
Hybrid Particle Swarm Optimization Algorithm Based on the Theory of Reinforcement Learning in Psychology



Abstract
:1. Introduction
- (1)
- A Hybrid Reinforcement Learning Particle Swarm Algorithm was proposed. To enhance the optimization capability of HRLPSO, five strategies were applied to improve the traditional PSO in this work. (i) An opposition-based learning strategy was combined with random mapping to generate the initial population; (ii) cubic mapping and adaptive strategies were combined and applied to the weights; (iii) the ci parameter was controlled to vary nonlinearly within a certain range; (iv) a dimensional learning strategy was applied to the optimal solution; (v) Cauchy and Gaussian mutation strategies were used in the optimal solution to increase the diversity of the solutions.
- (2)
- The results regarding standard functions show that the proposed HRLPSO strategy works well in both stand-alone and ensemble applications, and the results regarding the CEC2013 test suite further demonstrate the good optimization capability of HRLPSO.
- (3)
- Compared with the existing schemes, the main contributions of the proposed HRLPSO are as follows: (i) The theory of reinforcement learning in psychology is firstly applied and the opposition-based learning strategy is proposed to generate the initial population of the PSO. (ii) Unlike the traditional PSO algorithm, which only uses a few hybrid methods, the proposed HRLPSO fully considers the improvement measures at each stage and the five hybrid methods stated above in (1) are applied to improve the optimization performance.
2. Particle Swarm Optimization Algorithm
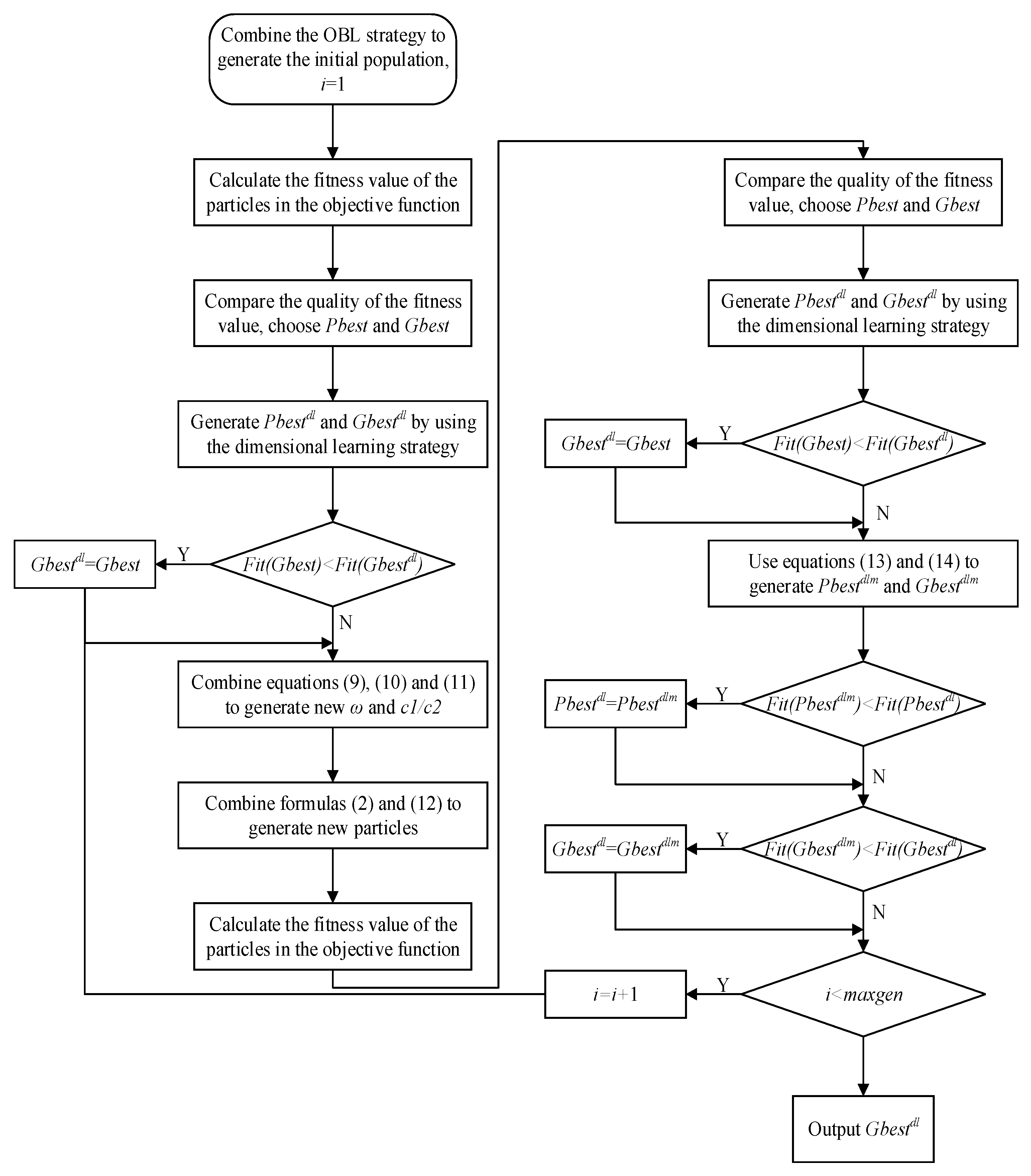
3. Hybrid Reinforcement Learning Particle Swarm Optimization Algorithm
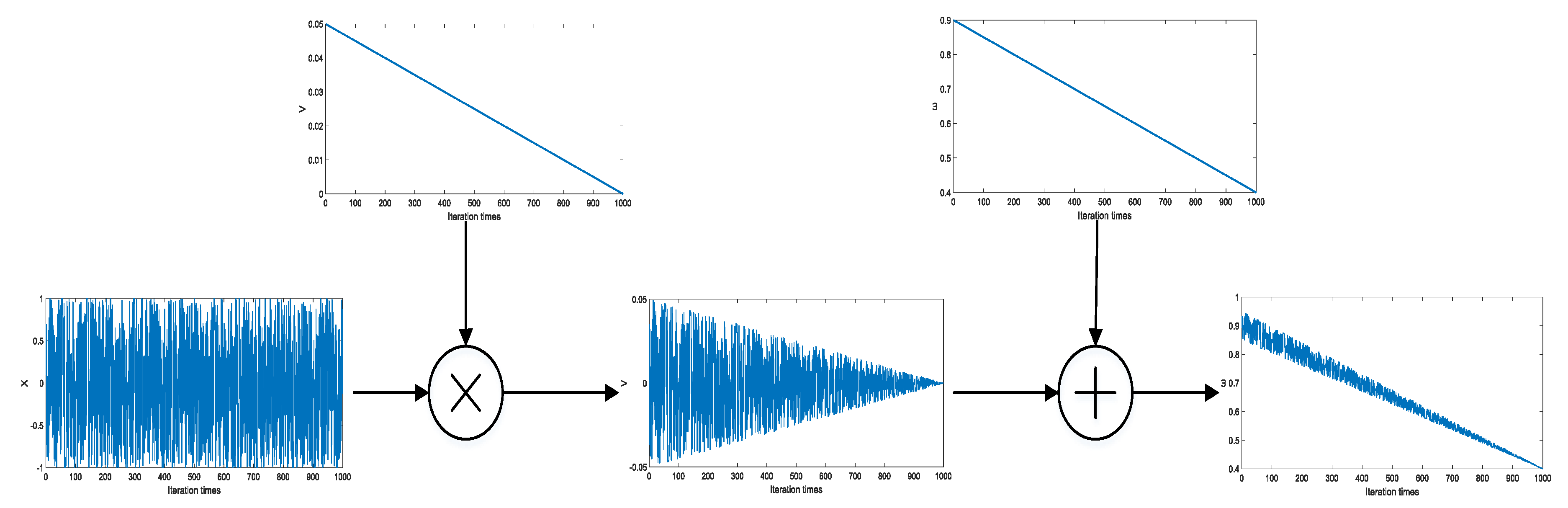
3.1. Initial Population Based on Positive Reinforcement Learning
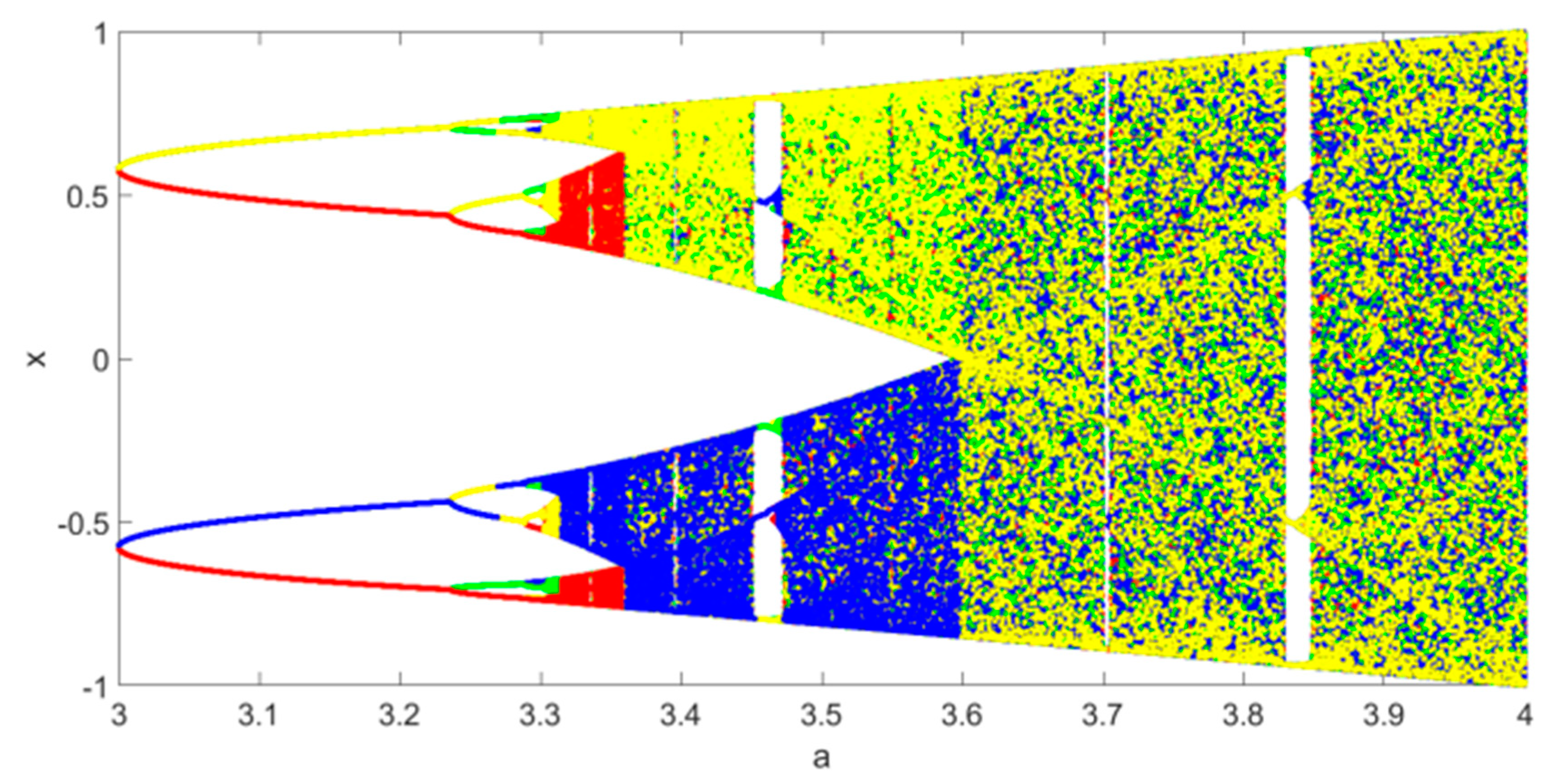
3.2. Chaos Adaptive Inertia Weight
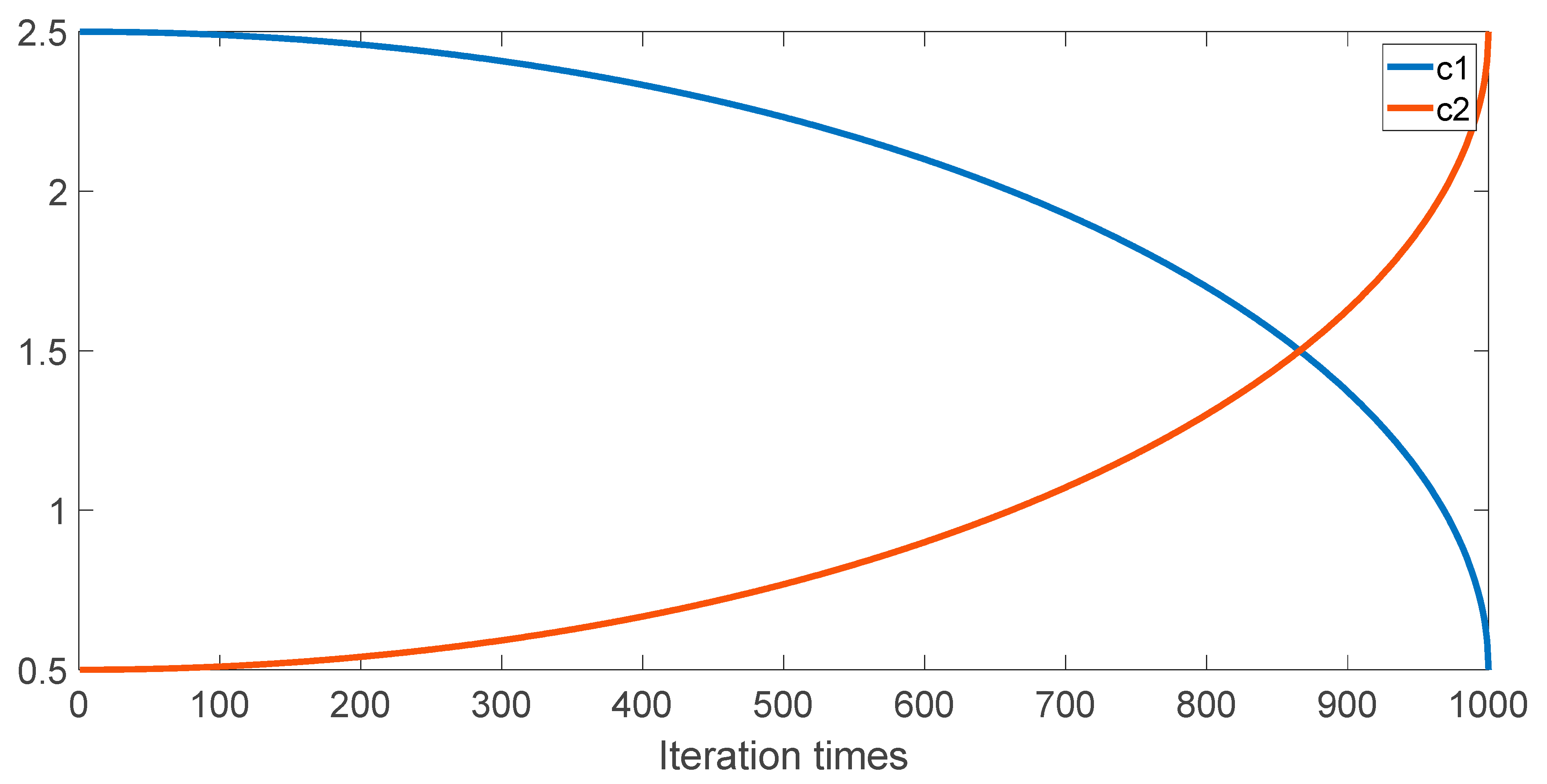
3.3. Adaptive Learning Factor
3.4. Update Strategy
3.4.1. Dimension Learning
3.4.2. Mutation
4. Experimental Setup
5. Discussion
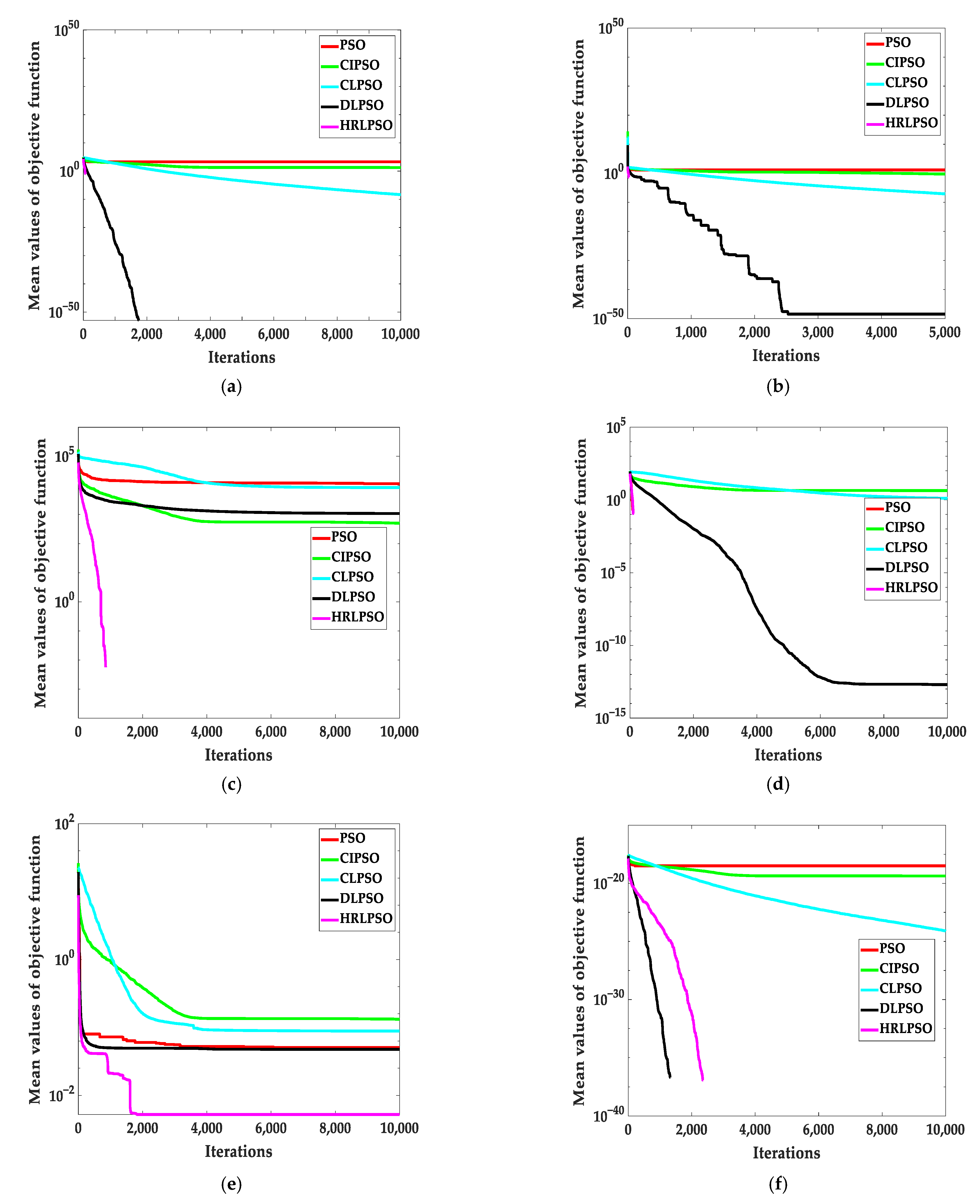
5.1. Test Results of the PSO Variants under Benchmark
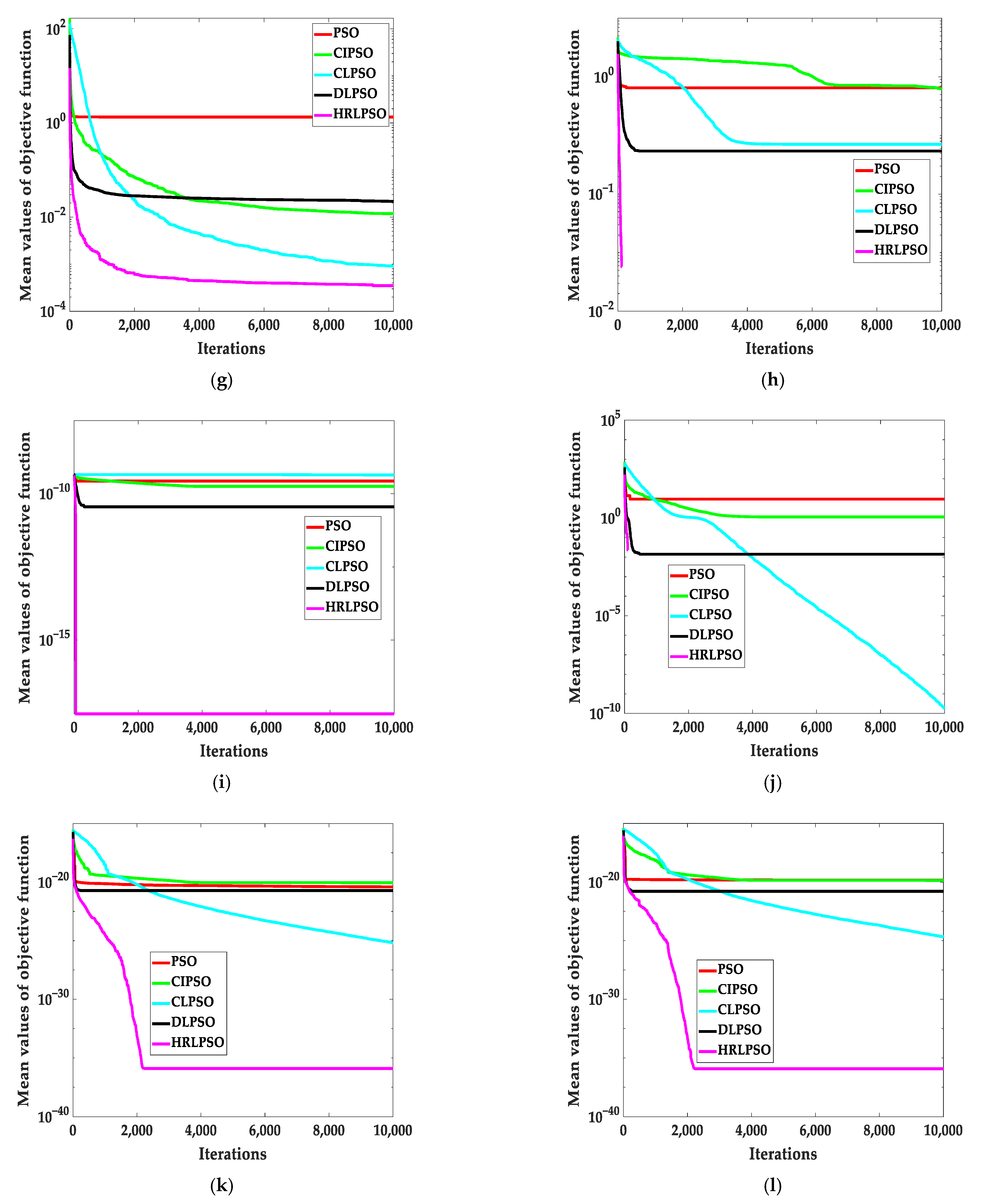
5.2. Test Results of the PSO Variants under CEC2013 Test Suite
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sheng, X.; Lan, K.; Jiang, X.; Yang, J. Adaptive Curriculum Sequencing and Education Management System via Group-Theoretic Particle Swarm Optimization. Systems 2023, 11, 34. [Google Scholar] [CrossRef]
- Wang, R.; Hao, K.; Chen, L.; Wang, T.; Jiang, C. A novel hybrid particle swarm optimization using adaptive strategy. Inf. Sci. 2021, 579, 231–250. [Google Scholar] [CrossRef]
- Li, T.; Liu, Y.; Chen, Z. Application of Sine Cosine Egret Swarm Optimization Algorithm in Gas Turbine Cooling System. Systems 2022, 10, 201. [Google Scholar] [CrossRef]
- Shi, L.; Cheng, Y.; Shao, J.; Sheng, H.; Liu, Q. Cucker-Smale flocking over cooperation-competition networks. Automatica 2022, 135, 109988. [Google Scholar] [CrossRef]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature Selection: A Data Perspective. ACM Comput. Surv. 2016, 50, 94. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M.; Browne, W.N.; Yao, X. A Survey on Evolutionary Computation Approaches to Feature Selection. IEEE Trans. Evol. Comput. 2016, 20, 606–626. [Google Scholar] [CrossRef]
- Dokeroglu, T.; Deniz, A.; Kiziloz, H.E. A comprehensive survey on recent metaheuristics for feature selection. Neurocomputing 2022, 494, 269–296. [Google Scholar] [CrossRef]
- Schockenhoff, F.; Zähringer, M.; Brönner, M.; Lienkamp, M. Combining a Genetic Algorithm and a Fuzzy System to Optimize User Centricity in Autonomous Vehicle Concept Development. Systems 2021, 9, 25. [Google Scholar] [CrossRef]
- Ganguli, C.; Shandilya, S.K.; Nehrey, M.; Havryliuk, M. Adaptive Artificial Bee Colony Algorithm for Nature-Inspired Cyber Defense. Systems 2023, 11, 27. [Google Scholar] [CrossRef]
- Abdelbari, H.; Shafi, K. A System Dynamics Modeling Support System Based on Computational Intelligence. Systems 2019, 7, 47. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Wei, K.; Yang, W.; Wang, Q. Improving wind turbine blade based on multi-objective particle swarm optimization. Renew. Energy 2020, 161, 525–542. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995. [Google Scholar]
- Shi, Y.; Eberhart, R. A modified particle swarm optimizer. In Proceedings of the 1998 IEEE International Conference on Evolutionary Computation Proceedings, Anchorage, AK, USA, 4–9 May 1998. [Google Scholar]
- Tian, D.; Shi, Z. MPSO: Modified particle swarm optimization and its applications. Swarm Evol. Comput. 2018, 41, 49–68. [Google Scholar] [CrossRef]
- Chen, K.; Zhou, F.; Yin, L.; Wang, S.; Wang, Y.; Wan, F. A hybrid particle swarm optimizer with sine cosine acceleration coefficients. Inf. Sci. 2018, 422, 218–241. [Google Scholar] [CrossRef]
- Ahandani, M.A. Opposition-based learning in the shuffled bidirectional differential evolution algorithm. Swarm Evol. Comput. 2016, 26, 64–85. [Google Scholar] [CrossRef]
- Gao, W.F.; Liu, S.Y.; Huang, L.L. Particle swarm optimization with chaotic opposition-based population initialization and stochastic search technique. Commun. Nonlinear Sci. Numer. Simul. 2012, 17, 4316–4327. [Google Scholar] [CrossRef]
- Malik, R.F.; Rahman, T.A.; Hashim, S.Z.M.; Ngah, R. New particle swarm optimizer with sigmoid increasing inertia weight. Int. J. Comput. Sci. Secur. 2007, 1, 35–44. [Google Scholar]
- Robati, A.; Barani, G.A.; Pour, H.N.A.; Fadaee, M.J.; Anaraki, J.R.P. Balanced fuzzy particle swarm optimization. Appl. Math. Model. 2012, 36, 2169–2177. [Google Scholar] [CrossRef]
- Ratnaweera, A.; Halgamuge, S.K.; Watson, H.C. Self-organizing hierarchical particle swarm optimizer with time-varying acceleration coefficients. IEEE Trans. Evol. Comput. 2004, 8, 240–255. [Google Scholar] [CrossRef]
- Tanweer, M.R.; Suresh, S.; Sundararajan, N. Self regulating particle swarm optimization algorithm. Inf. Sci. 2015, 294, 182–202. [Google Scholar] [CrossRef]
- Liang, J.J.; Qin, A.K.; Suganthan, P.N.; Baskar, S. Comprehensive learning particle swarm optimizer for global optimization of multimodal functions. IEEE Trans. Evol. Comput. 2006, 10, 281–295. [Google Scholar] [CrossRef]
- Li, W.; Meng, X.; Huang, Y.; Fu, Z.H. Multipopulation cooperative particle swarm optimization with a mixed mutation strategy. Inf. Sci. 2020, 529, 179–196. [Google Scholar] [CrossRef]
- Mendes, R.; Kennedy, J.; Neves, J. The fully informed particle swarm: Simpler, maybe better. IEEE Trans. Evol. Comput. 2004, 8, 204–210. [Google Scholar] [CrossRef]
- Wang, L.; Yang, B.; Orchard, J. Particle swarm optimization using dynamic tournament topology. Appl. Soft Comput. 2016, 48, 584–596. [Google Scholar] [CrossRef]
- Wang, H.; Wang, W.; Wu, Z. Particle swarm optimization with adaptive mutation for multimodal optimization. Appl. Math. Comput. 2013, 221, 296–305. [Google Scholar] [CrossRef]
- Mirjalili, S.; Hashim, S.Z.M. A new hybrid PSOGSA algorithm for function optimization. In Proceedings of the 2010 International Conference on Computer and Information Application, Tianjin, China, 2–4 November 2010. [Google Scholar]
- Fakhouri, H.N.; Hudaib, A.; Sleit, A. Hybrid particle swarm optimization with sine cosine algorithm and nelder–mead simplex for solving engineering design problems. Arab. J. Sci. Eng. 2020, 45, 3091–3109. [Google Scholar] [CrossRef]
- Sedki, A.; Ouazar, D. Hybrid particle swarm optimization and differential evolution for optimal design of water distribution systems. Adv. Eng. Inform. 2012, 26, 582–591. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl.-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Rogers, T.D.; Whitley, D.C. Chaos in the cubic mapping. Math. Model. 1983, 4, 9–25. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Parameter | Reference | |
|---|---|---|---|
| PSO | the population size is 30, each algorithm is optimized 20 times, the number of iterations is 10,000, the maximal speed is within the range of F1~F12 | w: 1, c1: 2, c2: 2 | [8] |
| CIPSO | w: 0.9~0.4, c1: 3.5~0.5, c2: 0.5~3.5 | [31] | |
| CLPSO | w: 0.9~0.4, c: 1.5 | [18] | |
| DLPSO | w: 0.7298, c1: 1.5, c2: 0.5~2.5 | [3] | |
| HRLPSO | w: 0.9~0.6, c1: 2.5~0.5, c2: 0.5~2.5, a: 4, Max: 0.05 | - | |
| F | D | Item | PSO | CIPSO | CLPSO | DLPSO | HRLPSO |
|---|---|---|---|---|---|---|---|
| F1 | 30 | Mean | 2 × 103 | 1.72 × 101 | 4.43 × 10−9 | 0.00 | 0.00 |
| S.D. | 5.23 × 103 | 8.42 | 2.53 × 10−9 | 0.00 | 0.00 | ||
| Rank | 4 | 3 | 2 | 1 | 1 | ||
| F2 | 30 | Mean | 1.50 × 101 | 5.86 × 10−1 | 8.66 × 10−8 | 3.49 × 10−43 | 0.00 |
| S.D. | 8.89 | 3.02 × 10−1 | 3.54 × 10−8 | 1.53 × 10−48 | 0.00 | ||
| Rank | 5 | 4 | 3 | 2 | 1 | ||
| F3 | 30 | Mean | 1.15 × 104 | 4.96 × 102 | 8.40 × 103 | 1.07 × 103 | 0.00 |
| S.D. | 1.08 × 104 | 2.25 × 102 | 8.92 × 103 | 2.35 × 103 | 0.00 | ||
| Rank | 5 | 2 | 4 | 3 | 1 | ||
| F4 | 30 | Mean | 0.00 | 4.35 | 1.28 | 2.01 × 10−13 | 0.00 |
| S.D. | 0.00 | 1.06 | 5.87 × 10−1 | 8.98 × 10−13 | 0.00 | ||
| Rank | 1 | 4 | 3 | 2 | 1 | ||
| F5 | 30 | Mean | 5.70 × 101 | 6.31 × 102 | 2.31 × 102 | 4.91 × 101 | 1.99 × 10−1 |
| S.D. | 1.26 × 102 | 4.24 × 102 | 6.75 × 102 | 4.01 × 101 | 8.91 × 10−1 | ||
| Rank | 3 | 5 | 4 | 2 | 1 | ||
| F6 | 30 | Mean | 1.01 × 103 | 1.80 × 101 | 6.38 × 10−9 | 0.00 | 0.00 |
| S.D. | 3.11 × 103 | 6.69 | 4.53 × 10−9 | 0.00 | 0.00 | ||
| Rank | 4 | 3 | 2 | 1 | 1 | ||
| F7 | 30 | Mean | 1.34 | 1.19 × 10−2 | 9.17 × 10−4 | 2.16 × 10−2 | 3.49 × 10−4 |
| S.D. | 3.54 | 5.20 × 10−3 | 3.78 × 10−4 | 1.46 × 10−2 | 3.13 × 10−4 | ||
| Rank | 5 | 3 | 2 | 4 | 1 | ||
| F8 | 30 | Mean | 6.51 × 101 | 6.20 × 101 | 7.06 | 5.42 | 0.00 |
| S.D. | 4.26 × 101 | 1.54 × 101 | 2.58 | 3.88 | 0.00 | ||
| Rank | 5 | 4 | 3 | 2 | 1 | ||
| F9 | 30 | Mean | 7.24 | 3.11 | 1.90 × 101 | 1.25 × 10−1 | 8.88 × 10−16 |
| S.D. | 8.44 | 4.73 × 10−1 | 4.70 × 10−1 | 3.85 × 10−1 | 0.00 | ||
| Rank | 4 | 3 | 5 | 2 | 1 | ||
| F10 | 30 | Mean | 9.02 × 101 | 1.11 | 1.85 × 10−10 | 1.41 × 10−2 | 0.00 |
| S.D. | 2.78 × 101 | 3.84 × 10−2 | 1.54 × 10−1 | 2.24 × 10−2 | 0.00 | ||
| Rank | 5 | 4 | 2 | 3 | 1 | ||
| F11 | 30 | Mean | 1.49 × 10−1 | 7.92 × 10−1 | 4.23 × 10−11 | 3.63 × 10−2 | 1.57 × 10−32 |
| S.D. | 3.87 × 10−2 | 3.83 × 10−1 | 2.78 × 10−11 | 5.07 × 10−2 | 2.81 × 10−48 | ||
| Rank | 4 | 5 | 2 | 3 | 1 | ||
| F12 | 30 | Mean | 2.07 | 1.93e | 4.38 × 10−10 | 2.69 × 10−2 | 1.35 × 10−32 |
| S.D. | 3.20 | 1.13 | 3.05 × 10−10 | 9.00 × 10−2 | 2.81 × 10−48 | ||
| Rank | 5 | 4 | 2 | 3 | 1 | ||
| Average Rank | 4 | 3.89 | 2.78 | 2.44 | 1 | ||
| Final Rank | 5 | 4 | 3 | 2 | 1 | ||
| Indicators | PSO | CIPSO | CLPSO | DLPSO | HRLPSO |
|---|---|---|---|---|---|
| Running times | 30 | 30 | 30 | 30 | 30 |
| Average computational time (s) | 13.57 | 14.11 | 14.92 | 14.89 | 14.88 |
| Average rank | 4 | 3.89 | 2.78 | 2.44 | 1 |
| Functions | Dimensions | Indicators | PSO | CIPSO | CLPSO | DLPSO | HDLPSO |
|---|---|---|---|---|---|---|---|
| F13 | 30 | M | 1.21 × 104 | −1.38 × 103 | −1.01 × 103 | −1.40 × 103 | −1.40 × 103 |
| S | 5.90 × 103 | 7.15 | 4.79 × 102 | 3.54 × 10−13 | 1.88 × 10−13 | ||
| R | 6 | 2 | 3 | 1 | 1 | ||
| F14 | 30 | M | 1.31 × 108 | 6.17 × 106 | 3.96 × 107 | 6.61 × 106 | 2.31 × 104 |
| S | 8.72 × 107 | 2.37 × 106 | 2.76 × 107 | 3.74 × 106 | 2.25 × 104 | ||
| R | 7 | 2 | 5 | 3 | 1 | ||
| F15 | 30 | M | 6.53 × 1013 | 2.75 × 108 | 3.31 × 1010 | 2.36 × 109 | 3.22 × 108 |
| S | 1.91 × 1014 | 1.44 × 108 | 1.83 × 1010 | 2.20 × 109 | 5.37 × 108 | ||
| R | 7 | 1 | 4 | 3 | 2 | ||
| F16 | 30 | M | 7.83 × 104 | 4.19 × 103 | 1.65 × 104 | 9.77 × 103 | −6.81 × 102 |
| S | 5.77 × 104 | 1.77 × 103 | 8.83 × 103 | 3.85 × 103 | 2.98 × 102 | ||
| R | 7 | 2 | 4 | 3 | 1 | ||
| F17 | 30 | M | 7.80 × 103 | −9.80 × 102 | −6.36 × 102 | −1.00 × 103 | −1.00 × 103 |
| S | 5.16 × 103 | 9.81 | 5.56 × 102 | 1.37 × 10−9 | 1.14 × 10−13 | ||
| R | 6 | 2 | 3 | 1 | 1 | ||
| F18 | 30 | M | 1.02 × 103 | −8.34 × 102 | −8.30 × 102 | −8.62 × 102 | −8.81 × 102 |
| S | 1.73 × 103 | 1.53 × 101 | 3.18 × 101 | 1.99 × 101 | 1.68 × 101 | ||
| R | 7 | 3 | 4 | 2 | 1 | ||
| F19 | 30 | M | 9.21 × 102 | 7.73 × 102 | −6.88 × 102 | −7.06 × 102 | −7.27 × 102 |
| S | 4.22 × 103 | 8.66 | 3.79 × 101 | 1.66 × 101 | 1.99 × 101 | ||
| R | 7 | 1 | 4 | 3 | 2 | ||
| F20 | 30 | M | −6.79 × 102 | 6.79 × 102 | −6.79 × 102 | −6.79 × 102 | −6.79 × 102 |
| S | 5.67 × 10−2 | 5.05 × 10−2 | 6.81 × 10−2 | 4.32 × 10−2 | 6.91 × 10−2 | ||
| R | 1 | 1 | 1 | 1 | 1 | ||
| F21 | 30 | M | −5.67 × 102 | 5.80 × 102 | −5.62 × 102 | −5.70 × 102 | −5.78 × 102 |
| S | 2.40 | 2.15 | 1.24 | 3.16 | 3.33 | ||
| R | 5 | 1 | 6 | 3 | 2 | ||
| F22 | 30 | M | 1.19 × 103 | −4.76 × 102 | −1.91 × 102 | −4.88 × 102 | −5.00 × 102 |
| S | 9.47 × 102 | 1.32 × 101 | 1.79 × 102 | 1.74 × 101 | 4.31 × 10−2 | ||
| R | 7 | 3 | 5 | 2 | 1 | ||
| F23 | 30 | M | 1.74 × 101 | −2.94 × 102 | −3.54 × 102 | −3.82 × 102 | −3.64 × 102 |
| S | 8.17 × 101 | 2.13 × 101 | 2.26 × 101 | 6.48 | 9.35 | ||
| R | 7 | 4 | 3 | 1 | 2 | ||
| F24 | 30 | M | 8.52 × 101 | −1.91 × 102 | −1.14 × 102 | −1.95 × 102 | −2.19 × 102 |
| S | 9.44 × 101 | 2.08 × 101 | 2.32 × 101 | 3.29 × 101 | 1.85 × 101 | ||
| R | 7 | 3 | 4 | 2 | 1 | ||
| F25 | 30 | M | 1.71 × 102 | 7.48 × 101 | -2.15 × 101 | −4.37 × 101 | −5.41 × 101 |
| S | 7.00 × 101 | 2.08 × 101 | 1.62 × 101 | 3.04 × 101 | 3.26 × 101 | ||
| R | 7 | 1 | 4 | 3 | 2 | ||
| F26 | 30 | M | 6.50 × 103 | 4.33 × 103 | 2.26 × 103 | 1.47 × 102 | 1.16 × 103 |
| S | 4.74 × 102 | 5.89 × 102 | 4.72 × 102 | 1.88 × 102 | 3.45 × 102 | ||
| R | 7 | 6 | 3 | 1 | 2 | ||
| F27 | 30 | M | 7.42 × 103 | 4.60 × 103 | 7.20 × 103 | 5.03 × 103 | 4.08 × 103 |
| S | 3.63 × 102 | 5.32 × 102 | 3.28 × 102 | 6.75 × 102 | 5.63 × 102 | ||
| R | 7 | 2 | 6 | 3 | 1 | ||
| F28 | 30 | M | 2.02 × 102 | 2.02 × 102 | 2.02 × 102 | 2.02 × 102 | 2.01 × 102 |
| S | 3.12 × 10−1 | 2.47 × 10−1 | 2.74 × 10−1 | 3.40 × 10−1 | 2.06 × 10−1 | ||
| R | 2 | 2 | 2 | 2 | 1 | ||
| F29 | 30 | M | 8.38 × 102 | 4.61 × 102 | 3.42 × 102 | 3.44 × 102 | 3.42 × 102 |
| S | 1.41 × 102 | 3.09 × 101 | 2.51 | 4.72 | 7.69 | ||
| R | 6 | 3 | 1 | 2 | 1 | ||
| F30 | 30 | M | 8.66 × 102 | 5.72 × 102 | 5.87 × 102 | 5.52 × 102 | 4.87 × 102 |
| S | 1.27 × 102 | 1.90 × 101 | 1.01 × 101 | 2.72 × 101 | 1.70 × 101 | ||
| R | 7 | 3 | 4 | 2 | 1 | ||
| F31 | 30 | M | 1.35 × 105 | 5.12 × 102 | 2.23 × 103 | 5.03 × 102 | 5.03 × 102 |
| S | 2.64 × 105 | 2.26 | 2.50 × 103 | 1.04 | 1.25 | ||
| R | 6 | 2 | 5 | 1 | 1 | ||
| F32 | 30 | M | 6.13 × 102 | 6.11 × 102 | 6.12 × 102 | 6.14 × 102 | 6.12 × 102 |
| S | 3.90 × 10−1 | 1.37 | 4.38 × 10−1 | 8.16 × 10−1 | 9.72 × 10−1 | ||
| R | 3 | 1 | 2 | 4 | 2 | ||
| F33 | 30 | M | 2.24 × 103 | 1.10 × 103 | 1.10 × 103 | 1.03 × 103 | 1.02 × 103 |
| S | 5.14 × 102 | 5.13 × 101 | 1.65 × 102 | 1.53 × 102 | 5.91 × 101 | ||
| R | 6 | 3 | 3 | 2 | 1 | ||
| F34 | 30 | M | 7.96 × 103 | 5.09 × 103 | 2.89 × 103 | 1.38 × 103 | 2.02 × 103 |
| S | 5.85 × 102 | 5.47 × 102 | 5.56 × 102 | 3.83 × 102 | 3.87 × 102 | ||
| R | 7 | 4 | 3 | 1 | 2 | ||
| F35 | 30 | M | 8.13 × 103 | 5.55 × 103 | 8.14 × 103 | 6.53 × 103 | 5.11 × 103 |
| S | 4.65 × 102 | 7.54 × 102 | 2.75 × 102 | 6.16 × 102 | 8.07 × 102 | ||
| R | 6 | 2 | 7 | 4 | 1 | ||
| F36 | 30 | M | 1.30 × 103 | 1.26 × 103 | 1.28 × 103 | 1.28 × 103 | 1.27 × 103 |
| S | 7.28 | 6.62 | 5.07 | 1.03 × 101 | 7.17 | ||
| R | 5 | 1 | 3 | 3 | 2 | ||
| F37 | 30 | M | 1.42 × 103 | 1.38 × 103 | 1.39 × 103 | 1.39 × 103 | 1.38 × 103 |
| S | 1.45 × 101 | 1.07 × 101 | 9.56 | 7.53 | 8.22 | ||
| R | 5 | 1 | 2 | 2 | 1 | ||
| F38 | 30 | M | 1.56 × 103 | 1.47 × 103 | 1.50 × 103 | 1.40 × 103 | 1.40 × 103 |
| S | 7.22 × 101 | 7.39 × 101 | 9.29 × 101 | 4.01 × 10−1 | 1.30 × 10−3 | ||
| R | 5 | 2 | 3 | 1 | 1 | ||
| F39 | 30 | M | 2.57 × 103 | 2.08 × 103 | 2.51 × 103 | 2.39 × 103 | 2.25 × 103 |
| S | 1.16 × 102 | 7.64 × 101 | 9.04 × 101 | 8.60 × 101 | 9.18 × 101 | ||
| R | 7 | 1 | 6 | 3 | 2 | ||
| F40 | 30 | M | 4.69 × 103 | 1.87 × 103 | 3.18 × 103 | 2.08 × 103 | 1.76 × 103 |
| S | 6.74 × 102 | 6.70 × 101 | 3.92 × 102 | 5.11 × 102 | 2.59 × 102 | ||
| R | 7 | 2 | 4 | 3 | 1 | ||
| Average R | 5.96 | 2.18 | 3.71 | 2.21 | 1.36 | ||
| Final R | 7 | 2 | 4 | 3 | 1 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, W.; Liu, Y.; Zhang, X. Hybrid Particle Swarm Optimization Algorithm Based on the Theory of Reinforcement Learning in Psychology. Systems 2023, 11, 83. https://doi.org/10.3390/systems11020083
Huang W, Liu Y, Zhang X. Hybrid Particle Swarm Optimization Algorithm Based on the Theory of Reinforcement Learning in Psychology. Systems. 2023; 11(2):83. https://doi.org/10.3390/systems11020083
Chicago/Turabian StyleHuang, Wenya, Youjin Liu, and Xizheng Zhang. 2023. "Hybrid Particle Swarm Optimization Algorithm Based on the Theory of Reinforcement Learning in Psychology" Systems 11, no. 2: 83. https://doi.org/10.3390/systems11020083
APA StyleHuang, W., Liu, Y., & Zhang, X. (2023). Hybrid Particle Swarm Optimization Algorithm Based on the Theory of Reinforcement Learning in Psychology. Systems, 11(2), 83. https://doi.org/10.3390/systems11020083