1. Introduction
Image completion, as an import image editing operation, aims to fill the missing area of an image in a semantically reasonable manner, bearing true fidelity to the original pixels of the real image. The traditional image completion methods which are based on diffusion [
1] or based on matching [
2] are effective in texture inpainting. However, they are inadequate for face completion with high semantics.
In recent years, with the rapid development of deep learning, the emergence of image inpainting methods based on feature learning have just managed to compensate for the shortcomings of traditional image inpainting methods. On the one hand, feature learning-based methods are based on Convolutional Neural Networks (CNN), which have been proven to bear the ability to extract features and semantic information from images, making them effective tools for image inpainting. On the other hand, through extensive research on the Generative Adversarial Network (GAN) [
3], it has been confirmed to be capable of generating certain types of imagery with rich detailed information, thus providing a new concept of the inpainting of specific types of images. For example, Zhao et al. [
4] proposed a method based on GAN and achieved convincing results for 3D face reconstruction from a single color image under occluded scenes. Pathak et al. [
5] first proposed an image inpainting algorithm based on unsupervised visual feature learning based on contextual pixel prediction using CNN. They used adversarial loss to maximize the realism of the completed image. Based on this algorithm, Yeh et al. [
6] applied DCGAN (Deep Convolutional GAN) [
7] to complete images, and their method can generate and fill the missing area of images effectively. In addition, their method is suitable for masks of any shape. Iizuka et al. [
8] proposed a new creative generation model, which contains a generator, a local discriminator and a global discriminator to ensure the local consistency and global consistency of the in-painted image. Based on this model, Li et al. [
9] proposed another generational model, which combined reconstruction loss, two adversarial losses and semantic parsing loss to further ensure the authenticity of synthetic pixels and the consistency of local and global content. Yu et al. [
10] also proposed a coarse to fine network structure based on the model proposed by Iizuka et al. [
8], in which a context attention layer was added to copy or obtain feature information about the background to generate real pixels. Zeng et al. [
11] proposed a progressive inpainting structure, which is constructed on the basis of the U-Net [
12] structure. The structure allowed for encoding the context semantics of full resolution input, and decoding the learned semantic features back to the image to realize image completion. Further, for the general convolution process, indiscriminate convolution is performed on the effective pixel area and the pixel area to be inpainted, which usually leads to artifacts such as chromatic aberration and blurring in the final result. In [
13,
14], they applied partial convolutions and gated convolution to complete images. Yang et al. [
15] proposed a generative landmark-guided face inpainting method, which use landmarks of the face predicted by the information about the unobstructed area to inpaint face imagery.
Although these methods have achieved good results in face image completion, the use of high-resolution face data sets makes network training difficult and the generation of credible high-resolution images challenging, leading to suboptimal repair of high-resolution face images. Karras et al. [
16] proposed StyleGAN, which can generate
high-resolution face images gradually.
Inspired by StyleGAN, we propose a high resolution face inpainting method. We first use ResNet(Deep Residual Network) [
17] to predict the latent vector of the face image, then generate the face image through the StyleGAN model, and finally use the Poisson mixing method [
18] to fuse the generated image with the original image. This method can repair masks of any shape and size.
Figure 1 displays some examples of the repair results of our method.
The contributions of this paper are as follows:
1. We propose an effective high-resolution face image completion method based on StyleGAN, which solves the problem of the high-resolution image completion network model being difficult to converge in training.
2. In our method, a model is designed to complete face image completion, face image editing, face-image watermark clearing and other image processes without the network training process of different repair masks.
3. In our model, we adopt a new latent vector processing method to improve the quality of repaired images and obtain diverse repair results.
3. The Approach
In this section, we describe the proposed method of high-resolution face image completion. Given a masked face image, our goal is to synthesize the missing content, which is not only semantically consistent with the whole image, but also visually reasonable and real.
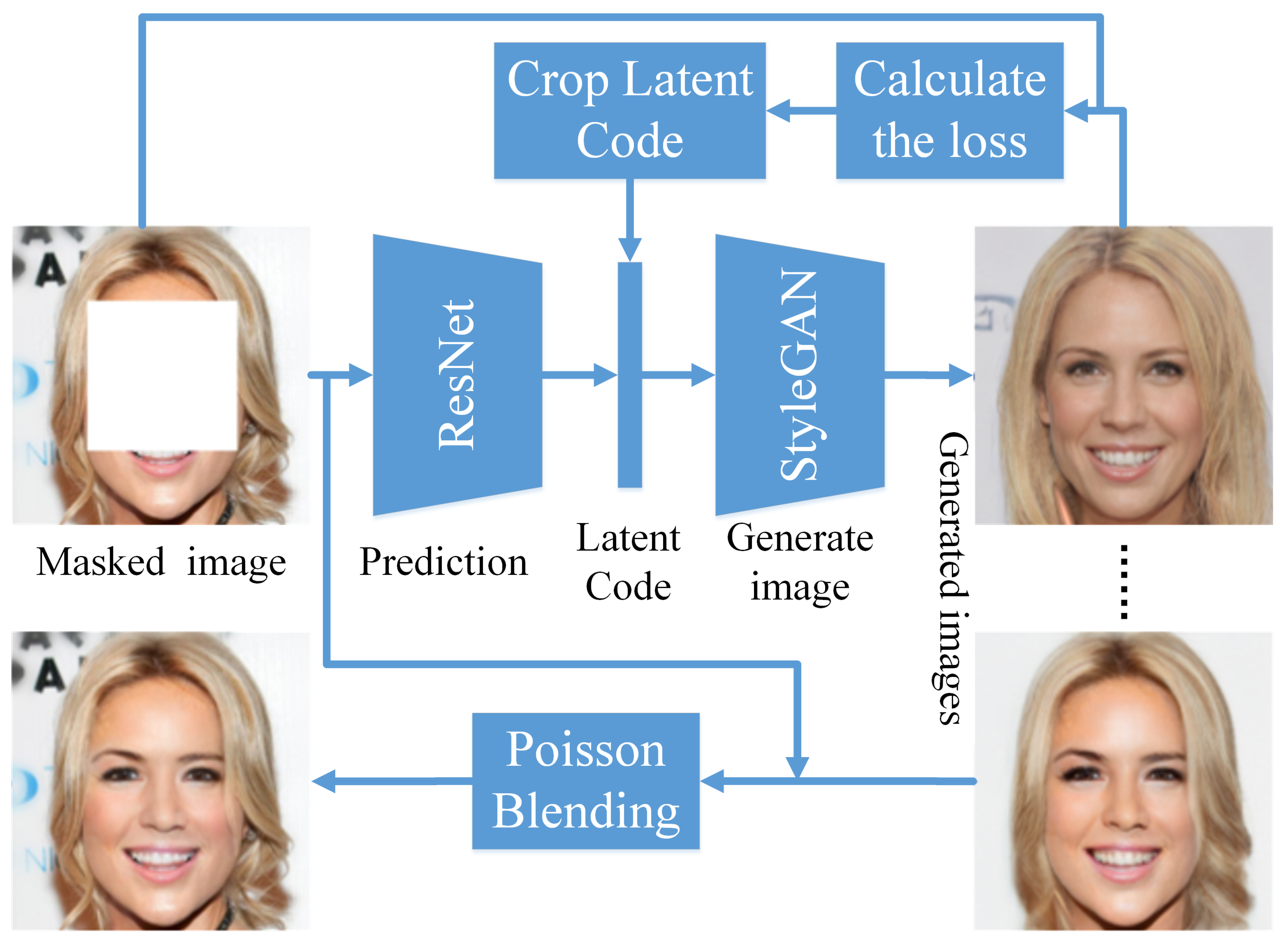
Figure 2 shows the procedure of our method.
Each image generated by StyleGAN is generated by a random latent vector. We assume that each picture corresponds to a latent vector. If we find the latent vector corresponding to a picture, we can complete the original image through it. The method behind extraction of the latent vector of an image is an important issue to be resolved. Different from the method proposed by LIPTON Z. C. et al. [
21], we first employ ResNet50 to predict the latent vector of the image through migration learning, then use the SytleGAN to generate a face image. Finally, we use the corresponding loss functions to generate the inpainting image iteratively. Throughout the entire process, the training data of ResNet50 are directly generated by StyleGAN. This accelerates the process of generating images and makes the generated image more realistic than an image constructed using only StyleGAN. Our comparison results are shown in
Figure 3. In the loss calculation, we only calculate the undamaged area of the input image, that is:
where
X is an input image,
M is a mask image to label the missing area (the value of missing area is 0, the other area is 1), and ⊙ means element by element multiplication.
After determining the network structure, the loss function bears a great impact on the final results. We analyze the final inpainting results for different loss functions. Specifically, we choose the following loss functions to fine-tune the repaired image: Loss, Loss, Loss, Loss, Loss, Loss.
(1) VGG Loss
We use VGGNet [
22] to extract the feature map of the original image, then use the
distance between the feature map of the original image and the feature map of the generated image as VGG loss. The VGG loss is defined as:
where
represents StyleGAN generator,
represents extracting feature map by VGG.
(2) Loss
Loss is defined as the
distance between the original image and the generated image:
(3) Loss
Loss is defined as logarithm of hyperbolic cosine of prediction error of original image and generated image:
where
n and
m represent the width and height of the image to be inpainted, respectively.
(4) and Loss
(Structural SIMilarity) [
23], as a measure of similarity between two images, is compared with three aspects: brightness, contrast and structure similarity.
(MultiScale Structure SIMilarity) [
24] is more flexible than the single-scale method under different observation conditions.
is defined as:
where
,
,
are used to adjust the weight of each component and they are generally set as 1;
uses the means (
and
) of
X and
to estimate the similarity of luminance;
uses the variances (
and
) of
X and
to estimate the similarity of contrast;
uses the co-variance (
) to estimate the similarity of structure.
,
and
are constants used to maintain stability, where
L is the dynamic range of the pixel value in the images. According to past experience,
is set as
and
is set as
.
The calculation of
is to take the original image
X and the generated image
as input, then iteratively employ a low-pass filter and
down-sampling to build image sets of different scales for both
X and
. Assuming that the original image scale is 1, and the highest scale is
M, which is obtained after
iterations. For the
scale, only the similarity between contrast
and the similarity of structure
are calculated. The similarity of luminance
is calculated only at scale
M.
is defined as:
where
,
and
are weight parameters (usually:
, and
).
The closer the values of
and
are to 1, the more similar the two images. On the contrary, the closer they are to 0, the greater the difference between the two images. So based on the definitions of
and
, the
and
losses are defined as:
(5) Loss
Zhang R et al. [
25] proposed that the traditional similarity measurement methods (e.g.,
and
) are often inconsistent with human judgment. They find that
(Learned Perceptual Image Patch Similarity) outperforms all previous metrics by large margins of their dataset.
For calculating the perceptual similarity between two images
,
, given a base network
F (e.g., SqueezeNet, AlexNet, VGG), we first calculate the deep embeddings of
and
on network
F, respectively, normalize the activations in each channel dimension, use the vector
to scale the size of each channel, and calculate the
distance of the scaled features of each channel. Finally, we average across spatial dimension and across all layers to obtain the perceptual similarity between the two patches
,
.
where
l represents the
layer of the network
F, the result of
layer
is obtained by inputting
into the network
F, and
H,
W are the height and width of the feature map of the
layer.
The
perception distance needs to be trained to predict the perception judgment from a distance calculated by Equation (
9). Then the network of computer distance needs to be trained. The training methods include lin method, tune method and scratch method, which are described in the literature [
25].
The lower the value of
, the more similar the two images are, and vice versa, the greater the difference. The
loss is represented by the distance between
X and
calculated by Equation (
10).
We analyze the impact on different loss functions of the final inpainting results through two types of experiments. The first type of experiment is to complete the face image completion through only one loss function. The experimental results of the two groups are shown in
Figure 4. Column
a is the images that need to be inpainted. Column
b,
c,
d and
e are inpainted images by using only
,
,
,
losses, respectively. Column f is the original images. It can be found that the images generated by only using
loss are too smooth and losing more details; the images generated by only using
loss are better, but they also have a problem of excessive smoothness in the hair area; the generated images only using
loss are not ideal and only have the structural integrity of the faces; the inpainted images by only using
loss also have the structural integrity, but they have obvious brightness deviations.
The second type of experiment describes the inpaint of face images by combining different types of loss functions. The experimental results of two groups are shown in
Figure 5. The amazing inpainting results can be clearly seen, and are obtained through the combination of various loss functions (as shown in
Figure 5g). After generating high-resolution face images by using various loss functions, the generated images must be processed to complete the entire inpainting work. A simple processing method is to directly paste the to-be-repaired area corresponding to the generated image into the to-be-repaired image. This processing method can cause boundary marks to appear in the final inpainting results. In experiments, we process the inpainting boundary via Poisson mixing [
18] to make the boundary of the final inpainting results more natural (
Figure 5h).
Specifically, in the follow-up experiments, we completed the inpainting of high-resolution face images through a combination of four losses:
,
,
and
. The overall loss function is shown in Equation (
11).
where
,
,
and
are the weights of
Loss,
Loss,
Loss and
Loss.
4. Experimental Results and Analysis
To objectively and comprehensively evaluate the performance of our method, this section compares the completed results of various models through qualitative evaluation and quantitative evaluation. We evaluate the proposed method on the public dataset
.
is a high-resolution face image dataset and contains 30,000
high-definition frontal face images. In our experiments, the weight values of Equation (
11) are set as
= 0.4,
= 1.5,
= 100,
= 100, respectively. In this paper, we use TensorFlow framework as the development environment. The configuration of the experimental platform is an Intel(R) Core(TM) i7-9750H 2.60GHz CPU, and an NVIDIA GeForce GTX 1650 GPU. The images of our intermediate generation process are shown in
Figure 6. It can be seen that as the iteration progresses, the details of the generated face images become increasingly rich, and the visual consistency gradually improves in quality.
4.1. The Qualitative Evaluation
The center rectangle mask is the most common comparison method in image completion. CE [
5] uses a method based on context coding to complete the missing region. GLCIC [
8] uses global and local discriminators to complete images. Because each method has different requirements for the input size of the masked images, each method has different resolution of output images. The default resolution of output images by using GLCIC method is
and the default resolution of output images by using CE is
. The method proposed in this paper is for high-resolution face image completion, and the resolution of output images is
. For uniform comparison, we re-scaled the resolution of all inpainted images to
. The central rectangular mask is a common damaged shape in face completion tasks. For a fair comparison, we ensure that the mask area occupies the same proportion of the entire image area in different methods. In the experiment, we set the proportion to be one-fourth, that is, for CE, GLCIC and our proposed method, we use
,
and
center rectangle mask inputs to achieve face image inpainting.
As shown in
Figure 7, we show four groups of the result images inpainted by these three methods. Regarding the experimental results, there are unnatural contents in the results of face completion by the GLCIC method, and there are conspicuous color differences on the edges inpainted by CE method. However, the results of our proposed method contain more detailed information while ensuring the consistency of visual effects. In addition, by using the Poisson fusion method, traces of inpainting boundaries are invisible in the completion imagery.
To compare the inpainting effect with GLICI more comprehensively, we also compare the inpainted images by using the large-area rectangular mask and the irregular mask.
Figure 8 shows the inpainting results by using the large-area rectangular mask.
Figure 9 shows the inpainting results by using the large-area irregular mask. The experimental results in
Figure 8 show that the inpainting results of the method proposed in this paper have richer face structures and more coherent edges. In addition, the inpainting results are already very similar to the original image, especially in the case of symmetrical information loss. In the case of using arbitrary shape masks (
Figure 9, the repair marks are very obvious in the repair results of the CE method, and some results even exist face distortion. The method in this paper ensures that the face structure is reasonable, and the color and facial expression are basically the same as the original image.
The method proposed in this paper does not need to retrain the model for different repair areas. Thus, it can repair images of any mask easily. In our experiments, we repair the images under different damage conditions, with the experimental results shown in
Figure 10 and
Figure 11.
Figure 10 shows the completed results of images damaged by 20%, 30%, 40% and 50% random noise masks. We can see that in the case of 20% and 30% noise masks, the completed results are not visually different from the original images, and in the case of 40% and 50% noise, the completed results are only slightly blurred.
Figure 11 shows the completed results of images damaged by free-form brushes accounting for 10–20%, 20–30%, 30–40% and 40–50% of image pixels, the conclusion is still consistent with
Figure 10. We also try to repair the image damaged by 90% random noise masks, our method can still achieve good repair effect, as shown in
Figure 12. Therefore, our method can effectively repair face images with random damage.
4.2. The Quantitative Evaluation
In order to evaluate the image inpainting effect of these methods objectively, in this section we select the experimental results of using the rectangular center mask for quantitative comparison. PSNR(Peak Signal-to-noise Ratio) and SSIM(Structural similarity) are measures to evaluate the quality of completed images. In the image evaluation measures, PSNR is used most, but its value can not well reflect the subjective feeling of human eyes.
Table 1 is the performance comparison on the CelebA-HQ dataset. In this table, the best value of each measure are indicated in bonds. From this table we can infer that the SSIM of our results is better than other compared methods and the highest PSNR is obtained by CE method.
In addition, the flexibility of CE and GLCIC is insufficient. For masks of different shapes, they all need to train a new inpainting model. However, our method can complete face images with arbitrary shape masks by training only one model.
In order to further prove the effectiveness of our method, we select 1000 face images in CelebA-HQ database randomly, destroy them with random noise masks and random free-form brush masks, respectively, and then repair the damaged images by our method. The experimental results are shown in
Figure 10 and
Figure 11. Furthermore, we calculated the average values of PSNR and SSIM shown in
Table 2. It can be seen, the values in
Table 2 are higher than the values in
Table 1, which shows that our method is universal in repairing arbitrarily damaged face images.
4.3. Network Complexity
The networks used in our method include StyleGAN and ResNet. We use StyleGAN network pre-trained on CelebA data-set and ResNet50 network pre-trained on ImageNet data-set to obtain latent vector prediction network. Stylegan network includes parameters and ResNet50 network includes parameters. Therefore, the whole network include parameters.
In
Figure 13, we show the average value of the total weighted loss values in 100 times inpainting process about 1000 face images with random noise masks and random free-form brush masks. It can be seen that our method converges after 80 rounds of iteration for different types of masks.
In
Figure 14, we show the average completion time of 1000 face images with random noise masks and random free-form brush masks. The completion time of each image includes the time of repair phase and fusion phase. It can be seen, the difference in completion time is caused by the fusion stage. As shown in
Figure 14, the completion times of inpainting images with random noise masks are longer than that of the random free form brush masks, which is mainly due to the images of random noise masks need more fusion time because random noise is more dispersed. The average completion time of repairing a
face image with 20% free-form brush masks is 122 s. The average completion time of repairing a
face image with 20% random noise masks is 143 s. Nevertheless, the cost of these time can still meet the requirements of practical application.
4.4. Application and Failure Case
Because our method can complete high resolution images with random masks and large damaged area, it can be applied to face image editing, face image subtitle removal, face image watermark removal and other practical applications. The specific experimental results are given in
Figure 15.
Our method also has some failure cases shown in
Figure 16. This is mainly because the main purpose of our face generation network is to generate face images. The generation of the face images with other objects (such as sunglasses) are not ideal.
4.5. Diversity of Completion Results
For an occluded face image, there should be multiple possible inpainting results. Although there are many methods that can complete reasonable inpainting, these methods often have only one output. The inpainting model proposed in this paper can obtain diverse inpainting results after simple adjustment. When our method completes a high-resolution face image, it will obtain a corresponding latent vector . Further, by editing , multiple completion results can be obtained. StyleGAN establishes a mapping relationship between an (18, 512) dimensional vector to a (1024, 1024, 3) dimensional vector(face image), which has some attribute such as age, gender, expression, etc. If we can explore the relationship between the change of the face attribute and the corresponding change of , then the attributes of the generated face image can be edited and manipulated through the adjustment of .
We can first use the face feature extraction method to extract the attribute features of each face image, and use the numerical value to represent each attribute to constitute the feature vector
V of each face image attribute. For the convenience of operation, the range of the value for each dimension in the vector
V is normalized to the
. Then, for the data of each dimension in
V (such as the data representing the age feature), we explore the relationship between the change of its value and the change of the corresponding latent vector value. This changing relationship can be represented by the direction vector
, which has the same dimension as the latent vector.
is calculated by the ratio of the difference value of the latent vector to the difference value of the corresponding attribute. In order to obtain an accurate
, it is necessary to calculate the mean of the ratios for each pair of sample in a large number of face attribute data-sets, which is very difficult. In fact, the solution of
can be carried out through an optimization strategy. First, the median
of the
i-th dimension (corresponding to an attribute) of the feature vector
is used as the dividing line to establish a new two-class sample. For the samples whose corresponding attribute values are lower than
in the original samples, the labels
are set to 0. The samples whose corresponding attribute values are higher than
, the labels
are set to be 1.
represents the attribute feature of the
j-th face sample image. Then we construct the objective function and use logistic regression to solve the binary classification problem. The objective function is defined as:
, where
is the value of the
i-th dimension of
and
is the label value of the binary classification. By using this optimization method,
can be solved in a relatively fast time and
can be approximately represented by using
. According to the latent vector of the face image to be completed and the direction vector
, the following formula can be used to realize the editing of the corresponding features of the face to achieve Diversification of completed results.
where
is the editing parameter. Different latent vectors can be obtained by giving different values to
.
In this way, by editing the latent vector
, we can achieve the generation of face images with different attributes, such as facial expressions. Then, the image to be inpainted and the generated image are fused by the Poisson fusion method to achieve the diversity of repair results.
Figure 17 shows the diversity inpainting results we obtained by editing the latent vector.
6. Conclusions
A new high-resolution face images completion method has been proposed in this paper. This method first uses ResNet to predict the latent vector of a face image, and then generates high-resolution face images through the StyleGAN model to repair damaged face imagery. This method can successfully synthesize the missing content in the face image, so that the inpainted image is semantically effective and visually reasonable. StyleGAN model can first train the generator and discriminator with low spatial resolution, and gradually add layers to the generator and discriminator network to increase the resolution of the generated image. In this way, the problem that it is difficult to converge in training high-resolution networks has been solved. Although the proposed model is only used for facial image completion, after training the generation network with other types of imagery, this method can be used for the restoration of other types of image restoration.
Our proposed method performs iterative repair process by calculating the loss of the known area of the image to be repaired and the corresponding area of the generated image, so the shape of the mask areas are not a factor that directly affects the completed results. There is no need to train and modify our model for different masks, which renders our method easy to apply to face image editing, face-image watermark removal, face image subtitles removal and so forth.
In addition, when the incomplete image is repaired, we can obtain the latent vector corresponding to the inpainted image. Next, we can then modify the vector value representing the specific area in the latent vector, finally generating a new face image through the modified latent vector. In this way, our method can realize the editing of specific facial regions and the diversity of face image completion results with the same mask. This method can also be used to edit facial features, such as the repaired image results of a person with or without glasses, which can be successfully obtained by using this method.
Further, the method proposed in this paper can be extended to repair and edit various high-resolution images.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}