
A Review of Algorithms and Hardware Implementations for Spiking Neural Networks


Abstract
:1. Introduction
2. Fundamentals of Spiking Neural Networks
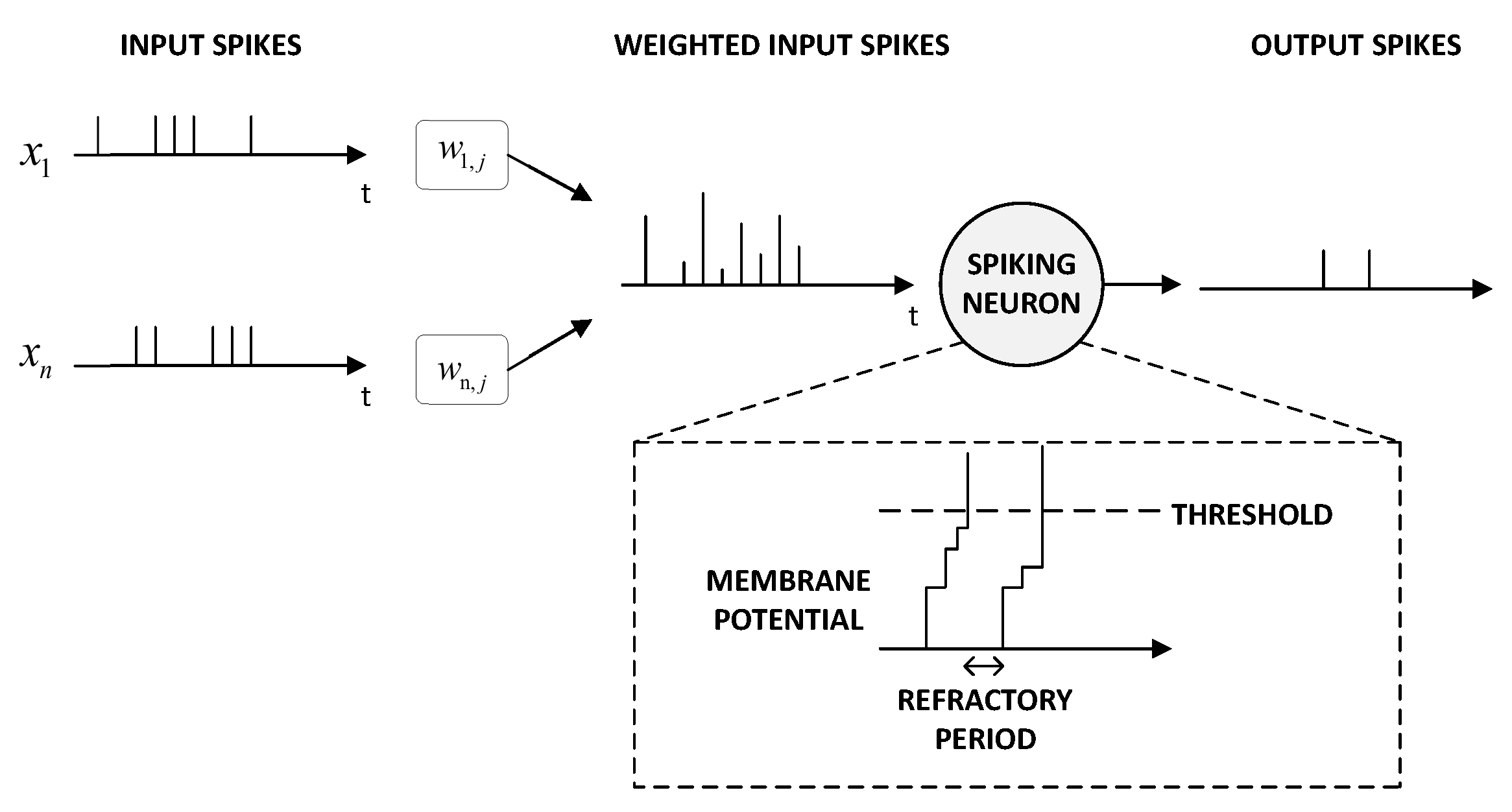
2.1. Neuron Models
2.2. Synapse Models
2.3. Encoding Information with Binary Input Spikes in SNNs
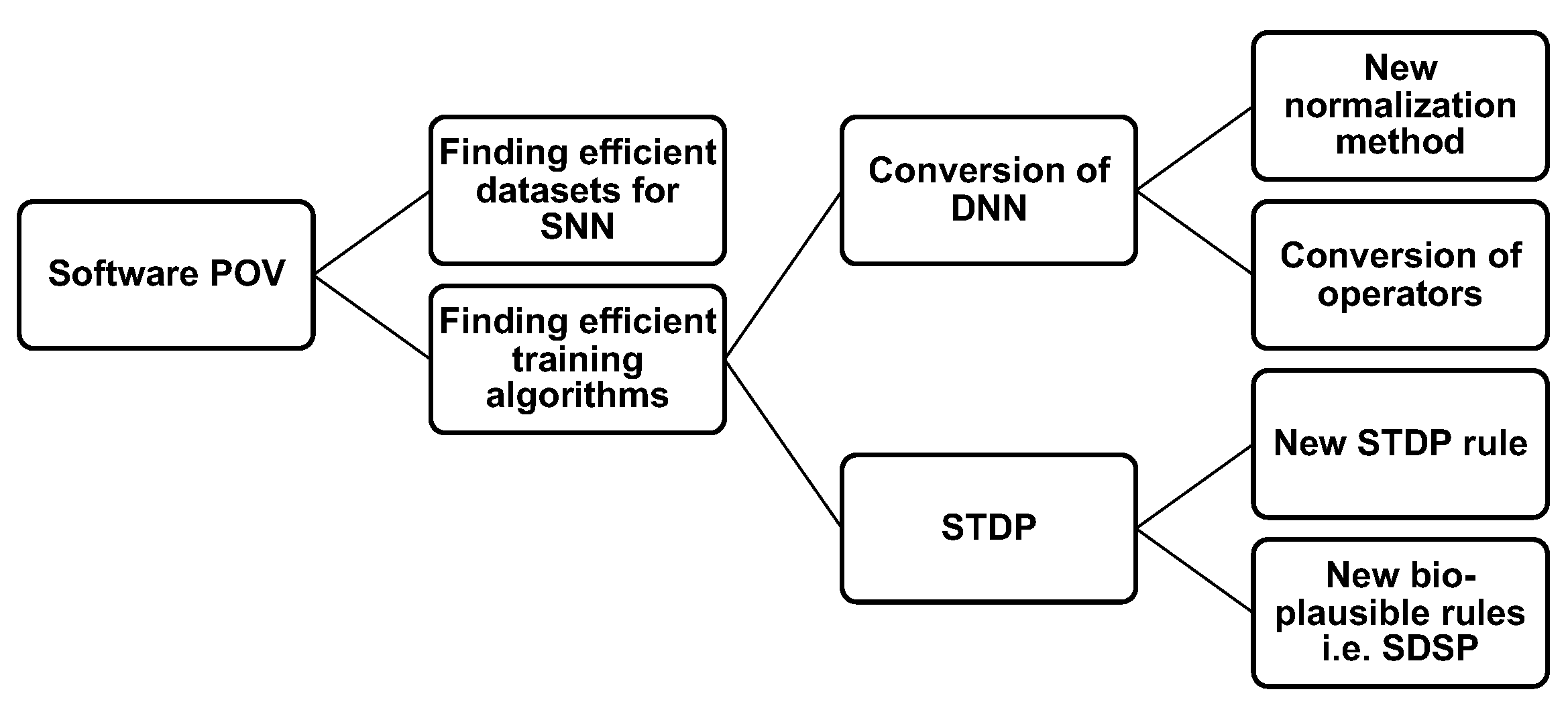
3. Learning Rules in Spiking Neural Networks
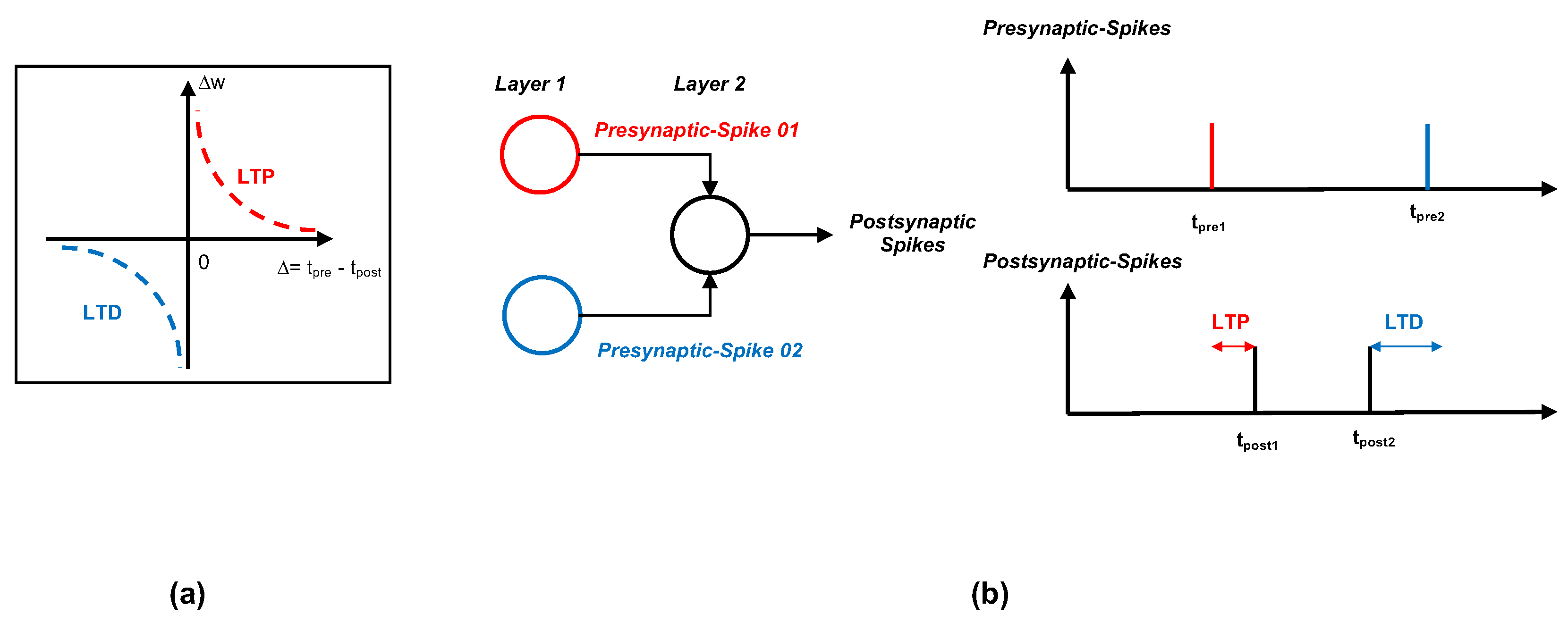
3.1. Unsupervised Learning with STDP
3.2. Supervised Learning with Backpropagation
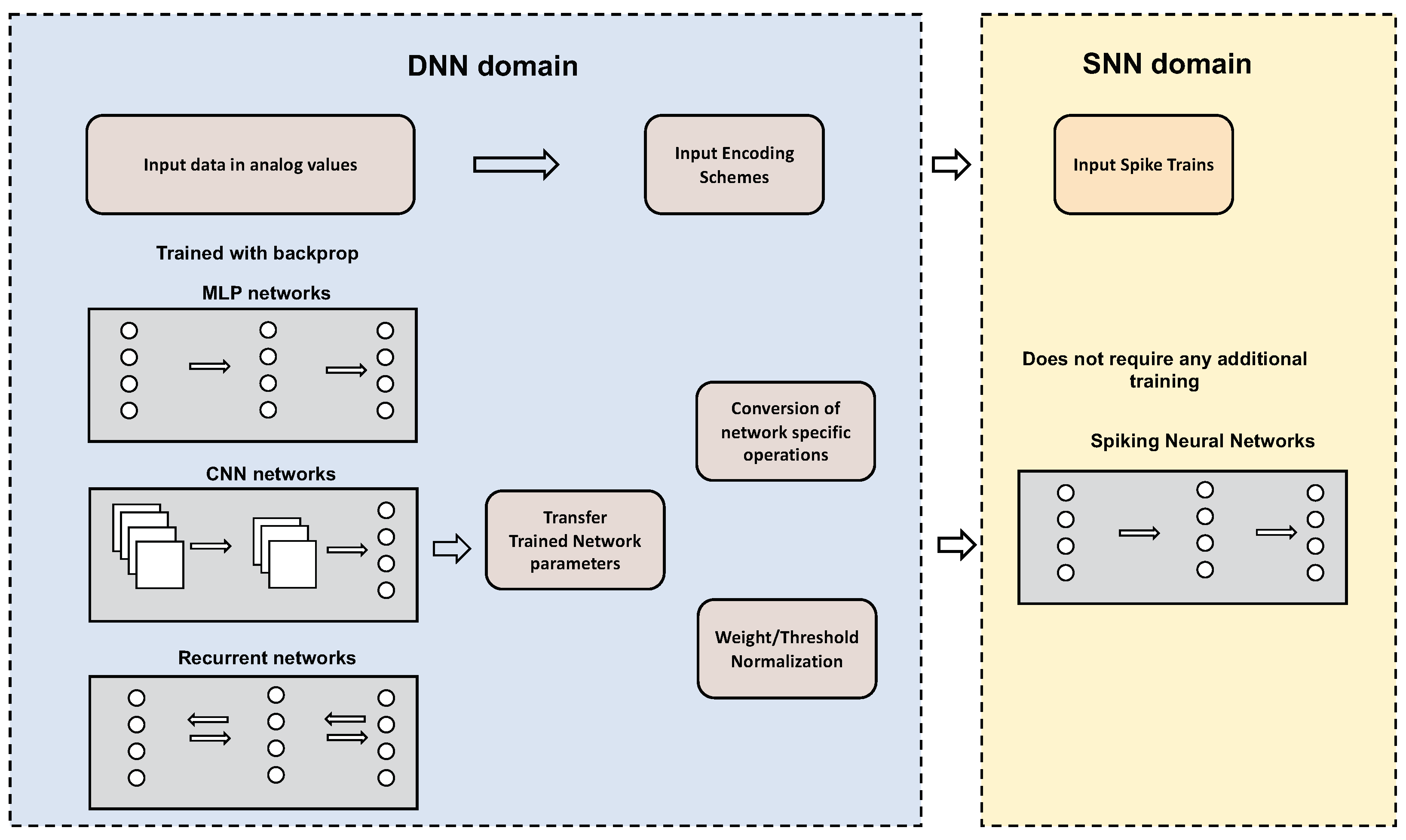
3.3. Conversion of SNN from DNN
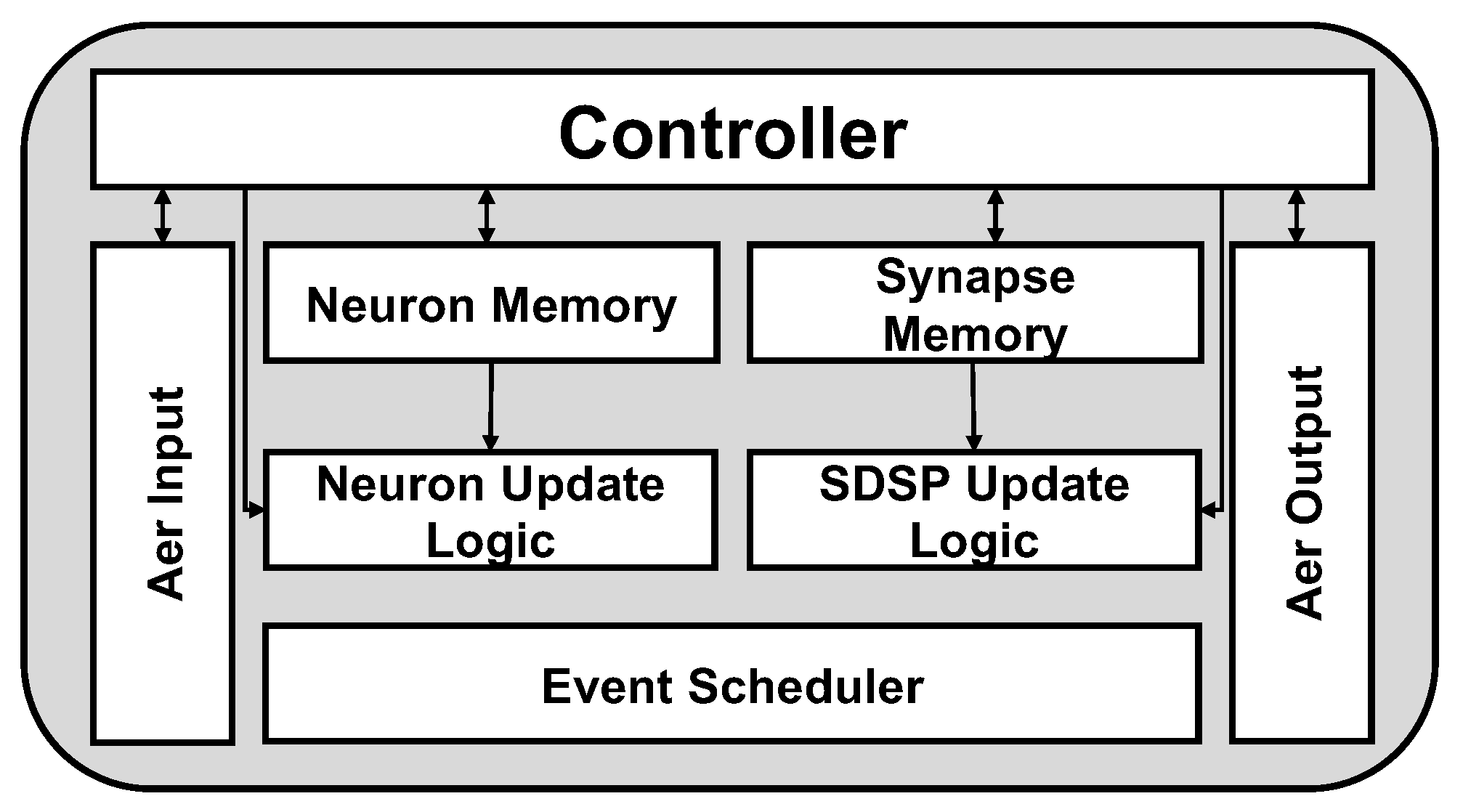
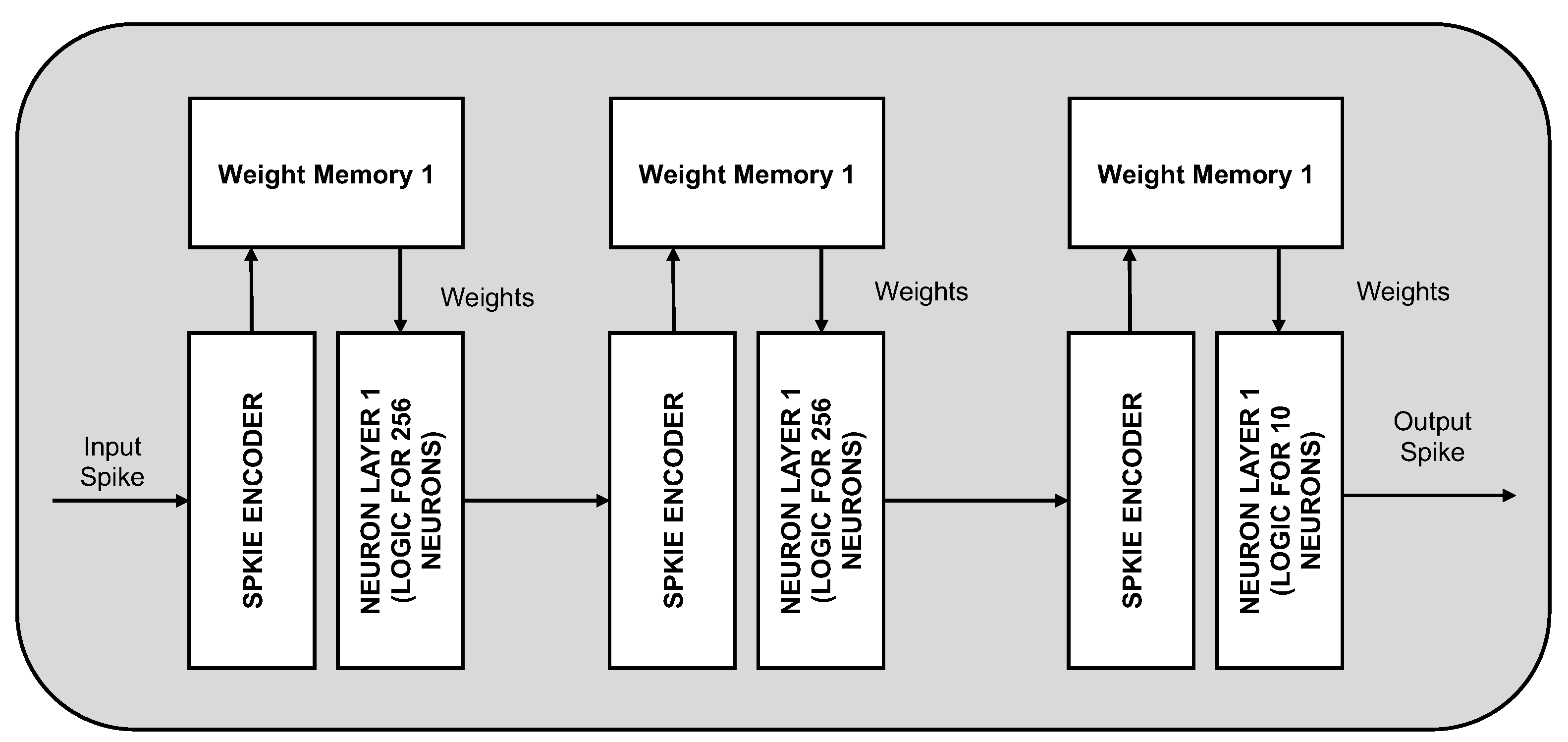
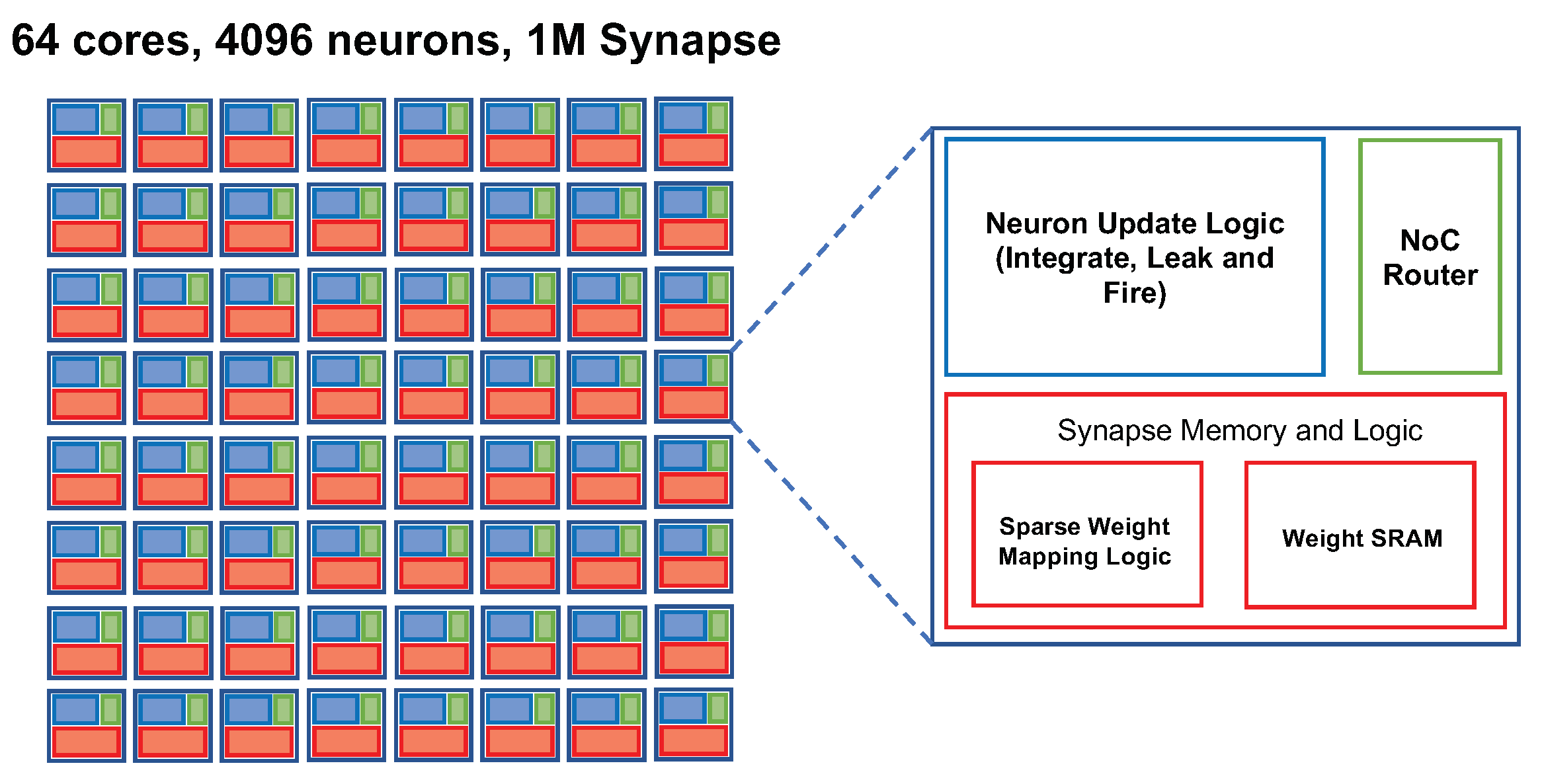
4. Hardware Implementations of SNNs
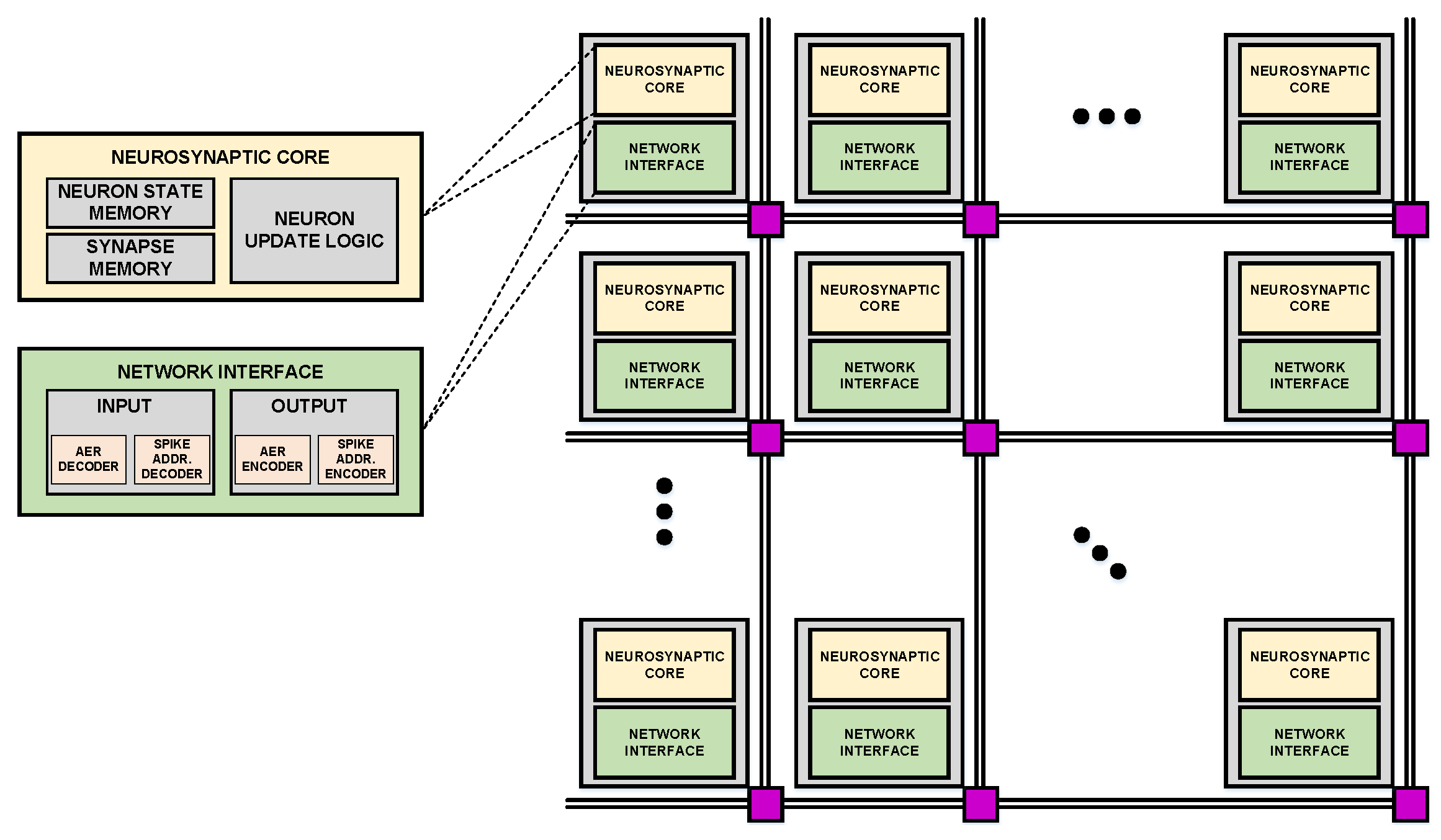
4.1. Large-Scale Neuromorphic Accelerator
4.1.1. General Strategy
4.1.2. Comparison of Large-Scale Neuromorphic Accelerator
4.2. Low-Power SNN Accelerator
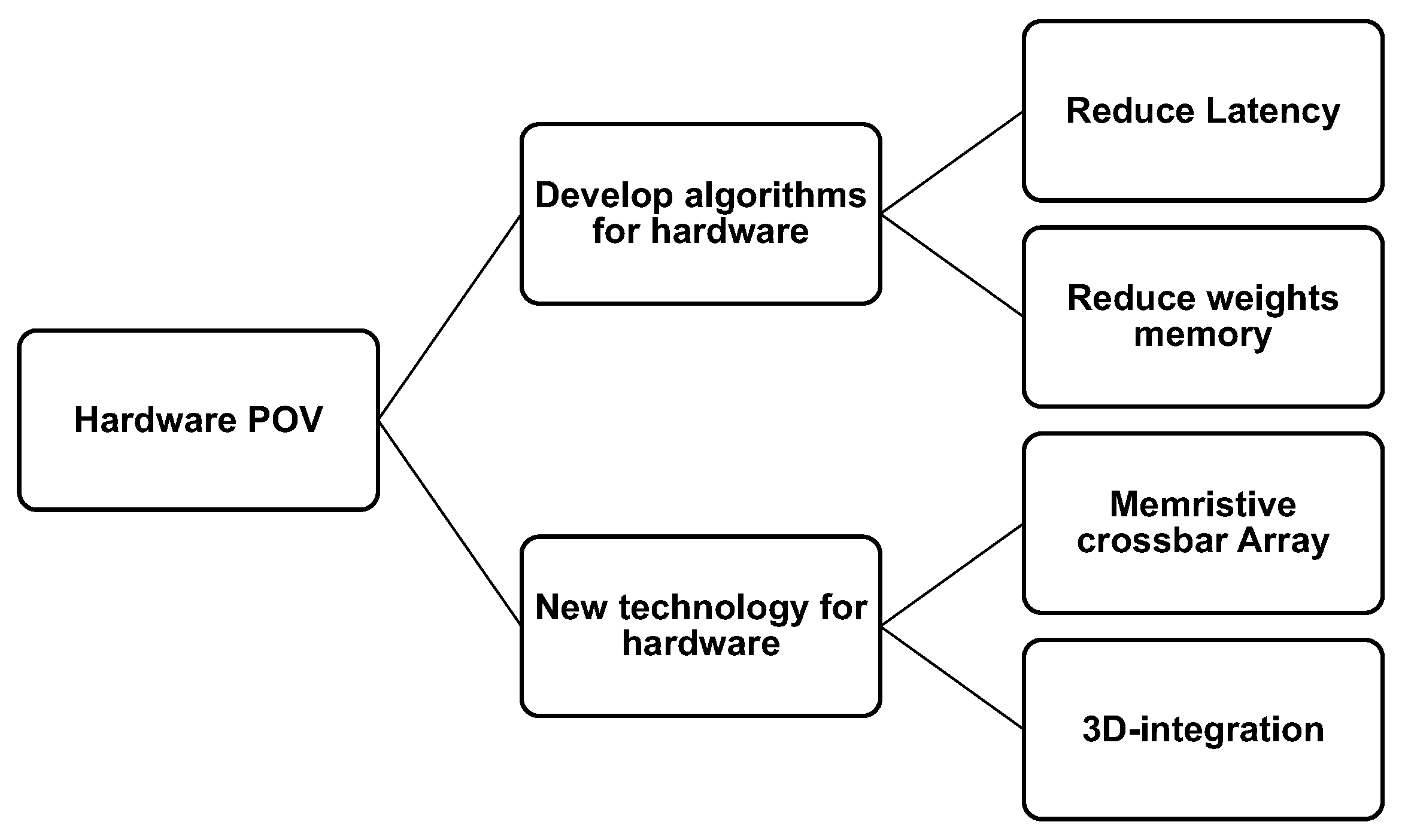
5. Future Possibilities for Spiking Neural Networks
6. Conclusions
Funding
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Siem Reap, Cambodia, 13–16 December 2018. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Maass, W. Networks of spiking neurons: The third generation of neural network models. Neural Netw. 1997, 10, 1659–1671. [Google Scholar] [CrossRef]
- Gupta, A.; Long, L.N. Character Recognition using Spiking Neural Networks. In Proceedings of the 2007 International Joint Conference on Neural Networks, Orlando, FL, USA, 12–17 August 2007; pp. 53–58. [Google Scholar]
- Meftah, B.; Lezoray, O.; Benyettou, A. Segmentation and Edge Detection Based on Spiking Neural Network Model. Neural Process. Lett. 2010, 32, 131–146. [Google Scholar] [CrossRef]
- Escobar, M.J.; Masson, G.S.; Vieville, T.; Kornprobst, P. Action Recognition Using a Bio-Inspired Feedforward Spiking Network. Int. J. Comput. Vis. 2009, 82, 284. [Google Scholar] [CrossRef]
- Tavanaei, A.; Maida, A. Bio-inspired Multi-layer Spiking Neural Network Extracts Discriminative Features from Speech Signals. In Neural Information Processing; Liu, D., Xie, S., Li, Y., Zhao, D., El-Alfy, E.S.M., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 899–908. [Google Scholar]
- Loiselle, S.; Rouat, J.; Pressnitzer, D.; Thorpe, S. Exploration of rank order coding with spiking neural networks for speech recognition. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; Volume 4, pp. 2076–2080. [Google Scholar]
- Ghosh-Dastidar, S.; Adeli, H. Improved Spiking Neural Networks for EEG Classification and Epilepsy and Seizure Detection. Integr. Comput. Aided Eng. 2007, 14, 187–212. [Google Scholar] [CrossRef]
- Kasabov, N.; Feigin, V.; Hou, Z.G.; Chen, Y.; Liang, L.; Krishnamurthi, R.; Othman, M.; Parmar, P. Evolving spiking neural networks for personalised modelling, classification and prediction of spatio-temporal patterns with a case study on stroke. Neurocomputing 2014, 134, 269–279. [Google Scholar] [CrossRef] [Green Version]
- Hodgkin, A.L.; Huxley, A.F. A quantitative description of membrane current and its application to conduction and excitation in nerve. J. Physiol. 1952, 117, 500–544. [Google Scholar] [CrossRef] [PubMed]
- Izhikevich, E.M. Simple model of spiking neurons. IEEE Trans. Neural Netw. 2003, 14, 1569–1572. [Google Scholar] [CrossRef] [Green Version]
- Cassidy, A.S.; Merolla, P.; Arthur, J.V.; Esser, S.K.; Jackson, B.; Alvarez-Icaza, R.; Datta, P.; Sawada, J.; Wong, T.M.; Feldman, V.; et al. Cognitive computing building block: A versatile and efficient digital neuron model for neurosynaptic cores. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–10. [Google Scholar] [CrossRef]
- Indiveri, G.; Linares-Barranco, B.; Hamilton, T.; van Schaik, A.; Etienne-Cummings, R.; Delbruck, T.; Liu, S.C.; Dudek, P.; Häfliger, P.; Renaud, S.; et al. Neuromorphic Silicon Neuron Circuits. Front. Neurosci. 2011, 5, 73. [Google Scholar] [CrossRef] [Green Version]
- Camunas-Mesa, L.; Acosta-Jimenez, A.; Serrano-Gotarredona, T.; Linares-Barranco, B. Fully digital AER convolution chip for vision processing. In Proceedings of the 2008 IEEE International Symposium on Circuits and Systems (ISCAS), Seattle, WA, USA, 18–21 May 2008; pp. 652–655. [Google Scholar] [CrossRef]
- Nguyen, D.A.; Bui, D.H.; Iacopi, F.; Tran, X.T. An Efficient Event-driven Neuromorphic Architecture for Deep Spiking Neural Networks. In Proceedings of the 2019 32nd IEEE International System-on-Chip Conference (SOCC), Singapore, 3–6 September 2019; pp. 144–149. [Google Scholar] [CrossRef]
- Haghiri, S.; Naderi, A.; Ghanbari, B.; Ahmadi, A. High Speed and Low Digital Resources Implementation of Hodgkin-Huxley Neuronal Model Using Base-2 Functions. IEEE Trans. Circuits Syst. I Regul. Pap. 2020. [Google Scholar] [CrossRef]
- Andreev, V.; Ostrovskii, V.; Karimov, T.; Tutueva, A.; Doynikova, E.; Butusov, D. Synthesis and Analysis of the Fixed-Point Hodgkin–Huxley Neuron Model. Electronics 2020, 9, 434. [Google Scholar] [CrossRef] [Green Version]
- Levi, T.; Khoyratee, F.; Saïghi, S.; Ikeuchi, Y. Digital implementation of Hodgkin–Huxley neuron model for neurological diseases studies. Artif. Life Robot. 2018, 23, 10–14. [Google Scholar] [CrossRef] [Green Version]
- Yaghini Bonabi, S.; Asgharian, H.; Safari, S.; Nili Ahmadabadi, M. FPGA implementation of a biological neural network based on the Hodgkin-Huxley neuron model. Front. Neurosci. 2014, 8, 379. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pu, J.; Goh, W.L.; Nambiar, V.P.; Chong, Y.S.; Do, A.T. A Low-Cost High-Throughput Digital Design of Biorealistic Spiking Neuron. IEEE Trans. Circuits Syst. II Express Briefs 2020. [Google Scholar] [CrossRef]
- Soleimani, H.; Ahmadi, A.; Bavandpour, M. Biologically inspired spiking neurons: Piecewise linear models and digital implementation. IEEE Trans. Circuits Syst. I Regul. Pap. 2012, 59, 2991–3004. [Google Scholar] [CrossRef]
- Leigh, A.J.; Mirhassani, M.; Muscedere, R. An Efficient Spiking Neuron Hardware System Based on the Hardware-Oriented Modified Izhikevich Neuron (HOMIN) Model. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 3377–3381. [Google Scholar] [CrossRef]
- Kumar, A.; Rotter, S.; Aertsen, A. Spiking activity propagation in neuronal networks: Reconciling different perspectives on neural coding. Nat. Rev. Neurosci. 2010, 11, 615–627. [Google Scholar] [CrossRef]
- Rueckauer, B.; Liu, S.C. Conversion of analog to spiking neural networks using sparse temporal coding. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar]
- Reich, D.S.; Mechler, F.; Purpura, K.P.; Victor, J.D. Interspike Intervals, Receptive Fields, and Information Encoding in Primary Visual Cortex. J. Neurosci. 2000, 20, 1964–1974. [Google Scholar] [CrossRef]
- Caporale, N.; Dan, Y. Spike Timing–Dependent Plasticity: A Hebbian Learning Rule. Annu. Rev. Neurosci. 2008, 31, 25–46. [Google Scholar] [CrossRef] [Green Version]
- Markram, H.; Gerstner, W.; Sjöström, P.J. A history of spike-timing-dependent plasticity. Front. Synaptic Neurosci. 2011, 3, 4. [Google Scholar] [CrossRef] [Green Version]
- Dan, Y.; Poo, M.M. Spike Timing-Dependent Plasticity: From Synapse to Perception. Physiol. Rev. 2006, 86, 1033–1048. [Google Scholar] [CrossRef] [PubMed]
- Gerstner, W.; Kistler, W.M. Spiking Neuron Models: Single Neurons, Populations, Plasticity; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Bohte, S.M.; Kok, J.N.; Poutré, H.L. Error-backpropagation in temporally encoded networks of spiking neurons. Neurocomputing 2002, 48, 17–37. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.H.; Delbruck, T.; Pfeiffer, M. Training Deep Spiking Neural Networks Using Backpropagation. Front. Neurosci. 2016, 10, 508. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mostafa, H. Supervised Learning Based on Temporal Coding in Spiking Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3227–3235. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, Y.; Deng, L.; Li, G.; Zhu, J.; Shi, L. Spatio-Temporal Backpropagation for Training High-Performance Spiking Neural Networks. Front. Neurosci. 2018, 12, 331. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Tang, H.; Wang, Y.; Pan, G. Spiking Deep Residual Network. arXiv 2018, arXiv:1805.01352. [Google Scholar]
- Sengupta, A.; Ye, Y.; Wang, R.; Liu, C.; Roy, K. Going Deeper in Spiking Neural Networks: VGG and Residual Architectures. Front. Neurosci. 2019, 13, 95. [Google Scholar] [CrossRef]
- Pérez-Carrasco, J.A.; Zhao, B.; Serrano, C.; Acha, B.; Serrano-Gotarredona, T.; Chen, S.; Linares-Barranco, B. Mapping from Frame-Driven to Frame-Free Event-Driven Vision Systems by Low-Rate Rate Coding and Coincidence Processing–Application to Feedforward ConvNets. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2706–2719. [Google Scholar] [CrossRef]
- Diehl, P.U.; Neil, D.; Binas, J.; Cook, M.; Liu, S.; Pfeiffer, M. Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar] [CrossRef]
- Cao, Y.; Chen, Y.; Khosla, D. Spiking Deep Convolutional Neural Networks for Energy-Efficient Object Recognition. Int. J. Comput. Vis. 2015, 113, 54–66. [Google Scholar] [CrossRef]
- Furber, S.B.; Galluppi, F.; Temple, S.; Plana, L.A. The SpiNNaker Project. Proc. IEEE 2014, 102, 652–665. [Google Scholar] [CrossRef]
- Akopyan, F.; Sawada, J.; Cassidy, A.; Alvarez-Icaza, R.; Arthur, J.; Merolla, P.; Imam, N.; Nakamura, Y.; Datta, P.; Nam, G.; et al. TrueNorth: Design and Tool Flow of a 65 mW 1 Million Neuron Programmable Neurosynaptic Chip. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2015, 34, 1537–1557. [Google Scholar] [CrossRef]
- Benjamin, B.V.; Gao, P.; McQuinn, E.; Choudhary, S.; Chandrasekaran, A.R.; Bussat, J.M.; Alvarez-Icaza, R.; Arthur, J.V.; Merolla, P.A.; Boahen, K. Neurogrid: A mixed-analog-digital multichip system for large-scale neural simulations. Proc. IEEE 2014, 102, 699–716. [Google Scholar] [CrossRef]
- Davies, M.; Srinivasa, N.; Lin, T.H.; Chinya, G.; Cao, Y.; Choday, S.H.; Dimou, G.; Joshi, P.; Imam, N.; Jain, S.; et al. Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Frenkel, C.; Lefebvre, M.; Legat, J.D.; Bol, D. A 0.086-mm2 12.7-pJ/SOP 64k-Synapse 256-Neuron Online-Learning Digital Spiking Neuromorphic Processor in 28-nm CMOS. IEEE Trans. Biomed. Circuits Syst. 2019, 13, 145–158. [Google Scholar] [CrossRef] [Green Version]
- Yin, S.; Venkataramanaiah, S.K.; Chen, G.K.; Krishnamurthy, R.; Cao, Y.; Chakrabarti, C.; Seo, J. Algorithm and hardware design of discrete-time spiking neural networks based on back propagation with binary activations. In Proceedings of the 2017 IEEE Biomedical Circuits and Systems Conference (BioCAS), Turin, Italy, 19–21 October 2017; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Zheng, N.; Mazumder, P. A Low-Power Hardware Architecture for On-Line Supervised Learning in Multi-Layer Spiking Neural Networks. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Chen, G.K.; Kumar, R.; Sumbul, H.E.; Knag, P.C.; Krishnamurthy, R.K. A 4096-Neuron 1M-Synapse 3.8-pJ/SOP Spiking Neural Network With On-Chip STDP Learning and Sparse Weights in 10-nm FinFET CMOS. IEEE J. Solid-State Circuits 2019, 54, 992–1002. [Google Scholar] [CrossRef]
- Deng, L.; Wu, Y.; Hu, X.; Liang, L.; Ding, Y.; Li, G.; Zhao, G.; Li, P.; Xie, Y. Rethinking the performance comparison between SNNS and ANNS. Neural Netw. 2020, 121, 294–307. [Google Scholar] [CrossRef]
- Mozafari, M.; Ganjtabesh, M.; Nowzari-Dalini, A.; Thorpe, S.J.; Masquelier, T. Combining STDP and reward-modulated STDP in deep convolutional spiking neural networks for digit recognition. arXiv 2018, arXiv:1804.00227. [Google Scholar]
- Kheradpisheh, S.R.; Ganjtabesh, M.; Masquelier, T. Bio-inspired unsupervised learning of visual features leads to robust invariant object recognition. Neurocomputing 2016, 205, 382–392. [Google Scholar] [CrossRef] [Green Version]
- Thiele, J.C.; Bichler, O.; Dupret, A. Event-based, timescale invariant unsupervised online deep learning with STDP. Front. Comput. Neurosci. 2018, 12, 46. [Google Scholar] [CrossRef]
- Toomey, E.; Segall, K.; Berggren, K.K. Design of a Power Efficient Artificial Neuron Using Superconducting Nanowires. Front. Neurosci. 2019, 13, 933. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Burr, G.; Narayanan, P.; Shelby, R.; Sidler, S.; Boybat, I.; di Nolfo, C.; Leblebici, Y. Large-scale neural networks implemented with non-volatile memory as the synaptic weight element: Comparative performance analysis (accuracy, speed, and power). In Proceedings of the 2015 IEEE International Electron Devices Meeting (IEDM), Washington, DC, USA, 7–9 December 2015; p. 4. [Google Scholar]
- Burr, G.W.; Shelby, R.M.; Sebastian, A.; Kim, S.; Kim, S.; Sidler, S.; Virwani, K.; Ishii, M.; Narayanan, P.; Fumarola, A.; et al. Neuromorphic computing using non-volatile memory. Adv. Phys. X 2017, 2, 89–124. [Google Scholar] [CrossRef]
- Ankit, A.; Sengupta, A.; Panda, P.; Roy, K. Resparc: A reconfigurable and energy-efficient architecture with memristive crossbars for deep spiking neural networks. In Proceedings of the 54th Annual Design Automation Conference 2017, Austin, TX, USA, 18–22 June 2017; pp. 1–6. [Google Scholar]
- Kim, S.; Ishii, M.; Lewis, S.; Perri, T.; BrightSky, M.; Kim, W.; Jordan, R.; Burr, G.; Sosa, N.; Ray, A.; et al. NVM neuromorphic core with 64k-cell (256-by-256) phase change memory synaptic array with on-chip neuron circuits for continuous in-situ learning. In Proceedings of the 2015 IEEE International Electron Devices Meeting (IEDM), Washington, DC, USA, 7–9 December 2015. [Google Scholar]
- Prezioso, M.; Merrikh-Bayat, F.; Hoskins, B.; Adam, G.C.; Likharev, K.K.; Strukov, D.B. Training and operation of an integrated neuromorphic network based on metal-oxide memristors. Nature 2015, 521, 61–64. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.; Lim, M.; Kim, Y.; Kim, H.D.; Choi, S.J. Impact of synaptic device variations on pattern recognition accuracy in a hardware neural network. Sci. Rep. 2018, 8, 1–7. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Processor | SpiNNaker [44] | Neurogrid [46] | TrueNorth [45] | Loihi [47] |
|---|---|---|---|---|
| Implementation | Digital | Analog | Digital | Digital |
| Technology | 130 nm | 180 nm | 28 nm | 14 nm |
| Weight Resolution | 8b–32b | 13b | 1b–4b | 1b–64b |
| Online learning | Yes | No | No | Yes |
| Neurons per cores | 1000 | 65,000 | 256 | 1024 |
| Cores per chip | 16 | 1 | 4096 | 128 |
| Energy/SOPS (pJ) | 27,000 | 941 | 26 | 15 |
| Processor | Frenkel et al. [48] | Yin et al. [49] | Zheng et al. [50] | Chen et al. [51] |
|---|---|---|---|---|
| Implementation | Digital | Digital | Digital | Digital |
| Technology | 28 nm | 28 nm | 65 nm | 10 nm |
| Weight Resolution | 4b | 7b | 16b | 8b |
| Online learning | Yes | No | Yes | Yes |
| Networks models | FC | FC | FC | FC |
| 1 layer | 3 layers | 3 layers | 4 layers | |
| Input coding scheme | Rate coding | Rate coding | Rate coding | Rate coding |
| MNIST accuracy | 85.4% | 98.7% | 90% | 97.9% |
| Core Area (mm2) | 16 | 1 | 4096 | 128 |
| Energy/classification | 15 nJ | 773 nJ | 1.12 J | 1.7 J |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, D.-A.; Tran, X.-T.; Iacopi, F. A Review of Algorithms and Hardware Implementations for Spiking Neural Networks. J. Low Power Electron. Appl. 2021, 11, 23. https://doi.org/10.3390/jlpea11020023
Nguyen D-A, Tran X-T, Iacopi F. A Review of Algorithms and Hardware Implementations for Spiking Neural Networks. Journal of Low Power Electronics and Applications. 2021; 11(2):23. https://doi.org/10.3390/jlpea11020023
Chicago/Turabian StyleNguyen, Duy-Anh, Xuan-Tu Tran, and Francesca Iacopi. 2021. "A Review of Algorithms and Hardware Implementations for Spiking Neural Networks" Journal of Low Power Electronics and Applications 11, no. 2: 23. https://doi.org/10.3390/jlpea11020023
APA StyleNguyen, D. -A., Tran, X. -T., & Iacopi, F. (2021). A Review of Algorithms and Hardware Implementations for Spiking Neural Networks. Journal of Low Power Electronics and Applications, 11(2), 23. https://doi.org/10.3390/jlpea11020023