1. Introduction
Optical tomography is a well-defined inverse problem. In the lab, laser beams with high-energy photons are injected into bio-tissues to detect the interior optical property [
1]. This helps identify unhealthy bio-tissues for treatment. Mathematically, this amounts to reconstructing the optical coefficients, such as the scattering and the absorption coefficients in the radiative transfer equation (RTE), which is a model equation that describes the propagation of photon particles [
2]. The equation, in its simplest form, reads
The unknown
describes the number of photon particles at time
, location
, and traveling with velocity
. The dimension of the problem is
.
v is the travel direction of the particles and therefore belongs to a unit ball. The two terms in the equation represent the transport and the scattering effect, respectively. The transport term characterizes
, while the scattering term
describes the way the photon particles interact with the media. When the temperature is fixed, this operator is a linear operator, whereas if the laser beam heats up the tissue,
reflects the nonlinear dependence on the temperature. This is the term that encodes the optical property of the media.
In the steady state, the
term is dropped, and the equation balances the transport term and the scattering term. The equation is well-posed if equipped with Dirichlet-type boundary condition [
3,
4,
5,
6]:
where
collects the coordinates on the physical boundary
with the velocity either pointing in or out of the domain:
In practice, the laser light is shined into the domain, meaning that
is prescribed. Then, one detects the number of photons scattered out of the domain by measuring
. We term this operator the albedo operator:
where the subindex
reflects the influence of
. Therefore, optical tomography amounts to reconstructing the coefficients in
using the information in the operator
. The general well-posedness theory of such an inverse problem was addressed in the pioneering papers [
7,
8]. The result on the stability was established in [
9,
10,
11], and see [
12] for a review.
One key parameter in Equation (
1) is
, which is the Knudsen number. It describes the regime the system is in. By definition, the Knudsen number is the ratio of the mean-free path and the domain length. Physically, if a photon has low energy (visible or near-infrared light), it travels only a short distance before being scattered, and the mean-free path is short compared to the domain length, leading to a small
. When this happens, one typically observes a diffused light phenomenon, and the received images are blurred. The situation is termed the diffusion effect, and in this regime, RTE, either linear or nonlinear, can be asymptotically approximated by a diffusive equation that characterizes macroscopic quantities such as the density
. Depending on the form of
, this limiting equation for
is accordingly adjusted. Details regarding the diffusion limit can be found in [
13,
14].
Intuitively, as one decreases the photon energy, the received picture loses its crisp, and the reconstruction becomes more unstable. The perturbation observed in the measurement is enlarged in the reconstructed coefficients. This phenomenon has been been numerically observed in [
1,
15,
16] and proved rigorously in [
17], in which the authors investigate the stability deterioration of the inverse problem as
. However, all these results heavily depend on the theoretical framework where it is assumed that one has the access to the
full map. This amounts to sending in all kinds of incoming data
and taking the measurement over the entire
.
These theoretical results are helpful in building the foundation for understanding the stability deterioration, but the setup is infeasible numerically or practically. In the lab, a
finite number of incoming configurations can be taken, and the detectors can measure outgoing photons in a finite number of locations. Therefore, new theory needs to be developed to account for this real situation [
18,
19]. To put the problem in a mathematical framework, we denote
as the incoming data and
as the location of the detectors; then, the measurements are
Equivalently, denoting
as the solution to (
1) with the boundary condition in (
2) being
, then:
With the finite amount of data points, to find the coefficients in
, one can either adopt the PDE-constrained minimization algorithms [
20,
21,
22] or employ the Bayesian inference [
23,
24,
25]. While this finite setting greatly affects the well-posedness argument [
26,
27,
28], the physical intuition still holds true in the sense that the reconstruction is expected to become more and more unstable as
diminishes.
In this paper, we quantify the stability deterioration in the Bayesian inference framework with a finite number of data points. To quantify “stability”, we propose two measures: one is a global measure that evaluates the information gain by comparing the posterior and prior distributions, and the other is a local measure that characterizes the “flatness” of the posterior distribution around the MAP (maximum a posteriori) point. More particularly, at the global level, we measure the difference between the posterior and prior distributions using the KL (Kullback–Leibler) divergence. Since the posterior distribution of the coefficients takes both the prior knowledge and the measured data into account, this divergence essentially characterizes by how much the data are driving the final guess away from the prior guess. At the local level, we estimate the Hessian of the posterior distribution around the MAP point, which essentially describes the uncertainty level of the optimizer. For both measures, we analyze their dependence on
, and we reveal the stability relation between two regimes, the transport regime and diffusive regime, in a more rigorous way. We will present our theory through the lens of both linear and nonlinear RTEs, but we shall mention that other multiscale kinetic models may have such a relation in the inverse setting; see for instance in [
29,
30,
31].
The rest of the paper is organized as follows. In the next section, we recall some formulation in the Bayesian inference problem and demonstrate a general relation in the KL divergence between prior and posterior distribution, through which we will address the stability deterioration from the global point of view. In
Section 3, we consider the inverse problem for the linear radiative transfer equation, and we show that the KL divergence is of order
, which diminishes as we approach the diffusive regime. We extend the investigation to the nonlinear RTE in
Section 4 and obtain similar results. In
Section 5, we focus on the local viewpoint by estimating the second derivative of the parameter-to-measurement map, and we show that it decreases at the order of
, indicating that the posterior distribution becomes flatter near the diffusive regime and therefore is less sensitive to the measurement data, rendering the inverse problem more unstable. We summarize our theoretical results and provide some numerical evidence in
Section 6. A final conclusion of the paper is drawn in
Section 7.
All the discussion in these sections finally achieve the following aim of the paper: to demonstrate, in the Bayesian inference framework, the stability deterioration of optical imaging when the impinging light uses low-energy photons.
2. Bayesian Formulation Basics
Bayesian inference is one of the most popular numerical methods for inferring unknown parameters. In this section, we give a quick overview of definitions to be used in this paper.
To start, we define the parameter to measurement map
and denote
the measurement error:
where the measurement
, the measurement error
, and
, the admissible set in a pre-defined Banach space
:
Note that
can be a function space specified in (
10), and
is a function in this space. Throughout the paper, we assume that
is an additive noise generated by a Gaussian distribution
, and
is a
dimensional matrix.
In Bayesian inference, one needs to prepare a prior distribution for
. Denote
as the
-algebra of
B and
as the prior probability measure on
B. According to the Bayes’ rule, the posterior distribution
is given according to its Radon–Nikodym derivative with respect to
:
where
Z is the normalization constant:
and the mismatch is weighted by
Suppose
are two distinct probability measures; then, the KL divergence measures the distance between them:
when this definition is used in Bayesian inference to quantify the relative gain through the measurement process, one defines the relative entropy, and in the particular setting of (
4), we have the following proposition.
Proposition 1. Assume ; then, the KL divergence between and has the following estimate:for some positive constant C independent of B. Proof. Since
and
are mutually absolutely continuous, according to (
4), we have
Denoting
, we proceed with:
where we used the Lipschitz continuity of
in a bounded interval. The constant
C depends on the size of
d and the boundedness of
. Since
, according to (
3),
, making
. The inequality (
5) holds if we plug in the expression of
to get:
□
In view of (
5), given that
and
are at least bounded, the difference between
and
is controlled by the difference between
and
. This means if
is a slow-varying map over the whole admissible set
B, then
only slightly differs from
, indicating that the information gain is small. In the following sections, we justify this property for RTE in both linear and nonlinear settings in the
regime.
5. Local Behavior around the MAP Point
The KL divergence between the prior and the posterior distribution is a global quantity: it characterizes the information gain from the measured data in the whole distribution. We are also concerned about the local behavior of the posterior distribution, especially around the maximum a posteriori (MAP) point, which is denoted by . Suppose the posterior distribution around the MAP point is rather “flat”; then, the probability is unchanged in a fairly large area around , meaning that all the configuration in this flat area can be approximately taken as the optimal point, and the reconstruction is insensitive to data, demonstrating the instability.
This behavior can be characterized well if the problem is linear. Suppose
; then, assuming the prior distribution is a Gaussian centered at
with covariance
, the posterior distribution is uniquely determined by
and
by:
The “flatness” of a Gaussian is characterized by its covariance matrix. Indeed, with a quick derivation, one can show that:
Therefore, the less informative the forward map is, the smaller
G is, and then the bigger
gets, indicating the higher mean-square error. Geometrically, it means the Gaussian is flatter.
We would like to understand this local behavior around the MAP point. However, the forward map we have is nonlinear, so the argument above only serves as a guidance. To start, we denote:
Then, the convexity of the posterior distribution is uniquely determined by the hessian of
A. For that, we quote:
Proposition 7. Let be admissible and be an admissible variation. The Hessian of the posterior distribution is expressed in terms of the forward map as: Proof. We begin by expanding out
:
where the remainder term has no
dependence. Expand
around
for small
t:
where
. Plug this in the expression of
A and collect the second power of
t; then, we have:
concluding the proof. □
This formula holds true for all that is admissible and thus is valid at MAP as well. According to this proposition, to show the “flatness” of the distribution at MAP, we essentially need to show the smallness of both and for all i. All derivations below are to justify this statement for both the linear and nonlinear RTE.
5.1. Linear RTE
We begin with the linear RTE. The following proposition, due to [
4], characterizes the second derivative of the parameter-to-solution map
, which we will compute its dependence on
.
Proposition 8. Denote , , and . Then, for any admissible and admissible variations , , H is the unique solution of the following equation:where is the solution to (6) with parameter and are the solutions to (11) with parameters , respectively. Moreover, there holds: Proof. Considering the second derivative of
G in Equation (
24), all
satisfy the RTE with different
as shown below, and the same incoming boundary condition
g,
and combining these equations gives
Here, we have used the fact that
C is linear in
. Dividing by
and taking the limit as
then gives
The boundedness is seen from Theorem 3.7 in [
4]. □
We next determine the dependence of the forward map’s second derivative in terms of .
Proposition 9. For every , admissible , and admissible variation , there holds: Proof. Considering (
48) with fixed
and boundary measurement location
, we expand
Using (
48), at
, we obtain
From Proposition 2,
and
have no velocity dependence, which gives
; thus,
has no velocity dependence. Additionally, from the zero boundary condition of
H, we have
.
At
,
and thus
Since
and
, we have
Finally at
, we have
Integrating over velocity, we obtain an equation for the leading order term
, which is in closed form, since
are written in terms of
(see [
4])
Upon averaging over velocity, we obtain the second derivative of the operator
with the
perturbation,
The contribution from the
term becomes zero due to its trivial boundary condition, and
H is bounded from [
4]. □
Directly from Propositions 3, 7 and 9, we have the following corollary.
Corollary 1. For and admissible variation , the diagonal elements of the Hessian of the posterior distribution satisfies: 5.2. Nonlinear RTE
We repeat the analysis for the nonlinear RTE, for the case when
has been linearized. Using similar notatinos, we let
and have the following proposition regarding the boundedness of
and
.
Proposition 10. For and admissible variations , are the unique solution to the following system:where denotes the first derivative of the parameter-to-solution map for f in the direction, and similarly for , and . Moreover, there holds:where and depends on . Proof. We let
, and
. Each
satisfies the nonlinear RTE with a variety of
shown below:
where
.
We begin by computing various combinations of
. First, we recall:
and expand
Similarly for
and
respectively,
Combining these,
so that
To derive the equations for
and
, we take (
49), subtract (
50) and (
51), and add (
52). Using (
53),
To show the boundedness, we note that
solve the nonlinear RTE with a modified right-hand side only containing bounded terms, so we again use Theorem 3.1 from [
33] to obtain the boundedness:
□
Proposition 11. For every and functions in the admissible set, the second derivative of the forward map is of order ϵ, Proof. We start with arbitrary directions
and
and later choose the
direction. To find the
dependence of
and
, we expand:
and plug this in to (
54). At order
, we obtain
subtracting these two equations, we obtain
so
loses its velocity dependence. At
, we obtain
so
Finally, at
, we obtain
and
Integrating equation (
55) over velocity, subtracting (
56), and using Green’s theorem, we obtain
Since
has trivial boundary condition, its contribution drops out.
therefore, with the boundedness of
H from from Proposition 10, we have
. □
Corollary 2. For and admissible variation , the diagonal elements of the Hessian of the posterior distribution based on the nonlinear RTE satisfies: This is a direct corollary from Propositions 3, 7, and 11.
6. Research Results and Discussion
As is well known, the radiative transfer equation, in the high-energy regime where the scattering is dominating, is well approximated by the diffusion equation. This asymptotic relation constitutes a major part in model reduction for the forward setting. On the contrary, it has an adverse effect for the inverse problem. In particular, the reconstruction becomes increasingly unstable as we approach the diffusive regime. This relation has been investigated numerically in [
1,
15,
16] and analytically in [
17], where a full data to measurement map, named the Albedo operator, is assumed to be given.
However, in practice, only partial data are available, and the previously obtained well-posedness results are no longer feasible. We focus our investigation in this paper for this scenario, using Bayesian inference as the basic tool. We have proposed two new measures to characterize the stability and its deterioration in the diffusion regime. One is the KL divergence between the posterior and prior distribution, which implies the overall information gain from the data. We show that the information gain is less in the small Knudsen number regime. The other is the Hessian of the posterior distribution, which is related to the mean square error of the posterior and quantifies the uncertainty of the optimizer; therefore, it serves as a local measure around the MAP. We find that the posterior distribution is more and more “flat” and thus carries no useful information when the diffusion effect is strong. Both measures are taken for the linear RTE and are extended to, for the first time in the literature, treat the nonlinear RTE as well.
Although the paper is completely theoretical, it gives guidance on conducting numerical experiments. The discussion in this paper essentially suggests that the problem is intrinsically bad in the diffusion regime and thus rules out all possible algorithms that could potentially deliver a good numerical recovery.
There are some natural follow-up questions that need to be answered in the near future. One task is to clearly identify the number and the quality of the measurements for a unique reconstruction. Suppose the reconstructed function is represented by an
N dimensional vector; then, how many experiments and measurements exactly are needed for a unique reconstruction, and where should the source and detector be located? The answer to this question for EIT (electrical impedance tomography) was given in [
26], but one needs to tune the process to fit the situation for the radiative transfer equation used in the current paper. Another question concerns the numerical stability. While it is true that the information gain deteriorates as
becomes small, there might be numerical approaches that gradually incorporate information from high-energy to low-energy photons. One possible strategy is to use a large number of experimental measurements conducted with low-energy photons to build a rough initial guess as a “warm start” before adding in information obtained at a high-energy level. The warm start given by the low-energy level results serves as a good initial guess toward a final convergence. The process is parallel to Bayesian tempering, which saw some good developments in the past few years [
34,
35], and the inverse scattering problem that combines information from multiple frequencies [
36]. Another approach is to use a hybrid image modality, such as photoacoustic tomography. where acoustic measurement generated by the photoacoustic effect is used to infer the optimal properties of the media. In this case, an improved stability is anticipated [
37,
38].
Numerical Evidence
Here, we conduct two numerical tests to further support our theoretical findings. In particular, we consider the following linear radiative transfer equation:
The data are prepared as follows. For the
i-th experiment, we prescribe incoming data
and measure the output intensity
f at location
j on
, which is denoted as
. Here,
and detect location
j are chosen randomly, and
number of experiments are conducted with
number of receivers for each experiment. These data pairs
are kept fixed for various choices of Knudsen number
for a fair comparison.
In the first test, we assume
has the form
where
is a two-dimensional normal distribution with mean zero and a fixed covariance matrix
. The parameter
is the parameter to be inferred. We assume the ground-truth
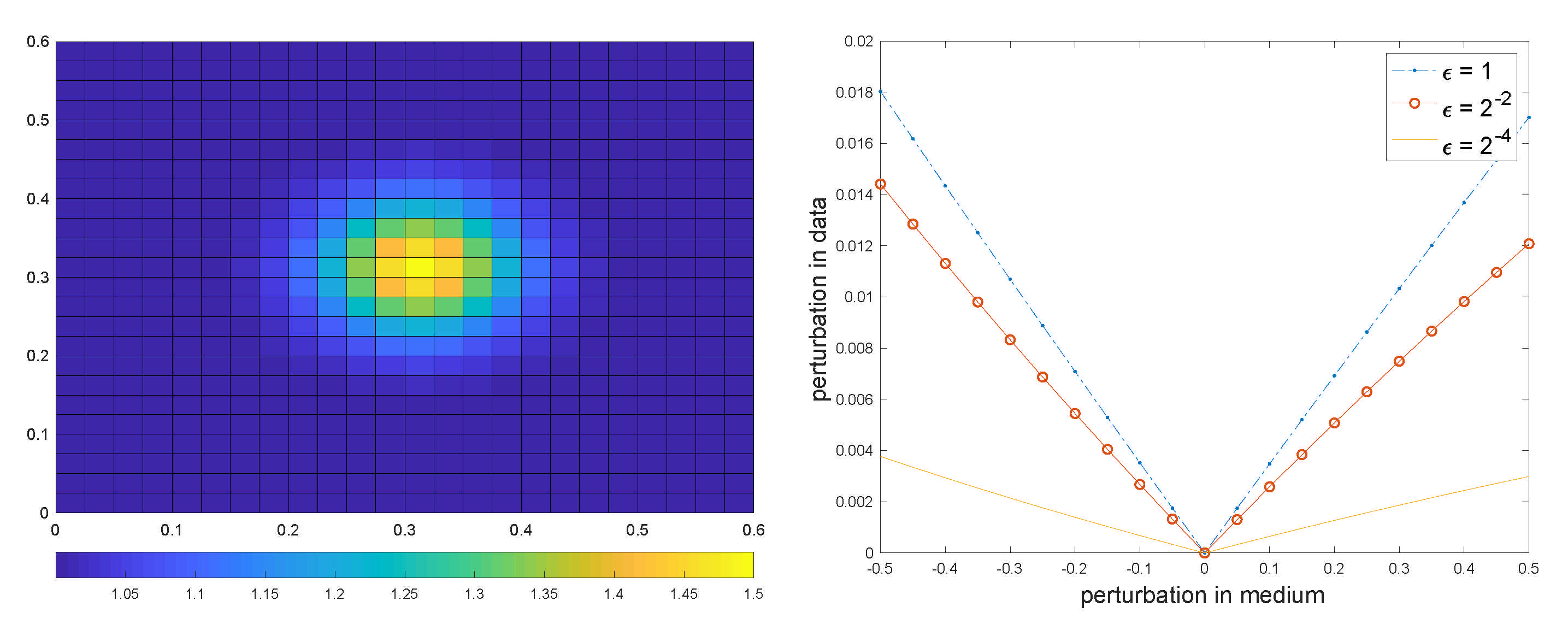
, and the ground-truth medium is plotted on the left of
Figure 1. The inverse problem aims at inferring this ground-truth from the prescribed data pairs. To illustrate the stability of the inverse problem, we show how, for different choices of
away from the truth, the measurements differ from the true measurements. More precisely, we denote
as the perturbation in the measurement, where
is the measurement with a fixed
for the
i-th experiment and
j-th measurement, and
is the measurement with true
. In the right panel of
Figure 1, we plot the difference in measurement data (
58) versus the perturbation in
for three different
. It is clear that with smaller
, the difference in measurement becomes more indistinguishable, which means that a smaller perturbation in measurement can lead to larger deviation in reconstruction. This is in consistent with our theory on the stability deterioration with decreasing
.
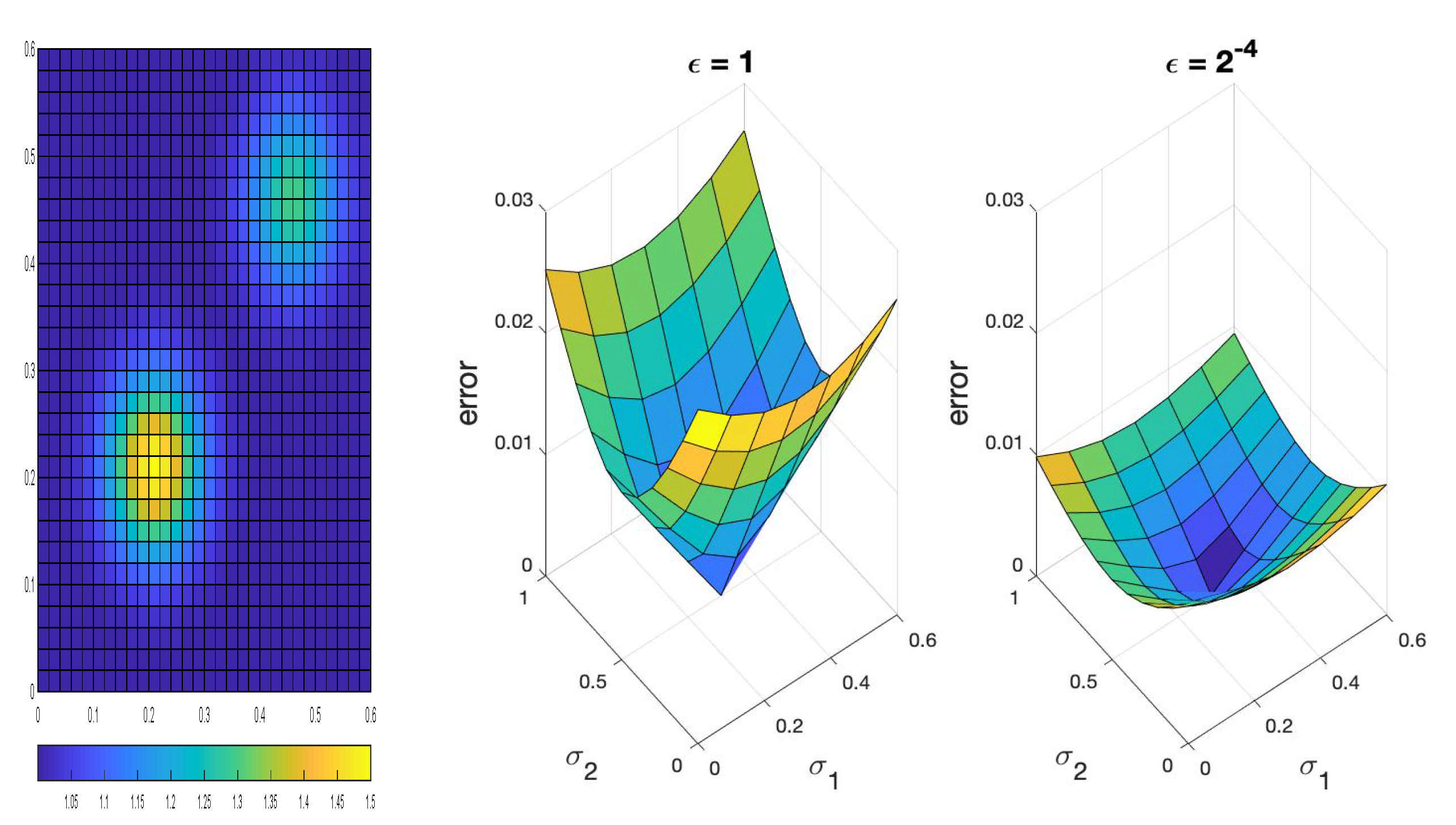
In the second test, we consider a different form of
:
Here, the to-be-reconstructed parameters are
and
. We choose
and
to be the ground-truth and display the medium in
Figure 2. Similar to the previous case, we plot the difference in measurement
with respect to
and
. It is again evident that for smaller
,
becomes flatter, leading to a deterioration in stability, as shown in
Figure 2. In addition, we identify the data that are above
in
Figure 3. Here, the horizontal axis is the index for the experiment, and the vertical axis is the index for the receiver. It is seen that a larger
gives a sparse dataset, whereas small
gives a dense dataset, meaning that all receivers receive some information about the source. This indicates that the data are more spread out for smaller
, which makes the inverse problem harder to solve.



{kind=link}
{kind=link}
{kind=link}


