
Low-Power Audio Keyword Spotting Using Tsetlin Machines


 ,
, 

Abstract
:1. Introduction
- How effective is the TM at solving real-world KWS problems?
- Does the Tsetlin Machine scale well as the KWS problem size is increased?
- How robust is the Tsetlin Machine in the KWS-AI pipeline when dealing with dataset irregularities and overlapping features?
1.1. Contributions
- Development of a pipeline for KWS using the TM.
- Using data encoding techniques to control feature granularity in the TM pipeline.
- Exploration of how the Tsetlin Machine’s parameters and architectural components can be adjusted to deliver better performance.
1.2. Paper Structure
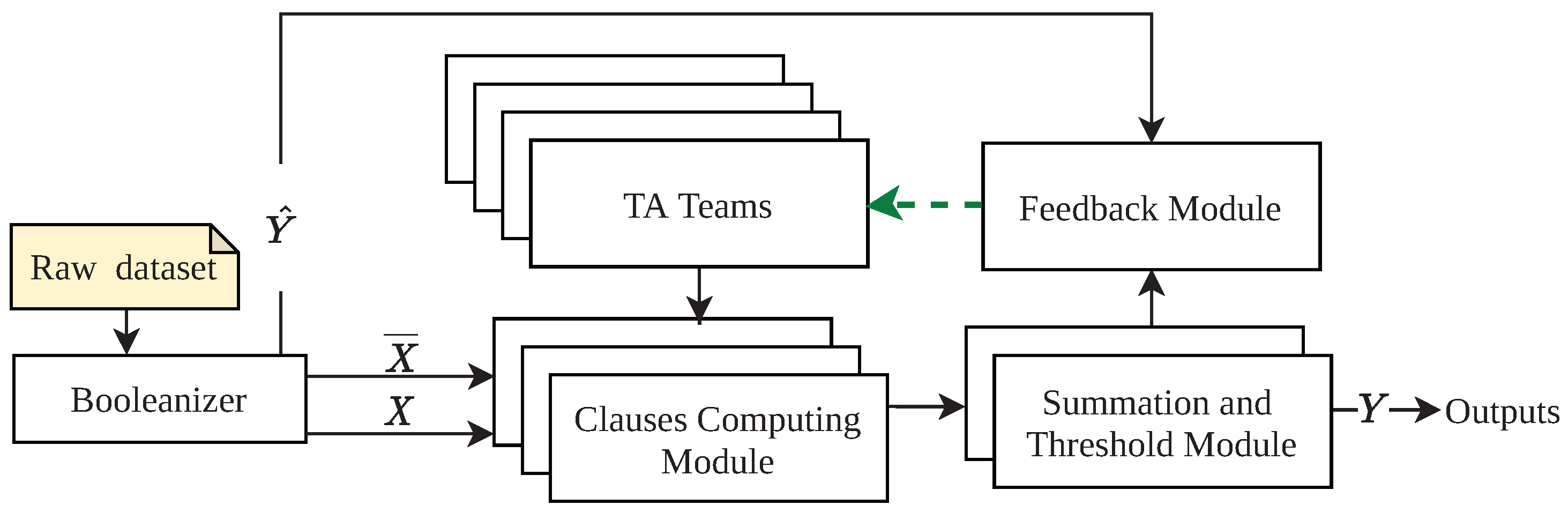
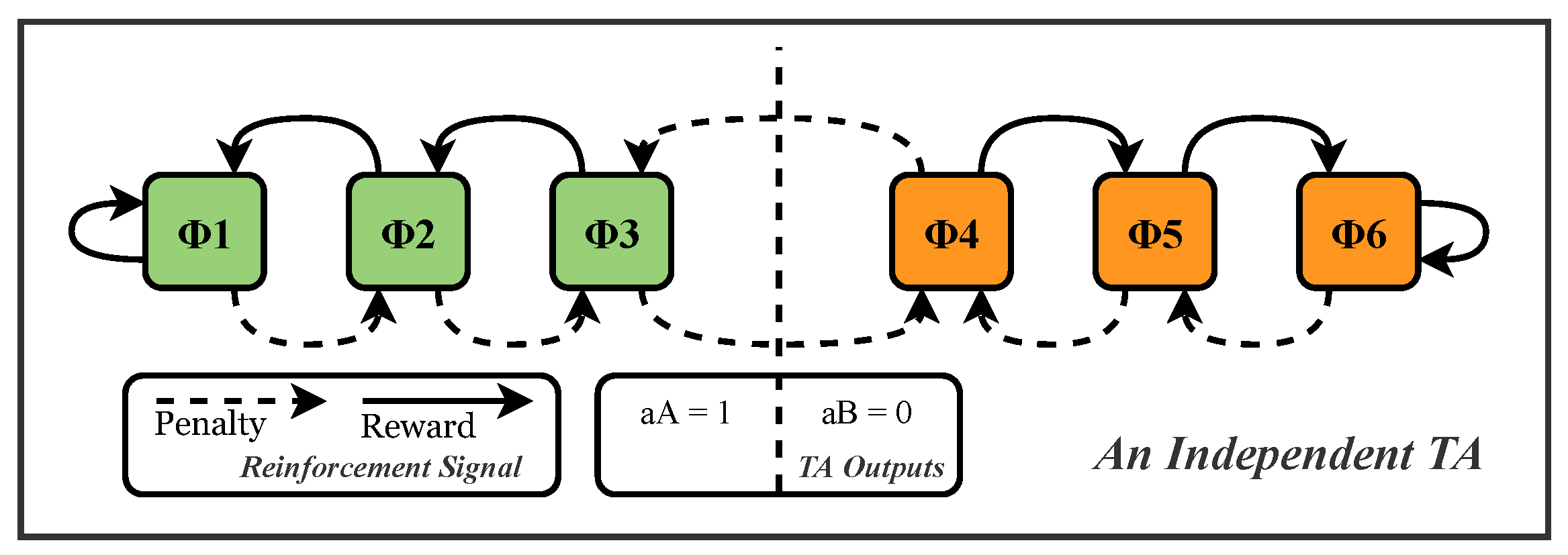
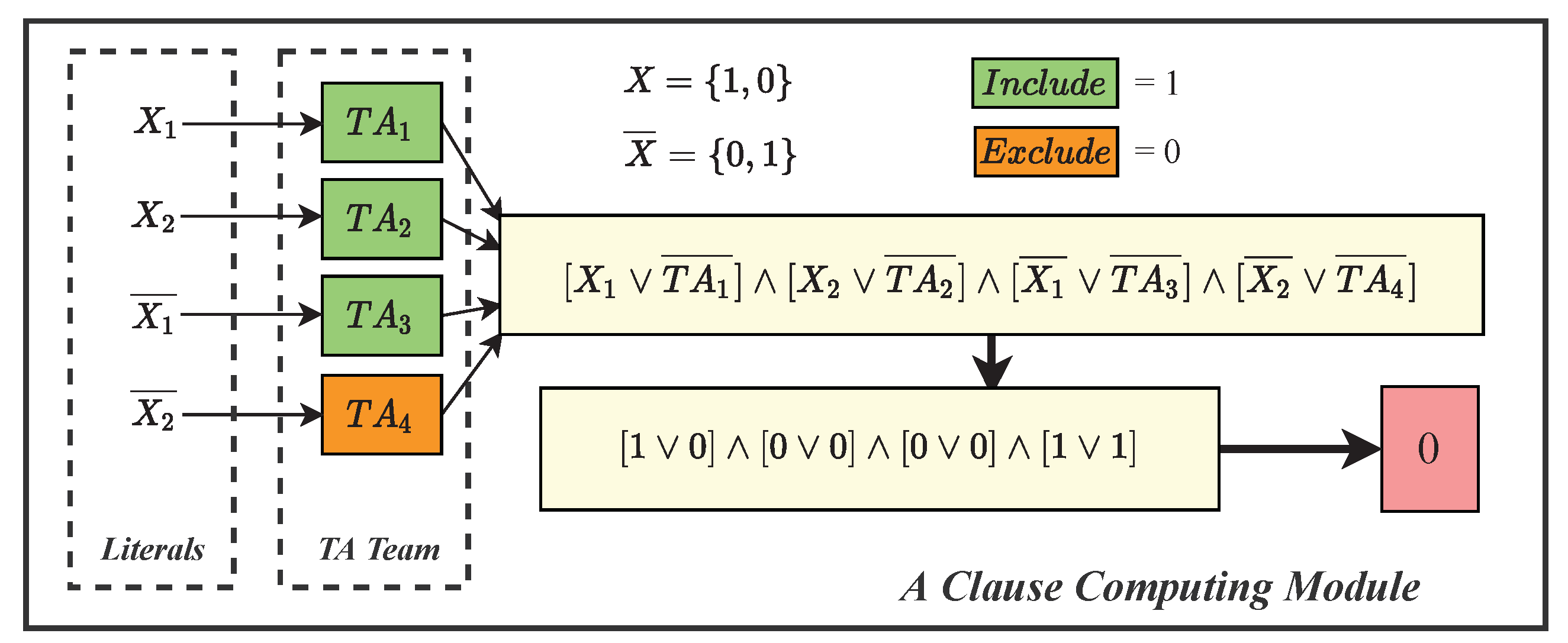
2. A Brief Introduction to Tsetlin Machine
3. Audio Pre-Processing Techniques for KWS
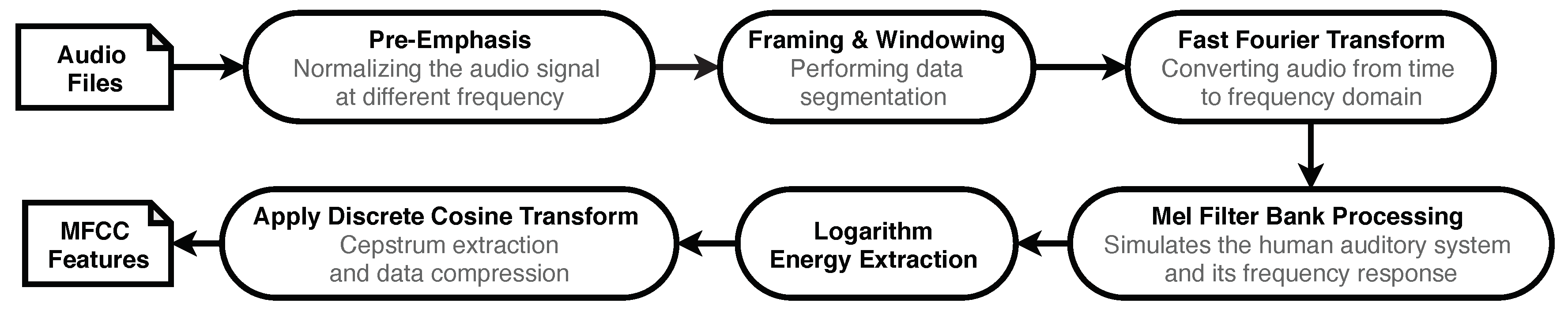
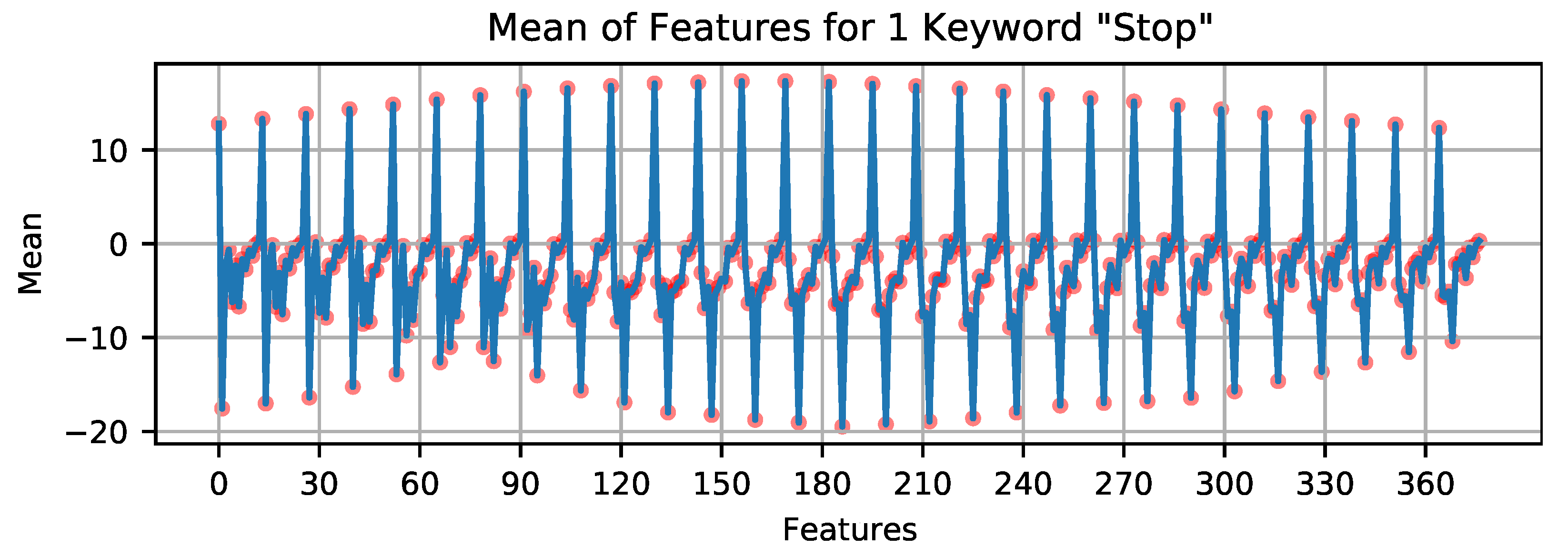
3.1. Audio Feature Extraction Using MFCC
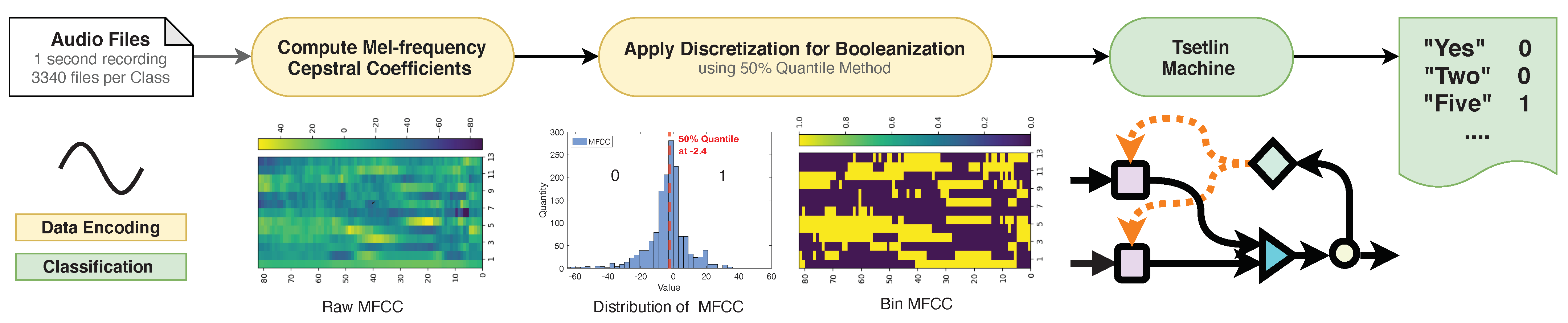
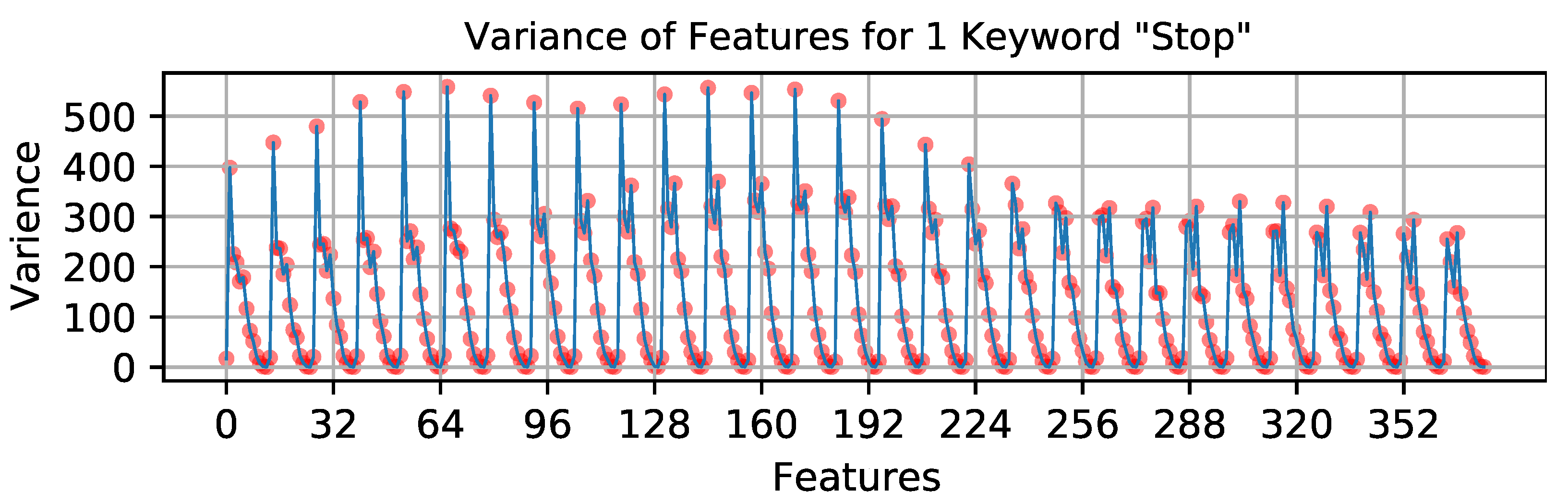
3.2. Feature Booleanization
3.3. The KWS-TM Pipeline
4. Experimental Results
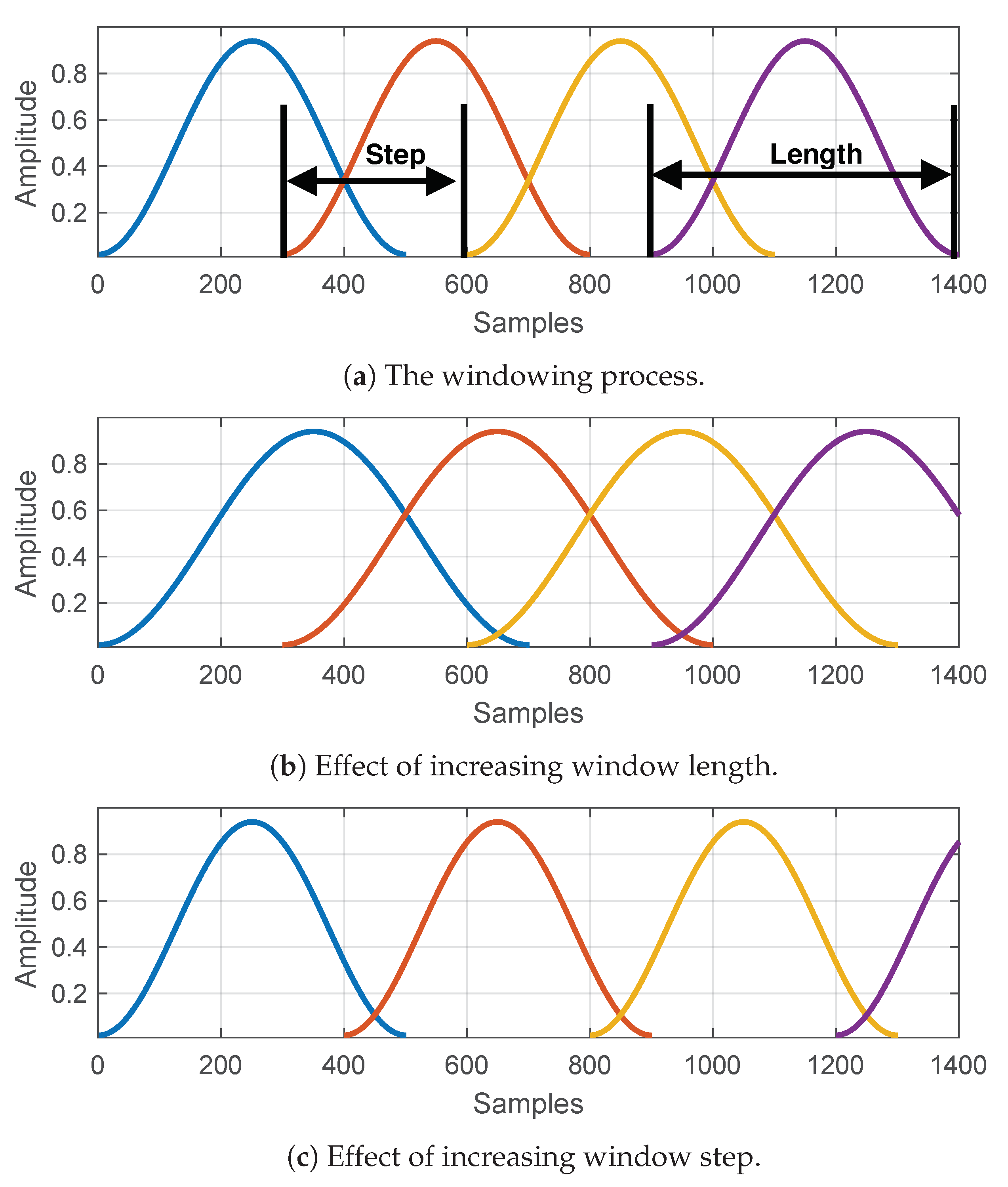
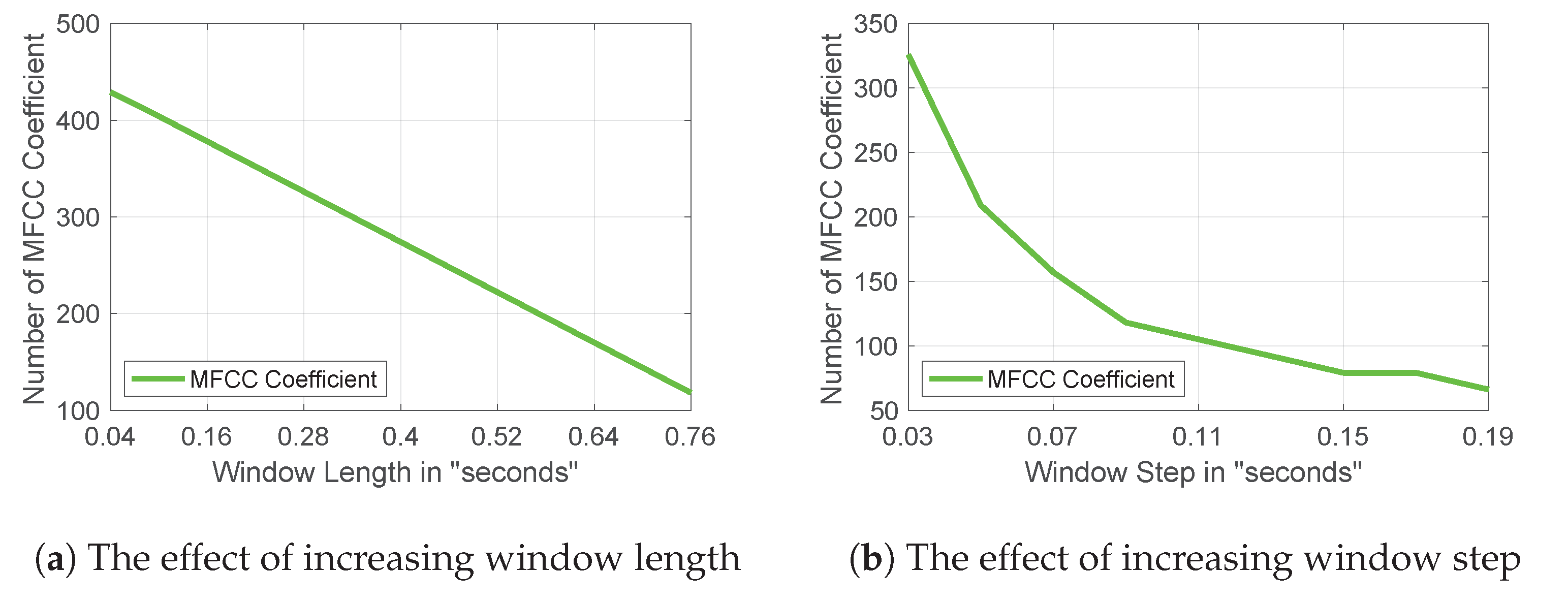
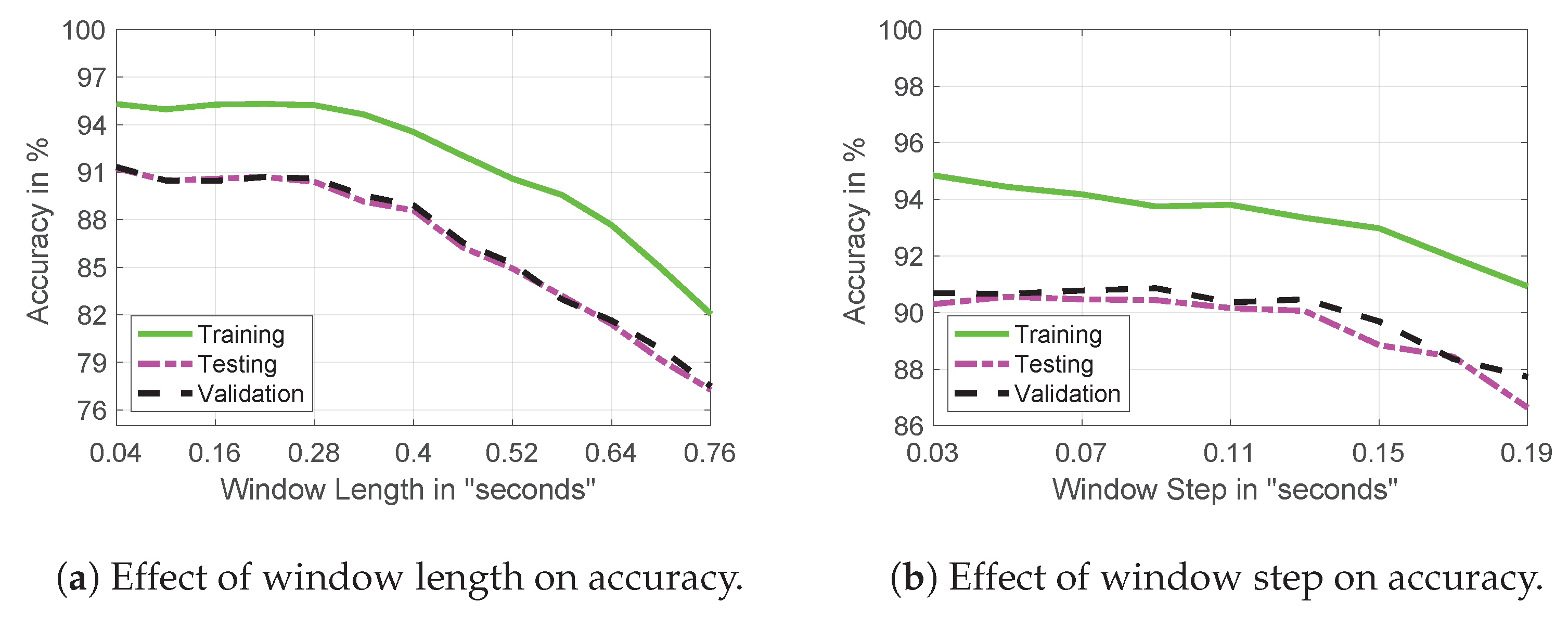
- Manipulating the window length and window steps to control the number of MFCCs generated.
- Exploring the effect of different quantile bins to change the number of Boolean features.
- Using a different number of the keywords ranging from 2 to 9 to explore the scalability of the pipeline.
- Testing the effect on performance of acoustically different and similar keywords.
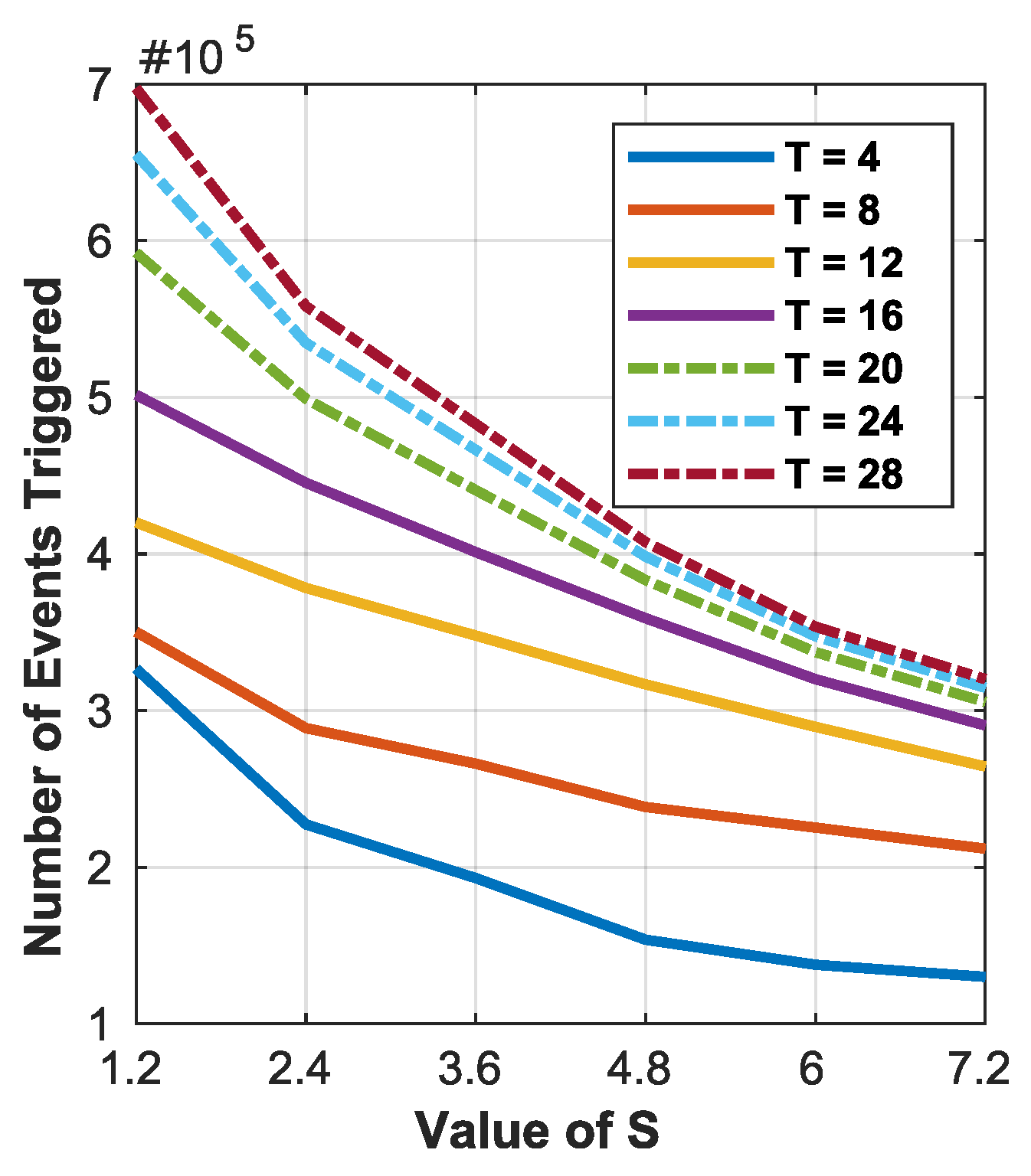
- Changing the size of the TM through manipulating the number of clause computation modules, optimizing performance through tuning the feedback control parameters s and T.
4.1. MFCC Setup
4.2. Impact of Number of Quantiles
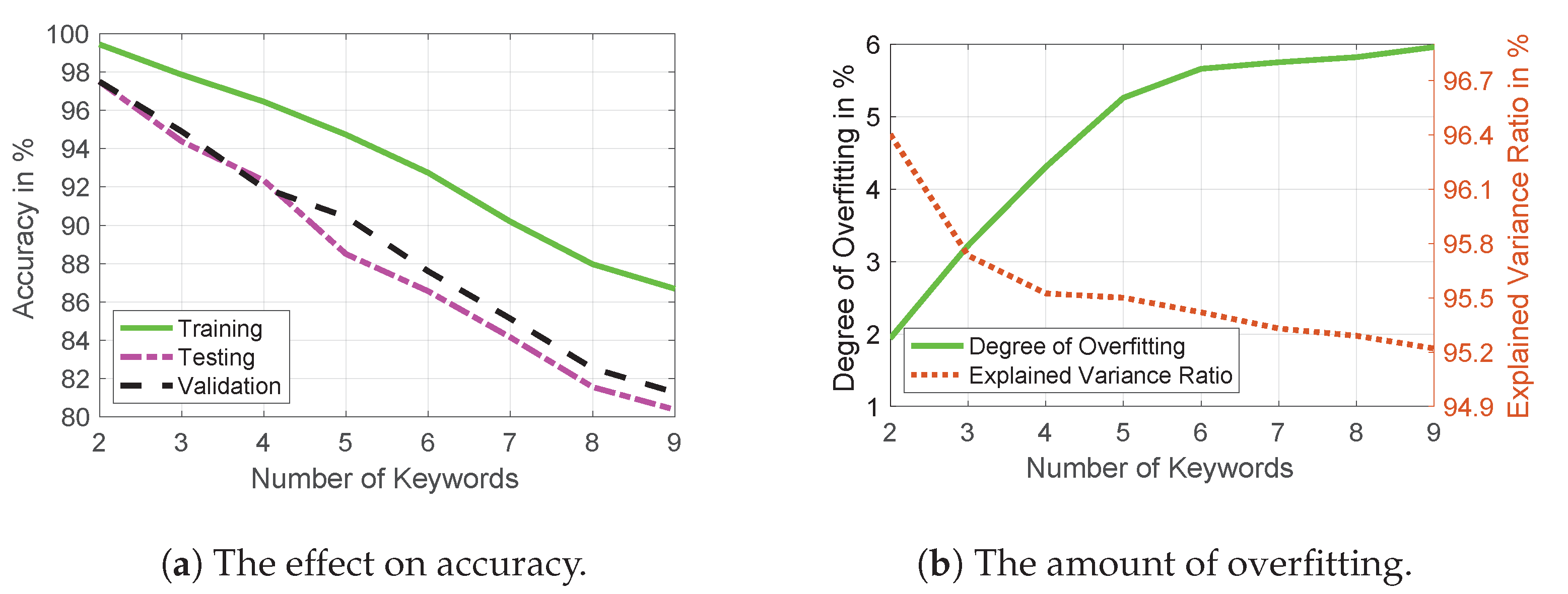
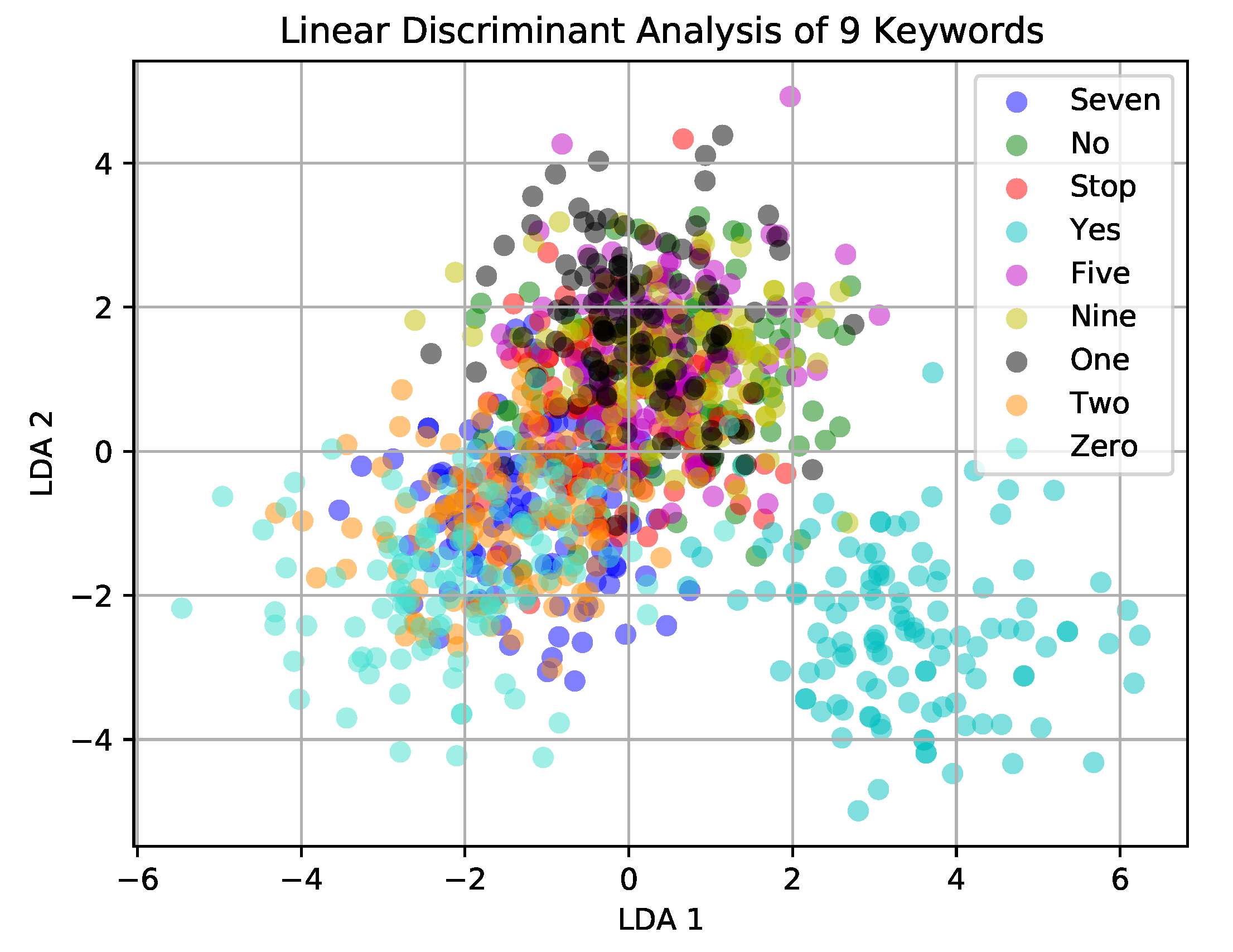
4.3. Impact of Increasing the Number of Keywords
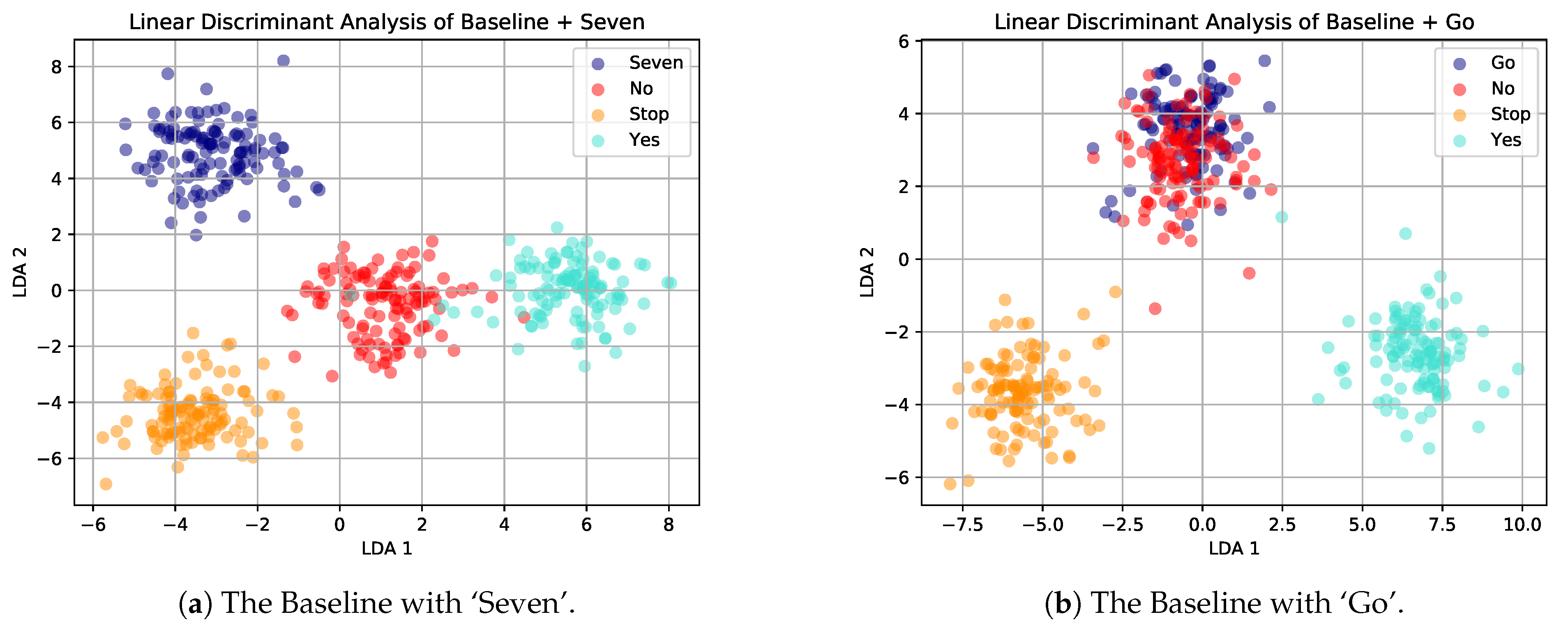
4.4. Acoustically Similar Keywords
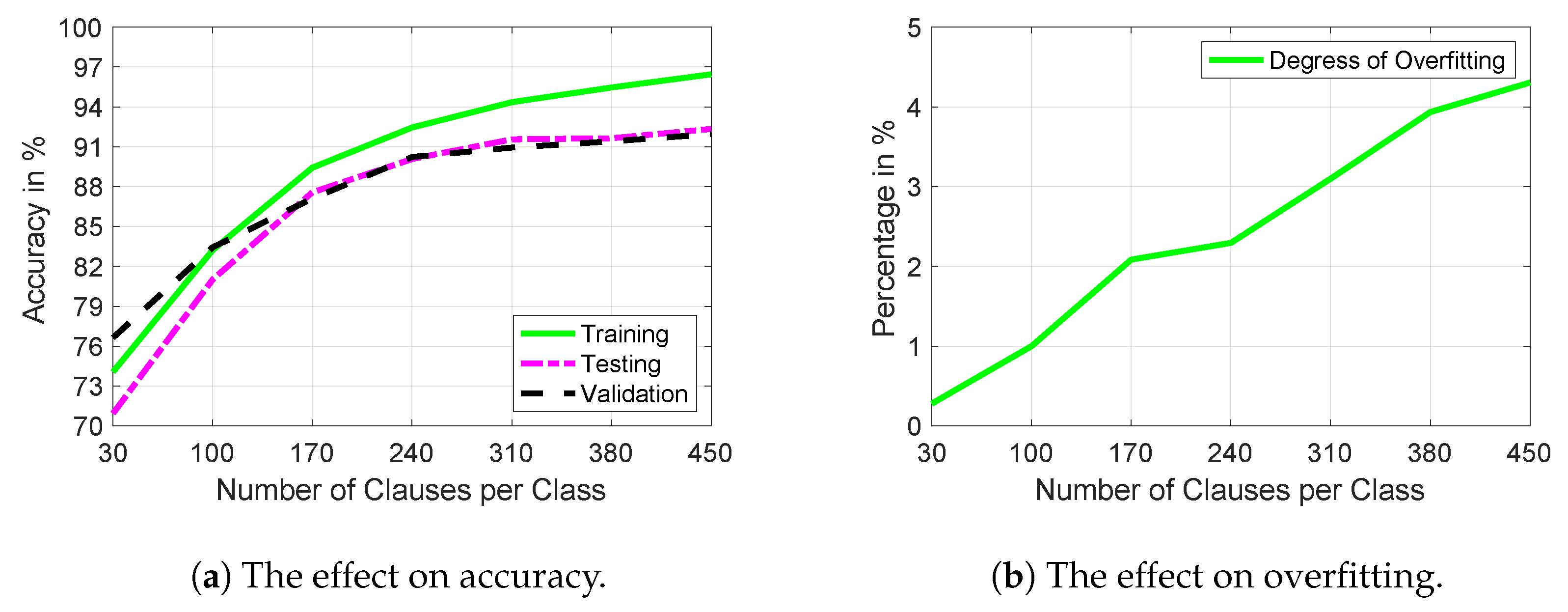
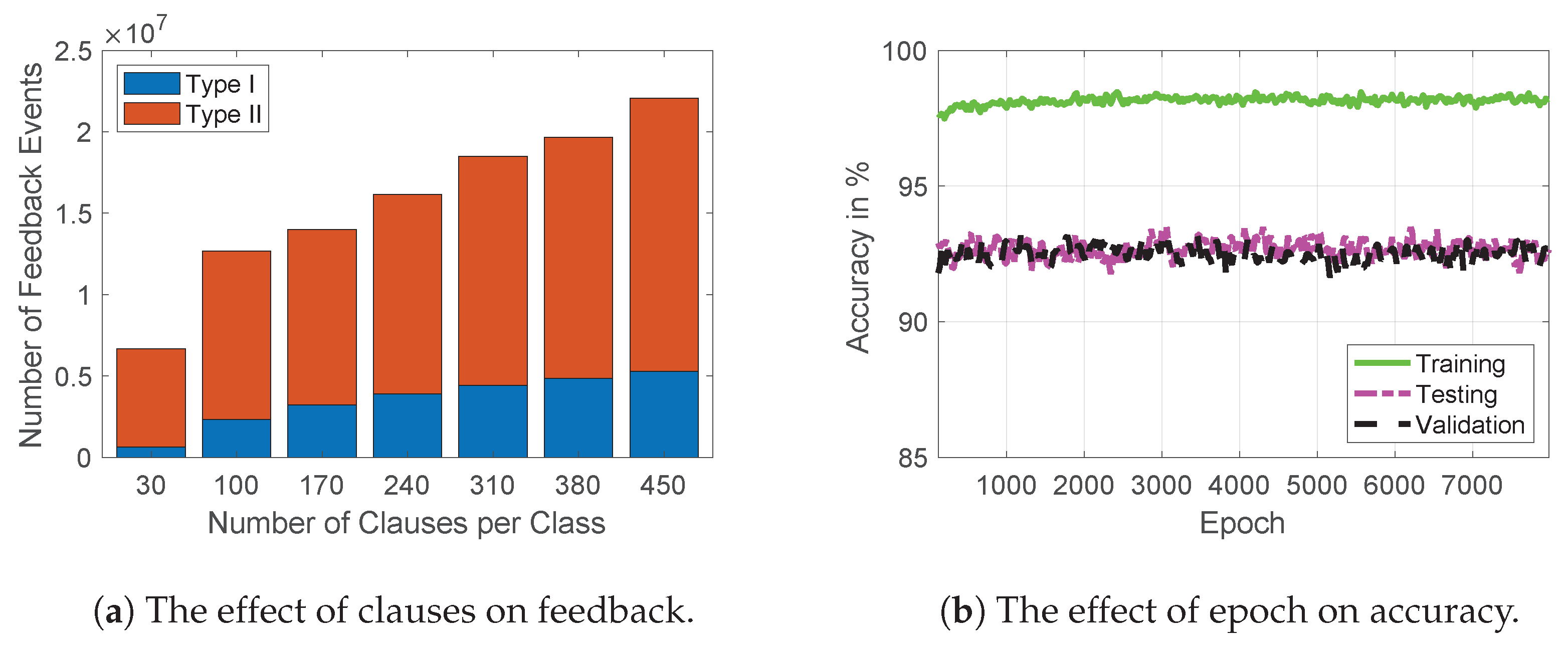
4.5. Number of Clauses per Class
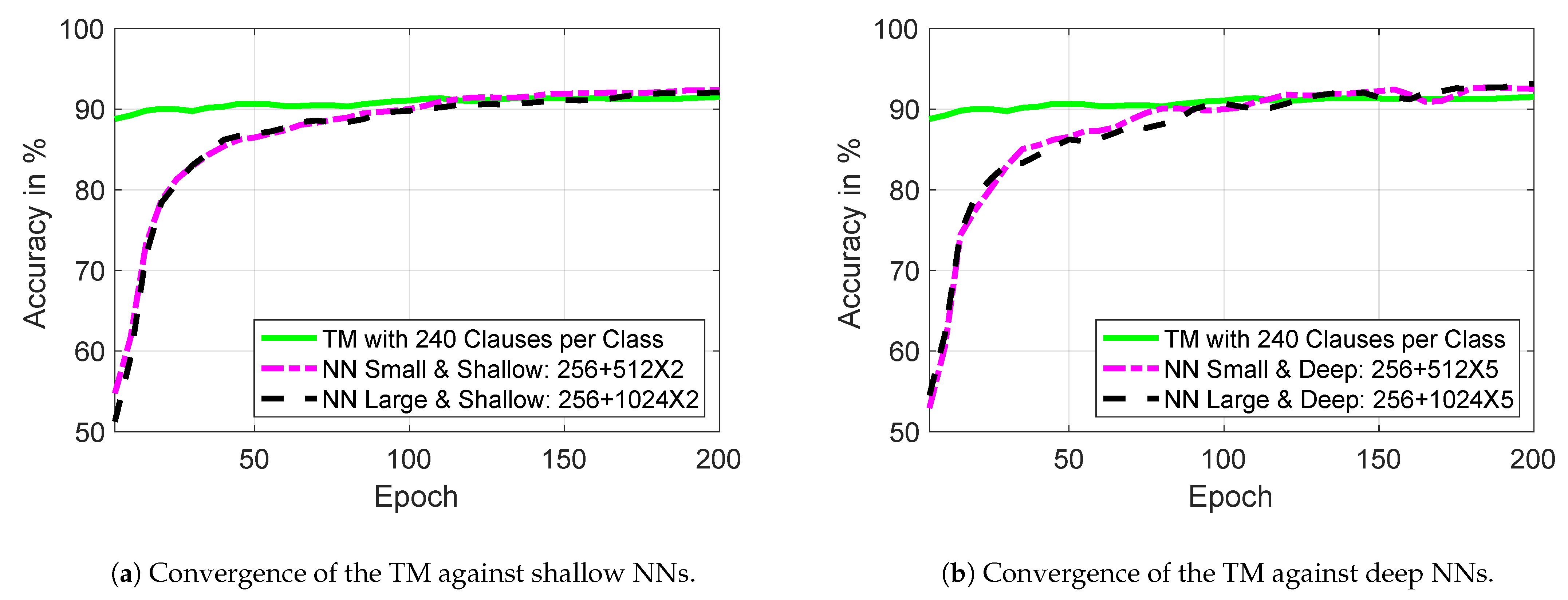
4.6. Comparative Learning Convergence and Complexity Analysis of KWS-TM
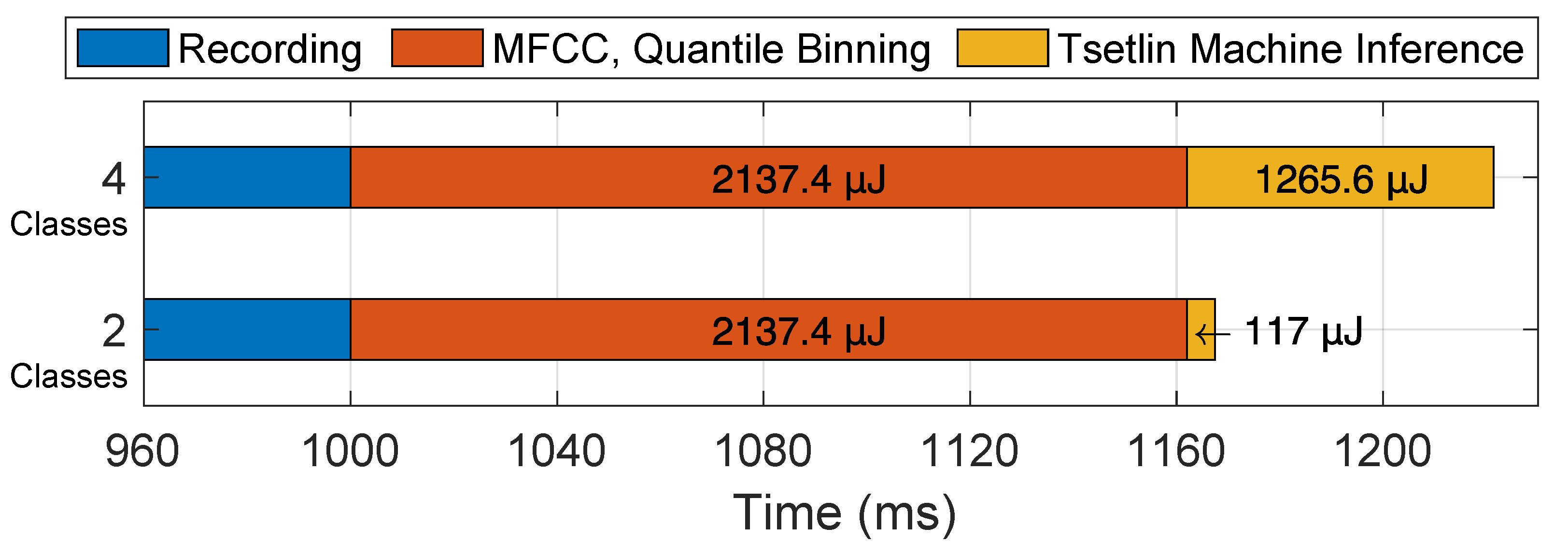
4.7. KWS-TM on the Embedded System
5. Related Work
5.1. Current KWS Developments
5.2. The Tsetlin Machine
6. Summary and Conclusions
7. Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Rausch, T.; Dustdar, S. Edge Intelligence: The Convergence of Humans, Things, and AI. In Proceedings of the 2019 IEEE International Conference on Cloud Engineering (IC2E), Prague, Czech Republic, 24–27 June 2019; pp. 86–96. [Google Scholar] [CrossRef]
- Osawa, I.; Goto, T.; Yamamoto, Y.; Tsugawa, Y. Machine-learning-based prediction models for high-need high-cost patients using nationwide clinical and claims data. NPJ Digit. Med. 2020, 3, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Fernández-Caramés, T.M.; Fraga-Lamas, P. Towards the internet-of-smart-clothing: A review on IoT wearables and garments for creating intelligent connected E-textiles. Electronics 2018, 7, 405. [Google Scholar] [CrossRef] [Green Version]
- Abeyrathna, K.D.; Granmo, O.C.; Zhang, X.; Goodwin, M. Adaptive Continuous Feature Binarization for Tsetlin Machines Applied to Forecasting Dengue Incidences in the Philippines. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, Australia, 1–4 December 2020; pp. 2084–2092. [Google Scholar] [CrossRef]
- Hirata, K.; Kato, T.; Oshima, R. Classification of Environmental Sounds Using Convolutional Neural Network with Bispectral Analysis. In Proceedings of the 2019 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Taipei, Taiwan, 3–6 December 2019; pp. 1–2. [Google Scholar] [CrossRef]
- Benisty, H.; Katz, I.; Crammer, K.; Malah, D. Discriminative Keyword Spotting for limited-data applications. Speech Commun. 2018, 99, 1–11. [Google Scholar] [CrossRef]
- Giraldo, J.S.P.; O’Connor, C.; Verhelst, M. Efficient Keyword Spotting through Hardware-Aware Conditional Execution of Deep Neural Networks. In Proceedings of the 2019 IEEE/ACS 16th International Conference on Computer Systems and Applications (AICCSA), Abu Dhabi, United Arab Emirates, 3–7 November 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Giraldo, J.S.P.; Lauwereins, S.; Badami, K.; Van Hamme, H.; Verhelst, M. 18uW SoC for near-microphone Keyword Spotting and Speaker Verification. In Proceedings of the 2019 Symposium on VLSI Circuits, Kyoto, Japan, 9–14 June 2019; pp. C52–C53. [Google Scholar] [CrossRef]
- Leem, S.; Yoo, I.; Yook, D. Multitask Learning of Deep Neural Network-Based Keyword Spotting for IoT Devices. IEEE Trans. Consum. Electron. 2019, 65, 188–194. [Google Scholar] [CrossRef]
- A depthwise separable convolutional neural network for keyword spotting on an embedded system. EURASIP J. Audio 2020, 2020, 10. [CrossRef]
- Merenda, M.; Porcaro, C.; Iero, D. Edge machine learning for ai-enabled iot devices: A review. Sensors 2020, 20, 2533. [Google Scholar] [CrossRef]
- Liu, B.; Wang, Z.; Zhu, W.; Sun, Y.; Shen, Z.; Huang, L.; Li, Y.; Gong, Y.; Ge, W. An Ultra-Low Power Always-On Keyword Spotting Accelerator Using Quantized Convolutional Neural Network and Voltage-Domain Analog Switching Network-Based Approximate Computing. IEEE Access 2019, 7, 186456–186469. [Google Scholar] [CrossRef]
- Yin, S.; Ouyang, P.; Zheng, S.; Song, D.; Li, X.; Liu, L.; Wei, S. A 141 UW, 2.46 PJ/Neuron Binarized Convolutional Neural Network Based Self-Learning Speech Recognition Processor in 28NM CMOS. In Proceedings of the 2018 IEEE Symposium on VLSI Circuits, Honolulu, HI, USA, 18–22 June 2018; pp. 139–140. [Google Scholar] [CrossRef]
- Bacanin, N.; Bezdan, T.; Tuba, E.; Strumberger, I.; Tuba, M. Optimizing Convolutional Neural Network Hyperparameters by Enhanced Swarm Intelligence Metaheuristics. Algorithms 2020, 13, 67. [Google Scholar] [CrossRef] [Green Version]
- Shafik, R.; Yakovlev, A.; Das, S. Real-power computing. IEEE Trans. Comput. 2018, 67, 1445–1461. [Google Scholar] [CrossRef]
- Granmo, O.C. The Tsetlin Machine—A Game Theoretic Bandit Driven Approach to Optimal Pattern Recognition with Propositional Logic. arXiv 2018, arXiv:1804.01508. [Google Scholar]
- Shafik, R.; Wheeldon, A.; Yakovlev, A. Explainability and Dependability Analysis of Learning Automata based AI Hardware. In Proceedings of the 2020 IEEE 26th International Symposium on On-Line Testing and Robust System Design (IOLTS), Napoli, Italy, 13–15 July 2020. [Google Scholar]
- Wheeldon, A.; Shafik, R.; Rahman, T.; Lei, J.; Yakovlev, A.; Granmo, O.C. Learning Automata based AI Hardware Design for IoT. Philos. Trans. R. Soc. A 2020, 378, 20190593. [Google Scholar] [CrossRef] [PubMed]
- Lei, J.; Wheeldon, A.; Shafik, R.; Yakovlev, A.; Granmo, O.C. From Arithmetic to Logic based AI: A Comparative Analysis of Neural Networks and Tsetlin Machine. In Proceedings of the 2020 27th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Glasgow, UK, 23–25 November 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Chu, S.; Narayanan, S.; Kuo, C.J. Environmental Sound Recognition With Time–Frequency Audio Features. IEEE Trans. Audio Speech Lang. Process. 2009, 17, 1142–1158. [Google Scholar] [CrossRef]
- Mushtaq, Z.; Su, S.F. Environmental sound classification using a regularized deep convolutional neural network with data augmentation. Appl. Acoust. 2020, 167, 107389. [Google Scholar] [CrossRef]
- Xiang, L.; Lu, S.; Wang, X.; Liu, H.; Pang, W.; Yu, H. Implementation of LSTM Accelerator for Speech Keywords Recognition. In Proceedings of the 2019 IEEE 4th International Conference on Integrated Circuits and Microsystems (ICICM), Beijing, China, 25–27 October 2019; pp. 195–198. [Google Scholar] [CrossRef]
- Kaur, K.; Jain, N. Feature Extraction and Classification for Automatic Speaker Recognition System—A Review. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2015, 5, 1–6. [Google Scholar]
- Picone, J.W. Signal modeling techniques in speech recognition. Proc. IEEE 1993, 81, 1215–1247. [Google Scholar] [CrossRef] [Green Version]
- Automatic Speech Recognition. In Speech and Audio Signal Processing; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2011; pp. 299–300. [CrossRef]
- Nalini, N.; Palanivel, S. Music emotion recognition: The combined evidence of MFCC and residual phase. Egypt. Inform. J. 2016, 17, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Yang, Y.; Lan, T.; Zhu, H.; Wei, Q.; Qiao, F.; Liu, X.; Yang, H. MSP-MFCC: Energy-Efficient MFCC Feature Extraction Method with Mixed-Signal Processing Architecture for Wearable Speech Recognition Applications. IEEE Access 2020, 8, 48720–48730. [Google Scholar] [CrossRef]
- Kamath, U.; Liu, J.; Whitaker, J. Automatic Speech Recognition. In Deep Learning for NLP and Speech Recognition; Springer International Publishing: Cham, Switzerland, 2019; pp. 369–404. [Google Scholar] [CrossRef]
- De la Torre, A.; Peinado, A.M.; Segura, J.C.; Perez, J.L.; Bentez, C.; Rubio, A.J. Histogram Equalization of speech representation for robust speech recognition. IEEE Trans. Speech Audio Process. 2005, 13, 355–366. [Google Scholar] [CrossRef] [Green Version]
- Hilger, F.; Ney, H. Quantile based histogram equalization for noise robust large vocabulary speech recognition. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 845–854. [Google Scholar] [CrossRef]
- Segura, J.C.; Benitez, C.; de la Torre, A.; Rubio, A.J.; Ramirez, J. Cepstral domain segmental nonlinear feature transformations for robust speech recognition. IEEE Signal Process. Lett. 2004, 11, 517–520. [Google Scholar] [CrossRef]
- Warden, P. Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition. arXiv 2018, arXiv:1804.03209. [Google Scholar]
- Zhang, Y.; Suda, N.; Lai, L.; Chandra, V. Hello Edge: Keyword Spotting on Microcontrollers. arXiv 2017, arXiv:1711.07128. [Google Scholar]
- Zhang, Z.; Xu, S.; Zhang, S.; Qiao, T.; Cao, S. Learning Attentive Representations for Environmental Sound Classification. IEEE Access 2019, 7, 130327–130339. [Google Scholar] [CrossRef]
- Deng, M.; Meng, T.; Cao, J.; Wang, S.; Zhang, J.; Fan, H. Heart sound classification based on improved MFCC features and convolutional recurrent neural networks. Neural Netw. 2020, 130, 22–32. [Google Scholar] [CrossRef]
- Sainath, T.; Parada, C. Convolutional Neural Networks for Small-Footprint Keyword Spotting. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Wilpon, J.G.; Rabiner, L.R.; Lee, C.; Goldman, E.R. Automatic recognition of keywords in unconstrained speech using hidden Markov models. IEEE Trans. Acoust. Speech Signal Process. 1990, 38, 1870–1878. [Google Scholar] [CrossRef]
- Fernández, S.; Graves, A.; Schmidhuber, J. An Application of Recurrent Neural Networks to Discriminative Keyword Spotting. In ICANN’07: Proceedings of the 17th International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2007; pp. 220–229. [Google Scholar]
- Chen, G.; Parada, C.; Heigold, G. Small-footprint keyword spotting using deep neural networks. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4087–4091. [Google Scholar] [CrossRef] [Green Version]
- Min, C.; Mathur, A.; Kawsar, F. Exploring Audio and Kinetic Sensing on Earable Devices. In WearSys ’18: Proceedings of the 4th ACM Workshop on Wearable Systems and Applications; Association for Computing Machinery: New York, NY, USA, 2018; pp. 5–10. [Google Scholar] [CrossRef]
- Kawsar, F.; Min, C.; Mathur, A.; Montanari, A. Earables for Personal-Scale Behavior Analytics. IEEE Pervasive Comput. 2018, 17, 83–89. [Google Scholar] [CrossRef]
- Wheeldon, A.; Yakovlev, A.; Shafik, R.; Morris, J. Low-Latency Asynchronous Logic Design for Inference at the Edge. arXiv 2020, arXiv:2012.03402. [Google Scholar]
- Jiao, L.; Zhang, X.; Granmo, O.C.; Abeyrathna, K.D. On the Convergence of Tsetlin Machines for the XOR Operator. arXiv 2021, arXiv:2101.02547. [Google Scholar]
- Bhattarai, B.; Granmo, O.C.; Jiao, L. Measuring the Novelty of Natural Language Text Using the Conjunctive Clauses of a Tsetlin Machine Text Classifier. arXiv 2020, arXiv:2011.08755. [Google Scholar]
- Gorji, S.R.; Granmo, O.C.; Phoulady, A.; Goodwin, M. A Tsetlin Machine with Multigranular Clauses. arXiv 2019, arXiv:1909.07310. [Google Scholar]
- Abeyrathna, K.D.; Granmo, O.C.; Zhang, X.; Jiao, L.; Goodwin, M. The regression Tsetlin machine: A novel approach to interpretable nonlinear regression. Philos. Trans. R. Soc. A 2019. [Google Scholar] [CrossRef] [Green Version]
- Granmo, O.; Glimsdal, S.; Jiao, L.; Goodwin, M.; Omlin, C.W.; Berge, G.T. The Convolutional Tsetlin Machine. arXiv 2019, arXiv:1905.09688. [Google Scholar]
- Abeyrathna, K.D.; Bhattarai, B.; Goodwin, M.; Gorji, S.; Granmo, O.C.; Jiao, L.; Saha, R.; Yadav, R.K. Massively Parallel and Asynchronous Tsetlin Machine Architecture Supporting Almost Constant-Time Scaling. arXiv 2020, arXiv:2009.04861. [Google Scholar]
- Abeyrathna, K.D.; Granmo, O.C.; Shafik, R.; Yakovlev, A.; Wheeldon, A.; Lei, J.; Goodwin, M. A Novel Multi-step Finite-State Automaton for Arbitrarily Deterministic Tsetlin Machine Learning. In International Conference on Innovative Techniques and Applications of Artificial Intelligence; Springer: Cham, Switzerland, 2020; pp. 108–122. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | Testing | Validation | Num. Bins | Bools per Feature | Total Bools |
|---|---|---|---|---|---|
| 94.8% | 91.3% | 91.0% | 2 | 1 | 377 |
| 96.0% | 92.0% | 90.7% | 4 | 2 | 757 |
| 95.9% | 90.5% | 91.0% | 6 | 3 | 1131 |
| 95.6% | 91.8% | 92.0% | 8 | 3 | 1131 |
| 97.1% | 91.0% | 90.8% | 10 | 4 | 1511 |
| Experiments | Training | Testing | Validation |
|---|---|---|---|
| Baseline | 94.7% | 92.6% | 93.1% |
| Baseline + ‘Seven’ | 92.5% | 90.1% | 90.2% |
| Baseline + ‘Go’ | 85.6% | 82.6% | 80.9% |
| Clauses | Current | Time | Energy | Accuracy | |
|---|---|---|---|---|---|
| Training | 100 | 0.50 A | 68 s | 426.40 J | - |
| Training | 240 | 0.53 A | 96 s | 636.97 J | - |
| Inference | 100 | 0.43 A | 12 s | 25.57 J | 80% |
| Inference | 240 | 0.47 A | 37 s | 87.23 J | 90% |
| Clauses | T | Training | Testing | Validation | Better Classification |
|---|---|---|---|---|---|
| 30 | 2 | 83.5% | 80.5% | 83.8% | ✓ |
| 30 | 23 | 74.9% | 71.1% | 76.1% | |
| 450 | 2 | 89.7% | 86.1% | 84.9% | |
| 450 | 23 | 96.8% | 92.5% | 92.7% | ✓ |
| KWS-ML Configuration | Num. Neurons | Num. Hyperparameters |
|---|---|---|
| NN Small & Shallow: 377 + 256 + 512 × 2 + 4 | 1661 | 983,552 |
| NN Small & Deep: 377 + 256 + 512 × 5 + 4 | 3197 | 2,029,064 |
| NN Large & Shallow: 377 + 256 + 1024 × 2 + 4 | 2.685 | 2,822,656 |
| NN Large & Deep: 377 + 256 + 1024 × 5 + 4 | 5757 | 7,010,824 |
| TM with 240 Clauses per Class | 960 (clauses in total) | 2 hyperparameters with 725,760 TAs |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, J.; Rahman, T.; Shafik, R.; Wheeldon, A.; Yakovlev, A.; Granmo, O.-C.; Kawsar, F.; Mathur, A. Low-Power Audio Keyword Spotting Using Tsetlin Machines. J. Low Power Electron. Appl. 2021, 11, 18. https://doi.org/10.3390/jlpea11020018
Lei J, Rahman T, Shafik R, Wheeldon A, Yakovlev A, Granmo O-C, Kawsar F, Mathur A. Low-Power Audio Keyword Spotting Using Tsetlin Machines. Journal of Low Power Electronics and Applications. 2021; 11(2):18. https://doi.org/10.3390/jlpea11020018
Chicago/Turabian StyleLei, Jie, Tousif Rahman, Rishad Shafik, Adrian Wheeldon, Alex Yakovlev, Ole-Christoffer Granmo, Fahim Kawsar, and Akhil Mathur. 2021. "Low-Power Audio Keyword Spotting Using Tsetlin Machines" Journal of Low Power Electronics and Applications 11, no. 2: 18. https://doi.org/10.3390/jlpea11020018
APA StyleLei, J., Rahman, T., Shafik, R., Wheeldon, A., Yakovlev, A., Granmo, O. -C., Kawsar, F., & Mathur, A. (2021). Low-Power Audio Keyword Spotting Using Tsetlin Machines. Journal of Low Power Electronics and Applications, 11(2), 18. https://doi.org/10.3390/jlpea11020018