
A Path Planning Strategy of Wearable Manipulators with Target Pointing End Effectors

 ,
,
Abstract
:1. Introduction
2. Degree of Freedom Allocation Scheme of Wearable Target Pointing End Effector Manipulators
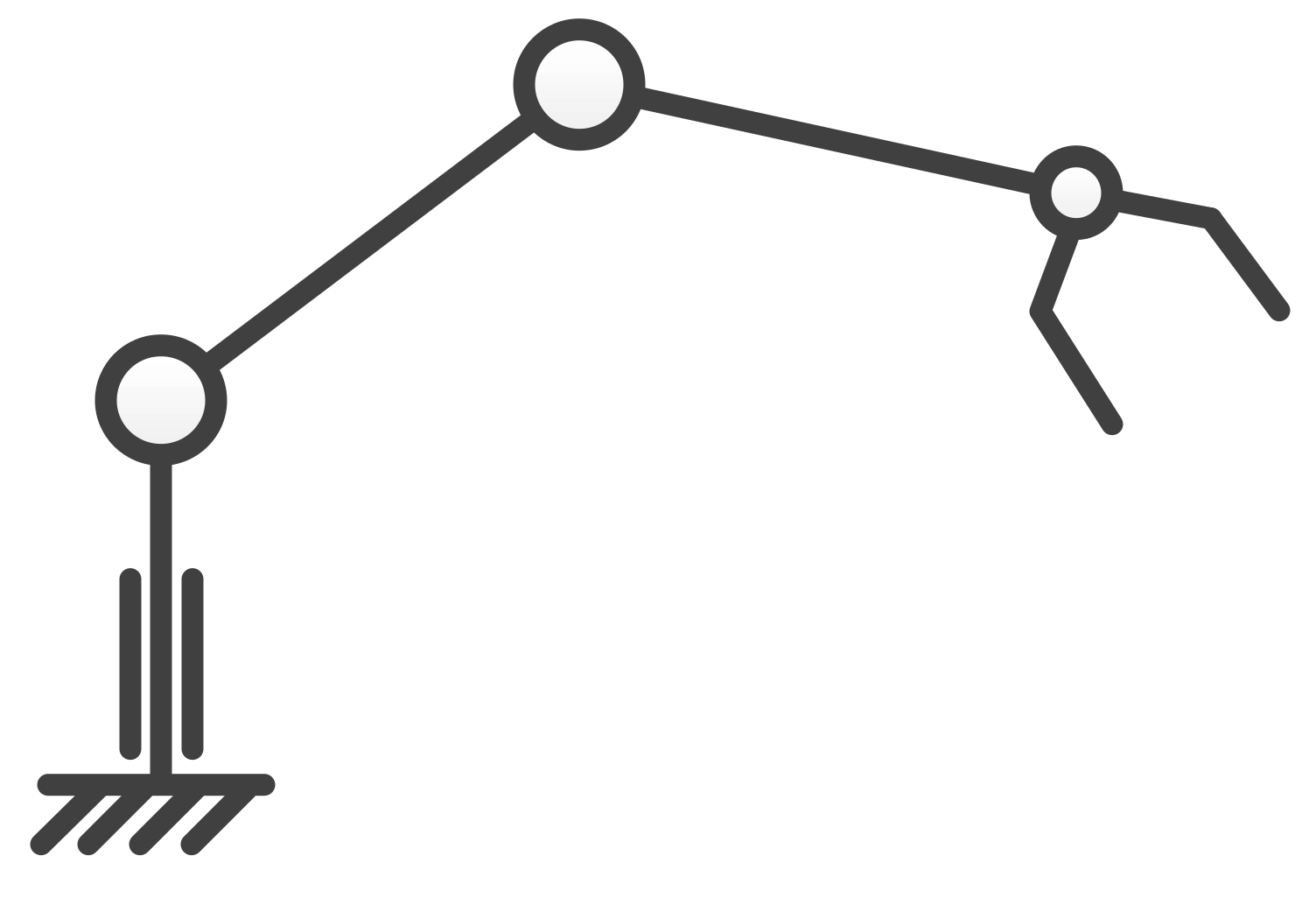
2.1. Problem Description (Target Pointing End Effector Task Description)
2.2. The Degree of Freedom Assignment Scheme
2.3. Inverse Kinematics Calculation of Four-Degrees-of-Freedom Manipulator with the Target Pointing End Effector
3. A Path Planning Strategy of Target Pointing End Effector Wearable Manipulators
4. The Path Planning Strategy Target Pointing End Effector Manipulators
4.1. Dimension Rapid-Exploration Random Tree
4.1.1. Rapid-Exploration Random Tree and Optimization Algorithm Principle
4.1.2. Application of Dimension Rapid-Exploration Random Tree Path Optimization Algorithm
4.1.3. Limitations of Dimension Rapid-Exploration Random Tree Algorithm
4.2. Manipulator with Target Pointing End Effector Path Imitation by Dynamic Movement Primitives Algorithm
4.2.1. Introduction to Dynamic Movement Primitives Algorithm
4.2.2. Building a Path Library
4.2.3. Trajectory Reproduction and Generalization
5. Experimental Verifications
5.1. Dimension Rapid-Exploration Random Tree Algorithm Effect Verification
5.2. Cross Sector Motion Planning
6. Discussion
7. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, C.; Liu, Y.; Li, Z. Biomechtronic Design of a Supernumerary Robotic Limbs for Industrial Assembly. In Proceedings of the IEEE 4th International Conference on Advanced Robotics and Mechatronics (ICARM) IEEE, Toyonaka, Japan, 3–5 July 2019; pp. 553–558. [Google Scholar]
- Vatsal, V.; Hoffman, G. Design and Analysis of a Wearable Robotic Forearm. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA) IEEE, Brisbane, Australia, 21–25 May 2018; pp. 5489–5496. [Google Scholar]
- Kurek, D.A.; Asada, H.H. The MantisBot: Design and impedance control of supernumerary robotic limbs for near-ground work. In Proceedings of the IEEE International Conference on Robotics & Automation IEEE, Singapore, 29 May–3 June 2017; pp. 5942–5947. [Google Scholar]
- Véronneau, C.; Denis, J.; Lebel, L.P.; Denninger, M.; Blanchard, V.; Girard, A.; Plante, J.S. Multifunctional Remotely Actuated 3-DOF Supernumerary Robotic Arm Based on Magnetorheological Clutches and Hydrostatic Transmission Lines. IEEE Robot. Autom. Lett. 2020, 5, 2546–2553. [Google Scholar] [CrossRef]
- William, J.G.; Daniel, M.B.; Zachary, K.W.; Frank, M.; Angela, C.B. Third Arm Weapon Interface System. U.S. Patent No. US10393476B2, 20 December 2018. [Google Scholar]
- Wang, Y.P.; Jiang, Q. A Wearable Weapon Arm Device with Double Shooting Mode. CN112665462A, 16 April 2021. (In Chinese). [Google Scholar]
- Website: China National Knowledge Infrastructure. Available online: http://kns.cnki.net/kcms/detail/44.1240.TP.20210806.1351.028.html (accessed on 15 August 2021).
- LaValle, S.M.; Kuffner, J.J., Jr. Randomized kinodynamic planning. IJRR 2001, 20, 378–400. [Google Scholar] [CrossRef]
- Karaman, S.; Frazzoli, E. Sampling-based algorithms for optimal motion planning. IJRR 2011, 30, 846–894. [Google Scholar] [CrossRef]
- Burget, F.; Bennewitz, M.; Burgard, W. BI 2 RRT *: An efficient sampling-based path planning framework for task-constrained mobile manipulation. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–17 October 2016; pp. 3714–3721. [Google Scholar]
- Gammell, J.D.; Srinivasa, S.S.; Barfoot, T.D. Informed RRT *: Optimal sampling-based path planning focused via direct sampling of an admissible ellipsoidal heuristic. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2014), Chicago, IL, USA, 14–18 September 2014; pp. 2997–3004. [Google Scholar]
- Li, B.H.; Chen, B.D. An Adaptive Rapidly-Exploring Random Tree. IEEE/CAA J. Autom. Sin. 2022, 9, 283–294. [Google Scholar] [CrossRef]
- Ganesan, S.; Natarajan, S.K.; Srinivasan, J. A Global Path Planning Algorithm for Mobile Robot in Cluttered Environments with an Improved Initial Cost Solution and Convergence Rate. Arab. J. Sci. Eng. 2022, 47, 3633–3647. [Google Scholar] [CrossRef]
- Guo, Y.C.; Liu, X.X.; Liu, X.H.; Yang, Y.; Zhang, W.G. FC-RRT *: An Improved Path Planning Algorithm for UAV in 3D Complex Environment. Int. J. Geo-Inf. 2022, 11, 112. [Google Scholar] [CrossRef]
- Wang, H.; Li, G.Q.; Hou, J.; Chen, L.Y.; Hu, N.L. A Path Planning Method for Underground Intelligent Vehicles Based on an Improved RRT * Algorithm. Electronics 2022, 11, 294. [Google Scholar] [CrossRef]
- Zang, X.Z.; Yu, W.T.; Zhang, L.; Iqbal, S. Path Planning Based on Bi-RRT Algorithm for Redundant Manipulator. In Proceedings of the International Conference of Electrical, Automation and Mechanical Engineering (EAME 2015), Phuket, Thailand, 26–27 July 2015; pp. 189–191. [Google Scholar]
- Khan, A.T.; Li, S.; Kadry, S.; Nam, Y. Control Framework for Trajectory Planning of Soft Manipulator Using Optimized RRT Algorithm. IEEE Access 2020, 8, 171730–171743. [Google Scholar] [CrossRef]
- Yang, W.; Wen, H.Y.; Zhang, Z.S. Obstacle Avoidance Path Planning of Manipulator Based on Improved RRT Algorithm. In Proceedings of the 2021 International Conference on Computer, Control and Robotics (ICCCR), Shanghai, China, 8–10 January 2021; pp. 104–109. [Google Scholar]
- Wei, H.H.; Zheng, Y.; Gu, G.Y. RRT-Based Path Planning for Follow-the-Leader Motion of Hyper-Redundant Manipulators. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 3198–3204. [Google Scholar]
- Shao, J.; Xiong, H.; Liao, J.F.; Song, W.; Chen, Z.; Gu, J.; Zhu, S.Q. RRT-GoalBias and Path Smoothing Based Motion Planning of Mobile Manipulators with Obstacle Avoidance. In Proceedings of the 2021 IEEE International Conference on Real-time Computing and Robotics, Xining, China, 15–19 July 2019; pp. 217–222. [Google Scholar]
- Yi, J.; Yuan, Q.; Run, S.; Bai, H. Path Planning of a Manipulator Based on an Improved P_RRT* Algorithm. Complex Intell. Syst. 2022. Available online: https://doi.org/10.1007/s40747-021-00628-y (accessed on 18 April 2022).
- Wang, Y.F.; Gui, Z.C.; He, J.; Zhang, X.W.; Wang, C.S. Autonomous Intelligent Mine Clearance and Explosive Distributing Mechanical System. CN107246824A, 13 October 2017. (In Chinese). [Google Scholar]
- Wang, Q.F.; Liu, M.Y.; Liu, J.D. Dual-arm Robot Mine Clearance Cooperative Control System and Mine Clearance Method. CN109807913A, 28 May 2019. (In Chinese). [Google Scholar]
- Ding, H.G. Intelligent Demining Robot. CN109696085A, 30 April 2019. (In Chinese). [Google Scholar]
- Wang, C. Study on the Design of Remote Control Weapon Station Structure; National University of Defense Technology: Changsha, China, 2018. [Google Scholar]
- Wu, D.; Gu, Z.C.; Wang, Y.J.; Xu, C. Electromechanical Joint Simulation of a Small Unmanned Combat Platform. J. Ordnance Equip. Eng. 2020, 41, 92–96. [Google Scholar]
- Zhu, Z.Y.; Yang, Z.G.; Wang, J.B.; Zhang, Q.; Fan, X.J.; Wu, W. Machine Gun Remote Control Weapon Station. CN207716963U, 10 August 2018. (In Chinese). [Google Scholar]
- Chang, T. Automatic Defense Weapon Station. CN111486751A, 4 August 2020. (In Chinese). [Google Scholar]
- Qiu, S.P.; Chen, B. An Unmanned Weapon Station. CN211668356U, 25 September 2019. (In Chinese). [Google Scholar]
- Berenson, D.; Srinivasa, S.; Kuffner, J. Task Space Regions: A Framework for Pose-Constrained Manipulation Planning. Int. J. Robot. Res. 2011, 30, 1435–1460. [Google Scholar] [CrossRef]
- Kim, J.; Ko, I.; Park, F.C. Randomized Path Planning on Foliated Configuration Spaces. In Proceedings of the 11th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI 2014), Kuala Lumpur, Malaysia, 12–15 November 2014; pp. 209–214. [Google Scholar]
- Chen, Z.; Ma, L.; Shao, Z. Path Planning for Obstacle Avoidance of Manipulators Based on Improved Artificial Potential Field. In Proceedings of the Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 2991–2996. [Google Scholar]
- Henten, E.; Hemming, J.; Tuijl, B.; Kornet, J.G.; Bontsema, J. Collision-free Motion Planning for a Cucumber Picking Robot. Biosyst. Eng. 2003, 86, 135–144. [Google Scholar] [CrossRef]
- Islam, F.; Nasir, J.; Malik, U.; Ayaz, Y.; Osman, H. RRT *-Smart: Rapid convergence implementation of RRT * towards optimal solution. In Proceedings of the 2012 IEEE International Conference on Mechatronics and Automation, Chengdu, China, 5–8 August 2012; pp. 1651–1656. [Google Scholar]
- Huang, Y.; Abu-Dakka, F.J.; Silvério, J.; Caldwell, D.G. Generalized Orientation Learning in Robot Task Space. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montréal, QC, Canada, 20–24 May 2019; pp. 2531–2537. [Google Scholar]
- Muelling, K.; Kober, J.; Peters, J. Learning Table Tennis with a Mixture of Motor Primitives. In Proceedings of the 2010 IEEE-RAS International Conference on Humanoid Robots, Nashville, TN, USA, 6–8 December 2010; pp. 411–416. [Google Scholar]
- Shyam, R.A.; Zhou, H.; Montanaro, U.; Neumann, G. Imitation Learning for Autonomous Trajectory Learning of Robot Arms in Space. arXiv preprint 2020, arXiv:2008.04007. [Google Scholar]
- Schaal, S. Dynamic Movement Primitives—A Framework for Motor Control in Humans and Humanoid Robotics. In Adaptive Motion of Animals and Machines; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Huang, Y.L.; Xu, D.; Tan, M. On imitation learning of robot movement trajectories: A survey. Acta Autom. Sin. 2022, 48, 315–334. [Google Scholar]
- Mei, Z.; Chen, Y.; Zhang, S.L.; Zheng, X.J.; Wu, H.Y. Mobile Robot Path Planning Based on Continuous Dynamic Movement Primitives. Inf. Control 2019, 48, 12–20. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Posture Sector | DOF1 | DOF2 |
|---|---|---|
| 1 | −50 | 160 |
| 2 | 50 | 160 |
| 3 | −50 | 20 |
| 4 | 50 | 20 |
| Pointing Sector | Judgment Criteria |
|---|---|
| 1 | x ≥ 0 and y < x ∗ tan(30°); x < 0 and z > x ∗ tan(200°) and y < x ∗ tan(160°) |
| 2 | x < 0 and z > x ∗ tan(200°) and y > x ∗ tan(200°); x ≥ 0 and y > x ∗ tan(−30°) |
| 3 | y < x ∗ tan(160°) and x < 0 and z < x ∗ tan(160°); x ≥ 0 and y < x ∗ tan(30°) |
| 4 | x < 0 and z < x ∗ tan(160°) and y > x ∗ tan(200°); x ≥ 0 and y > x ∗ tan(−30°) |
| Start Posture Sector | Target Posture Sector | (DOF1, DOF2) Path Data |
|---|---|---|
| 1 | 2 | [−50, 160], [−30, 150], [−15, 140], [0, 140], [15, 140], [30, 150], [50, 160] |
| 1 | 3 | [−50, 160], [−50, 136], [−50, 113], [−50, 90], [−50, 67], [−50, 44], [−50, 20] |
| 1 | 4 | [−50, 160], [−40, 136], [−20, 113], [0, 90], [20, 67], [40, 44], [20, 50] |
| 2 | 1 | [50, 160], [30, 150], [15, 140], [0, 140], [−15, 140], [−30, 150], [−50, 160] |
| 2 | 3 | [50, 160], [40, 136], [20, 113], [0, 90], [−20, 67], [−40, 44], [−50, 20] |
| 2 | 4 | [50, 160], [50, 136], [50, 113], [50, 90], [50, 67], [50, 44], [50, 20] |
| 3 | 1 | [−50, 20], [−50, 44], [−50, 67], [−50, 90], [−50, 113], [−50, 136], [−50, 160] |
| 3 | 2 | [−50, 20], [−40, 44], [−20, 67], [0, 90], [20, 113], [40, 136], [50, 160] |
| 3 | 4 | [−50, 20], [−40, 30], [−20, 40], [0, 40], [20, 40], [40, 30], [50, 20] |
| 4 | 1 | [50, 20], [40, 44], [20, 67], [0, 90], [−20, 113], [−40, 136], [−50, 160] |
| 4 | 2 | [50, 20], [50, 44], [50, 67], [50, 90], [50, 113], [50, 136], [50, 160] |
| 4 | 3 | [50, 20], [40, 30], [20, 40], [0, 40], [−20, 40], [−40, 30], [−50, 20] |
| Random Points Number in Optimization | Time Consuming Comparison | Path Length Comparison | Path Length Comparison of the Second DOF Group | Path Length Comparison of the First DOF Group |
|---|---|---|---|---|
| 500 | 0.523 | 0.500 | 0.409 | 0.582 |
| 1000 | 0.492 | 0.566 | 0.464 | 0.651 |
| 1500 | 0.462 | 0.636 | 0.531 | 0.714 |
| 2000 | 0.401 | 0.666 | 0.565 | 0.737 |
| 2500 | 0.377 | 0.684 | 0.585 | 0.745 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, K.; Guan, X.; Li, Z.; Li, H.; Gao, X.; Zhu, M.; Tong, W.; Wang, X. A Path Planning Strategy of Wearable Manipulators with Target Pointing End Effectors. Electronics 2022, 11, 1615. https://doi.org/10.3390/electronics11101615
Zou K, Guan X, Li Z, Li H, Gao X, Zhu M, Tong W, Wang X. A Path Planning Strategy of Wearable Manipulators with Target Pointing End Effectors. Electronics. 2022; 11(10):1615. https://doi.org/10.3390/electronics11101615
Chicago/Turabian StyleZou, Kaifan, Xiaorong Guan, Zhong Li, Huibin Li, Xin’an Gao, Meng Zhu, Wei Tong, and Xinrui Wang. 2022. "A Path Planning Strategy of Wearable Manipulators with Target Pointing End Effectors" Electronics 11, no. 10: 1615. https://doi.org/10.3390/electronics11101615
APA StyleZou, K., Guan, X., Li, Z., Li, H., Gao, X., Zhu, M., Tong, W., & Wang, X. (2022). A Path Planning Strategy of Wearable Manipulators with Target Pointing End Effectors. Electronics, 11(10), 1615. https://doi.org/10.3390/electronics11101615