A Machine Learning Framework for Detecting COVID-19 Infection Using Surface-Enhanced Raman Scattering

 , , ,
, , ,  and
and
Abstract
:1. Introduction
2. Materials and Methods
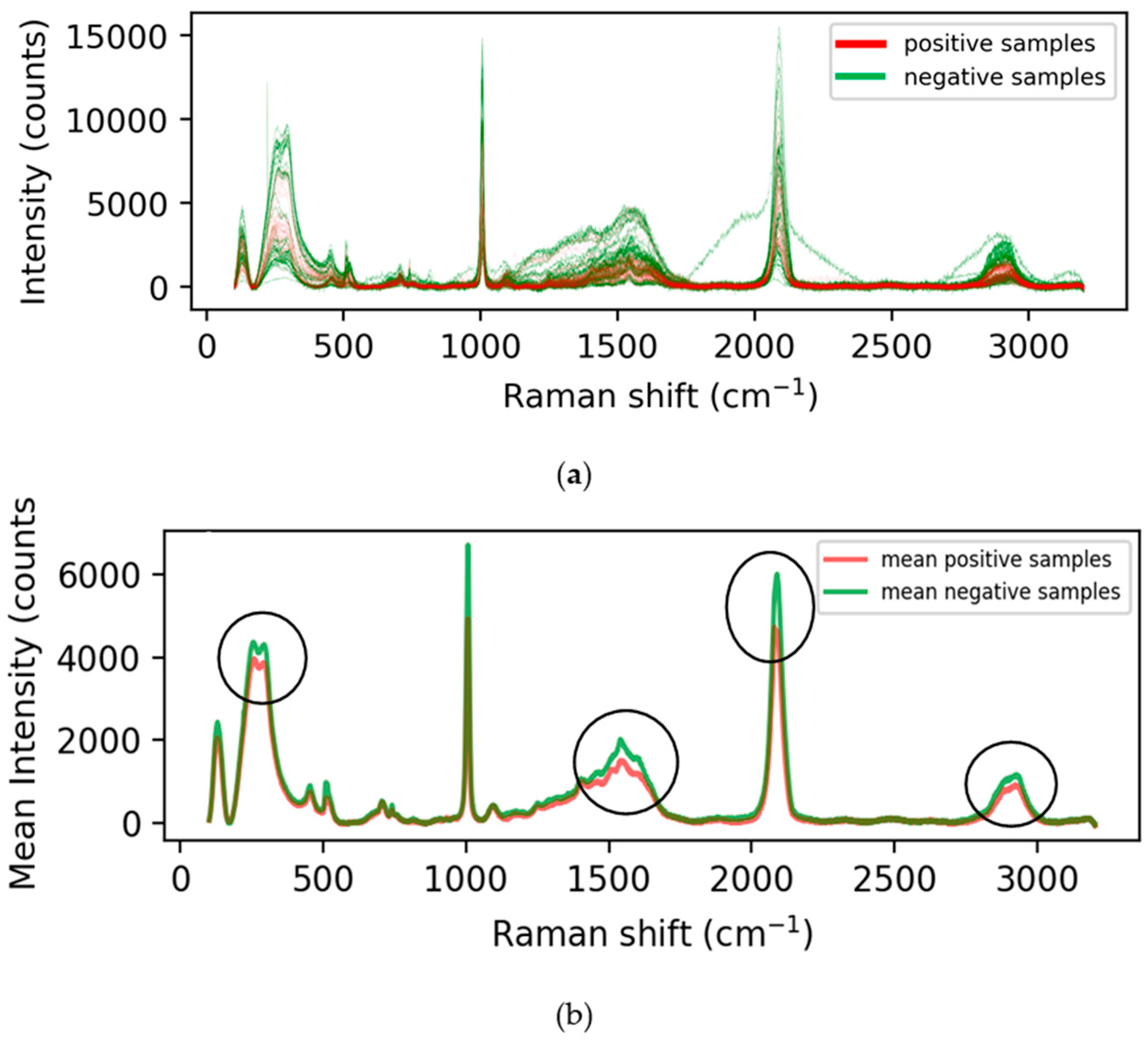
2.1. Data Collection and Preprocessing
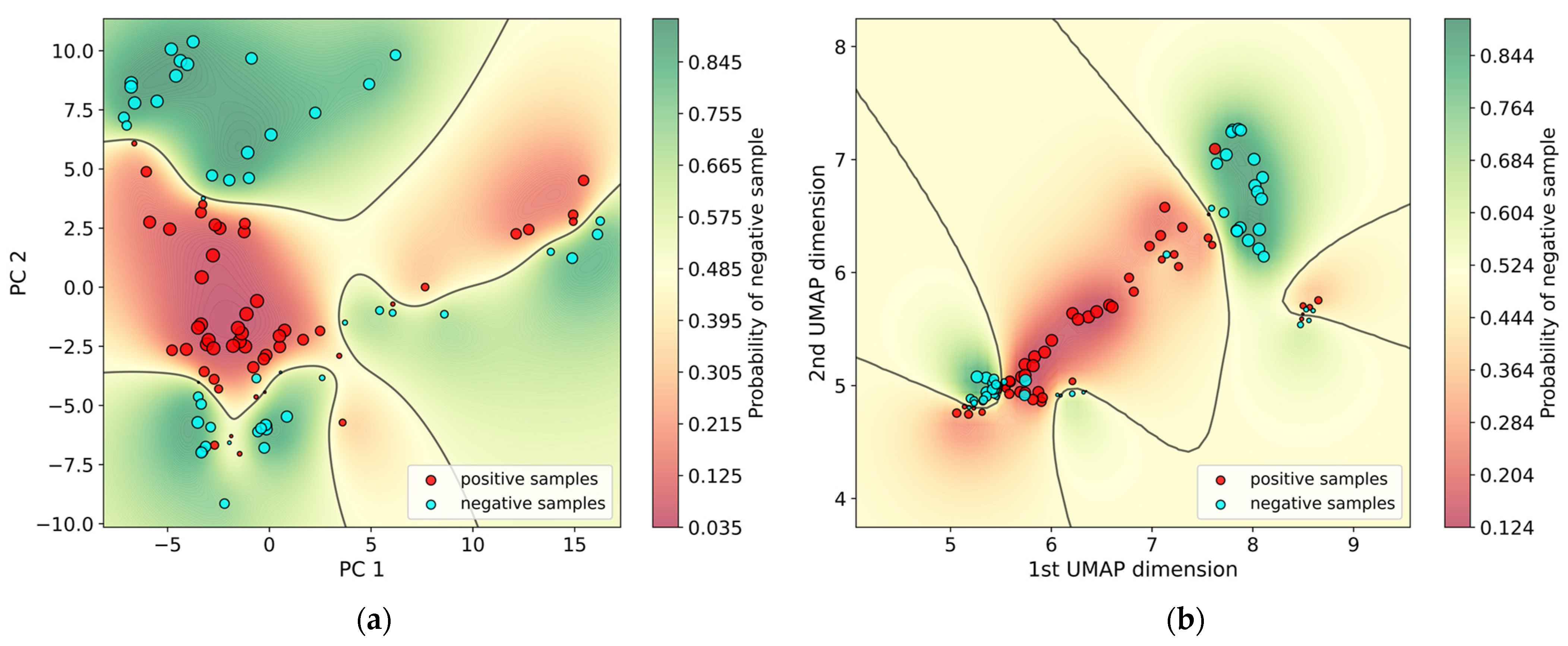
2.2. Dimensionality Reduction
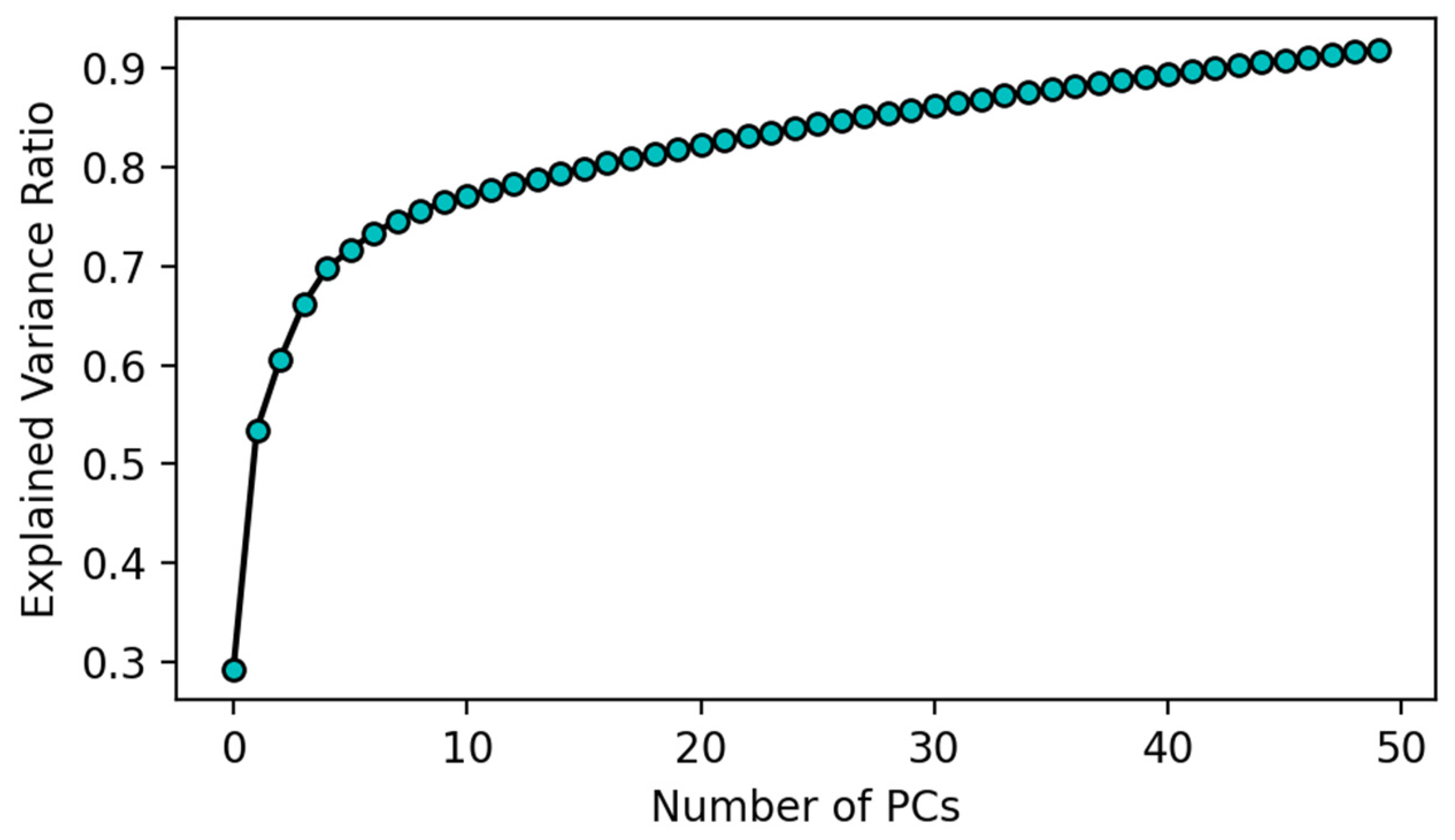
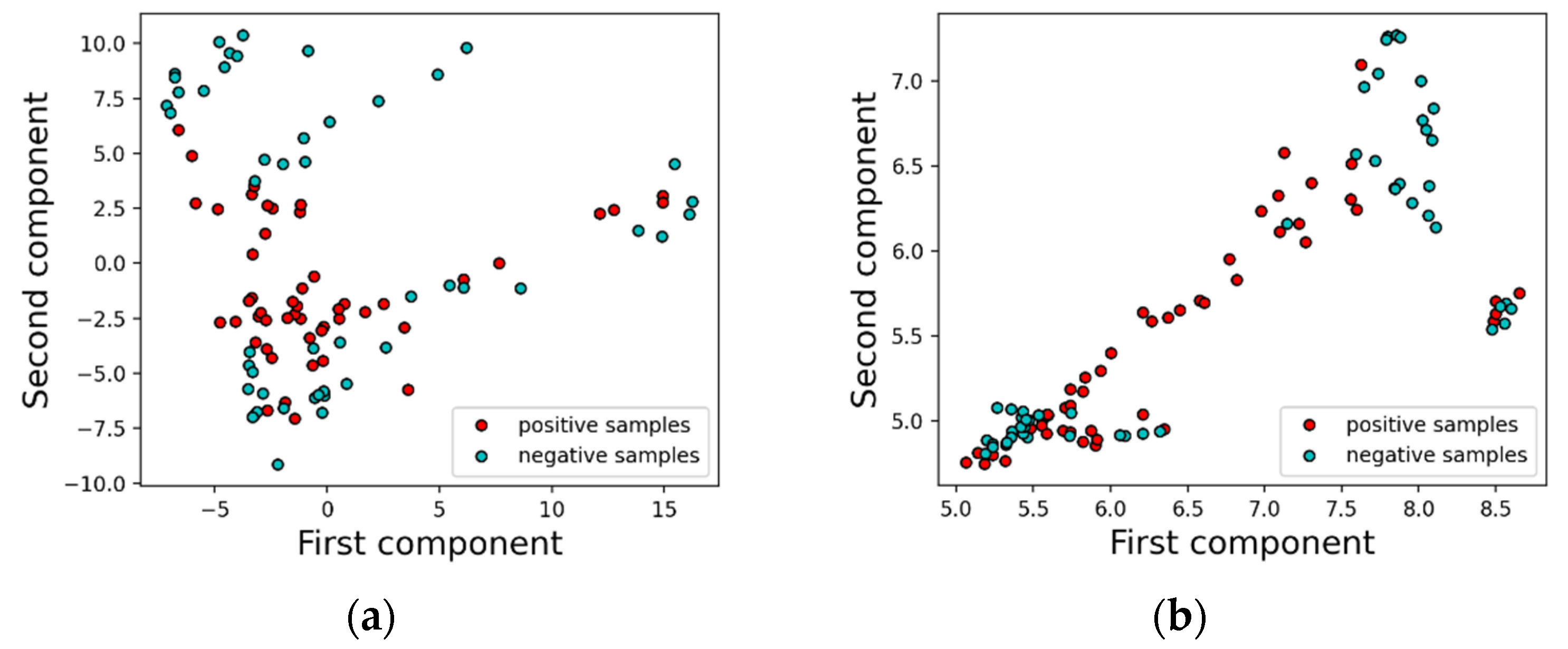
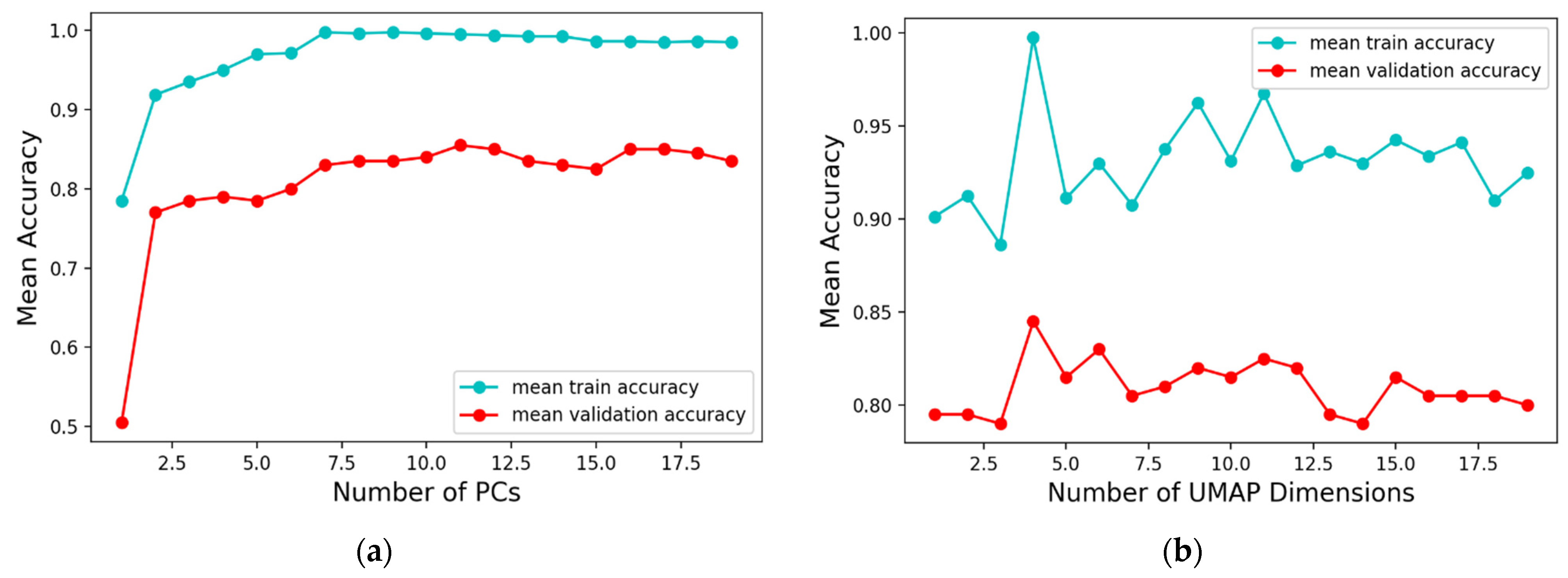
2.2.1. Principal Component Analysis (PCA)
2.2.2. Uniform Manifold Approximation and Projection (UMAP)
- The number of neighbors: This controls the focus on local or global structure in the data. Lower values of this parameter force the UMAP to focus on a very local structure, while the higher values will make the UMAP focus on larger or global structures.
- The minimum distance: This parameter governs how closely UMAP can pack points together. Lower numbers indicate that the points will be tightly clustered and vice versa.
- The number of components: This determines the dimensionality of the low-dimensional space.
2.3. Machine Learning Classification
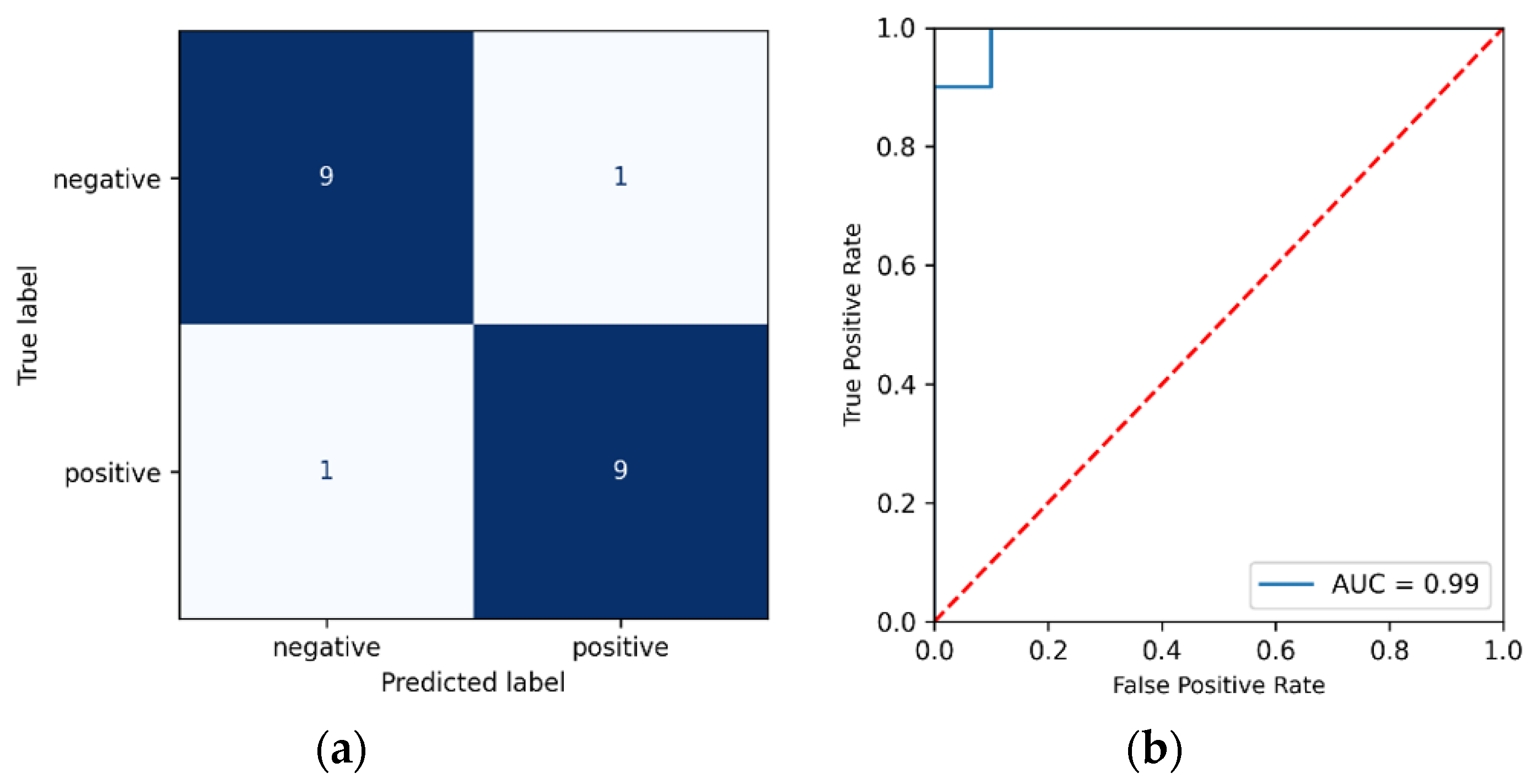
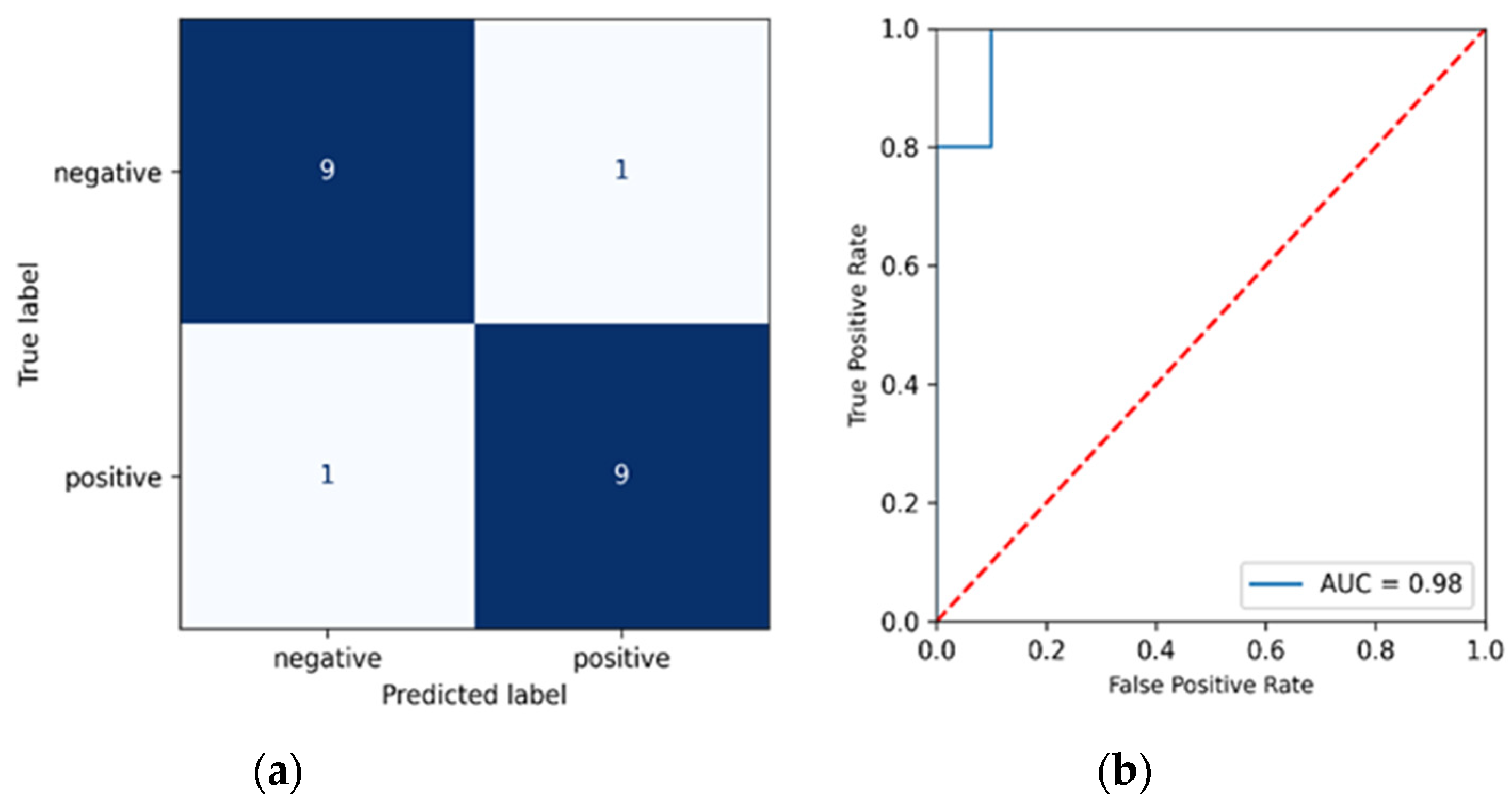
3. Results and Discussion
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, J.; Du, G. COVID-19 may transmit through aerosol. Ir. J. Med. Sci. 2020, 189, 1143–1144. [Google Scholar] [CrossRef] [Green Version]
- Emery, S.L.; Erdman, D.D.; Bowen, M.D.; Newton, B.R.; Winchell, J.M.; Meyer, R.F.; Tong, S.; Cook, B.T.; Holloway, B.P.; McCaustland, K.A. Real-time reverse transcription–polymerase chain reaction assay for SARS-associated coronavirus. Emerg. Infect. Dis. 2004, 10, 311. [Google Scholar] [CrossRef]
- Kyosei, Y.; Yamura, S.; Namba, M.; Yoshimura, T.; Watabe, S.; Ito, E. Antigen tests for COVID-19. Biophys. Physicobiol. 2021, 18, 28–39. [Google Scholar] [CrossRef] [PubMed]
- Chen, D. Analysis of Machine Learning Methods for COVID-19 Detection Using Serum Raman Spectroscopy. Appl. Artif. Intell. 2021, 35, 1147–1168. [Google Scholar] [CrossRef]
- Schmittgen, T.D.; Livak, K.J. Analyzing real-time PCR data by the comparative CT method. Nat. Protoc. 2008, 3, 1101–1108. [Google Scholar] [CrossRef] [PubMed]
- Yin, G.; Li, L.; Lu, S.; Yin, Y.; Su, Y.; Zeng, Y.; Luo, M.; Ma, M.; Zhou, H.; Orlandini, L. An efficient primary screening of COVID-19 by serum Raman spectroscopy. J. Raman Spectrosc. 2021, 52, 949–958. [Google Scholar] [CrossRef] [PubMed]
- Lequin, R.M. Enzyme immunoassay (EIA)/enzyme-linked immunosorbent assay (ELISA). Clin. Chem. 2005, 51, 2415–2418. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Desai, S.; Mishra, S.V.; Joshi, A.; Sarkar, D.; Hole, A.; Mishra, R.; Dutt, S.; Chilakapati, M.K.; Gupta, S.; Dutt, A. Raman spectroscopy-based detection of RNA viruses in saliva: A preliminary report. J. Biophotonics 2020, 13, e202000189. [Google Scholar] [CrossRef] [PubMed]
- Carlomagno, C.; Bertazioli, D.; Gualerzi, A.; Picciolini, S.; Banfi, P.; Lax, A.; Messina, E.; Navarro, J.; Bianchi, L.; Caronni, A. COVID-19 salivary Raman fingerprint: Innovative approach for the detection of current and past SARS-CoV-2 infections. Sci. Rep. 2021, 11, 4943. [Google Scholar] [CrossRef] [PubMed]
- Deng, X.; Milligan, K.; Ali-Adeeb, R.; Shreeves, P.; Brolo, A.; Lum, J.J.; Andrews, J.L.; Jirasek, A. Group and Basis Restricted Non-Negative Matrix Factorization and Random Forest for Molecular Histotype Classification and Raman Biomarker Monitoring in Breast Cancer. Appl. Spectrosc. 2022, 76, 462–474. [Google Scholar] [CrossRef]
- Ralbovsky, N.M.; Lednev, I.K. Towards development of a novel universal medical diagnostic method: Raman spectroscopy and machine learning. Chem. Soc. Rev. 2020, 49, 7428–7453. [Google Scholar] [CrossRef]
- Milligan, K.; Deng, X.; Shreeves, P.; Ali-Adeeb, R.; Matthews, Q.; Brolo, A.; Lum, J.J.; Andrews, J.L.; Jirasek, A. Raman spectroscopy and group and basis-restricted non negative matrix factorisation identifies radiation induced metabolic changes in human cancer cells. Sci. Rep. 2021, 11, 3853. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.; Ullah, R.; Khan, A.; Ashraf, R.; Ali, H.; Bilal, M.; Saleem, M. Analysis of hepatitis B virus infection in blood sera using Raman spectroscopy and machine learning. Photodiagnosis Photodyn. Ther. 2018, 23, 89–93. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.; Ullah, R.; Shahzad, S.; Anbreen, N.; Bilal, M.; Khan, A. Analysis of tuberculosis disease through Raman spectroscopy and machine learning. Photodiagnosis Photodyn. Ther. 2018, 24, 286–291. [Google Scholar] [CrossRef]
- Khan, S.; Ullah, R.; Khan, A.; Wahab, N.; Bilal, M.; Ahmed, M. Analysis of dengue infection based on Raman spectroscopy and support vector machine (SVM). Biomed. Opt. Express 2016, 7, 2249–2256. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Park, S.-G.; Choi, N.; Moon, J.-I.; Dang, H.; Das, A.; Lee, S.; Kim, D.-G.; Chen, L.; Choo, J. SERS imaging-based aptasensor for ultrasensitive and reproducible detection of influenza virus A. Biosens. Bioelectronics 2020, 167, 112496. [Google Scholar] [CrossRef] [PubMed]
- Howley, T.; Madden, M.G.; O’Connell, M.-L.; Ryder, A.G. The effect of principal component analysis on machine learning accuracy with high dimensional spectral data. In Proceedings of the International Conference on Innovative Techniques and Applications of Artificial Intelligence, Cambridge, UK, 12–14 December 2005; pp. 209–222. [Google Scholar]
- Vermeulen, M.; Smith, K.; Eremin, K.; Rayner, G.; Walton, M. Application of Uniform Manifold Approximation and Projection (UMAP) in spectral imaging of artworks. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2021, 252, 119547. [Google Scholar] [CrossRef] [PubMed]
- He, C.; Zhu, S.; Wu, X.; Zhou, J.; Chen, Y.; Qian, X.; Ye, J. Accurate Tumor Subtype Detection with Raman Spectroscopy via Variational Autoencoder and Machine Learning. ACS Omega 2022, 7, 10458–10468. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform manifold approximation and projection for dimension reduction. arXiv 2020, arXiv:1802.03426. [Google Scholar]
- Vidales, K.H.; Guevara, E.; Illana, V.O.; González, F.J. Multivariate analysis of Raman spectroscopy of wild type and mutants p53 cancer biomarker. In Proceedings of the Imaging Spectrometry XXIII: Applications, Sensors, and Processing, San Diego, CA, USA, 11–15 August 2019; p. 1113005. [Google Scholar]
- Bovenkamp, D.; Sentosa, R.; Rank, E.; Erkkilä, M.T.; Placzek, F.; Püls, J.; Drexler, W.; Leitgeb, R.A.; Garstka, N.; Shariat, S.F. Combination of high-resolution optical coherence tomography and raman spectroscopy for improved staging and grading in bladder cancer. Appl. Sci. 2018, 8, 2371. [Google Scholar] [CrossRef] [Green Version]
- Lyng, F.M.; Traynor, D.; Nguyen, T.N.Q.; Meade, A.D.; Rakib, F.; Al-Saady, R.; Goormaghtigh, E.; Al-Saad, K.; Ali, M.H. Discrimination of breast cancer from benign tumours using Raman spectroscopy. PLoS ONE 2019, 14, e0212376. [Google Scholar]
- Moitra, P.; Alafeef, M.; Dighe, K.; Frieman, M.B.; Pan, D. Selective naked-eye detection of SARS-CoV-2 mediated by N gene targeted antisense oligonucleotide capped plasmonic nanoparticles. ACS Nano 2020, 14, 7617–7627. [Google Scholar] [CrossRef]
- Alafeef, M.; Dighe, K.; Moitra, P.; Pan, D. Rapid, ultrasensitive, and quantitative detection of SARS-CoV-2 using antisense oligonucleotides directed electrochemical biosensor chip. ACS Nano 2020, 14, 17028–17045. [Google Scholar] [CrossRef]
- Alafeef, M.; Moitra, P.; Dighe, K.; Pan, D. RNA-extraction-free nano-amplified colorimetric test for point-of-care clinical diagnosis of COVID-19. Nat. Protoc. 2021, 16, 3141–3162. [Google Scholar] [CrossRef]
- Alafeef, M.; Moitra, P.; Dighe, K.; Pan, D. Hyperspectral mapping for the detection of SARS-CoV-2 using nanomolecular probes with yoctomole sensitivity. ACS Nano 2021, 15, 13742–13758. [Google Scholar] [CrossRef] [PubMed]
- Moitra, P.; Alafeef, M.; Dighe, K.; Sheffield, Z.; Dahal, D.; Pan, D. Synthesis and characterisation of N-gene targeted NIR-II fluorescent probe for selective localisation of SARS-CoV-2. Chem. Commun. 2021, 57, 6229–6232. [Google Scholar] [CrossRef]
- Dighe, K.; Moitra, P.; Alafeef, M.; Gunaseelan, N.; Pan, D. A rapid RNA extraction-free lateral flow assay for molecular point-of-care detection of SARS-CoV-2 augmented by chemical probes. Biosens. Bioelectron. 2022, 200, 113900. [Google Scholar] [CrossRef] [PubMed]
- Moitra, P.; Chaichi, A.; Hasan, S.M.A.; Dighe, K.; Alafeef, M.; Prasad, A.; Gartia, M.R.; Pan, D. Probing the mutation independent interaction of DNA probes with SARS-CoV-2 variants through a combination of surface-enhanced Raman scattering and machine learning. Biosens. Bioelectron. 2022, 208, 114200. [Google Scholar] [CrossRef]
- Sheffield, Z.; Alafeef, M.; Moitra, P.; Ray, P.; Pan, D. N-gene-complementary antisense-oligonucleotide directed molecular aggregation of dual-colour carbon dots, leading to efficient fluorometric sensing of SARS-COV-2 RNA. Nanoscale 2022, 14, 5112–5120. [Google Scholar] [CrossRef]
- Moitra, P.; Alafeef, M.; Dighe, K.; Ray, P.; Chang, J.; Thole, A.; Punshon-Smith, B.; Tolosa, M.; Ramamurthy, S.S.; Ge, X. Rapid and low-cost sampling for detection of airborne SARS-CoV-2 in dehumidifier condensate. Biotechnol. Bioeng. 2021, 118, 3029–3036. [Google Scholar] [CrossRef] [PubMed]
- Das, A.; Kim, K.; Park, S.-G.; Choi, N.; Choo, J. SERS-based serodiagnosis of acute febrile diseases using plasmonic nanopopcorn microarray platforms. Biosens. Bioelectron. 2021, 192, 113525. [Google Scholar] [CrossRef] [PubMed]
- Laing, S.; Gracie, K.; Faulds, K. Multiplex in vitro detection using SERS. Chem. Soc. Rev. 2016, 45, 1901–1918. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Vajapeyam, S. Understanding Shannon’s entropy metric for information. arXiv 2014, arXiv:1405.2061. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Folds | Accuracy | Precision | Recall | F1 Score | ROC_AUC |
|---|---|---|---|---|---|
| Fold 1 | 0.800 | 1.000 | 0.600 | 0.750 | 0.920 |
| Fold 2 | 0.900 | 0.900 | 0.900 | 0.900 | 0.980 |
| Fold 3 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| Fold 4 | 0.750 | 0.727 | 0.800 | 0.762 | 0.860 |
| Fold 5 | 0.700 | 0.750 | 0.600 | 0.667 | 0.810 |
| Fold 6 | 0.950 | 1.000 | 0.900 | 0.947 | 0.970 |
| Fold 7 | 0.850 | 1.000 | 0.700 | 0.824 | 0.920 |
| Fold 8 | 0.800 | 0.875 | 0.700 | 0.778 | 0.950 |
| Fold 9 | 0.900 | 0.900 | 0.900 | 0.900 | 0.990 |
| Fold 10 | 0.900 | 1.000 | 0.800 | 0.889 | 0.980 |
| Mean | 0.855 | 0.915 | 0.740 | 0.842 | 0.941 |
| Folds | Accuracy | Precision | Recall | F1 Score | ROC_AUC |
|---|---|---|---|---|---|
| Fold 1 | 0.800 | 1.000 | 0.600 | 0.750 | 0.920 |
| Fold 2 | 0.900 | 0.900 | 0.900 | 0.900 | 0.980 |
| Fold 3 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| Fold 4 | 0.750 | 0.727 | 0.800 | 0.762 | 0.860 |
| Fold 5 | 0.700 | 0.750 | 0.600 | 0.667 | 0.810 |
| Fold 6 | 0.950 | 1.000 | 0.900 | 0.947 | 0.970 |
| Fold 7 | 0.850 | 1.000 | 0.700 | 0.824 | 0.920 |
| Fold 8 | 0.800 | 0.875 | 0.700 | 0.778 | 0.950 |
| Fold 9 | 0.900 | 1.000 | 0.800 | 0.889 | 0.900 |
| Fold 10 | 0.900 | 1.000 | 0.800 | 0.889 | 0.980 |
| Mean | 0.855 | 0.925 | 0.780 | 0.841 | 0.929 |
| Samples | Class 1 prob | Class 2 prob | True Class | Predicted Class | Uncertainty |
|---|---|---|---|---|---|
| 1 | 0.500 | 0.500 | 1 | 0 | 1.00 |
| 2 | 0.376 | 0.624 | 1 | 1 | 0.95 |
| 3 | 0.245 | 0.755 | 1 | 1 | 0.80 |
| 4 | 0.608 | 0.392 | 0 | 0 | 0.97 |
| 5 | 0.196 | 0.804 | 1 | 1 | 0.71 |
| 6 | 0.689 | 0.311 | 0 | 0 | 0.89 |
| 7 | 0.822 | 0.178 | 0 | 0 | 0.68 |
| 8 | 0.179 | 0.821 | 1 | 1 | 0.68 |
| 9 | 0.732 | 0.268 | 0 | 0 | 0.84 |
| 10 | 0.231 | 0.769 | 1 | 1 | 0.78 |
| 11 | 0.257 | 0.743 | 1 | 1 | 0.82 |
| 12 | 0.238 | 0.762 | 1 | 1 | 0.79 |
| 13 | 0.341 | 0.659 | 1 | 1 | 0.93 |
| 14 | 0.466 | 0.534 | 0 | 1 | 1.00 |
| 15 | 0.760 | 0.240 | 0 | 0 | 0.80 |
| 16 | 0.654 | 0.346 | 0 | 0 | 0.93 |
| 17 | 0.870 | 0.130 | 0 | 0 | 0.56 |
| 18 | 0.686 | 0.314 | 0 | 0 | 0.90 |
| 19 | 0.463 | 0.537 | 1 | 1 | 1.00 |
| 20 | 0.764 | 0.236 | 0 | 0 | 0.79 |
| Samples | Class 1 prob | Class 2 prob | True Class | Predicted Class | Uncertainty |
|---|---|---|---|---|---|
| 1 | 0.707 | 0.293 | 0 | 0 | 0.87 |
| 2 | 0.760 | 0.240 | 0 | 0 | 0.80 |
| 3 | 0.361 | 0.639 | 1 | 1 | 0.94 |
| 4 | 0.840 | 0.160 | 0 | 0 | 0.63 |
| 5 | 0.480 | 0.520 | 1 | 1 | 1.00 |
| 6 | 0.696 | 0.304 | 0 | 0 | 0.89 |
| 7 | 0.777 | 0.223 | 0 | 0 | 0.77 |
| 8 | 0.832 | 0.168 | 0 | 0 | 0.65 |
| 9 | 0.351 | 0.649 | 1 | 1 | 0.93 |
| 10 | 0.165 | 0.835 | 1 | 1 | 0.65 |
| 11 | 0.452 | 0.548 | 1 | 1 | 0.99 |
| 12 | 0.587 | 0.413 | 0 | 0 | 0.98 |
| 13 | 0.466 | 0.534 | 0 | 1 | 1.00 |
| 14 | 0.187 | 0.813 | 1 | 1 | 0.70 |
| 15 | 0.329 | 0.671 | 1 | 1 | 0.91 |
| 16 | 0.789 | 0.211 | 0 | 0 | 0.74 |
| 17 | 0.544 | 0.456 | 1 | 0 | 0.99 |
| 18 | 0.611 | 0.389 | 0 | 0 | 0.96 |
| 19 | 0.285 | 0.715 | 1 | 1 | 0.86 |
| 20 | 0.336 | 0.664 | 1 | 1 | 0.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ikponmwoba, E.; Ukorigho, O.; Moitra, P.; Pan, D.; Gartia, M.R.; Owoyele, O. A Machine Learning Framework for Detecting COVID-19 Infection Using Surface-Enhanced Raman Scattering. Biosensors 2022, 12, 589. https://doi.org/10.3390/bios12080589
Ikponmwoba E, Ukorigho O, Moitra P, Pan D, Gartia MR, Owoyele O. A Machine Learning Framework for Detecting COVID-19 Infection Using Surface-Enhanced Raman Scattering. Biosensors. 2022; 12(8):589. https://doi.org/10.3390/bios12080589
Chicago/Turabian StyleIkponmwoba, Eloghosa, Okezzi Ukorigho, Parikshit Moitra, Dipanjan Pan, Manas Ranjan Gartia, and Opeoluwa Owoyele. 2022. "A Machine Learning Framework for Detecting COVID-19 Infection Using Surface-Enhanced Raman Scattering" Biosensors 12, no. 8: 589. https://doi.org/10.3390/bios12080589
APA StyleIkponmwoba, E., Ukorigho, O., Moitra, P., Pan, D., Gartia, M. R., & Owoyele, O. (2022). A Machine Learning Framework for Detecting COVID-19 Infection Using Surface-Enhanced Raman Scattering. Biosensors, 12(8), 589. https://doi.org/10.3390/bios12080589