1. Introduction
Human beings have always explored the ocean, and this exploration has impacted the fields of commerce, the military and scientific research. With the developments brought about by this exploration, about half of the world’s energy and means of production are obtained from the ocean, on which human beings are becoming increasingly dependent. The initiatives of the “Maritime Silk Road” and “the Belt and Road” in the twenty-first century greatly promoted the development of marine transportation, marine industry and marine energy worldwide [
1]. Therefore, deep-sea diving has been widely used in navigation, ocean development, military navigation, ocean rescue and other fields [
2]. In addition, more and more people are taking up deep-sea diving.
In common diving activities, also known as “scuba diving”, divers rely on gas that is contained in a cylinder and composed of about 20% oxygen and 80% nitrogen to dive. Nitrogen does not affect the human body at normal air pressure. However, as the diving depth increases, nitrogen molecules fuse with nerve cells under increasingly high pressure, causing varying degrees of anesthesia. At depths of up to 30 m, a paralyzing phenomenon known as nitrogen anesthesia can occur in divers. In addition, high-pressure oxygen might cause brain poisoning, which can seriously threaten divers’ lives [
3]. Research has shown that divers can avoid this physiological reaction when they breathe a mixture of helium and oxygen (helium–oxygen) instead of air at high pressure [
4]. Therefore, helium–oxygen mixtures have been widely used in deep-sea saturation diving. Since the physical properties of helium–oxygen (He-O
2) at high pressure are very different from those of atmospheric air at normal pressure, the acoustics of speech produced at great depths are very different from that produced at normal pressure. Speech produced in a high-pressure helium–oxygen environment, which is called “helium speech”, sounds like “Donald Duck” and is difficult to understand. This could affect divers’ work, and even threaten their lives if not properly handled.
It is well known that breathing gases lighter than air will cause speech distortions. However, the study of helium speech did not begin until the 1960s. In 1962, the United States Navy biologists carried out the first saturated diving experiment using helium–oxygen at normal pressure. The experiment was a biological success, but due to the low intelligibility of helium speech, it was difficult for volunteers to communicate [
5]. Subsequent experiments also showed that helium speech distortion interferes with smooth communication. In the same year, Beil mixed air and helium gas in certain proportions, and then, breathed through a mask and analyzed the sound spectrum of the speech. He pointed out that the formant frequency and pitch of the speech roughly increased at a certain proportion [
6].
In 1967, Sergeant first gave a report on helium speech acoustics, and determined the intelligibility of syllabic words in helium–oxygen under normal pressure [
7]. In 1968, Hollien and Thompson studied the intelligibility of monosyllabic English words in a variety of gases and the relationship between pressure and intelligibility [
8,
9]. They pointed out that communication is impossible if depth increases. Many attempts have been made to improve the intelligibility of helium speech [
10,
11,
12,
13]. Copel first split the sound spectrum into two bandwidths, and each moved independently toward lower frequencies through a beat. In the late 1960s, there were many studies on helium speech under high pressure, and many methods of unscrambling helium speech were proposed. Among them, Fant and Sonesson first explained the formant frequency variation of speech in high-pressure gas based on the speech generation model and acoustic theory.
There are various helium speech unscrambling methods. However, they are divided into time-domain processing technology and frequency-domain processing technology, mainly from the perspective of signal processing methods. In time-domain segmentation processing, the helium speech signal is divided into several segments [
14]. Each segment is stretched, and then, connected to form an enhanced helium speech signal. This can correct formant frequency distortion and even pitch distortion. Linear prediction and homomorphic filtering are also used to estimate and correct the channel impulse response in helium speech. They can achieve more accurate correction of the spectral envelope [
15] or reduce the impact of noise on helium speech interpretation using autocorrelation between helium speech segments [
16]. In the frequency subtraction method, the heterodyne technique is used to subtract some frequencies from the original helium speech signal spectrum to reduce the resonance peak frequency [
17]. In fact, the main cause of helium speech distortion is the diver’s voice cavity, rather than the helium–oxygen environment itself. Using vocoder to compress the spectrum envelope of the helium speech signal not only restores the position of the vowel formant, but also preserves the resonance structure of the helium speech [
18]. Richards proposed a short-time Fourier transform enhancement algorithm based on helium speech [
19]. Like the segmented processing in the time domain, this follows the segmented modification cascade method, but is processed in the Fourier transform of signal segmentation. This can arbitrarily map the spectrum envelope of helium speech without changing the pitch information of helium speech. Duncan and Jack proposed a helium speech interpretation system consisting of a residual excitation linear prediction encoder [
20]. They used a joint processing method in the time and frequency domains to improve the clarity and naturalness of the decoded speech output.
As saturation diving operations deepen, existing helium speech unscrambling technology, which is based on traditional time-domain or frequency-domain signal processing technology, struggles to clearly unscramble helium speech and is unable to adapt to the dynamic changes at the depths of such diving operations. The research on helium speech has met a bottleneck problem. There have been few breakthroughs in helium speech unscrambling, and few results have been published on this topic [
21,
22,
23]. Machine learning has been widely used in speech recognition in recent years [
24,
25]. Many companies have their own products, based on their technologies, such as Apple’s Siri, and have achieved great success [
26]. Speech recognition based on machine learning opens up a new way to unscramble helium speech.
Deep learning is a complex machine learning algorithm that tries to learn the internal rules and representation levels of sample data [
27,
28]. It has been widely used in image processing [
29,
30], speech recognition [
31,
32], natural language processing [
33,
34], etc. There are three typical deep learning neural network models: convolution neural networks (CNNs) [
35,
36], recurrent neural networks (RNNs) and deep belief networks (DBNs). A CNN is usually used for visual frame processing and the automatic extraction of visual features [
37]. They are also used for acoustic signals to process spectrograms [
38] or raw waveforms [
39]. The authors of [
40] developed a deep learning model to predict emotion from speech. A speech enhancement method based on deep learning is analyzed in [
41]. The authors of [
42] proposed a speech signal processing mobile application based on deep learning, which can perform three functions: speech enhancement, model adaptation and background noise conversion. The information obtained in the learning process is very useful in the interpretation of data such as text, image and speech. Deep learning has enabled many more achievements to be made in speech and image recognition.
To date, most speech recognition technologies based on deep learning have been used to recognize normal Mandarin, and there are also some speech recognition technologies for dialects. However, there has been little work on helium speech recognition technology based on deep learning, except reference [
43], due to the lack of a large corpus. However, the authors only present their initial work on isolated helium speech recognition, and not on continuous helium speech recognition.
The main contributions of this paper are as follows:
Chinese helium speech corpora are built. When building the corpora, we design one algorithm to automatically generate label files and one algorithm to select the continuous helium speech corpus, which reduces the scale of the training set without changing the corpus size.
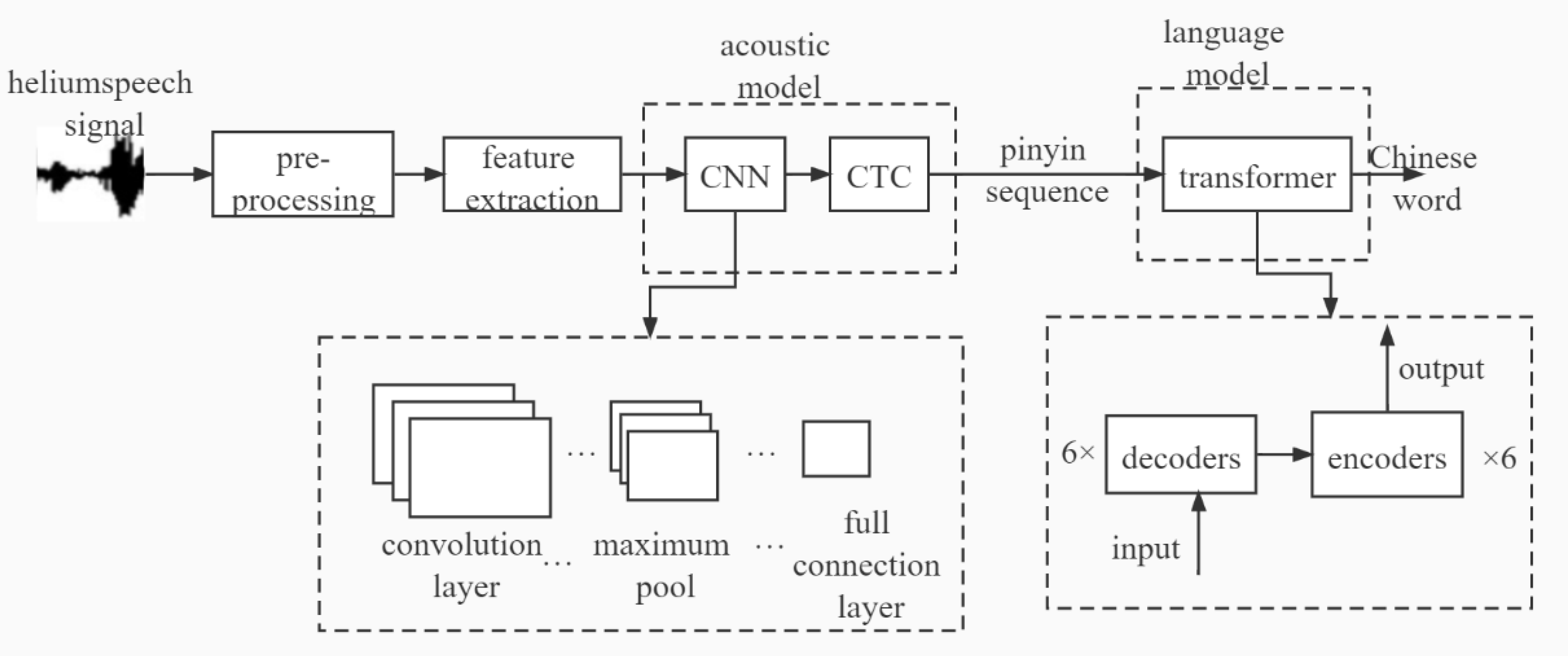
A helium speech recognition algorithm combining a CNN, connectionist temporal classification (CTC) and a transformer model is proposed to improve the intelligibility of helium speech. Furthermore, the influence of the complexity of the algorithm and language model on the recognition rate is analyzed.
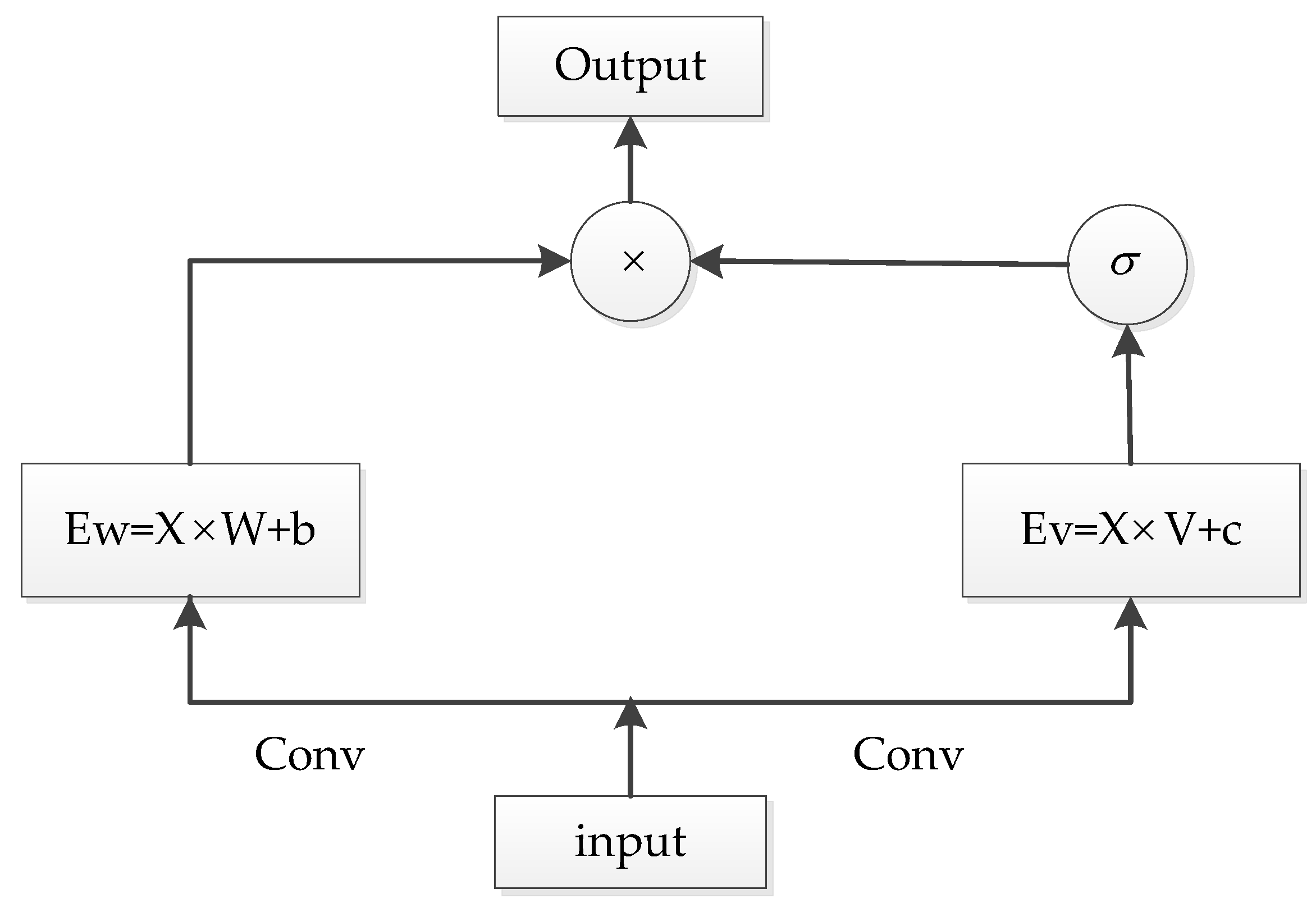
To improve the recognition rate of the helium speech recognition algorithm for continuous helium speech, an optimization algorithm is proposed. The algorithm combines depth-wise separable convolution (DSC), a gated linear unit (GLU) and a feedforward neural network (FNN) to improve the recognition rate of continuous helium speech.
The rest of the paper is organized as follows. In
Section 2, we briefly introduce the features of helium speech and existing helium speech unscramblers.
Section 3 designs speech recognition networks to unscramble helium speech.
Section 4 describes the process of constructing the helium speech corpora. The experimental results are shown and discussed in
Section 5. Finally, the conclusions are provided in
Section 6.
4. Construction of Helium Speech Corpus
Helium speech is a term used to describe the voice of divers speaking in high-pressure helium–oxygen environments. There are two necessary conditions for its formation: high pressure and a helium–oxygen environment. Moreover, deep-sea saturation diving is a highly specialized field. Divers need to acclimatize to the underwater environment in a living chamber filled with a mixture of helium–oxygen gas before working. After diving, they need to decompress; otherwise, they will suffer from the bends, which can threaten their lives. In the course of their work, a diver’s daily life is very inconvenient. In sum, deep-sea saturation diving is not only time-consuming, but also dangerous, which makes helium speech a low-resource speech.
A corpus is a structured dataset of language instances that forms the heart of many natural language processing (NLP) tools. In recent years, numerous corpora of various scales have been established [
57]. However, there is no corpus of helium speech available in China. In order to combine speech recognition technology with helium speech, a helium speech corpus is necessary. Due to the particularity of helium speech and the limitation of experimental conditions, a corpus of helium speech under normal pressure was constructed for preliminary study. We successively constructed two corpora: an isolated helium speech corpus and a continuous helium speech corpus. The steps that we followed to build the helium speech corpus are as follows:
- (1)
Selecting text content:
The first task when building a corpus is to collect corpus texts. With the popularization of the Internet in daily life, there were many text materials available for us to choose from.
For the isolated helium speech corpus, text selection was relatively simple. We selected 10 professional Chinese words in the field of communication. For the continuous helium speech corpus, we chose press releases and Mandarin exams.
- (2)
Collecting raw speech:
Once the text is prepared, the next task is to collect raw speech via recording. We bought dozens of tanks of 99.99% helium, and we simulated a normal-pressure helium–oxygen environment by pumping helium into balloons and inhaling it. Phones (iPhone 11) were used as recording devices, and the recording environment was a quiet office measuring 20 square meters. In order to eliminate the effect of ambient noise on text recording, we recorded the text at night when noise at its lowest. To obtain an isolated corpus, the recording was carried out by two men and one woman. Each person read an isolated word about 70 times and recorded each instance. There were 2106 recordings in total. For the continuous corpus, we made full use of the text data in the network and selected 11,890 sentences to construct a continuous corpus. These sentences were read by 14 men and 12 women and recorded. The length of all recordings was approximately 25 h. We converted the format of all audio files to WAV files and set the sampling frequency to 16 kHz.
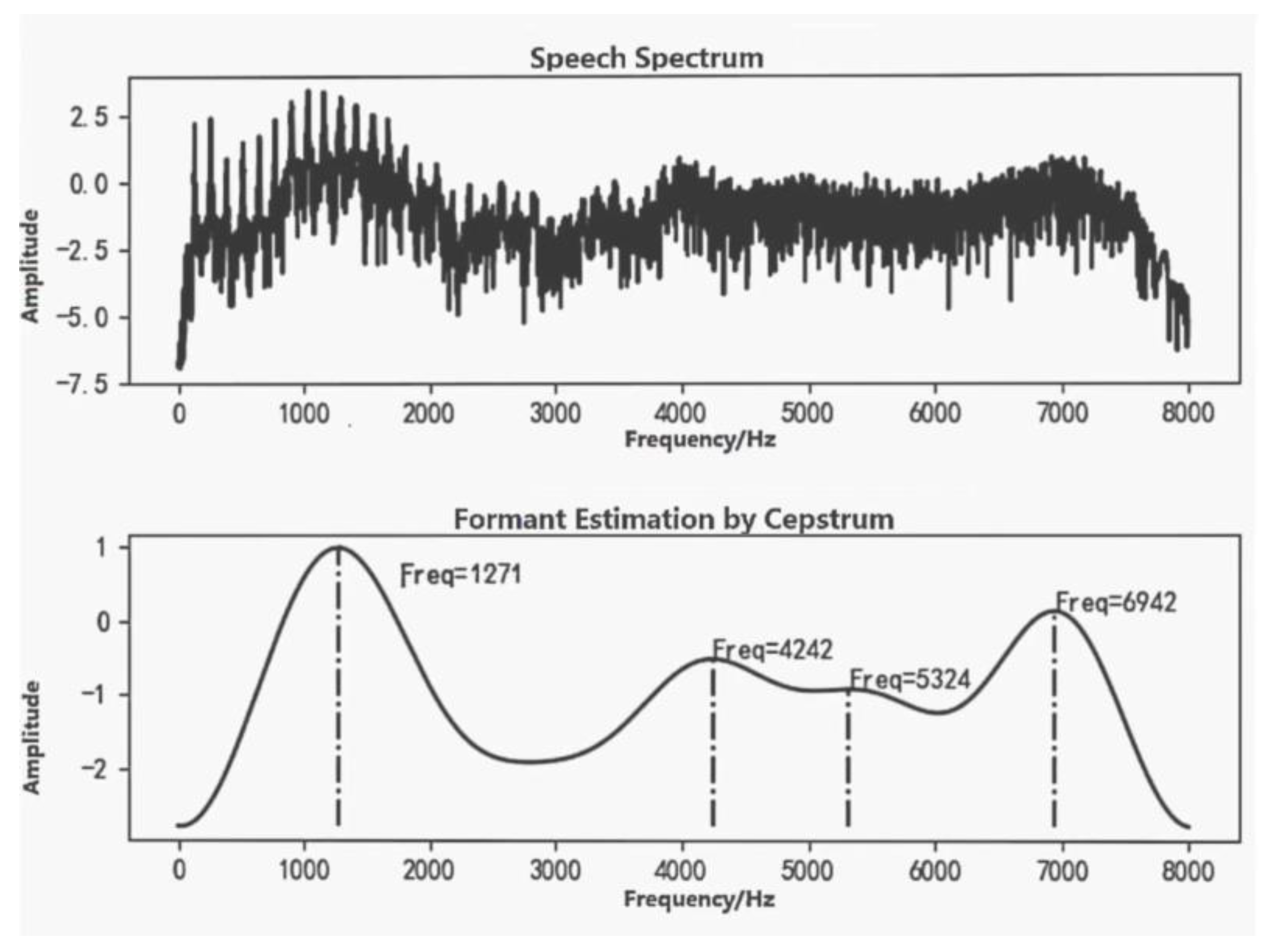
Further, we recorded the vowel "a" in the same way and compared the formant frequency of this with that in normal environments, as shown in
Figure 5 and
Figure 6. The formant information was obtained using a cepstrum [
58]. The first four formant frequencies of normal speech were 941 Hz, 2603 Hz, 4231 Hz and 6064 Hz, as shown in
Figure 5, and the first four formant frequencies of helium speech were 1271 Hz, 4242 Hz, 5324 Hz and 6942 Hz, as shown in
Figure 6. The speech following the inhalation of helium gas showed an increase in formant frequency and variation in bandwidth compared with normal speech. This is consistent with typical features of helium speech. Therefore, it is feasible to use helium speech at atmospheric pressure instead of helium speech at high pressure for preliminary research.
- (3)
Converting the file format:
The files recorded using phones were MP4 files, which needed to be converted into WAV files. To achieve this, we directly used the existing software. The sampling rate of the converted files was set to 16 KHz.
- (4)
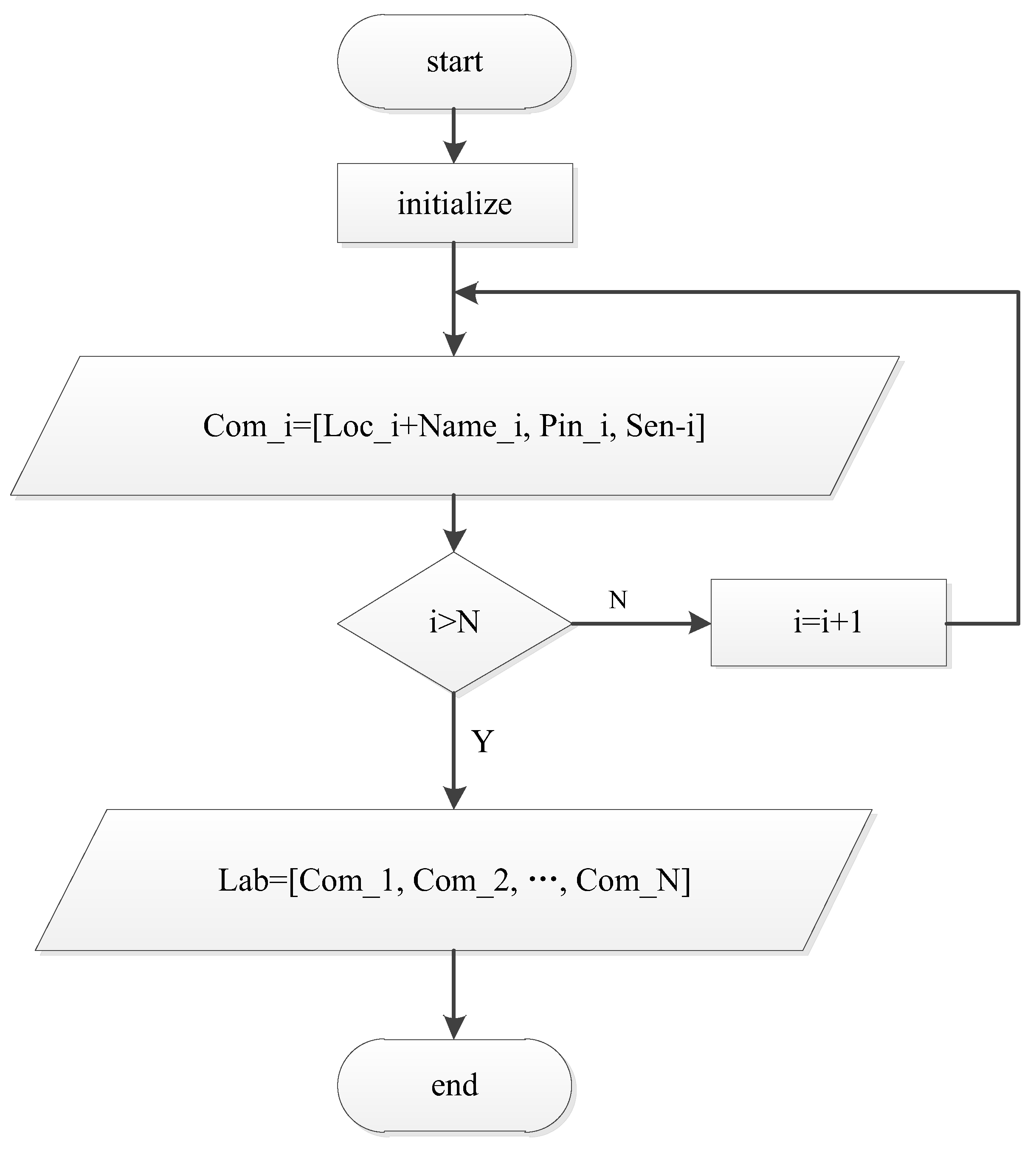
Labeling the corpus:
To save time spend on manual labeling, an algorithm was designed to automatically generate label files. For the convenience of explanation, the following parameters were introduced into the algorithm:
: the file name of the i-th file.
: the text content corresponding to the i-th recording.
: the location of the i-th file.
: the pinyin sequence of .
: the entire label of the i-th recording.
N: the number of sentences in the corpus.
Lab: the content of the label files.
The process that the algorithm used to generate label files is shown in
Figure 7.
- (5)
Grouping recordings:
The available corpora generally contain training sets and test sets, and contain validation sets. In this paper, all the recordings were split into a training set, a test set and a validation set, with a ratio of 8:1:1.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}