In this section the major methods that will be used in mode detection are discussed. Being one type of SVM, SVC will be leveraged to identifying the traffic mode with GPS data. Compared to the multinomial logit (MNL) model, which has the limitation of determining alternatives with significant correlation (such as bus and car), SVC can provide us with higher prediction accuracy. Besides, GA will also be employed to optimize the major parameters in SVC in order to enhance the solution quality and calculation efficiency of the model.
4.1. SVC
Being a popular disaggregate model, the MNL model has been widely used in mode prediction and identification. However, it imposes the restriction that the distribution of the random error terms is independent and identical over alternatives. This restriction leads to limitation of random taste variation and the independence of irrelevant alternatives, which causes the cross-elastics among all pairs of alternatives to be identical [
21]. Compared to the MNL model, SVC has been more frequently applied in modeling disaggregate choices in recent years due to its ability to enhance the prediction accuracy and calculation efficiency [
22]. Therefore, this paper will introduce SVC in estimating of travel mode with GPS data.
SVC is one of the SVM (
i.e., machine learning) methods analyzing data and recognizing patterns. Given a set of input-output data pairs (
x1,
y1), (
x2,
y2), …, (
xl,
yl) (
,
,
l is the number of training samples) that are randomly and independently generated from an unknown function, SVM estimates the function using the following Equation [
23]:
where
represents the high-dimensional feature spaces that are nonlinearly mapped from the input space
x.
w denotes a parameter vector and
b is the threshold [
24]. If the interpretation
y only takes category values,
i.e., −1 and +1, it denotes SVC. Otherwise, if the domain of output space
y contains continuous real values, the learning problem then refers to Support Vector Regression (SVR) [
25].
For classification about the training data, SVM’s linear soft margin algorithm is to solve the following regularized risk function:
The first term
is called the regularized term, which is used as a measurement of the function flatness. The second term
is the so-called loss function to measure the empirical error.
C is a regularization constant that determines the trade-off between the training error and the generalization performance. Here, the ε-insensitive loss function is employed to measure empirical error:
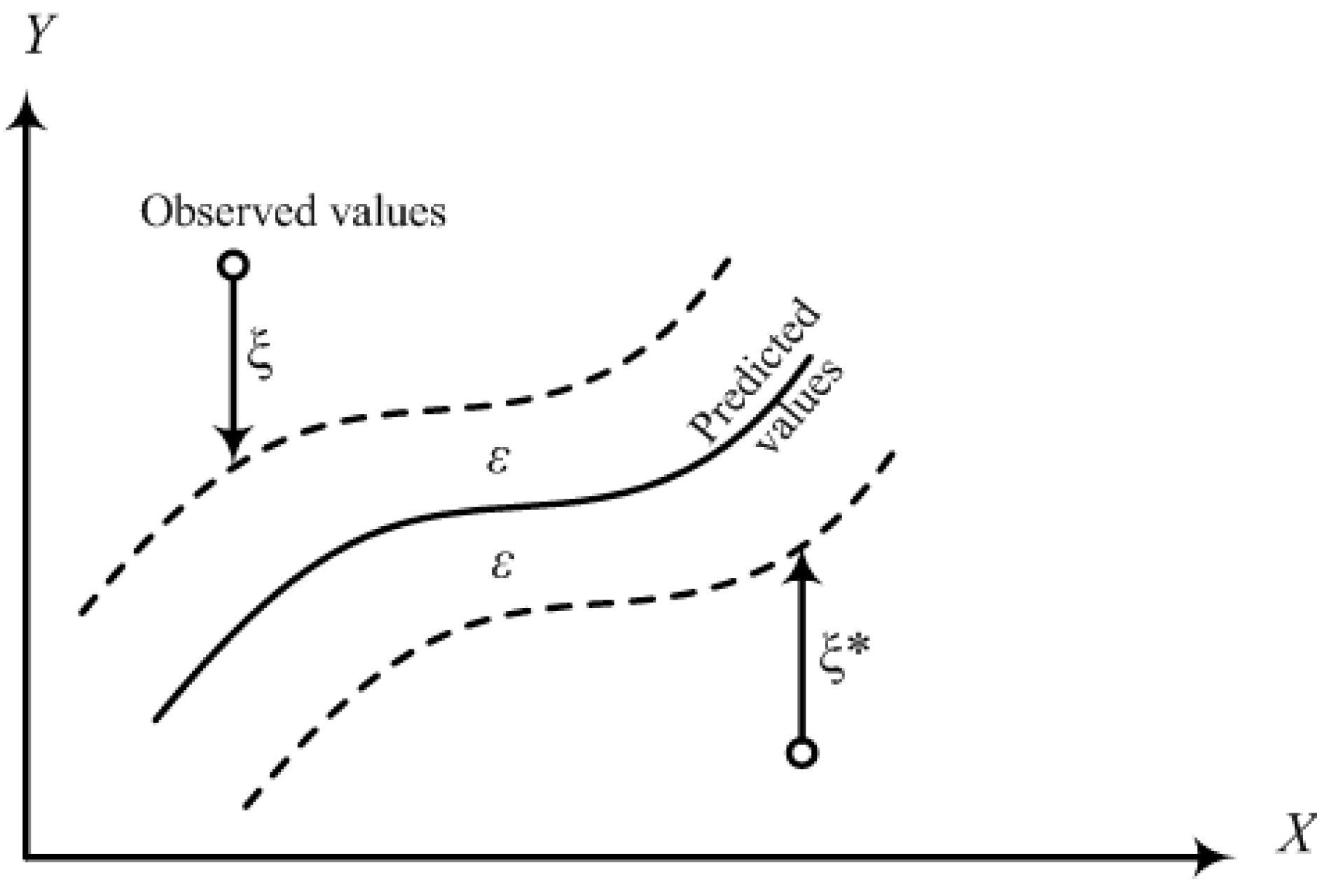
Equation (3) defines a ε tube (shown in
Figure 2). The loss is zero if the predicted value is within the tube. If it is outside the tube, the loss is the magnitude of the difference between the predicted value and the radius
ε of the tube. Both
C and
ε are user-determined parameters. Two positive slack variables ξ, ξ
* are used to cope with the constraints of the optimization problem. To get the estimation of
w and
b, Equation (2) can be transformed to a primal objective function, Equation (4):
Figure 2.
The parameters for SVC.
This constrained optimization problem is solved by using the following primal Lagrangian form:
where
L is the Lagrangian, and
,
,
,
are Lagrange multipliers. Hence the dual variables in Equation (5) have to satisfy the positive constraints:
The above problem can be converted into a dual problem where the task is to optimize the Lagrangian multipliers,
and
. The dual problem contains a quadratic objective function of
and
with one linear constraint:
Let
Thus,
By introducing kernel function
K(
xi,xj), Equation (9) can be rewritten as follows:
where
K(
xi,
xj) is the so-called kernel function which is equal to the inner product of two vectors
xi and
xj in the feature space
and
; that is,
.
The kernel function would be more simply without the compution of Ф(X). Some popular kernel functions are the linear kernel, polynomial kernel, and radial-basis function (RBF) kernel. Using different kernel functions, one can construct different learning machines with arbitrary types of decision surfaces. In general, the RBF kernel, as a nonlinearly kernel function, is a reasonable first choice [
26]. Thus, the RBF kernel is chosen in this work:
where σ is a parameter that determines the area of influence this support vector has over the data space.
As user-determined parameters in SVC and the RBF kernel, C, ε, and σ will greatly influence the estimation efficiency and prediction accuracy of the models, especially for large-scale or real-time feature practice application. This paper will optimize the parameters by employing GA. Being a part of evolutionary computing, GA is a rapidly growing area of artificial intelligence. The process of GA is presented as follows.
4.2. Parameter Optimization with GA
Being the key elements in SVC, the parameters C, ε, and σ directly decide the prediction performance of the model. Therefore, the parameter optimization is an important factor for improving the prediction accuracy of SVC. In this paper, GA is applied to optimize C, ε, and σ in SVC. GA is inspired by evolutionary biology processes like inheritance, selection, crossover, and mutation. Based on a fitness function, GA attempts to retain relatively good genetic information from generation to generation. The process of GA can be divided into six steps, which will be described briefly in the following section.
4.2.1. Encoding of Chromosomes
GA starts with a set of solutions (represented by chromosomes) called population. The individuals comprising the population are known as chromosomes. In most GA applications, the chromosomes are encoded as a series of zeroes and ones, or a binary bit string. For the mode detection model with SVC, the real encodings were adopted since the parameters C, ε, and σ are continuous-valued. To represent the parameters in SVC, each chromosome consists of , , and (n refers to the current generation), which represent three parameters, respectively.
To reduce the search space referring to previous literature using SVC, the three parameters should within the range
,
, and
[
27]. An example of the encoding of a chromosome is shown in
Table 2.
Table 2.
An example of chromosome encoding.
| 2−6 ≤ C ≤ 26 | 2−12 ≤ ε ≤ 2−1 | 0 ≤ σ ≤ 2 |
| genn 1 | genn 2 | genn 3 |
4.2.2. Fitness Function
Fitness function determines possible solutions to the problem and is used to estimate the quality of the represented solution (chromosome). For parameter optimizations in SVC, the best solution is able to maximize the accuracy rate of prediction. Generally, GA is an optimal searching method to find the maximum fitness of the individual chromosome. Thus, Hit ratio is adopted in this paper. Here, Hit ratio (
HitR) refers to the fitting degree of the identification results to the observed samples.
where
N1 is the number of hit records (travel mode) predicted by the model and
N2 is the total number of observations.
4.2.3. Crossover Operator
Crossover is a reproduction technique that takes two parent chromosomes and produces two child chromosomes. In this paper, an arithmetic crossover is used to create new offspring [
28].
where
,
is a pair of “parent” chromosomes;
,
is a pair of “children” chromosomes;
is a random number between (0, 1); and
(
k is the total genes of the crossover operation).
Table 3 shows the parents selected for crossover. When k = 1 and
= 0.4, the children chromosomes after crossover are shown in
Table 4.
Table 3.
An example of chromosome encoding.
| Parent I | genn−1 1, I | genn−1 2, I | genn−1 3, I |
| Parent II | genn−1 1, II | genn−1 2, II | genn−1 3, II |
Table 4.
Children chromosomes after crossover.
| Children I | 0.4genn 1,I + 0.6genn 1,II | genn−1 2,I | genn−1 3,I |
| Children II | 0.4genn 1,II + 0.6genn 1,I | genn−1 2,II | genn−1 3,II |
4.2.4. Mutation Operator
Mutation is a common reproduction operator used for finding new points in the searching space to evaluate. A genetic mutation operation is used in this paper [
27].
Assuming a chromosome is
, if the
is selected for the mutation, the mutation can be shown with Equation (14):
Then, the function
returns a value between [0,
y] given in Equation (15):
where
r is a random number between [0,1];
Tmax is maximum number of generations; and λ = 3. This property causes this operation to make a uniform search in the initial space when
n is small, and a very local one in later stages.
To deal with the problem that the mutation may violate the parameters’ constraints, this paper will assign a relatively high weight to reduce their probability of being selected in the following search [
27,
29].
4.2.5. Termination
The search continues until
HitRn-
HitRn-1 < 0.001% or the number of generation reaches the maximum number of generations
Tmax, which is set to be 5000 [
30].
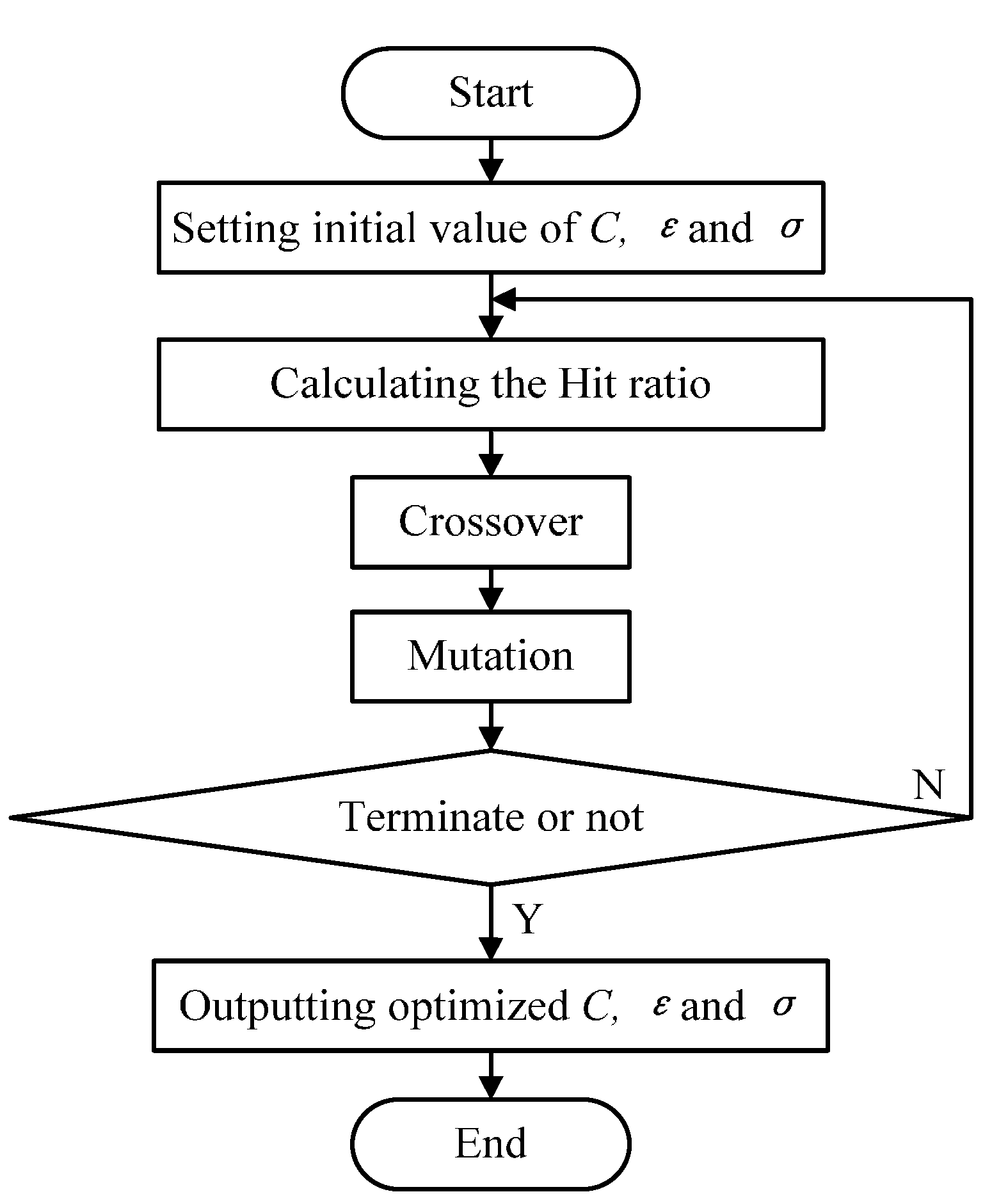
4.2.6. The procedure of GA
The major steps of GA are shown in
Figure 3.
Figure 3.
The basic procedure of GA.




{kind=link}
{kind=link}
{kind=link}
{kind=link}



