

A Survey on Feature Selection Techniques Based on Filtering Methods for Cyber Attack Detection


Abstract
:1. Introduction
1.1. Cyber Attacks and Their Danger
1.2. Cyber Attack Detection
1.3. The Importance of Feature Selection for Attack Detection
- (A)
- Reducing the cost of acquiring data.
- (B)
- Reducing the cost of training classification models.
- (C)
- Reducing model size.
- (D)
- Making classification models easier to understand.
- (E)
- Improving detection performance (maybe).
1.4. Our Motivation
2. Feature Selection Algorithms
2.1. Filter-Based Techniques
- (A)
- They are independent of classifiers (classification algorithms) as they only use feature relevance that is evaluated according to inherent properties of the data itself.
- (B)
- They are computationally efficient.
- (C)
- They scale easily to datasets with many features (high-dimensional datasets).
- (D)
- The process of feature selection is performed only once, and the result of feature selection can be used for different classifiers [12].
- (E)
- They can be used in a supervised or unsupervised manner depending on the availability of labeled training data. This flexibility allows it to be used in a wide range of IDS applications [29].
| Algorithm 1: General filter-based technique |
| Input: ) //a training dataset with N features //a subset from which start the search //a stopping criterion Output: //an optimal subset 01 Begin 02 Initialize: ; 03 ; //evaluate 04 do begin 05 ; //generate a subset for evaluation 06 ; //evaluate the current subset S by M 07 if ( is better than ) then 08 ; 09 ; 10 end until (); 11 return ; 12 End |
2.2. Wrapper Techniques
2.3. Embedded Techniques
2.4. Hybrid Techniques
2.5. Some Other Techniques
3. Search Algorithms in Filter-Based Feature Selection Methods
- (A)
- High-dimensional datasets: when the number of features is very large, it can be computationally expensive to evaluate all possible feature subsets, but search algorithms can help to efficiently identify the most important features by only evaluating a subset of them.
- (B)
- Overfitting: when a model utilizes too many features, it may fit the training data too well and yet perform poorly on new data, and search algorithms can help to find a minimal subset of features that can prevent overfitting.
- (C)
- Improving model interpretability: search algorithms can help to identify a subset of features that are most informative, thus making the model more interpretable.
- (D)
- Reducing computational complexity: when the number of features is very large, it can also be computationally expensive to train and evaluate a model, but using search algorithms to identify a subset of important features can reduce the computational complexity.
- (E)
- Improving generalization: search algorithms can help to identify a subset of features that generalize well to new data.
3.1. Greedy Hill Climbing
| Algorithm 2: Greddy Hill Climbing |
| Input: ) //a training dataset with N features //a start state Output: //an optimal state 01 Begin 02 Initialize: ; 03 Expand by making each possible local change 04 ; //get the child t of with the highest e(t) 05 if () then 06 ; 07 ; 08 goto 04; 09 else 10 return ; 11 End |
3.2. Best First Search
| Algorithm 3: Best First Search |
| Input: ) //a training dataset with N features //a start state Output: //an optimal state 01 Begin 02 Initialize: Set an OPEN list containing the start state; 03 Set a CLOSED list; 04 ; 05 ; //get the state from OPEN with the highest evaluation 06 if () then 07 ; 08 For each child t of S that is not in the OPEN or COSED list, evaluate and add to OPEN; 09 if ( has changed in the last set of expansions) then 10 goto 05; 11 else 12 return ; 13 End |
3.3. Genetic Algorithms
| Algorithm 4: Genetic Algorithm |
| Input: ) //a training dataset with N features Output: x // for which e(x) is highest. 01 Begin 02 Initialize: Objective function 03 Encode the solutions into chromosomes (strings); 04 Define fitness F (eg, for maximization); 05 Generate the initial population P; 06 Initialize the probabilities of crossover () and mutation (); 07 while (t < Max number of generations) 08 Generate new population P′ by crossover and mutation; 09 Crossover with a crossover probability ; 10 Mutate with a mutation probability ; 11 if () then //Accept the new solution if their fitness increase 12 ; 13 else 14 goto 08; 15 t = t+1; 16 end while 17 return ; 18 End |
4. Relevance Measures for the Filter-Based Feature Selection Methods
4.1. Pearson Correlation
4.2. Chi-Square
4.3. Information Gain (IG)
4.4. Mutual Information (MI)
4.5. Minimum Redundancy Maximum Relevance Feature Selection (MRMR)
4.6. Fast Correlation Based Filter (FCBF)
4.7. FCBF#
4.8. Multivariate Mutual Information (MMI)
4.9. Mutal Information Feature Selection (MIFS)
4.10. Multivariate Mutual Information-Based Feature Selection (MMIFS)
4.11. Correlation Based Feature Selection (CFS)
4.12. Efficient Correlation-Based Feature Selection (ECOFS)
5. Experiments and Result
5.1. Common Datasets for Studies on Network Anomaly Detection
5.1.1. KDDcup’99 and NSL-KDD
- (A)
- The training set and test set of the NSL-KDD dataset do not contain redundant records, making the detection more accurate.
- (B)
- The number of records in training and testing is set reasonably, which makes it cheap to run experiments on the full set without randomly selecting a small subset. Therefore, the evaluation results of different research efforts will be consistent and comparable.
5.1.2. ISCX
5.1.3. CIC-IDS2017
5.1.4. MQTT-IoT-IDS2020
5.2. A Comparative Study on the Performance of Filter-Based Feature Selection Techniques
6. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kaspersky Report. Available online: https://www.kaspersky.com/about/press-releases/2022_cybercriminals-attack-users-with-400000-new-malicious-files-daily---that-is-5-more-than-in-2021 (accessed on 26 January 2023).
- The Hacker News. Available online: https://thehackernews.com/2022/01/microsoft-mitigated-record-breaking-347.html (accessed on 28 January 2023).
- Hao, Z.; Feng, Y.; Koide, H.; Sakurai, K. A sequential detection method for intrusion detection system based on artificial neural networks. Int. J. Netw. Comput. 2020, 10, 213–226. [Google Scholar] [CrossRef]
- Cybercrime Magazine, Cybercrime to Cost the World $10.5 Trillion Annually by 2025. Available online: https://cybersecurityventures.com/cybercrime-damages-6-trillion-by-2021/ (accessed on 26 January 2023).
- Ravale, U.; Marathe, N.; Padiya, P. Feature selection based hybrid anomaly intrusion detection system using K means and RBF kernel function. Procedia Comput. Sci. 2015, 45, 428–435. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.M.; Chen, Y.L.; Lin, H.C. An efficient network intrusion detection. Comput. Commun. 2010, 33, 477–484. [Google Scholar] [CrossRef]
- Shams, E.A.; Rizaner, A. A novel support vector machine based intrusion detection system for mobile ad hoc networks. Wirel. Netw. 2018, 24, 1821–1829. [Google Scholar] [CrossRef]
- Stein, G.; Chen, B.; Wu, A.S.; Hua, K.A. Decision tree classifier for network intrusion detection with GA-based feature selection. In Proceedings of the 43rd Annual Southeast Regional Conference, Kennesaw, GA, USA, 18–20 March 2005; Volume 2, pp. 136–141. [Google Scholar]
- Farnaaz, N.; Jabbar, M.A. Random forest modeling for network intrusion detection system. Procedia Comput. Sci. 2016, 89, 213–217. [Google Scholar] [CrossRef] [Green Version]
- Ashiku, L.; Dagli, C. Network intrusion detection system using deep learning. Procedia Comput. Sci. 2021, 185, 239–247. [Google Scholar] [CrossRef]
- Zl-Zubaidie, M.; Zhang, Z.; Zhang, J. RAMHU: A New Robust Lightweight Scheme for Mutual Users Authentication in Healthcare Applications. Secur. Commun. Netw. 2019, 2019, 1–26. [Google Scholar] [CrossRef]
- Saeys, Y.; Inza, I.; Larranaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef] [Green Version]
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A. A review of feature selection methods on synthetic data. Knowl. Inf. Syst. 2013, 34, 483–519. [Google Scholar] [CrossRef]
- Soe, Y.N.; Feng, Y.; Santosa, P.I.; Hartanto, S.; Sakurai, K. Implementing lightweight IoT-IDS on raspberry pi using correlation-based feature selection and its performance evaluation. In Proceedings of the 33rd International Conference on Advanced Information Networking and Applications (AINA-2019), Matsue, Japan, 27–29 March 2019; pp. 458–469. [Google Scholar]
- Soe, Y.N.; Feng, Y.; Santosa, P.I.; Hartanto, S.; Sakurai, K. Towards a lightweight detection system for cyber attacks in the IoT environment using corresponding features. Electronics 2020, 9, 144. [Google Scholar] [CrossRef] [Green Version]
- Image Filtering Overview. Available online: https://www.ni.com/ja-jp/innovations/white-papers/06/image-filtering-overview.html (accessed on 5 March 2023).
- Zhang, X.; He, S.; Stojanovic, V.; Luan, X.; Liu, F. Finite-time asynchronous dissipative filtering of conic-type nonlinear Markov jump systems. Sci. China Inf. Sci. 2021, 64, 152206. [Google Scholar] [CrossRef]
- Cheng, P.; Wang, J.; He, S.; Luan, X.; Liu, F. Observer-based asynchronous fault detection for conic-type nonlinear jumping systems and its application to separately excited DC motor. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 67, 951–962. [Google Scholar] [CrossRef]
- Cheng, P.; He, S.; Stojanovic, V.; Luan, X.; Liu, F. Fuzzy fault detection for Markov jump systems with partly accessible hidden information: An event-triggered approach. IEEE Trans. Cybern. 2022, 52, 7352–7361. [Google Scholar] [CrossRef] [PubMed]
- Sharma, N.; Arora, B. A Critical Review of Feature Selection Techniques for Network Anomaly Detection: Methodologies, Challenges, Evaluation, and Opportunities. 2022. Available online: https://www.researchsquare.com/article/rs-1940841/v1 (accessed on 26 January 2023).
- Yu, L.; Liu, H. Feature selection for high-dimensional data: A fast correlation-based filter solution. In Proceedings of the 20th International Conference on Machine Learning (ICML-2003), Washington, DC, USA, 21–24 August 2003; pp. 856–863. [Google Scholar]
- Senliol, B.; Gulgezen, G.; Yu, L.; Cataltepe, Z. Fast correlation based filter (FCBF) with a different search strategy. In Proceedings of the 23rd International Symposium on Computer and Information Sciences 2008, Istanbul, Turkey, 27–29 October 2008; pp. 1–4. [Google Scholar] [CrossRef]
- Wah, Y.B.; Ibrahim, N.; Hamid, H.A.; Abdul-Rahman, S.; Fong, S. Feature selection methods: Case of filter and wrapper approaches for maximising classification accuracy. Pertanika J. Sci. Technol. 2018, 26, 329–340. [Google Scholar]
- Hoque, N.; Bhattacharyya, D.K.; Kalita, J.K. MIFS-ND: A mutual information-based feature selection method. Expert Syst. Appl. 2014, 41, 6371–6385. [Google Scholar] [CrossRef]
- Ladha, L.; Deepa, T. Feature selection methods and algorithms. Int. J. Comput. Sci. Eng. IJCSE 2011, 3, 1787–1797. [Google Scholar]
- Cantu-Paz, E. Feature subset selection, class separability, and genetic algorithms. In Proceedings of the Genetic and Evolutionary Computation—GECCO 2004: Genetic and Evolutionary Computation Conference, Seattle, WA, USA, 26–30 June 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 959–970. [Google Scholar]
- Bolón-Canedo, V.; Sánchez-Marono, N.; Alonso-Betanzos, A.; Benítez, J.M.; Herrera, F. A review of microarray datasets and applied feature selection methods. Inf. Sci. 2014, 282, 111–135. [Google Scholar] [CrossRef]
- Thakkar, A.; Lohiya, R. A survey on intrusion detection system: Feature selection, model, performance measures, application perspective, challenges, and future research directions. Artif. Intell. Rev. 2022, 55, 453–563. [Google Scholar] [CrossRef]
- Sánchez-Maroño, N.; Alonso-Betanzos, A.; Calvo-Estévez, R.M. A wrapper method for feature selection in multiple classes datasets. In Proceedings of the International Work-Conference on Artificial Neural Networks 2009, Limassol, Cyprus, 14–17 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 456–463. [Google Scholar]
- Piao, Y.; Piao, M.; Park, K.; Ryu, K.H. An ensemble correlation-based gene selection algorithm for cancer classification with gene expression data. Bioinformatics 2012, 28, 3306–3315. [Google Scholar] [CrossRef] [Green Version]
- Yusta, S.C. Different metaheuristic strategies to solve the feature selection problem. Pattern Recognit. Lett. 2009, 30, 525–534. [Google Scholar] [CrossRef]
- Jović, A.; Brkić, K.; Bogunović, N. A review of feature selection methods with applications. In Proceedings of the 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 25–29 May 2015; pp. 1200–1205. [Google Scholar] [CrossRef]
- Zuech, R.; Khoshgoftaar, T.M. A survey on feature selection for intrusion detection. In Proceedings of the 21st ISSAT International Conference on Reliability and Quality in Design, Philadelphia, PA, USA, 6–8 August 2015; pp. 150–155. [Google Scholar]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Maldonado, S.; Weber, R.; Basak, J. Simultaneous feature selection and classification using kernel-penalized support vector machines. Inf. Sci. 2011, 181, 115–128. [Google Scholar] [CrossRef]
- Loh, W.Y. Classification and regression trees. Wiley Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Patel, H.H.; Prajapati, P. Study and analysis of decision tree based classification algorithms. Int. J. Comput. Sci. Eng. 2018, 6, 74–78. [Google Scholar] [CrossRef]
- Sandri, M.; Zuccolotto, P. Variable selection using random forests. In Data Analysis, Classification and the Forward Search, Proceedings of the Meeting of the Classification and Data Analysis Group (CLADAG) of the Italian Statistical Society, University of Parma, Parma, Italy, 6–8 June 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 263–270. [Google Scholar]
- Cawley, G.; Talbot, N.; Girolami, M. Sparse multinomial logistic regression via bayesian l1 regularisation. In Proceedings of the Advances in Neural Information Processing Systems 19 (NIPS 2006), Vancouver, BC, Canada, 4–5 December 2006; Volume 19. [Google Scholar]
- Das, S. Filters, wrappers and a boosting-based hybrid for feature selection. InIcml 2001, 1, 74–81. [Google Scholar]
- Hsu, H.H.; Hsieh, C.W.; Lu, M.D. Hybrid feature selection by combining filters and wrappers. Expert Syst. Appl. 2011, 38, 8144–8150. [Google Scholar] [CrossRef]
- Naqvi, S. A Hybrid Filter-Wrapper Approach for Feature Selection. Master’s Thesis, the Department of Technology, Örebro University, Örebro, Sweden, 2012. Available online: http://www.diva-portal.org/smash/get/diva2:567115/FULLTEXT01.pdf (accessed on 5 March 2023).
- Cadenas, J.M.; Garrido, M.C.; MartíNez, R. Feature subset selection filter–wrapper based on low quality data. Expert Syst. Appl. 2013, 40, 6241–6252. [Google Scholar] [CrossRef]
- Oh, I.S.; Lee, J.S.; Moon, B.R. Hybrid genetic algorithms for feature selection. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1424–1437. [Google Scholar]
- Ali, S.I.; Shahzad, W. A feature subset selection method based on conditional mutual information and ant colony optimization. Int. J. Comput. Appl. 2012, 60, 5–10. [Google Scholar]
- Sarafrazi, S.; Nezamabadi-Pour, H. Facing the classification of binary problems with a GSA-SVM hybrid system. Math. Comput. Model. 2013, 57, 270–278. [Google Scholar] [CrossRef]
- Ma, S.; Huang, J. Penalized feature selection and classification in bioinformatics. Brief. Bioinform. 2008, 9, 392–403. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Nakashima, M.; Sim, A.; Kim, Y.; Kim, J.; Kim, J. Automated feature selection for anomaly detection in network traffic data. ACM Trans. Manag. Inf. Syst. 2021, 12, 1–28. [Google Scholar] [CrossRef]
- Liu, H.; Motoda, H. Feature Selection for Knowledge Discovery and Data Mining; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 454. [Google Scholar]
- Kittler, J. Feature set search algorithms. In Pattern Recognition and Signal Processing; Springer: Dordrecht, The Netherlands, 1978. [Google Scholar]
- Miller, A. Subset Selection in Regression; Monographs on Statistics and Applied Probability 95; Chapman & Hall/CRC: Boca Raton, FL, USA, 2002. [Google Scholar]
- Hall, M.A. Correlation-Based Feature Selection for Machine Learning. Ph.D. Thesis, The University of Waikato, Hamilton, New Zealand, 1999. [Google Scholar]
- Winston, P.H. Artificial Intelligence; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1984. [Google Scholar]
- Holland, J.H. Adaptation in Natural and Artificial Systems; An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; MIT Press: Cambridge, MA, USA; London, UK, 1992. [Google Scholar]
- Teukolsky, S.A.; Flannery, B.P.; Press, W.H.; Vetterling, W.T. Numerical Recipes in C; SMR.693; WH Press: Cambridge, MA, USA, 1992.
- Eid, H.F.; Hassanien, A.E.; Kim, T.H.; Banerjee, S. Linear correlation-based feature selection for network intrusion detection model. In Proceedings of the International Conference on Security of Information and Communication Networks 2013, Cairo, Egypt, 3–5 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 240–248. [Google Scholar]
- Li, Y.; Fang, B.X.; Chen, Y.; Guo, L. A lightweight intrusion detection model based on feature selection and maximum entropy model. In Proceedings of the 2006 International Conference on Communication Technology, Guilin, China, 27–30 November 2006; pp. 1–4. [Google Scholar]
- Liu, H.; Setiono, R. Chi2: Feature selection and discretization of numeric attributes. In Proceedings of the 7th IEEE International Conference on Tools with Artificial Intelligence, Herndon, VA, USA, 5–8 November 1995; pp. 388–391. [Google Scholar]
- Salzberg, S.L. C4.5: Programs for Machine Learning by J. Ross Quinlan. Morgan Kaufmann Publishers, Inc., 1993. Mach. Learn. 1994, 16, 235–240. [Google Scholar] [CrossRef] [Green Version]
- Ullah, I.; Mahmoud, Q.H. A filter-based feature selection model for anomaly-based intrusion detection systems. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data) 2017, Boston, MA, USA, 11–14 December 2017; pp. 2151–2159. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]
- Kushwaha, P.; Buckchash, H.; Raman, B. Anomaly based intrusion detection using filter based feature selection on KDD-CUP 99. In Proceedings of the TENCON 2017—2017 IEEE Region 10 Conference, Penang, Malaysia, 5–8 November 2017; pp. 839–844. [Google Scholar]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [Green Version]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Mohammadi, S.; Desai, V.; Karimipour, H. Multivariate mutual information-based feature selection for cyber intrusion detection. In Proceedings of the 2018 IEEE Electrical Power and Energy Conference (EPEC), Toronto, ON, Canada, 10–11 October 2018; pp. 1–6. [Google Scholar]
- Battiti, R. Using mutual information for selecting features in supervised neural net learning. IEEE Trans. Neural Netw. 1994, 5, 537–550. [Google Scholar] [CrossRef] [Green Version]
- Shahbaz, M.B.; Wang, X.; Behnad, A.; Samarabandu, J. On efficiency enhancement of the correlation-based feature selection for intrusion detection systems. In Proceedings of the 2016 IEEE 7th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 13–15 October 2016; pp. 1–7. [Google Scholar]
- Wang, W.; Du, X.; Wang, N. Building a cloud IDS using an efficient feature selection method and SVM. IEEE Access 2018, 7, 1345–1354. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Revathi, S.; Malathi, A. A detailed analysis on NSL-KDD dataset using various machine learning techniques for intrusion detection. Int. J. Eng. Res. Technol. IJERT 2013, 2, 1848–1853. [Google Scholar]
- Lashkari, A.H.; Draper-Gil, G.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of Tor Traffic Using Time Based Features. In Proceedings of the International Conference on Information Systems Security and Privacy, Porto, Portugal, 19–21 February 2017; pp. 253–262. [Google Scholar]
- D’hooge, L.; Wauters, T.; Volckaert, B.; De Turck, F. Inter-dataset generalization strength of supervised machine learning methods for intrusion detection. J. Inf. Secur. Appl. 2020, 54, 102564. [Google Scholar] [CrossRef]
- Hindy, H.; Bayne, E.; Bures, M.; Atkinson, R.; Tachtatzis, C.; Bellekens, X. Machine learning based IoT intrusion detection system: An MQTT case study (MQTT-IoT-IDS2020 dataset). In Selected Papers from the 12th International Networking Conference; Springer International Publishing: Cham, Switzerland, 2020; pp. 73–84. [Google Scholar]
- Ullah, I.; Mahmoud, Q.H. Design and development of a deep learning-based model for anomaly detection in IoT networks. IEEE Access 2021, 9, 103906–103926. [Google Scholar] [CrossRef]
- Nguyen, H.; Franke, K.; Petrovic, S. Improving effectiveness of intrusion detection by correlation feature selection. In Proceedings of the 2010 International Conference on Availability, Reliability and Security 2010, Krakow, Poland, 15–18 February 2010; pp. 17–24. [Google Scholar]
- Wahba, Y.; ElSalamouny, E. ElTaweel, GImproving the performance of multi-class intrusion detection systems using feature reduction. arXiv 2015, arXiv:1507.06692. [Google Scholar]


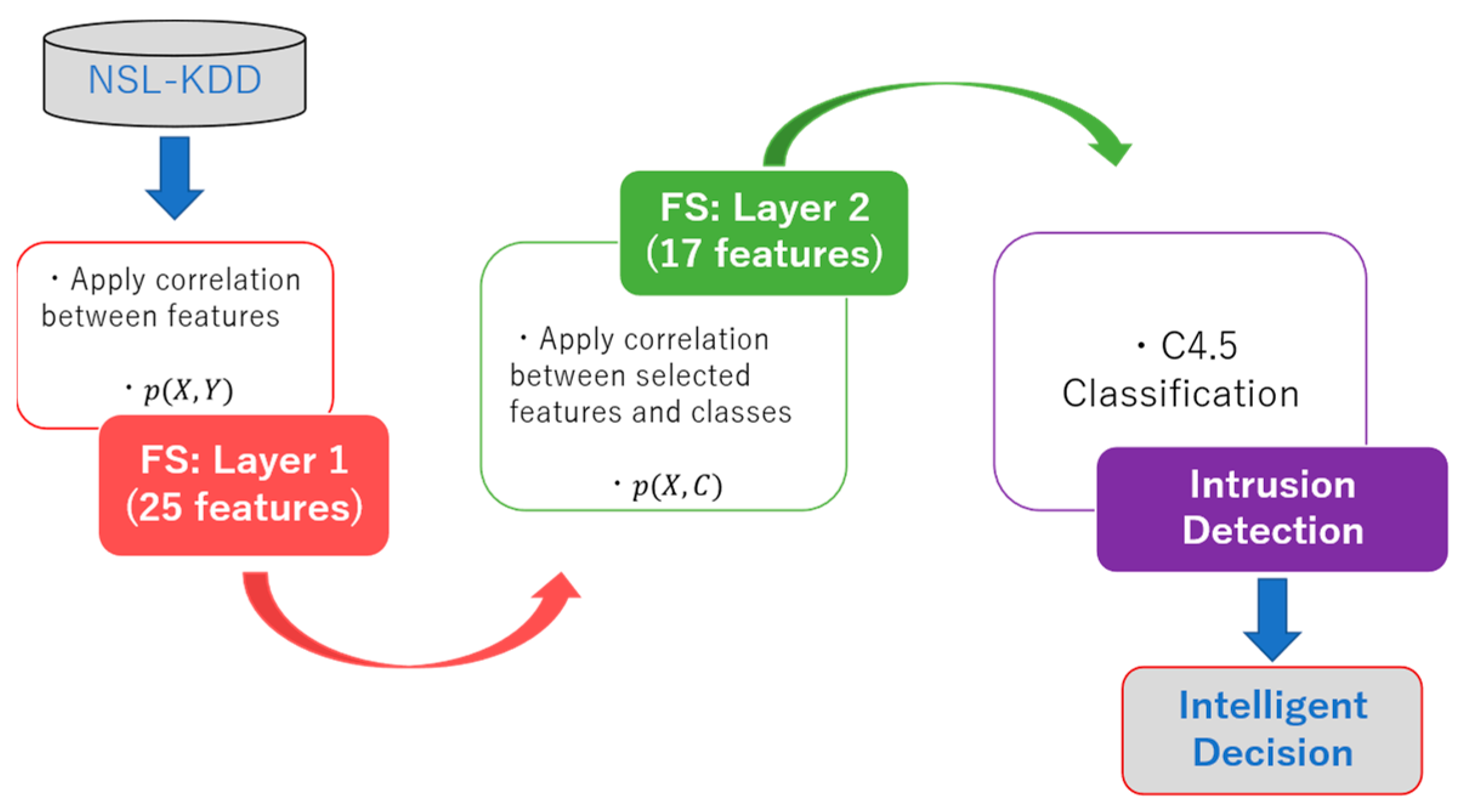{kind=link}
| Feature Selection Approach | Pros | Cons |
|---|---|---|
| Filter-based |
|
|
| Wrapper |
|
|
| Embedded |
|
|
| KDDcup’99 Dataset | #Samples | #Features | #Classes | Multi Classification |
|---|---|---|---|---|
| Tran data (10%) | 494,021 | 41 | 5(22) | Normal, DoS, Probe, U2R, R2L |
| Test data | 311,029 | 41 | 5(39) | Normal, DoS, Probe, U2R, R2L |
| NSL-KDD Dataset | #Samples | #Features | #Classes | Multi Classification |
|---|---|---|---|---|
| Tran data | 125,973 | 41 | 5(23) | Normal, DoS, Probe, U2R, R2L |
| Test data | 22,544 | 41 | 5(38) | Normal, DoS, Probe, U2R, R2L |
| Attack Category | Attacks in KDDcup’99 Training Set | Additional Attacks in KDDcup’99 Test Set |
|---|---|---|
| DoS | back, neptune, smurf, teardrop, land, pod | apache2, mailbomb, processtable, udpstorm |
| Probe | satan, portsweep, ipsweep, nmap | mscn, saint |
| R2L | warezmaster, warezclient, ftp_write, guess_password, imap, multihop, phf, spy | sendmail, named, snmpgetattack, snmpguess, xlock, xsnoop, worm |
| U2R | rootkit, buffer_overflow, loadmodule, perl | httptunnel, ps, sqlattack, xterm |
| Attacks in Dataset | Attack Type (37) |
|---|---|
| DoS | back, land, neptune, pod, smurf, teardrop, mailbomb, processtable, udpstorm, apache2, worm |
| Probe | satan, ipsweep, nmap, portsweep, mscan, saint |
| R2L | guess_password, ftp_write, imap, phf, multihop, warezmaster, xlock, xsnoop, snmpguess, snmpgetattack, httptunnel, sendmail, named |
| U2R | buffer_overflow, loadmodule, rootkit, perl, sqlattack, xterm, ps |
| Data | #Instances | Normal | L2L | SSH | Botnet | DoS |
|---|---|---|---|---|---|---|
| Train | 6937 | 2002 | 4499 | 418 | 16 | 2 |
| Test | 13,952 | 8063 | 3994 | 1812 | 72 | 11 |
| Days | Labels |
|---|---|
| Monday | Benign |
| Tuesday | BForce, SFTP and SSH |
| Wednesday | DoS and Hearbleed Attacks slowloris, Slowhttptest, Hulk and GoldenEye |
| Thursday | Web and Infifiltration Attacks Web BForce, XSS and Sql Inject. Infifiltration Dropbox Download and Cool disk |
| Friday | DDoS LOIT, Botnet ARES, PortScans (sS, sT, sF, sX, sN, sP, sV, sU, sO, sA, sW, sR, sL and B) |
| Author/Year | FS Method | No. of Features | Detection Method | Dataset | Performance Metrics |
|---|---|---|---|---|---|
| Li et al. (2006) [58] | IG + Chi2 | 6 | Maximum Entropy Model (ME) | KDDcup’99 | ACC(%): 99.82 Time(s): 4.44 |
| Nguyen et al. (2010) [76] | CFS | 12 | C4.5 NB | KDDcup’99 | ACC(%): 99.41 (C4.5) 98.82 (NB) |
| Eid et al. (2013) [57] | Pearson correlation | 17 | C4.5 | NSL-KDD | ACC(%): 99.1, Time(s): 12.02 |
| Wahba et al. (2015) [77] | CFS + IG (Adaboost) | 13 | NB | NSL-KDD | ACC(%): 99.3 |
| Shahbaz et al. (2016) [68] | CFS | 4 | J48 | NSL-KDD | ACC(%): 86.1, Time(s): <15 |
| Ullah et al. (2017) [61] | IG | ISCX: 4 NSL-KDD: 6 | J48 | ISCX NSL-KDD | ACC(%): 99.70 (ISCX) 99.90 (NSL-KDD), Time(s): 15 |
| Kushwaha et al. (2017) [63] | MI | 5 | Support vector machine (SVM) | KDDcup’99 | ACC(%): 99.91 |
| Moham madi et al. (2018) [66] | MI | / | least square version of SVM (LSSVM) | KDDcup’99, NSL-KDD, Kyoto 2006+ | ACC(%): 94.31 (KDDcup’99) 98.31 (NSL-KDD) 99.11 (Kyoto 2006+) |
| Wang et al. (2019) [69] | Efficient CFS (MIFS + Symmetric Uncertainty) | KDDcup’99: 9 NSL-KDD: 10 | One-class SVM | KDDcup’99, NSL-KDD | ACC(%): 99.85 (KDDcup’99) 98.64 (NSL-KDD), Time(s): 5.3 (KDDcup’99) 1.7 (NSL-KDD) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lyu, Y.; Feng, Y.; Sakurai, K. A Survey on Feature Selection Techniques Based on Filtering Methods for Cyber Attack Detection. Information 2023, 14, 191. https://doi.org/10.3390/info14030191
Lyu Y, Feng Y, Sakurai K. A Survey on Feature Selection Techniques Based on Filtering Methods for Cyber Attack Detection. Information. 2023; 14(3):191. https://doi.org/10.3390/info14030191
Chicago/Turabian StyleLyu, Yang, Yaokai Feng, and Kouichi Sakurai. 2023. "A Survey on Feature Selection Techniques Based on Filtering Methods for Cyber Attack Detection" Information 14, no. 3: 191. https://doi.org/10.3390/info14030191
APA StyleLyu, Y., Feng, Y., & Sakurai, K. (2023). A Survey on Feature Selection Techniques Based on Filtering Methods for Cyber Attack Detection. Information, 14(3), 191. https://doi.org/10.3390/info14030191