
Sentiment Analysis in the Age of COVID-19: A Bibliometric Perspective


 ,
,  ,
,
Abstract
:1. Introduction
- Which are the most impactful articles in the area of sentiment analysis published during the COVID-19 pandemic?
- Who are the most prominent authors in the area of sentiment analysis published during the COVID-19 pandemic?
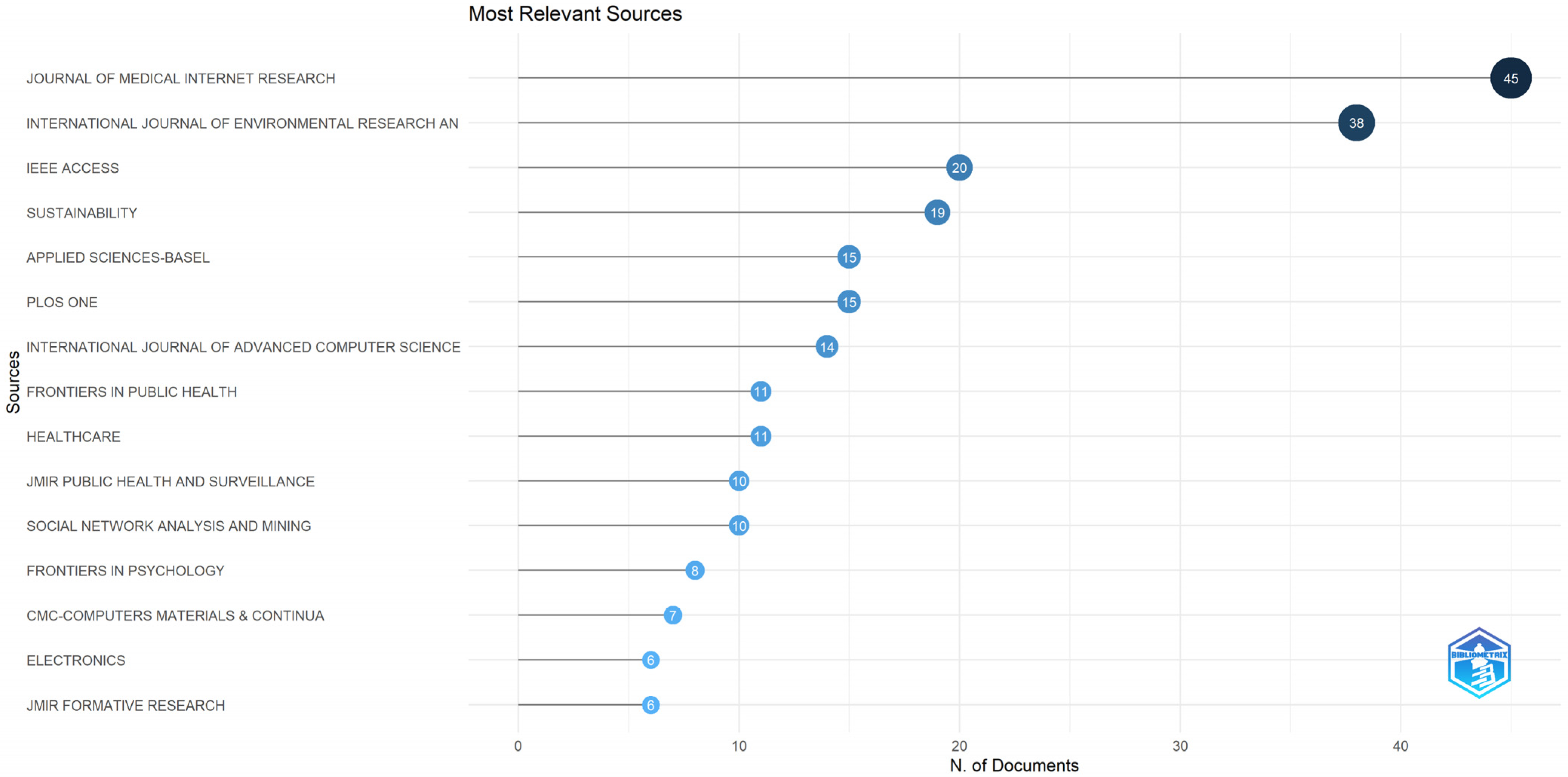
- Which have been the preferred journals for the papers published in the area of sentiment analysis during the COVID-19 pandemic?
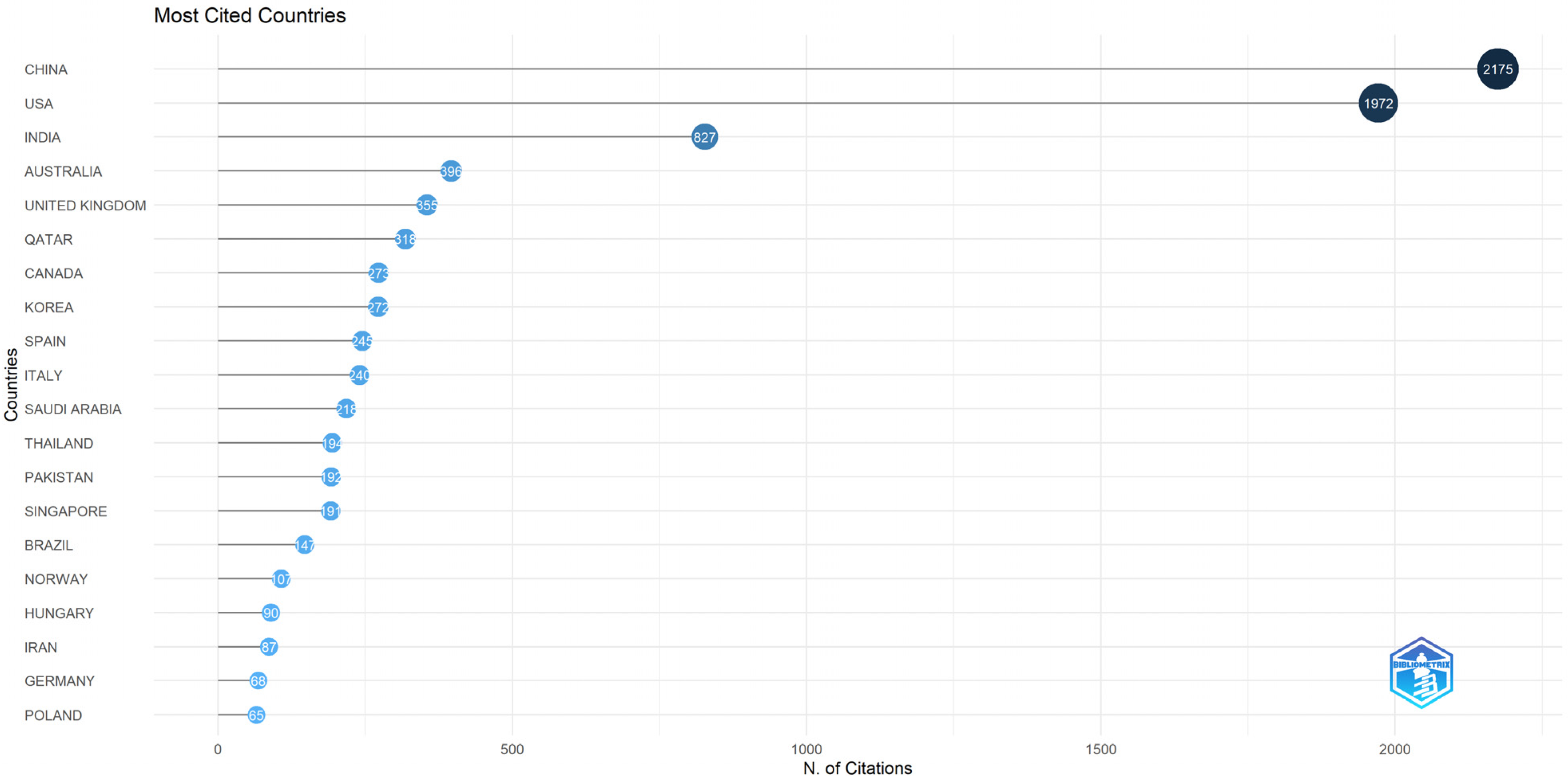
- Which have been the most impactful journals in the area of sentiment analysis during the COVID-19 pandemic?
- Which are the leading universities in the area of sentiment analysis considering the papers published during the COVID-19 pandemic?
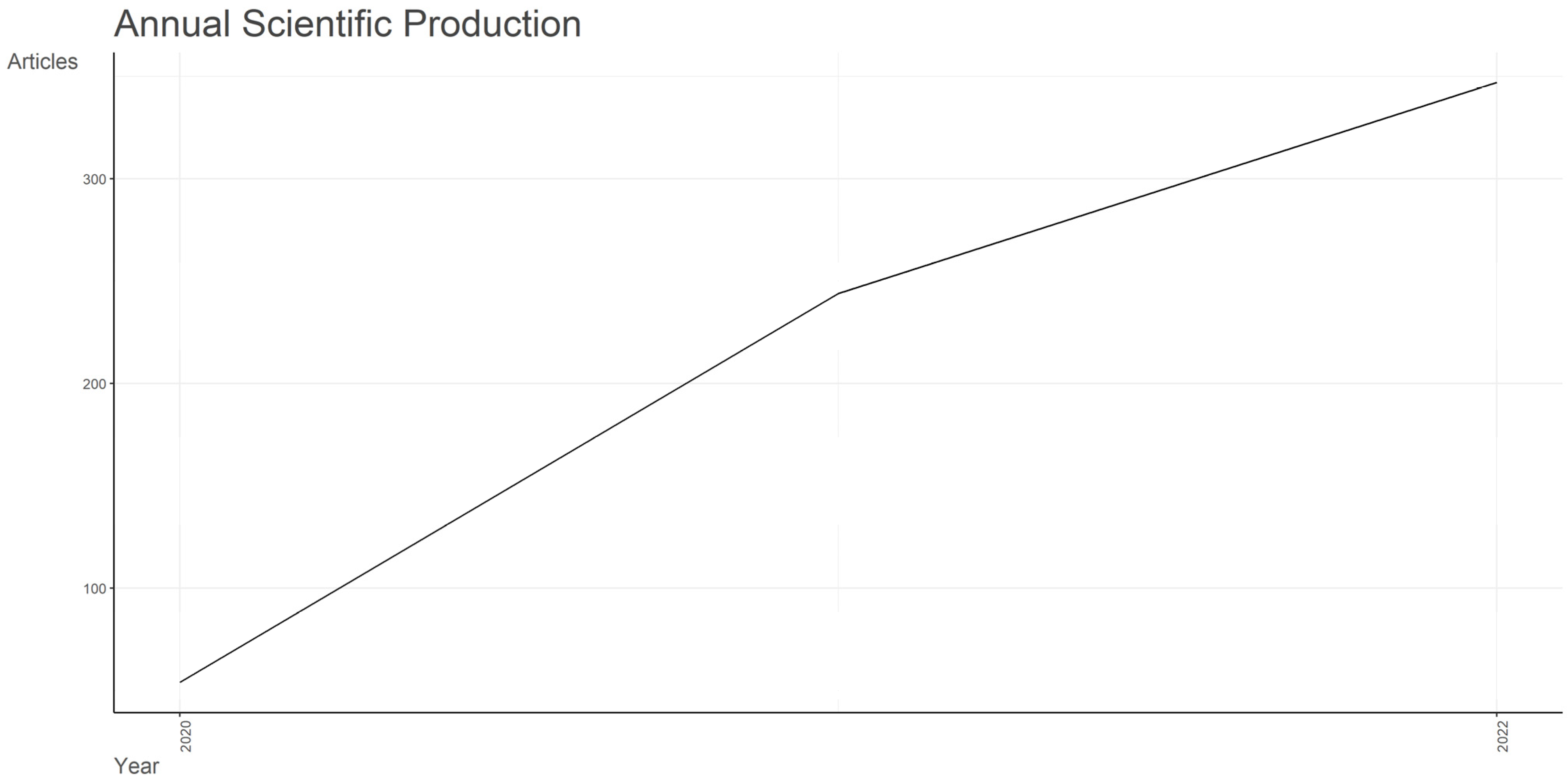
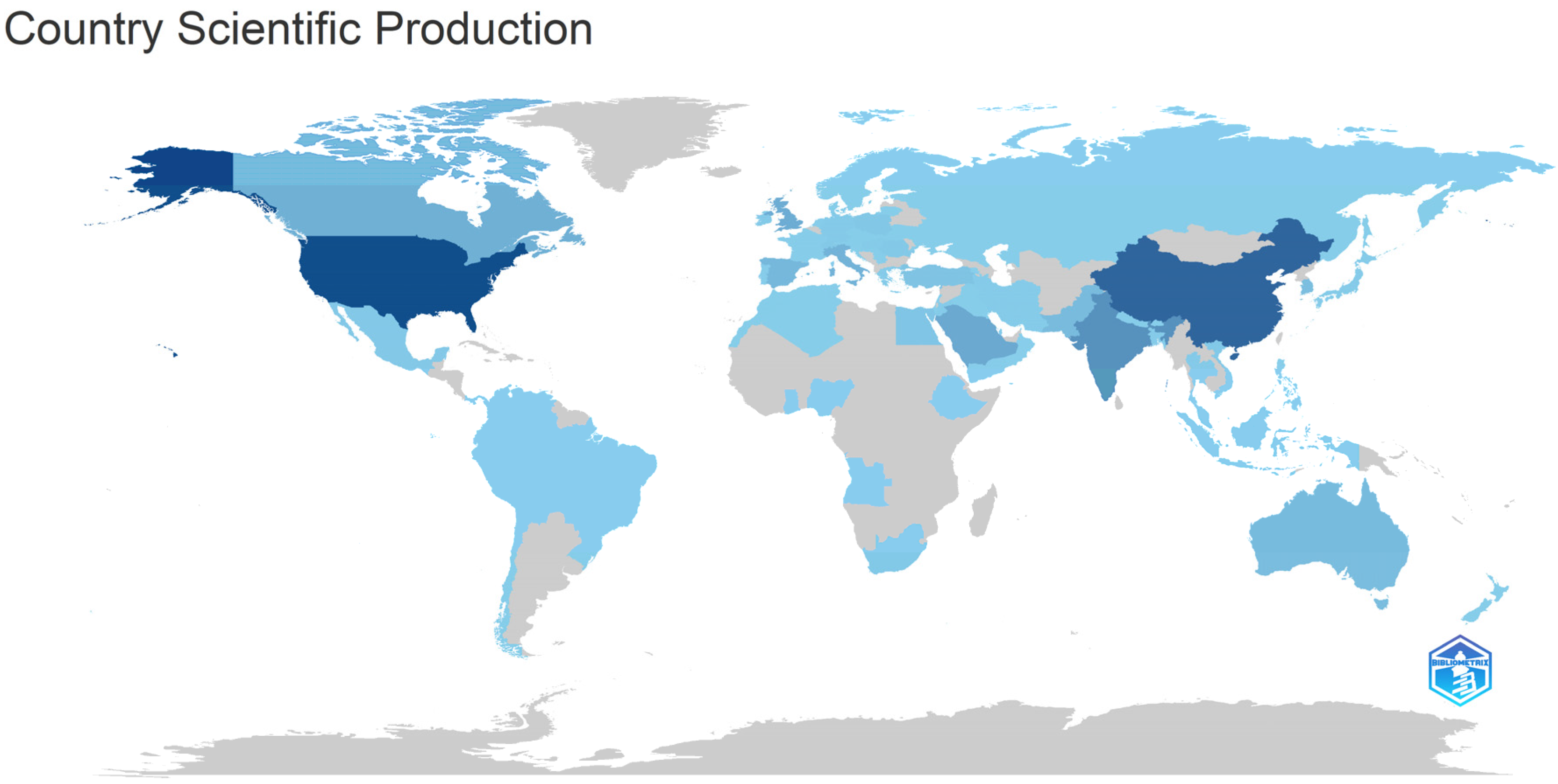
- How has the scientific production related to sentiment analysis evolved during the COVID-19 pandemic?
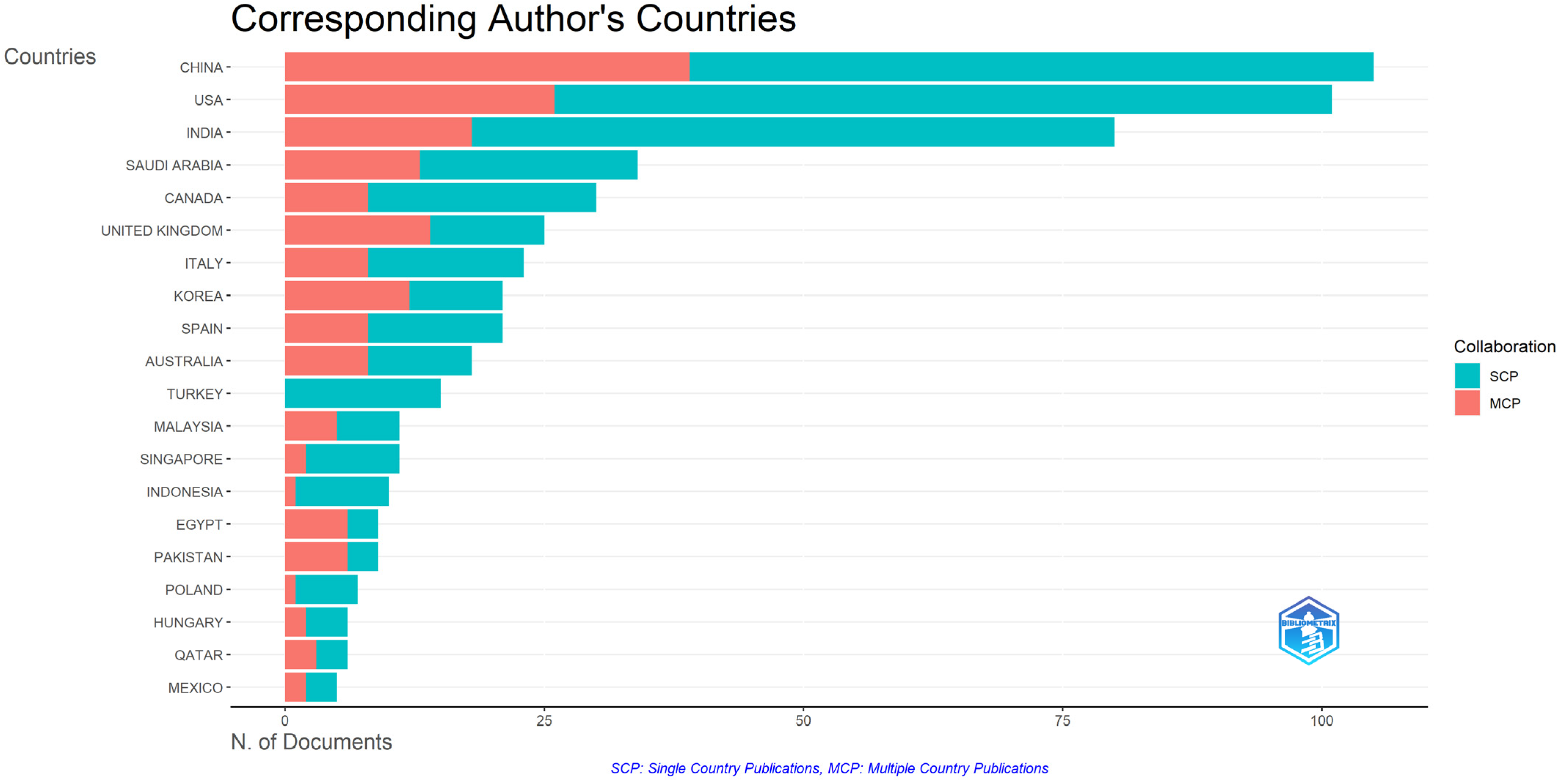
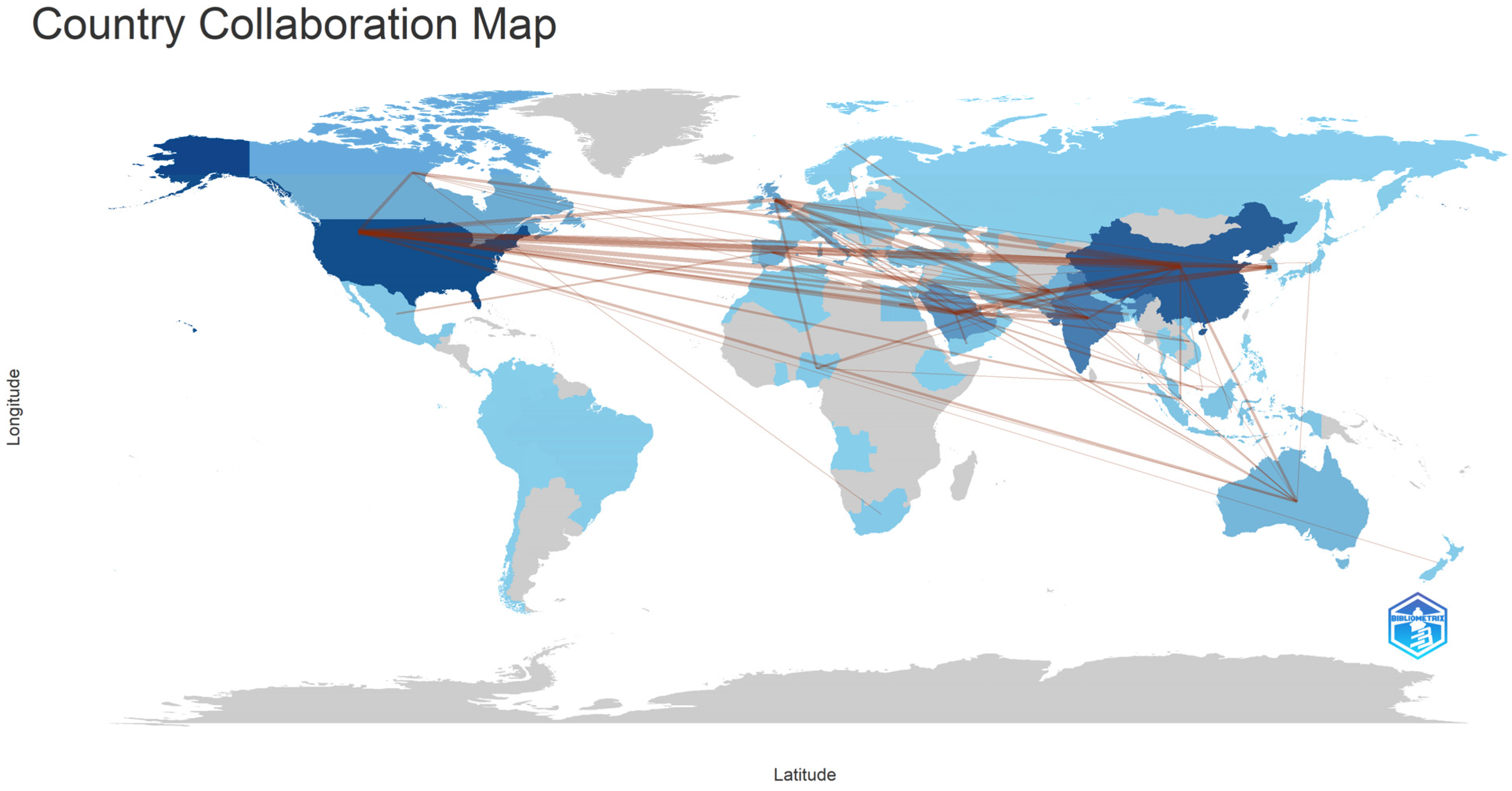
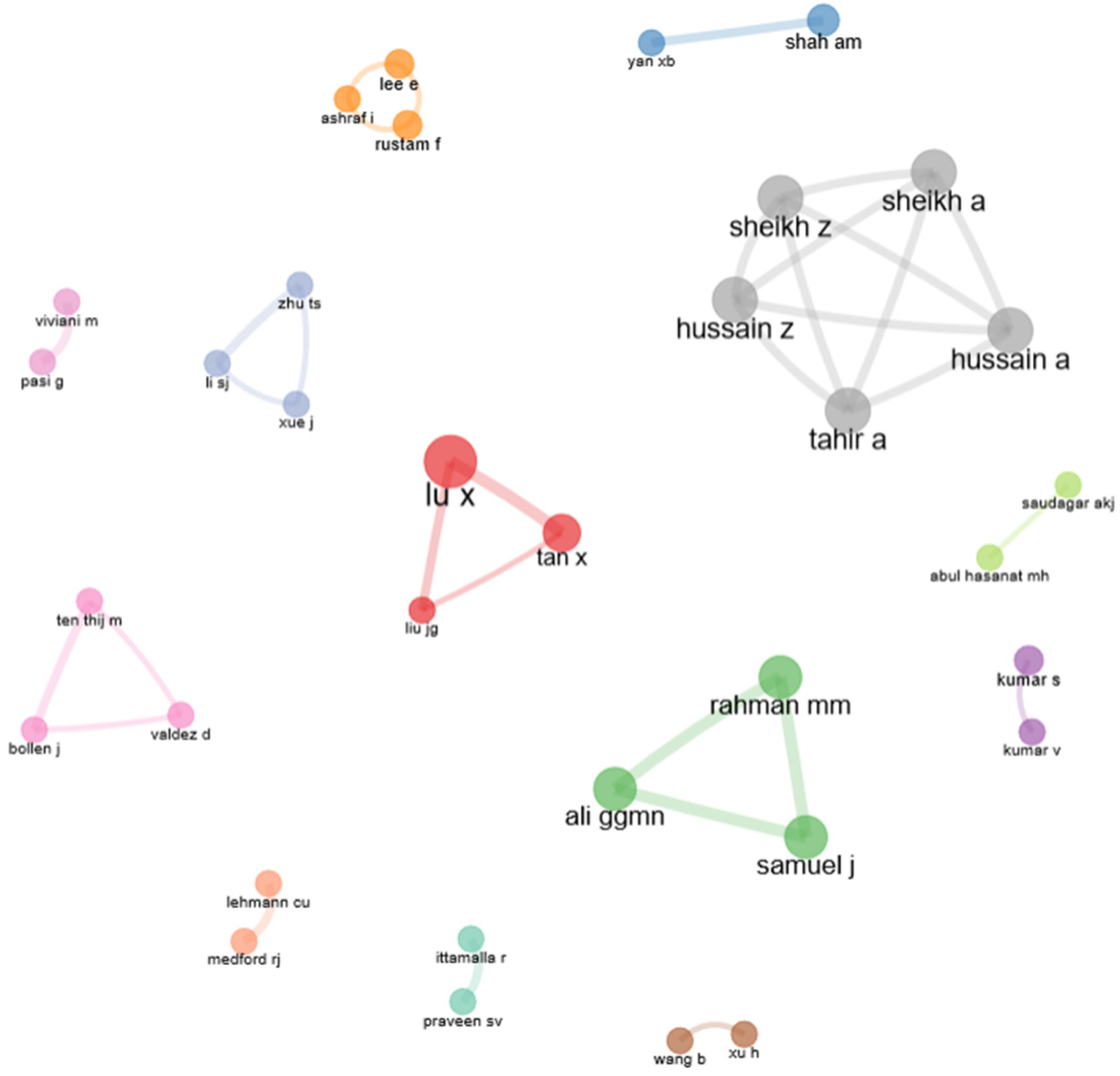
- What are the characteristics of the collaboration network between the authors who have published in the area of sentiment analysis during the COVID-19 pandemic?
2. Materials and Methods
- Science Citation Index Expanded (SCIE)—1900–present;
- Social Sciences Citation Index (SSCI)—1975–present;
- Emerging Sources Citation Index (ESCI)—2005–present;
- Arts and Humanities Citation Index (A&HCI)—1975–present;
- Conference Proceedings Citation Index—Social Sciences and Humanities (CPCI-SSH)—1990–present;
- Conference Proceedings Citation Index—Science (CPCI-S)—1990–present;
- Book Citation Index—Science (BKCI-S)—2010–present;
- Book Citation Index—Social Sciences and Humanities (BKCI-SSH)—2010–present;
- Current Chemical Reactions (CCR-Expanded)—2010–present;
- Index Chemicus (IC)—2010–present.
3. Dataset Analysis
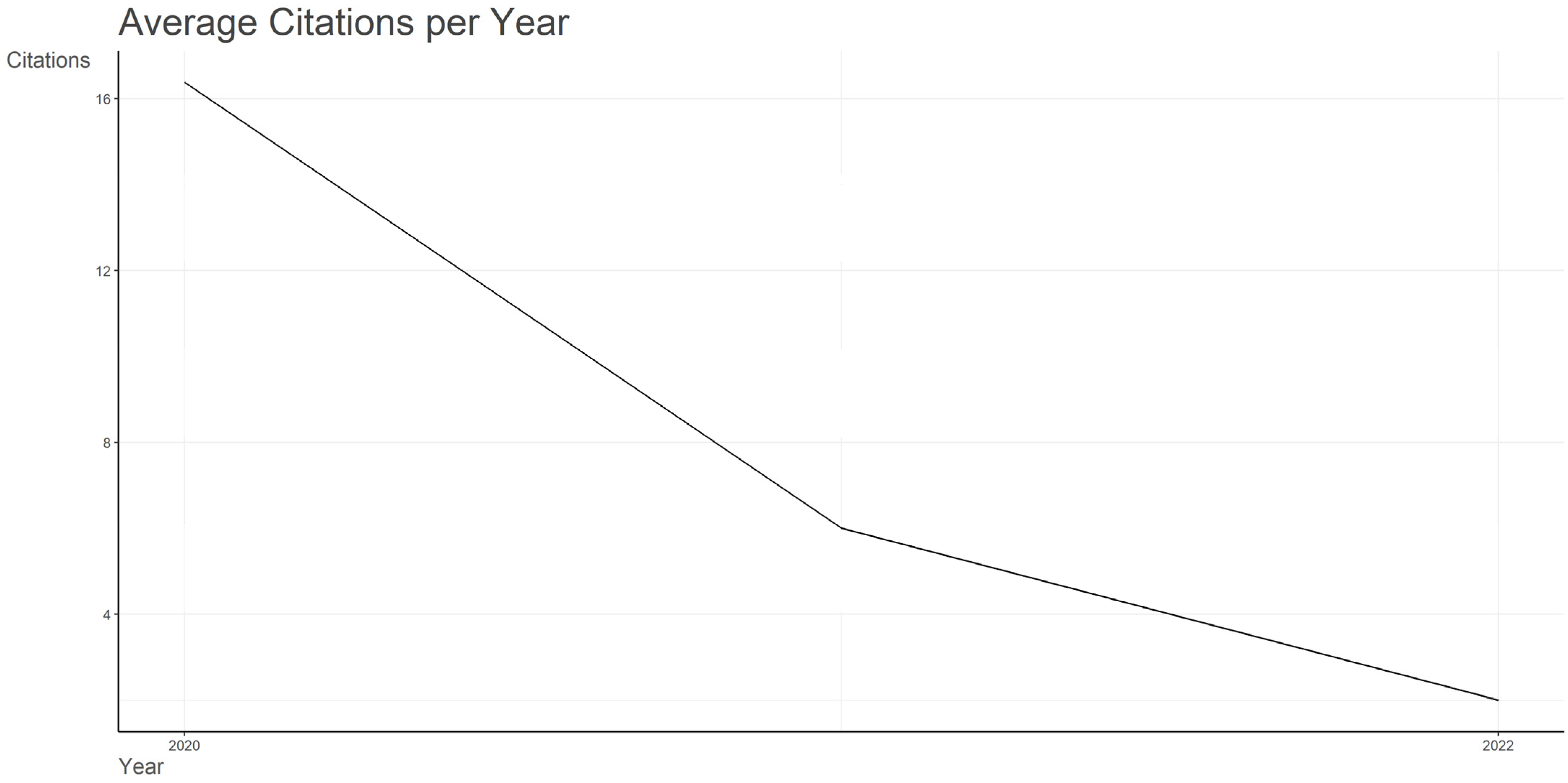
3.1. Dataset Overview
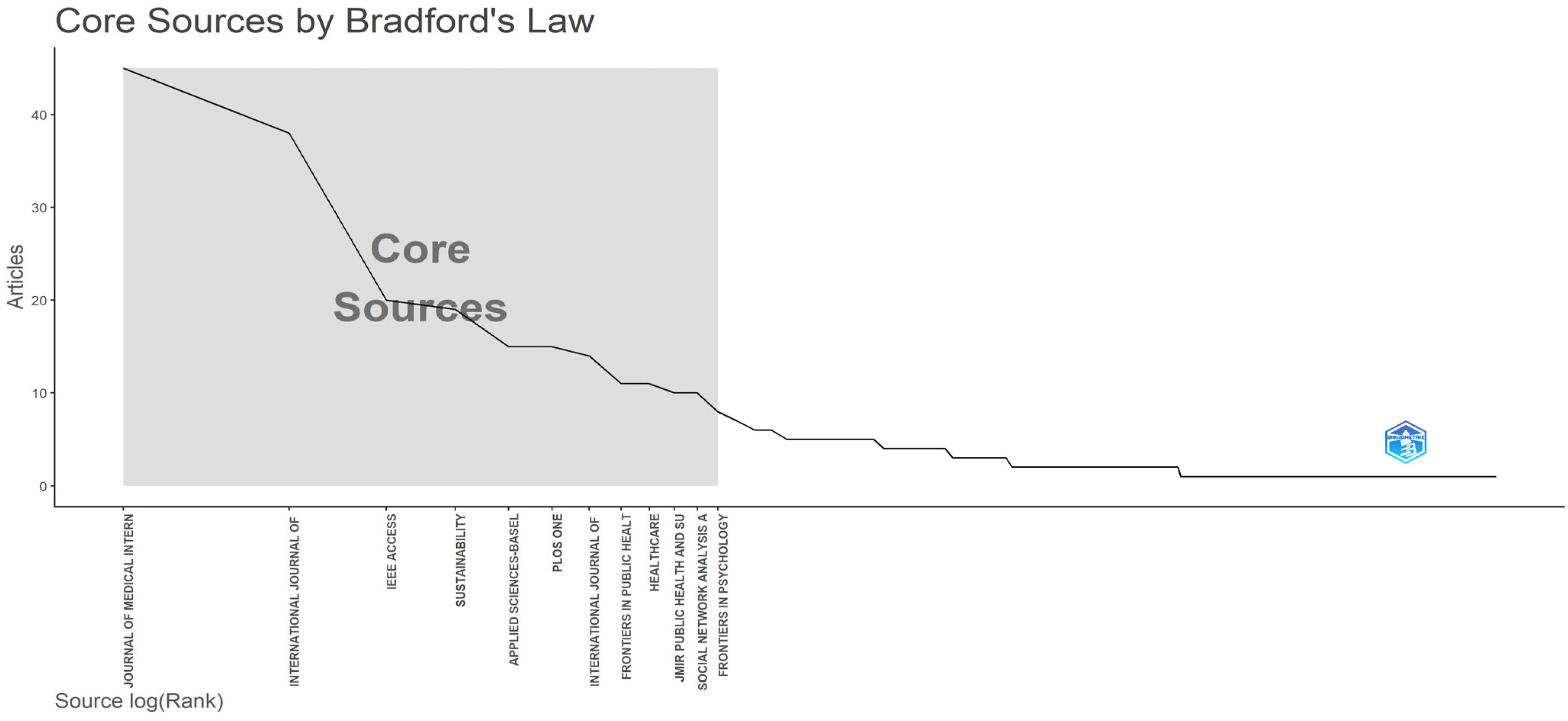
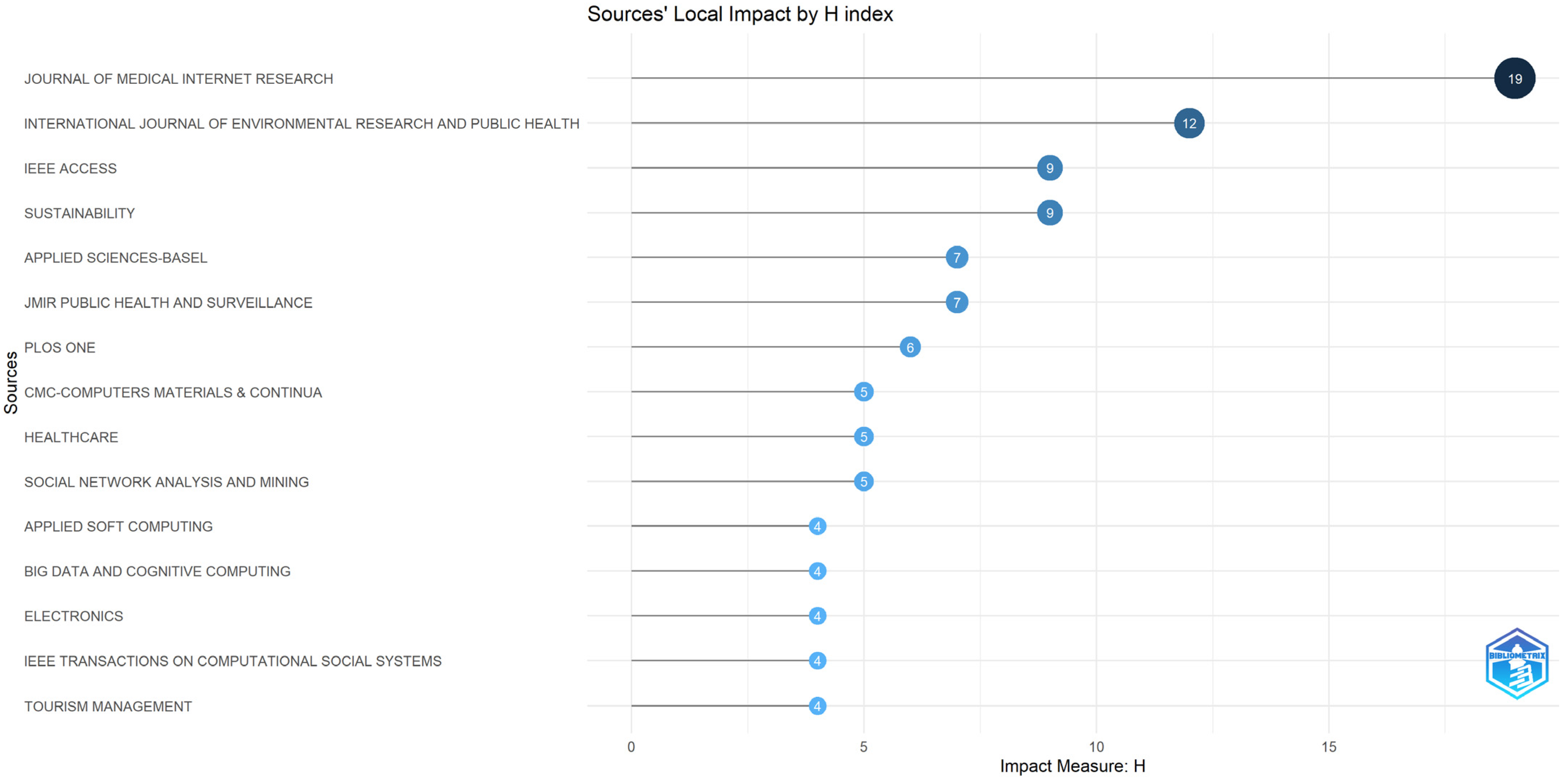
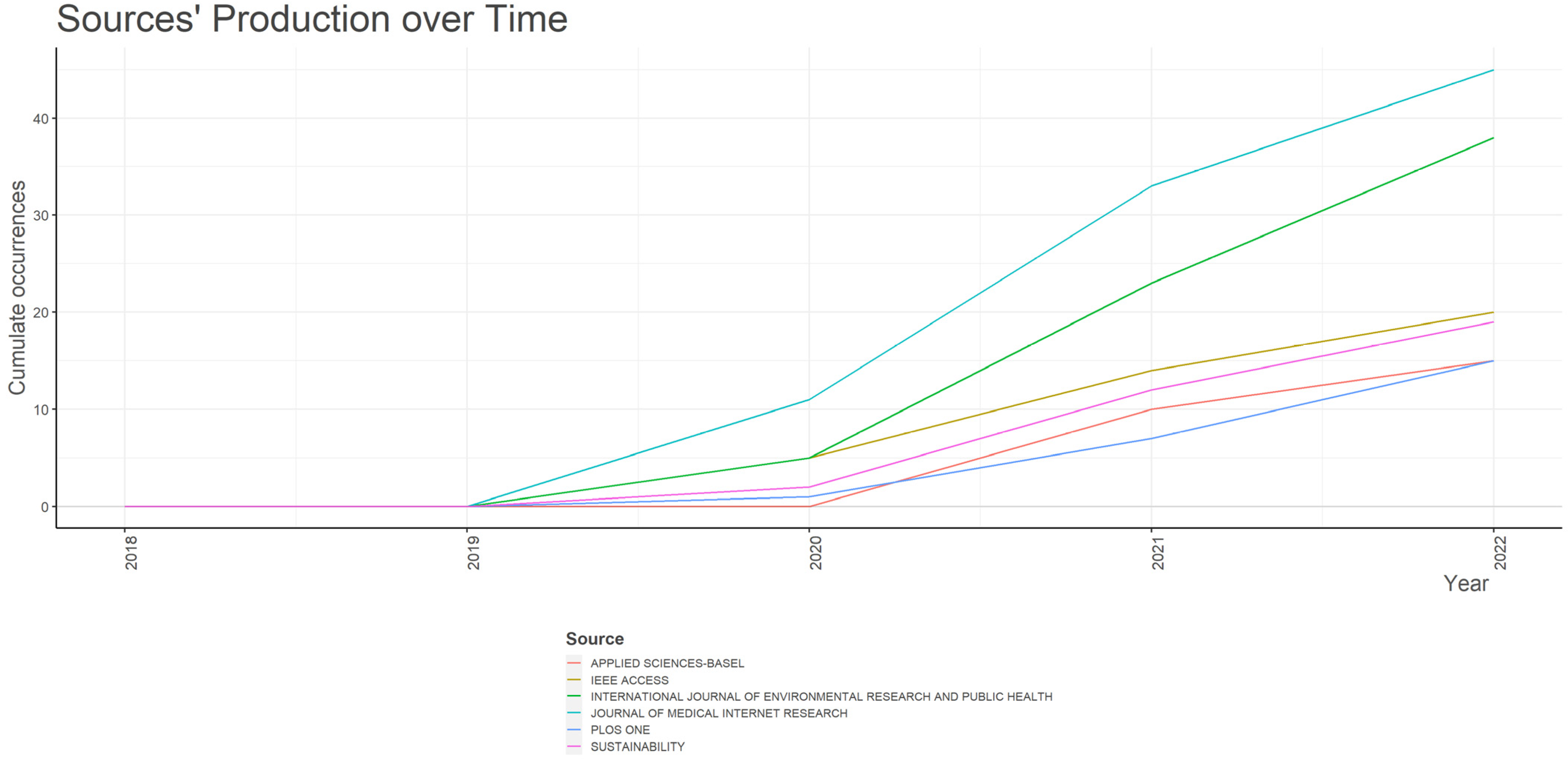
3.2. Sources
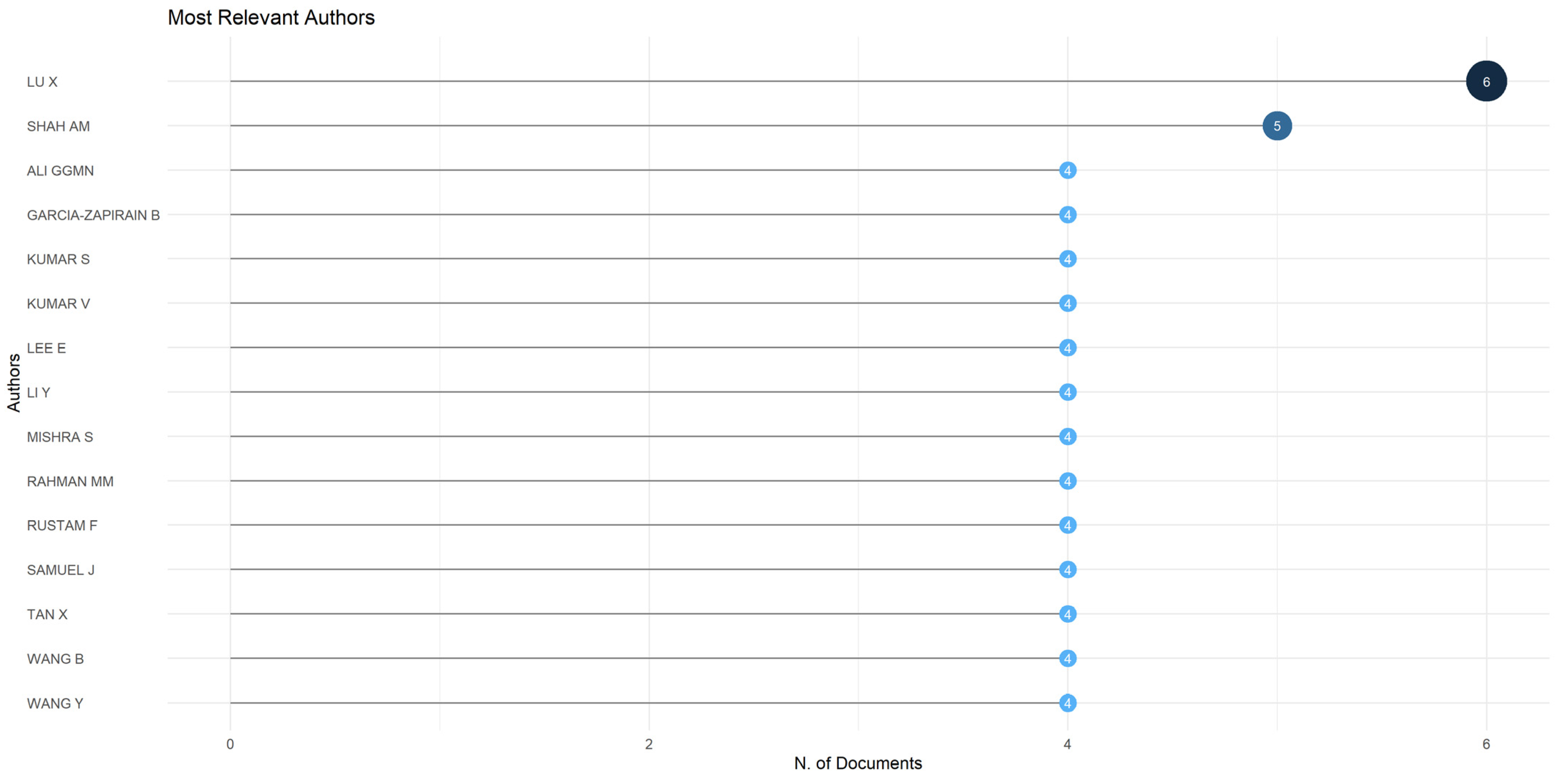
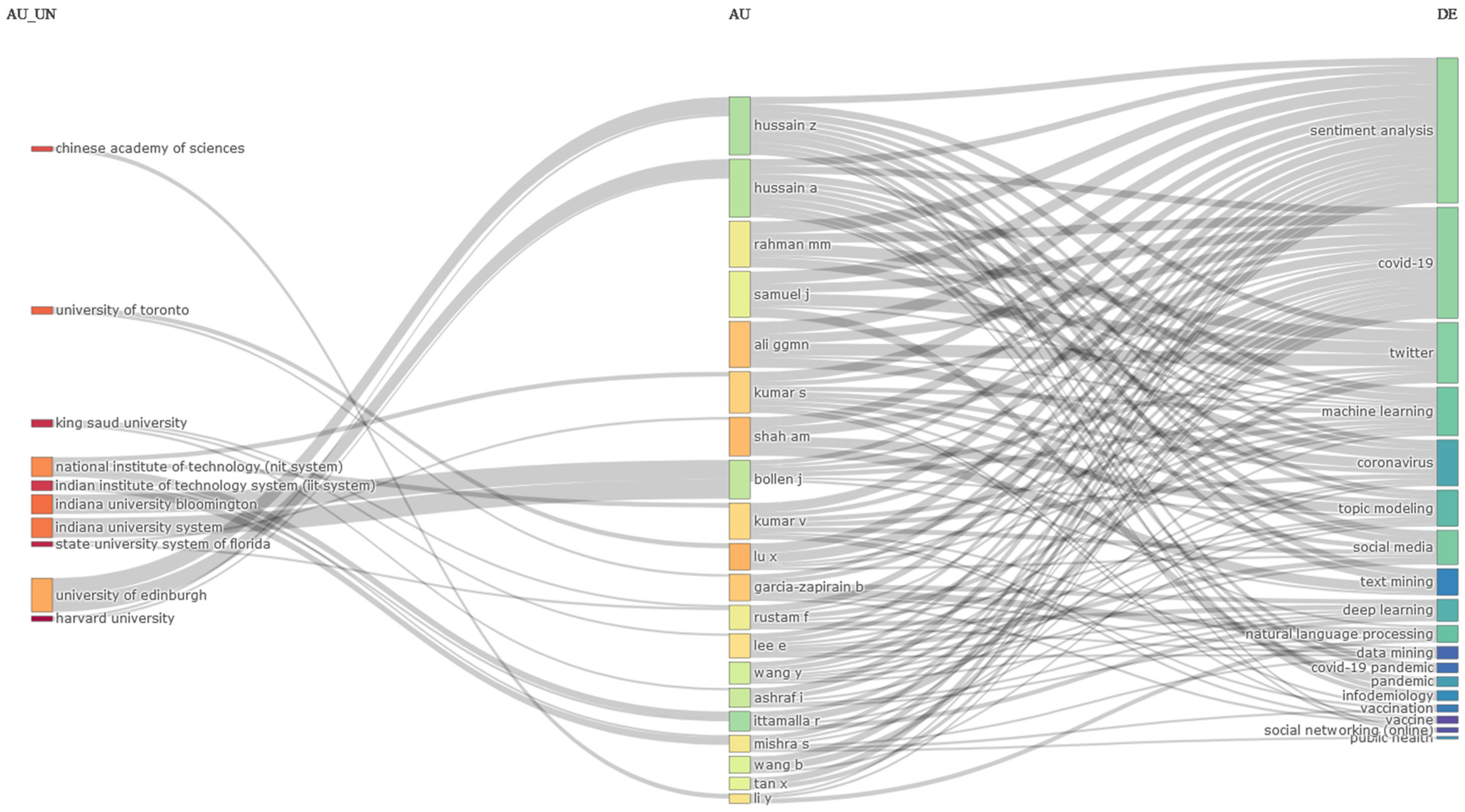
3.3. Authors
3.4. Analysis of Literature
3.4.1. Top 10 Most Cited Papers—Overview
3.4.2. Top 10 Most Cited Papers—Review
3.4.3. Words Analysis
3.5. Mixed Analysis
4. Discussions
- Psychological impact and well-being: examining the psychological impact of the COVID-19 pandemic on mental well-being [56], sentiment analysis during the COVID-19 pandemic with a focus on fear [58], analyzing emotional responses and concerns of the public during the early stages of the epidemic [61];
- Social media analysis: identifying common topics on Twitter related to the COVID-19 pandemic [57], raising awareness about pandemic trends and concerns expressed by Twitter users [59], investigating public discourse on social media, including topics, themes, emotional reactions, and sentiment changes [65];
- Media and communication: examining trends in media-driven health communications in the context of the COVID-19 pandemic and gathering media reports to understand media’s role in the pandemic [64];
- Considering the above-mentioned themes, it can be observed, as expected, that all of them are gravitating around the COVID-19-pandemic-generated situation and are trying to address sentiment analysis through a multifaceted approach.
5. Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, D.D.; Wang, J.; Sun, M. The Progress That Natural Language Processing Has Made Towards Human-Level AI. J. Artif. Intell. Pract. 2020, 3, 38–47. [Google Scholar]
- Hirschberg, J.; Manning, C.D. Advances in Natural Language Processing. Science 2015, 349, 261–266. [Google Scholar] [CrossRef]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment Analysis Algorithms and Applications: A Survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef]
- Jemai, F.; Hayouni, M.; Baccar, S. Sentiment Analysis Using Machine Learning Algorithms. In Proceedings of the 2021 International Wireless Communications and Mobile Computing (IWCMC), Harbin City, China, 28 June 2021–2 July 2021. [Google Scholar] [CrossRef]
- Wankhade, M.; Rao, A.C.S.; Kulkarni, C. A Survey on Sentiment Analysis Methods, Applications, and Challenges. Artif. Intell. Rev. 2022, 55, 5731–5780. [Google Scholar] [CrossRef]
- Mercha, E.M.; Benbrahim, H. Machine Learning and Deep Learning for Sentiment Analysis across Languages: A Survey. Neurocomputing 2023, 531, 195–216. [Google Scholar] [CrossRef]
- Costola, M.; Hinz, O.; Nofer, M.; Pelizzon, L. Machine Learning Sentiment Analysis, COVID-19 News and Stock Market Reactions. Res. Int. Bus. Financ. 2023, 64, 101881. [Google Scholar] [CrossRef] [PubMed]
- Jalil, Z.; Abbasi, A.; Javed, A.R.; Khan, M.B.; Hasanat, M.H.A.; Malik, K.M.; Saudagar, A.K.J. COVID-19 Related Sentiment Analysis Using State-of-the-Art Machine Learning and Deep Learning Techniques. Front. Public Health 2022, 9, 812735. [Google Scholar] [CrossRef] [PubMed]
- Ainapure, B.S.; Pise, R.N.; Reddy, P.; Appasani, B.; Srinivasulu, A.; Khan, M.S.; Bizon, N. Sentiment Analysis of COVID-19 Tweets Using Deep Learning and Lexicon-Based Approaches. Sustainability 2023, 15, 2573. [Google Scholar] [CrossRef]
- Vijayaraj, A.; Bhavana, K.; SreeDurga, S.; Naik, S.L. Twitter Based Sentimental Analysis of COVID-19 Observations. Mater. Today Proc. 2022, 64, 713–719. [Google Scholar] [CrossRef] [PubMed]
- Chandra, R.; Krishna, A. COVID-19 Sentiment Analysis via Deep Learning during the Rise of Novel Cases. PLoS ONE 2021, 16, e0255615. [Google Scholar] [CrossRef] [PubMed]
- Dangi, D.; Dixit, D.K.; Bhagat, A. Sentiment Analysis of COVID-19 Social Media Data through Machine Learning. Multimed. Tools Appl. 2022, 81, 42261–42283. [Google Scholar] [CrossRef]
- Jain, V.; Kashyap, K.L. Analyzing Research Trends of Sentiment Analysis and Its Applications for Coronavirus Disease (COVID-19): A Systematic Review. J. Intell. Fuzzy Syst. 2023, 45, 731–742. [Google Scholar] [CrossRef]
- Erfina, A.; Rosita Ndk, M.D.; Hidayat, R.; Subagja, A.; Ramadhan, H.; Lesmana, C.S.A.T.; Saepudin, S.; Muslih, M. Indonesian Twitter Sentiment Analysis Application on The Covid L9 Vaccine Using Naive Bayes Classifier. In Proceedings of the 2021 IEEE 7th International Conference on Computing, Engineering and Design (ICCED), Sukabumi, Indonesia, 5–6 August 2021; pp. 1–6. [Google Scholar]
- Endo, P.T.; Santos, G.L.; De Lima Xavier, M.E.; Nascimento Campos, G.R.; De Lima, L.C.; Silva, I.; Egli, A.; Lynn, T. Illusion of Truth: Analysing and Classifying COVID-19 Fake News in Brazilian Portuguese Language. Big Data Cogn. Comput. 2022, 6, 36. [Google Scholar] [CrossRef]
- Catelli, R.; Pelosi, S.; Comito, C.; Pizzuti, C.; Esposito, M. Lexicon-Based Sentiment Analysis to Detect Opinions and Attitude towards COVID-19 Vaccines on Twitter in Italy. Comput. Biol. Med. 2023, 158, 106876. [Google Scholar] [CrossRef]
- Ghasiya, P.; Okamura, K. Investigating COVID-19 News Across Four Nations: A Topic Modeling and Sentiment Analysis Approach. IEEE Access 2021, 9, 36645–36656. [Google Scholar] [CrossRef] [PubMed]
- Obiedat, R.; Harfoushi, O.; Qaddoura, R.; Al-Qaisi, L.; Al-Zoubi, A.M. An Evolutionary-Based Sentiment Analysis Approach for Enhancing Government Decisions during COVID-19 Pandemic: The Case of Jordan. Appl. Sci. 2021, 11, 9080. [Google Scholar] [CrossRef]
- Barkur, G.; Vibha; Kamath, G.B. Sentiment Analysis of Nationwide Lockdown Due to COVID-19 Outbreak: Evidence from India. Asian J. Psychiatry 2020, 51, 102089. [Google Scholar] [CrossRef]
- Khasnis, N.S.; Sen, S.; Khasnis, S.S. A Machine Learning Approach for Sentiment Analysis to Nurture Mental Health Amidst COVID-19. In Proceedings of the International Conference on Data Science, Machine Learning and Artificial Intelligence, Windhoek, Namibia, 9 August 2021; pp. 284–289. [Google Scholar]
- Tran, M.; Draeger, C.; Wang, X.; Nikbakht, A. Monitoring the Well-Being of Vulnerable Transit Riders Using Machine Learning Based Sentiment Analysis and Social Media: Lessons from COVID-19. Environ. Plan. B Urban Anal. City Sci. 2023, 50, 60–75. [Google Scholar] [CrossRef]
- Iwendi, C.; Mohan, S.; Khan, S.; Ibeke, E.; Ahmadian, A.; Ciano, T. COVID-19 Fake News Sentiment Analysis. Comput. Electr. Eng. 2022, 101, 107967. [Google Scholar] [CrossRef]
- Naseem, U.; Razzak, I.; Khushi, M.; Eklund, P.W.; Kim, J. COVIDSenti: A Large-Scale Benchmark Twitter Data Set for COVID-19 Sentiment Analysis. IEEE Trans. Comput. Soc. Syst. 2021, 8, 1003–1015. [Google Scholar] [CrossRef]
- Delcea, C.; Cotfas, L.-A.; Crăciun, L.; Molănescu, A.G. New Wave of COVID-19 Vaccine Opinions in the Month the 3rd Booster Dose Arrived. Vaccines 2022, 10, 881. [Google Scholar] [CrossRef]
- Block, J.H.; Fisch, C. Eight Tips and Questions for Your Bibliographic Study in Business and Management Research. Manag. Rev. Q. 2020, 70, 307–312. [Google Scholar] [CrossRef]
- Moreno-Guerrero, A.-J.; López-Belmonte, J.; Marín-Marín, J.-A.; Soler-Costa, R. Scientific Development of Educational Artificial Intelligence in Web of Science. Future Internet 2020, 12, 124. [Google Scholar] [CrossRef]
- Yu, J.; Muñoz-Justicia, J. A Bibliometric Overview of Twitter-Related Studies Indexed in Web of Science. Future Internet 2020, 12, 91. [Google Scholar] [CrossRef]
- Ravšelj, D.; Umek, L.; Todorovski, L.; Aristovnik, A. A Review of Digital Era Governance Research in the First Two Decades: A Bibliometric Study. Future Internet 2022, 14, 126. [Google Scholar] [CrossRef]
- Fatma, N.; Haleem, A. Exploring the Nexus of Eco-Innovation and Sustainable Development: A Bibliometric Review and Analysis. Sustainability 2023, 15, 12281. [Google Scholar] [CrossRef]
- Stefanis, C.; Giorgi, E.; Tselemponis, G.; Voidarou, C.; Skoufos, I.; Tzora, A.; Tsigalou, C.; Kourkoutas, Y.; Constantinidis, T.C.; Bezirtzoglou, E. Terroir in View of Bibliometrics. Stats 2023, 6, 956–979. [Google Scholar] [CrossRef]
- Gorski, A.-T.; Ranf, E.-D.; Badea, D.; Halmaghi, E.-E.; Gorski, H. Education for Sustainability—Some Bibliometric Insights. Sustainability 2023, 15, 14916. [Google Scholar] [CrossRef]
- Delcea, C.; Javed, S.A.; Florescu, M.-S.; Ioanas, C.; Cotfas, L.-A. 35 Years of Grey System Theory in Economics and Education. Kybernetes 2023. [Google Scholar] [CrossRef]
- Cibu, B.; Delcea, C.; Domenteanu, A.; Dumitrescu, G. Mapping the Evolution of Cybernetics: A Bibliometric Perspective. Computers 2023, 12, 237. [Google Scholar] [CrossRef]
- WoS Web of Science. Available online: https://webofknowledge.com (accessed on 9 September 2023).
- Cobo, M.J.; Martínez, M.A.; Gutiérrez-Salcedo, M.; Fujita, H.; Herrera-Viedma, E. 25 Years at Knowledge-Based Systems: A Bibliometric Analysis. Knowl.-Based Syst. 2015, 80, 3–13. [Google Scholar] [CrossRef]
- Modak, N.M.; Merigó, J.M.; Weber, R.; Manzor, F.; Ortúzar, J.D.D. Fifty Years of Transportation Research Journals: A Bibliometric Overview. Transp. Res. Part A Policy Pract. 2019, 120, 188–223. [Google Scholar] [CrossRef]
- Mulet-Forteza, C.; Martorell-Cunill, O.; Merigó, J.M.; Genovart-Balaguer, J.; Mauleon-Mendez, E. Twenty Five Years of the Journal of Travel & Tourism Marketing: A Bibliometric Ranking. J. Travel Tour. Mark. 2018, 35, 1201–1221. [Google Scholar] [CrossRef]
- Bakır, M.; Özdemir, E.; Akan, Ş.; Atalık, Ö. A Bibliometric Analysis of Airport Service Quality. J. Air Transp. Manag. 2022, 104, 102273. [Google Scholar] [CrossRef]
- Tay, A. Using VOSviewer as a Bibliometric Mapping or Analysis Tool in Business, Management & Accounting. Available online: https://library.smu.edu.sg/topics-insights/using-vosviewer-bibliometric-mapping-or-analysis-tool-business-management (accessed on 22 November 2023).
- Aria, M.; Cuccurullo, C. Bibliometrix: An R-Tool for Comprehensive Science Mapping Analysis. J. Informetr. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Liu, W. The Data Source of This Study Is Web of Science Core Collection? Not Enough. Scientometrics 2019, 121, 1815–1824. [Google Scholar] [CrossRef]
- Liu, F. Retrieval Strategy and Possible Explanations for the Abnormal Growth of Research Publications: Re-Evaluating a Bibliometric Analysis of Climate Change. Scientometrics 2023, 128, 853–859. [Google Scholar] [CrossRef]
- Donner, P. Document Type Assignment Accuracy in the Journal Citation Index Data of Web of Science. Scientometrics 2017, 113, 219–236. [Google Scholar] [CrossRef]
- WoS Document Types. Available online: https://webofscience.help.clarivate.com/en-us/Content/document-types.html (accessed on 3 December 2023).
- Scopus Content Coverage. Available online: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwizod31mvOCAxWV2QIHHffEDYwQFnoECA8QAQ&url=http%3A%2F%2Fwww.auric.or.kr%2FUserFiles_news%2FFile%2Fcontent_coverage.pdf&usg=AOvVaw1fa-aDwsxvgc8OoNO6lGNO&opi=89978449 (accessed on 12 March 2023).
- Liu, W. Caveats for the Use of Web of Science Core Collection in Old Literature Retrieval and Historical Bibliometric Analysis. Technol. Forecast. Soc. Chang. 2021, 172, 121023. [Google Scholar] [CrossRef]
- Dahish, Z.; Miah, S.J. A Bibliometric Analysis to Explore Sentiment Analysis in the Domain of Social Media Research. Res. Sq. 2022. [Google Scholar] [CrossRef]
- Wardikar, V. Application of Bradford’s Law of Scattering to the Literature of Library & Information Science: A Study of Doctoral Theses Citations Submitted to the Universities of Maharashtra, India. Libr. Philos. Pract. 2013. Available online: https://www.proquest.com/openview/da430b54ea4de9f3096198d323027642/1?pq-origsite=gscholar&cbl=54903 (accessed on 3 December 2023).
- RDRR Website Bradford: Bradford’s Law in Bibliometrix: Comprehensive Science Mapping Analysis. Available online: https://rdrr.io/cran/bibliometrix/man/bradford.html (accessed on 21 November 2023).
- Sarirete, A. A Bibliometric Analysis of COVID-19 Vaccines and Sentiment Analysis. Procedia Comput. Sci. 2021, 194, 280–287. [Google Scholar] [CrossRef]
- Kamath, A.; Shenoy, S.; Kumar, S. An Overview of Investor Sentiment: Identifying Themes, Trends, and Future Direction through Bibliometric Analysis. Invest. Manag. Financ. Innov. 2022, 19, 229–242. [Google Scholar] [CrossRef]
- Kale, A.S. Sentiment Analysis in Library and Information Science: A Bibliometric Study. Available online: https://www.proquest.com/openview/4413eac1c9486d2492b58929b57cadf3/1?pq-origsite=gscholar&cbl=5170426 (accessed on 3 December 2023).
- Yaqub, A.; Thalib, H.; Brahimi, T.; Sarirete, A. A Bibliometric of Sentiment Analysis in Tourism Industry during COVID-19 Pandemic. In Proceedings of the International Conference on Industrial Engineering and Operations Management, Istanbul, Turkey, 7 March 2022; pp. 2383–2393. [Google Scholar]
- Qiang, Y.; Tao, X.; Gou, X.; Lang, Z.; Liu, H. Towards a Bibliometric Mapping of Network Public Opinion Studies. Information 2022, 13, 17. [Google Scholar] [CrossRef]
- Nyakurukwa, K.; Seetharam, Y. The Evolution of Studies on Social Media Sentiment in the Stock Market: Insights from Bibliometric Analysis. Sci. Afr. 2023, 20, e01596. [Google Scholar] [CrossRef]
- Li, S.; Wang, Y.; Xue, J.; Zhao, N.; Zhu, T. The Impact of COVID-19 Epidemic Declaration on Psychological Consequences: A Study on Active Weibo Users. Int. J. Environ. Res. Public Health 2020, 17, 2032. [Google Scholar] [CrossRef] [PubMed]
- Abd-Alrazaq, A.; Alhuwail, D.; Househ, M.; Hamdi, M.; Shah, Z. Top Concerns of Tweeters During the COVID-19 Pandemic: Infoveillance Study. J. Med. Internet Res. 2020, 22, e19016. [Google Scholar] [CrossRef]
- Samuel, J.; Ali, G.M.N.; Rahman, M.M.; Esawi, E.; Samuel, Y. COVID-19 Public Sentiment Insights and Machine Learning for Tweets Classification. Information 2020, 11, 314. [Google Scholar] [CrossRef]
- Boon-Itt, S.; Skunkan, Y. Public Perception of the COVID-19 Pandemic on Twitter: Sentiment Analysis and Topic Modeling Study. JMIR Public Health Surveill. 2020, 6, e21978. [Google Scholar] [CrossRef]
- Chakraborty, K.; Bhatia, S.; Bhattacharyya, S.; Platos, J.; Bag, R.; Hassanien, A.E. Sentiment Analysis of COVID-19 Tweets by Deep Learning Classifiers—A Study to Show How Popularity Is Affecting Accuracy in Social Media. Appl. Soft Comput. 2020, 97, 106754. [Google Scholar] [CrossRef]
- Zhao, Y.; Cheng, S.; Yu, X.; Xu, H. Chinese Public’s Attention to the COVID-19 Epidemic on Social Media: Observational Descriptive Study. J. Med. Internet Res. 2020, 5, e18825. [Google Scholar] [CrossRef] [PubMed]
- Shorten, C.; Khoshgoftaar, T.M.; Furht, B. Deep Learning Applications for COVID-19. J. Big Data 2021, 8, 18. [Google Scholar] [CrossRef] [PubMed]
- Lyu, J.C.; Han, E.L.; Luli, G.K. COVID-19 Vaccine–Related Discussion on Twitter: Topic Modeling and Sentiment Analysis. J. Med. Internet Res. 2021, 23, e24435. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Zheng, Z.; Zheng, J.; Chen, Q.; Liu, G.; Chen, S.; Chu, B.; Zhu, H.; Akinwunmi, B.; Huang, J.; et al. Health Communication Through News Media During the Early Stage of the COVID-19 Outbreak in China: Digital Topic Modeling Approach Health Communication Through News Media During the Early Stage of the COVID-19 Outbreak in China: Digital Topic Modeling Approach. J. Med. Internet Res. 2020, 22, e19118. [Google Scholar] [CrossRef]
- Xue, J.; Chen, J.; Chen, C.; Zheng, C.; Li, S.; Zhu, T. Public Discourse and Sentiment during the COVID 19 Pandemic: Using Latent Dirichlet Allocation for Topic Modeling on Twitter. PLoS ONE 2020, 15, e0239441. [Google Scholar] [CrossRef]
- Sanchez-Nunez, P.; Cobo, M.J.; Heras-Pedrosa, C.D.L.; Pelaez, J.I.; Herrera-Viedma, E. Opinion Mining, Sentiment Analysis and Emotion Understanding in Advertising: A Bibliometric Analysis. IEEE Access 2020, 8, 134563–134576. [Google Scholar] [CrossRef]
- Puteh, N.; Ali bin Saip, M.; Zabidin Husin, M.; Hussain, A. Sentiment Analysis with Deep Learning: A Bibliometric Review. Turk. J. Comput. Math. Educ. 2021, 12, 1509–1519. [Google Scholar]
- Casas-Valadez, M.A.; Faz-Mendoza, A.; Medina-Rodriguez, C.E.; Castorena-Robles, A.; Gamboa-Rosales, N.K.; Lopez-Robles, J.R. Decision Models in Marketing: The Role of Sentiment Analysis from Bibliometric Analysis. In Proceedings of the 2020 International Conference on Decision Aid Sciences and Application (DASA), Sakheer, Bahrain, 8 November 2020; pp. 561–565. [Google Scholar]
- Bagane, P.; Mehta, N.; Kakde, P.; Bramhbhatt, N.; Sahni, I.; Kotrappa, S. Bibliometric Survey for Stock Market Prediction Using Sentimental Analysis and LSTM. Libr. Philos. Pract. 2021. Available online: https://digitalcommons.unl.edu/libphilprac/5335 (accessed on 3 December 2023).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Exploration Steps | Filters on WoS | Description | Query | Query Number | Count |
|---|---|---|---|---|---|
| 1 | Title/Abstract/Keywords | Contains the specific keyword related to sentiment analysis | ((TI = (sentiment_analysis)) OR AB = (sentiment_analysis)) OR AK = (sentiment_analysis) | #1 | 16,710 |
| Contains one of the specific keywords related to COVID-19 | (((((TI = (COVID-19)) OR TI = (coronavirus)) OR AB = (COVID-19)) OR AB = (coronavirus)) OR AK = (COVID-19)) OR AK = (coronavirus) | #2 | 464,584 | ||
| Contains #1 and #2 | #2 AND #1 | #3 | 1127 | ||
| 2 | Language | Limit to English | (#3) AND LA = (English) | #4 | 1116 |
| 3 | Document Type | Limit to Article | (#4) AND DT = (Article) | #5 | 882 |
| 4 | Year | Limit to 2022 | (#5) NOT PY = (2023) | #6 | 646 |
| Indicator | Value |
|---|---|
| Timespan | 2020:2022 |
| Sources | 310 |
| Documents | 646 |
| Average years from publication | 1.55 |
| Average citations per documents | 14.43 |
| Average citations per year per document | 4.709 |
| References | 24,445 |
| Indicator | Value |
|---|---|
| Keywords plus | 620 |
| Author’s keywords | 1640 |
| Indicator | Value |
|---|---|
| Authors | 2458 |
| Author appearances | 2779 |
| Authors of single-authored documents | 31 |
| Authors of multi-authored documents | 2427 |
| Indicator | Value |
|---|---|
| Single-authored documents | 31 |
| Documents per author | 0.263 |
| Authors per document | 3.8 |
| Co-authors per documents | 4.3 |
| Collaboration index | 3.95 |
| No. | Paper (First Author, Year, Journal, Reference) | Number of Authors | Region | Total Citations (TC) | Total Citations per Year (TCY) | Normalized TC (NTC) |
|---|---|---|---|---|---|---|
| 1 | Li SJ, 2020, International Journal of Environmental Research and Public Health [56] | 5 | China, Canada | 888 | 222.00 | 13.55 |
| 2 | Abd-Alrazaq A, 2020, Journal of Medical Internet Research [57] | 5 | Qatar, Kuwait | 289 | 72.25 | 4.41 |
| 3 | Samuel J, 2020, Information [58] | 5 | USA, Bangladesh | 175 | 43.75 | 2.67 |
| 4 | Boon-Itt S, 2020, JMIR Public Health and Surveillance [59] | 2 | Thailand | 172 | 43.00 | 2.62 |
| 5 | Chakraborty K, 2020, Applied Soft Computing [60] | 6 | India, Saudi Arabia, Czech Republic, Egypt | 149 | 37.25 | 2.27 |
| 6 | Zhao YX, 2020, Journal of Medical Internet Research [61] | 4 | China | 147 | 36.75 | 2.24 |
| 7 | Shorten C, 2021, Journal of Big Data [62] | 3 | USA | 125 | 41.67 | 6.95 |
| 8 | Lyu JC, 2021, Journal of Medical Internet Research [63] | 3 | USA | 121 | 40.33 | 6.73 |
| 9 | Liu Q, 2020, Journal of Medical Internet Research [64] | 12 | China, USA, United Kingdom | 121 | 30.25 | 1.85 |
| 10 | Xue J, 2020, PLOS ONE [65] | 6 | Canada, USA, China | 120 | 30.00 | 1.83 |
| No. | Paper (First Author, Year, Journal, Reference) | Title | Methods Used | Data | Purpose |
|---|---|---|---|---|---|
| 1 | Li SJ, 2020, International Journal of Environmental Research and Public Health [56] | The Impact of COVID-19 Epidemic Declaration on Psychological Consequences: A Study on Active Weibo Users | Online Ecological Recognition (OER) based on machine-learning predictive models | The dataset consists of various Weibo posts from 17,865 active users, gathered over an interval of two weeks from 13 January to 26 January 2020. | Examine how the COVID-19 pandemic affects mental well-being from a psychological perspective, along with helping clinical practitioners and assisting policy makers, for improving the services and decisions. |
| 2 | Abd-Alrazaq A, 2020, Journal of Medical Internet Research [57] | Top Concerns of Tweeters During the COVID-19 Pandemic: Infoveillance Study | Data collection using APIs, Twitter Python Library, and PostgreSQL database. Predefined search terms. Extraction of text and metadata. Analysis of word frequency—unigrams and bigrams. Latent Dirichlet allocation for topic modeling. Sentiment analysis. Mean metrics. | The dataset consists of 167,073 unique English tweets from 160,829 unique users between 2 February and 15 March 2020 | Identify the most common topics posted on Twitter about the COVID-19 pandemic. |
| 3 | Samuel J, 2020, Information [58] | COVID-19 Public Sentiment Insights and Machine Learning for Tweets Classification | Textual Analytics. NRC sentiment lexicon. Data visualization. Machine learning techniques. | COVID-19 tweets, mostly based on fear and negative sentiments. | Understand the impact of COVID-19 pandemic on public sentiment, especially fear. Additionally, demonstrating the viability of machine learning classification methods on sentiment analysis. |
| 4 | Boon-Itt S, 2020, JMIR Public Health and Surveillance [59] | Public Perception of the COVID-19 Pandemic on Twitter: Sentiment Analysis and Topic Modeling Study | Sentiment analysis using frequency of words analysis. NLP and National Research Council (NRC) sentiment lexicon. Latent Dirichlet allocation algorithm for topic modeling. | 107,990 COVID-19 tweets in English, collected between 13 December and 9 March 2020. | Raise public awareness about COVID-19 pandemic trends and identify meaningful themes of concern expressed by Twitter users. |
| 5 | Chakraborty K, 2020, Applied Soft Computing [60] | Sentiment Analysis of COVID-19 tweets by Deep Learning Classifiers—A study to show how popularity is affecting accuracy in social media | Naïve Bayes classifiers. Ensemble models—AdaBoost classifier. Support vector machine (SVM) models. Linear models: logistic regression, linear model. N-grams: unigrams, bigrams, trigrams. Doc2Vec model | Dataset 1—23,000 retweeted tweets collected between 1 January 2019 and 23 March 2020. Dataset 2—226,668 tweets collected between December 2019 and May 2020. | Sentiment analysis during COVID-19 pandemic, along with the usage and evaluation of deep learning classifiers. |
| 6 | Zhao YX, 2020, Journal of Medical Internet Research [61] | Chinese Public’s Attention to the COVID-19 Epidemic on Social Media: Observational Descriptive Study | Trend analysis. Keyword analysis. Sentiment analysis. Social network analysis. | Data related to COVID-19 extracted from Sina Microblog hot search list between 31 December 2019 and 20 February 2020. | Investigate and analyze the public’s attention, emotional responses, and key concerns regarding the COVID-19 epidemic during its early stages in China, with the goal of providing valuable insights to aid government and health departments |
| 7 | Shorten C, 2021, Journal of Big Data [62] | Deep Learning applications for COVID-19 | Supervised learning. Unsupervised learning. Semi-supervised learning. Self-supervised learning. Reinforcement learning. Meta-learning. | Medical imaging data. Text and literature data. Health records data. Molecular and biological data. Mobility and Interaction Data. | Enhancing public health outcomes by using Deep Learning and various data to fight against COVID-19. |
| 8 | Lyu JC, 2021, Journal of Medical Internet Research [63] | COVID-19 Vaccine-Related Discussion on Twitter: Topic Modeling and Sentiment Analysis | Topic modeling. Sentiment analysis. Emotion analysis. Statistical analysis. Text mining and natural language processing (NLP). | 1,499,421 unique English-language tweets from 583,499 different users, related to COVID-19, collected between 11 March 2020 and 31 January 2021. | Contribute to a deeper understanding of public perceptions, concerns, and sentiments surrounding the existing COVID-19 vaccines. |
| 9 | Liu Q, 2020, Journal of Medical Internet Research [64] | Health Communication Through News Media During the Early Stage of the COVID-19 Outbreak in China: Digital Topic Modeling Approach | Data collection. Data processing. Topic modeling using latent Dirichlet allocation (LDA). | 7791 Chinese news articles extracted from WiseSearch database, collected between 1 January and 20 February 2020, which are related to COVID-19. | Gather media reports, examine the trends in media-driven health communications and analyze the media’s role in COVID-19 pandemic context. |
| 10 | Xue J, 2020, PLOS One [65] | Public discourse and sentiment during the COVID-19 pandemic: Using Latent Dirichlet Allocation for topic modeling on Twitter | Data preparation. Unsupervised machine learning using latent Dirichlet allocation (LDA) for topic modeling. Qualitative analysis. Sentiment analysis. | 1,963,285 English tweets related to COVID-19, collected from 23 January to 7 March 2020. | Investigate public discourse from social media network, identify topics, themes, emotional reactions, and sentiment changes during COVID-19 outbreak, providing insights for real-time surveillance and targeted interventions. |
| Words | Occurrences |
|---|---|
| social media | 69 |
| sentiment analysis | 49 |
| 49 | |
| impact | 43 |
| information | 29 |
| health | 28 |
| classification | 24 |
| media | 22 |
| COVID-19 | 21 |
| model | 19 |
| Words | Occurrences |
|---|---|
| sentiment analysis | 426 |
| COVID-19 | 401 |
| 159 | |
| social media | 142 |
| machine learning | 75 |
| natural language processing | 71 |
| topic modeling | 53 |
| deep learning | 46 |
| coronavirus | 45 |
| pandemic | 42 |
| Bigrams in Abstracts | Occurrences | Bigrams in Titles | Occurrences |
|---|---|---|---|
| sentiment analysis | 633 | sentiment analysis | 190 |
| social media | 553 | COVID-pandemic | 133 |
| COVID-pandemic | 424 | social media | 85 |
| public health | 186 | machine learning | 34 |
| machine learning | 160 | twitter data | 34 |
| natural language | 115 | deep learning | 32 |
| topic modeling | 102 | COVID-vaccines | 25 |
| COVID-vaccines | 101 | COVID-vaccine | 24 |
| language processing | 100 | public sentiment | 24 |
| public opinion | 99 | topic modeling | 23 |
| Trigrams in Abstracts | Occurrences | Trigrams in Titles | Occurrences |
|---|---|---|---|
| natural language processing | 100 | natural language processing | 16 |
| social media platforms | 61 | social media data | 14 |
| latent dirichlet allocation | 56 | twitter sentiment analysis | 12 |
| coronavirus disease COVID | 48 | COVID-sentiment analysis | 6 |
| support vector machine | 36 | deep learning model | 6 |
| language processing nlp | 35 | text mining approach | 6 |
| social media data | 32 | COVID-vaccine hesitancy | 5 |
| world health organization | 32 | sentiment analysis approach | 5 |
| dirichlet allocation lda | 27 | social media sentiment | 5 |
| machine learning models | 25 | aspect-based sentiment analysis | 4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sandu, A.; Cotfas, L.-A.; Delcea, C.; Crăciun, L.; Molănescu, A.G. Sentiment Analysis in the Age of COVID-19: A Bibliometric Perspective. Information 2023, 14, 659. https://doi.org/10.3390/info14120659
Sandu A, Cotfas L-A, Delcea C, Crăciun L, Molănescu AG. Sentiment Analysis in the Age of COVID-19: A Bibliometric Perspective. Information. 2023; 14(12):659. https://doi.org/10.3390/info14120659
Chicago/Turabian StyleSandu, Andra, Liviu-Adrian Cotfas, Camelia Delcea, Liliana Crăciun, and Anca Gabriela Molănescu. 2023. "Sentiment Analysis in the Age of COVID-19: A Bibliometric Perspective" Information 14, no. 12: 659. https://doi.org/10.3390/info14120659
APA StyleSandu, A., Cotfas, L. -A., Delcea, C., Crăciun, L., & Molănescu, A. G. (2023). Sentiment Analysis in the Age of COVID-19: A Bibliometric Perspective. Information, 14(12), 659. https://doi.org/10.3390/info14120659