A Green Supplier Assessment Method for Manufacturing Enterprises Based on Rough ANP and Evidence Theory


Abstract
:1. Introduction
- (1)
- Supplier assessment models based on Analytic Hierarchy Process (AHP) [10] or Analytic Network Process (ANP) [11]. Noci [12] used AHP to evaluate supplier’s environmental efficiency. Lee et al. [13] used the Delphi technique to distinguish the evaluation criterion difference between the traditional supplier and the green supplier, and then used Fuzzy Analytic Hierarchy Process (FAHP) to solve the green supplier selection process. Hsu and Hu [14] contained the interdependence between components of decision structure and used ANP for green supplier selection which reflected a more realistic result.
- (2)
- Supplier assessment model based on mathematical Programming. Yeh and Chuang [15] put forward a mathematical programming model of green partner selection, which includes four goals: cost, time, product quality, and green score. They adopted two multi-objective genetic algorithms (MOGA) to find a set of Pareto optimal solutions, and used weighted summation to generate more solutions. Yousefi et al. [16] used Dynamic Data Envelopment Analysis (D-DEA) and scenario-based robust model for supplier selection. In this supplier selection model, the shortcomings of the DEA model (the benchmarks were determined based on previous performance) were overcome, and the disadvantages of the D-DEA model (the decision unit couldn’t get a unified efficiency score) were avoided.
- (3)
- Supplier assessment model based on Technique for Order Preference by Similarity to an Ideal Solution (TOPSIS). Awasthi et al. [17] proposed a three-step method for green supplier evaluation: identification standard, expert score, evaluate expert score by fuzzy TOPSIS. The fuzzy TOPSIS method integrated profit and cost standard, and this method is suitable for the situation of lack of partial quantitative information. Kannan and Jabbour [18] used fuzzy TOPSIS to solve the problem of green supplier selection, and applies three types of fuzzy TOPSIS method to sort green suppliers.
- (4)
- Other hybrid models for supplier assessment. Gandhi et al. [5] proposed a combined approach using AHP and Decision-Making and Trial Evaluation Laboratory (DEMATEL) for evaluating success factors in implementation of green supply chain management and gave a case study in Indian manufacturing industries. Chatterjee et al. [19] combined DEMATEL and ANP in a rough context, and then proposed a rough DEMATEL-ANP (R’AMATEL) method to evaluate the performance of suppliers for green supply chain implementation in electronics industry. Wu et al. [20] used the Continuous Ordered Weighted Averaging (COWA) operator to transform the trapezoid fuzzy number into the exact real number to select the green supplier, and make a sensitivity analysis according to the degree of risk of decision-maker to rank the suppliers. Luo and Peng [21] proposed a multi-level supplier evaluation and selection model. In this model, AHP is used to determine the weights, and then TOPSIS is used for supplier evaluation. Kuo and Lin [22] integrated ANP and DEA and proposed a green supplier evaluation method. The interdependence between standards were considered by ANP, which allowed users to choose their own weight preferences to limit weights, expanded DEA method, and allowed more flexible number of decision units. Shi et al. [23] used the improved attribute reduction algorithm based on rough set to reduce the index of the green supplier evaluation index system, and then evaluated the data by RBF neural network training. Akman [24] identified the suppliers that should be included in the green supplier development plan through the C mean clustering algorithm and the VIKOR method. This method can be used to solve the problem of supplier classification and evaluation.
- (1)
- The information of the suppliers to be assessed is not clear enough in the actual work of green supplier assessment. There is often no information sharing between manufacturing enterprise and suppliers, and the information between them is often ambiguous or even absent. The deterministic assessing model can no longer meet the needs of the increasingly complex decision-making environment.
- (2)
- Green supplier assessment is a complex decision problem and its indexes are interrelated. When calculating the index weight, the core idea of traditional AHP is to divide the index system into isolated and hierarchical levels. Only the upper level elements’ dominating effect on the lower level elements is considered and the elements in the same level are deemed to be independent of each other. However, the relationships among the indexes are often interdependent and sometimes provide feedback-like effects in green supplier assessment. Therefore, traditional AHP cannot solve the complex relationships among indexes to obtain the weight in green supplier assessment.
- (3)
- The accurate number is used to describe the relative importance of the indexes in the expression of experts’ judgment in most of the existing research, which cannot reflect the ambiguities and subjectivity of the actual thinking. It is more reasonable to use fuzzy numbers [25] to express the experts’ judgment. After introducing fuzzy numbers to express experts’ judgment, analyzing and processing the imprecise and inconsistent information becomes a difficult problem.
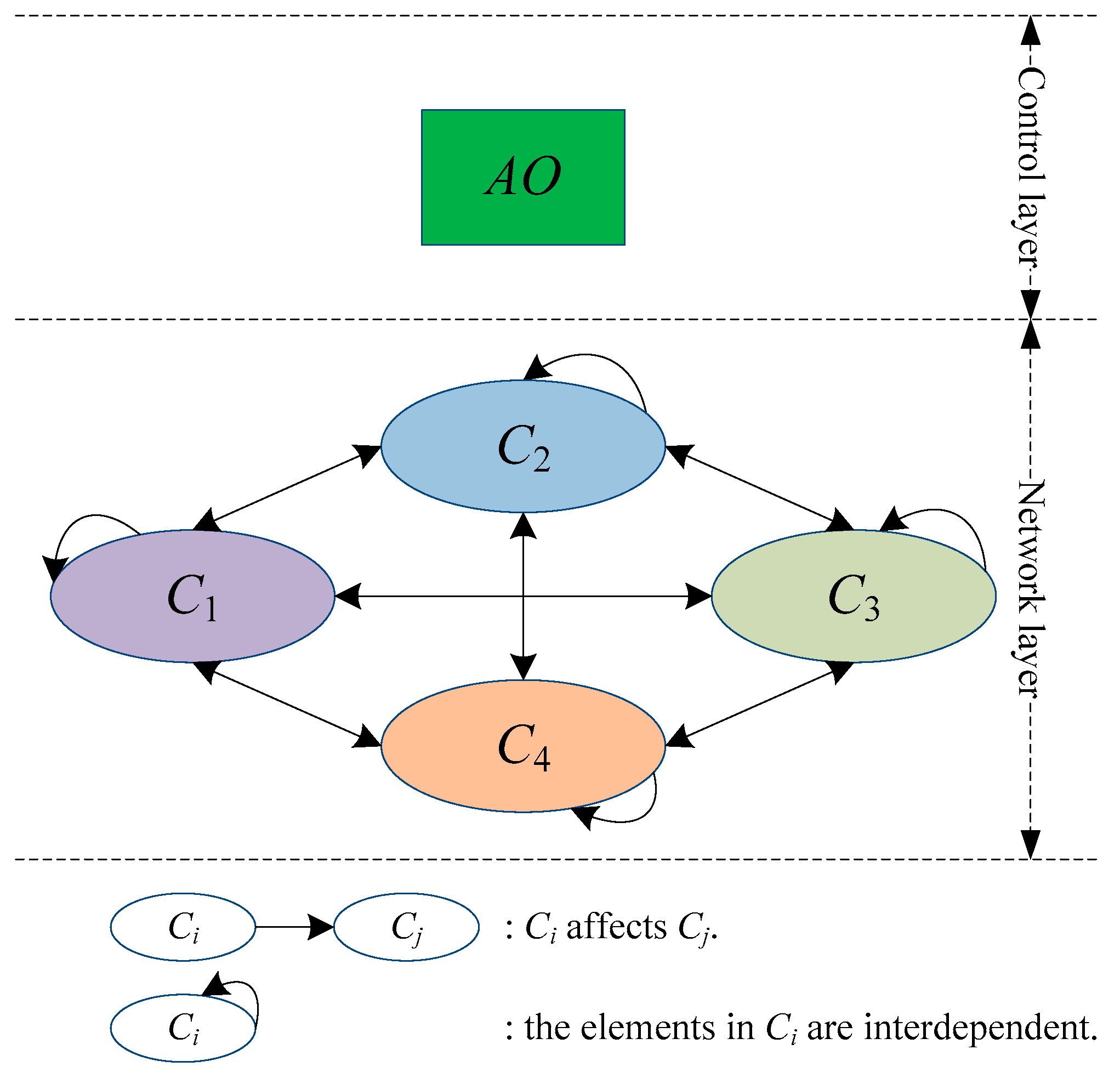
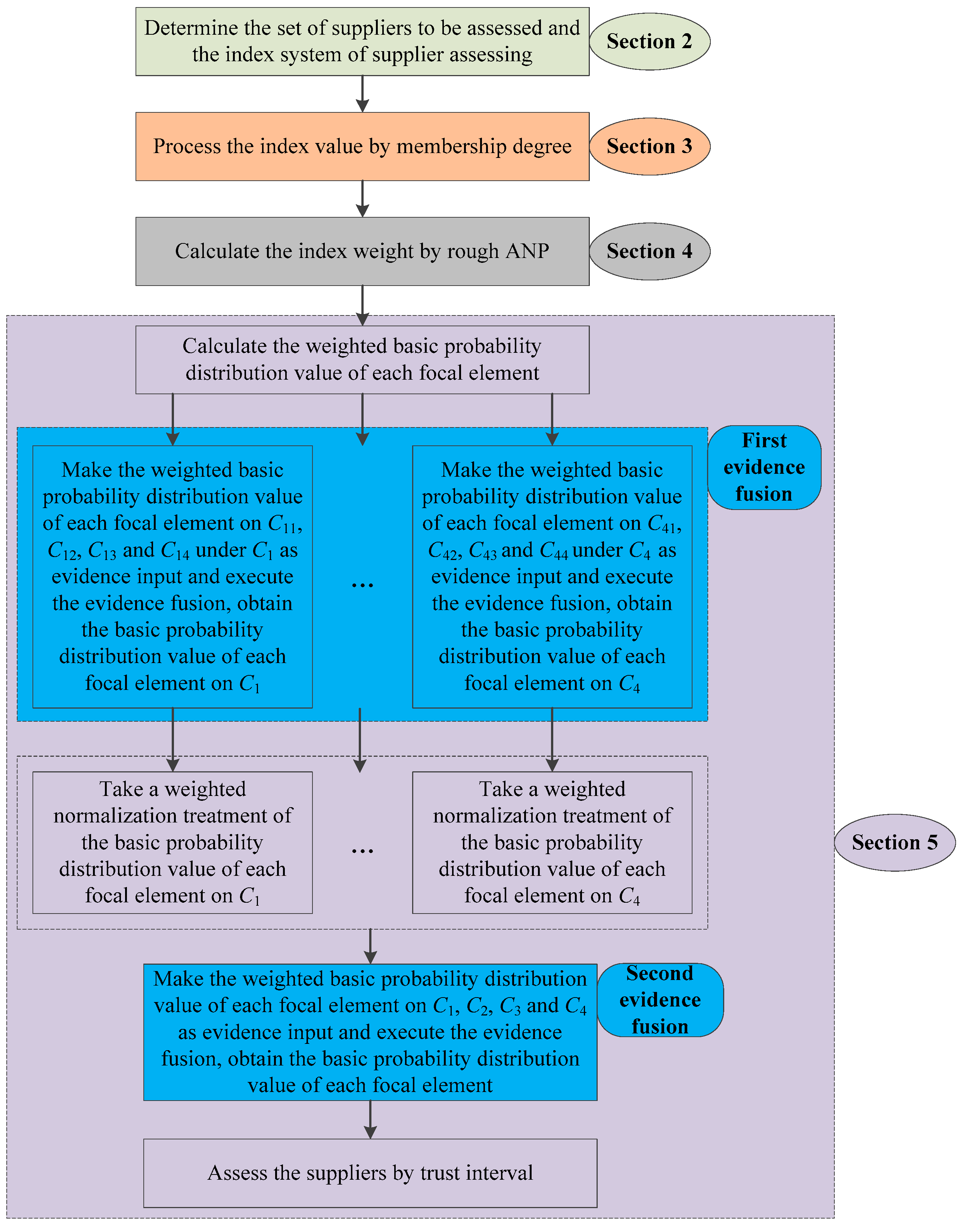
2. Index System
- C1 is decomposed into four second-level indexes: cost (C1,1), quality (C1,2), service (C1,3) and flexibility (C1,4). C1,1 and C1,2 belong to quantitative type, and C1,3 and C1,4 belong to qualitative type.
- C2 is decomposed into three second-level indexes: innovation capacity (C2,1), manufacturing capacity (C2,2) and agility capacity (C2,3). C2,1, C2,2 and C2,3 all belong to qualitative type.
- C3 is decomposed into four second-level indexes: economic environment (C3,1), geographical environment (C3,2), social environment (C3,3) and legal environment (C3,4). C3,1, C3,2, C3,3 and C3,4 all belong to qualitative type.
- C4 is decomposed into four second-level indexes: technical compatibility degree (C4,1), cultural compatibility degree (C4,2), information platform compatibility degree (C4,3) and reputation (C4,4). C4,1, C4,2, C4,3 and C4,4 all belong to qualitative type.
3. Index Value Processing
4. Index Weight Calculating
5. Green Supplier Assessment
5.1. Related Concepts of Evidence Theory
- If , is better than (recorded as );
- If , is worse than (recorded as );
- If , and are equal (recorded as );
- For three suppliers , and , if and , is better than and is better than , so .
5.2. Green Supplier Assessing Procedure
6. Case Study
6.1. An Application Case of Bearing Cage Supplier Assessment
- (1)
- = 0.0825, = 0.1252, = 0.7423, = 0.0500;
- (2)
- = 0.4121, = 0.4121, = 0.0458, = 0.1300;
- (3)
- = 0.3456, = 0.3999, = 0.0444, = 0.2100;
- (4)
- = 0.0374, = 0.3363, = 0.3363, = 0.2900;
- (5)
- = 0.1272, = 0.2820, = 0.4008, = 0.1900;
- (6)
- = 0.3141, = 0.4463, = 0.0496, = 0.1900;
- (7)
- = 0.3684, = 0.5234, = 0.0582, = 0.0500;
- (8)
- = 0.8550, = 0.0950, = 0.0500;
- (9)
- = 0.0691, = 0.6218, = 0.0691, = 0.2400;
- (10)
- = 0.3683, = 0.3508, = 0.0409, = 0.2400;
- (11)
- = 0.2947, = 0.4188, = 0.0465, = 0.2400;
- (12)
- = 0.8550, = 0.0950, = 0.0500;
- (13)
- = 0.6449, = 0.0726, = 0.0726, = 0.2100;
- (14)
- = 0.0790, = 0.7110, = 0.2100;
- (15)
- = 0.3912, = 0.5029, = 0.0559, = 0.0500.
- (1)
- = 0.0491, = 0.6871, = 0.1938, = 0.0700;
- (2)
- = 0.2305, = 0.7000, = 0.0345, = 0.0350;
- (3)
- = 0.8165, = 0.1122, = 0.0033, = 0.0679;
- (4)
- = 0.0104, = 0.9841, = 0.0008, = 0.0046.
- (1)
- = 0.0466, = 0.6527, = 0.1841, = 0.1165;
- (2)
- = 0.0991, = 0.3010, = 0.0148, = 0.5851;
- (3)
- = 0.3103, = 0.0426, = 0.0013, = 0.6458;
- (4)
- = 0.0052, = 0.4921, = 0.0004, = 0.5023.
- (1)
- = 0.0042;
- (2)
- = 0.4160;
- (3)
- = 0.0006;
- (4)
- = 0.5792;
- (1)
- = [0.0042, 0.5834];
- (2)
- = [0.4160, 0.9952];
- (3)
- = [0.0006, 0.5798].
- (1)
- P(x1 > x2) = 0, so ;
- (2)
- P(x1 > x3) = 1, so .
6.2. Discussion
- To , the performance is the best on ten of the fifteen indexes (i.e., quality (C1,2), service (C1,3), flexibility (C1,4), manufacturing capacity (C2,2), agility capacity (C2,3), geographical environment (C3,2), legal environment (C3,4), technical compatibility degree (C4,1), information platform compatibility degree (C4,3) and reputation (C4,4)).
- To , the performance is the worst on twelve of the fifteen indexes (i.e., cost (C1,1), quality (C1,2), service (C1,3), manufacturing capacity (C2,2), agility capacity (C2,3), economic environment (C3,1), geographical environment (C3,2), social environment (C3,3), legal environment (C3,4), technical compatibility degree (C4,1), cultural compatibility degree (C4,2) and reputation (C4,4)).
- To , the performance is the worst on four indexes (i.e., flexibility (C1,4), innovation capacity (C2,1), geographical environment (C3,2) and information platform compatibility degree (C4,3)), and the performance is the best on five indexes (i.e., cost (C1,1), quality (C1,2), economic environment (C3,1), social environment (C3,3), cultural compatibility degree (C4,2) and reputation (C4,4)).
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Jiang, W.; Huang, C. A Multi-criteria Decision-making Model for Evaluating Suppliers in Green SCM. Int. J. Comput. Commun. Control 2018, 13, 337–352. [Google Scholar] [CrossRef]
- Mangla, S.K.; Kumar, P.; Barua, M.K. Flexible Decision Modeling for Evaluating the Risks in Green Supply Chain Using Fuzzy AHP and IRP Methodologies. Glob. J. Flex. Syst. Manag. 2015, 16, 19–35. [Google Scholar] [CrossRef]
- Banaeian, N.; Mobli, H.; Fahimnia, B.; Nielsen, I.E.; Omid, M. Green Supplier Selection Using Fuzzy Group Decision Making Methods: A Case Study from the Agri-Food Industry. Comput. Oper. Res. 2016, 89, 337–347. [Google Scholar] [CrossRef]
- Yu, F.; Yang, Y.; Chang, D. Carbon footprint based green supplier selection under dynamic environment. J. Clean. Prod. 2018, 170, 880–889. [Google Scholar] [CrossRef]
- Gandhi, S.; Mangla, S.K.; Kumar, P.; Kumar, D. A combined approach using AHP and DEMATEL for evaluating success factors in implementation of green supply chain management in Indian manufacturing industries. Int. J. Logist. Res. Appl. 2016, 19, 537–561. [Google Scholar] [CrossRef]
- Mangla, S.K.; Kumar, P.; Barua, M.K. Risk analysis in green supply chain using fuzzy AHP approach: A case study. Resour. Conserv. Recycl. 2015, 104, 375–390. [Google Scholar] [CrossRef]
- Mangla, S.K.; Kumar, P.; Barua, M.K. Prioritizing the responses to manage risks in green supply chain: An Indian plastic manufacturer perspective. Sustain. Prod. Consum. 2015, 1, 67–86. [Google Scholar] [CrossRef]
- Tang, X.; Wei, G. Models for Green Supplier Selection in Green Supply Chain Management with Pythagorean 2-Tuple Linguistic Information. IEEE Access 2018, 6, 18042–18060. [Google Scholar] [CrossRef]
- Mangla, S.K.; Govindan, K.; Luthra, S. Critical success factors for reverse logistics in Indian industries: A structural model. J. Clean. Prod. 2016, 129, 608–621. [Google Scholar] [CrossRef]
- Saaty, T.L. The Analytic Hierarchy Process; McGraw-Hill: New York, NY, USA, 1980. [Google Scholar]
- Saaty, T.L. Fundamentals of the analytic network process—Dependence and feedback in decision-making with a single network. J. Syst. Sci. Syst. Eng. 2004, 13, 129–157. [Google Scholar] [CrossRef]
- Noci, G. Designing ‘green’ vendor rating systems for the assessment of a supplier’s environmental performance. Eur. J. Purch. Supply Manag. 1997, 3, 103–114. [Google Scholar] [CrossRef]
- Lee, A.H.I.; Kang, H.Y.; Hsu, C.F.; Hung, H.C. A green supplier selection model for high-tech industry. Expert Syst. Appl. 2009, 36, 7917–7927. [Google Scholar] [CrossRef]
- Hsu, C.W.; Hu, A.H. Applying hazardous substance management to supplier selection using analytic network process. J. Clean. Prod. 2009, 17, 255–264. [Google Scholar] [CrossRef]
- Yeh, W.C.; Chuang, M.C. Using multi-objective genetic algorithm for partner selection in green supply chain problems. Expert Syst. Appl. 2011, 38, 4244–4253. [Google Scholar] [CrossRef]
- Yousefi, S.; Shabanpour, H.; Fisher, R.; Saen, R.F. Evaluating and ranking sustainable suppliers by robust dynamic data envelopment analysis. Measurement 2016, 83, 72–85. [Google Scholar] [CrossRef]
- Awasthi, A.; Chauhan, S.S.; Goyal, S.K. A fuzzy multicriteria approach for evaluating environmental performance of suppliers. Int. J. Prod. Econ. 2010, 126, 370–378. [Google Scholar] [CrossRef]
- Kannan, D.; Jabbour, C.J.C. Selecting green suppliers based on GSCM practices: Using fuzzy TOPSIS applied to a Brazilian electronics company. Eur. J. Oper. Res. 2014, 233, 432–447. [Google Scholar] [CrossRef]
- Chatterjee, K.; Pamucar, D.; Zavadskas, E.K. Evaluating the performance of suppliers based on using the R’AMATEL-MAIRCA method for green supply chain implementation in electronics industry. J. Clean. Prod. 2018, 184, 101–129. [Google Scholar] [CrossRef]
- Wu, J.; Cao, Q.W.; Li, H. A Method for Choosing Green Supplier Based on COWA Operator under Fuzzy Linguistic Decision-Making. J. Ind. Eng. Eng. Manag. 2010, 24, 61–65. [Google Scholar]
- Luo, X.X.; Peng, S.H. Research on the Vendor Evaluation and Selection Based on AHP and TOPSIS in Green Supply Chain. Soft Sci. 2011, 25, 53–56. [Google Scholar]
- Kuo, R.J.; Lin, Y.J. Supplier selection using analytic network process and data envelopment analysis. Int. J. Prod. Res. 2012, 50, 2852–2863. [Google Scholar] [CrossRef]
- Shi, L. Green Supplier Evaluation of RS-RBF Neural Network Model. Sci. Technol. Manag. Res. 2012, 32, 198–201. [Google Scholar]
- Akman, G. Evaluating suppliers to include green supplier development programs via fuzzy c-means and VIKOR methods. Comput. Ind. Eng. 2015, 86, 69–82. [Google Scholar] [CrossRef]
- Pamučar, D.; Petrović, I.; Ćirović, G. Modification of the Best-Worst and MABAC methods: A novel approach based on interval-valued fuzzy-rough numbers. Expert Syst. Appl. 2018, 91, 89–106. [Google Scholar] [CrossRef]
- Li, L.; Mo, R.; Chang, Z.; Zhang, H. Priority evaluation method for aero-engine assembly task based on balanced weight and improved TOPSIS. Comput. Integr. Manuf. Syst. 2015, 21, 1193–1201. (In Chinese) [Google Scholar]
- Wang, X.; Xiong, W. Rough AHP approach for determining the importance ratings of customer requirements in QFD. Comput. Integr. Manuf. Syst. 2010, 16, 763–771. (In Chinese) [Google Scholar]
- Vasiljević, M.; Fazlollahtabar, H.; Stević, Z.; Vesković, S. A rough multicriteria approach for evaluation of the supplier criteria in automotive industry. Decis. Mak. Appl. Manag. Eng. 2018, 1, 82–96. [Google Scholar] [CrossRef]
- Pamučar, D.; Stević, Ž.; Zavadskas, E.K. Integration of interval rough AHP and interval rough MABAC methods for evaluating university web pages. Appl. Soft Comput. 2018, 67, 141–163. [Google Scholar] [CrossRef]
- Zhu, G.N.; Hu, J.; Qi, J.; Gu, C.C.; Peng, Y.H. An integrated AHP and VIKOR for design concept evaluation based on rough number. Adv. Eng. Inform. 2015, 29, 408–418. [Google Scholar] [CrossRef]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976. [Google Scholar]
- Sarabi-Jamab, A.; Araabi, B.N. How to decide when the sources of evidence are unreliable: A multi-criteria discounting approach in the Dempster–Shafer theory. Inf. Sci. 2018, 448, 233–248. [Google Scholar] [CrossRef]
- Li, R.; Jin, Y. The early-warning system based on hybrid optimization algorithm and fuzzy synthetic evaluation model. Inf. Sci. 2017, 435, 296–319. [Google Scholar] [CrossRef]
- Haider, H.; Hewage, K.; Umer, A.; Ruparathna, R.; Chhipi-Shrestha, G.; Culver, K.; Holland, M.; Kay, J.; Sadiq, R. Sustainability Assessment Framework for Small-sized Urban Neighbourhoods: An Application of Fuzzy Synthetic Evaluation. Sustain. Cities Soc. 2017, 36, 21–32. [Google Scholar] [CrossRef]
- Zhu, J. Evaluation of supplier strength based on fuzzy synthetic assessment method. In Proceedings of the International Conference on Test and Measurement, Hong Kong, China, 5–6 December 2009; pp. 247–250. [Google Scholar]
- Deepika, M.; Kannan, A.S.K. Global supplier selection using intuitionistic fuzzy Analytic Hierarchy Process. In Proceedings of the International Conference on Electrical, Electronics, and Optimization Techniques, Chennai, India, 3–5 March 2016; pp. 2390–2395. [Google Scholar]
- Torng, C.; Tseng, K.W. Using Fuzzy Analytic Hierarchy Process to Construct Green Suppliers Assessment Criteria and Inspection Exemption Guidelines. In Proceedings of the International Conference on Human-Computer Interaction; Springer: Berlin/Heidelberg, Germany, 2013; pp. 729–732. [Google Scholar]
- Labib, A.W. A supplier selection model: A comparison of fuzzy logic and the analytic hierarchy process. Int. J. Prod. Res. 2011, 49, 6287–6299. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Supplier | C1,1 | C1,2 | C1,3 | C1,4 | C2,1 | C2,2 | C2,3 | C3,1 | C3,2 | C3,3 | C3,4 | C4,1 | C4,2 | C4,3 | C4,4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 6.4 × 101 | 0.01 | 0.7 | 0.1 | [0.1, 0.3] | 0.5 | 0.7 | 0.5 | 0.5 | 0.7 | 0.7 | / | [0.7, 0.9] | 0.5 | 0.7 | |
| 1.9 × 103 | 0.01 | 0.9 | 0.7 | 0.5 | 0.7 | 0.9 | / | 0.7 | [0.5, 0.7] | 0.9 | 0.7 | 0.5 | 0.7 | 0.9 | |
| 2.8 × 104 | 0.03 | 0.1 | 0.7 | 0.7 | 0.1 | 0.3 | 0.1 | 0.5 | 0.1 | 0.3 | 0.1 | 0.5 | / | 0.1 |
| Supplier | C1,1 | C1,2 | C1,3 | C1,4 | C2,1 | C2,2 | C2,3 | C3,1 | C3,2 | C3,3 | C3,4 | C4,1 | C4,2 | C4,3 | C4,4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.0023 | 1.0000 | 0.7778 | 0.1429 | [0.1429, 0.4286] | 0.7143 | 0.7778 | 1.0000 | 0.7143 | 1.0000 | 0.7778 | / | [0.7778, 1.0000] | 0.7143 | 0.7778 | |
| 0.0669 | 1.0000 | 1.0000 | 1.0000 | 0.7143 | 1.0000 | 1.0000 | / | 1.0000 | [0.7143, 1.0000] | 1.0000 | 1.0000 | 0.5556 | 1.0000 | 1.0000 | |
| 1.0000 | 0.3333 | 0.1111 | 1.0000 | 1.0000 | 0.1429 | 0.3333 | 0.2000 | 0.7143 | 0.1429 | 0.3333 | 0.1429 | 0.5556 | / | 0.1111 |
| Supplier | C1,1 | C1,2 | C1,3 | C1,4 | C2,1 | C2,2 | C2,3 | C3,1 | C3,2 | C3,3 | C3,4 | C4,1 | C4,2 | C4,3 | C4,4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.1000 | 0.9000 | 0.7778 | 0.1000 | 0.2857 | 0.6333 | 0.6334 | 0.9000 | 0.1000 | 0.9000 | 0.6334 | / | 0.8889 | 0.1000 | 0.7000 | |
| 0.1518 | 0.9000 | 0.9000 | 0.9000 | 0.6333 | 0.9000 | 0.9000 | / | 0.9000 | 0.8572 | 0.9000 | 0.9000 | 0.1000 | 0.9000 | 0.9000 | |
| 0.9000 | 0.1000 | 0.1000 | 0.9000 | 0.9000 | 0.1000 | 0.1000 | 0.1000 | 0.1000 | 0.1000 | 0.1000 | 0.1000 | 0.1000 | / | 0.1000 |
| Supplier | Ranking of Three Suppliers | ||
|---|---|---|---|
| Proposed Method | FSE | FAHP | |
| 2 | 3 | 3 | |
| 1 | 1 | 1 | |
| 3 | 2 | 2 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Wang, H. A Green Supplier Assessment Method for Manufacturing Enterprises Based on Rough ANP and Evidence Theory. Information 2018, 9, 162. https://doi.org/10.3390/info9070162
Li L, Wang H. A Green Supplier Assessment Method for Manufacturing Enterprises Based on Rough ANP and Evidence Theory. Information. 2018; 9(7):162. https://doi.org/10.3390/info9070162
Chicago/Turabian StyleLi, Lianhui, and Hongguang Wang. 2018. "A Green Supplier Assessment Method for Manufacturing Enterprises Based on Rough ANP and Evidence Theory" Information 9, no. 7: 162. https://doi.org/10.3390/info9070162
APA StyleLi, L., & Wang, H. (2018). A Green Supplier Assessment Method for Manufacturing Enterprises Based on Rough ANP and Evidence Theory. Information, 9(7), 162. https://doi.org/10.3390/info9070162