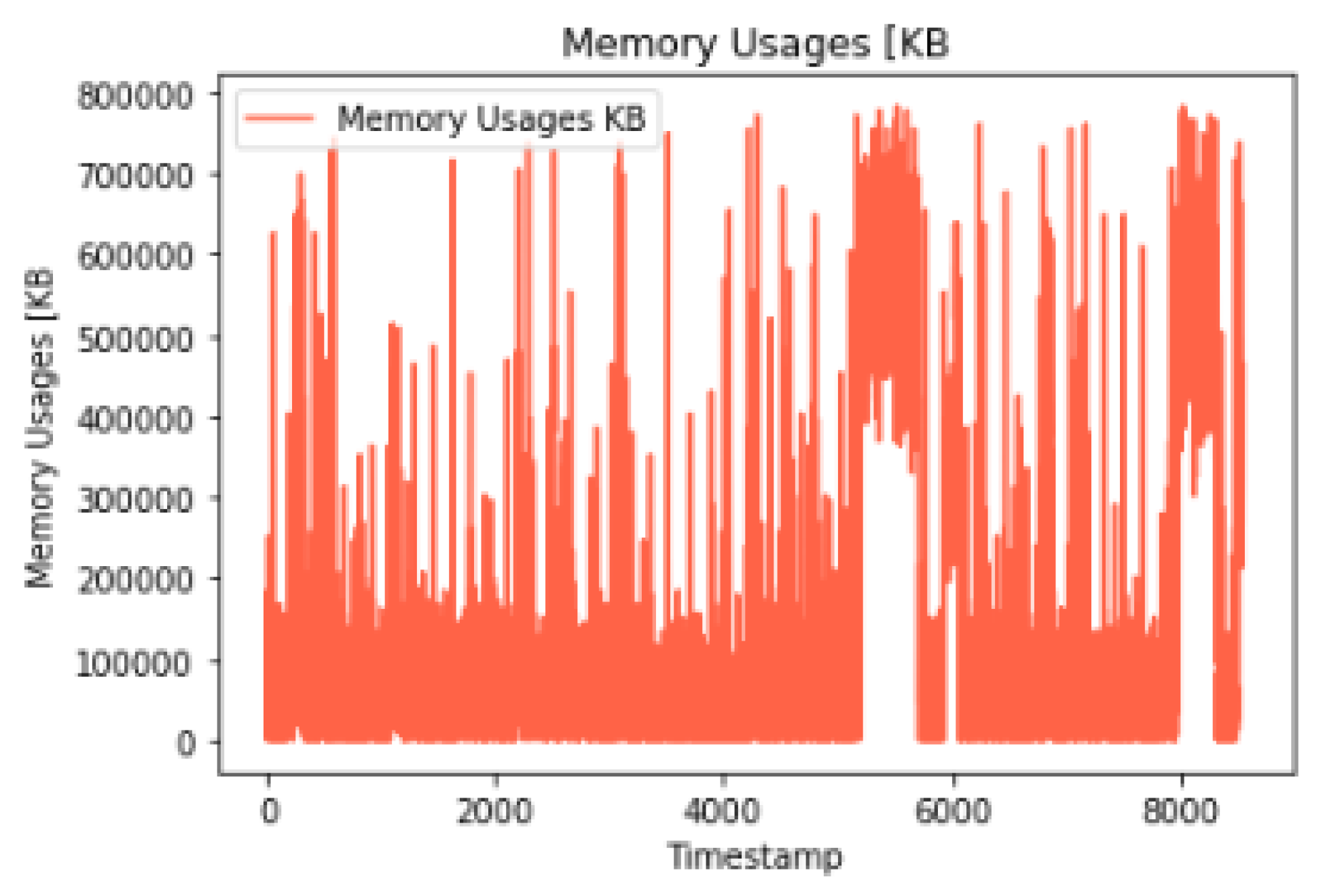
Figure 14 presents the memory utilization data, demonstrating the patterns and trends in memory usage over a specific period. The visualization offers valuable insights into how memory resources are being utilized within the cloud environment, aiding in the assessment of memory allocation and requirements. Understanding memory utilization is critical for optimizing resource allocation and ensuring the efficient performance of cloud-based applications and services.
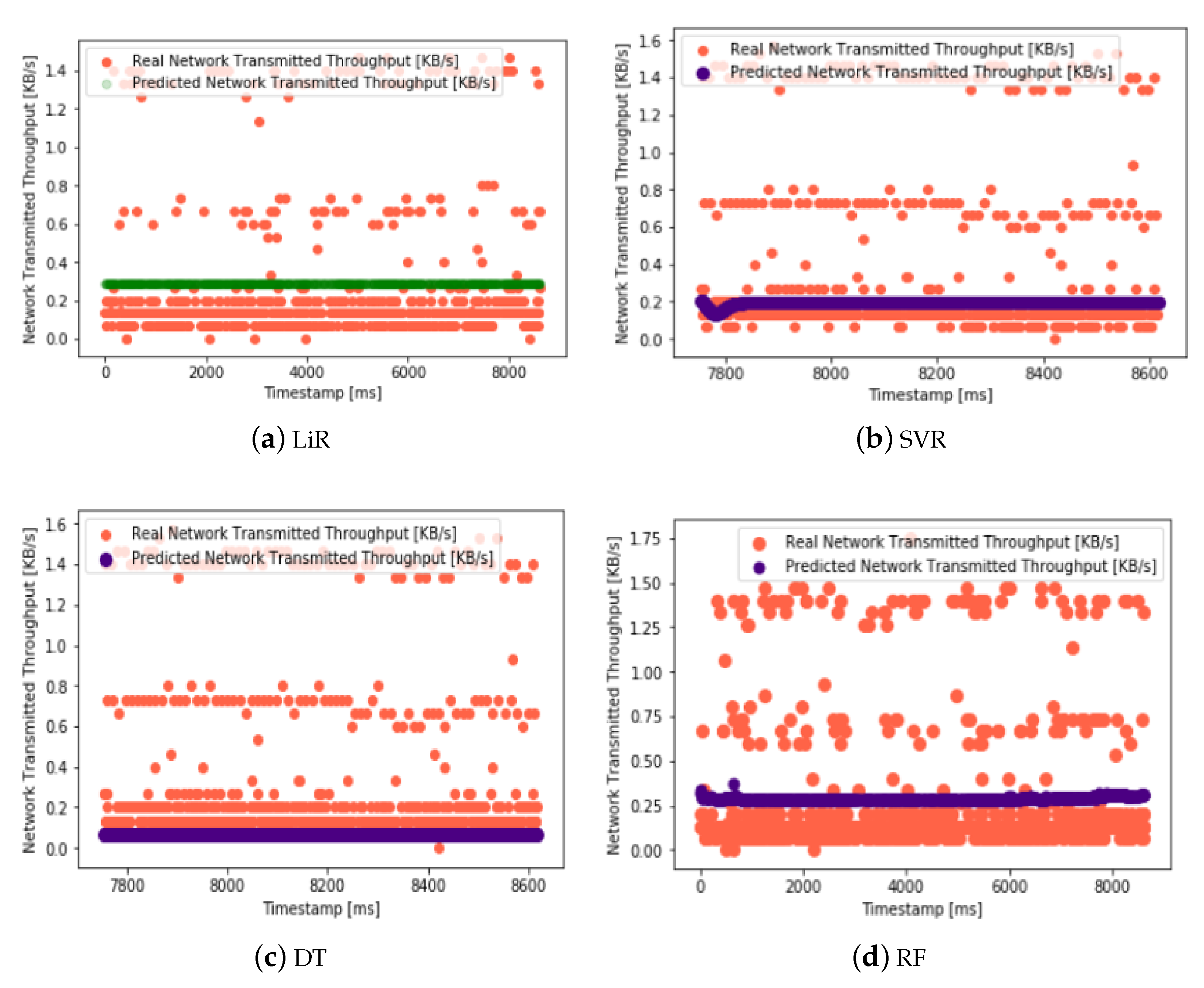
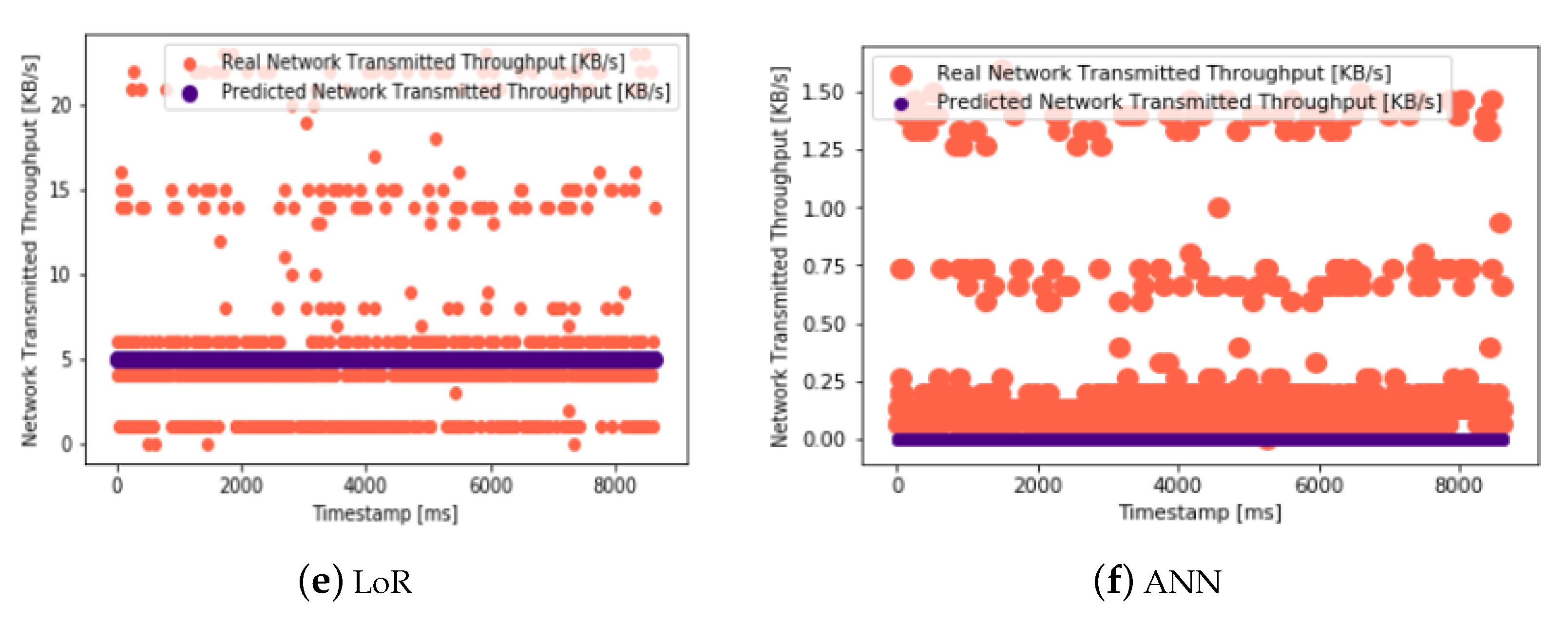
Figure 15 presents the predictions for the network-transmitted throughput, utilizing various machine learning techniques, including Linear Regression (LiR), Support Vector Regression (SVR), Decision Tree (DT), Random Forest (RF), Logistic Regression (LoR), and Artificial Neural Network (ANN). These predictions offer valuable insights into the anticipated network throughput trends and patterns within the cloud infrastructure, aiding in the proactive management and optimization of network resources.
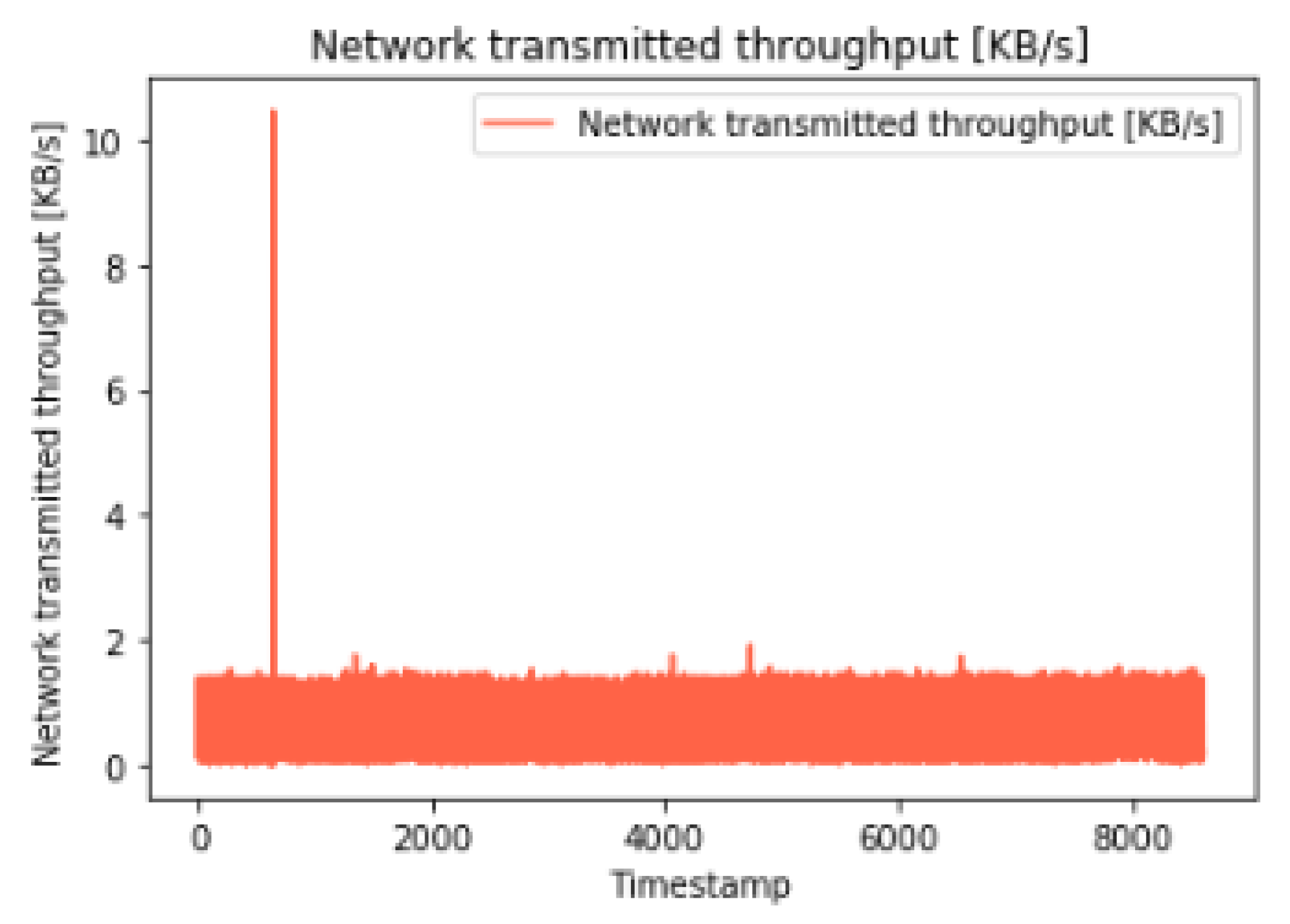
Figure 16 depicts the network-transmitted throughput within the cloud environment, illustrating the dynamic changes and fluctuations in the network data transmission rates over a specific time period. The graph serves as a visual representation of the actual network throughput data, providing insights into the overall network performance and data transmission patterns, which are crucial for understanding the network’s efficiency and capacity utilization.
7.6. Evaluation of Machine Learning Predictions
Evaluating the prediction accuracy of machine learning models is essential in ensuring the reliability and effectiveness of the proposed approach. By assessing metrics such as the Root Mean Square Error (RMSE) and Mean Absolute Error (MAE), this study can effectively quantify the extent of the prediction errors, thus providing valuable insights into the performance of various machine learning algorithms in forecasting resource parameters. Lower values of the RMSE and MAE signify improved predictive accuracy and model performance, thereby establishing the credibility of the predictive models in the context of resource monitoring and management in cloud environments.
Table 8 evaluates the prediction accuracy of different ML approaches for CPU utilization. The evaluation metrics used are the Root Mean Square Error (RMSE) and Mean Absolute Error (MAE). These metrics help us understand how close the predicted values are to the actual values, with lower values indicating better prediction accuracy. In this table, we observe that SVR (Support Vector Regression) has the lowest RMSE and MAE values compared to the other ML models. This indicates that SVR provides the most accurate predictions for CPU utilization among the models evaluated. Lower RMSE and MAE values mean that the predicted values closely match the actual CPU utilization, which is crucial for efficient resource management in a cloud environment.
Table 9 assesses the prediction accuracy of the different ML models for memory usage, similar to
Table 8. Again, the RMSE and MAE are used as the evaluation metrics, with lower values indicating better prediction accuracy. In this table, we can see that SVR (Support Vector Regression) has the lowest RMSE and MAE values for the memory usage predictions. This suggests that SVR is the most accurate model for predicting memory usage, providing predictions that closely align with the actual values.
Similar to
Table 8 and
Table 9,
Table 10 evaluates the prediction accuracy of the various ML models but this time for network-transmitted throughput. The RMSE and MAE are once again used as metrics to assess the accuracy. In
Table 10, SVR (Support Vector Regression) consistently stands out as the model with the lowest RMSE and MAE values for the network-transmitted throughput predictions. This means that SVR excels in accurately predicting the network-transmitted throughput values, which is critical for maintaining efficient network resource management.
In summary, across all three tables, SVR consistently demonstrates the highest prediction accuracy among the evaluated ML approaches. This indicates that SVR is a robust choice for predicting CPU utilization, memory usage, and network-transmitted throughput in cloud environments, making it a valuable tool for optimizing resource allocation and reducing monitoring overhead.
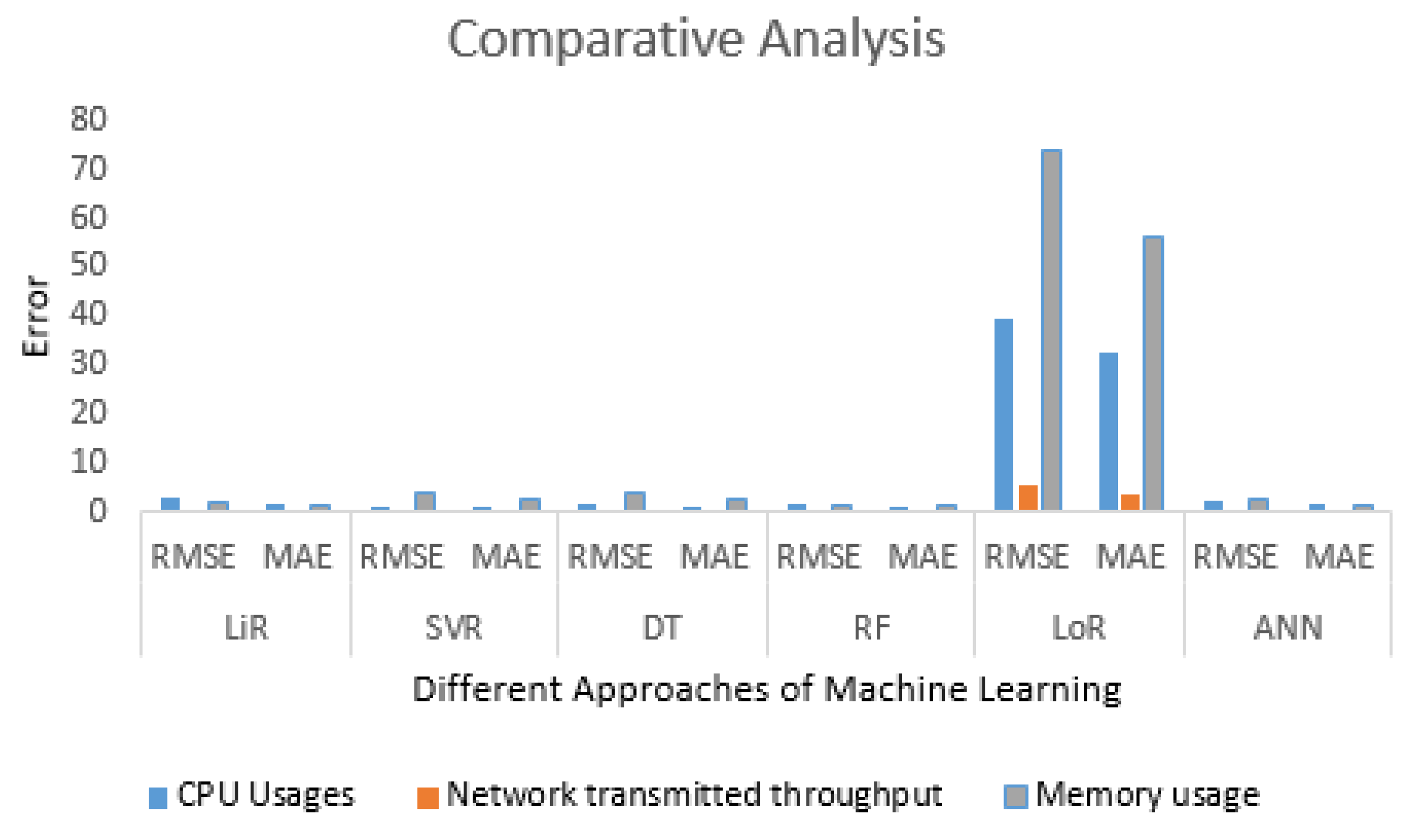
Figure 17 offers an overall comparison of the entire parameter set, encompassing CPU usage, memory usage, and network-transmitted throughput, across various ML techniques. It is evident that ANN, RF, and SVR consistently outperform the other ML techniques in terms of prediction accuracy. These predicted values, reflecting cloud resource parameters—CPU usage (in percentage), memory usage (in percentage), and network-transmitted throughput (in KB/s)—serve as input for the metrics, guiding resource management actions within the cloud.
Forecast accuracy and reliability are critical in the field of cloud workload prediction. To do this, we use a diverse set of machine learning (ML) algorithms, each chosen for its own capabilities and adaptability to distinct data features. Linear Regression (LiR), Support Vector Regression (SVR), Decision Tree (DT), Random Forest (RF), Logistic Regression (LoR), and Artificial Neural Network (ANN) are examples of these algorithms. Support Vector Regression, for example, captures non-linear patterns, while Linear Regression establishes a linear link between input characteristics and workload. Logistic Regression can be modified for probabilistic workload prediction, while Decision Trees provide interpretability. Random Forest mixes many trees for increased accuracy. Finally, Artificial Neural Networks are very good at capturing complex data patterns. Our research is built on the systematic application of these techniques to the workload dataset. The decision on which algorithm to use for a certain prediction task is data-driven, informed by statistical analysis and insights gained from previous conversations and research in the fields of cloud computing and machine learning. This entire method seeks to provide a strong and scalable framework for workload prediction, guaranteeing that our conclusions are technically sound as well as statistically rigorous.
The reduction in the Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) values across these machine learning (ML) algorithms underscores their ability to achieve precise Infrastructure as a Service (IaaS) resource prediction. This crucial feature is aligned with the overarching objective of ensuring accurate workload predictions, ultimately enabling the provisioning of an optimal amount of resources. The effective alignment of workloads and resources is vital for sustaining the reliable availability of cloud services, contributing to the overall efficiency and effectiveness of cloud-based operations.
Consequently, a diverse array of ML models has been employed in this domain, trained to cater to a variety of scenarios pertinent to the utility of diverse cloud resources and their predictive applications. To further bolster the predictive capabilities and resource management, tailored to the specific workloads, the machine learning model that furnishes the most precise forecasts will be selected for deployment.


 ,
, 





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}