
Rough Set-Probabilistic Neural Networks Fault Diagnosis Method of Polymerization Kettle Equipment Based on Shuffled Frog Leaping Algorithm

Abstract
:1. Introduction
2. Polyvinyl Chloride (PVC) Polymerization Process
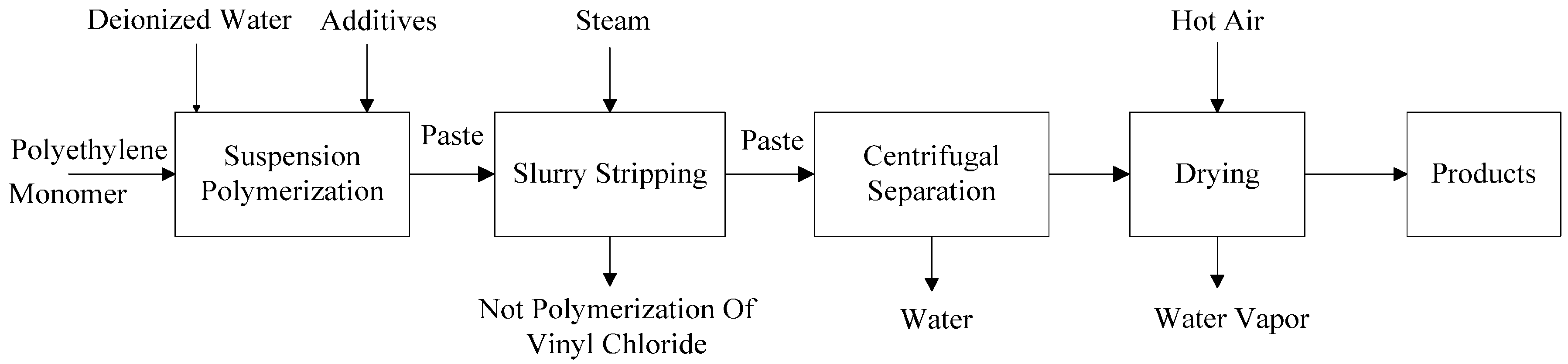
2.1. Technique Flowchart


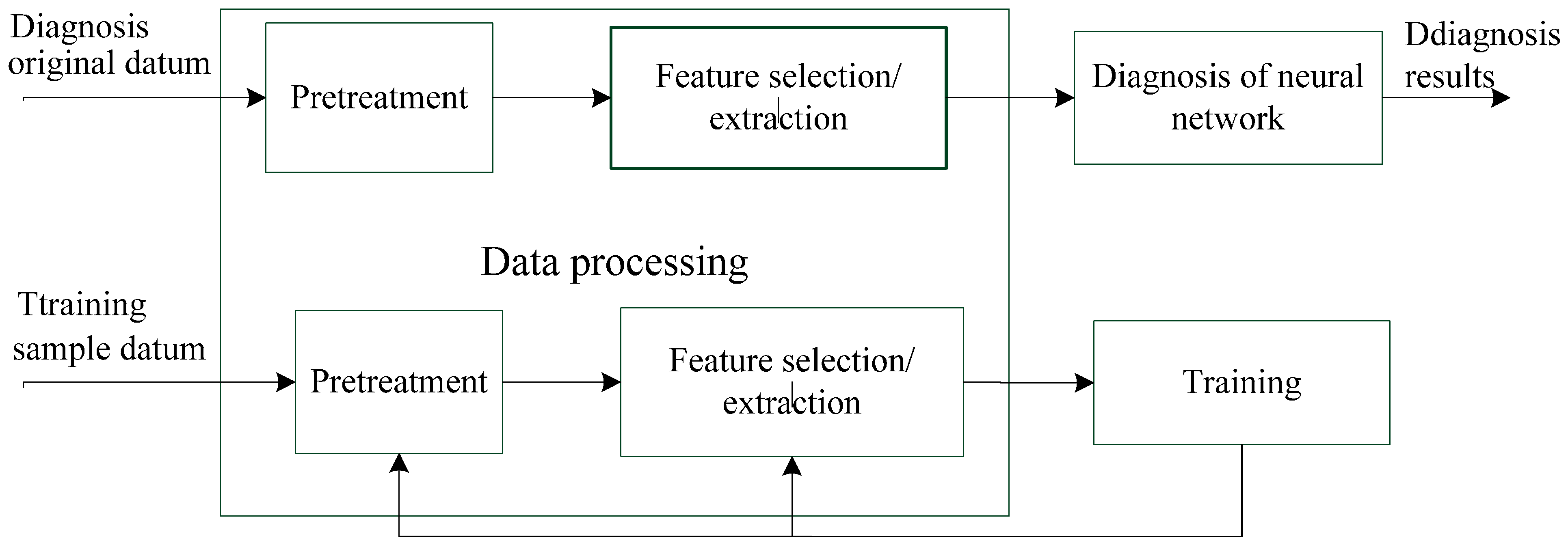
2.2. Structure of Fault Diagnosis System and Information Table


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
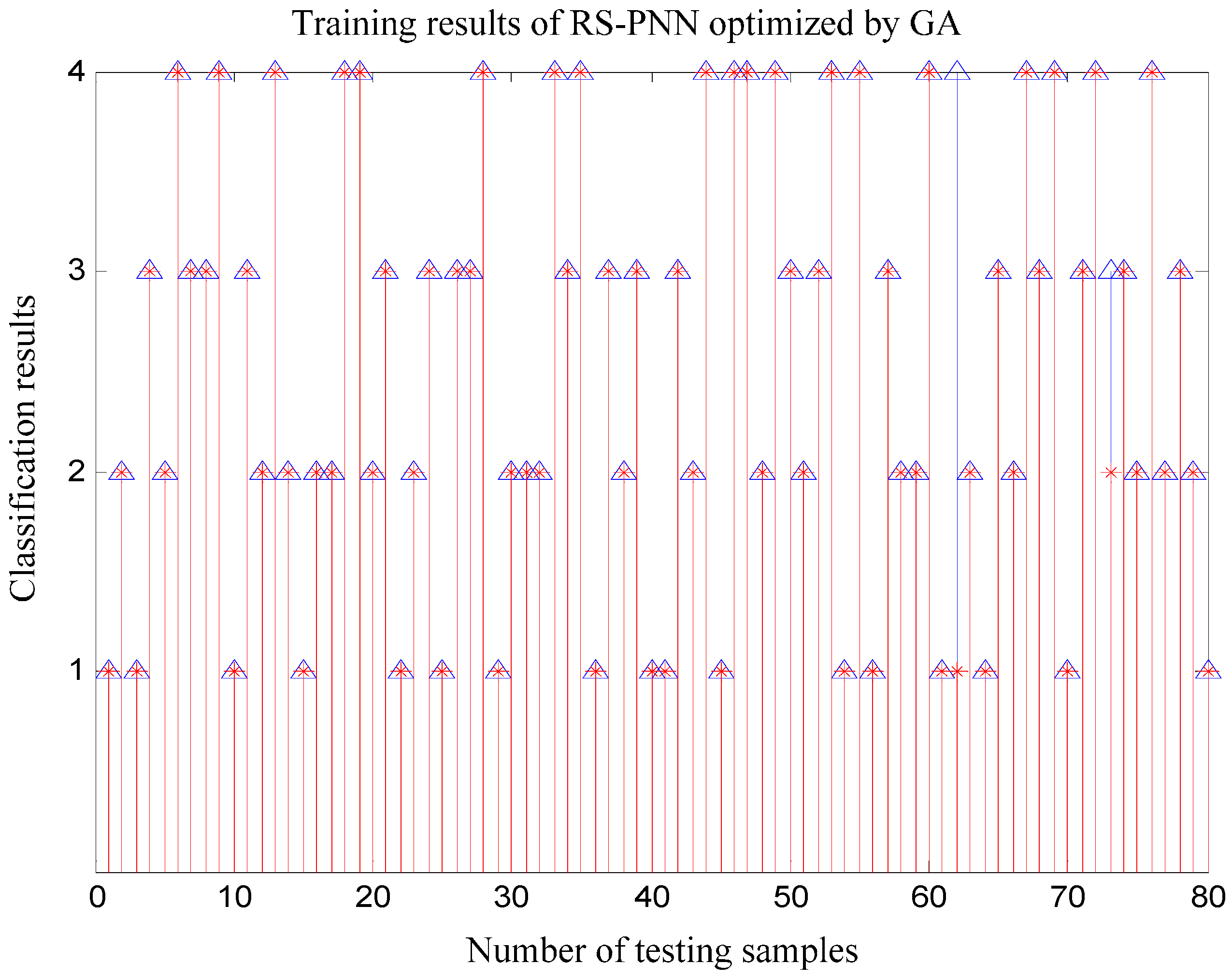{kind=link}
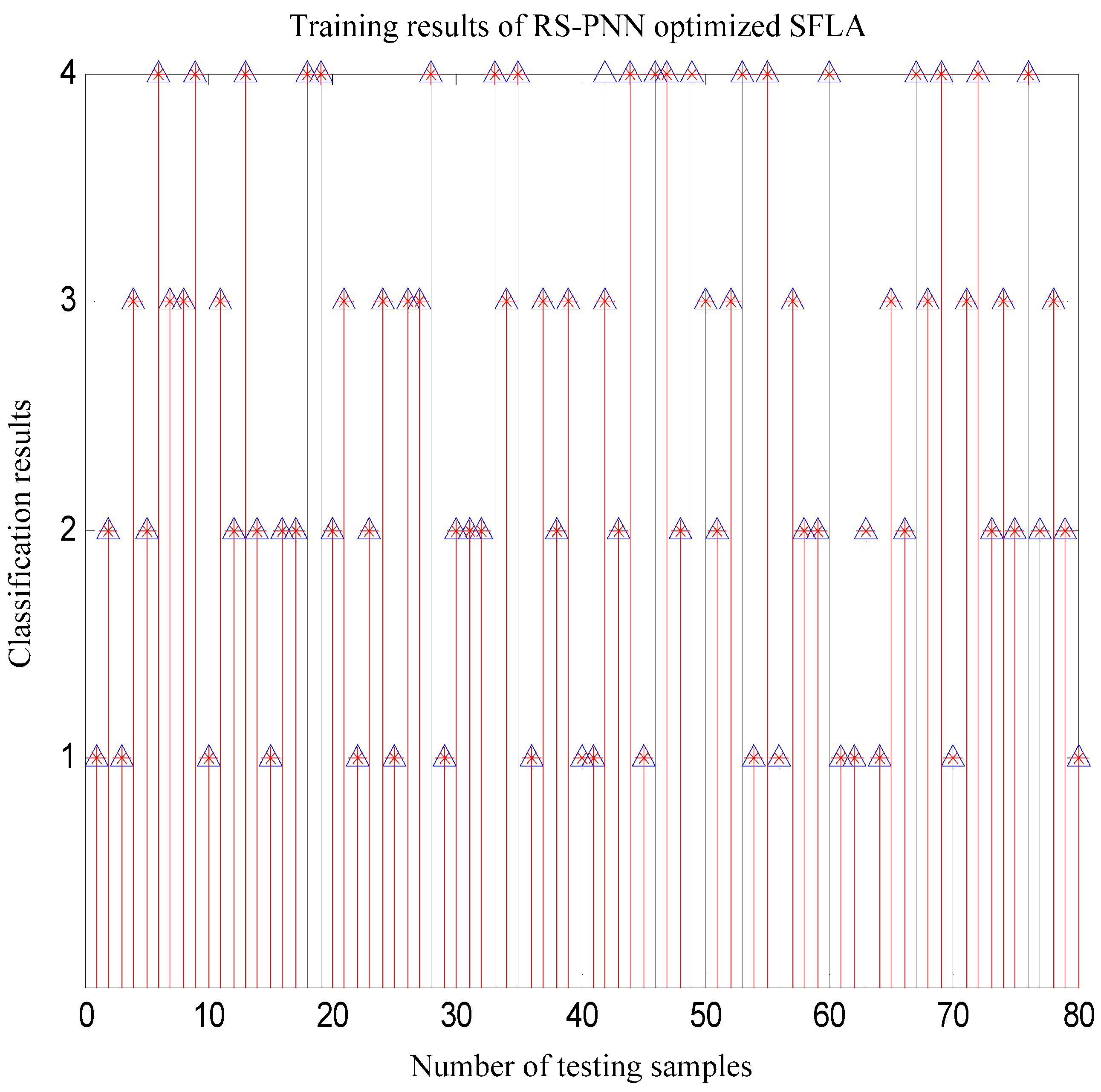{kind=link}
| Sample(U) | Historical Datum of Polymerizer | Diagnosis Type (D) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| a | b | c | d | e | f | g | h | ||
| 1 | 0.38 | 119.1 | 1.55 | 1.45 | 93.10 | 42.6 | 76.13 | 29.52 | 4 |
| 2 | 0.44 | 188.8 | 1.00 | 1.51 | 93.70 | 78.9 | 65.44 | 82.64 | 3 |
| 3 | 0.39 | 138.9 | 1.01 | 1.78 | 93.10 | 92.3 | 66.83 | 29.39 | 1 |
| 4 | 0.38 | 133.4 | 0.88 | 1.34 | 92.80 | 59.9 | 60.32 | 83.50 | 0 |
| 5 | 0.40 | 140.1 | 1.61 | 0.86 | 56.49 | 41.5 | 54.21 | 29.43 | 0 |
| 380 | 0.38 | 138.1 | 1.15 | 1.35 | 91.85 | 78.8 | 52.39 | 29.99 | 0 |
3. Probabilistic Neural Network
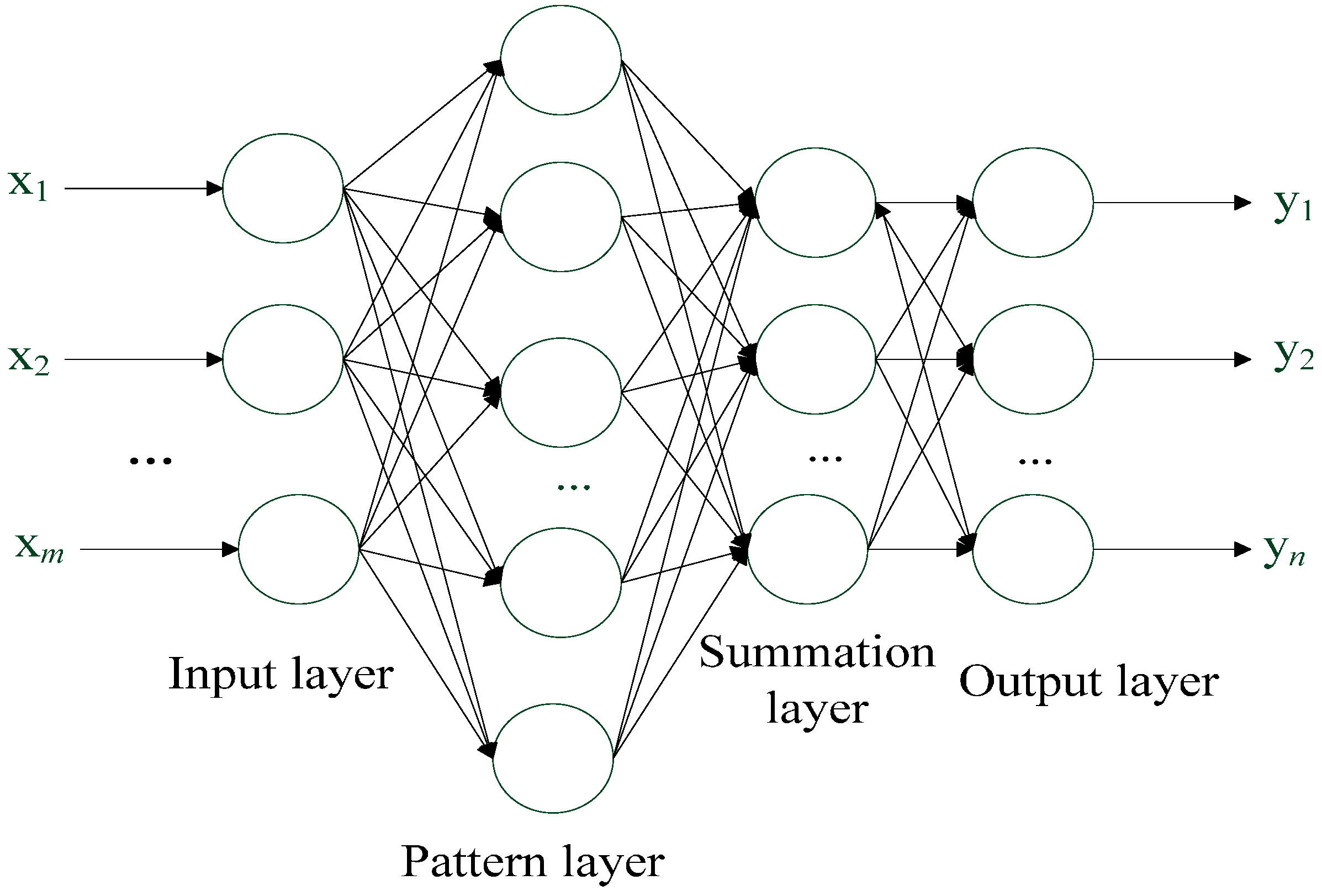
3.1. Structure of PNN

3.2. Learning Algorithm of PNN
4. Rough Set-Probabilistic Neural Network Fault Diagnosis Method Optimized by Shuffled Frog Leaping Algorithm
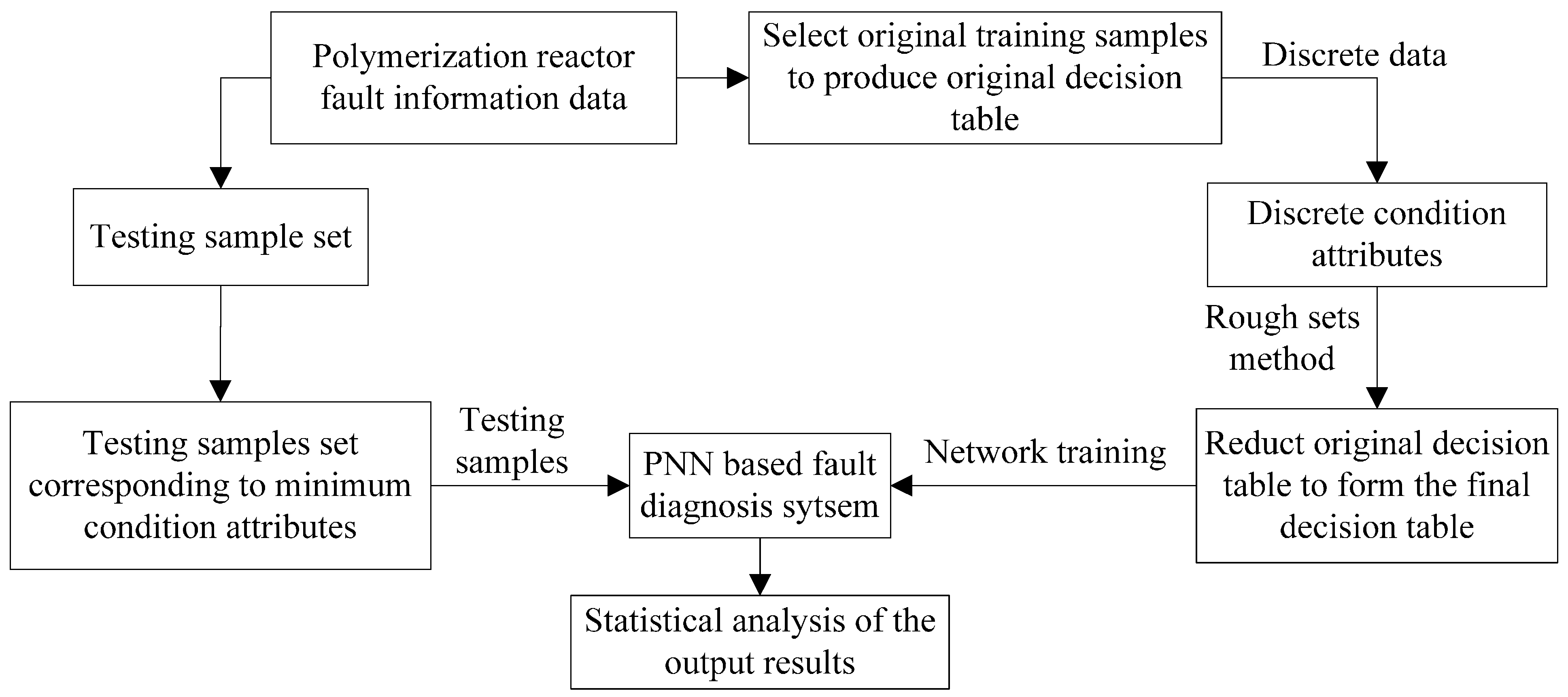
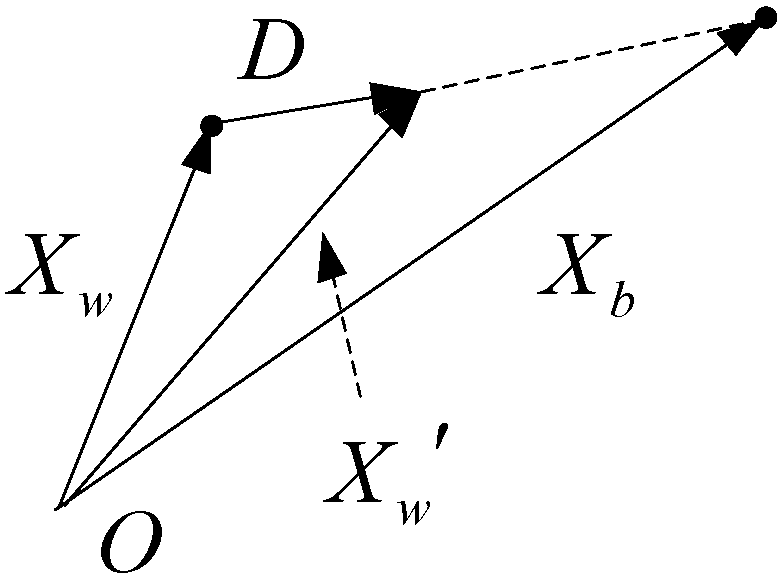
4.1. Polymerization Fault Diagnosis System Based on Rough Set and PNN

4.2. Attribute Reduction Based on Rough Set (RS) Theory
| Sample (U) | Condition Attribute | Decision Attribute (D) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| S1 | S2 | S3 | S4 | S5 | S6 | S7 | S8 | ||
| 1 | 1 | 1 | 2 | 4 | 2 | 2 | 5 | 1 | 4 |
| 2 | 1 | 2 | 1 | 3 | 2 | 1 | 1 | 1 | 0 |
| 3 | 1 | 2 | 1 | 3 | 1 | 2 | 1 | 1 | 0 |
| 4 | 1 | 1 | 2 | 5 | 2 | 4 | 2 | 1 | 1 |
| 5 | 1 | 2 | 1 | 4 | 2 | 2 | 2 | 2 | 3 |
| 380 | 1 | 1 | 2 | 4 | 2 | 2 | 5 | 1 | 4 |
4.3. Shuffled Frog Leaping Algorithm

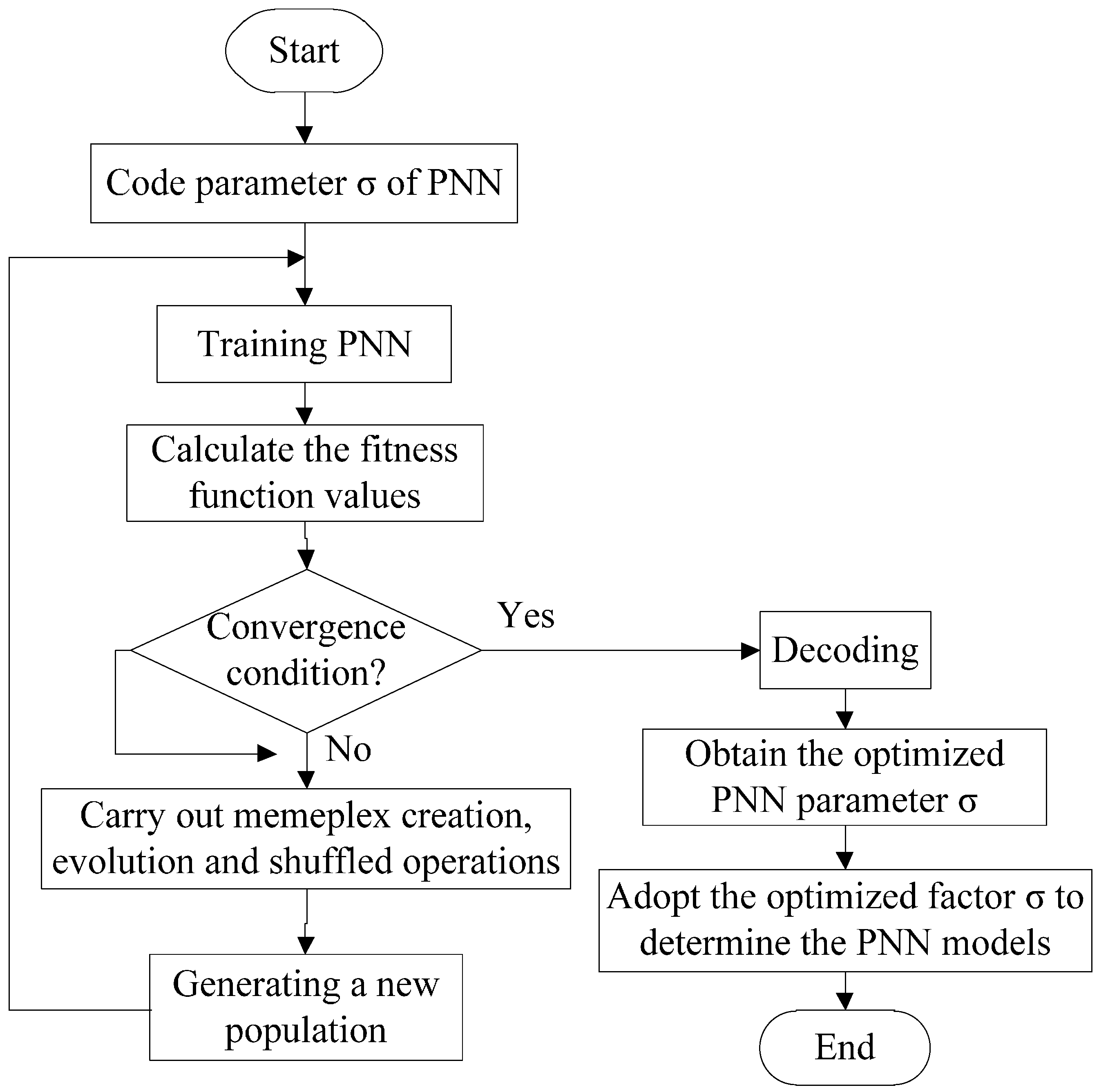
4.4. PNN Optimized by SFLA

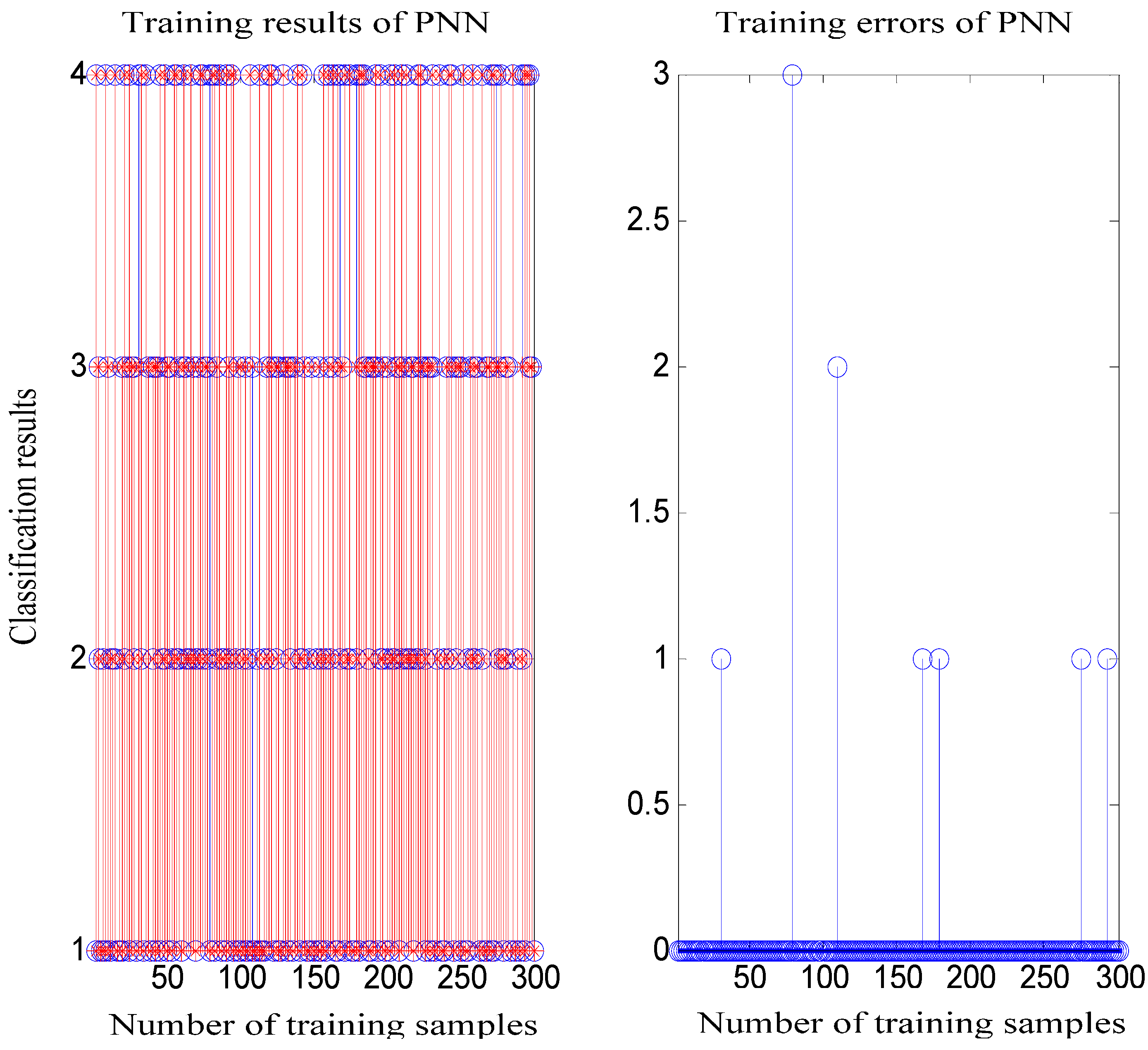
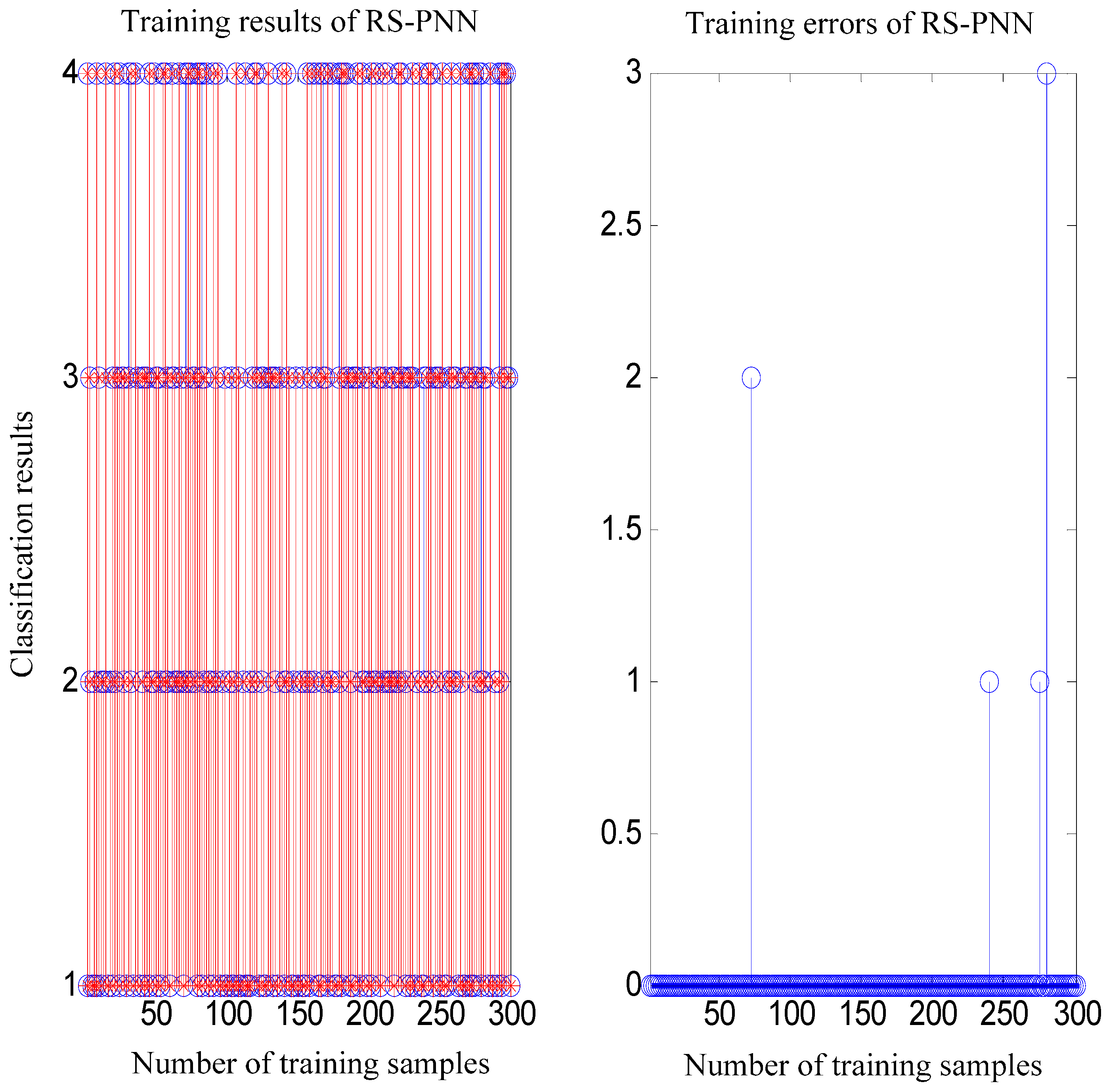
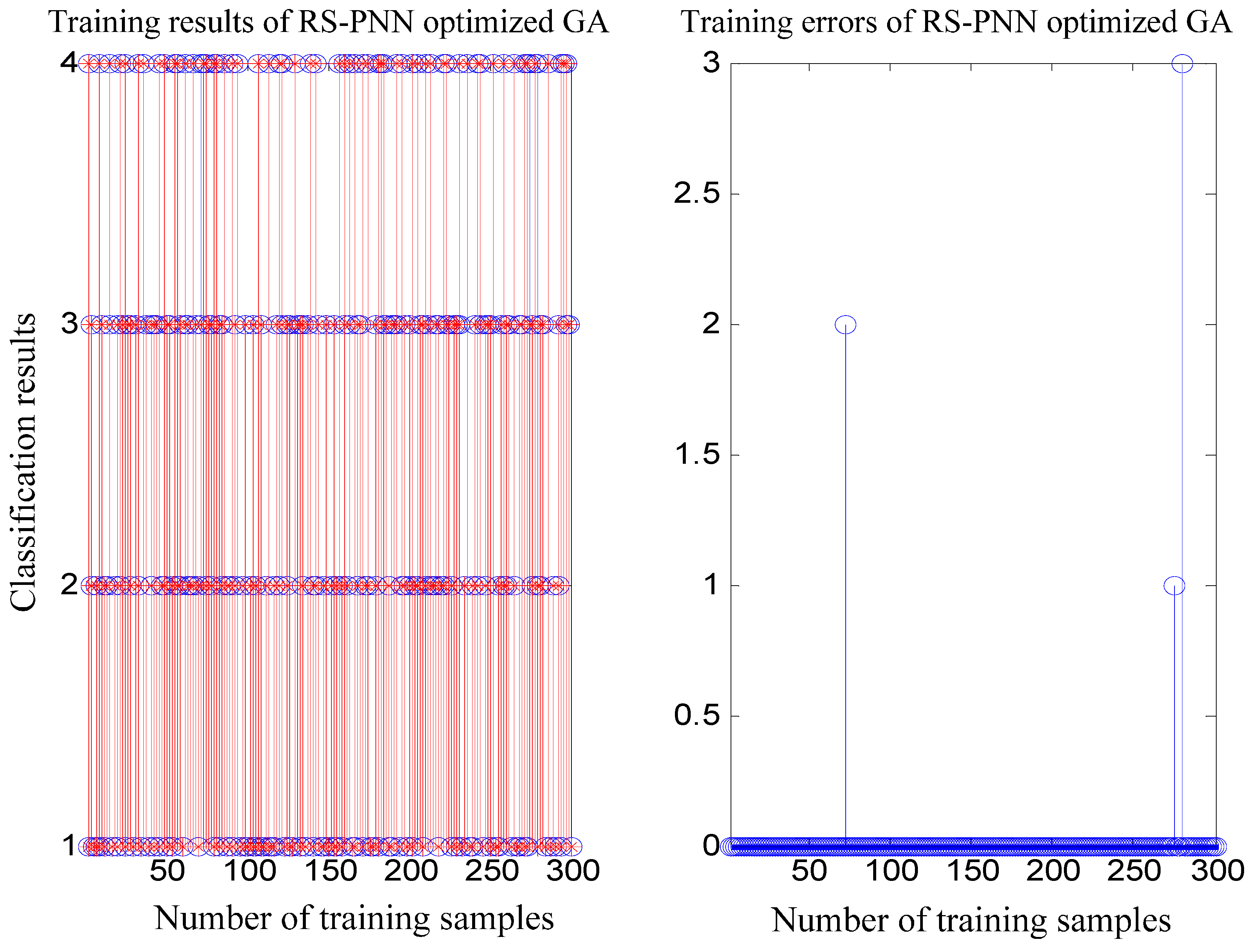
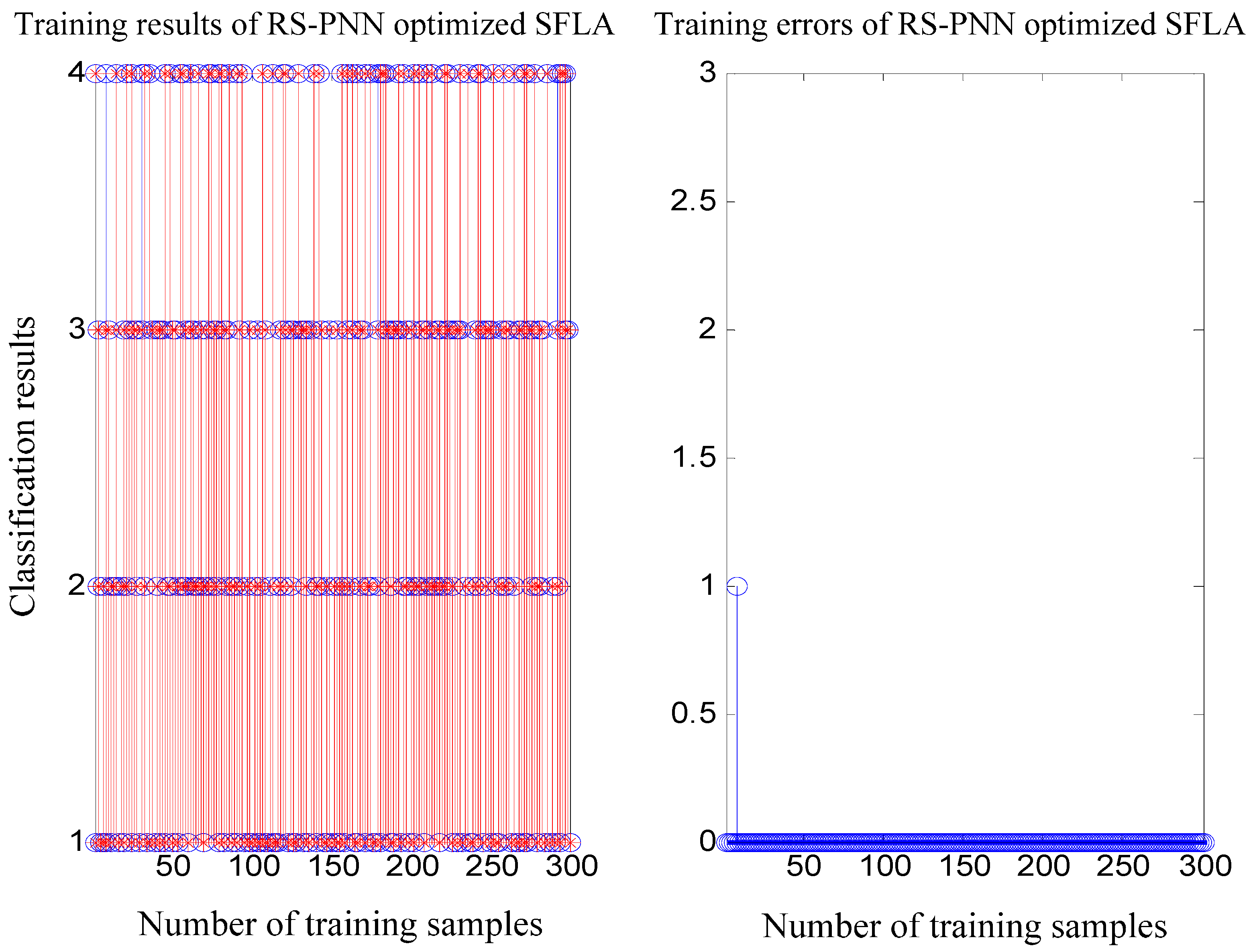
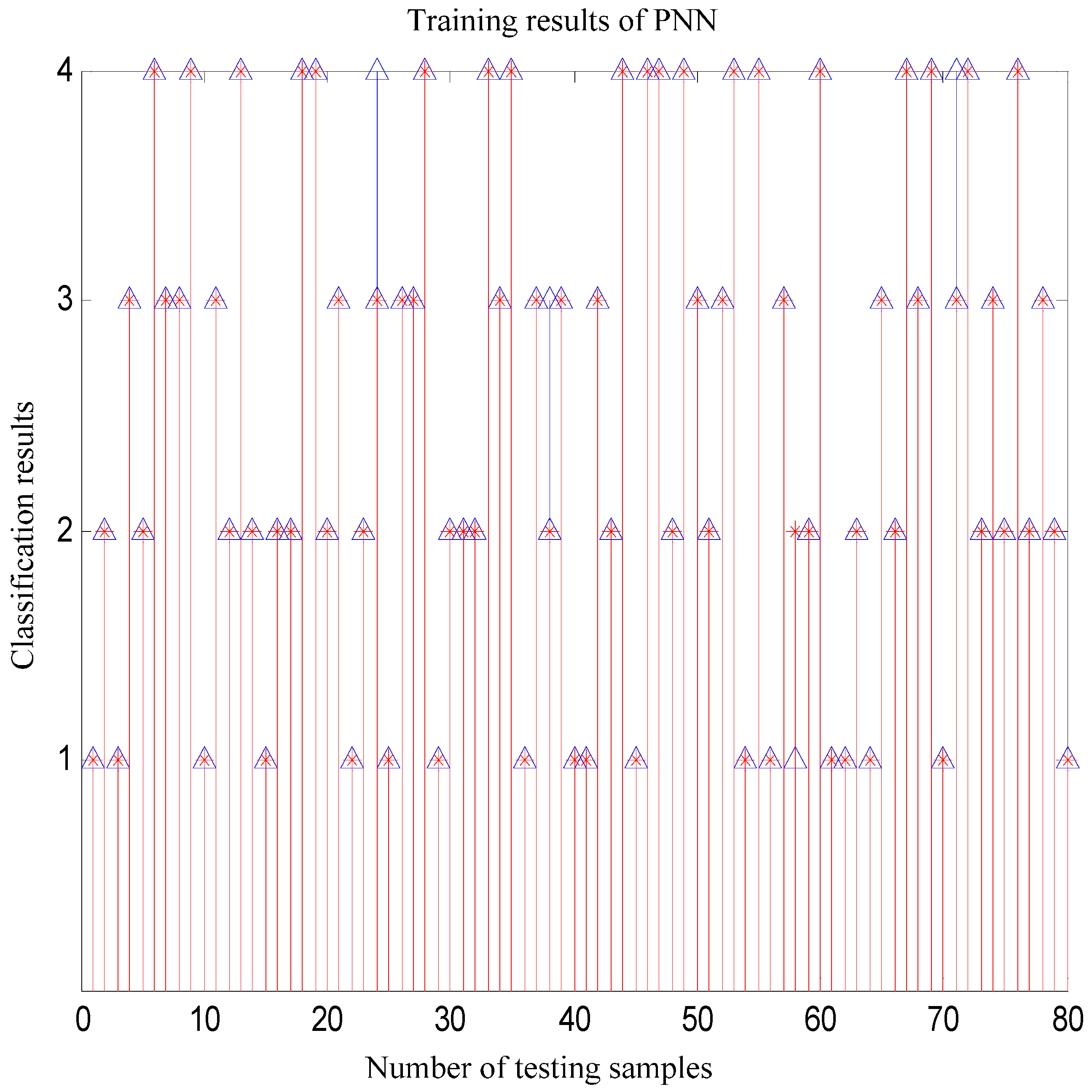
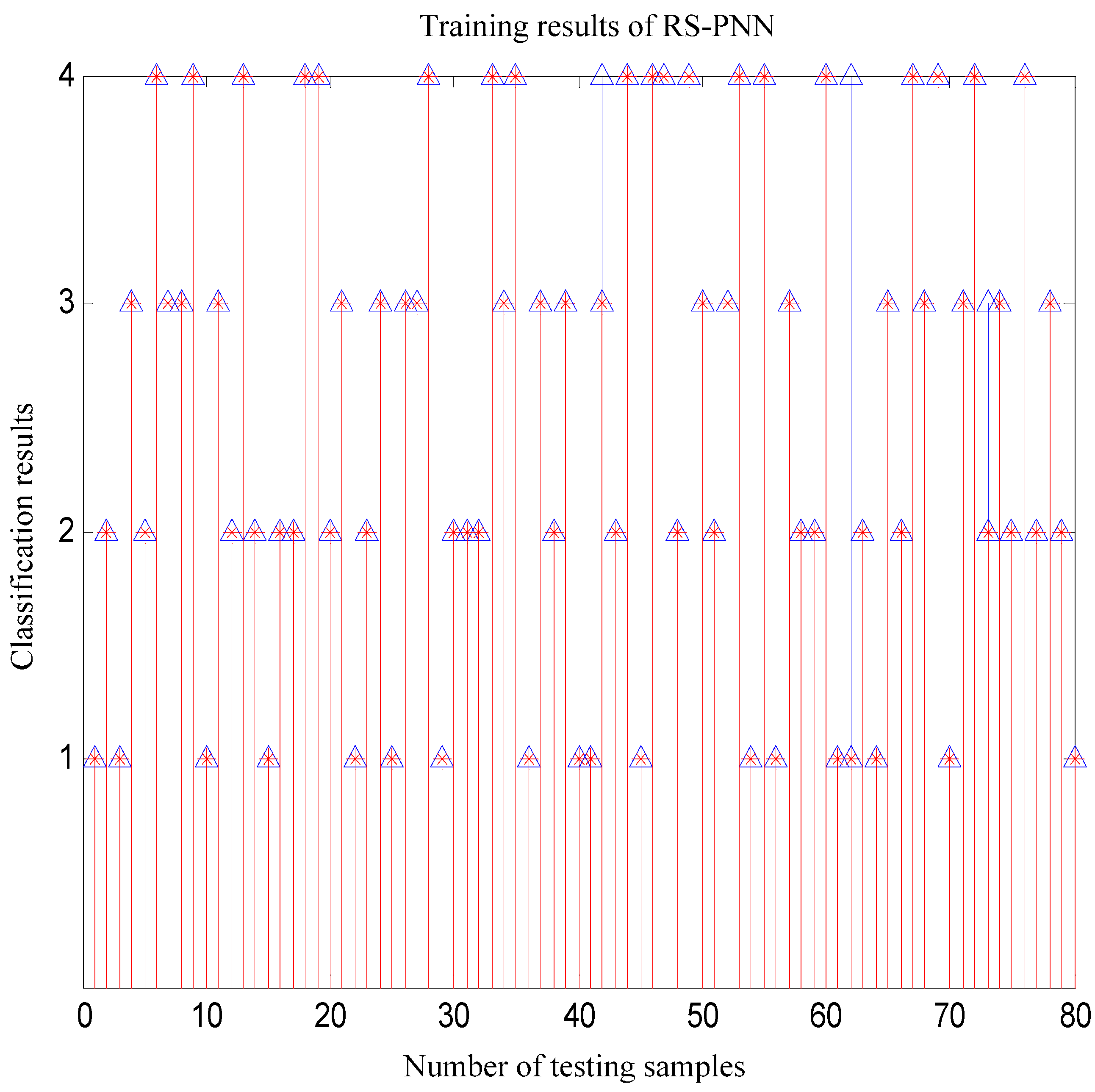
5. Simulation Experiments and Results Analysis








6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Zhou, S.; Ji, G.; Yang, Z.; Chen, W. Hybrid intelligent control scheme of a polymerization kettle for ACR production. Knowl.-Based Syst. 2011, 24, 1037–1047. [Google Scholar] [CrossRef]
- Gao, S.Z.; Wang, J.S. Design of fault diagnosis system for polymerizer process based on neural network expert system. In Proceedings of the 2011 International Conference on Electric Information and Control Engineering (ICEICE 2011), Wuhan, China, 15–17 April 2011; pp. 3171–3174.
- Gao, S.Z.; Wang, J.S.; Zhao, N. Fault Diagnosis Method of Polymerization Kettle Equipment Based on Rough Sets and BP Neural Network. Math. Probl. Eng. 2013, 2013, 768018. [Google Scholar]
- Wang, J.S.; Gao, J. Data driven fault diagnose method of polymerize kettle equipment. In Proceedings of the 2013 32nd Chinese Control Conference (CCC 2013), Xi’an, China, 26–28 July 2013; pp. 7912–7917.
- Venkatesh, S.; Gopal, S. Orthogonal least square center selection technique—A robust scheme for multiple source Partial Discharge pattern recognition using Radial Basis Probabilistic Neural Network. Expert Syst. Appl. 2011, 38, 8978–8989. [Google Scholar] [CrossRef]
- Saritha, M.; Joseph, K.P.; Mathew, A.T. Classification of MRI brain images using combined wavelet entropy based spider web plots and probabilistic neural network. Pattern Recognit. Lett. 2013, 34, 2151–2156. [Google Scholar] [CrossRef]
- Chung, T.Y.; Chen, Y.M.; Tang, S.C. A hybrid system integrating signal analysis and probabilistic neural network for user motion detection in wireless networks. Expert Syst. Appl. 2012, 39, 3392–3403. [Google Scholar] [CrossRef]
- Timung, S.; Mandal, T.K. Prediction of flow pattern of gas-liquid flow through circular microchannel using probabilistic neural network. Appl. Soft Comput. 2013, 13, 1674–1685. [Google Scholar] [CrossRef]
- Jiang, S.F.; Fu, C.; Zhang, C. A hybrid data-fusion system using modal data and probabilistic neural network for damage detection. Adv. Eng. Softw. 2011, 42, 368–374. [Google Scholar] [CrossRef]
- Xu, J.; Liu, C.; Zhou, Q. Study on Steam Turbine Fault Diagnosis of Fish-Swarm Optimized Probabilistic Neural Network Algorithm. In Future Intelligent Information Systems; Springer: Berlin/Heidelberg, Germany, 2011; pp. 65–72. [Google Scholar]
- Ngaopitakkul, A.; Jettanasen, C. Combination of discrete wavelet transform and probabilistic neural network algorithm for detecting fault location on transmission system. Int. J. Innov. Comput. Inf. Control 2011, 7, 1861–1874. [Google Scholar]
- Wang, C.; Zhou, J.; Qin, H.; Li, C.; Zhang, Y. Fault diagnosis based on pulse coupled neural network and probability neural network. Expert Syst. Appl. 2011, 38, 14307–14313. [Google Scholar]
- Er, O.; Tanrikulu, A.C.; Abakay, A.; Temurtas, F. An approach based on probabilistic neural network for diagnosis of Mesothelioma’s disease. Comput. Electr. Eng. 2012, 38, 75–81. [Google Scholar] [CrossRef]
- Mantzaris, D.; Anastassopoulos, G.; Adamopoulos, A. Genetic algorithm pruning of probabilistic neural networks in medical disease estimation. Neural Netw. 2011, 24, 831–835. [Google Scholar] [CrossRef] [PubMed]
- Sankari, Z.; Adeli, H. Probabilistic neural networks for diagnosis of Alzheimer’s disease using conventional and wavelet coherence. J. Neurosci. Methods 2011, 197, 165–170. [Google Scholar] [CrossRef] [PubMed]
- Chatterjee, S.; Bandopadhyay, S. Reliability estimation using a genetic algorithm-based artificial neural network: An application to a load-haul-dump machine. Expert Syst. Appl. 2012, 39, 10943–10951. [Google Scholar] [CrossRef]
- Yao, Y. The superiority of three-way decisions in probabilistic rough set models. Inf. Sci. 2011, 181, 1080–1096. [Google Scholar] [CrossRef]
- Qian, Y.; Liang, J.; Pedrycz, W.; Dang, C. An efficient accelerator for attribute reduction from incomplete data in rough set framework. Pattern Recognit. 2011, 44, 1658–1670. [Google Scholar] [CrossRef]
- Chen, Y.; Miao, D.; Wang, R.; Wu, K. A rough set approach to feature selection based on power set tree. Knowl.-Based Syst. 2011, 24, 275–281. [Google Scholar] [CrossRef]
- Yao, Y.; Zhao, Y. Discernibility matrix simplification for constructing attribute reducts. Inf. Sci. 2009, 7, 867–882. [Google Scholar] [CrossRef]
- Huynh, T.-H. A modified shuffled frog leaping algorithm for optimal tuning of multivariable PID controllers. In Proceedings of the 2008 IEEE International Conference on Industrial Technology, Chengdu, China, 21–24 April 2008; pp. 1–6.
- Eusuff, M.M.; Lansey, K.E. Optimization of water distribution network design using the shuffled frog leaping algorithm. J. Water Resour. Plan. Manag. 2003, 129, 210–225. [Google Scholar] [CrossRef]
- Elbeltagi, E.; Hezagy, T.; Grierson, D. Comparison among five evolutionary-based optimization algorithms. Adv. Eng. Inform. 2005, 19, 43–53. [Google Scholar] [CrossRef]
- Rahimi-Vahed, A.; Mirzaei, A.H. A hybrid multi-objective shuffled frog-leaping algorithm for a mixed-model assembly line sequencing problem. Comput. Ind. Eng. 2007, 53, 642–666. [Google Scholar] [CrossRef]
- Zhu, G.-Y. Meme triangular probability distribution shuffled frog-leaping algorithm. Comput. Integr. Manuf. Syst. 2009, 15, 1979–1985. [Google Scholar]
- Rahimi-Vahed, A.; Dangchi, M.; Rafiei, H. A novel hybrid multi-objective shuffled frog-leaping algorithm for a bi-criteria permutation flow shop scheduling problem. Int. J. Adv. Manuf. Technol. 2009, 41, 1227–1239. [Google Scholar] [CrossRef]
- Amiri, B.; Fathian, M.; Maroosi, A. Application of Shuffled frog-leaping algorithm on clustering. Int. J. Adv. Manuf. Technol. 2009, 45, 199–209. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.-S.; Song, J.-D.; Gao, J. Rough Set-Probabilistic Neural Networks Fault Diagnosis Method of Polymerization Kettle Equipment Based on Shuffled Frog Leaping Algorithm. Information 2015, 6, 49-68. https://doi.org/10.3390/info6010049
Wang J-S, Song J-D, Gao J. Rough Set-Probabilistic Neural Networks Fault Diagnosis Method of Polymerization Kettle Equipment Based on Shuffled Frog Leaping Algorithm. Information. 2015; 6(1):49-68. https://doi.org/10.3390/info6010049
Chicago/Turabian StyleWang, Jie-Sheng, Jiang-Di Song, and Jie Gao. 2015. "Rough Set-Probabilistic Neural Networks Fault Diagnosis Method of Polymerization Kettle Equipment Based on Shuffled Frog Leaping Algorithm" Information 6, no. 1: 49-68. https://doi.org/10.3390/info6010049
APA StyleWang, J. -S., Song, J. -D., & Gao, J. (2015). Rough Set-Probabilistic Neural Networks Fault Diagnosis Method of Polymerization Kettle Equipment Based on Shuffled Frog Leaping Algorithm. Information, 6(1), 49-68. https://doi.org/10.3390/info6010049