
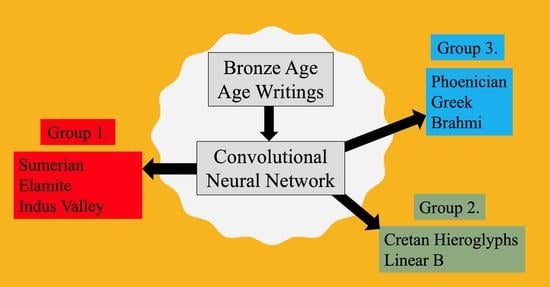
Convolutional Neural Networks Analysis Reveals Three Possible Sources of Bronze Age Writings between Greece and India †


Abstract
:
1. Introduction
2. Data Source
- 2.
- 3.
- 4.
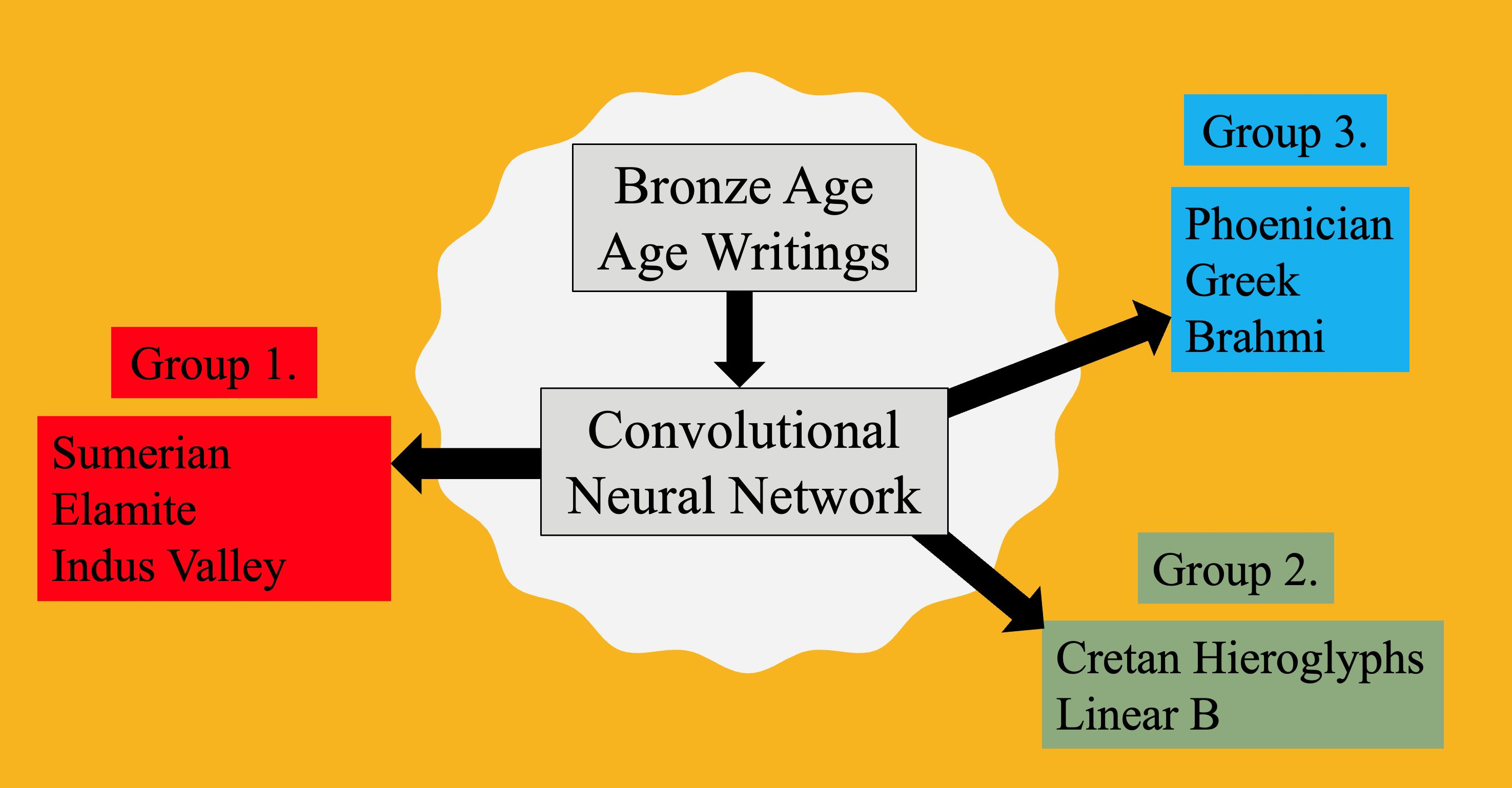
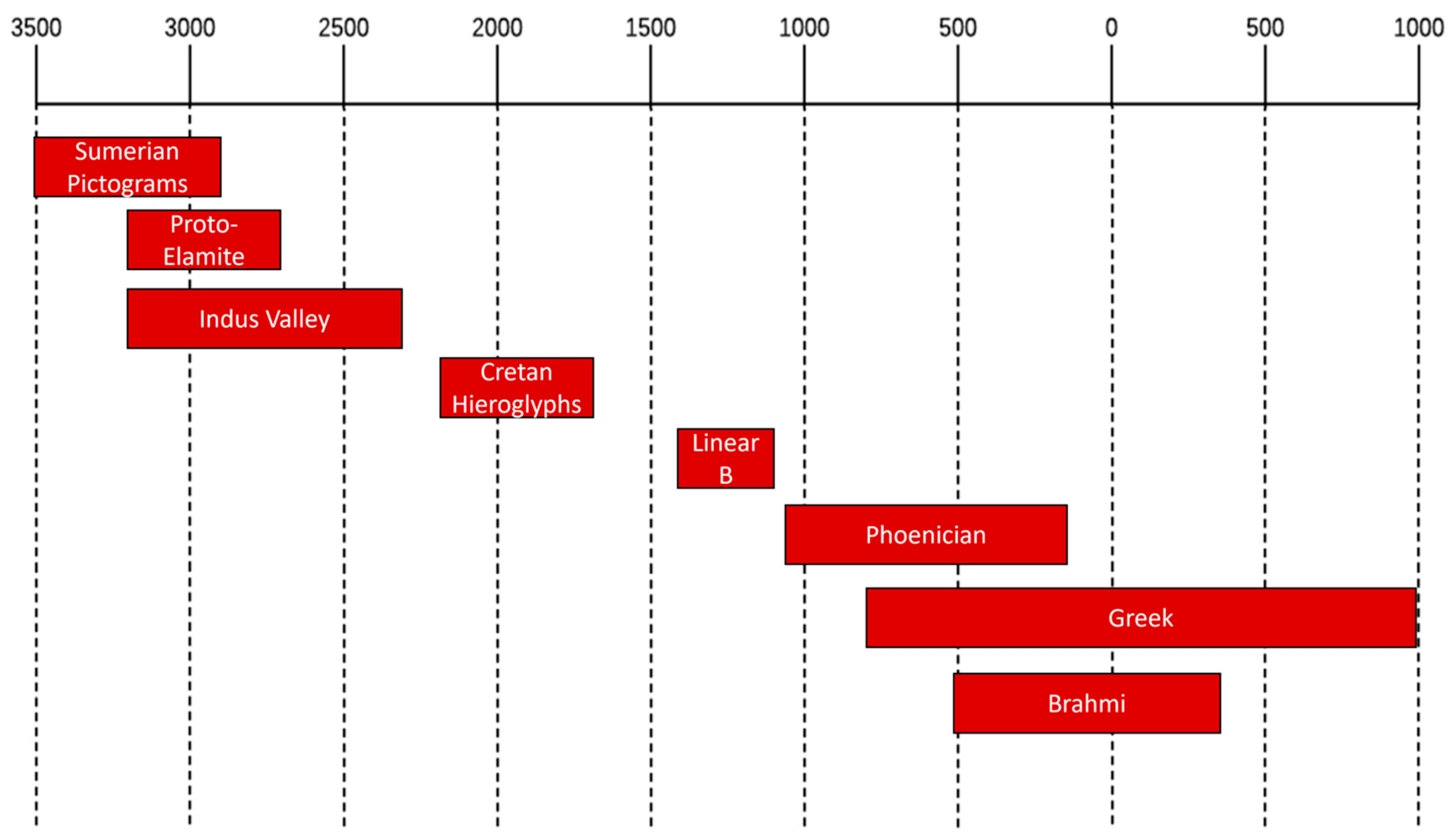
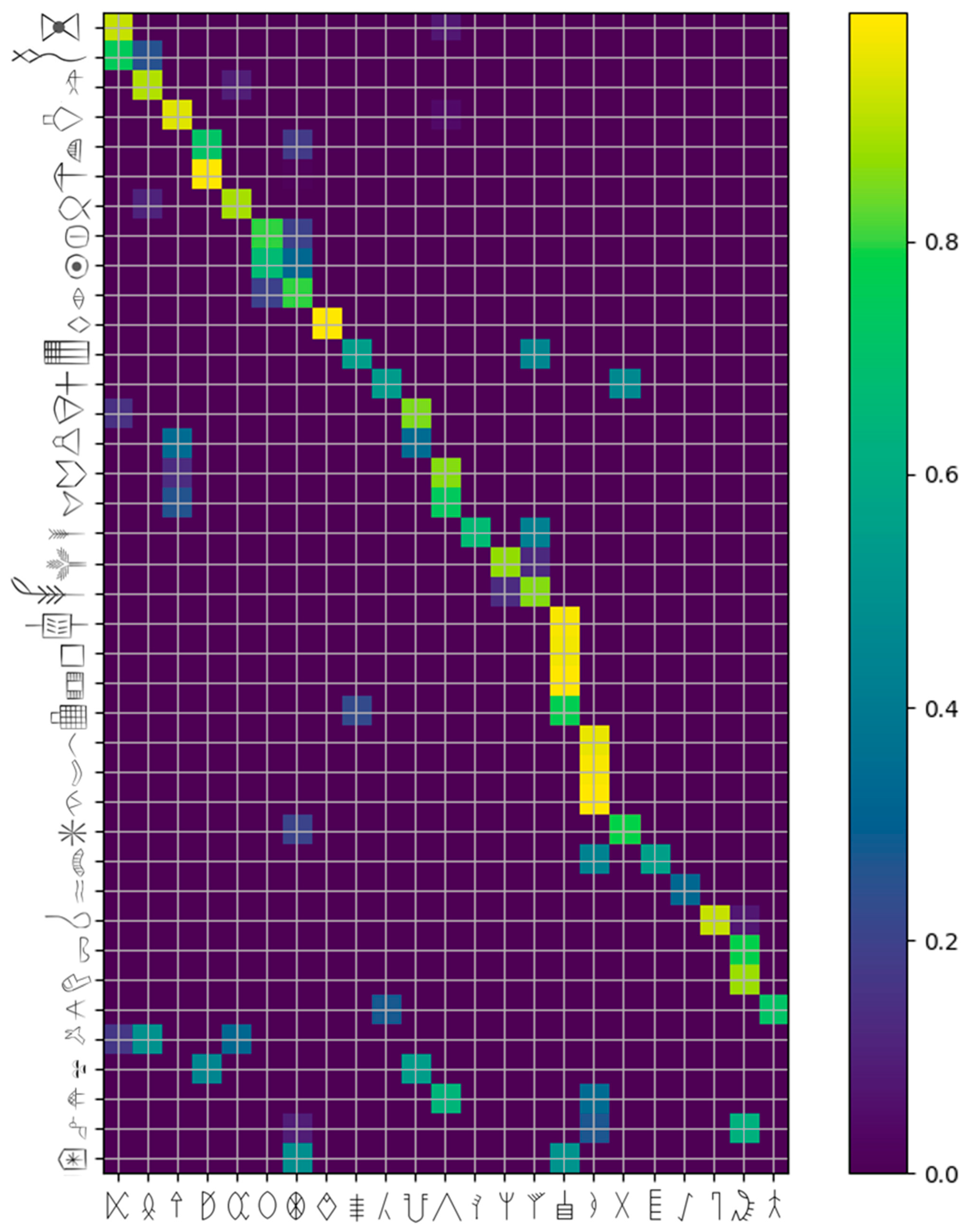
- The Indus Valley script was in use in what is today Pakistan and India from around 2400 BCE to 1900 BCE [4,5,6,7,8]. Its writing direction was mainly right-to-left, although there are some left-to-right and boustrophedon writing examples, too. Remarkably, the Indus Valley script has over 700 different signs. Since only those signs that occur at least three times seem significant, we used only the 23 most frequent Indus Valley script signs, as shown in Figure 5.
- 5.
- The Mycenaean Greeks used the Linear B script, which is an adaptation of the earlier Linear A that was used by the Minoans. In 1952, Michael Ventris succeeded in determining that Linear B was the older written form of the Greek language that was written using syllabic signs [9]. We used 20 signs from Linear B, as shown in Figure 6.
- 6.
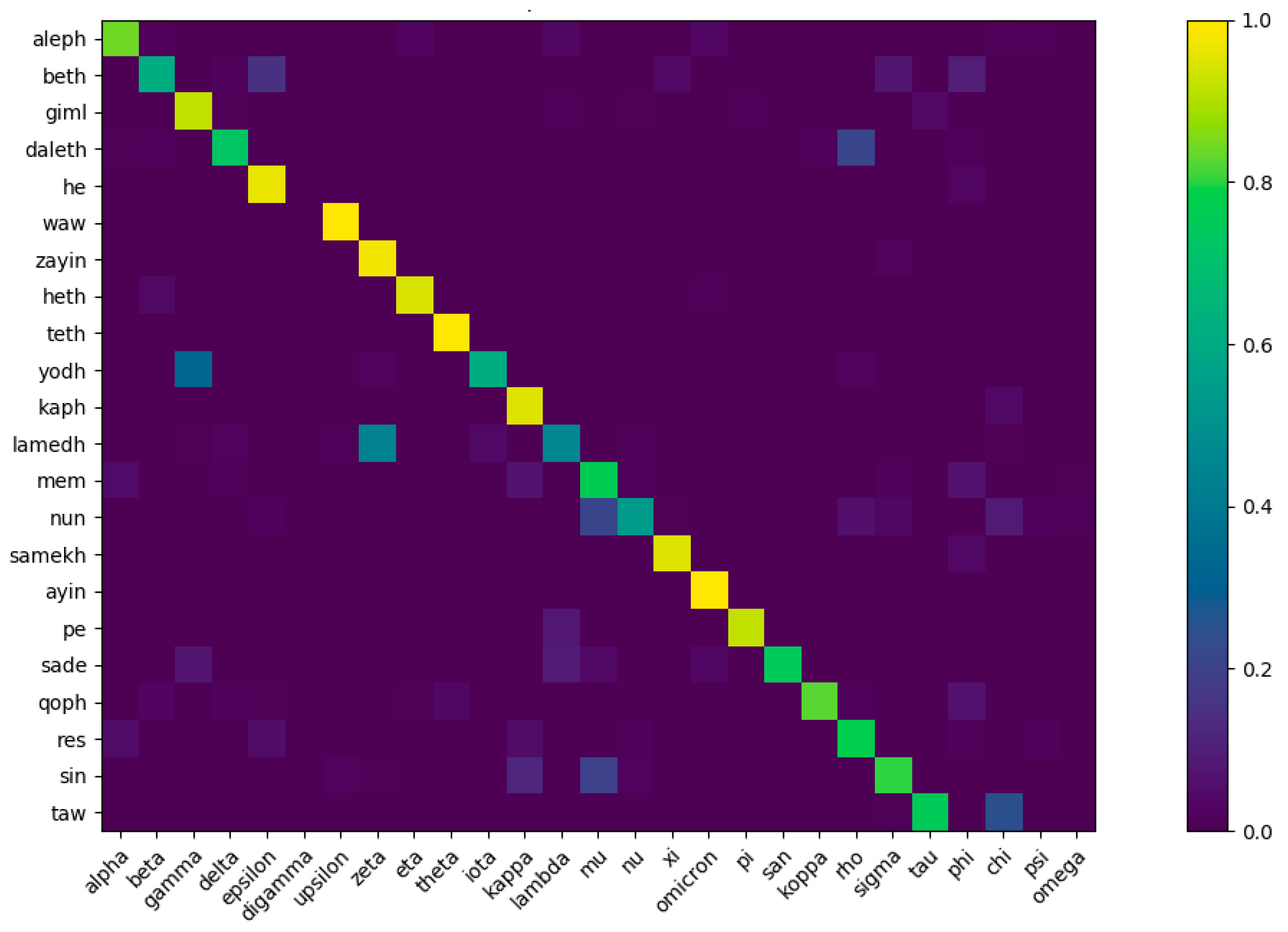
- Beginning around 1200 BCE, the Phoenician alphabet was written on clay tablets [10]. According to some proposals, the Phoenician alphabet may be derived from Egyptian hieroglyphs [11], but its development may also have been influenced by Linear B [12]. Since the 22 Phoenician alphabet letters originally denoted only consonants, it is classified as an abjad. Phoenician texts also usually run right-to-left. We used all 22 Phoenician alphabet letters, as shown in Figure 7.
- 7.
- The proto-Elamite script existed primarily in the region that today is Iran during the fourth millennium BCE [13]. The proto-Elamite script had almost two thousand signs, but most of those signs were used infrequently [14]. Currently, the proto-Elamite script is currently undeciphered. We used 17 signs from the proto-Elamite script, as shown in Figure 8.
- 8.
- Sumerian pictograms were a novel development and were mostly logographic, according to researchers. They were formed in the fourth millennium BCE, but they developed into cuneiform signs, which were used over several millennia until the first century [15]. The Sumerian language is distantly related to the Dravidian and Uralic languages [16,17]. We used 34 signs from the Sumerian pictograms, as shown in Figure 9.
 . These two forms of the letter E are considered allographs of each other and should be treated as a single letter during script comparisons. Neural networks can also learn to recognize mirror-symmetric signs if the training examples include mirror-symmetric examples of the signs.
. These two forms of the letter E are considered allographs of each other and should be treated as a single letter during script comparisons. Neural networks can also learn to recognize mirror-symmetric signs if the training examples include mirror-symmetric examples of the signs.3. Experimental Design
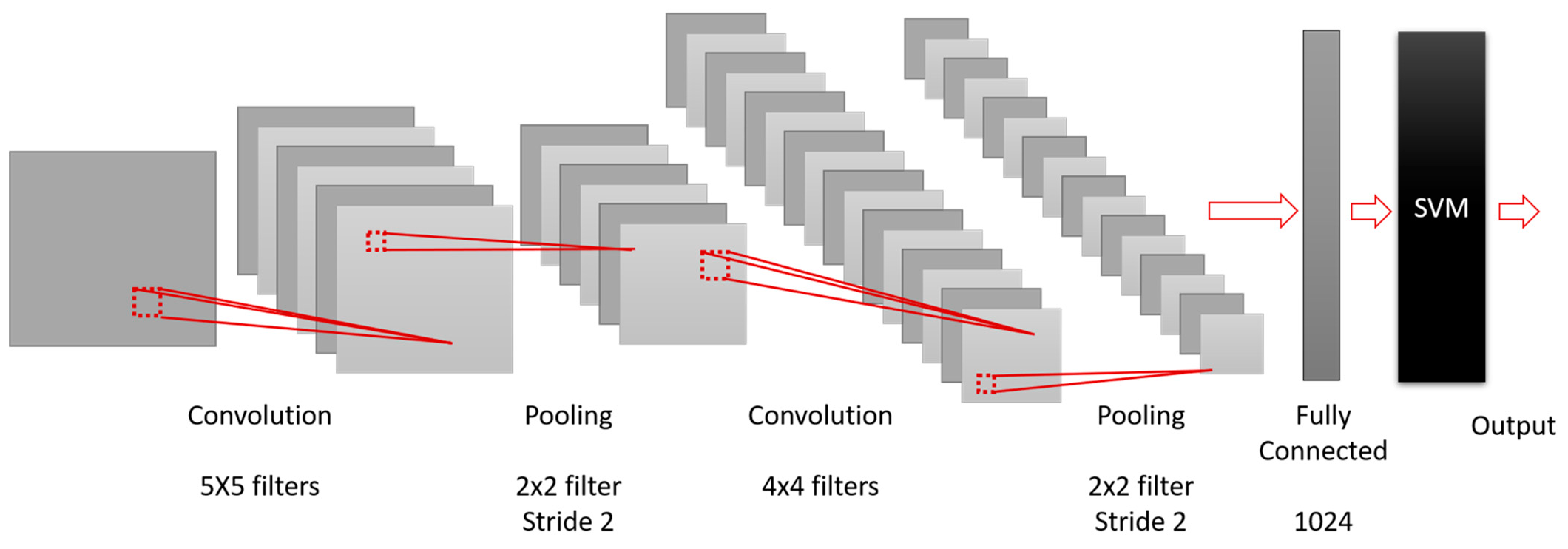
3.1. Design of the CNN
3.2. Design of the SVM
3.3. The Sign Classifier
- The average of all considers all the of signs by averaging the maximum probability matches between the input signs and the trained script signs. If an input sign had a low correlation with all of the trained signs, then the average of all value would be lowered.
- The selective average takes the average of only those pairs of signs which have a higher than 75 percent (or other chosen threshold) similarity match.
3.4. Generation of Classification Dendrograms
- Similarity classification dendrograms: The weighted pair group method with arithmetic mean (WPGMA) algorithm was used to create a dendrogram as follows. We repeatedly merged those sets of scripts that were most similar according to the similarity matrix. The similarity matrix was updated after each merge. The update requires that the most similar script sets, x and y, are merged into the union x ∪ y of the two sets. This means merging the corresponding two rows into one row and the corresponding two columns into one column in the similarity matrix. In addition, the distance to another set, z and x ∪ y, is updated using the following equation:
- 2.
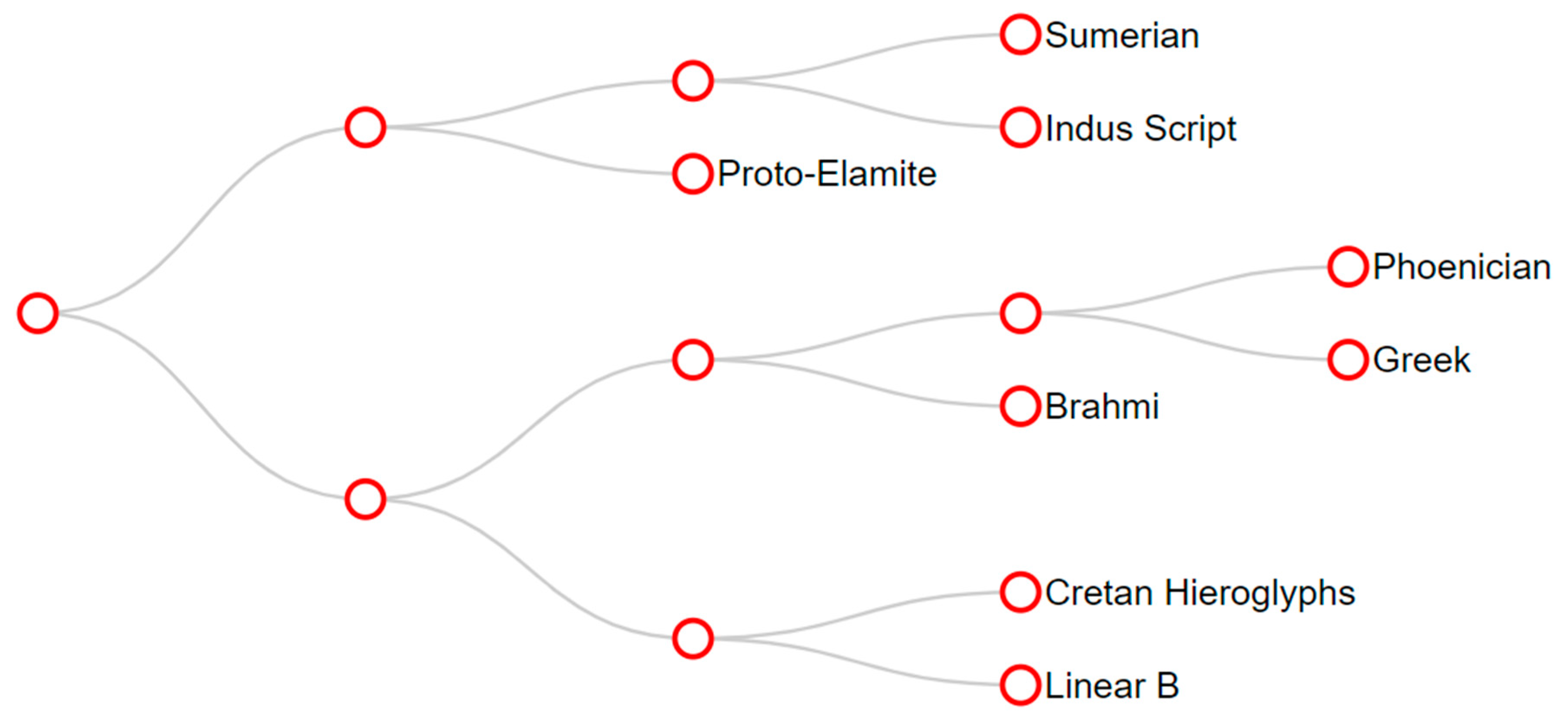
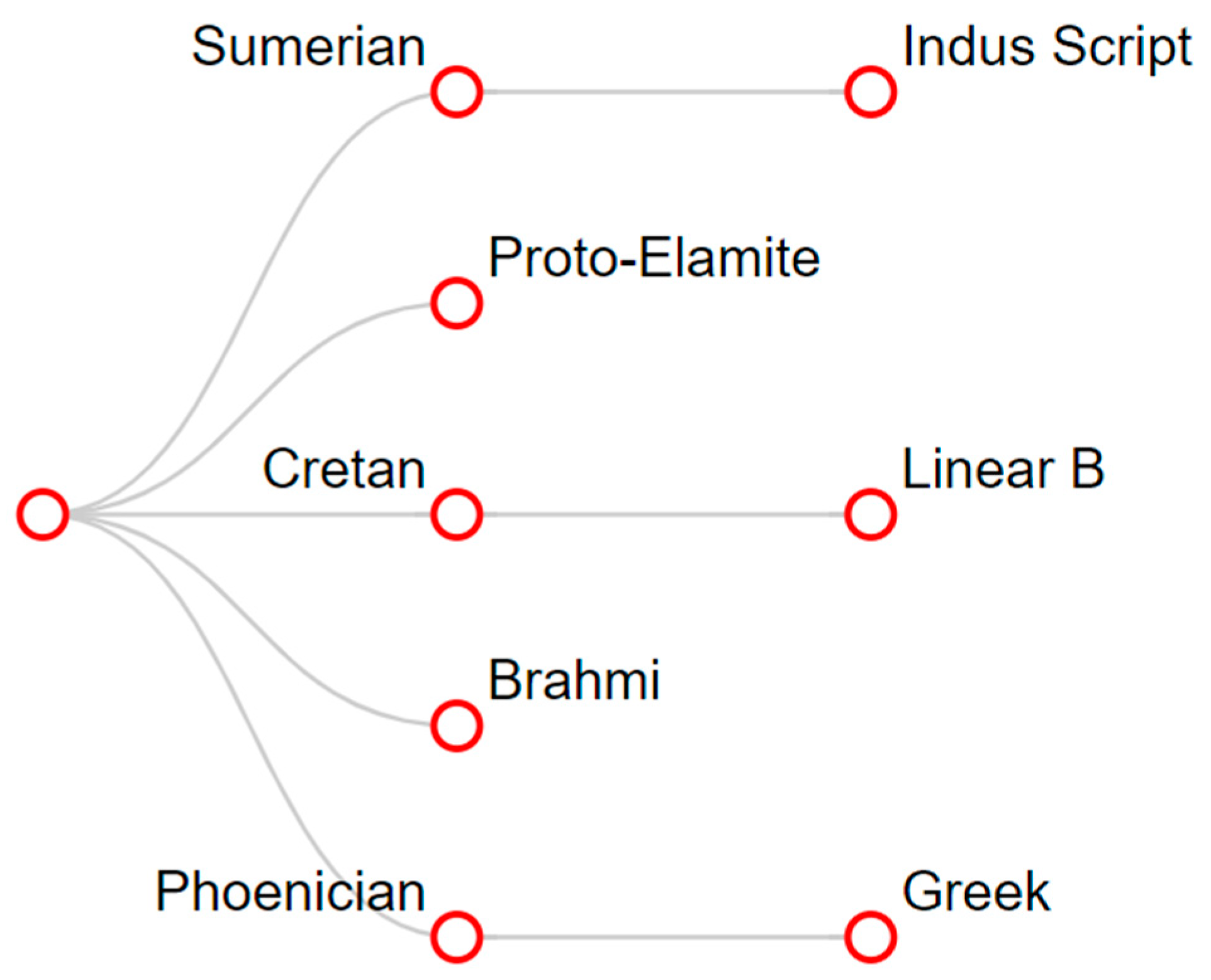
- Hierarchical classification dendrograms: In generating a hierarchal tree, it is assumed that some scripts have an ancestor–descendant relationship. This requires a modification of the WPGMA algorithm, but must also consider the periods during which the scripts were used. If x and y are the most similar to each other, that is, they can be considered to be closest script pair, and x’s period of use preceded y’s period of use, or vice versa, then we consider x to be an ancestor or parent of y. Algorithm 1 was built on this idea.
| Algorithm 1 Time-Based Descendant Tree |
| 1: Create parent node P 2: Create a node for each script 3: for all Closest Script Pairs Sx and Sy do 4: if Sx.Time > Sy.Time then 5: Parent of Sx is P 6: Parent of Sy is Sx 7: else 8: Parent of Sy is P 9: Parent of Sx is Sy 10: for all Singleton Scripts Sz do 11: Parent of Sz is P 12: return Tree |
4. Experimental Results
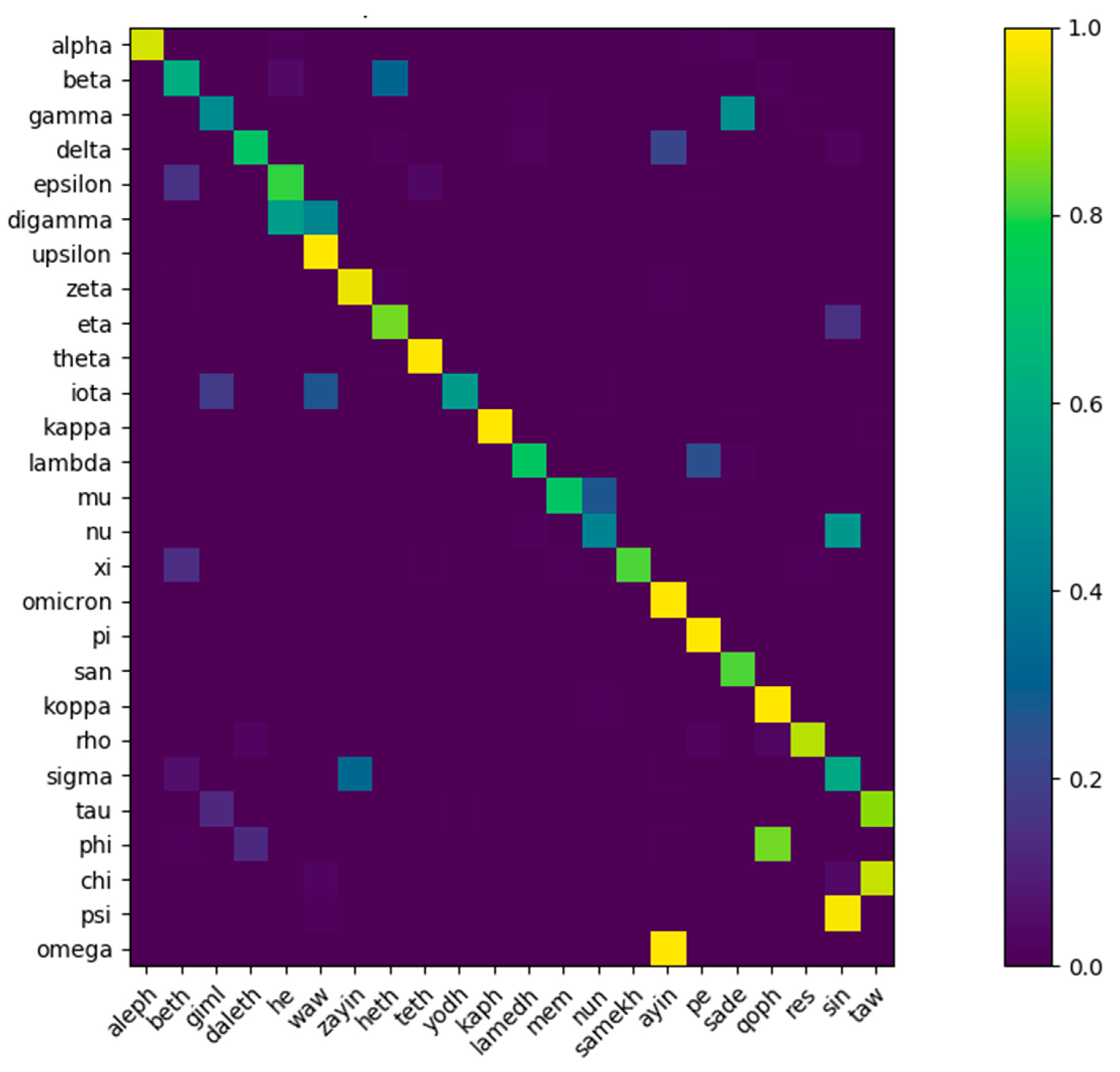
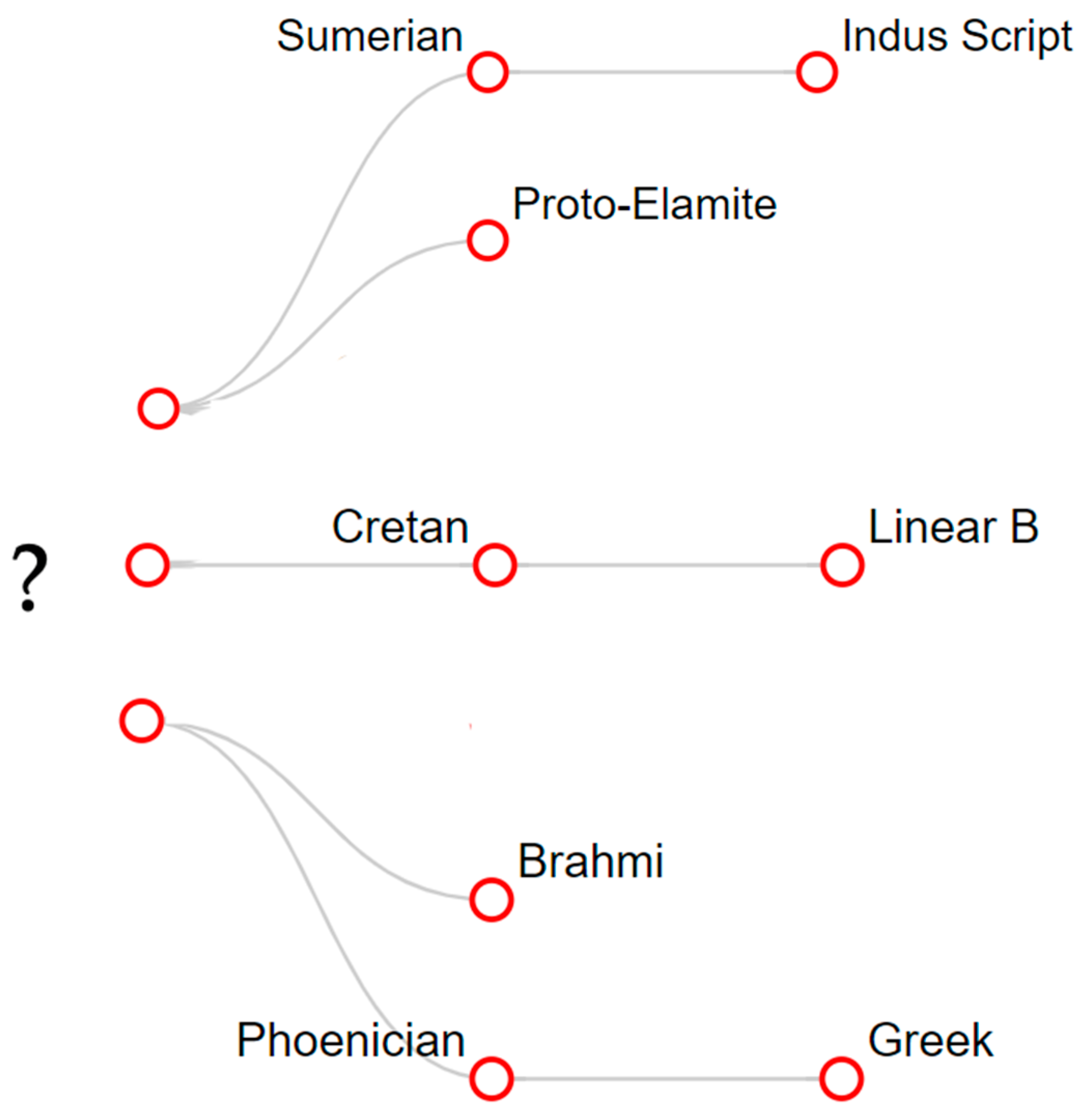
- Known Origin: It is well-known that the Phoenician alphabet was adopted by the ancient Greeks, who extended it by four letters that are specific to the Greek alphabet, as is shown in Table 2. It is also known to be an ancestor of Aramaic, which is an ancestor of Brahmi. By transitivity, Phoenician is an ancestor of Brahmi too. In addition, Cretan hieroglyphics are often said to be an ancestor of the Linear B script.
- Unknown Origin: Sumerian pictographs have no known ancestors. A similar situation holds for the proto-Elamite and Indus Valley scripts.
5. Discussion of the Results
5.1. Related Work
5.2. Machine Learning
6. Conclusions and Open Problems
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Salomon, R. Indian Epigraphy: A Guide to the Study of Inscriptions in Sanskrit, Prakrit, and the other Indo-Aryan Languages; Oxford University Press: Oxford, UK, 1998. [Google Scholar]
- Olivier, J.-P. Cretan writing in the second millennium BCE. World Archaeol. 1986, 17, 377–389. [Google Scholar] [CrossRef]
- Cook, B.F. Greek Inscriptions; University of California Press: Berkeley, CA, USA, 1987; Volume 5. [Google Scholar]
- Mahadevan, I. The Indus Script: Texts, Concordance and Tables, Memoirs; Archaeological Survey of India: Delhi, India, 1977; Volume 77.
- Joshi, J.P.; Parpola, A. Corpus of Indus Seals and Inscriptions. vol. 1, Collections in India. In Annales Academiae Scientiarum Fennicae; Series B; Suomalainen Tiedeakatemia: Helsinki, Finland, 1987; Volume 239. [Google Scholar]
- Shah, S.G.M.; Parpola, A. Corpus of Indus Seals and Inscriptions, vol 2. Collections in Pakistan. In Annales Academiae Scientiarum Fennicae; Series B; Suomalainen Tiedeakatemia: Helsinki, Finland, 1991; Volume 240. [Google Scholar]
- Parpola, A.; Pande, B.M.; Koskikallio, P. Corpus of Indus Seals and Inscriptions, Vol. 3. New Material, Untraced Objects, and Collections Outside India and Pakistan; Suomalainen Tiedeakatemia: Helsinki, Finland, 2010. [Google Scholar]
- Parpola, A. Deciphering the Indus Script; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Chadwick, J. The Decipherment of Linear B; Cambridge University Press: Cambridge, UK, 1958. [Google Scholar]
- Fischer, S.R. History of Writing; Reaktion Books: London, UK, 2004. [Google Scholar]
- Colless, B.E. The origin of the alphabet: An examination of the Goldwasser hypothesis. Antig. Oriente 2014, 12, 71–104. [Google Scholar]
- Revesz, P.Z. Bioinformatics evolutionary tree algorithms reveal the history of the Cretan Script Family. Int. J. Appl. Math. Inform. 2016, 10, 67–76. [Google Scholar]
- Englund, R.K. The Proto-Elamite script. In The World’s Writing Systems; Daniels, P.T., Bright, W., Eds.; Oxford University Press: Oxford, UK, 1996; pp. 160–164. [Google Scholar]
- Dahl, J.L. Complex graphemes in Proto-Elamite. Cuneif. Digit. Libr. J. 2005, 4. Available online: https://cdli.mpiwg-berlin.mpg.de/articles/cdlj/2005-3 (accessed on 3 April 2023).
- Labat, R.; Malbran-Labat, F. Manuel D’épigraphie Akkadienne: Signes, Syllabaire, Idéogrammes, Librairie Orientaliste Paul Geuthner; Enlarged édition (1 avril 2002). Available online: https://www.amazon.fr/Manuel-dépigraphie-akkadienne-Syllabaire-Idéogrammes/dp/2705335838 (accessed on 3 April 2023).
- Parpola, S. Etymological Dictionary of the Sumerian Language. J. Indo-Eur. Stud. 2022, 3, 247–252. [Google Scholar]
- Revesz, P.Z. Sumerian contains Dravidian and Uralic substrates associated with the Emegir and Emesal dialects. WSEAS Trans. Inf. Sci. Appl. 2019, 16, 8–30. [Google Scholar]
- LeCun, Y.; Cortes, C.; Burges, C. MNIST Handwritten Digit Database. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 5 April 2019).
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Elleuch, M.; Tagougui, N.; Kherallah, M. A novel architecture of CNN based on SVM classifier for recognizing Arabic handwritten script. Int. J. Intell. Syst. Technol. Appl. 2016, 15, 323–340. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Yann, M.L.; Tang, Y. Learning deep convolutional neural networks for X-ray protein crystallization image analysis. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; AAAI Press: Palo Alto, CA, USA, 2016; pp. 1373–1379. [Google Scholar]
- Collon, D. Mesopotamia and the Indus: The evidence of the seals. In The Indian Ocean in Antiquity; The British Museum and Kegan Paul International: London, UK; New York, NY, USA, 1996; pp. 209–225. [Google Scholar]
- Howard, M.C. Transnationalism in Ancient and Medieval Societies: The Role of Cross-Border Trade and Travel; McFarland: Jefferson, NC, USA, 2014. [Google Scholar]
- Revesz, P.Z. Data science applied to discover ancient Minoan-Indus Valley trade routes implied by common weight measures. In Proceedings of the 26th International Database Engineered Applications Symposium (IDEAS), Budapest, Hungary, 22–24 August 2022; ACM Press: New York, NY, USA, 2022; pp. 150–155. [Google Scholar]
- Rao, R.P.; Yadav, N.; Vahia, M.N.; Joglekar, H.; Adhikari, R.; Mahadevan, I. Entropic evidence for linguistic structure in the Indus script. Science 2009, 324, 5931. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rao, R.P.; Yadav, N.; Vahia, M.N.; Joglekar, H.; Adhikari, R.; Mahadevan, I. A Markov model of the Indus Script. Proc. Natl. Acad. Sci. USA 2009, 106, 13685–13690. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wells, B.K. Epigraphic Approaches to Indus Writing; Oxbow Books: Oxford, UK, 2011. [Google Scholar]
- Zide, A.R.; Zvelebil, K.V. (Eds.) The Soviet Decipherment of the Indus Valley Script: Translation and Critique. In Janua Linguarum. Series Practica; de Gruyter Mouton: Berlin, Germany, 1976; Volume 156. [Google Scholar] [CrossRef]
- Salomon, R. On the origin of the early Indian scripts. J. Am. Orient. Soc. 1995, 115, 271–279. [Google Scholar] [CrossRef]
- McAlpin, D.W. Proto-Elamo-Dravidian: The evidence and its implications. Trans. Am. Philos. Soc. 1981, 71, 1–155. [Google Scholar] [CrossRef] [Green Version]
- Farmer, S.; Sproat, R.; Witzel, M. The collapse of the Indus-script thesis: The myth of a literate Harappan civilization. Electron. J. Vedic Stud. 2016, 11, 19–57. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Reading text in the wild with convolutional neural networks. Int. J. Comput. Vis. 2016, 116, 1–20. [Google Scholar] [CrossRef] [Green Version]
- He, M.; Zhang, S.; Mao, H.; Jin, L. Recognition confidence analysis of hand-written Chinese character with CNN. In Proceedings of the 13th International Conference on Document Analysis and Recognition, Nancy, France, 23–26 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 61–65. [Google Scholar]
- Yang, W.; Jin, L.; Liu, M. Chinese character-level writer identification using path signature feature, DropStroke and deep CNN. In Proceedings of the 13th International Conference on Document Analysis and Recognition, Nancy, France, 23–26 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 546–550. [Google Scholar]
- Arora, S.; Bhattacharjee, D.; Nasipuri, M.; Malik, L.; Kundu, M.; Basu, D.K. Performance comparison of SVM and ANN for handwritten Devnagari character recognition. arXiv 2010, arXiv:1006.5902. [Google Scholar]
- Daggumati, S.; Revesz, P.Z. Data mining ancient script image data using convolutional neural networks. In Proceedings of the 22nd International Database Engineering and Applications Symposium, Villa San Giovanni, Italy, 18–20 June 2018; ACM Press: New York, NY, USA, 2018; pp. 267–272. [Google Scholar]
- Daggumati, S.; Revesz, P.Z. Data mining ancient scripts to investigate their relationships and origins. In Proceedings of the 23rd International Database Engineering and Applications Symposium, Athens, Greece, 10–12 June 2019; ACM Press: New York, NY, USA, 2019; pp. 209–218. [Google Scholar]
- Daggumati, S.; Revesz, P.Z. A method of identifying allographs in undeciphered scripts and its application to the Indus Valley Script. Humanit. Soc. Sci. Commun. 2021, 8, 50. [Google Scholar] [CrossRef]
- Revesz, P.Z. A translation of the Arkalochori Axe and the Malia Altar Stone. WSEAS Trans. Inf. Sci. Appl. 2017, 14, 124–133. [Google Scholar]
- Revesz, P.Z. Establishing the West-Ugric language family with Minoan, Hattic and Hungarian by a decipherment of Linear, A. WSEAS Trans. Inf. Sci. Appl. 2017, 14, 306–335. [Google Scholar]
- Revesz, P.Z. Decipherment challenges due to tamga and letter mix-ups in an Old Hungarian runic inscription from the Altai Mountains. Information 2022, 13, 422. [Google Scholar] [CrossRef]
- Revesz, P.Z. Experimental evidence for a left-to-right reading direction of the Phaistos Disk. Mediterr. Archaeol. Archaeom. 2022, 22, 79–96. [Google Scholar]
- Hosszú, G. Scriptinformatics: Extended Phenetic Approach to Script Evolution; Nap Kiadó: Budapest, Hungary, 2021. [Google Scholar]
- Tóth, L.; Hosszú, G.; Kovács, F. Deciphering Historical Inscriptions Using Machine Learning Methods. In Proceedings of the 10th International Conference on Logistics, Informatics and Service Sciences, Beijing, China, 23 February 2020; Liu, S., Bohács, G., Shi, X., Shang, X., Huang, A., Eds.; Springer: Singapore, 2020; pp. 419–435. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
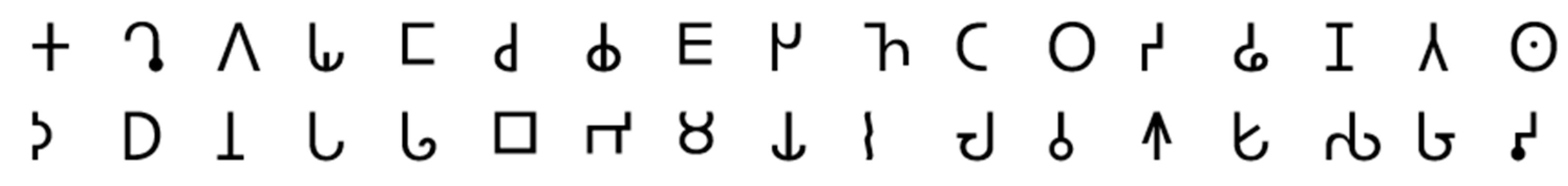{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
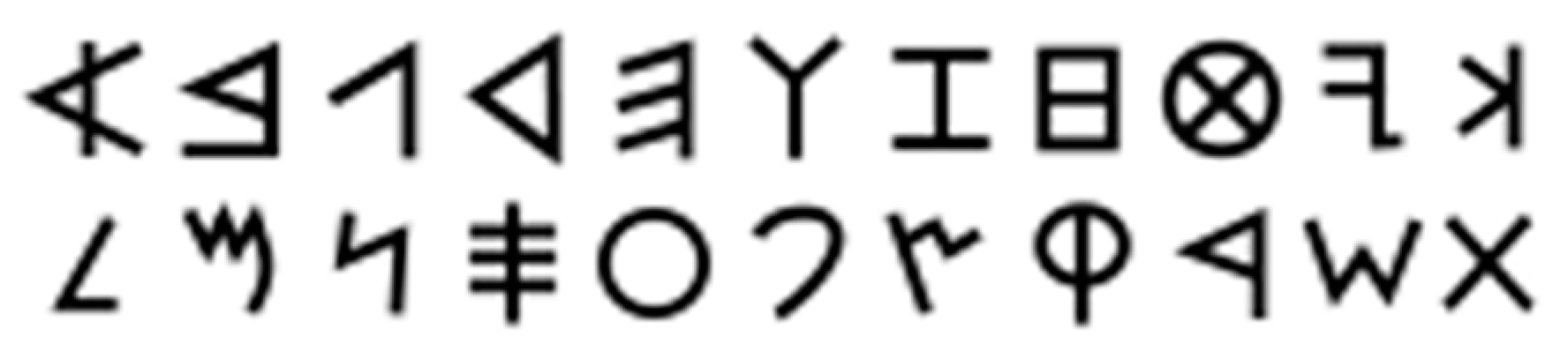{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Script | 25 | 50 | 75 | 100 |
|---|---|---|---|---|
| Brahmi Script | 95.09 | 98.15 | 98.24 | 99.35 |
| Cretan Hieroglyphs | 91.09 | 92.84 | 94.47 | 97.53 |
| Greek Alphabet | 93.49 | 96.26 | 97.23 | 98.63 |
| Indus Valley Script | 93.50 | 95.70 | 96.85 | 98.23 |
| Linear B Script | 91.19 | 93.15 | 96.42 | 99.48 |
| Phoenician Alphabet | 93.18 | 94.77 | 95.36 | 97.52 |
| Proto-Elamite Script | 91.93 | 94.55 | 97.05 | 99.09 |
| Sumerian Pictograms | 90.79 | 93.21 | 96.94 | 97.40 |
| Phoenician Letter | Phoenician Name | Greek Letter | Greek Name |
|---|---|---|---|
 | aleph |  | alpha |
 | beth |  | beta |
 | giml |  | gamma |
 | daleth |  | delta |
 | he |  | epsilon |
 | waw |  or or  | digamma or upsilon |
 | zayin |  | zeta |
 | heth |  | eta |
 | teth |  | theta |
 | yodh |  | iota |
 | kaph |  | kappa |
 | lamedh |  | lambda |
 | mem |  | mu |
 | nun |  | nu |
 | samekh |  | xi |
 | ayin |  | omicron |
 | pe |  | pi |
 | sade |  | san |
 | qoph |  | koppa |
 | res |  | rho |
 | sin |  | sigma |
 | taw |  | tau |
 | phi | ||
 | chi | ||
 | psi | ||
 | omega |
| Brahmi | Cretan Hieroglyphs | Greek | Indus Valley | Linear B | Phoenician | Proto-Elam. | Sumerian Pictograms | |
|---|---|---|---|---|---|---|---|---|
| Brahmi | 34 | 2 | 9 | 8 | 3 | 9 | 2 | 6 |
| Cretan Hieroglyphs | 2 | 22 | 4 | 5 | 20 | 6 | 2 | 6 |
| Greek | 9 | 4 | 26 | 9 | 7 | 22 | 2 | 7 |
| Indus Valley | 8 | 5 | 9 | 23 | 4 | 9 | 4 | 20 |
| Linear B | 3 | 20 | 7 | 4 | 20 | 9 | 0 | 5 |
| Phoenician | 9 | 6 | 22 | 9 | 9 | 22 | 3 | 7 |
| Proto-Elamite | 2 | 2 | 2 | 4 | 0 | 3 | 17 | 3 |
| Sumerian Pictograms | 6 | 6 | 7 | 20 | 5 | 7 | 3 | 39 |
| Arabic | Hebrew | English | German | Finnish | Hungarian | |
|---|---|---|---|---|---|---|
| Arabic | 8 | 2 | 1 | 1 | 1 | |
| Hebrew | 8 | 2 | 4 | 1 | 1 | |
| English | 2 | 2 | 9 | 2 | 1 | |
| German | 1 | 4 | 9 | 2 | 3 | |
| Finish | 1 | 1 | 2 | 2 | 4 | |
| Hungarian | 1 | 1 | 1 | 3 | 4 |
| Brahmi | Greek | Phoenician | Cretan Hieroglyphs | Linear B | Indus Valley | Proto-Elam. | Sumerian Pictograms | |
|---|---|---|---|---|---|---|---|---|
| Brahmi | 9 | 9 | 2 | 3 | 8 | 2 | 6 | |
| Greek | 9 | 22 | 4 | 7 | 9 | 2 | 7 | |
| Phoenician | 9 | 22 | 6 | 9 | 9 | 3 | 7 | |
| Cretan Hieroglyphs | 2 | 4 | 6 | 20 | 5 | 2 | 6 | |
| Linear B | 3 | 7 | 9 | 20 | 4 | 0 | 5 | |
| Indus Valley | 8 | 9 | 9 | 5 | 4 | 4 | 20 | |
| Proto-Elamite | 2 | 2 | 3 | 2 | 0 | 4 | 3 | |
| Sumerian Pictograms | 6 | 7 | 7 | 6 | 5 | 20 | 3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Daggumati, S.; Revesz, P.Z. Convolutional Neural Networks Analysis Reveals Three Possible Sources of Bronze Age Writings between Greece and India. Information 2023, 14, 227. https://doi.org/10.3390/info14040227
Daggumati S, Revesz PZ. Convolutional Neural Networks Analysis Reveals Three Possible Sources of Bronze Age Writings between Greece and India. Information. 2023; 14(4):227. https://doi.org/10.3390/info14040227
Chicago/Turabian StyleDaggumati, Shruti, and Peter Z. Revesz. 2023. "Convolutional Neural Networks Analysis Reveals Three Possible Sources of Bronze Age Writings between Greece and India" Information 14, no. 4: 227. https://doi.org/10.3390/info14040227
APA StyleDaggumati, S., & Revesz, P. Z. (2023). Convolutional Neural Networks Analysis Reveals Three Possible Sources of Bronze Age Writings between Greece and India. Information, 14(4), 227. https://doi.org/10.3390/info14040227