1. Introduction
(Temporal) conformance checking is increasingly at the heart of
Artificial Intelligence activities: due to its logical foundation, assessing whether a sequence of distinguishable events (i.e., a
trace) does not conform to the expected process behaviour (
process model) reduces to the identification of the specific unfulfilled temporal patterns, represented as logical
clauses. This leads to Explainable AI, as the process model’s violation becomes apparent. Clauses are the instantiation of a specific behavioural pattern (i.e.,
template) that expresses temporal correlation between actions being carried out (
activations) and their expected results (
targets). These, therefore, differ from traditional association rules [
1], as they can also describe complex temporal requirements: e.g., whether the target should immediately follow (
ChainResponse) or precede (
ChainPrecedence) the activation, if the former might happen any time in the future (
Response), or if the target should have never happened in the past (
Precedence). These temporal constraints can be fully expressed in a
Linear Temporal Logic over Finite Traces (LTL
f) and its extensions; this logic is referred to as linear as it assumes that, in a given sequence of events of interest, only one possible future event exists immediately following a given one. This differs from stochastic process modelling, where each event is associated with a probabilistic distribution of possibly following events [
2,
3]. Such a formal language can be extended to express correlations between activations and targets through binary predicates correlating data payloads. Events are also associated with either an action or a piece of state information represented as an
activity label. Collections of traces are usually referred to as
log.
Despite its theoretical foundations, state-of-the-art conformance checking techniques for entire logs expose sub-optimal run-time behaviour [
4]. The reasons are the following: while performing conformance checking over relational databases requires computing costly aggregation conditions [
5], tailored solutions do not exploit efficient query planning and data access minimisation, thus requiring scanning the traces multiple times [
6]. Efficiency becomes of the uttermost importance after observing that conformance checking’s run-time enhancement has a strong impact on a whole wide range of practical use case scenarios (
Section 1.1). To make conformance checking computations efficient, we synthesise temporal data derived from a system (be it digital or real) to a simplified representation in the Relational Database model. In this instance, we use
xtLTL
f, our proposed extension of LTL
f, to represent process models. While the original LTL
f merely asserts whether a trace is
conformant to the model, our proposed algebra returns all of the traces satisfying the temporal behaviour, as well as activated and targeted events. As a temporal representation in the declarative model provides a point-of-relativity in the context of correctness (i.e., time itself may dictate if traces maintain correctness throughout the logical declarations expressed by the model), the considerations of such temporal issues significantly increase the checking requirement. This is due to a need to visit logical declarations for correctness in the context of each temporal instance.
This paper extends our previous work [
4], where we clearly showed the disruptiveness of the relational model for efficiently running temporal queries outperforming state-of-the-art model checking systems. While our original work [
4] provided just a brief rationale behind the success of KnoBAB (The acronym stands for
KNOwledge Base for Alignments and Business process modelling). The Business Process Mining literature often uses the term Knowledge Base differently from customary database literature: while in the former, the intended meaning is a customary relational representation for trace data, in the latter, we often require that such representation provides a machine-readable representation of data in order to infer novel facts or to detect inconsistencies., this paper wants to dive deep into each possible contribution leading to our implementation success.
As an extension from our previous work, we fully formalise the logical data model (
Section 3.1) and characterise the physical one (
Section 4) in order to faithfully represent our log. This will prelude the full formalisation of the
xtLTL
f algebra;
Contextually, we also show for the first time that the
xtLTL
f algebra (
Section 3.2) can not only express declarative languages such as Declare [
7] as in our previous work but can express the semantics of LTL
f formula by returning any non-empty finite trace satisfying the latter if loaded in our relational representation (see
Appendix A.2). We also show for the first time a formalisation for data correlation conditions associated with binary temporal operators;
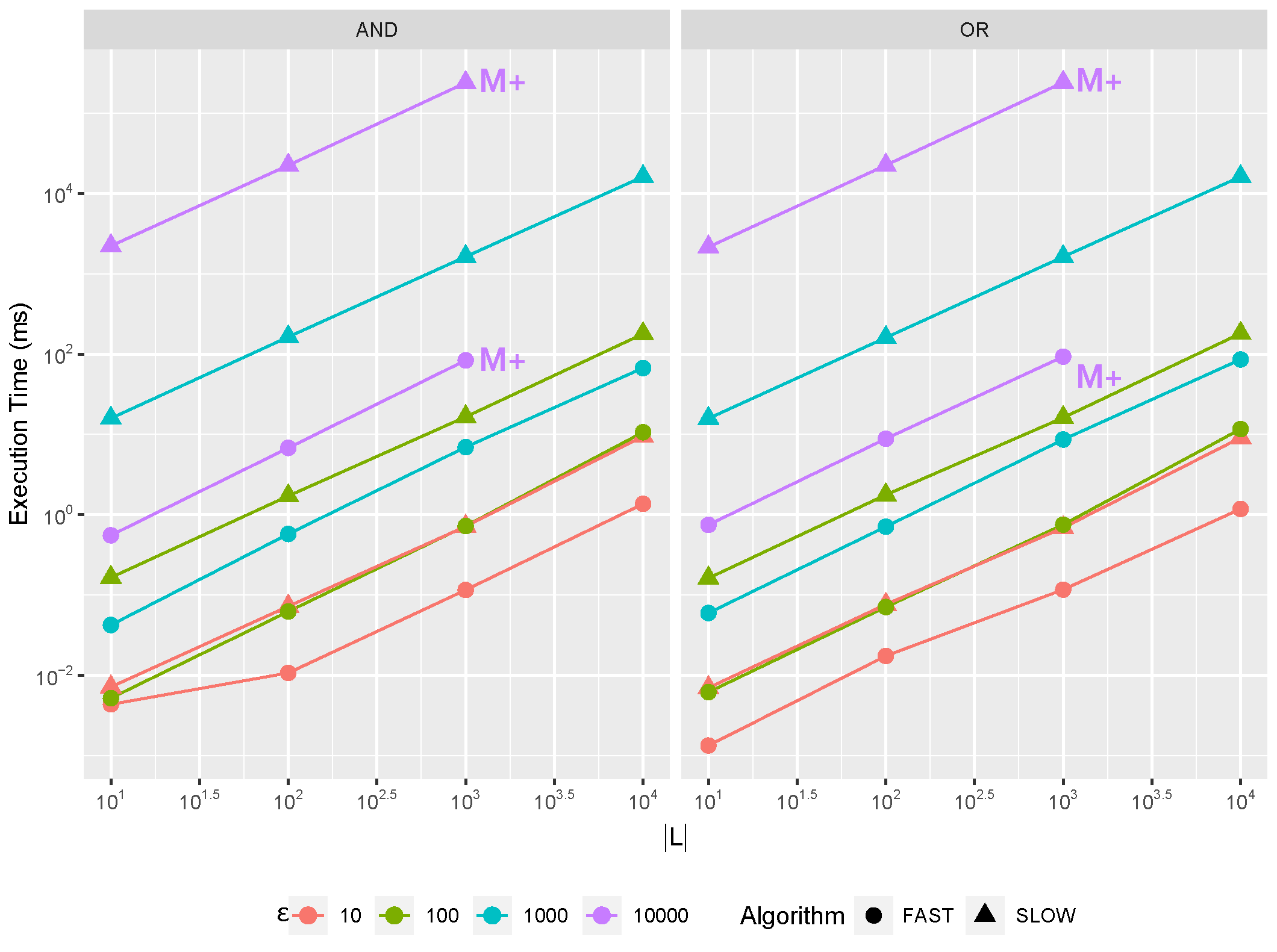
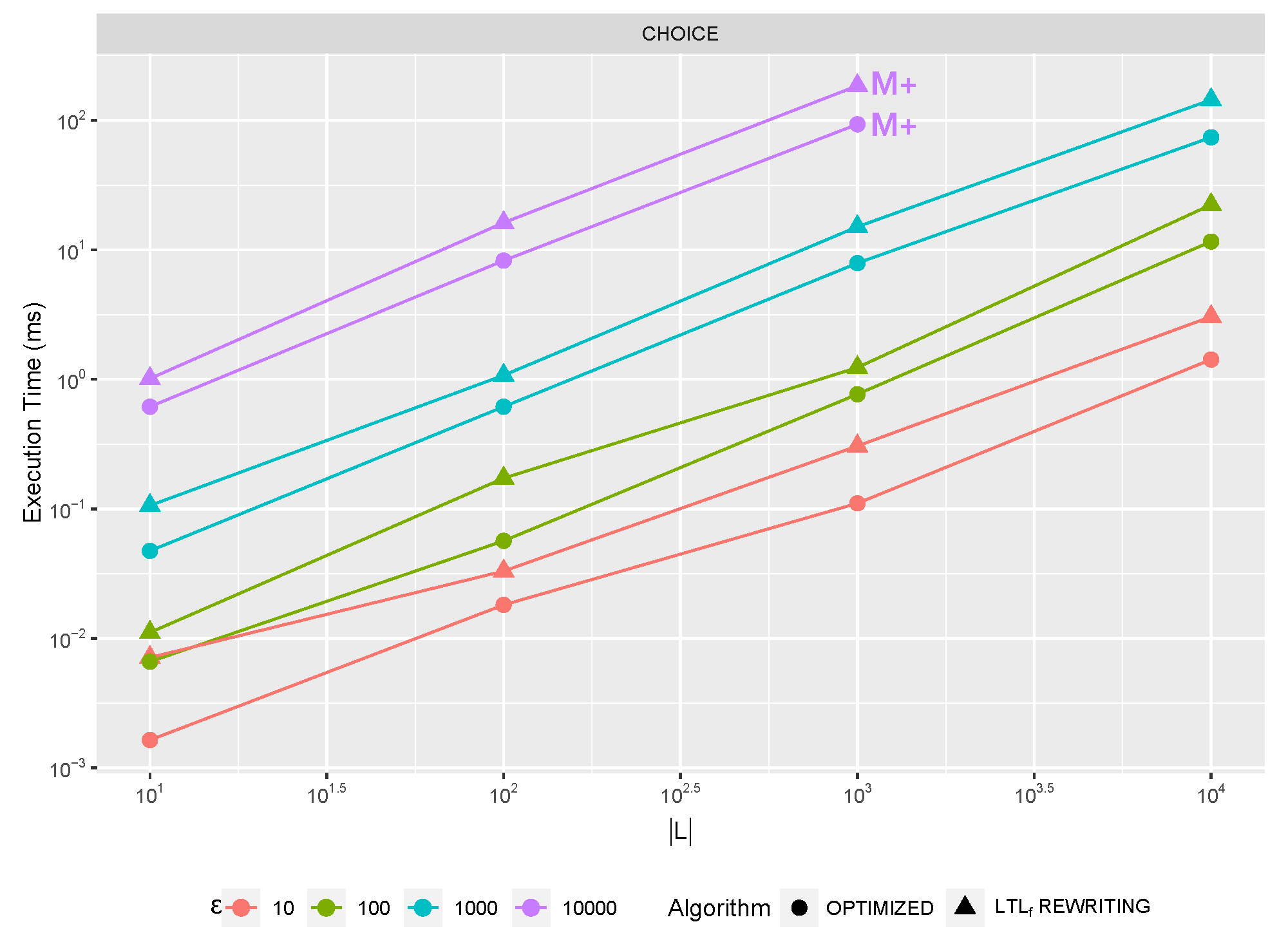
Differently from our previous work, where we just hinted at the implementation of each operator with some high level, we now propose different possible algorithms for some
xtLTL
f operators (
Section 6), and we then discuss both theoretically (
Supplement II.2) and empirically (
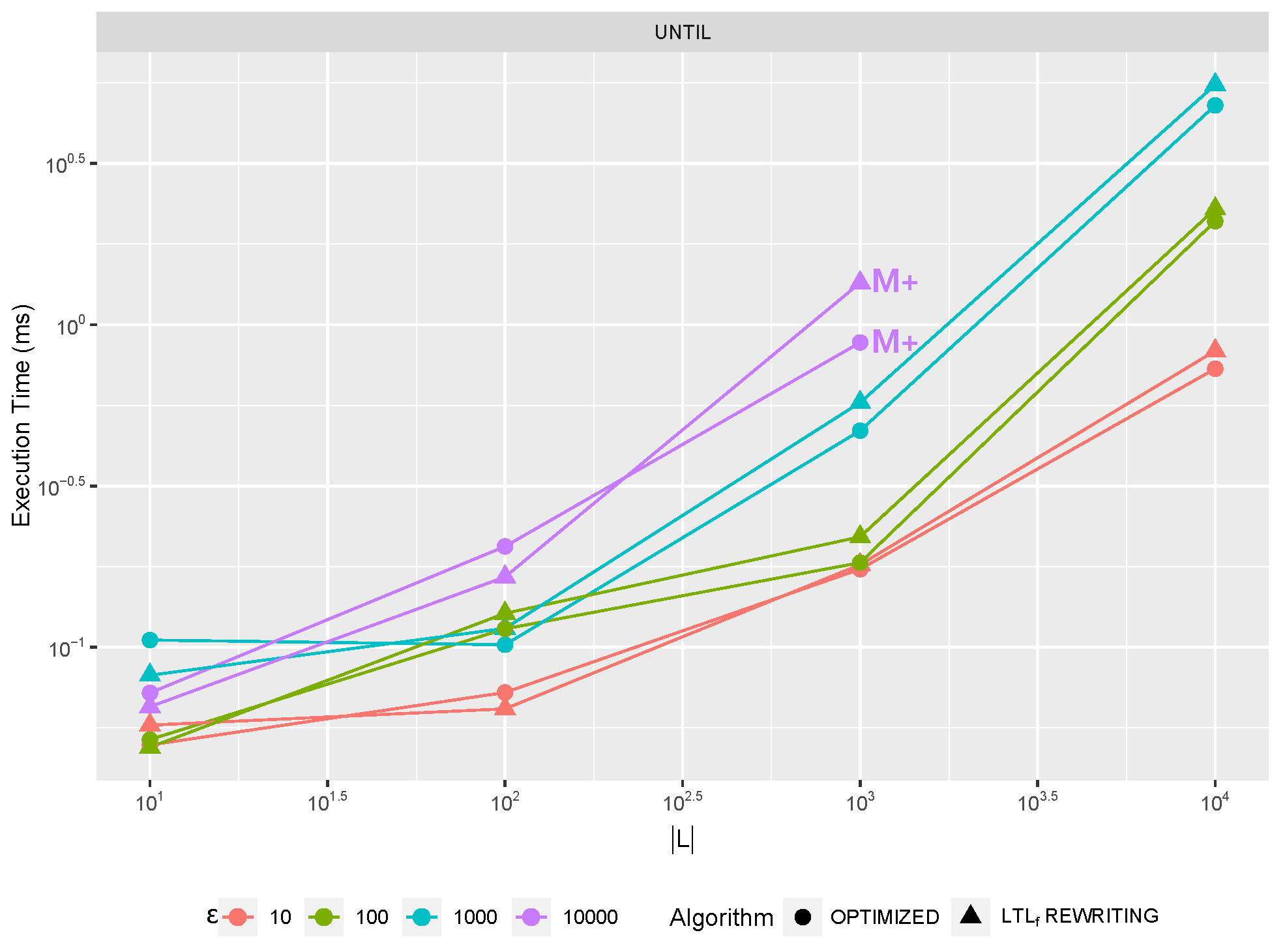
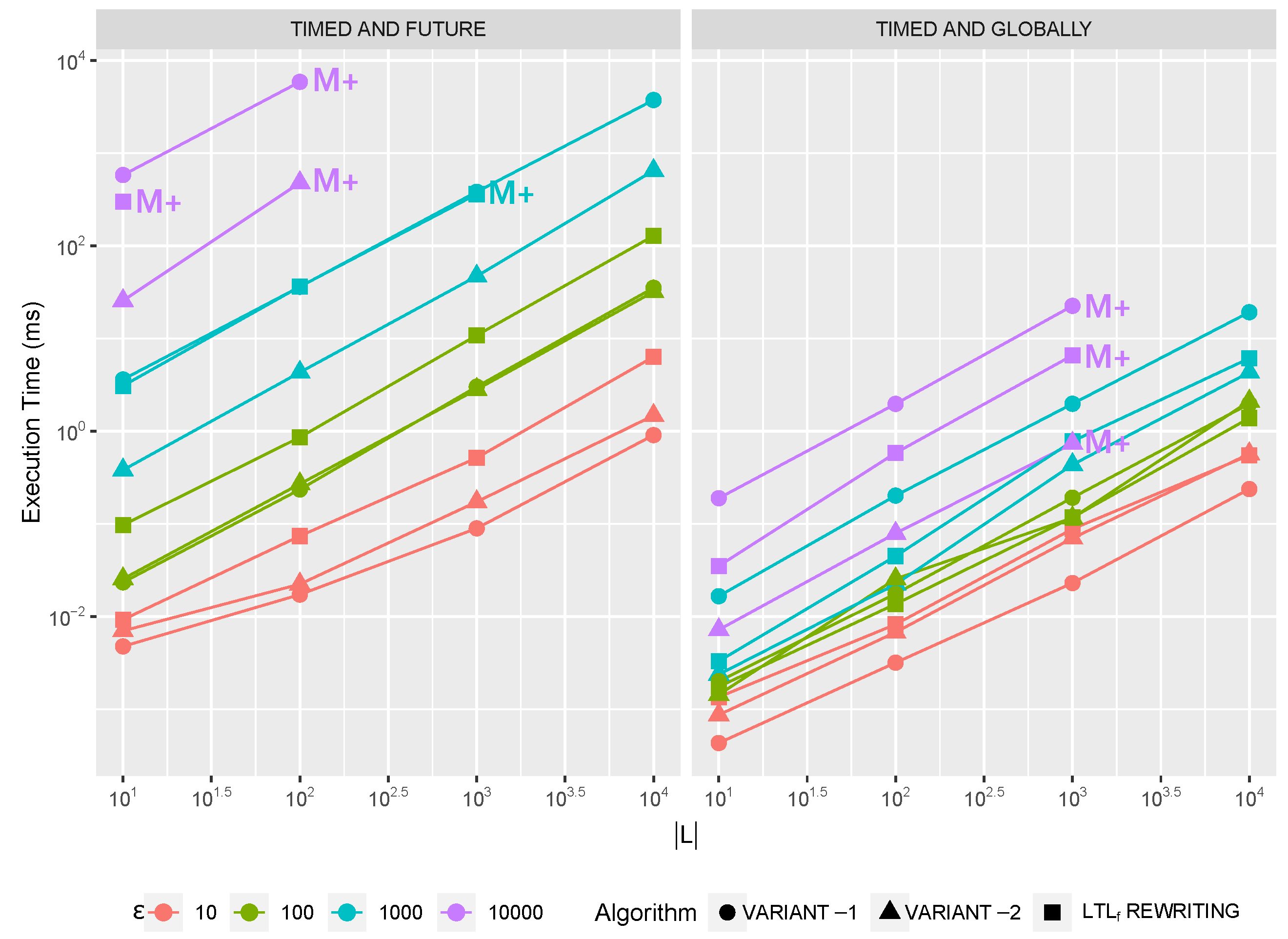
Section 7.1) which might be preferred under different trace length
or log size
conditions. This leads to the definition of hybrid algorithms [
8];
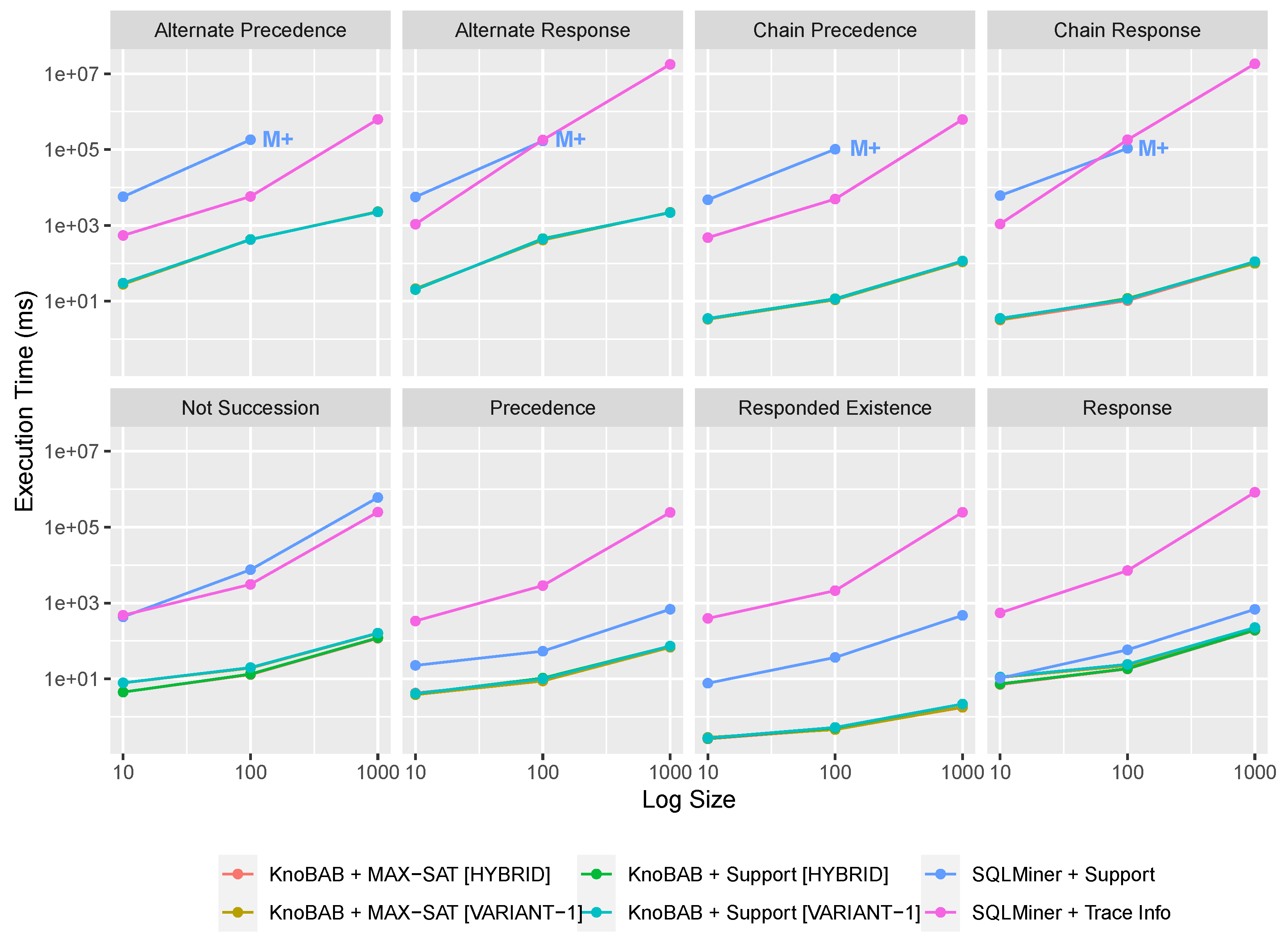
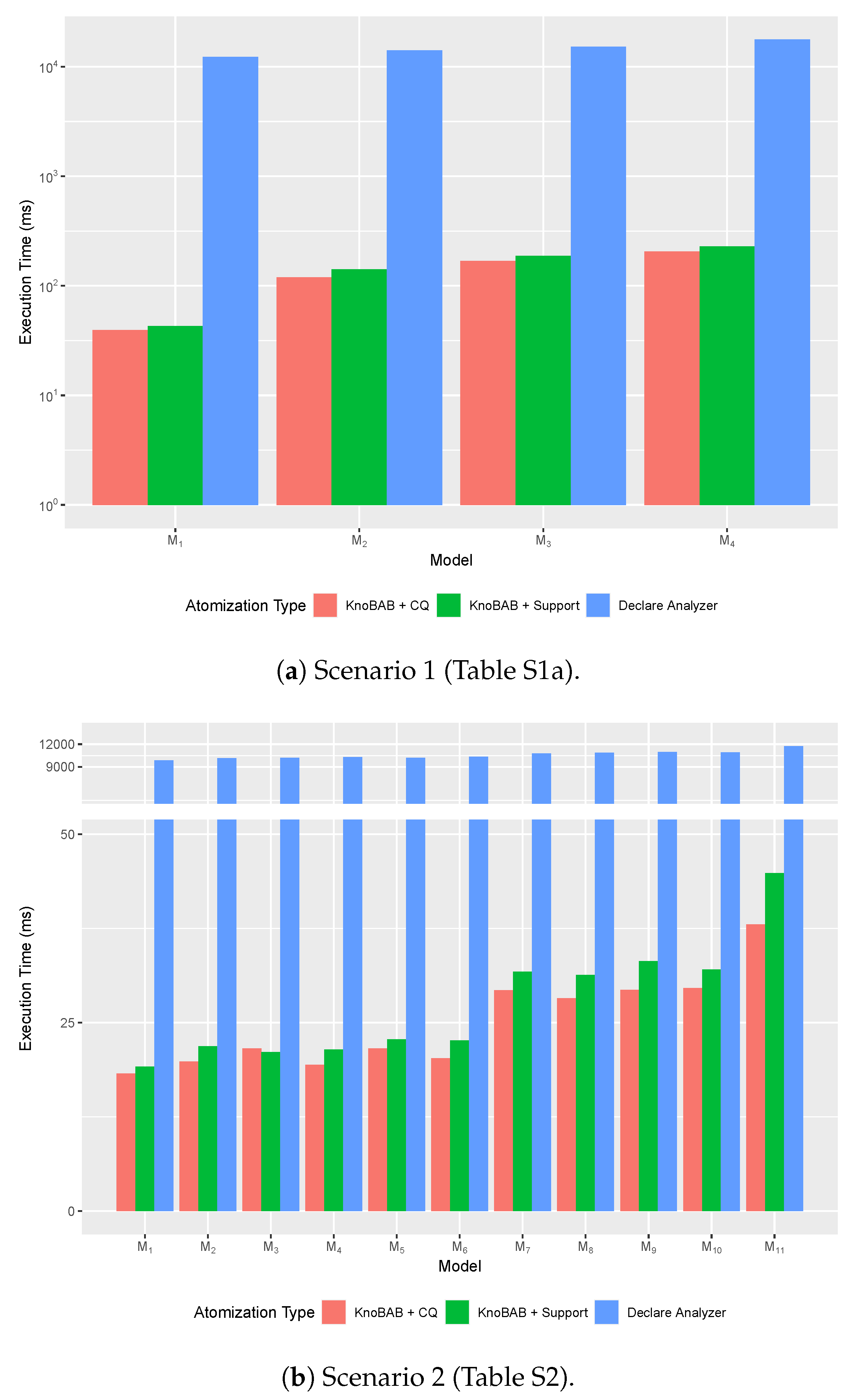
Our benchmarks demonstrate that our implementation outperforms conformance checking techniques running on both relational databases (
Section 7.2) and on tailored solutions (
Section 7.5) when customary algorithms are chosen for implementing
xtLTL
f operators;
Finally, this paper considerably extends the experimental section from our previous work. First, we show (
Section 7.3) how the query plan’s execution might be parallelised, thus further improving with super-linear speed-up our previous running time results. Then, we also discuss (
Section 7.4) how different data accessing strategies achievable through query rewriting might affect the query’s running time.
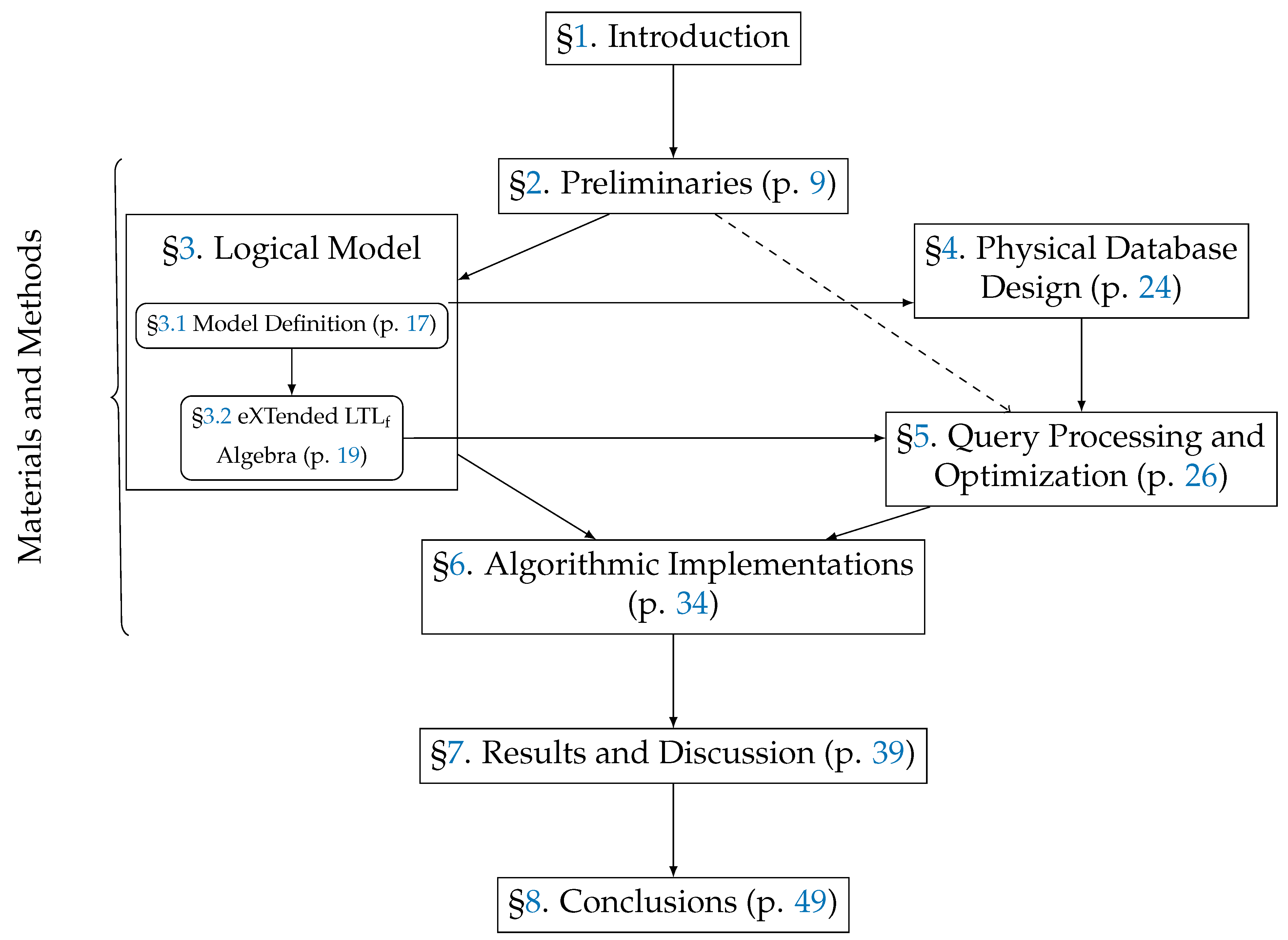
Figure 1 provides a graphical depiction of this paper’s table of contents, with the mutual dependencies between its sections. Appendices and Supplements start from p. 50.
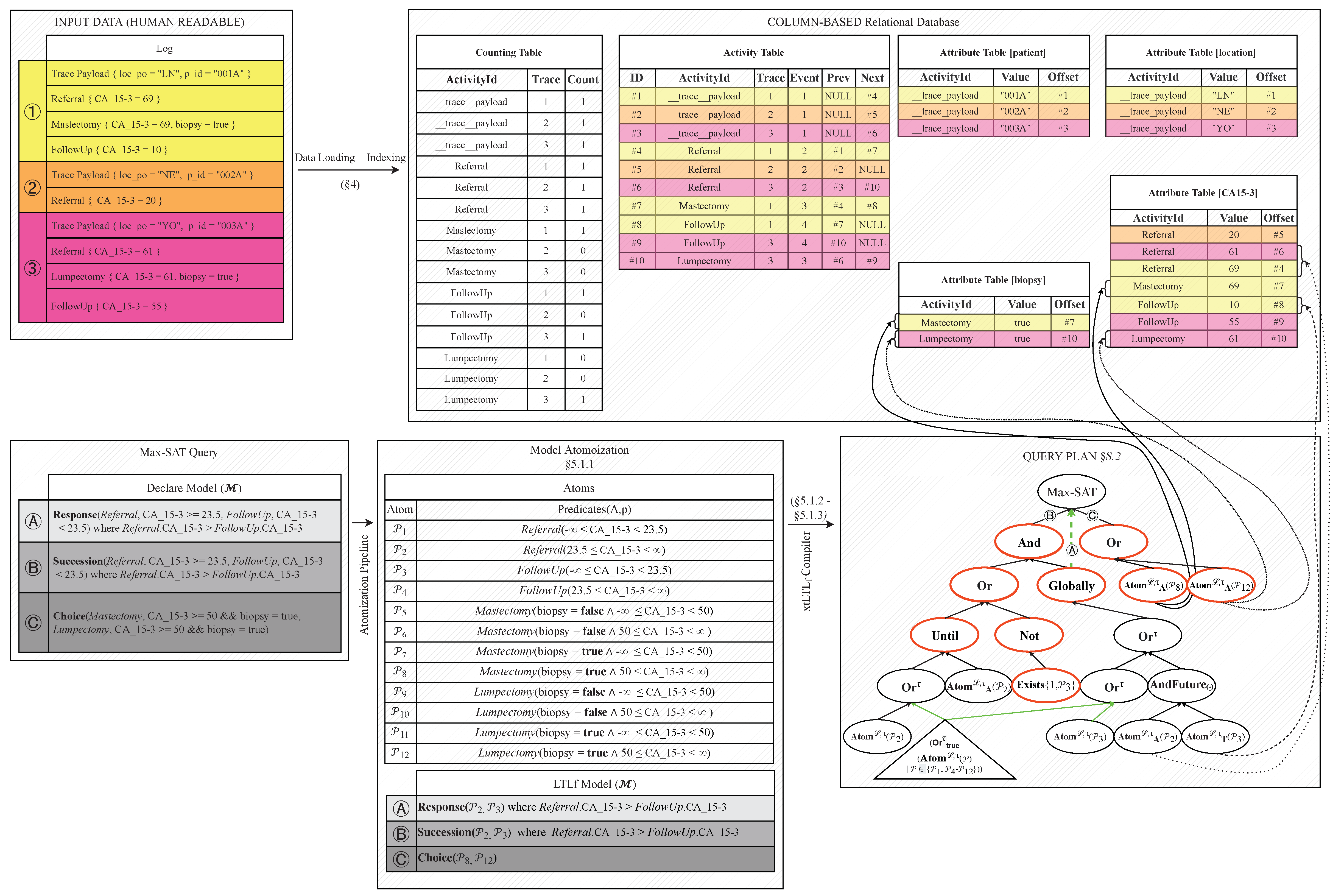
Figure 2 provides a bird-eye view of the overall KnoBAB architecture: in the upper half, we show how a log is loaded in our business process management system as a series of distinct tables providing some activity statistics (
CountingTable) and full payload information (
AttributeTable) in addition to reconstructing the unravelling of the events as described by their traces (
ActivityTable). On the other hand, the lower half shows the main steps of the query engine transforming a declarative model into a DAG query plan accessing the previously-loaded relational tables. The most recent version of our system is on GitHub (
https://github.com/datagram-db/knobab as accessed the 5 March 2023). When not explicitly stated, all the links were last accessed the 5 March 2023.
2. Preliminaries
eXtensible Event Stream (XES). This paper relies on temporal data represented as a temporally ordered sequence of events (
trace or
streams), where events are associated with at most one action described by a single
activity label [
24]. In this paper, we formally characterize payloads as part of both events and traces while, in our previous work, we only considered payloads from events [
25].
Given an arbitrarily ordered set of keys
K and a set of values
V, a
tuple [
26] is a finite function
(also
), where each key is either associated with a value in
V or is undefined. After denoting ⊥ as a
null element missing from the set of values (
), we can express that
is not associated with a value in
p as
, thus
. An empty tuple
has an empty domain.
(Data) payloads are tuples, where values can represent either categorical data or numerical data. An event is a pair , where is a finite set of activity labels, and p is a finite function describing the data payload. A trace is an ordered sequence of distinct events , which is distinguished from the other traces by a case id i; n represents the trace’s length (). If a payload is also associated with the whole trace, this can be easily mimicked by adding an extra initial event containing such a payload with an associated label of __trace_payload. A log is a finite set of traces . In this paper, we further restrict our interest to the traces containing at least one event, as empty traces are meaningless as they are not describing any temporal behaviour of interest. Finally, we denote as the bijection mapping each activity label occurring in the log to an unique id.
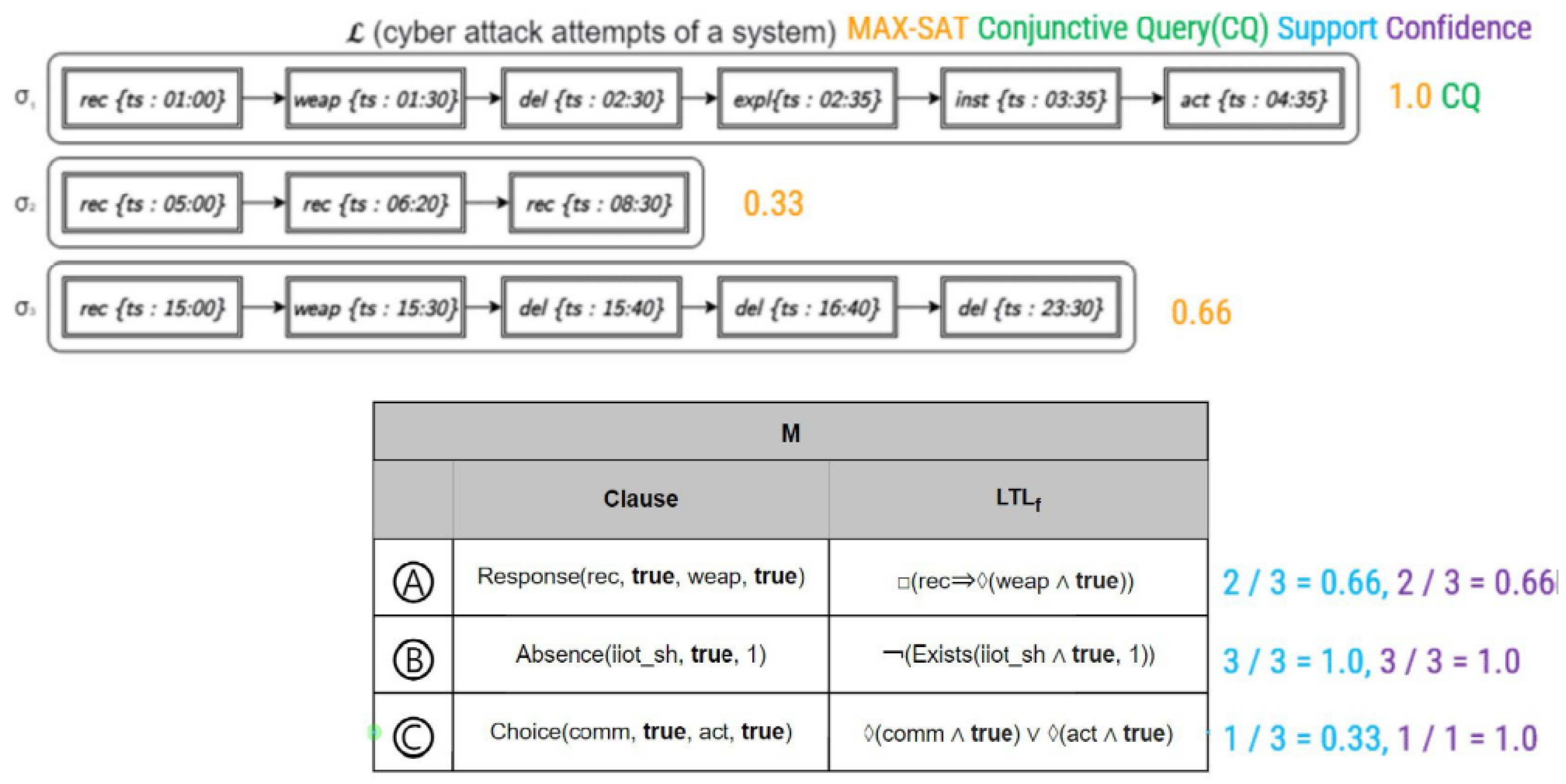
Example 3. The log in Figure 2 comprises three distinct traces . In particular, the second trace comprises two events , where the first event represents the trace payload, and therefore having and . The other event is , where payload is only associated with the CA-13.5 levels as . Similar considerations can be carried out for the other log traces. Linear Temporal Logic over finite traces (LTLf). LTL
f is a well-established extension of
modal logic considering the possible worlds as finite traces, where each event represents a single relevant instant of time. The time is thereby linear, discrete, and future-oriented. This entails that that the events represented in each trace are totally ordered and, as LTL
f quantifies only on events reported in the trace, all the events of interest are fully observable. The
syntax of an well-formed LTL
f formula
is defined as follows:
where
. Its
semantics is usually defined in terms of First Order Logic [
27] for a given trace
at a current time
j (e.g., for event
) as follows:
An event satisfies the activity label iff. its activity labels is : ;
An event satisfies the negated formula iff. the same event does not satisfy the non-negated formula: ;
An event satisfies the disjunction of LTLf sub-formulæ iff. the event satisfies one of the two sub-formulæ: ;
An event satisfies the conjunction of LTLf formulæ iff. the event satisfies all of the sub-formulæ: ;
An event satisfies a formula at the next step iff. the formula is satisfied in the incoming event if present: ;
An event globally satisfies a formula iff. the formula is satisfied in all the following events, including the current one: ;
An event eventually satisfies a formula iff. the formula is satisfied in either the present or in any future event: ;
An event satisfies until holds iff. holds at least until becomes true, which must hold at the current or a future position:
Other operators can be seen as syntactic sugar: Weak-Until is denoted as
, while the implication can be rewritten as
. Generally, binary operators bridge activation and target conditions appearing in two distinct sub-formulæ. The semantics associated with activity labels, consistently with the literature on business process execution traces [
25], assumes that, in each point of the sequence, one and only one element from
holds. We state that a trace
is
conformant to an LTL
f formula iff. it satisfies it starting from the first event:
, and is
deviant otherwise [
25]. The Declare language described in the next paragraph provides an application for such logic. As relational algebra describes the semantics for SQL [
28,
29], LTL
f is extensively applied [
30] as a semantics for formally expressing temporal and human-readable declarative constraints such as Declare.
At the time of the writing, different authors proposed several extensions for representing data conditions in LTL
f. The simplest extensions are
compound conditions , which are the conjunction of data predicate
to the activity label a [
25]. Nevertheless, this straightforward solution is not able to express correlation conditions in the data which might be relevant in business scenarios [
31], as representing correlations as single atoms requires decomposing the former into disjunctions of formulae [
32]. Despite prior attempts to define a temporal logic expressing correlation conditions, no explicit formal semantics on how this can be evaluated was provided [
6]. This poses a problem to the current practitioner, as this hinders the process of both checking formally the equivalence among two languages expressing correlation conditions, as well as providing a correct implementation of such an operator. We, on the other hand, propose a relational representation of
xtLTL
f, where the semantics of all of the operators, thus including the ones requiring correlation conditions, is clearly laid out and implemented.
Declare. Temporal declarative languages pinpoint highly variable scenarios, where state machines provide complicated graph models that can be hardly understandable by the common business stake-holder [
33]. Among all possible temporal declarative languages, we constrain our interest to Declare, originally proposed in [
7]. Every single temporal pattern is expressed through
templates (i.e., an abstract parameterised property:
Table 1 column 2), which are parametrised over activation, target, or correlation conditions. Template names induce the semantic representation in LTL
f of each model clause
. Therefore, a trace
is conformant to a Declare clause iff. it satisfies its associated semantic representation in LTL
f (
). At this stage,
activation (and
target)
conditions are predicates
(and
) in such a clause asserting required properties for the events’ activity label (
and
) and payload (
p and
q). An event in a given trace
activates (or
targets) a given clause if they satisfy the activation (or target) condition. Please observe that neither activation nor target conditions postulate the temporal (co)occurrence between activating or targeting events, as this is duty is transferred to the specific LTL
f semantics of the clause. A trace
vacuously satisfies a clause if the trace satisfies the clause despite no event in the trace satisfied the activation condition. After this, we state that a trace
non-vacuously satisfies the declarative clause if the trace satisfies the clause and one of the following conditions is satisfied:
The clause provides no target condition and it exists at least one activating event;
The clause provides a target condition but no binary (payload) predicate , and the declarative clause establishes a temporal correlation between (at least one) activating event and (at least one) targeting one;
The clause provides both a target condition and a binary predicate , while the activating and targeting events satisfying the temporal correlation as in the previous case also satisfy a binary predicate over their payloads; in this situation, we state that the activating and targeting event match as they jointly satisfy the correlation condition .
Finally, the presence of activating events is a necessary condition for non-vacuous satisfiability.
We can then categorize each Declare template from [
30] through these conditions and the ability to express correlations between two temporally distant events happening in one trace: simple templates (
Table 1, rows 1–3) only involving activation conditions; (mutual) correlation templates (rows from 4 to 15), which describe a dependency between activation and target conditions, thus including correlations between the two; and negative relation templates (last 2 rows), which describe a negative dependency between two events in correlation. Despite these templates possibly appearing quite similar, they generate completely different finite state machines, thus suggesting that these conditions are not interchangeable (
http://ltlf2dfa.diag.uniroma1.it/, 5 March 2023).
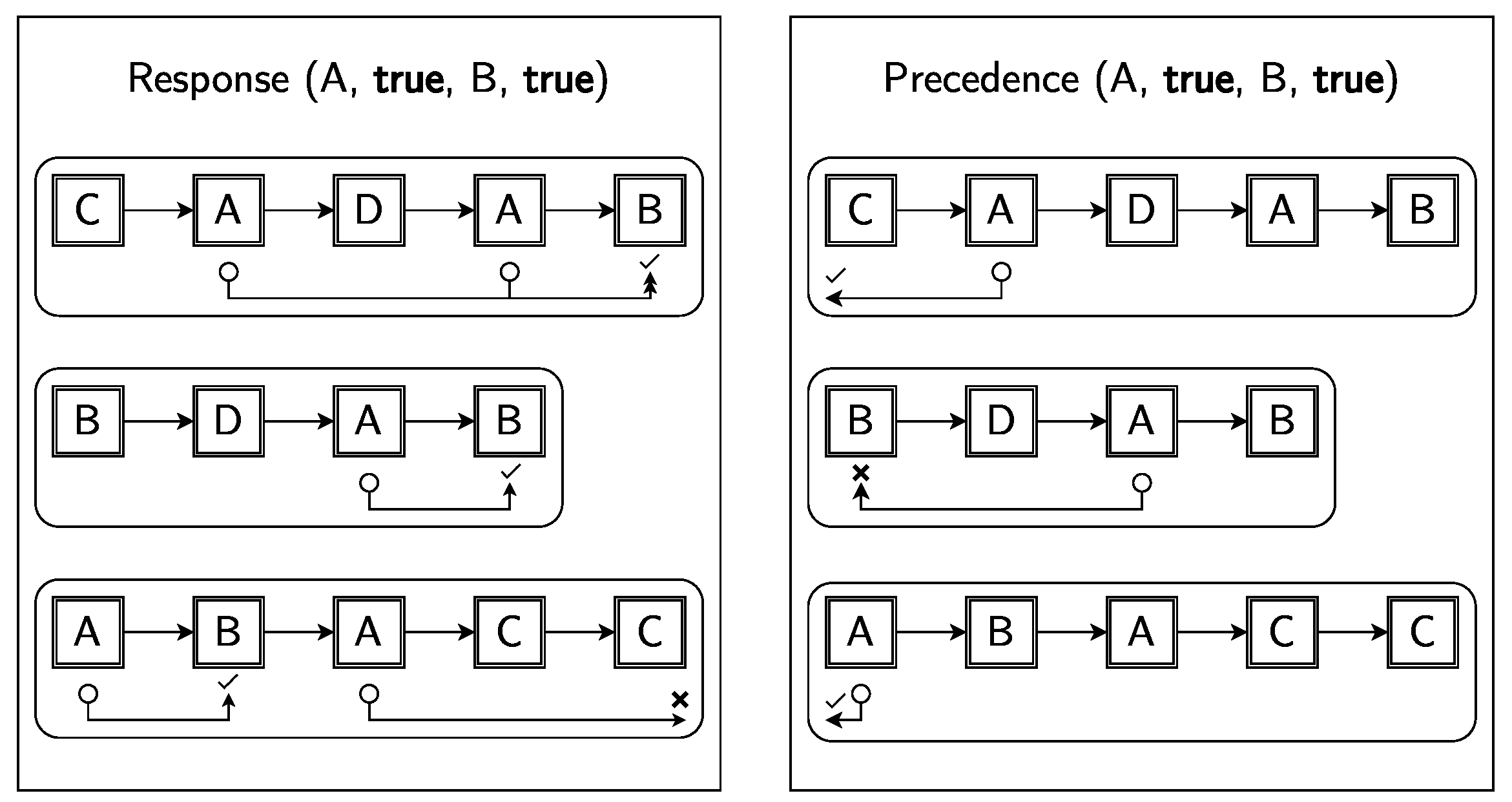
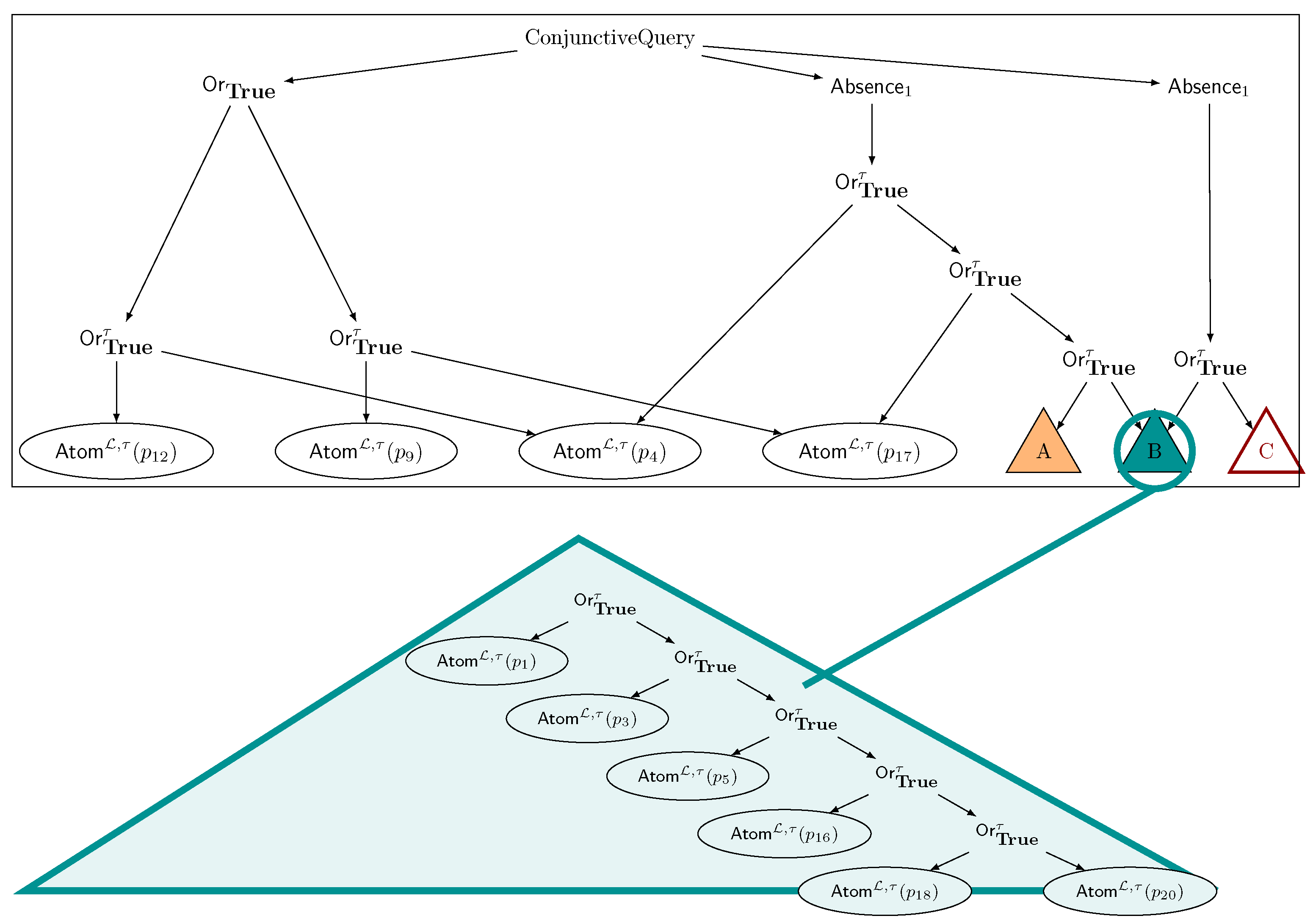
Figure 4 exemplifies the behavioural difference between two clauses differing only on the template of choice.
A Declare Model is composed of a set of clauses
which have to be contemporarily satisfied in order to be true. A trace
is conformant to a model
iff. such a trace satisfies each LTL
f formula
associated with the model clause
. Consequently, a Declare model can be represented as a finitary conjunction of the LTL
f representation of each of its clauses,
: for this, the
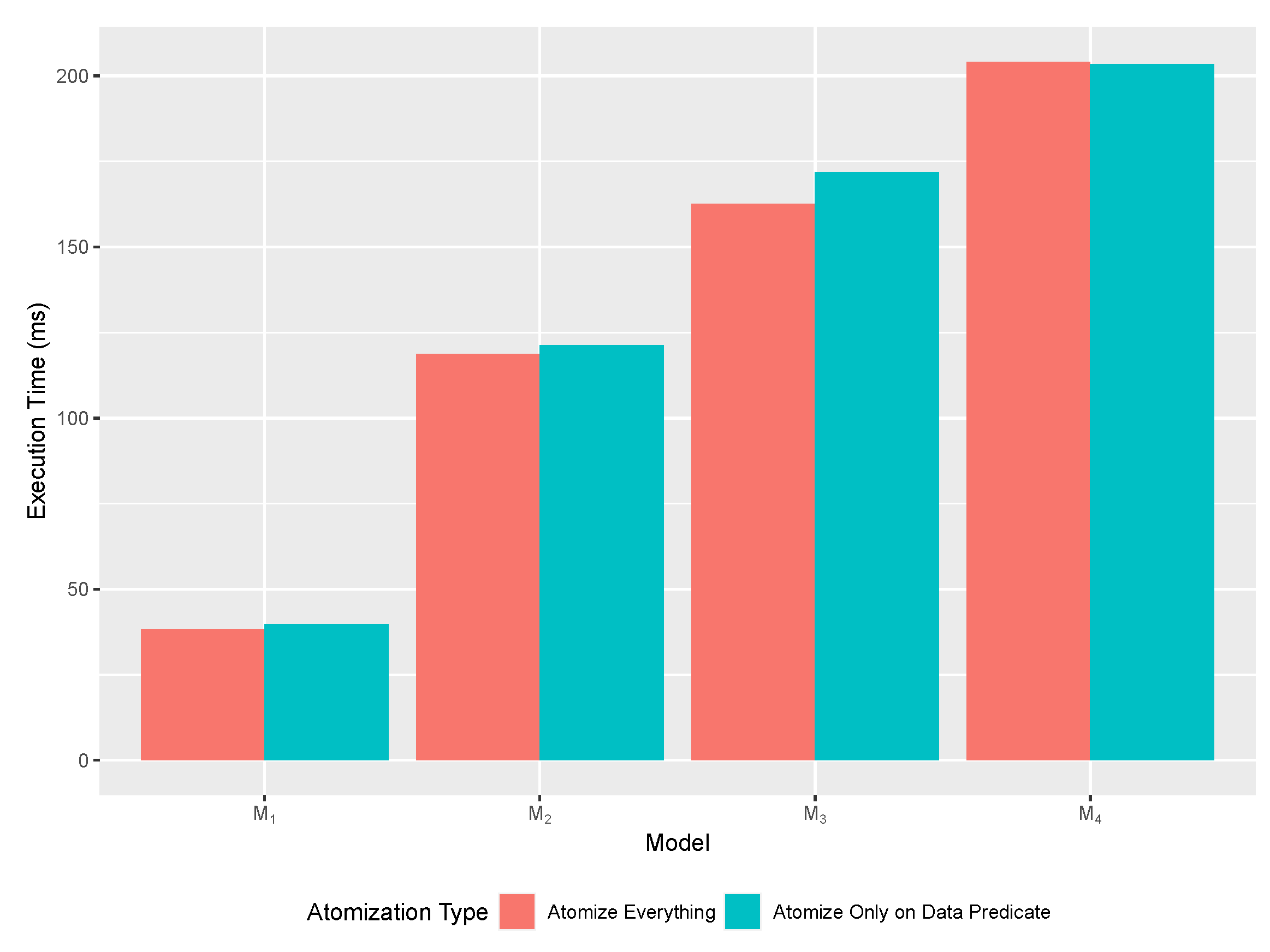
Maximum-SATisfiability problem (Max-SAT) for each trace counts the ratio between the satisfied clauses over the whole model size. This consideration can be extended later on to also data predicates through predicate atomisation [
25], as discussed in the next paragraph.
Relational Models and Algebras. The
relational model was firstly introduced by Codd [
34] to compactly operate over tuples grouped into tables. Such tables are represented as mathematical n-ary relations
ℜ that can be handled through a relational algebra. Upon the effective implementation of the first
Relational Database Management Systems (RDBMS), such algebra expressed the semantics of the well-known declarative query language, SQL. The rewriting of SQL in algebraic terms allowed the efficient execution of the declarative queries through abstract syntax tree manipulations [
28]. Our proposed
xtLTL
f (
Section 3.2) takes inspiration from this historical precedent, in order to run conformance checking and temporal model mining queries over an relational representation of the log via relational tables (
Section 3.1).
More recently,
column-oriented DBMS such as MonetDB [
35] proposed a new way to store data tables: instead of representing these per row, these were stored by column. There are several advantages to this approach, including better access to data when querying only a subset of columns (by eliminating the need to read columns that are not relevant) as well as discarding null-valued cells. This is achieved by representing each relation
in the database schema as distinct binary relations
for each attribute
in
ℜ. As this decomposition guarantees that the full-outer natural join
over the decomposed tables is equivalent to the initial relation
, we can avoid representing
NULL values in each single binary relation, thus limiting our space allocation to the values effectively present in the data. We therefore took inspiration from this intuition for representing the payload information, thus storing one single table per payload attribute. To further optimise the query engine, it is also possible to boost the query performance by guaranteeing that the results always have a fixed schema, mainly listing the record ids satisfying the query conditions [
36]. As we will see while introducing our temporal operators (
Section 3.2), we will also guarantee that each operator returns the output in the same schema, thus guaranteeing time and memory optimality.
Finally, the
nested relational model [
37] extends the relational model by relaxing its first normal form (1NF), thus allowing table cells to contain tables and relations as values. Relaxing this 1NF allows for storing data in a hierarchical way in order to access an entire sub-tree with a single read operation. We will leverage this representation for our intermediate result representation, in order to associate multiple activation, target, or correlation conditions to one single event, thus including any relevant future event occurring after it.
Common Subquery Problem. Query caching mechanisms [
38] are customary solutions for improving query runtime by holding partially-computed results in temporary tables referred to as materialised views, under the assumption that the queries sharing common data are pipelined [
39]. Recently, Kechar et al. [
9] proposed a novel approach that can also be run when queries are run contemporarily: it is sufficient to find the shared subqueries before actually running them so that, when they are run, their result is stored into materialised views thus guaranteeing that these are computed at most once.
Example 4. Figure 2 shows how this idea might be transferred to our use case scenario requiring running multiple declarative clauses: Response is both a subquery of Succession as well as a distinct declarative clause of interest. Green arrows indicate operators’ output shared among operators expressed in our proposed xt LTL
f extension of xt LTL
f. Please also observe that operators with the same name and arguments but marked either with activation, target, or no specification are considered different as they provide different results, and therefore are not merged together. This includes distinctions between timed and untimed operators, which will be discussed in greater detail in Section 3.2. To further minimize tables’ access times, it is possible to take this reasoning to its extreme by minimising the data access per data predicate in order to avoid accessing the same table multiple times. In order to do so, we need to partition the data space according to the queries at our disposal as in our previous work [
25]. This process can be eased if we assume that each payload condition
p and
for the declarative clauses within a model
is represented in
Disjunctive Normal Form (DNF) [
40]: in this scenario, data predicates
q are in DNF if they are a disjunction of one or more conjunctions of one or more data intervals referring to just one payload key.
Example 5. The model illustrated in Figure 3a and discussed in former Example 1 comes with data conditions associated with neither activation nor target conditions. Therefore, no atomisation process is performed. Thus, each event in a log might just be distinguished by its activity label [25]. Given an LTL
f expression
containing compound conditions, we denote
as the set of distinct compound conditions in
. We refer to the items in
as
atoms iff. for each pair of distinct compound conditions in it, they never jointly satisfy any possible payload
p (More formally,
). Ref. [
25] shows a procedure showing how any formula
can be rewritten into an equivalent one
by ensuring that
contains atoms. This can be achieved by constructing
first from
(Algorithm 1), and then converting each compound conditions in
as disjunctions of atoms in
, thus obtaining
.
| Algorithm 1 Atomisation: -encoding pipeline. |
- 1:
global ; ; -
- 2:
procedure CollectIntervals(, DNF) ▹ DNF - 3:
for all and do - 4:
- 5:
end for -
- 6:
procedure CollectIntervals() ▹ - 7:
for all do - 8:
if then CollectIntervals() - 9:
if then CollectIntervals() - 10:
end for -
- 11:
procedure -encoding( ) - 12:
for all do - 13:
for all do - 14:
SegmentTree() - 15:
end for - 16:
for all do
▹ - 17:
new atom() - 18:
- 19:
- 20:
for all do - 21:
- 22:
end for - 23:
end for - 24:
if then - 25:
- 26:
end if - 27:
end for
|
We collect all the conjunctions referring to the same payload key into a map
μ(
a,
κ) (Line 4). After doing so, we can construct a Segment Tree [
41] from the intervals in
μ(
a,
κ), thus identifying the
elementary intervals partitioning the collected intervals (Line 14). These elementary intervals also partition the payload data space associated with events for each activity label
a. This can be achieved by combining each elementary interval in each dimension
for
a (Line 16) and then associating it with a new atom representing such a partition (Line 18) that is then guaranteed to be an atom by construction. This entails that each interval
will be characterised by the disjunction of all of the atoms
comprising such interval (Line 21). Given this, we can then associate to each activation condition
A that is associated with an activation payload condition
p the disjunction of atoms that are collected by the following formula:
Example 6. Each distinct payload conditions associated with either activation or target conditions in Figure 2 can be expressed as one single atom, as there are no overlapping data conditions associated with the same activity label, and each data condition can be mapped into one single elementary interval associated with an activity label. The next example will provide another use case example and a different model on the same dataset leading to a decomposition of payload conditions into a disjunction of several atoms. Table 2 shows the partitioning of the data payloads associated with each activity label in the log by the elementary interval of interest. Example 7. Let us suppose to return all the false negative and false positive Mastectomy cases that are not caused by data imputation errors. For this, we want to obtain all of the negative biopsies having CA15.3 levels greater than the guard level of 50 and positive biopsies having CA15.3 below the same threshold. Under the assumption that biopsy values were imputed through numerical numbers thus leading to more imputation errors, we are ignoring cases where both CA15.3 and biopsy values are out of scale, that is, we want to ignore the data where CA15.3 levels are negative or above 1000, and where the biopsy values are neither true () nor false (). For this, we can outline the following model: This implies that we are interested in decomposing the intervals pertaining to both CA-15.3 and biopsy into elementary intervals: Table 3a shows that only and are decomposed into two elementary intervals, as the former also includes the range , while the latter also includes . Elementary intervals not occurring in the initially collected ones are not reported in this graphical representation. Table 3b shows the partitioning of the Mastectomy data payload induced by the elementary intervals of interest; the former data conditions can be now rewritten after Equation (2) in the Supplement as follows: - 1.
- 2.
- 3.
- 4.
where each atom is defined as a conjunction of compound conditions defined upon the previously collected elementary intervals. Some examples are then the following:
This decomposition will enable us to reduce the data access time while scanning the tables efficiently.
Further Notation. We represent relational tables as a sequence of records indexed by id as per the physical relational model: given a relational table
T,
represents the
i-th record in
T counting from 1. We denote
as a finite function such that
and
.
Table 4 collects the notation used throughout the paper.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}