1. Introduction
High Energy Physics (HEP) aims to understand the structure of elementary particles, which are the fundamental constituents of matter. The great success of the so-called Standard Model (SM) has not only given us the interpretation of many interactions between particles, but also has built a basis for continuing to understand their nature. Beyond the SM we can begin to deeply explore the origin of matter in the Universe, what dark matter and dark energy are, the physics of the Big Bang and other untangled structures of space–time. To do this, the main experiments at the Large Hadron Collider (LHC) at CERN in Geneva (Switzerland) are now being updated to what is called Phase II high-luminosity upgrade [
1]. In particular, the LHC experiments use detectors to study the particles produced by collisions in the accelerator. These experiments are carried out by huge collaborations of scientists from all over the world. Each experiment is unique and characterized by its detectors and the way in which the generated data are analyzed. In general, the data obtained through the detectors were filtered and grouped into physical
Events [
2]. Then, a complex off-line reconstruction put together the
Events belonging to a common time slot, to make sure that they were generated almost simultaneously, being products of a common interaction. The
Trigger [
3] is an electronic system dedicated to the selection of potential physical data, among the huge amount of noise. More specifically, this
Trigger is also a complex system made up of many internal components. The first of these, the one that makes the first selection, can be made of an electronic pattern recognition apparatus. It can also be composed of a relatively simple and fast analog device or it can be constituted by a more complex programmable digital system built with commercial components such as CPUs, GPUs and/or FPGAs. The study presented in this paper describes a recognition system based on the Hough Transform (HT) [
4,
5], implemented on a frontier FPGA. The proposed recognition system reads out that data originated in a detection system located close to the beam lines: The
Tracker [
6,
7]. In addition, for HEP experiments that take years for the construction of the entire apparatus, it is not possible to test the hardware in a real environment in advance with respect to the final commissioning. These experiments are unique systems that cannot be fully reproduced elsewhere. However, parts of the system can be evaluated in advance using demonstrators that are used as proofs of concepts. With this study we have demonstrated, through post-layout simulations and performance comparisons, that the entire system can be implemented on a single FPGA. This is a proof of concept obtained in advance without incurring the high costs of this frontier electronics.
2. Hough Transform as Pattern Recognition Algorithm
The HT in general is a known extraction technique mainly implemented in image analysis and digital image processing. Over recent years other studies have proposed hardware implementations of the HT [
8,
9], but using smaller FPGAs and less aggressive target performance. The thousands of lanes processed in parallel in this design is something never investigated and this is to fulfill the specifications of the HEP experiments at CERN, which are unique in the field of physics research. Here, the HT algorithm is used as a tracking method for pattern recognition. In more details, it is used to extract trajectories, straight or curved lines within digital images representing the particle space.
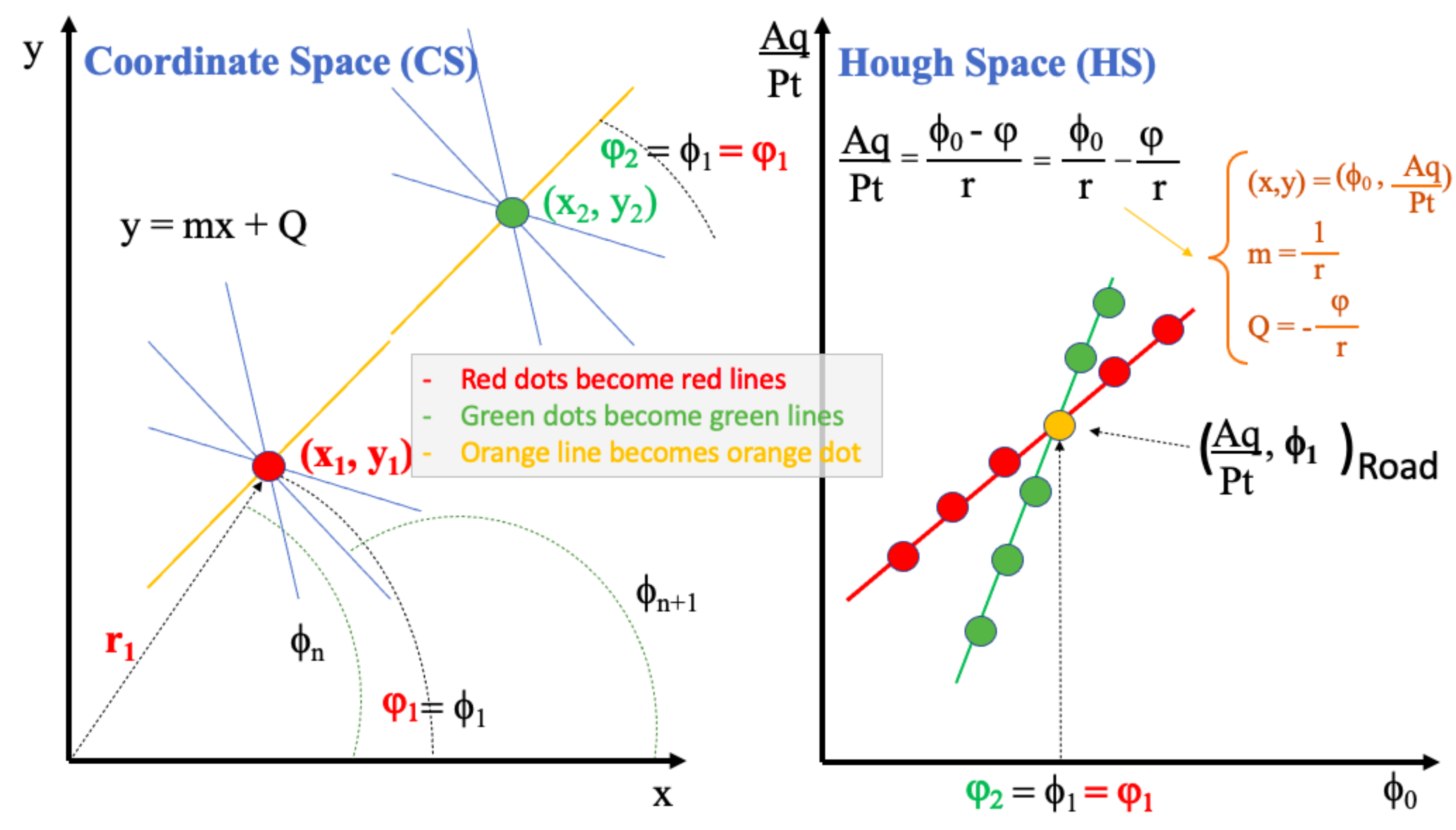
Figure 1 shows the concept: Let us imagine to have a beam of particles, moving focused clockwise and anti clockwise in an accelerator like the CERN, close to the speed of light. These particles move in opposite directions along what we define
z coordinate. Then, the interaction point where these two beams collide defines not only the origin for the
z coordinate but also explicits the transverse plane
x, y where the products of the particle interactions are spread out in any direction. Among these, we consider only the orthogonal tracks with respect to the beam line. Hence, the new particles of interest, originated by the collisions, are studied on a bi-dimensional space that we represent as a
x, y plane, orthogonal to the beam line. On this plane the trajectories represent the particle paths crossing the detectors. If the particles are charged—many of them are—and embedded in a magnetic field, they can describe a circular or helicoidal track that should be detected immediately in the
Tracker, the innermost portion of the whole detector [
6,
7]. Left side of the
Figure 1 shows this. Then, using the straight line expression:
the line parameters can be converted in terms of slope
m and intercept
Q, as
and the Formula (
2) can be rewritten as
being
the radius in the Coordinate Space (CS),
the angle of the straight line with respect to the horizontal axis, again the CS, and
the angle at the origin of any other straight line crossing the (
x, y) or (
) pair.
Figure 1 shows these lines with different
angles crossing in one point. Only one of these lines share the
=
angle with the other bundle of straight lines crossing in other points.
and
are divided here in bins for histogram plots. In Formula (
3),
represents the particle momentum
Pt in kg · m/s, the charge
q in Coulomb, including a unity constant factor
A that turns the units of
in rad/m. The process to execute the Formula (
3) for all the
Hits of an input
Event is here called
Forward Computation.
Through this change of coordinates we move from the particle space
x, y to what we call parameter or Hough Space (HS) (
, ). It is shown that the straight lines in the CS turn into points in the HS. It is also shown that each point in the CS, as it can belong to an infinite bundle of straight lines, turns into a straight line in the HS. Right part of
Figure 1 shows this. Hence, if we look at a given number of points in the CS that compose a straight line, as all these share the same slope and intercept, all these turn into a single point (
, ) in the HS. Thus, by recognizing and extracting which points in the HS are parametrized by a given (
, ) pair, we can identify which original tracks, parametrized by (
x, y) or (
r, ϕ) couples, are compatible with that pair. Given this concept, the HT algorithm proposed here is based on the filling the HS with a huge number of straight lines. These lines are generated, for each (
r, ϕ) couple, and for each input channel, by carrying out all the possible values of the
0 angle (see below). In this way for each
0 angle inserted in the Formula (
3), a correspondent momentum
is calculated. Again, this is repeated for all the
Hits of the input channels. It should be noted that
and
are divided here in bins for histogram plots.
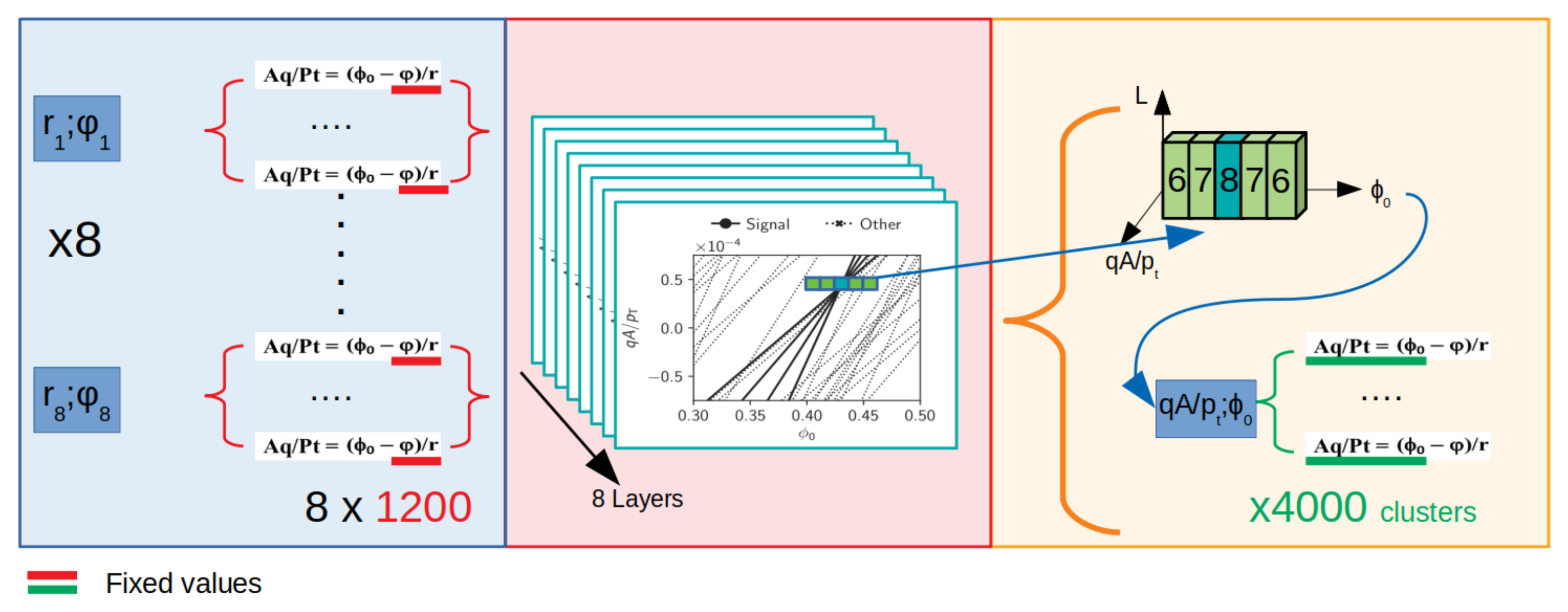
In the reality, every HEP experiment deals with a given number of input-output specifications provided by software simulations. What we do here is to emulate the behaviour and performance of a physical apparatus in advance, providing all the expected physical parameters before the system is built. The main system performance is the track recognition capability, which is the number of detected tracks over the total number of expected tracks to be found. In this study the parameters that we are using to emulate a physical pattern recognition of real trajectories are summarized below.
Eight input data channels, originated by the Tracker.
The eight channels, in parallel, provide up to 500 inputs for a total number of data up to 4000 pair: These are called input Hits.
Each of the eight channels provides integer number for the x and y CS couples, digitized using 18 bits.
Each Hit is also provided on-the-fly with the CS pairs in the polar representation, besides the cartesian. The polar data are (r, ϕ) represented respectively with 12 and 16 digital bits.
The system is targeted to work at a clock frequency of 250 MHz.
For each input Hit 1200 0 angles are created to cover the desired spread of angles in the HS (1200 bins so using 11 bits).
The momenta
of the HT Formula (
3) are binned in 64 bins, so using 6 digital bits.
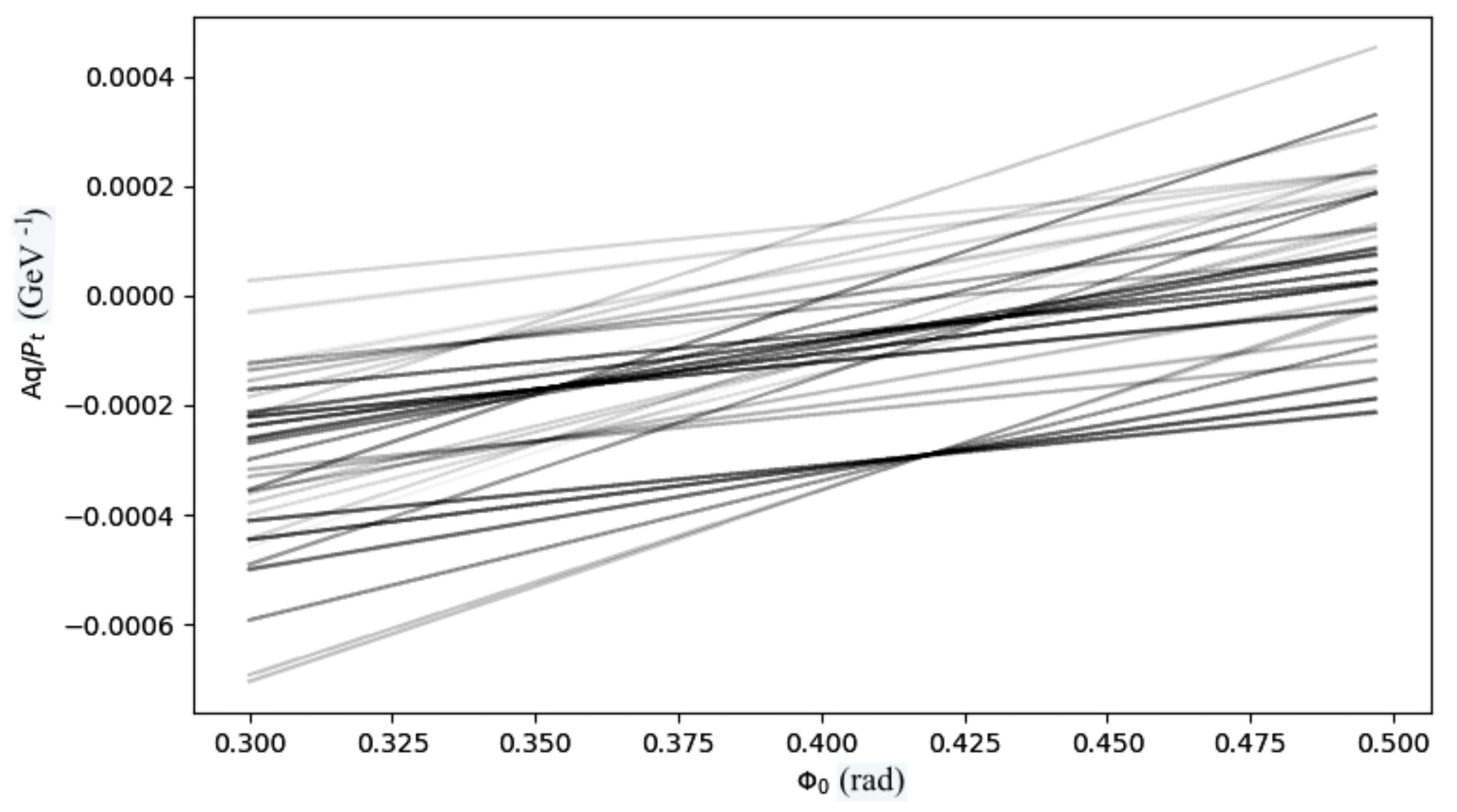
Figure 2 shows a reduced bin representation of all the tracks reconstructed using the HT Formula (
3) and the consequent HS space. The hardware block that holds the HS space is called
Accumulator, a 3D histogram binned horizontally along 1200
ϕ0 angles and vertically along 64
momenta. A physical
Event is represented by a pair (
ϕ0,
) nominated as candidate
Road, (
ϕ0,
)
. The
Accumulator is filled by applying the Hough Formula (
3) to the whole set of inputs
Hits (
r, ϕ) pairs from the physics experiment. In particular, each pair (
r, ϕ) defines a straight line in the
Accumulator, drawn along the bins, as shown in
Figure 2. The
Accumulator can be imagined like a set of individual
Towers.
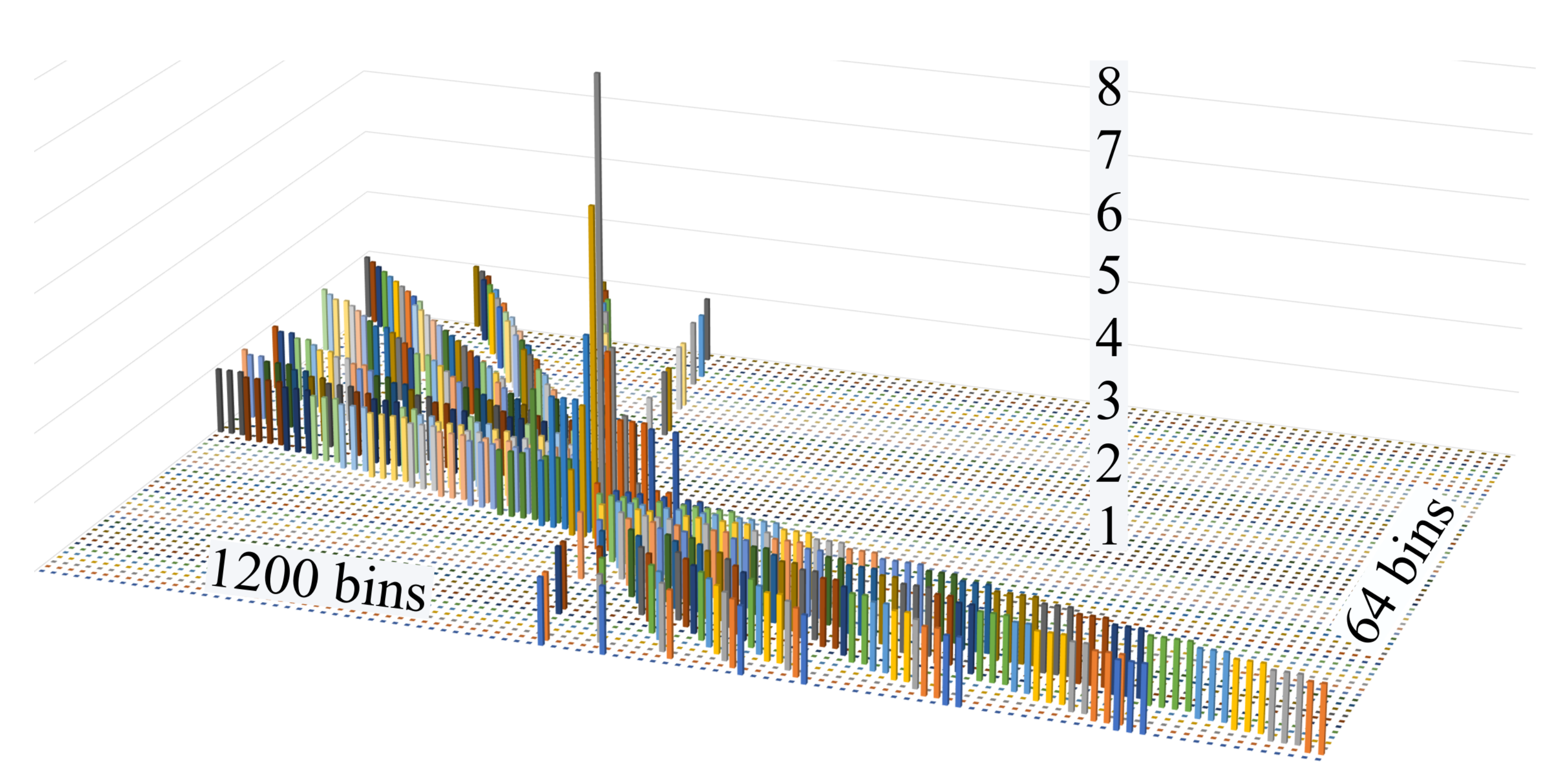
Figure 3 shows an example of a 3D picture of the
Accumulator filled up with many straight lines crossing in a (
ϕ0,
)
. In this example the
Road is the only
Tower 8 high.
Each Tower is composed of eight elements (indicized with n) that hold the information of whether that Tower has been touched at least by one line originated by the n-th input channel.
For example, if a
Hit belonging to the 5th input channel generates through the HT Formula (
3) a line crossing the
Accumulator and passing through the n-th row, m-th column, the
Tower identified at n-th row (representing one of the 64
) and the m-th column (representing one of the 1200
ϕ0) is updated with a “1” in its 5th floor. This is done for all the
Towers touched by that straight lines. This is shown in the
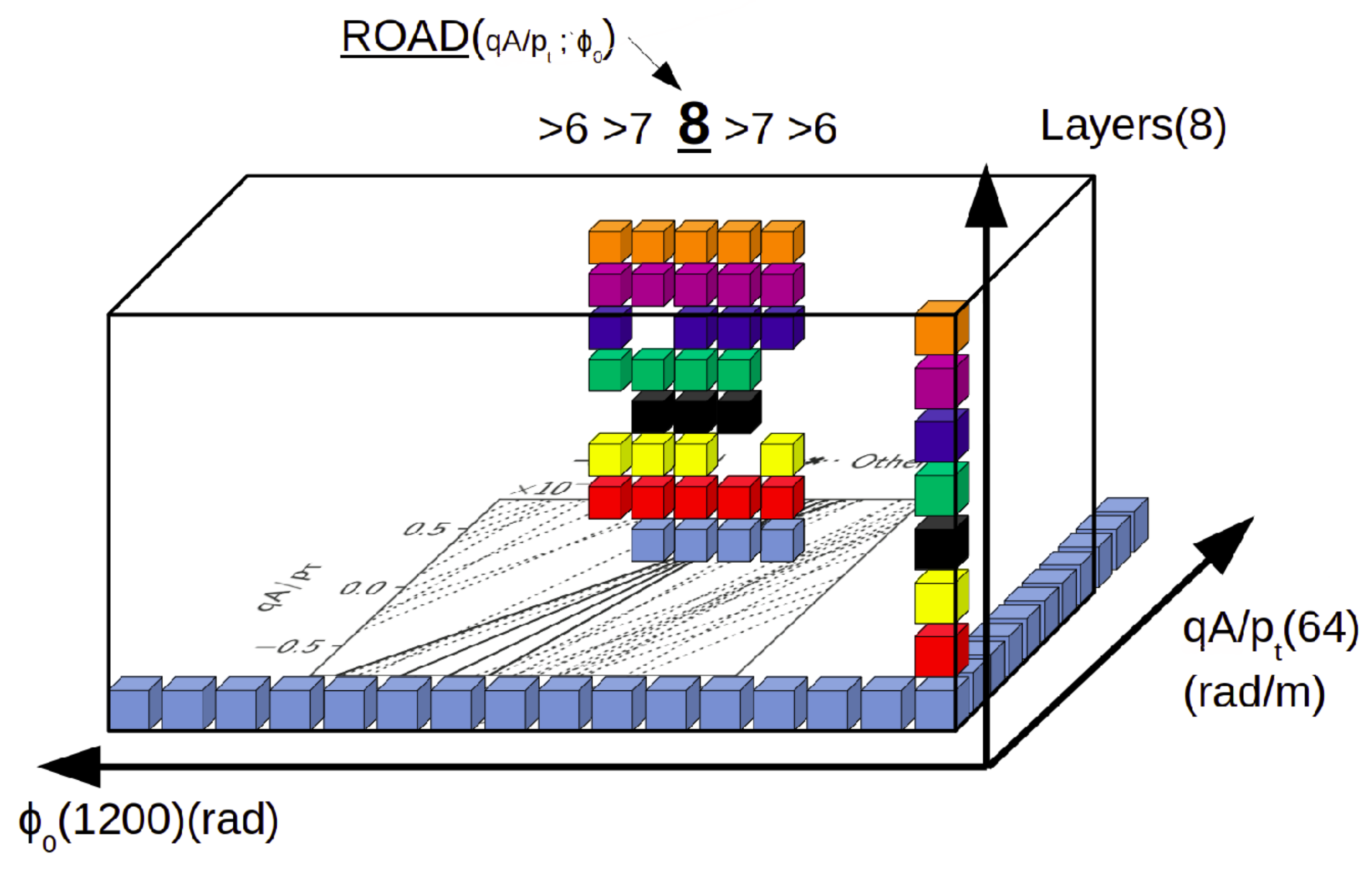
Figure 4 using colored cubes. Each colour, in fact, represents a layer/input channel (floor).
In the
Figure 4 the numbers 6, 7, 8, 7, 6 mean that, in this case, a
Road is detected when adjacent
Towers of the
Accumulator contribute with these numbers to the sequence of counts, hence there is a sequence of
Towers 6, 7, 8, 7, 6 high.
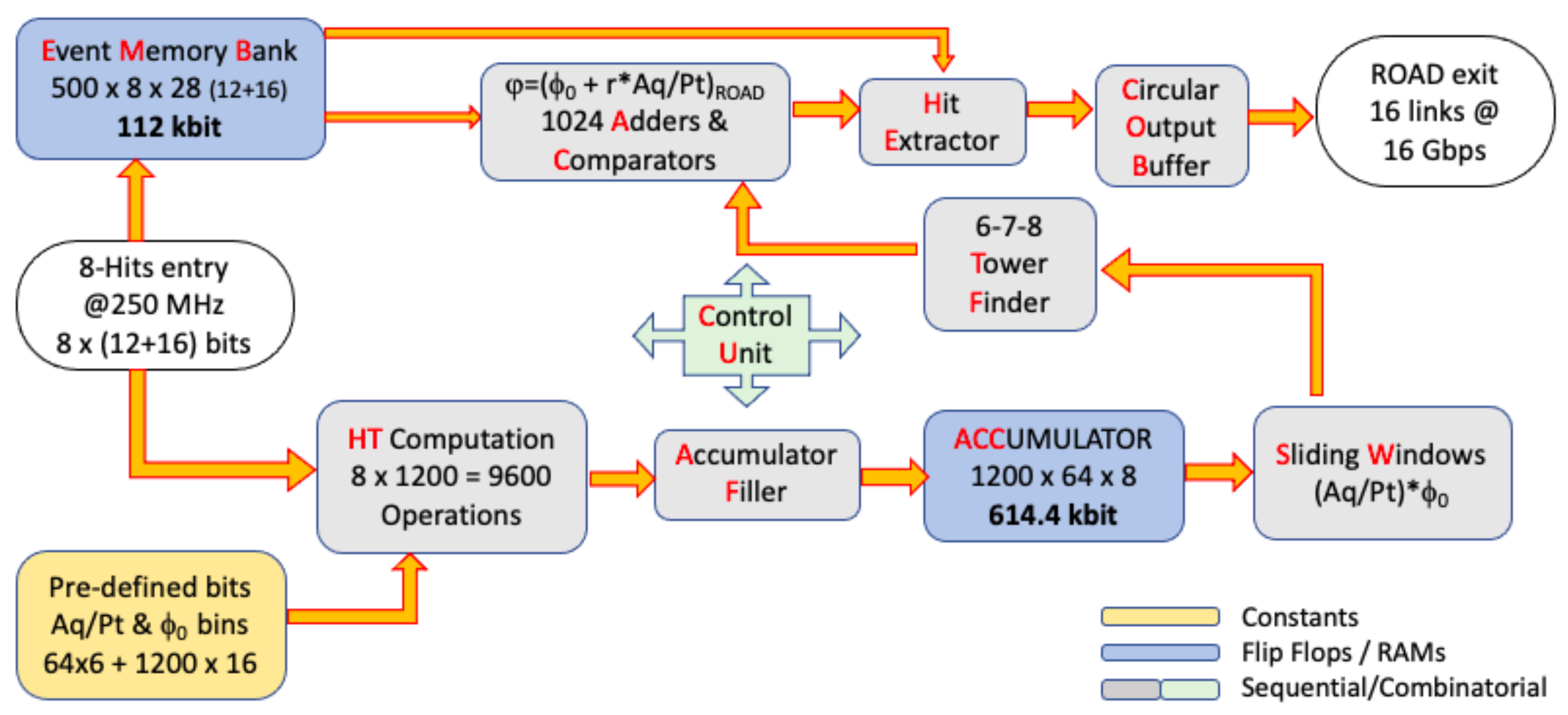
3. Block Diagram of the HT Implementation on FPGA
Figure 5 shows how the HT algorithm has been divided in logic blocks, as they have been separately designed following the firmware (FM) functional description. We did not design the inner blocks with a further nested structure, hence each block is here presented with a behavioural description only. We have used a low-level of abstraction approach for the FM development, so not using predefined vendor macro blocks and with no high-level synthesis [
10]. We wanted a FM description at the level of the individual components, simulating the VHDL code in steps. First, the behavioural code was simulated block by block to make sure the functionality of the system was correct. Then, after synthesizing and extracting the parasitics from the netlist we run post-synthesis simulations and, finally, the same approach was used to run post-layout simulations to include all the parasitics extracted after the layout was produced. The post-synthesis and post-layout simulations were used mainly to find the limits of operation of the entire circuits in terms of maximum clock frequency, input to output latency and area occupation on the FPGA. Moreover, we were able to tune the synthesis and layout steps to better optimize the critical nets and bottlenecks of the system.
Let us summarize briefly the scope of each block of the diagram, after the eight
Hits enter the system (see first left block in the
Figure 5). As a caption for the figure, the circuits based on flip-flops are blue blocks, yellow blocks refer to predefined constant valued that can be hardwired to logic “0” s and “1” s and can be modified with a new synthesis of the blocks. For some blocks the latency was a compromise between introducing digital pipelines [
11] to speed up the circuit and the need to reduce the area occupied in the FPGA layout.
The input data enter in parallel two blocks: The Event Memory Bank and the HT computation.
3.1. Event Memory Bank
This is a bank of Flip-Flops and internal RAM memories used to save the entire set of Hits that compose one Event. Its size is dimensioned depending on the number of input channels, Hits and on the number of bits used to represent the data.
3.2. HT Computation
This HT Computation circuit carries out the Formula (3) in parallel for the eight inputs and for the 1200 bins, performing 9600 operations every clock period. It generates all the points that compose all the 9600 straight lines. The FW for this circuit is synthesized in Look Up Tables (LUTs) as far as the additions/subtractions and in Digital Signal Processing (DSPs) for multiplications/divisions.
3.3. Accumulator Filler
This circuit updates the Accumulator, once all the points are calculated from the Formula (3) for all the inputs, by saving “1” s in the proper positions of the Towers. This is implemented with LUTs only.
3.4. Accumulator
This is a Flop-Flop based memory, composed of 8-element Towers accounting for the HS. The Accumulator size is defined by the (ϕ0,) bin numbers. For our study we have investigated the 1200 × 64 size because these have been found as largest numbers compatible with the resources of the FPGA. However, some smaller configurations have also been studied, for not launching too long processing times, and are shown in the next sections.
Accumulator Sectors
A strategy to reduce greatly the FPGA resource utilization is what we call
Sector method. To better share the available electronics components within the FPGA, the HT Formula (
3) is applied in parallel to two different types of data. In more detail,
r and
are fixed values while
ϕ0 increases linearly in steps. This can be expressed via the Formula:
being
=
, with n
and
is the constant width of the
0 bins. Here
is the angle of the first bin. In other words we calculate the
value for the first bin then we reitarate n times an addition of a constant value expressing the horizontal step
of the line. The
Accumulator is hence divided in
Sectors of equal ranges alongside
0. By applying this strategy we reduce the computational logic as we need only mathematical sums to carry out the multiplications
. This circuit is implemented using DSPs to calculate the division in the first bin, then all the other sectors are implemented using LUTs only, as these are carried out with additions. In any case all these computations are executed in parallel.
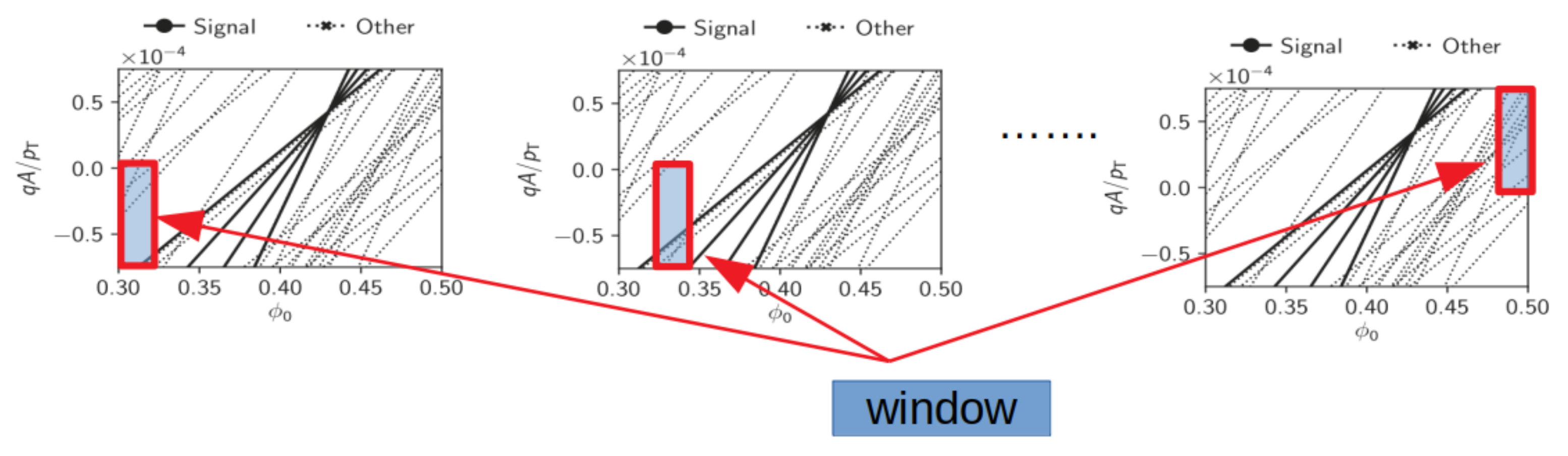
3.5. Sliding Windows
As the Accumulator becomes easily too big to be processed within one clock period, to identify all the candidate Roads, it is scanned in successive smaller windows, one at a time. Of course, the greater the number of the windows, the smaller the circuit at the expense of a longer latency. This circuit is synthesized using LUTs only.
3.6. Tower Finder
This circuits sets, for each Tower of the Accumulator, a couple of bits to identify if the number of “1” s in the Tower is lower than 6, 6, 7 or 8. Hence, the system is ready to start finding the Roads as candidate tracks. As described above, the sequence of 6, 7, 8, 7, 6 is the minimum set of heights, in adjacent Towers, representing a Roads candidate. This circuit is synthesized using LUTs only.
3.7. Adders and Comparators
This circuit compares the
Roads which have been found, in terms of
0,
)
coordinates, with all the (
r, ϕ) input compatible
Hts that were saved into the
Event Memory Bank. This compatibility is asserted by performing the HT Formula (
3), in a reverse manner. In fact this process, namely the
Backward Computation, carries out the mathematical expression:
In other terms we insert the 0 and the Hit numbers (r, ϕ) in the Formula (3), so we extract the value and compare it to the . This process is done in parallel for the entire Event composed of the 4000 Hits saved in the Event Memory Bank. This circuit is synthezized in DSPs for the divisions and LUTs for the additions.
3.8. Hit Extractor
This circuit, depending on the result of the
Backward Computation HT Formula (
5), hence depending on the difference (
)
−
has the capability to accept or reject the
Hit coordinates (
r, ϕ) as
Hit candidates for that
Road. This circuit is synthesized using LUTs only.
3.9. Circular Output Buffer
This simply put all the extracted
Hits, once have passed the previous selection, in a circular FIFO memory to be sent to output. This component is connected to a certain number of UltraScale+ GTH (16.3 Gb/s) transceivers [
12] of the FPGA, with a frequency targeted up to 250 MHz. The Aurora 64b/66b [
13] data encoding protocol has been chosen as standard protocol. This circuit is synthesized using First In Fisrt Out circuits (FIFOs), i.e., Flip-Flops.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}