
Mapping the Landscape of Misinformation Detection: A Bibliometric Approach


 ,
, 
Abstract
:1. Introduction
- Q1: What are the cutting-edge trends that research articles on misinformation detection are unveiling?
- Q2: Which are the tendencies in the area of misinformation detection?
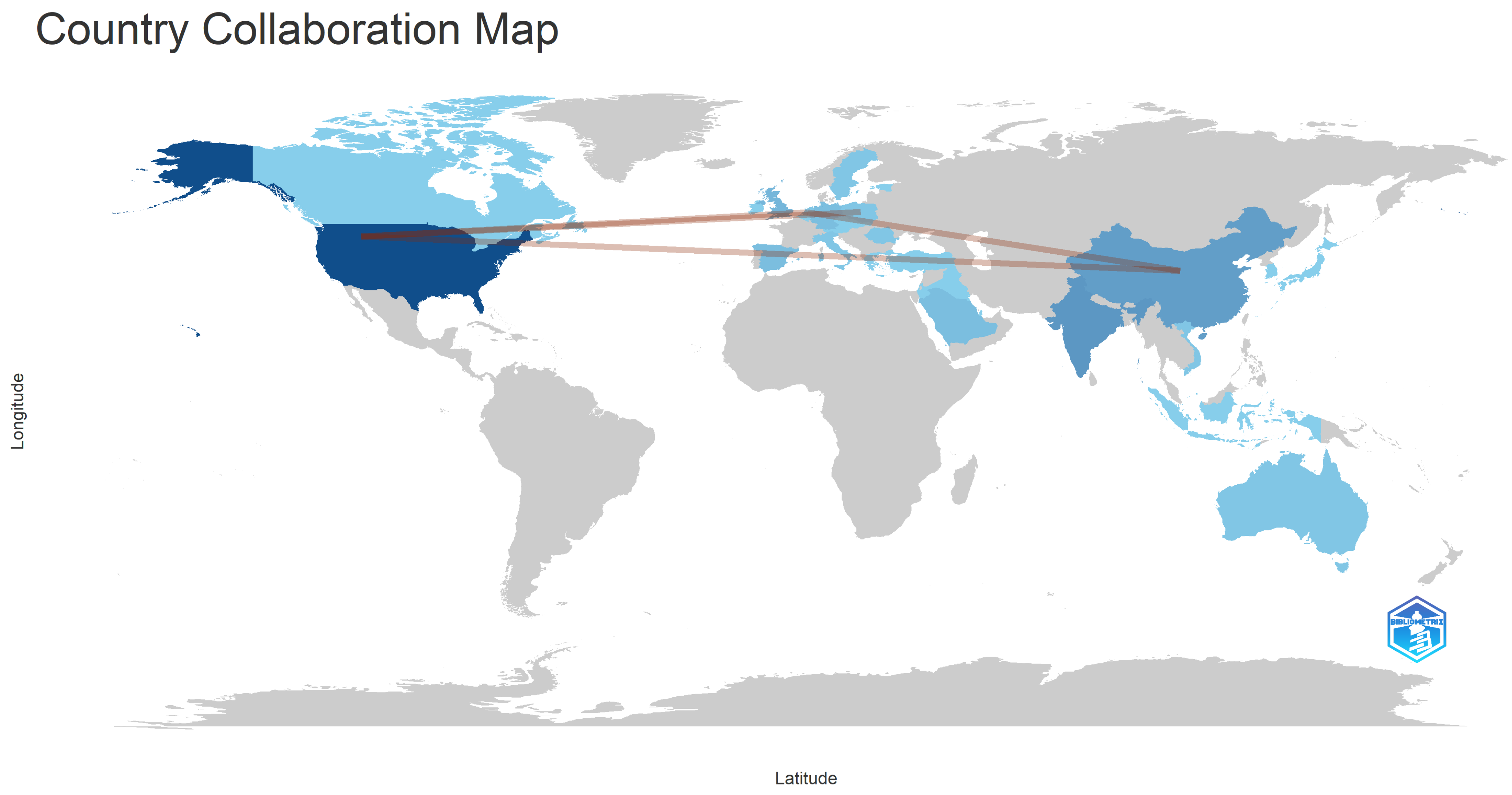
- Q3: Which countries have made significant contributions to misinformation detection, and what insights can be drawn regarding intra-country and inter-country collaborations?
- Q4: What is the impact of the extracted articles, how relevant is this domain nowadays, and what findings can be drawn concerning the number of citations, over the period under analysis?
- Q5: Is there any connection between the geographical area of a country and the number of published articles related to misinformation detection?
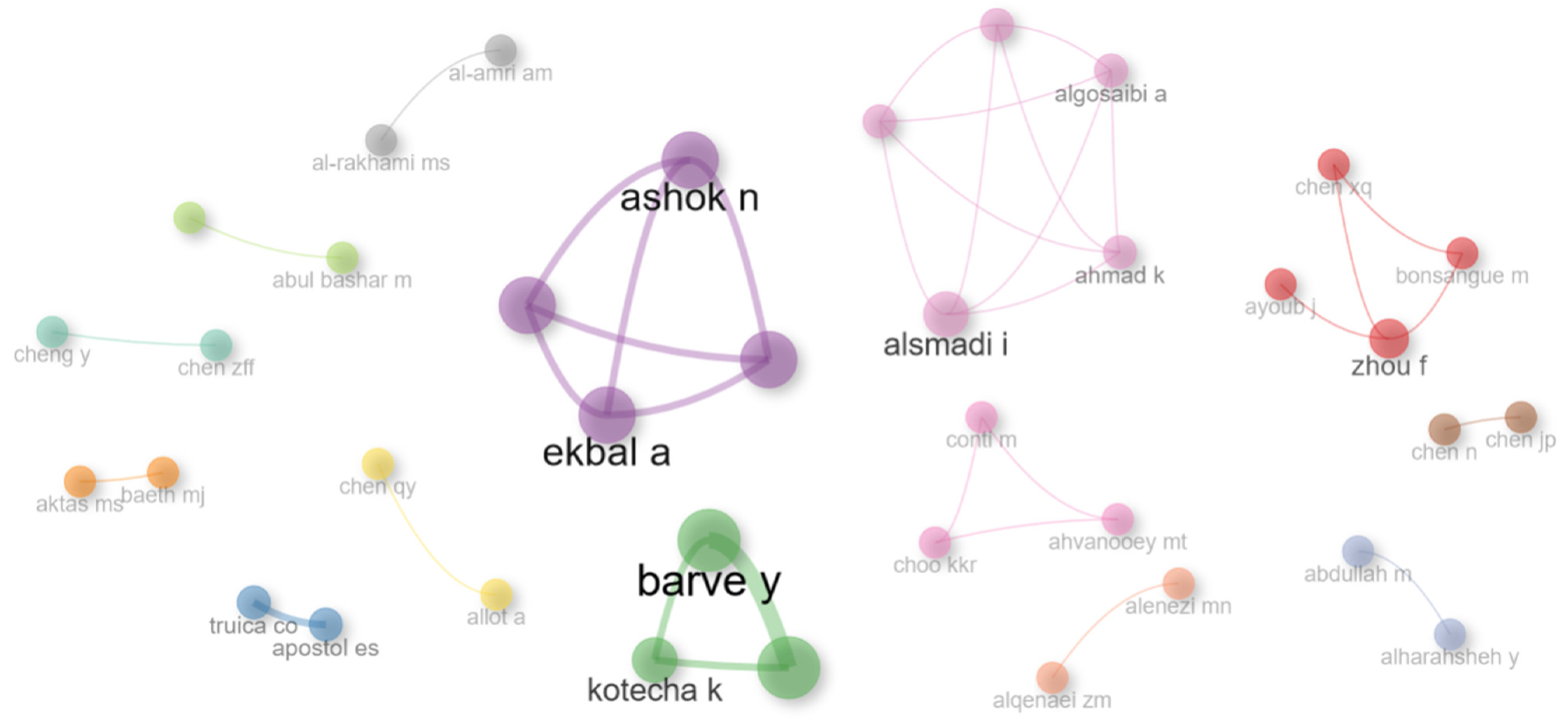
- Q6: How can the collaboration network among authors who have published in the field of misinformation detection be characterized?
2. Materials and Methods
2.1. Part 1: Dataset Extraction
2.2. Part 2: Performing Bibilometric Analysis
3. Dataset Analysis
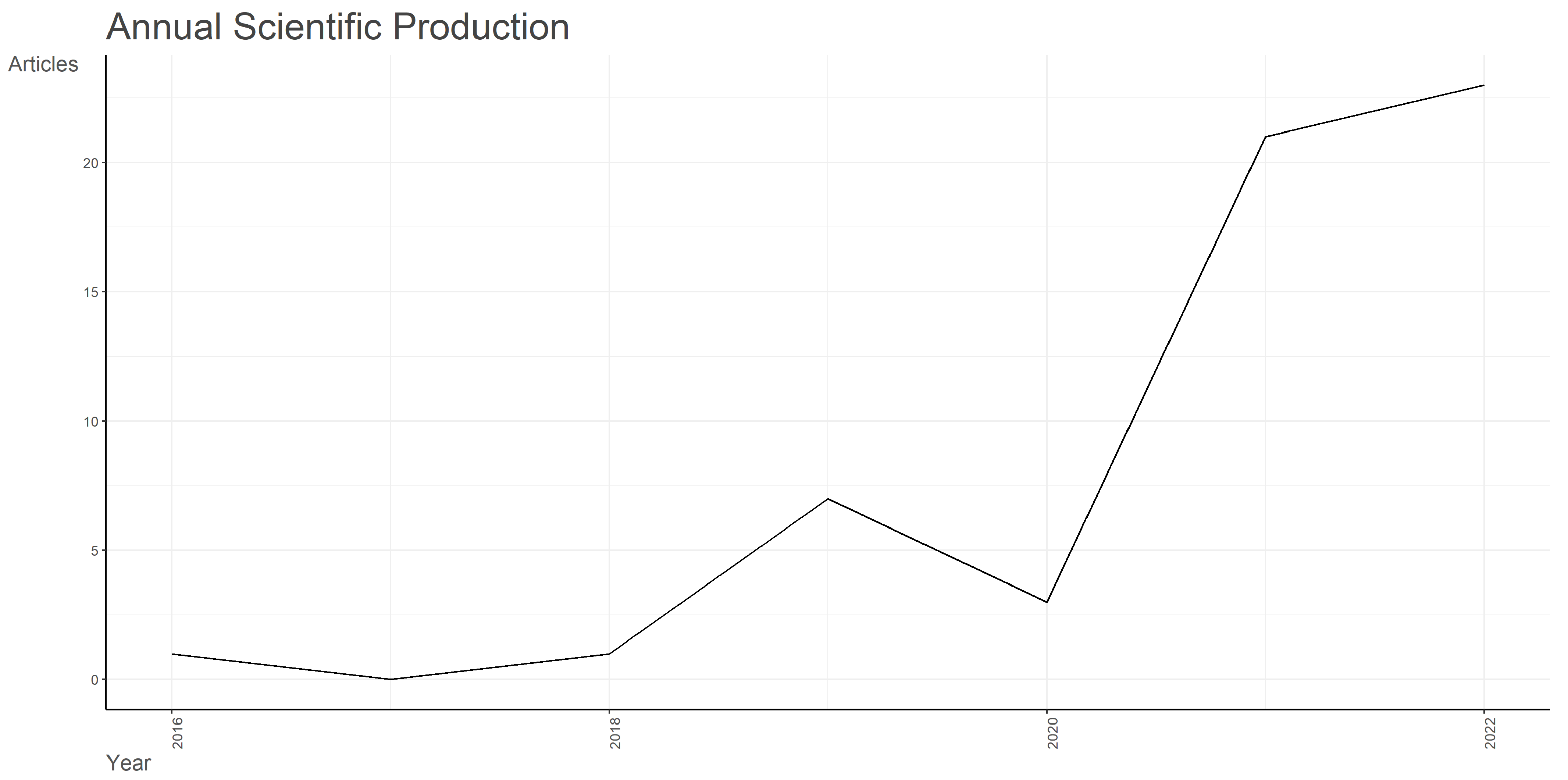
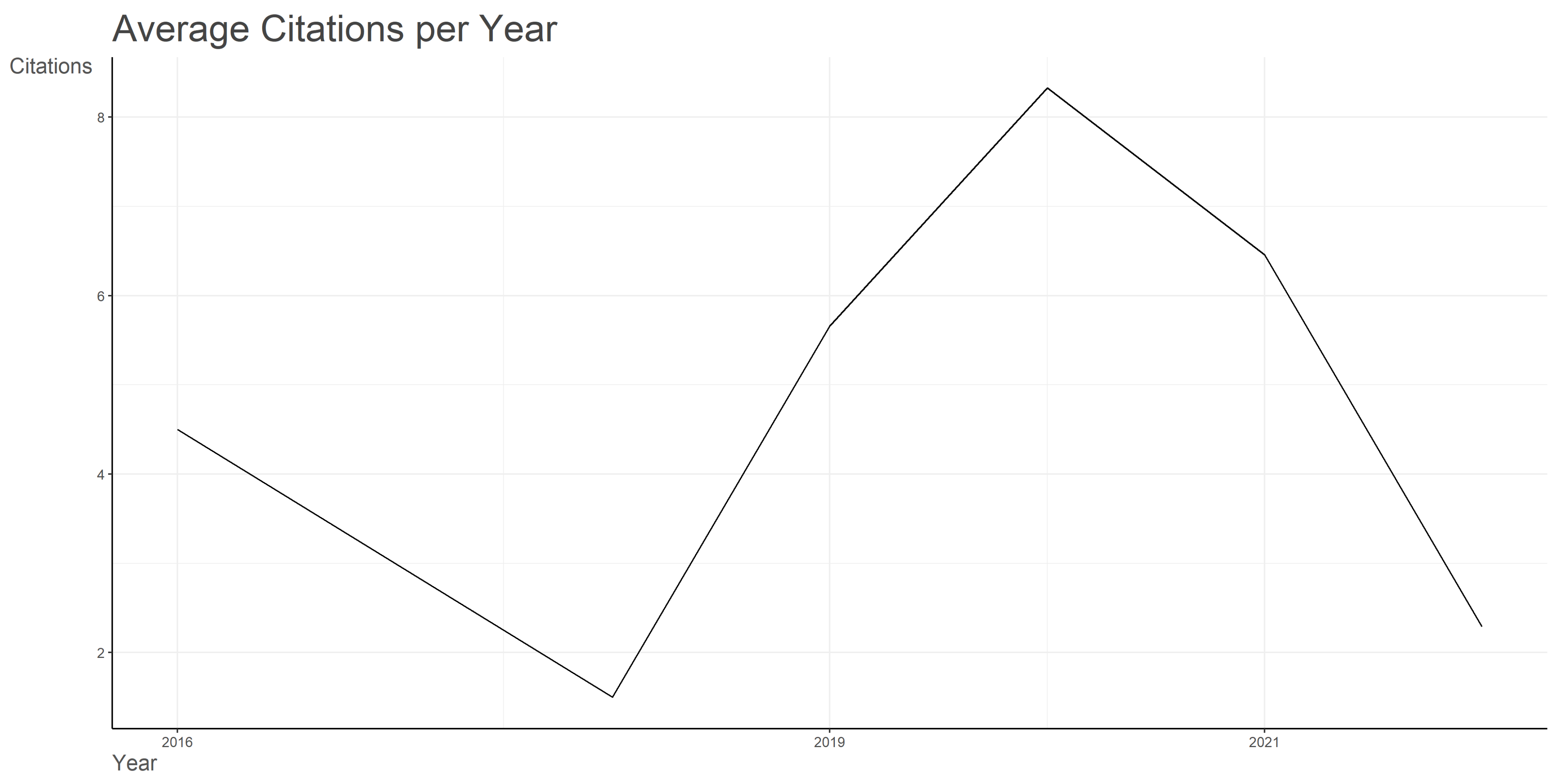
3.1. Dataset Overview
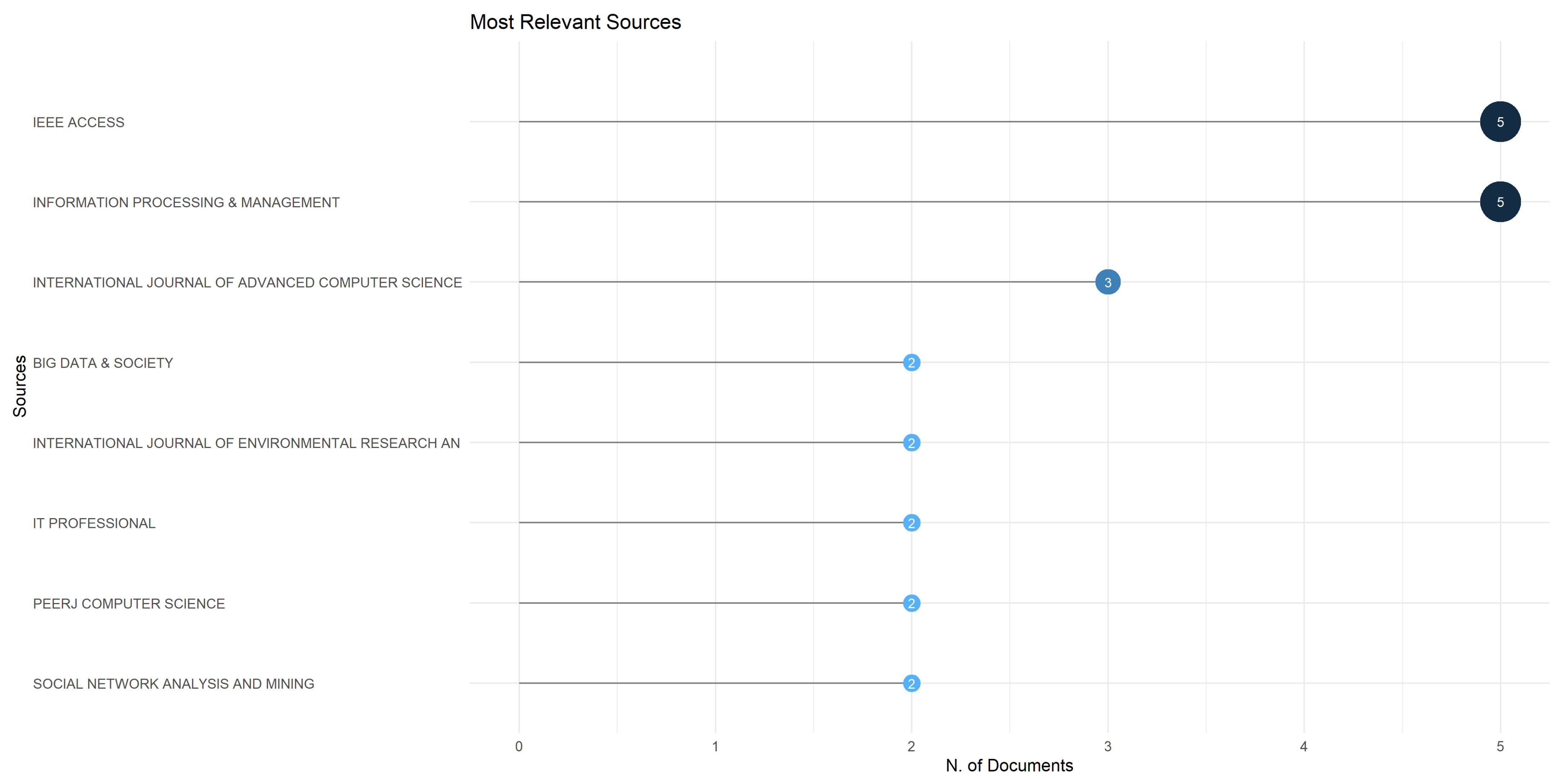
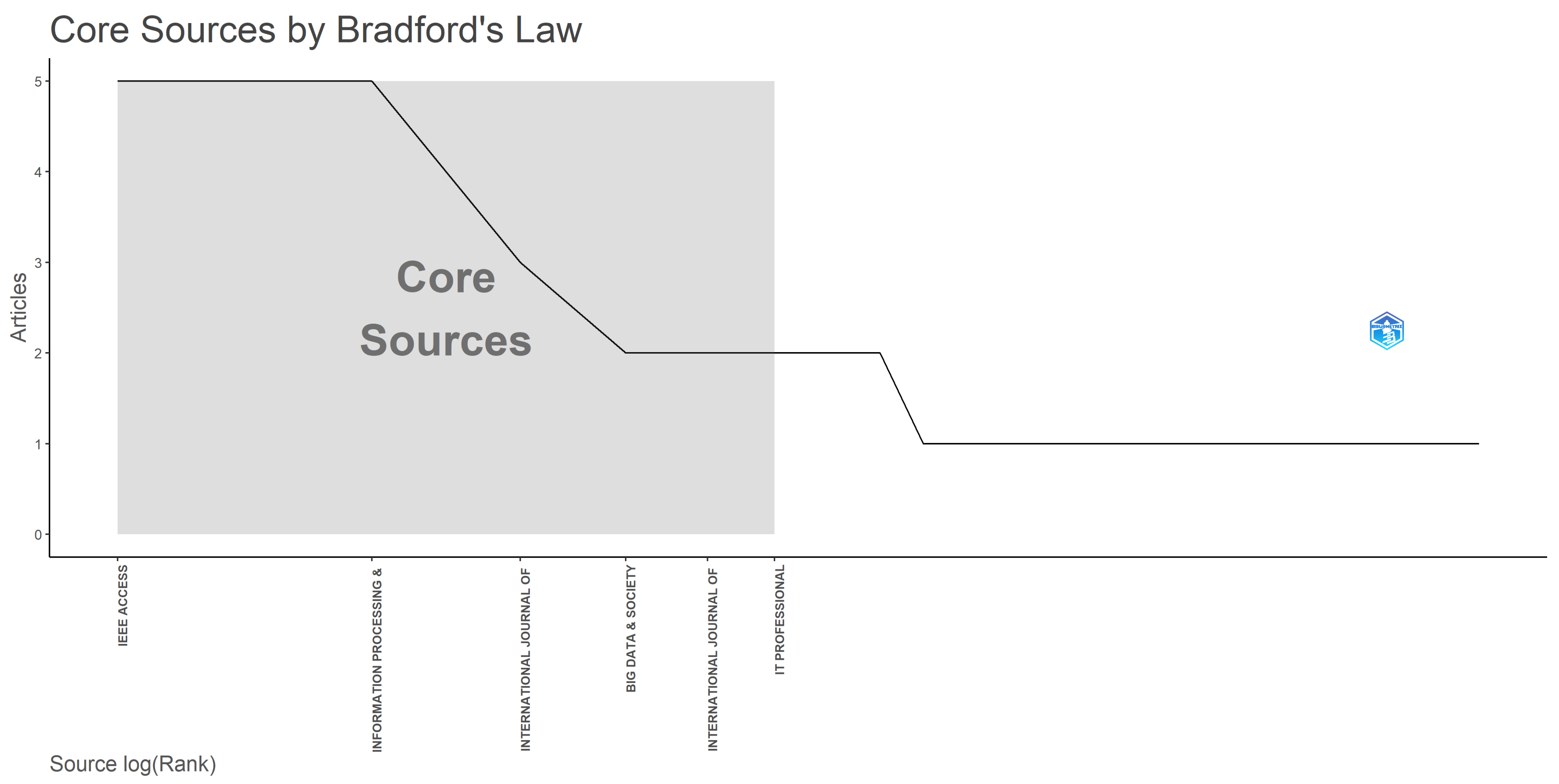
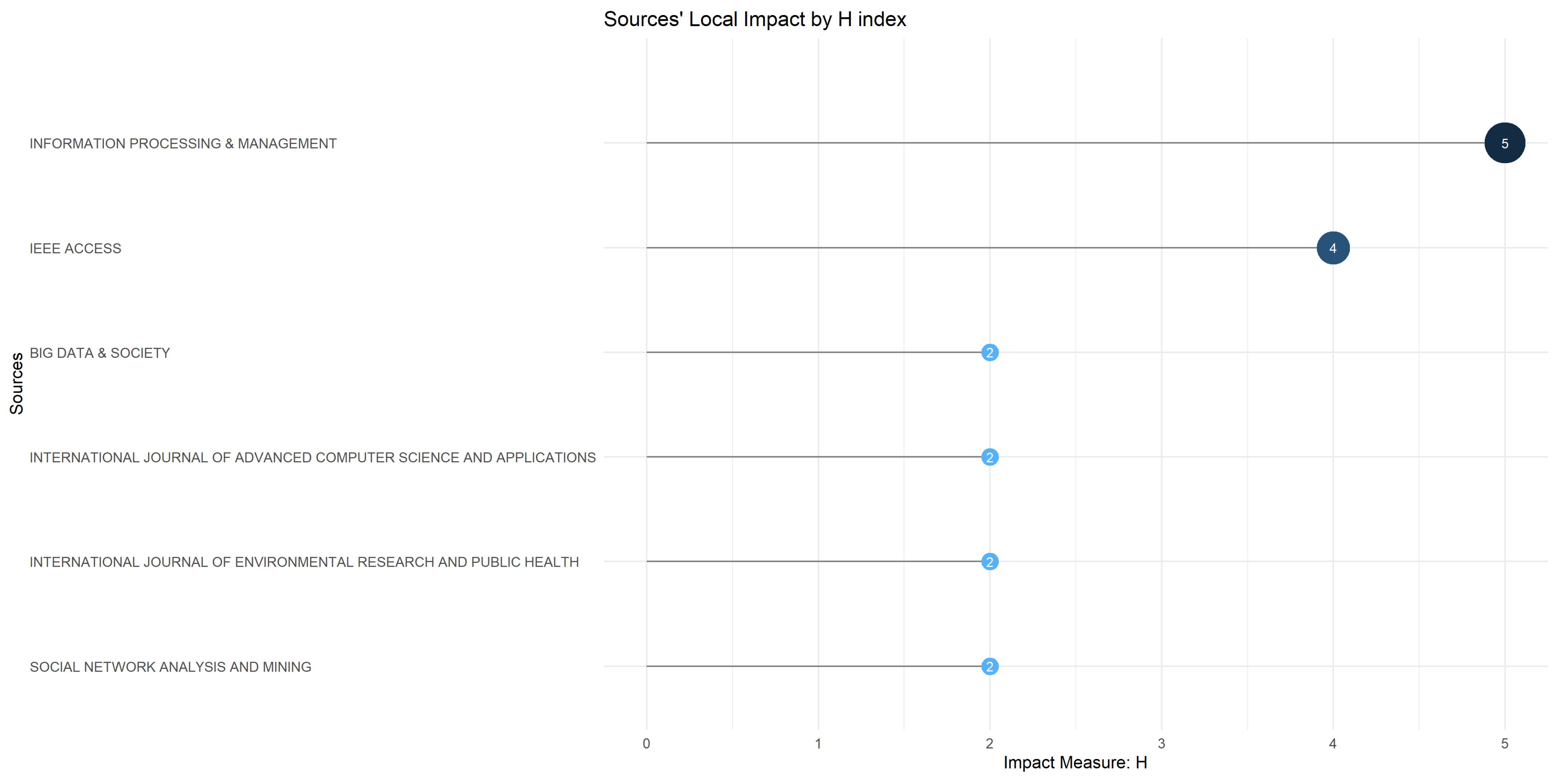
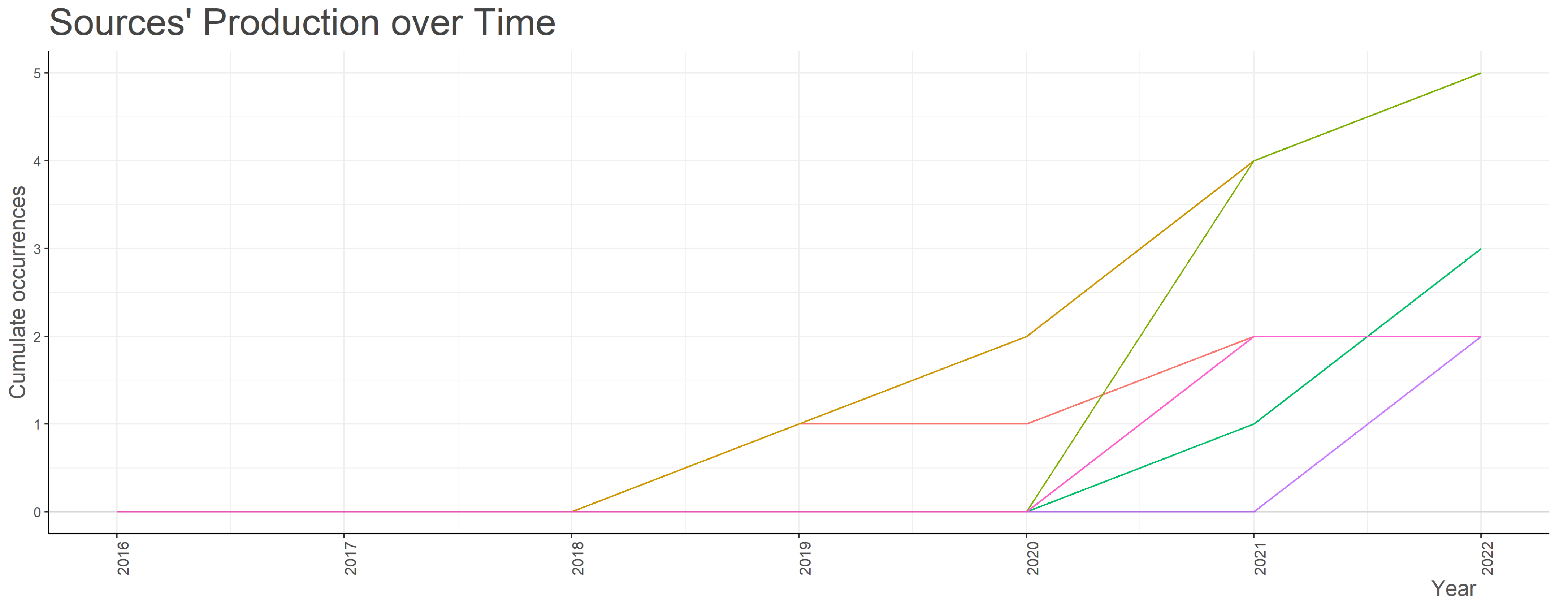
3.2. Sources Analysis
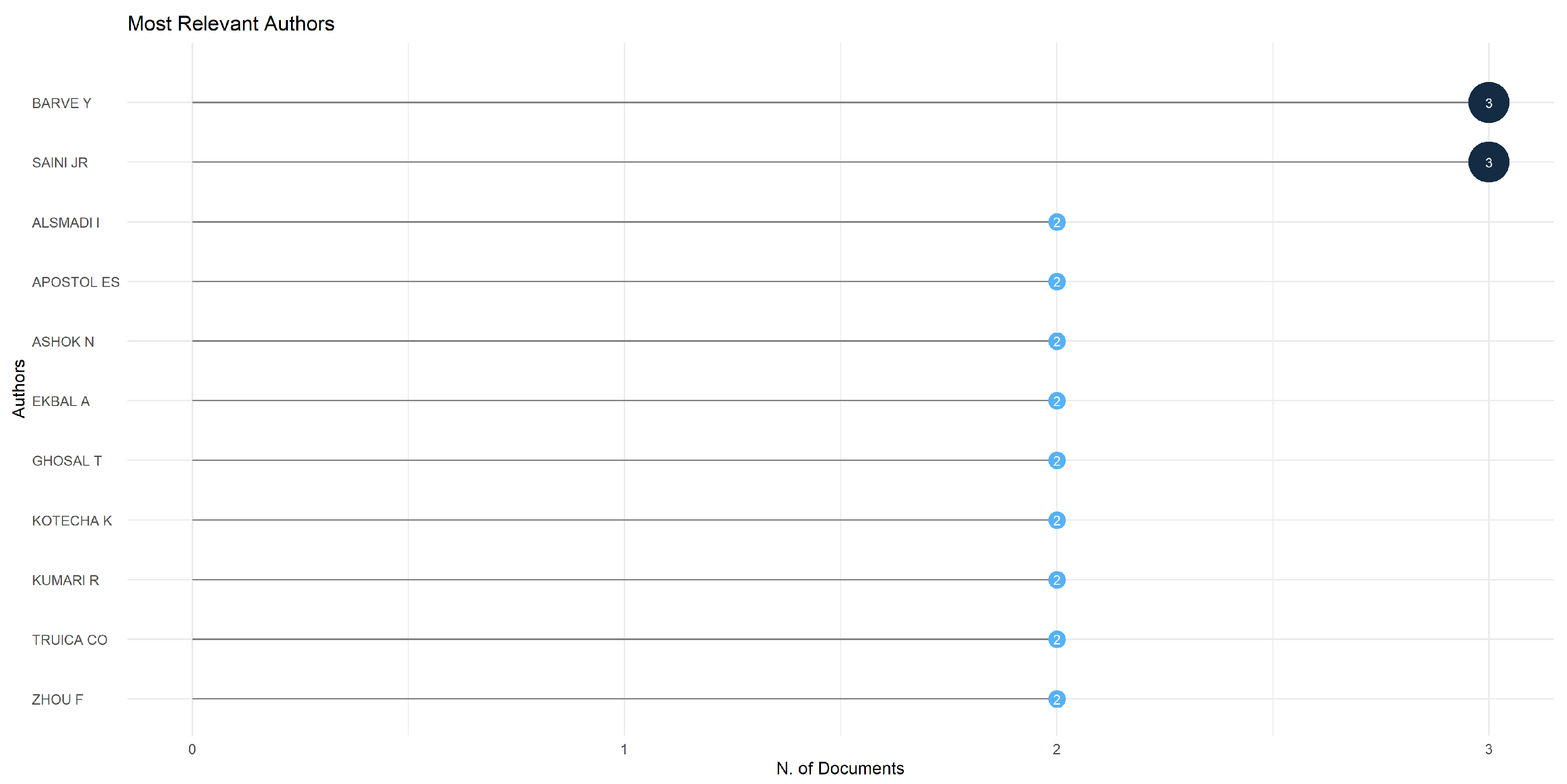
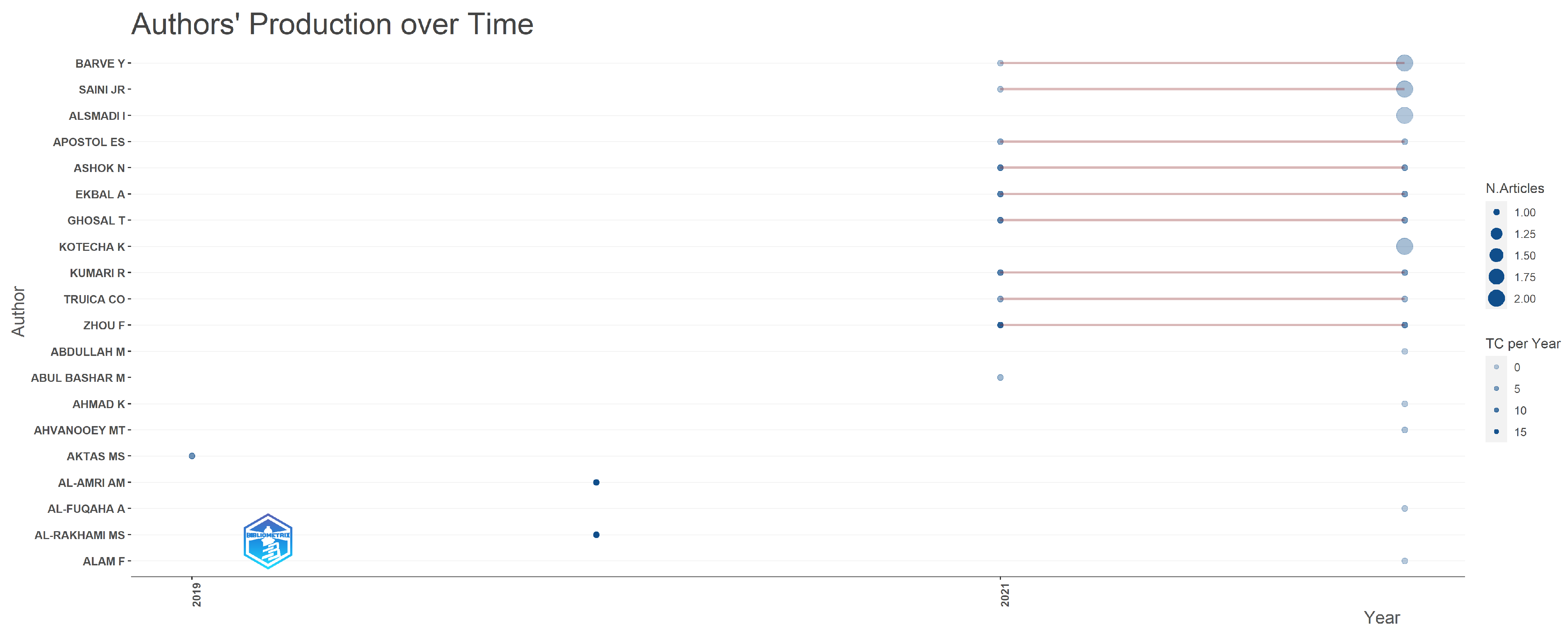
3.3. Authors Analysis
3.4. Papers Analysis
3.4.1. Top 10 Most Cited Papers—Overview
3.4.2. Top 10 Most Cited Papers—Review
3.4.3. Papers Brief Overview
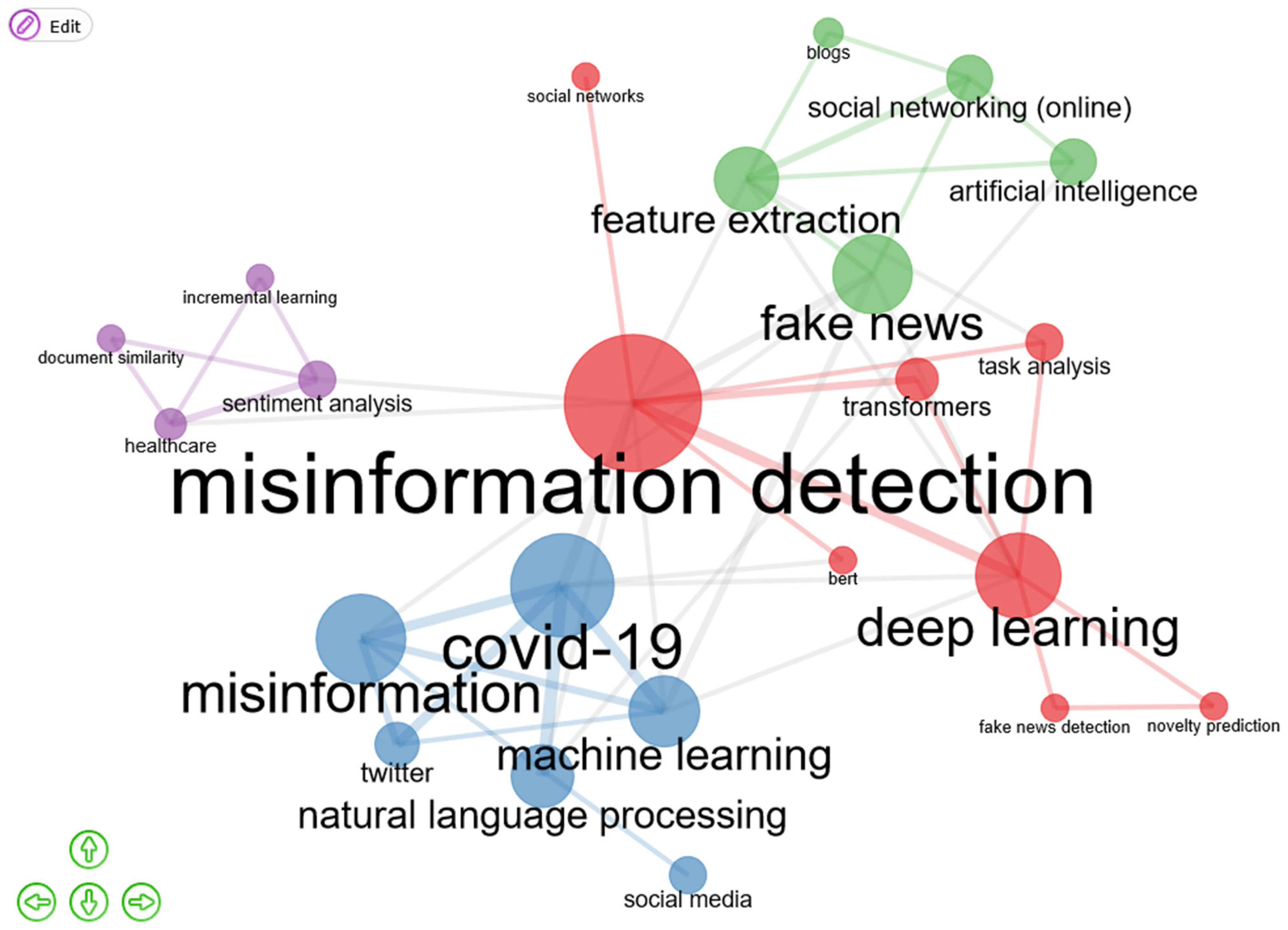
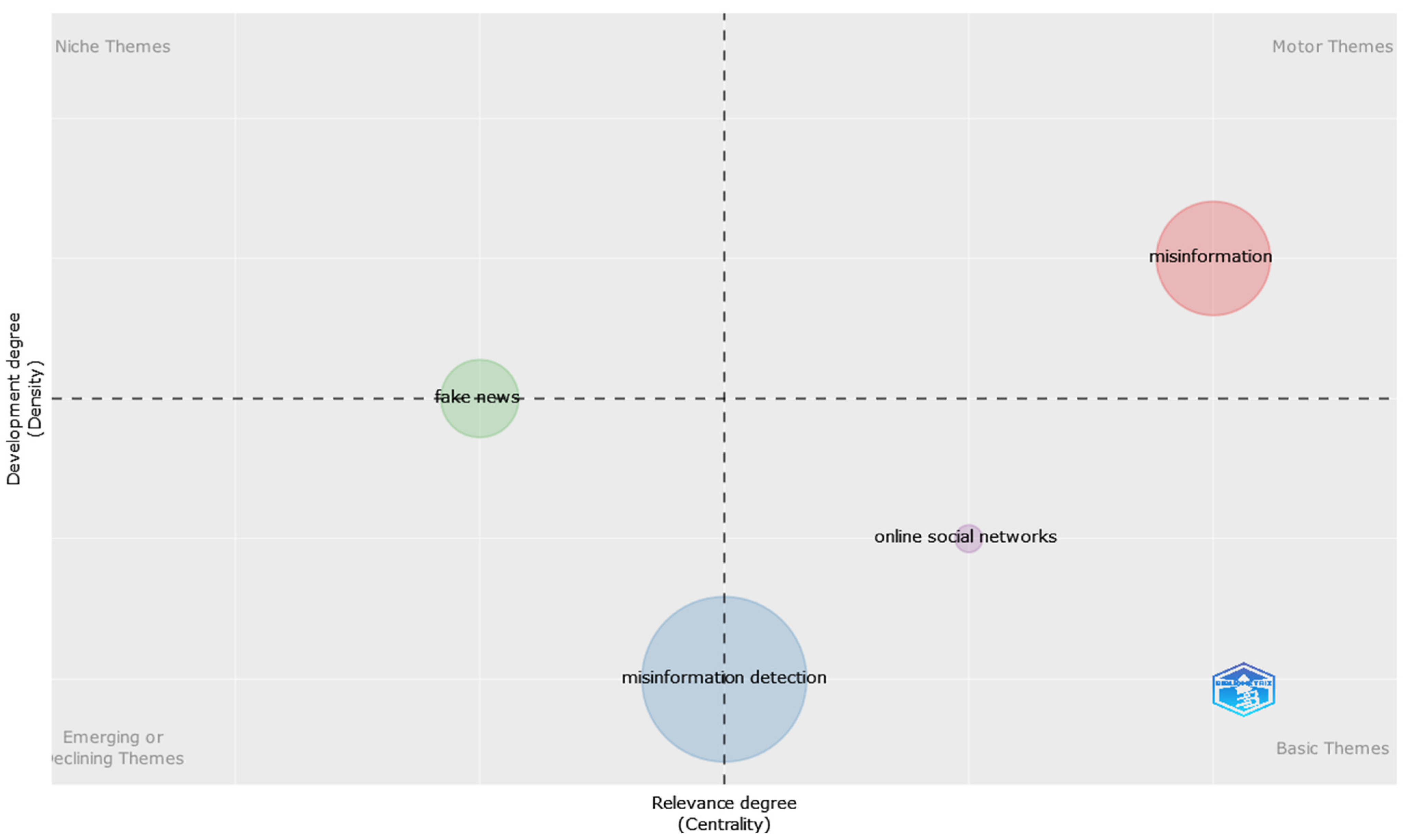
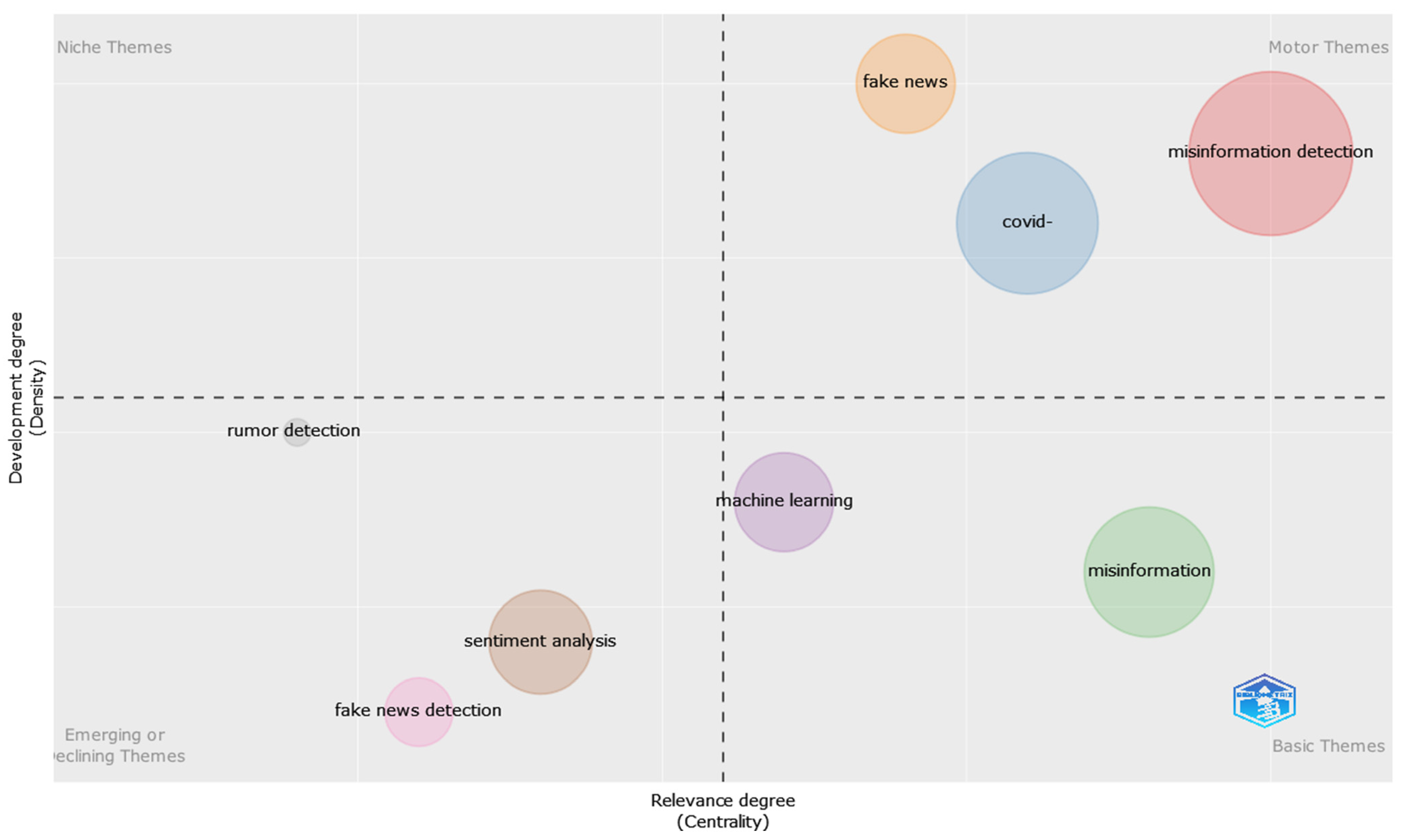
3.4.4. Words Analysis
- Cluster 1 (in red): misinformation detection; deep learning; fake news detection; transformers; bert; novelty prediction; social networks; task analysis.
- Cluster 2 (in blue): COVID-19; misinformation; machine learning; natural language processing; twitter; social media.
- Cluster 3 (in green): feature extraction; fake news; artificial intelligence; social networking (online); blogs.
- Cluster 4 (in violet): healthcare; document similarity; sentiment analysis; incremental learning.
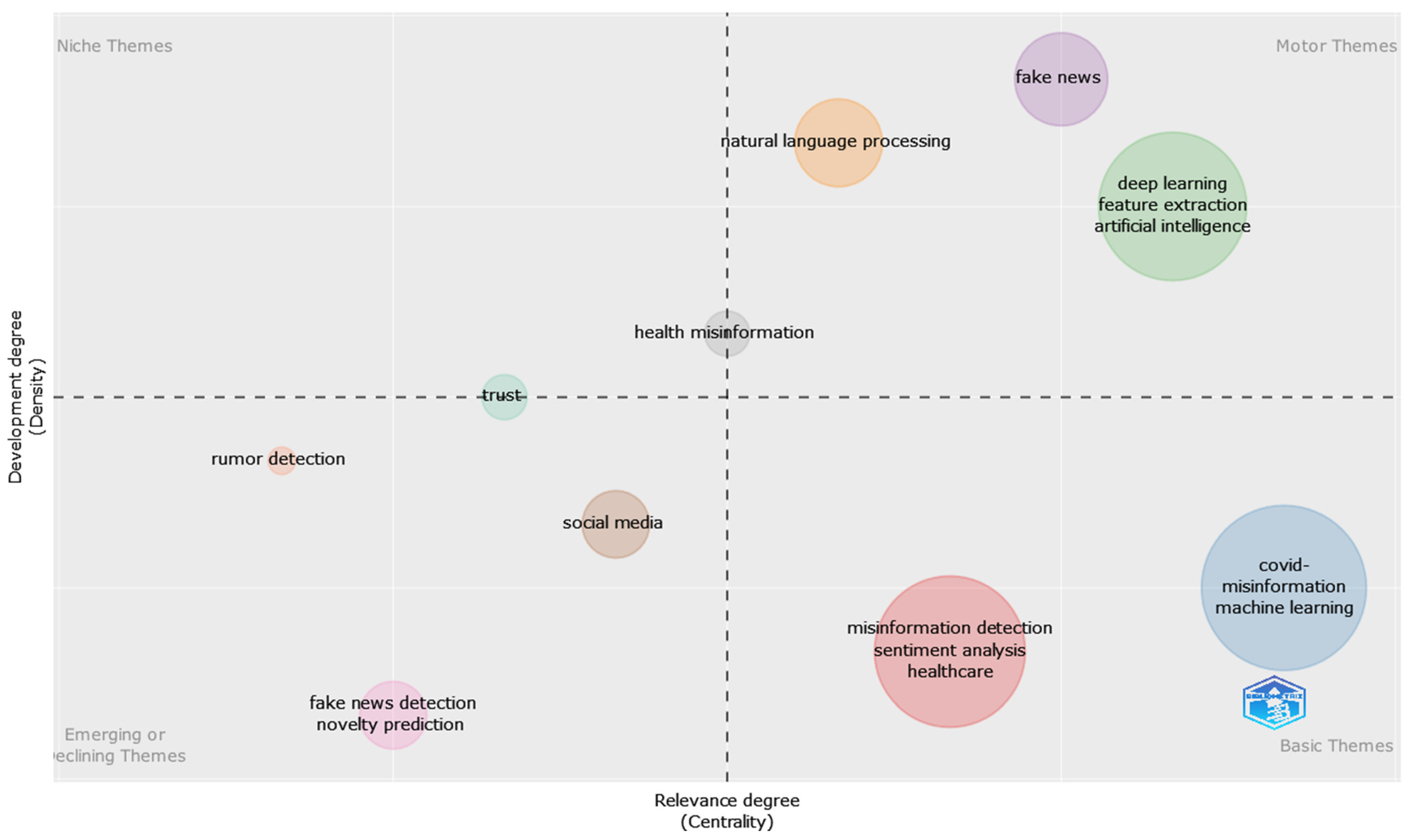
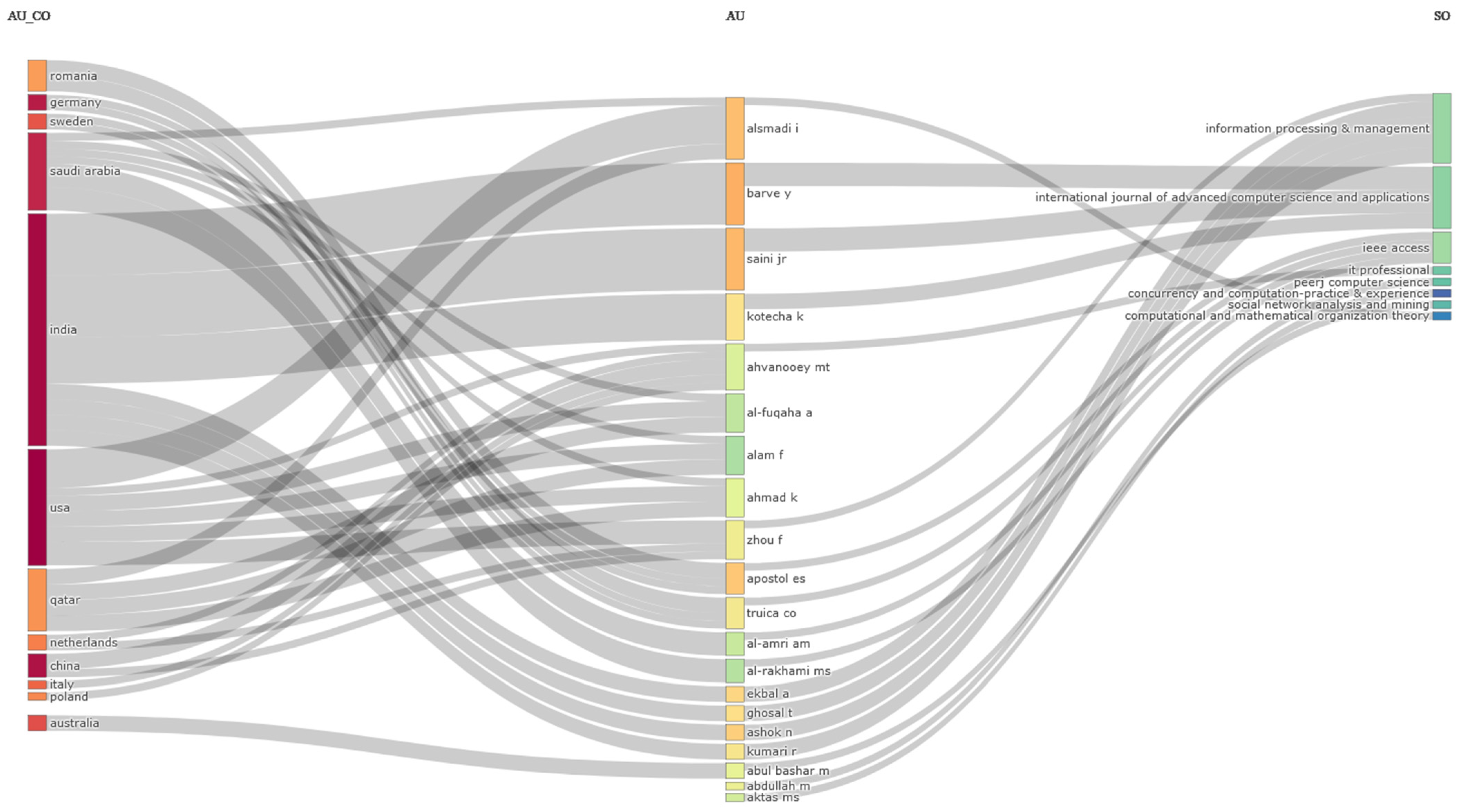
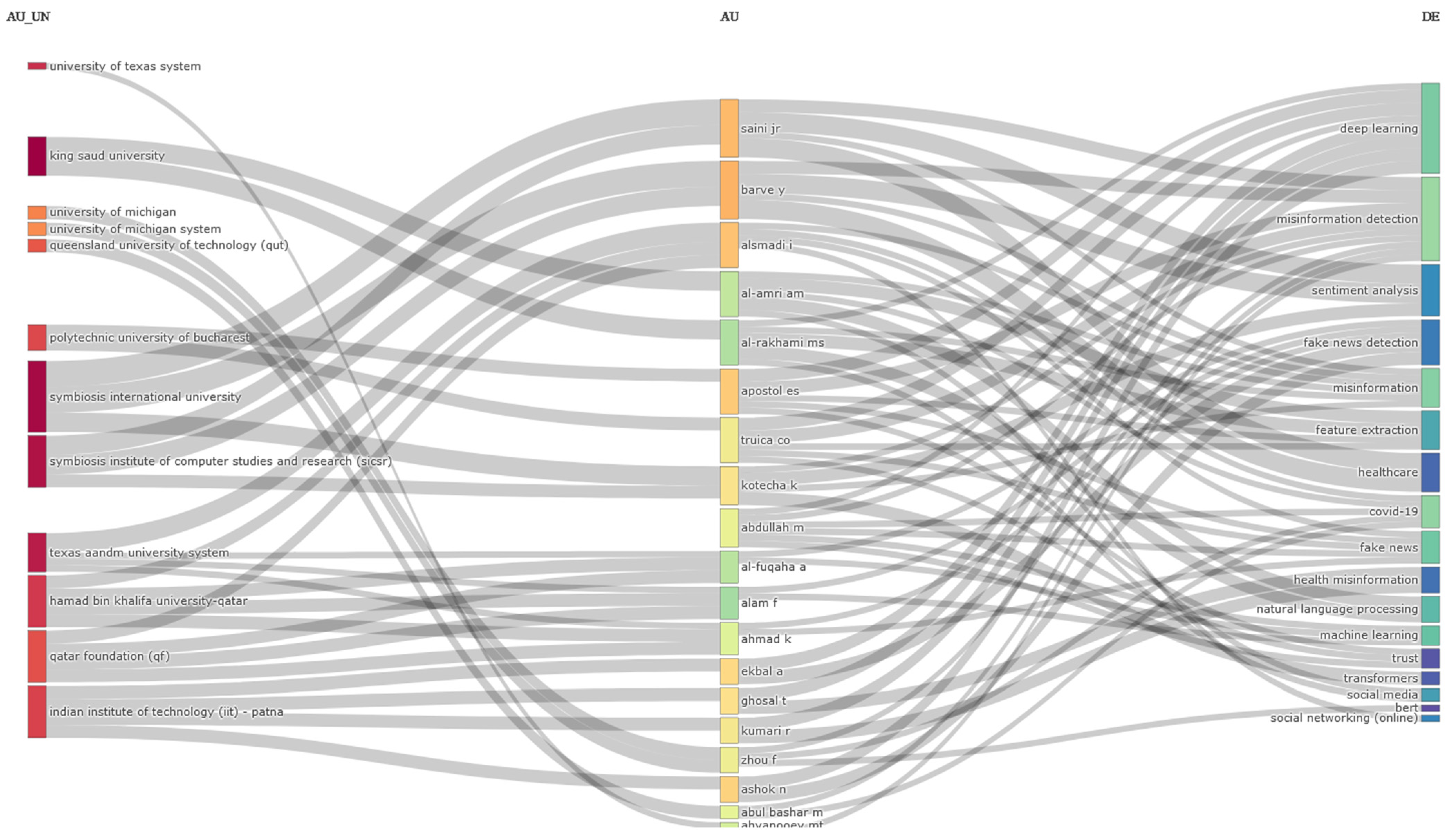
3.5. Mixed Analysis
4. Discussions
5. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gradoń, K.T.; Hołyst, J.A.; Moy, W.R.; Sienkiewicz, J.; Suchecki, K. Countering Misinformation: A Multidisciplinary Approach. Big Data Soc. 2021, 8, 205395172110138. [Google Scholar] [CrossRef]
- Wardle, C.; Dias, P. Information Disorder: Toward an Interdisciplinary Framework for Research and Policy Making (2017); Council of Europe: Strasbourg, France, 2017. [Google Scholar]
- Segura-Bedmar, I.; Alonso-Bartolome, S. Multimodal Fake News Detection. Information 2022, 13, 284. [Google Scholar] [CrossRef]
- Thakur, N. Social Media Mining and Analysis: A Brief Review of Recent Challenges. Information 2023, 14, 484. [Google Scholar] [CrossRef]
- Leonardi, S.; Rizzo, G.; Morisio, M. Automated Classification of Fake News Spreaders to Break the Misinformation Chain. Information 2021, 12, 248. [Google Scholar] [CrossRef]
- Del Vicario, M.; Bessi, A.; Zollo, F.; Petroni, F.; Scala, A.; Caldarelli, G.; Stanley, H.E.; Quattrociocchi, W. The Spreading of Misinformation Online. Proc. Natl. Acad. Sci. USA 2016, 113, 554–559. [Google Scholar] [CrossRef] [PubMed]
- Carmi, E.; Yates, S.J.; Lockley, E.; Pawluczuk, A. Data Citizenship: Rethinking Data Literacy in the Age of Disinformation, Misinformation, and Malinformation. Internet Policy Rev. 2020, 9, 1–22. [Google Scholar] [CrossRef]
- House of Commons. Disinformation and ‘Fake News’: Final Report; House of Commons: London, UK, 2019. [Google Scholar]
- Dennis, A.R.; Galletta, D.F.; Webster, J. Special Issue: Fake News on the Internet. J. Manag. Inf. Syst. 2022, 38, 893–897. [Google Scholar] [CrossRef]
- Siino, M.; Di Nuovo, E.; Tinniriello, I.; La Cascia, M. Fake News Spreaders Detection: Sometimes Attention Is Not All You Need. Information 2022, 13, 426. [Google Scholar] [CrossRef]
- Tsfati, Y.; Boomgaarden, H.G.; Strömbäck, J.; Vliegenthart, R.; Damstra, A.; Lindgren, E. Causes and Consequences of Mainstream Media Dissemination of Fake News: Literature Review and Synthesis. Ann. Int. Commun. Assoc. 2020, 44, 157–173. [Google Scholar] [CrossRef]
- Kasnesis, P.; Toumanidis, L.; Patrikakis, C. Combating Fake News with Transformers: A Comparative Analysis of Stance Detection and Subjectivity Analysis. Information 2021, 12, 409. [Google Scholar] [CrossRef]
- Taylor and Francis Website Misinformation, vs. Disinformation—Taylor & Francis Insights. Available online: https://insights.taylorandfrancis.com/social-justice/misinformation-vs-disinformation/ (accessed on 9 December 2023).
- Lazer, D.M.J.; Baum, M.A.; Benkler, Y.; Berinsky, A.J.; Greenhill, K.M.; Menczer, F.; Metzger, M.J.; Nyhan, B.; Pennycook, G.; Rothschild, D.; et al. The Science of Fake News. Science 2018, 359, 1094–1096. [Google Scholar] [CrossRef] [PubMed]
- Zareie, A.; Sakellariou, R. Minimizing the Spread of Misinformation in Online Social Networks: A Survey. J. Netw. Comput. Appl. 2021, 186, 103094. [Google Scholar] [CrossRef]
- Chen, S.; Xiao, L.; Kumar, A. Spread of Misinformation on Social Media: What Contributes to It and How to Combat It. Comput. Hum. Behav. 2023, 141, 107643. [Google Scholar] [CrossRef]
- Cotfas, L.-A.; Delcea, C.; Roxin, I.; Ioanas, C.; Gherai, D.S.; Tajariol, F. The Longest Month: Analyzing COVID-19 Vaccination Opinions Dynamics from Tweets in the Month Following the First Vaccine Announcement. IEEE Access 2021, 9, 33203–33223. [Google Scholar] [CrossRef] [PubMed]
- Delcea, C.; Cotfas, L.-A.; Crăciun, L.; Molănescu, A.G. New Wave of COVID-19 Vaccine Opinions in the Month the 3rd Booster Dose Arrived. Vaccines 2022, 10, 881. [Google Scholar] [CrossRef]
- Caceres, M.M.F.; Sosa, J.P.; Lawrence, J.A.; Sestacovschi, C.; Tidd-Johnson, A.; Rasool, M.H.U.; Gadamidi, V.K.; Ozair, S.; Pandav, K.; Cuevas-Lou, C.; et al. The Impact of Misinformation on the COVID-19 Pandemic. AIMS Public Health 2022, 9, 262–277. [Google Scholar] [CrossRef] [PubMed]
- Barua, Z.; Barua, S.; Aktar, S.; Kabir, N.; Li, M. Effects of Misinformation on COVID-19 Individual Responses and Recommendations for Resilience of Disastrous Consequences of Misinformation. Prog. Disaster Sci. 2020, 8, 100119. [Google Scholar] [CrossRef] [PubMed]
- Krittanawong, C.; Kagan, N.; Narasimhan, B.; Virk, H.U.H.; Narasimhan, H.; Hahn, J.; Wang, Z.; Tang, W.H.W. Misinformation Dissemination in Twitter in the COVID-19 Era. Am. J. Med. 2020, 133, 1367–1369. [Google Scholar] [CrossRef]
- Jerit, J.; Zhao, Y. Political Misinformation. Annu. Rev. Polit. Sci. 2020, 23, 77–94. [Google Scholar] [CrossRef]
- De Angelis, A.; Farhart, C.E.; Merkley, E.; Stecula, D.A. Editorial: Political Misinformation in the Digital Age During a Pandemic: Partisanship, Propaganda, and Democratic Decision-Making. Front. Polit. Sci. 2022, 4, 897095. [Google Scholar] [CrossRef]
- Porter, E.; Wood, T.J. Political Misinformation and Factual Corrections on the Facebook News Feed: Experimental Evidence. J. Polit. 2022, 84, 1812–1817. [Google Scholar] [CrossRef]
- Flynn, D.J.; Horiuchi, Y.; Zhang, D. Misinformation, Economic Threat and Public Support for International Trade. Rev. Int. Political Econ. 2022, 29, 571–597. [Google Scholar] [CrossRef]
- Vicari, R.; Komendatova, N. Systematic Meta-Analysis of Research on AI Tools to Deal with Misinformation on Social Media during Natural and Anthropogenic Hazards and Disasters. Humanit. Soc. Sci. Commun. 2023, 10, 332. [Google Scholar] [CrossRef]
- Block, J.H.; Fisch, C. Eight Tips and Questions for Your Bibliographic Study in Business and Management Research. Manag. Rev. Q. 2020, 70, 307–312. [Google Scholar] [CrossRef]
- WoS Web of Science. Available online: http://webofknowledge.com (accessed on 9 September 2023).
- Anaç, M.; Gumusburun Ayalp, G.; Erdayandi, K. Prefabricated Construction Risks: A Holistic Exploration through Advanced Bibliometric Tool and Content Analysis. Sustainability 2023, 15, 11916. [Google Scholar] [CrossRef]
- Marín-Rodríguez, N.J.; González-Ruiz, J.D.; Valencia-Arias, A. Incorporating Green Bonds into Portfolio Investments: Recent Trends and Further Research. Sustainability 2023, 15, 14897. [Google Scholar] [CrossRef]
- Bakır, M.; Özdemir, E.; Akan, Ş.; Atalık, Ö. A Bibliometric Analysis of Airport Service Quality. J. Air Transp. Manag. 2022, 104, 102273. [Google Scholar] [CrossRef]
- Cobo, M.J.; Martínez, M.A.; Gutiérrez-Salcedo, M.; Fujita, H.; Herrera-Viedma, E. 25 Years at Knowledge-Based Systems: A Bibliometric Analysis. Knowl. Based Syst. 2015, 80, 3–13. [Google Scholar] [CrossRef]
- Modak, N.M.; Merigó, J.M.; Weber, R.; Manzor, F.; Ortúzar, J.D.D. Fifty Years of Transportation Research Journals: A Bibliometric Overview. Transp. Res. Part Policy Pract. 2019, 120, 188–223. [Google Scholar] [CrossRef]
- Mulet-Forteza, C.; Martorell-Cunill, O.; Merigó, J.M.; Genovart-Balaguer, J.; Mauleon-Mendez, E. Twenty Five Years of the Journal of Travel & Tourism Marketing: A Bibliometric Ranking. J. Travel Tour. Mark. 2018, 35, 1201–1221. [Google Scholar] [CrossRef]
- VOSviewer—Visualizing Scientific Landscapes. Available online: https://www.vosviewer.com// (accessed on 5 December 2023).
- Aria, M.; Cuccurullo, C. Bibliometrix: An R-Tool for Comprehensive Science Mapping Analysis. J. Informetr. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Liu, W. The Data Source of This Study Is Web of Science Core Collection? Not Enough. Scientometrics 2019, 121, 1815–1824. [Google Scholar] [CrossRef]
- Liu, F. Retrieval Strategy and Possible Explanations for the Abnormal Growth of Research Publications: Re-Evaluating a Bibliometric Analysis of Climate Change. Scientometrics 2023, 128, 853–859. [Google Scholar] [CrossRef] [PubMed]
- Yeung, A.W.K.; Tosevska, A.; Klager, E.; Eibensteiner, F.; Tsagkaris, C.; Parvanov, E.D.; Nawaz, F.A.; Völkl-Kernstock, S.; Schaden, E.; Kletecka-Pulker, M.; et al. Medical and Health-Related Misinformation on Social Media: Bibliometric Study of the Scientific Literature. J. Med. Internet Res. 2022, 24, e28152. [Google Scholar] [CrossRef] [PubMed]
- Mahajan, R.; Gupta, P. A Bibliometric Analysis On The Dissemination Of COVID-19 Vaccine Misinformation On Social Media. J. Content Community Commun. 2021, 14, 218–229. [Google Scholar] [CrossRef]
- WoS Document Types. Available online: https://webofscience.help.clarivate.com/en-us/Content/document-types.html (accessed on 3 December 2023).
- Donner, P. Document Type Assignment Accuracy in the Journal Citation Index Data of Web of Science. Scientometrics 2017, 113, 219–236. [Google Scholar] [CrossRef]
- Aria, M.; Cuccurullo, C. A Brief Introduction to Bibliometrix. Available online: https://www.bibliometrix.org/vignettes/Introduction_to_bibliometrix.html (accessed on 22 November 2023).
- Delcea, C.; Cotfas, L.-A. Hybrid Approaches Featuring Grey Systems Theory. In Advancements of Grey Systems Theory in Economics and Social Sciences; Series on Grey System; Springer Nature: Singapore, 2023; pp. 281–333. ISBN 978-981-19993-1-4. [Google Scholar]
- Zardari, S.; Alam, S.; Al Salem, H.A.; Al Reshan, M.S.; Shaikh, A.; Malik, A.F.K.; Masood Ur Rehman, M.; Mouratidis, H. A Comprehensive Bibliometric Assessment on Software Testing (2016–2021). Electronics 2022, 11, 1984. [Google Scholar] [CrossRef]
- Marín-Rodríguez, N.J.; González-Ruiz, J.D.; Botero Botero, S. Dynamic Co-Movements among Oil Prices and Financial Assets: A Scientometric Analysis. Sustainability 2022, 14, 12796. [Google Scholar] [CrossRef]
- Gorski, A.-T.; Ranf, E.-D.; Badea, D.; Halmaghi, E.-E.; Gorski, H. Education for Sustainability—Some Bibliometric Insights. Sustainability 2023, 15, 14916. [Google Scholar] [CrossRef]
- Madsen, D.Ø.; Berg, T.; Di Nardo, M. Bibliometric Trends in Industry 5.0 Research: An Updated Overview. Appl. Syst. Innov. 2023, 6, 63. [Google Scholar] [CrossRef]
- Ionescu, Ș.; Delcea, C.; Chiriță, N.; Nica, I. Exploring the Use of Artificial Intelligence in Agent-Based Modeling Applications: A Bibliometric Study. Algorithms 2024, 17, 21. [Google Scholar] [CrossRef]
- Domenteanu, A.; Delcea, C.; Chiriță, N.; Ioanăș, C. From Data to Insights: A Bibliometric Assessment of Agent-Based Modeling Applications in Transportation. Appl. Sci. 2023, 13, 12693. [Google Scholar] [CrossRef]
- Delcea, C.; Javed, S.A.; Florescu, M.-S.; Ioanas, C.; Cotfas, L.-A. 35 Years of Grey System Theory in Economics and Education. Kybernetes 2023. [Google Scholar] [CrossRef]
- Delcea, C.; Domenteanu, A.; Ioanăș, C.; Vargas, V.M.; Ciucu-Durnoi, A.N. Quantifying Neutrosophic Research: A Bibliometric Study. Axioms 2023, 12, 1083. [Google Scholar] [CrossRef]
- Cibu, B.; Delcea, C.; Domenteanu, A.; Dumitrescu, G. Mapping the Evolution of Cybernetics: A Bibliometric Perspective. Computers 2023, 12, 237. [Google Scholar] [CrossRef]
- Wardikar, V. Application of Bradford’s Law of Scattering to the Literature of Library & Information Science: A Study of Doctoral Theses Citations Submitted to the Universities of Maharashtra, India. Libr. Philos. Pract. 2013, 1–45. Available online: https://digitalcommons.unl.edu/cgi/viewcontent.cgi?article=2569&context=libphilprac (accessed on 21 November 2023).
- RDRR Website Bradford: Bradford’s Law in Bibliometrix: Comprehensive Science Mapping Analysis. Available online: https://rdrr.io/cran/bibliometrix/man/bradford.html (accessed on 21 November 2023).
- Liu, W. Caveats for the Use of Web of Science Core Collection in Old Literature Retrieval and Historical Bibliometric Analysis. Technol. Forecast. Soc. Change 2021, 172, 121023. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M.; Furht, B. Deep Learning Applications for COVID-19. J. Big Data 2021, 8, 18. [Google Scholar] [CrossRef]
- Khan, M.L.; Idris, I.K. Recognise Misinformation and Verify before Sharing: A Reasoned Action and Information Literacy Perspective. Behav. Inf. Technol. 2019, 38, 1194–1212. [Google Scholar] [CrossRef]
- Al-Rakhami, M.S.; Al-Amri, A.M. Lies Kill, Facts Save: Detecting COVID-19 Misinformation in Twitter. IEEE Access 2020, 8, 155961–155970. [Google Scholar] [CrossRef]
- Zhao, Y.; Da, J.; Yan, J. Detecting Health Misinformation in Online Health Communities: Incorporating Behavioral Features into Machine Learning Based Approaches. Inf. Process. Manag. 2021, 58, 102390. [Google Scholar] [CrossRef]
- Ayoub, J.; Yang, X.J.; Zhou, F. Combat COVID-19 Infodemic Using Explainable Natural Language Processing Models. Inf. Process. Manag. 2021, 58, 102569. [Google Scholar] [CrossRef]
- Asr, F.T.; Taboada, M. Big Data and Quality Data for Fake News and Misinformation Detection. Big Data Soc. Sage J. 2019, 6, 2053951719843310. [Google Scholar] [CrossRef]
- Zhang, H.; Alim, M.A.; Li, X.; Thai, M.T.; Nguyen, H.T. Misinformation in Online Social Networks: Detect Them All with a Limited Budget. ACM Trans. Inf. Syst. 2016, 34, 1–24. [Google Scholar] [CrossRef]
- Baeth, M.J.; Aktas, M.S. Detecting Misinformation in Social Networks Using Provenance Data. Concurr. Comput. Pract. Exp. 2018, 31, e4793. [Google Scholar] [CrossRef]
- Hayawi, K.; Shahriar, S.; Serhani, M.A.; Taleb, I.; Mathew, S.S. ANTi-Vax: A Novel Twitter Dataset for COVID-19 Vaccine Misinformation Detection. Public Health 2022, 203, 23–30. [Google Scholar] [CrossRef] [PubMed]
- Kumari, R.; Ashok, N.; Ghosal, T.; Ekbal, A. Misinformation Detection Using Multitask Learning with Mutual Learning for Novelty Detection and Emotion Recognition. Inf. Process. Manag. 2021, 58, 102631. [Google Scholar] [CrossRef]
- Zhou, C.; Li, K.; Lu, Y. Linguistic Characteristics and the Dissemination of Misinformation in Social Media: The Moderating Effect of Information Richness. Inf. Process. Manag. 2021, 58, 102679. [Google Scholar] [CrossRef]
- Schuster, T.; Schuster, R.; Shah, D.J.; Barzilay, R. The Limitations of Stylometry for Detecting Machine-Generated Fake News. Comput. Linguist. 2020, 46, 499–510. [Google Scholar] [CrossRef]
- Thornhill, C.; Meeus, Q.; Peperkamp, J.; Berendt, B. A Digital Nudge to Counter Confirmation Bias. Front. Big Data 2019, 2, 11. [Google Scholar] [CrossRef]
- Gläßel, C.; Paula, K. Sometimes Less Is More: Censorship, News Falsification, and Disapproval in 1989 East Germany. Am. J. Polit. Sci. 2020, 64, 682–698. [Google Scholar] [CrossRef]
- Yeo, S.K.; McKasy, M. Emotion and Humor as Misinformation Antidotes. Proc. Natl. Acad. Sci. USA 2021, 118, e2002484118. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Zhou, F.; Trajcevski, G.; Bonsangue, M. Multi-View Learning with Distinguishable Feature Fusion for Rumor Detection. Knowl. Based Syst. 2022, 240, 108085. [Google Scholar] [CrossRef]
- Chen, Q.; Leaman, R.; Allot, A.; Luo, L.; Wei, C.-H.; Yan, S.; Lu, Z. Artificial Intelligence in Action: Addressing the COVID-19 Pandemic with Natural Language Processing. Annu. Rev. Biomed. Data Sci. 2021, 4, 313–339. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Yu, K.; Wu, X.; Qing, L.; Peng, Y. Analysis and Detection of Health-Related Misinformation on Chinese Social Media. IEEE Access 2019, 7, 154480–154489. [Google Scholar] [CrossRef]
- Alenezi, M.N.; Alqenaei, Z.M. Machine Learning in Detecting COVID-19 Misinformation on Twitter. Future Internet 2021, 13, 244. [Google Scholar] [CrossRef]
- Cheng, Y.; Chen, Z.F. Encountering Misinformation Online: Antecedents of Trust and Distrust and Their Impact on the Intensity of Facebook Use. Online Inf. Rev. 2020, 45, 372–388. [Google Scholar] [CrossRef]
- Ilie, V.-I.; Truica, C.-O.; Apostol, E.-S.; Paschke, A. Context-Aware Misinformation Detection: A Benchmark of Deep Learning Architectures Using Word Embeddings. IEEE Access 2021, 9, 162122–162146. [Google Scholar] [CrossRef]
- Kumari, R.; Ashok, N.; Ghosal, T.; Ekbal, A. What the Fake? Probing Misinformation Detection Standing on the Shoulder of Novelty and Emotion. Inf. Process. Manag. 2022, 59, 102740. [Google Scholar] [CrossRef]
- Di Sotto, S.; Viviani, M. Health Misinformation Detection in the Social Web: An Overview and a Data Science Approach. Int. J. Environ. Res. Public. Health 2022, 19, 2173. [Google Scholar] [CrossRef]
- Amith, M.; Tao, C. Representing Vaccine Misinformation Using Ontologies. J. Biomed. Semant. 2018, 9, 22. [Google Scholar] [CrossRef] [PubMed]
- Martin-Gutierrez, D.; Hernandez-Penaloza, G.; Hernandez, A.B.; Lozano-Diez, A.; Alvarez, F. A Deep Learning Approach for Robust Detection of Bots in Twitter Using Transformers. IEEE Access 2021, 9, 54591–54601. [Google Scholar] [CrossRef]
- Komendantova, N.; Ekenberg, L.; Svahn, M.; Larsson, A.; Shah, S.I.H.; Glinos, M.; Koulolias, V.; Danielson, M. A Value-Driven Approach to Addressing Misinformation in Social Media. Humanit. Soc. Sci. Commun. 2021, 8, 33. [Google Scholar] [CrossRef]
- Pham, C.V.; Pham, D.V.; Bui, B.Q.; Nguyen, A.V. Minimum Budget for Misinformation Detection in Online Social Networks with Provable Guarantees. Optim. Lett. 2022, 16, 515–544. [Google Scholar] [CrossRef]
- Balasubramaniam, T.; Nayak, R.; Luong, K.; Bashar, M.A. Identifying COVID-19 Misinformation Tweets and Learning Their Spatio-Temporal Topic Dynamics Using Nonnegative Coupled Matrix Tensor Factorization. Soc. Netw. Anal. Min. 2021, 11, 57. [Google Scholar] [CrossRef]
- Weinzierl, M.A.; Harabagiu, S.M. Automatic Detection of COVID-19 Vaccine Misinformation with Graph Link Prediction. J. Biomed. Inform. 2021, 124, 103955. [Google Scholar] [CrossRef]
- Karnyoto, A.; Sun, C.; Liu, B.; Wang, X. Transfer Learning and GRU-CRF Augmentation for COVID-19 Fake News Detection. Comput. Sci. Inf. Syst. 2022, 19, 639–658. [Google Scholar] [CrossRef]
- Mishima, K.; Yamana, H. A Survey on Explainable Fake News Detection. IEICE Trans. Inf. Syst. 2022, 105, 1249–1257. [Google Scholar] [CrossRef]
- Arquam, M.; Singh, A.; Sharma, R. A Blockchain-Based Secured and Trusted Framework for Information Propagation on Online Social Networks. Soc. Netw. Anal. Min. 2021, 11, 49. [Google Scholar] [CrossRef]
- Truică, C.-O.; Apostol, E.-S. MisRoBÆRTa: Transformers versus Misinformation. Mathematics 2022, 10, 569. [Google Scholar] [CrossRef]
- Kim, M.G.; Kim, M.; Kim, J.H.; Kim, K. Fine-Tuning BERT Models to Classify Misinformation on Garlic and COVID-19 on Twitter. Int. J. Environ. Res. Public. Health 2022, 19, 5126. [Google Scholar] [CrossRef] [PubMed]
- Simko, J.; Racsko, P.; Tomlein, M.; Hanakova, M.; Moro, R.; Bielikova, M. A Study of Fake News Reading and Annotating in Social Media Context. New Rev. Hypermedia Multimed. 2021, 27, 97–127. [Google Scholar] [CrossRef]
- Hashemi, M. Discovering Social Media Topics and Patterns in the Coronavirus and Election Era. J. Inf. Commun. Ethics Soc. 2021, 20, 1–17. [Google Scholar] [CrossRef]
- Safarnejad, L.; Xu, Q.; Ge, Y.; Chen, S. A Multiple Feature Category Data Mining and Machine Learning Approach to Characterize and Detect Health Misinformation on Social Media. IEEE Internet Comput. 2021, 25, 43–51. [Google Scholar] [CrossRef]
- Alsudias, L.; Rayson, P. Social Media Monitoring of the COVID-19 Pandemic and Influenza Epidemic With Adaptation for Informal Language in Arabic Twitter Data: Qualitative Study. JMIR Med. Inform. 2021, 9, e27670. [Google Scholar] [CrossRef]
- Barve, Y.; Saini, J.R.; Kotecha, K.; Gaikwad, H. Detecting and Fact-Checking Misinformation Using “Veracity Scanning Model. ” Int. J. Adv. Comput. Sci. Appl. 2022, 13, 201–209. [Google Scholar] [CrossRef]
- Barve, Y.; Saini, J.R. Healthcare Misinformation Detection and Fact-Checking: A Novel Approach. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 295–303. [Google Scholar] [CrossRef]
- Ahvanooey, M.T.; Zhu, M.X.; Mazurczyk, W.; Choo, K.-K.R.; Conti, M.; Zhang, J. Misinformation Detection on Social Media: Challenges and the Road Ahead. IT Prof. 2022, 24, 34–40. [Google Scholar] [CrossRef]
- Freiling, I.; Waldherr, A. Why Trusting Whom? Motivated Reasoning and Trust in the Process of Information Evaluation. In Trust and Communication; Blöbaum, B., Ed.; Springer International Publishing: Cham, Switzerland, 2021; pp. 83–97. ISBN 978-3-030-72944-8. [Google Scholar]
- González-Fernández, C.; Fernández-Isabel, A.; Martín De Diego, I.; Fernández, R.R.; Viseu Pinheiro, J.F.J. Experts Perception-Based System to Detect Misinformation in Health Websites. Pattern Recognit. Lett. 2021, 152, 333–339. [Google Scholar] [CrossRef]
- Barve, Y.; Saini, J.R.; Pal, K.; Kotecha, K. A Novel Evolving Sentimental Bag-of-Words Approach for Feature Extraction to Detect Misinformation. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 266–275. [Google Scholar] [CrossRef]
- Jalal, N.; Ghafoor, K.Z. Machine Learning Algorithms for Detecting and Analyzing Social Bots Using a Novel Dataset. ARO- Sci. J. KOYA Univ. 2022, 10, 11–21. [Google Scholar] [CrossRef]
- Alsmadi, I.; Rice, N.M.; O’Brien, M.J. Fake or Not? Automated Detection of COVID-19 Misinformation and Disinformation in Social Networks and Digital Media. Comput. Math. Organ. Theory 2022, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Yu, W.; Chen, N.; Chen, J. Characterizing Chinese Online Public Opinions towards the COVID-19 Recovery Policy. Electron. Libr. 2022, 40, 140–159. [Google Scholar] [CrossRef]
- Wei, H.; Kang, X.; Wang, W.; Ying, L. QuickStop: A Markov Optimal Stopping Approach for Quickest Misinformation Detection. Proc. ACM Meas. Anal. Comput. Syst. 2019, 3, 41. [Google Scholar] [CrossRef]
- Fernández-Pichel, M.; Losada, D.E.; Pichel, J.C. A Multistage Retrieval System for Health-Related Misinformation Detection. Eng. Appl. Artif. Intell. 2022, 115, 105211. [Google Scholar] [CrossRef]
- Obeidat, R.; Gharaibeh, M.; Abdullah, M.; Alharahsheh, Y. Multi-Label Multi-Class COVID-19 Arabic Twitter Dataset with Fine-Grained Misinformation and Situational Information Annotations. PeerJ Comput. Sci. 2022, 8, e1151. [Google Scholar] [CrossRef] [PubMed]
- Indu, V.; Thampi, S.M. Cognitive AI for Mitigation of Misinformation in Online Social Networks. IT Prof. 2022, 24, 37–45. [Google Scholar] [CrossRef]
- Mahbub, S.; Pardede, E.; Kayes, A.S.M. COVID-19 Rumor Detection Using Psycho-Linguistic Features. IEEE Access 2022, 10, 117530–117543. [Google Scholar] [CrossRef]
- Alsmadi, I.; Ahmad, K.; Nazzal, M.; Alam, F.; Al-Fuqaha, A.; Khreishah, A.; Algosaibi, A. Adversarial NLP for Social Network Applications: Attacks, Defenses, and Research Directions. IEEE Trans. Comput. Soc. Syst. 2023, 10, 3089–3108. [Google Scholar] [CrossRef]
- Zeng, X.; Zubiaga, A. Aggregating Pairwise Semantic Differences for Few-Shot Claim Verification. PeerJ Comput. Sci. 2022, 8, e1137. [Google Scholar] [CrossRef]
- Ananthi, G.; Sridevi, S. Stacking Dilated Convolutional AutoEncoder Beamforming for THz Wave Vehicular Ad-Hoc Networks. Wirel. Pers. Commun. 2022, 126, 2985–3000. [Google Scholar] [CrossRef]
- Michailidis, P.D. Visualizing Social Media Research in the Age of COVID-19. Information 2022, 13, 372. [Google Scholar] [CrossRef]
- Puteh, N.; Ali bin Saip, M.; Zabidin Husin, M.; Hussain, A. Sentiment Analysis with Deep Learning: A Bibliometric Review. Turk. J. Comput. Math. Educ. TURCOMAT 2021, 12, 1509–1519. [Google Scholar]
- Sarirete, A. A Bibliometric Analysis of COVID-19 Vaccines and Sentiment Analysis. Procedia Comput. Sci. 2021, 194, 280–287. [Google Scholar] [CrossRef] [PubMed]
- Sandu, A.; Cotfas, L.-A.; Delcea, C.; Craciun, L.; Molanescu, A.-G. Sentiment Analysis in the Age of COVID-19: A Bibliometric Perspective. Inf. J. Rev. 2023, 14, 659. [Google Scholar] [CrossRef]
- Sanchez-Nunez, P.; Cobo, M.J.; Heras-Pedrosa, C.D.L.; Pelaez, J.I.; Herrera-Viedma, E. Opinion Mining, Sentiment Analysis and Emotion Understanding in Advertising: A Bibliometric Analysis. IEEE Access 2020, 8, 134563–134576. [Google Scholar] [CrossRef]
- Yu, J.; Muñoz-Justicia, J. A Bibliometric Overview of Twitter-Related Studies Indexed in Web of Science. Future Internet 2020, 12, 91. [Google Scholar] [CrossRef]
- Casas-Valadez, M.A.; Faz-Mendoza, A.; Medina-Rodriguez, C.E.; Castorena-Robles, A.; Gamboa-Rosales, N.K.; Lopez-Robles, J.R. Decision Models in Marketing: The Role of Sentiment Analysis from Bibliometric Analysis. In Proceedings of the International Conference on Decision Aid Sciences and Application (DASA), Sakheer, Bahrain, 8 November 2020; pp. 561–565. [Google Scholar]
- Kamath, A.; Shenoy, S.; Kumar, S. An Overview of Investor Sentiment: Identifying Themes, Trends, and Future Direction through Bibliometric Analysis. Invest. Manag. Financ. Innov. 2022, 19, 229–242. [Google Scholar] [CrossRef]
- Qiang, Y.; Tao, X.; Gou, X.; Lang, Z.; Liu, H. Towards a Bibliometric Mapping of Network Public Opinion Studies. Information 2022, 13, 17. [Google Scholar] [CrossRef]
- Kale, A.S. Sentiment Analysis in Library and Information Science: A Bibliometric Study. Available online: https://www.proquest.com/openview/4413eac1c9486d2492b58929b57cadf3/1?pq-origsite=gscholar&cbl=5170426 (accessed on 3 December 2023).
- Nyakurukwa, K.; Seetharam, Y. The Evolution of Studies on Social Media Sentiment in the Stock Market: Insights from Bibliometric Analysis. Sci. Afr. 2023, 20, e01596. [Google Scholar] [CrossRef]
- Yaqub, A.; Thalib, H.; Brahimi, T.; Sarirete, A. A Bibliometric of Sentiment Analysis in Tourism Industry during COVID-19 Pandemic. In Proceedings of the International Conference on Industrial Engineering and Operations Management, IEOM Society International, Istanbul, Turkey, 7–10 March 2022; pp. 2383–2393. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Exploration Steps | Filters | Description | Query Used in WoS | Query ID | Number of Papers Extracted |
|---|---|---|---|---|---|
| 1 | Title/ Abstract/ Keywords | Title contains misinformation detection | (TI = (misinformation_detection)) OR TI = (detect_misinformation) | #1 | 56 |
| Abstract contains misinformation detection | (AB = (misinformation_detection)) OR AB = (detect_misinformation) | #2 | 151 | ||
| Keywords contains misinformation detection | (AK = (misinformation_detection)) OR AK = (detect_misinformation) | #3 | 58 | ||
| Title/Abstract/Keywords contain misinformation detection | #1 OR #2 OR #3 | #4 | 185 | ||
| 2 | Language | Limit to papers written in English | (#4) AND LA = (English) | #5 | 185 |
| 3 | Document Type | Limit to papers marked as “Article” by WoS | (#5) AND DT = (Article) | #6 | 79 |
| 4 | Year | Exclude the year 2023 | (#6) NOT PY = (2023) | #7 | 56 |
| Bibliometric Analysis Steps | Name | Description | Indicators Considered |
|---|---|---|---|
| 1 | Dataset Overview | Main information about data | Timespan; Number of sources; Number of documents; Average years from publication; Average citations per document; Average citations per year per document; Number of references. |
| Documents content analysis | Number of keywords plus; Number of author’s keywords. | ||
| General information on authors | Number of authors; Author appearances; authors of single-authored documents; Authors of multi-authored documents. | ||
| General information on authors’ collaboration | Number of single-authored documents; Number of documents per author; Number of authors per document; Number of co-authors per documents; Collaboration index. | ||
| 2 | Sources Analysis | Analysis of the journals in terms of published items and their impact | Most relevant sources; Bradford’s law on source clustering; Journals’ impact based on H-index; Journals’ growth (cumulative) based on the number of papers. |
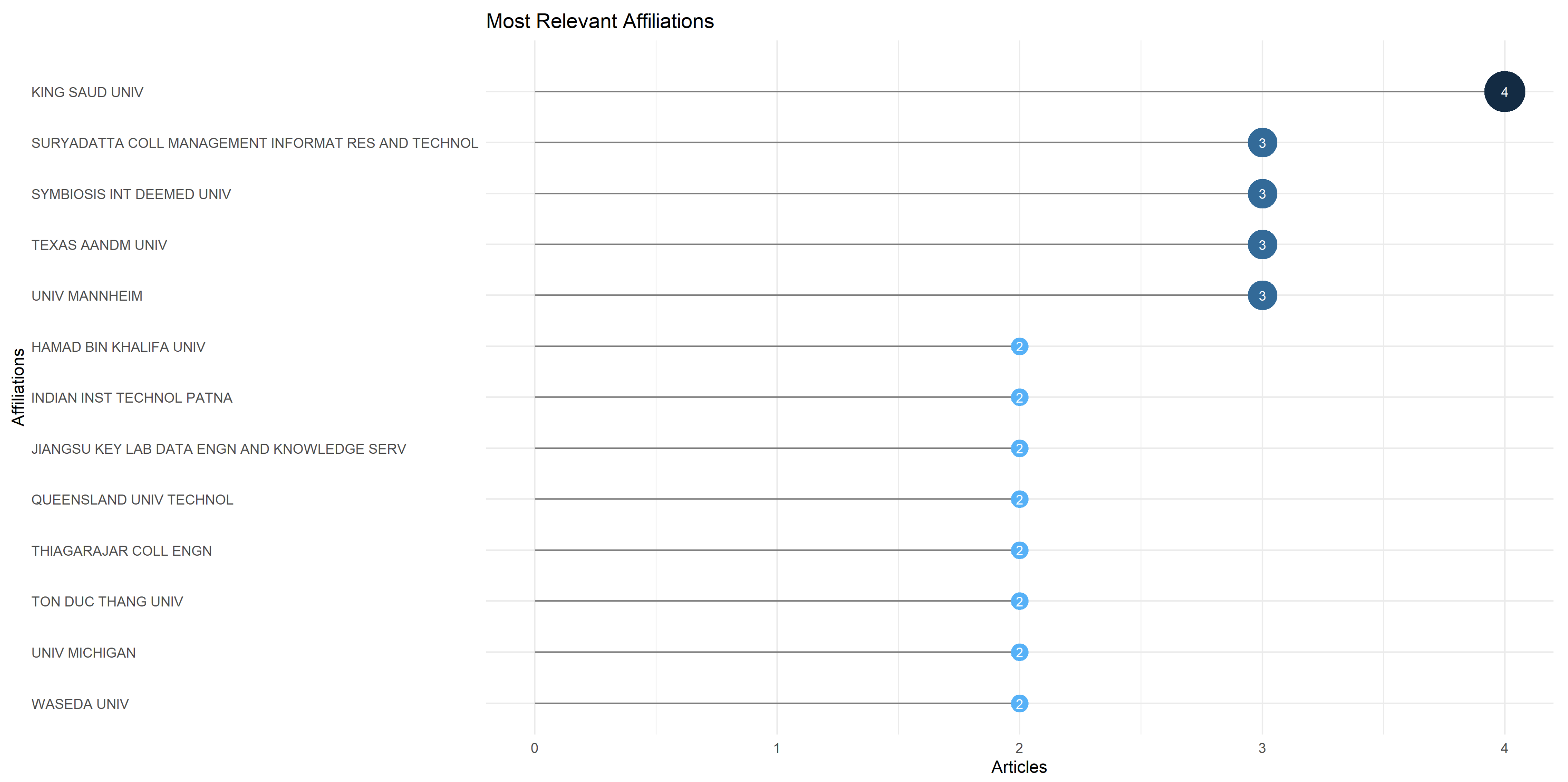
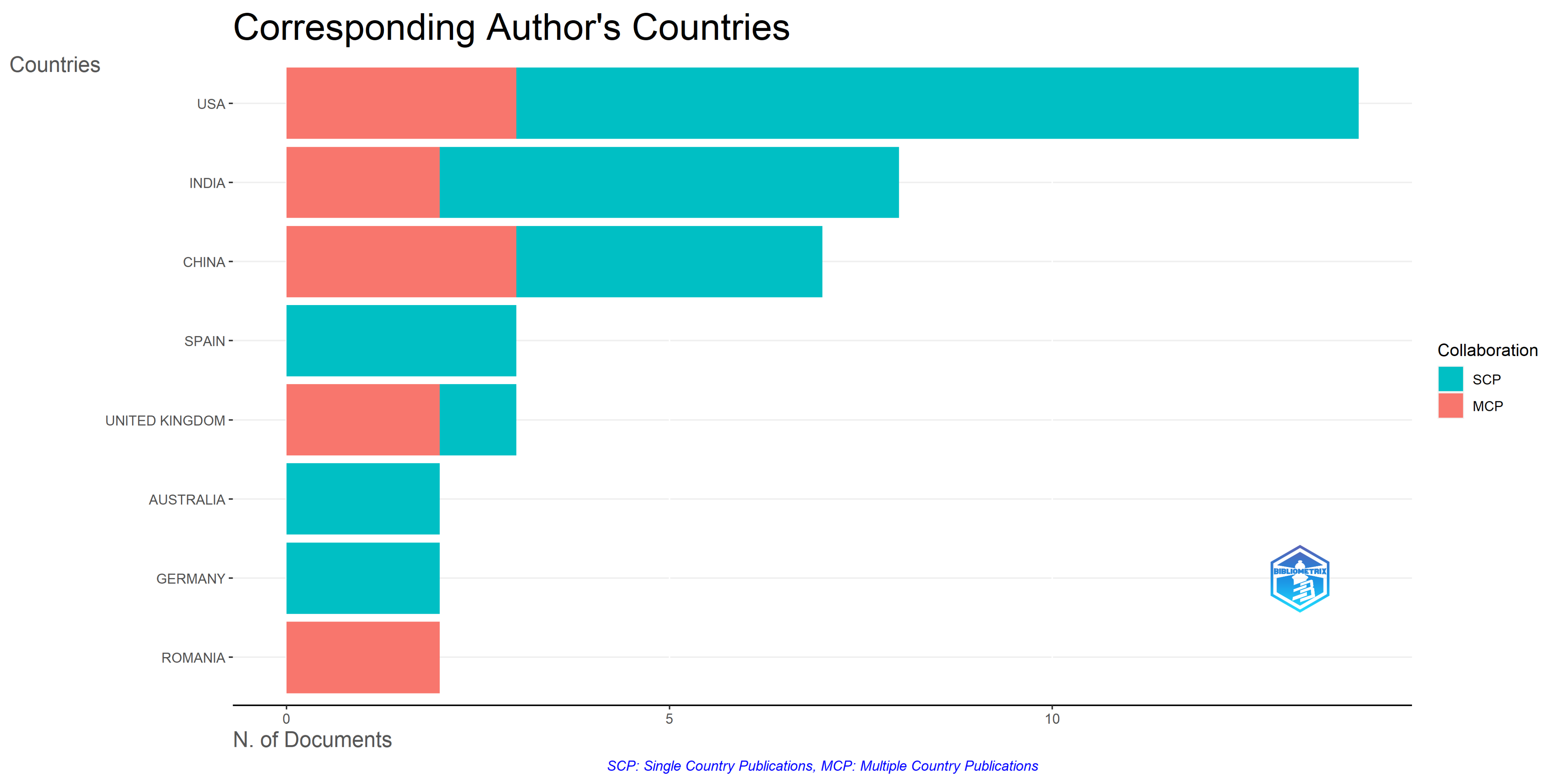
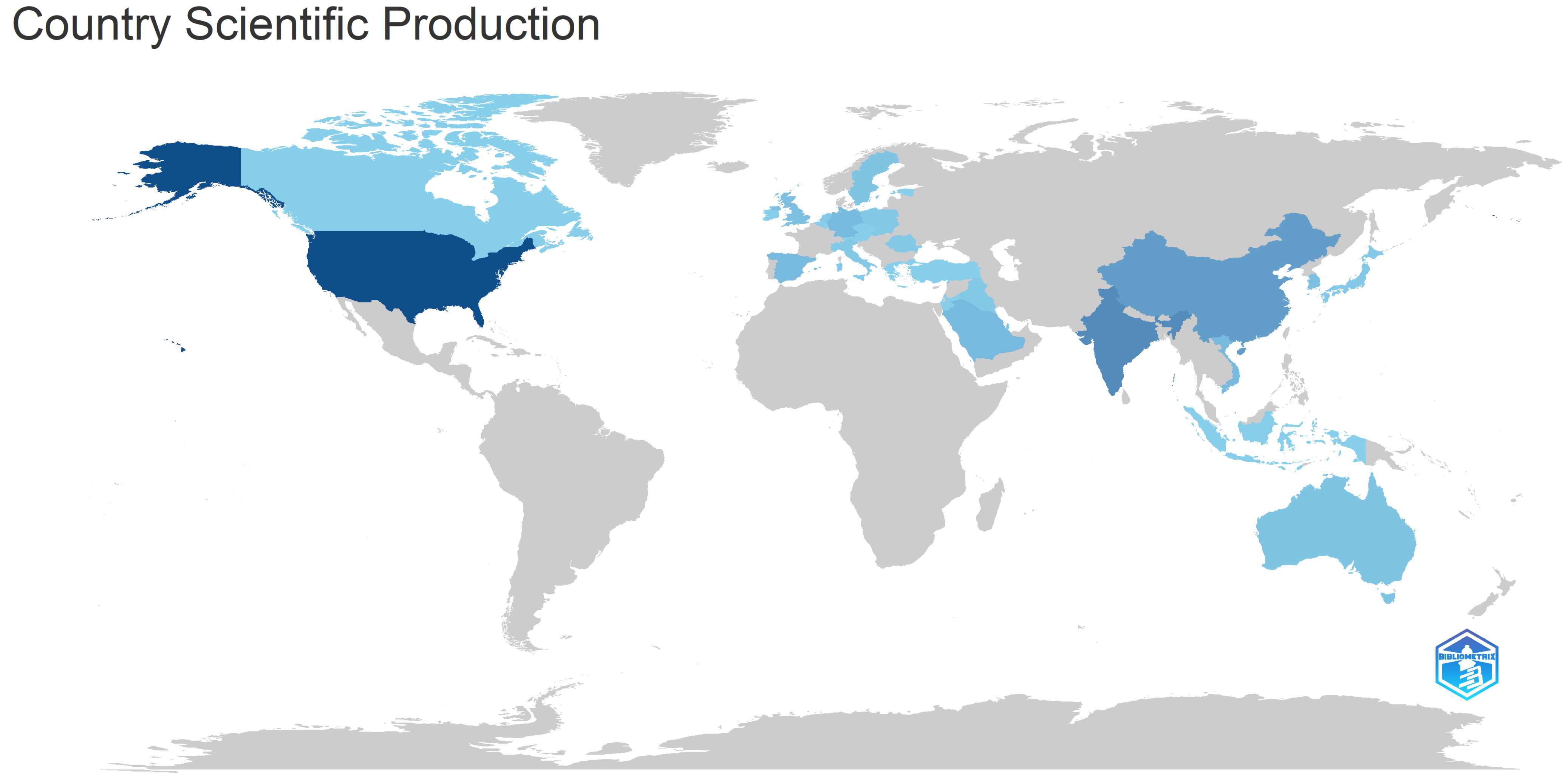
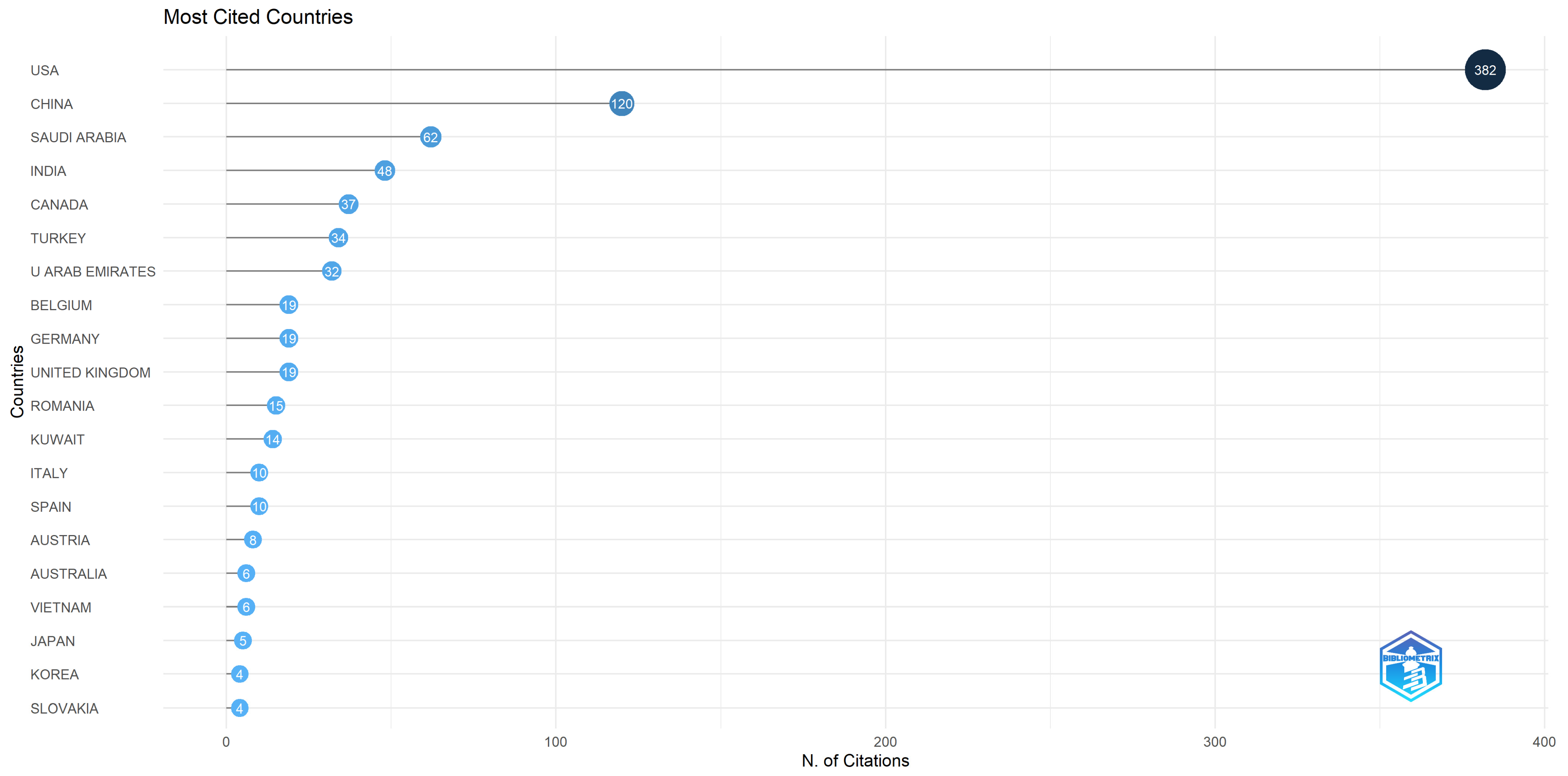
| 3 | Authors Analysis | Analysis of the authors in terms of published items, characteristics of the authors, and impact of the research | Top authors based on number of documents; Top-authors’ production over time; Most relevant affiliations; Most relevant corresponding author’s country; Scientific production based on country; Countries with the most citations; Country collaboration map; Top 50 authors’ collaboration network. |
| 4 | Papers Analysis | Analysis of the papers and the words extracted from the papers | Total citations (TC); Total citations per year (TCY); Normalized TC (NTC); Most frequent words in Keywords plus; Most frequent words in authors’ keywords; Most frequent bigrams in abstracts and titles; Most frequent trigrams in abstracts and titles. |
| 5 | Mixed Analysis | Point out the complex connections between countries, authors, journals, affiliations, and keywords | Three-field plots. |
| Indicator | Value |
|---|---|
| Timespan | 2016:2022 |
| Number of sources | 41 |
| Number of documents | 56 |
| Average years from publication | 2.04 |
| Average citations per documents | 15.27 |
| Average citations per year per document | 4.621 |
| Number of references | 2821 |
| Indicator | Value |
|---|---|
| Number of keywords plus | 78 |
| Number of author’s keywords | 199 |
| Indicator | Value |
|---|---|
| Number of authors | 178 |
| Author appearances | 191 |
| Authors of single-authored documents | 2 |
| Authors of multi-authored documents | 176 |
| Indicator | Value |
|---|---|
| Number of single-authored documents | 2 |
| Number of documents per author | 0.315 |
| Number of authors per document | 3.18 |
| Number of co-authors per document | 3.41 |
| Collaboration index | 3.26 |
| No. | Paper (First Author, Year, Journal, Reference) | Number of Authors | Region | Total Citations (TC) | Total Citations per Year (TCY) | Normalized TC (NTC) |
|---|---|---|---|---|---|---|
| 1 | Shorten C, 2021, Journal of Big Data, [57] | 3 | USA | 125 | 41.67 | 6.45 |
| 2 | Khan ML, 2019, Behaviour & Information Technology, [58] | 2 | USA, Indonesia | 92 | 18.40 | 3.25 |
| 3 | Al-Rakhami MS, 2020, IEEE Access, [59] | 2 | Saudi Arabia | 62 | 15.50 | 1.86 |
| 4 | Zhao YH, 2021, Information Processing & Management, [60] | 3 | China | 56 | 18.67 | 2.89 |
| 5 | Ayoub J, 2021, Information Processing & Management, [61] | 3 | USA | 39 | 13.00 | 2.01 |
| 6 | Asr FT, 2019, Big Data & Society: Sage Journals, [62] | 2 | Canada | 37 | 7.40 | 1.31 |
| 7 | Zhang HL, 2016, ACM Transactions on Information Systems, [63] | 5 | Florida, Vietnam | 36 | 4.50 | 1.00 |
| 8 | Baeth MJ, 2019, Concurrency and Computation: Practice and Experience, [64] | 2 | Turkey | 34 | 6.80 | 1.20 |
| 9 | Hayawi K, 2022, Public Health, [65] | 5 | United Arab Emirates | 32 | 16.00 | 7.01 |
| 10 | Kumari R, 2021, Information Processing & Management, [66] | 4 | India, Czech Republic | 27 | 9.00 | 1.39 |
| No. | Reference | Title | Methods Used | Data | Purpose |
|---|---|---|---|---|---|
| 1 | Shorten et al. [57] | Deep Learning applications for COVID-19 | Deep learning techniques—supervised, semi-supervised, self-supervised learning, federated learning, data augmentation. Deep neural networks. Meta-learning, transfer learning. | COVID-19 data—medical images, text data, clinical data | Outlines the uses, advantages, and restrictions of applying deep learning to combat COVID-19 challenges. |
| 2 | Khan and Idris [58] | Recognise misinformation and verify before sharing: a reasoned action and information literacy perspective | Data Collection. Statistical Analysis—multiple linear regression analysis | 396 people in Indonesia answered survey questions to provide data for this study. | Identify the elements impacting people’s sharing habits on social media and their self-efficacy in identifying misinformation. |
| 3 | Al-Rakhami and Al-Amri [59] | Lies Kill, Facts Save: Detecting COVID-19 Misinformation in Twitter | Data Collection. Data Annotation and Reliability. Feature Extraction. Ensemble-Learning-Based Model Selecting the Appropriate Meta-Model (C4.5, SVM, RF, Naive Bayes, Bayes net, and kNN) Selection of Weak-Learners. Selecting the Top Features. | 121,950 credible tweets and 287,534 non-credible tweets related to COVID-19 from Twitter’s streaming API, collected between 15 January 2020, and 15 April 2020. | Understand the impact of misinformation. Use machine learning techniques for determining the accuracy of the tweets. Develop a framework for detecting and combating COVID-19-related misinformation on Twitter. |
| 4 | Zhao et al. [60] | Detecting health misinformation in online health communities: Incorporating behavioral features into machine learning based approaches | Machine Learning. Feature Selection. Classification Models (Random Forest) | 151,719 records collected from the autism forum, between 2 January 2017, and 19 May. | Detect health misinformation in online health communities using machine learning and feature analysis. |
| 5 | Ayoub et al. [61] | Combat COVID-19 infodemic using explainable natural language processing models | Data Collection. Back-Translation Augmentation. Model Building—employed NLP models, including BERT, DistilBERT. SHAP Explanation. Model Evaluation. | 984 claims about COVID-19 | Addressing the difficulties associated with managing disinformation about COVID-19, creating a trustworthy prediction model to confirm the accuracy of COVID-19 claims, and increasing awareness of the significance of misinformation detection. |
| 6 | Asr et al. [62] | Big Data and quality data for fake news and misinformation detection | Scraping and collecting datasets. Automatic and manual procedures. Topic modeling techniques—Latent Dirichlet Allocation (LDA). | The Buzzfeed dataset—1380 news articles related to the 2016 US election. The Snopes dataset—around 4000 rows, each containing a claim, its veracity label, and the text of a news article related to the claim. The Emergent dataset—1612 articles. The datasets cover different topics (politics, sports, environment, health). | Tackle the issue of inaccurate information and fake news, propose text classification as a method for automatic identification, emphasize the importance of large, labeled datasets, and promote cooperation within the scientific community in the fight against misleading data. |
| 7 | Zhang et al. [63] | Misinformation in Online Social Networks: Detect Them All with a Limited Budget | Monitor Placement. Greedy Strategy. Τ-MP Problem. Sampling Techniques. | The dataset is comprised of information from various online social networks: Twitter, Epinion, and Slashdot. | Develop and evaluate strategies for placing monitors effectively in online social networks in order to quickly detect and prevent the dissemination of misleading data. |
| 8 | Baeth and Aktas [64] | Detecting misinformation in social networks using provenance data | Analysis of social workflows. Distance from positivity metric. Analytic Hierarchy Process (AHP). Fuzzy AHP. Synthetic social provenance dataset. Machine learning for misinformation detection. | Twitter data collected from Twitter’s stream and search APIs. | Use Twitter data to examine social processes, evaluate social network user reliability, and investigate the quality of the information, regarding disinformation detection. |
| 9 | Hayawi et al. [65] | ANTi-Vax: a novel Twitter dataset for COVID-19 vaccine misinformation detection | Feature Extraction. Classification models: XGBoost, LSTM, and BERT transformer model. | 15,465,687 English tweets related to COVID-19 vaccines collected between 1 December 2020, and 31 July 2021. | Examine and comprehend the dynamics of misleading information regarding COVID-19 and vaccines on social media, especially Twitter. |
| 10 | Kumari et al. [66] | Misinformation detection using multitask learning with mutual learning for novelty detection and emotion recognition | Multitask learning framework. Deep learning techniques. Neural networks. Pretrained embeddings (Glove- and BERT-based embeddings). Cross-entropy loss. | News articles and text data collected from various sources. | Improve the capacity to identify false information on social media by using information about novelty and emotion in news. |
| No. | Reference | Misinformation Category | Channel | Approach | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Health | Politics | Personal, Environment | Science | Sports, Market, Police, Legislation, Technology | Other/Unspecified/No Accent on the Category | Social Media | News | Unspecified | Machine Learning | Survey | Other (Proof of Concept; Text Analysis; Writing Style Analysis; Ontology; Greedy Approximation Algorithms; Graph Link Prediction; Blockchain; Eye-Tracking, etc.) | ||||||||||
| Vaccines (COVID-19 and in General) | COVID-19 Pandemic | Health Aspects in General | Reddit, ByteDance | Epinion, Slashdot | Health Communities/Healthcare Web URL | Social Media in General/Other | |||||||||||||||
| 1 | Shorten et al. [57] | ✔ | ✔ | ||||||||||||||||||
| 2 | Khan and Idris [58] | ✔ | ✔ | ✔ | |||||||||||||||||
| 3 | Al-Rakhami and Al-Amri [59] | ✔ | ✔ | ✔ | |||||||||||||||||
| 4 | Zhao et al. [60] | ✔ | ✔ | ✔ | |||||||||||||||||
| 5 | Ayoub et al. [61] | ✔ | ✔ | ✔ | |||||||||||||||||
| 6 | Asr et al. [62] | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |||||||||||||
| 7 | Zhang et al. [63] | ✔ | ✔ | ✔ | ✔ | ✔ | |||||||||||||||
| 8 | Baeth and Aktas [64] | ✔ | ✔ | ✔ | ✔ | ✔ | |||||||||||||||
| 9 | Hayawi et al. [65] | ✔ | ✔ | ✔ | |||||||||||||||||
| 10 | Kumari et al. [66] | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |||||||||||||
| 11 | Zhou et al. [67] | ✔ | ✔ | ✔ | |||||||||||||||||
| 12 | Schuster et al. [68] | ✔ | ✔ | ✔ | |||||||||||||||||
| 13 | Thornhill et al. [69] | ✔ | ✔ | ✔ | |||||||||||||||||
| 14 | Glabel and Paula [70] | ✔ | ✔ | ✔ | |||||||||||||||||
| 15 | Yeo and McKasy [71] | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||||||||||||||
| 16 | Chen et al. [72] | ✔ | ✔ | ✔ | ✔ | ||||||||||||||||
| 17 | Chen et al. [73] | ✔ | ✔ | ✔ | |||||||||||||||||
| 18 | Kasper et al. [1] | ✔ | ✔ | ✔ | |||||||||||||||||
| 19 | Liu et al. [74] | ✔ | ✔ | ✔ | ✔ | ✔ | |||||||||||||||
| 20 | Alenezi et al. [75] | ✔ | ✔ | ✔ | |||||||||||||||||
| 21 | Cheng and Chen [76] | ✔ | ✔ | ✔ | |||||||||||||||||
| 22 | Ilie et al. [77] | ✔ | ✔ | ✔ | |||||||||||||||||
| 23 | Kumari et al. [78] | ✔ | ✔ | ✔ | ✔ | ||||||||||||||||
| 24 | Sotto and Viviani [79] | ✔ | ✔ | ✔ | ✔ | ||||||||||||||||
| 25 | Amith and Tao [80] | ✔ | ✔ | ✔ | |||||||||||||||||
| 26 | Martin-Gutierrez et al. [81] | ✔ | ✔ | ✔ | |||||||||||||||||
| 27 | Komendantova et al. [82] | ✔ | ✔ | ||||||||||||||||||
| 28 | Pham et al. [83] | ✔ | ✔ | ✔ | |||||||||||||||||
| 29 | Balasubramaniam et al. [84] | ✔ | ✔ | ✔ | |||||||||||||||||
| 30 | Weinzierl and Harabagiu [85] | ✔ | ✔ | ✔ | |||||||||||||||||
| 31 | Karnyoto et al. [86] | ✔ | ✔ | ✔ | |||||||||||||||||
| 32 | Mishima and Yamana [87] | ✔ | ✔ | ✔ | |||||||||||||||||
| 33 | Arquam et al. [88] | ✔ | ✔ | ✔ | ✔ | ||||||||||||||||
| 34 | Truica and Apostol [89] | ✔ | ✔ | ✔ | |||||||||||||||||
| 35 | Kim et al. [90] | ✔ | ✔ | ✔ | |||||||||||||||||
| 36 | Simko et al. [91] | ✔ | ✔ | ✔ | |||||||||||||||||
| 37 | Hashemi [92] | ✔ | ✔ | ✔ | ✔ | ||||||||||||||||
| 38 | Safarnejad et al. [93] | ✔ | ✔ | ✔ | |||||||||||||||||
| 39 | Alsudias and Rayson [94] | ✔ | ✔ | ✔ | ✔ | ||||||||||||||||
| 40 | Barve et al. [95] | ✔ | ✔ | ✔ | |||||||||||||||||
| 41 | Barve and Saini [96] | ✔ | ✔ | ✔ | |||||||||||||||||
| 42 | Ahvanooey et al. [97] | ✔ | ✔ | ✔ | |||||||||||||||||
| 43 | Freiling and Waldherr [98] | ✔ | ✔ | ✔ | |||||||||||||||||
| 44 | Gonzalez-Fernandez et al. [99] | ✔ | ✔ | ✔ | |||||||||||||||||
| 45 | Barve et al. [100] | ✔ | ✔ | ✔ | |||||||||||||||||
| 46 | Jalal and Ghafoor [101] | ✔ | ✔ | ✔ | |||||||||||||||||
| 47 | Alsmadi et al. [102] | ✔ | ✔ | ✔ | ✔ | ||||||||||||||||
| 48 | Yu et al. [103] | ✔ | ✔ | ✔ | |||||||||||||||||
| 49 | Wei et al. [104] | ✔ | ✔ | ✔ | |||||||||||||||||
| 50 | Fernandez-Pichel et al. [105] | ✔ | ✔ | ✔ | |||||||||||||||||
| 51 | Obeidat et al. [106] | ✔ | ✔ | ✔ | |||||||||||||||||
| 52 | V and Thampi [107] | ✔ | ✔ | ✔ | |||||||||||||||||
| 53 | Mahbub et al. [108] | ✔ | ✔ | ✔ | |||||||||||||||||
| 54 | Alsmadi et al. [109] | ✔ | ✔ | ✔ | |||||||||||||||||
| 55 | Xia and Zubiaga [110] | ✔ | ✔ | ✔ | |||||||||||||||||
| 56 | Ananthi and Sridevi [111] | ✔ | ✔ | ✔ | |||||||||||||||||
| Words | Occurrences |
|---|---|
| social media | 6 |
| credibility | 5 |
| fake news | 5 |
| information | 5 |
| classification | 3 |
| communication | 3 |
| media | 3 |
| news | 3 |
| engagement | 2 |
| health | 2 |
| Words | Occurrences |
|---|---|
| misinformation detection | 19 |
| COVID-19 | 13 |
| misinformation | 13 |
| deep learning | 10 |
| fake news | 9 |
| machine learning | 9 |
| natural language processing | 8 |
| 6 | |
| feature extraction | 5 |
| social media | 5 |
| Bigrams in Abstracts | Occurrences | Bigrams in Titles | Occurrences |
| misinformation detection | 43 | misinformation detection | 11 |
| social media | 41 | social media | 8 |
| fake news | 32 | social networks | 7 |
| detect misinformation | 24 | fake news | 5 |
| deep learning | 19 | online social | 5 |
| machine learning | 16 | covid-misinformation | 4 |
| social networks | 15 | machine learning | 4 |
| detecting misinformation | 13 | deep learning | 3 |
| language processing | 12 | health misinformation | 3 |
| natural language | 12 | vaccine misinformation | 3 |
| Trigrams in Abstracts | Occurrences | Trigrams in Titles | Occurrences |
|---|---|---|---|
| natural language processing | 12 | online social networks | 5 |
| fake news detection | 8 | covid-vaccine misinformation | 2 |
| social media platforms | 7 | detecting covid-misinformation | 2 |
| online social networks | 6 | fake news detection | 2 |
| bidirectional encoder representations | 5 | natural language processing | 2 |
| support vector machine | 5 | ae rta transformers | 1 |
| misrob ae rta | 4 | aggregating pairwise semantic | 1 |
| coupled matrix tensor | 3 | analyzing social bots | 1 |
| dilated convolutional autoencoder | 3 | applications attacks defenses | 1 |
| language processing nlp | 3 | Arabic Twitter data | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sandu, A.; Ioanăș, I.; Delcea, C.; Geantă, L.-M.; Cotfas, L.-A. Mapping the Landscape of Misinformation Detection: A Bibliometric Approach. Information 2024, 15, 60. https://doi.org/10.3390/info15010060
Sandu A, Ioanăș I, Delcea C, Geantă L-M, Cotfas L-A. Mapping the Landscape of Misinformation Detection: A Bibliometric Approach. Information. 2024; 15(1):60. https://doi.org/10.3390/info15010060
Chicago/Turabian StyleSandu, Andra, Ioana Ioanăș, Camelia Delcea, Laura-Mădălina Geantă, and Liviu-Adrian Cotfas. 2024. "Mapping the Landscape of Misinformation Detection: A Bibliometric Approach" Information 15, no. 1: 60. https://doi.org/10.3390/info15010060
APA StyleSandu, A., Ioanăș, I., Delcea, C., Geantă, L. -M., & Cotfas, L. -A. (2024). Mapping the Landscape of Misinformation Detection: A Bibliometric Approach. Information, 15(1), 60. https://doi.org/10.3390/info15010060