1. Introduction
The cloud can be viewed as an easily usable and accessible pool of resources that can be configured dynamically. The more work needs to be done, the more resources can be acquired. However, exposing hardware as a service to other users, especially to untrusted ones, may not be a good idea because of security risks involved. Infrastructure as a service (IaaS) cloud computing service model allows the user to obtain access to virtual machines instances and install his own operating systems inside them without having the security risks of the hardware as a service (HaaS) cloud [
1].
Public cloud virtual machines startup takes from tens of seconds to several minutes, because they boot a full operating system every time. Recently the cloud industry is moving beyond self-contained, isolated, and monolithic virtual machine images in favor of container-type virtualization [
2]. Virtualization containers do not contain any operating system kernel, which makes them faster and more agile than virtual machines. The container startup time is about a second. Containers keep applications and their runtime components together by combining lightweight application isolation with an image-based deployment method. The most popular container platform is Docker.
The role of orchestration and scheduling within the popular container platforms is to match applications to resources. One of the most in-demand container orchestration tools available today is Google Kubernetes [
3]. At a very high level, Kubernetes has the following main components: one or more master nodes, one or more worker nodes, and a distributed key-value etcd data store. The role of the Kubernetes scheduler is to assign new containers to cloud nodes. The scheduler running on a master node obtains resource usage data for each worker node in the cluster from the etcd data store. The scheduler also receives the new container’s requirements from the API server. After successful node choice and a new container startup, the resulting state of the Kubernetes cluster is saved in the etcd data store for persistence. Kubernetes is extensible and its micro-service architecture allows the use of a custom container scheduler.
Cloud platform node roles increase the deployment complexity. Thus, there exist first interesting ideas that elastic container platforms should be more like Peer-to-Peer (P2P) networks composed of equally privileged and equipotent nodes. Some authors believe that this could be a fruitful research direction [
4]. A resurgence of interest in decentralized approaches known from P2P related research is clearly observable. This seems to change and might be an indicator where cloud computing could be heading in the future [
5]. In this paper, such a P2P-like decentralized system for scheduling of containerized microservices is proposed. There is no distinction between master and worker nodes: all nodes are equal. There is no database, where the cluster state is saved. There is no central scheduling system and hence the containers can dynamically (re)schedule themselves during their lifetime.
Most existing container orchestrators schedule containers to run on hosts in the cluster based on resources availability. For example Docker’s native clustering solution Docker Swarm [
6] ships with two main scheduling strategies, spread and bin pack. The spread strategy will attempt to distribute containers evenly across hosts, whereas the bin pack strategy will place containers on the most-loaded host that still has enough resources to run the given containers. The advantage of spread is that should a host go down, the number of affected containers is minimized. The advantages of bin pack are that it drives resource usage up and can help ensure there is spare capacity for running containers that require significant resources. In this paper, we focus on the bin pack strategy of container scheduling.
The commercial schedulers mentioned above are interesting because of their maturity. Numerous clients from small to big infrastructures use them in production. However, they are also limited in terms of features. For example, none of them proposes any dynamic scheduling feature. This means that the scheduler cannot revise the current placement when the environment is changing (typically when a load spike occurs or when the client expectations change). The containers can only be stopped and started again on new nodes. In this way their runtime (i.e., volatile) state is lost. The scheduler proposed in this paper allows for such state preserving dynamic reconfiguration using container live migration.
One of the original motivation behind the use of live migration to perform dynamic scheduling of virtual machines was green computing [
7,
8]. For example in [
9] adaptive heuristics for dynamic consolidation of virtual machines significantly reducing energy consumption by the cloud servers have been proposed. The efficiency of these algorithms was evaluated by extensive simulations using CloudSim framework [
10,
11], which were based on real-world workload traces from PlanetLab virtual machines. The distributed scheduler proposed in this paper regularly analyses the environment to check if a better container consolidation on cloud nodes is possible. Unused nodes can be switched off.
The problem the cloud schedulers address is an instance of the vector packing problem, a NP-hard problem in a strong sense [
12]. Thus, the scheduler latency necessarily increases exponentially with the size of the cloud infrastructure. Several approaches were proposed to improve scheduler scalability. The Borg scheduler of Google runs multiple independent copies of a scheduler on a shared infrastructure and conciliate conflicts lazily [
13]. Sparrow [
14] proposes a two-level scheduling algorithm to schedule jobs at a very low latency. DVMS [
15] leverages Peer-to-Peer architecture to reconfigure the virtual machine placement. However, it requires a fairly complicated deadlock detection and resolution mechanism. Firmament [
16] exhibits a centralized approach that is scalable enough to support large Google-size data centers. The system proposed in this paper can be considered to be the extreme case of fully distributed schedulers. In addition to cloud application processes each container runs an additional scheduling process. Technically, it could be added as an additional container to the pod encapsulating the application container without the need for modifying it. This is a so-called sidecar cloud design pattern [
17].
Recently, an overwhelming spread of smart devices and appliances, namely Internet-of-Things (IoT), has pointed out all the limitations of cloud computing centralized paradigm [
18]. The continuously generated sensor data streams need to be processed by various Artificial Intelligence (AI) algorithms of different computational complexities [
19]. The idea of Edge computing is to extend cloud computing to the network edge with the aim of having the computation as close to the data sources, i.e., IoT devices, as possible [
18]. Fog computing is extending Edge computing by transferring computation from the IoT devices to more powerful fixed nodes with built-in data storage, computing, and communication devices [
20].
Microservices running inside virtualization containers represent a valid solution for code execution in such systems [
21], and their controlled migration is expected to play an important role in future IoT deployments [
22,
23]. Possible migration scenarios involve moving IoT devices, such as cars and robots, in which case computation and storage service may need to be moved from one Edge node to another one in order remain in close proximity of the IoT device. Another scenario is to offload running containers from an Edge node to a Fog or Cloud node, when the Edge node is overloaded and it has a limited amount of computation power or storage capacity at runtime [
19]. Resource provisioning remains the Achilles heel of efficiency for Edge and Fog computing applications [
24]. Our goal in this paper is to design a self-adaptive distributed container orchestration system that could potentially be used for management of the cloud, Fog, and Edge nodes.
This paper is organized as follows. In
Section 2 the distributed biology inspired swarm-like container scheduling algorithm implementing the spread strategy [
25] is recalled and generalized to the case of heterogeneous containers. In
Section 3 it is extended to encompass the bin pack strategy and analyzed mathematically using coupled differential equations. In
Section 4 some results and conclusions from experiments using OpenVZ containers are presented. In
Section 5 we study the performance and scaling of the distributed algorithm proposed in a simulated cloud. In
Section 6 the discussion of the results and comparison with previous approaches is presented. We finish with some conclusions and remarks about future research directions in
Section 7. Notations used in this paper are presented in
Appendix A. The pseudo-code of the scheduling process running inside each container is listed in
Appendix B.
2. Distributed Algorithm for a Heterogeneous Cloud
For the purpose of this paper we will come up with a very simple working definition of the cloud. It says that a cloud consists of computing nodes running virtualization containers. Let us consider a given node of the cloud and denote by its capacity, where Let us denote by the number of resources of kind k used by all containers running on it. If for all k nothing happens. This situation is optimal. If for some k, then the node is overloaded and a spread-like strategy needs to be employed in order to expel excess containers to other nodes. Otherwise, if for some k, then the node is not fully used and can be potentially switched off to save electrical energy if another nodes can accommodate its containers. This is the case we will deal with in this paper.
In general, the task of allocating virtualization containers to cloud nodes can be considered to be an optimization problem. For example in [
26] the authors present a multi-objective optimization model that aims to assist horizontal (changes in the number of instances) and vertical (changes in the computational resources available to instances) scaling in a cloud platform. The platform to be scaled is based on virtualization containers running inside virtual machines obtained from commercial IaaS providers. The model aims to minimize the total leasing cost of the virtual machines. The solution is found using a IBM CPLEX optimization solver.
The goal of an optimization algorithm is to minimize the value of some objective (cost) function by tuning the values of its parameters. Genetic algorithms, particle swarm optimization and self-organizing migrating algorithm (SOMA) [
27] belong to the most popular global stochastic optimization algorithms. In our case, the system orchestrating containers in the cloud is distributed and no global information about the state of the nodes is known. Therefore no single-objective function can be defined. Instead the problem considered in this paper is inherently a multi-objective one. Therefore a cost function depending only on the values of
and
will be assigned to every cloud node.
In [
25] we proposed to carry out load balancing in cloud container setups using a swarm model based on the idea of swarms of autonomous “pheromone” robots [
28,
29,
30,
31,
32,
33,
34,
35]. Our approach treats the containers as mobile agents moving between the cloud nodes. In addition to cloud application each container runs an additional process implementing the mobile agent intelligence. It periodically checks resource usage of the hosts on which it is running. We considered a single type of container and homogeneous nodes. Later experiments were performed for heterogeneous nodes [
36], but the containers remained to be identical.
However, this swarm-like model can be easily generalized to the case of nonidentical containers. As with the Dominant Resource Fairness algorithm [
37], the dominant resource kind can be found as:
This kind might be different for different nodes (even if their capacities are the same). Although not formulated in this way, the algorithm introduced in [
25,
36] can be understood as a multi-objective optimization algorithm where the cost functions are defined for each node by Equation (
1). The optimization goal is to
minimize them to a value
same for all nodes so they are equally loaded.
In this paper, we aim to extend this model not only to provide simple load balancing, but also define richer execution policies that will be capable of grouping the containers into as few nodes as possible. The goal is to
maximize the least dominant resource use for each node:
while keeping the dominant resource use given by Equation (
1) below the overload threshold. The choice of least dominant resource in the cost function allows making changes to a server packed only in one dimension (i.e.,
for some
k), which otherwise would not accept new containers (each container consumes some resources of all kinds).
The SOMA optimization algorithm [
27] is based on the self-organizing behavior of groups of individuals in a “social environment”. SOMA was inspired by the competitive-cooperative behavior of intelligent creatures solving a common problem. Group of animals looking for food may be a good example. If a member of this group is more successful than the others than again all members change their trajectories towards him. This procedure is repeated until all members meet around the food source.
Individuals in the SOMA algorithm are abstract points in a N-dimensional space of optimization parameters and are initially generated at random. Each individual is evaluated by cost function and they migrate through the N-dimensional hyperplane of variables and try to find better solutions. In one strategy the leader (individual with the highest fitness) is chosen in each step of the migration loop. Then all other individuals begin to jump (with some randomness added) towards the leader.
In our case, containers are real entities (i.e., groups of processes) that move between the nodes of the cloud. For this purpose each container computes its migration probability. If the node is overloaded and a spread-like strategy is employed to expel excess containers to other nodes then the following expression for the migration probability can be used [
25]:
The function from Equation (
3) simply maps the cost function from Equation (
1) onto the interval
(if the node is overloaded). The probability
p is the same for all containers on the given node and plays the role of an repulsive “pheromone” [
25]. Thus, the containers more likely move
away from a node with high value of the objective function
(lowering it). After container migration the value of
p decreases on the initial node, but increases on the target node.
If the node is not overloaded and not fully loaded then it can be potentially switched off to save electrical energy if another nodes can accommodate its containers. To implement bin pack-like strategy we propose the migration probability that decreases linearly from 1 at
(single container on the host) to 0 at
(node is fully loaded):
where
n and
are given by Equation (
2). In this case the containers more likely move away from a node with low value of the objective function
(lowering it even further). After migration the value of
p increases on the initial node, but decreases on the target node. The form of the “pheromone” function given by Equation (
4) will be investigated (and modified) in the following section using a simple mathematical model of the cloud.
3. Mathematical Model of a Homogeneous Cloud
To come up with a model we will assume that all nodes and containers are identical. Thus, the dominant resource from Equation (
1) will be simply the number of containers. Moreover the numbers of containers on different nodes will not be treated as discrete variables, but rather as continuous functions of time. In addition, the destination node will be chosen randomly. Theses assumptions allow us to describe the dynamics of the cloud using a system of coupled differential rate equations. The time change of the occupation
of the
i-th node reads as:
The first term on the right side of Equation (
5) are containers migrating away from the
i-th node to other nodes. The second term describes the containers incoming randomly to the
i-th node from other nodes.
T denotes a characteristic time scale related to the container migration time, and
N is the number of nodes. Let us now substitute into Equation (
5) the definition of
p from Equation (
3). This spread strategy was studied extensively in our previous paper [
38]. It leads to a system of linear equations and the solutions decay exponentially (negative eigenvalues) with time leading to a stable stationary state
for all nodes (eigenvalue zero).
We will now focus on the more interesting bin pack strategy. It turns out that the proper choice of the repulsive “pheromone” function is not necessarily a trivial task in this case. Let us first consider a cluster of
nodes, one of which can be empty:
The system of Equation (
5) together with Equations (
4) and (
6) gives only a static solution, regardless of the initial state.
More interesting solutions appear for
nodes, one of which can be empty:
Equations (
5) reduce to the system of two coupled Bernoulli equations, which is chaotic one and therefore extremely sensitive to the initial conditions. It has the desired stationary solutions:
but the corresponding fixed points of Equations (
5) are saddles (the Jacobi matrix has one negative eigenvalue, one positive, and one zero).
To deal with this instability we propose a different “pheromone” function implementing the bin pack strategy. Let us square the right hand side of Equation (
4):
Please note that for identical containers
in Equation (
9). For two nodes
the system of Equations (
5) together with the initial condition Equation (
6) now reduces to the equation:
which has the following solution:
where:
It is seen from inspection of Equation (
10) that it has three fixed points: one unstable
and two stable
and
. The corresponding solutions are distinguished in Equation (
11) by the choice of the ± sign. For large
t the function from Equation (
11) corresponding to the − sign decays exponentially. Therefore the bin-packing algorithm for two nodes has logarithmic time complexity. As we will see in
Section 5 this holds also for a larger cloud.
For three hosts
the system of Equation (
5) together with the “pheromone” function Equation (
9) has also three stable fixed points corresponding to one empty node and the remaining full Equation (
8) (one eigenvalue of the Jacobi matrix is negative and the remaining zero). There is also and unstable fixed point corresponding to the equal occupation of all nodes:
and three unwanted stable fixed points:
To prevent the system from reaching these unwanted final configurations of the cloud the container jumps cannot be done randomly. The notion of an attractive “pheromone” needs to be introduced. It is not possible to do this within the coupled differential equations model. Therefore in the following section some results and conclusions from experiments using OpenVZ containers will be presented. It turns out that this modification also greatly improves the performance of the algorithm.
4. Experimental Results for a Small Cloud
Process migration is an old and well researched subject [
39]. During container migration a group of processes is transferred from one server to another. Processes running inside virtualization containers are isolated from the rest of the system using special kernel mechanisms like, e.g., namespaces and control groups in the case of Linux. Therefore in theory their migration should be easier than ordinary processes. At the time the experiments described here were performed, Docker offered some support for checkpointing a running container to the disk, and restoring it to memory using CRIU (
https://www.redhat.com/en/blog/checkpointrestore-container-migration, accessed on 26 June 2021). However, our experience was that this could not be done reliably.
Live migration refers to the process of moving a running virtual machine between different physical machines without disconnecting the client of an internet application running inside it. Virtualization container live migration is also possible, but is supported on some container platforms only, e.g., OpenVZ [
40]. Others (like Docker) have not reached this level of maturity yet. OpenVZ system consists of a Linux kernel, user-level tools and templates, which are needed to create containers. Live migration of containers is achieved using lazy and iterative migration of memory pages.
To perform the experiments described in this section we created three identical virtualized KVM nodes and installed OpenVZ 7 on them. Next, 100 identical containers was launched on these nodes. In addition to that, on each node a custom written Python REST service was started. It allows the containers to check the occupation of each node, and ask their host node to migrate them to another node. In a large cloud these REST services will form a P2P network aiding the containers in finding a suitable destination node to migrate to. In our previous experiments with containers [
25] OpenVZ 6 with a Linux kernel modified in order to add custom system functions were used.
At the DockerCon conference in 2015 a demonstration was shown during which 50,000 containers were launched on
nodes (
https://twitter.com/dockercon/status/666199498016821248, accessed on 26 June 2021). To replicate this case we will set
in Equation (
19). The initial state of our system of
nodes is:
The experiment ends after time
if the final state is reached:
In addition to the cloud application each container runs a scheduling process written in Python (cf.,
Appendix B). It periodically generates a random number
r and compares it to the calculated migration probability
p. If
an migration event is triggered. Container chooses its destination node and asks the host node to migrate it there. On the destination node the initial loop is resumed. This random nature of the algorithm allows it to leave unstable equilibriums like the one from Equation (
14).
Container migration is not instantaneous—it takes some time
T usually of the order of seconds. Thus, the question arises how to calculate the “pheromone” value during container migration? Based on our previous experience with spread-like strategy [
41] the number of containers on the
i-th will be modified as follows:
where
and
are the sizes of the emigration and immigration queues on this node (in [
41] only
was used). These numbers are calculated by the Python REST service running on the node. Each container wanting to migrate puts a marker on the destination node, which allows us to calculate
. After migration this marker is cleared. The expressions for migration probabilities on the
i-th node read as:
where the modified value of
from Equation (
18) is used. Thus, the container migration as seen by the “pheromone” calculation is instantaneous. This greatly improves the performance of the system (i.e.,
is about 50 times less).
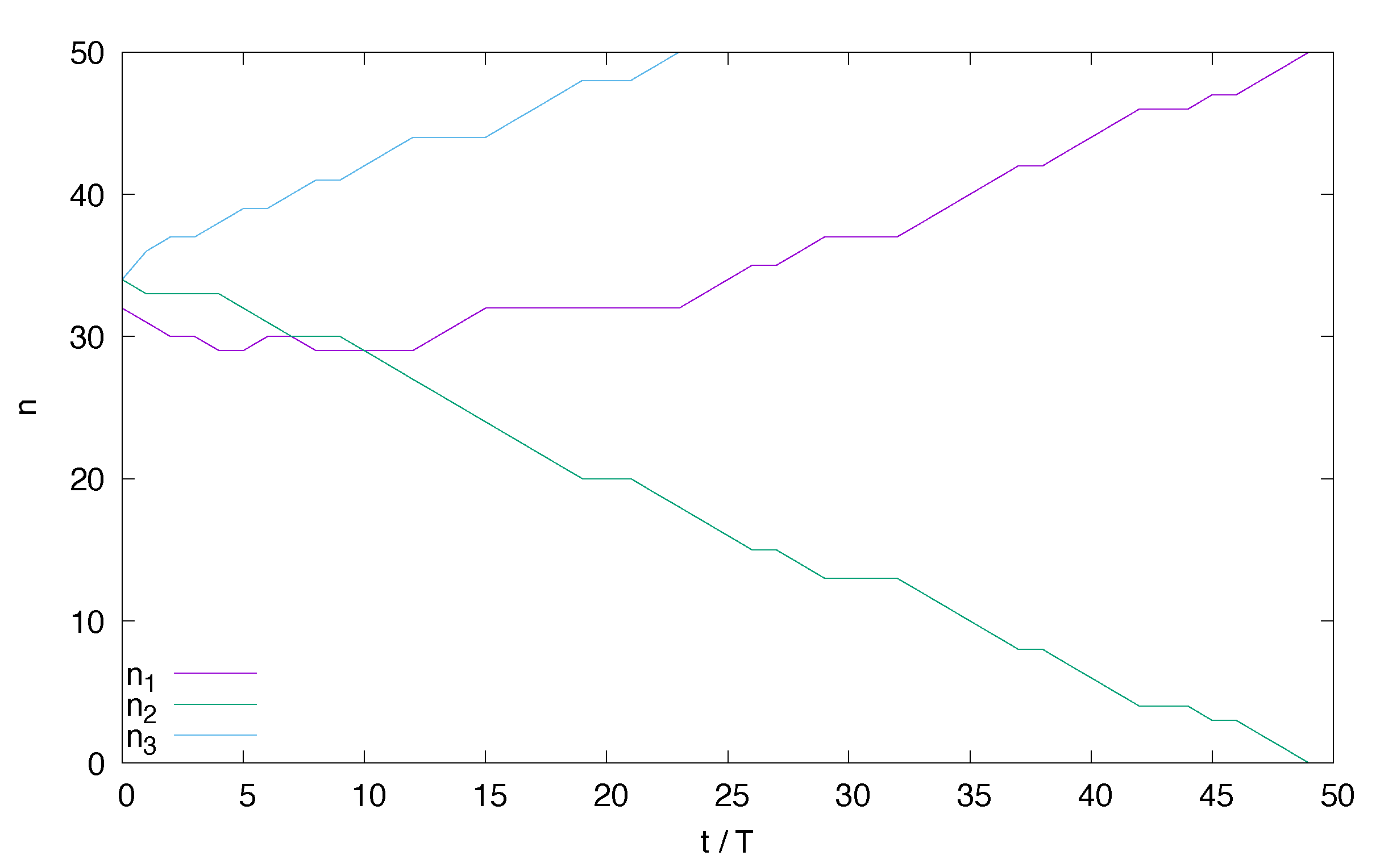
In our experiments the containers were about 50 MB large and a 100 Mb/s network was used to migrate them. The migration time was about 5 s and the application inside stopped working for about 1 s. If a container wants to migrate, then it chooses its destination node randomly. The results of a typical experiment are depicted in
Figure 1. It is seen that not necessarily the node with the lowest initial number of containers is empty at the end. However, the time
is about 50% larger than the time 32 T needed to move the 32 containers sequentially in an optimal way. Such an experiment was repeated 10,000 times yielding different plots of container numbers (only a typical example is presented here), and different values of
. It turns out that
is the most probable value of
, but the distribution of stabilization times has a long tail giving an average value
.
Please note that the results depicted in
Figure 1 are impossible to obtain within the mathematical model from
Section 3. Indeed, for the initial state given Equation (
16), the system of Equation (
5) reduces to one equation similar to Equation (
10) which has a solution
where the occupation of the first node is the lowest one. This is not the case with
Figure 1 where
. However, in a real experiment some container always jumps first. Here it was the one from the second node.
We will now extend our algorithm by a more intelligent choice of the destination node by a container. This is not possible within the differential equations model (where the jumps to other nodes are random). To prevent the system from reaching the unwanted stationary state from Equation (
15) migration will only be possible if there is free space on the destination node
j. This means that
after the migration:
In our experiments with 100 containers on three nodes, this improved the average stabilization time almost two times. The best speedup is achieved, if the value of
given by Equation (
18) is used in Equation (
20). It follows from our experiments that the performance of the bin pack-like strategy is further improved (about 5 times as compared to the random choice) if destination node
j is chosen in such a way that its occupation
after the migration is larger than the occupation of the initial host
i before the migration:
Now the most probable and average value of
is
. The distribution has a very small tail corresponding to the solutions similar to this from
Figure 1 when not the first host is empty at the end. The largest observed value of
was
.
Please note that Equation (
18) can be easily generalized to the case of nonidentical containers and heterogeneous nodes. It is simply the amount of the least dominant resource from Equation (
2) after all containers waiting in the outgoing and incoming queues have been migrated. Similarly, Equations (
20) and (
21) also hold in a general case (cf.,
Section 6.3).
In the next section we will study the performance and scaling of the distributed algorithm proposed in a simulated cloud. It was not possible to do this experimentally due to the limitations of our setup. The analysis of the scaling of the number of parallel migrations with cloud size will allow us to estimate the time complexity of the algorithm.
5. Computer Simulation of a Large Cloud
To investigate scaling of the number of parallel migrations with the number of nodes N let us now build a cellular automaton-like simulator of the cloud. It is our own tool, written in Python. Its main design goals are to reproduce the experimental results from the previous section and allow the study of our algorithm in an arbitrarily large cloud.
We will assume that all nodes have the same capacity
and all containers are identical. Thus, the occupations of the nodes will be represented by an array of natural numbers
. This is the number of currently running containers executing the cloud application. Some of them are waiting in the
migration queues. The algorithm works in a time loop with step
T until the final condition Equation (
17) is met and all migration queues are empty.
At each time step a loop over nodes is executed. For each node the pheromone value is calculated according to Equations (
18) and (
19). Than in another loop each of
containers decides with probability
if it wants to migrate to another node. If so, then it starts a search for a suitable node that matches the conditions Equations (
20) and (
21). If the search fails nothing happens. If the search is successful, then the destination host
j is added to the migration queue
and the counter
is incremented.
To model the finite network throughput we will assume that at each time step of the simulation only one container can leave a given node and that migration of each container takes time T. Thus, after the addition of the containers to the migration queues another loop over nodes is executed. For each node i the first value j is taken from the queue and the value of is increased while decreasing the counter .
We prepared an initial state in which all the cloud nodes are equally occupied:
Three choices for
were considered:
,
, and 1. To guarantee that the final state given by Equation (
17) will be reached the number of nodes
N was chosen as a multiplicity of
. Thus, for
the numerical experiment was performed for
. Depending of the choice of
at the end of the simulation 2%, 50%, and 98% nodes are empty and the remaining 98%, 50%, and 2%—full.
For each value of
N the simulation was repeated 10,000 times. The output from the program is a histogram of the number of steps
needed to reach the final state Equation (
17). Example results for
and
(2% nodes empty and 98% full at the end) and
(50% nodes empty and 50% full at the end) are plotted in
Figure 2.
If we assume that the containers can leave a node only sequentially, but arrive to a node in parallel, then an ideal algorithm would need only
steps to reach the final state Equation (
17) from the initial state Equation (
22). In the most realistic case, when 2% nodes are empty and can be switched off at the end our algorithm works only about two times worse than that (the average value
and
). The case of 50% empty nodes is about 4 times worse (
and
). Notice however the long tail of the distribution. The least realistic case with 98% empty servers (not plotted to keep the figure more clear) is more than 40 times worse than the optimal one (
and
).
Analogous distributions were obtained for different values of
N and the average values computed. The resulting average time needed to reach equilibrium
versus cloud size
N is plotted in
Figure 3 using logarithmic scale on the horizontal axis. In both cases we obtain a straight line (this is also true in the case of
not plotted here). Thus,
.
A very important component not accounted for in our numerical experiments is the time needed by a container to find a suitable node to migrate onto. In the simulation all the nodes were arranged in a ring and linear search was used starting at the node after the current node. Search is done in parallel by all nodes. Therefore the search time needed to be added to at each time step is proportional to N (the worst case is 50% empty, 50% full because the number of containers needed to be migrated is largest). Thus, the time-complexity of the distributed algorithm for scheduling containers to cloud nodes presented in this paper should be (at least) linear-logarithmic .
Better search algorithms for Peer-to-Peer networks exist with
time complexity. One example is Chord [
42]. If it would be possible to use such an Chord-like algorithm to find the node suitable for container migration, then the time complexity of our algorithm would reduce to polylogarithmic one
. It would be better than known approximations for the classic bin-packing problem with linear or linear-logarithmic complexity (but our system is inherently parallel). This is a topic of ongoing research on our part.
7. Conclusions
In summary, a swarm-like algorithm for virtualization container scheduling in the cloud using live migration was proposed. Each cloud node is assigned a “pheromone” value, which is calculated taking into account the resource usage of containers that are scheduled for execution on this node, as well as the node capacity. This value is evaluated on set time intervals by each container, which—when necessary—asks the host to migrate it to another execution node. Migration is possible only to the nodes with an attractive “pheromone”. Finally, after several periods, the system converges to optimal load, providing a decentralized method to establish a desired configuration of the cloud.
Two main scheduling strategies were considered. The spread-like strategy applied to the microservice-based application running in the cloud causes virtualization containers to disperse evenly on the cloud nodes. This approach minimizes the risk of application failure when a node fails (because of the small number of containers on it). The bin pack-like strategy applied to the virtualization containers running in the cloud causes the application to run on as few servers as possible allowing savings of electrical energy powering the cloud cluster (because unused servers may be turned off). The cloud administrator using the system proposed can easily switch between these strategies by simply sending a single threshold parameter to cloud nodes using, e.g., the gossip protocol [
46].
Usually, swarm models use a large number of unintelligent actors in order to produce complex global behaviors. It was shown that in the case that the bin pack strategy local (i.e., limited to the cloud node on which they are running) interactions between the containers are not sufficient. Some intelligence needs to be added to the swarm. It turns out that in order to yield a satisfactory performance of the algorithm a search for a suitable destination node is necessary.
The performance of the algorithm proposed has been studied using a cellular automaton-like cloud simulator. It was shown that depending if the search time is included or not the system can reach an optimal configuration in a polylogarithmic or logarithmic time. This result holds also in the case of the spread strategy (where local interactions are sufficient) and is better than existing container orchestrators that require at least linear time.
Our system uses live migration of containers (which is difficult to implement in centralized systems because all changes to the cloud configuration must be stored in a central database) and allows for the redistribution of already running containers. There are no master nodes, which need to be replicated. Each container schedules itself. This yields in a better failure tolerance. There is no lower limit on the container lifetime and no need to shutdown and restart containers in order to change their location in the cloud.
Please note that the algorithm proposed in this paper is general, and in principle could be used for virtual machine management. However, adding a mobile agent process requires changing a virtual machine setting. This is not always possible. In the case of containers both the application container and the mobile agent container can be combined together in a pod without the need for modifying them.
In the long-run, we believe we will see a move towards bin pack style scheduling for containers in the cloud in order to reduce hosting costs. Using stateless microservices where possible can mitigate the risk of service downtime—such services can be automatically and quickly migrated to new hosts with minimal disruption to availability. However, if one uses bin pack today, he needs to be aware of how to deal with co-scheduling of containers, i.e., how to ensure two or more containers are always run on the same host. In our approach this could be done by appropriately introducing attractive “pheromone” values. Such an analysis cannot be made using a cellular automaton model studied in this paper. It requires a real cloud application and a real cloud to analyze its performance experimentally. This will be the topic of our future work.
In this paper, only swarms formed by containers were studied. An important point left out for a future paper was building a P2P network from the supplementary REST services launched on each node. As described at the end of
Section 5 they will implement a Chord-like search algorithm, aiding the containers in finding a suitable migration destination. This requires a fairly large experimental setup using modern container technology. Last but not least, also other research directions mentioned in
Section 6 look interesting: the experimental study of different migration priorities for containers of different sizes and resource requirements, and the proper analysis of the network impact of the proposed scheme.





{kind=link}
{kind=link}
{kind=link}


