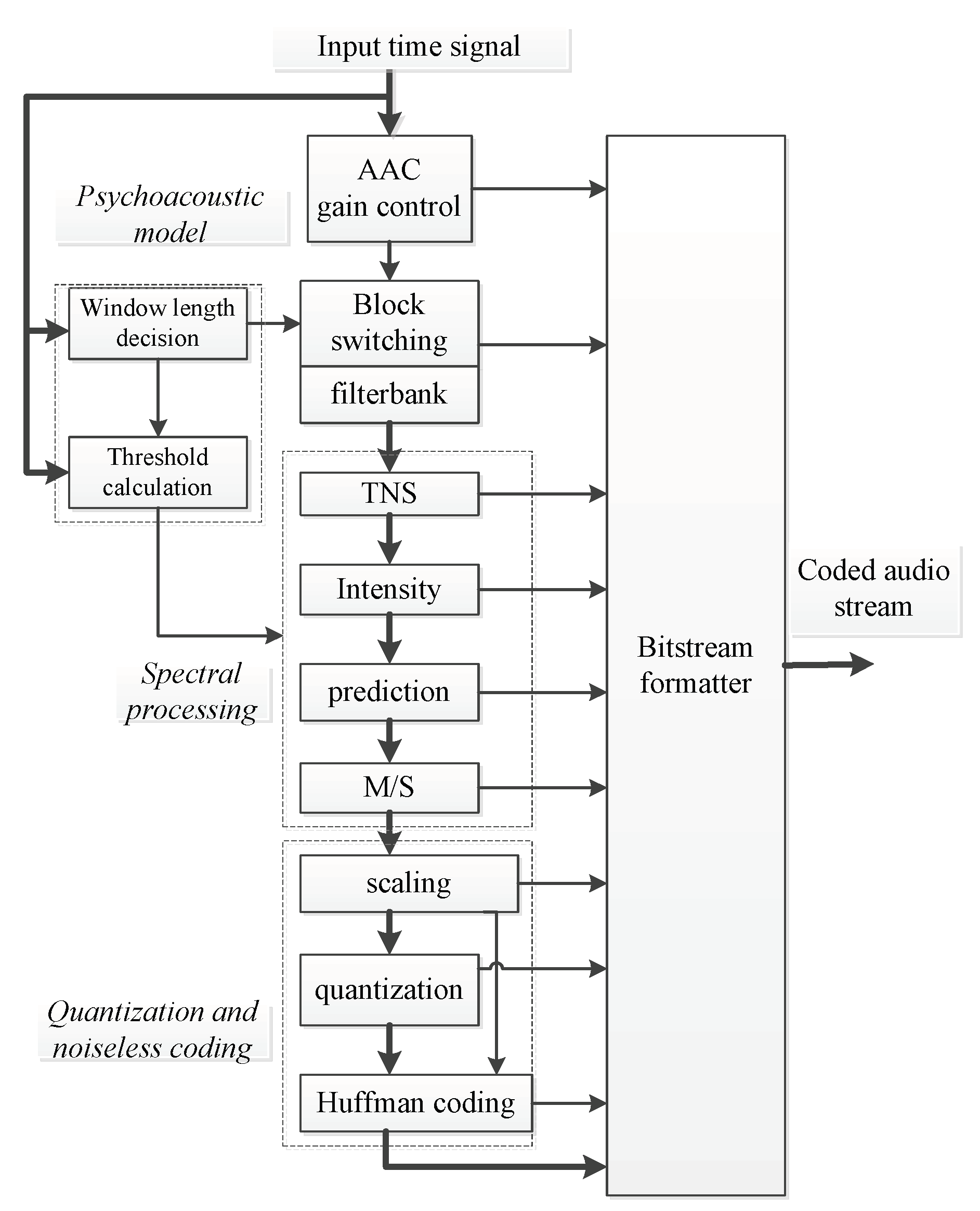
4.4. Detection Results of Fusion Feature Sets
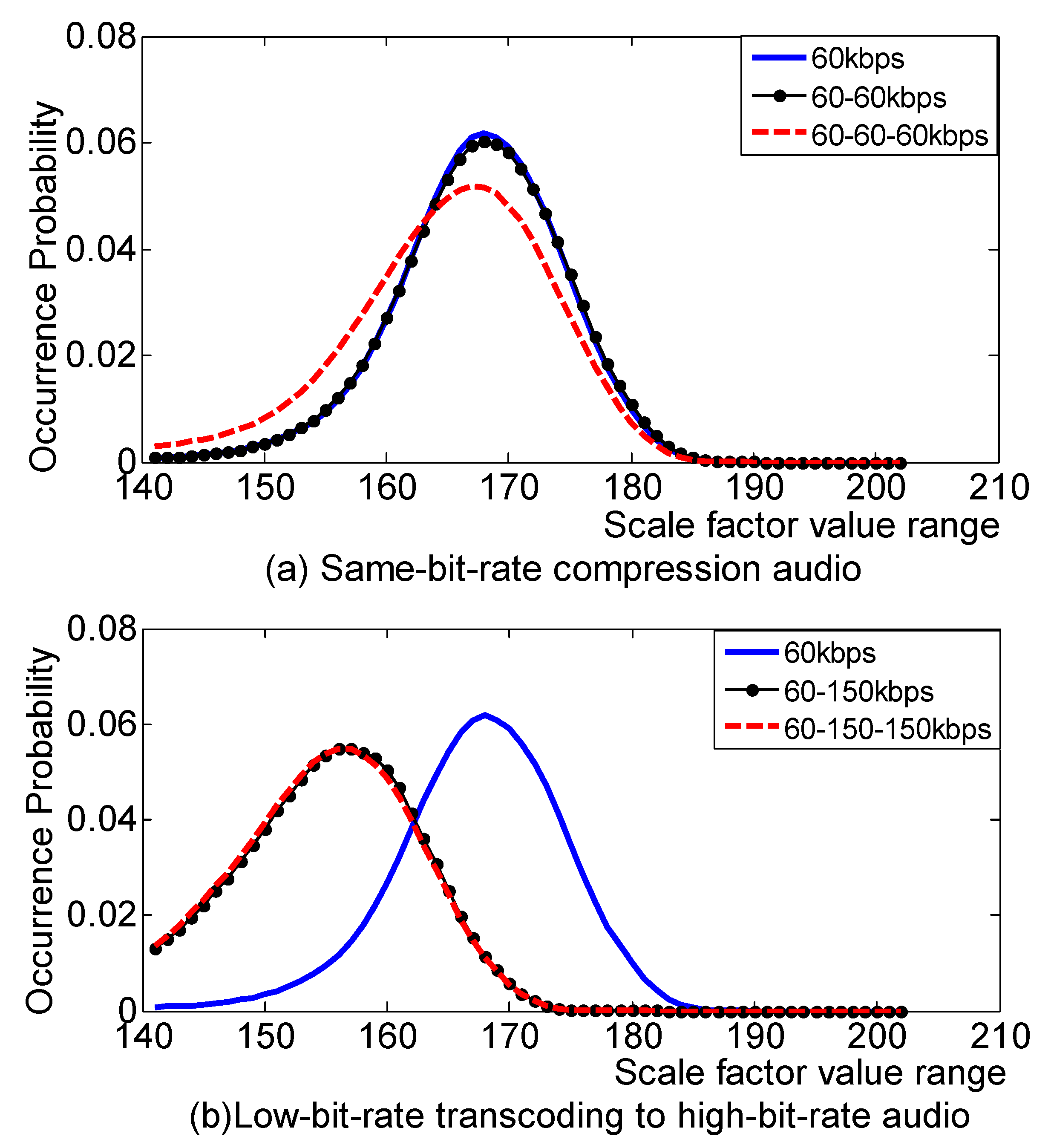
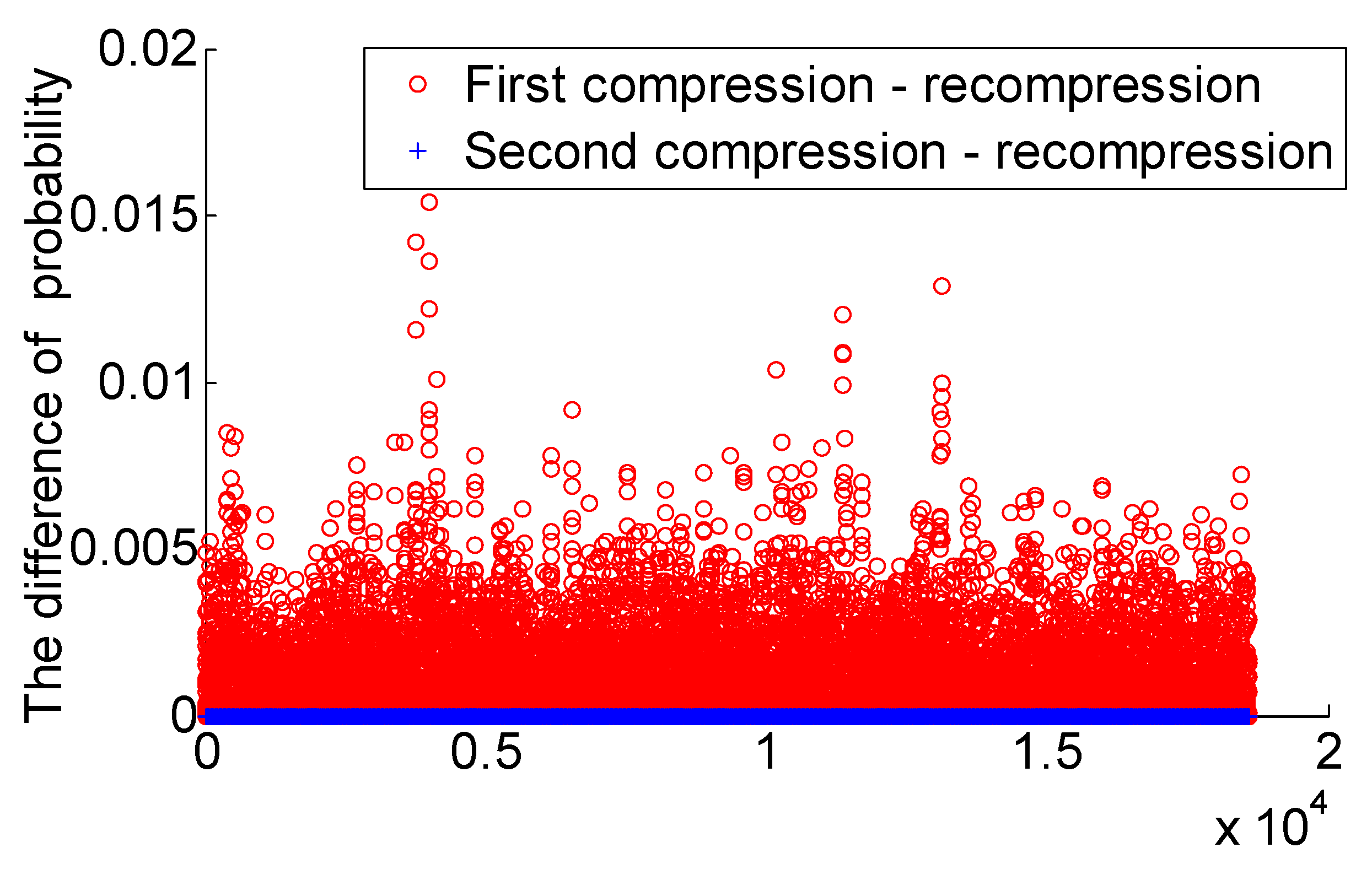
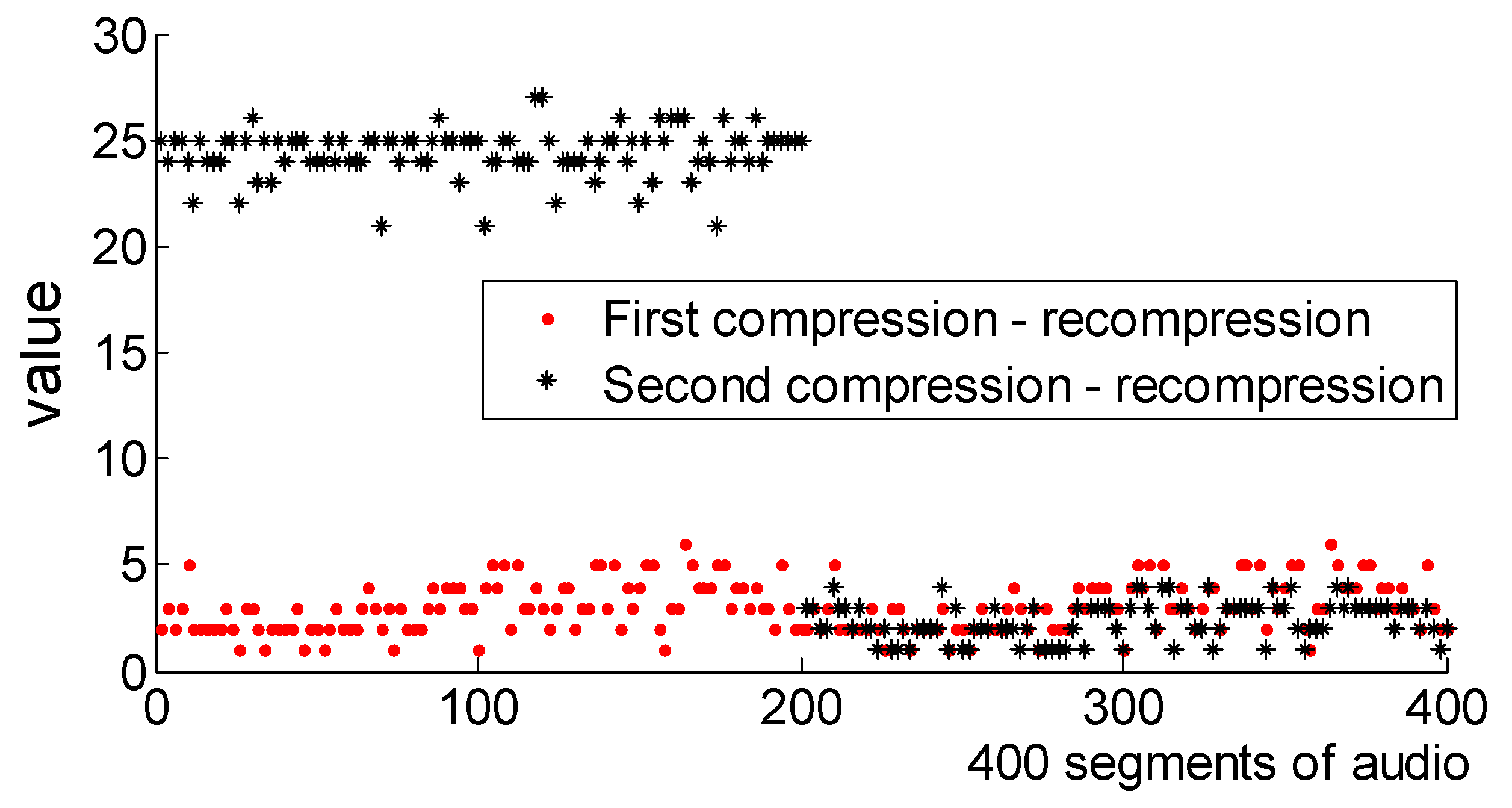
Insufficient detection of the same code rate double compression audio for feature set
in the previous section. In combination with the construction method of feature set
in
Section 4.2, this section improves the classification performance of the method at the same code rate by adding
statistical features to the
. Now we use the different weight ratios of
and
, update the fusion weights of different features iteratively, and finally use the fusion weights to classify the output of different feature sets. The iterative process is as follows.
(1) Different feature sets initialize the fusion weight coefficient
is the number of different feature sets, here
,
during initialization. That is, at the initial iteration, the
and
are assigned a weight coefficient of 0.5.
(2) Iteratively updates
Assume that the actual tag of AAC audio is
,
. Where
means that the sample is a positive sample that is a single compressed AAC audio, and
represents that the sample is a negative sample that is double compressed AAC audio. And the classification tag of its feature fusion is
. If
, the classification tag of feature fusion is compared with the classification tag of each feature. For sub-features that are judged to be incorrect (that is, the classification tag of feature fusion is inconsistent with the classification tag of sub-feature—
), the weight coefficient is subtracted from
, and the correct sub-feature is judged (that is, the classification tag of the feature fusion is consistent with the classification tag of the sub-feature—
), with the weight coefficient plus
.
represents the error constant
indicates the integrated error rate of two sub-features when the classification is detected, and
represents the total number of samples.
Get updated weight coefficient
For the and initial weight coefficients are 0.5, 0.5. For example, one AAC audio sample, the actual tag is , and the tagged note of its fusion feature set is. If , we compare the fusion feature set classification results with the and feature set classification results. Assume that for a certain AAC audio sample, the classification label of the fusion feature set is 1 and the classification label of the sub-feature set is 0, and the weight coefficient is updated. . In this case, in order to maintain the weight coefficient and always be 1, the weight coefficient of the is also updated accordingly, .
If
, discard the sample, perform the above operation on the next sample, and repeat the above steps until all samples have been traversed. The resulting fusion feature set is recorded as
Table 3 shows the detection accuracy of the fusion feature,
= 0.463,
= 0.537. The average detection accuracy of low-rate transcoding to high-rate AAC audio is 99.91%, and the average accuracy of same-rate compression detection is 97.98%.
Table 3 compares
Table 1 with
Table 2 and finds that for the detection rate of AAC recompressed audio, the
further improves it. Compared with the
, the detection accuracy of AAC audio with low bit rate transcoding to high bit rate increased by 1.45 and 0.61 percentage points, respectively. Compared with the
, the detection accuracy of compression between the same-rate AAC audio increased by 5.31, 2.66 percentage points, respectively. The experimental results show that
integrates
together well, which makes up for some deficiencies of the sub-feature set in AAC double compression audio detection.
In this paper, the first compressed AAC audio is a positive sample and the second compressed AAC audio is a negative sample. True Positives (
) indicates that the positive class is positive, True Negatives (
) indicates that the negative class is negative, False Positives (
) indicates that the negative class is positive, and False negatives (
) indicates that the positive class is negative class. The data in
Table 3 is the accuracy of the test, that is, the ratio of the number of samples correctly classified by the classifier to the total number of samples for a given test data set.
The precision (
), which is for the prediction result, indicates that the prediction result is the number of positive samples that have positive samples. There are two possibilities for the prediction. One is to predict the positive class as a positive class (
) and the other is to predict the negative class as a positive class (
).
The recall
indicates the proportion of positive samples in the sample that are predicted correctly. There are two possibilities. One is to predict the positive class as a positive class (
), and the other is to predict the original positive class as a negative class (
).
The
value is an evaluation index that combines the precision rate and the recall rate and is used to comprehensively reflect the overall indicators. When
, it is the most common
value.
Table 4 shows the
values detected under the scale factor fusion feature set.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}