
Towards Hybrid Multimodal Manual and Non-Manual Arabic Sign Language Recognition: mArSL Database and Pilot Study



Abstract
:1. Introduction
2. Literature Review
2.1. Sign Language Databases
2.2. Sign Language Recognition Systems
3. mArSL Database
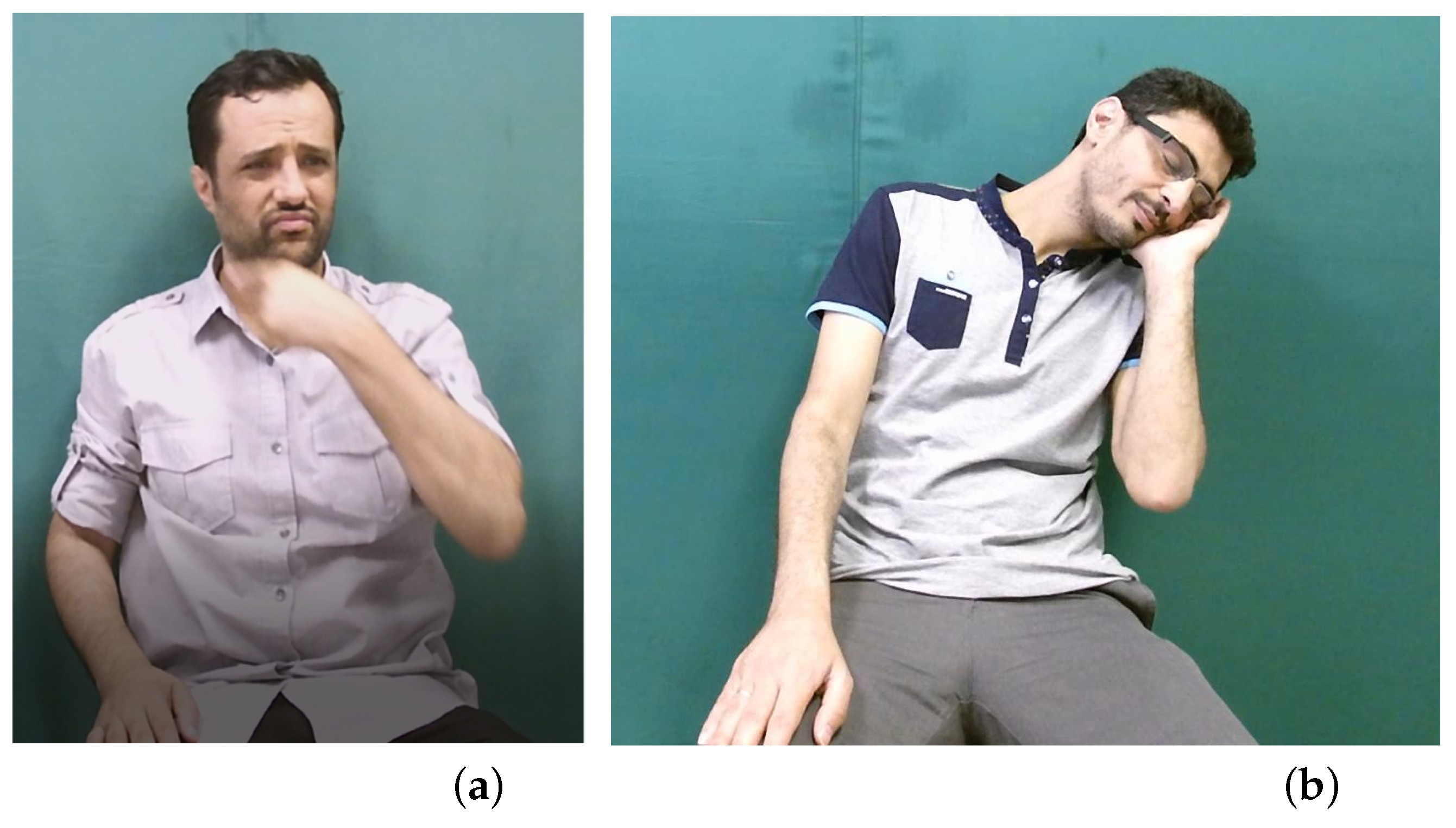
3.1. Motivation
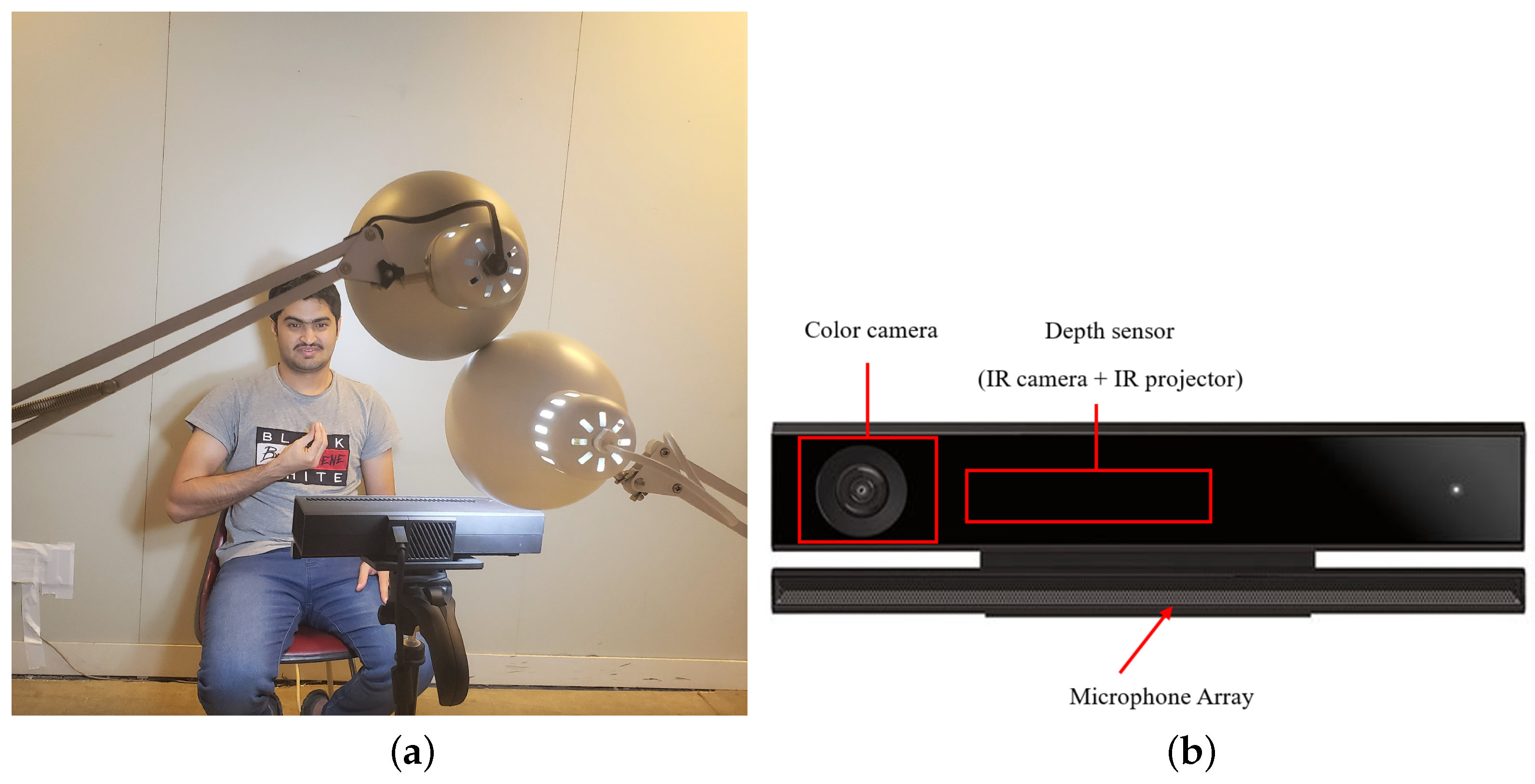
3.2. Recording Setup
3.3. Sign Capturing Vision System
3.4. Database Statistics
3.5. Database Organization
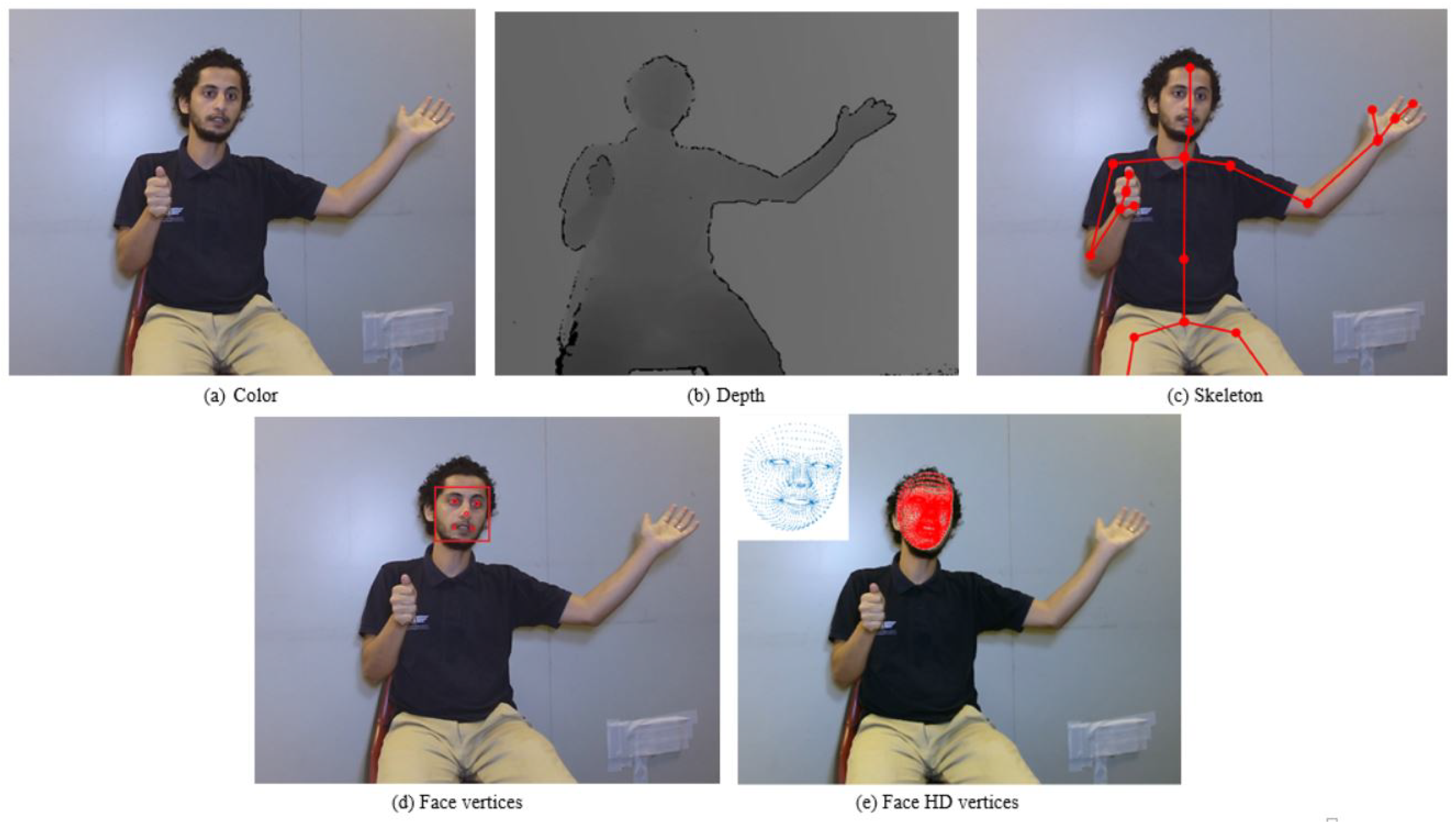
- Color data: Kinect V2 provides an RGB video stream of the captured gestures recorded at a frame rate of 30 fps (frames per second). This frame rate can keep the motion smooth and capture the gesture details efficiently. The color camera has a resolution of 1920 × 1080 pixels with a Field of View (FoV) of 84.1 × 53.8. This RGB video stream of each sign sample is saved in an MP4 format.
- Depth map: Another datum that is provided by Kinect V2 is the depth map, which is captured simultaneously with the color data. A depth map describes, at each pixel, the distance to the signer from the front-facing camera. Each captured sign has a depth map which consists of a sequence of frames with a resolution of 512 × 424 pixels saved in an MP4 format.
- Skeleton joint points: Kinect captures the human skeleton using an integrated depth camera. This camera can detect and track the human skeleton and presents it using 25 joint points. The coordinates of each joint point are available in three spaces—color, depth, and camera. The color space describes the joint point coordinates (x and y) on the color image provided by the color camera. The depth space describes the 2D location of the joint point on the depth image. The coordinates of the joint point in the camera space are 3D (x, y, z) and are measured in meters. The coordinates (x, y) can be positive or negative, as they extend in both directions from the sensor while the z coordinate is always positive as it grows out from the sensor. In addition, the orientation information of each joint point is provided by Kinect as a quaternion which consists of four values and is mathematically represented by a real part and 3D vector as follows: , where i, j, and k are unit vectors in the direction of the x, y and z axes, respectively.
- Face information: One of the state-of-the-art capabilities of the Kinect device is face tracking. The Kinect sensor utilizes infrared and color cameras to track facial points. These points can be used in several applications related to facial expressions such as recognition and Avatar development. Two types of face information are provided for each tracked face: Face Basics and Face HD [44]. The former provides information about the signer face which includes:
- -
- Face Box: the coordinates of the face position in the color space (left, top, right, bottom);
- -
- Face Points: the center coordinates of the five face landmarks (left and right eyes, nose, right and left mouth boundaries);
- -
- Face Rotation: a vector containing pitch, yaw, and roll angles;
- -
- Face Properties: a 1 × 8 vector containing the detection result of certain face properties (0: unknown, 1: no, 2: maybe, 3: yes) of the following face properties: happy, engaged, wearing glasses, left eye closed, right eye closed, mouth open, mouth moved, and looking away.
On the other hand, Face HD provides high definition face information with 94 facial points which are expressed in a camera space point. In addition to the Face Box and Rotation, each captured Face HD has the following information (https://docs.microsoft.com/en-us/previous-versions/windows/kinect/dn799271(v=ieb.10) (accesssed on 30 May 2021)):- -
- Head Pivot: the head center which the face may be rotated around. This point is defined in the Kinect body coordinate system;
- -
- Animation Units: a 1 × 17 vector containing the animation units. Most of these units are expressed as a numeric weight varying between 0 and 1;
- -
- Shape Units: a 1 × 94 vector containing the shape units which are expressed as a numeric weight that typically varies between −2 and +2;
- -
- Face Model: the coordinates of 1347 points of a 3D face model (Figure 4e).
4. Pilot Study and Benchmark Results
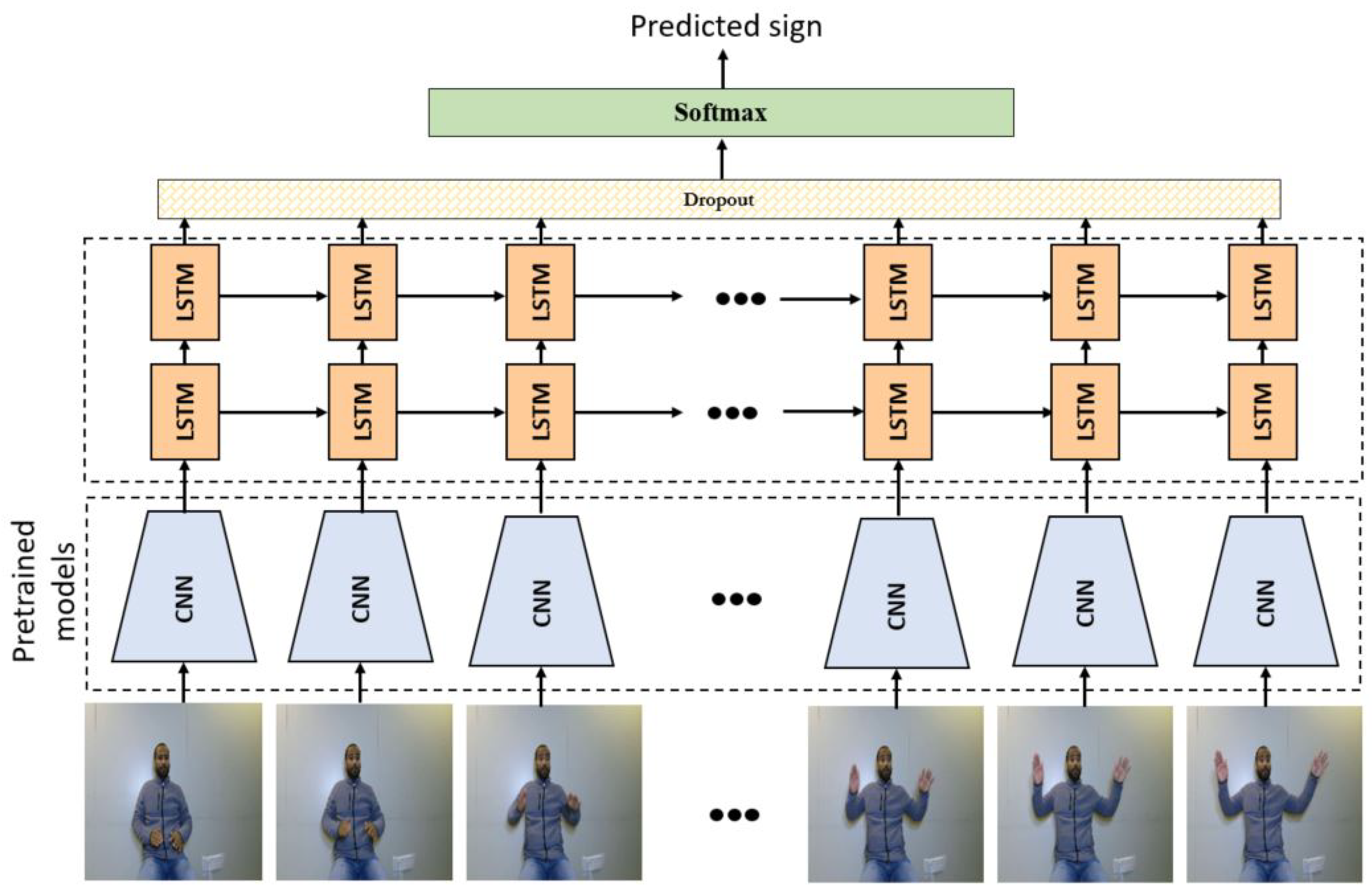
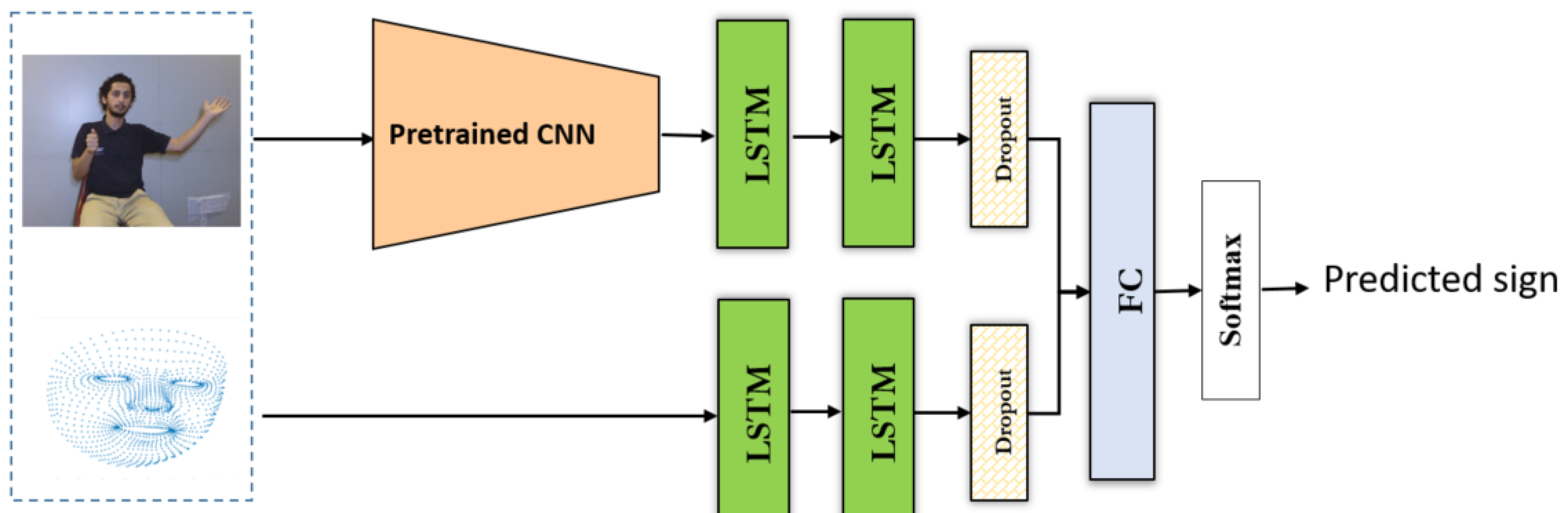
4.1. Manual Gestures
4.2. Non-Manual Gestures
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Galindo, N.M.; Sá, G.G.d.M.; Pereira, J.d.C.N.; Barbosa, L.U.; Barros, L.M.; Caetano, J.Á. Information about COVID-19 for deaf people: An analysis of Youtube videos in Brazilian sign language. Rev. Bras. Enferm. 2021, 74. [Google Scholar] [CrossRef]
- Makhashen, G.B.; Luqman, H.A.; El-Alfy, E.S. Using Gabor Filter Bank with Downsampling and SVM for Visual Sign Language Alphabet Recognition. In Proceedings of the 2nd Smart Cities Symposium (SCS 2019), Bahrain, Bahrain, 24–26 March 2019; pp. 1–6. [Google Scholar]
- Sidig, A.A.I.; Luqman, H.; Mahmoud, S.A. Transform-based Arabic sign language recognition. Procedia Comput. Sci. 2017, 117, 2–9. [Google Scholar] [CrossRef]
- Pisharady, P.K.; Saerbeck, M. Recent methods and databases in vision-based hand gesture recognition: A review. Comput. Vis. Image Underst. 2015, 141, 152–165. [Google Scholar] [CrossRef]
- Luqman, H.; Mahmoud, S.A. Automatic translation of Arabic text-to-Arabic sign language. In Universal Access in the Information Society; Springer: Berlin/Heidelberg, Germany, 2018; pp. 1–13. [Google Scholar]
- Nair, A.V.; Bindu, V. A Review on Indian Sign Language Recognition. Int. J. Comput. Appl. 2013, 73, 33–38. [Google Scholar]
- Gupta, P.; Agrawal, A.K.; Fatima, S. Sign Language Problem and Solutions for Deaf and Dumb People. In Proceedings of the 3rd International Conference on System Modeling & Advancement in Research Trends (SMART), Sicily, Italy, 30 May–4 June 2004. [Google Scholar]
- Von Agris, U.; Knorr, M.; Kraiss, K.F. The significance of facial features for automatic sign language recognition. In Proceedings of the 8th IEEE International Conference on Automatic Face & Gesture Recognition, Amsterdam, The Netherlands, 17–19 September 2008; pp. 1–6. [Google Scholar]
- Sidig, A.A.I.; Luqman, H.; Mahmoud, S.A. Arabic Sign Language Recognition Using Optical Flow-Based Features and HMM. In International Conference of Reliable Information and Communication Technology; Springer: Berlin/Heidelberg, Germany, 2017; pp. 297–305. [Google Scholar]
- LAS: Second Part of the Unified Arabic Sign Dictionary; The League of Arab States & the Arab League Educational, Cultural and Scientific Organization: Tunis, Tunisia, 2006.
- LAS: First Part of the Unified Arabic Sign Dictionary; The League of Arab States & the Arab League Educational, Cultural and Scientific Organization: Tunis, Tunisia, 2000.
- Luqman, H.; Mahmoud, S.A. A machine translation system from Arabic sign language to Arabic. In Universal Access in the Information Society; Springer: Berlin/Heidelberg, Germany, 2019; pp. 1–14. [Google Scholar]
- Ong, E.J.; Cooper, H.; Pugeault, N.; Bowden, R. Sign language recognition using sequential pattern trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2200–2207. [Google Scholar]
- Oszust, M.; Wysocki, M. Polish sign language words recognition with kinect. In Proceedings of the 6th IEEE International Conference on Human System Interactions (HSI), Sopot, Poland, 6–8 June 2013; pp. 219–226. [Google Scholar]
- Kapuscinski, T.; Oszust, M.; Wysocki, M.; Warchol, D. Recognition of hand gestures observed by depth cameras. Int. J. Adv. Robot. Syst. 2015, 12, 36. [Google Scholar] [CrossRef]
- Chai, X.; Wang, H.; Zhou, M.; Wu, G.; Li, H.; Chen, X. DEVISIGN: Dataset and Evaluation for 3D Sign Language Recognition; Technical Report; Beijing, China, 2015. [Google Scholar]
- Neidle, C.; Thangali, A.; Sclaroff, S. Challenges in development of the american sign language lexicon video dataset (asllvd) corpus. In 5th Workshop on the Representation and Processing of Sign Languages: Interactions between Corpus and Lexicon, LREC; Available online: https://open.bu.edu/handle/2144/31899 (accessed on 30 May 2021).
- Li, D.; Rodriguez, C.; Yu, X.; Li, H. Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1459–1469. [Google Scholar]
- Ravi, S.; Suman, M.; Kishore, P.; Kumar, K.; Kumar, A. Multi modal spatio temporal co-trained CNNs with single modal testing on RGB–D based sign language gesture recognition. J. Comput. Lang. 2019, 52, 88–102. [Google Scholar] [CrossRef]
- Martínez, A.M.; Wilbur, R.B.; Shay, R.; Kak, A.C. Purdue RVL-SLLL ASL database for automatic recognition of American Sign Language. In Proceedings of the 4th IEEE International Conference on Multimodal Interfaces, Pittsburgh, PA, USA, 16 October 2002; pp. 167–172. [Google Scholar]
- Zahedi, M.; Keysers, D.; Deselaers, T.; Ney, H. Combination of tangent distance and an image distortion model for appearance-based sign language recognition. In Joint Pattern Recognition Symposium; Springer: Berlin/Heidelberg, Germany, 2005; pp. 401–408. [Google Scholar]
- Nandy, A.; Prasad, J.S.; Mondal, S.; Chakraborty, P.; Nandi, G.C. Recognition of isolated Indian sign language gesture in real time. In International Conference on Business Administration and Information Processing; Springer: Berlin/Heidelberg, Germany, 2010; pp. 102–107. [Google Scholar]
- Kurakin, A.; Zhang, Z.; Liu, Z. A real time system for dynamic hand gesture recognition with a depth sensor. In Proceedings of the 2012 Proceedings of the 20th European Signal Processing Conference (EUSIPCO), Bucharest, Romania, 27–31 August 2012; pp. 1975–1979. [Google Scholar]
- Ronchetti, F.; Quiroga, F.; Estrebou, C.; Lanzarini, L.; Rosete, A. LSA64: A Dataset of Argentinian Sign Language. In Proceedings of the XX II Congreso Argentino de Ciencias de la Computación (CACIC), San Luis, Argentina, 3–7 October 2016. [Google Scholar]
- Ansari, Z.A.; Harit, G. Nearest neighbour classification of Indian sign language gestures using kinect camera. Sadhana 2016, 41, 161–182. [Google Scholar] [CrossRef]
- Camgöz, N.C.; Kındıroğlu, A.A.; Karabüklü, S.; Kelepir, M.; Özsoy, A.S.; Akarun, L. BosphorusSign: A Turkish sign language recognition corpus in health and finance domains. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portoroz, Slovenia, 23–28 May 2016; pp. 1383–1388. [Google Scholar]
- Özdemir, O.; Kındıroğlu, A.A.; Camgöz, N.C.; Akarun, L. BosphorusSign22k Sign Language Recognition Dataset. arXiv 2020, arXiv:2004.01283. [Google Scholar]
- Hassan, S.; Berke, L.; Vahdani, E.; Jing, L.; Tian, Y.; Huenerfauth, M. An Isolated-Signing RGBD Dataset of 100 American Sign Language Signs Produced by Fluent ASL Signers. In Proceedings of the LREC2020 9th Workshop on the Representation and Processing of Sign Languages: Sign Language Resources in the Service of the Language Community, Technological Challenges and Application Perspectives, Marseille, France, 16 May 2020; pp. 89–94. [Google Scholar]
- Yang, S.; Jung, S.; Kang, H.; Kim, C. The Korean Sign Language Dataset for Action Recognition. In International Conference on Multimedia Modeling; Springer: Berlin/Heidelberg, Germany, 2020; pp. 532–542. [Google Scholar]
- Krňoul, Z.; Hrúz, M.; Campr, P. Correlation analysis of facial features and sign gestures. In Proceedings of the IEEE 10th International Conference on Signal Processing, Beijing, China, 24–28 October 2010; pp. 732–735. [Google Scholar]
- Caridakis, G.; Asteriadis, S.; Karpouzis, K. Non-manual cues in automatic sign language recognition. Pers. Ubiquitous Comput. 2014, 18, 37–46. [Google Scholar] [CrossRef]
- Sabyrov, A.; Mukushev, M.; Kimmelman, V. Towards Real-time Sign Language Interpreting Robot: Evaluation of Non-manual Components on Recognition Accuracy. In Proceedings of the CVPR Workshops, Long Beeach, CA, USA, 16–20 June 2019. [Google Scholar]
- Elons, A.S.; Ahmed, M.; Shedid, H. Facial expressions recognition for arabic sign language translation. In Proceedings of the 9th IEEE International Conference on Computer Engineering & Systems (ICCES), Cairo, Egypt, 22–23 December 2014; pp. 330–335. [Google Scholar]
- Paulraj, M.; Yaacob, S.; Desa, H.; Hema, C.R.; Ridzuan, W.M.; Ab Majid, W. Extraction of head and hand gesture features for recognition of sign language. In Proceedings of the 2008 International Conference on Electronic Design, Penang, Malaysia, 1–3 December 2008; pp. 1–6. [Google Scholar]
- Rao, G.A.; Kishore, P. Selfie video based continuous Indian sign language recognition system. Ain Shams Eng. J. 2018, 9, 1929–1939. [Google Scholar] [CrossRef]
- Al-Rousan, M.; Assaleh, K.; Tala’a, A. Video-based signer-independent Arabic sign language recognition using hidden Markov models. Appl. Soft Comput. 2009, 9, 990–999. [Google Scholar] [CrossRef]
- Kelly, D.; Reilly Delannoy, J.; Mc Donald, J.; Markham, C. A framework for continuous multimodal sign language recognition. In Proceedings of the 2009 international conference on Multimodal Interfaces, Wenzhou, China, 26–29 November 2009; pp. 351–358. [Google Scholar]
- Sarkar, S.; Loeding, B.; Parashar, A.S. Fusion of manual and non-manual information in american sign language recognition. In Handbook of Pattern Recognition and Computer Vision; World Scientific: Singapore, 2010; pp. 477–495. [Google Scholar]
- Quesada, L.; Marín, G.; Guerrero, L.A. Sign language recognition model combining non-manual markers and handshapes. In International Conference on Ubiquitous Computing and Ambient Intelligence; Springer: Berlin/Heidelberg, Germany, 2016; pp. 400–405. [Google Scholar]
- Kumar, P.; Roy, P.P.; Dogra, D.P. Independent bayesian classifier combination based sign language recognition using facial expression. Inf. Sci. 2018, 428, 30–48. [Google Scholar] [CrossRef]
- Camgoz, N.C.; Koller, O.; Hadfield, S.; Bowden, R. Multi-channel transformers for multi-articulatory sign language translation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 301–319. [Google Scholar]
- Camgoz, N.C.; Hadfield, S.; Koller, O.; Ney, H.; Bowden, R. Neural sign language translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7784–7793. [Google Scholar]
- Lachat, E.; Macher, H.; Landes, T.; Grussenmeyer, P. Assessment and calibration of a RGB-D camera (Kinect v2 Sensor) towards a potential use for close-range 3D modeling. Remote Sens. 2015, 7, 13070–13097. [Google Scholar] [CrossRef] [Green Version]
- Terven, J.R.; Córdova-Esparza, D.M. Kin2. A Kinect 2 toolbox for MATLAB. Sci. Comput. Program. 2016, 130, 97–106. [Google Scholar] [CrossRef]
- Shohieb, S.M.; Elminir, H.K.; Riad, A. Signsworld atlas; a benchmark Arabic sign language database. J. King Saud Univ. Comput. Inf. Sci. 2015, 27, 68–76. [Google Scholar] [CrossRef] [Green Version]
- Shanableh, T.; Assaleh, K. Arabic sign language recognition in user-independent mode. In Proceedings of the 2007 International Conference on Intelligent and Advanced Systems, Kuala Lumpur, Malaysia, 25–28 November 2007; pp. 597–600. [Google Scholar]
- Sidig, A.A.I.; Luqman, H.; Mahmoud, S.; Mohandes, M. KArSL: Arabic Sign Language Database. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 20. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zach, C.; Pock, T.; Bischof, H. A duality based approach for realtime tv-l 1 optical flow. In Joint Pattern Recognition Symposium; Springer: Berlin/Heidelberg, Germany, 2007; pp. 214–223. [Google Scholar]
- Pérez, J.S.; Meinhardt-Llopis, E.; Facciolo, G. TV-L1 optical flow estimation. Image Process. Line 2013, 2013, 137–150. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Dataset | Language | Type | #Signs | #Signers | #Samples/Videos |
|---|---|---|---|---|---|---|
| 2002 | Purdue ASL [20] | American | RGB | 184 | 14 | 3576 |
| 2005 | RWTH-BOSTON50 [21] | American | RGB | 50 | 3 | 483 |
| 2010 | IIITA -ROBITA [22] | Indian | RGB | 22 | - | 605 |
| 2012 | ASLLVD [17] | American | RGB | 3300+ | 6 | 9800 |
| 2012 | MSR Gesture 3D [23] | American | RGB | 12 | 10 | 336 |
| 2012 | DGS Kinect 40 [13] | German | Multi * | 40 | 15 | 3000 |
| 2012 | GSL 982 [13] | Greek | Multi | 982 | 1 | 4910 |
| 2013 | PSL Kinect 30 [14] | Polish | Multi | 30 | 1 | 300 |
| 2015 | PSL ToF 84 [15] | Polish | Multi | 84 | 1 | 1680 |
| 2015 | DEVISIGN-L [16] | Chinese | Multi | 2000 | 8 | 24,000 |
| 2016 | LSA64 [24] | Argentine | RGB | 64 | 10 | 3200 |
| 2016 | Indian Kinect [25] | Indian | Multi | 140 | 18 | 5041 |
| 2016 | BosphorusSign Kinect [26] | Turkish | Multi | 855 | 10 | - |
| 2019 | BVCSL3D [19] | Indian | Multi | 200 | 10 | 20,000 |
| 2020 | BosphorusSign22k [27] | Turkish | Multi | 744 | 6 | 22,542 |
| 2020 | ASL-100-RGBD DATASET [28] | American | Multi | 100 | 22 | 4150 |
| 2020 | KSL DATASET [29] | Korean | RGB | 77 | 20 | 1229 |
| 2020 | WLASL2000 [18] | American | RGB | 2000 | 119 | 21,083 |
| Year | Dataset | Type | Manual | Non-Manual | #Signs | #Signers | #Samples |
|---|---|---|---|---|---|---|---|
| 2007 | Shanableh et al. [46] | RGB | ✓ | 23 | 3 | 3450 | |
| 2015 | SignsWorld Atlas [45] | RGB | ✓ | ✓ | 264+ | 10 | 535+ |
| 2020 | KArSL [47] | Multi | ✓ | 502 | 3 | 75,300 | |
| 2021 | mArSL | Multi | ✓ | ✓ | 50 | 4 | 6748 |
| Input Data | Tested Signer | CNN-LSTM | Inception-LSTM | Xception-LSTM | ResNet50-LSTM | VGG-16-LSTM | MobileNet-LSTM | |
|---|---|---|---|---|---|---|---|---|
| Signer-Dependent | Color | 1 | 0.969 | 1.0 | 1.0 | 0.993 | 1.0 | 1.0 |
| 2 | 0.988 | 0.992 | 1.0 | 0.972 | 0.996 | 0.996 | ||
| 3 | 0.993 | 1.0 | 0.989 | 0.935 | 0.982 | 1.0 | ||
| 4 | 0.993 | 0.986 | 0.982 | 0.883 | 0.986 | 0.993 | ||
| All | 0.989 | 0.995 | 0.994 | 0.964 | 0.991 | 0.996 | ||
| Average | 0.986 | 0.995 | 0.993 | 0.949 | 0.991 | 0.997 | ||
| Depth | 1 | 0.960 | 0.995 | 1.0 | 0.832 | 0.981 | 1.0 | |
| 2 | 0.952 | 0.984 | 0.992 | 0.712 | 0.964 | 0.988 | ||
| 3 | 0.813 | 0.993 | 0.996 | 0.640 | 0.946 | 0.996 | ||
| 4 | 0.979 | 0.986 | 0.993 | 0.714 | 0.926 | 0.993 | ||
| All | 0.989 | 0.996 | 0.994 | 0.722 | 0.980 | 0.996 | ||
| Average | 0.939 | 0.991 | 0.995 | 0.724 | 0.959 | 0.995 | ||
| Signer-Independent | Color | 1 | 0.060 | 0.289 | 0.287 | 0.074 | 0.330 | 0.566 |
| 2 | 0.022 | 0.317 | 0.317 | 0.238 | 0.541 | 0.501 | ||
| 3 | 0.137 | 0.369 | 0.295 | 0.165 | 0.271 | 0.361 | ||
| 4 | 0.039 | 0.259 | 0.341 | 0.120 | 0.546 | 0.550 | ||
| Average | 0.065 | 0.309 | 0.310 | 0.149 | 0.422 | 0.495 | ||
| Depth | 1 | 0.042 | 0.382 | 0.331 | 0.158 | 0.305 | 0.541 | |
| 2 | 0.093 | 0.408 | 0.446 | 0.162 | 0.372 | 0.641 | ||
| 3 | 0.137 | 0.325 | 0.357 | 0.132 | 0.245 | 0.476 | ||
| 4 | 0.200 | 0.568 | 0.528 | 0.128 | 0.252 | 0.530 | ||
| Average | 0.118 | 0.421 | 0.416 | 0.145 | 0.294 | 0.547 |
| Input Data | Tested Signer | CNN-LSTM | Inception-SLSTM | Xception-LSTM | ResNet50-LSTM | VGG-16-LSTM | MobileNet-LSTM |
|---|---|---|---|---|---|---|---|
| Color | 1 | 0.558 | 0.608 | 0.636 | 0.025 | 0.387 | 0.490 |
| 2 | 0.439 | 0.769 | 0.761 | 0.020 | 0.441 | 0.784 | |
| 3 | 0.449 | 0.757 | 0.795 | 0.020 | 0.336 | 0.863 | |
| 4 | 0.519 | 0.732 | 0.667 | 0.021 | 0.466 | 0.760 | |
| Average | 0.491 | 0.717 | 0.715 | 0.021 | 0.408 | 0.724 | |
| Depth | 1 | 0.455 | 0.599 | 0.490 | 0.024 | 0.220 | 0.581 |
| 2 | 0.474 | 0.641 | 0.609 | 0.020 | 0.174 | 0.638 | |
| 3 | 0.411 | 0.614 | 0.582 | 0.020 | 0.185 | 0.643 | |
| 4 | 0.519 | 0.678 | 0.696 | 0.014 | 0.221 | 0.726 | |
| Average | 0.465 | 0.633 | 0.594 | 0.020 | 0.200 | 0.647 |
| Tested Signer | AU | Raw Images | Optical Flow | |||
|---|---|---|---|---|---|---|
| MobileNet-LSTM | MobileNet-LSTM+AU | MobileNet-LSTM | MobileNet-LSTM+AU | |||
| Color | 1 | 0.174 | 0.566 | 0.603 | 0.490 | 0.589 |
| 2 | 0.132 | 0.501 | 0.597 | 0.784 | 0.787 | |
| 3 | 0.142 | 0.361 | 0.280 | 0.863 | 0.858 | |
| 4 | 0.153 | 0.550 | 0.534 | 0.760 | 0.805 | |
| Average | 0.150 | 0.495 | 0.504 | 0.724 | 0.760 | |
| Depth | 1 | 0.174 | 0.541 | 0.551 | 0.581 | 0.593 |
| 2 | 0.132 | 0.641 | 0.620 | 0.638 | 0.622 | |
| 3 | 0.142 | 0.476 | 0.519 | 0.643 | 0.656 | |
| 4 | 0.153 | 0.530 | 0.599 | 0.726 | 0.664 | |
| Average | 0.150 | 0.547 | 0.572 | 0.647 | 0.634 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luqman, H.; El-Alfy, E.-S.M. Towards Hybrid Multimodal Manual and Non-Manual Arabic Sign Language Recognition: mArSL Database and Pilot Study. Electronics 2021, 10, 1739. https://doi.org/10.3390/electronics10141739
Luqman H, El-Alfy E-SM. Towards Hybrid Multimodal Manual and Non-Manual Arabic Sign Language Recognition: mArSL Database and Pilot Study. Electronics. 2021; 10(14):1739. https://doi.org/10.3390/electronics10141739
Chicago/Turabian StyleLuqman, Hamzah, and El-Sayed M. El-Alfy. 2021. "Towards Hybrid Multimodal Manual and Non-Manual Arabic Sign Language Recognition: mArSL Database and Pilot Study" Electronics 10, no. 14: 1739. https://doi.org/10.3390/electronics10141739
APA StyleLuqman, H., & El-Alfy, E. -S. M. (2021). Towards Hybrid Multimodal Manual and Non-Manual Arabic Sign Language Recognition: mArSL Database and Pilot Study. Electronics, 10(14), 1739. https://doi.org/10.3390/electronics10141739