Make Flows Great Again: A Hybrid Resilience Mechanism for OpenFlow Networks

Abstract
:1. Introduction
2. Preliminaries
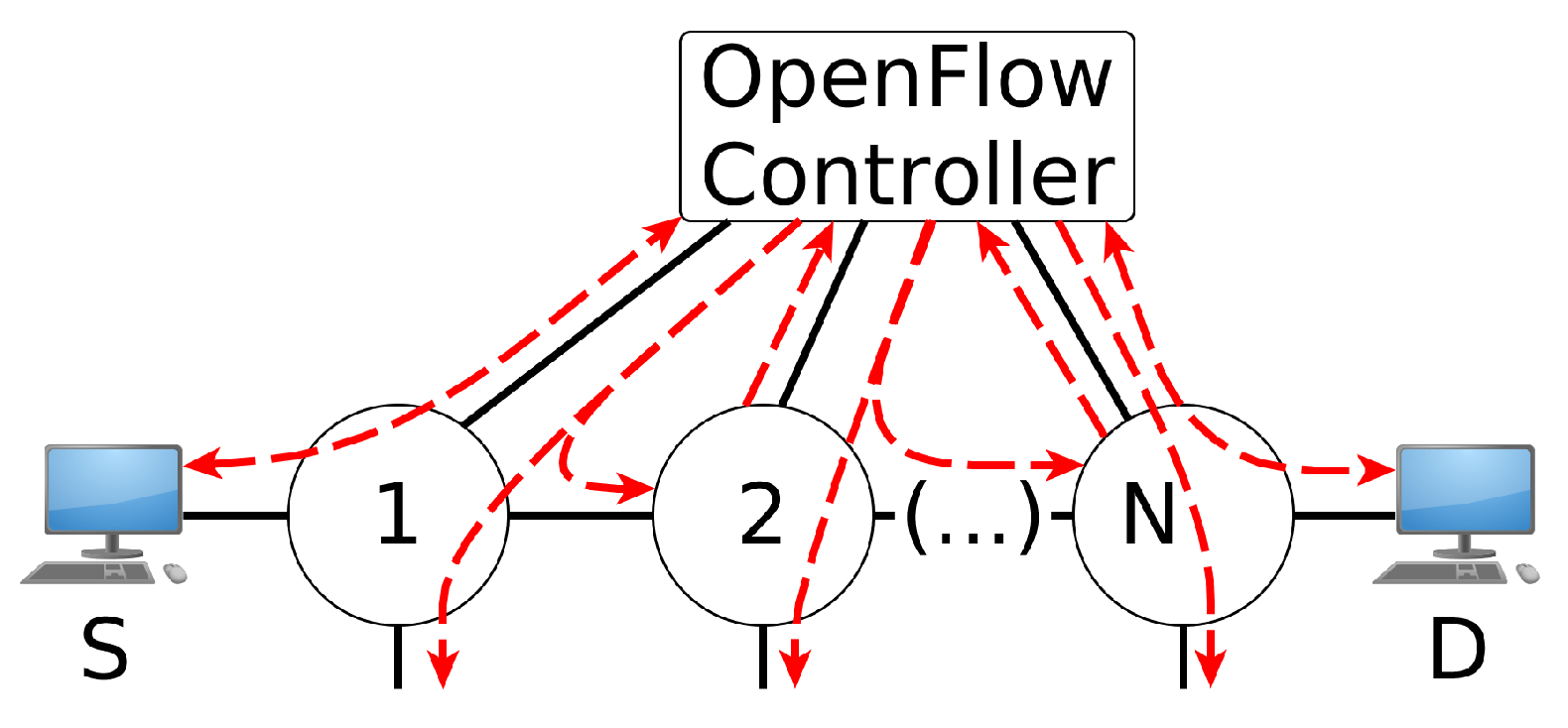
2.1. Topology Discovery
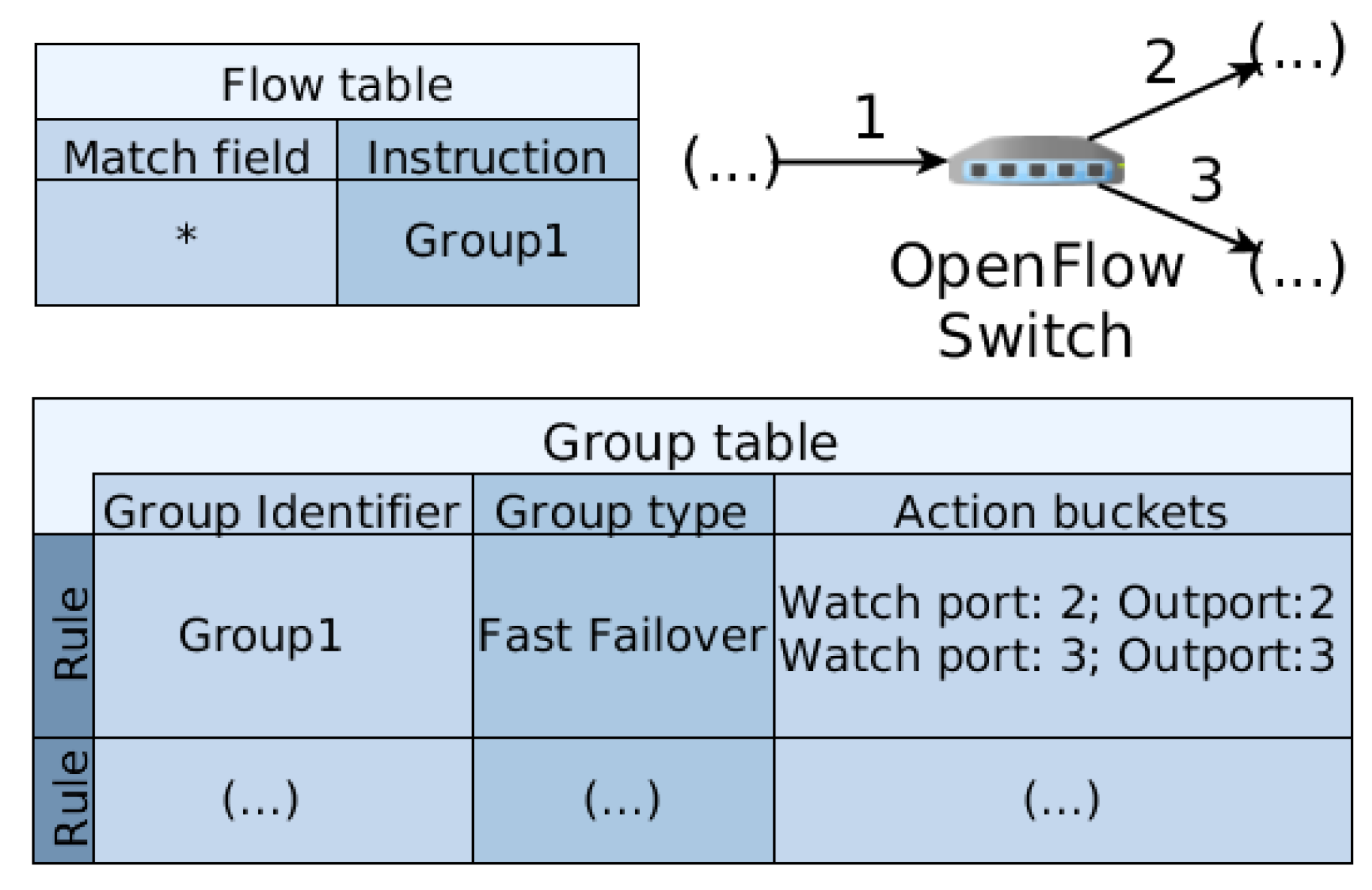
2.2. OpenFlow Fast Failover Group Table
3. Related Works
3.1. Classification of Resilience Mechanisms
3.2. Schemes of Resilience Mechanisms
3.3. Resilience Mechanisms
4. Local Group Node Fast Reroute
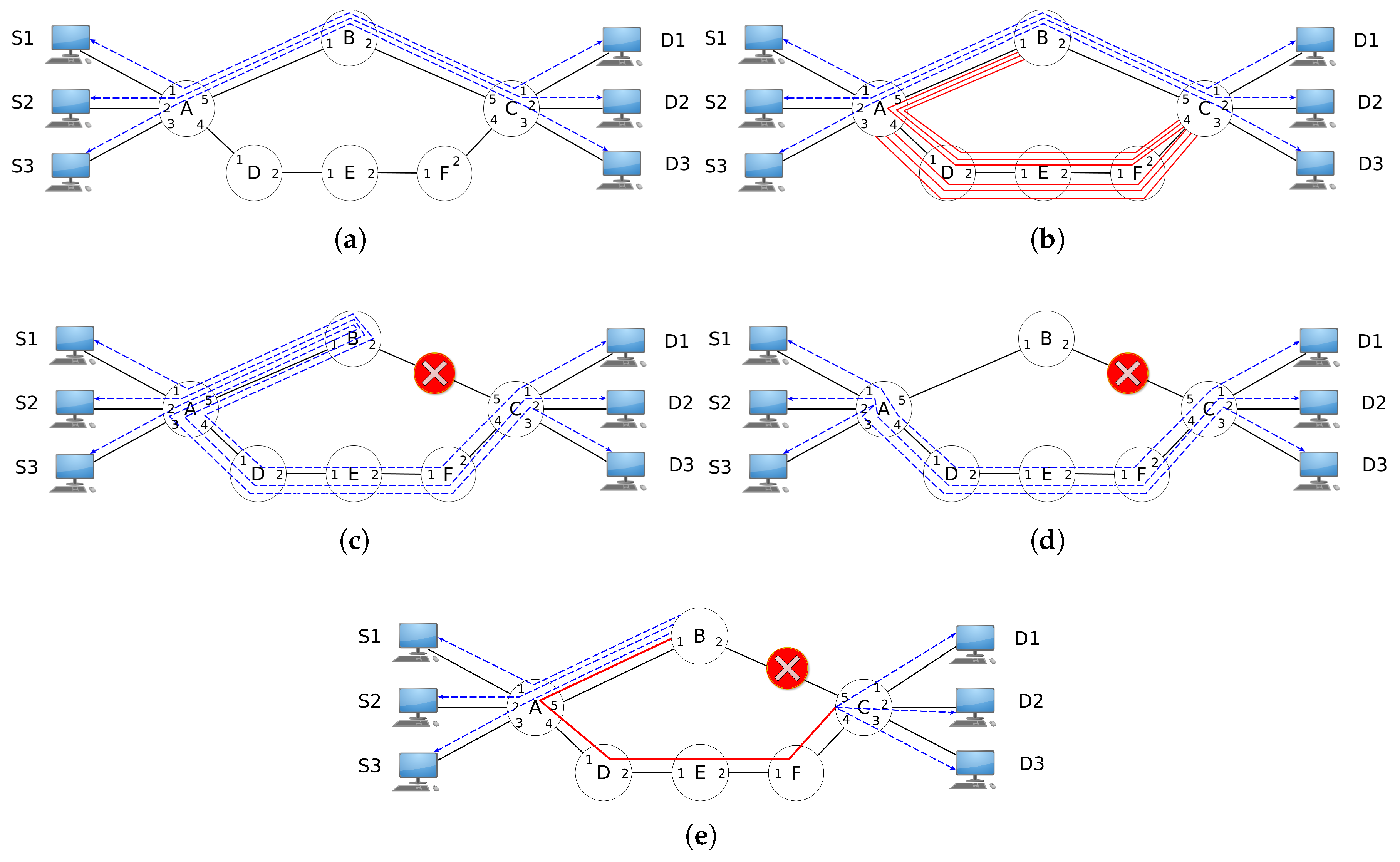
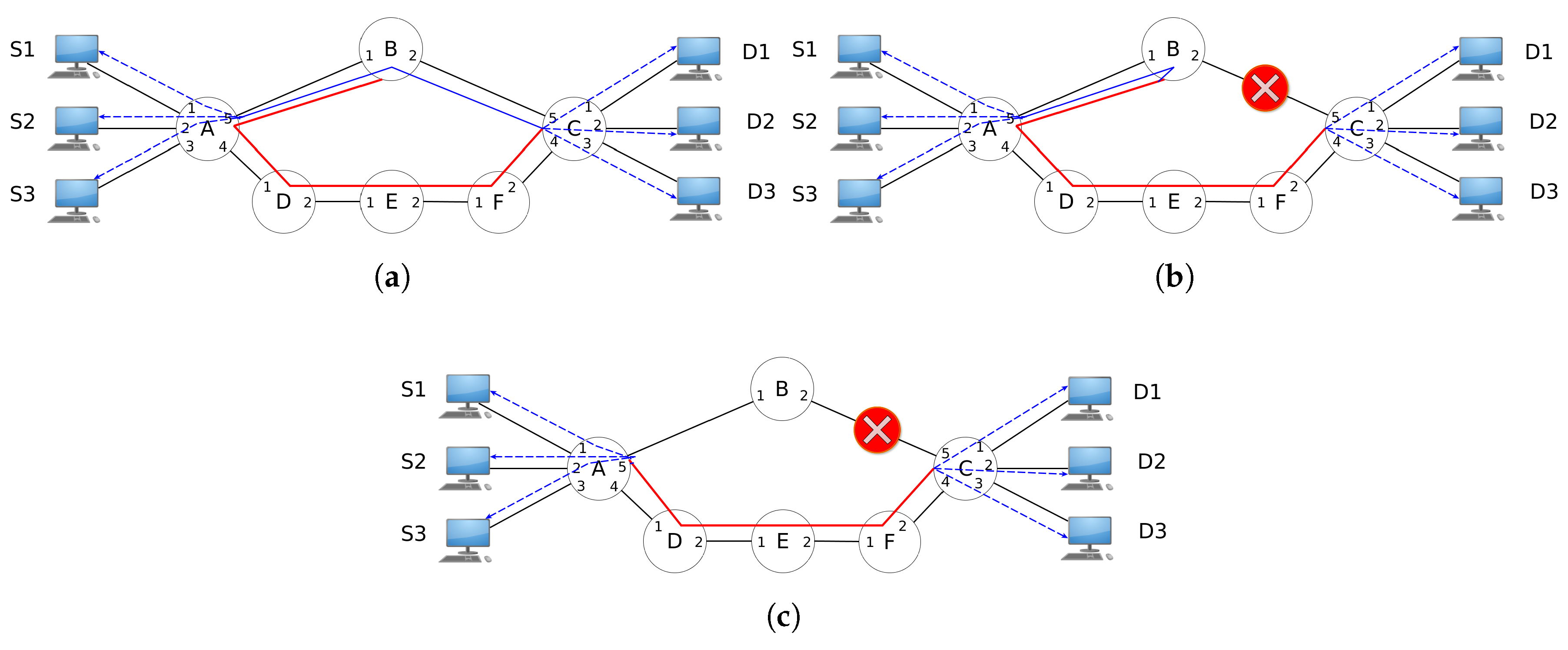
4.1. An Example
4.2. Notation and Concepts
4.3. LONG Protection Phase
| Algorithm 1 The algorithm of LONG for the protection phase. |
| Input: The network topology , set of endpoints O, set of identifiers I. Output: For all endpoints, install primary and backup paths between source and destination.
|
| Algorithm 2 Install primary path. |
| Input: The network topology , an identifier i, switch source , switch destination , path from to Output: Install a primary path between switch source and switch destination using the selected identifier.
|
| Algorithm 3 Install backup paths. |
| Input: The network topology , an identifier i, switch source , switch destination , path from to Output: Install backup paths between switch source and switch destination using the selected tag.
|
4.4. LONG Restoration Phase
| Algorithm 4 The algorithm of LONG for the restoration phase. |
| Input: The network topology , set of F, set of identifiers I and . Output: The flows will follow the shortest path.
|
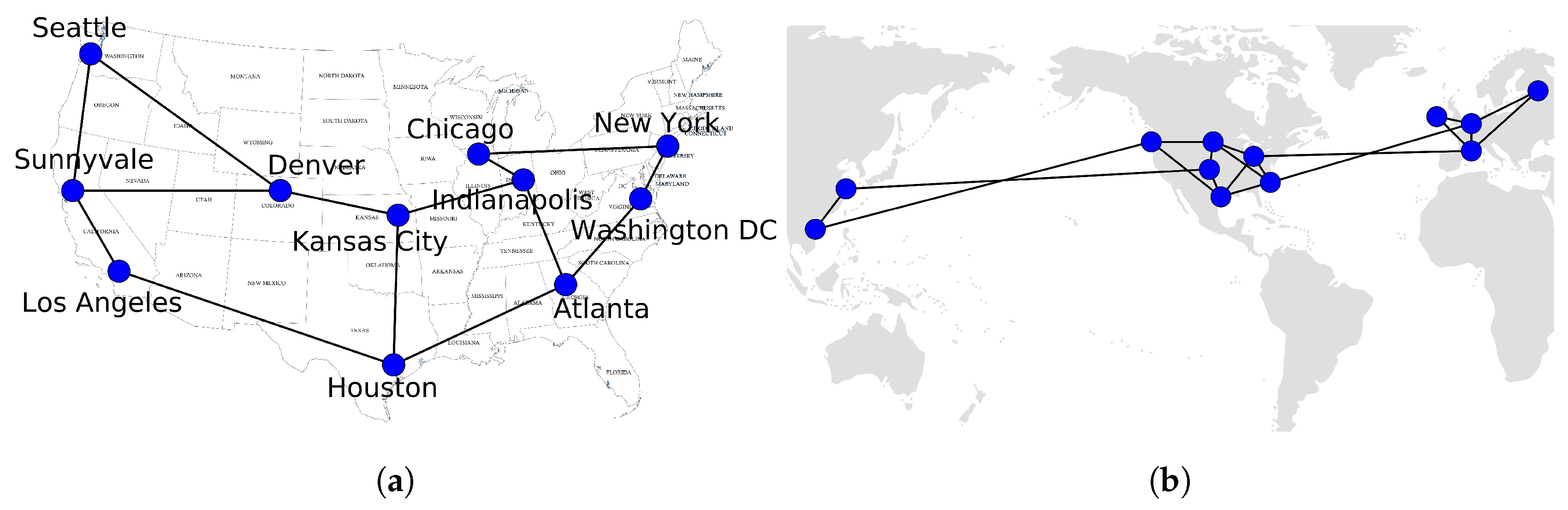
5. Evaluation
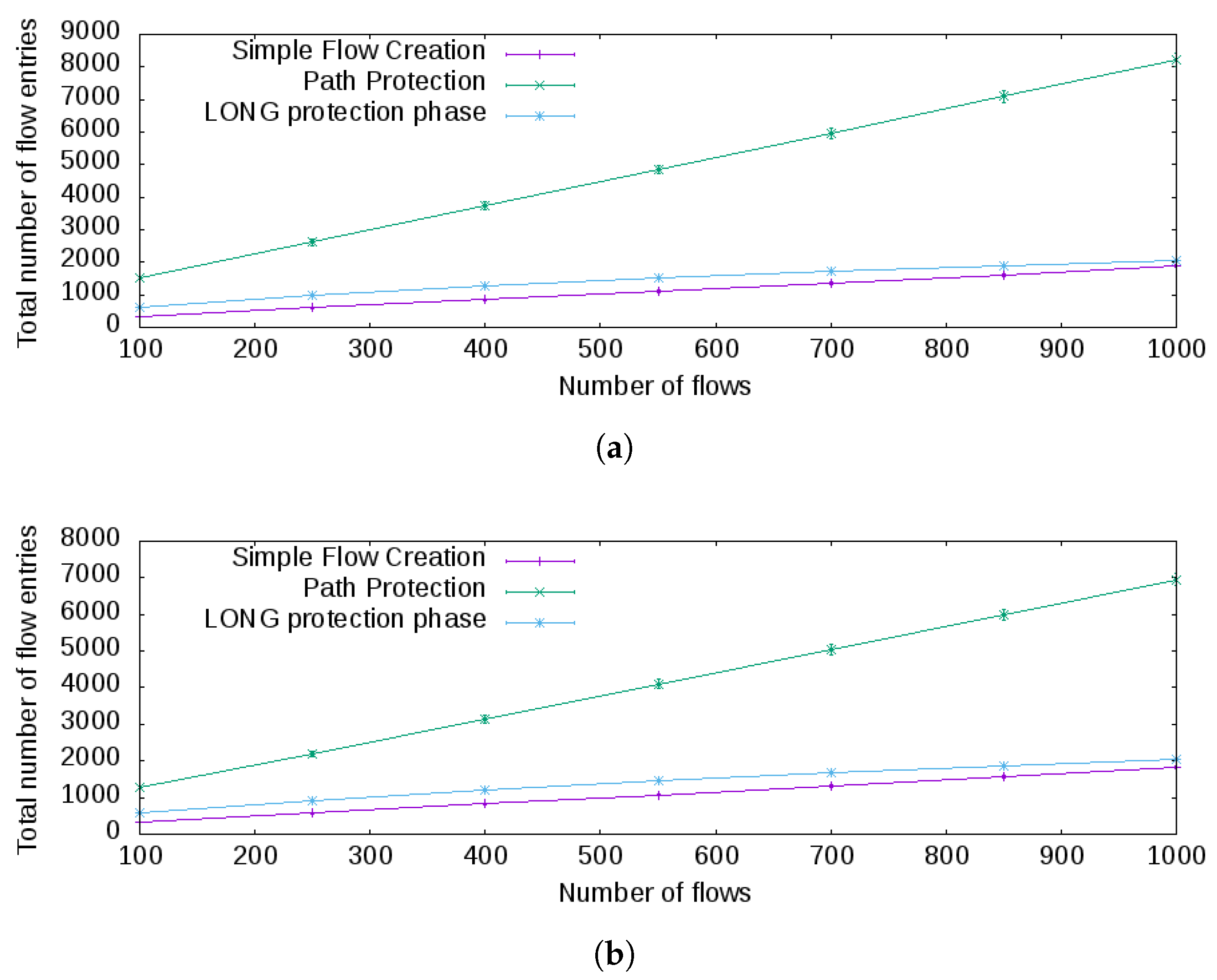
5.1. Flows Entries
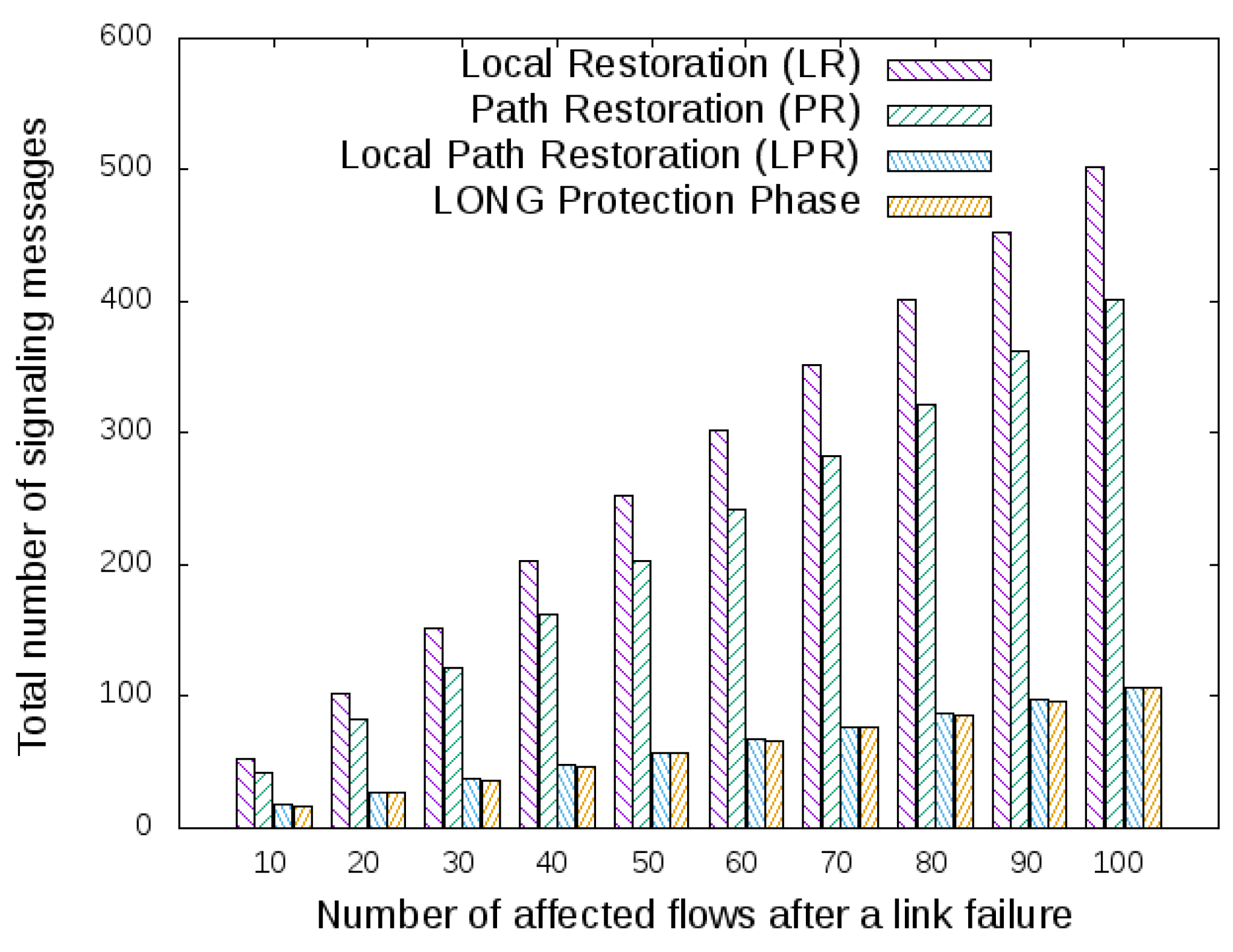
5.2. Signaling Overhead
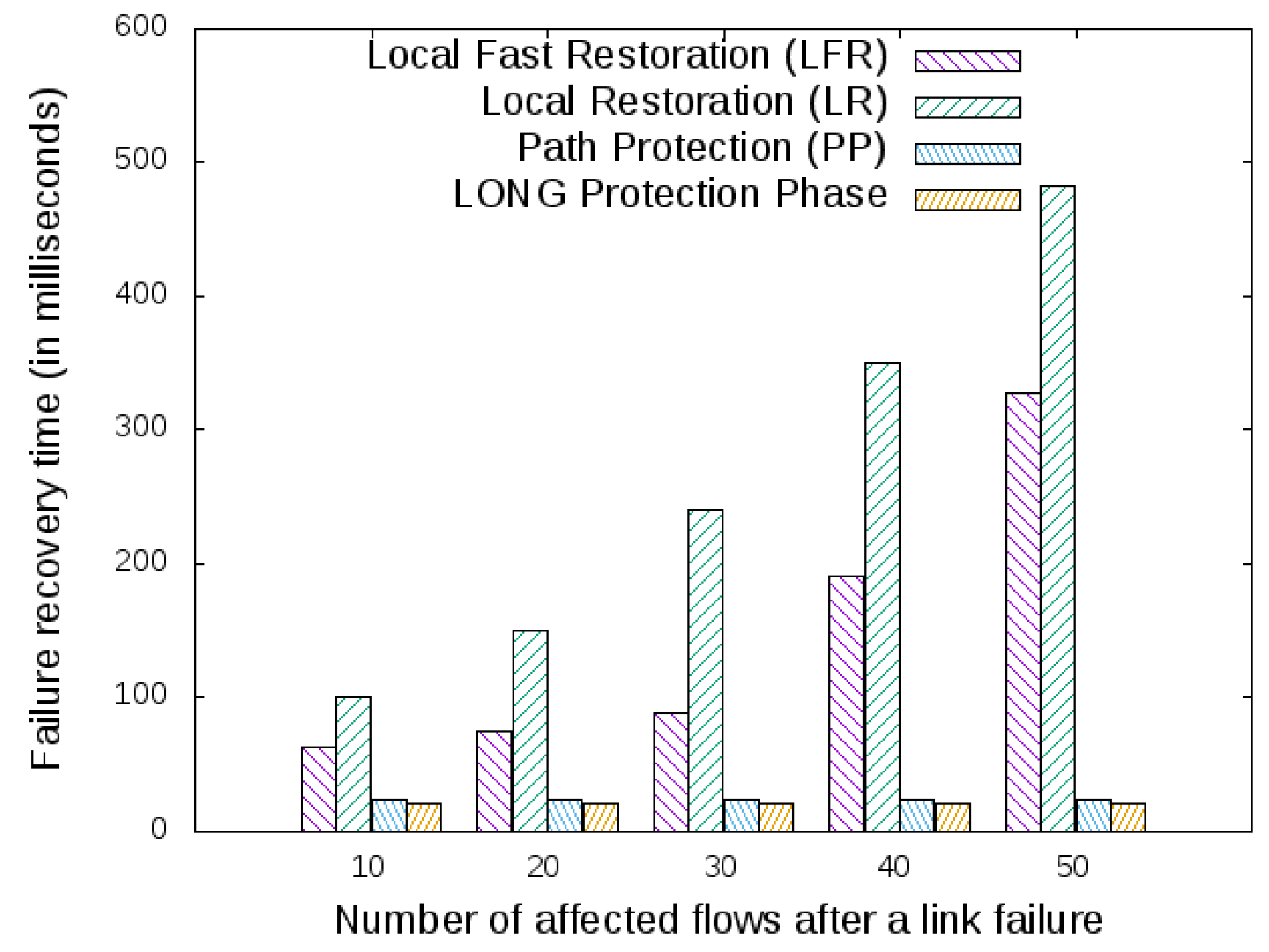
5.3. Failure Recovery Time
6. Further Discussion
7. Conclusions
Funding
Conflicts of Interest
References
- Singh, S.; Jha, R.K. A Survey on Software Defined Networking: Architecture for Next Generation Network. J. Netw. Syst. Manag. 2017, 25, 321–374. [Google Scholar] [CrossRef]
- Nunes, B.A.A.; Mendonca, M.; Nguyen, X.N.; Obraczka, K.; Turletti, T. A survey of software-defined networking: Past, present, and future of programmable networks. IEEE Commun. Surv. Tutor. 2014, 16, 1617–1634. [Google Scholar] [CrossRef]
- Silva, W.J.A. An Architecture to Manage Incoming Traffic of Inter-Domain Routing Using OpenFlow Networks. Information 2018, 9, 92. [Google Scholar] [CrossRef]
- Silva, W.J.A.; Sadok, D.F.H. Control Inbound Traffic: Evolving the Control Plane Routing System with Software Defined Networking. In Proceedings of the 18th International Conference on High Performance Switching and Routing (HPSR), Campinas, Brazil, 18–21 June 2017. [Google Scholar]
- Kreutz, D.; Ramos, F.M.V.; Veríssimo, P.E.; Rothenberg, C.E.; Azodolmolky, S.; Uhlig, S. Software-Defined Networking: A Comprehensive Survey. Proc. IEEE 2015, 103, 14–76. [Google Scholar] [CrossRef] [Green Version]
- Silva, W.J.A.; Sadok, D.F.H. A Survey on Efforts to Evolve the Control Plane of Inter-Domain Routing. Information 2018, 9, 125. [Google Scholar] [CrossRef]
- Feamster, N.; Rexford, J.; Zegura, E. The road to SDN: An Intellectual History of Programmable Networks. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 87–98. [Google Scholar] [CrossRef]
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parulkar, G.; Peterson, L.; Rexford, J.; Shenker, S.; Turner, J. OpenFlow: Enabling Innovation in Campus Networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 38, 69. [Google Scholar] [CrossRef]
- Sharma, S.; Staessens, D.; Colle, D.; Palma, D.; Goncalves, J.; Figueiredo, R.; Morris, D.; Pickavet, M.; Demeester, P. Implementing Quality of Service for the Software Defined Networking Enabled Future Internet. In Proceedings of the 2014 Third European Workshop on Software Defined Networks, London, UK, 1–3 September 2014; pp. 49–54. [Google Scholar]
- Vishnoi, A.; Poddar, R.; Mann, V.; Bhattacharya, S. Effective Switch Memory Management in OpenFlow Networks. In Proceedings of the 8th ACM International Conference on Distributed Event-Based Systems, Mumbai, India, 26–29 May 2014. [Google Scholar]
- Silva, W.J.A. Avoiding Inconsistency in OpenFlow Stateful Applications Caused by Multiple Flow Requests. In Proceedings of the International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 5–8 March 2018; pp. 543–548. [Google Scholar]
- Rothenberg, C.E.; Nascimento, M.R.; Salvador, M.R.; Corrêa, C.N.A.; Cunha de Lucena, S.; Raszuk, R. Revisiting routing control platforms with the eyes and muscles of software-defined networking. In Proceedings of the First Workshop on Hot Topics in Software Defined Networks, Helsinki, Finland, 13 August 2012; p. 13. [Google Scholar]
- Zhang, X.; Cheng, Z.; Lin, R.; He, L.; Yu, S.; Luo, H. Local Fast Reroute with Flow Aggregation in Software Defined Networks. IEEE Commun. Lett. 2016, 7798, 1–4. [Google Scholar] [CrossRef]
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. Enabling Fast Failure Recovery in OpenFlow Networks. In Proceedings of the 2011 8th International Workshop on the Design of Reliable Communication Networks (DRCN), Krakow, Poland, 10–12 October 2011; pp. 164–171. [Google Scholar]
- Pfaff, B.; Lantz, B.; Heller, B.; Barker, C.; Cohn, D.; Talayco, D.; Erickson, D.; Crabbe, E.; Gibb, G.; Appenzeller, G.; et al. OpenFlow 1.1 Specification; Open Networking Foundation: Menlo Park, CA, USA, 2011; pp. 1–56. [Google Scholar]
- Lin, Y.D.; Teng, H.Y.; Hsu, C.R.; Liao, C.C.; Lai, Y.C. Fast failover and switchover for link failures and congestion in software defined networks. In Proceedings of the 2016 IEEE International Conference on Communications, ICC 2016, Kuala Lumpur, Malaysia, 22–27 May 2016. [Google Scholar]
- Adrichem, N.L.V.; Asten, B.J.V.; Kuipers, F.A. Fast Recovery in Software-Defined Networks. In Proceedings of the 2014 3rd European Workshop on Software Defined Networks, London, UK, 1–3 September 2014; pp. 61–66. [Google Scholar]
- Nguyen, X.N.; Saucez, D.; Barakat, C.; Turletti, T. Rules Placement Problem in OpenFlow Networks: A Survey. IEEE Commun. Surv. Tutor. 2016, 18, 1273–1286. [Google Scholar] [CrossRef]
- Pfaff, B.; Lantz, B.; Heller, B.; Barker, C.; Cohn, D.; Casado, M. OpenFlow Switch Specification—1.3 Version; Open Networking Foundation: Menlo Park, CA, USA, 2012. [Google Scholar]
- Katz, D.; Ward, D. BFD for IPv4 and IPv6 Single Hop. arXiv, 2010; arXiv:1011.1669v3. [Google Scholar]
- Cascone, C.; Pollini, L.; Sanvito, D.; Capone, A.; Sanso, B. SPIDER: Fault resilient SDN pipeline with recovery delay guarantees. In Proceedings of the IEEE NETSOFT 2016 IEEE NetSoft Conference and Workshops, Software-Defined Infrastructure for Networks, Clouds, IoT and Services, Seoul, Korea, 6–10 June 2016; pp. 295–302. [Google Scholar]
- Bianchi, G.; Bonola, M.; Capone, A.; Cascone, C. OpenState: Programming Platform-independent Stateful OpenFlow Applications Inside the Switch. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 44–51. [Google Scholar] [CrossRef]
- Silva, W.J.A. Performance Evaluation of Flow Creation Inside an OpenFlow Network. In Proceedings of the XXXV Simpósio Brasileiro de Telecomunicações e Processamento de Sinais—SBrT2017, São Pedro, SP, Brazil, 3–6 September 2017; pp. 102–106. [Google Scholar]
- Silva, W.J.A.; Dias, K.L.; Sadok, D.F.H. A Performance Evaluation of Software Defined Networking Load Balancers Implementations. In Proceedings of the International Conference on Information Networking (ICOIN), Da Nang, Vietnam, 11–13 January 2017. [Google Scholar]
- Fernandez, M.P. Comparing OpenFlow controller paradigms scalability: Reactive and proactive. In Proceedings of the International Conference on Advanced Information Networking and Applications, AINA, Barcelona, Spain, 25–28 March 2013; pp. 1009–1016. [Google Scholar]
- Akyildiz, I.F.; Lee, A.; Wang, P.; Luo, M.; Chou, W. A roadmap for traffic engineering in software defined networks. Comput. Netw. 2014, 71, 1–30. [Google Scholar] [CrossRef]
- Beheshti, N.; Zhang, Y. Fast Failover for Control Traffic in Software-defined Networks. In Proceedings of the 2012 IEEE Global Communications Conference (GLOBECOM), Anaheim, CA, USA, 3–7 December 2012; pp. 2665–2670. [Google Scholar]
- Katz, D.; Ward, D. Bidirectional Forwarding Detection. J. Phys. A Math. Theor. 2010, 53, 160. [Google Scholar]
- OpenvSwitch. Open vSwitch. 2016. Available online: http://openvswitch.org/ (accessed on 13 June 2018).
- Stephens, B.; Cox, A.L.; Rixner, S. Scalable Multi-Failure Fast Failover via Forwarding Table Compression. In Proceedings of the Symposium on SDN Research, Santa Clara, CA, USA, 14–15 March 2016; pp. 1–12. [Google Scholar]
- Gill, P.; Jain, N.; Nagappan, N. Understanding network failures in data centers. ACM SIGCOMM Comput. Commun. Rev. 2011, 41, 350. [Google Scholar] [CrossRef]
- Zheng, J.; Xu, H.; Zhu, X.; Chen, G.; Geng, Y. We’ve got you covered: Failure recovery with backup tunnels in traffic engineering. In Proceedings of the 2016 IEEE 24th International Conference on Network Protocols (ICNP), Singapore, 8–11 November 2016; pp. 1–10. [Google Scholar]
- Liu, H.H.; Kandula, S.; Mahajan, R.; Zhang, M.; Gelernter, D. Traffic Engineering with Forward Fault Correction. In Proceedings of the 2014 ACM Conference on SIGCOMM, Chicago, IL, USA, 17–22 August 2014; pp. 527–538. [Google Scholar]
- Ryu. A Component-Based Software Defined Networking Framework—Ryu. 2016. Available online: https://osrg.github.io/ryu/ (accessed on 13 June 2018).
- Mininet. Mininet—An Instant Virtual Network on Your Laptop (Or Other PC). Available online: https://github.com/mininet/mininet (accessed on 13 June 2018).
- Topology-zoo. The internet topology zoo. IEEE J. Sele. Areas Commun. 2017, 29, 1765–1775. [Google Scholar]
- Jain, S.; Zhu, M.; Zolla, J.; Hölzle, U.; Stuart, S.; Vahdat, A.; Kumar, A.; Mandal, S.; Ong, J.; Poutievski, L.; et al. B4: experience with a globally-deployed software defined wan. In Proceedings of the ACM SIGCOMM 2013 Conference on SIGCOMM, Hong Kong, China, 12–16 August 2013; p. 3. [Google Scholar]
- Mendiola, A.; Astorga, J.; Jacob, E.; Higuero, M. A Survey on the Contributions of Software-Defined Networking to Traffic Engineering. IEEE Commun. Surv. Tutor. 2017, 19, 918–953. [Google Scholar] [CrossRef]
- Gupta, A.; MacDavid, R.; Birkner, R.; Canini, M.; Feamster, N.; Rexford, J.; Vanbever, L. An Industrial-Scale Software Defined Internet Exchange Point. In Proceedings of the 13th USENIX Symposium on Networked Systems Design and Implementation (NSDI 16), Santa Clara, CA, USA, 16–18 March 2016; pp. 1–14. [Google Scholar]
- Iperf. Iperf-Perform Network Throughput Tests. 2016. Available online: http://iperf.sourceforge.net/ (accessed on 13 June 2018).
- Fonseca, P.; Mota, E. A Survey on Fault Management in Software-Defined Networks. IEEE Commun. Surv. Tutor. 2017, 19, 2284–2321. [Google Scholar] [CrossRef]
- Kanizo, Y.; Hay, D.; Keslassy, I. Palette: Distributing tables in software-defined networks. In Proceedings of the IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 545–549. [Google Scholar]
- Kang, N.; Liu, Z.; Rexford, J.; Walker, D. Optimizing the “one big switch” abstraction in software-defined networks. In Proceedings of the 9th ACM Conference on Emerging Networking Experiments and Technologies, Santa Barbara, CA, USA, 9–12 December 2013; pp. 13–24. [Google Scholar]
- Nguyen, X.N.; Saucez, D.; Barakat, C.; Turletti, T.; Sophia, I.; Méditerranée, A. Optimizing Rules Placement in OpenFlow Networks: Trading Routing for Better Efficiency. In Proceedings of the Third Workshop on Hot Topics in Software Defined Networking, Chicago, IL, USA, 22 August 2014; pp. 127–132. [Google Scholar]
- Wang, Y.; Bi, J.; Lin, P.; Lin, Y.; Zhang, K. SDI: A multi-domain SDN mechanism for fine-grained inter-domain routing. Ann. Telecommun. 2016, 71, 625–637. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Works | Type | Main Metrics | Validation |
|---|---|---|---|
| Sharma et al. [14] | Restoration | Switchover time, round-trip time and packet loss | Emulation and simulation |
| Beheshti and Zhang [27] | Protection | Unprotectability | Simulation |
| Liu et al. [33] | Protection | Data loss and throughput | Emulation |
| Adrichem et al. [17] | Protection | Recovery time | Prototype |
| Stephens, Cox and Rixner [30] | Protection | TCAM utilization | Simulation |
| Lin et al. [16] | Protection | Flow entries, packet loss and average recovery time | Emulation |
| Cascone et al. [21] | Restoration | Packet loss and flow entries | Emulation and simulation |
| Zhang et al. [13] | Restoration | Flow entries and failure recovery time | Emulation |
| LONG | Restoration and protection | Packet loss, memory utilization, and recovery time | Emulation and simulation |
| Notation | Description |
|---|---|
| The network topology, where V denotes the set of nodes (switches) and E the set of edges (links between switches) | |
| O | Set of endpoints (source and destination of a flow) |
| I | A set of path identifiers |
| s | Source endpoint (source a flow) |
| d | Destination endpoint (destination a flow) |
| Function that returns the output port for destination d of switch v | |
| Function that returns the match for a given argument | |
| OpenFlow packet port status event | |
| OpenFlow packet output event | |
| Function that sends an packet. | |
| F | All flows installed and active in the network. |
| v | An OpenFlow switch |
| l | A failed link |
| Provides the number of elements in a given set |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silva, W.J.A. Make Flows Great Again: A Hybrid Resilience Mechanism for OpenFlow Networks. Information 2018, 9, 146. https://doi.org/10.3390/info9060146
Silva WJA. Make Flows Great Again: A Hybrid Resilience Mechanism for OpenFlow Networks. Information. 2018; 9(6):146. https://doi.org/10.3390/info9060146
Chicago/Turabian StyleSilva, Walber José Adriano. 2018. "Make Flows Great Again: A Hybrid Resilience Mechanism for OpenFlow Networks" Information 9, no. 6: 146. https://doi.org/10.3390/info9060146
APA StyleSilva, W. J. A. (2018). Make Flows Great Again: A Hybrid Resilience Mechanism for OpenFlow Networks. Information, 9(6), 146. https://doi.org/10.3390/info9060146