2. Literature Review
The research in this paper is focused on the credit risk model conducted to assess Chinese-listed firms. This section introduces the theoretical development of credit risk models and the application status of default prediction of Chinese-listed firms.
To date, credit risk models fall into three main categories: market implied, structural, and reduced-form models. In this paper, we measure the credit risk of Chinese-listed firms using a reduced-form model. The earliest and best-known reduced-form models were proposed by Altman and Edward [
5] and Beaver William [
6]. Many firm-specific variables are still widely used in the default risk literature today. However, the models only calculate credit scores rather than the PDs at that time. Ohlson [
7] and Zmijewski and Mark [
8] estimated firms’ PDs using regression models, but the default term structures were not considered in their models. Most Contemporary literature considered the prediction horizon of the measurement to be 1 year and did not concern default term structures too. Duffie et al. [
3] exploited the time-series dynamics of the explanatory covariates to estimate probabilities of corporate default over several future periods (quarters or years) and provided a solid theoretical basis for multi-period default risk measurement. Default risk has always been a concern of scholars. Among them, Gredil et al. [
9] studied the ability of ratings and market-based measures to predict defaults. They argue that ratings are more accurate within a year, and that ratings are not redundant in predicting defaults across maturities. Their research ideas and model testing inspired our paper. Luong and Scheule [
10] developed a hybrid model to predict default probability and analyzed the data of US prime mortgages from 2000 to 2016. They found that common borrowers, loan contracts, and external characteristics play an important role in explaining long-term credit risk. Matanda et al. [
11] proposed a new Kealhofer–Merton–Vasicek (KMV) model to estimate bank default risk and verified the new default risk model with cross-sectional financial data from eight commercial banks from several emerging economies in southern Africa. Finally, it was demonstrated that this model has high stability. In terms of the modeling of default intensity, Bu et al. [
12] modeled the default intensity of the company based on the proportional form and rated the enterprise accordingly. This method of modeling the default intensity was instructive for our methodology. Duan et al. [
1] proposed a forward intensity approach that could also produce the term structure of PDs without estimating the high-dimensional state variable process and made the model more stable, robust, and feasible. In order to retain these advantages, we chose the forward intensity approach as a base method and considered both defaults and other exits as in the approach of Duan [
1].
There are fewer studies on the credit risk of Chinese-listed firms than U.S.-listed firms. However, with the growth of China’s economy, the development of Chinese enterprises has attracted worldwide attention and the prediction of Chinese-listed firms’ credit risk has become a focus of study. Zhang et al. [
13] constructed a credit risk assessment model based on the modified KMV model and Copula function from the perspective of China’s automobile supply chain to study the measurement of supply chain finance credit risk. Liu et al. [
14] employed factor analysis and logistic regression analysis to build a mixed model for the bond credit risk assessment of small and medium enterprises (SMEs) with data from 46 SMEs in China. They found that corporate profitability and solvency affect the credit risk of bonds. The logistic model has also been used in many studies to analyze the default of Chinese firms because this model does not make any assumptions about the default probabilities of firms’ and the distribution of sample data. Default probability of firm loans can be obtained through the calculation of the enterprise financial ratio. The prediction effect is good, and it is suitable for the risk assessment of small- and medium-sized enterprises (Ma and Zhou [
15,
16]). Thereafter, Zhang and Deng [
17] and Peng [
18] predicted PDs using factor analysis and the logistic model to overcome the multi-collinearity of selected indicators. Gao et al. [
19] constructed a fusion model using integrating logistic regression, support vector machine, random forest, and ultimate gradient boost to predict the credit risk of SMEs in China. They found that this model is more accurate than a single machine learning algorithm. In addition, Abedin et al. [
20] proposed an extended integration method based on the weighted synthetic minority oversampling technique and collected 3111 records from a Chinese commercial bank to predict the credit risk of small enterprises. They found that the integration model can improve the predictive accuracy ratio by 15.16%. Zhang et al. [
21] argued that the determinants of default risk of Chinese enterprises have not yet been well established. They used a unique dataset of default events in the Chinese market for empirical analysis and demonstrated that the default probability estimated using the widely used structural model could not fully reflect the default risk of Chinese enterprises. Shih et al. [
22] studied the impact of corporate environmental responsibility on the default risk of Chinese-listed companies and found that environmental performance has a strong negative impact on default risk. Liu et al. [
23] found that default risk is positively correlated with expected stock returns in China, and China’s state-owned firms are highly exposed to default. Thereafter, Jing et al. [
24] proposed a hybrid model combining the zero-price probability model with long-term and short-term memory (ZPP-LSTM) to estimate the default probability of Chinese firms and selected relevant data from the construction and real estate industries for their analyses.
As a result of a lack of data, the research on credit risk models for Chinese-listed firms is limited. However, with the large CRI datasets, it is possible to build models to predict actual default. Unlike the aforementioned literature, this paper employs the forward intensity model to predict the future multi-period PDs of firms. We are concerned that Chinese-listed firms have different default tendencies even though their financial positions are similar. The default intensity calculated using the forward intensity model was adjusted using Bayesian estimation and the PDs were re-calculated. We found that the prediction accuracy ratio of our model improved for all prediction horizons. This is of great significance to the credit risk measurement system of Chinese enterprises and the development of the bank credit business.
3. The Forward Intensity Model with Bayesian Estimation
Duffie et al. [
3] employed a doubly stochastic Poisson intensity model to predict corporate defaults by exploiting the dynamics of firm-specific and macroeconomic covariates to estimate the term structures of firms’ PDs. Duan et al. [
1] proposed a forward intensity approach that can be implemented by maximizing a pseudo-likelihood function constructed with overlapping data. Because the function is decomposable for different forward periods, it is able to predict the probabilities of default over multiple periods. This paper is inspired by this premise.
The forward intensity model is a reduced form credit risk model that can compute PDs for a range of horizons by modeling a firm’s default as a Poisson process. The model includes a forward intensity function constructed using different input variables that can be calibrated by maximum pseudo-likelihood estimation on a large sample of firms in an economy. However, all firms in this economy will share the same parameter value in the forward intensity function in which the firm’s default heterogeneity is not taken into account.
For ease of understanding, the forward intensity approach framework is first explored. In the forward intensity approach, there are three possibilities for one firm at the same time: survive, default, and other exit. A listed firm can be delisted for many reasons, such as bankruptcy by default, merger, and acquisition. The firm can only be delisted for one reason at each time point. Therefore, probabilities of default, other exit, and survival are mutually exclusive and we must take other exit into account when analyzing the firm’s default. In the forward intensity model, occurrences of default and other exit are described as two independent doubly stochastic Poisson processes. If we estimate the default or other exit forward intensities of a firm during any time period within the prediction range, we can calculate the conditional PDs and POEs during that period. The condition of conditional PDs and POEs is that the firm will survive between the prediction time points. Then we multiply survival probabilities before the prediction time and the conditional PDs together and we can get forward PDs. Adding the forward PDs up, we can calculate the accumulated PDs of this firm for different horizons. In the forward intensity approach, as long as we can estimate the default or other exit forward intensities over multiple periods, we can achieve multi-period default prediction. In this paper, PDs and POEs estimated using the forward intensity approach are taken as prior probabilities. We used Bayesian estimation to optimize the model.
We still use a double stochastic Poisson process to describe a firm’s default and other exit and suppose that
and
are the default and other exit forward intensities, respectively, of the
i-th firm at time
t. Intensity denotes the average number of events in unit time and is also known as the arrival rate in the literature. The PD and POE of the
i-th firm for the period
can be derived as
Note that if POE should exclude the probabilities that default and other exit happen in the same time interval, then the POE is the probability of exit for the reasons excluding bankruptcy by default in the period. If a firm survives in this period, which means that there is no event of default or other exits,
Here, PS is the probability of survival. Then, the probabilities of three possibilities in the period satisfy the following relation:
In this paper, we regard the PD calculated using the original approach, which did not consider the firm’s past credit, as the prior probability. We obtain posterior probabilities based on the firm’s past credit standing. According to the properties of the Poisson process, the number of defaults for firm
i in 1 month follows the Poisson distribution with parameter
. The conjugate prior distribution of
is a gamma distribution, which is denoted
. The density function of
is
To implement the model in the discrete framework, the basic time interval
τ was set as 1 month:
.We assume that the default forward intensity of firms during the period
follows the gamma distribution
In the forward intensity approach, the forward intensity
is the annual default arrival rate and
is the average annual default arrival rate during the period
. In our model,
is the default arrival rate in 1 month, so
denotes the average monthly default arrival rate, which is equal to
. When
, the average monthly default arrival rate can be expressed as
Let
be the number of defaults of the
i-th firm during the period
. When the observation time is after
,
, then we can obtain the posterior distribution of
:
Because the default in 1 month is a small probability event, we only consider two possibilities in 1 month: default one time or survive. Then,
can only be equal to 0 or 1 and
. Let
be the parameter of the posterior intensity of
:
According to the properties of the gamma distribution and the discrete time framework, the expectation of the posterior default intensity during the period
can be expressed as the form of the prior default intensity’s expectation:
Combine Formulas (6) and (9) to eliminate
, and then we have a relationship between
and
:
According to properties of conjugate distributions,
quantifies confidence in the empirical judgment from the forward intensity approach. The higher
, the more confidence we have in the PDs estimated by the forward intensity. Specifically, as
approaches positive infinity,
, which means the default intensity computed by the forward intensity approach completely dominates. On the contrary, if
is low, the posterior PDs depend more on the firm’s past credit standing. Specifically, if
, the posterior PDs all depend on the actual past defaults. In addition, if
is determined, the more times a firm has defaulted in the past, the higher the firm’s default tendency, and the higher its estimated posterior PDs will be. On the contrary, if a firm has not defaulted for a long time after default, the firm’s default tendency will decrease and we estimate lower posterior PDs for the firm. On the other hand, if a firm has had a good credit status for a long time without default, its posterior default intensity will be lower than the prior default intensity. Conversely, if the firm defaults, its posterior PD will be higher than the original prior PD.
Appendix A shows details about the overlapped pseudo-likelihood function of
and
Appendix B shows pseudo log-likelihood function and its gradient.
In order to extend our notations, it should be noted that the calculation of
relies on the observation time point. Then, the default forward intensity
can be extended to
. To implement the model in the discrete framework, let
be the average default forward intensity during the interval
viewed at
for firm
i, where
n and
m are positive integers satisfying
. Here,
can be regarded as the default forward intensity in the
-th month predicted from the first day of the
-th month. Then, we implement the model in the discrete framework as follows:
We can compute the default arrival rate for the period
:
here, we maintain the same form for the posterior default forward intensity:
Furthermore, here,
m denotes the observation month and
n denotes the prediction month. Then,
was modeled as the proportional-hazards form used by Duffie et al. [
3]:
where
Here,
is an intercept term set by one and
is a vector of variables on the first day of month
m that is common to all firms.
is a vector of variables related to the
i-th firm. Then,
is a vector obtained by merging
,
and
. Here,
is the vector of model parameters for prediction horizon
, where
This determines the dependencies of the default forward intensities on the variables. Specifically, when
,
denotes the default intensity in the
m-th month viewed at the beginning of the month. For convenience,
is the first month of firm
i. We assume that we can only obtain the default information before the
k-th month, which means we can only calculate
when
. If we set
in Formula (10), it can be expressed as the following formula:
Then, we discretize the left-hand side and introduce extended definitions:
For prediction horizon
l,We combine Formulas (17) and (18):
We assume that the
i-th firm’s default forward intensity for prediction horizon
l shares the common parameter
which quantifies confidence in the empirical judgment from the prior forward intensity. Then, we extend Formula (16) with extended definitions of
and
and combine it with Formula (19):
here,
is the model’s parameter for prediction horizon
l, characterizing the confidence in the forward intensity estimated by the original model. The higher the value of
, the more influence
has on
, and the less influence past default records have on
. We introduce the
i-th firm’s default heterogeneity
to describe the
i-th firm’s default tendency. Here,
is defined as the average ratio of the posterior default intensity to the prior default intensity before the
k-th month for the prediction horizon
l:
Combined with Formula (20), the
i-th firm’s default heterogeneity
can be expressed as:
Obviously, the firm’s heterogeneity depends on the firm’s past default status and the duration that the firm has been operating. According to the law of large numbers, we need a large enough sample size to estimate the default heterogeneity, which is close to the true situation. To reduce the impact of an extreme case, we ensure that the interval between month
and month
is at least 30 months. We have assumed that we can only obtain the default information before the
k-th month of
i-th firm, which means we do not know whether firm
i will default in the month (
. We assume that the firm’s default intensity will remain as heterogeneous as before and
. Therefore, when
, the relationship between the posterior default forward intensity and the prior default forward intensity is as follows:
If
, we use the variables at the beginning of the month to predict the default in the current month. The estimation of firm’s default heterogeneity is the core problem to be solved, which is introduced in
Appendix A. The revised PDs after the current month are affected by the current corporate heterogeneity, which is only inferred from the information before the current month. Because all PDs can only be revised based on the information before the current month. Formula (23) describes how our model revises the original default intensity using past information. For the
i-th firm,
is the predictions of the prior default cumulative probability from month
to month
viewed by
l months, correspondingly, and
is the real number of default events during the same period. If
, the forward intensity model underestimates the credit risk of the
i-th firm, and the posterior PD will be larger than the prior PD. On the contrary, if we overestimate the credit risk, the posterior PD will be adjusted to a value smaller than the prior PD. If
is close to
, the posterior PD will also be close to the prior PD.
In our preliminary analysis, we found that the POEs of firms with a default record are significantly higher than those of the others. However, there is no evidence that firms with an other exit have higher PDs or POEs. On the other hand, firms that have defaulted have a frequency of other exits that is close to even for 20 years after default. A firm-specific variable that indicates whether the
i-th firm has defaulted is added to fit this situation. POEs are not adjusted further and the same other exit forward intensity function form as the original model of Duan et al. is maintained [
1]:
Here,
is the parameter vector of the other exit forward intensity function, which determines the dependencies of the other exit forward intensities on the variables. The parameter vector is for prediction horizon
, where
In fact,
and
do not share the same variables and we can set some parameters to zero. The details of
are introduced in the next section. As long as we estimate
,
and
, we can calculate
. With
, we can compute the revised conditional POE, PD, and PS for the period [
, (
]:
Obviously, if we add the above three terms together, the sum of the three probabilities is 1 for the period [
, (
]:
Note that
and
are the other exit intensity and other exit probability of the
i-th firm, while
and
are the revised default intensity and the revised PD of the
i-th firm. We can obtain the cumulative PS by adding up the conditional PS:
With
, we can compute the forward POEs and the revised forward PDs for the period [
, (
], with the condition that the firm survives between [
, n
]:
Thus, the revision of the default risk measure of Chinese-listed companies for muti-period is complete. Finally, we can obtain the cumulative POE and PD for different prediction horizons.
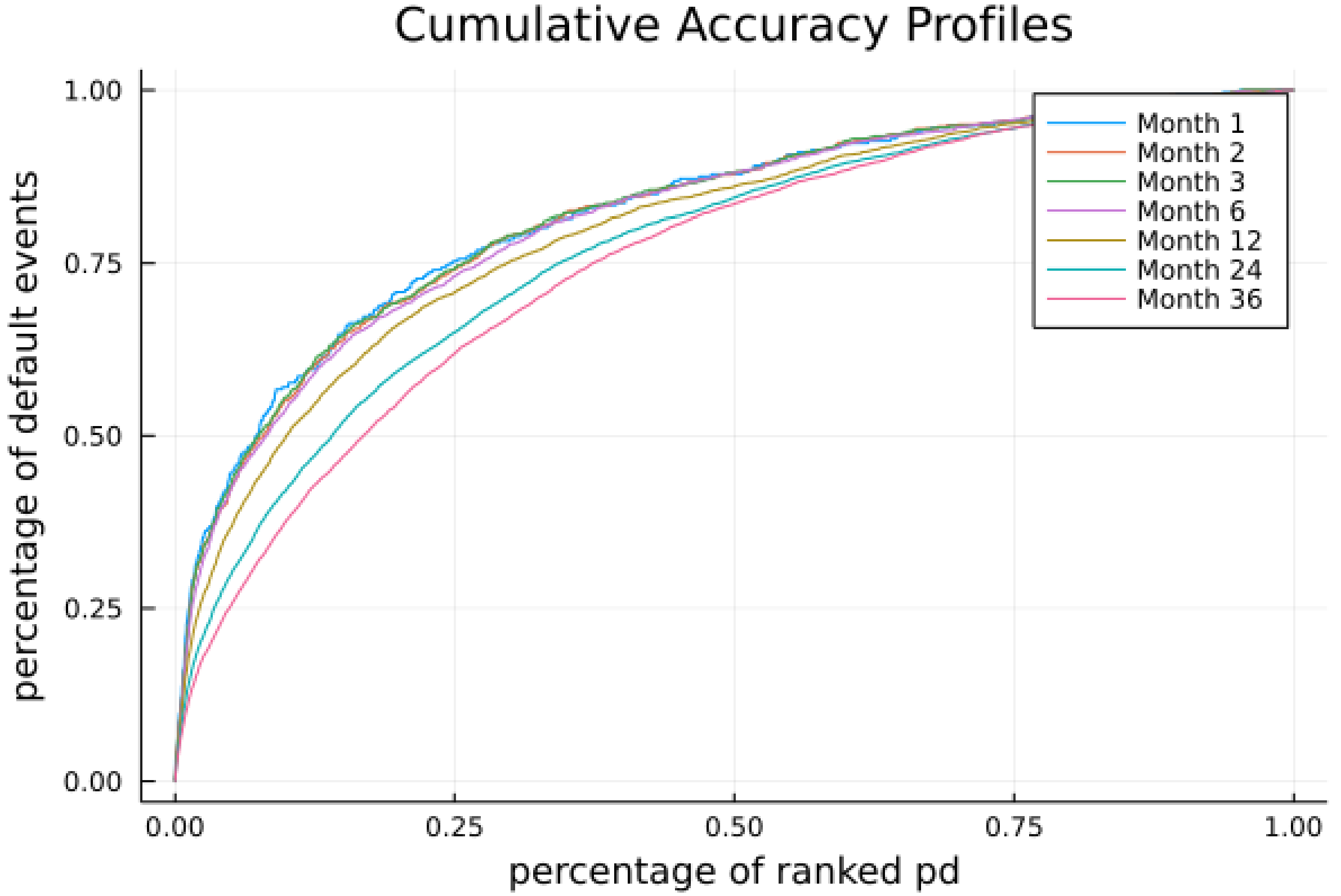
Here, the prediction horizon
. In this paper, we present the cumulative PDs for horizons from 1 month to 36 months and compare the prediction accuracy with the cumulative PDs estimated using the original model in
Section 5.
4. Data and Preliminary Analysis
Our data source is the Credit Research Initiative (CRI) database of the National University of Singapore. These data come from CRI, Bloomberg, Moodys reports, TEJ, Compustat, CRSP, exchange websites, and news sources. In our sample, the data contain firm information concerning timing of survival, default, and other exit from 1991 to 2020. The default events that are recognized in the CRI are as follows: (1) Bankruptcy filing, receivership, administration, liquidation; (2) a missed or delayed payment of interest and/or principal; and (3) debt restructuring/distressed exchange.
We built the original forward intensity model using common factors, i.e., firm-specific attributes from 2000 to 2020, as shown in
Table 1 and
Table 2, in accordance with Duan et al. [
1].
In the original paper (Duan 2012), the above variables, except the default record, were used to estimate U.S.-listed firms’ PDs. They found that introducing the trend and level to certain variables can improve the predictive power of the model. DTD was calculated using NUS-CRI according to an adjustment method provided by Duan and Wang [
25]. Default record is only used in the other exit intensity function. For firm-specific variable
, the firm has one more default before time point
, and it is set to 1. Otherwise, it is set to 0.
We preliminarily explored the credit situation of all Chinese-listed companies, as shown in the
Figure 1 and
Figure 2.
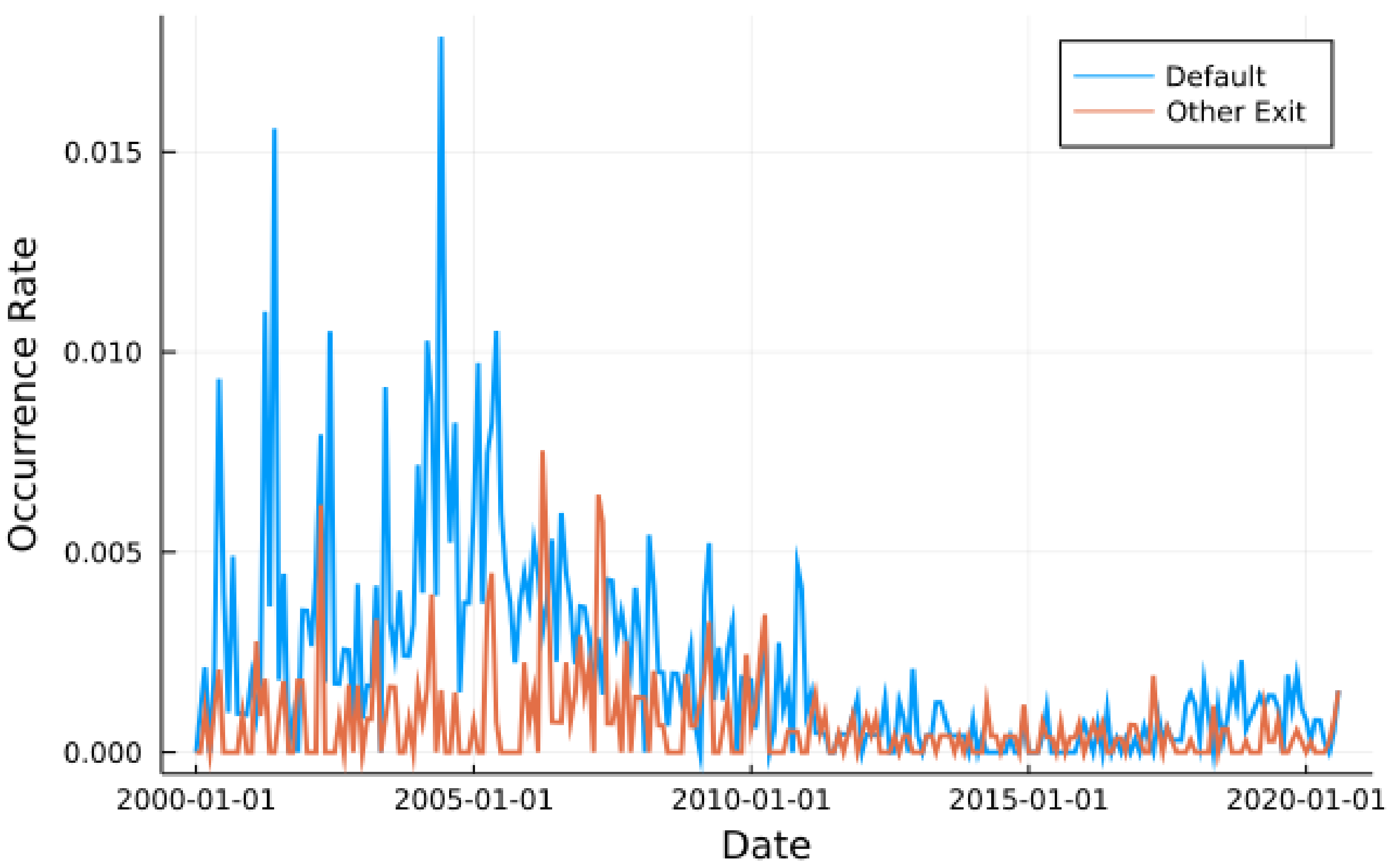
Figure 1 shows the monthly occurrence rate of default and other exit of Chinese-listed firms from 2000 to 2020. The occurrence rate is the frequency, i.e., the percentage of all active firms that defaulted or exited for other reasons. In general, Chinese-listed companies’ default events were shown to be more than other exits. Before 2011, the default monthly frequency was relatively high, peaking at over 1.5%. After 2011, the overall default frequency began to decrease and remained below 0.25% for the whole period.
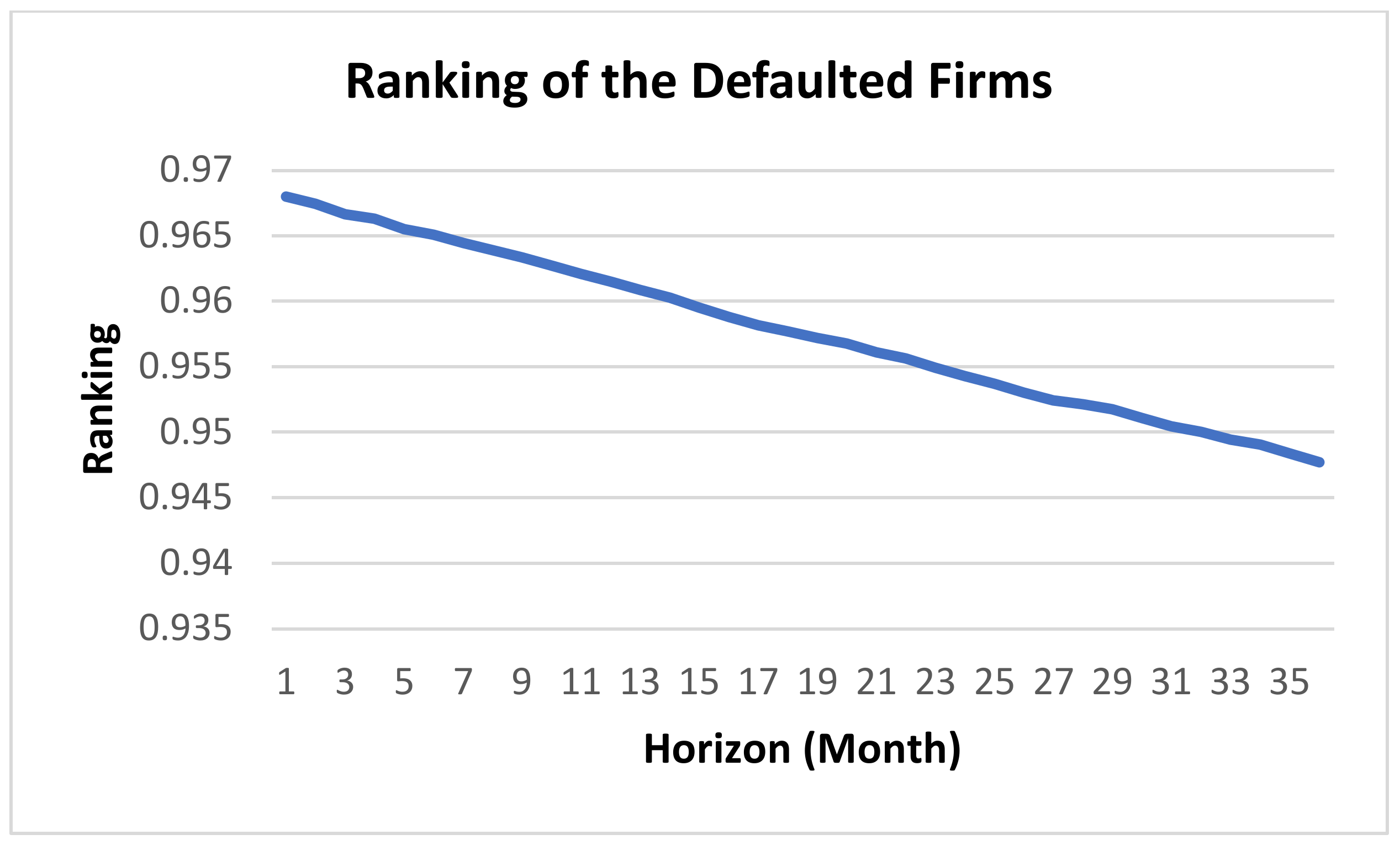
Figure 2 shows the monthly occurrence rate of default and other exits of Chinese-listed firms for 7 months to 20 years following their first default. The situation within 6 months after a firm’s default is complex and is excluded from the sample. It is clear to see that in the 100 months following the first default, the default probability is significantly higher than the average default rate and gradually decreases as time goes by. Moreover, firms that have defaulted are more likely to default again or experience other type of exits in the future as compared with the average. The original method did not take this into account, which leads to deviations in predictions concerning firms in emerging markets such as China.
On the other hand, for all firms that have defaulted, if they do not exit the market, the probability of re-defaulting decreases over 10 years as the firm continues to operate.
We believe that the tendency to re-default decreases the longer the firm remains in business. In other words, the default heterogeneity of firms is also changing. We use Bayesian estimation to capture this. The PDs estimated using the original method were adjusted according to the past default status of the firm. Note that we still follow the assumption that the occurrences of default obey a doubly stochastic Poisson process proposed by Duffie et al. [
3]. For each firm, if its default heterogeneity does not change, the number of defaults is still an independent incremental process, which means the time of each default does not affect the probability of future defaults. The change in the PD is mainly attributed to the change in the default heterogeneity of the firm. Moreover, among all firms that default, the frequency of other exits is more uniform over all future periods and significantly higher than that of other firms with a good credit status. For this near uniform frequency change, we added a state variable of whether the firm has defaulted into the variables of the other exit intensity function.
To check the out-of-sample performance, we divided the samples into an experimental group and evaluation group at a ratio of 5 to 1. After removing firms with too much missing data or too short a survival time, we were left with 4216 active firms. We randomly selected 3513 firms to form the experimental group in order to estimate the parameters, and we took the remaining 703 firms as the evaluation group to test the out-of-sample predictive ability.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}