
Fire Detection Method in Smart City Environments Using a Deep-Learning-Based Approach



Abstract
:1. Introduction
2. Related Work
2.1. Fire Detection and Segmentation Method Based on DL
2.2. Fire Detection and Segmentation Method Based on Transformers
3. Fire Detection and Classification
3.1. Dataset
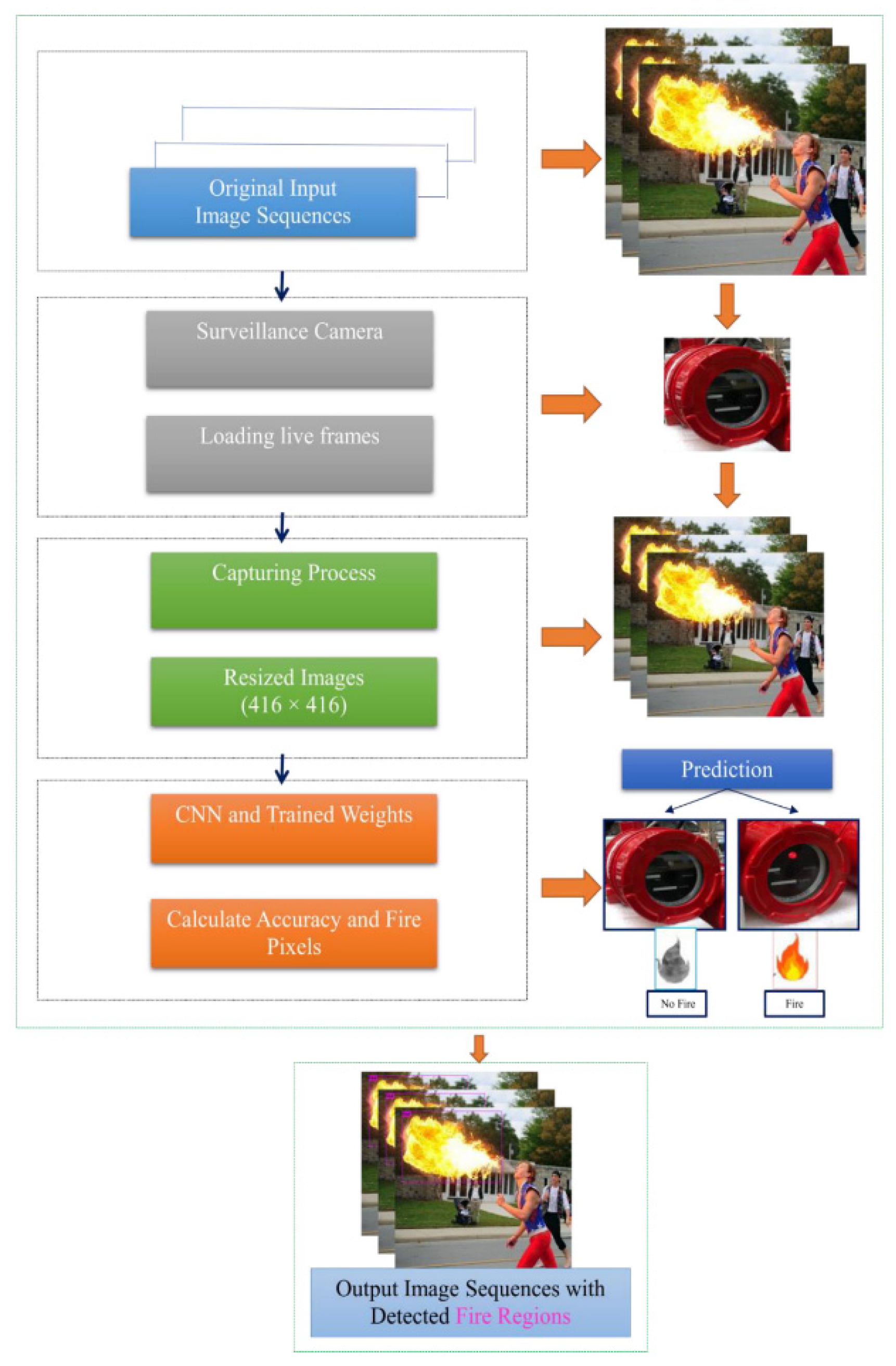
3.2. System Overview
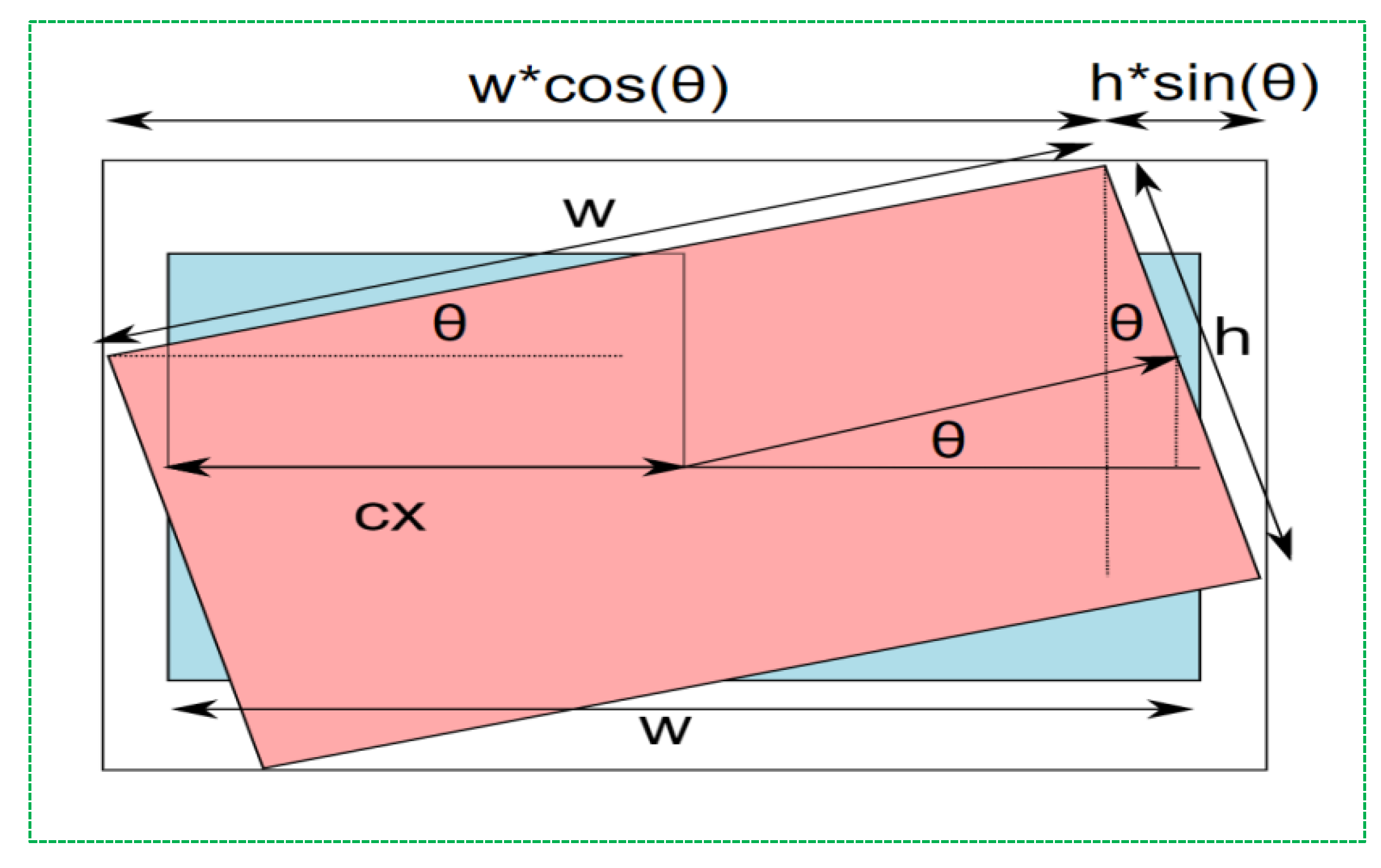
3.3. Fire Detection Process
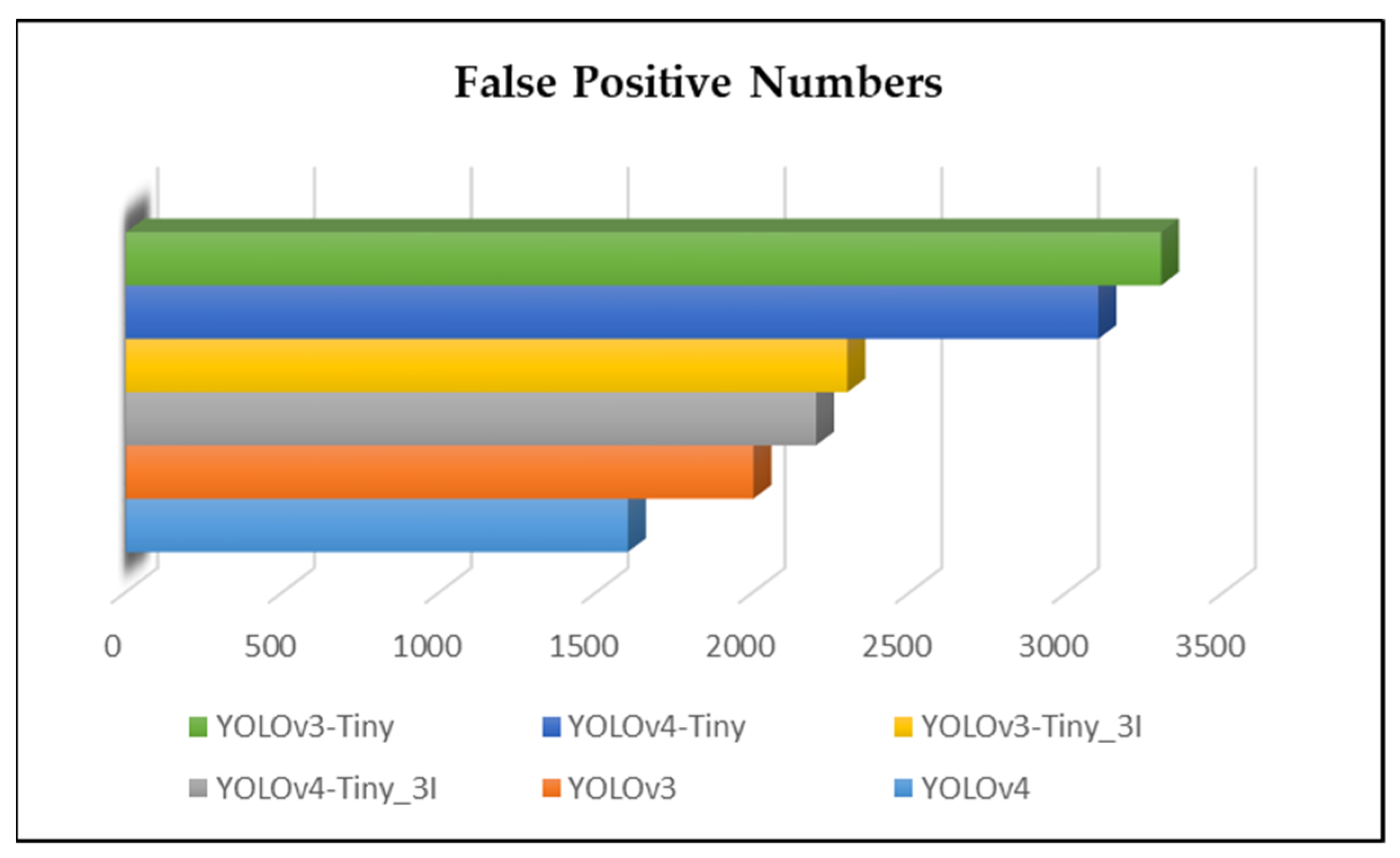
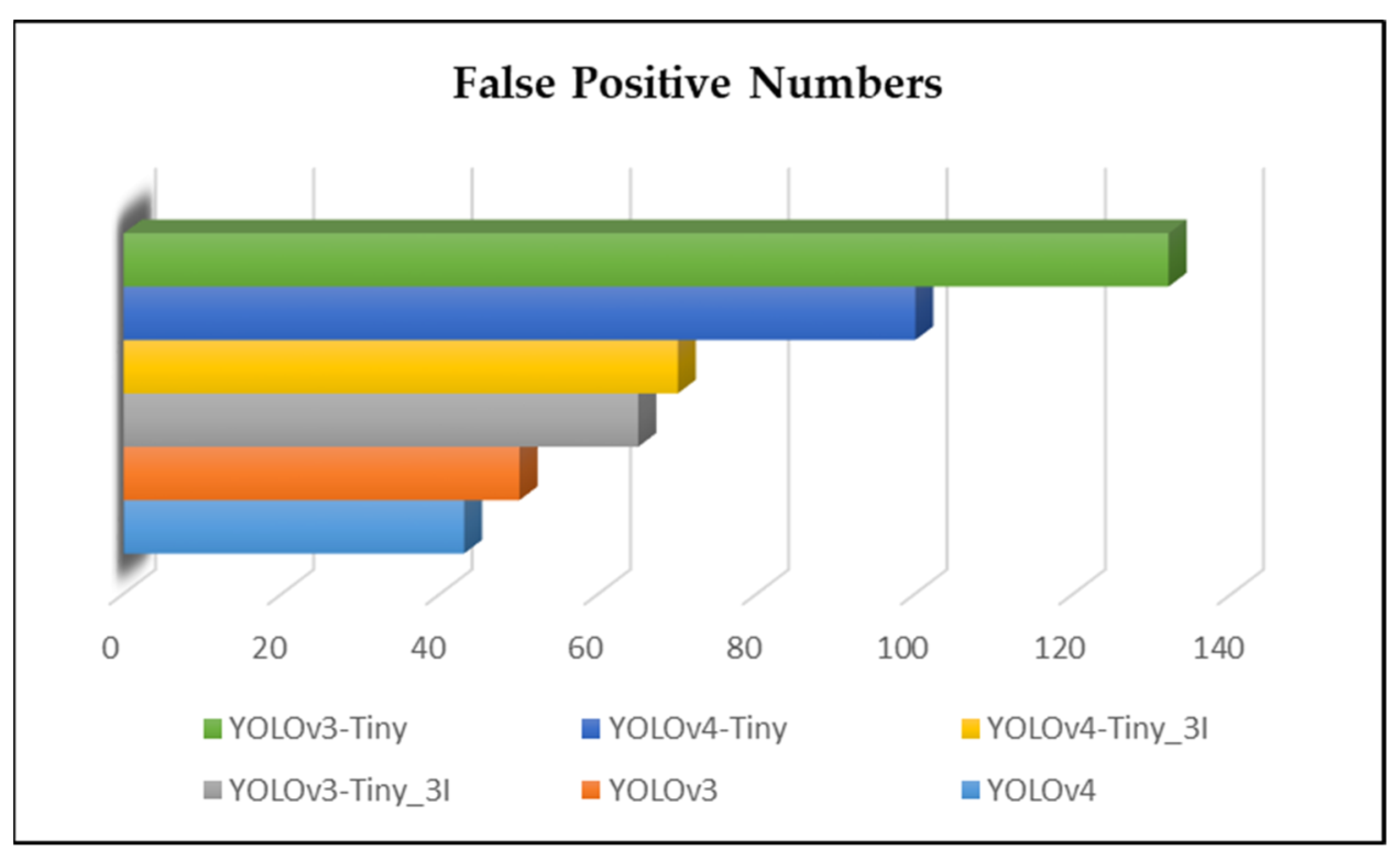
4. Experimental Results and Discussions
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hong, X.; Wang, W.; Liu, Q. Design and Realization of Fire Detection Using Computer Vision Technology. In Proceedings of the 2019 Chinese Control and Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 5645–5649. [Google Scholar]
- Zhang, F.; Zhao, P.; Xu, S.; Wu, Y.; Yang, X.; Zhang, Y. Integrating multiple factors to optimize watchtower deployment for wildfire detection. Sci. Total Environ. 2020, 737, 139561. [Google Scholar] [CrossRef]
- Zhang, F.; Zhao, P.; Thiyagalingam, J.; Kirubarajan, T. Terrain-influenced incremental watchtower expansion for wildfire detection. Sci. Total Environ. 2018, 654, 164–176. [Google Scholar] [CrossRef]
- Lee, B.; Kwon, O.; Jung, C.; Park, S. The development of UV/IR combination flame detector. J. KIIS 2001, 16, 1–8. [Google Scholar]
- Kang, D.; Kim, E.; Moon, P.; Sin, W.; Kang, M. Design and analysis of flame signal detection with the combination of UV/IRsensors. J. Korean Soc. Int. Inf. 2013, 14, 45–51. [Google Scholar]
- Fernandes, A.M.; Utkin, A.B.; Lavrov, A.V.; Vilar, R.M. Development of neural network committee machines for automatic forestfire detection using lidar. Pattern Recognit. 2004, 37, 2039–2047. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Mehmood, I.; Rho, S.; Baik, S.W. Convolutional Neural Networks Based Fire Detection in Surveillance Videos. IEEE Access 2018, 6, 18174–18183. [Google Scholar] [CrossRef]
- Tao, C.; Zhang, J.; Wang, P. Smoke detection based on deep convolutional neural networks. In Proceedings of the 2016 International Conference on Industrial Informatics -Computing Technology, Intelligent Technology, Industrial Information Integration (ICIICII), Wuhan, China, 3–4 December 2016; pp. 150–153. [Google Scholar]
- Filonenko, A.; Kurnianggoro, L.; Jo, K.-H. Comparative study of modern convolutional neural networks for smoke detection on image data. In Proceedings of the 2017 10th International Conference on Human System Interactions (HSI), Ulsan, Korea, 17–19 July 2017; pp. 64–68. [Google Scholar]
- Yin, Z.; Wan, B.; Yuan, F.; Xia, X.; Shi, J. A Deep Normalization and Convolutional Neural Network for Image Smoke Detection. IEEE Access 2017, 5, 18429–18438. [Google Scholar] [CrossRef]
- Dunnings, A.J.; Breckon, T.P. Experimentally defined convolutional neural network architecture variants for non-temporal real-time fire detection. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1558–1562. [Google Scholar]
- Mao, W.; Wang, W.; Dou, Z.; Li, Y. Fire Recognition Based on Multi-Channel Convolutional Neural Network. Fire Technol. 2018, 54, 531–554. [Google Scholar] [CrossRef]
- Hu, Y.; Lu, X. Real-time video fire smoke detection by utilizing spatial-temporal ConvNet features. Multimed. Tools Appl. 2018, 77, 29283–29301. [Google Scholar] [CrossRef]
- Ghali, R.; Akhloufi, M.A.; Jmal, M.; Souidene Mseddi, W.; Attia, R. Wildfire Segmentation Using Deep Vision Transformers. Remote Sens. 2021, 13, 3527. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Dimitropoulos, K.; Kaza, K.; Grammalidis, N. Fire Detection from Images Using Faster R-CNN and Multidimensional Texture Analysis. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8301–8305. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Baratov, N.; Kutlimuratov, A.; Whangbo, T.K. An Improvement of the Fire Detection and Classification Method Using YOLOv3 for Surveillance Systems. Sensors 2021, 21, 6519. [Google Scholar] [CrossRef]
- Nguyen, A.Q.; Nguyen, H.T.; Tran, V.C.; Pham, H.X.; Pestana, J. A Visual Real-time Fire Detection using Single Shot MultiBox Detector for UAV-based Fire Surveillance. In Proceedings of the 2020 IEEE Eighth International Conference on Communications and Electronics (ICCE), IEEE, Phu Quoc Island, Vietnam, 13–15 January 2021; pp. 338–343. [Google Scholar]
- Gaur, A.; Singh, A.; Kumar, A.; Kumar, A.; Kapoor, K. Video Flame and Smoke Based Fire Detection Algorithms: A Literature Review. Fire Technol. 2020, 56, 1943–1980. [Google Scholar] [CrossRef]
- Bu, F.; Gharajeh, M.S. Intelligent and vision-based fire detection systems: A survey. Image Vis. Comput. 2019, 91, 103803. [Google Scholar] [CrossRef]
- Fonollosa, J.; Solórzano, A.; Santiago, M. Chemical sensor systems and associated algorithms for fire detection: A review. Sensors 2018, 18, 553. [Google Scholar] [CrossRef] [Green Version]
- Mahdipour, E.; Dadkhah, C. Automatic fire detection based on soft computing techniques: Review from 2000 to 2010. Artif. Intell. Rev. 2012, 42, 895–934. [Google Scholar] [CrossRef]
- Bakator, M.; Radosav, D. Deep Learning and Medical Diagnosis: A Review of Literature. Multimodal Technol. Interact. 2018, 2, 47. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-Of-The-Art Review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: ASurvey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1. [Google Scholar] [CrossRef]
- Pan, Z.; Xu, J.; Guo, Y.; Hu, Y.; Wang, G. Deep Learning Segmentation and Classification for Urban Village Using a WorldviewSatellite Image Based on U-Net. Remote Sens. 2020, 12, 1574. [Google Scholar] [CrossRef]
- Bragilevsky, L.; Baji´c, I.V. Deep learning for Amazon satellite image analysis. In Proceedings of the IEEE Pacific Rim Conferenceon Communications, Computers and Signal Processing (PACRIM), Victoria, BC, Canada, 21–23 August 2017; pp. 1–5. [Google Scholar]
- Muhammad, K.; Ahmad, J.; Lv, Z.; Bellavista, P.; Yang, P.; Baik, S.W. Efficient Deep CNN-Based Fire Detection and Locali-zation inVideo Surveillance Applications. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 1419–1434. [Google Scholar] [CrossRef]
- Iandola, F.N.; Moskewicz, M.W.; Ashraf, K.; Han, S.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewerparameters and <1 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Gonzalez, A.; Zuniga, M.D.; Nikulin, C.; Gonzalo, C.; Cardenas, D.G.; Pedraza, M.A.; Fernandez, C.A.; Munoz, R.I.; Castro, N.A.; Rosales, B.F.; et al. Accurate fire detection through fully convolutional network. In Proceedings of the 7th Latin American Conference on Networked and Electronic Media (LACNEM 2017), Valparaiso, Chile, 6–7 November 2017; pp. 1–6. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Li, P.; Wangda, Z. Image fire detection algorithms based on convolutional neural networks. Case Stud. Therm. Eng. 2020, 19, 100625. [Google Scholar] [CrossRef]
- Xing, Y.; Zhong, L.; Zhong, X. An Encoder-Decoder Network Based FCN Architecture for Semantic Segmentation. Wirel. Commun. Mob. Comput. 2020, 2020, 8861886. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, H.; Wang, P.; Ling, X. ATT Squeeze U-Net: A Lightweight Network for Forest Fire Detection and Recognition. IEEE Access 2021, 9, 10858–10870. [Google Scholar] [CrossRef]
- Akhloufi, M.A.; Tokime, R.B.; Elassady, H. Wildland fires detection and segmentation using deep learning. Pattern recognitionand tracking xxix. Int. Soc. Opt. Photonics Proc. SPIE 2018, 10649, 106490B. [Google Scholar]
- Bochkov, V.S.; Kataeva, L.Y. wUUNet: Advanced Fully Convolutional Neural Network for Multiclass Fire Segmentation. Symmetry 2021, 13, 98. [Google Scholar] [CrossRef]
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A Forest Fire Detection System Based on Ensemble Learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Jocher, G.; Stoken, A.; Chaurasia, A.; Borovec, J.; Chanvichet, V.; Kwon, Y.; TaoXie, S.; Changyu, L.; Abhiram, V.; Skalski, P.; et al. Yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 20 September 2021).
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference onComputer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Shahid, M.; Hua, K.-L. Fire Detection using Transformer Network. In Proceedings of the Proceedings of the 2021 International Conference on Multimedia Retrieval. ACM 2021, 627–630. [Google Scholar]
- Valanarasu, J.M.J.; Oza, P.; Hacihaliloglu, I.; Patel, V.M. Medical Transformer: Gated Axial-Attention for Medical ImageSegmentation. arXiv 2021, arXiv:2102.10662. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encodersfor Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Marcu, A.-E.; Suciu, G.; Olteanu, E.; Miu, D.; Drosu, A.; Marcu, I. IoT system for forest monitoring. In Proceedings of the 42nd International Conference on Telecommunications and Signal Processing (TSP), Budapest, Hungary, 1–3 July 2019. [Google Scholar]
- Zhou, H.; Taal, A.; Koulouzis, S.; Wang, J.; Hu, Y.; Suciu, G.; Poenaru, V.; Laat, C.D.; Zhao, Z. Dynamic real-time infrastructure planning and deployment for disaster early warning systems. In Proceedings of the International Conference on Computational Science; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Ghosh, S.; Mukherjee, A.; Ghosh, S.K.; Buyya, R. Mobi-iost: Mobility-aware cloud-fog-edge-iot collaborative framework for time-critical applications. IEEE Trans. Netw. Sci. Eng. 2019, 7, 2271–2285. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.J.; Kim, B.H.; Kim, M.Y. Multi-Saliency Map and Machine Learning Based Human Detection for the Embedded Top-View Imaging System. IEEE Access 2021, 9, 70671–70682. [Google Scholar] [CrossRef]
- Szeliski, R. Computer Vision Algorithms and Applications. 2011. Available online: http://dx.doi.org/10.1007/978-1-84882-935-0 (accessed on 25 October 2021).
- Abdusalomov, A.; Whangbo, T.K. An improvement for the foreground recognition method using shadow removal technique for indoor environments. Int. J. Wavelets Multiresolution Inf. Process. 2017, 15, 1750039. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Whangbo, T.K. Detection and Removal of Moving Object Shadows Using Geometry and Color Information for Indoor Video Streams. Appl. Sci. 2019, 9, 5165. [Google Scholar] [CrossRef] [Green Version]
- Abdusalomov, A.; Mukhiddinov, M.; Djuraev, O.; Khamdamov, U.; Whangbo, T.K. Automatic Salient Object Extraction Based on Locally Adaptive Thresholding to Generate Tactile Graphics. Appl. Sci. 2020, 10, 3350. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Papaioannou, P.; Dimitropoulos, K.; Grammalidis, N. A Review on Early Forest Fire Detection Systems Using Optical Remote Sensing. Sensors 2020, 20, 6442. [Google Scholar] [CrossRef]
- Redmon, J. Darknet: Open-Source Neural Networks in C. 2013–2016. Available online: http://pjreddie.com/darknet/ (accessed on 22 August 2021).
- Bochkovskiy, A.; Wang, C.-Y.; Mark Liao, H.-Y. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Valikhujaev, Y.; Abdusalomov, A.; Cho, Y. Automatic Fire and Smoke Detection Method for Surveillance Systems Based on Dilated CNNs. Atmosphere 2020, 11, 1241. [Google Scholar] [CrossRef]
- Yolo v5. In GitHub. 2021. Available online: https://github.com/ultralytics/yolov (accessed on 31 May 2021).
- Dufour, D.; Le Noc, L.; Tremblay, B.; Tremblay, M.N.; Généreux, F.; Terroux, M.; Vachon, C.; Wheatley, M.J.; Johnston, J.M.; Wotton, M.; et al. A Bi-Spectral Microbolometer Sensor for Wildfire Measurement. Sensors 2021, 21, 3690. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Shi, F.; Qian, H.; Chen, W.; Huang, M.; Wan, Z. A Fire Monitoring and Alarm System Based on YOLOv3 with OHEM. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 7322–7327. [Google Scholar] [CrossRef]
- Cao, C.; Tan, X.; Huang, X.; Zhang, Y.; Luo, Z. Study of Flame Detection based on Improved YOLOv4. J. Phys. 2021, 1952. [Google Scholar] [CrossRef]
- Kim, B.; Lee, J. A Video-Based Fire Detection Using Deep Learning Models. Appl. Sci. 2019, 9, 2862. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Publicly Available Datasets | Video Frames | Total |
|---|---|---|---|
| Flame Frames | 4336 | 4864 | 9200 |
| Database | Training Images | Testing Images | Total |
|---|---|---|---|
| Flame frames Flame-like images | 24,385 10,000 | 3215 0 | 27,600 10,000 |
| Algorithm | Input Size | Training Accuracy (AP50) | Testing Accuracy (AP50) | Weight Size | Number of Iterations | Training Time (h) |
|---|---|---|---|---|---|---|
| YOLOv4 | 608 × 608 416 × 416 | 81.1% | 74.3% | 245 MB | 50,000 | 67 h |
| YOLOv4 | 84.5% | 79.1% | 245 MB | 45 h |
| Before | After Filtering | After Contrast Increase (Double) | After Contrast Decrease (Half) |
|---|---|---|---|
| 20,100 | 20,100 | 20,100 | 20,100 |
| Algorithm | Input Size | Training Accuracy (AP50) | Testing Accuracy (AP50) | Weight Size | Number of Iterations | Training Time |
|---|---|---|---|---|---|---|
| YOLOv4 | 608 × 608 416 × 416 | 95.1% | 94.7% | 245 MB | 50,000 | 87 h |
| YOLOv4 | 98.8% | 96.3% | 245 MB | 72 h |
| Algorithms | Input Size | Training Accuracy (AP50) | Testing Accuracy (AP50) | Weight Size | Number of Iterations | Training Time |
|---|---|---|---|---|---|---|
| YOLOv4 | 416 × 416 | 98.8% | 96.3% | 245 MB | 50,000 | 72 h |
| YOLOv4-tiny_3l | 89.9% | 85.7% | 57 MB | 37 h | ||
| YOLOv4-tiny | 93.8% | 91.2% | 85 MB | 43 h | ||
| YOLOv3 | 97.1% | 94.6% | 236 MB | 82 h | ||
| YOLOv3-tiny_3l | 92.6% | 90.4% | 63.7 MB | 39 h | ||
| YOLOv3-tiny | 85.3% | 82.7% | 53 MB | 37.5 h |
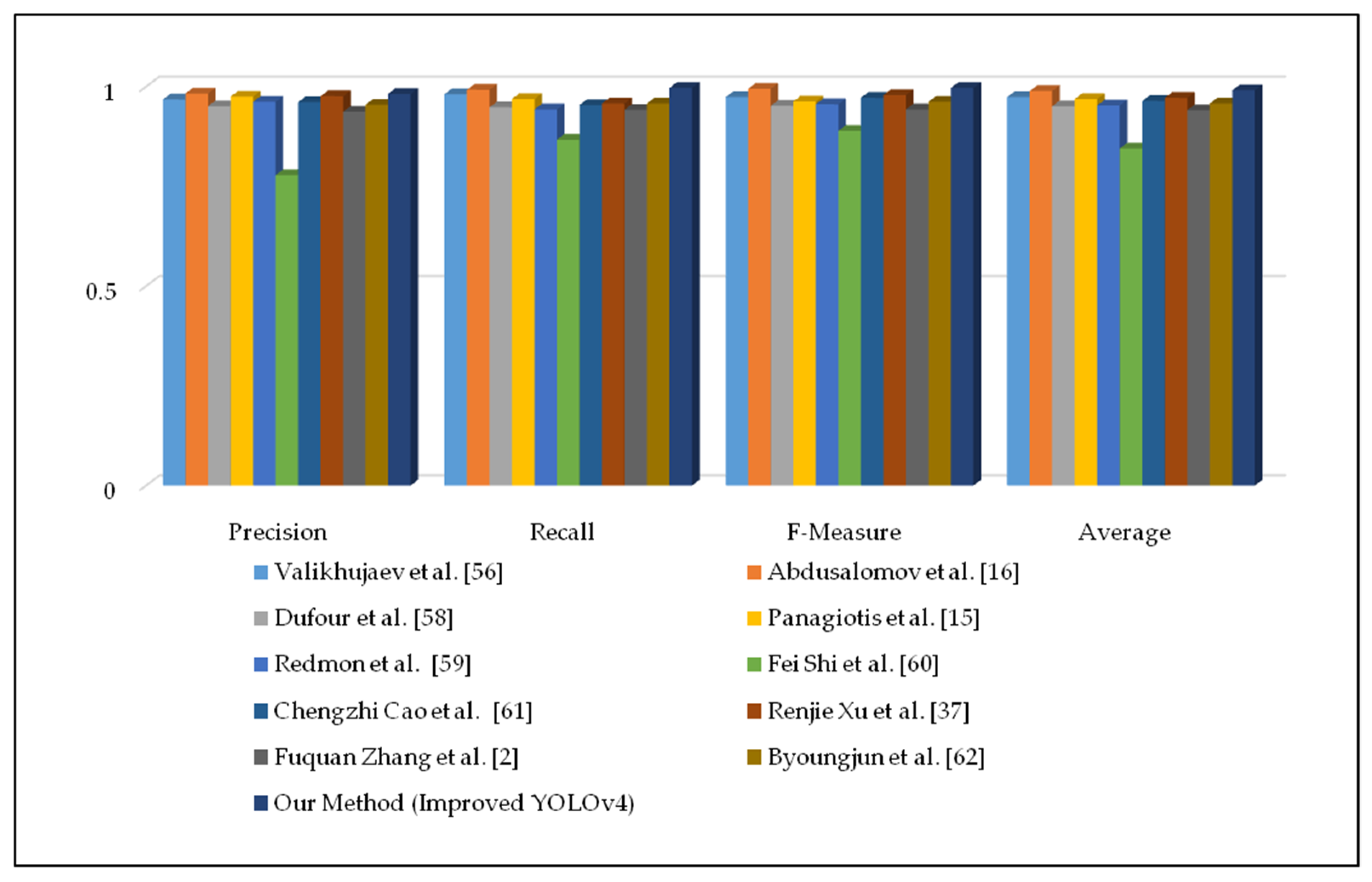
| Approach | Precision | Recall | FM | Average |
|---|---|---|---|---|
| Valikhujaev et al. [56] | 0.968 | 0.981 | 0.974 | 0.974 |
| Abdusalomov et al. [16] | 0.983 | 0.992 | 0.995 | 0.989 |
| Dufour et al. [58] | 0.951 | 0.948 | 0.952 | 0.951 |
| Panagiotis et al. [15] | 0.975 | 0.969 | 0.963 | 0.969 |
| Redmon et al. [59] | 0.962 | 0.943 | 0.956 | 0.953 |
| Fei Shi et al. [60] | 0.778 | 0.867 | 0.889 | 0.845 |
| Chengzhi Cao et al. [61] | 0.961 | 0.954 | 0.972 | 0.964 |
| Renjie Xu et al. [37] | 0.976 | 0.958 | 0.979 | 0.972 |
| Fuquan Zhang et al. [2] | 0.937 | 0.942 | 0.943 | 0.941 |
| Byoungjun et al. [62] | 0.955 | 0.958 | 0.962 | 0.958 |
| Our Method (Improved YOLOv4) | 0.982 | 0.997 | 0.997 | 0.991 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Avazov, K.; Mukhiddinov, M.; Makhmudov, F.; Cho, Y.I. Fire Detection Method in Smart City Environments Using a Deep-Learning-Based Approach. Electronics 2022, 11, 73. https://doi.org/10.3390/electronics11010073
Avazov K, Mukhiddinov M, Makhmudov F, Cho YI. Fire Detection Method in Smart City Environments Using a Deep-Learning-Based Approach. Electronics. 2022; 11(1):73. https://doi.org/10.3390/electronics11010073
Chicago/Turabian StyleAvazov, Kuldoshbay, Mukhriddin Mukhiddinov, Fazliddin Makhmudov, and Young Im Cho. 2022. "Fire Detection Method in Smart City Environments Using a Deep-Learning-Based Approach" Electronics 11, no. 1: 73. https://doi.org/10.3390/electronics11010073
APA StyleAvazov, K., Mukhiddinov, M., Makhmudov, F., & Cho, Y. I. (2022). Fire Detection Method in Smart City Environments Using a Deep-Learning-Based Approach. Electronics, 11(1), 73. https://doi.org/10.3390/electronics11010073