Rapid Characterization of Black Tea Taste Quality Using Miniature NIR Spectroscopy and Electronic Tongue Sensors

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Collection
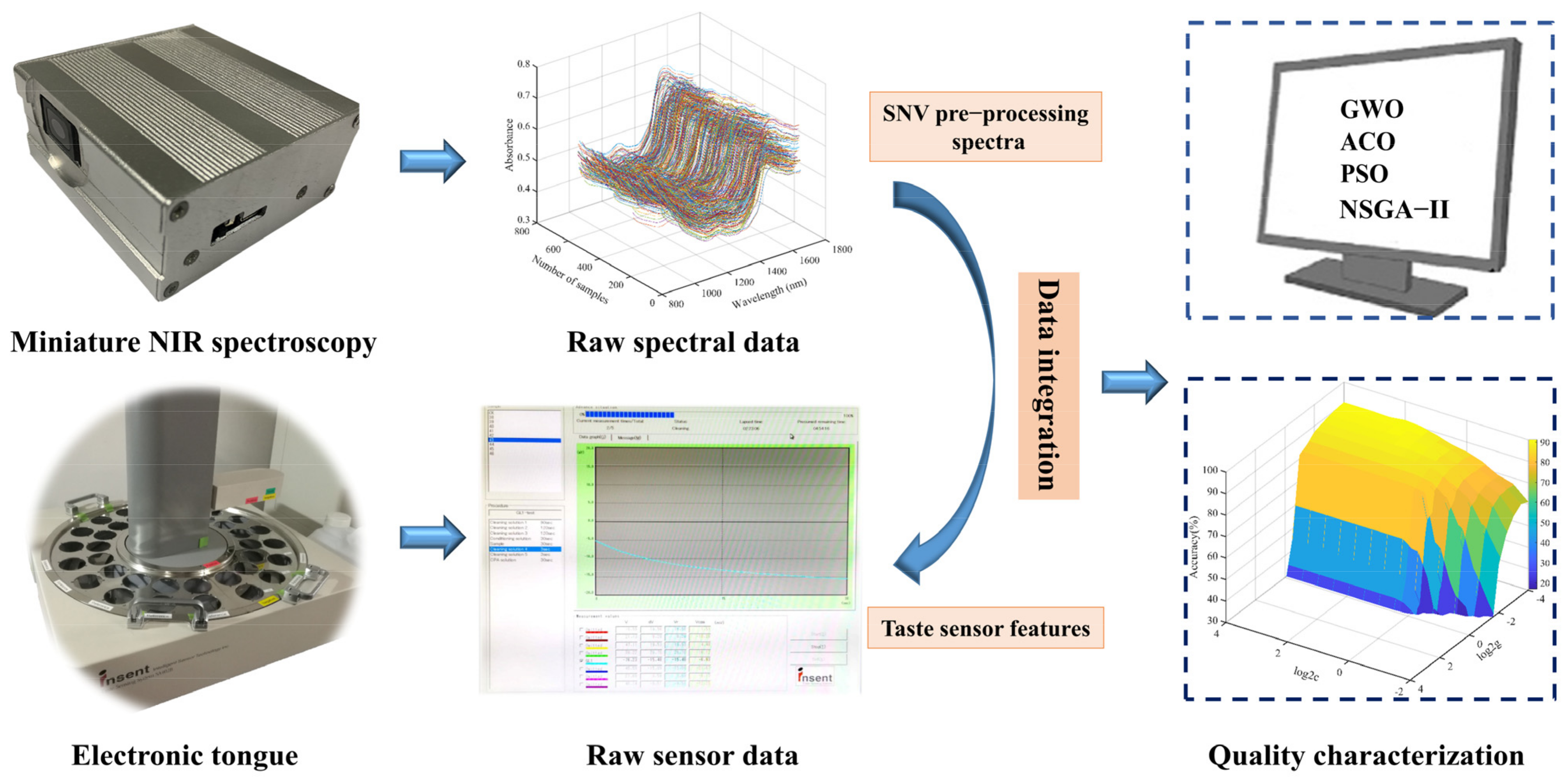
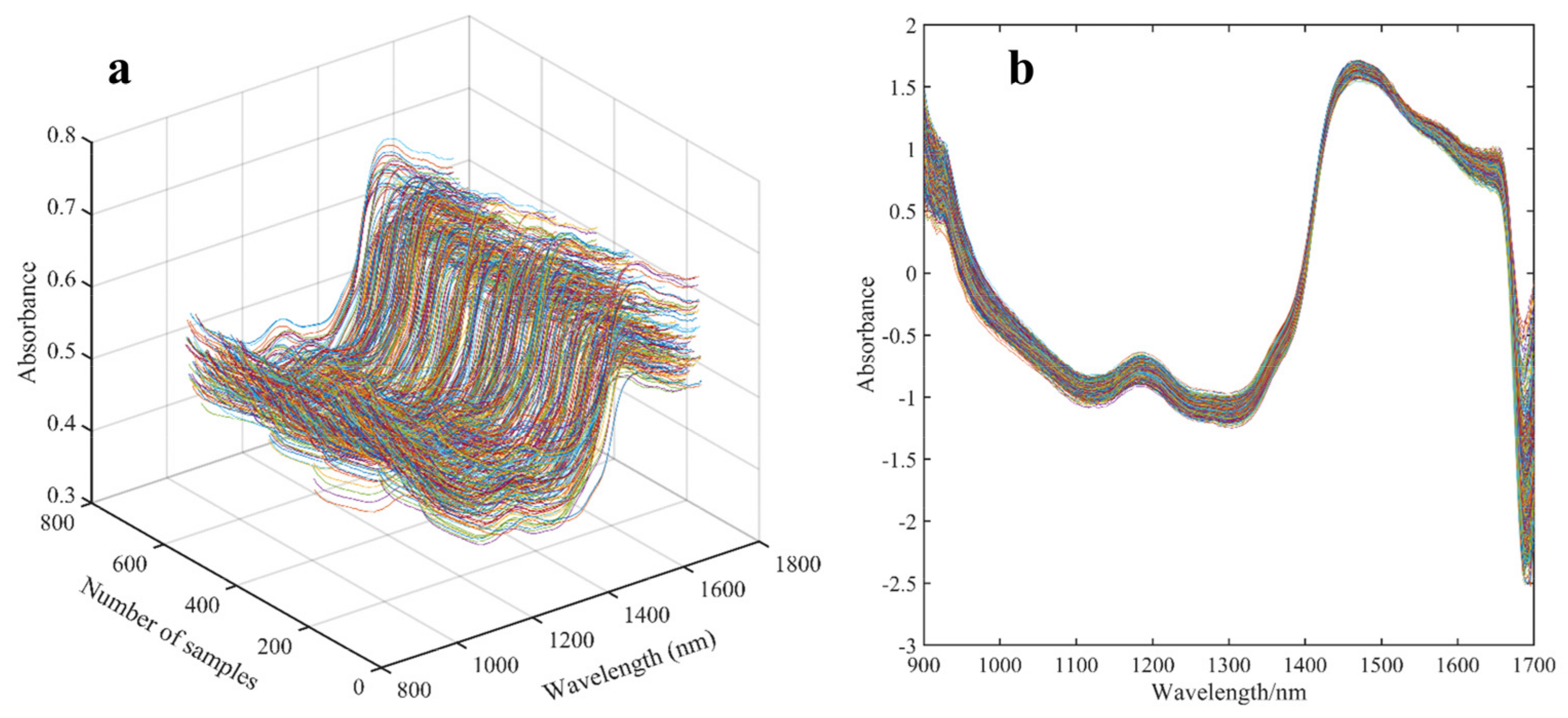
2.2. Miniature NIR Spectroscopy and Data Pre-Processing
2.3. Electronic Tongue Signal Acquisition
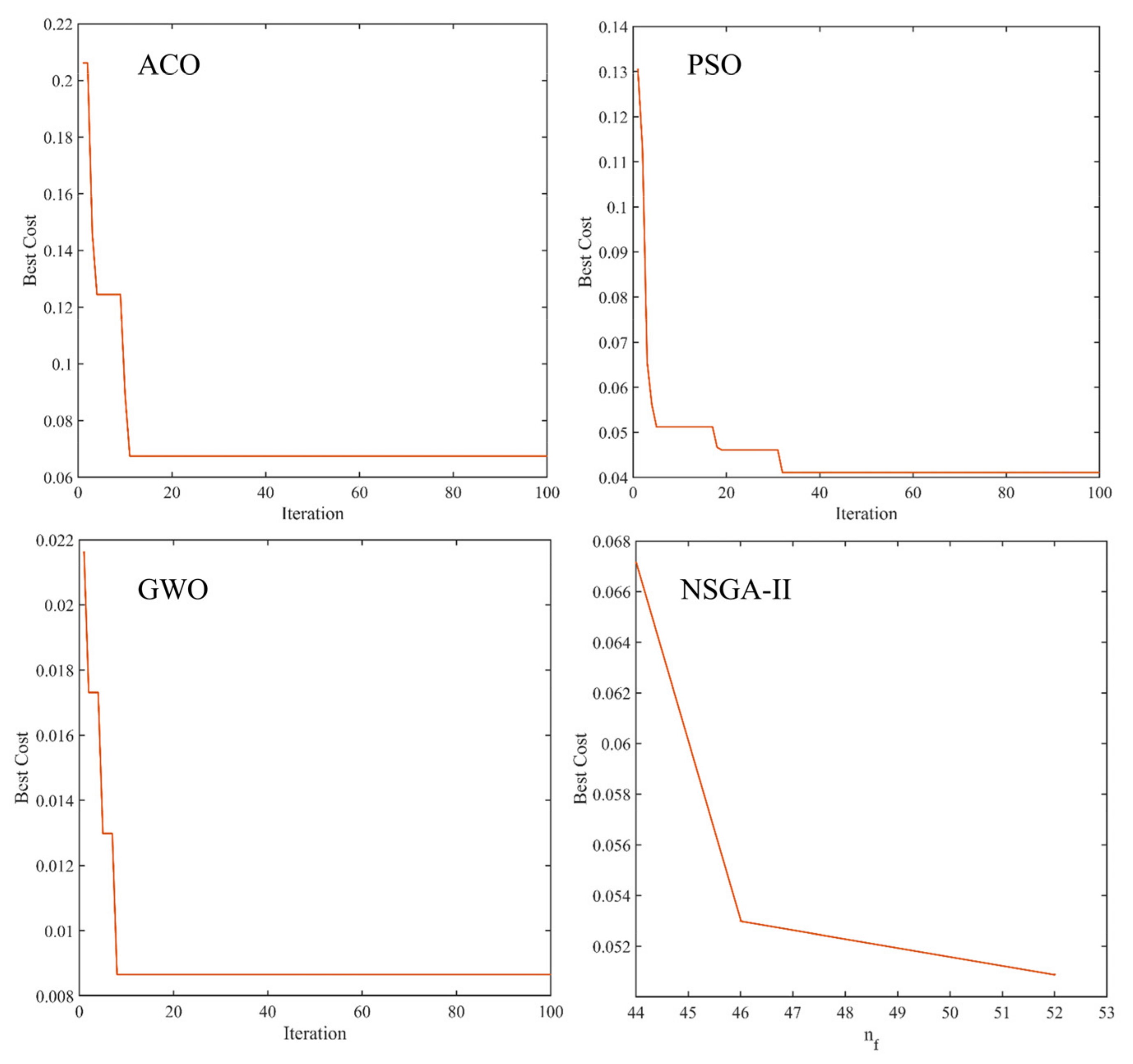
2.4. Feature Selection Strategy
2.5. Modeling Algorithms
2.6. Model Evaluation
3. Results and Discussion
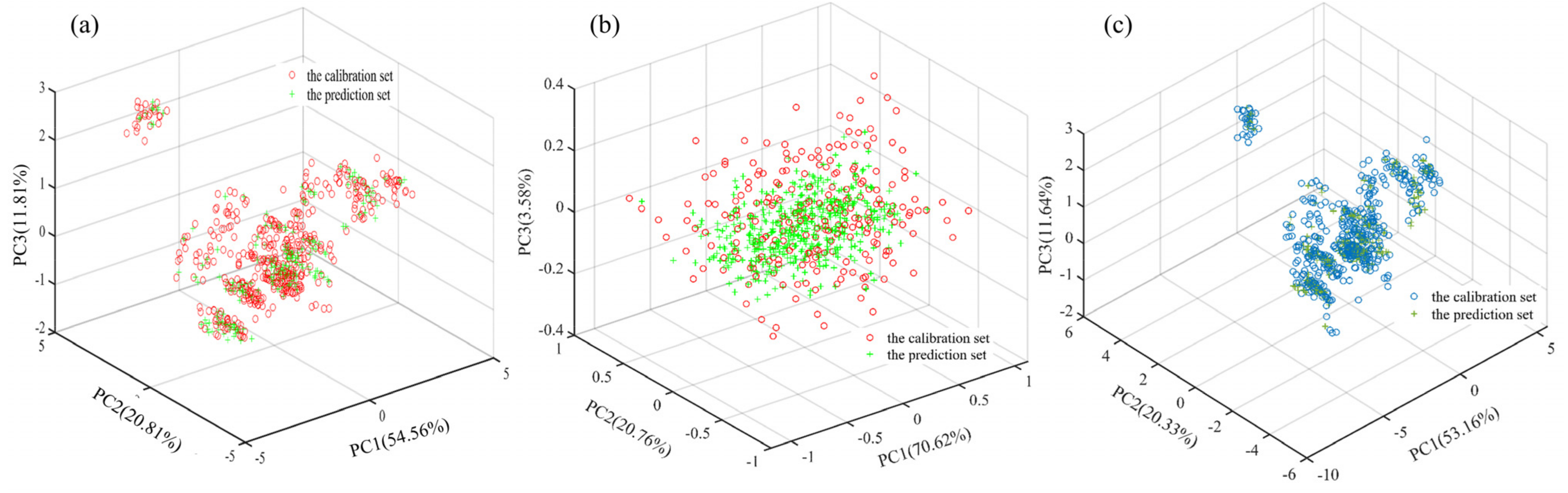
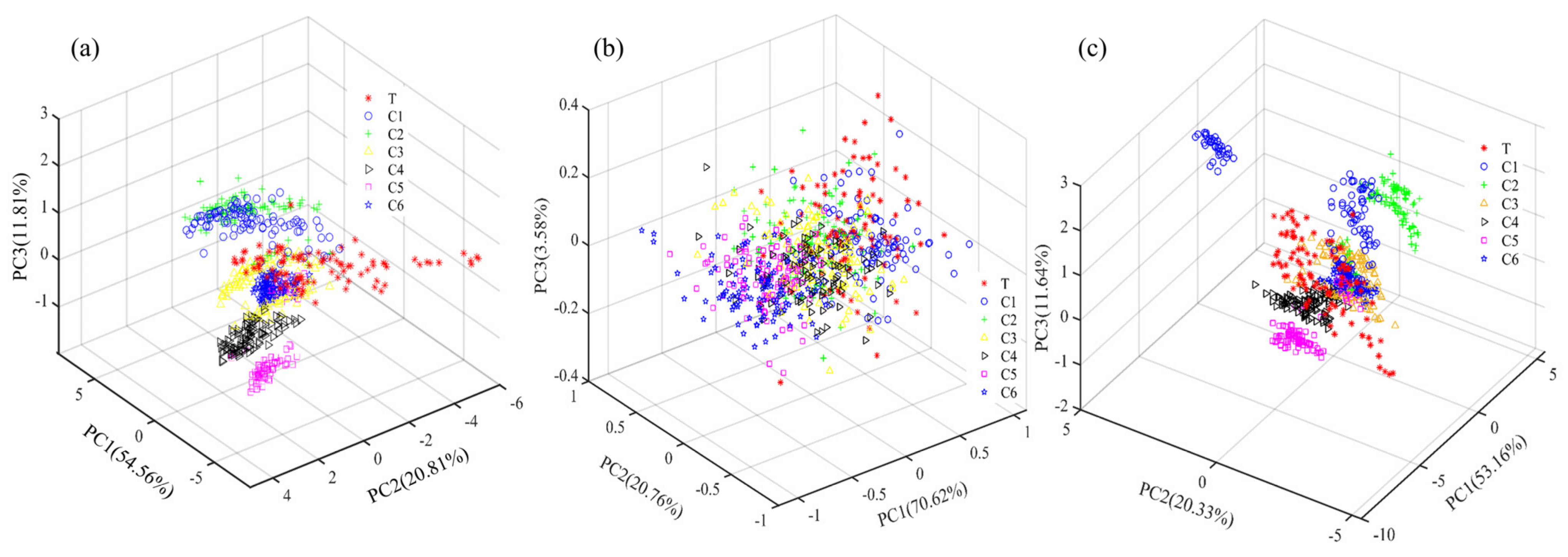
3.1. Sample Set Division and Principal Component Analysis
3.2. Selection of Taste Characteristic Variables
3.3. Results of The Optimal Models
3.4. Discussion of the Optimal Models
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, L.; Cui, Q.; Li, M.; Li, T.; Cao, S.; Dong, S.; Wang, Y.; Dai, Q.; Ning, J. Rapid detection of multiple colorant adulteration in Keemun black tea based on hemp spherical AgNPs-SERS. Food Chem. 2023, 398, 133841. [Google Scholar] [CrossRef] [PubMed]
- Ren, G.; Fan, Q.; He, X.; Li, W.; Tang, X. Applicability of multifunctional preprocessing device for simultaneous estimation of spreading of green tea, withering of black tea and shaking of oolong tea. J. Sci. Food Agric. 2020, 100, 560–569. [Google Scholar] [CrossRef] [PubMed]
- Han, Z.; Wen, M.; Zhang, H.; Zhang, L.; Wan, X.; Ho, C.-T. LC-MS based metabolomics and sensory evaluation reveal the critical compounds of different grades of Huangshan Maofeng green tea. Food Chem. 2022, 374, 131796. [Google Scholar] [CrossRef] [PubMed]
- Ren, Y.; Hou, Y.; Granato, D.; Zha, M.; Xu, W.; Zhang, L. Metabolomics, sensory evaluation, and enzymatic hydrolysis reveal the effect of storage on the critical astringency-active components of crude Pu-erh tea. J. Food Compost. Anal. 2022, 107, 104387. [Google Scholar] [CrossRef]
- Wang, Y.; Cui, Q.; Jin, S.; Zhuo, C.; Luo, Y.; Yu, Y.; Ning, J.; Zhang, Z. Tea Analyzer: A low-cost and portable tool for quality quantification of postharvest fresh tea leaves. LWT-Food Sci. Technol. 2022, 159, 113248. [Google Scholar] [CrossRef]
- Wang, Z.; Gan, S.; Sun, W.; Chen, Z. Quality characteristics of Oolong tea products in different regions and the contribution of thirteen phytochemical components to its taste. Horticultura 2022, 8, 278. [Google Scholar] [CrossRef]
- Li, Q.; Jin, Y.; Jiang, R.; Xu, Y.; Zhang, Y.; Luo, Y.; Huang, J.; Wang, K.; Liu, Z. Dynamic changes in the metabolite profile and taste characteristics of Fu brick tea during the manufacturing process. Food Chem. 2021, 344, 128576. [Google Scholar] [CrossRef]
- Shen, S.; Huang, J.; Li, T.; Wei, Y.; Xu, S.; Wang, Y.; Ning, J. Untargeted and targeted metabolomics reveals potential marker compounds of an tea during storage. LWT-Food Sci. Technol. 2022, 154, 112791. [Google Scholar] [CrossRef]
- Yang, Y.; Xie, J.; Chen, J.; Deng, Y.; Shen, S.; Hua, J.; Wang, J.; Zhu, J.; Yuan, H.; Jiang, Y. Characterization of N,O-heterocycles in green tea during the drying process and unraveling the formation mechanism. Food Control 2022, 139, 109079. [Google Scholar] [CrossRef]
- Li, H.; Geng, W.; Zhang, M.; He, Z.; Haruna, S.A.; Ouyang, Q.; Chen, Q. Qualitative and quantitative analysis of volatile metabolites of foodborne pathogens using colorimetric-bionic sensor coupled robust models. Microchem. J. 2022, 177, 107282. [Google Scholar] [CrossRef]
- Barbosa, M.F.; Santos, J.R.B.; Silva, A.N.; Soares, S.F.C.; Araujo, M.C.U. A cheap handheld NIR spectrometric system for automatic determination of methane, ethane, and propane in natural gas and biogas. Microchem. J. 2021, 170, 106752. [Google Scholar] [CrossRef]
- Ito, A.; Yanase, E. Study into the chemical changes of tea leaf polyphenols during japanese black tea processing. Food Res. Int. 2022, 160, 111731. [Google Scholar] [CrossRef]
- Lin, J.; Liu, F.; Zhou, X.; Tu, Z.; Chen, L.; Wang, Y.; Yang, Y.; Wu, X.; Lv, H.; Zhu, H.; et al. Effect of red light on the composition of metabolites in tea leaves during the withering process using untargeted metabolomics. J. Sci. Food Agric. 2022, 102, 1628–1639. [Google Scholar] [CrossRef]
- Luo, X.; Gouda, M.; Perumal, A.B.; Huang, Z.; Lin, L.; Tang, Y.; Sanaeifar, A.; He, Y.; Li, X.; Dong, C. Using surface-enhanced Raman spectroscopy combined with chemometrics for black tea quality assessment during its fermentation process. Sens. Actuators B Chem. 2022, 373, 132680. [Google Scholar] [CrossRef]
- Ren, G.; Wang, Y.; Ning, J.; Zhang, Z. Highly identification of keemun black tea rank based on cognitive spectroscopy: Near infrared spectroscopy combined with feature variable selection. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2020, 230, 118079. [Google Scholar] [CrossRef]
- Ren, G.; Wang, S.; Ning, J.; Xu, R.; Wang, Y.; Xing, Z.; Wan, X.; Zhang, Z. Quantitative analysis and geographical traceability of black tea using Fourier transform near-infrared spectroscopy (FT-NIRS). Food Res. Int. 2013, 53, 822–826. [Google Scholar] [CrossRef]
- Yang, Z.; Miao, N.; Zhang, X.; Li, Q.; Wang, Z.; Li, C.; Sun, X.; Lan, Y. Employment of an electronic tongue combined with deep learning and transfer learning for discriminating the storage time of Pu-erh tea. Food Control 2021, 121, 107608. [Google Scholar] [CrossRef]
- Ren, G.; Li, T.; Wei, Y.; Ning, J.; Zhang, Z. Estimation of Congou black tea quality by an electronic tongue technology combined with multivariate analysis. Microchem. J. 2021, 163, 105899. [Google Scholar] [CrossRef]
- Zaukuu, J.-L.Z.; Soós, J.; Bodor, Z.; Felföldi, J.; Magyar, I.; Kovacs, Z. Authentication of tokaj wine (Hungaricum) with the electronic tongue and near infrared spectroscopy. J. Food Sci. 2019, 84, 3437–3444. [Google Scholar] [CrossRef]
- Sobrino-Gregorio, L.; Tanleque-Alberto, F.; Bataller, R.; Soto, J.; Escriche, I. Using an automatic pulse voltammetric electronic tongue to verify the origin of honey from Spain, Honduras, and Mozambique. J. Sci. Food Agric. 2020, 100, 212–217. [Google Scholar] [CrossRef]
- Lu, L.; Hu, Z.; Hu, X.; Han, J.; Zhu, Z.; Tian, S.; Chen, Z. Quantitative approach of multidimensional interactive sensing for rice quality using electronic tongue sensor array based on information entropy. Sens. Actuators B Chem. 2021, 329, 129254. [Google Scholar] [CrossRef]
- Li, L.; Wang, Y.; Jin, S.; Li, M.; Chen, Q.; Ning, J.; Zhang, Z. Evaluation of black tea by using smartphone imaging coupled with micro-near-infrared spectrometer. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2021, 246, 118991. [Google Scholar] [CrossRef] [PubMed]
- Ouyang, Q.; Yang, Y.; Wu, J.; Chen, Q.; Guo, Z.; Li, H. Measurement of total free amino acids content in black tea using electronic tongue technology coupled with chemometrics. LWT-Food Sci. Technol. 2020, 118, 108768. [Google Scholar] [CrossRef]
- Ding, Y.; Yan, Y.; Li, J.; Chen, X.; Jiang, H. Classification of tea quality levels using near-infrared spectroscopy based on CLPSO-SVM. Foods 2022, 11, 1658. [Google Scholar] [CrossRef] [PubMed]
- Liu, T.; Jiang, H.; Chen, Q. Input features and parameters optimization improved the prediction accuracy of support vector regression models based on colorimetric sensor data for detection of aflatoxin B1 in corn. Microchem. J. 2022, 178, 107407. [Google Scholar] [CrossRef]
- Zhao, J.; Tian, G.; Qiu, Y.; Qu, H. Rapid quantification of active pharmaceutical ingredient for sugar-free Yangwei granules in commercial production using FT-NIR spectroscopy based on machine learning techniques. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2021, 245, 118878. [Google Scholar] [CrossRef]
- Jiang, H.; Liu, T.; He, P.; Ding, Y.; Chen, Q. Rapid measurement of fatty acid content during flour storage using a color-sensitive gas sensor array: Comparing the effects of swarm intelligence optimization algorithms on sensor features. Food Chem. 2021, 338, 127828. [Google Scholar] [CrossRef]
- Liu, T.; He, J.; Yao, W.; Jiang, H.; Chen, Q. Determination of aflatoxin B1 value in corn based on Fourier transform near-infrared spectroscopy: Comparison of optimization effect of characteristic wavelengths. LWT-Food Sci. Technol. 2022, 164, 113657. [Google Scholar] [CrossRef]
- Modupalli, N.; Naik, M.; Sunil, C.K.; Natarajan, V. Emerging non-destructive methods for quality and safety monitoring of spices. Trends Food Sci. Technol. 2021, 108, 133–147. [Google Scholar] [CrossRef]
- Cordeiro, F.R.; da Silva-Filho, A.G. Multi-objective optimization applied to unified second level cache memory hierarchy tuning aiming at energy and performance optimization. Appl. Soft. Comput 2016, 49, 603–610. [Google Scholar] [CrossRef]
- Tu, Q.; Chen, X.; Liu, X. Multi-strategy ensemble grey wolf optimizer and its application to feature selection. Appl. Soft. Comput 2019, 76, 16–30. [Google Scholar] [CrossRef]
- Too, J.; Abdullah, A.R. Opposition based competitive grey wolf optimizer for EMG feature selection. Evol. Intell. 2021, 14, 1691–1705. [Google Scholar] [CrossRef]
- Panero, F.D.; Smiderle, O.; Panero, J.S.; Faria, F.S.D.V.; Panero, P.d.S.; Rodriguez, A.F.R. Non-destructive genotyping of cultivars and strains of sesame through NIR spectroscopy and chemometrics. Biosensors 2022, 12, 69. [Google Scholar] [CrossRef]
- Ren, G.; Sun, Y.; Li, M.; Ning, J.; Zhang, Z. Cognitive spectroscopy for evaluating Chinese black tea grades (Camellia sinensis): Near-infrared spectroscopy and evolutionary algorithms. J. Sci. Food Agric. 2020, 100, 3950–3959. [Google Scholar] [CrossRef]
- Miao, X.; Miao, Y.; Tao, S.; Liu, D.; Chen, Z.; Wang, J.; Huang, W.; Yu, Y. Classification of rice based on storage time by using near infrared spectroscopy and chemometric methods. Microchem. J. 2021, 171, 106841. [Google Scholar] [CrossRef]
- Dong, C.; An, T.; Yang, M.; Yang, C.; Liu, Z.; Li, Y.; Duan, D.; Fan, S. Quantitative prediction and visual detection of the moisture content of withering leaves in black tea (Camellia sinensis) with hyperspectral image. Infrared Phys. Technol. 2022, 123, 104118. [Google Scholar] [CrossRef]
- An, T.; Yu, S.; Huang, W.; Li, G.; Tian, X.; Fan, S.; Dong, C.; Zhao, C. Robustness and accuracy evaluation of moisture prediction model for black tea withering process using hyperspectral imaging. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2022, 269, 120791. [Google Scholar] [CrossRef]
- Jia, H.; Yuan, W.; Ren, Z.; Ning, J.; Xu, Y.-Q.; Wang, Y.; Deng, W.-W. Cost-effective and sensitive indicator-displacement array (IDA) assay for quality monitoring of black tea fermentation. Food Chem. 2023, 403, 134340. [Google Scholar] [CrossRef]
- Bian, X.; Wu, D.; Zhang, K.; Liu, P.; Shi, H.; Tan, X.; Wang, Z. Variational mode decomposition weighted multiscale support vector regression for spectral determination of rapeseed oil and rhizoma alpiniae offcinarum adulterants. Biosensors 2022, 12, 586. [Google Scholar] [CrossRef]
- Wang, Y.; Ren, Z.; Li, M.; Yuan, W.; Zhang, Z.; Ning, J. pH indicator-based sensor array in combination with hyperspectral imaging for intelligent evaluation of withering degree during processing of black tea. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2022, 271, 120959. [Google Scholar] [CrossRef]
- Ren, G.; Zhang, X.; Wu, R.; Zhang, X.; Xie, T.; Zhang, Z. Digital depiction of the quality of Dianhong black tea based on pocket-sized near infrared spectroscopy. Infrared Phys. Technol. 2022, 127, 104418. [Google Scholar] [CrossRef]
- Jia, J.; Zhou, X.; Li, Y.; Wang, M.; Liu, Z.; Dong, C. Establishment of a rapid detection model for the sensory quality and components of Yuezhou Longjing tea using near-infrared spectroscopy. LWT-Food Sci. Technol. 2022, 164, 113625. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Number of Variables | Best Cost | Selected Variables |
|---|---|---|---|
| ACO | 12 | 0.0665 | 957.03 nm, 977.51 nm, 1004.20 nm, 1024.41 nm, 1286.39 nm,1332.25 nm, 1485.71 nm, 1492.12 nm, 1544.94 nm, 1574.00 nm, astringent aftertaste, umami |
| PSO | 15 | 0.0411 | 985.16 nm, 1013.06 nm, 1063.20 nm, 1066.93 nm, 1164.82 nm, 1176.84 nm, 1201.94 nm, 1210.26 nm, 1395.17 nm, 1599.64 nm, 1634.02 nm, bitter aftertaste, astringent aftertaste, umami, saltiness |
| GWO | 83 | 0.0084 | 953.17 nm, 964.72 nm, 973.68 nm, 981.33 nm, 985.16 nm, 996.60 nm, 1020.63 nm, 1024.41 nm, 1039.48 nm, 1051.98 nm, 1059.46 nm, 1070.65 nm, 1074.38 nm, 1085.51 nm, 1108.90 nm, 1146.70 nm, 1150.33 nm, 1161.21 nm, 1180.44 nm, 1198.37 nm, 1206.70 nm, 1224.46 nm, 1238.60 nm, 1257.35 nm, 1264.34 nm, 1274.81 nm, 1278.29 nm, 1282.92 nm, 1293.32 nm, 1318.57 nm, 1321.99 nm, 1325.42 nm, 1332.25 nm, 1335.66 nm, 1342.46 nm, 1353.77 nm, 1367.27 nm, 1373.99 nm, 1380.70 nm, 1387.39 nm, 1395.17 nm, 1398.50 nm, 1408.47 nm, 1418.39 nm, 1426.08 nm, 1435.93 nm, 1442.48 nm, 1445.75 nm, 1449.02 nm, 1452.27 nm, 1458.78 nm, 1463.11 nm, 1469.59 nm, 1476.05 nm, 1479.27 nm, 1485.71 nm, 1496.39 nm, 1499.59 nm, 1505.97 nm, 1512.33 nm, 1515.51 nm, 1525.01 nm, 1551.20 nm, 1554.32 nm, 1557.44 nm, 1560.56 nm, 1567.81 nm, 1570.91 nm, 1580.18 nm, 1583.26 nm, 1596.58 nm, 1599.64 nm, 1602.69 nm, 1614.87 nm, 1631.01 nm, 1634.02 nm, 1640.03 nm, sourness, astringency, bitter aftertaste, astringent aftertaste, umami, richness |
| NSGA−II | 52 | 0.0509 | 960.88 nm, 969.84 nm, 992.79 nm, 996.60 nm, 1024.41 nm, 1035.71 nm, 1070.65 nm, 1074.38 nm, 1078.09 nm, 1108.90 nm, 1112.58 nm, 1116.25 nm, 1128.47 nm, 1132.12 nm, 1135.77 nm, 1150.33 nm, 1169.64 nm, 1194.79 nm, 1213.82 nm, 1235.07 nm, 1238.60 nm, 1246.82 nm, 1250.33 nm, 1325.42 nm, 1339.06 nm, 1353.77 nm, 1363.90 nm, 1391.84 nm, 1418.39 nm, 1429.37 nm, 1432.65 nm, 1435.93 nm, 1442.48 nm, 1445.75 nm, 1449.02 nm, 1472.82 nm, 1488.92 nm, 1541.81 nm, 1554.32 nm, 1570.91 nm, 1589.42 nm, 1596.58 nm, 1605.74 nm, 1611.83 nm, 1617.91 nm, 1620.94 nm, 1623.97 nm, sourness, bitter aftertaste, astringent aftertaste, umami, sweetness |
| Data | Model | Parameters | CCR/% | |||
|---|---|---|---|---|---|---|
| Calibration Set | Prediction Set | |||||
| ET | ELM | nn a = 45 | 358/467 | 76.66 | 178/233 | 76.39 |
| KNN | PCs = 4, K = 1 | 408/467 | 87.37 | 201/233 | 86.27 | |
| SVM | c = 16, g = 5.66 | 422/467 | 90.36 | 210/233 | 90.13 | |
| NIR | ELM | nn a = 38 | 328/467 | 70.24 | 150/233 | 64.38 |
| KNN | PCs = 3 K = 3 | 333/467 | 71.31 | 152/233 | 65.24 | |
| SVM | c = 16, g = 0.062 | 425/467 | 91.01 | 198/233 | 84.98 | |
| Low−level Fused data | ELM | nn a = 97 | 376/467 | 80.51 | 185/233 | 79.40 |
| KNN | PCs = 6, K = 5 | 370/467 | 79.23 | 182/233 | 78.11 | |
| SVM | c = 16, g = 0.062 | 455/467 | 97.43 | 215/233 | 92.27 | |
| Model | Parameters | CCR/% | |||
|---|---|---|---|---|---|
| Calibration Set | Prediction Set | ||||
| GWO−ELM | nn a = 73 | 397/467 | 85.01 | 196/233 | 84.12 |
| GWO−KNN | PCs = 5, K = 3 | 408/467 | 87.37 | 203/233 | 87.12 |
| GWO−SVM | c = 16, g = 0.25 | 450/467 | 96.36 | 216/233 | 92.70 |
| ACO−ELM | nn a = 83 | 398/467 | 85.22 | 197/233 | 84.55 |
| ACO−KNN | PCs = 9, K = 7 | 421/467 | 90.15 | 210/233 | 90.13 |
| ACO−SVM | c = 16, g = 0.70 | 448/467 | 95.93 | 218/233 | 93.56 |
| PSO−ELM | nn a = 97 | 386/467 | 82.66 | 189/233 | 81.12 |
| PSO−KNN | PCs = 8, K = 7 | 421/467 | 90.15 | 208/233 | 89.27 |
| PSO−SVM | c = 11.31, g = 2.83 | 440/467 | 94.22 | 217/233 | 93.13 |
| NSGA−II−ELM | nn a = 73 | 394/467 | 84.37 | 195/233 | 83.69 |
| NSGA−II−KNN | PCs = 6, K = 5 | 412/467 | 88.22 | 205/233 | 87.98 |
| NSGA−II−SVM | c = 16, g = 0.35 | 455/467 | 97.43 | 216/233 | 92.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, G.; Zhang, X.; Wu, R.; Yin, L.; Hu, W.; Zhang, Z. Rapid Characterization of Black Tea Taste Quality Using Miniature NIR Spectroscopy and Electronic Tongue Sensors. Biosensors 2023, 13, 92. https://doi.org/10.3390/bios13010092
Ren G, Zhang X, Wu R, Yin L, Hu W, Zhang Z. Rapid Characterization of Black Tea Taste Quality Using Miniature NIR Spectroscopy and Electronic Tongue Sensors. Biosensors. 2023; 13(1):92. https://doi.org/10.3390/bios13010092
Chicago/Turabian StyleRen, Guangxin, Xusheng Zhang, Rui Wu, Lingling Yin, Wenyan Hu, and Zhengzhu Zhang. 2023. "Rapid Characterization of Black Tea Taste Quality Using Miniature NIR Spectroscopy and Electronic Tongue Sensors" Biosensors 13, no. 1: 92. https://doi.org/10.3390/bios13010092
APA StyleRen, G., Zhang, X., Wu, R., Yin, L., Hu, W., & Zhang, Z. (2023). Rapid Characterization of Black Tea Taste Quality Using Miniature NIR Spectroscopy and Electronic Tongue Sensors. Biosensors, 13(1), 92. https://doi.org/10.3390/bios13010092