
Deep Gradient Prior Regularized Robust Video Super-Resolution


Abstract
:1. Introduction
2. Background
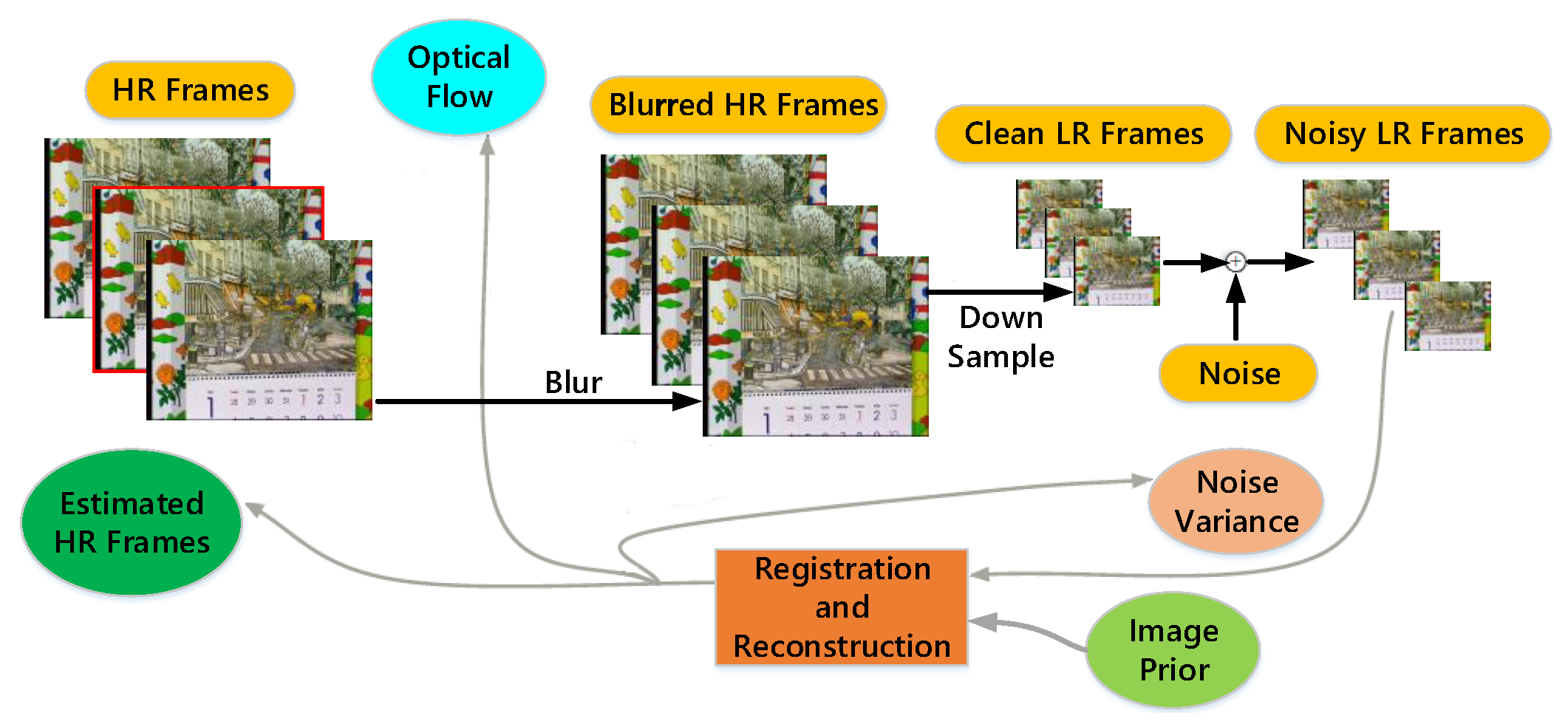
2.1. Framework of Multiple Frames SR Reconstruction
2.2. Gradient-Based Super-Resolution
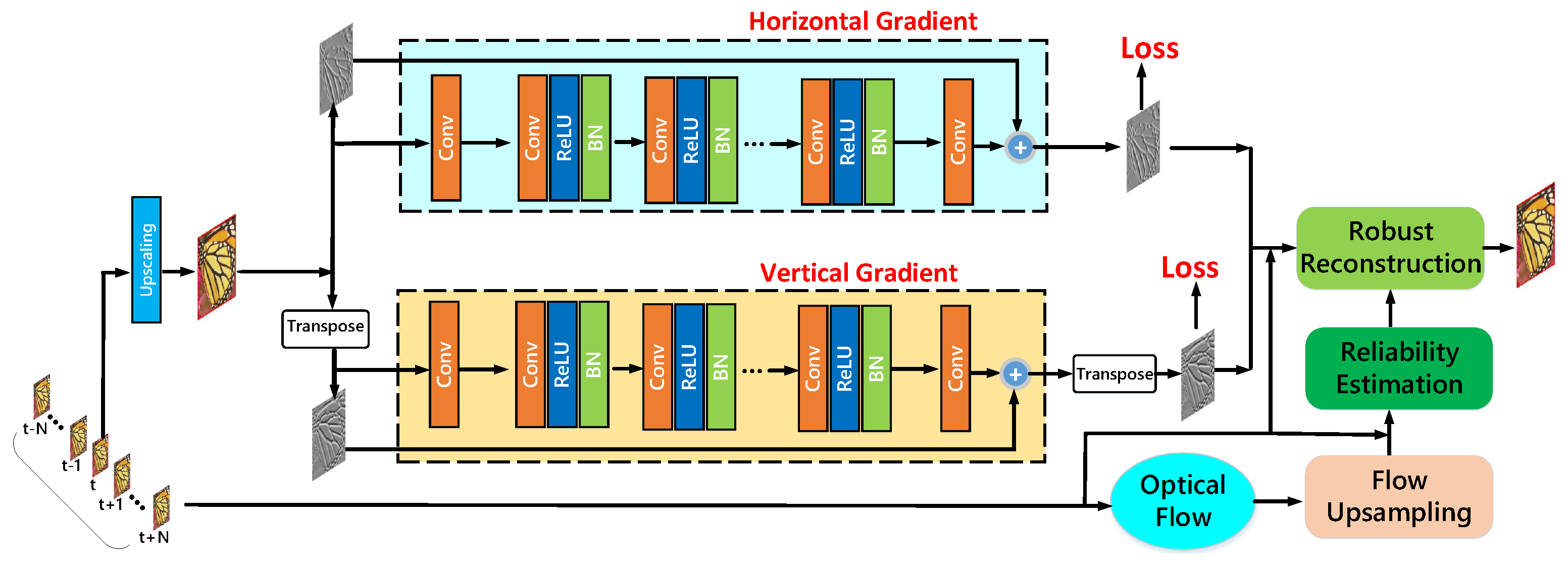
3. Deep Gradient Prior Learning Network
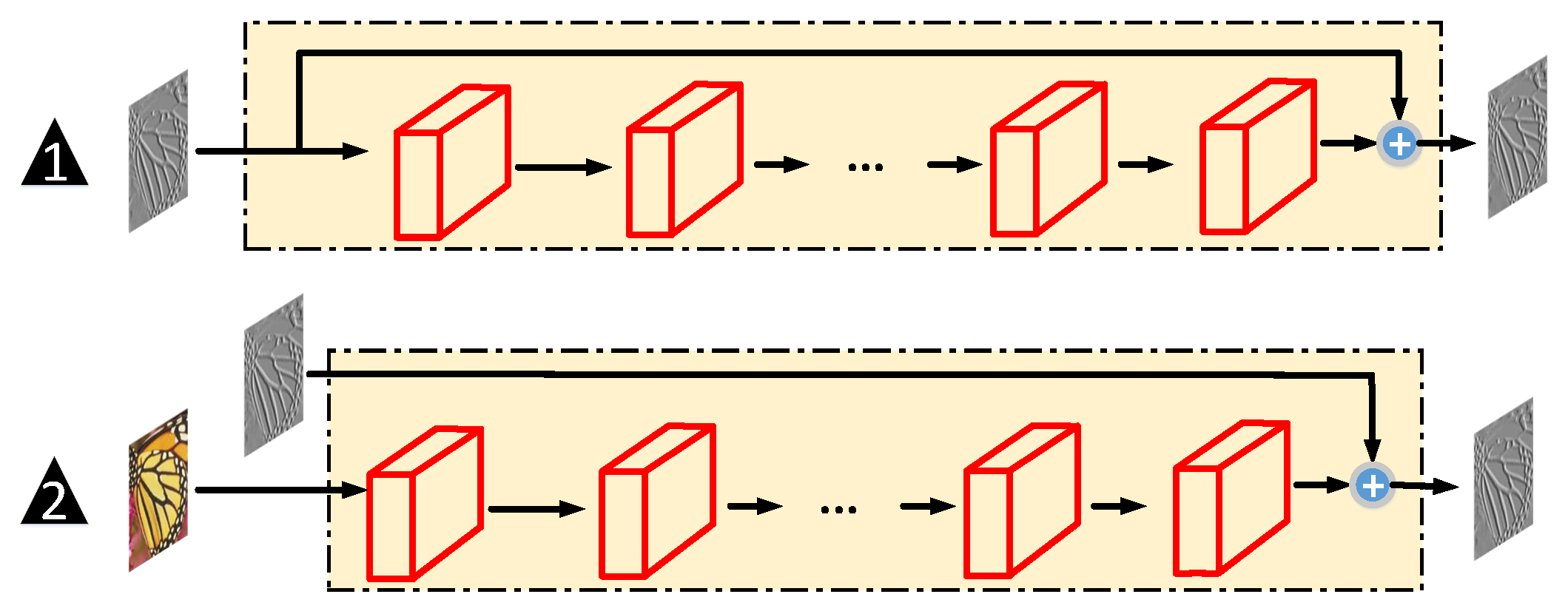
3.1. Gradient-Learning Network
3.2. Training Loss Function
3.3. Further Study of the Gradient Prior Learning Network
4. Robust Super-Resolution Reconstruction from Multiple Frames
4.1. Displacement Estimation for the Warping Operator
4.2. Robust SR Reconstruction
5. Experimental Results
5.1. Experimental Settings
5.2. Training Details
5.3. Comparisons with the State-of-the-Art Methods
5.4. Comparisons on Running Time
5.5. Ablation Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.; Wu, X. Image interpolation by adaptive 2-D autoregressive modeling and soft-decision estimation. IEEE Trans. Image Process. 2008, 17, 887–896. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Orchard, M.T. New edge-directed interpolation. IEEE Trans. Image Process. 2000, 10, 1521–1527. [Google Scholar]
- Dai, S.; Mei, H.; Wei, X.; Ying, W.; Gong, Y. Soft edge smoothness prior for alpha channel super resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Xie, J.; Feris, R.; Sun, M.T. Edge-Guided Single Depth Image Super Resolution. IEEE Trans. Image Process. 2016, 25, 428–438. [Google Scholar] [CrossRef] [PubMed]
- Dong, W.; Zhang, L.; Lukac, R.; Shi, G. Sparse Representation Based Image Interpolation With Nonlocal Autoregressive Modeling. IEEE Trans. Image Process. 2013, 22, 1382–1394. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image Super-Resolution via Sparse Representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Timofte, R.; Smet, V.D.; Gool, L.V. A+: Adjusted Anchored Neighborhood Regression for Fast Super-Resolution. Lect. Notes Comput. Sci. 2014, 9006, 111–126. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Freeman, W.T.; Jones, T.R.; Pasztor, E.C. Example-Based Super-Resolution. IEEE Comput. Graph. Appl. 2002, 22, 56–65. [Google Scholar] [CrossRef] [Green Version]
- Timofte, R.; De, V.; Van Gool, L. Anchored Neighborhood Regression for Fast Example-Based Super-Resolution. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1920–1927. [Google Scholar]
- Freedman, G.; Fattal, R. Image and video upscaling from local self-examples. ACM Trans. Graph. 2011, 30, 474–484. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-Recursive Convolutional Network for Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar]
- Shi, W.; Caballero, J.; Huszar, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning Deep CNN Denoiser Prior for Image Restoration. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2808–2817. [Google Scholar]
- Donn, S.; Meeus, L.; Luong, H.Q.; Goossens, B.; Philips, W. Exploiting Reflectional and Rotational Invariance in Single Image Superresolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1043–1049. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar]
- Fan, Y.; Shi, H.; Yu, J.; Liu, D.; Han, W.; Yu, H.; Wang, Z.; Wang, X.; Huang, T.S. Balanced Two-Stage Residual Networks for Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1157–1164. [Google Scholar]
- Sina, F.; M Dirk, R.; Michael, E.; Peyman, M. Fast and robust multiframe super resolution. IEEE Trans. Image Process. 2004, 13, 1327–1344. [Google Scholar]
- Matan, P.; Michael, E.; Hiroyuki, T.; Peyman, M. Generalizing the nonlocal-means to super-resolution reconstruction. IEEE Trans. Image Process. 2009, 18, 36. [Google Scholar]
- Hiroyuki, T.; Peyman, M.; Matan, P.; Michael, E. Super-resolution without explicit subpixel motion estimation. IEEE Trans. Image Process. 2009, 18, 1958–1975. [Google Scholar]
- Ce, L.; Deqing, S. On Bayesian adaptive video super resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 346–360. [Google Scholar]
- K?hler, T.; Huang, X.; Schebesch, F.; Aichert, A.; Maier, A.; Hornegger, J. Robust Multi-Frame Super-Resolution Employing Iteratively Re-Weighted Minimization. IEEE Trans. Comput. Imaging 2016, 2, 42–58. [Google Scholar] [CrossRef]
- Qiangqiang, Y.; Liangpei, Z.; Huanfeng, S.; Pingxiang, L. Adaptive multiple-frame image super-resolution based on U-curve. IEEE Trans. Image Process. 2010, 19, 3157–3170. [Google Scholar] [CrossRef]
- Huang, Y.; Wang, W.; Wang, L. Video Super-Resolution via Bidirectional Recurrent Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1015–1028. [Google Scholar] [CrossRef] [PubMed]
- Liao, R.; Xin, T.; Li, R.; Ma, Z.; Jia, J. Video Super-Resolution via Deep Draft-Ensemble Learning. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Kappeler, A.; Yoo, S.; Dai, Q.; Katsaggelos, A.K. Video Super-Resolution with Convolutional Neural Networks. IEEE Trans. Comput. Imaging 2016, 2, 109–122. [Google Scholar] [CrossRef]
- Ding, L.; Wang, Z.; Fan, Y.; Liu, X.; Wang, Z.; Chang, S.; Wang, X.; Huang, T.S. Learning Temporal Dynamics for Video Super-Resolution: A Deep Learning Approach. IEEE Trans. Image Process. 2018, 27, 3432–3445. [Google Scholar]
- Li, D.; Wang, Z. Video Super-Resolution via Motion Compensation and Deep Residual Learning. IEEE Trans. Comput. Imaging 2017, 3, 749–762. [Google Scholar] [CrossRef]
- Dai, Q.; Yoo, S.; Kappeler, A.; Katsaggelos, A.K. Sparse Representation Based Multiple Frame Video Super-Resolution. IEEE Trans. Image Process. 2017, 26, 765–781. [Google Scholar] [CrossRef]
- Borsoi, R.A.; Costa, G.H.; Bermudez, J.C.M. A New Adaptive Video Super-Resolution Algorithm With Improved Robustness to Innovations. IEEE Trans. Image Process. 2018, 28, 673–686. [Google Scholar] [CrossRef]
- Liu, X.; Chen, L.; Wang, W.; Zhao, J. Robust Multi-Frame Super-Resolution Based on Spatially Weighted Half-Quadratic Estimation and Adaptive BTV Regularization. IEEE Trans. Image Process. 2018, 27, 4971–4986. [Google Scholar] [CrossRef] [PubMed]
- Marquina, A.; Osher, S.J. Image Super-Resolution by TV Regularization and Bregman Iteration. J. Sci. Comput. 2008, 37, 367–382. [Google Scholar] [CrossRef]
- Fang, L.; Li, S.; Cunefare, D.; Farsiu, S. Segmentation Based Sparse Reconstruction of Optical Coherence Tomography Images. IEEE Trans. Med Imaging 2016, 36, 407–421. [Google Scholar] [CrossRef] [Green Version]
- Fernandez-Granda, C.; Cands, E.J. Super-resolution via Transform-Invariant Group-Sparse Regularization. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 3336–3343. [Google Scholar]
- Rida, I.; Al-Maadeed, S.; Mahmood, A.; Bouridane, A.; Bakshi, S. Palmprint Identification Using an Ensemble of Sparse Representations. IEEE Access 2018, 6, 3241–3248. [Google Scholar] [CrossRef]
- Rida, I.; Maadeed, N.A.; Maadeed, S.A. A Novel Efficient Classwise Sparse and Collaborative Representation for Holistic Palmprint Recognition. In Proceedings of the 2018 NASA/ESA Conference on Adaptive Hardware and Systems (AHS), Edinburgh, UK, 6–9 August 2018. [Google Scholar]
- Zhang, K.; Gao, X.; Tao, D.; Li, X. Single image super-resolution with non-local means and steering kernel regression. IEEE Trans. Image Process. 2012, 21, 4544–4556. [Google Scholar] [CrossRef]
- Freeman, W.T.; Pasztor, E.C.; Carmichael, O.T. Learning Low-Level Vision. Int. J. Comput. Vis. 2000, 40, 25–47. [Google Scholar] [CrossRef]
- Xiong, R.; Liu, H.; Zhang, X.; Zhang, J.; Ma, S.; Wu, F.; Gao, W. Image Denoising via Bandwise Adaptive Modeling and Regularization Exploiting Nonlocal Similarity. IEEE Trans. Image Process. 2016, 25, 5793–5805. [Google Scholar] [CrossRef]
- Liu, H.; Xiong, R.; Zhang, X.; Zhang, Y.; Ma, S.; Gao, W. Non-Local Gradient Sparsity Regularization for Image Restoration. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 1909–1921. [Google Scholar] [CrossRef]
- Zhang, J.; Xiong, R.; Zhao, C.; Zhang, Y.; Ma, S.; Gao, W. CONCOLOR: COnstrained Non-COnvex LOw-Rank Model for Image Deblocking. IEEE Trans. Image Process. 2016, 25, 1246–1259. [Google Scholar] [CrossRef]
- Sun, J.; Sun, J.; Xu, Z.; Shum, H.Y. Gradient profile prior and its applications in image super-resolution and enhancement. IEEE Trans. Image Process. 2011, 20, 1529–1542. [Google Scholar] [PubMed]
- Fattal, R. Image upsampling via imposed edge statistics. ACM Trans. Graph. 2007, 26, 95. [Google Scholar] [CrossRef]
- Qiang, S.; Xiong, R.; Dong, L.; Xiong, Z.; Feng, W.; Wen, G. Fast Image Super-Resolution via Local Adaptive Gradient Field Sharpening Transform. IEEE Trans. Image Process. 2018, 27, 4. [Google Scholar]
- Zhu, Y.; Zhang, Y.; Bonev, B.; Yuille, A.L. Modeling deformable gradient compositions for single-image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5417–5425. [Google Scholar]
- Yang, W.; Feng, J.; Yang, J.; Zhao, F.; Liu, J.; Guo, Z.; Yan, S. Deep Edge Guided Recurrent Residual Learning for Image Super-Resolution. IEEE Trans. Image Process. 2017, 26, 5895–5907. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, J.; Pan, J.; Lai, W.S.; Lau, R.; Yang, M.H. Learning Fully Convolutional Networks for Iterative Non-blind Deconvolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6969–6977. [Google Scholar]
- Xu, L.; Ren, J.S.J.; Yan, Q.; Liao, R.; Jia, J. Deep edge-aware filters. In Proceedings of the International Conference on Machine Learning, Lile, France, 6–11 July 2015; pp. 1669–1678. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Las Vegas, NV, USA, 27–30 June 2016; pp. 1026–1034. [Google Scholar]
- Ma, Z.; Liao, R.; Xin, T.; Li, X.; Jia, J.; Wu, E. Handling motion blur in multi-frame super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Scale | Bicubic | Scheme#1 | Scheme#2 |
|---|---|---|---|---|
| Set5 | x3 | 47.07 | 21.99 | 20.04 |
| Set14 | x3 | 75.15 | 55.82 | 54.41 |
| BSD100 | x3 | 90.91 | 73.66 | 71.85 |
| General100 | x3 | 59.54 | 40.16 | 38.35 |
| Data | Bicubic | SRCNN [8] | VDSR [13] | Draft [27] | LTD [29] | Proposed | Bayesian [23] | Proposed |
|---|---|---|---|---|---|---|---|---|
| B | B | B | B | B | B | G | G | |
| calendar | 20.55 | 21.43 | 21.71 | 22.23 | 22.10 | 22.51 | 24.08 | 24.35 |
| city | 24.57 | 24.98 | 25.18 | 25.82 | 25.76 | 26.29 | 27.46 | 28.82 |
| walk | 26.19 | 27.75 | 28.14 | 26.79 | 28.39 | 28.50 | 27.80 | 28.38 |
| foliage | 23.40 | 24.14 | 24.35 | 24.94 | 24.97 | 25.49 | 26.13 | 26.14 |
| jvc009001 | 25.42 | 26.74 | 27.16 | – | – | 28.37 | – | 29.34 |
| jvc004001 | 26.19 | 28.20 | 28.94 | – | – | 29.91 | – | 30.88 |
| AMVTG004 | 23.57 | 24.65 | 25.15 | – | – | 25.52 | – | 25.35 |
| Data | Bicubic | SRCNN [8] | VDSR [13] | Draft [27] | LTD [29] | Proposed | Bayesian [23] | Proposed |
|---|---|---|---|---|---|---|---|---|
| B | B | B | B | B | B | G | G | |
| calendar | 0.568 | 0.647 | 0.677 | 0.710 | 0.702 | 0.737 | 0.824 | 0.833 |
| city | 0.573 | 0.615 | 0.638 | 0.697 | 0.694 | 0.735 | 0.811 | 0.844 |
| walk | 0.796 | 0.842 | 0.856 | 0.799 | 0.857 | 0.859 | 0.855 | 0.864 |
| foliage | 0.563 | 0.630 | 0.643 | 0.735 | 0.696 | 0.734 | 0.792 | 0.776 |
| jvc009001 | 0.754 | 0.806 | 0.828 | – | – | 0.867 | – | 0.900 |
| jvc004001 | 0.884 | 0.919 | 0.936 | – | – | 0.946 | – | 0.959 |
| AMVTG004 | 0.557 | 0.621 | 0.650 | – | – | 0.721 | – | 0.734 |
| Scale | SRCNN [8] | VDSR [13] | Bayesian [23] | Draft | LTD [29] | Proposed |
|---|---|---|---|---|---|---|
| x4 | 12.32 | 1.5 (GPU) | 633.91 | 2367.71 | – | 163.75 |
| Data | Base-1 | Base-2 | Base |
|---|---|---|---|
| calendar | 22.39 | 22.42 | 22.51 |
| city | 26.18 | 25.77 | 26.29 |
| walk | 27.94 | 25.96 | 28.50 |
| foliage | 25.35 | 22.56 | 25.49 |
| jvc009001 | 28.04 | 28.63 | 28.37 |
| jvc004001 | 29.23 | 29.98 | 29.91 |
| AMVTG004 | 25.11 | 25.50 | 25.52 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Q.; Liu, H. Deep Gradient Prior Regularized Robust Video Super-Resolution. Electronics 2021, 10, 1641. https://doi.org/10.3390/electronics10141641
Song Q, Liu H. Deep Gradient Prior Regularized Robust Video Super-Resolution. Electronics. 2021; 10(14):1641. https://doi.org/10.3390/electronics10141641
Chicago/Turabian StyleSong, Qiang, and Hangfan Liu. 2021. "Deep Gradient Prior Regularized Robust Video Super-Resolution" Electronics 10, no. 14: 1641. https://doi.org/10.3390/electronics10141641
APA StyleSong, Q., & Liu, H. (2021). Deep Gradient Prior Regularized Robust Video Super-Resolution. Electronics, 10(14), 1641. https://doi.org/10.3390/electronics10141641