1. Introduction
Big Data is an abstract concept that tends to be generalized in a framework through methods and paradigms of data generation, collection, and analysis. It is also responsible for dealing with high scalability, reliability and fault tolerance on a large number of data [
1]. Furthermore, Big Data offers a solid foundation to solve socio-economic, socio-political, health and national security problems through data analysis [
2,
3].
Much has been written about Big Data problems and its solutions, challenges about software development, system deployment, network infrastructure and data collection have been kept in focus throughout the years [
4]. There are several Big Data applications due to the high data generation rate caused by continuous improvements in the data science area [
5], mostly influenced by the digital expansion and the global access to technology. In those Big Data applications,
Hadoop MapReduce and
Hadoop Distributed File System (HDFS) have been used in commercial solutions and in research areas [
4]—the first one supports data analytical processing, and the second one performs a distributed file-block storage [
6].
However, an examination of the factors that impact the data distribution is necessary. Some arguments were formalized by Khalid, Afzal and Aftab [
7] and Souza et al. [
8], but none of them introduced the methodology to choose the computational model—for the purposes of this paper, the terms “computational architecture” and “computational model” are not distinguished. Thus, following the reasoning set forth by the mentioned authors, we hypothesized that the process of choosing a computational model to implement Hadoop can be methodologically defined.
The literature review showed that the distributed Hadoop has been implemented, but there were neither discussion nor questions addressing how to implement it for a given scenario or which is the most preferred model for that. This work stands alone from the benchmark tools introduced by the literature [
9,
10,
11,
12]. Each tool aims to increase the server load and its stress, but they do not introduce a methodology to apply the tool and evaluate it.
Souza et al. [
13] presented a study using the Hadoop framework as a learning tool—students were invited to use complex data, system architectures, network infrastructure, trending technologies, and algorithms to create evaluation scenarios, in order to define metrics and use the obtained results on benchmark analysis. Difficulties observed during hands sections on Hadoop planning are addressed in this work. We propose a methodology to support the Hadoop cluster usage suitable to performance assessment. Focusing on improving the cluster planning process, we introduced a step-by-step approach to guide the cluster deployment. In addition, we used the computing time of all architectures as a measurement to obtain evidence that the proposed methodology has achieved good results.
The Hadoop file system is based on the Hadoop Distributed File System (HDFS) and performs its work using distributed computing provided by MapReduce. The proposed methodology addresses the implementation of Hadoop in alternative computational models, allowing studies, proposals and analyzes supported by the search for the best performance and processing power of the model. We applied the proposed methodology to guide the cluster deployments and to analyze such architecture through benchmark tests both on local and on clouding—using centralized servers as well as locally and geographically distributed. Both the methodology, its application and results obtained are presented in this paper.
This paper is organized as follows:
Section 2 presents a brief list of related works;
Section 3 presents the computational architecture and a brief description of relevant server layouts found in the literature, and an overview of Hadoop;
Section 4 presents steps and results to guide the cluster planning process introducing the application of our methodology;
Section 5 illustrates one application of the proposed methodology;
Section 6 presents the final remarks.
4. Proposed Methodology
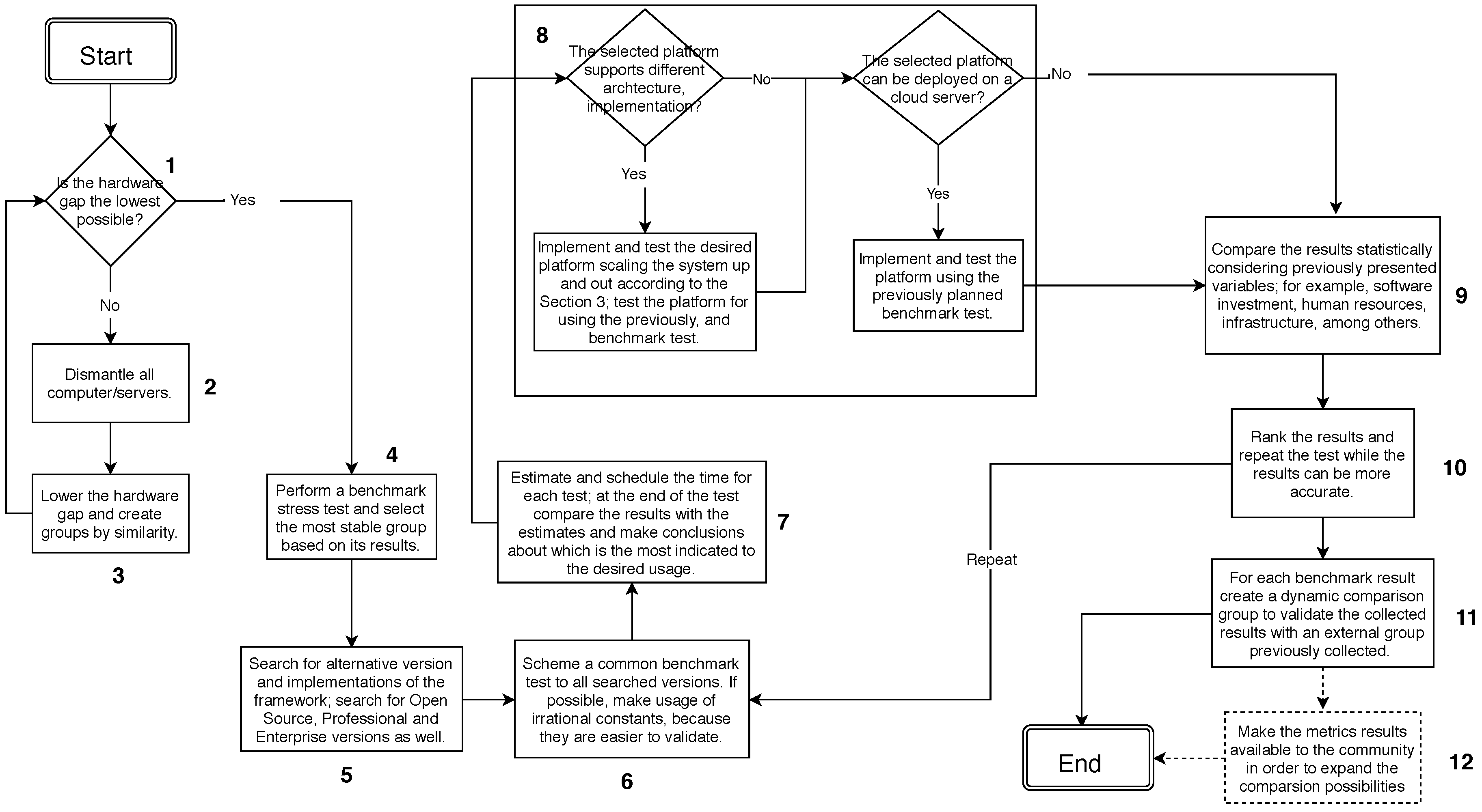
The proposed methodology aims to help the deployment of the most suitable architecture to the Hadoop cluster. Thus, the methodology makes use of benchmark tests, performing comparisons with reliable cluster groups, in which each cluster group is a benchmark milestone, created from an already deployed server.
As explained in previous sections, there are several conditions to be considered before choosing the cluster architecture. It is necessary to evaluate the performance of each possibility in the same way to make a reliable choice based on the benchmark results. For that, it is crucial to cause the same load and stress in each architecture as well as to perform metrical analysis on the results.
To clarify the discussion, we present a step-by-step description of our metrics, methodology and its results. To exemplify the process, a diagram is illustrated in
Figure 3, without considering any specific application, but to demonstrate the decision-making process.
Initially, it is necessary to check if the hardware gap between available computers is as small as possible (see Step 1). If not, it is necessary to disassemble the machines and reassemble them in order to reduce the gap until the condition in Step 1 is satisfied (see Step 2). These initial steps are intended to create groups of computers with similar hardware (see Step 3). If there is more than one group with similar hardware, where each group is similar to other computers in the same group and unlike any other group, we will evaluate each group as a single instance. After that, stress tests will be performed for each group for information on processor and hard drive overheating. Stress tests are run using Tera Sort, which allows you to make use of all processor cores to sort a file of numbers into terabytes, stored on the hard drive. With the results of each distribution, it is proposed to analyze each group with all the others. At this point we should select the most efficient in all tests, and if there is any doubt about the efficiency, the stress test should be redone (see Step 4).
When the stress test is complete, it is important to retest different distributions, such as Open Source, Enterprise, and Professional ones. Each distribution has its own modifications in the Hadoop core and, for scalability purposes, they can act differently while the server is stressed (Step 5). The Hadoop has more than one version and each one performs differently in a server; for instance, Hadoop MapReduce (present in early versions of Apache Hadoop) has centralized management of task execution capabilities while Hadoop YARN (present from Apache Hadoop 2.0) distributes resource management and scheduling/monitoring the execution of tasks in separated modules, which makes it faster at runtime than Hadoop MapReduce.
Equivalent to the cluster nodes evaluation, the computing architecture will be tested with a benchmark that will be compared with a similar cluster using the same computing architecture. The difference is on the benchmark test, once we already tested processing time, core capability and the hard drives, at this step we test the processing time in memory considering the network impact (see Steps 6 and 7). To do so, we make use of the approximation of irrational number like Pi, Euler’s number, golden ratio, among others. Basically, the approximation can be made in memory and it is easy to be validated. The same can be done in a vector of numbers stored in the memory and sorted by a MapReduce algorithm.
After selecting the cluster nodes, it is necessary to guarantee the lowest CPU time to achieve a better platform for data storage and analysis. Thus, we test different computing architectures for the cluster adding network interference as another variable (see Step 8). To perform that interference, we made network attacks to our nodes using Distributed Denial of Service (DDoS), making some nodes, or all nodes, fail during the test. With the node failures, the Hadoop should reach the next node with the requested information, impacting the processing time and sometimes will cause the abortion of the job, because the information requested is not available. The information about the attacks does not need to be stored; at this time, we just need to attack all nodes in the same way and for each architecture store determine the time needed to finish the requested job.
At the end of the analysis, there should be sufficient information to make a choice about the machines to be used, the distribution of Hadoop and its computing architecture (see Steps 9 to 11). To validate the obtained results, the collected information should be compared to other similar clusters. In order to create a benchmark milestone, the collected results should be available to others which will build its own cluster (see Step 12).
To illustrate the usage of this methodology, the next section presents its appliance and the decisions made to build our own cluster.
5. Methodology Appliance
This section illustrates the methodology applied in one scenario inside UNESP research laboratory. To start the analysis, we used 30 tower computers granted by the computer science department (DMC) of UNESP. The available hardware was not uniform, requiring disassembling of all the computers to separate the common hardware and allocating on new computers. As a result, we got different homogeneous processing architecture, half AMD and the other half Intel, with a stress test by a Tera Sort benchmark we decided to use the Intel architecture because they do not overheat as easy as AMD.
Subsequently, we proceeded with research about the distribution of Cloudera—available at
http://www.cloudera.com/, Hortonworks—available at
http://hortonworks.com/—and MapR—available at
https://www.mapr.com/—of the Hadoop 2.4.0 from April 2014. We are sure that they are all excellent and complete platforms, but each one behaved differently on our computers. To quantify the difference between the distributions, we set our computers as a virtual server and, at next, we quantified the processing time of each alternative.
To analyze the distribution results and others in the following, the benchmark chosen method was the Pi estimator with exponential growth, as shown in
Table 1. The two input variables (i.e., mapping and sample number) started, respectively, with two and 10 units. For each 100 looping counts, we increased the exponential factor until it reached 512 mapping, and one billion samples.
According to the test preparation, we estimate about 36 h to complete the benchmark in each distribution where all tests occurred individually. For each test, the output is not considered, we just take into account the time, because time is the central point to fit performance and usage need to the same cluster. In addition, the output is a result of the conceptual study and not of the implementation (
Section 2).
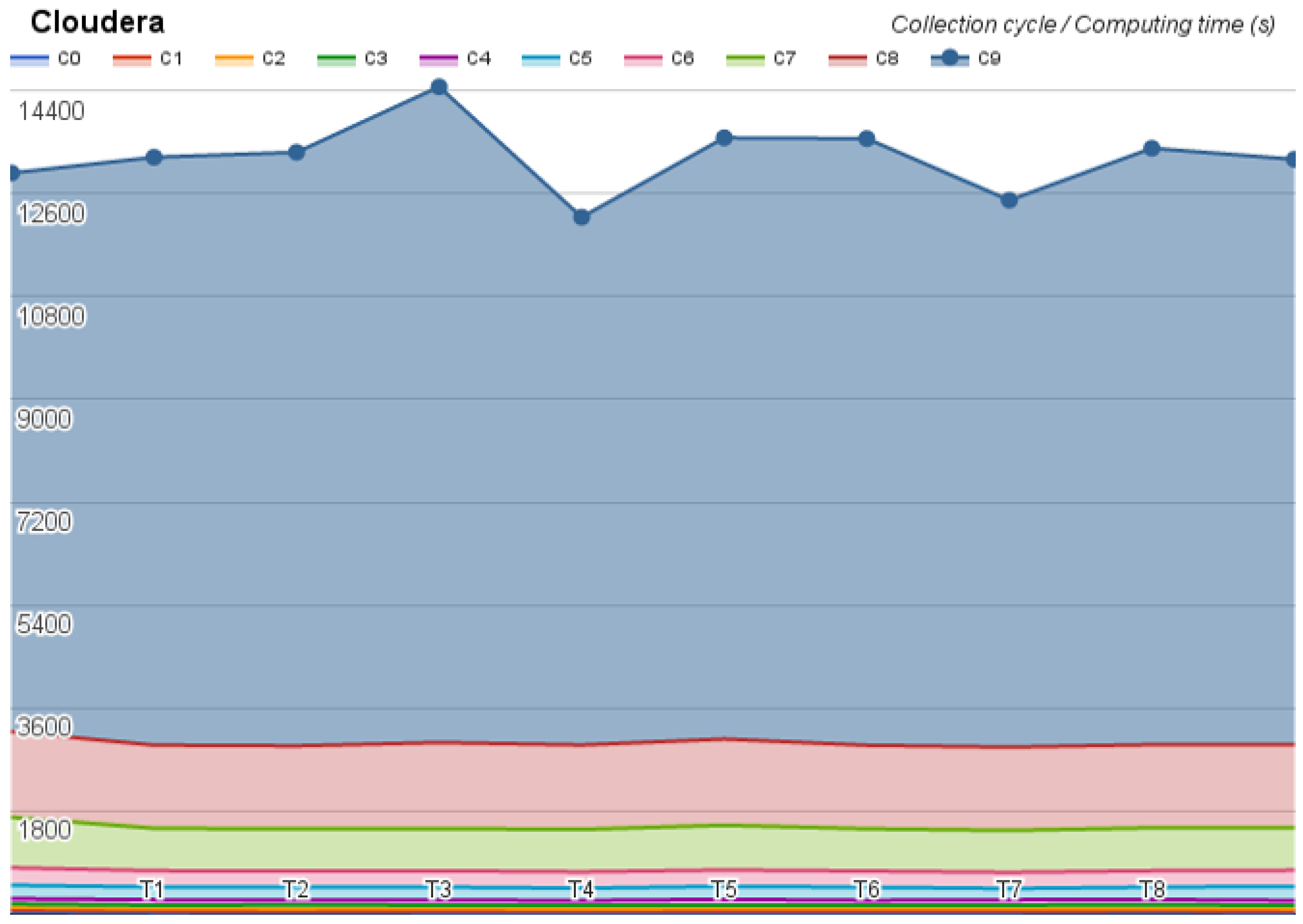
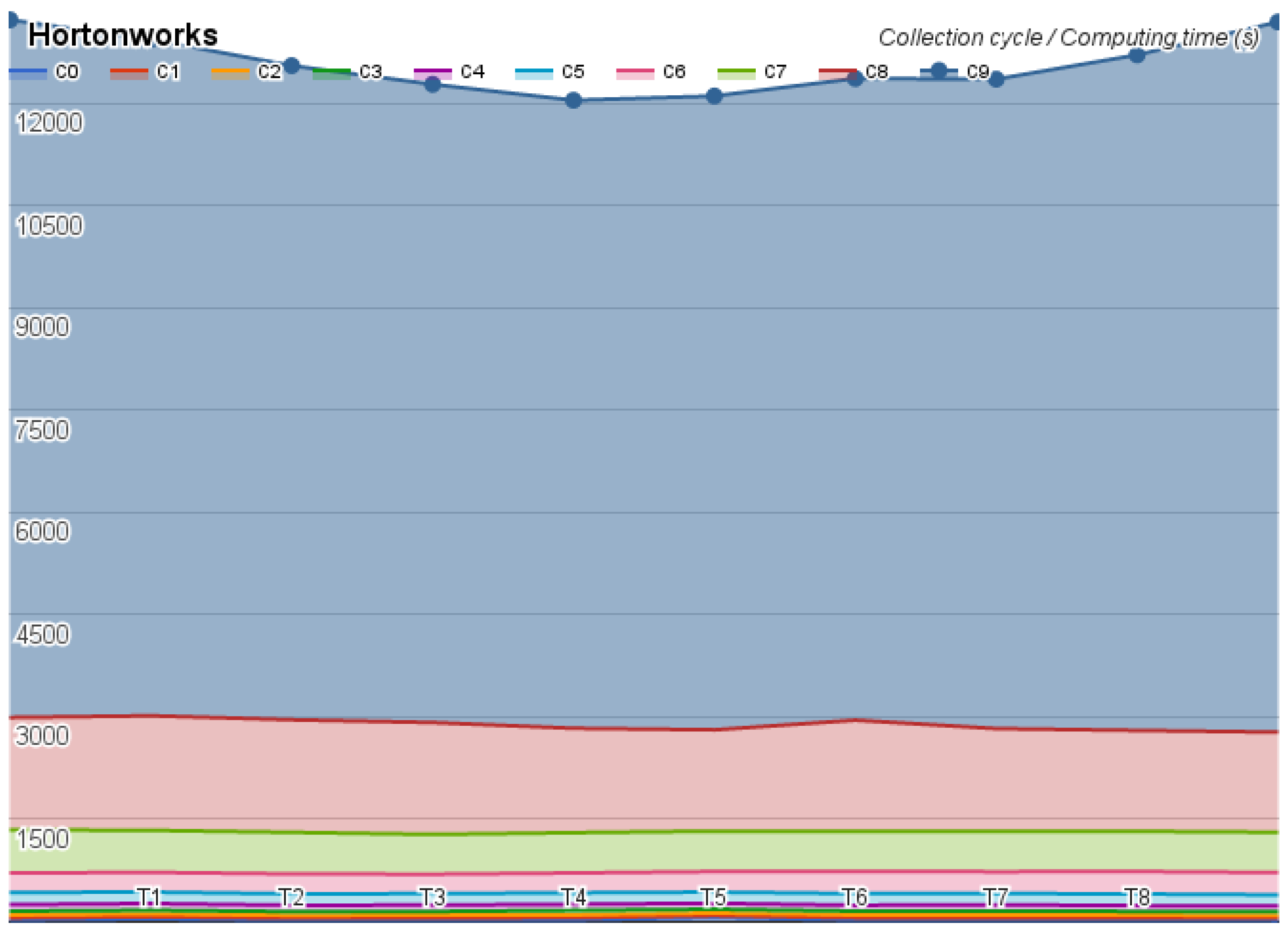
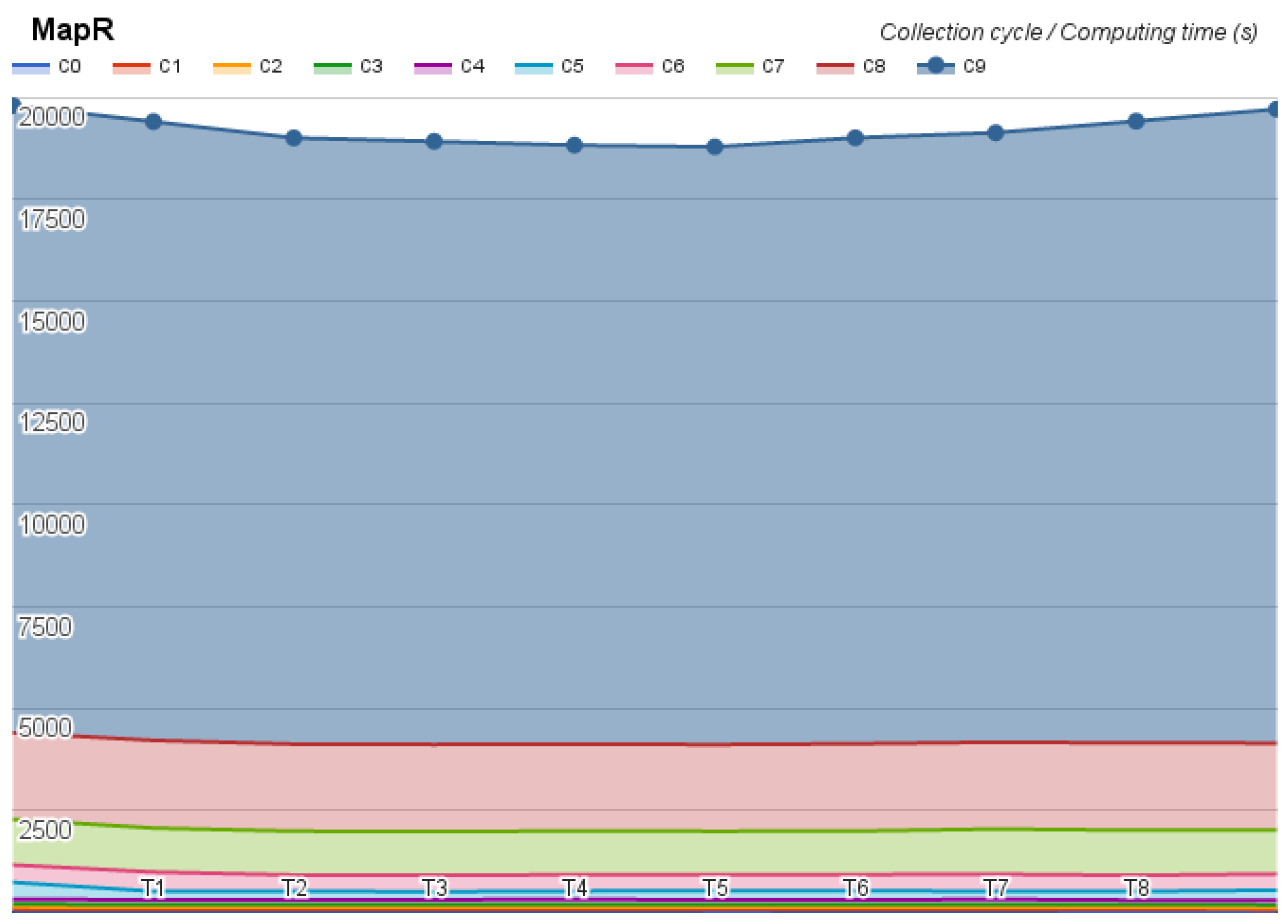
The first test was on the Hortonworks, which took 34 h and did not present any error. The second test was on the MapR, which took 53 h and returned one error message, omitted almost 24 results, kept on looping on two tests, and aborted the Pi estimator at the last step of the test. The last test was on Cloudera, whose test took 36 h and did not present any error, but revealed an interesting time oscillation. The benchmark results were divided by collection cycle and they are depicted in
Figure 4,
Figure 5 and
Figure 6.
For a complete side-by-side analysis, we execute the same test in the
Apache Hadoop, whose results are detailed in
Table 2.
Analyzing the results, we conclude that among the different platforms of data management, the usage of Apache Hadoop is faster than others. Principally because it took less than 30 h to complete the tasks without a single error. In a superficial analysis, we can list some possibilities of why this happened: the network, tasks starvation and deadlock, the computing infrastructure, as well as the distribution and scalability of data. Considering the results, we decided to use it on our computers as the Apache Hadoop.
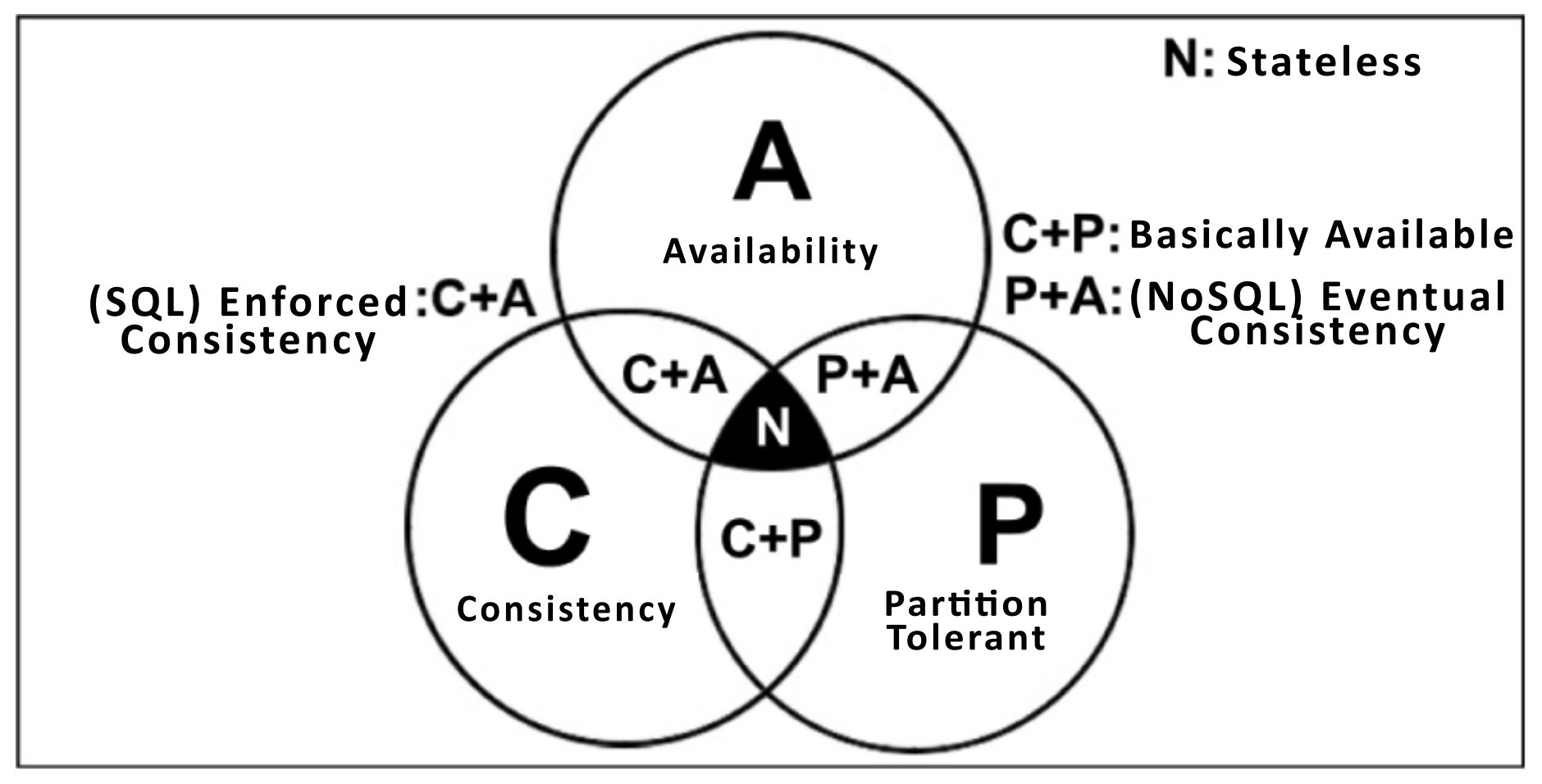
As previously explained, there is a limit for centralization. The closer this limit is, the higher is the financial cost. For our servers, the centralization limit was two real cores, eight gigs of ram and one terabyte of storage using RAID. To expand this model we used distribution, which requires high numbers of servers and these numbers and many other factors characterize performance gain, processing power, storage space and data availability. Consequently, the investment in local servers can be expensive and the financial cost is a common barrier to its usage. For instance, in our experiments, it was necessary to acclimatize our laboratory and invest in power supplies.
Cloud servers are an interesting alternative to perform acceptable results, in order to suit the need of Hadoop usage. To quantify the cloud server performance on benchmark tests, we deployed on a cloud server a few servers to test the centralization, the local and geographical distribution. It is important to know that most of cloud servers are centralized on blade servers on different data centers. In this case, it is clear that the centralization limit of a cloud server is much higher than what we have in our laboratory. Therefore, a single centralized server can have more processor cores, memory and storage in our cluster.
The first analysis on the cloud was on the distributed (scaled-out) server. On the master, we had two cores, two gigs of ram and SSD storage; on the six slaves, we had one core, one gig of ram and SSD storage. We deployed the
Apache Hadoop on the cloud cluster and we executed the same benchmark test as before, the results are detailed in
Table 3.
The second analysis on the cloud was on the centralized (scaled-up) server. At the master/slave server, we had eight cores, eight gigs of ram and SSD storage. We deployed the
Apache Hadoop on a single node and we executed the benchmark test as shown in
Table 4.
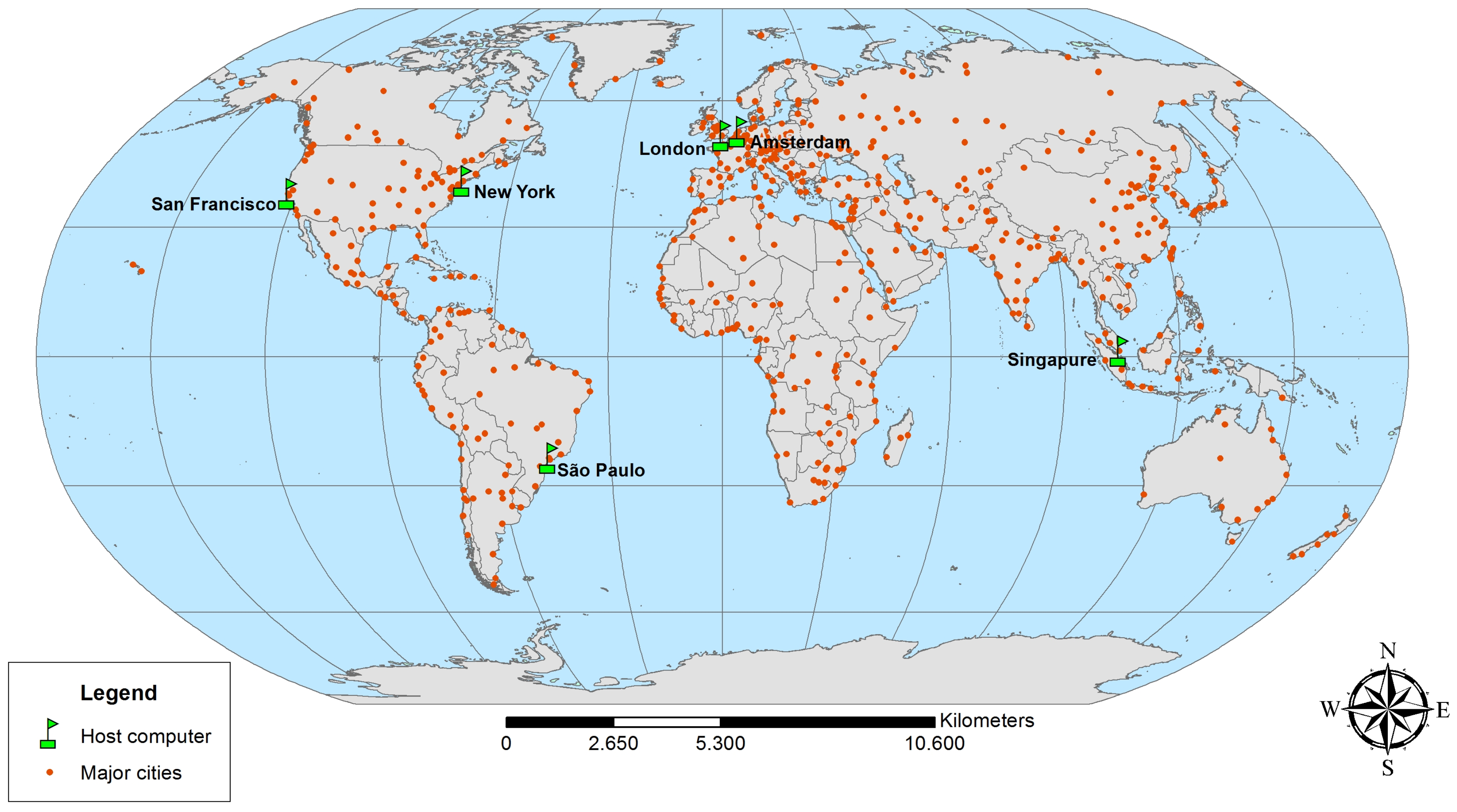
At last, we analyze the geographical distribution model to quantify the network interference on one data center to multiple data centers interacting over the internet. We use the same configuration as the distributed cloud server, but we share the servers in different data centers in the world. The server distribution can be seen in
Figure 7 and the results of the test are detailed in the
Table 5.
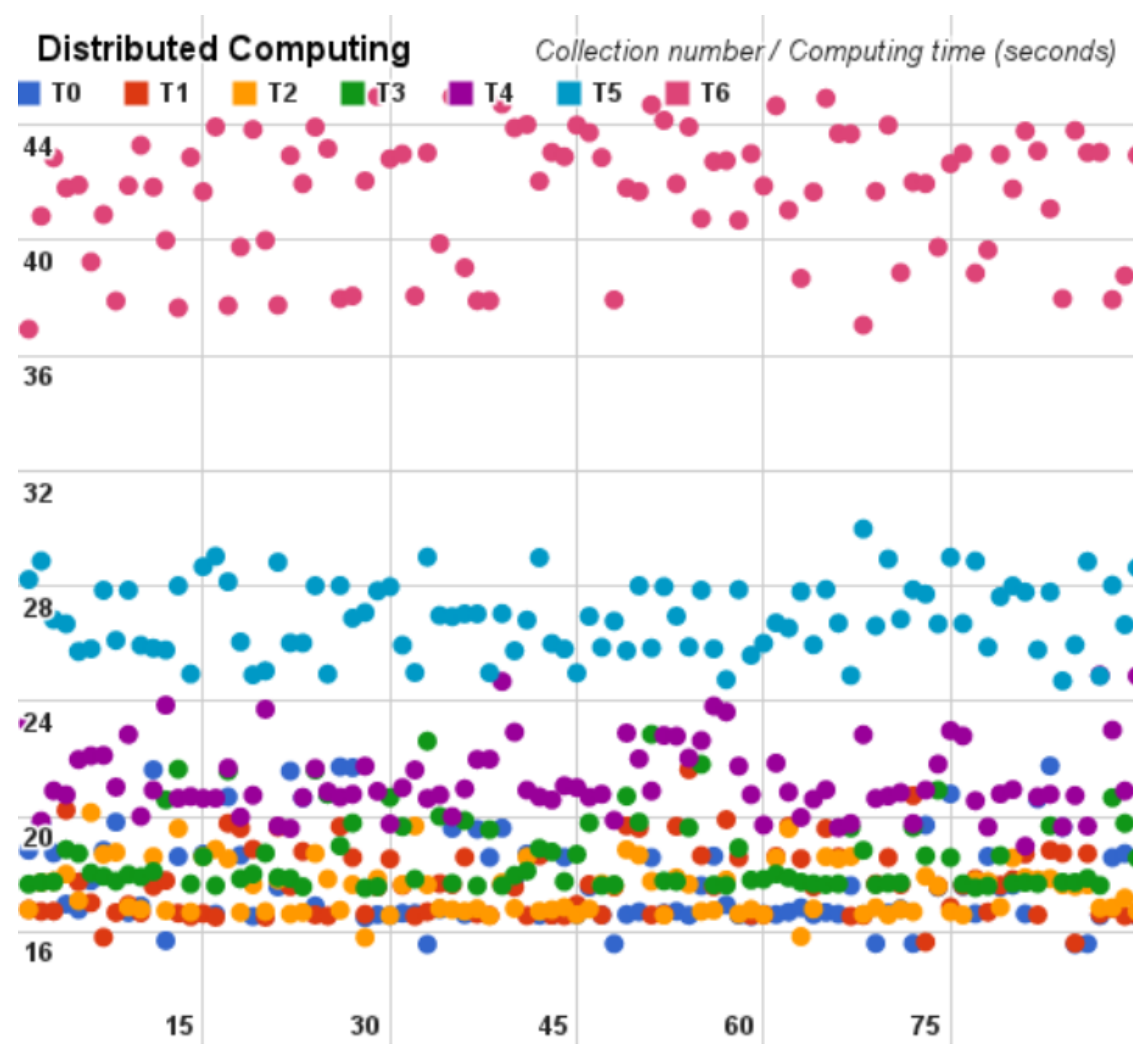
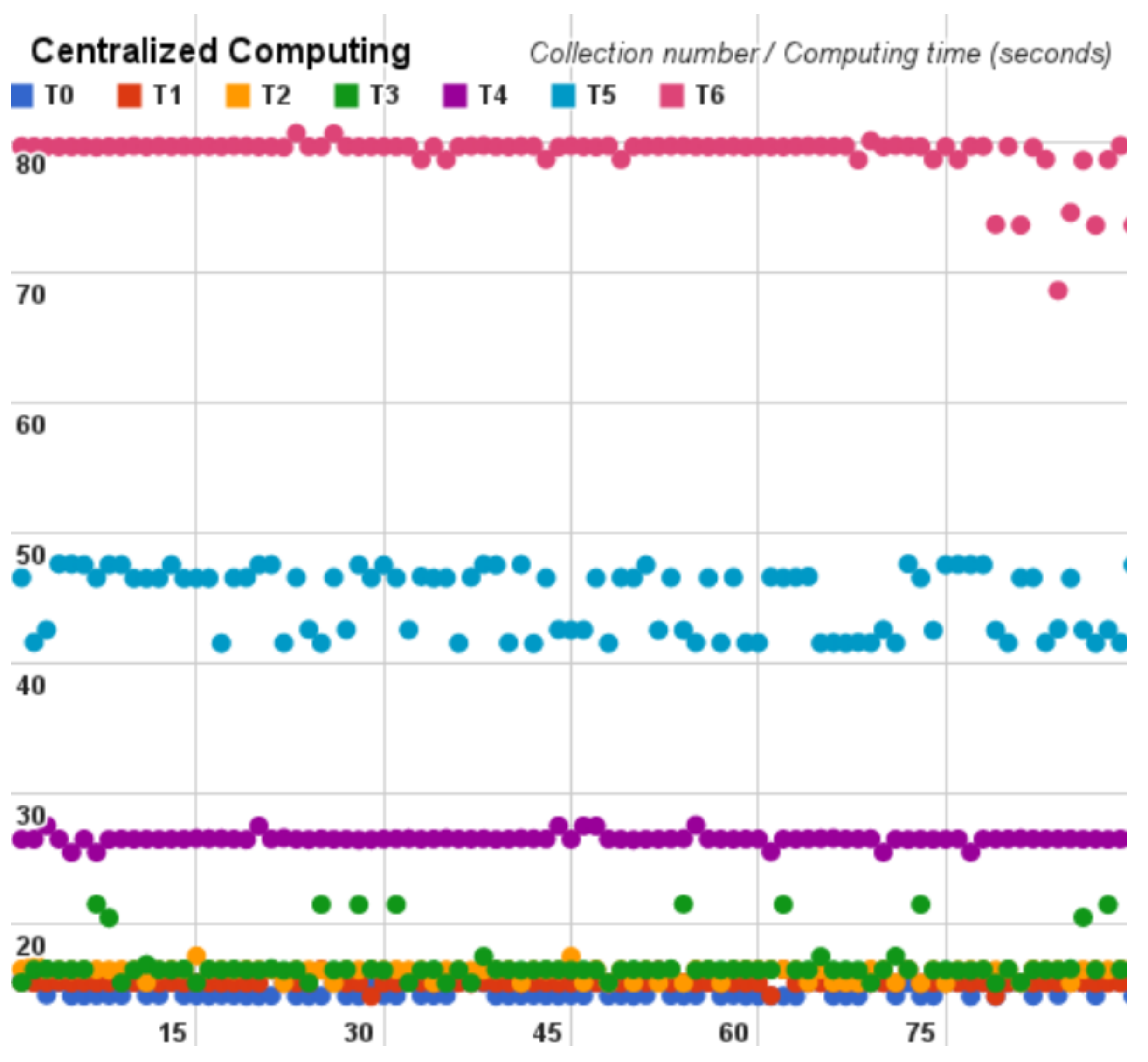
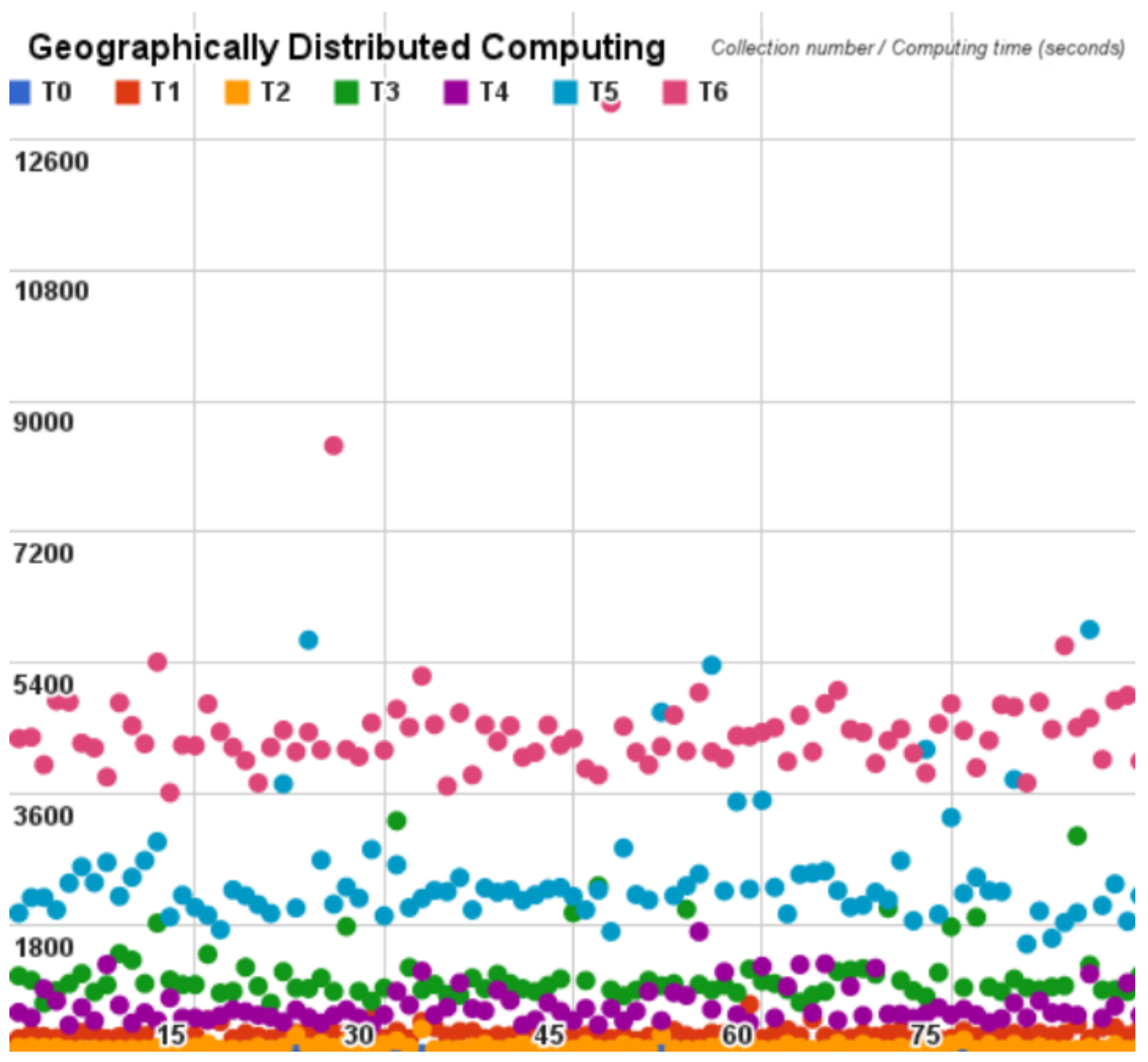
Following, for each cloud benchmark we plot the time spent on each Pi estimator cycle on dispersion graphs, that are depicted hereinafter in
Figure 8,
Figure 9 and
Figure 10.
According to the cycles of each analysis, from
Table 3,
Table 4 and
Table 5, we observed that the distributed model and the centralized model obtained similar values, alternating between which is faster. On the other hand, the geographically distributed model provided the worst times in all cycles.
It is possible to observe that the last cycle of each analysis had a much higher standard deviation and variance than the other cycles. This occurs because the number of samples increases in each cycle by the network interference.
Additionally, the centralized results show an almost continuous processing time in 80 seconds. Subsequently the distributed result shows us the timing difference in each cycle and considering the timing variation the highest processing time is almost half of the centralized model. Finally, the geographically distributed model shows us the network interference into the Hadoop; in this model we were only able to compute results until the cycle number six (T6). On the other cycles, the exit rate of the program was so high that it prevented execution of the test, presenting the internet as a harmful medium.
Considering our methodology, at the end of the tests we collected sufficient data to speculate about investment in local or cloud server. Not only to decide, but to create a dynamic comparison method for planning clusters in local or cloud servers, as we performed. Besides, the benchmark results can be used to support reliable comparison among different architectures. The main point of the methodology is the hardware gap; it must be as low as possible during the test to get better results.
Considering our initial cluster and the analyzed cloud server, in our case, the investment could be reverted to a highly scalable cloud server that could deploy more slaves as needed, not demanding investment in local infrastructure. On performance, the distribution is still the answer because the parallel processing, the distributed storage, as well as the higher processing time, is more efficient with scaled-out servers.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}