
Machine Learning-Based Model Predictive Control for Collaborative Production Planning Problem with Unknown Information



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- The production planning problem is formulated using a discrete time system, with task performance judged by net profit;
- A gradient descent machine learning procedure with an adaptive learning scheme is developed to estimate the unknown parameters of the revenue in Q using historical data via solving a regression problem;
- An MPC method uses the estimated values of Q as its user-defined weight factors to predict the optimal decisions to maximize net profit;
- A machine learning-based MPC algorithm with low complexity is proposed and validated in a simulation-based case study;
- A comparison with individual and pure MPC decisions is performed to show the increase in profit.
| is an n-dimensional Euclidean vector space, | |
| is an real matrix space, | |
| is the element in ith row and jth column of A, | |
| is a diagonal matrix of its argument, | |
| is the spectral radius of a given matrix, | |
| is an input constraint set, | |
| is a cost function of the performance index, | |
| is the infinity norm of the vector x, | |
| is the projection of x onto the set , | |
| is the representation of normal distribution, | |
| is the estimated value of x, | |
| is a loss function, | |
| is the set of integer numbers, | |
| is the set of non-negative integer numbers, | |
| s | is the production demand, |
| Q | is the weighting parameters of the revenue, |
| R | is the weighting parameters of the productivity effort, |
| P | is the decision bias parameters of the participants, |
| is the benchmark of the unknown parameters. |
2. Problem Formulation
2.1. System Dynamics
2.2. System Constraints
2.3. Production Planning Design Objectives
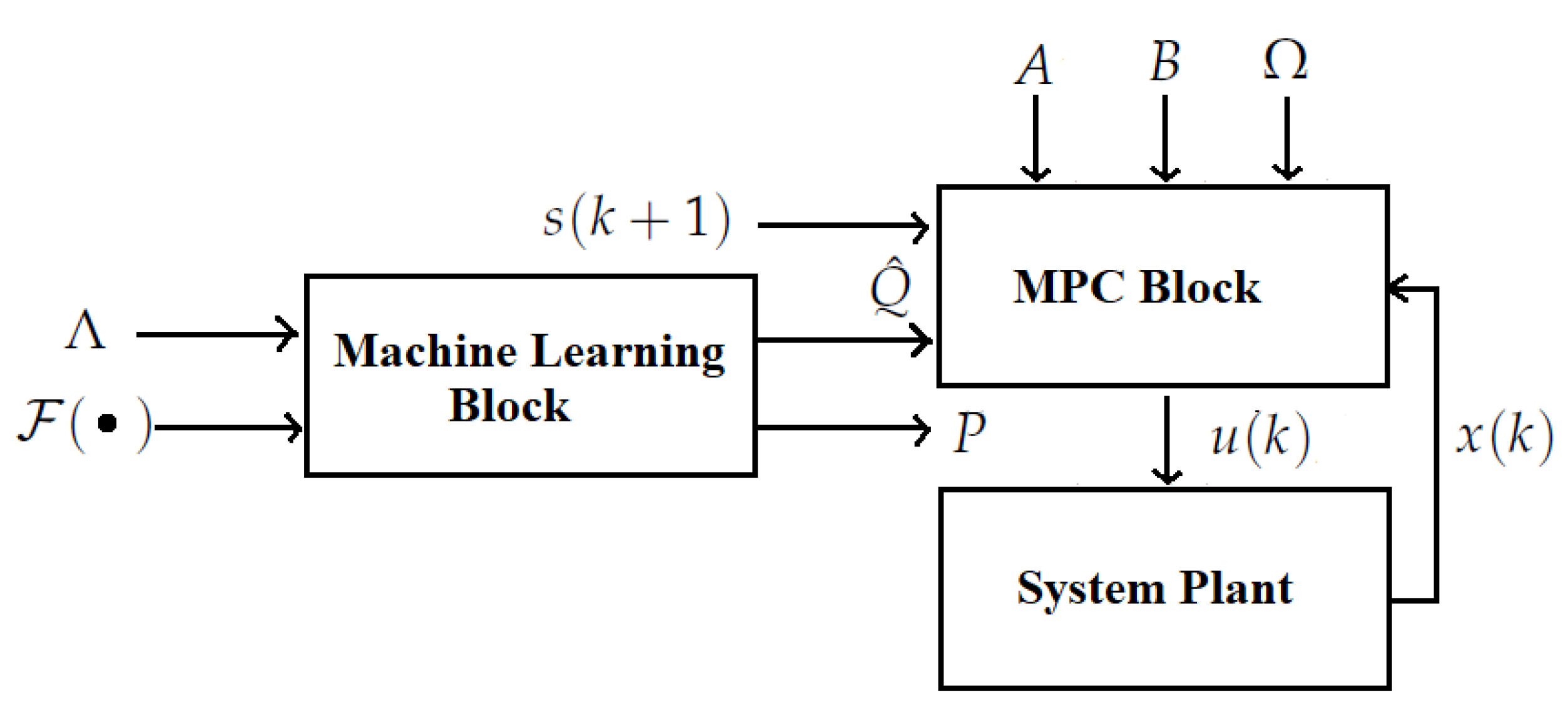
3. Machine Learning-Based MPC
3.1. Individual Decision Modeling
3.2. Gradient Descent Machine Learning
3.3. MPC Production Planning Problem
4. Implementation Instructions
4.1. Instructions on Projection Solution
4.2. Instructions on Initial Estimate Choice
4.3. Instructions for Partial Derivative Estimation
4.4. Instructions for MPC Problem Solution
4.5. Production Planning Comprehensive Algorithm
| Algorithm 1 Machine learning based MPC |
| Input: System dynamics (1), cost function , production demand , initial state , initial estimate , decision loss function and historical data set . |
| Output: Estimate , optimal decision . |
| 1: initialization: Set training epoch number , sample time index and randomly split elements of the set to a training set and the rest to a testing set . |
| 2: while not do |
| 3: Perform the training procedure (31) to update the estimate using all elements in . |
| 4: Perform the evaluation (30) to compute the decision loss , using all elements in . |
| 5: Set to the next training epoch. |
| 6: end while |
| 7: Set the estimate as the unknown matrix Q. |
| 8: while do |
| 9: Solve the MPC problem (35) to obtain . |
| 10: Record the optimal decisions . |
| 11: Set to the next sample time index. |
| 12: end while |
| 13: return , , |
5. Simulation-Based Case Study
5.1. Problem Design Specifications
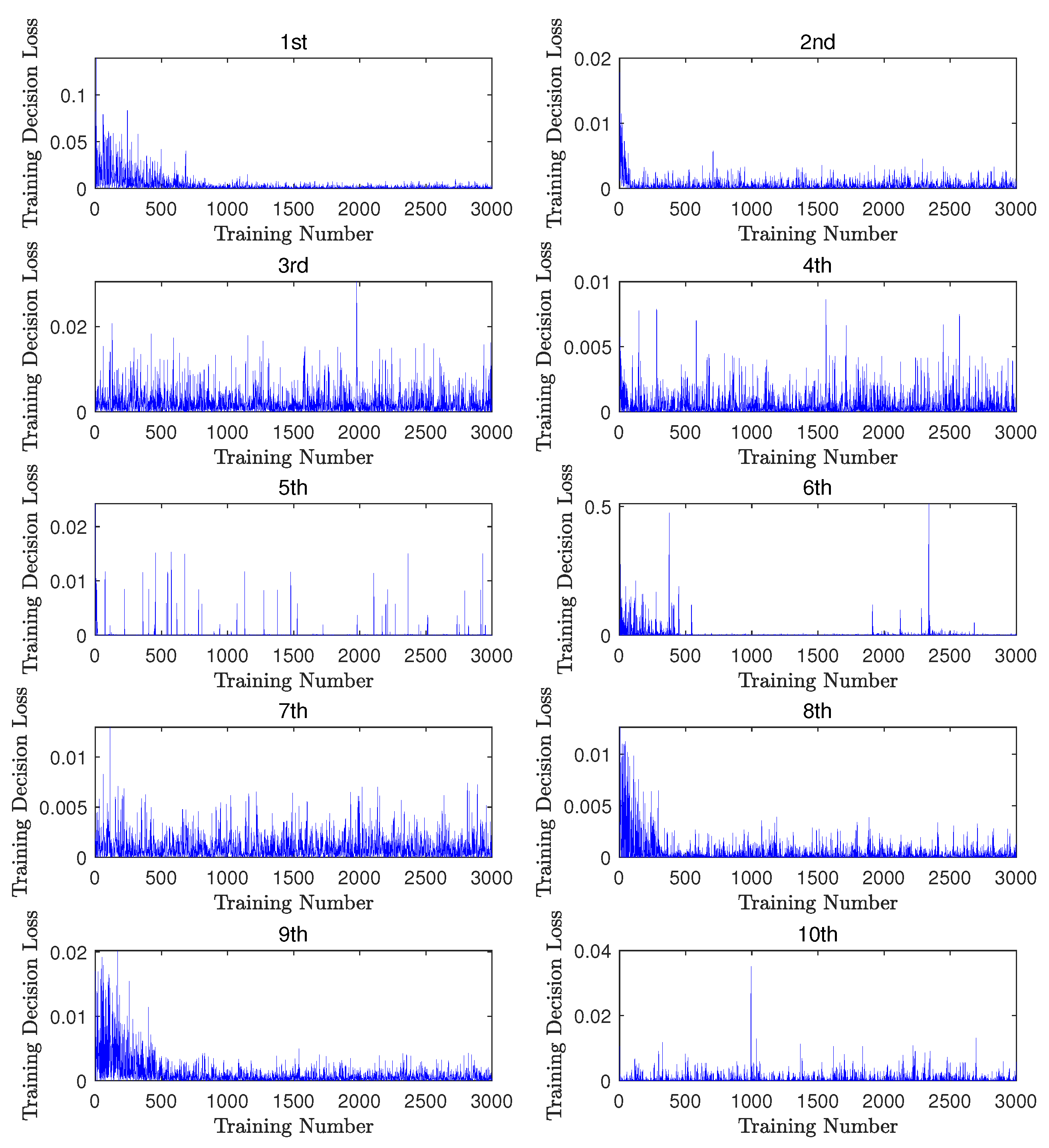
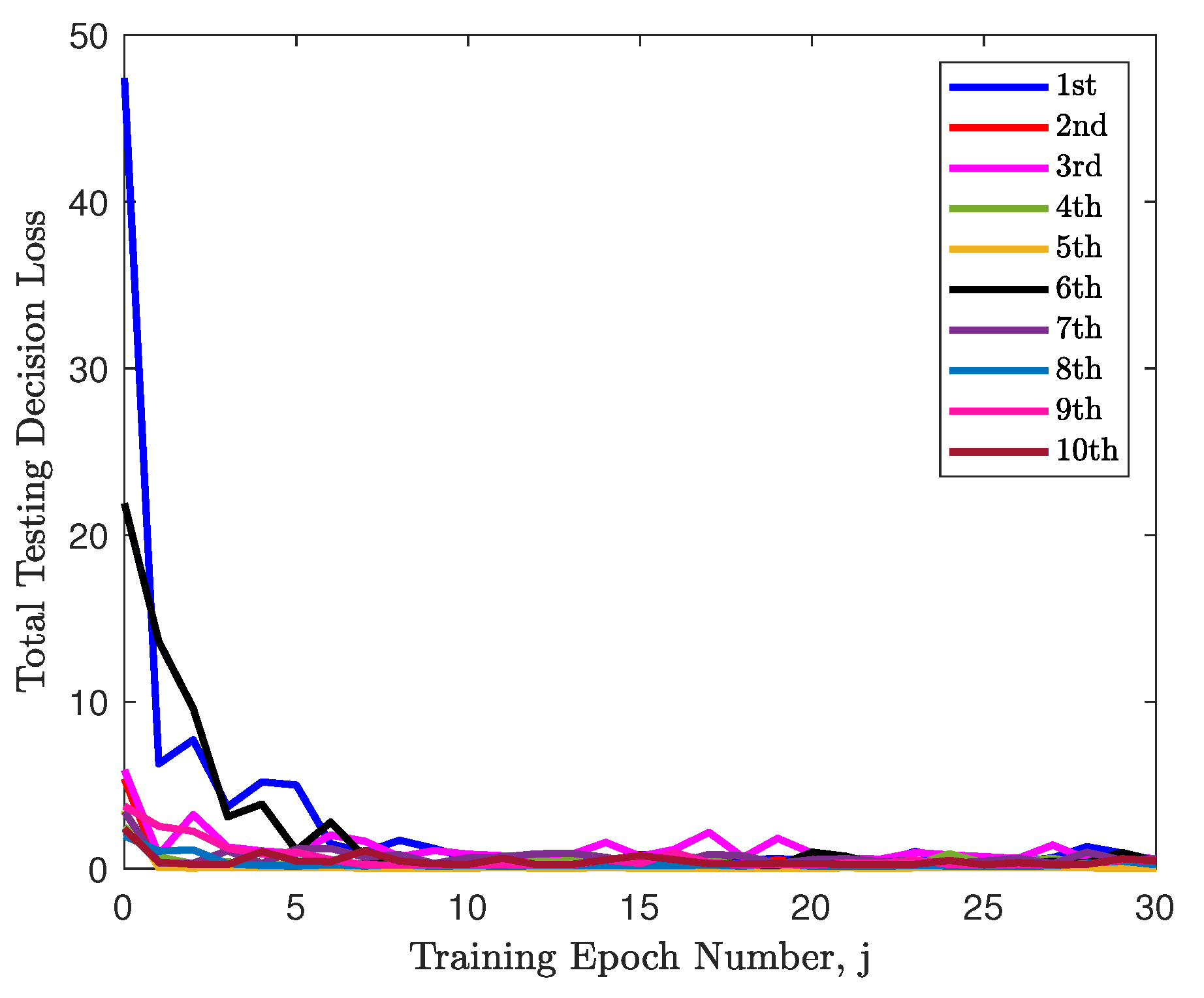
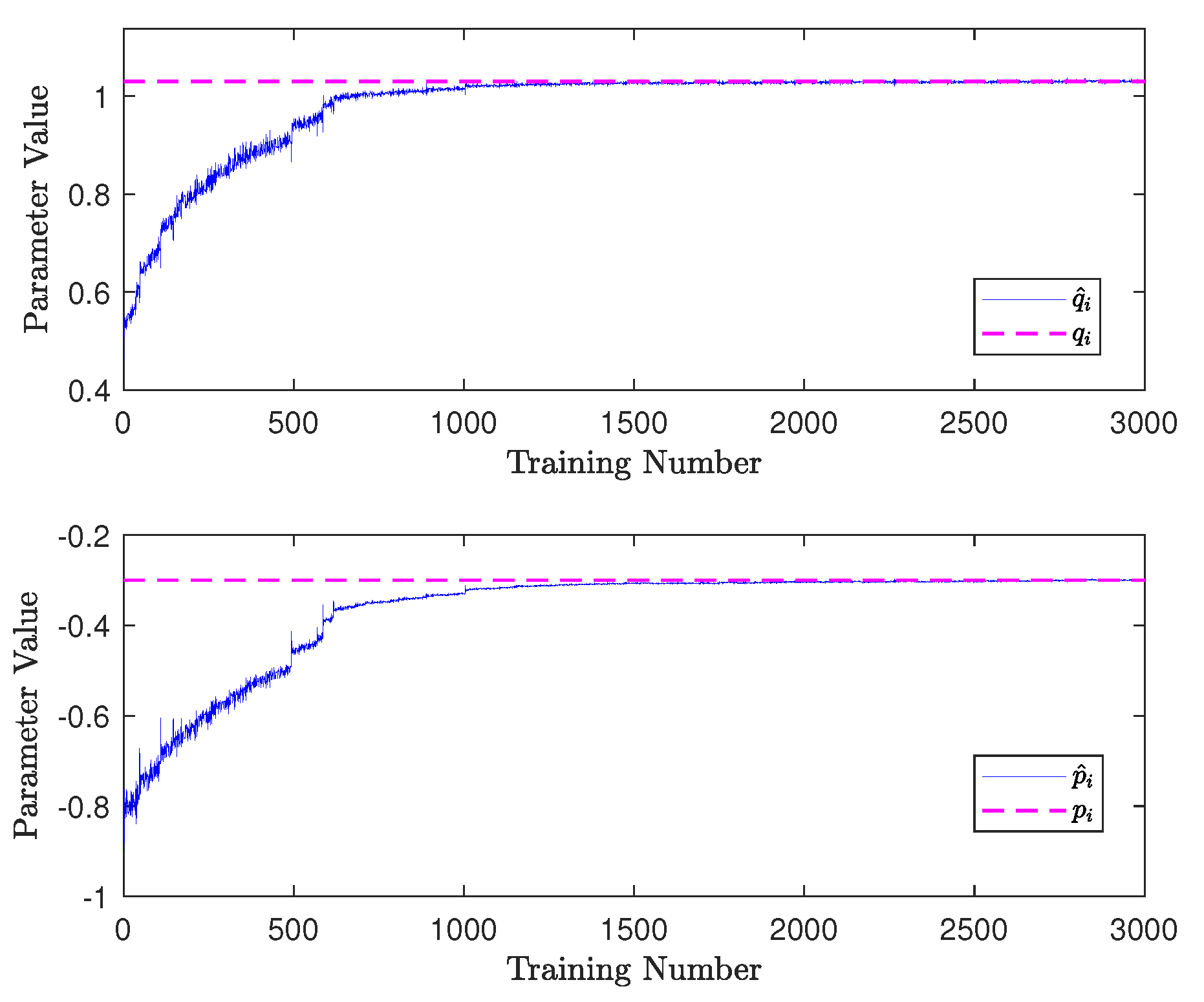
5.2. Parameter Estimation Using Machine Learning
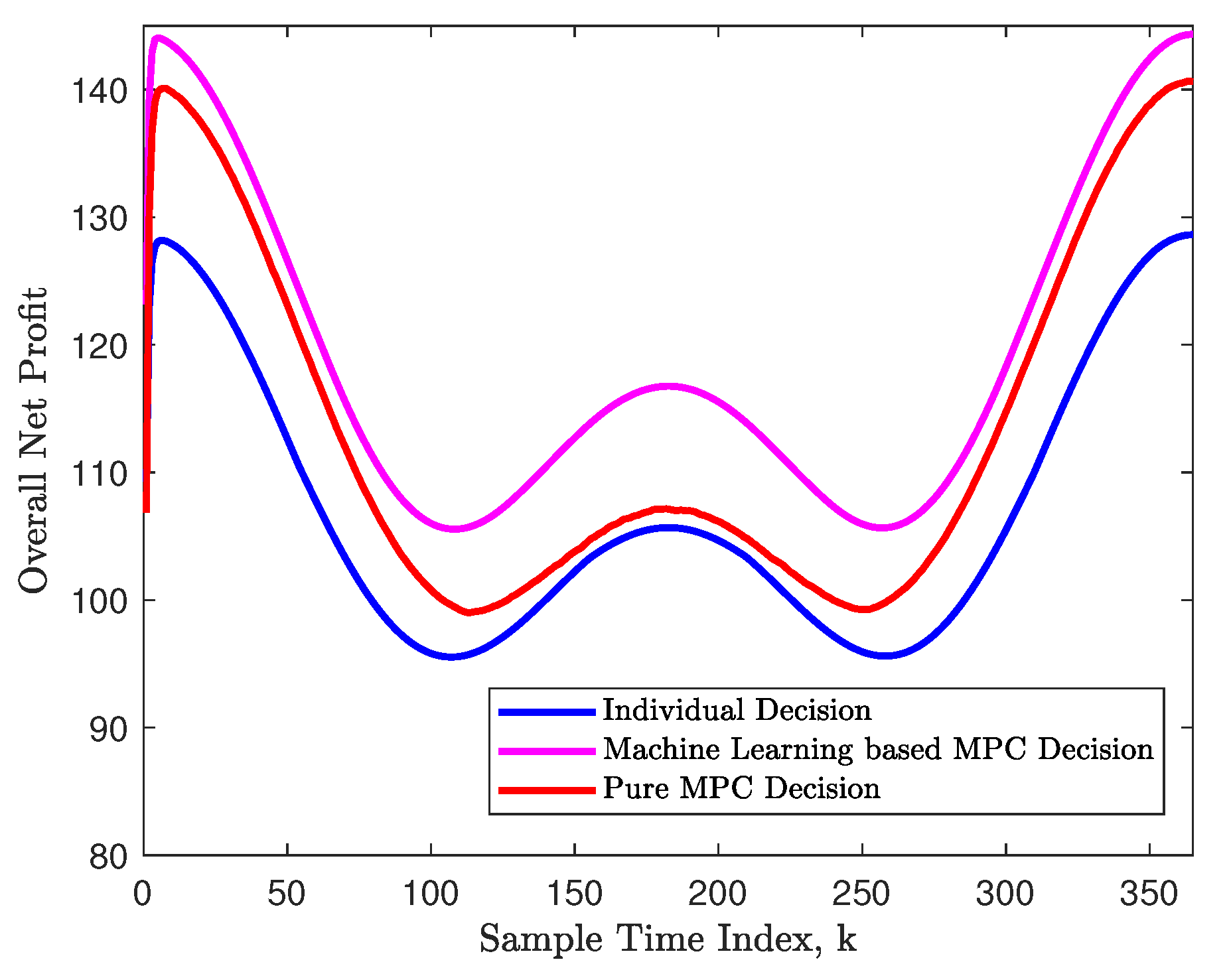
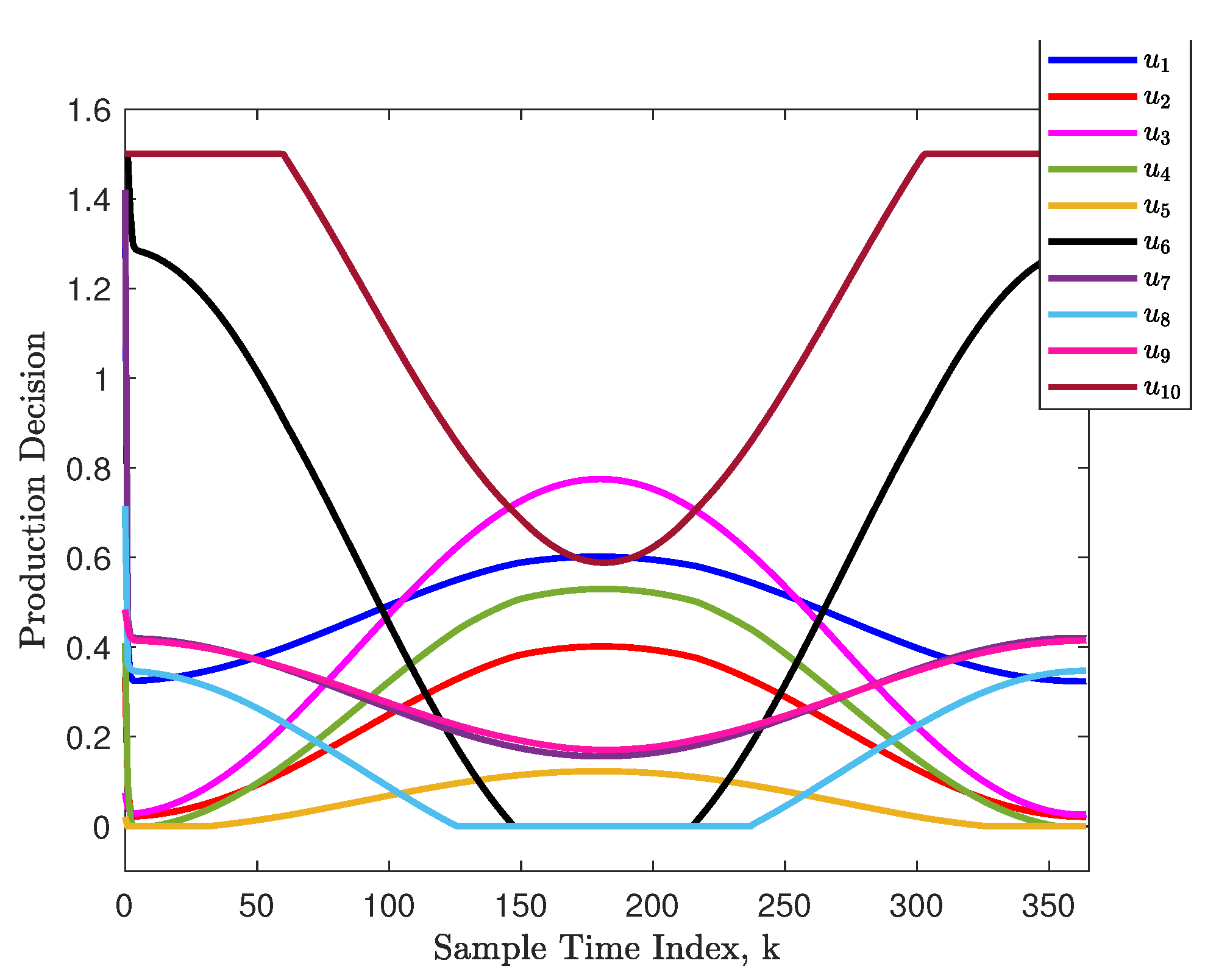
5.3. Decision Making Using MPC
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Cao, M.; Zhang, Q. Supply chain collaboration: Impact on collaborative advantage and firm performance. J. Oper. Manag. 2011, 29, 163–180. [Google Scholar] [CrossRef]
- Zhang, D.; Shi, P.; Wang, Q.G.; Yu, L. Analysis and synthesis of networked control systems: A survey of recent advances and challenges. ISA Trans. 2017, 66, 376–392. [Google Scholar] [CrossRef]
- Osborne, M.J.; Rubinstein, A. A Course in Game Theory; The MIT Press: Cambridge, MA, USA, 1994. [Google Scholar]
- Park, Y.B. An integrated approach for production and distribution planning in supply chain management. Int. J. Prod. Res. 2005, 43, 1205–1224. [Google Scholar] [CrossRef]
- Huang, S.; Yang, C.; Zhang, X. Pricing and production decisions in dual-channel supply chains with demand disruptions. Comput. Ind. Eng. 2012, 62, 70–83. [Google Scholar] [CrossRef]
- Kopanos, G.M.; Georgiadis, M.C.; Pistikopoulos, E.N. Energy production planning of a network of micro combined heat and power generators. Appl. Energy 2013, 102, 1522–1534. [Google Scholar] [CrossRef]
- Selim, H.; Araz, C.; Ozkarahan, I. Collaborative production-distribution planning in supply chain: A fuzzy goal programming approach. Transp. Res. Part E 2008, 44, 396–419. [Google Scholar] [CrossRef]
- Ma, Y.; Yan, F.; Kang, K.; Wei, X. A novel integrated production-distribution planning model with conflict and coordination in a supply chain network. Knowl.-Based Syst. 2016, 105, 119–133. [Google Scholar] [CrossRef]
- Hu, Z.; Ma, N.; Gao, W.; Lv, C.; Yao, L. Modelling diffusion for multi-generational product planning strategies using bi-level optimization. Knowl.-Based Syst. 2017, 123, 254–266. [Google Scholar] [CrossRef]
- Eduardo, L.; Cardenas-Barron. Economic production quantity with rework process at a single-stage manufacturing system with planned backorders. Comput. Ind. Eng. 2009, 57, 1105–1113. [Google Scholar]
- Zhang, B.; Xu, L. Multi-item production planning with carbon cap and trade mechanism. Int. J. Prod. Econ. 2013, 144, 118–127. [Google Scholar] [CrossRef]
- Gong, X.; Zhou, S.X. Optimal Production Planning with Emissions Trading. Oper. Res. 2013, 61, 908–924. [Google Scholar] [CrossRef]
- Stevenson, M.; Hendry, L.C.; Kingsman, B.G. A review of production planning and control: The applicability of key concepts to the make-to-order industry. Int. J. Prod. Res. 2005, 43, 869–898. [Google Scholar] [CrossRef]
- Wang, L.; Keshavarzmanesh, S.; Feng, H.Y.; Buchal, R.O. Assembly process planning and its future in collaborative manufacturing: A review. Int. J. Adv. Manuf. Technol. 2009, 41, 132–144. [Google Scholar] [CrossRef]
- Maravelias, C.T.; Sung, C. Integration of production planning and scheduling: Overview, challenges and opportunities. Comput. Chem. Eng. 2009, 33, 1919–1930. [Google Scholar] [CrossRef]
- Fahimnia, B.; Farahani, R.Z.; Marian, R.; Luong, L. A review and critique on integrated production-distribution planning models and techniques. J. Manuf. Syst. 2013, 32, 1–19. [Google Scholar] [CrossRef]
- Biel, K.; Glock, C.H. Systematic literature review of decision support models for energy-efficient production planning. Comput. Ind. Eng. 2016, 101, 243–259. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: Berlin, Germany, 2001. [Google Scholar]
- Nasrabadi, N.M. Pattern recognition and machine learning. J. Electron. Imaging 2007, 16, 049901. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 2012 International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Qi, Z.; Tian, Y.; Shi, Y. Structural twin support vector machine for classification. Knowl.-Based Syst. 2013, 43, 74–81. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Li, X.; Wu, S. Intelligent fault diagnosis of rolling bearing using deep wavelet auto-encoder with extreme learning machine. Knowl.-Based Syst. 2018, 140, 1–14. [Google Scholar]
- Cai, J.; Luo, J.; Wang, S.; Yang, S. Feature selection in machine learning: A new perspective. Neurocomputing 2018, 300, 70–79. [Google Scholar] [CrossRef]
- Jeon, H.K.; Yang, C.S. Enhancement of Ship Type Classification from a Combination of CNN and KNN. Electronics 2021, 10, 1169. [Google Scholar] [CrossRef]
- Chen, Y.; Zhou, Y. Machine learning based decision making for time varying systems: Parameter estimation and performance optimization. Knowl.-Based Syst. 2020, 190, 105479. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 2013 International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3234–3243. [Google Scholar]
- Tao, H.; Wang, P.; Chen, Y.; Stojanovic, V.; Yang, H. An unsupervised fault diagnosis method for rolling bearing using STFT and generative neural networks. J. Frankl. Inst. 2020, 357, 7286–7307. [Google Scholar] [CrossRef]
- Samanta, A.; Chowdhuri, S.; Williamson, S.S. Machine Learning-Based Data-Driven Fault Detection/Diagnosis of Lithium-Ion Battery: A Critical Review. Electronics 2021, 10, 1309. [Google Scholar] [CrossRef]
- Garcia, C.E.; Prett, D.M.; Morari, M. Model predictive control: Theory and practice—A survey. Automatica 1989, 25, 335–348. [Google Scholar] [CrossRef]
- Yang, T.; Qiu, W.; Ma, Y.; Chadli, M.; Zhang, L. Fuzzy model-based predictive control of dissolved oxygen in activated sludge processes. Neurocomputing 2014, 136, 88–95. [Google Scholar] [CrossRef]
- Parisio, A.; Rikos, E.; Glielmo, L. A Model Predictive Control Approach to Microgrid Operation Optimization. IEEE Trans. Control Syst. Technol. 2014, 22, 1813–1827. [Google Scholar] [CrossRef]
- Geyer, T.; Quevedo, D.E. Performance of Multistep Finite Control Set Model Predictive Control for Power Electronics. IEEE Trans. Power Electron. 2015, 30, 1633–1644. [Google Scholar] [CrossRef]
- Froisy, J. Model predictive control: Past, present and future. ISA Trans. 1994, 33, 235–243. [Google Scholar] [CrossRef]
- Qin, S.; Badgwell, T.A. A survey of industrial model predictive control technology. Control Eng. Pract. 2003, 11, 733–764. [Google Scholar] [CrossRef]
- Mayne, D.Q. Model predictive control: Recent developments and future promise. Automatica 2014, 50, 2967–2986. [Google Scholar] [CrossRef]
- Mula, J.; Poler, R.; Garcia-Sabater, J.P.; Lario, F.C. Models for production planning under uncertainty: A review. Int. J. Prod. Econ. 2006, 103, 271–285. [Google Scholar] [CrossRef] [Green Version]
- Shi, J.; Zhanga, G.; Sha, J. Optimal production planning for a multi-product closed loop system with uncertain demand and return. Comput. Oper. Res. 2011, 38, 641–650. [Google Scholar] [CrossRef] [Green Version]
- Kenne, J.P.; Dejax, P.; Gharbi, A. Production planning of a hybrid manufacturing-remanufacturing system under uncertainty within a closed-loop supply chain. Int. J. Prod. Econ. 2012, 135, 81–93. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Zhou, D.; Gao, F. Iterative learning model predictive control for multi-phase batch processes. J. Process Control 2008, 18, 543–557. [Google Scholar] [CrossRef]
- Aswani, A.; Master, N.; Taneja, J.; Culler, D.; Tomlin, C. Reducing Transient and Steady State Electricity Consumption in HVAC Using Learning-Based Model-Predictive Control. Proc. IEEE 2012, 100, 240–253. [Google Scholar] [CrossRef]
- Aswani, A.; Sastry, H.G.S.S.; ClaireTomlin. Provably safe and robust learning-based model predictive control. Automatica 2013, 49, 1216–1226. [Google Scholar] [CrossRef] [Green Version]
- Kayacan, E.; Kayacan, E.; Ramon, H.; Saeys, W. Learning in centralized nonlinear model predictive control: Application to an autonomous tractor-trailer system. IEEE Trans. Control Syst. Technol. 2015, 23, 197–205. [Google Scholar] [CrossRef]
- Chen, Y.; Zhou, Y.; Zhang, Y. Collaborative Production Planning with Unknown Parameters using Model Predictive Control and Machine Learning. In Proceedings of the 2020 China Automation Congress (CAC), Shanghai, China, 6–8 November 2020. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin, Germany, 2013. [Google Scholar]
- Kohavi, R. A Study of CrossValidation and Bootstrap for Accuracy Estimation and Model Selection. In Proceedings of the 1995 International Joint Conference on Articial Intelligence (IJCAI), Montreal, QC, Canada, 20–25 August 1995; pp. 1137–1145. [Google Scholar]
- Chen, Y.; Chu, B.; Freeman, C.T. Point-to-Point Iterative Learning Control with Optimal Tracking Time Allocation. IEEE Trans. Control Syst. Technol. 2018, 26, 1685–1698. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Chu, B.; Freeman, C.T. Generalized Iterative Learning Control using Successive Projection: Algorithm, Convergence and Experimental Verification. IEEE Trans. Control Syst. Technol. 2020, 28, 2079–2091. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Chu, B.; Freeman, C.T. Iterative Learning Control for Path-Following Tasks With Performance Optimization. IEEE Trans. Control. Syst. Technol. 2021, 1–13. [Google Scholar] [CrossRef]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Zhou, Y.; Zhang, Y. Machine Learning-Based Model Predictive Control for Collaborative Production Planning Problem with Unknown Information. Electronics 2021, 10, 1818. https://doi.org/10.3390/electronics10151818
Chen Y, Zhou Y, Zhang Y. Machine Learning-Based Model Predictive Control for Collaborative Production Planning Problem with Unknown Information. Electronics. 2021; 10(15):1818. https://doi.org/10.3390/electronics10151818
Chicago/Turabian StyleChen, Yiyang, Yingwei Zhou, and Yueyuan Zhang. 2021. "Machine Learning-Based Model Predictive Control for Collaborative Production Planning Problem with Unknown Information" Electronics 10, no. 15: 1818. https://doi.org/10.3390/electronics10151818
APA StyleChen, Y., Zhou, Y., & Zhang, Y. (2021). Machine Learning-Based Model Predictive Control for Collaborative Production Planning Problem with Unknown Information. Electronics, 10(15), 1818. https://doi.org/10.3390/electronics10151818