
Graph Regularized Within-Class Sparsity Preserving Projection for Face Recognition


Abstract
:1. Introduction
2. Sparsity Preserving Projections
3. Graph Regularized Within-Class Sparsity Preserving Analysis
3.1. Preserve the Sparsity Structure for Within-Class Samples
3.2. Discover the Discriminant Structure for between Class Samples
3.3. GRWSPA
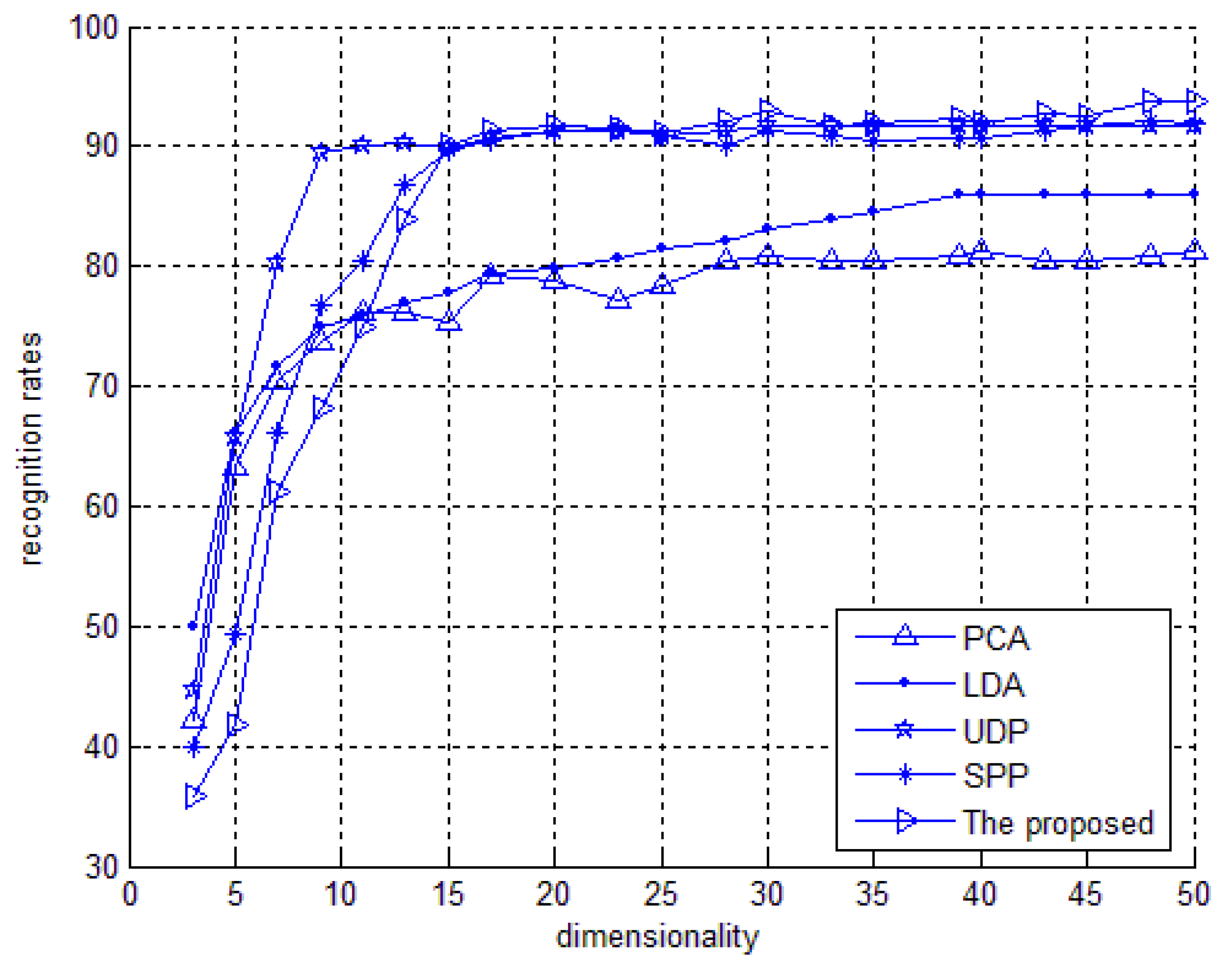
4. Experimental Section


{kind=link}
{kind=link}
{kind=link}
| Training | PCA | LDA | UDP | SPP | GRWSPA |
|---|---|---|---|---|---|
| 3 | 78.2 | 84.7 | 82.8 | 83.2 | 82.8 |
| 4 | 83.7 | 90.8 | 88.2 | 88.8 | 89.9 |
| 5 | 86.8 | 93.7 | 88.7 | 90.4 | 95.2 |
| 6 | 89.1 | 95.6 | 93.8 | 91.5 | 96.8 |
| 7 | 92.4 | 96.9 | 94.7 | 94.8 | 98.1 |


| Training | PCA | LDA | UDP | SPP | GRWSPA |
|---|---|---|---|---|---|
| 3 | 70.9 | 72.9 | 74.8 | 75.7 | 76.5 |
| 4 | 73.4 | 74.5 | 75.8 | 77.4 | 75.9 |
| 5 | 73.9 | 75.9 | 78.2 | 79.3 | 82.6 |
| 6 | 75.3 | 76.2 | 80.5 | 81.4 | 85.5 |
| 7 | 76.8 | 78.1 | 82.4 | 83.6 | 87.8 |
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Sandbach, G.; Zafeiriou, S.; Pantic, M.; Yin, L. Static and Dynamic 3D Facial Expression Recognition: A Comprehensive Survey. Image Vis. Comput. 2012, 30, 683–697. [Google Scholar] [CrossRef]
- Vezzetti, E.; Marcolin, F. 3D human face description: Landmarks measures and geometrical feature. Image Vis. Comput. 2012, 30, 698–712. [Google Scholar] [CrossRef]
- Pears, N.; Heseltine, T.; Romero, M. From 3D point clouds to pose-normalised depth maps. Int. J. Comput. Vis. 2010, 89, 152–176. [Google Scholar] [CrossRef]
- Vezzetti, E.; Marcolin, F.; Stola, V. 3D human face soft tissues landmarking method: An advanced approach. Comput. Ind. 2013, 64, 1326–1354. [Google Scholar] [CrossRef]
- Turk, M.; Pentland, A. Eigenfaces for recognition. Cogn. Neurosci. 1991, 3, 71–86. [Google Scholar] [CrossRef]
- Belhume, P.N.; Hespanha, J.P.; Kriegman, D.J. Eigenfaces vs. Fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef]
- Seung, H.S.; Lee, D.D. The Manifold Ways of Perception. Science 2000, 290, 2268–2269. [Google Scholar] [CrossRef] [PubMed]
- Scholkopf, B.; Smola, A.; Smola, E.; Müller, K.-R. Nonlinear Component Analysis as a Kernel Eigenvalue Problem. Neural Comput. 1998, 10, 1299–1399. [Google Scholar] [CrossRef]
- Baudat, G.; Anouar, F. Generalized Discriminant Analysis Using Kernel Approach. Neural Comput. 2000, 12, 2385–2404. [Google Scholar] [CrossRef] [PubMed]
- Tenenbaum, J.B.; de Silva, V.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef] [PubMed]
- Rowies, S.T.; Saul, L.K. Nonliear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed]
- Belkin, M.; Niyogo, P. Laplacian eigenmaps for dimensionality reduction and data representation. Neural Comput. 2003, 15, 1373–1396. [Google Scholar] [CrossRef]
- Raducanu, B.; Dornaika, F. Embedding new observations via sparse-coding for non-linear manifold learning. Pattern Recognit. 2014, 47, 480–492. [Google Scholar] [CrossRef]
- He, X.; Yan, S.; Hu, Y.; Niyogi, P.; Zhang, H.-J. Face recognition using Laplacianfaces. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 328–340. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.-T.; Chang, H.-W.; Liu, T.-L. Local Discriminant Embedding and Its Variants. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05), San Diego, CA, USA, 20–25 June 2005; IEEE Computer Society: Washington, DC, USA, 2005; pp. 846–853. [Google Scholar]
- Yan, S.; Xu, D.; Zhang, B.; Zhang, H.-J.; Yang, Q.; Lin, S. Graph embedding and extensions: A general framework for dimensionality reduction. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 40–51. [Google Scholar] [CrossRef] [PubMed]
- Fu, Y.; Yan, S.; Huang, T.S. Classification and feature extraction by simplexization. IEEE Trans. Inf. Forensics Secur. 2008, 3, 91–100. [Google Scholar] [CrossRef]
- Zhang, T.; Yang, J.; Wang, H.; Du, C.; Zhao, D. Maximum variance projections for face recognition. Opt. Eng. 2007, 46, 067206:1–067206:8. [Google Scholar]
- Wang, Y.; Zhao, Y.; Zhang, L.; Liang, J.; Zeng, M.; Liu, X. Graph Construction Based on Re-weighted Sparse Representation for Semi-supervised Learning. J. Inf. Comput. Sci. 2013, 10, 375–383. [Google Scholar]
- Cheng, H.; Liu, Z.; Yang, J. Sparsity induced similarity measure for label propagation. In Proceedings of IEEE 12th International Conference on Computer Vision (ICCV), Kyoto, Japan, 27 September–4 October 2009; pp. 317–324.
- Yan, S.; Wang, H. Semi-supervised Learning by Sparse Representation. In Proceedings of the 9th SIAM International Conference on Data Mining (SDM 09), Sparks, NV, USA, 30 April–2 May 2009; pp. 792–801.
- Wright, J.; Yang, A.Y.; Ganesh, A.; Shankar, S.S.; Ma, Y. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Qiao, L.; Chen, S.; Tan, X. Sparsity Preserving Projections with Applications to Face Recognition. Pattern Recognit. 2010, 43, 331–341. [Google Scholar] [CrossRef]
- Chen, S.S.; Donoho, D.L.; Saunders, M.A. Atomic decomposition by basis pursuit. SIAM Rev. 2001, 43, 129–159. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, D.; Yang, J.-Y.; Niu, B. Globally maximizing, locally minimizing: Unsupervised discriminant projection with application to face and palm biometrics. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 650–664. [Google Scholar] [CrossRef] [PubMed]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lou, S.; Zhao, X.; Guo, W.; Chen, Y. Graph Regularized Within-Class Sparsity Preserving Projection for Face Recognition. Information 2015, 6, 152-161. https://doi.org/10.3390/info6020152
Lou S, Zhao X, Guo W, Chen Y. Graph Regularized Within-Class Sparsity Preserving Projection for Face Recognition. Information. 2015; 6(2):152-161. https://doi.org/10.3390/info6020152
Chicago/Turabian StyleLou, Songjiang, Xiaoming Zhao, Wenping Guo, and Ying Chen. 2015. "Graph Regularized Within-Class Sparsity Preserving Projection for Face Recognition" Information 6, no. 2: 152-161. https://doi.org/10.3390/info6020152
APA StyleLou, S., Zhao, X., Guo, W., & Chen, Y. (2015). Graph Regularized Within-Class Sparsity Preserving Projection for Face Recognition. Information, 6(2), 152-161. https://doi.org/10.3390/info6020152