
Piecewise Parabolic Approximate Computation Based on an Error-Flattened Segmenter and a Novel Quantizer

 , , , and
, , , and
Abstract
:1. Introduction
- The proposed method reduces the number of segments to the theoretical minimum value in any given precision to reduce the size of the LUTs, which has obvious advantages in reducing the area of applications that implement multiple functions simultaneously, such as SFU.
- The proposed arithmetic circuits can be implemented without a waste of hardware resources. With the help of an innovative quantizer, we quantize the coefficients to the minimum bit width, which can guarantee the precision up to 1 ulp.
- It is a calculation method with an absolutely controllable error. The exact bits of the result in hardware can be set in advance.
- The proposed method is applicable to all unary functions with finite codomain.
2. Basic Principles
2.1. Basis of Piecewise Parabola Approximation
2.2. Discretization
2.3. Metric for Error Evaluation
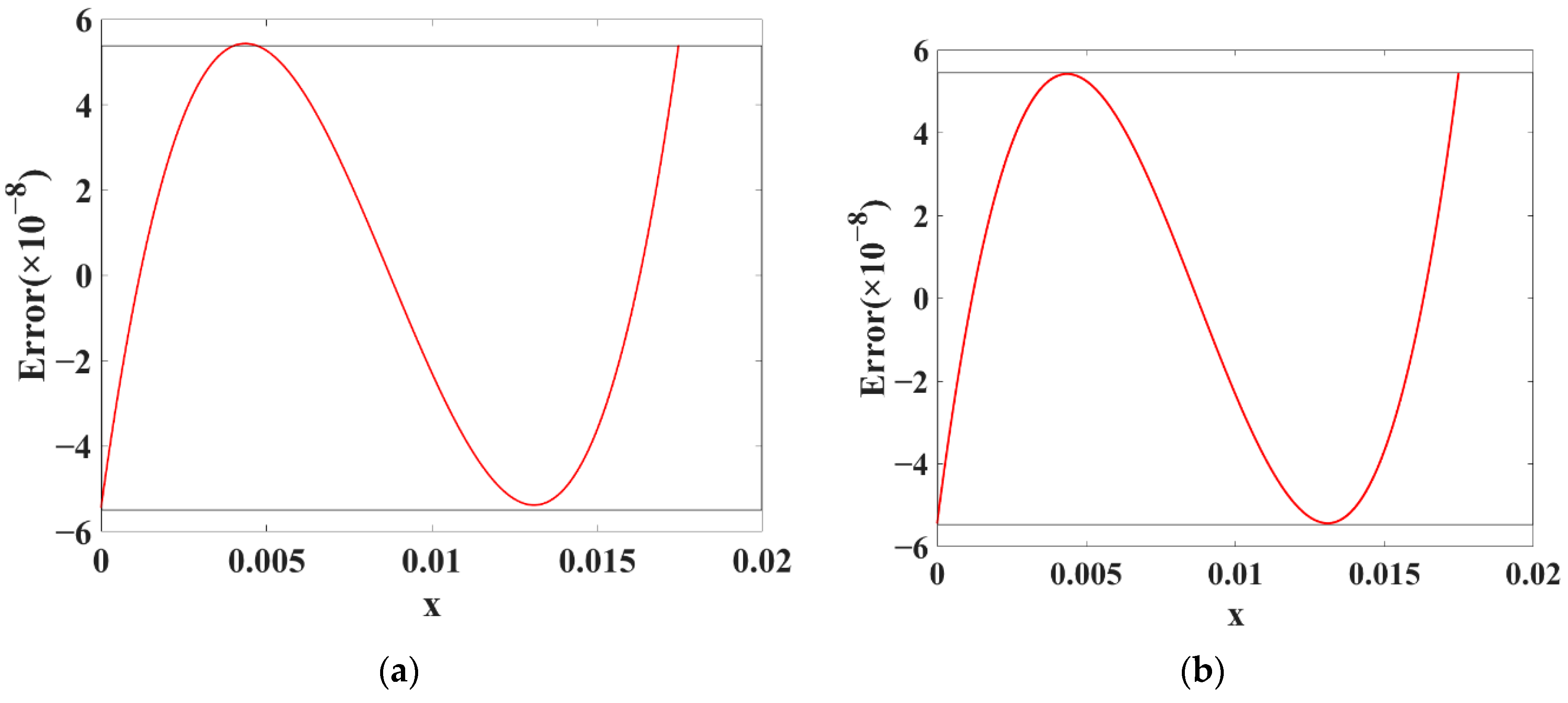
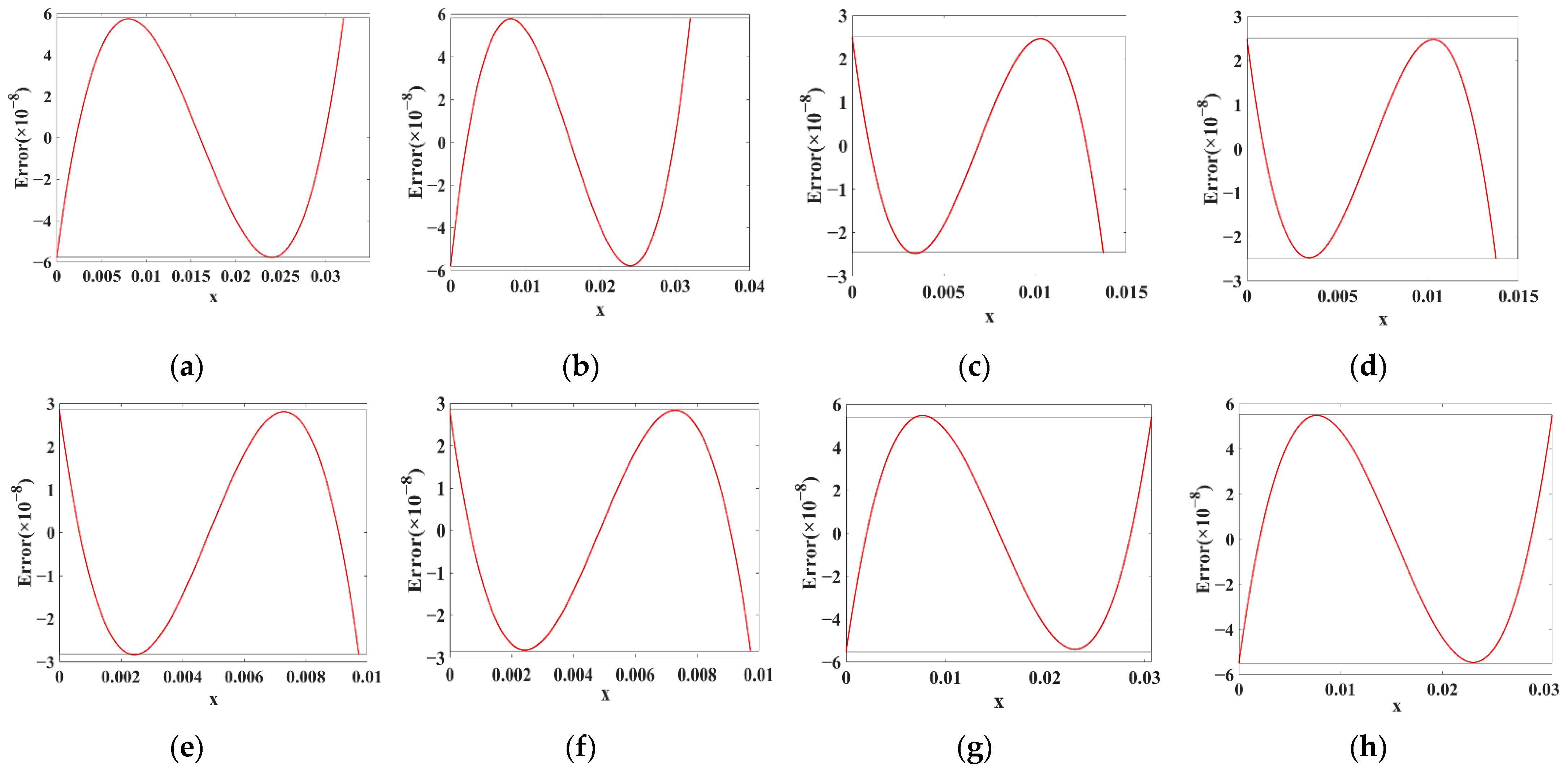
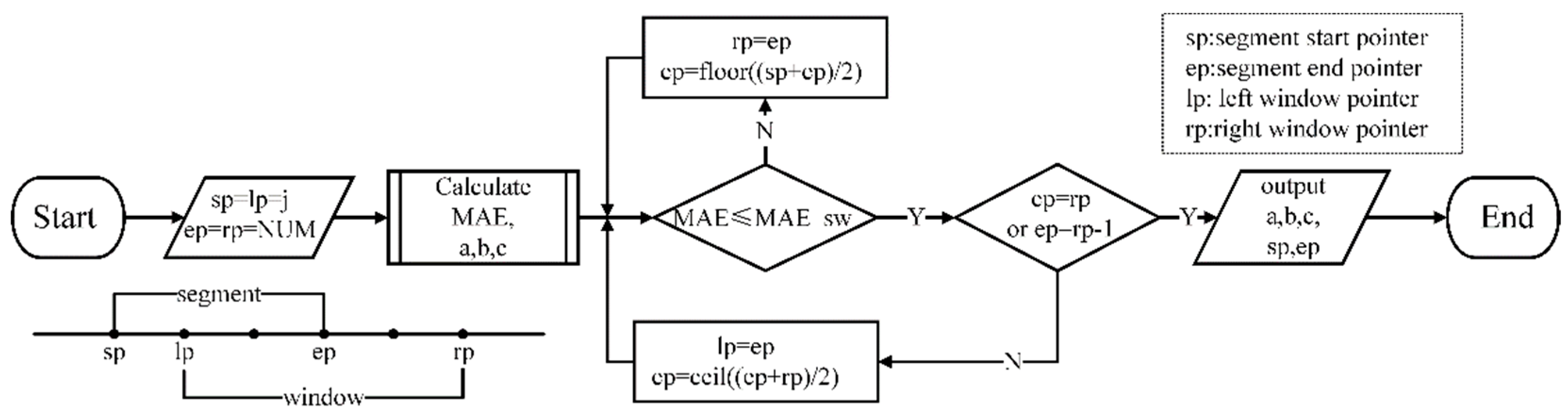
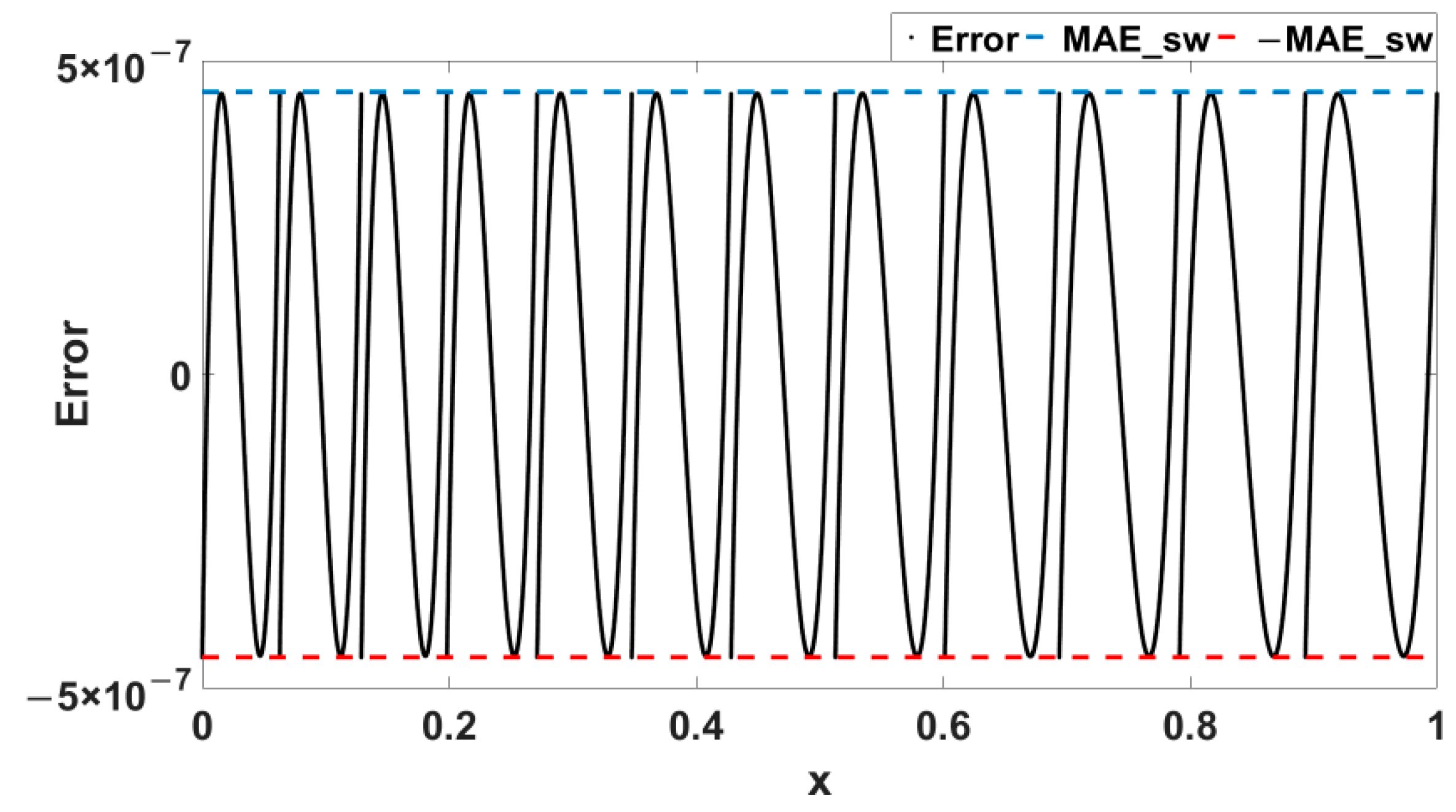
3. Error-Flattened Segmenter
3.1. Minimization of MAE
3.2. Minimization of the Segments Number with a Given Precision
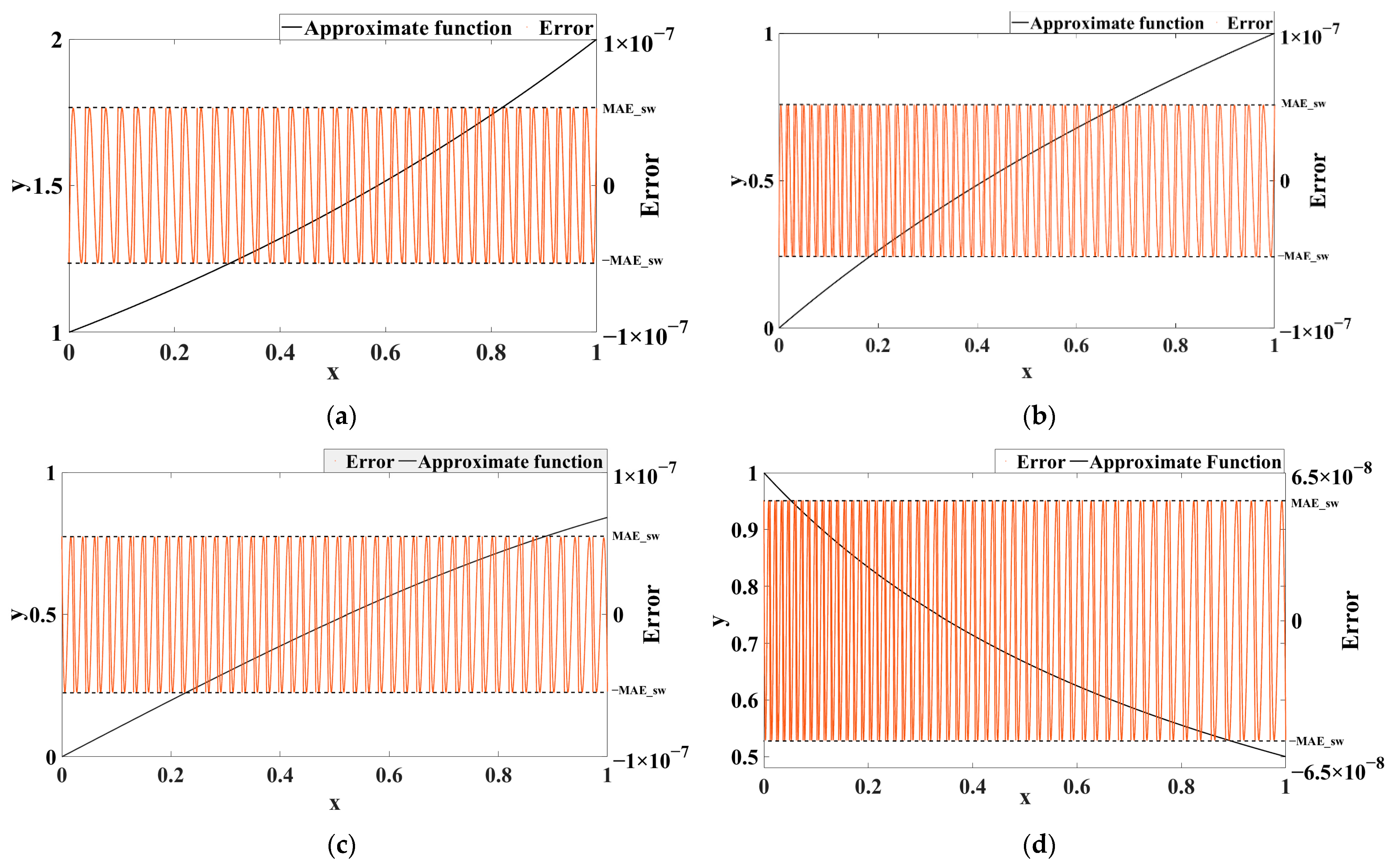
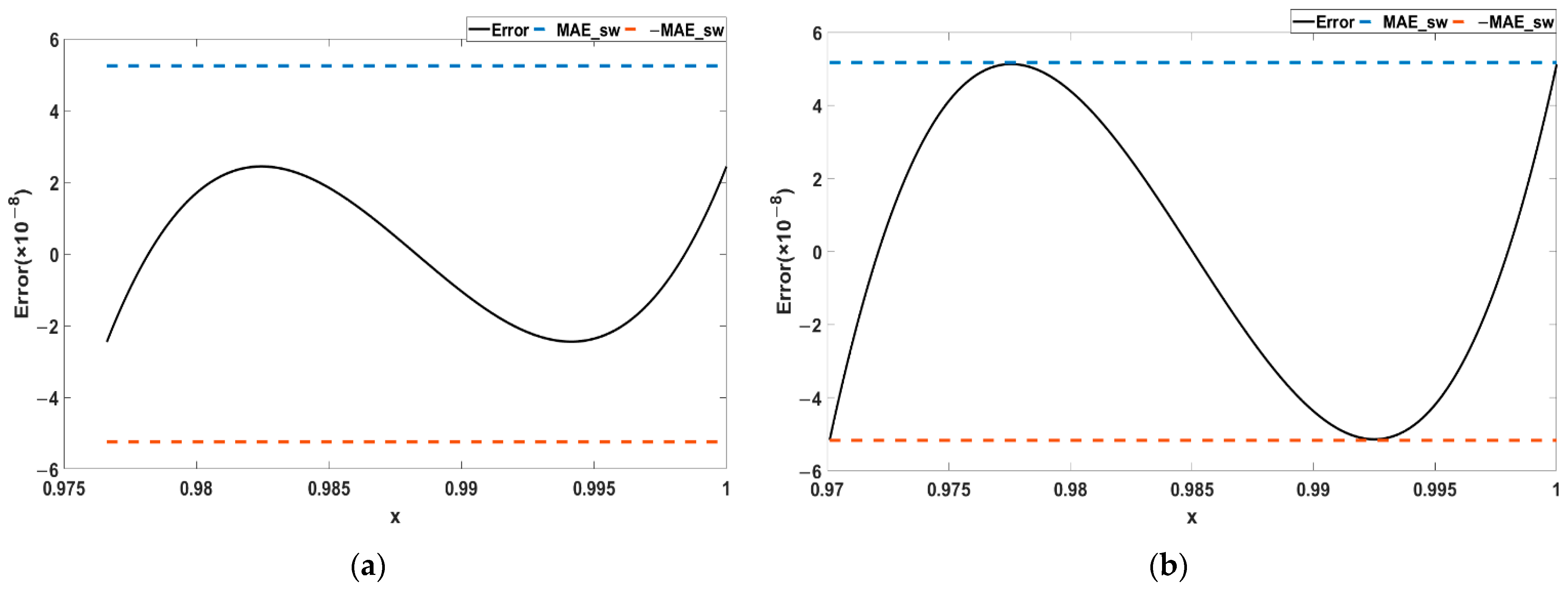
3.3. Test of Segmenter Performance
4. Hardware Architecture and Quantizer
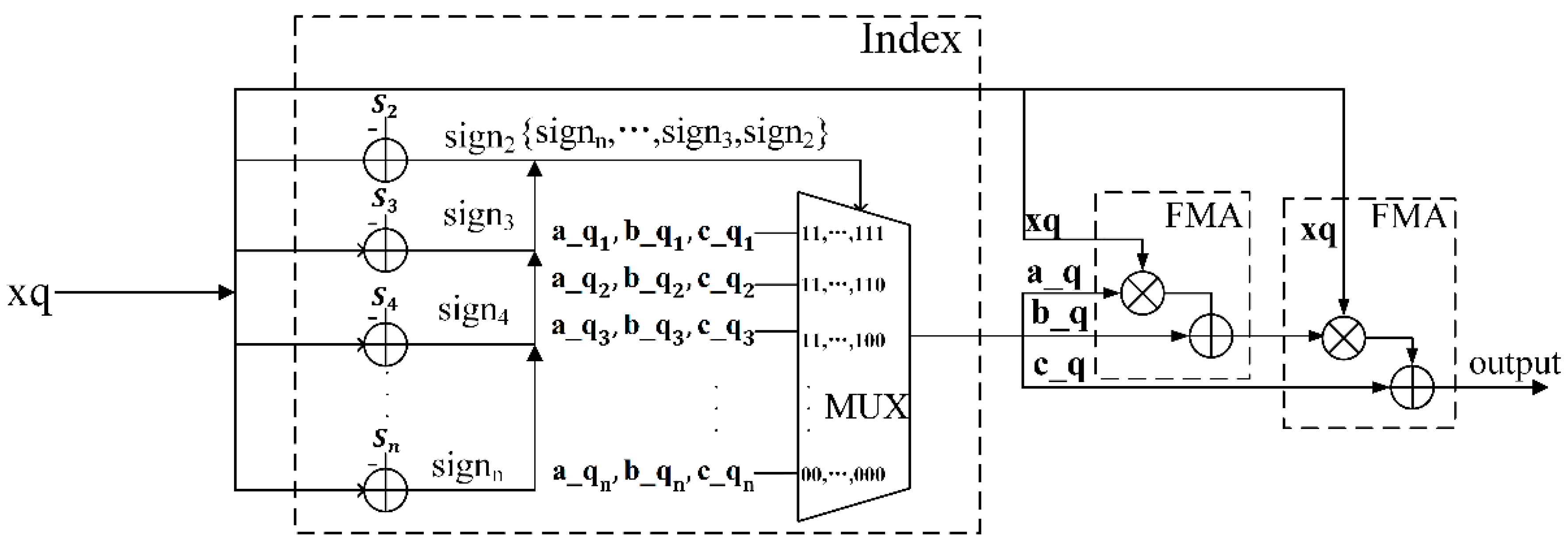
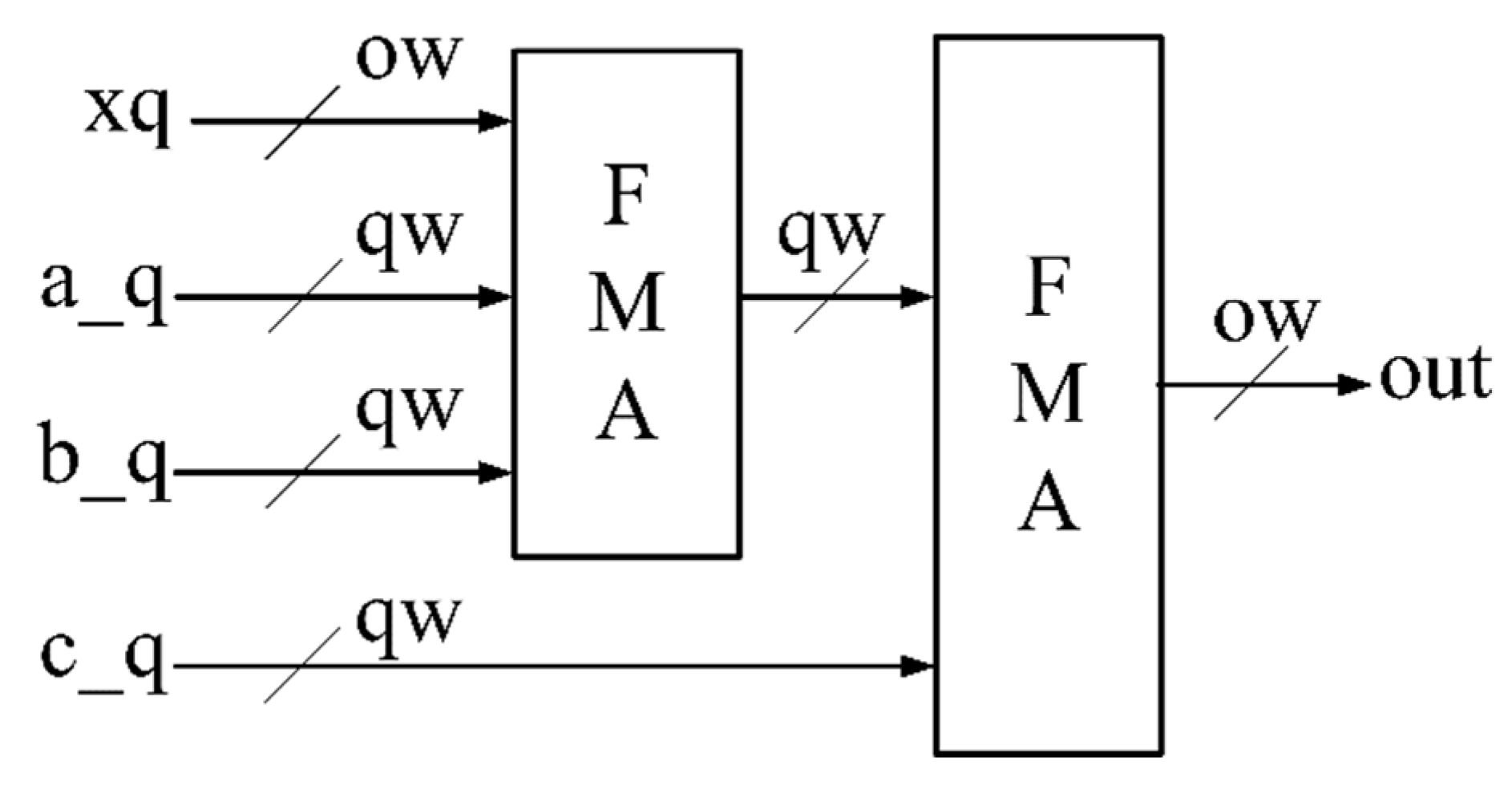
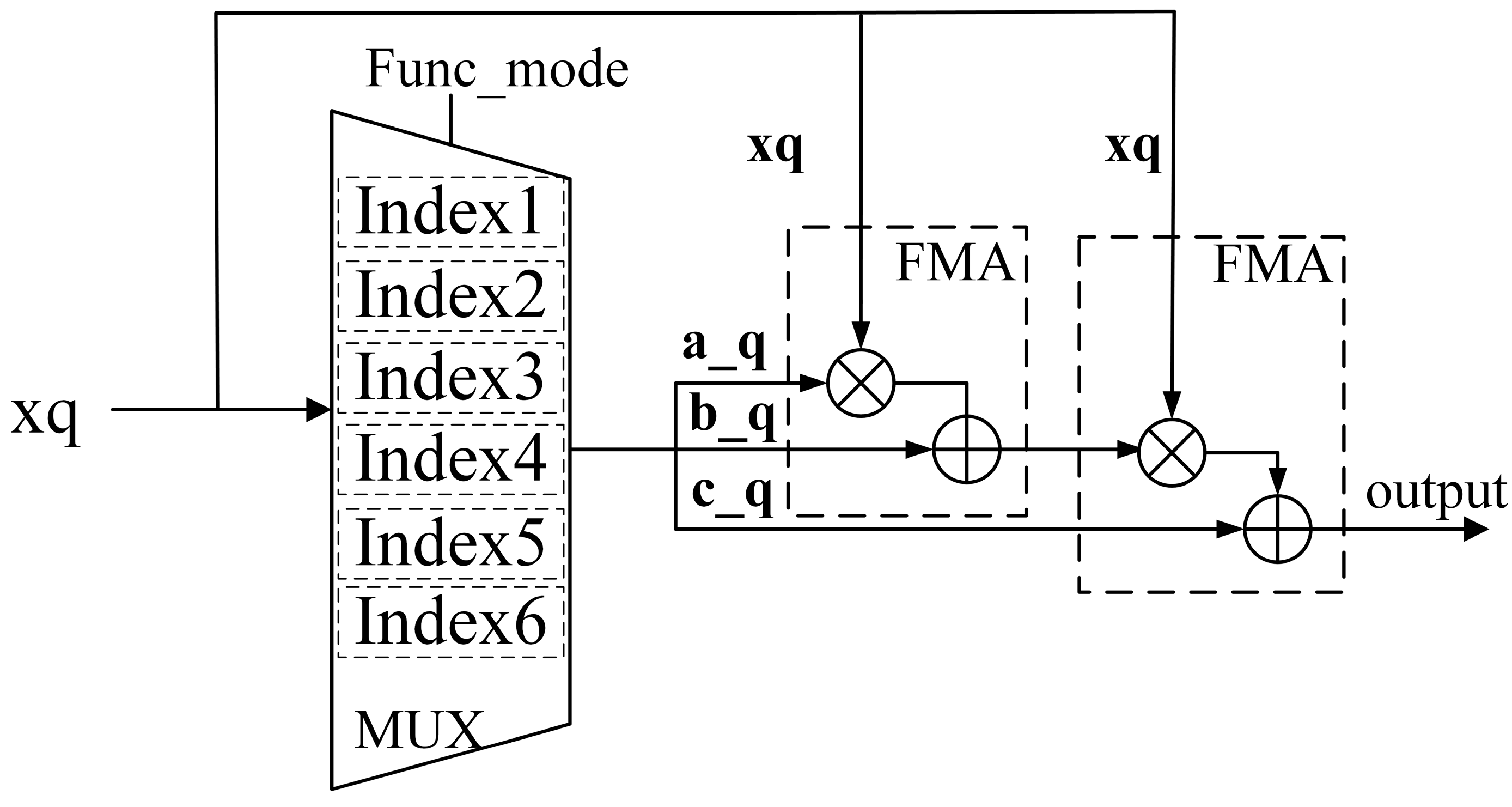
4.1. Hardware Architecture
4.2. A Novel Quantizer
| Algorithm 1: A novel quantizer | |
| Input Discretized input xq, | |
| benchmark f, | |
| fractional bit width of input and output ow, | |
| set of segment start pointers S = {S1, S2, S3,…, Sn}, | |
| set of segment end pointers E = {E1, E2, E3,…, En}, | |
| number of segments n, | |
| number of sample points for the objective function NUM; | |
| output Fractional bit width of coefficients and intermediate results qw, | |
| MAE in circuits MAE_C; | |
| Initialization | |
| 1: MAE_C = 2 ulp; | % initial MAE_C |
| 2: gw = −1; | % initial guard bit width |
| Begin | |
| 5: while (MAE_C > 1 ulp) | % fail to search guard bit |
| 6: gw = gw +1; | % update gw |
| 7: qw = ow + gw; | % update qw |
| 8: a_q = round (a × 2qw) × 2−qw; | % quantize a |
| 9: b_q = round (b × 2qw) × 2−qw; | % quantize b |
| 10: c_q = round (c × 2qw) × 2−qw; | % quantize c |
| 11: for i = 1:n do | |
| 12: R1_q(Si:Ei) = floor((a_q(i) × xq(Si:Ei) + b_q(i)) × 2qw) × 2−qw; | |
| 13: R(Si:Ei) = round((R1_q(Si:Ei) × xq(Si:Ei) + c_q(i)) × 2ow) × 2−ow | |
| % calculate result in circuits | |
| 17: end for | |
| 18: MAE_C = max(|f – R|); | % MAE in circuits |
| 19: end while | |
| end | |
5. Hardware Implementation and Comparison
5.1. Simulation on CPU
5.2. Comparison of LUT Size
5.3. Implementations and Comparisons in 90 nm CMOS
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Oberman, S.F.; Siu, M.Y. A high-performance area-efficient multifunction interpolator. In Proceedings of the 17th IEEE Symposium on Computer Arithmetic (ARITH’05), Cape Cod, MA, USA, 27–29 June 2005; pp. 272–279. [Google Scholar]
- Ng, S.W. A variable dimension Newton method. IEEE Int. Symp. Circuits Syst. 1994, 6, 129–132. [Google Scholar]
- Oberman, S.F. Floating point division and square root algorithms and implementation in the amd-k7TM microprocessor. In Proceedings of the IEEE Symposium on Computer Arithmetic (Cat. No.99CB36336), Adelaide, Australia, 14–16 April 1999; pp. 106–115. [Google Scholar]
- Volder, J.E. The CORDIC trigonometric computing technique. In Proceedings of the IRE Transactions on Electronic Computers; IEEE: New York, NY, USA, 1959; pp. 330–334. [Google Scholar]
- Luo, Y.; Wang, Y.; Ha, Y.; Wang, Z.; Chen, S.; Pan, H. Generalized hyperbolic CORDIC and its logarithmic and exponential computation with arbitrary fixed base. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 2156–2169. [Google Scholar] [CrossRef]
- Das Sarma, D.; Matula, D.W. Faithful bipartite ROM reciprocal tables. In Proceedings of the 12th Symposium on Computer Arithmetic, Bath, UK, 19–21 July 1995; pp. 17–28. [Google Scholar]
- Muller, J.-M. A few results on table-based methods. In Developments in Reliable Computing; Springer: Dordrecht, Germany, 1999; pp. 279–288. [Google Scholar]
- Sun, H.; Luo, Y.; Ha, Y.; Shi, Y.; Gao, Y.; Shen, Q.; Pan, H. A universal method of linear approximation with controllable error for the efficient implementation of transcendental functions. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 67, 177–188. [Google Scholar] [CrossRef]
- Dong, H.; Wang, M.; Luo, Y.; Zheng, M.; An, M.; Ha, Y.; Pan, H. PLAC: Piecewise linear approximation computation for all nonlinear unary functions. IEEE Trans. VLSI 2020, 28, 2014–2027. [Google Scholar] [CrossRef]
- Hsiao, S.; Ko, H.; Wen, C. Two-level hardware function evaluation based on correction of normalized piecewise difference functions. IEEE Trans. Circuits Syst. II Express Briefs 2012, 59, 292–296. [Google Scholar] [CrossRef]
- Strollo, A.G.M.; De Caro, D.; Petra, N. Elementary functions hardware implementation using constrained piecewise-polynomial approximations. IEEE Trans. Comput. 2011, 60, 418–432. [Google Scholar] [CrossRef]
- Lee, D.; Cheung, R.; Luk, W.; Villasenor, J. Hardware implementation trade-offs of polynomial approximations and interpolations. IEEE Trans. Comput. 2008, 57, 686–701. [Google Scholar] [CrossRef] [Green Version]
- Schulte, M.J.; Swartzlander, E.E. Hardware designs for exactly rounded elementary functions. IEEE Trans. Comput. 1994, 43, 964–973. [Google Scholar] [CrossRef]
- Muller, J.-M. Elementary functions. In Algorithms and Implementation, 3rd ed.; Springer: New York, NY, USA, 2016. [Google Scholar]
- Pineiro, J.; Oberman, S.F.; Muller, J.; Bruguera, J.D. High-speed function approximation using a minimax quadratic interpolator. IEEE Trans. Comput. 2005, 54, 304–318. [Google Scholar] [CrossRef] [Green Version]
- De Caro, D.; Napoli, E.; Esposito, D.; Castellano, G.; Petra, N.; Strollo, A.G.M. Minimizing coefficients wordlength for piecewisepolynomial hardware function evaluation with exact or faithful rounding. IEEE Trans. Circuits Syst. I Regul. Pap. 2017, 64, 1187–1200. [Google Scholar] [CrossRef]
- Ellaithy, D.M.; El-Moursy, M.A.; Zaki, A.; Zekry, A. Dual-channel multiplier for piecewise-polynomial function evaluation for low-power 3-D graphics. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 790–798. [Google Scholar] [CrossRef]
- Lee, D.; Cheung, R.C.C.; Luk, W.; Villasenor, J.D. Hierarchical segmentation for hardware function evaluation. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2009, 17, 103–116. [Google Scholar] [CrossRef] [Green Version]
- Lee, D.; Luk, W.; Villasenor, J.; Cheung, P.Y.K. Hierarchical segmentation schemes for function evaluation. In Proceedings of the IEEE International Conference on Field-Programmable Technology (FPT) (IEEE Cat. No.03EX798), Tokyo, Japan, 9–11 December 2003; pp. 92–99. [Google Scholar]
- Ge, L.; Chen, S.; Yoshimura, T. Automatic implementation of arithmetic functions in high-level synthesis. In Proceedings of the 9th International Conference on Solid-State and Integrated-Circuit Technology, Beijing, China, 20–23 October 2008; pp. 2349–2352. [Google Scholar]
- Sasao, T.; Nagayama, S.; Butler, J.T. Numerical function generators using LUT cascades. IEEE Trans. Comput. 2007, 56, 826–838. [Google Scholar] [CrossRef] [Green Version]
- Ko, H.; Hsiao, S.; Huang, W. A new non-uniform segmentation and addressing remapping strategy for hardware-oriented function evaluators based on polynomial approximation. In Proceedings of the IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; pp. 4153–4156. [Google Scholar]
- Hsiao, S.; Ko, H.; Tseng, Y.; Huang, W.; Lin, S.; Wen, C. Design of hardware function evaluators using low-overhead nonuniform segmentation with address remapping. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2013, 21, 875–886. [Google Scholar] [CrossRef]
- Cao, J.; Wei, B.W.Y. High-performance hardware for function generation. In Proceedings of the 13th IEEE Symposium on Computer Arithmetic, Asilomar, CA, USA, 6–9 July 1997; pp. 184–188. [Google Scholar]
- Kuang, S.; Wang, J.; Chang, K.; Hsu, H. Energy-efficient high throughput Montgomery modular multipliers for RSA cryptosystems. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2013, 21, 1999–2009. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, D.; Ko, S. Efficient multiple-precision floating point fused multiply-add with mixed-precision support. IEEE Trans. Comput. 2019, 68, 1035–1048. [Google Scholar] [CrossRef]
- Walters, E.G.; Schulte, M.J. Efficient function approximation using truncated multipliers and squarers. In Proceedings of the 17th IEEE Symp. Computer Arithmetic (ARITH’05), Cape Cod, MA, USA, 27–29 June 2005; pp. 232–239. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function | Function | ||
|---|---|---|---|
| 0.01 | sin(1 + x) | 0 | |
| −0.02 | cos(1 + x) | 0 | |
| −0.02 | −0.01 | ||
| −0.02 | 0 | ||
| ln(1 + x) | −0.02 | −0.01 |
| Function | Number of Segments | q | LUT(bit) | |
|---|---|---|---|---|
| 0.493 | 42 | 31 | 3096 | |
| 0.459 | 43 | 28 | 3612 | |
| 0.428 | 44 | 28 | 3696 | |
| 0.401 | 45 | 28 | 3780 | |
| 0.375 | 46 | 27 | 3726 |
| Function | Accuracy | Segmenter CPU Time(s) | Quantizer CPU Times(s) |
|---|---|---|---|
| 0.02 | 0.03 | ||
| 8.28 | 3.64 | ||
| 52.41 | 18.97 | ||
| 318.58 | 92.00 | ||
| 0.02 | 0.03 | ||
| 8.44 | 6.68 | ||
| 48.85 | 31.68 | ||
| 275.01 | 126.20 | ||
| y = In(1 + ex) | 0.02 | 0.03 | |
| 4.50 | 5.01 | ||
| 23.47 | 19.75 | ||
| 127.18 | 66.56 |
| Function | Accuracy | Method | Number of Segments | c bit | b bit | a bit | LUT Size(bit) | Normal of LUT Size |
|---|---|---|---|---|---|---|---|---|
| Uniform [15] | 16 | 22 | 20 | 18 | 960 | 1.56 | ||
| Non-uniform [22] | 13 | 22 | 20 | 18 | 780 | 1.27 | ||
| This paper | 11 | 17 | 19 | 20 | 616 | 1 | ||
| Uniform [15] | 128 | 30 | 25 | 20 | 9600 | 1.75 | ||
| Non-uniform [22] | 91 | 30 | 25 | 20 | 6825 | 1.25 | ||
| This paper | 66 | 26 | 28 | 29 | 5478 | 1 | ||
| Uniform [15] | 16 | 22 | 21 | 18 | 976 | 1.84 | ||
| ILP [16] | 16 | 19 | 9 | 10 | 608 | 1.15 | ||
| Non-uniform [22] | 13 | 22 | 21 | 18 | 739 | 1.39 | ||
| This paper | 9 | 18 | 20 | 21 | 531 | 1 | ||
| Uniform [15] | 128 | 30 | 26 | 20 | 9728 | 2.06 | ||
| ILP [16] | 128 | 26 | 15 | 10 | 6556 | 1.39 | ||
| Non-uniform [22] | 80 | 30 | 26 | 20 | 6080 | 1.29 | ||
| This paper | 57 | 26 | 28 | 29 | 4731 | 1 | ||
| Uniform [15] | 16 | 24 | 18 | 17 | 944 | 2.27 | ||
| Non-uniform [22] | 15 | 24 | 18 | 17 | 885 | 2.13 | ||
| This paper | 8 | 16 | 19 | 17 | 416 | 1 | ||
| Uniform [15] | 64 | 32 | 23 | 15 | 4480 | 1.17 | ||
| Non-uniform [22] | 64 | 32 | 23 | 15 | 4480 | 1.17 | ||
| This paper | 46 | 26 | 29 | 28 | 3818 | 1 | ||
| Uniform [15] | 8 | 20 | 17 | 13 | 400 | 1.33 | ||
| Non-uniform [22] | 8 | 20 | 17 | 13 | 400 | 1.33 | ||
| This paper | 6 | 15 | 18 | 17 | 300 | 1 | ||
| Uniform [15] | 64 | 31 | 23 | 18 | 4608 | 1.60 | ||
| Non-uniform [22] | 64 | 31 | 23 | 18 | 4608 | 1.60 | ||
| This paper | 38 | 24 | 26 | 26 | 2888 | 1 |
| Function | Accuracy | Method | LUT Size (bit) | Normal of LUT Size |
|---|---|---|---|---|
| [12] | 1664 | 1.60 | ||
| [16] | 1312 | 1.26 | ||
| This paper | 1040 | 1 | ||
| [12] | 7808 | 1.85 | ||
| [16] | 6912 | 1.64 | ||
| This paper | 4212 | 1 | ||
| [11] | 528 | 1.18 | ||
| [16] | 560 | 1.25 | ||
| [27] | 672 | 1.50 | ||
| This paper | 448 | 1 | ||
| [11] | 2432 | 1.64 | ||
| [16] | 1696 | 1.15 | ||
| [27] | 2880 | 1.95 | ||
| This paper | 1480 | 1 | ||
| [11] | 6144 | 1.48 | ||
| [16] | 6656 | 1.60 | ||
| [27] | 7040 | 1.69 | ||
| This paper | 4160 | 1 |
| Function | Method | LUT & Address Generation Area | Normal Area | Delay [ns] | Normal Delay | Area × Delay | |
|---|---|---|---|---|---|---|---|
| Cheyshev [10,13] | 7228 | 28,886 | 1.53 | 9.28 | 1.39 | 268,062 | |
| Minimax [10,15] | 6945 | 28,428 | 1.50 | 9.71 | 1.46 | 276,036 | |
| Two-level [10] | 5595 | 24,023 | 1.27 | 12.69 | 1.91 | 304,852 | |
| ILP [16] | 5325 1 | 21,560 | 1.14 | 6.36 | 0.95 | 137,122 | |
| This paper | 2804 | 18,908 | 1 | 6.66 | 1 | 125,927 | |
| Cheyshev [10,13] | 4270 | 29,063 | 1.62 | 9.79 | 1.48 | 284,527 | |
| Minimax [10,15] | 3880 | 26,635 | 1.49 | 9.8 | 1.48 | 261,023 | |
| Two-level [10] | 5452 | 18,913 | 1.06 | 12.16 | 1.84 | 229,982 | |
| ILP [16] | 2273 1 | 18,963 | 1.06 | 5.79 | 0.88 | 109,796 | |
| This paper | 2159 | 17,905 | 1 | 6.60 | 1 | 118,173 | |
| Cheyshev [10,13] | 6859 | 28,177 | 1.46 | 9.75 | 1.46 | 274,726 | |
| Minimax [10,15] | 6712 | 27,855 | 1.44 | 9.71 | 1.45 | 270,472 | |
| Two-level [10] | 5564 | 24,137 | 1.25 | 12.63 | 1.89 | 304,850 | |
| ILP [16] | 5377 1 | 22,243 | 1.15 | 6.92 | 1.03 | 153,922 | |
| This paper | 3063 | 19,310 | 1 | 6.69 | 1 | 129,184 | |
| Cheyshev [10,13] | 10,230 | 31,700 | 2.00 | 9.36 | 1.38 | 296,712 | |
| Minimax [10,15] | 3627 | 26,036 | 1.64 | 9.8 | 1.45 | 255,153 | |
| Two-level [10] | 4437 | 16,043 | 1.01 | 12.03 | 1.77 | 192,997 | |
| ILP [16] | 4072 1 | 17,618 | 1.11 | 6.35 | 0.94 | 111,874 | |
| This paper | 1456 | 15,888 | 1 | 6.78 | 1 | 107,721 | |
| Cheyshev [10,13] | 18,453 | 39,737 | 2.29 | 9.45 | 1.50 | 375,515 | |
| Minimax [10,15] | 6535 | 29,678 | 1.71 | 9.71 | 1.54 | 288,173 | |
| Two-level [10] | 5388 | 22,317 | 1.29 | 12.83 | 2.03 | 286,327 | |
| ILP [16] | 63151 | 18,460 | 1.07 | 6.89 | 1.09 | 127,189 | |
| This paper | 2254 | 17,332 | 1 | 6.31 | 1 | 109,365 | |
| Cheyshev [10,13] | 4015 | 28,144 | 1.48 | 9.52 | 1.42 | 267,931 | |
| Minimax [10,15] | 3795 | 26,400 | 1.39 | 9.67 | 1.44 | 255,288 | |
| Two-level [10] | 5496 | 22,890 | 1.21 | 13.08 | 1.95 | 299,401 | |
| ILP [16] | 2684 1 | 18,743 | 0.99 | 6.28 | 0.94 | 117,706 | |
| This paper | 2566 | 18,993 | 1 | 6.71 | 1 | 127,443 | |
| Multi-function | Cheyshev [10,13] | 51,052 | 77,864 | 2.42 | 11.50 | 1.55 | 895,436 |
| Minimax [10,15] | 31,496 | 56,224 | 1.75 | 11.22 | 1.51 | 630,833 | |
| Two-level [10] | 16,211 | 49,548 | 1.54 | 15.07 | 2.03 | 746,688 | |
| ILP [16] | 26,546 1 | 43,668 1 | 1.36 1 | 8.03 1 | 1.08 1 | 350,654 1 | |
| This paper | 13,757 | 32,182 | 1 | 7.41 | 1 | 238,469 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
An, M.; Luo, Y.; Zheng, M.; Wang, Y.; Dong, H.; Wang, Z.; Peng, C.; Pan, H. Piecewise Parabolic Approximate Computation Based on an Error-Flattened Segmenter and a Novel Quantizer. Electronics 2021, 10, 2704. https://doi.org/10.3390/electronics10212704
An M, Luo Y, Zheng M, Wang Y, Dong H, Wang Z, Peng C, Pan H. Piecewise Parabolic Approximate Computation Based on an Error-Flattened Segmenter and a Novel Quantizer. Electronics. 2021; 10(21):2704. https://doi.org/10.3390/electronics10212704
Chicago/Turabian StyleAn, Mengyu, Yuanyong Luo, Muhan Zheng, Yuxuan Wang, Hongxi Dong, Zhongfeng Wang, Chenglei Peng, and Hongbing Pan. 2021. "Piecewise Parabolic Approximate Computation Based on an Error-Flattened Segmenter and a Novel Quantizer" Electronics 10, no. 21: 2704. https://doi.org/10.3390/electronics10212704
APA StyleAn, M., Luo, Y., Zheng, M., Wang, Y., Dong, H., Wang, Z., Peng, C., & Pan, H. (2021). Piecewise Parabolic Approximate Computation Based on an Error-Flattened Segmenter and a Novel Quantizer. Electronics, 10(21), 2704. https://doi.org/10.3390/electronics10212704