


Adapting Feature Selection Algorithms for the Classification of Chinese Texts

 ,
, 
 , , , and
, , , and 
Abstract
:1. Introduction
2. Related Work
- (1)
- Search for basic theory. In the 1950s, Dr. Luhn proposed the method of automatically creating article abstracts by word frequency statistics, which constituted the core idea of early text classification [11]. In 1960, Maron and Kuhn proposed a probabilistic indexing model for document indexing and searching in the library scene [12].
- (2)
- Experimental exploration. Maron designed an experiment based on the ‘Bayesian hypothesis’ to realize automatic indexing of texts according to text keyword information [13]. The ‘Vector Space Model’ proposed by Salton and Wang represented those terms with text topic features in the text as feature vectors and transformed the problem of calculating the similarity of text into the issue of calculating the cosine of the included angle for the feature vector corresponding to the text [14].
- (3)
- Application of machine learning. In 2000, scholars proposed a model that can learn through the distribution of words and the probability function of word sequences and achieved good results [15]. In 2008, scholars proposed a general deep neural network (DNN) when dealing with natural language process tasks [16]. After that, they offered a multi-functional learning algorithm and obtained a relatively unified neural network with word vectors [17]. In 2013, researchers from Google used the continuous skip-gram model to train the distributed representation of words and phrases and proposed a harmful sampling method that can replace hierarchical softmax [18]. In the same year, Brandon proposed for the first time a network model using a multi-layer neural network, which has a more vital learning ability [19]. In 2014, Kim used convolutional neural networks (CNN) in text classification and achieved excellent results [20].
3. Materials and Methods
3.1. Workflow
3.2. Corpus Selection
3.3. Data Preprocessing
3.3.1. Removing Marks
3.3.2. Text Segmentation
3.3.3. Removing Functional Words
3.3.4. Structured Representation
3.4. Adjusting Feature Selection Algorithms
3.4.1. A CHMI Algorithm Considering Word Frequency
- (1)
- Improvement of CHI algorithm
- (2)
- Improvement of MI algorithm
- (3)
- Formation of CHMI algorithm
3.4.2. A TF–CHI Algorithm Considering Word Weights
- (1)
- TF–IDF algorithm
- (2)
- The TF–CHI algorithm
3.4.3. A TF–XGB Algorithm for Dimension Reduction
- (1)
- The XGBoost algorithm
- (2)
- The TF–XGB algorithm
- (1)
- According to the distribution of terms in the data set, Equation (5) of the TF–IDF algorithm is used to calculate the weight values of all terms, and then a unique index is generated for each term. This study then selects the most prominent feature words and obtains their term indexes, orders them by weight, and saves them as a sequence (.
- (2)
- According to the term index obtained in Step (1), this study obtains and generates a corresponding set of terms: (from large to small).
- (3)
- For all the words in the set of terms, the number of times each word in the decision tree is selected as the optimal partition attribute to separately count the importance of these words [40] until the optimal partition attribute times of all the words are obtained and recorded as (from large to small).
- (4)
- This study then uses Equation (8) to calculate the importance values of all the words, which are arranged in descending order and recorded as .
- (5)
- are accumulated and calculated according to method, and the results are recorded as .
- (6)
- The term set can be obtained, as shown in Equation (9). is the threshold to choose feature words and could only be determined after multiple classification experiments on the same data set by manually evaluating the variation trend of the -score of the classification result.
3.5. Classifier Selection and Evaluation Setting
- (1)
- Number of features for evaluation with SVM classifier
- (2)
- Number of features for evaluations with NB classifier
3.6. Evaluation of the Performance of Feature Selection Algorithms
- (1)
- Precision
- (2)
- Recall Rate
- (3)
- F1-score
4. Results
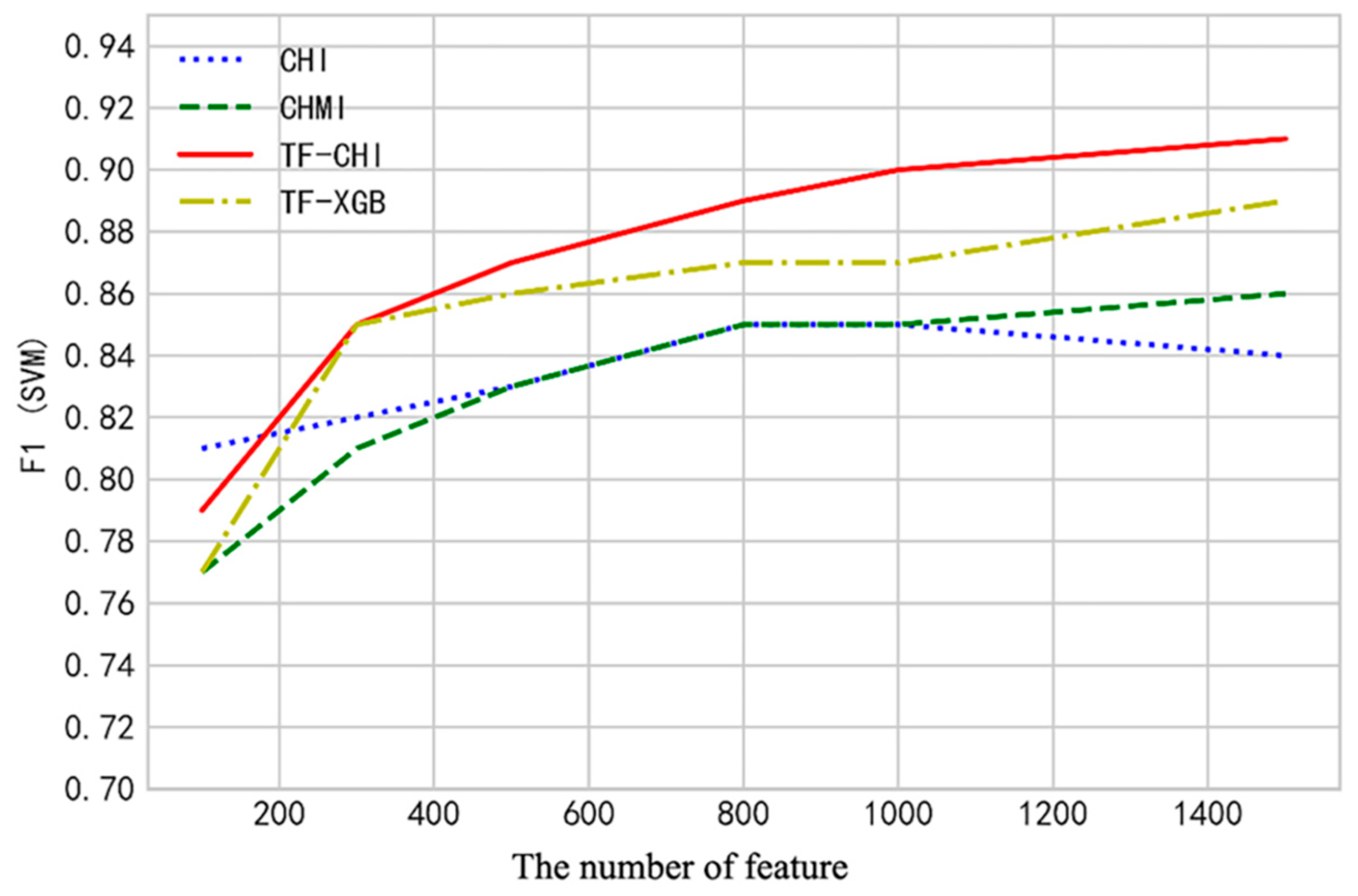
4.1. Classification Results and Comparison for SVM Classifier
4.2. Classification Results and Comparison for NB Classifier
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, X.; Shi, T.; Zhou, G.; Liu, M.; Yin, Z.; Yin, L.; Zheng, W. Emotion classification for short texts: An improved multi-label method. Humanit. Soc. Sci. Commun. 2023, 10, 306. [Google Scholar] [CrossRef]
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Jiang, A.-H.; Huang, X.-C.; Zhang, Z.-H.; Li, J.; Zhang, Z.-Y.; Hua, H.-X. Mutual information algorithms. Mech. Syst. Signal Process. 2010, 24, 2947–2960. [Google Scholar] [CrossRef]
- Lancaster, H.O.; Seneta, E. Chi-Square Distribution. In Encyclopedia of Biostatistics; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar] [CrossRef]
- Bai, L.; Li, H.; Gao, W.; Xie, J.; Wang, H. A joint multiobjective optimization of feature selection and classifier design for high-dimensional data classification. Inf. Sci. 2023, 626, 457–473. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, G.; Kong, M.; Yin, Z.; Li, X.; Yin, L.; Zheng, W. Developing Multi-Labelled Corpus of Twitter Short Texts: A Semi-Automatic Method. Systems 2023, 11, 390. [Google Scholar] [CrossRef]
- Bai, R.; Wang, X.; Liao, J. Extract semantic information from wordnet to improve text classification performance. In Proceedings of the International Conference on Advanced Computer Science and Information Technology, Miyazaki, Japan, 23–25 June 2010; pp. 409–420. [Google Scholar] [CrossRef]
- Shi, F.; Chen, L.; Han, J.; Childs, P. A data-driven text mining and semantic network analysis for design information retrieval. J. Mech. Des. 2017, 139, 111402. [Google Scholar] [CrossRef]
- Wang, W.; Yan, Y.; Winkler, S.; Sebe, N. Category specific dictionary learning for attribute specific feature selection. IEEE Trans. Image Process. 2016, 25, 1465–1478. [Google Scholar] [CrossRef]
- Szczepanek, R. A Deep Learning Model of Spatial Distance and Named Entity Recognition (SD-NER) for Flood Mark Text Classification. Water 2023, 15, 1197. [Google Scholar] [CrossRef]
- Luhn, H.P. The automatic creation of literature abstracts. IBM J. Res. Dev. 1958, 2, 159–165. [Google Scholar] [CrossRef]
- Maron, M.E.; Kuhns, J.L. On relevance, probabilistic indexing and information retrieval. J. ACM 1960, 7, 216–244. [Google Scholar] [CrossRef]
- Maron, M.E. Automatic indexing: An experimental inquiry. J. ACM 1961, 8, 404–417. [Google Scholar] [CrossRef]
- Salton, G.; Wong, A.; Yang, C.-S. A vector space model for automatic indexing. Commun. ACM 1975, 18, 613–620. [Google Scholar] [CrossRef]
- Bengio, Y.; Ducharme, R.; Vincent, P. A neural probabilistic language model. In Proceedings of the 13th 2000 Neural Information Processing Systems (NIPS) Conference, Denver, CO, USA, 29 November–4 December 1999. [Google Scholar]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Carson City, NV, USA, 5–10 December 2013. [Google Scholar]
- Barakat, B.K.; Seitz, A.R.; Shams, L. The effect of statistical learning on internal stimulus representations: Predictable items are enhanced even when not predicted. Cognition 2013, 129, 205–211. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef]
- Cao, S.; Lu, W.; Zhou, J.; Li, X. cw2vec: Learning Chinese word embeddings with stroke n-gram information. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar] [CrossRef]
- Wan, C.; Wang, Y.; Liu, Y.; Ji, J.; Feng, G. Composite feature extraction and selection for text classification. IEEE Access 2019, 7, 35208–35219. [Google Scholar] [CrossRef]
- Zhu, M.; Yang, X. Chinese texts classification system. In Proceedings of the 2019 IEEE 2nd International Conference on Information and Computer Technologies (ICICT), Kahului, HI, USA, 14–17 March 2019; pp. 149–152. [Google Scholar] [CrossRef]
- Pan, L.; Hang, C.-W.; Sil, A.; Potdar, S. Improved text classification via contrastive adversarial training. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; pp. 11130–11138. [Google Scholar] [CrossRef]
- Zhang, M.-L.; Zhou, Z.-H. A review on multi-label learning algorithms. IEEE Trans. Knowl. Data Eng. 2013, 26, 1819–1837. [Google Scholar] [CrossRef]
- Onan, A.; Korukoğlu, S.; Bulut, H. Ensemble of keyword extraction methods and classifiers in text classification. Expert Syst. Appl. 2016, 57, 232–247. [Google Scholar] [CrossRef]
- Kang, M.; Ahn, J.; Lee, K. Opinion mining using ensemble text hidden Markov models for text classification. Expert Syst. Appl. 2018, 94, 218–227. [Google Scholar] [CrossRef]
- Azam, N.; Yao, J. Comparison of term frequency and document frequency based feature selection metrics in text categorization. Expert Syst. Appl. 2012, 39, 4760–4768. [Google Scholar] [CrossRef]
- Omuya, E.O.; Okeyo, G.O.; Kimwele, M.W. Feature Selection for Classification using Principal Component Analysis and Information Gain. Expert Syst. Appl. 2021, 174, 114765. [Google Scholar] [CrossRef]
- Vora, S.; Yang, H. A comprehensive study of eleven feature selection algorithms and their impact on text classification. In Proceedings of the 2017 Computing Conference, London, UK, 18–20 July 2017; pp. 440–449. [Google Scholar] [CrossRef]
- Qaiser, S.; Ali, R. Text mining: Use of TF-IDF to examine the relevance of words to documents. Int. J. Comput. Appl. 2018, 181, 25–29. [Google Scholar] [CrossRef]
- Sun, J. Jieba Chinese Word Segmentation Tool. 2012. Available online: https://github.com/fxsjy/jieba (accessed on 1 September 2022).
- Yao, Z.; Ze-wen, C. Research on the construction and filter method of stop-word list in text preprocessing. In Proceedings of the 2011 Fourth International Conference on Intelligent Computation Technology and Automation, Shenzhen, China, 28–29 March 2011; pp. 217–221. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, X.; Yu, S.; Wang, Y. Research on keyword extraction of Word2vec model in Chinese corpus. In Proceedings of the 2018 IEEE/ACIS 17th International Conference on Computer and Information Science (ICIS), Singapore, 6–8 June 2018; pp. 339–343. [Google Scholar] [CrossRef]
- Shah, F.P.; Patel, V. A review on feature selection and feature extraction for text classification. In Proceedings of the 2016 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, India, 23–25 March 2016; pp. 2264–2268. [Google Scholar] [CrossRef]
- Zhai, Y.; Song, W.; Liu, X.; Liu, L.; Zhao, X. A chi-square statistics-based feature selection method in text classification. In Proceedings of the 2018 IEEE 9th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 23–25 November 2018; pp. 160–163. [Google Scholar] [CrossRef]
- Liang, D.; Yi, B. Two-stage three-way enhanced technique for ensemble learning in inclusive policy text classification. Inf. Sci. 2021, 547, 271–288. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Approximating XGBoost with an interpretable decision tree. Inf. Sci. 2021, 572, 522–542. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Real Category (Positive) | Real Category (Negative) | |
|---|---|---|
| Forecast category: (Positive) | TP | FP |
| Forecast category: (Negative) | FN | TN |
| Category | Military | Sports | IT | Economy | Automobile | Health | Average | ||
|---|---|---|---|---|---|---|---|---|---|
| Evaluate | |||||||||
| Precision | CHI | 66% | 91% | 87% | 76% | 93% | 85% | 83% | |
| CHMI | 70% | 95% | 90% | 79% | 97% | 87% | 86% | ||
| TF–CHI | 88% | 95% | 92% | 84% | 99% | 83% | 90% | ||
| TF–XGB | 89% | 94% | 89% | 79% | 100% | 77% | 88% | ||
| -score | CHI | 76% | 92% | 75% | 78% | 90% | 79% | 81% | |
| CHMI | 79% | 93% | 81% | 82% | 93% | 83% | 85% | ||
| TF–CHI | 90% | 95% | 85% | 86% | 97% | 87% | 90% | ||
| TF–XGB | 89% | 95% | 80% | 82% | 91% | 83% | 87% | ||
| Real Category | ||||||||
|---|---|---|---|---|---|---|---|---|
| Military | Sports | IT | Economy | Automobile | Health | |||
| Forecast category | Military | CHI | 138 | 8 | 18 | 13 | 18 | 19 |
| CHMI | 136 | 3 | 15 | 10 | 13 | 15 | ||
| TF–CHI | 140 | 5 | 3 | 7 | 1 | 4 | ||
| TF–XGB | 138 | 3 | 2 | 7 | 4 | 3 | ||
| Sports | CHI | 3 | 138 | 4 | 2 | 1 | 2 | |
| CHMI | 3 | 143 | 2 | 1 | 0 | 2 | ||
| TF–CHI | 5 | 145 | 1 | 0 | 0 | 1 | ||
| TF–XGB | 4 | 146 | 1 | 0 | 0 | 1 | ||
| IT | CHI | 1 | 1 | 91 | 9 | 0 | 3 | |
| CHMI | 2 | 1 | 104 | 4 | 2 | 2 | ||
| TF–CHI | 0 | 0 | 109 | 7 | 0 | 2 | ||
| TF–XGB | 1 | 1 | 100 | 6 | 2 | 2 | ||
| Economy | CHI | 3 | 0 | 15 | 115 | 0 | 16 | |
| CHMI | 5 | 1 | 14 | 119 | 0 | 13 | ||
| TF–CHI | 3 | 1 | 15 | 127 | 0 | 6 | ||
| TF–XGB | 2 | 1 | 21 | 123 | 0 | 8 | ||
| Automobile | CHI | 2 | 0 | 6 | 1 | 130 | 1 | |
| CHMI | 1 | 2 | 2 | 1 | 136 | 0 | ||
| TF–CHI | 0 | 3 | 0 | 0 | 140 | 1 | ||
| TF–XGB | 0 | 0 | 0 | 0 | 134 | 0 | ||
| Health | CHI | 5 | 3 | 4 | 5 | 0 | 111 | |
| CHMI | 3 | 3 | 5 | 4 | 1 | 122 | ||
| TF–CHI | 4 | 1 | 10 | 4 | 8 | 138 | ||
| TF–XGB | 5 | 2 | 14 | 9 | 9 | 138 | ||
| Category | Military | Sports | IT | Economy | Automobile | Health | Average | ||
|---|---|---|---|---|---|---|---|---|---|
| Evaluate | |||||||||
| Precision | CHI | 93% | 93% | 56% | 77% | 94% | 91% | 85% | |
| CHMI | 97% | 96% | 60% | 82% | 97% | 97% | 88% | ||
| TF–CHI | 95% | 94% | 83% | 83% | 97% | 94% | 91% | ||
| TF–XGB | 96% | 92% | 81% | 77% | 99% | 90% | 90% | ||
| -score | CHI | 78% | 94% | 67% | 82% | 86% | 84% | 82% | |
| CHMI | 85% | 96% | 72% | 87% | 88% | 90% | 86% | ||
| TF–CHI | 92% | 96% | 84% | 87% | 97% | 91% | 91% | ||
| TF–XGB | 91% | 95% | 80% | 83% | 97% | 89% | 89% | ||
| Real Category | ||||||||
|---|---|---|---|---|---|---|---|---|
| Military | Sports | IT | Economy | Automobile | Health | |||
| Forecast category | Military | CHI | 111 | 1 | 0 | 4 | 1 | 3 |
| CHMI | 126 | 0 | 0 | 2 | 0 | 2 | ||
| TF–CHI | 132 | 1 | 0 | 1 | 0 | 5 | ||
| TF–XGB | 143 | 0 | 0 | 2 | 0 | 4 | ||
| Sports | CHI | 4 | 143 | 2 | 1 | 0 | 3 | |
| CHMI | 2 | 147 | 1 | 1 | 1 | 2 | ||
| TF–CHI | 6 | 147 | 2 | 0 | 0 | 1 | ||
| TF–XGB | 7 | 148 | 2 | 1 | 0 | 3 | ||
| IT | CHI | 22 | 2 | 115 | 8 | 32 | 17 | |
| CHMI | 11 | 3 | 118 | 5 | 29 | 14 | ||
| TF–CHI | 4 | 1 | 116 | 8 | 6 | 4 | ||
| TF–XGB | 3 | 1 | 108 | 9 | 8 | 4 | ||
| Economy | CHI | 11 | 0 | 17 | 128 | 0 | 10 | |
| CHMI | 9 | 0 | 11 | 128 | 0 | 8 | ||
| TF–CHI | 5 | 0 | 15 | 134 | 0 | 7 | ||
| TF–XGB | 8 | 1 | 21 | 129 | 1 | 8 | ||
| Automobile | CHI | 2 | 0 | 3 | 1 | 117 | 1 | |
| CHMI | 1 | 0 | 2 | 1 | 120 | 0 | ||
| TF–CHI | 0 | 0 | 3 | 0 | 143 | 1 | ||
| TF–XGB | 0 | 0 | 2 | 0 | 141 | 0 | ||
| Health | CHI | 4 | 4 | 1 | 3 | 0 | 118 | |
| CHMI | 1 | 2 | 0 | 1 | 0 | 136 | ||
| TF–CHI | 3 | 1 | 2 | 2 | 1 | 134 | ||
| TF–XGB | 5 | 0 | 5 | 4 | 0 | 133 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Wang, S.; Lu, S.; Yin, Z.; Li, X.; Yin, L.; Tian, J.; Zheng, W. Adapting Feature Selection Algorithms for the Classification of Chinese Texts. Systems 2023, 11, 483. https://doi.org/10.3390/systems11090483
Liu X, Wang S, Lu S, Yin Z, Li X, Yin L, Tian J, Zheng W. Adapting Feature Selection Algorithms for the Classification of Chinese Texts. Systems. 2023; 11(9):483. https://doi.org/10.3390/systems11090483
Chicago/Turabian StyleLiu, Xuan, Shuang Wang, Siyu Lu, Zhengtong Yin, Xiaolu Li, Lirong Yin, Jiawei Tian, and Wenfeng Zheng. 2023. "Adapting Feature Selection Algorithms for the Classification of Chinese Texts" Systems 11, no. 9: 483. https://doi.org/10.3390/systems11090483
APA StyleLiu, X., Wang, S., Lu, S., Yin, Z., Li, X., Yin, L., Tian, J., & Zheng, W. (2023). Adapting Feature Selection Algorithms for the Classification of Chinese Texts. Systems, 11(9), 483. https://doi.org/10.3390/systems11090483