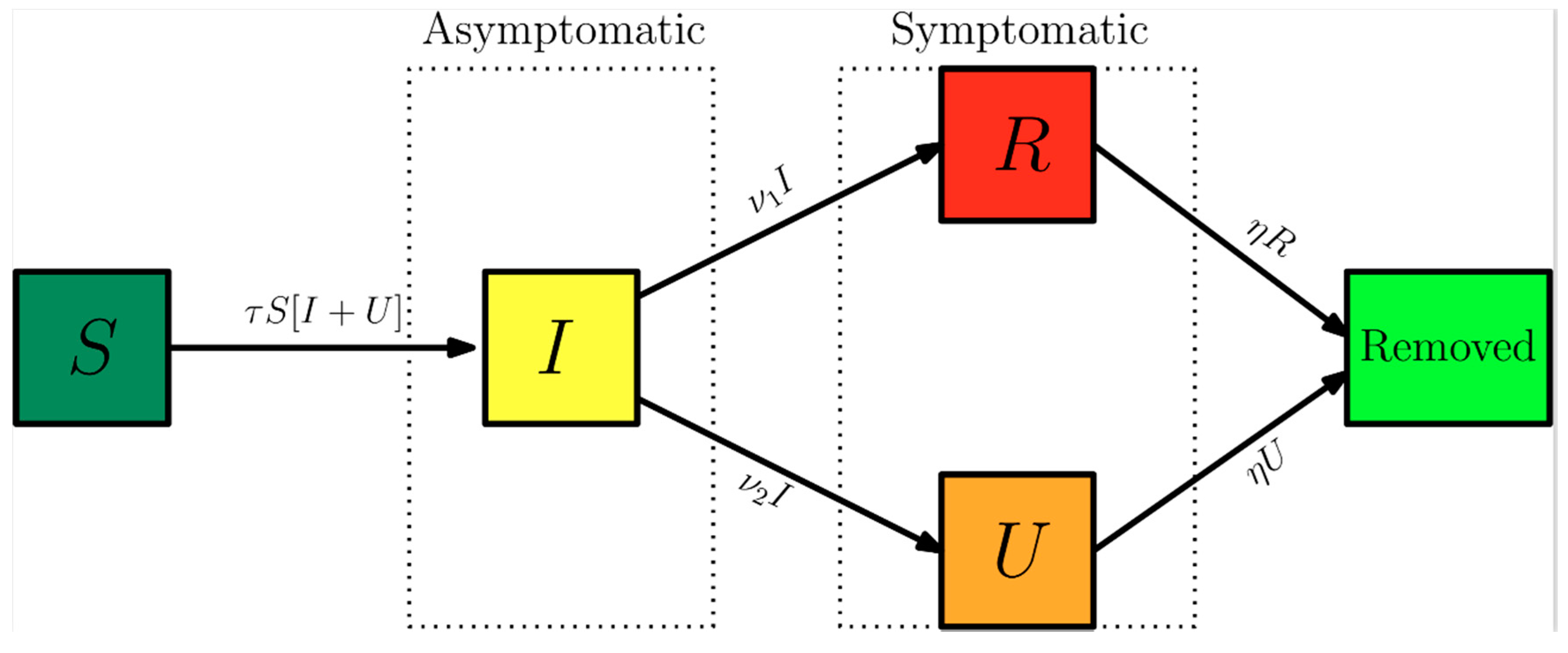
4.1. Model Validation: China
Before proceeding to the analysis of the COVID-19 epidemy evolution within Brazil, the proposed direct-inverse problem analysis approach is validated. In this sense, due to the availability of the earliest dataset on this pandemic, we have chosen to use the information from China in terms of the accumulated reported infectious cases. The data for China was extracted from Reference [
6], complemented by the more recent data from Reference [
25] from 1 January up to 17 April 2020. The exponential fit for the early phase of the China CR(t) dataset provided the estimates of the three parameters,
from which we have estimated
. The remaining data for the initial conditions,
, and the early stage transmission rate,
, are in fact recalculated from within the MCMC algorithm, since the changing values of
f will affect them, according to Equation (7c–e). The average times in the model were first taken as 1/
ν = 7 and 1/
η = 7 days and the isolation measures were taken at
n = 25 days [
6]. First, experimental data from China from the period of 19 January up to 17 February was employed in demonstrating the estimation of three parameters,
assuming there is no significant time variation in the function
f(
t) (
). In the absence of more informative priors, uniform distributions were employed for all three parameters under estimation.
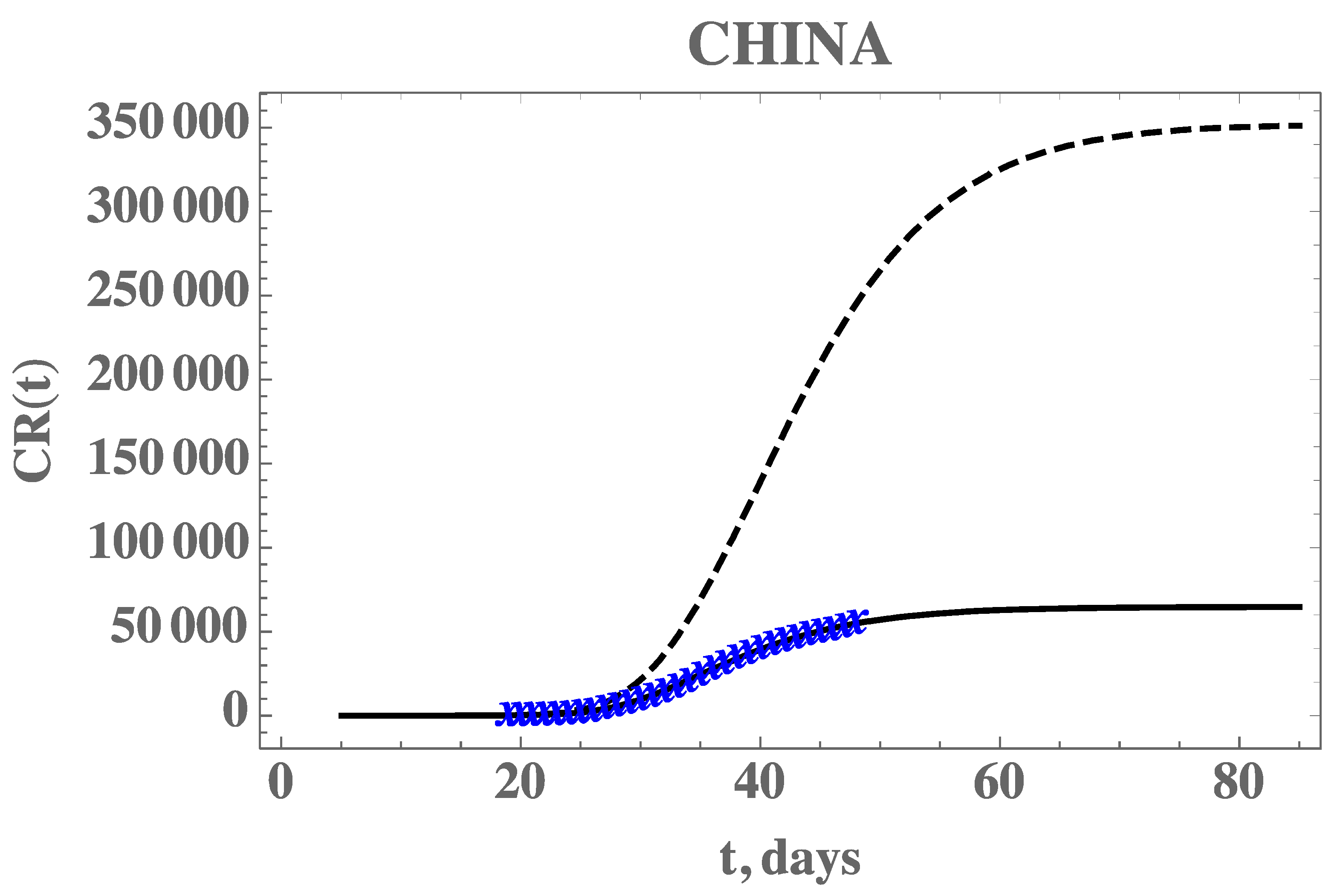
Table 2 presents the prior information and the initial guesses for the parameters. If the initial guesses were used to predict the CR(t) behavior, a marked over-estimation of the accumulated reported infected individuals would occur, especially in the long term, as can be noticed in
Figure 2, confirming the need for a proper parameter estimation, as will be shown.
The central tendency (mean value) of the posteriors here sampled, after neglecting the first 20,000 burning in states of the chain, are called the estimated values. Both the estimated values and their 99% confidence intervals are presented in
Table 3. It should be mentioned that these values are fairly close to those employed in Reference [
6], where τ
0 was estimated as 4.51 × 10
−8. Once a value of
f0 = 0.8 was assumed, which means that 20% of symptomatic infectious cases go unreported, it led to a good agreement with the data by taking
μ = 0.139 in Reference [
6].
Figure 2 also demonstrates the adherence of the model with the data within this portion of the dataset, once the estimated values in
Table 3 are employed in the forward problem solution, as can be seen from the excellent agreement between the estimated CR(t) (solid line) and the experimental data from China (blue stars). The desired model validation is illustrated in
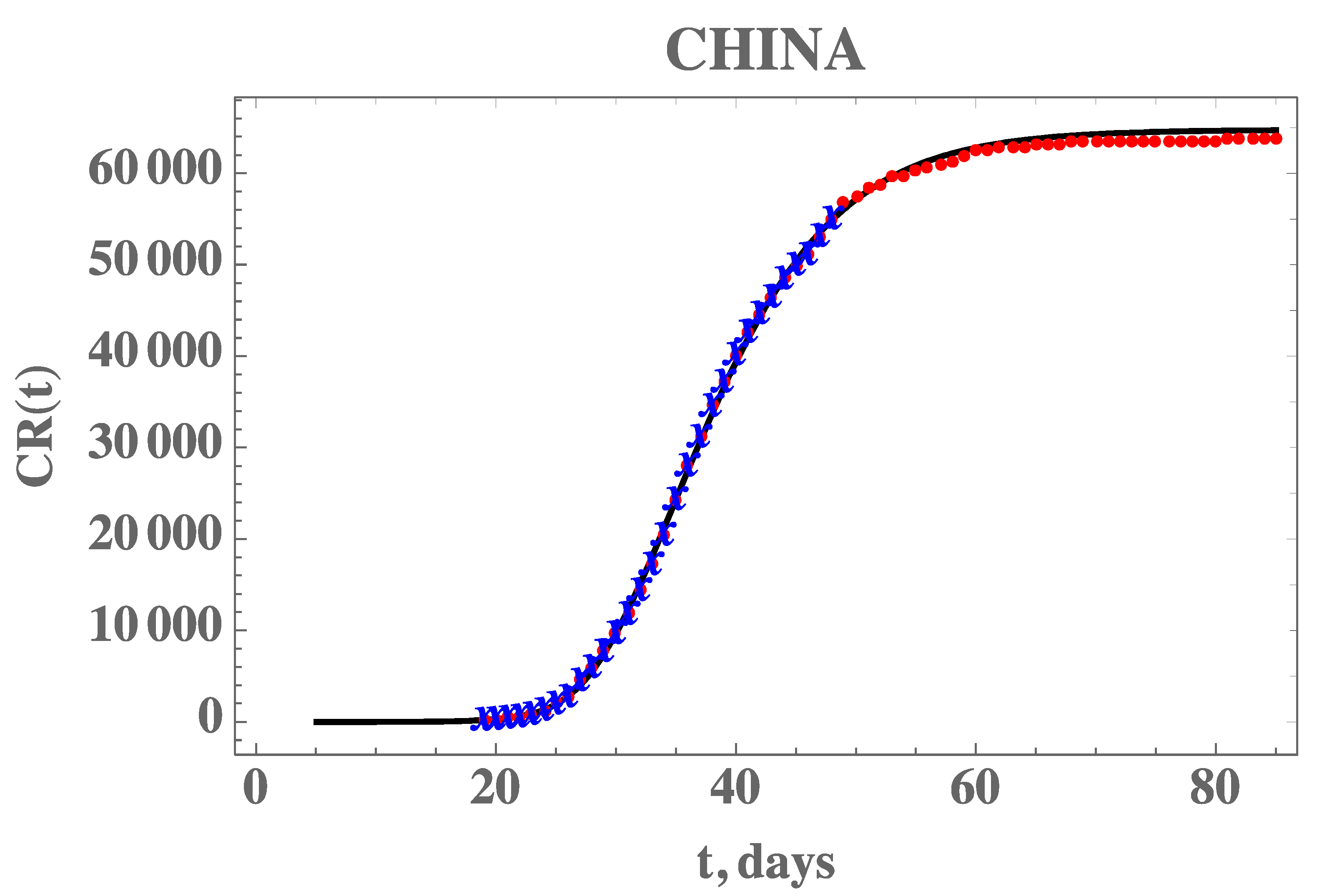
Figure 3, confirming the excellent agreement of China’s full dataset (period from 19 January until 16 April) with the mathematical model predictions, after adopting the estimated values for the parameters in
Table 3. It should be recalled that non-informative priors were adopted for the three parameters, as presented in
Table 2, and except for the transmission rate, when Equation (7e) provides an excellent initial guess, the remaining guesses were completely arbitrary. A uniform prior means that all possible values, in the specified limits, are equally likely to be sampled, i.e., no prior information can be distinguished among possible values.
Although the presently estimated parameters have led to a good prediction of the second phase of the China epidemy evolution data, there are still uncertainties associated with the average times here assumed both equal to seven days, according to Reference [
6]. This choice was based on early observations of the infected asymptomatic and symptomatic patients in Wuhan, but more recent studies have been refining the information on the epidemy evolution and the disease itself, such as in References [
26,
27,
28]. For this reason, we have also implemented a statistical inverse analysis with the full dataset of China, but now seeking the estimation of five parameters, to simultaneously estimate the average times (1/
ν and 1/
η). Both uniform and Gaussian distributions were adopted for the two new parameters, with initial guesses of 1/
ν = 7 days and 1/
η = 7 days, and
n = 25 days, as employed in Reference [
6].
Table 4 presents the prior information and the initial guesses for the parameters.
Table 5 provides the estimated values and 99% confidence intervals for all five parameters, with Gaussian priors for the two average times with data obtained from References [
26,
27,
28], after neglecting the first 15,000 burning in states of the chain. The most affected parameter in comparison with the previous estimates is the average time 1/η, which is also the one with the widest confidence interval. This behavior is also evident from the Markov chains for this parameter, now simultaneously estimated.
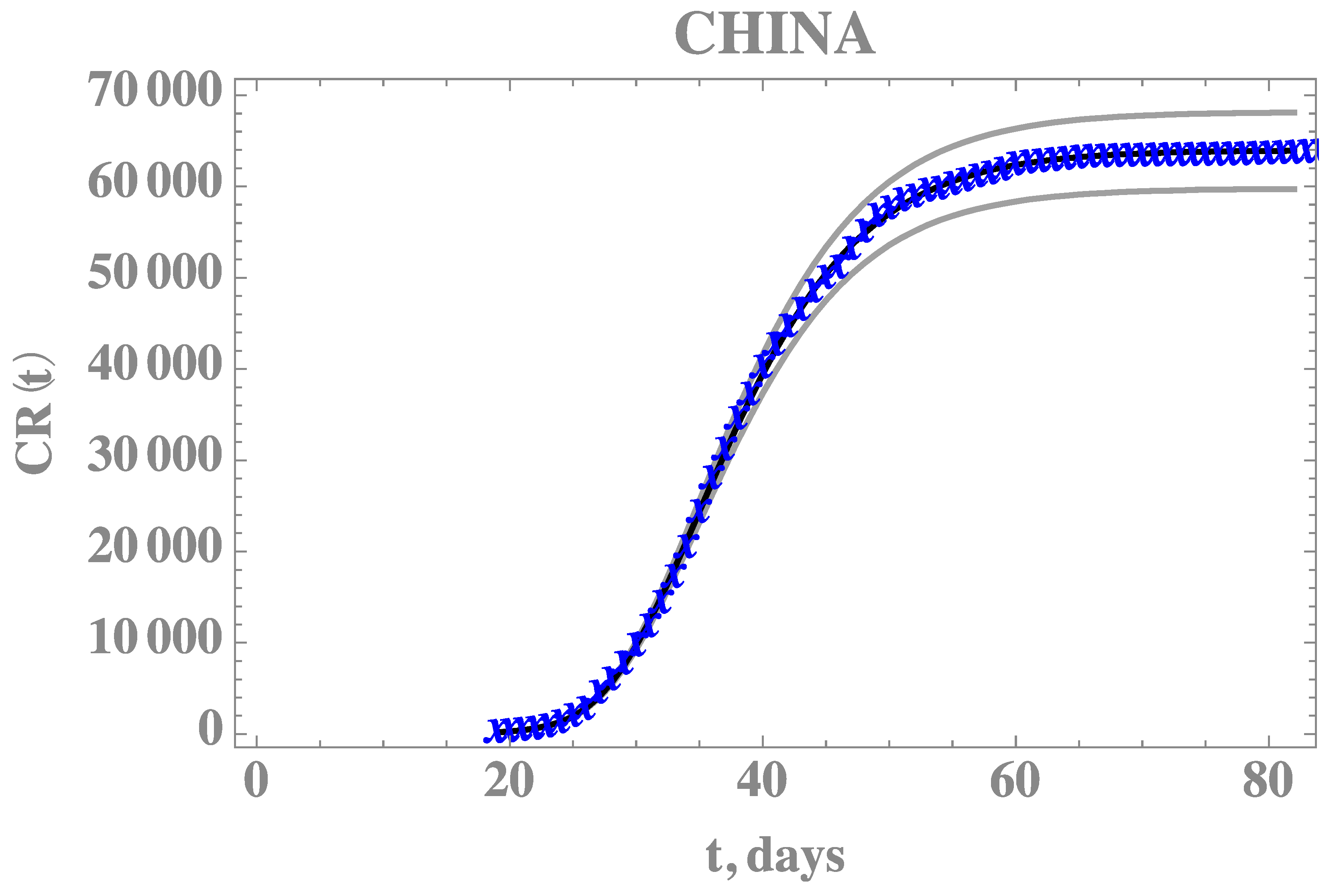
Figure 4 compares the theoretical predictions with the model incorporating the five estimated parameters as in
Table 5, against the full CR(t) dataset for China, confirming the improved agreement. The 99% confidence interval bounds for this predicted behavior is also shown in
Figure 4, bounded by the grey lines.
4.2. Model Application: Brazil
The CR(t) data for the accumulated reported infectious in Brazil, from 25 February (day 1), when the first infected individual was reported, up to 29 June (day 127), is presented in
Appendix A. Similarly to the previous example with the data from China, a portion of the available data on accumulated reported infectious was employed in the estimation of model parameters, up to 29 March (day 35), when the present study was initiated. Then, a second portion of the data, from 30 March (day 36) up to 23 April (day 60), was utilized in verifying this first constructed model.
Following the hybrid procedure described above, the exponential phase of the evolution was first fitted, taking the data from day 10 to 25, yielding the estimates of the three parameters,
from which we have estimated
. The remaining data for the initial conditions,
, and the early stage transmission rate,
, are in fact recalculated from within the MCMC algorithm, since the changing values of
will affect them, according to Equation (7c–e). The average times in the model were taken as 1/
ν = 6.20798 days and 1/
η = 11.2784 days, which were obtained from the MCMC simulation on the full dataset for China (
Table 5), as discussed in the previous section.
The Brazilian states governments took isolation measures starting on n = 21 days, which was enforced by most states and municipalities throughout the country within a few days. Moreover, there were initially only 30,000 exam kits available, and an additional 30,000 were later acquired. However, until mid-April at least, the resulting rather small ration of testing per million inhabitants in Brazil and the retardation in the exam results confirmation, due to a centralized operation, has caused a perceptible change in the data structure for the reported infectious cases, which can only be represented by a time-varying function f(t). The progressive reduction on the number of executed exams of the symptomatic individuals and the delay of the results availability, has certainly affected the partition of reported to unreported cases by the end of this period covered by the dataset for this first stage. Therefore, the more general model, including the time variation of the partition f(t), and Equation (4c,d), was here implemented for a more refined inverse problem analysis. It is then expected that a reduction on the f value can be identified (), with an abrupt variation on the exponential behavior, here assumed as a sharp, functional time dependence (large ). Therefore, a statistical inverse problem analysis is undertaken, this time for estimating five parameters, namely, (Case 3—BR5p) aimed at enhancing the overall agreement with the CR(t) data behavior, with a likely reduction on the partition of the reported and unreported infectious cases.
With uniform distributions for all five parameters, guided by the previous estimates for the first three parameters, and arbitrary guesses for
, the prior distributions and initial guesses for the five parameters are presented in
Table 6 and the five estimated quantities, after neglecting the first 80,000 burning in states of the chain are shown in
Table 7, together with the 99% confidence interval for each parameter.
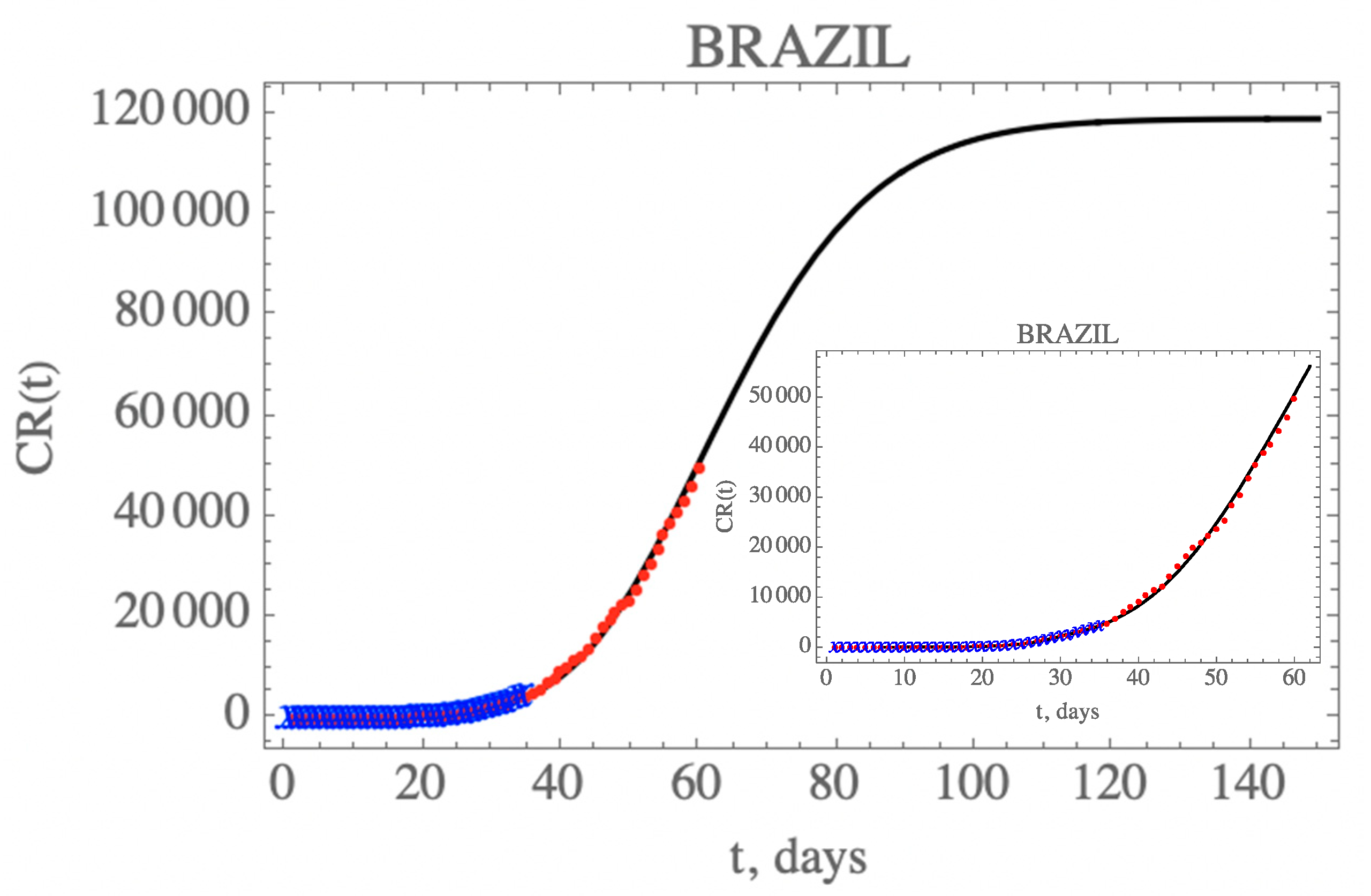
Figure 5 presents the predicted evolution of the accumulated reported infectious cases in Brazil, CR(t), from 25 February up to day 150, plotted as the solid black line. Also shown in this figure are the blue crosses in the first portion of the available data, up to 29 March, which were employed in the estimation of the parameters in
Table 7, that compose this initial model. In addition, the red dots represent the second portion of the available data from 30 March until 23 April (day 60), that were not employed in the parametric estimation, but were saved for model validation. It is clear that the built model has an excellent predictive feature, reproducing the epidemy evolution up to the end of the reserved data for validation (up to day 60), with a relative error below 5.8% during this first phase of the epidemy evolution.
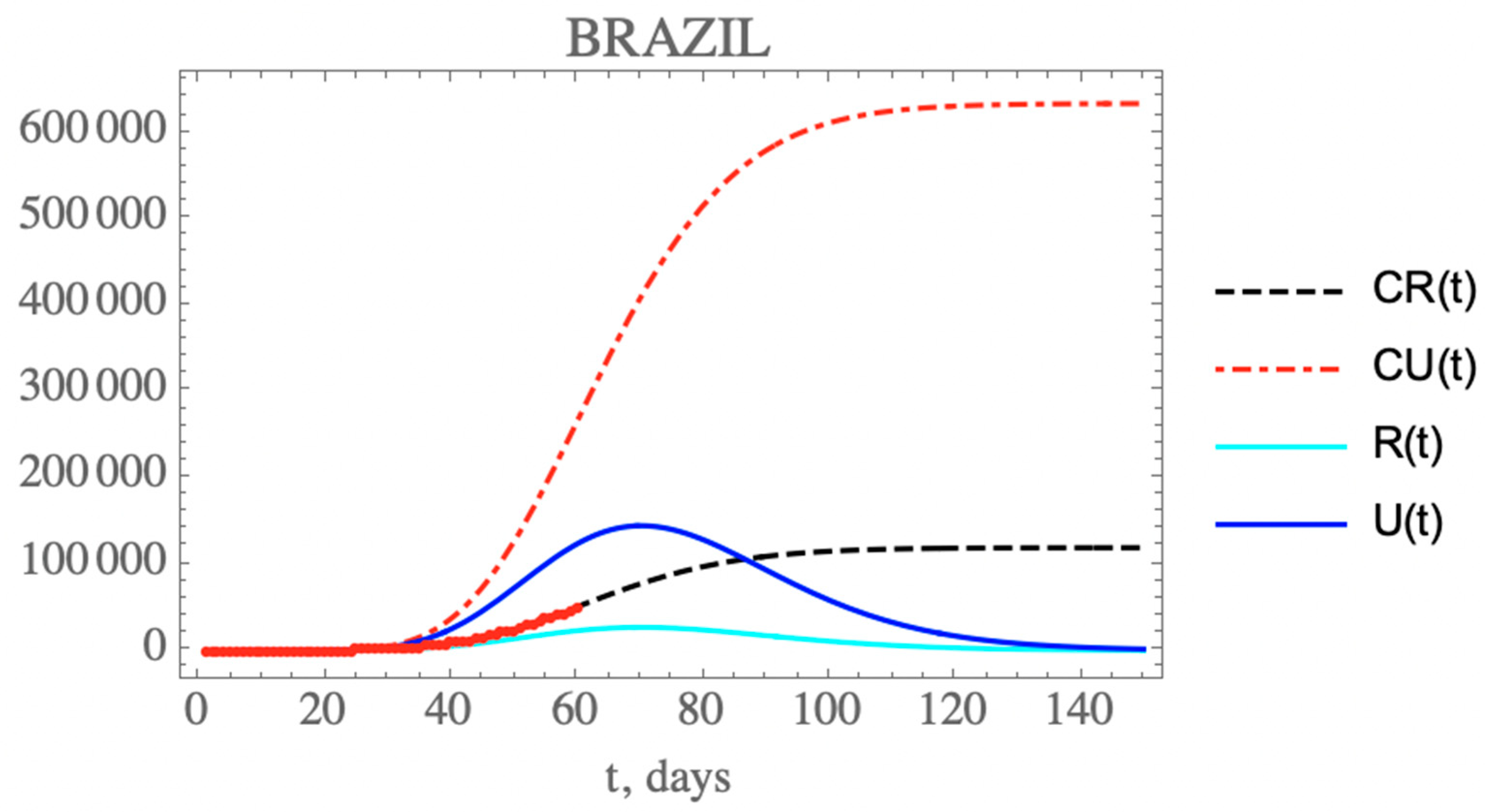
One can see the marked reduction on the
f(
t) parameter from the estimates in
Table 7, which results in the increase of the unreported to reported infectious cases, as is shown in
Figure 6 for CR(t) and CU(t) predictions up to 150 days. Clearly, the reduction on the testing, and thus, on the isolation of reported infectious individuals, leads to an increase on the total number of infected symptomatic individuals after 150 days (752,888 cases), including unreported (633,698) and reported cases (119,190). Both the reported and unreported infectious individual curves, R(t) and U(t), show a peak at around the 70th day (3 May). Naturally, these projections are inherently assuming that no new interventions or changes in public health would occur from day 35 on, including circulation alterations and more intensive testing, or otherwise, the estimated parameters would not represent such a new phenomenological situation.
The initial phase estimation was repeated, starting with the first 35 data points, and successively implementing another extra 10 points, up to 55 data points. The final behavior of the reported cases to the graphical scale remains essentially the same, reproducing quite well the remaining available data up to around day 65. Therefore, the essential phenomenological characteristics of this initial phase are captured by the adopted 35 points estimates, and was basically confirmed by increasing the number of considered data points. As will be shown in what follows, though this initially constructed model led to an accurate prediction of the actual epidemy evolution even up to around day 65, the data for accumulated reported cases started detaching from the theoretical curve after this period, yielding much higher values after a few weeks. For this reason, it is crucial to implement a scenarios analysis to anticipate such a behavior, based on likely measures or unplanned changes in public health, as will be discussed in the next section.
4.3. Scenarios Analyses: Brazil
Next, the model constructed with this initial parametric estimation is employed in the prediction of the COVID-19 evolution in Brazil under different hypothesis. By the end of this initial period of 60 days, though the proposed model with parameters estimated from the data up to day 35 gave very good predictions, it was already evident that the circulation in the country, as observed from the COVID-19 mobility reports made available [
29,
30], was progressively increasing in comparison to the first few weeks after the isolation measures, with respect to workplaces and groceries/pharmacies, especially associated with private vehicles and pedestrian circulation. This tendency becomes more evident after the Easter holiday, corresponding to day 50 onward, and it could be expected that a reduction on the transmissivity attenuation factor would result. Besides, the first set of 500,000 testing kits from a planned amount of 10 million [
31], finally arrived in Brazil by day 60, with an expected impact on increasing the partition factor, and thus, on increasing the number of reported cases with respect to unreported ones, in the following days. Thus, the prospective scenarios here proposed are aimed at interpreting the epidemy evolution as a result of these two alterations in public health.
Five scenarios were here explored: (i) This is the base case above proposed, assuming that the initial public health interventions remain effective, with the same transmission rate decay due to isolation and the same low partition parameter identified through the first 35 data points; (ii) due to the progressive reduction on part of the circulation modes, a reduction on the transmission rate decay parameter is implemented after day 50, but maintaining the same testing capability as before; (iii) the same reduction on the transmission rate decay parameter of the previous scenario is kept, but now with an increase in the partition coefficient representing an enhanced testing capability starting at day 64; (iv) the transmission rate decay parameter is further reduced, to explore the influence of further circulation increase, while keeping the same fraction of reported cases of the previous scenario, through a more intensive testing; (v) a combination of interventions leading to further increasing the transmission rate by reducing the decay parameter, but simultaneously further increasing the conversion factor of unreported to reported cases with respect to the initially estimated value, f0.
Table 8 summarizes both the fixed and variable parameter values adopted for these five scenarios. The additional public health interventions simulated in the above scenarios act on either the time variation of the transmission coefficient or on the reported to unreported partition coefficient. The parametric changes are assumed to start at chosen dates further ahead of the initial set of data (day 35), in the present case t = 50 and 64 days (
N2 = 50;
Nf2 = 64), respectively, for acting on the coefficients,
and
according to the following parametrizations:
with
with
In the first scenario, it is assumed that no additional public health interventions are implemented, other than those already reflected by the data up to 29 March (day 35), which would then be fully maintained throughout the control period, and the epidemy should evolve from that date, under the parameters above identified.
Figure 5 has already shown the evolution of the accumulated and instantaneous reported, CR(t) and R(t), unreported, CU(t) and U(t), infectious individuals, up to 150 days. Due to the fairly low value of
f(
t) starting with
and dropping to
in light of the fairly low number of PCR kits made available and other implementation difficulties during this initial phase, the accumulated number of reported infectious cases is quite low with respect to the unreported ones, as already discussed. No predictions on casualties are here proposed, since these are highly dependent on age structure, social-economic conditions, and health system response. It should be recalled that this initial period of 35 days reflects the strict initial quarantine that was applied at least at the most affected regions, starting in day 21, which is confirmed through the global mobility reports [
29,
30]. However, these are ideal conditions that would be rather unlikely to be enforced for a much longer period, due to the sociological and economic characteristics of the country. As will be discussed more closely in what follows, the available mobility reports later on made available have in fact clearly indicated that especially after the Easter holiday weekend (day 50 and on), the circulation was progressively increased in average terms within the country, despite the quarantine measures retained by most of the federation states.
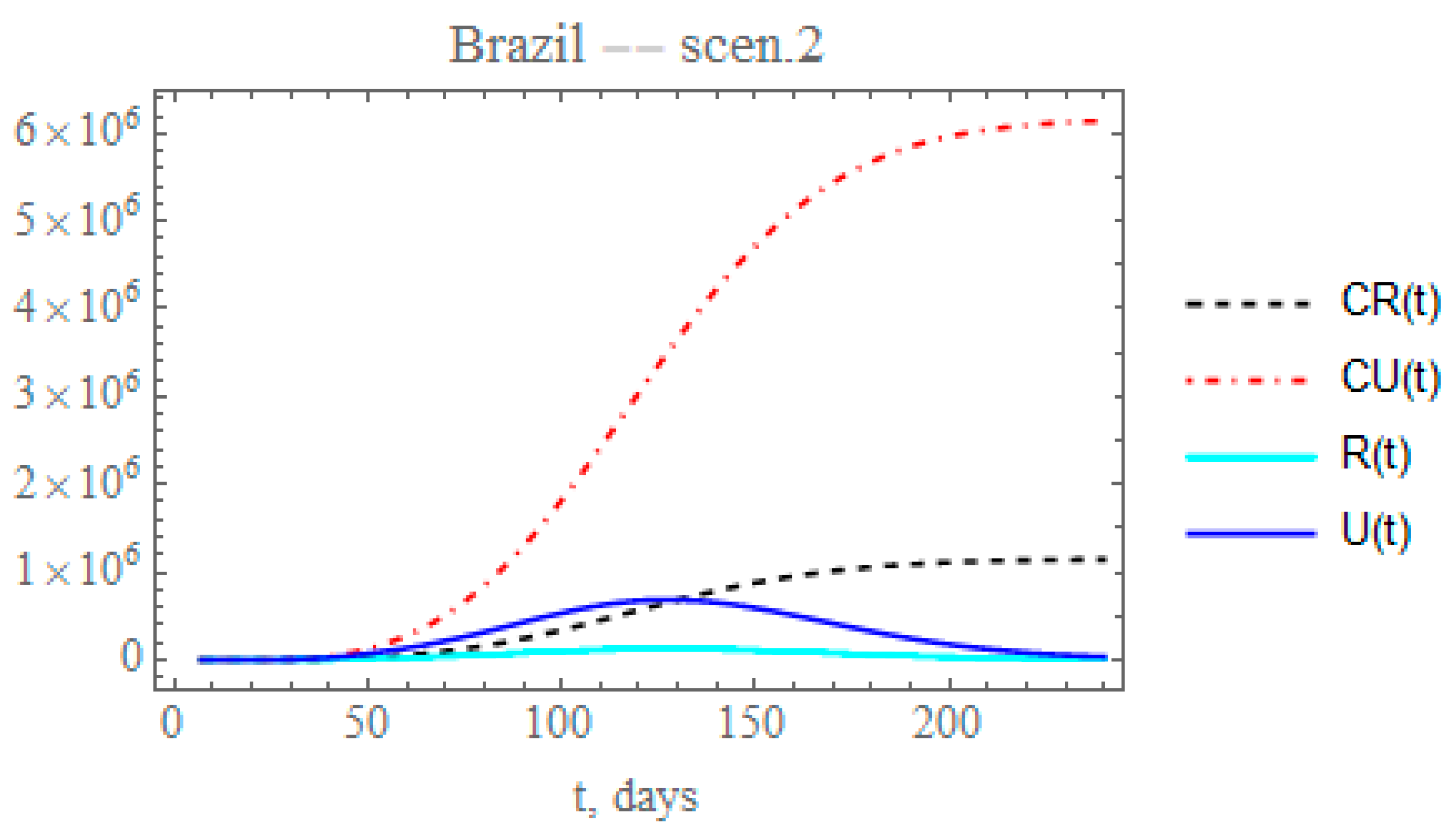
Therefore, the second scenario explores the implementation of a reduced decay of the transmission rate by assuming, after day
N2 = 50 (Equation (10c)), that the value of
here identified could be reduced by a factor of 0.2, thus around
= 0.007793. The time variable transmission rate is then computed from Equation (12c) after t >
N2. The changes in the accumulated reported and unreported cases, as shown in
Figure 7, are quite significant. The predicted number of unreported symptomatic infectious cases is now much higher reaching after 240 days around 6.14454 × 10
6 individuals, while the reported cases would reach 1.1436 × 10
6 individuals, with a total of 7.28814 × 10
6 symptomatic infected individuals and an impressive difference between reported and unreported cases, due to the maintained low value of
.
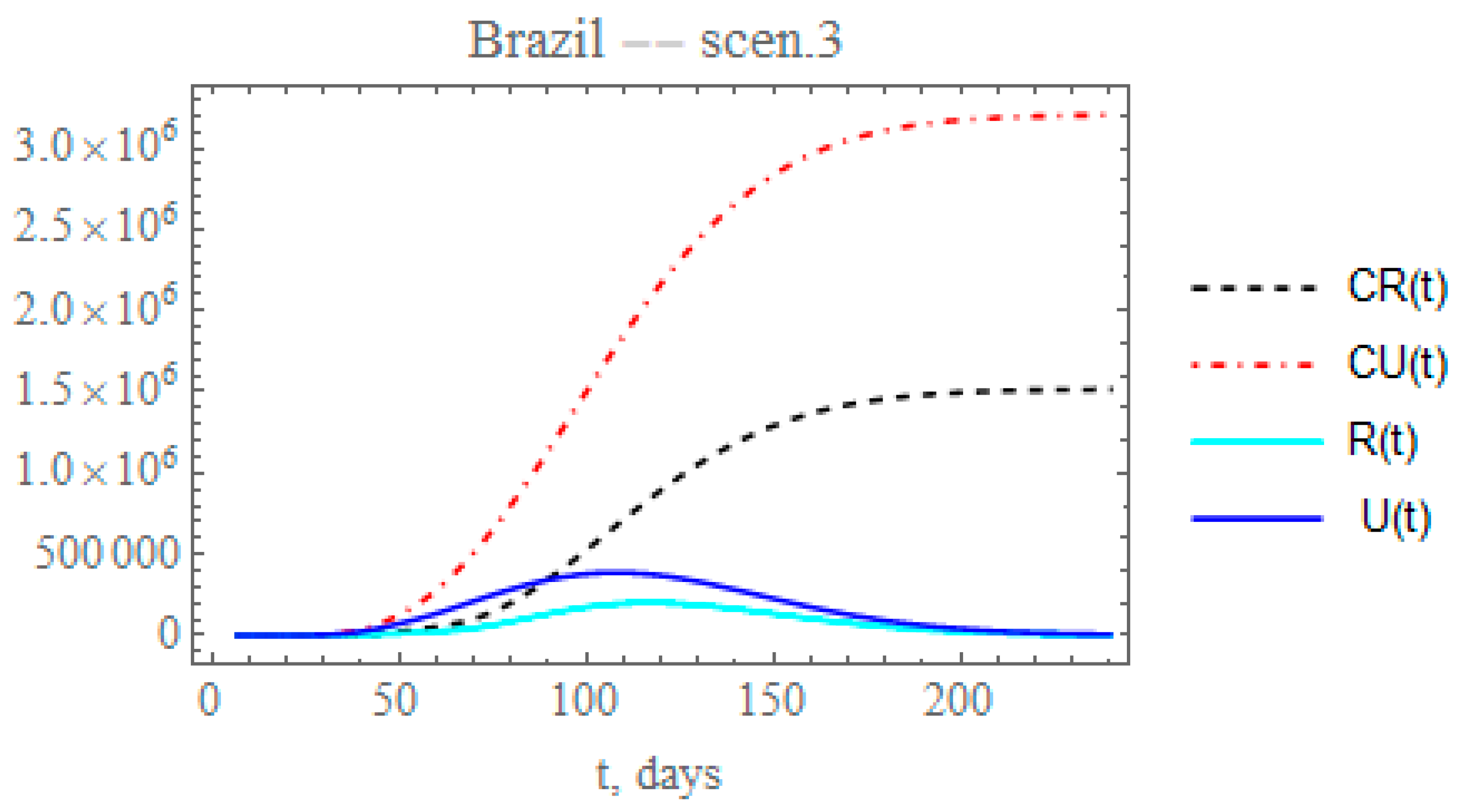
Though the reduced decay of the transmission rate shows a more realistic picture of the epidemy evolution after day 60, it is known from the Brazilian Ministry of Health site [
31] that the PCR testing was markedly intensified after around day 60, corresponding to a total of about 3,820,000 applied tests by 26 June, and continuously increasing, as opposed to only 60,000 tests applied in the initial phase of the epidemy. Therefore, a more realistic picture of the ratio of reported to unreported cases is achieved by simultaneously increasing the partition factor. Through the third scenario, one can predict the consequences of reducing the exponential parameter that affects transmission rate, as in the previous scenario, and increasing by 25% the partition with respect to the initial factor (
). This is simulated here by progressively increasing the partition factor, starting after day
= 64, taking an exponential parameter of
= 0.05, as expressed by Equation (12g), to allow for a gradual increase in testing. The changes in the accumulated and instantaneous reported and unreported symptomatic cases, as shown in
Figure 8, are even more significant than in the second scenario (ii),
Figure 7. The predicted number of accumulated unreported infectious cases is now reaching after 240 days around 3.2041 × 10
6 individuals, while the reported cases would reach 1.51472 × 10
6 individuals, with a marked decrease to a total of around 4.71882 × 10
6 infectious symptomatic cases with respect to scenario (ii). Besides acting on the transmission rate along time, public health measures may also be effective in reducing the overall epidemic dynamics through the ratio of reported to the unreported infectious case, since the reported cases are, in general, directly isolated, and thus, interrupting the contamination path, as demonstrated in this third scenario, where a marked reduction in the total number of symptomatic infectious individuals from around 7.3 to 4.7 million is observed.
By analyzing the data on the percentual average circulation increase from day 50 to day 120 [
29,
30], assuming that the transmission rate can be approximately parametrized with the circulation, a reduction on the exponential factor of 0.177 could be expected, lower than that proposed in scenario (iii). Therefore, the fourth scenario examines the effect of further reducing the transmission factor coefficient, again starting at day N
2 = 50, by a factor of 0.15, thus around
μ2 = 0.005845. The fraction of reported and unreported infectious cases parameter, again reaches
, starting at
such as in the previous scenario. Therefore,
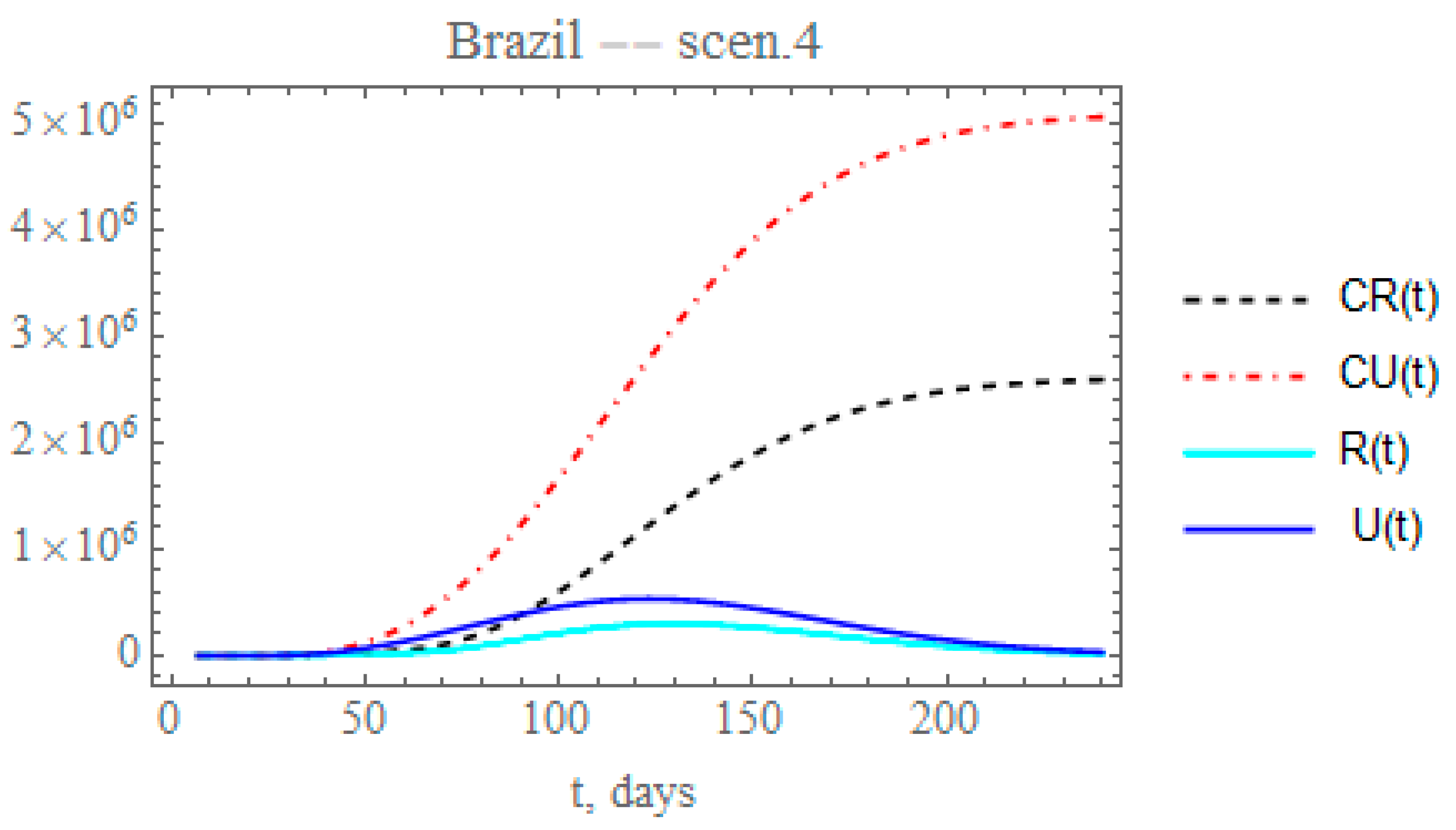
Figure 9 shows the behavior of CR(t), R(t) and CU(t), U(t). The predicted number of unreported infectious cases would now reach, after 240 days, around 5.06029 × 10
6 individuals, while the reported cases should reach 2.5922 × 10
6 individuals, with an also marked reduction to a total of around 7.65249 × 10
6 infectious cases. The predicted total number of infectious cases becomes even higher than that achieved in scenario (ii), illustrating the importance of an accurate estimation of the parameter that governs the temporal attenuation behavior of the transmission factor.
By the time the final revision of this paper was being prepared, different cities and states throughout Brazil were taking partial isolation relaxation measures, while massive testing was being implemented in various locations. In light of the continental dimensions of the country and the fairly heterogeneous and non-simultaneous public health measures, the average overall response to these measures can be analyzed by simultaneously reducing the transmission exponential factor and increasing the maximum partition factor. Therefore, in the fifth scenario, the combination of public health measures affecting both the transmission rate and the conversion factor of unreported to reported cases is analyzed for Brazil. Let us consider that after day N
2 = 50, the partial relaxation of social distancing leads to a reduction of 0.1 on
value previously identified, thus around,
= 0.0038964, and simultaneously increasing the fraction of reported and unreported infectious cases, to provide
, also starting after
with
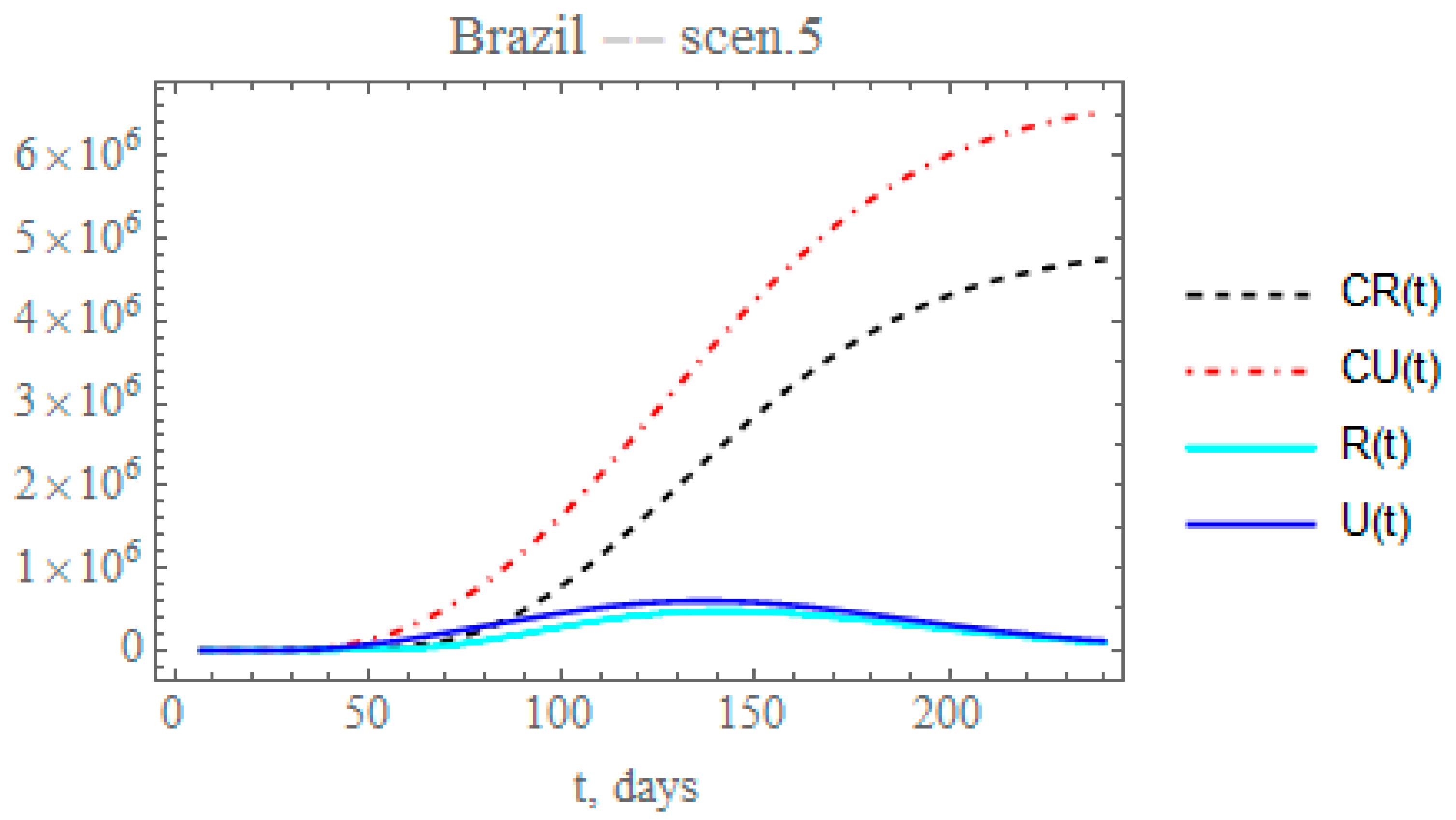
= 0.05. The changes in the accumulated and instantaneous reported and unreported cases are shown in
Figure 10. The predicted number of unreported infectious cases is now reaching after 240 days around 6.5372 × 10
6 individuals, while the reported cases should reach 4.74799 × 10
6 individuals, with a total of 11.2852 × 10
6 infectious symptomatic cases, around 47.5% increase with respect to the previous scenario with lower transmission rates. Again, through the increased testing, a number of mild symptomatic cases were moved from the unreported to the reported cases evolution, thus moved to monitored isolation earlier, with some impact on the contagious chain, as can be observed through the final ratio of reported to unreported cases. In overall terms, the results for scenario (v) are markedly different from those for the previous scenario (iv), thus pointing out the importance of careful control of the social distancing relaxation measures, together with more intensive testing, to avoid such a marked change.
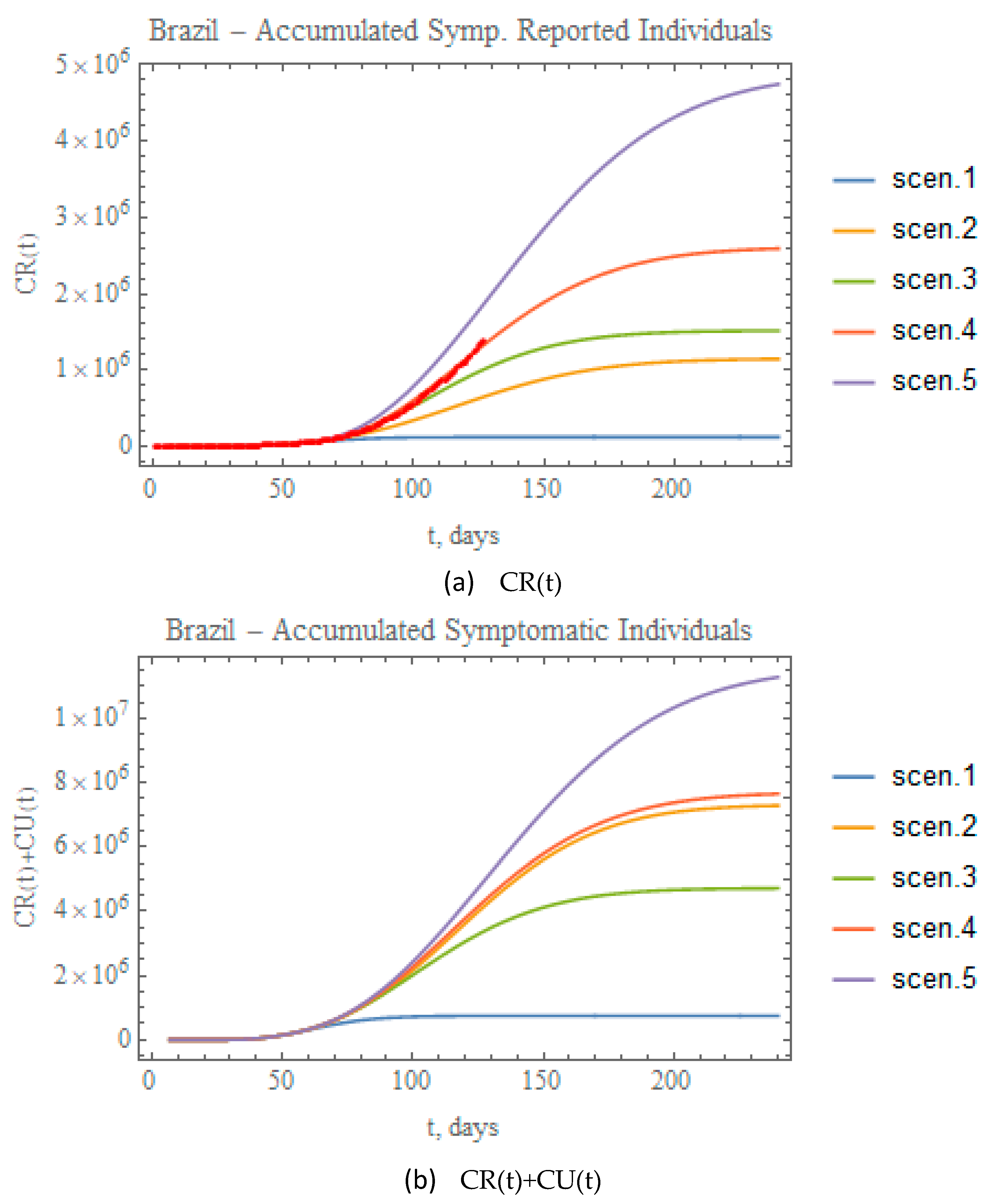
Figure 11a,b combine the data on accumulated reported and total (reported+unreported) infectious symptomatic individuals, respectively, for the predictions provided through the five scenarios here considered. Clearly, scenario (ii), though involving a more mild reduction in transmission rate attenuation coefficient, leads to significant numbers of total symptomatic infectious individuals, close to the values achieved for scenario (iv), essentially due to the fairly low partition factor that was retained in this case. On the other hand, when examining the fairly different total infectious cases curves for scenarios 4 and 5, it is clear that a proper combination of public health interventions, which would involve a more careful control on the relaxation of social distancing and further intensification of testing, should be implemented to achieve final results for scenario (v) closer to (iv), but with less strict circulation restrictions. The red dots in
Figure 11a represent the actual accumulated reported cases data available up to 29 June. Clearly, these results are already closely represented by the conditions proposed for scenario (iv), without any previous parametric estimation. Such observation offers possible initial guesses for the model redefinition that shall be undertaken in the next section, based on the full dataset available at the completion of this work.
4.4. Model Redefinition: Brazil
The first model construction for Brazil in
Section 4.2, employing only the first 35 days of data (up to 29 March) for the parametric estimation task, provided a fairly accurate prediction up to day 65 roughly to within 5% relative error on the accumulated reported cases evolution at this initial stage, which corresponds to the end of April. However, expected alterations on public health measures and behaviors that were initiated in the second half of April, have markedly modified the phenomenological pattern and the corresponding mathematical representation of the epidemy evolution. The scenarios analyzed in the previous section already anticipate the need for a model redefinition through a complementary inverse problem analysis that accounts for the added information from day 36 up to the last data available up to this work completion (day 127). The new parameters to be estimated correspond to those introduced through Equation (10c,d,f,g), not accounted for in the first model proposition and that were varied in the previous scenarios analysis, namely,
,
,
,
, and
. As previously discussed, there is some prior information for the two date parameters,
, based on the fixed values adopted in the scenarios analysis (days 50 and 64, respectively), and therefore, an informative normal priori was employed for these two parameters. For the other three parameters, non-informative uniform priors were employed, with initial guesses provided by scenario (iv) previously discussed.
Table 9 below summarizes the estimated values for the five parameters, together with the corresponding 99% confidence intervals.
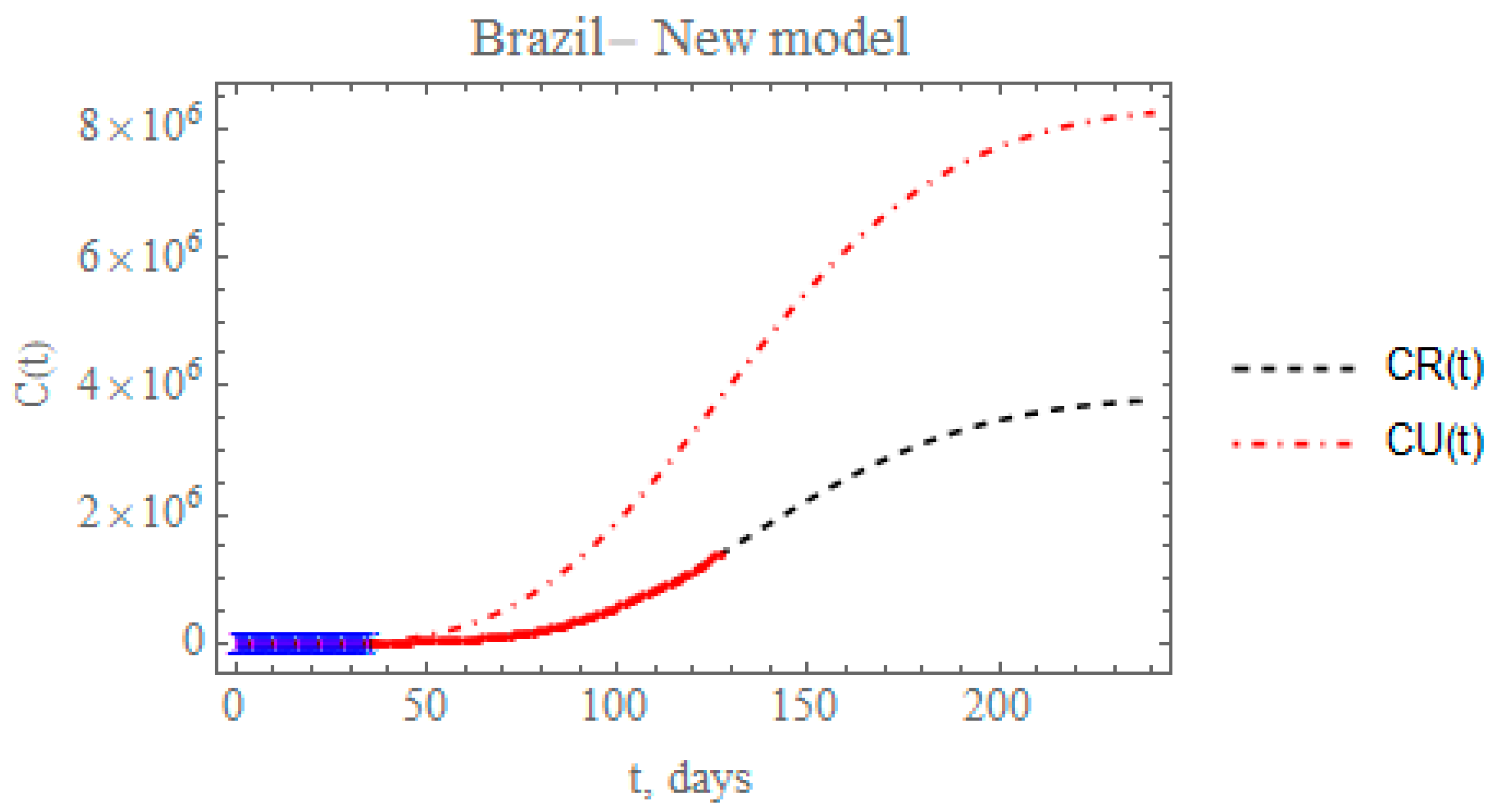
Figure 12 presents the predicted evolution of the accumulated reported and unreported infectious cases in Brazil, CR(t) and CU(t), from 25 February up to day 240, plotted as black and red dashed lines, respectively. Also shown in this figure are the blue crosses in the first portion of the available data, up to 29 March, which were employed in the estimation of the parameters in
Table 7 that compose the initially proposed model. In addition, the red dots represent the second portion of the available data from 30 March until 29 June, that were now employed in the parametric estimation for the additional five parameters in
Table 9. The predicted number of unreported infectious cases is now reaching after 240 days around 8.24397 × 10
6 individuals, while the reported cases reach 3.78342 × 10
6 individuals, with a total of 12.0274 × 10
6 infectious symptomatic cases. From the identified value of the partition factor in
Table 9, which is still well below the value encountered from the China analysis, there is space for further intensification of the testing campaigns throughout Brazil, towards a reduction on the total number of symptomatic infectious individuals in the long term.
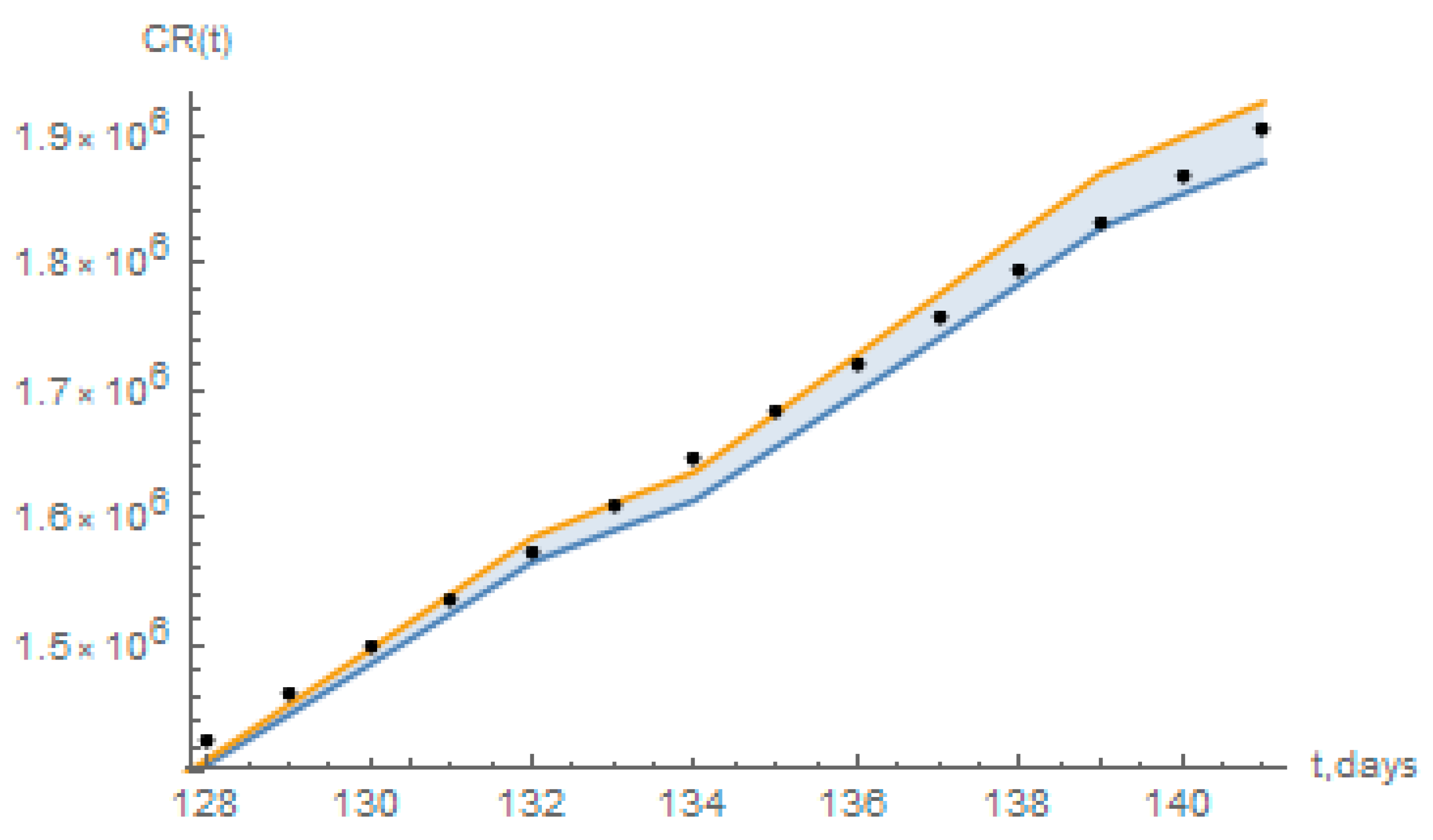
The short term predictions from the redefined model have also been compared to a statistical simulation that employs a basic logistic growth model [
32], essentially based on the data for reported infectious individuals. From the application in Reference [
32] it has been computed from the data up to 29 June, the values of accumulated reported cases estimated from 30 June (day 128) up to 13 July (day 141), with 95% confidence intervals, as shown in
Figure 13 below, together with the predictions of the present redefined model. As can be seen, the present short-term predictions for the days 128 to 141 mostly fall within the 95% confidence interval estimates of the logistic growth model in Reference [
32].
Finally,
Table 10 summarizes the predicted accumulated reported, unreported, and total symptomatic infectious individuals at day t = 240 for each of the five scenarios previously considered and for the redefined model with the full data set for Brazil (
Appendix A). Also shown is the maximum value of the number of instantaneous reported cases, R
max, and the time of its occurrence, t
max. Once more, it is quite evident that the first built model with the initial 35 data points could only capture the phenomenological characteristics of the epidemy up to a certain date (roughly up to day 65, as previously discussed). Then, the combination of circulation augmentation and intensified testing led to a markedly different evolution, later confirmed by the redefined model. The marked differences between these two models are observable through the predicted total number of symptomatic individuals at day 240, varying from around 0.75 million in the first model to 12.03 million in the second one. Moreover, the peaks of the instantaneous reported infectious individuals varied from around day 70 in the first model to about day 147 in the second one. In between these two models, one can observe from
Table 10, the number of accumulated symptomatic individuals at 240 days and the reported infections peaks predictions for the other four scenarios. Again we point out the importance of the intensified testing and the proper isolation of those positively tested in the epidemy evolution control, which is evident in the total number of symptomatic individuals, being much lower for scenario (iii) with respect to (ii), while the peak of reported symptomatic cases is noticeably advanced in time (roughly from day 127 down to day 117).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












