1. Short-Term Memory Capacity Can Be Estimated from Literary Texts
This paper aims to propose that short-term memory (STM)—which refers to the ability to remember a small number of items for a short period—is likely made by two consecutive (in series) and uncorrelated processing units with similar capacity. The clues for conjecturing this model emerge from studying many novels from Italian and English Literature. Although simple, because only the surface structure of texts is considered, the model seems to mathematically describe the input-output characteristics of a complex mental process, which is largely unknown.
To model a two-unit STM processing, we further develop our previous studies based on a parameter called the “word interval”, indicated by
, given by the number of words between any two contiguous interpunctions [
1,
2,
3,
4,
5,
6,
7,
8]. The term “interval” arises by noting that
does measure an “interval”—expressed in words—which can be transformed into time through a reading speed [
9], as shown in [
1].
The parameter
varies in the same range of the STM capacity, given by Miller’s
law [
10], a range that includes 95% of cases. As discussed in [
1], the two ranges are deeply related because interpunctions organize small portions of more complex arguments (which make a sentence) in short chunks of text, which represent the natural STM input (see [
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31], a sample of the many papers appeared in the literature, and also the discussion in Reference [
1]). It is interesting to recall that
, drawn against the number of words per sentence,
, approaches a horizontal asymptote as
increases [
1,
2,
3]. The writer, therefore, maybe unconsciously, introduces interpunctions as sentences get longer because he/she also acts as a reader, therefore limiting
approximately in the Miller’s range.
The presence of interpunctions in a sentence and its length in words are, very likely, the tangible consequence of two consecutive processing units necessary to deliver the meaning of the sentence, the first of which we have already studied with regard to
and the linguistic I-channel [
1,
2,
3,
4,
5,
6,
7,
8].
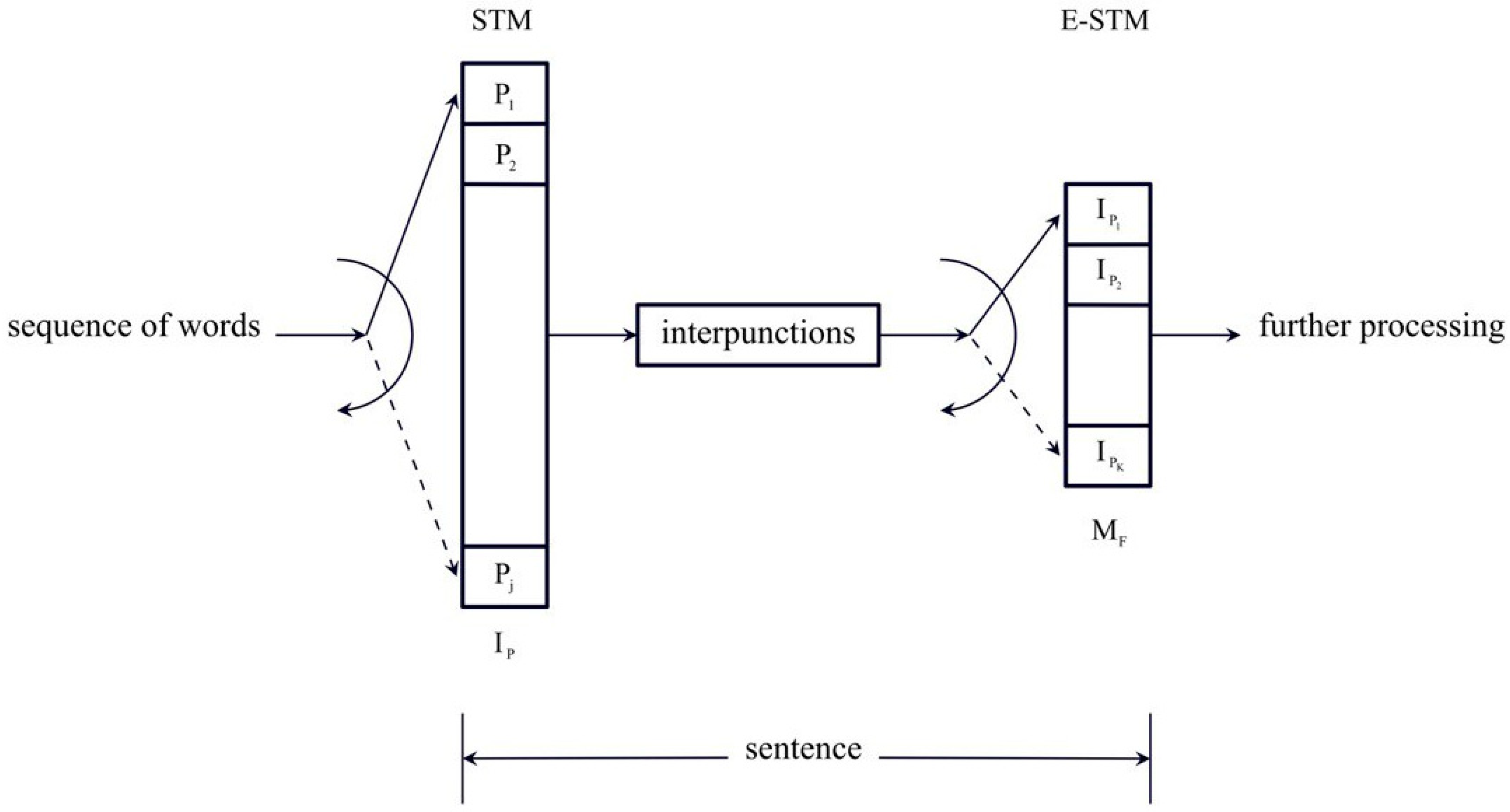
A two-unit STM processing can be justified, at least empirically, according to how a human mind is thought to memorize “chunks” of information in the STM. When we start reading a sentence, the mind tries to predict its full meaning from what it has already read, and only when an in-sentence interpunction is found (i.e., comma, colon, semicolon), it can partially understand the text, whose full meaning is finally revealed when a final interpunction (question mark, exclamation mark, full-stop) is found. This first processing, therefore, is revealed by
, the second processing is revealed by
and by the number of word intervals
contained in the sentence, the latter indicated by
[
1,
2,
3,
4,
5,
6,
7,
8].
The longer a sentence is, with many clauses, the longer the ideas remain deferred until the mind can establish its meaning from all its words, resulting in the text being less readable. The readability can be measured by the universal readability index, which includes the two-unit STM processing [
6].
In synthesis, in the present paper, we conjecture that in reading a full sentence, humans engage a second STM capacity—quantitatively measured by
—which works in series with the first STM—quantitatively measured by
. We refer to the second STM capacity as the “extended” STM (E-STM) capacity. The modeling of the STM capacity with
has never been considered in the literature [
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31] before our paper in 2019 [
1]. The number
, of
contained in a sentence studied previously in I-channels [
4], is now associated with the E-STM.
The E-STM should not be confused with the intermediate memory [
32,
33], not to mention the long-term memory. It should also be clear that the E-STM is not modeled by studying neuronal activity but from counting words and interpunctions, whose effects hundreds of writers—both modern and classic—and millions of people have experienced through reading.
The stochastic variables
,
,
, and the number of characters per word,
, are loosely termed deep-language variables in this paper, following our general statistical theory on alphabetical languages and their linguistic channels, developed in a series of papers [
1,
2,
3,
4,
5,
6,
7,
8]. These parameters refer, of course, to the “surface” structure of texts, not to the “deep” structure mentioned in cognitive theory.
These variables allow us to perform “experiments” with ancient or modern readers by studying the literary works read. These “experiments” have revealed unexpected similarities and dependence between texts because the deep-language variables may not be consciously controlled by writers. Moreover, the linear linguistic channels present in texts can further assess, by a sort of “fine tuning”, how much two texts are mathematically similar.
In the present paper, we base our study on a large database of texts (novels) belonging to Italian literature spanning seven centuries [
1] and to English Literature spanning four centuries [
5]. In References [
1,
5], the reader can find the list of novels considered in the present paper with their full statistics on the linguistic variables recalled above.
In the following sections, we will show that the two literary corpora can be merged to study the surface structure of texts; therefore, they make a reliable data set from which the size of the two STM capacities can be conjectured.
After this introduction,
Section 2 recalls the deep-language parameters and shows some interesting relationships between them, applied to Italian and English Literature.
Section 3 recalls the nature of linguistic communication channels present in texts.
Section 4 shows relationships with a universal readability index.
Section 5 models the two STM processing units in series.
Section 6 concludes and proposes future work.
3. Linguistic Communication Channels in Texts
To study the chaotic data that emerge in any language, the theory developed in Reference [
2] compares a text (the reference, or input text, written in a language) to another text (output text, “cross–channel”, written in any language) or to itself (“self-channel”), with a complex communication channel—made of several parallel single channels, two of which were explicitly considered in [
2,
4,
5,
7]—in which both input and output are affected by “noise”, i.e., by diverse scattering of the data around a mean linear relationship, namely a regression line, as those shown in
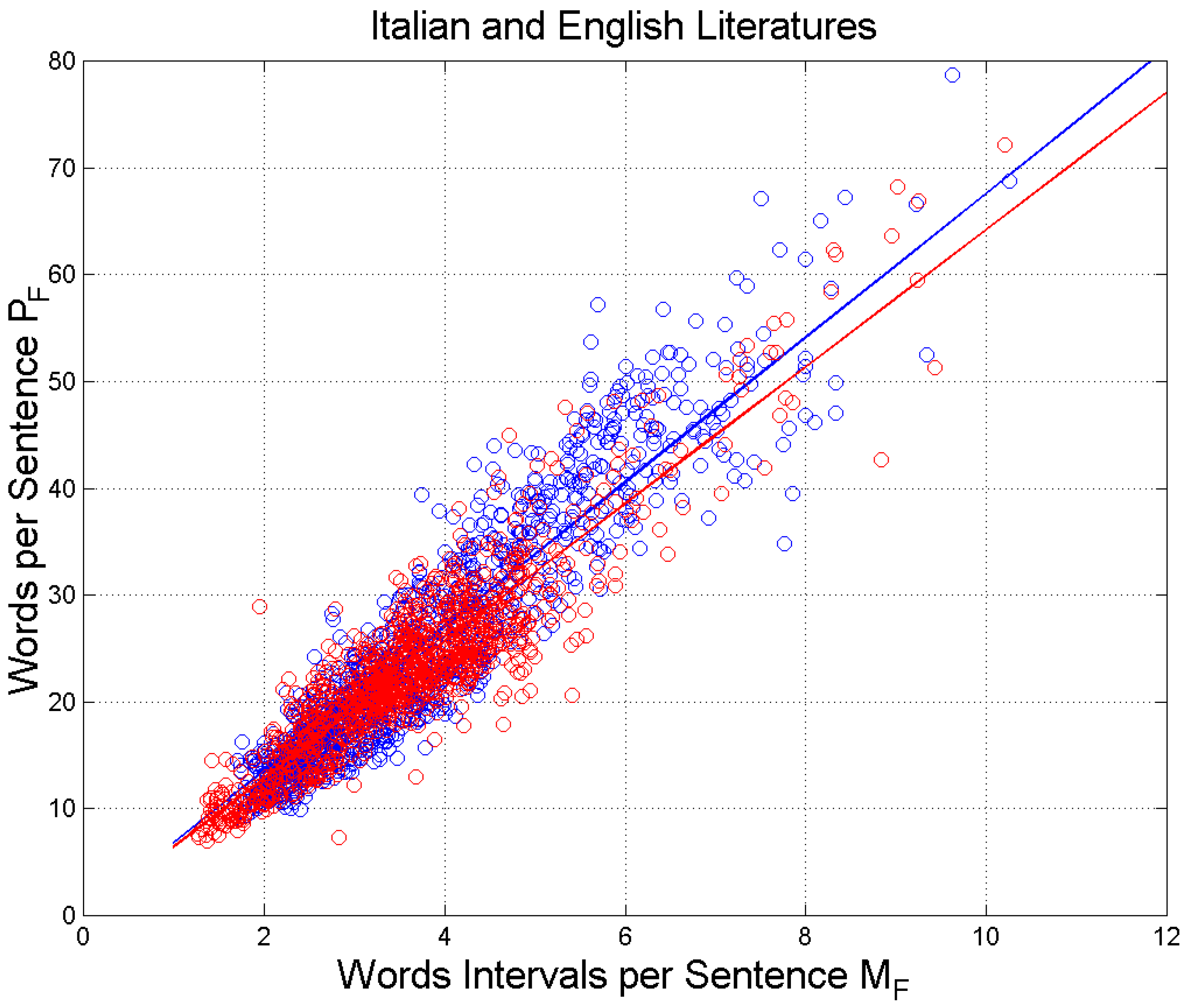
Figure 1,
Figure 2 and
Figure 3 above.
In Reference [
3], we have applied the theory of linguistic channels to show how an author shapes a character speaking to diverse audiences by diversifying and adjusting (“fine tuning”) two important linguistic communication channels, namely the Sentences channel (S-channel) and the Interpunctions channel (I-channel). The S-channel links
of the output text to
of the input text for the same number of words. The I-channel links
(i.e., the number of
) of the output text to
of the input text for the same number of sentences.
In Reference [
5], we have further developed the theory of linguistic channels by applying it to Charles Dickens’ novels and to other novels of English Literature (the same literary corpus considered in the present paper) and found, for example, that this author was very likely affected by King James’ New Testament.
In S–channels, the number of sentences of two texts is compared for the same number of words; therefore, they describe how many sentences the writer of text
(output) uses to convey a meaning, compared to the writer of text
(input)—who may convey, of course, a diverse meaning—by using the same number of words. Simply stated, it is about how a writer shapes his/her style for communicating the full meaning of a sentence with a given number of words available; therefore, it is more linked to the author’s style. These channels are those described by the scatterplots and regression lines—shown in
Figure 1—in which we get rid of the independent variable
.
In I-channels, the number of word intervals
of two texts is compared for the same number of sentences; therefore, they describe how many short texts make a full sentence. Since
is connected to the STM capacity (Miller’s Law) and
is linked—in our present conjecture—to the E-STM, the I-channels are more related to how the human mind processes information than to the authors’ style. These channels are those described by the scatterplots and regression lines—shown in
Figure 2—in which we get rid of the independent variable
.
In the present paper, for the first time, we consider linguistic channels which compare
of two texts for the same number of
; therefore, these channels are connected with the E-STM, as they are a kind of “inverse” channel of the I-channels. These channels are those described by the scatterplots and regression lines—shown in
Figure 3—in which we get rid of the independent variable
. We refer to these channels as the
-channels.
Recall that regression lines, however, consider and describe only one aspect of the linear relationship, namely that concerning (conditional) mean values. They do not consider the scattering of data, which may not be similar when two regression lines almost coincide, as
Figure 1,
Figure 2 and
Figure 3 show. The theory of linguistic channels, on the contrary, by considering both slopes and correlation coefficients, provides a reliable tool to compare two sets of data fully, and it can be applied to any discipline in which regression lines are found.
To apply the theory of linguistic channels [
2,
3], we need the slope
and the correlation coefficient
of the regression line between (a)
and
to study the S–channels (
Figure 1); (b)
and
to study the I-channels (
Figure 2); (c)
and
to study
—channels (
Figure 3), values listed in
Table 1,
Table 2 and
Table 3.
In synthesis, the theory calculates the slope and the correlation coefficient of the regression line between the same linguistic parameters by linking the input k (independent variable) to the output j (dependent variable) of the virtual scatterplot in the three linguistic channels mentioned above.
The similarity of the two data sets (regression lines and correlation coefficients) are synthetically measured by the theoretical signal-to-noise ratio
(dB) [
2]. First, the noise-to-signal ratio
, in linear units, is calculated from:
Secondly, from Equation (7), the total signal-to-noise ratio is given (in dB) by:
Notice that when a text is compared to itself , because , .
Table 6 shows the results when Italian is the input language
and English is the output language
;
Table 7 shows the results when English is the input language
and Italian is the output language
.
- (a)
The slopes are very close to unity, implying, therefore, that the two languages are very similar in average values (i.e., the regression line).
- (b)
The correlation coefficients are very close to 1, implying, therefore, that data scattering is very small.
- (c)
The remarks in (a) and (b) are synthesized by
which is always significantly large. Its values are in the range of reliable results (see the discussion in References [
2,
3,
4,
5,
6,
7]).
- (d)
The slight asymmetry of the two channels, Italian
English (
Table 6) and English
Italian (
Table 7), is typical of linguistic channels [
2,
3,
4,
5,
6,
7].
In other words, the “fine tuning” done through the three linguistic channels strongly reinforces the conclusion that the two literary corpora are “extracted” from the same data set, from the same “book”, whose “text” is interweaved in a universal surface mathematical structure that human mind imposes to alphabetical languages. The next section further reinforces this conclusion when text readability is considered.
4. Relationships with a Universal Readability Index
In Reference [
6], we have proposed a universal readability index that includes the STM capacity, modeled by
, applicable to any alphabetical language, given by:
In Equation (12), the E-STM is also indirectly present with the variable of Equation (13). Notice that text readability increases (text more readable) as increases.
The observation that differences between the readability indices give more insight than absolute values has justified the development of Equation (12).
By using Equations (13) and (14), the average value
of any language is forced to be equal to that found in Italian, namely
. In doing so, if it is of interest,
can be linked to the number of years of schooling in Italy [
1,
6].
There are two arguments in favor of Equation (14); the first is that
affects a readability formula much less than
[
1]. The second is that
is a parameter typical of a language which, if not scaled, would bias
without really quantifying the change in reading difficulty of readers who are accustomed to reading shorter or longer words in their language, on average, than those found in Italian. This scaling, therefore, avoids changing
only because in a language, on average, words are shorter or longer than in Italian.
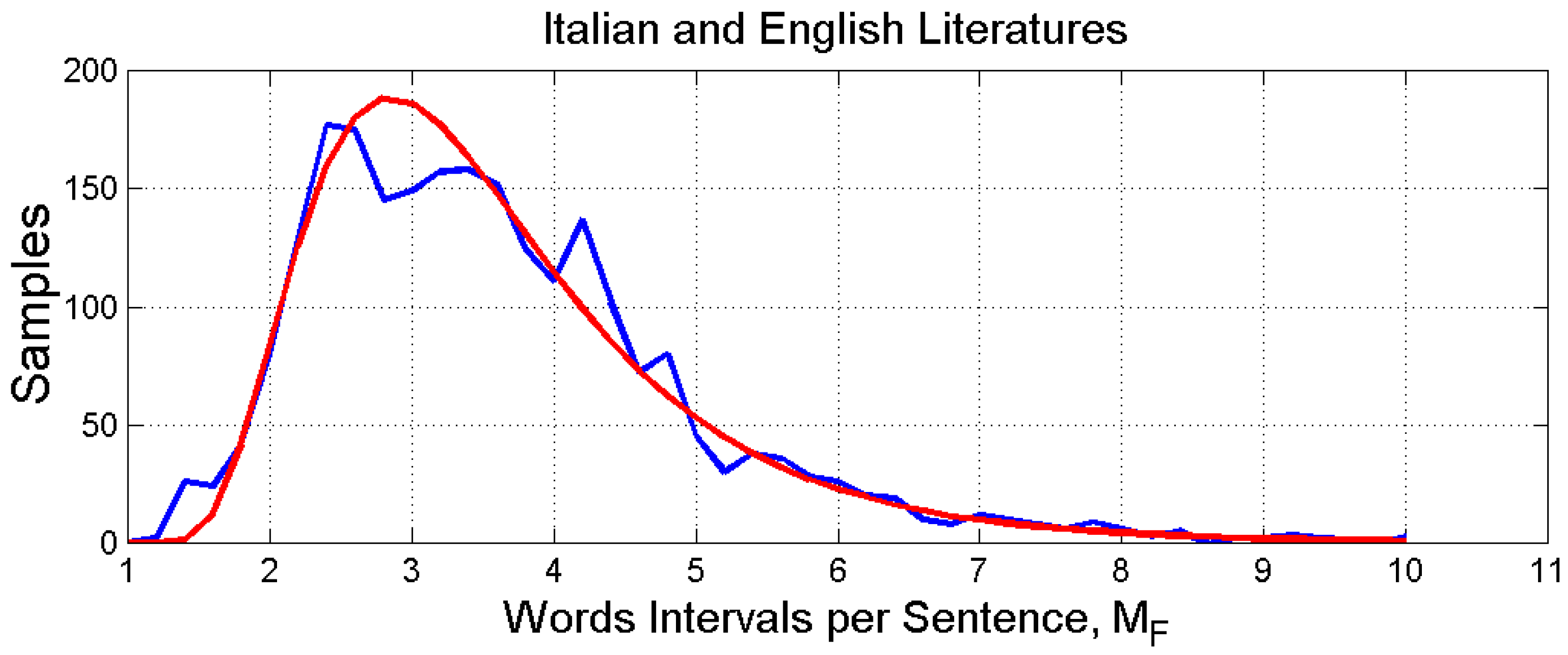
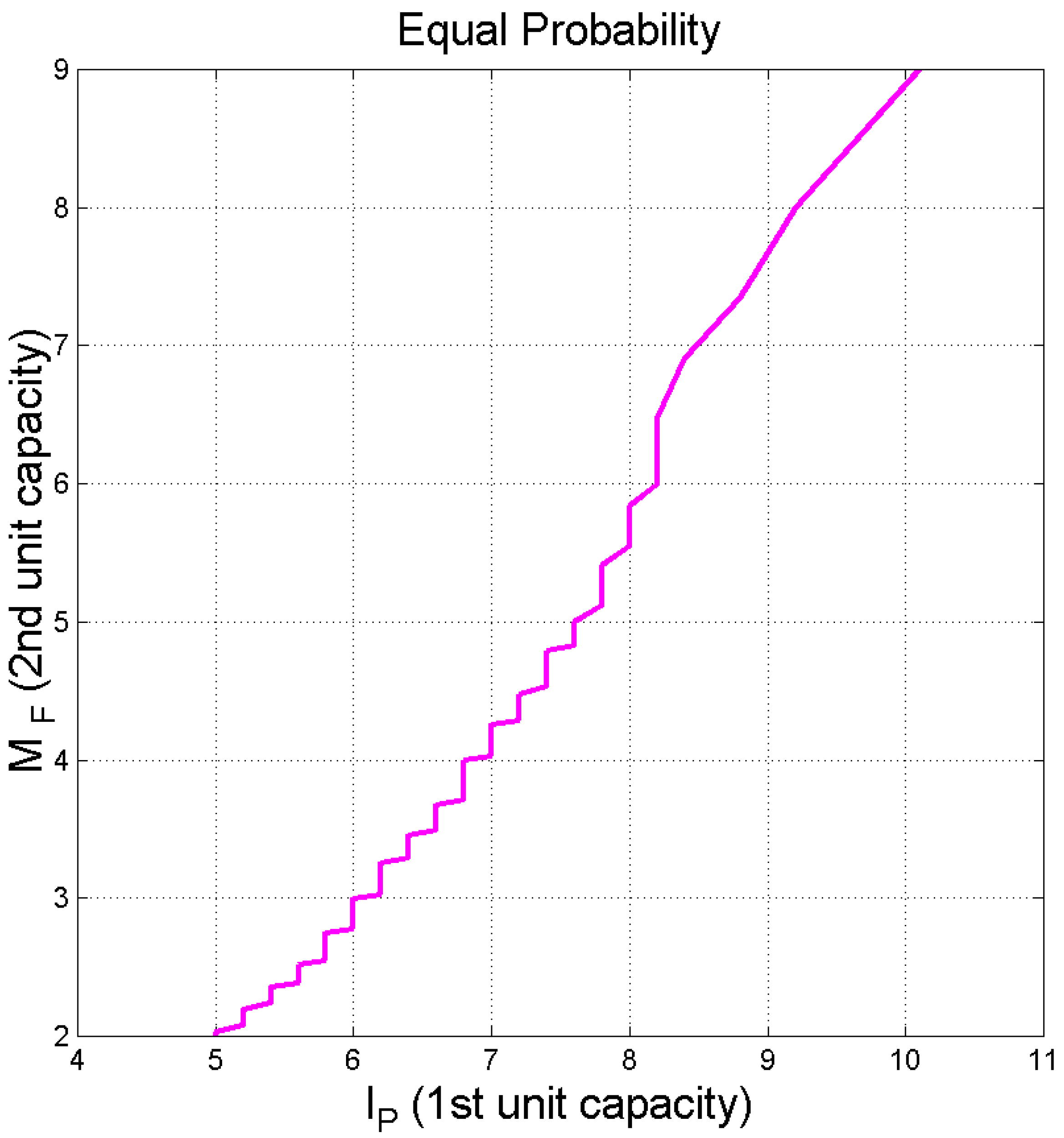
Figure 9 shows the histogram of
. The mean value is
, the standard deviation is
and the 95% range is
.
Figure 10 shows the scatterplot of
versus
in the Italian and English Literature. There are no significant differences between the two languages; therefore, we can merge all samples. The vertical black lines are drawn at the mean value
and at the values exceeded with probability
(
and
(
The range
includes, therefore, 95% of the samples, and it corresponds to Miller’s range (
Table 5).
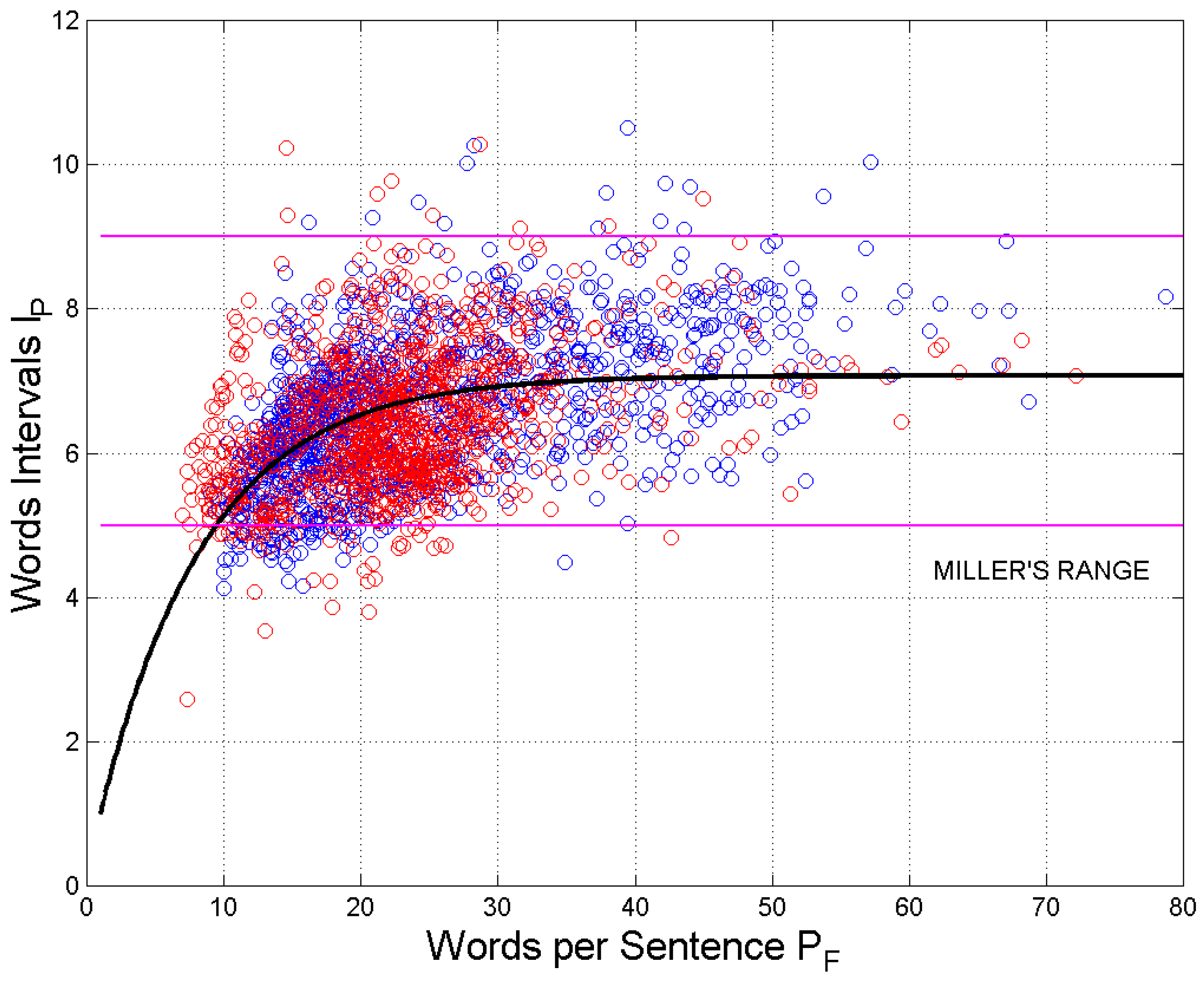
Figure 11 shows the scatterplot of
versus
. The vertical black lines are drawn at the mean value
and at the values exceeded with probability
(
and
(
The range
includes 95% of the merged samples corresponding to Miller’s range (
Table 5). The horizontal green lines refer to
(95% range
).
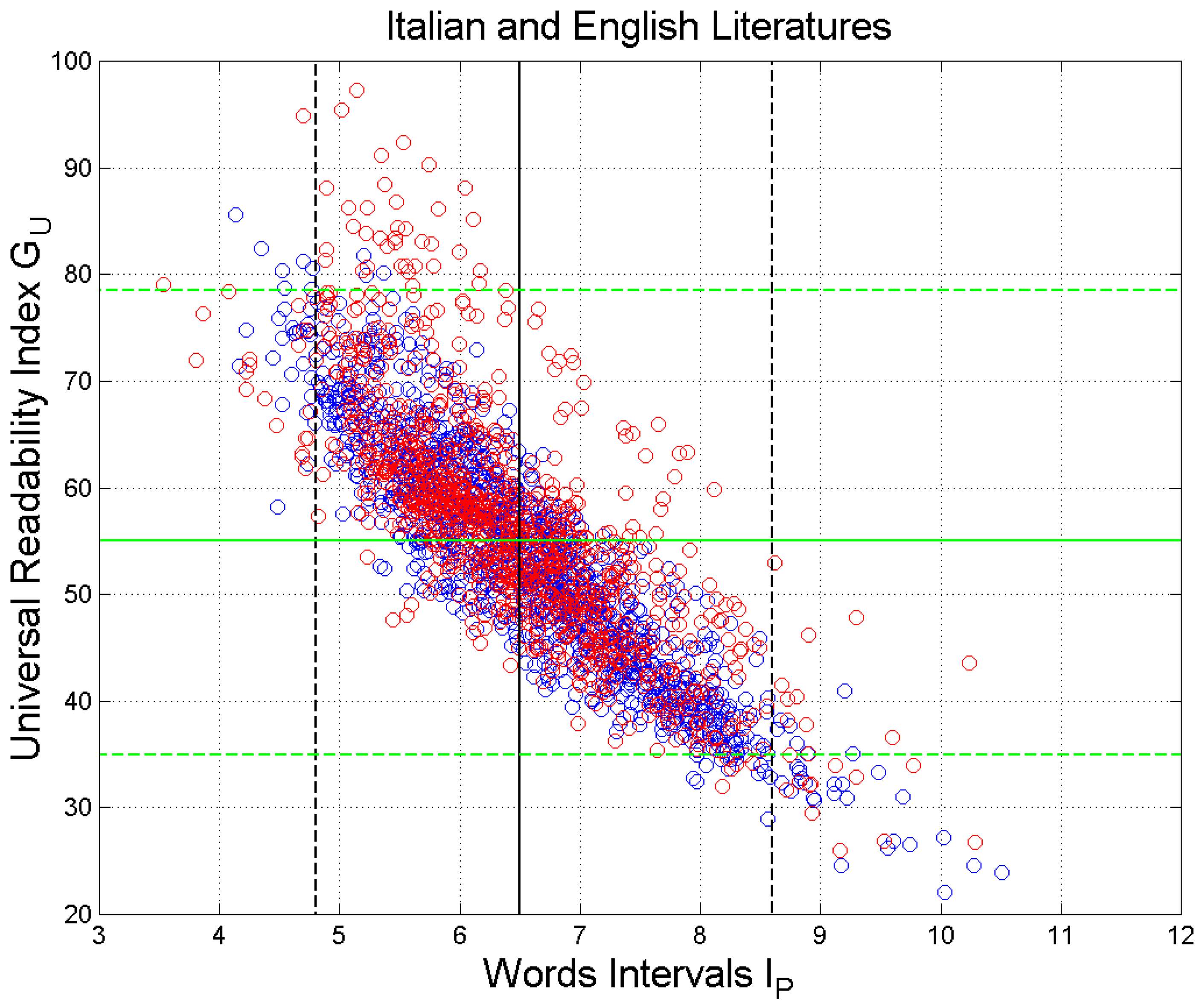
Figure 12 shows the scatterplot of
versus
. The vertical black lines are drawn at the mean value
and at the values exceeded with probability
(
and
(
The range
includes, therefore, 95% of the samples, and it corresponds to Miller’s range (
Table 5). The horizontal green lines refer to
(95% range
).
In all cases, we can observe that , as expected, is inversely proportional to the deep-language variable involved in the STM processing. In other words, the larger the independent variable, the lower the readability index.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}