Improving the Accuracy in Sentiment Classification in the Light of Modelling the Latent Semantic Relations †


Abstract
:1. Introduction
- firstly, they suggest using only one of the listed methods (belonging to a group of discriminant or probabilistic methods respectively) with characterizing its shortcomings and limitations;
- secondly, the results obtained during the research are not associated by authors with the possibility of their further use for conducting not only context-semantic but also context-sentiment classification.
- secondly, they do not focus their scientific interests on the creation of a multi-level sentiment dictionary that reflects the contextual dependencies of the words tonality on different hierarchical levels of document contextual structure (topic/subtopic).
- combining linear algebra and probabilistic topic models methods for LSR revealing allowed to eliminate their limitations;
- retrieving the knowledge about the hierarchical topical structure of the analysed text allowed (1) development of the hierarchical contextually-oriented sentiment dictionary and (2) performance of the context-sensitive sentiment classification on the paragraph- and document-level.
- an extended version of experimental results and discussion section for latent semantic relations revealing phase;
- representation of the new stage of research based on the results obtained in the original paper (the section describes the methodological and experimental parts of the sentiment classification phase based on the CBSD).
2. Theoretical Background of the Research
2.1. Vector Space Model Concept
2.2. Latent Semantic Indexing
2.3. Probabilistic Topic Models
2.3.1. Latent Dirichlet Allocation Model
- Randomly select its text distribution by topic .
- For each word in the text: (a) randomly select a topic from the distribution obtained at the 1st step; (b) randomly select a word from the distribution of words in the selected topic .
2.3.2. Results Quality Evaluation
2.4. Text Sentiment Classification
3. Research Methodology
- Term is a basic unit of discrete data.
- Contextual fragment (CF) is an indivisible, topically completed set of terms, located within a document’s paragraph.
- Document is a set of CF.
- Topic is the label (one term) that defines the main semantic context of the text.
- Contextual dictionary (CD) is a set of keywords that describe the semantic context of the topic.
- Semantic cluster (SC) is the set of CF that characterized by high hidden semantic closeness.
- Contextually-oriented corpus (HC) is a hierarchical structure of semantically close CF, built via application of unsupervised machine learning discriminant and probabilistic methods of the topic modelling and latent semantic relations analysis.
- Corpora-based sentiment dictionary (CBSD) is a manually created dictionary, which has semantic and hierarchical structure thanks to using the contextually-oriented corpus for its building.
3.1. Novelty and Motivation
- eliminate the existing limitations of the discriminant and probabilistic approaches by their joint use and adjustment for latent semantic relations revealing;
- customize the context-sensitive sentiment classification process to the more accurate recognition of the text tonality in the light of the semantic context of the topic.
- such a document will have a wide palette of topics and sub-topics, which allows guaranteeing a high accuracy of the formation of the hierarchical contextual structure of the document;
- the completeness of the authors’ vocabulary should be sufficiently broad and meaningful to create a sentiment dictionary adequate to the general context of the dataset to be examined;
- the need to express the authors’ own opinion in such type of document will allow to carry out a qualitative evaluation of the sentiment classification results on a guaranteed relevant dataset.
- quality of LDA-method of topics recognition via an increased level of probability of assigning the topic to a particular CF by considering the hidden LSR phenomena (eliminating the Lim#5);
- quality of LSA-method of LSR recognition via adjusting the consequences of the influence of the uniform distribution of the topics within the document by considering probabilistic approaches (eliminating the Lim#3 and Lim#4).
- adequacy of tonality assessment instruments via building and manually creating a hierarchical contextually-oriented and semantically structured corpora-based sentiment dictionary;
- quality of the sentiment analysis results via adjusting the algorithms of using the tonality assessment instruments by applying integral evaluation of its individual topically-oriented fragments using the CBSD and considering the tonality subjectively assigned to texts by the author.
- latent semantic relations revealing phase;
- sentiment classification based on the CBSD phase.
- film reviews are a bright representative of a persuasive type of the group of documents;
- the choice of Polish-language texts makes it possible to simultaneously fill in the existing gap in such a study direction for a given language.
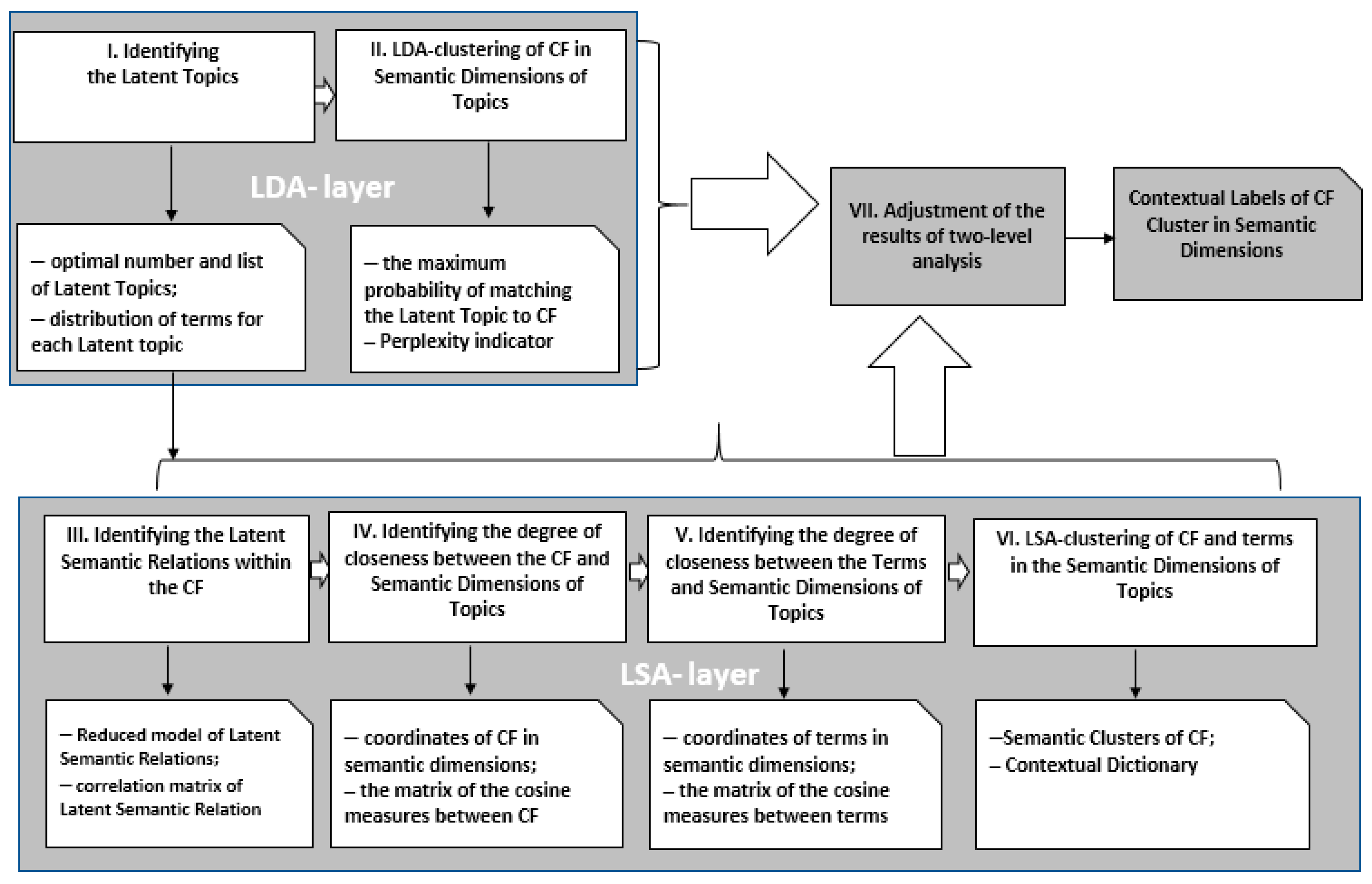
3.2. Latent Semantic Relations Revealing Phase
3.2.1. LDA-Based Analysis of Latent Semantic Relations Layer
- to reveal the optimal number of latent probabilistic topics that describe the main semantic context of the analysed document;
- to assign these revealed topics to the CFs based on the discovered probabilistic Latent Semantic Relations within the paragraphs.
3.2.2. The LSA-Based Analysis of Latent Semantic Relations Layer
3.2.3. Adjustments of the Results of the Two Layers of Analysis
- Development and implementation of the rules of adjustments of the results obtained in the LSA- and LDA-analysis layers.
- to improve the quality of LDA-method recognition of the CF’s topics (rules 3, 4) due to the possibility of correcting those clustering results, which are characterized by the low level of probability of a CF belonging to a particular topic. Suggested instrument—the specificity of the LSA method, consisting of the ability to extract knowledge of latent semantic relationships;
- to improve the quality of LSA-method recognition of hidden relations between the CF (rules 2, 5) due to the possibility of correcting those clustering results, which are characterized by the situations, when the particular CF coordinates are located on the cluster’s boundary. Suggested instrument—the specificity of LDA method, consisting in the ability to extract the knowledge from latent topics probabilistic characteristics.
3.2.4. Experimental Results and Discussion
- on the 1st level of the hierarchy is equal to 5 for SNCS and is equal to 4 for SNSC;
- on the 2nd level of the hierarchy is equal to 4 for SNCS and is equal to 3 for SNSC.
- to improve the qualitative characteristics of LSR analysis: recall rate (as a ratio of the number of semantically clustered/recognized paragraphs to the total number of paragraphs in the dataset) to 90–95%; precision indicator (as the average probability of significantly clustered/recognized paragraphs) from 62 to 70–75%;
- to increase the depth of recognition of latent semantic relations by providing the mathematical and methodological basis for building the contextual hierarchical structure of semantic topics.
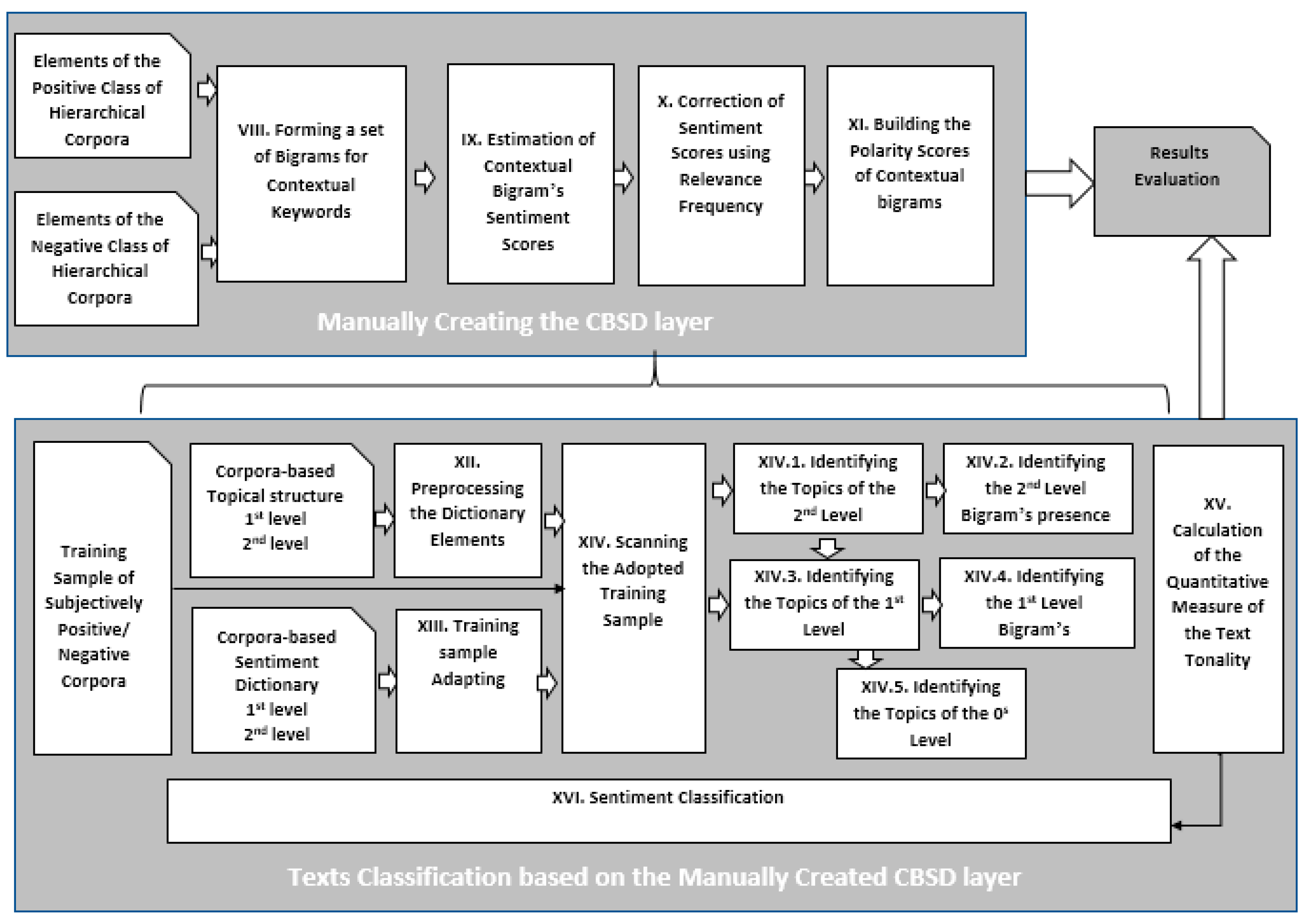
3.3. Sentiment Classification Based on the Contextually-Oriented Sentiment Dictionary Phase
3.3.1. Creating the Corpora-Based Sentiment Dictionary Layer
- 0s level is the set of dictionary items without taking into account the contextual hierarchical structure of topics;
- 1st level is the set of dictionary items taking into account the 1st level of CHST;
- 2nd level is the set of dictionary items taking into account the 2nd level of CHST.
- to teach the developed sentiment classification algorithm to classify the texts, based on the quantitative measures of the tonality (sentiment scores) and considering one-level and two-level hierarchical structure of the corpora-based sentiment dictionary
- to evaluate the quality of the conducted classification for the purpose of modification/improvement of the applied algorithm via comparing the results of the sentiment classification.
3.3.2. Sentiment Classification Based on the Manually Created CBSD Layer
- For subjectively positive corpora sample (SPCS):
- C1.
- The text has high positive tonality (HP).
- C2.
- The text has quite positive tonality (QP).
- C3.
- The text has reasonably positive tonality (RP).
- For subjectively negative corpora sample (SNCS):
- C4.
- The text has rather negative tonality (RN).
- C5.
- The text has clearly negative tonality (CN).
- C6.
- The text has absolutely negative tonality (AN).
3.3.3. Experimental Results and Discussion
CBSD Creation Algorithm
- for positive class of CBSD: almost equal numbers of bigrams of neutral and positive polarity. This suggests that half of the adjectives and verbs used to characterize the reviewer’s opinion without having a positive colouring, formally confirm (ascertain) the existing facts. 10% of negatively coloured bigram, indicating that, despite the truly positive tonality of reviews, the reviewer doubts about the positivity of certain shades (elements) of the film. The greatest number of positively coloured Bigram is related to the to the topics: Role/Actors and Script/History.
- for the negative class of CBSD: more bigrams are negative and, less are neutral polarity. Negative reviews are characterized, in turn, by a large number of oppositely painted bigrams. Perhaps some of these positive emotions are introduced by the authors for comparison or contrast. most of the negatively coloured bigram refers to the topics: Scene/Actor and Role/Scene.
Sentiment Classification Algorithm
- A large part of reviews is characterized by an average degree of density of the distribution of words with recognizable tonality. This fact complicates the process of an assessment of the rating of the film.
- The morphological analysis of training sample testifies that [38]:
- the positive reviews characterized by highly semantic structured opinion are expressed in a careful and balanced manner. In this connection, they have a more even (in comparison with negative) distribution of words that have the explicit tonality colour.
- the negative reviews characterized by an average level of semantic structure of the opinion are expressed more spontaneously and under the influence of emotions. However, this spontaneity causes less variability of the words used, and, as a consequence, greater probability of their precise recognition and classification.
- Recognize the sentiment of texts paragraphs taking into account the 1st level topics of CBSD (Table 19).
- Recognize the sentiment of texts paragraphs taking into account the 2nd level topics of CBSD (Table 20).
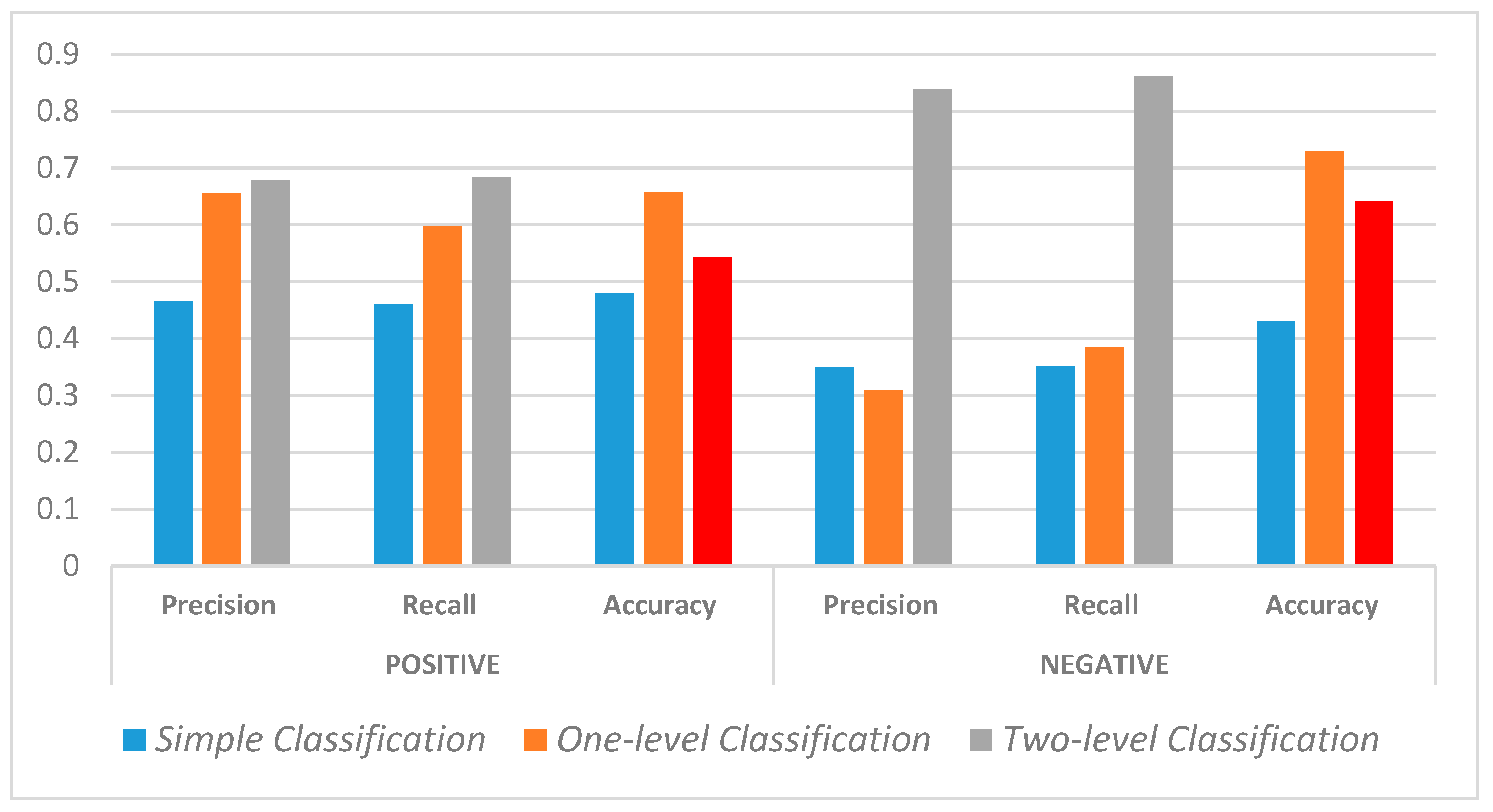
- To compare the quality of simple, one-level and two-level sentiment classification of the film reviews results (Figure 3).
- Indicators of precision and recall for subjectively positive sample grow from 0s level step to 2nd level step linearly and gradually. This confirms the previous conclusions that, in general, positive reviews have a higher level of semantic structure and orderliness in expressing emotions. In this regard, the process of recognizing the tonality of the text is better and more accurate even without using the hierarchical context structure of the sentiment dictionary;
- Indicators for indicators of precision and recall for a subjectively negative sample at the 2nd level step grow steeply. This can be explained by the following facts:
- during the process of sentiment classification using the 1st level of the CBSD, the topic “Actor” was not recognized for any paragraph of the SNCS. However, when using CBSD of the 2nd level, 2 of 3 subtopics of the topic “Actor” were recognized and assigned to paragraphs of the analysed sample. This fact, on the one hand, affected the stepwise increase in the recognition of quality indicators at the two-level sentiment classification, on the other hand, it explains the decrease in the precision indicator for the one-level sentiment classification;
- this phenomenon is also explained by the results of research conducted at the previous stages, indicating the spontaneous, unstructured and sometimes illogical use of words of different tonality when writing negative reviews under the influence of emotions.
- A slight decrease in the average accuracy indicator for both samples could be caused by:
- too many topics of the second level of the hierarchy used for reviews analysis,
- provided in the algorithm 6-class tonality classification of each paragraph, which makes the matrix of the results of the classification sufficiently sparse. For the first level of the hierarchy, accuracy values are much higher.
4. Conclusions and Discussion
- Detection of the hierarchical (in this study—maximal two-level) topical structure of the document and its context-sensitive sentiment.
- Combining linear algebra and probabilistic topic models methods for LSR revealing allowed to eliminate their limitations.Such an approach allowed to bring the average value of the topic recognition recall rate indicator close to 90–95% and increase the precision indicator from 62 to 70–75% (Hypothesis 1 is accepted).
- Retrieving the hierarchical topical structure of the analysed text, which allowed (1) to develop the hierarchical (in this study—two-level) contextually-oriented sentiment dictionary; (2) to use it to perform the context-sensitive sentiment classification in a paragraph- and then full document-level.
- Taking into account the specific features of the document types affects the quality of the topic modelling process results. One of the identified manifestations of this effect is the possibility of flexible adaptation of topic modelling algorithms for the sentiment classification process. for example, persuasive type of the analysed texts allowed to consider each document as a collection of topically completed fragments (paragraphs), which positively affects the classification quality (RQ_1).
- It is possible to increase the level of quality of the topic modelling process results by using the combination of the discriminant and probabilistic methods. One of the identified manifestations of this effect is the possibility to apply the rules of adjustments of the results obtained in levels of semantic clustering of the LSA- and LDA-analysis in order to obtain the final result, what allows to eliminate the individual limitations of the methods being combined (RQ_2).
- Taking into account the hierarchical structure of latent semantic relations within the corpus affects the accuracy of the sentiment classification results. One of the identified manifestations of this effect is allowing to customize the sentiment classification process by hierarchical iterative recognition of the topics of each paragraph of the document (from the lower to the higher level of contextual hierarchical structure of topics) with the subsequent use of the elements of the CBSD corresponding to the identified topic (RQ_3 and RQ_4).
- The tone, expressed in the document by its author, has a significant but not critical effect on the qualitative indicators of document sentiment recognition. Negative emotions of the author usually, on the one hand, reduce the level of variability of the words used and the variety of topics raised in the document, on the other—increase the level of unpredictability of contextual use of words with both positive and negative emotional colouring. At the same time, for authors’ negative opinions, there is an increase in the quality indicators characterizing tonality recognition (recall and precision) but with a slight decrease in the indicator of the accuracy of the tonality recognition as a whole (RQ_5).
Author Contributions
Funding
Conflicts of Interest
References
- Furnas, G.W.; Deerwester, S.; Dumais, S.T.; Landauer, T.K.; Harshman, R.A.; Streeter, L.A.; Lochbaum, K.E. Information retrieval using a singular value decomposition model of latent semantic structure. In Proceedings of the 11th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Grenoble, France, 13–15 June 1998; pp. 465–480. [Google Scholar]
- Anaya, L.H. Comparing Latent Dirichlet Allocation and Latent Semantic Analysis as Classifiers; Doctor of Philosophy (Management Science); ProQuest LLC: Ann Arbor, MI, USA, 2011; 226p. [Google Scholar]
- Papadimitrious, C.H.; Raghavan, P.; Tamaki, H.; Vempala, S. Latent semantic indexing: A probabilistic analysis. J. Comput. Syst. Sci. 2000, 61, 217–235. [Google Scholar] [CrossRef]
- Rizun, N.; Kapłanski, P.; Taranenko, Y. Method of a Two-Level Text-Meaning Similarity Approximation of the Customers’ Opinions; Economic Studies—Scientific Papers; Nr. 296/2016; University of Economics in Katowice: Katowice, Poland, 2016; pp. 64–85. [Google Scholar]
- Teh, Y.W.; Jordan, M.I.; Beal, M.J.; Blei, D.M. Sharing clusters among related groups: Hierarchical Dirichlet processes. In Advances in Neural Information Processing Systems; Neural Information Processing Systems: Vancouver, BC, Canada, 2005; pp. 1385–1392. [Google Scholar]
- Xuan, J.; Lu, J.; Zhang, G.; Da Xu, R.Y.; Luo, X. Bayesian nonparametric relational topic model through dependent gamma processes. IEEE Trans. Knowl. Data Eng. 2017, 29, 1357–1369. [Google Scholar] [CrossRef]
- Xuan, J.; Lu, J.; Zhang, G.; Da Xu, R.Y.; Luo, X. Doubly nonparametric sparse nonnegative matrix factorization based on dependent Indian buffet processes. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 1835–1849. [Google Scholar] [CrossRef] [PubMed]
- Rizun, N.; Taranenko, Y.; Waloszek, W. The Algorithm of Building the Hierarchical Contextual Framework of Textual Corpora. In Proceedings of the Eighth IEEE International Conference on Intelligent Computing and Information System, ICICIS 2017, Cairo, Egypt, 5–7 December 2017; pp. 366–372. [Google Scholar]
- Blei, D. Introduction to Probabilistic Topic Models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef]
- Blei, D.; Lafferty, J.D. Topic Modeling. Available online: http://www.cs.columbia.edu/~blei/papers/BleiLafferty2009.pdf (accessed on 4 December 2018).
- Gramacki, J.; Gramacki, A. Metody algebraiczne w zadaniach eksploracji danych na przykładzie automatycznego analizowania treści dokumentów. In Proceedings of the XVI Konferencja PLOUG, Kościelisko, Poland, 19–20 October 2010; pp. 227–249. [Google Scholar]
- Titov, I. Modeling Online Reviews with Multi-grain Topic Models. In Proceedings of the 17th International Conference on World Wide Web (WWW’08), Beijing, China, 21–25 April 2008; pp. 111–120. [Google Scholar]
- Griffiths, T.; Steyvers, M. Finding scientific topics. Proc. Natl. Acad. Sci. USA 2004, 101, 5228–5235. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aggarwal, C.; Zhai, X. Mining Text Data; Springer: New York, NY, USA, 2012. [Google Scholar]
- Canini, K.R.; Shi, L.; Griffiths, T. Online Inference of Topics with Latent Dirichlet Allocation. J. Mach. Learn. Res. 2009, 5, 65–72. [Google Scholar]
- Blei, D.; Ng, A.; Jordan, M. Latent Dirichlet allocation. J. Mach. Learn. Res. 2013, 3, 993–1022. [Google Scholar]
- Asgari, E.; Bastani, K. The Utility of Hierarchical Dirichlet Process for Relationship Detection of Latent Constructs. Acad. Manag. Proc. 2017, 1, 16300. [Google Scholar] [CrossRef]
- Klekovkina, M.V.; Kotelnikov, E.V. The automatic sentiment text classification method based on emotional vocabulary. In Proceedings of the Digital libraries: Advanced Methods and Technologies, Digital Collections (RCDL-2012), Pereslavl-Zalessky, Moscow, 15–18 October 2012; pp. 118–123. [Google Scholar]
- Kim, S.-M.; Hovy, E. Determining the sentiment of opinions. In Proceedings of the 20th International Conference on Computational Linguistics (COLING ’04), Geneva, Switzerland, 23–27 August 2004; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; p. 1367. [Google Scholar] [Green Version]
- Choi, Y.; Cardie, C.; Riloff, E.; Patwardhan, S. Identifying sources of opinions with conditional random fields and extraction patterns. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; Association for Computational Linguistics: Stroudsburg, PA, USA, 2005; pp. 355–362. [Google Scholar] [Green Version]
- Whitelaw, C.; Garg, N.; Argamon, S. Using appraisal groups for sentiment analysis. In Proceedings of the 14th ACM International Conference on Information and Knowledge Management (CIKM ’05), Bremen, Germany, 31 October–5 November 2005; pp. 625–631. [Google Scholar]
- Pang, B.; Lee, L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics (ACL ’04), Barcelona, Spain, 21–26 July 2004; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; p. 271. [Google Scholar]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up?: Sentiment classification using machine learning techniques. In Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing (EMNLP ’02), Philadelphia, PA, USA, 6–7 June 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 79–86. [Google Scholar]
- Turney, P.D.; Littman, M.L. Unsupervised learning of semantic orientation from a hundred-billion-word corpus. CoRR, 2002; arXiv:cs/0212012. [Google Scholar]
- Taboada, M.; Brooke, J.; Tofiloski, M.; Voll, K.; Stede, M. Lexicon-based methods for sentiment analysis. Comput. Linguist. 2011, 37, 267–307. [Google Scholar] [CrossRef]
- Boiy, E. Automatic Sentiment Analysis in On-line Text. In Proceedings of the 11th International Conference on Electronic Publishing (ELPUB 2007), Vienna, Austria, 13–15 June 2007; pp. 349–360. [Google Scholar]
- Boucher, J.D.; Osgood, C.E. The Pollyanna hypothesis. J. Memory Lang. 1969, 8, 1–8. [Google Scholar] [CrossRef]
- Pang, B. Opinion Mining and Sentiment Analysis. Found. Trends Inf. Retr. 2008, 2, 18–22. [Google Scholar] [CrossRef]
- Liu, B. Sentiment Analysis and Opinion Mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–67. [Google Scholar] [CrossRef]
- Tomanek, K. Analiza sentymentu—Metoda analizy danych jakościowych. Przykład zastosowania oraz ewaluacja słownika RID i metody klasyfikacji Bayesa w analizie danych jakościowych. Przegląd Socjologii Jakościowej. 2014, pp. 118–136. Available online: www.przegladsocjologiijakosciowej.org (accessed on 30 November 2018).
- Lin, C.; He, Y. Joint sentiment/topic model for sentiment analysis. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; pp. 375–384. [Google Scholar]
- Rao, Y.; Li, Q.; Mao, X.; Wenyin, L. Sentiment topic models for social emotion mining. Inf. Sci. 2014, 266, 90–100. [Google Scholar] [CrossRef]
- Mei, Q.; Ling, X.; Wondra, M.; Su, H.; Zhai, C. Topic sentiment mixture: Modeling facets and opinions in weblogs. In Proceedings of the 16th international conference on World Wide Web (WWW ’07), Banff, AB, Canada, 8–12 May 2007. [Google Scholar]
- Titov, I.; McDonald, R. A joint model of text and aspect ratings for sentiment summarization. In Proceedings of the ACL-08: HLT, Columbus, OH, USA, 19 June 2008; Association for Computational Linguistics: Stroudsburg, PA, USA, 2008; pp. 308–316. [Google Scholar]
- Rizun, N.; Taranenko, Y.; Waloszek, W. The Algorithm of Modelling and Analysis of Latent Semantic Relations: Linear Algebra vs. Probabilistic Topic Models. In Proceedings of the 8th International Conference on Knowledge Engineering and Semantic Web, Szczecin, Poland, 8–10 November 2017; pp. 53–68. [Google Scholar]
- Baeza-Yates, R.; Ribeiro-Neto, B. Modern Information Retrieval, 2nd ed.; Addison-Wesley: Wokingham, UK, 2011. [Google Scholar]
- Salton, G.; Michael, J. McGill Introduction to Modern Information Retrieval; McGraw-Hill Computer Science Series, XV; McGraw-Hill: New York, NY, USA, 1983; 448p. [Google Scholar]
- Rizun, N.; Taranenko, Y. Methodology of Constructing and Analyzing the Hierarchical Contextually-Oriented Corpora. In Proceedings of the Federated Conference on Computer Science and Information Systems, Poznań, Poland, 9–12 September 2018; pp. 501–510. [Google Scholar]
- Rizun, N.; Kapłanski, P.; Taranenko, Y. Development and Research of the Text Messages Semantic Clustering Methodology. In Proceedings of the Third European Network Intelligence Conference, Wroclaw, Poland, 5–7 September 2016; pp. 180–187. [Google Scholar]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data Clustering: A Review. ACM Comput. Surv. 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Deerwester, S. Using latent semantic analysis to improve information retrieval. In Proceedings of the CHI’88: Conference on Human Factors in Computing; ACM: New York, NY, USA, 1988; pp. 281–285. [Google Scholar]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by Latent Semantic Analysis. 1990. Available online: http://lsa.colorado.edu/papers/JASIS.lsi.90.pdf (accessed on 30 November 2018).
- Xu, R.; Wunsch, D. Survey of clustering algorithms. IEEE Trans. Neural Netw. 2005, 16, 645–678. [Google Scholar] [CrossRef] [PubMed]
- Bahl, L.; Baker, J.; Jelinek, E.; Mercer, R. Perplexity—A measure of the difficulty of speech recognition tasks. J. Acoust. Soc. Am. 1977, 62 (Suppl. 1), S63. [Google Scholar]
- Rizun, N.; Taranenko, Y. Development of the Algorithm of Polish Language Film Reviews Preprocessing. Rocznik Naukowy Wydzialu Zarzadzania w Ciechanowie 2017, XI, 168–188. [Google Scholar]
- Rizun, N.; Waloszek, W. Methodology for Text Classification using Manually Created Corpora-based Sentiment Dictionary. In Proceedings of the 10th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2018), Seville, Spain, 18–20 September 2018; Volume 1, KDIR. pp. 212–220, ISBN 978-989-758-330-8. [Google Scholar]
- Ivanov, V.; Tutubalina, E.; Mingazov, N.; Alimova, I. Extracting Aspects, Sentiment and Categories of Aspects in User Reviews about Restaurants and Cars. In Proceedings of the International Conference “Dialogue 2015”, Moscow, Russia, 27–30 May 2015; pp. 22–33. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Perplexity | Number of Topics (t) | Number of Terms | Number of Passes | Alpha Parameter | Eta Parameter | Max Probability Topic | Max Probability of Terms in the Topics |
|---|---|---|---|---|---|---|---|
| 3336 | 10 | 10 | 100 | 1.70 | 1.00 | 0.102 | 0.057 |
| 633 | 7 | 7 | 100 | 1.50 | 1.00 | 0.605 | 0.177 |
| 202 | 5 | 5 | 100 | 1.50 | 1.00 | 0.713 | 0.167 |
| 64 | 3 | 5 | 100 | 1.50 | 1.00 | 0.841 | 0.132 |
| 63 | 3 | 7 | 100 | 1.50 | 1.00 | 0.841 | 0.166 |
| Terms | Probability | Terms | Probability | Terms | Probability |
|---|---|---|---|---|---|
| Topic #0 | Topic #1 | Topic #2 | |||
| story | 0.080 | cinema | 0.109 | character | 0.166 |
| action | 0.062 | creator | 0.066 | playing | 0.140 |
| effect | 0.050 | woman | 0.062 | good | 0.130 |
| character | 0.047 | cast | 0.052 | character | 0.090 |
| book | 0.046 | stage | 0.051 | role | 0.040 |
| image | 0.044 | main | 0.050 | typical | 0.030 |
| history | 0.042 | director | 0.049 | intrigue | 0.029 |
| CF | CF_5 | CF_0 | CF_1 | CF_4 | CF_6 | CF_2 | CF_3 |
|---|---|---|---|---|---|---|---|
| # topic (cluster) | 0 | 1 | 1 | 1 | 1 | 2 | 2 |
| Probability | 0.8411 | 0.6228 | 0.8022 | 0.7039 | 0.4800 | 0.7957 | 0.6603 |
| Terms | CF_0 | CF_1 | CF_2 | CF_3 | CF_4 | CF_5 | CF_6 |
|---|---|---|---|---|---|---|---|
| character | 1.115 | 2.785 | 2.974 | 3.535 | 1.676 | 2.907 a | 1.636 |
| movie | 0.384 | 0.964 | 0.888 | 1.071 | 0.537 | 0.626 | 0.508 |
| good | 0.162 | 0.406 | 0.401 | 0.481 | 0.234 | 0.338 | 0.225 |
| main | 0.479 | 1.211 | 0.687 | 0.882 | 0.542 | −0.369 b | 0.459 |
| cinema | 0.963 | 2.431 | 1.512 | 1.915 | 1.129 | −0.384 | 0.978 |
| woman | 0.569 | 1.440 | 0.725 | 0.950 | 0.617 | −0.687 | 0.508 |
| Terms | CF_0 | CF_1 | CF_2 | CF_3 | CF_4 | CF_5 | CF_6 | Sum |
|---|---|---|---|---|---|---|---|---|
| character | 1 | 1 | 4 | 5 | 2 | 2 | 1 | 16 |
| movie | 0 | 2 | 1 | 0 | 0 | 1 | 1 | 5 |
| good | 0 | 1 | 0 | 2 | 1 | 3 | 2 | 9 |
| main | 1 | 3 | 0 | 2 | 1 | 0 | 2 | 9 |
| cinema | 0 | 3 | 0 | 0 | 1 | 0 | 0 | 4 |
| woman | 1 | 2 | 1 | 0 | 0 | 0 | 0 | 4 |
| Source | Absolute Frequency Terms-CF Matrix | Reduced Model for Identifying the Hidden Connection | |
|---|---|---|---|
| Terms | |||
| Character. Movie | −0.333 | 0.985 | |
| Cinema. Woman | 0.641 | 0.984 | |
| CF | CF_0 | CF_1 | CF_5 | CF_2 | CF_3 | CF_4 | CF_6 |
|---|---|---|---|---|---|---|---|
| Cluster | 0 | 0 | 1 | 2 | 2 | 2 | 2 |
| LDA-Level | LSA-Level | |||
|---|---|---|---|---|
| CF | # Topic (Cluster) | Probability | CF | Cluster |
| CF_0 | 1 | 0.6228 | CF_0 | 0 |
| CF_1 | 1 | 0.8022 | CF_1 | 0 |
| CF_2 | 2 | 0.7957 | CF_2 | 2 |
| CF_3 | 2 | 0.6603 | CF_3 | 2 |
| CF_4 | 1 | 0.7039 | CF_4 | 2 |
| CF_5 | 0 | 0.8411 | CF_5 | 1 |
| CF_6 | 1 | 0.4800 | CF_6 | 2 |
| Rule | LSA-Analysis Result | Comparison Result | LDA-Analysis Result | LDA Probability (p) | Assignable Cluster |
|---|---|---|---|---|---|
| 1 | LSA Cluster | = | LDA Cluster | p > 0.3 | LSA Cluster = LDA Cluster |
| 2 | LSA Cluster | = | LDA Cluster | p ≤ 0.3 | Cluster is Not recognized |
| 3 | LSA Cluster | ≠ | LDA Cluster | p ≤ 0.3 | LSA Cluster |
| 4 | LSA Cluster | ≠ | LDA Cluster | 0.3 < p ≤ 0.7 | LSA Cluster/Re-clustering |
| 5 | LSA Cluster | ≠ | LDA Cluster | p > 0.7 | LDA Cluster |
| CF | CF_5 | CF_0 | CF_1 | CF_4 | CF_2 | CF_3 | CF_6 |
|---|---|---|---|---|---|---|---|
| # topic | 0 | 1 | 1 | 1 | 2 | 2 | 2 |
| Topics of the 1st Level | Topics of the 2nd Level | LSA&LDA, % | Topics of the 1st Level | Topics of the 2nd Level | LSA&LDA, % |
|---|---|---|---|---|---|
| Hero | Actor/Play | 24 | Hero | Action/History | 49 |
| History/Film | 43 | Director/Cinema | 21 | ||
| Picture/Scene | 30 | Scene/Actor | 31 | ||
| Director/Creator | 3 | Actor | Hero/Image | 24 | |
| Director | Film/Director | 30 | Role/Scene | 58 | |
| Scene/Story | 10 | Script/History | 18 | ||
| Style | 6 | Creator | Hero/Scene | 23 | |
| Creator/Author | 54 | Film/Script | 60 | ||
| Script | Film/Director | 8 | Picture/Actor | 18 | |
| Story/Hero | 58 | Plot | Story/Hero | 39 | |
| Author/Creator | 13 | Director/Image | 18 | ||
| Role/Actors | 21 | Creator/Film | 43 | ||
| Plot | Film/Effects | 5 | |||
| Portrait/Image | 31 | ||||
| Director/Production | 24 | ||||
| Script/History | 40 | ||||
| Spectator | Hero/Fan | 40 | |||
| Film/Aspects | 20 | ||||
| Role/Formulation | 16 | ||||
| Scene/Director | 24 | ||||
| CL of the 1st Level Topics | SPSC | Topics of the 1st Level | SNSC | ||||
|---|---|---|---|---|---|---|---|
| LSA, % | LDA, % | LSA&LDA, % | LSA, % | LDA, % | LSA&LDA, % | ||
| Hero | 29.05 | 23.50 | 32.50 | Hero | 35.10 | 38.40 | 37.30 |
| Director | 15.80 | 12.70 | 10.30 | Actor | 19.30 | 20.30 | 18.30 |
| Script | 30.11 | 26.19 | 30.94 | Creator | 28.10 | 29.10 | 29.20 |
| Plot | 9.50 | 12.40 | 15.11 | Plot | 17.50 | 12.20 | 15.20 |
| Spectator | 15.54 | 25.21 | 11.15 | ||||
| Topics | SPSC | Topics | SNSC | ||
|---|---|---|---|---|---|
| Indicator 1 | Indicator 2 | Indicator 1 | Indicator 2 | ||
| Hero | 7.70 | 8.56 | Hero | 9.23 | 4.18 |
| Director | 3.84 | 3.44 | Actor | 5.30 | 9.42 |
| Script | 4.19 | 16.60 | Creator | 2.45 | 12.10 |
| Plot | 6.11 | 7.30 | Plot | 6.47 | 4.11 |
| Spectator | 7.19 | 2.55 | |||
| Recall rate | 95.30 | Recall rate | 93.60 | ||
| Rules No | Rule | Execution Result |
|---|---|---|
| 1 | Presence the elements of the bigram at a distance of no more than 3 words from each other | True |
| 2 | Presence the elements of the bigram within one sentence | True |
| 3 | Presence the elements of the bigram within one phrase, not separated by commas | True |
| 4 | Presence of word-modifiers in the immediate vicinity of the elements of the bigram | True |
| Positive | Left Border | Right Border |
| Review expressed is high positive opinion | 8 | 10 |
| Review expressed is quite a positive opinion | 6 | 7 |
| Review expressed is reasonably positive opinion | 5 | |
| Negative | Left Border | Right Border |
| Review expressed is rather a negative opinion | 3 | 4 |
| Review expressed is obviously negative opinion | 2 | 3 |
| Review expressed is absolutely negative opinion | 0 | 1 |
| Positive | Left Border | Right Border |
| Review expressed is high positive opinion | ||
| Review expressed is quite a positive opinion | ||
| Review expressed is reasonably positive opinion | ||
| , —adjusters | ||
| Negative | Left Border | Right Border |
| Review expressed is rather a negative opinion | ||
| Review expressed is clearly negative opinion | ||
| Review expressed is absolutely negative opinion | ||
| Polarity | Positive Bigrams | Neutral Bigrams | Negative Bigrams |
|---|---|---|---|
| 2nd level of CBSD positive class | 43.70 | 46.30 | 9.91 |
| 2nd level of CBSD negative class | 20.75 | 37.53 | 41.72 |
| SPCS | SNCS | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Class | % | Precision | Recall | Accuracy | Class | % | Precision | Recall | Accuracy |
| HP | 28.57 | 53.57 | 51.72 | 47.96 | RN | 33.00 | 33.33 | 29.73 | 43.00 |
| QP | 47.96 | 51.06 | 53.33 | CN | 56.00 | 53.57 | 57.69 | ||
| RP | 23.47 | 34.78 | 33.33 | AN | 11.00 | 18.18 | 18.18 | ||
| Class | Hero | Director | Script | Plot | Spectator | Unrecognized |
| HP | 19.28 | 57.45 | 46.38 | 17.39 | 45.45 | 9.29 |
| QP | 37.35 | 34.04 | 37.68 | 26.09 | 31.82 | |
| RP | 43.37 | 8.51 | 15.94 | 56.52 | 22.73 | |
| Class | Hero | Actor | Creator | Plot | Unrecognized | |
| RN | 57.14 | - | 44.12 | 37.84 | 14.50 | |
| CN | 28.57 | - | 47.06 | 45.95 | ||
| AN | 14.29 | - | 8.82 | 16.22 |
| Topic | Classes | ||||||
|---|---|---|---|---|---|---|---|
| HP | QP | RP | Topic | RN | CN | AN | |
| Hero | Hero | ||||||
| Actor/Play | 7.14 | 53.57 | 39.29 | Action/History | 67.86 | 28.57 | 3.57 |
| History/Film | 2.33 | 55.81 | 41.86 | Director/Cinema | 77.78 | 22.22 | - |
| Picture/Scene | 21.54 | 48.46 | 30.00 | Scene/Actor | 80.23 | 16.28 | 3.49 |
| Director/Creator | - | 28.57 | 71.43 | ||||
| Director | Creator | ||||||
| Film/Director | 5.88 | 35.29 | 58.82 | Hero/Scene | 80.00 | 20.00 | - |
| Scene/Story | - | 100.00 | - | Film/Script | - | 100.00 | - |
| Style | 19.05 | 52.38 | 28.57 | Picture/Actor | 88.24 | 11.76 | - |
| Creator/Author | 18.52 | 55.56 | 25.93 | ||||
| Script | Plot | ||||||
| Film/Director | 12.00 | 48.00 | 40.00 | Story/Hero | 67.74 | 25.81 | 6.45 |
| Story/Hero | 15.49 | 50.70 | 33.80 | Director/Image | 61.40 | 36.84 | 1.75 |
| Author/Creator | 12.00 | 60.00 | 28.00 | Creator/Film | 85.71 | - | 14.29 |
| Role/Actors | - | 64.71 | 35.29 | ||||
| Plot | Actor | ||||||
| Film/Effects | 13.33 | 40.00 | 46.67 | Hero/Image | 73.68 | 15.79 | 10.53 |
| Portrait/Image | 0.00 | 66.67 | 33.33 | Role/Scene | – | - | - |
| Director/Production | 33.33 | 50.00 | 16.67 | Script/History | 63.64 | 27.27 | 9.09 |
| Script/History | - | 100.00 | - | ||||
| Spectator | |||||||
| Hero/Fan | 13.33 | 66.67 | 20.00 | ||||
| Film/Aspects | 37.50 | 37.50 | 25.00 | ||||
| Role/Formulation | - | - | - | ||||
| Scene/Director | - | 66.67 | 33.33 | ||||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rizun, N.; Taranenko, Y.; Waloszek, W. Improving the Accuracy in Sentiment Classification in the Light of Modelling the Latent Semantic Relations. Information 2018, 9, 307. https://doi.org/10.3390/info9120307
Rizun N, Taranenko Y, Waloszek W. Improving the Accuracy in Sentiment Classification in the Light of Modelling the Latent Semantic Relations. Information. 2018; 9(12):307. https://doi.org/10.3390/info9120307
Chicago/Turabian StyleRizun, Nina, Yurii Taranenko, and Wojciech Waloszek. 2018. "Improving the Accuracy in Sentiment Classification in the Light of Modelling the Latent Semantic Relations" Information 9, no. 12: 307. https://doi.org/10.3390/info9120307
APA StyleRizun, N., Taranenko, Y., & Waloszek, W. (2018). Improving the Accuracy in Sentiment Classification in the Light of Modelling the Latent Semantic Relations. Information, 9(12), 307. https://doi.org/10.3390/info9120307