An Extended-Tag-Induced Matrix Factorization Technique for Recommender Systems


Abstract
:1. Introduction
2. Materials and Methods
2.1. Primary Definition
2.2. Matrix Factorization
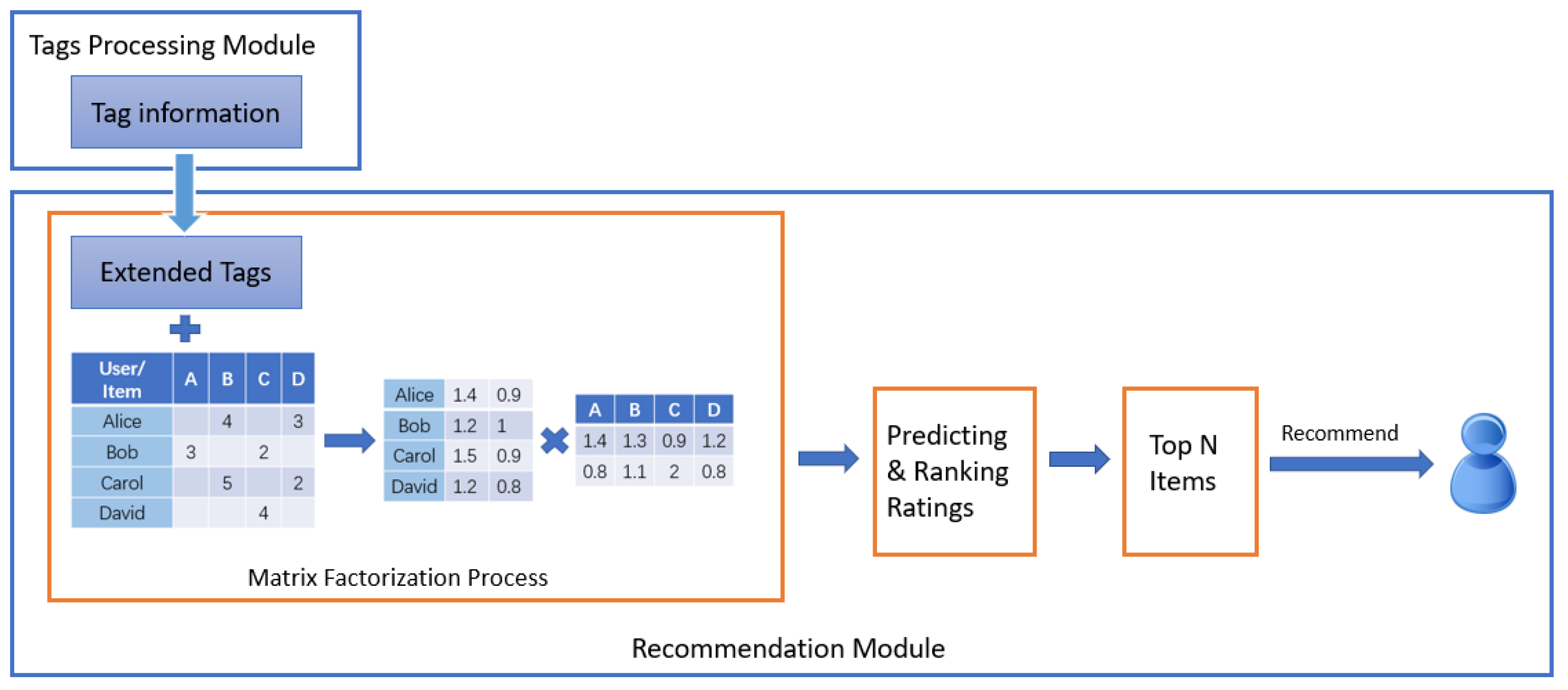
2.3. Extended-Tag-Induced Matrix Factorization
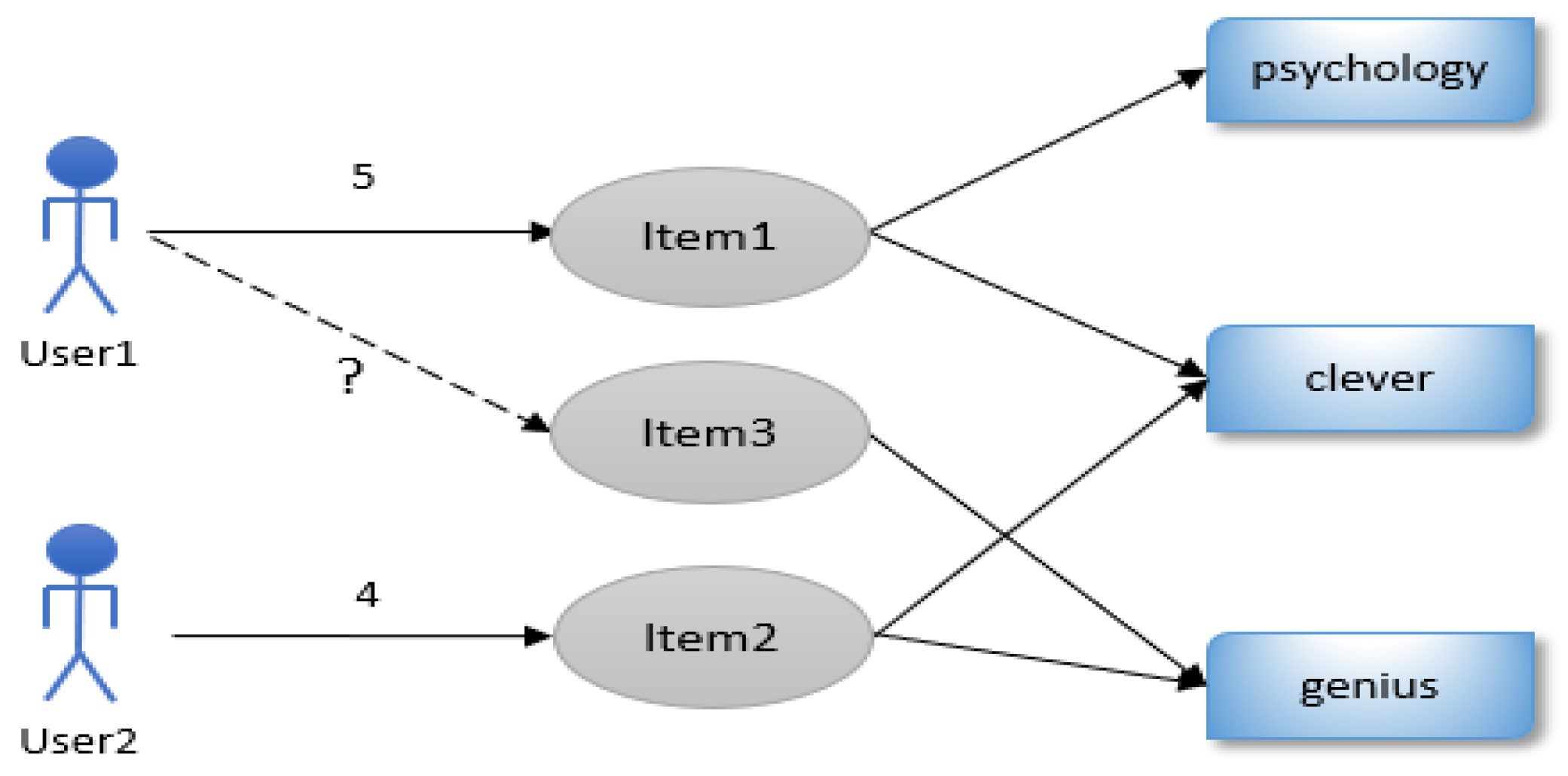
2.3.1. Tag-Tag Co-Occurrence Matrix
2.3.2. Tag Vectors of Item to Item
2.3.3. Extended Tag Vectors of Item to Item
2.3.4. Similarities of Items Based on Extended Tags
2.3.5. The Process of Matrix Factorization
| Algorithm 1. The Framework of Proposed Recommendation Algorithm ETIMF |
| Input: User-item rating matrix , the set of tags , the dimension of latent feature vector K, the number of iteration W, the step size of gradient descent , parameters and . Output: The user latent feature matrix and the item latent feature matrix . 1: Compute tag-tag similarity matrix by using Equation (3) 2: Create tag vectors of item to item 3: Recreate extended tag vectors of item to item 4: Using Equation (6) compute similarities of items according to extended tag vectors of item to item 5: Initialize and randomly 6: for w = 1 to W do 7: for k = 1 to K do 8: 9: 10: end for 11: end for |
3. Results
3.1. Dataset
3.2. Performance Evaluation
3.3. Recommendation Quality Comparisons
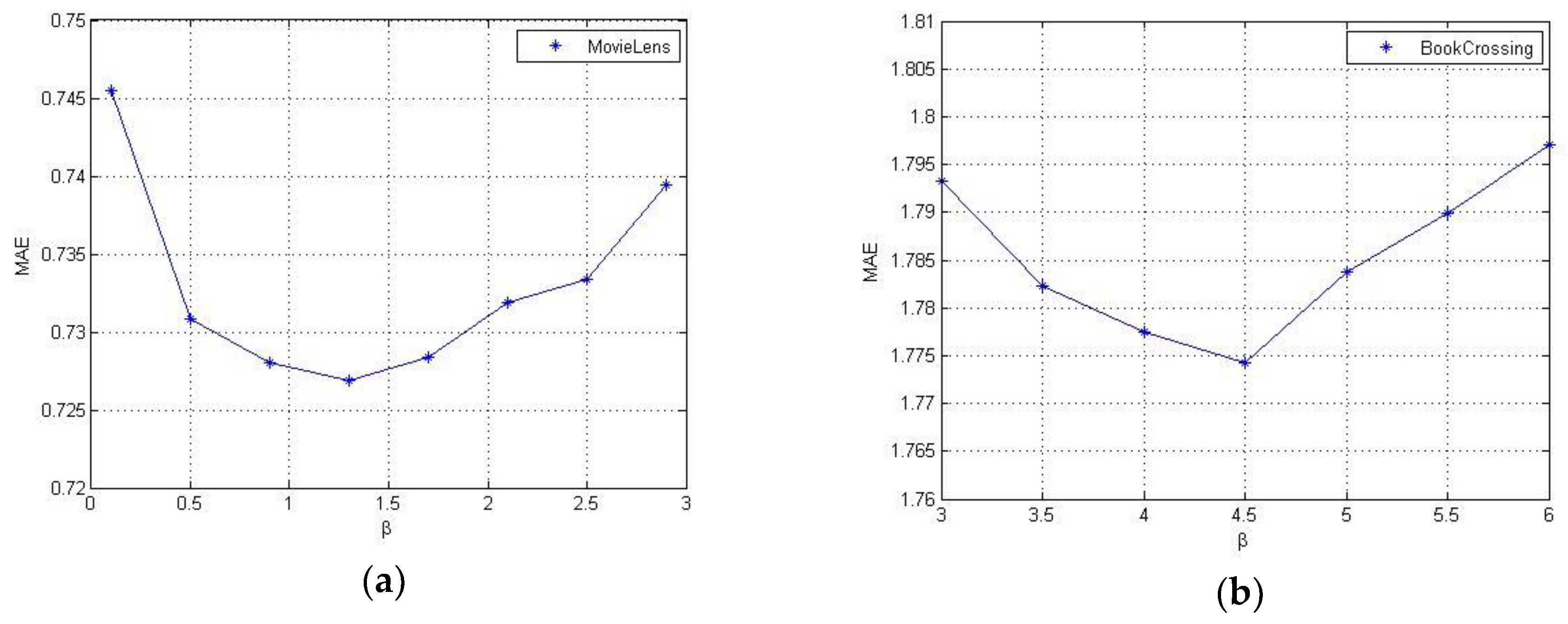
3.4. The Influence of Tagging Information
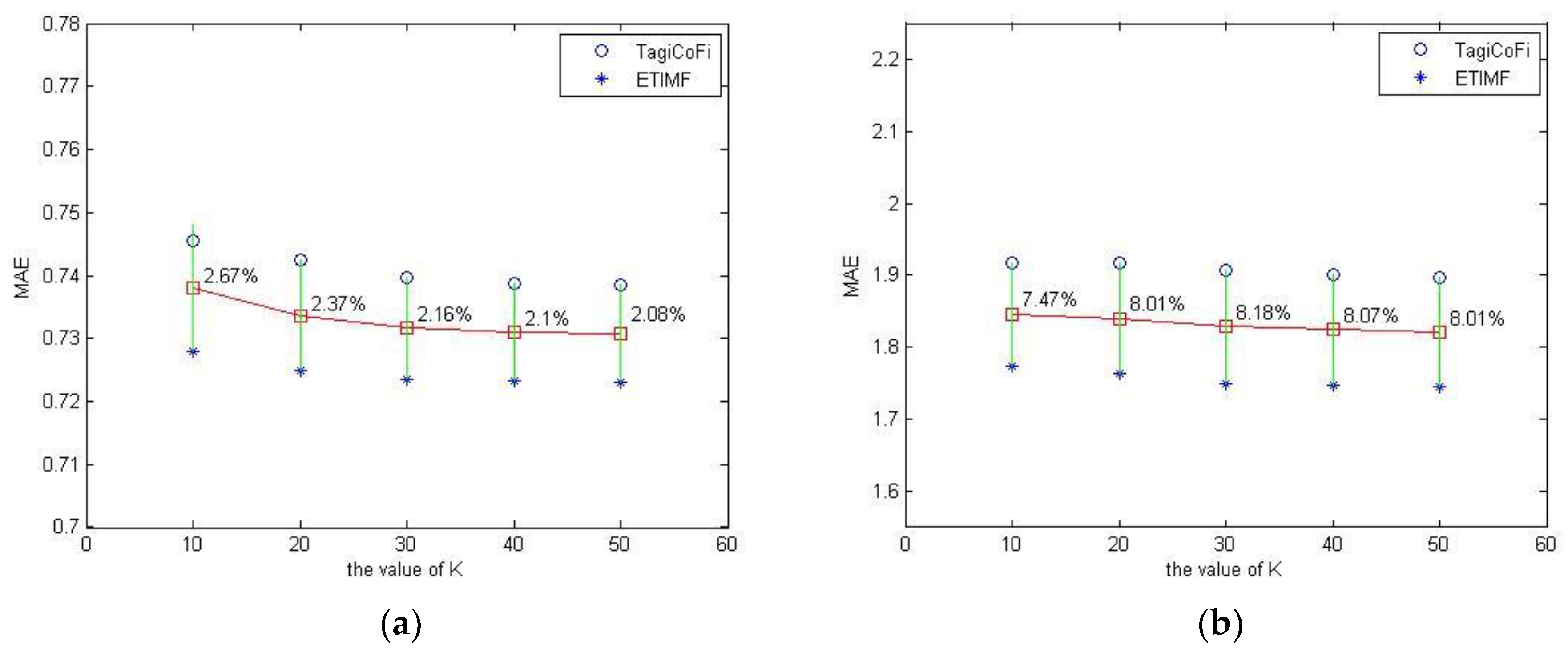
3.5. The Influence of Dimension of Latent Feature K
3.6. Efficiency Comparisons
3.7. Performance of Sparse Tagging Information
3.8. Performance of Item Cold Start Problem
4. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Karabadji, N.E.I.; Beldjoudi, S.; Seridi, H. Improving Memory-Based User Collaborative Filtering with Evolutionary Multi-Objective Optimization. Expert Syst. Appl. 2018, 98, 153–165. [Google Scholar] [CrossRef]
- Morozov, S.; Saiedian, H. An Empirical Study of the Recursive Input Generation Algorithm for Memory-based Collaborative Filtering Recommender Systems. Int. J. Inf. Decis. Sci. 2017, 5, 36–49. [Google Scholar] [CrossRef]
- Hu, Y.; Shi, W.; Li, H. Mitigating Data Sparsity Using Similarity Reinforcement-Enhanced Collaborative Filtering. ACM Trans. Int. Technol. 2017, 17, 1–20. [Google Scholar] [CrossRef]
- Zhang, Z.; Kudo, Y.; Murai, T. Neighbor selection for user-based collaborative filtering using covering-based rough sets. Ann. Oper. Res. 2017, 256, 359–374. [Google Scholar] [CrossRef]
- Colace, F.; De Santo, M.; Greco, L.; Moscato, V.; Picariello, A. A collaborative user-centered framework for recommending items in Online Social Networks. Comput. Hum. Behav. 2015, 51, 694–704. [Google Scholar] [CrossRef]
- Moscato, V.; Picariello, A.; Rinaldi, A.M. Towards a user based recommendation strategy for digital ecosystems. Knowl.-Based Syst. 2013, 37, 165–175. [Google Scholar] [CrossRef]
- Guo, G.; Zhang, J.; Zhu, F.; Wang, X. Factored similarity models with social trust for top-N item recommendation. Knowl.-Based Syst. 2017, 122, 17–25. [Google Scholar] [CrossRef]
- He, J.; Liu, H.; Xiong, H. SocoTraveler: Travel-package recommendations leveraging social influence of different relationship types. Inf. Manag. 2016, 53, 934–950. [Google Scholar] [CrossRef]
- Albanese, M.; Chianese, A.; d’Acierno, A.; Moscato, V.; Picariello, A. A multimedia recommender integrating object features and user behavior. Multimed. Tools Appl. 2010, 50, 563–585. [Google Scholar] [CrossRef]
- Yin, H.; Cui, B.; Zhou, X.; Wang, W.; Huang, Z.; Sadiq, S. Joint Modeling of User Check-in Behaviors for Real-time Point-of-Interest Recommendation. ACM Trans. Inf. Syst. 2016, 35, 11. [Google Scholar] [CrossRef]
- Manotumruksa, J.; Macdonald, C.; Ounis, I. Regularising Factorised Models for Venue Recommendation using Friends and their Comments. In Proceedings of the International Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 1981–1984. [Google Scholar]
- Kharrat, F.B.; Elkhleifi, A.; Faiz, R. Recommendation system based contextual analysis of Facebook comment. In Proceedings of the International Conference of Computer Systems and Applications, Agadir, Morocco, 29 November–2 December 2017; pp. 1–6. [Google Scholar]
- Yu, Y.; Wang, C.; Wang, H.; Gao, Y. Attributes coupling based matrix factorization for item recommendation. Appl. Intell. 2017, 46, 1–13. [Google Scholar] [CrossRef]
- Gedikli, F. Improving recommendation accuracy based on item-specific tag preferences. ACM Trans. Int. Syst. Technol. 2013, 4, 1–19. [Google Scholar] [CrossRef]
- Chatti, M.A.; Dakova, S.; Thus, H.; Schroeder, U. Tag-Based Collaborative Filtering Recommendation in Personal Learning Environments. IEEE Trans. Learn. Technol. 2013, 6, 337–349. [Google Scholar] [CrossRef]
- Peng, J.; Zeng, D. Topic-based web page recommendation using tags. In Proceedings of the IEEE International Conference on Intelligence and Security Informatics, Dallas, TX, USA, 8–11 June 2009; pp. 269–271. [Google Scholar]
- Blaze, J.; Asok, A.; Roth, T.L. Content-based tag propagation and tensor factorization for personalized item recommendation based on social tagging. ACM Trans. Interact. Intell. Syst. 2014, 3, 26. [Google Scholar]
- Tso-Sutter, K.H.L.; Marinho, L.B.; Schmidt-Thieme, L. Tag-aware recommender systems by fusion of collaborative filtering algorithms. In Proceedings of the ACM Symposium on Applied Computing, Fortaleza, Brazil, 16–20 March 2008; pp. 1995–1999. [Google Scholar]
- Zhen, Y.; Li, W.J.; Yeung, D.Y. TagiCoFi: Tag informed collaborative filtering. In Proceedings of the ACM Conference on Recommender Systems, New York, NY, USA, 22–25 October 2009; pp. 69–76. [Google Scholar]
- Huang, C.L.; Lin, C.W. Collaborative and content-based recommender system for social bookmarking website. World Acad. Sci. Eng. Technol. 2010, 68, 748. [Google Scholar]
- Kim, H.N.; Ji, A.T.; Ha, I.; Jo, G.S. Collaborative filtering based on collaborative tagging for enhancing the quality of recommendation. Electron. Commer. Res. Appl. 2010, 9, 73–83. [Google Scholar] [CrossRef]
- Nguyen, J.; Zhu, M. Content-boosted matrix factorization techniques for recommender systems. Stat. Anal. Data Min. ASA Data Sci. J. 2013, 6, 286–301. [Google Scholar] [CrossRef] [Green Version]
- Huang, C.L.; Yeh, P.H.; Lin, C.W.; Wu, D.C. Utilizing user tag-based interests in recommender systems for social resource sharing websites. Knowl.-Based Syst. 2014, 56, 86–96. [Google Scholar] [CrossRef]
- Rawashdeh, M.; Kim, H.N.; Alja’am, J.M.; El Saddik, A. Folksonomy link prediction based on a tripartite graph for tag recommendation. J. Intell. Inf. Syst. 2013, 40, 307–325. [Google Scholar]
- Kim, H.N.; Rawashdeh, M.; Saddik, A.E. Tailoring recommendations to groups of users. In Proceedings of the International Conference on Intelligent User Interfaces, Santa Monica, CA, USA, 19–22 March 2013; pp. 15–24. [Google Scholar]
- Ji, K.; Shen, H. Addressing cold-start: Scalable recommendation with tags and keywords. Knowl.-Based Syst. 2015, 83, 42–50. [Google Scholar] [CrossRef]
- Fang, Z.; Gao, S.; Li, B.; Li, J.; Liao, J. Cross-Domain Recommendation via Tag Matrix Transfer. In Proceedings of the IEEE International Conference on Data Mining Workshop, Atlantic City, NJ, USA, 14–17 November 2015; pp. 1235–1240. [Google Scholar]
- Paterek, A. Improving regularized singular value decomposition for collaborative filtering. In Proceedings of the Kdd Cup & Workshop, San Jose, CA, USA, 12 August 2007. [Google Scholar]
- Luo, X.; Xia, Y.; Zhu, Q. Incremental Collaborative Filtering recommender based on Regularized Matrix Factorization. Knowl.-Based Syst. 2012, 27, 271–280. [Google Scholar] [CrossRef]
- Dong, X.; Thanou, D.; Frossard, P.; Vandergheynst, P. Learning Laplacian Matrix in Smooth Graph Signal Representations. IEEE Trans. Signal Process. 2014, 64, 6160–6173. [Google Scholar] [CrossRef]
- Nemirovski, A.; Juditsky, A.; Lan, G.; Shapiro, A. Robust Stochastic Approximation Approach to Stochastic Programming. SIAM J. Optim. 2014, 19, 1574–1609. [Google Scholar] [CrossRef]
- GroupLens. MovieLens 20M Dataset. Available online: http://grouplens.org/datasets/movielens/20m/ (accessed on 10 June 2018).
- Ziegler, C.N.; McNee, S.M.; Konstan, J.A.; Lausen, G. Improving recommendation lists through topic diversification. In Proceedings of the International Conference on World Wide Web, Chiba, Japan, 10–14 May 2005; pp. 22–32. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Detailed Description |
|---|---|
| Social information | the “credibility” of users [7], social relationships of users discovered by social networks [8] |
| Social behaviors of users | Users’ browsing behaviors [9], users’ point of interest [10] |
| Opinions of users | Comments given by users [11,12] |
| Information of items | Items’ reputations, semantic contents [6] and items’ attributes [5,13] |
| Tag information | Tags annotated by users and tags provided by systems [14] |
| Items | Tags |
|---|---|
| I1 | {history, space, genius, psychology} |
| I2 | {revenge, violent, visual, psychology} |
| I3 | {teen, adventure, dancing, fantasy} |
| I4 | {romance, touching, fantasy} |
| I5 | { robots, sci-fi, quirky, genius} |
| Rank | Tags | Co-Occurrence Probability |
|---|---|---|
| 1 | space | 0.5917 |
| 2 | space opera | 0.5262 |
| 3 | aliens | 0.5136 |
| 4 | special effects | 0.5116 |
| 5 | action | 0.4965 |
| 6 | future | 0.4914 |
| 7 | spaceships | 0.4855 |
| 8 | science fiction | 0.4822 |
| 9 | futuristic | 0.4766 |
| 10 | far future | 0.4577 |
| Statistic | MovieLens 20M | Book-Crossing |
|---|---|---|
| No. of Ratings | 375,873 | 12,931 |
| No. of Users, m | 7711 | 1851 |
| No. of Items, n | 999 | 10,000 |
| No. of tag records | 187,100 | 145,707 |
| No. of tags | 1968 | 1210 |
| Training Set | K = 10 | K = 30 | K = 50 | K = Number of Tags | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MF | TagiCoFi | ETIMF | MF | TagiCoFi | ETIMF | MF | TagiCoFi | ETIMF | TMT | |
| 20% | 0.7535 | 0.7480 | 0.7269 | 0.7487 | 0.7424 | 0.7236 | 0.7457 | 0.7397 | 0.7231 | 0.7242 |
| 50% | 0.7380 | 0.7345 | 0.7231 | 0.7322 | 0.7289 | 0.7220 | 0.7322 | 0.7299 | 0.7195 | 0.7251 |
| 80% | 0.7312 | 0.7280 | 0.7215 | 0.7239 | 0.7235 | 0.7189 | 0.7255 | 0.7234 | 0.7166 | 0.7198 |
| Training Set | K = 10 | K = 30 | K = 50 | K = Number of Tags | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MF | TagiCoFi | ETIMF | MF | TagiCoFi | ETIMF | MF | TagiCoFi | ETIMF | TMT | |
| 20% | 2.1079 | 1.9175 | 1.7743 | 2.0600 | 1.9095 | 1.7636 | 2.0231 | 1.9025 | 1.7445 | 1.7710 |
| 50% | 1.9741 | 1.8708 | 1.7315 | 1.9605 | 1.8508 | 1.7261 | 1.9029 | 1.8503 | 1.7118 | 1.7301 |
| 80% | 1.9249 | 1.8375 | 1.6904 | 1.8717 | 1.8038 | 1.6884 | 1.8556 | 1.7903 | 1.6847 | 1.6895 |
| Training Set | MovieLens 20M | Book-Crossing | ||||||
|---|---|---|---|---|---|---|---|---|
| MF | TagiCoFi | TMT | ETIMF | MF | TagiCoFi | TMT | ETIMF | |
| 20% | 657 | 650 | 805 | 648 | 199 | 198 | 362 | 198 |
| 50% | 971 | 969 | 1244 | 978 | 634 | 632 | 893 | 634 |
| 80% | 1108 | 1104 | 1488 | 1127 | 1197 | 1189 | 1588 | 1199 |
| Algorithm | Tag Information Size | |||
|---|---|---|---|---|
| 80% | 50% | 30% | 10% | |
| TagiCoFi | 0.7402 | 0.7413 | 0.7429 | 0.7445 |
| TMT | 0.7323 | 0.7307 | 0.7318 | 0.7326 |
| ETIMF | 0.7283 | 0.7286 | 0.7288 | 0.7292 |
| Algorithm | Tag Information Size | |||
|---|---|---|---|---|
| 80% | 50% | 30% | 10% | |
| TagiCoFi | 1.9592 | 1.9735 | 1.9893 | 2.0117 |
| TMT | 1.7962 | 1.8432 | 1.8660 | 1.9060 |
| ETIMF | 1.7885 | 1.8343 | 1.8752 | 1.8973 |
| Type | 50 Cold-Start Items | 100 Cold-Start Items | ||||
|---|---|---|---|---|---|---|
| TagiCoFi | TMT | ETIMF | TagiCoFi | TMT | ETIMF | |
| Cold-start items | 1.0373 | 0.8983 | 0.8439 | 1.1728 | 0.9903 | 0.8851 |
| All items | 0.9678 | 0.8123 | 0.7729 | 1.1335 | 0.8603 | 0.8205 |
| Type | 50 Cold-Start Items | 100 Cold-Start Items | ||||
|---|---|---|---|---|---|---|
| TagiCoFi | TMT | ETIMF | TagiCoFi | TMT | ETIMF | |
| Cold-start items | 2.1477 | 2.0606 | 2.0571 | 2.2643 | 2.1953 | 2.1552 |
| All items | 1.9137 | 1.7299 | 1.7023 | 2.1456 | 2.0647 | 2.0223 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, H.; Huang, M.; Zhang, Y.; Bhatti, U.A. An Extended-Tag-Induced Matrix Factorization Technique for Recommender Systems. Information 2018, 9, 143. https://doi.org/10.3390/info9060143
Han H, Huang M, Zhang Y, Bhatti UA. An Extended-Tag-Induced Matrix Factorization Technique for Recommender Systems. Information. 2018; 9(6):143. https://doi.org/10.3390/info9060143
Chicago/Turabian StyleHan, Huirui, Mengxing Huang, Yu Zhang, and Uzair Aslam Bhatti. 2018. "An Extended-Tag-Induced Matrix Factorization Technique for Recommender Systems" Information 9, no. 6: 143. https://doi.org/10.3390/info9060143
APA StyleHan, H., Huang, M., Zhang, Y., & Bhatti, U. A. (2018). An Extended-Tag-Induced Matrix Factorization Technique for Recommender Systems. Information, 9(6), 143. https://doi.org/10.3390/info9060143