
A Universality–Distinction Mechanism-Based Multi-Step Sales Forecasting for Sales Prediction and Inventory Optimization


Abstract
:1. Introduction
- We propose a universality–distinction mechanism (UDM) framework, which consists of universality extraction and distinction-capturing components to improve the accuracy of predictions of multiple future steps.
- “Universality” refers to the inherent characteristics and common correlation patterns found in sales sequences with similar contexts. The shared knowledge is initially learned through a universality extraction component that ensures the overall prediction window’s accuracy.
- “Distinction” refers to the process of identifying differences between time series in a sales MTS. To achieve this more efficiently, we propose an attention-based encoder–decoder framework with query-sparsity measurements, which enables us to capture distinct signals based on the states of future multi-step sales.
- We developed a novel loss function called Pin-DTW by jointly combining the pinball and DTW losses to enhance predictive performance. The DTW loss can make better use of the representations obtained from UDM to handle issues of time delay and shape distortion in future multi-step predictions. The pinball loss can be used to control the inventory shortage risk.
2. Related Work
2.1. Time Series Prediction
2.2. Sales Forecasting
2.2.1. Machine Learning Methods
2.2.2. Deep Learning Models
2.2.3. Integrated Models
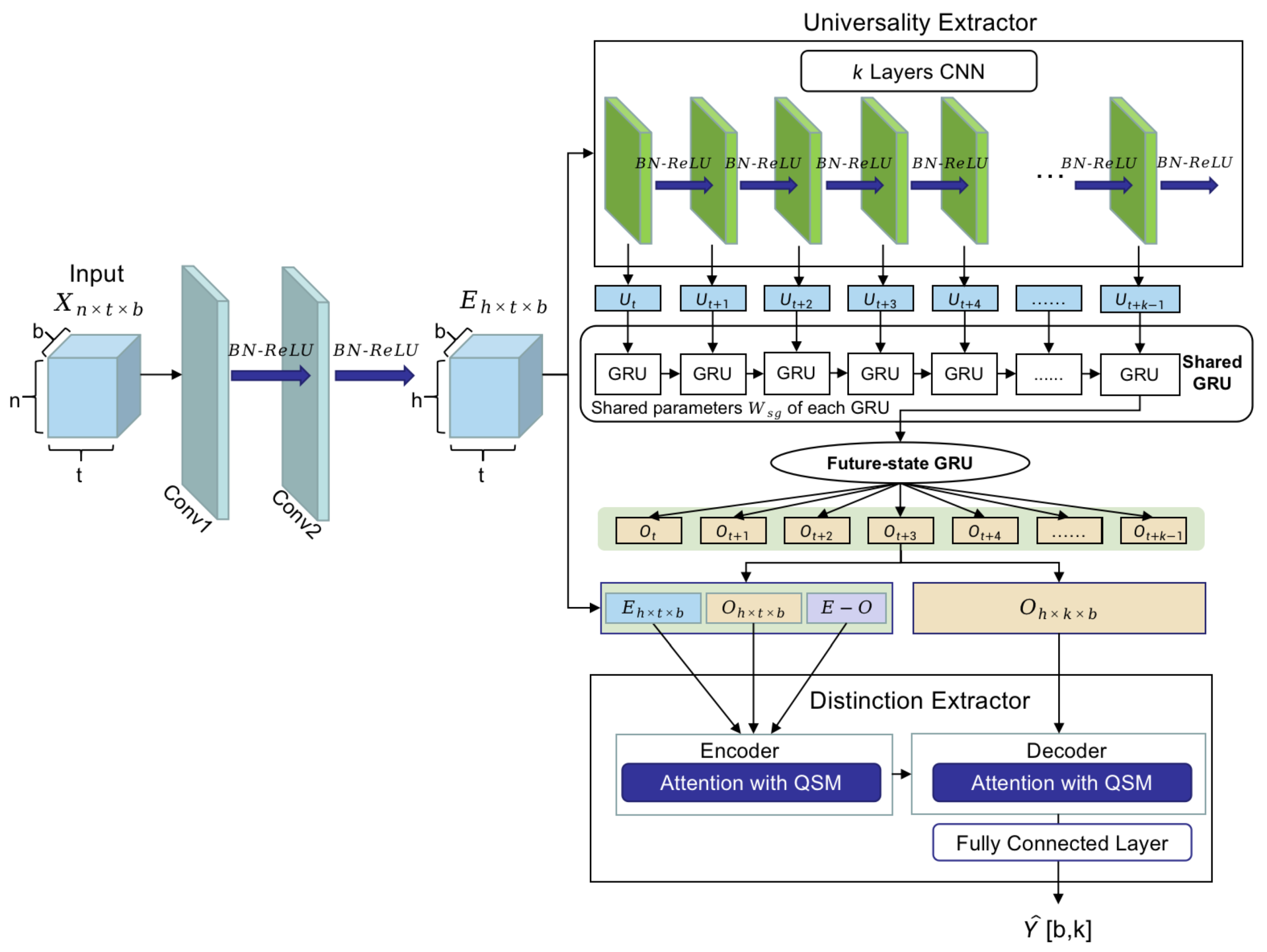
3. Model
3.1. Problem Statement
3.2. Convolutional Component
3.3. Universality Extracting
3.3.1. Shared GRU
3.3.2. Future-State GRU
3.4. Distinction Capturing
3.4.1. Encoder Layer
3.4.2. Query-Sparsity Measurement (QSM)-Based Attention
3.4.3. Decoder Layer
3.5. Loss Function
4. Experiments
4.1. Dataset
4.2. Metrics
- Mean absolute error (MAE):
- Mean Absolute percentage error (MAPE):
- Root mean squared error (RMSE):
- Empirical correlation coefficient (CORR):
4.3. Baselines
- Traditional TS modeling methods, including FBProphet [44], exponential smoothing [2], and ARIMA [45]. FBProphet is proposed by Facebook to forecast time series data based on an additive model, where non-linear trends are fit with yearly, weekly, and daily seasonalities. Exponential smoothing is one of the moving average methods, which is carried out according to the stability and regularity of the time series to reasonably extend the existing observation series and generate the prediction series. ARIMA stands for the autoregressive integrated moving average. It considers the previous values of the data, the degree of differencing required to achieve stationarity, and the moving average errors to make predictions for future values.
- Informer [10]: A model based on the transformer can effectively capture the dependencies in long sequences. It increases the capacities of long-time series predictions, and effectively controls the time and space complexities of model training.
- MLCNN [1]: This is a deep learning framework composed of a convolution neural network and recurrent neural network; it improves the predictive performance by fusing forecasting information of different future times.
4.4. Training Details
4.5. Main Results
4.5.1. The Advantage of the Informer
4.5.2. The Advantage of UDM
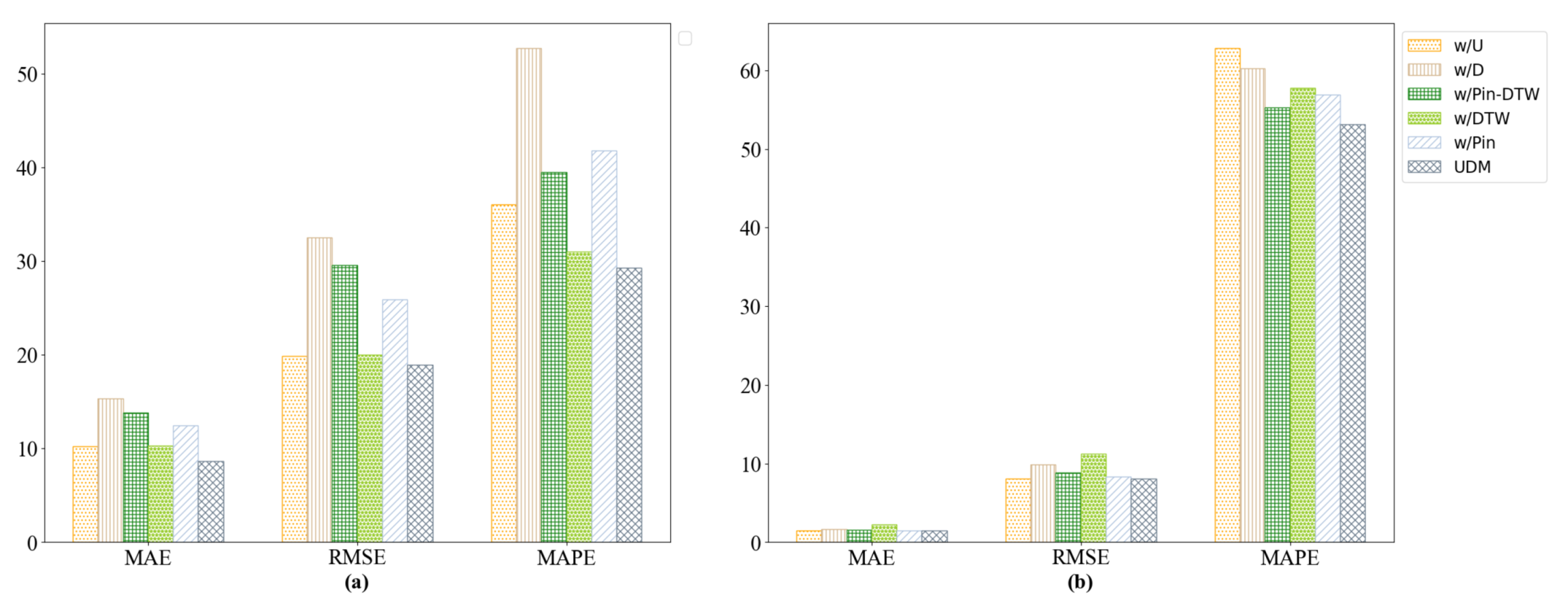
4.6. Ablation Study
- w/U: The universality-extracting component is removed from UDM.
- w/D: The distinction-capture component is removed from UDM.
- w/Pin-DTW: Pin-DTW loss is replaced by the MAE as the loss function.
- w/DTW: DTW is removed from the Pin-DTW loss function.
- w/Pin: Pinball loss is removed from the Pin-DTW loss function.
- Removing the distinction module causes great performance drops in terms of MAE metrics on the Galanz and Cainiao datasets; this proves that extracting the distinction module helps to achieve more accurate multi-step predictions.
- According to Figure 3a, the significant decline in MAE appears when the Pin-DTW loss is replaced by the MAE loss function. The metrics also clearly decrease when the pinball loss is removed from the Pin-DTW loss function, which illustrates the significant contributions of the joint Pin-DTW loss function, especially the pinball loss function, to the Galanz dataset. However, Figure 3b shows that the DTW component in the Pin-DTW loss function contributes more to the Cainiao dataset.
- Removing the universality module results in a more obvious decrease in MAE in the Galanz dataset than the Cainiao dataset, which indicates that capturing the common features of products from the same warehouse is effective in the Galanz dataset, and great differences exist between the different warehouses.
4.7. Further Analysis
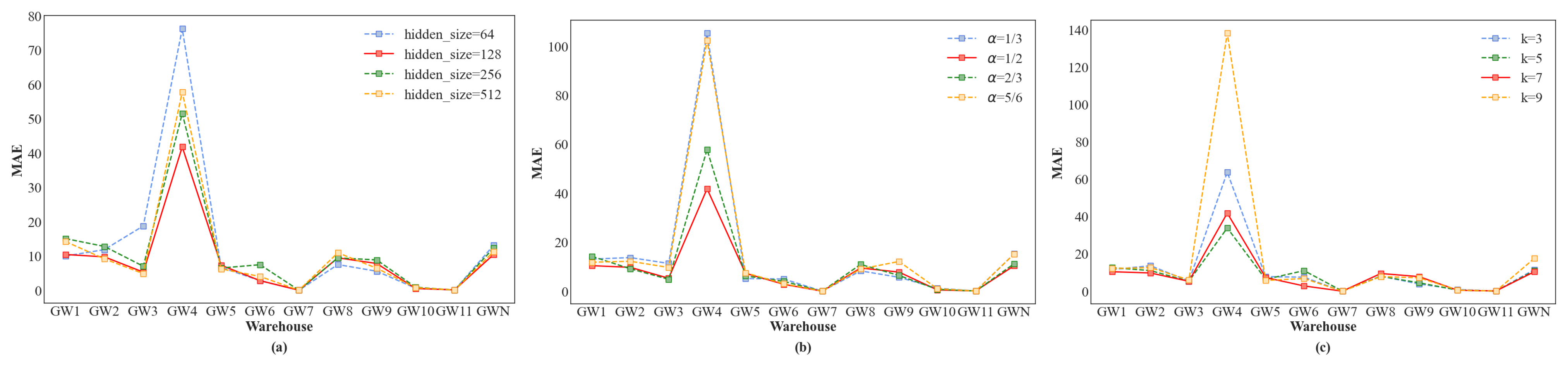
4.7.1. Parameter Sensitivity Analysis
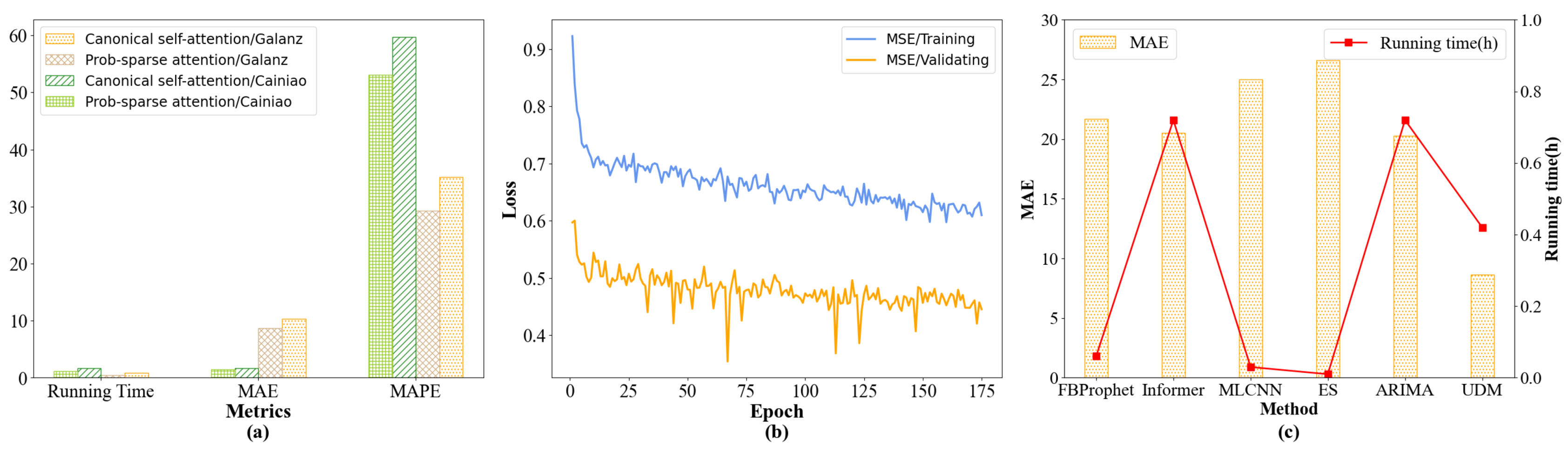
4.7.2. Comparative Analysis of Attention
4.7.3. Convergence and Time Complexity Analysis
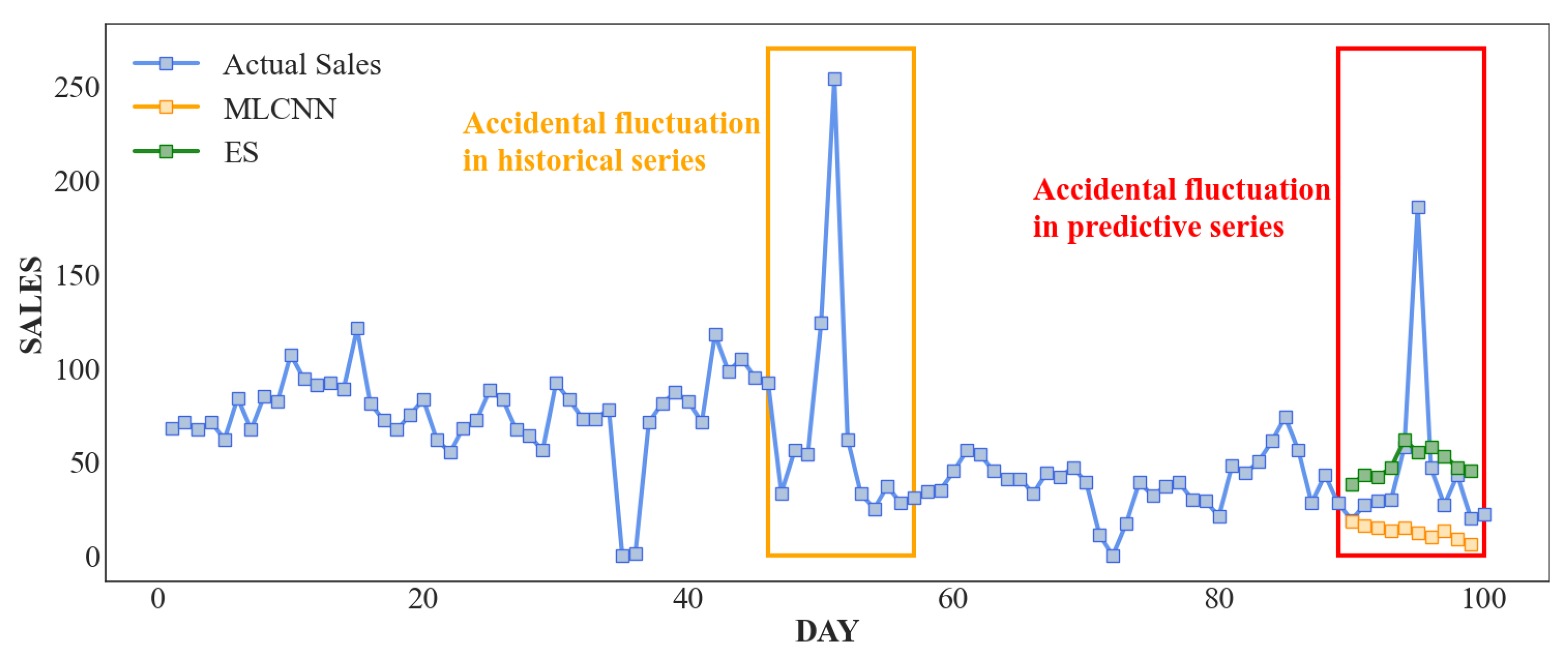
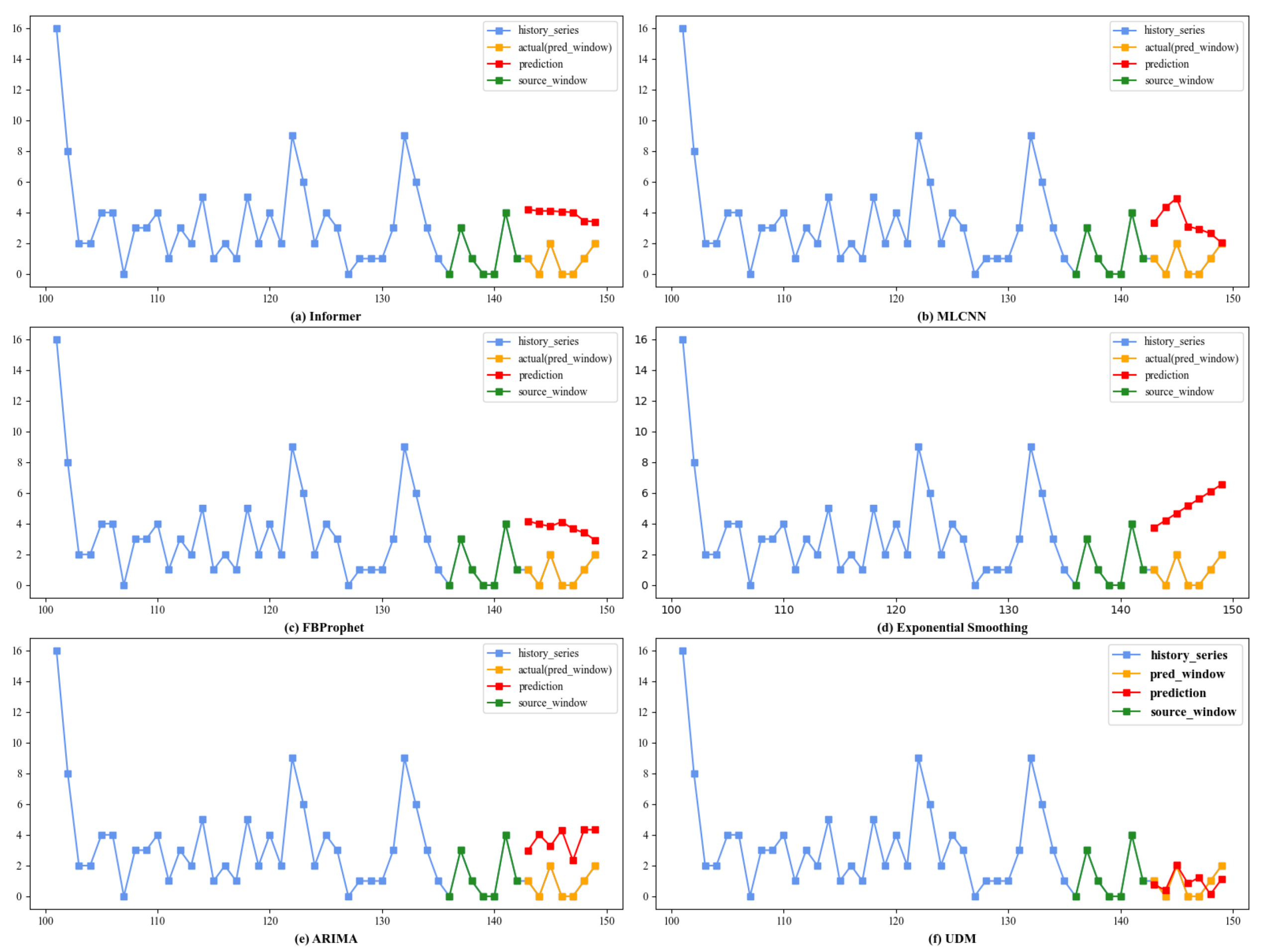
4.8. Case Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cheng, J.; Huang, K.; Zheng, Z. Towards Better Forecasting by Fusing Near and Distant Future Visions. Natl. Conf. Artif. Intell. 2020, 34, 3593–3600. [Google Scholar] [CrossRef]
- Harrison, P.J. Exponential Smoothing and Short-Term Sales Forecasting. Manag. Sci. 1967, 13, 821–842. [Google Scholar] [CrossRef]
- Slawek, S. A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting. Int. J. Forecast. 2020, 36, 75–85. [Google Scholar]
- David, S.; Valentin, F.; Jan, G.; Tim, J. DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks. Int. J. Forecast. 2020, 36, 1181–1191. [Google Scholar]
- Yudianto, M.R.A.; Agustin, T.; James, R.M.; Rahma, F.I.; Rahim, A.; Utami, E. Rainfall Forecasting to Recommend Crops Varieties Using Moving Average and Naive Bayes Methods. Int. J. Mod. Educ. Comput. Sci. 2021, 13, 23–33. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. Arch. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. Knowl. Discov. Data Min. 2016, 785–794. [Google Scholar]
- Lai, G.; Chang, W.C.; Yang, Y.; Liu, H. Modeling Long- and Short-Term Temporal Patterns with Deep Neural Networks. In Proceedings of the International Acm Sigir Conference on Research and Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 95–104. [Google Scholar]
- Lim, B.; Arik, S.O.; Loeff, N.; Pfister, T. Temporal Fusion Transformers for interpretable multi-horizon time series forecasting. Int. J. Forecast. 2021, 37, 1748–1764. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. Natl. Conf. Artif. Intell. 2021, 35, 11106–11115. [Google Scholar] [CrossRef]
- Qin, Y.; Song, D.; Chen, H.; Cheng, W.; Jiang, G.; Cottrell, G.W. A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction. arXiv 2017, arXiv:1704.02971. [Google Scholar]
- Farnoosh, A.; Azari, B.; Ostadabbas, S. Deep Switching Auto-Regressive Factorization:Application to Time Series Forecasting. Natl. Conf. Artif. Intell. 2021, 35, 7394–7403. [Google Scholar]
- Zhou, Q.; Han, R.; Li, T.; Xia, B. Joint prediction of time series data in inventory management. Knowl. Inf. Syst. 2019, 61, 905–929. [Google Scholar] [CrossRef]
- Hmamouche, Y.; Lakhal, L.; Casali, A. A scalable framework for large time series prediction. Knowl. Inf. Syst. 2021, 63, 1093–1116. [Google Scholar] [CrossRef]
- Tian, H.; Xu, Q. Time Series Prediction Method Based on E-CRBM. Electronics 2021, 10, 416. [Google Scholar] [CrossRef]
- Malhotra, P.; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P.; Shroff, G. LSTM-based Encoder-Decoder for Multi-sensor Anomaly Detection. arXiv 2016, arXiv:1607.00148. [Google Scholar]
- Wu, Y.; Ni, J.; Cheng, W.; Zong, B.; Song, D.; Chen, Z.; Liu, Y.; Zhang, X.; Chen, H.; Davidson, S.B. Dynamic Gaussian Mixture based Deep Generative Model For Robust Forecasting on Sparse Multivariate Time Series. Natl. Conf. Artif. Intell. 2021, 35, 651–659. [Google Scholar] [CrossRef]
- Eldele, E.; Ragab, M.; Chen, Z.; Wu, M.; Kwoh, C.K.; Li, X.; Guan, C. Time-Series Representation Learning via Temporal and Contextual Contrasting. arXiv 2021, arXiv:2106.14112. [Google Scholar]
- Pan, Q.; Hu, W.; Chen, N. Two Birds with One Stone: Series Saliency for Accurate and Interpretable Multivariate Time Series Forecasting. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; pp. 2884–2891. [Google Scholar]
- Chen, T.; Yin, H.; Chen, H.; Wang, H.; Zhou, X.; Li, X. Online sales prediction via trend alignment-based multitask recurrent neural networks. Knowl. Inf. Syst. 2020, 62, 2139–2167. [Google Scholar] [CrossRef]
- Hirche, M.; Farris, P.; Greenacre, L.; Quan, Y.; Wei, S. Predicting Under- and Overperforming SKUs within the Distribution–Market Share Relationship. J. Retail. 2021, 97, 697–714. [Google Scholar] [CrossRef]
- Jiang, H.; Ruan, J.; Sun, J. Application of Machine Learning Model and Hybrid Model in Retail Sales Forecast. In Proceedings of the 2021 IEEE 6th International Conference on Big Data, Xiamen, China, 5–8 March 2021; IEEE: Toulouse, France, 2021; pp. 69–75. [Google Scholar]
- Zhao, X.; Keikhosrokiani, P. Sales Prediction and Product Recommendation Model Through User Behavior Analytics. Cmc-Comput. Mater. Contin. 2022, 70, 3855–3874. [Google Scholar] [CrossRef]
- Ntakolia, C.; Kokkotiis, C.; Moustakidis, S.; Papageorgiou, E. An explainable machine learning pipeline for backorder prediction in inventory management systems. In Proceedings of the 25th Pan-Hellenic Conference on Informatics, Volos, Greece, 26–28 November 2021; pp. 229–234. [Google Scholar]
- Rohitash, C.; Shaurya, G.; Rishabh, G. Evaluation of Deep Learning Models for Multi-Step Ahead Time Series Prediction. IEEE Access 2021, 9, 83105–83123. [Google Scholar]
- Matteo, S.; Fabio, D. Robustness of LSTM neural networks for multi-step forecasting of chaotic time series. Chaos Solitons Fractals 2020, 139, 110045. [Google Scholar]
- Ou-Yang, C.; Chou, S.C.; Juan, Y.C. Improving the Forecasting Performance of Taiwan Car Sales Movement Direction Using Online Sentiment Data and CNN-LSTM Model. Appl. Sci. 2022, 12, 1550. [Google Scholar] [CrossRef]
- Paterakis, N.G.; Mocanu, E.; Gibescu, M.; Stappers, B.; van Alst, W. Deep learning versus traditional machine learning methods for aggregated energy demand prediction. In Proceedings of the IEEE Pes Innovative Smart Grid Technologies Conference, Turin, Italy, 26–29 September 2017; IEEE: Toulouse, France, 2017; pp. 1–6. [Google Scholar]
- Loureiro, A.L.D.; Miguéis, V.L.; da Silva, L.F.M. Exploring the use of deep neural networks for sales forecasting in fashion retail. Decis. Support Syst. 2018, 114, 81–93. [Google Scholar] [CrossRef]
- Qi, Y.; Li, C.; Deng, H.; Cai, M.; Qi, Y.; Deng, Y. A Deep Neural Framework for Sales Forecasting in E-Commerce. In Proceedings of the Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 299–308. [Google Scholar]
- Ma, S.; Fildes, R. Retail sales forecasting with meta-learning. Eur. J. Oper. Res. 2021, 288, 111–128. [Google Scholar] [CrossRef]
- Yaşar, B. Comparison of Forecasting Performance of ARIMA LSTM and HYBRID Models for The Sales Volume Budget of a Manufacturing Enterprise. Istanb. Bus. Res. 2021, 50, 15–46. [Google Scholar]
- Chen, I.F.; Lu, C.J. Demand Forecasting for Multichannel Fashion Retailers by Integrating Clustering and Machine Learning Algorithms. Processes 2021, 9, 1578. [Google Scholar] [CrossRef]
- Azadi, Z.; Eksioglu, S.; Eksioglu, B.; Palak, G. Stochastic optimization models for joint pricing and inventory replenishment of perishable products. Comput. Ind. Eng. 2019, 127, 625–642. [Google Scholar] [CrossRef]
- Perez, H.D.; Hubbs, C.D.; Li, C.; Grossmann, I.E. Algorithmic approaches to inventory management optimization. Processes 2021, 9, 102. [Google Scholar] [CrossRef]
- Junyoung, C.; Caglar, G.; KyungHyun, C.; Yoshua, B. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Shiyang, L.; Xiaoyong, J.; Yao, X.; Xiyou, Z.; Wenhu, C.; Yu-Xiang, W.; Xifeng, Y. Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting. Adv. Neural Inf. Process. Syst. 2019, 471, 5243–5253. [Google Scholar]
- Nikita, K.; Lukasz, K.; Anselm, L. Reformer: The Efficient Transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Fenglin, L.; Xuancheng, R.; Guangxiang, Z.; Chenyu, Y.; Xuewei, M.; Xian, W.; Xu, S. Rethinking and Improving Natural Language Generation with Layer-Wise Multi-View Decoding. arXiv 2020, arXiv:2005.08081. [Google Scholar]
- Tanveer, M.; Gupta, T.; Shah, M. Pinball Loss Twin Support Vector Clustering. Acm Trans. Multimed. Comput. Commun. Appl. 2021, 17, 1–23. [Google Scholar] [CrossRef]
- Guen, V.L.; Thome, N. Shape and Time Distortion Loss for Training Deep Time Series Forecasting Models. Neural Inf. Process. Syst. 2019, 377, 4189–4201. [Google Scholar]
- Daifeng, L.; Kaixin, L.; Xuting, L.; Jianbin, L.; Ruo, D.; Dingquan, C.; Andrew, M. Improved sales time series predictions using deep neural networks with spatiotemporal dynamic pattern acquisition mechanism. Inf. Process. Manag. 2022, 59, 102987. [Google Scholar]
- Chikkakrishna, N.K.; Hardik, C.; Deepika, K.; Sparsha, N. Short-Term Traffic Prediction Using Sarima and FbPROPHET. In Proceedings of the IEEE India Conference, Rajkot, India, 13–15 December 2019; IEEE: Toulouse, France, 2019; pp. 1–4. [Google Scholar]
- Gilbert, K. An ARIMA supply chain model. Manag. Sci. 2005, 51, 305–310. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Explain |
|---|---|
| The input time series | |
| The matrix of the encoded input time series | |
| The construals derived from CNNs | |
| The common correlation patterns | |
| The distinct fluctuation signals | |
| Three encoder functions with self-attention for , and | |
| A measurement function used to select important from matrix Q for the efficient attention calculation | |
| Decoder functions with cross-attention | |
| Shared weights of the GRU(Gate Recurrent Unit) component | |
| The parameters of the update gate and reset gate in the future-state GRU | |
| The k-step predictions for one batch | |
| A joint and loss function | |
| A loss function used to prevent higher out-of-stock costs | |
| A loss function used to align two sequences neatly, reducing the influence of delays and fluctuations |
| Dataset | Galanz | Cainiao |
|---|---|---|
| Warehouses | 11 | 5 |
| Product category quantity | 38 | 27 |
| Instances | 583 | 200 |
| Sample rate | 1 day | 1 day |
| Features | Product type | Product type |
| Historical sales | Historical sales | |
| Amount of shop discount | User visits records | |
| Perform discount amount | Visits to cart | |
| Discount rate | Collections user visits |
| Method | Metrics | GW1 | GW2 | GW3 | GW4 | GW5 | GW6 |
|---|---|---|---|---|---|---|---|
| FBProphet | MAE | 15.2847 | 30.3044 | 31.8755 | 34.4644 | 16.2163 | 16.7275 |
| MAPE | 57.9891 | 57.1674 | 55.8968 | 62.3766 | 55.8108 | 59.6338 | |
| RMSE | 52.4318 | 276.4578 | 277.0762 | 303.1195 | 61.2255 | 63.1584 | |
| CORR | 0.2373 | 0.1636 | 0.1613 | 0.2153 | 0.2248 | 0.2172 | |
| Informer | MAE | 17.6240 | 9.1548 | 4.1450 | 29.5429 | 5.1940 | 15.0258 |
| MAPE | 394.9109 | 22.5000 | 19.1176 | 80.0000 | 11.9055 | 457.2982 | |
| RMSE | 35.0193 | 38.1540 | 13.0211 | 41.3107 | 22.6037 | 17.4231 | |
| CORR | 0.3087 | 0.0000 | 0.0000 | 0.0000 | 0.0566 | 0.2400 | |
| MLCNN | MAE | 18.3824 | 33.6053 | 36.7638 | 37.6184 | 20.1129 | 20.7452 |
| MAPE | 371.8239 | 313.5209 | 312.2668 | 290.0065 | 354.7266 | 294.2883 | |
| RMSE | 60.9568 | 281.9341 | 286.2610 | 308.5424 | 72.1018 | 77.0757 | |
| CORR | 0.2163 | 0.1597 | 0.1681 | 0.1808 | 0.2084 | 0.1929 | |
| ES | MAE | 21.2214 | 34.1332 | 37.0971 | 40.3494 | 22.1497 | 23.0650 |
| MAPE | 267.1900 | 239.7035 | 254.3169 | 271.8555 | 258.0128 | 271.5501 | |
| RMSE | 63.8428 | 292.0610 | 294.4738 | 320.9468 | 72.0085 | 75.0383 | |
| CORR | 0.1986 | 0.1589 | 0.1545 | 0.1985 | 0.1934 | 0.1985 | |
| ARIMA | MAE | 14.2295 | 28.4680 | 30.0798 | 32.6718 | 15.3041 | 15.8134 |
| MAPE | 75.1275 | 67.6109 | 66.1797 | 76.7000 | 72.4418 | 75.8649 | |
| RMSE | 52.2138 | 282.8495 | 283.7393 | 309.1383 | 65.1573 | 66.4925 | |
| CORR | 0.1181 | 0.0961 | 0.0984 | 0.1154 | 0.1157 | 0.1146 | |
| UDM | MAE | 10.4198 | 9.7407 | 5.2871 | 41.7966 | 7.3015 | 2.8003 |
| MAPE | 82.7683 | 16.1626 | 16.4438 | 52.9563 | 10.2945 | 16.9803 | |
| RMSE | 34.2683 | 37.6247 | 12.4147 | 51.3284 | 21.7823 | 7.4525 | |
| CORR | 0.3373 | 0.0577 | 0.2435 | 0.5420 | 0.0703 | 0.0059 |
| Method | Metrics | GW7 | GW8 | GW9 | GW10 | GW11 | GW1-N |
|---|---|---|---|---|---|---|---|
| FBProphet | MAE | 9.0854 | 17.9634 | 28.0403 | 27.2752 | 11.2483 | 21.6805 |
| MAPE | 70.7815 | 59.7207 | 58.4812 | 51.8571 | 63.3920 | 59.3717 | |
| RMSE | 25.1791 | 74.1755 | 265.7824 | 266.1724 | 40.2530 | 155.0029 | |
| CORR | 0.2347 | 0.2153 | 0.1605 | 0.1716 | 0.2265 | 0.2025 | |
| Informer | MAE | 0.0089 | 135.4354 | 3.8177 | 5.6080 | 0.0470 | 20.5094 |
| MAPE | 4.2647 | 399.4997 | 25.7501 | 87.0297 | 1.2546 | 136.6846 | |
| RMSE | 0.0945 | 139.5018 | 8.4105 | 5.9640 | 0.1817 | 29.2440 | |
| CORR | 0.0000 | 0.1250 | 0.1975 | 0.0986 | 0.0097 | 0.0942 | |
| MLCNN | MAE | 10.5993 | 21.9535 | 31.4661 | 30.6287 | 13.3700 | 25.0223 |
| MAPE | 395.6474 | 296.0490 | 348.4923 | 282.7980 | 377.6082 | 330.6571 | |
| RMSE | 26.1790 | 84.4675 | 273.0667 | 269.1123 | 43.8731 | 162.1428 | |
| CORR | 0.2212 | 0.2081 | 0.1561 | 0.1635 | 0.2249 | 0.1909 | |
| ES | MAE | 12.4604 | 24.1590 | 31.9851 | 31.6545 | 14.2210 | 26.5905 |
| MAPE | 201.3380 | 271.0901 | 241.4655 | 210.1611 | 189.3783 | 243.2783 | |
| RMSE | 31.4932 | 84.5216 | 282.4325 | 282.8159 | 43.0267 | 167.5147 | |
| CORR | 0.2028 | 0.1968 | 0.1601 | 0.1616 | 0.1976 | 0.1837 | |
| ARIMA | MAE | 7.6219 | 16.8480 | 26.4030 | 25.6837 | 9.7364 | 20.2600 |
| MAPE | 74.3844 | 75.8856 | 68.5079 | 62.2803 | 70.6236 | 71.4188 | |
| RMSE | 23.0878 | 77.0473 | 270.6166 | 271.3406 | 38.8939 | 158.2343 | |
| CORR | 0.1303 | 0.1180 | 0.0938 | 0.0988 | 0.1200 | 0.1108 | |
| UDM | MAE | 0.0089 | 9.4581 | 7.7964 | 0.5114 | 0.1156 | 8.6579 |
| MAPE | 2.3156 | 11.5199 | 95.4989 | 7.0528 | 10.0944 | 29.2807 | |
| RMSE | 0.0943 | 31.7277 | 9.6884 | 1.6839 | 0.1855 | 18.9319 | |
| CORR | 0.0000 | 0.1028 | 0.2198 | 0.0846 | 0.0089 | 0.1521 |
| Method | Metrics | CW1 | CW2 | CW3 | CW4 | CW5 | CW1-N |
|---|---|---|---|---|---|---|---|
| FBProphet | MAE | 1.5912 | 1.3346 | 1.8584 | 2.3292 | 1.7956 | 1.7818 |
| MAPE | 62.1643 | 50.6469 | 67.7299 | 66.1445 | 61.5287 | 61.6429 | |
| RMSE | 7.5401 | 6.5327 | 7.9424 | 12.1592 | 8.3002 | 8.4949 | |
| CORR | 0.2532 | 0.2264 | 0.2422 | 0.2462 | 0.2480 | 0.2432 | |
| Informer | MAE | 1.8133 | 1.5807 | 2.1339 | 2.7799 | 2.0071 | 2.0630 |
| MAPE | 87.9340 | 78.3794 | 61.2950 | 66.2499 | 93.0463 | 77.3809 | |
| RMSE | 8.2744 | 7.2051 | 8.7268 | 13.8907 | 8.7783 | 9.3751 | |
| CORR | 0.2476 | 0.2369 | 0.2628 | 0.2601 | 0.2405 | 0.2496 | |
| MLCNN | MAE | 1.7142 | 1.4752 | 2.1640 | 2.6487 | 1.8236 | 1.9651 |
| MAPE | 63.3250 | 60.5524 | 94.3953 | 63.0208 | 88.9358 | 74.0459 | |
| RMSE | 7.8343 | 6.9332 | 9.4610 | 13.4777 | 8.8779 | 9.3168 | |
| CORR | 0.2353 | 0.2021 | 0.2581 | 0.2338 | 0.2190 | 0.2296 | |
| ES | MAE | 2.0410 | 1.9012 | 2.6317 | 3.2389 | 2.3219 | 2.4269 |
| MAPE | 70.3472 | 65.9903 | 86.5732 | 86.4917 | 81.6856 | 78.2176 | |
| RMSE | 8.3194 | 7.3440 | 9.4947 | 13.5777 | 9.5196 | 9.6511 | |
| CORR | 0.2449 | 0.2059 | 0.2686 | 0.2394 | 0.2080 | 0.2333 | |
| ARIMA | MAE | 1.6612 | 1.4361 | 1.8497 | 2.5363 | 1.6870 | 1.8340 |
| MAPE | 59.6706 | 49.3459 | 59.6440 | 63.6416 | 50.5761 | 56.5757 | |
| RMSE | 7.8752 | 7.0230 | 7.9706 | 12.6939 | 8.4314 | 8.7988 | |
| CORR | 0.1462 | 0.1392 | 0.1483 | 0.1527 | 0.1483 | 0.1460 | |
| UDM | MAE | 1.3642 | 1.1498 | 1.5688 | 2.0236 | 1.3251 | 1.4863 |
| MAPE | 55.6866 | 47.1187 | 55.7236 | 58.4229 | 48.7573 | 53.1418 | |
| RMSE | 7.2861 | 6.2559 | 7.3421 | 11.5921 | 7.7595 | 8.0472 | |
| CORR | 0.2680 | 0.1985 | 0.2697 | 0.2065 | 0.1967 | 0.2279 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, D.; Li, X.; Gu, F.; Pan, Z.; Chen, D.; Madden, A. A Universality–Distinction Mechanism-Based Multi-Step Sales Forecasting for Sales Prediction and Inventory Optimization. Systems 2023, 11, 311. https://doi.org/10.3390/systems11060311
Li D, Li X, Gu F, Pan Z, Chen D, Madden A. A Universality–Distinction Mechanism-Based Multi-Step Sales Forecasting for Sales Prediction and Inventory Optimization. Systems. 2023; 11(6):311. https://doi.org/10.3390/systems11060311
Chicago/Turabian StyleLi, Daifeng, Xin Li, Fengyun Gu, Ziyang Pan, Dingquan Chen, and Andrew Madden. 2023. "A Universality–Distinction Mechanism-Based Multi-Step Sales Forecasting for Sales Prediction and Inventory Optimization" Systems 11, no. 6: 311. https://doi.org/10.3390/systems11060311
APA StyleLi, D., Li, X., Gu, F., Pan, Z., Chen, D., & Madden, A. (2023). A Universality–Distinction Mechanism-Based Multi-Step Sales Forecasting for Sales Prediction and Inventory Optimization. Systems, 11(6), 311. https://doi.org/10.3390/systems11060311