
Towards a Unified Architecture Powering Scalable Learning Models with IoT Data Streams, Blockchain, and Open Data

 ,
,  , , ,
, , ,  , , , , , , , , and
, , , , , , , , and
Abstract
:1. Introduction
- Streaming Analytics, also called event stream processing, analyzes in real time the huge volume of data. This type of analysis is adapted to detect urgent situations and immediate actions such as medical monitoring, air fleet tracking, financial transactions, traffic analysis, etc.
- Spatial analysis analyzes geographic patterns to identify the relationships between IoT devices in the physical world. This analysis is used in applications such as smart parking.
- Time series analysis analyzes time series data to reveal trends and associated patterns. This form of analysis is used, for example, in weather forecasting, smart meters, health monitoring systems, etc.
- Prescriptive Analysis combines descriptive and predictive analysis to understand the best actions to take in each situation. This type of analysis is, for example, used in commercial IoT applications.
- Internet of Things (IoT) Predictive Maintenance: IoT devices generate a massive volume of data streams, which vary in arrival frequency, speeds, and quantities. In the context of predictive maintenance, combining these heterogeneous data sources is crucial for building accurate machine-learning models. Data from sensors, machine logs, maintenance records, and external sources need to be integrated and preprocessed to create a comprehensive training database.
- Fraud Detection in Financial Transactions: In the realm of financial transactions, fraud detection is a critical use case that requires combining diverse data sources to build a reliable training database. Various sources such as transaction logs, customer profiles, and external data feeds contribute to the training data. However, these sources often differ in data formats and quality. To ensure consistency, preprocessing steps such as data cleaning, normalization, and feature engineering are applied to consolidate the training database.
- Crop Yield Optimization in Smart Farming: In smart farming, optimizing crop yield and ensuring efficient resource utilization is crucial for sustainable and profitable agricultural practices. To achieve this, farmers often gather data from various sources such as soil sensors, weather stations, crop health monitors, and machinery telemetry. However, these data sources may have different quality levels, formats, and update frequencies. This is where the Consolidated Learning (CL) platform comes into play, facilitating the preprocessing and integration of data for effective decision making.
- Threat Detection and Response in Cybersecurity: In the field of cybersecurity, organizations face constant challenges in detecting and responding to evolving cyber threats. To effectively protect their systems and data, organizations rely on various security tools and systems that generate vast amounts of security event logs, network traffic data, and intrusion detection alerts. However, these data sources often differ in terms of data formats, protocols, and logging mechanisms, making it difficult to analyze and correlate them for accurate threat detection.
- An Integrated Architecture Edge-Fog-Cloud and Machine Learning;
- Complete automation of the data acquisition chain, data reconciliation, development, and training of machine learning models.
2. Related Works
3. Architecture Conceptualization
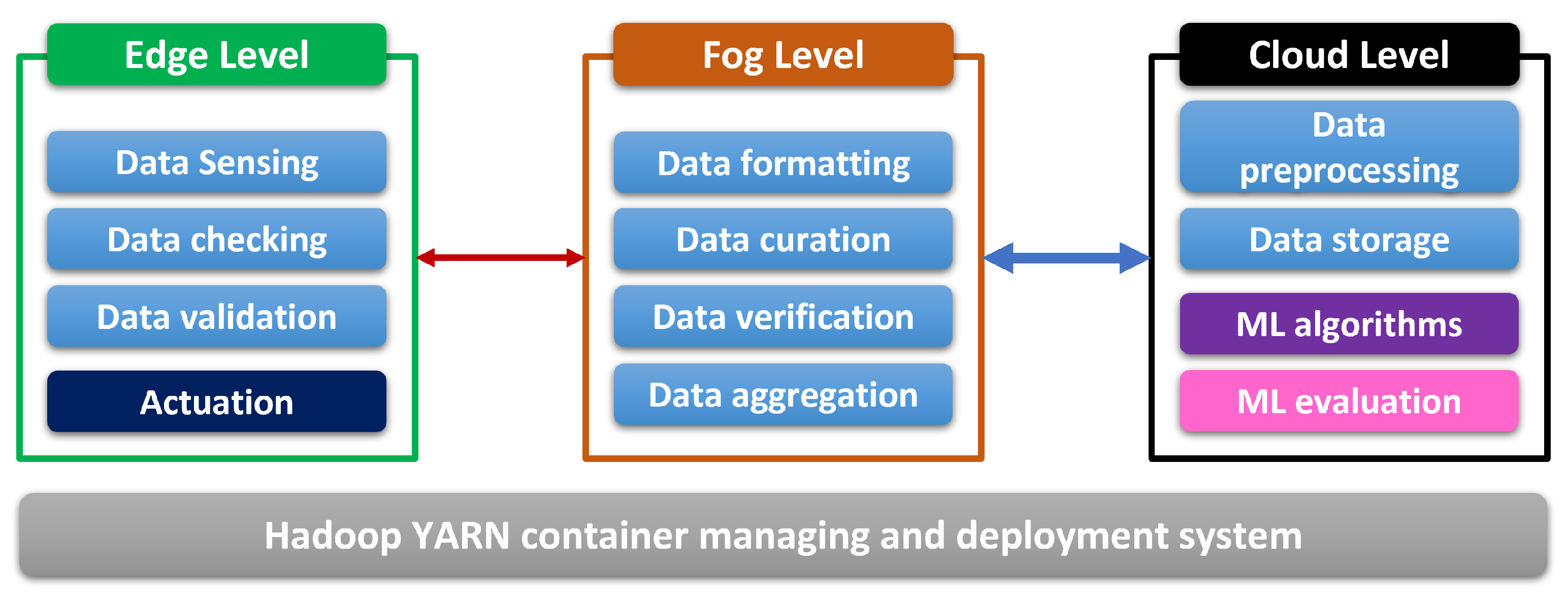
- An Edge layer (EL) is composed of microcontrollers where data are acquired using sensors and then checked and validated. EL is also responsible for the activation of the actuators that allow for acting on the environment of the subject of observation or the subject himself. See the left part of Figure 2. The EL operates at the edge of the network, closer to the data source, which offers several advantages. By processing data locally, the EL reduces latency and minimizes dependence on cloud-based services, making it well-suited for time-critical applications. Moreover, the EL enhances data security and privacy since sensitive information can be processed and analyzed locally, without necessarily transmitting it to external servers.
- A Fog level (FL) is the gateway that ensures network protocols commutation. At the same time, the data are centralized for verification and curated where possible before being transmitted to the cloud. See the middle section of Figure 2. The FL acts as a communication bridge, ensuring seamless connectivity between different network protocols utilized by the EL and the Cloud layer. It enables the exchange of data and commands, allowing for efficient and reliable communication across the entire system. By providing protocol commutation capabilities, the FL overcomes the challenges posed by heterogeneous network environments where various devices and protocols coexist.
- A Cloud level (CL) is where IoT data are processed and stored in a database as a time series. See the right part of Figure 2. In the CL, data received from the Fog level (FL) or other sources are processed and analyzed using various cloud-based services, algorithms, and machine learning models. This processing stage involves extracting valuable insights, detecting patterns, and generating actionable information from the collected IoT data. The CL leverages the computational resources and scalability of cloud platforms to handle large volumes of data and perform complex computations efficiently.
4. Architectural Proposal
4.1. Edge Layer
4.2. Fog Layer
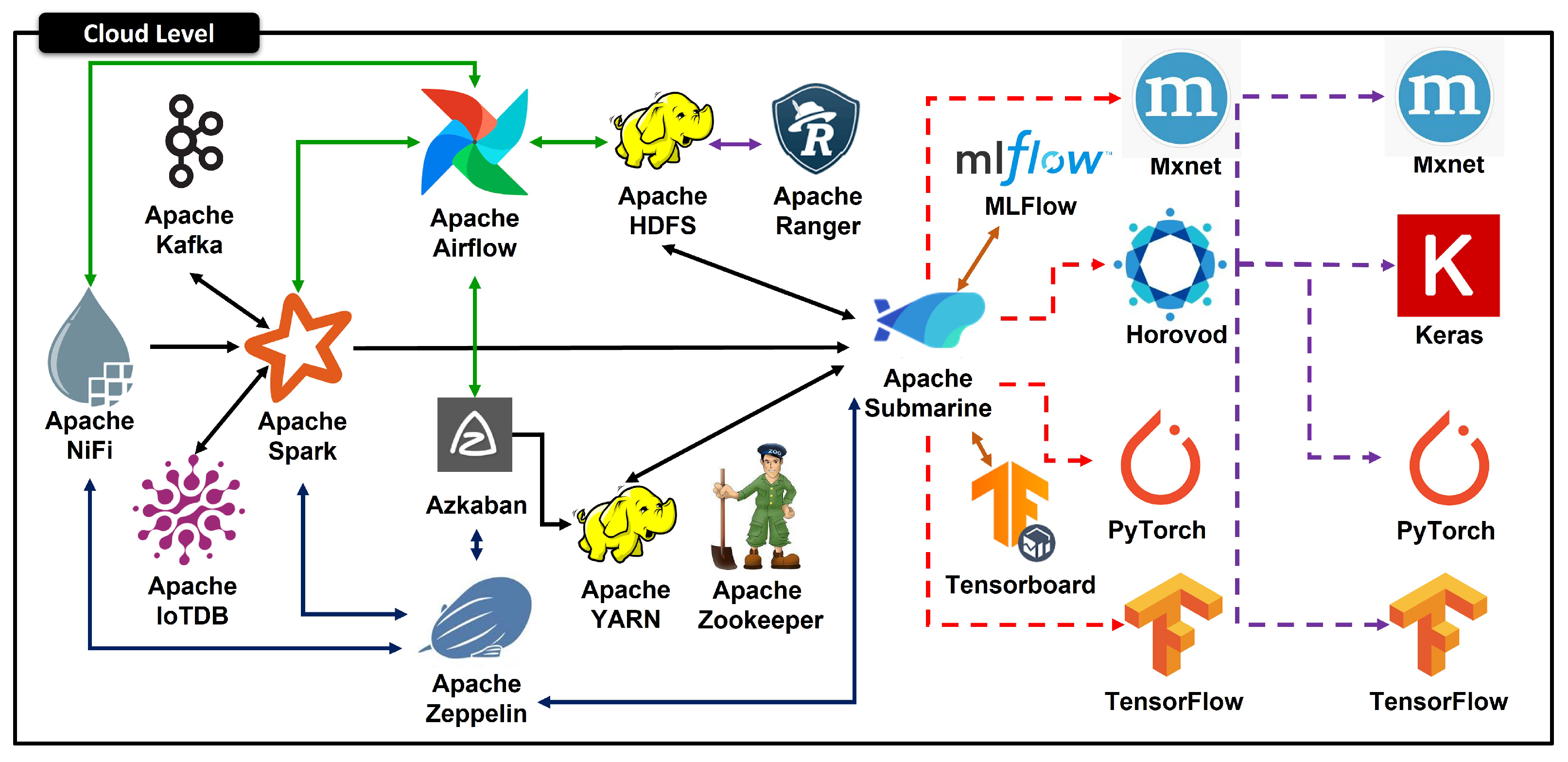
4.3. Cloud Layer
4.4. Security
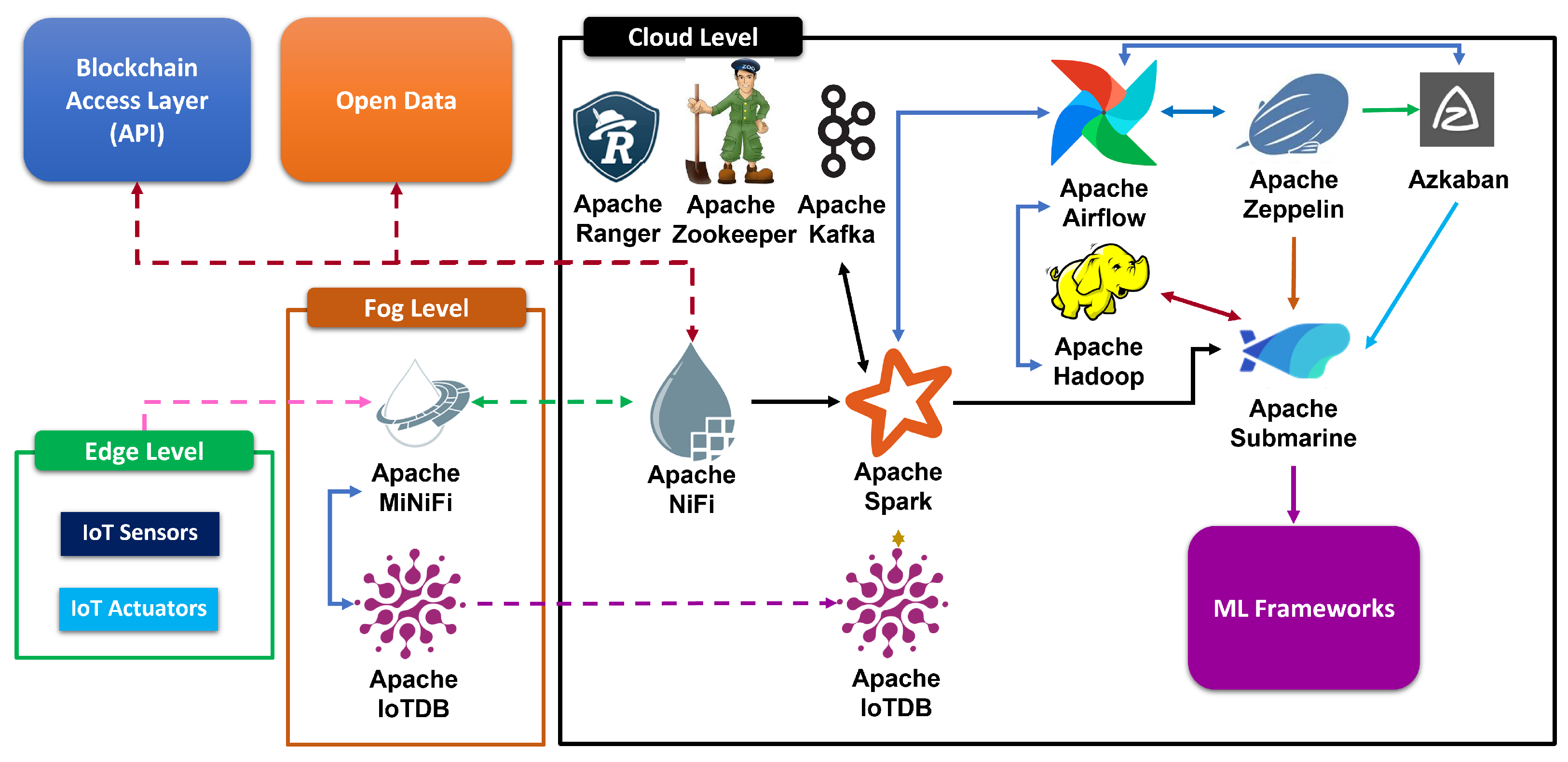
4.5. Software Components
5. Implementation
6. Experimentation
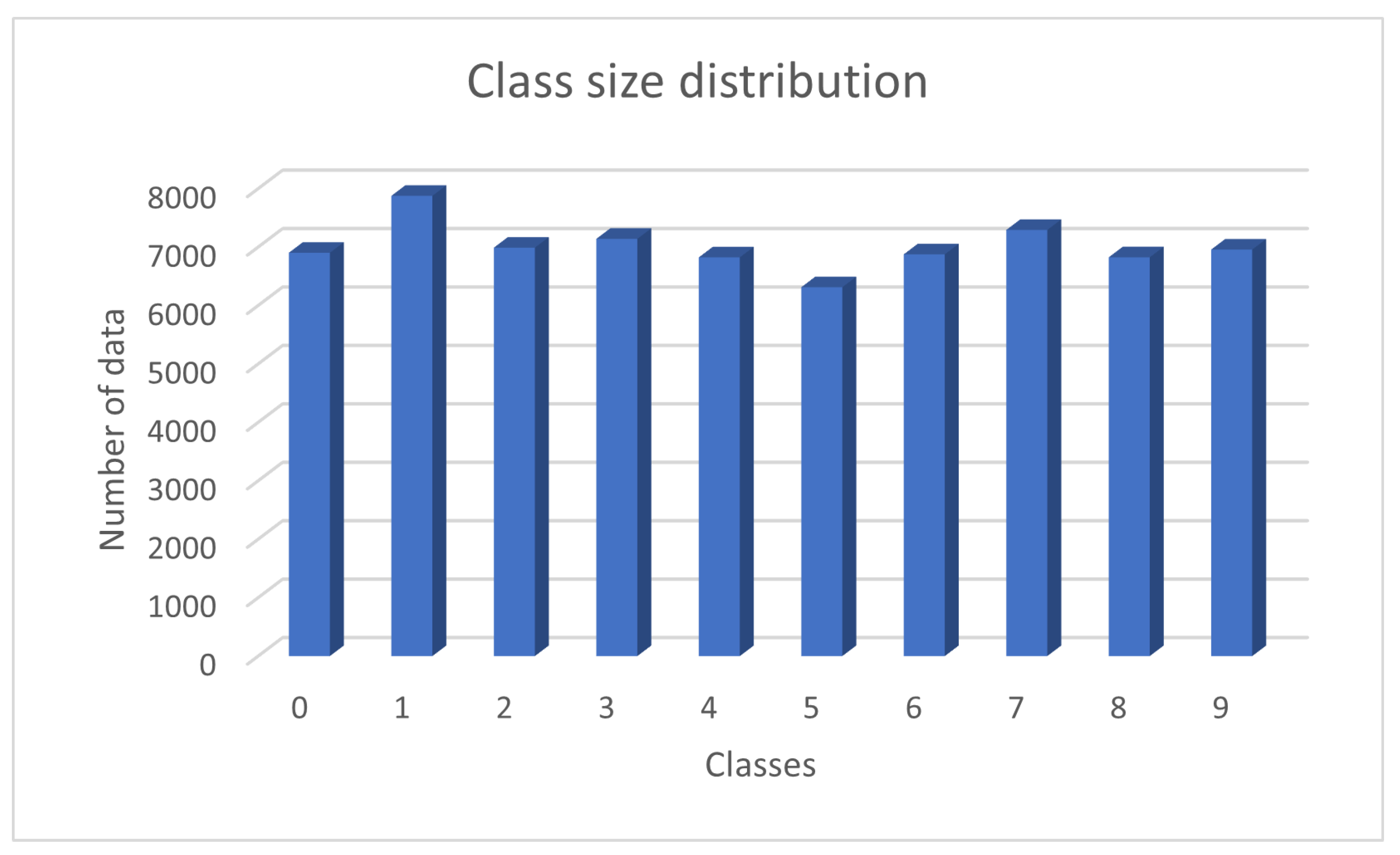
6.1. Description of the Dataset
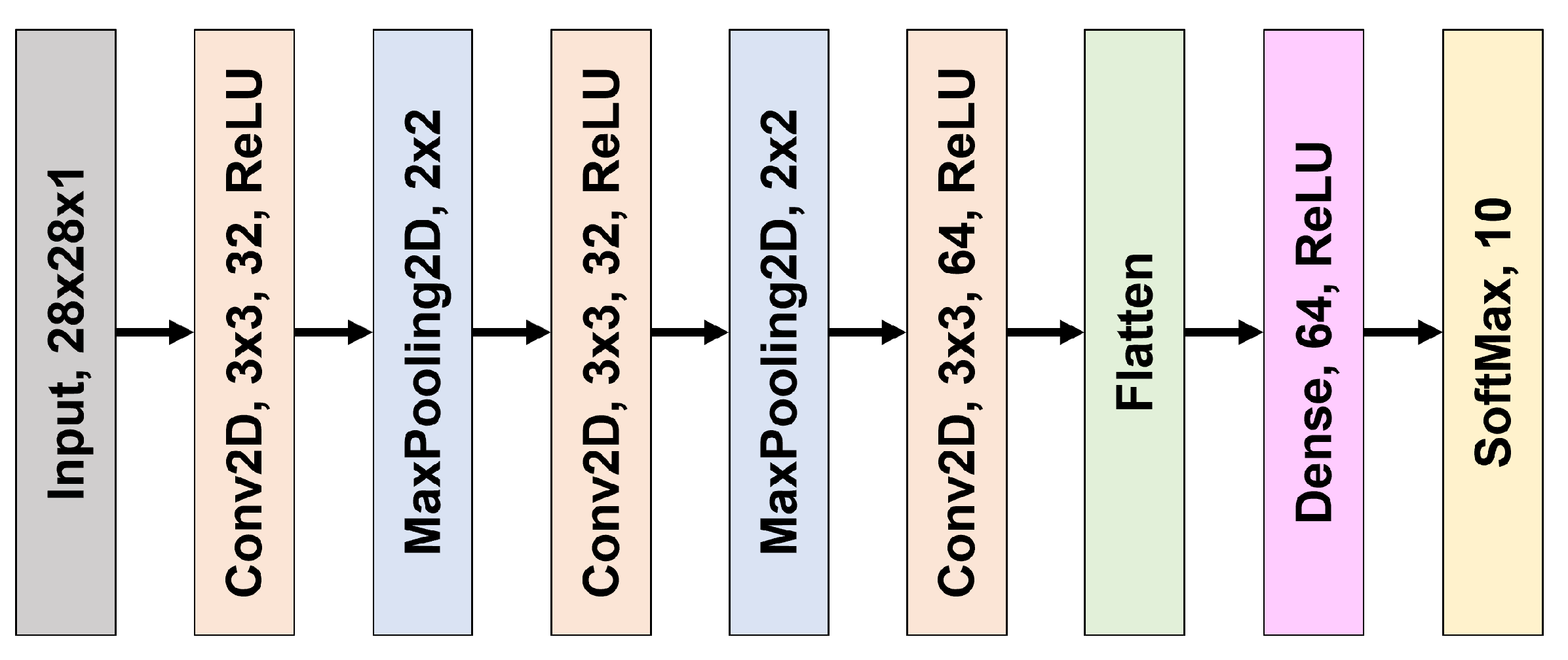
6.2. Structure of the Classifier
- Convolutional Layer 1 (Conv2D):
- Filters: 32;
- Kernel size: (3, 3);
- Activation function: ReLU;
- Input shape: (28, 28, 1) (images with a size of 28 × 28 and a single channel).
- Max Pooling Layer 1 (MaxPooling2D):
- Pool size: (2, 2).
- Convolutional Layer 2 (Conv2D):
- Filters: 64;
- Kernel size: (3, 3);
- Activation function: ReLU.
- Max Pooling Layer 2 (MaxPooling2D):
- Pool size: (2, 2).
- Convolutional Layer 3 (Conv2D):
- Filters: 64;
- Kernel size: (3, 3);
- Activation function: ReLU.
- Flatten Layer:
- Converts the 2D output from the previous layer into a 1D vector to feed into a dense layer.
- Dense Layer 1 (Dense):
- Neurons: 64;
- Activation function: ReLU.
- Dense Layer 2 (Dense):
- Neurons: 10;
- Activation function: Softmax;
- Output layer with 10 neurons, representing the probability distribution over the 10 classes.
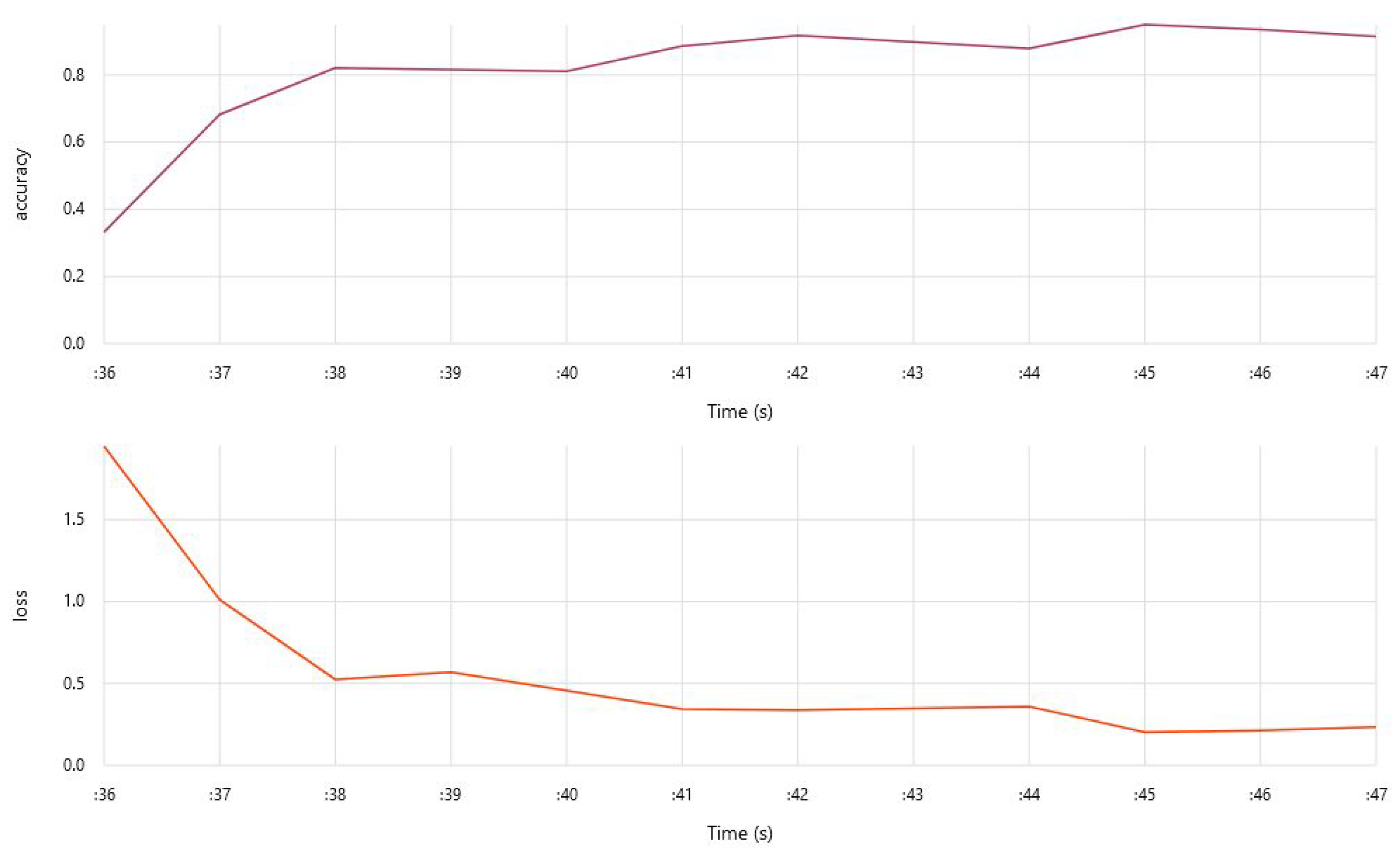
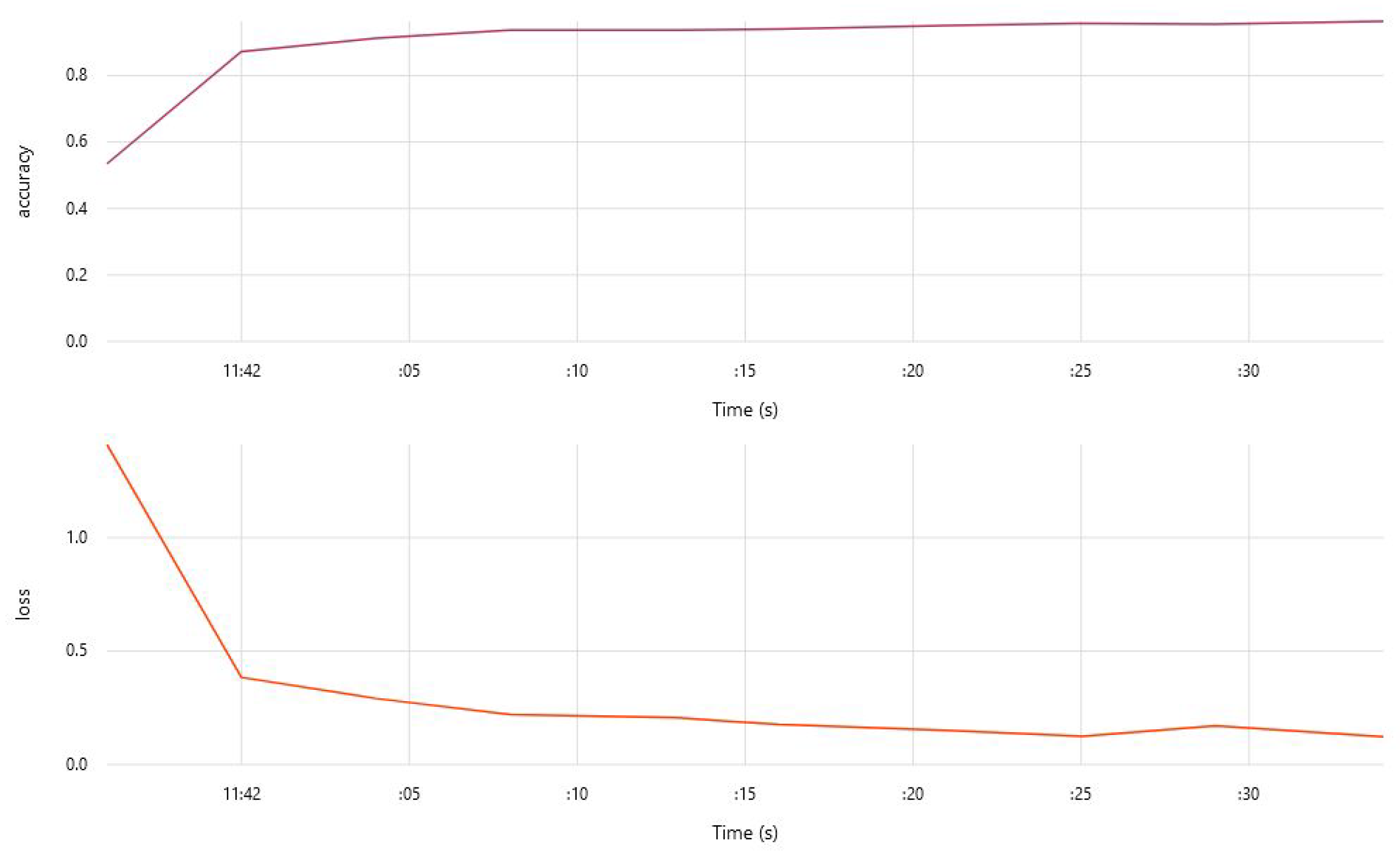
6.3. Training of the Model
7. Results and Discussion
8. Work Limitations
9. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AGV | Automated Guided Vehicles |
| AI | Artificial Intelligence |
| AMWR | Adaptive Moving Window Regression |
| API | Application Programming Interface |
| BD | Big Data |
| BDE | Big Data Exploration |
| CEP | Complex Event Processing |
| CL | Cloud Layer |
| CoAP | Constrained Application Protocol |
| CPS | Cyber-Physical Systems |
| CPU | Central Processing Unit |
| DL | Deep Learning |
| DM | Data Mining |
| DNN | Deep Neural Network |
| DS | Data Science |
| EL | Edge Layer |
| FL | Fog Layer |
| GUI | Graphical User Interface |
| GPU | Graphics Processing Unit |
| HDFS | Hadoop Distributed File System |
| HILDA | Human-In-the-Loop Data Analysis |
| HKMS | Hadoop Key Management Service |
| HPC | High Performance Computing |
| HTTP | Hypertext Transfer Protocol |
| IDEAaS | Interactive Data Exploration As-a-Service |
| IoT | Internet of Things |
| IP | Internet Protocol |
| JKS | Java KeyStore |
| JSON | JavaScript Object Notation |
| KDD | Knowledge Discovery in Databases |
| LR | Learning Rate |
| LSTM | Long-Short-Term-Memory |
| ML | Machine Learning |
| MPU | Memory Protection Unit |
| MQTT | MQ Telemetry Transport |
| RKMS | Ranger Key Management Service |
| TOS | Real-Time Operating System |
| REST | Representational State Transfer |
| SGX | Software Guard Extensions |
| TCP | Transmission Control Protocol |
| TLS | Transport Layer Security |
| UI | User Interface |
References
- Bagozi, A.; Bianchini, D.; De Antonellis, V.; Garda, M.; Marini, A. A Relevance-based approach for Big Data Exploration. Future Gener. Comput. Syst. 2019, 101, 51–69. [Google Scholar] [CrossRef]
- Lee, K.M.; Yoo, J.; Kim, S.W.; Lee, J.H.; Hong, J. Autonomic machine learning platform. Int. J. Inf. Manag. 2019, 49, 491–501. [Google Scholar] [CrossRef]
- Baylor, D.; Breck, E.; Cheng, H.-T.; Fiedel, N.; Foo, C.Y.; Haque, Z.; Haykal, S.; Ispir, M.; Jain, V.; Koc, L.; et al. Tfx: A tensorflow-based production-scale machine learning platform. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’17), Halifax, NS, Canada, 13 August 2017; pp. 1387–1395. [Google Scholar]
- Zaharia, M.; Chen, A.; Davidson, A.; Ghodsi, A.; Hong, S.A.; Konwinski, A.; Murching, S.; Nykodym, T.; Ogilvie, P.; Parkhe, M.; et al. Accelerating the machine learning lifecycle with MLflow. IEEE Data Eng. Bull. 2018, 41, 39–45. [Google Scholar]
- Nolack Fote, F.; Roukh, A.; Mahmoudi, S.; Mahmoudi, S.A.; Debauche, O. Toward a big data knowledge-base management system for precision livestock farming. Procedia Comput. Sci. 2020, 177, 136–142. [Google Scholar] [CrossRef]
- Debauche, O.; Trani, J.-P.; Mahmoudi, S.; Manneback, P.; Bindelle, J.; Mahmoudi, S.A.; Guttadauria, A.; Lebeau, F. Data management and internet of things: A methodological review in smart farming. Internet Things 2021, 14, 100378. [Google Scholar] [CrossRef]
- Debauche, O.; Mahmoudi, S.; Manneback, P.; Lebeau, F. Cloud and distributed architectures for data management in agriculture 4.0: Review and future trends. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 7494–7514. [Google Scholar] [CrossRef]
- Nkamla Penka, J.B.; Mahmoudi, S.; Debauche, O. An Optimized Kappa Architecture for IoT Data Management in Smart Farming. Int. J. Ubiquitous Syst. Pervasive Netw. 2022, 17, 59–65. [Google Scholar]
- Chen, T.; Li, M.; Li, Y.; Lin, M.; Wang, N.; Wang, M.; Xiao, T.; Xu, B.; Zhang, C.; Zhang, Z. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv 2015, arXiv:1512.01274. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2019; p. 4399. [Google Scholar]
- Sergeev, A.; Del Balso, M. Horovod: Fast and easy distributed deep learning in TensorFlow. arXiv 2018, arXiv:1802.05799. [Google Scholar]
- Chen, K.-H.; Su, H.-P.; Chuang, W.-C.; Hsiao, H.-C.; Tan, W.; Tang, Z.; Liu, X.; Liang, Y.; Lo, W.-C.; Ji, W.; et al. Apache submarine: A unified machine learning platform made simple. In Proceedings of the 2nd European Workshop on Machine Learning and Systems (EuroMLSys’22), Rennes, France, 5–8 April 2022; pp. 101–108. [Google Scholar]
- Aggarwal, C.C.; Philip, S.Y.; Han, J.; Wang, J. A framework for clustering evolving data streams. In Proceedings of the 29th International Conference on Very Large Databases (VLDB), Berlin, Germany, 12–13 September 2003; pp. R81–R92. [Google Scholar]
- Sayed, D.; Rady, S.; Aref, M. Enhancing CluStream algorithm for CLUSTERING big data streaming over sliding window. In Proceedings of the 12th International Conference on Electrical Engineering (ICEENG), Cairo, Egypt, 7–9 July 2020; pp. 108–114. [Google Scholar]
- Ahsani, S.; Sanati, M.Y.; Mansoorizadeh, M. Improvement of CluStream algorithm using sliding window for the clustering of data streams. In Proceedings of the 11th International Conference on Computer Engineering and Knowledge (ICCKE), Mashhad, Iran, 28–29 October 2021; pp. 434–440. [Google Scholar]
- Sangam, R.S.; Om, H. Equi-Clustream: A framework for clustering time evolving mixed data. Adv. Data Anal. Classif. 2018, 12, 973–995. [Google Scholar] [CrossRef]
- Wang, X.; Sun, Q. Research on Clustream Algorithm Based on Spark. In Proceedings of the 10th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 9–10 December 2017; Volume 2, pp. 219–222. [Google Scholar]
- Kumar, A.; Singh, A.; Singh, R. An efficient hybrid-clustream algorithm for stream mining. In Proceedings of the 13th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Jaipur, India, 4–7 December 2017; pp. 430–437. [Google Scholar]
- Grua, E.M.; Hoogendoorn, M.; Malavolta, I.; Lago, P.; Eiben, A.E. Clustream-GT: Online clustering for personalization in the health domain. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence (WI’19), Thessaloniki, Greece, 14–17 October 2019; pp. 270–275. [Google Scholar]
- Akbar, A.; Khan, A.; Carrez, F.; Moessner, K. Predictive Analytics for Complex IoT Data Streams. IEEE Internet Things J. 2017, 4, 1571–1582. [Google Scholar] [CrossRef] [Green Version]
- Calabrese, M.; Cimmino, M.; Fiume, F.; Manfrin, M.; Romeo, L.; Ceccacci, S.; Paolanti, M.; Toscano, G.; Ciandrini, G.; Carrotta, A.; et al. SOPHIA: An Event-Based IoT and Machine Learning Architecture for Predictive Maintenance in Industry 4.0. Information 2020, 11, 202. [Google Scholar] [CrossRef] [Green Version]
- Machorro-Cano, I.; Alor-Hernández, G.; Paredes-Valverde, M.A.; Rodríguez-Mazahua, L.; Sánchez-Cervantes, J.L.; Olmedo-Aguirre, J.O. HEMS-IoT: A Big Data and Machine Learning-Based Smart Home System for Energy Saving. Energies 2020, 13, 1097. [Google Scholar] [CrossRef] [Green Version]
- Rashid, R.A.; Chin, L.; Sarijari, M.A.; Sudirman, R.; Ide, T. Machine Learning for Smart Energy Monitoring of Home Appliances Using IoT. In Proceedings of the 2019 Eleventh International Conference on Ubiquitous and Future Networks (ICUFN), Zagreb, Croatia, 2–5 July 2019; pp. 66–71. [Google Scholar]
- Elsisi, M.; Tran, M.-Q. Development of an IoT Architecture Based on a Deep Neural Network against Cyber Attacks for Automated Guided Vehicles. Sensors 2021, 21, 8467. [Google Scholar] [CrossRef]
- Flores-Martin, D.; Rojo, J.; Moguel, E.; Berrocal, J.; Murillo, J.M. Smart Nursing Homes: Self-Management Architecture Based on IoT and Machine Learning for Rural Areas. Wirel. Commun. Mob. Comput. 2021, 2021, 8874988. [Google Scholar] [CrossRef]
- Anh Khoa, T.; Phuc, C.H.; Lam, P.D.; Nhu, L.M.B.; Trong, N.M.; Phuong, N.T.H.; Dung, N.V.; Tan-Y, N.; Nguyen, H.N.; Duc, D.N.M. Waste Management System Using IoT-Based Machine Learning in University. Wirel. Commun. Mob. Comput. 2020, 2020, 6138637. [Google Scholar] [CrossRef]
- Debauche, O.; Nkamla Penka, J.B.; Mahmoudi, S.; Lessage, X.; Hani, M.; Manneback, P.; Lufuluabu, U.K.; Bert, N.; Messaoudi, D.; Guttadauria, A. RAMi: A New Real-Time Internet of Medical Things Architecture for Elderly Patient Monitoring. Information 2022, 13, 2078–2489. [Google Scholar] [CrossRef]
- Wang, C.; Huang, X.; Qiao, J.; Jiang, T.; Rui, L.; Zhang, J.; Kang, R.; Feinauer, J.; McGrail, K.A.; Wang, P.; et al. Apache IoTDB: Time-series database for internet of things. Proc. VLDB Endow. 2020, 13, 2901–2904. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. arXiv 2015, arXiv:1603.04467. [Google Scholar]
- Roukh, A.; Fote, F.N.; Mahmoudi, S.A.; Mahmoudi, S. Big data processing architecture for smart farming. Procedia Comput. Sci. 2020, 177, 78–85. [Google Scholar] [CrossRef]
- Roukh, A.; Fote, F.N.; Mahmoudi, S.A.; Mahmoudi, S. Wallesmart: Cloud platform for smart farming. In Proceedings of the 32nd International Conference on Scientific and Statistical Database Management, Vienna, Austria, 7–9 July 2020; pp. 1–4. [Google Scholar]
- Kurtzer, G.M.; Sochat, V.; Bauer, M.W. Singularity: Scientific containers for mobility of compute. PLoS ONE 2017, 12, e0177459. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Pros | Cons |
|---|---|---|
| Lee et al. [2] | Minimize expert intervention | Focus on the cloud only |
| Bagozi et al. [1] | New approach to use data as a service | Complex and too theoretical |
| Apache Submarine [12] | Open for non-experts of ML | Difficult to install for non-IT Experts |
| Akbar et al. [20] | The AMWR algo to retrain the model with new data | Generic architecture |
| Calabrese et al. [21] | The idea of Lambda architecture with ML tools | More complex to maintain like Lambda |
| Machorro-Cano et al. [22] | Detailed layers | ML part is not clearly explained |
| Rashid et al. [23] | Detailed layers based on LSTM | Focuses on the network layer with ML |
| Elsisi et al. [24] | Used a DNN model against cyber-attacks | Implemented DNN is not clearly explained |
| Flores-Martin et al. [25] | Used ML for monitoring elderly people | The ML model tiers are partially defined |
| Anh Khoa et al. [26] | Lots of details about the materials | Lack of details on the ML model |
| Tools | Usage | Role |
|---|---|---|
| Apache MiNiFi | EL | Collects data at the source of its creation. |
| Apache NiFi | FL | Routes and transforms data on the desirable format. |
| Apache IoTDB | FL, CL | Addresses requirements of massive data storage with ingestion at high speed. |
| Apache Zookeeper | CL | Centralizes configuration details, and names and gives out distributed synchronization. |
| Apache Spark | CL | Distributes computing using implicit data parallelism and fault tolerance. |
| Apache Hadoop | CL | Permits the distributed handling of vast datasets across Computer clusters. |
| Apache Airflow | CL | Schedules and monitor workflows. |
| Apache Zeppelin | CL | Facilitates interactive data analytics. |
| Azkaban | CL | A batch workflow job scheduler that supports the composition of workflows. |
| Apache Ranger | CL | Defines, administers, and manages security policies for Hadoop clusters. |
| Apache Kafka | CL | Provides a unified, real-time, low-latency system for handling data streams. |
| Apache Submarine | CL | Helps to develop ML workflows. |
| TensorFlow | CL | Helps to develop ML model. |
| PyTorch | CL | Accelerates the path from research prototyping to production deployment. |
| Apache MXNet | CL | Uses for Deep Learning used to train and deploy deep neural networks. |
| Keras | CL | Helps to minimize the number of user actions required for common use cases. |
| Horovod | CL | A distributed deep-learning framework. |
| Service | Docker Image | Instance | Internal Port | Exposed Port | Mapped Port |
|---|---|---|---|---|---|
| Zookeeper | confluentinc/cp-zookeeper:7.2.1 | 1 | 2888, 3888 | 2181 | 2181 |
| Kafka | confluentinc/cp-kafka:7.2.1 | 1 | 19,092 | 9092, 29,092 | 9092, 29,092 |
| Kafka Schema Registry | confluentinc/cp-schema-registry:7.2.1 | 1 | 8081 | 8081 |
| Service | Docker Image | Instance | Internal Port | Exposed Port | Mapped Port |
|---|---|---|---|---|---|
| Zookeeper | bitnami/zookeeper:3.8.0 | 1 | 8082 | 2181 | 2181 |
| NiFi | apache/nifi:1.20.0 | 1 | 8082 | 8080 | 8091 |
| NiFi Registry | apache/nifi-registry:1.20.0 | 1 | 18,000 | 18,000 |
| Service | Docker Image | Instance | Internal Port | Exposed Port | Mapped Port |
|---|---|---|---|---|---|
| Zeppelin | Custom Dockerfile | 1 | 8080 | 5000 |
| Service | Docker Image | Instance | Internal Port | Exposed Port | Mapped Port |
|---|---|---|---|---|---|
| Airflow-scheduler | apache/airflow:2.6.0 | 1 | 8793 | 8793 | |
| Airflow-webserver | apache/airflow:2.6.0 | 1 | 8080 | 8080 | |
| Airflow-init | apache/airflow:2.6.0 | 1 | |||
| Postgresql | postgres:14 | 1 | 5432 | 5434 |
| Service | Docker Image | Instance | Internal Port | Exposed Port | Mapped Port |
|---|---|---|---|---|---|
| Docker Registry | registry:2.8.2 | 1 | 5000 | 5000 | |
| Redis | bitnami/redis:7.0.5 | 1 | 6379 | 6379 |
| Parameters | Accuracy | |||
|---|---|---|---|---|
| 1 cpu, 2 Gb | 1 cpu, 4 Gb | 2 cpu, 2 Gb | 2 cpu, 4 Gb | |
| lr = 0.01, batch size = 20 | 0.9349 | 0.9285 | 0.9396 | 0.915 |
| lr = 0.001, batch size = 20 | 0.9491 | 0.9380 | 0.9415 | 0.9484 |
| lr = 0.0001, batch size = 20 | 0.9069 | 0.8996 | 0.9069 | 0.9038 |
| lr = 0.01, batch size = 50 | 0.9496 | 0.9546 | 0.9430 | 0.9522 |
| lr = 0.001, batch size = 50 | 0.9603 | 0.9638 | 0.9610 | 0.9585 |
| lr = 0.0001, batch size = 50 | 0.9170 | 0.9188 | 0.9206 | 0.9206 |
| lr = 0.01, batch size = 100 | 0.9616 | 0.9604 | 0.9616 | 0.9236 |
| lr = 0.001, batch size = 100 | 0.9687 | 0.9664 | 0.9679 | 0.9679 |
| lr = 0.0001, batch size = 100 | 0.9244 | 0.9059 | 0.9262 | 0.9220 |
| lr = 0.01, batch size = 150 | 0.9668 | 0.9671 | 0.9644 | 0.9667 |
| lr = 0.001, batch size = 150 | 0.9716 | 0.9703 | 0.9711 | 0.9683 |
| lr = 0.0001, batch size = 150 | 0.9296 | 0.9287 | 0.9216 | 0.9297 |
| Service | Docker Image | License |
|---|---|---|
| Apache Airflow | apache/airflow:2.4.2 | Apache License 2.0 |
| Apache IoTDB | apache/iotdb:0.13.3 | Apache License 2.0 |
| Apache Kafka | confluentinc/cp-kafka:7.2.1 | Apache License 2.0 |
| Apache Hadoop | Apache License 2.0 | |
| Apache Horovod | Apache License 2.0 | |
| Apache Maven | Apache License 2.0 | |
| Apache MXNet | Apache License 2.0 | |
| NGINX | nginx:latest | BSD 2-clauses (d) |
| Apache NiFi | apache/nifi:1.20.0 | Apache License 2.0 |
| Apache NiFi Registry | apache/nifi-registry:1.20.0 | Apache License 2.0 |
| Apache NiFi Toolkit | apache/nifi-toolkit:1.20.0 | Apache License 2.0 |
| Postgresql | postgres:14 | PostgreSQL License (d) |
| Python | Python Software Foundation License | |
| PyTorch | BSD 3-clauses | |
| Apache Ranger | Apache License 2.0 | |
| Redis | bitnami/redis:7.0.5 | BSD 3-clauses |
| Registry | registry:2.8.1 | Apache License 2.0 |
| Apache Spark | Apache License 2.0 | |
| Apache Submarine | Apache License 2.0 | |
| Tensorflow | Apache License 2.0 | |
| Apache Zeppelin | apache/zeppelin:0.10.1 | Apache License 2.0 |
| Apache Zookeeper | bitnami/zookeeper:3.8.0 | Apache License 2.0 |
| Service | Docker Image | Instance | Internal Port | Exposed Port | Mapped Port |
|---|---|---|---|---|---|
| Zookeeper | bitnami/zookeeper:3.8.0 | 1 | 2181 | 2181 | |
| NiFi | apache/nifi:1.20.0 | min 2 | 8444, 8445 | 8444, 8445 | |
| NiFi Toolkit | apache/nifi-toolkit:1.20.0 | 1 | |||
| NiFi Registry | apache/nifi-registry:1.20.0 | 1 | 18,000 | 18,000 | |
| NGINX | nginx:latest | 1 | 8443 | 8443 |
| Service | Docker Image | Instance | Internal Port | Exposed Port | Mapped Port |
|---|---|---|---|---|---|
| Zookeeper | confluentinc/ | 3 | 2888, 3888 | 2181,2182, 2183 | 2181, 2182, 2183 |
| cp-zookeeper:7.2.1 | |||||
| Kafka | confluentinc/ | 3 | 19,092, 19,093, 19,094 | 9092, 9093, 9094 | 9092, 9093, 9094 |
| cp-kafka:7.2.1 | 29,092, 29,093, 29,094 | 29,092, 29,093, 29,094 | |||
| Kafka Schema | confluentinc/cp- | 1 | 8081 | 8081 | |
| Registry | schema-registry:7.2.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Debauche, O.; Nkamla Penka, J.B.; Hani, M.; Guttadauria, A.; Ait Abdelouahid, R.; Gasmi, K.; Ben Hardouz, O.; Lebeau, F.; Bindelle, J.; Soyeurt, H.; et al. Towards a Unified Architecture Powering Scalable Learning Models with IoT Data Streams, Blockchain, and Open Data. Information 2023, 14, 345. https://doi.org/10.3390/info14060345
Debauche O, Nkamla Penka JB, Hani M, Guttadauria A, Ait Abdelouahid R, Gasmi K, Ben Hardouz O, Lebeau F, Bindelle J, Soyeurt H, et al. Towards a Unified Architecture Powering Scalable Learning Models with IoT Data Streams, Blockchain, and Open Data. Information. 2023; 14(6):345. https://doi.org/10.3390/info14060345
Chicago/Turabian StyleDebauche, Olivier, Jean Bertin Nkamla Penka, Moad Hani, Adriano Guttadauria, Rachida Ait Abdelouahid, Kaouther Gasmi, Ouafae Ben Hardouz, Frédéric Lebeau, Jérôme Bindelle, Hélène Soyeurt, and et al. 2023. "Towards a Unified Architecture Powering Scalable Learning Models with IoT Data Streams, Blockchain, and Open Data" Information 14, no. 6: 345. https://doi.org/10.3390/info14060345
APA StyleDebauche, O., Nkamla Penka, J. B., Hani, M., Guttadauria, A., Ait Abdelouahid, R., Gasmi, K., Ben Hardouz, O., Lebeau, F., Bindelle, J., Soyeurt, H., Gengler, N., Manneback, P., Benjelloun, M., & Bertozzi, C. (2023). Towards a Unified Architecture Powering Scalable Learning Models with IoT Data Streams, Blockchain, and Open Data. Information, 14(6), 345. https://doi.org/10.3390/info14060345