
Enhanced Millimeter-Wave 3-D Imaging via Complex-Valued Fully Convolutional Neural Network

 , , , ,
, , , ,
Abstract
:1. Introduction
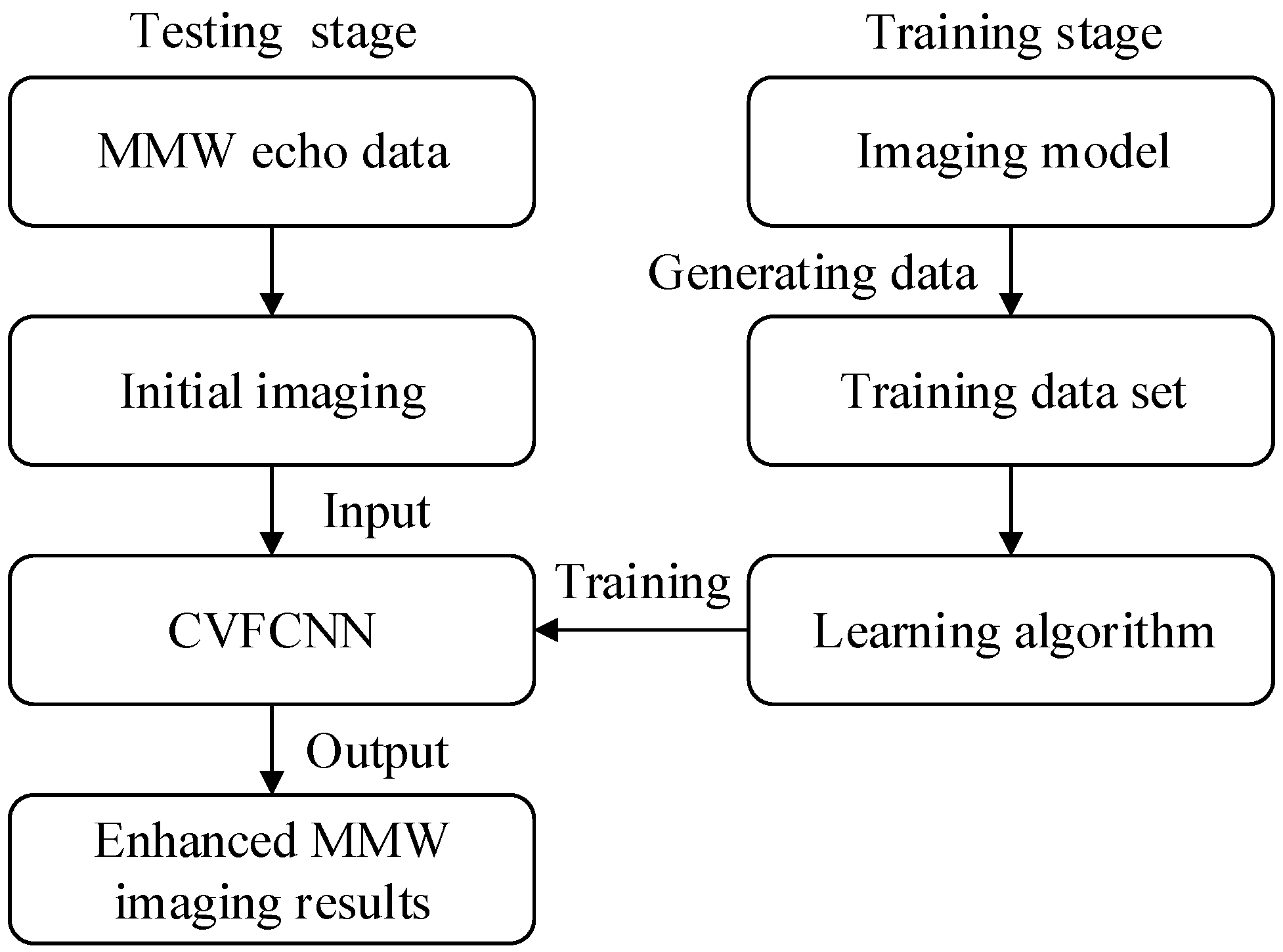
2. Enhanced MMW 3-D Imaging Using CVFCNN
2.1. Framework of Enhanced MMW Imaging via CVFCNN
2.2. Training Process
2.3. Parameter Initialization
3. Results
3.1. Numerical Simulations
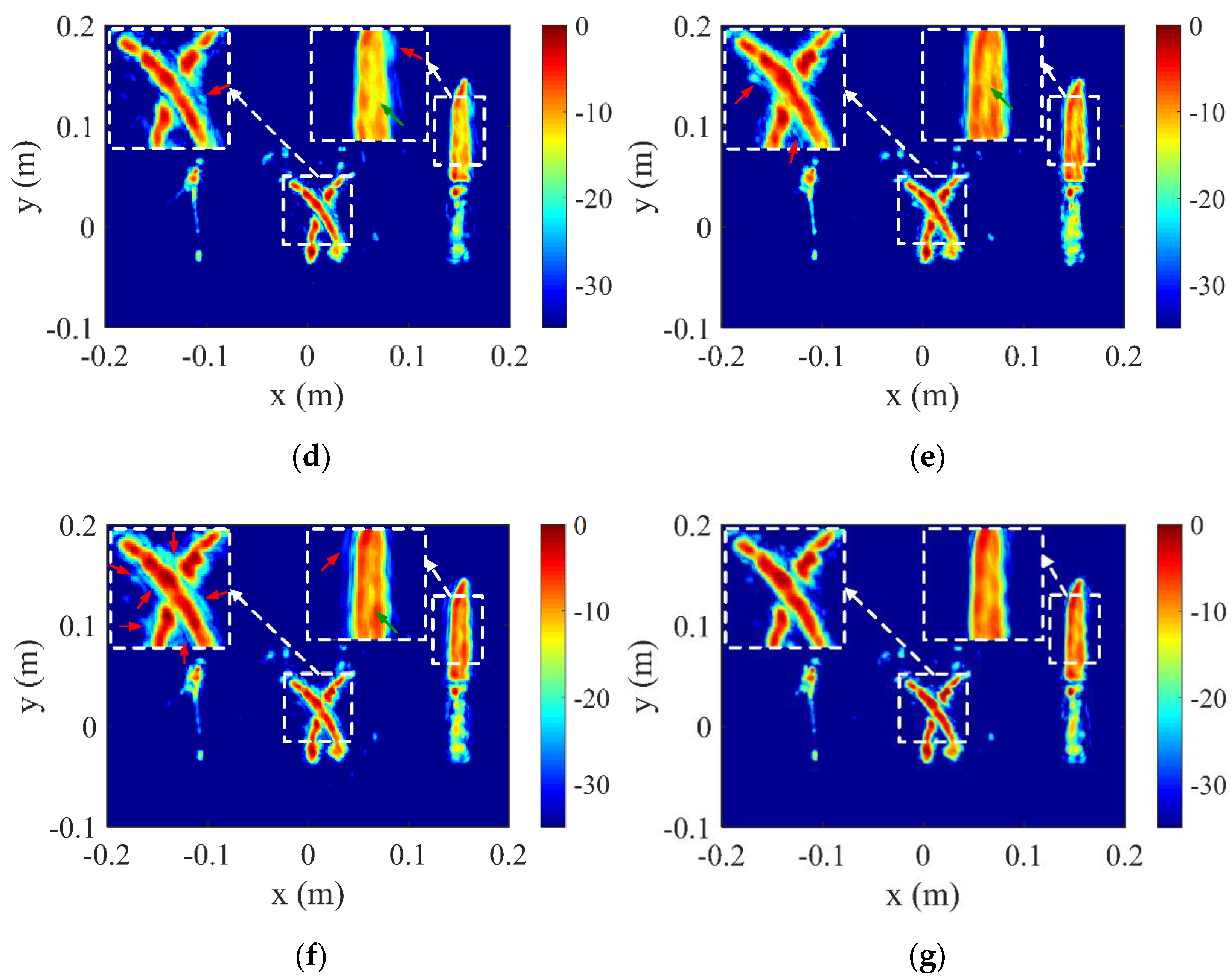
3.2. Results of the Measured Data
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Casalini, E.; Frioud, M.; Small, D.; Henke, D. Refocusing FMCW SAR Moving Target Data in the Wavenumber Domain. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3436–3449. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, H.; Dai, S.; Sun, Z. Azimuth Multichannel GMTI Based on Ka-Band DBF-SCORE SAR System. IEEE Geosci. Remote Sens. Lett. 2018, 15, 419–423. [Google Scholar] [CrossRef]
- Amin, M. Radar for Indoor Monitoring: Detection, Classification, and Assessment; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Sheen, D.; McMakin, D.; Hall, T. Near-Field Three-Dimensional Radar Imaging Techniques and Applications. Appl. Opt. 2010, 49, 83–93. [Google Scholar] [CrossRef] [PubMed]
- Sheen, D.M.; McMakin, D.L.; Hall, T.E. Three-Dimensional Millimeter-Wave Imaging for Concealed Weapon Detection. IEEE Trans. Microw. Theory Tech. 2001, 49, 1581–1592. [Google Scholar] [CrossRef]
- Oliveri, G.; Salucci, M.; Anselmi, N.; Massa, A. Compressive Sensing as Applied to Inverse Problems for Imaging: Theory, Applications, Current Trends, and Open Challenges. IEEE Antennas Propag. Mag. 2017, 59, 34–46. [Google Scholar] [CrossRef]
- Rani, M.; Dhok, S.B.; Deshmukh, R.B. A Systematic Review of Compressive Sensing: Concepts, Implementations and Applications. IEEE Access 2018, 6, 4875–4894. [Google Scholar] [CrossRef]
- Upadhyaya, V.; Salim, D.M. Compressive Sensing: Methods, Techniques, and Applications. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1099, 012012. [Google Scholar] [CrossRef]
- Seyfioglu, M.S.; Erol, B.; Gurbuz, S.Z.; Amin, M.G. DNN Transfer Learning from Diversified Micro-Doppler for Motion Classification. IEEE Trans. Aerosp. Electron. Syst. 2019, 55, 2164–2180. [Google Scholar] [CrossRef] [Green Version]
- Erol, B.; Gurbuz, S.Z.; Amin, M.G. Motion Classification Using Kinematically Sifted ACGAN-Synthesized Radar Micro-Doppler Signatures. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 3197–3213. [Google Scholar] [CrossRef] [Green Version]
- Skaria, S.; Al-Hourani, A.; Lech, M.; Evans, R.J. Hand-Gesture Recognition Using Two-Antenna Doppler Radar with Deep Convolutional Neural Networks. IEEE Sens. J. 2019, 19, 3041–3048. [Google Scholar] [CrossRef]
- Chen, Z.; Li, G.; Fioranelli, F.; Griffiths, H. Dynamic Hand Gesture Classification Based on Multistatic Radar Micro-Doppler Signatures Using Convolutional Neural Network. In Proceedings of the 2019 IEEE Radar Conference (RadarConf), Boston, MA, USA, 22–26 April 2019; pp. 1–5. [Google Scholar]
- Qin, D.; Liu, D.; Gao, X.; Jingkun, G. ISAR Resolution Enhancement Using Residual Network. In Proceedings of the 2019 IEEE 4th International Conference on Signal and Image Processing (ICSIP), Wuxi, China, 19–21 July 2019; pp. 788–792. [Google Scholar]
- Gao, X.; Qin, D.; Gao, J. Resolution Enhancement for Inverse Synthetic Aperture Radar Images Using a Deep Residual Network. Microw. Opt. Technol. Lett. 2020, 62, 1588–1593. [Google Scholar] [CrossRef]
- Hu, C.; Wang, L.; Li, Z.; Zhu, D. Inverse Synthetic Aperture Radar Imaging Using a Fully Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1203–1207. [Google Scholar] [CrossRef]
- Yang, T.; Shi, H.; Lang, M.; Guo, J. ISAR Imaging Enhancement: Exploiting Deep Convolutional Neural Network for Signal Reconstruction. Int. J. Remote Sens. 2020, 41, 9447–9468. [Google Scholar] [CrossRef]
- Cheng, Q.; Ihalage, A.A.; Liu, Y.; Hao, Y. Compressive Sensing Radar Imaging With Convolutional Neural Networks. IEEE Access 2020, 8, 212917–212926. [Google Scholar] [CrossRef]
- Mu, H.; Zhang, Y.; Ding, C.; Jiang, Y.; Er, M.H.; Kot, A.C. DeepImaging: A Ground Moving Target Imaging Based on CNN for SAR-GMTI System. IEEE Geosci. Remote Sens. Lett. 2021, 18, 117–121. [Google Scholar] [CrossRef]
- Pu, W. Shuffle GAN with Autoencoder: A Deep Learning Approach to Separate Moving and Stationary Targets in SAR Imagery. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Ding, J.; Wen, L.; Zhong, C.; Loffeld, O. Video SAR Moving Target Indication Using Deep Neural Network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7194–7204. [Google Scholar] [CrossRef]
- Fang, S.; Nirjon, S. SuperRF: Enhanced 3D RF Representation Using Stationary Low-Cost MmWave Radar. In Proceedings of the International Conference on Embedded Wireless Systems and Networks (EWSN), Lyon, France, 17–19 February 2020; Volume 2020, pp. 120–131. [Google Scholar]
- Sun, Y.; Huang, Z.; Zhang, H.; Cao, Z.; Xu, D. 3DRIMR: 3D Reconstruction and Imaging via MmWave Radar Based on Deep Learning. arXiv 2021, arXiv:2108.02858. [Google Scholar]
- Guan, J.; Madani, S.; Jog, S.; Gupta, S.; Hassanieh, H. Through Fog High-Resolution Imaging Using Millimeter Wave Radar. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Gao, J.; Qin, Y.; Deng, B.; Wang, H.; Li, X. A Novel Method for 3-D Millimeter-Wave Holographic Reconstruction Based on Frequency Interferometry Techniques. IEEE Trans. Microw. Theory Tech. 2018, 66, 1579–1596. [Google Scholar] [CrossRef]
- Minin, I.V.; Minin, O.V.; Castineira-Ibanez, S.; Rubio, C.; Candelas, P. Phase Method for Visualization of Hidden Dielectric Objects in the Millimeter Waveband. Sensors 2019, 19, 3919. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sadeghi, M.; Tajdini, M.M.; Wig, E.; Rappaport, C.M. Single-Frequency Fast Dielectric Characterization of Concealed Body-Worn Explosive Threats. IEEE Trans. Antennas Propag. 2020, 68, 7541–7548. [Google Scholar] [CrossRef]
- Aizenberg, N.N.; Ivaskiv, Y.L.; Pospelov, D.A.; Hudiakov, G.F. Multivalued Threshold Functions in Boolean Complex-Threshold Functions and Their Generalization. Cybern. Syst. Anal. 1971, 7, 626–635. [Google Scholar] [CrossRef]
- Hirose, A. Complex-Valued Neural Networks: Advances and Applications; Wiley: New York, NY, USA, 2013. [Google Scholar]
- Trabelsi, C.; Bilaniuk, O.; Zhang, Y.; Serdyuk, D.; Subramanian, D.; Santos, J.F.; Mehri, S.; Rostamzadeh, N.; Bengio, Y.; Pal, C.J. Deep Complex Networks. In Proceedings of the ICLR 2018 Conference, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gao, J.; Deng, B.; Qin, Y.; Wang, H.; Li, X. Enhanced Radar Imaging Using a Complex-Valued Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2019, 16, 35–39. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Yang, Q.; Zeng, Y.; Deng, B.; Wang, H.; Qin, Y. High-Quality Interferometric Inverse Synthetic Aperture Radar Imaging Using Deep Convolutional Networks. Microw. Opt. Technol. Lett. 2020, 62, 3060–3065. [Google Scholar] [CrossRef]
- Pu, W. Deep SAR Imaging and Motion Compensation. IEEE Trans. Image Process. 2021, 30, 2232–2247. [Google Scholar] [CrossRef] [PubMed]
- Mu, H.; Zhang, Y.; Jiang, Y.; Ding, C. CV-GMTINet: GMTI Using a Deep Complex-Valued Convolutional Neural Network for Multichannel SAR-GMTI System. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5201115. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the Importance of Initialization and Momentum in Deep Learning. In Proceedings of the 30th International Conference on International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Bengio, Y. Practical recommendations for gradient-based training of deep architectures. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 437–478. [Google Scholar]
- Li, S.; Zhao, G.; Sun, H.; Amin, M. Compressive Sensing Imaging of 3-D Object by a Holographic Algorithm. IEEE Trans. Antennas Propag. 2018, 66, 7295–7304. [Google Scholar] [CrossRef]
- Yang, G.; Li, C.; Wu, S.; Liu, X.; Fang, G. MIMO-SAR 3-D Imaging Based on Range Wavenumber Decomposing. IEEE Sens. J. 2021, 21, 24309–24317. [Google Scholar] [CrossRef]
- Gao, H.; Li, C.; Zheng, S.; Wu, S.; Fang, G. Implementation of the Phase Shift Migration in MIMO-Sidelooking Imaging at Terahertz Band. IEEE Sens. J. 2019, 19, 9384–9393. [Google Scholar] [CrossRef]
- Tan, W.; Huang, P.; Huang, Z.; Qi, Y.; Wang, W. Three-Dimensional Microwave Imaging for Concealed Weapon Detection Using Range Stacking Technique. Int. J. Antennas Propag. 2017, 2017, 1480623. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Frequency (GHz) | 34.5 |
| Aperture size (m) | 0.25 × 0.25 |
| Sampling interval (mm) | 5 |
| Imaging range (m) | 0.25 m~0.45 m |
| Beam width of antenna element (°) | 55 |
| Original resolution (mm) | 5 |
| Enhanced imaging resolution (mm) | 2.5 |
| Image pixels | 256 × 256 |
| Methods | 25% Data | 50% Data | 75% Data | 100% Data |
|---|---|---|---|---|
| PSM | 1214.51 | 653.47 | 392.01 | 261.44 |
| PSM-CS | 142.37 | 62.65 | 56.93 | 55.84 |
| RVFCNN (PReLU) | 83.57 | 58.54 | 47.82 | 39.68 |
| CVFCNN (CReLU) | 83.82 | 59.14 | 48.02 | 39.93 |
| CVFCNN (CPReLU1) | 84.87 | 61.39 | 50.47 | 42.67 |
| CVFCNN (CPReLU2) | 82.74 | 58.21 | 47.18 | 39.19 |
| Methods | CPU(h) |
|---|---|
| RVFCNN (PReLU) | 22.6 |
| CVFCNN (CReLU) | 13.3 |
| CVFCNN (CPReLU1) | 15.2 |
| CVFCNN (CPReLU2) | 15.4 |
| Methods | CPU(s) | GPU(s) |
|---|---|---|
| PSM | 0.12 | / |
| PSM-CS | 22.82 | / |
| RVFCNN (PReLU) | 1.18 | 0.10 |
| CVFCNN (CReLU) | 0.71 | 0.08 |
| CVFCNN (CPReLU1) | 0.72 | 0.08 |
| CVFCNN (CPReLU2) | 0.72 | 0.08 |
| Parameter | Value |
|---|---|
| Center frequency (GHz) | 34.5 |
| Bandwidth (GHz) | 5 |
| Sampling interval (mm) | Δx = 4, Δy = 5 |
| Beam width of antenna element (°) | 55 |
| Imaging range (m) | 0.3 m~0.42 m |
| Imaging range interval (mm) | 5 |
| Imaging range slices | 25 |
| Image pixels | 768 × 768 |
| Methods | CPU(s) | GPU(s) |
|---|---|---|
| PSM | 4.5 | / |
| PSM-CS | 647.2 | / |
| RVFCNN (PReLU) | 240.2 | 16.4 |
| CVFCNN (CReLU) | 143.6 | 11.9 |
| CVFCNN (CPReLU1) | 145.3 | 12.2 |
| CVFCNN (CPReLU2) | 145.3 | 12.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jing, H.; Li, S.; Miao, K.; Wang, S.; Cui, X.; Zhao, G.; Sun, H. Enhanced Millimeter-Wave 3-D Imaging via Complex-Valued Fully Convolutional Neural Network. Electronics 2022, 11, 147. https://doi.org/10.3390/electronics11010147
Jing H, Li S, Miao K, Wang S, Cui X, Zhao G, Sun H. Enhanced Millimeter-Wave 3-D Imaging via Complex-Valued Fully Convolutional Neural Network. Electronics. 2022; 11(1):147. https://doi.org/10.3390/electronics11010147
Chicago/Turabian StyleJing, Handan, Shiyong Li, Ke Miao, Shuoguang Wang, Xiaoxi Cui, Guoqiang Zhao, and Houjun Sun. 2022. "Enhanced Millimeter-Wave 3-D Imaging via Complex-Valued Fully Convolutional Neural Network" Electronics 11, no. 1: 147. https://doi.org/10.3390/electronics11010147
APA StyleJing, H., Li, S., Miao, K., Wang, S., Cui, X., Zhao, G., & Sun, H. (2022). Enhanced Millimeter-Wave 3-D Imaging via Complex-Valued Fully Convolutional Neural Network. Electronics, 11(1), 147. https://doi.org/10.3390/electronics11010147