
Genetic Algorithms to Maximize the Relevant Mutual Information in Communication Receivers †

 ,
,  ,
,
Abstract
:1. Introduction
- We develop and investigate the idea of applying genetic algorithms to maximize mutual information in a parametrized information bottleneck setup for communication receivers.
- We design very powerful parametrized compression mappings that preserve large amounts of relevant information with very few parameters. These mappings are based on exact and approximate nearest neighbor search algorithms.
- We illustrate enormous flexibility and generality of the considered approach.
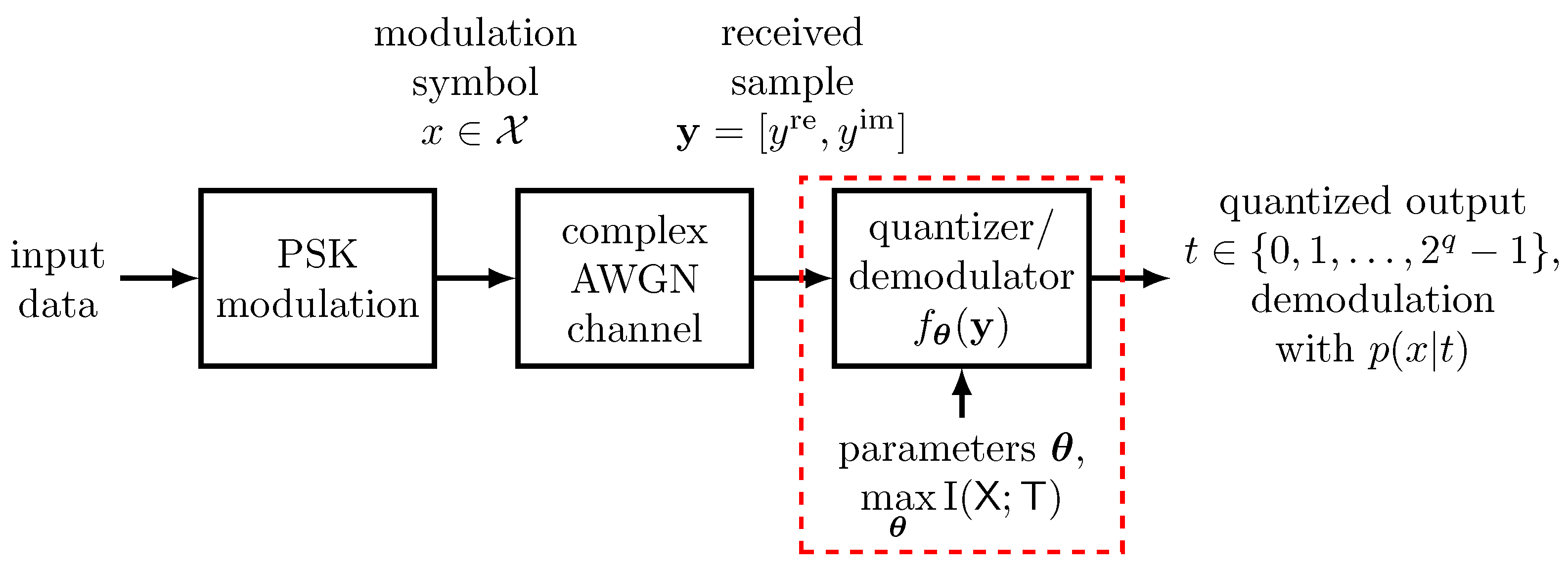
- We present results on channel output quantization and demodulation in communication receivers.
2. Preliminaries
2.1. The Information Bottleneck Method
2.2. Genetic Algorithms
2.3. Distance Metrics
3. Design of Parametrized Compression Mappings That Maximize Relevant Information for Communication Receivers
3.1. Flexible Parametrized Mappings
3.1.1. Clustering by Simple Exact Nearest Neighbor Search
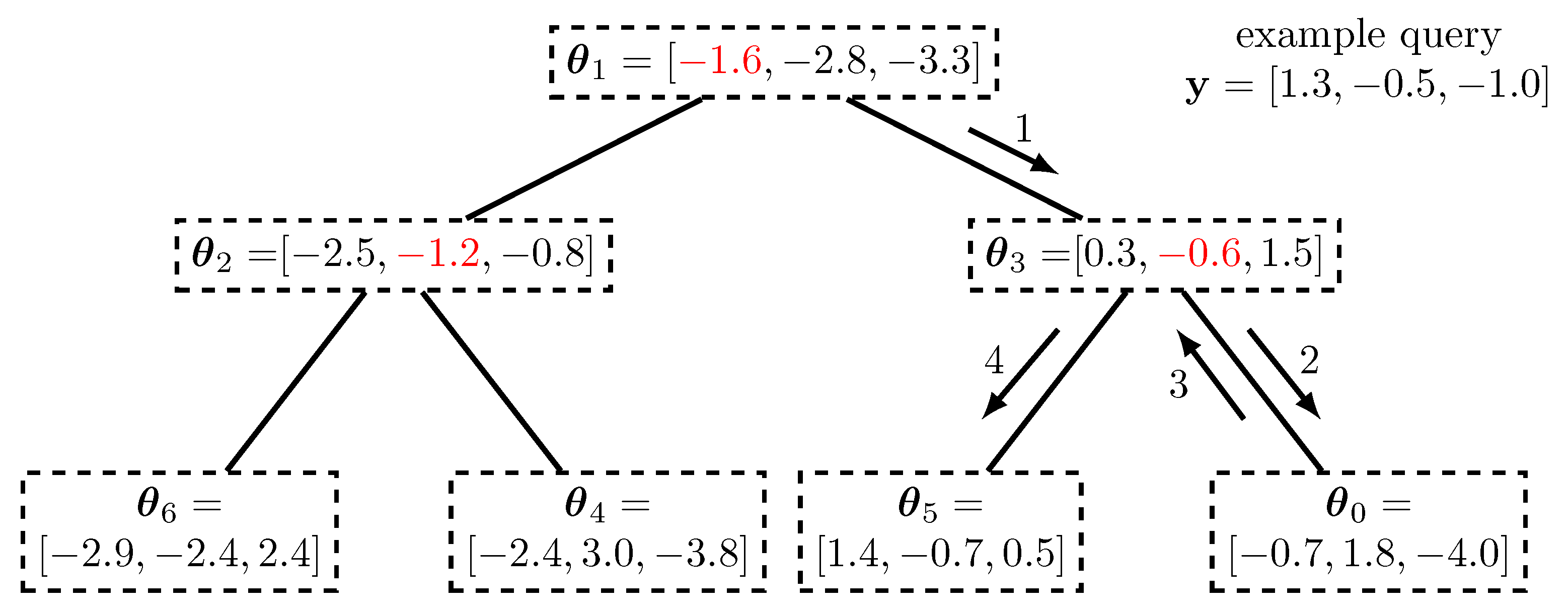
3.1.2. Exact and Approximate Nearest Neighbor Clustering Using K-Dimensional Trees
3.1.3. Approximate Nearest Neighbor Clustering Using Neighborhood Graphs
3.2. Genetic Algorithm Optimization
3.2.1. Why Genetic Algorithms?
3.2.2. Using Genetic Algorithms to Maximize the Preserved Relevant Information
4. Results and Discussion
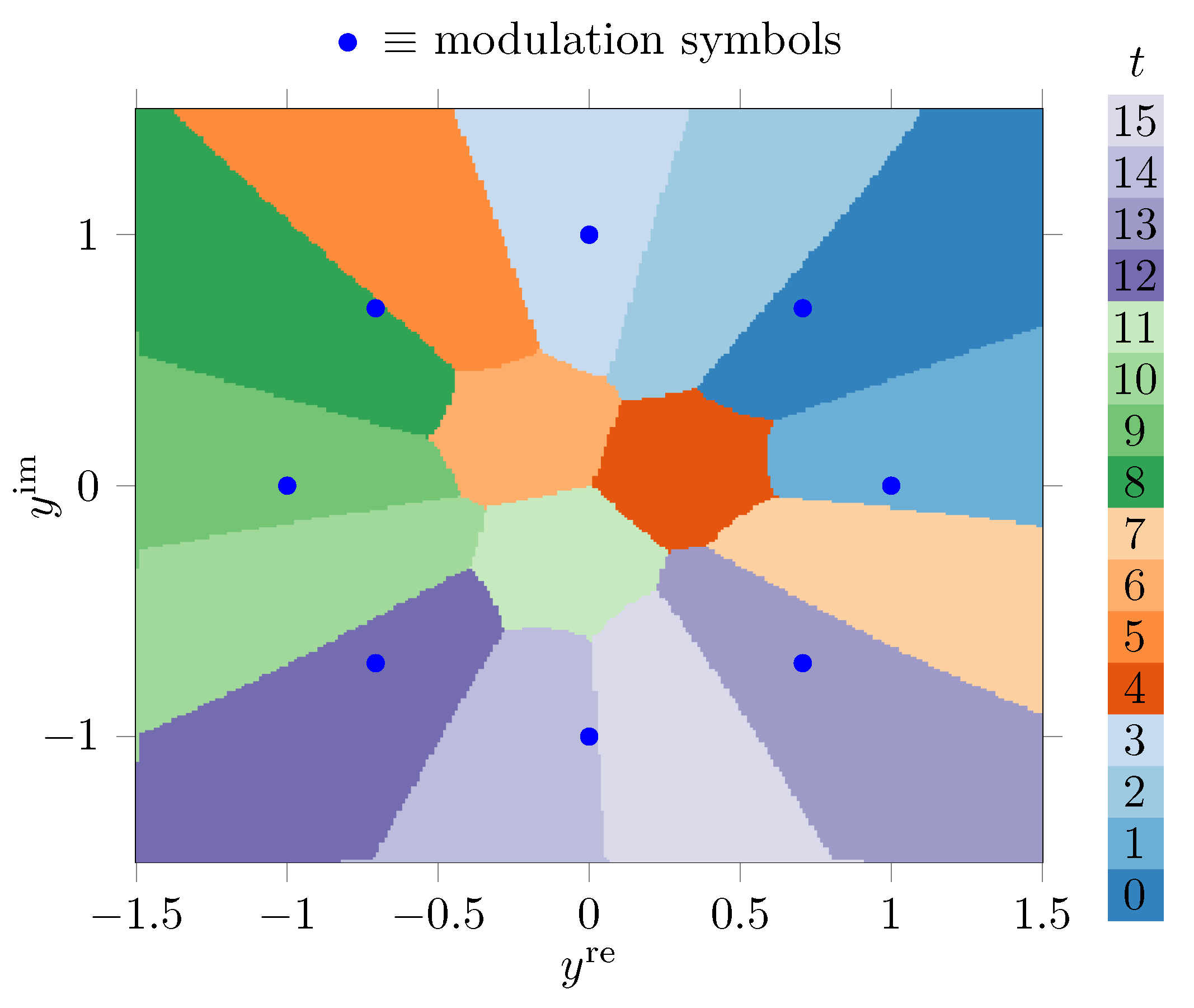
4.1. Quantization of the Channel Output with Minimum Loss of Relevant Information
4.1.1. Information Bottleneck Quantizer Design with the KL-Means Algorithm
4.1.2. Genetic Algorithm Quantizer Design Using Exact Nearest Neighbor Search
4.1.3. Genetic Algorithm Quantizer Design with Approximate Nearest Neighbor Search
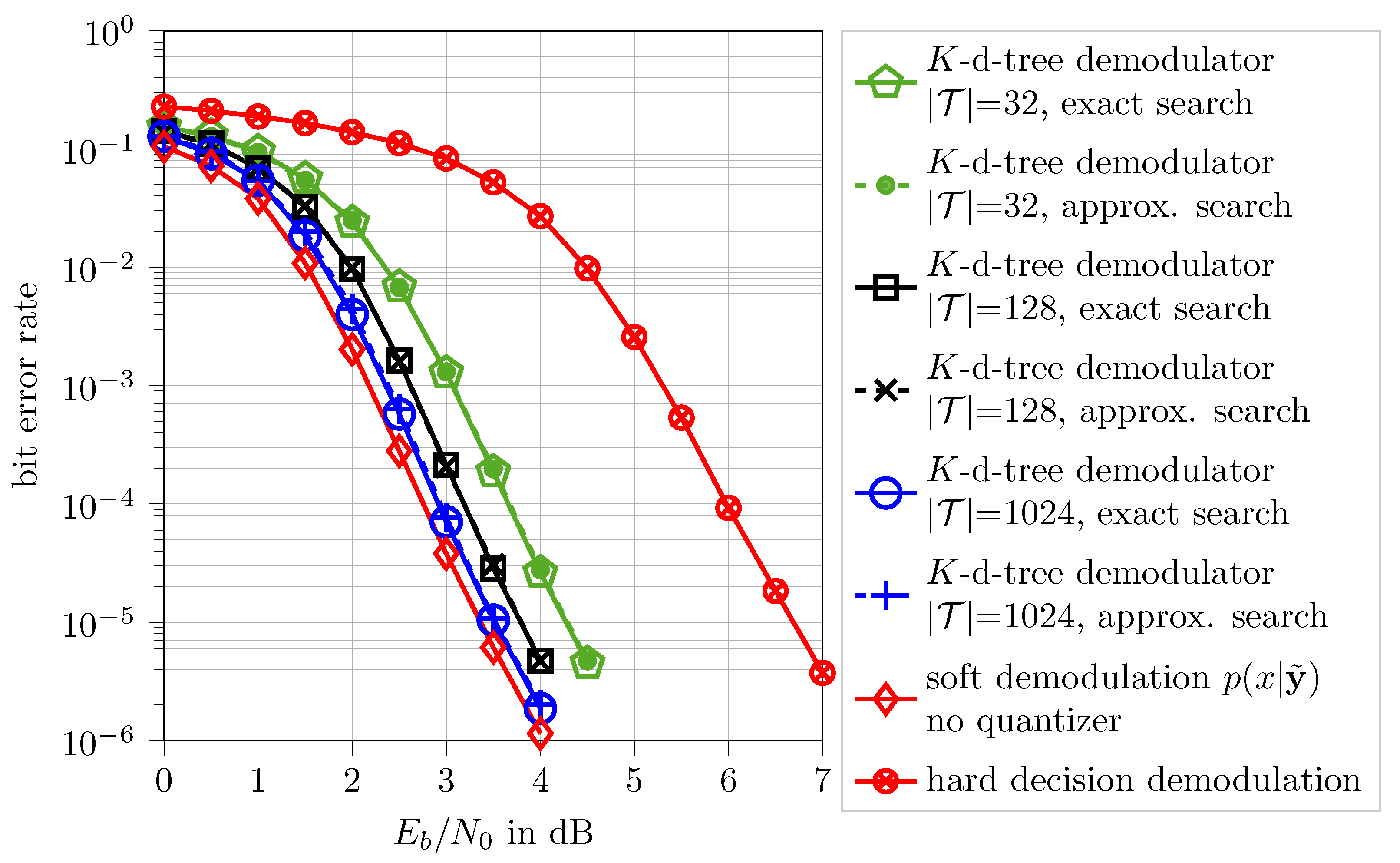
4.2. Genetic Algorithm Designed Demodulation Using K-Dimensional Trees
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tishby, N.; Pereira, F.C.; Bialek, W. The information bottleneck method. In Proceedings of the 37th Allerton Conference on Communication and Computation, Monticello, IL, USA, 22–24 September 1999; pp. 368–377. [Google Scholar]
- Slonim, N.; Somerville, R.; Tishby, N.; Lahav, O. Objective classification of galaxy spectra using the information bottleneck method. Mon. Not. R. Astron. Soc. 2001, 323, 270–284. [Google Scholar] [CrossRef] [Green Version]
- Bardera, A.; Rigau, J.; Boada, I.; Feixas, M.; Sbert, M. Image segmentation using information bottleneck method. IEEE Trans. Image Process. 2009, 18, 1601–1612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Buddha, S.; So, K.; Carmena, J.; Gastpar, M. Function identification in neuron populations via information bottleneck. Entropy 2013, 15, 1587–1608. [Google Scholar] [CrossRef] [Green Version]
- Romero, F.J.C.; Kurkoski, B.M. LDPC decoding mappings that maximize mutual information. IEEE J. Sel. Areas Commun. 2016, 34, 2391–2401. [Google Scholar] [CrossRef]
- Lewandowsky, J.; Bauch, G.; Tschauner, M.; Oppermann, P. Design and evaluation of information bottleneck LDPC decoders for digital signal processors. IEICE Trans. Commun. 2019, E102-B, 1363–1370. [Google Scholar] [CrossRef] [Green Version]
- Lewandowsky, J.; Stark, M.; Bauch, G. A discrete information bottleneck receiver with iterative decision feedback channel estimation. In Proceedings of the 2018 IEEE 10th International Symposium on Turbo Codes and Iterative Information Processing (ISTC), Hong Kong, China, 25–29 November 2018. [Google Scholar]
- Hassanpour, S.; Monsees, T.; Wübben, D.; Dekorsy, A. Forward-aware information bottleneck-based vector quantization for noisy channels. IEEE Trans. Commun. 2020, 68, 7911–7926. [Google Scholar] [CrossRef]
- Kern, D.; Kühn, V. On information bottleneck graphs to design compress and forward quantizers with side information for multi-carrier transmission. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017. [Google Scholar]
- Steiner, S.; Kühn, V. Optimization of distributed quantizers using an alternating information bottleneck approach. In Proceedings of the 2019 23rd International ITG Workshop on Smart Antennas (WSA), Vienna, Austria, 24–26 April 2019; pp. 1–6. [Google Scholar]
- Lewandowsky, J.; Bauch, G. Information-optimum LDPC decoders based on the information bottleneck method. IEEE Access 2018, 6, 4054–4071. [Google Scholar] [CrossRef]
- Shah, S.A.A.; Stark, M.; Bauch, G. Design of quantized decoders for polar codes using the information bottleneck method. In Proceedings of the 12th International ITG Conference on Systems, Communications and Coding 2019 (SCC’2019), Rostock, Germany, 11–14 February 2019; pp. 1–6. [Google Scholar]
- Shah, S.A.A.; Stark, M.; Bauch, G. Coarsely quantized decoding and construction of polar codes using the information bottleneck method. Algorithms 2019, 12, 192. [Google Scholar] [CrossRef] [Green Version]
- Malkov, Y.A.; Yashunin, D.A. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 824–836. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Prokhorenkova, L.; Shekhovtsov, A. Graph-based nearest neighbor search: From practice to theory. In Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; pp. 7803–7813. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Tishby, N.; Zaslavsky, N. Deep learning and the information bottleneck principle. In Proceedings of the 2015 IEEE Information Theory Workshop (ITW), Jerusalem, Israel, 26 April–1 May 2015; pp. 1–5. [Google Scholar]
- Alemi, A.; Fischer, I.; Dillon, J.; Murphy, K. Deep variational information bottleneck. In Proceedings of the 5th International Conference on Learning Representations (ICLR) 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Coley, D.A. An Introduction to Genetic Algorithms for Scientists and Engineers; World Scientific Publishing Co., Inc.: Singapore, 1998. [Google Scholar]
- Yu, X.; Gen, M. Introduction to Evolutionary Algorithms; Springer: London, UK, 2010. [Google Scholar]
- Elkelesh, A.; Ebada, M.; Cammerer, S.; ten Brink, S. Decoder-tailored polar code design using the genetic algorithm. IEEE Trans. Commun. 2019, 67, 4521–4534. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Li, L.; Chen, L. An advanced genetic algorithm for traveling salesman problem. In Proceedings of the 2009 Third International Conference on Genetic and Evolutionary Computing, Guilin, China, 14–17 October 2009; pp. 101–104. [Google Scholar]
- Lewandowsky, J.; Dongare, S.J.; Adrat, M.; Schrammen, M.; Jax, P. Optimizing parametrized information bottleneck compression mappings with genetic algorithms. In Proceedings of the 2020 14th International Conference on Signal Processing and Communication Systems (ICSPCS), Adelaide, Australia, 14–16 December 2020; pp. 1–8. [Google Scholar]
- Bentley, J.L. Multidimensional binary search trees used for associative searching. Commun. ACM 1975, 18, 509–517. [Google Scholar] [CrossRef]
- Brown, R.A. Building a Balanced k-d Tree in O(kn log n) Time. J. Comput. Graph. Tech. (JCGT) 2015, 4, 50–68. [Google Scholar]
- Zhang, J.A.; Kurkoski, B.M. Low-complexity quantization of discrete memoryless channels. In Proceedings of the 2016 International Symposium on Information Theory and Its Applications (ISITA), Monterey, CA, USA, 30 October–2 November 2016; pp. 448–452. [Google Scholar]
- Kurkoski, B.M. On the relationship between the KL means algorithm and the information bottleneck method. In Proceedings of the 2017 11th International ITG Conference on Systems, Communications and Coding (SCC), Hamburg, Germany, 6–9 February 2017; pp. 1–6. [Google Scholar]
- Hassanpour, S.; Wübben, D.; Dekorsy, A. A graph-based message passing approach for joint source-channel coding via information bottleneck principle. In Proceedings of the 2018 IEEE 10th International Symposium on Turbo Codes and Iterative Information Processing (ISTC), Hong Kong, China, 25–29 November 2018. [Google Scholar]
- Slonim, N. The Information Bottleneck: Theory and Applications. Ph.D. Dissertation, Hebrew University of Jerusalem, Jerusalem, Israel, 2002. [Google Scholar]
- Hassanpour, S.; Wübben, D.; Dekorsy, A.; Kurkoski, B. On the relation between the asymptotic performance of different algorithms for information bottleneck framework. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017. [Google Scholar]
- Lange, M.; Zühlke, D.; Holz, O.; Villmann, T. Applications of lp-norms and their smooth approximations for gradient based learning vector quantization. In Proceedings of the 22nd European Symposium on Artificial Neural Networks, Bruges, Belgium, 23–25 April 2014; pp. 271–276. [Google Scholar]
- Information Bottleneck Algorithms for Relevant-Information-Preserving Signal Processing in Python. Available online: https://collaborating.tuhh.de/cip3725/ib_base (accessed on 19 August 2020).
- Stark, M.; Bauch, G.; Lewandowsky, J.; Saha, S. Decoding of non-binary LDPC codes using the information bottleneck method. In Proceedings of the 2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Carrasco, R.A.; Johnston, M. Non-Binary Error Control Coding for Wireless Communication and Data Storage; Wiley: Chichester, UK, 2008. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description | Value |
|---|---|---|
| population size | 200 | |
| number of crossovers for genetic combination | 5 | |
| mutation probability of each bit in the genotype | ||
| number of bits to represent a parameter in the genotype | 10 | |
| number of elite population members (guaranteed to breed) | 20 | |
| number of evolved generations | 2000 |
| Parameter | Description | Value |
|---|---|---|
| q | bit width for channel output quantization | 4 |
| number of belief propagation decoding iterations | 20 | |
| field order of non-binary low-density parity-check code | 8 | |
| uncoded information per codeword (in GF(8) symbols) | 130 | |
| codeword length of non-binary code (in GF(8) symbols) | 260 | |
| R | code rate of non-binary low-density parity-check code | |
| check node degree of applied regular code | 4 | |
| variable node degree of applied regular code | 2 | |
| distance type used in K-dimenstional tree demodulator | Euclidean |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lewandowsky, J.; Dongare, S.J.; Martín Lima, R.; Adrat, M.; Schrammen, M.; Jax, P. Genetic Algorithms to Maximize the Relevant Mutual Information in Communication Receivers. Electronics 2021, 10, 1434. https://doi.org/10.3390/electronics10121434
Lewandowsky J, Dongare SJ, Martín Lima R, Adrat M, Schrammen M, Jax P. Genetic Algorithms to Maximize the Relevant Mutual Information in Communication Receivers. Electronics. 2021; 10(12):1434. https://doi.org/10.3390/electronics10121434
Chicago/Turabian StyleLewandowsky, Jan, Sumedh Jitendra Dongare, Rocío Martín Lima, Marc Adrat, Matthias Schrammen, and Peter Jax. 2021. "Genetic Algorithms to Maximize the Relevant Mutual Information in Communication Receivers" Electronics 10, no. 12: 1434. https://doi.org/10.3390/electronics10121434
APA StyleLewandowsky, J., Dongare, S. J., Martín Lima, R., Adrat, M., Schrammen, M., & Jax, P. (2021). Genetic Algorithms to Maximize the Relevant Mutual Information in Communication Receivers. Electronics, 10(12), 1434. https://doi.org/10.3390/electronics10121434